
CHAPTER 6
Management Plane and Business Continuity
This chapter covers the following topics from Domain 6 of the CSA Guidance:
• Management Plane Security
• Business Continuity and Disaster Recovery in the Cloud
• Architect for Failure
When you are thirsty, it’s too late to think about digging a well.
—Japanese proverb
Preparation is important if you want your business to survive: you need to be one step ahead—to act before you suffer any consequences of inaction. This chapter is all about thinking ahead and implementing security before things go sideways. The chapter marks somewhat of a transition in this book—from the business side of the cloud to the technical aspects associated with cloud computing. It begins with coverage of securing the management plane and then moves on to business continuity and disaster recovery in a cloud environment.
In the logical model, as covered in Chapter 1, you learned that the metastructure is the virtual world for which you need virtual tools. The management plane is the area where the virtual infrastructure of your cloud is built, configured, and destroyed. Remember that the management plane is a part of the metastructure. The management plane is your single interface to view, implement, and configure all of your resources in this virtual world.
The concept of a management plane isn’t anything new. In fact, the term “management plane” has been used in networking for years to describe the interface used to configure, control, and monitor networking devices. Unlike other environments, in which you could configure a particular port to be a management interface and that required direct physical access to the management plane, you (or anyone) can connect to the management plane supplied by a cloud provider across the Internet using APIs or web browsers.
The management plane is also where you implement most disaster recovery (DR) and business continuity planning (BCP) options. Many providers, especially Infrastructure as a Service (IaaS) providers, will make multiple data centers and multiple regions available to you. It is up to your company to determine an appropriate strategy and to execute that strategy by using those options. This involves an understanding of concepts such as recovery time and recovery point objectives (see the upcoming “BCP/DR Backgrounder” section if you’re unfamiliar with these terms) and choosing the best approach to meet these business requirements.
The bottom line is that saying “the provider does everything for me” is likely a fallacy. Sure, your Software as a Service (SaaS) provider may have dynamic failover from one region to another and you don’t need to do anything to have BCP/DR in place, but what about exporting data held in that SaaS? Does the provider do that for you automatically, or do you have to enable that export of data? What format is the exported data in? Can it be accessed only using a provider’s system? If so, where does that leave you if your provider goes bankrupt, is hacked and their system is destroyed, or is a victim of ransomware and all client data (including yours) is encrypted and the provider refuses to pay?
As the opening quote suggests, when you can’t access your data, it’s too late to think about recovery options.
Management Plane
The management plane is the most important area that you need to secure tightly—and it is solely your responsibility to secure access to it. Anyone with full access to the management plane quite simply has the power to build or destroy anything in your virtual world. Proper implementation and management of restricting access to the management plane is job number 1 as far as securing any cloud implementation. After you ensure that the management plane is secured, you can worry about securing your assets in a cloud environment. After all, an attacker may not be able to log on directly to a virtual server through the management plane and steal your data, but they could use the management plane to make copies of volumes and export them, or they could blow away any running instances and all backups. Simply stated, if someone has access to the management plane, they could find all kinds of inventive ways to gain access to your servers and other assets in the cloud.
Think about someone using your resources for bitcoin mining and sticking your organization with the bill. Want a super-inventive example? How about someone gaining access to the management plane in an IaaS environment and then using that access to add a script that will execute on one or all of your servers the next time they’re rebooted. Oh—and that script will install a back door and will succeed, because the script will run as the root user in Linux or the system account in Windows. I don’t want to muddy the waters and the difference between the metastructure and the applistructure, but I do want to give you an example of the unforeseen damage a malicious actor can cause if they have access to the management plane.
As you know, the cloud is a shared responsibility model, and this applies to the management plane as well. The provider is responsible for building a secure management plane for you to access, and you are responsible for ensuring that only appropriate people have appropriate qualifications to manage your virtual world and that every user has least privileges, and nothing more, to do only what they need to do.

NOTE The concept of least privilege is more important than ever when considering security of the management plane.
Application Programming Interface Backgrounder
An application programming interface (API) is a programmatic interface to a system that enables services to communicate without having to understand how a system is implemented. APIs are used behind the scenes (as discussed in Chapter 1), and it is very common for cloud providers to expose APIs to customers for programmatic access. This section covers APIs themselves, the leading API “standards” used in the cloud, and how customers can use these APIs to do remarkable things in a cloud environment.
Before we get to the use of publicly available open APIs as a customer in a cloud environment, let’s look at how a company used internal APIs to transform its business completely. In around 2002, Amazon was struggling with a computing environment that had become quite unmanageable. As a result of the challenges, CEO Jeff Bezos issued his now famous “API Mandate” that required every business group throughout Amazon to expose an internal API for everything they did. Want HR information? There’s an API for that. Need marketing information? There’s an API for that. Here are a few of the highlights from the API Mandate:
• All teams will expose their data and functionality through service interfaces.
• Teams must communicate with one another through these interfaces.
• There will be no other form of interprocess communication allowed: no direct linking, no direct reads of another team’s data store, no shared-memory model, and no back doors whatsoever. The only communication allowed is via service interface calls over the network.
• It doesn’t matter what technology you use.
• All service interfaces, without exception, must be designed from the ground up to be externalize-able. In other words, the team must plan and design to be able to expose the interface to developers in the outside world. No exceptions.
• Anyone who doesn’t do this will be fired.
I believe Mr. Bezos was dead serious about this transformation to APIs because he really felt Amazon could scale to meet increased demand only if the company took a highly modular approach to everything. By imposing these interfaces, the company could remove system-specific dependencies and therefore improve agility, efficiency, and speed as a result.
That was an example of internal APIs. But there are also external APIs that are exposed to the outside world. APIs that are meant to be consumed by others (such as customers and partners) are generally referred to as open APIs. You could also have private APIs, where access to the API is restricted.
Let’s look at a use case of externally available private APIs. Suppose you created an awesome new application with a proprietary algorithm that predicted neighborhood home price values ten years into the future. You could try to convince potential home buyers to pay for access themselves, or you could charge real estate brokers for access and make that valuable data available only under contract. Many companies in this scenario would likely go the private API route, because it’s probably a much cheaper way to enter the market as opposed to spending millions on marketing to the general public. In this scenario, APIs are critical to the success of the company from a revenue perspective, not just with regard to agility and other benefits of internal APIs.
Finally, and most importantly for our subject, we turn our attention to open APIs on the Web. These are the APIs that a web site (such as Twitter, Facebook, and so on) exposes to customers, but more importantly for this subject, these are the APIs that a cloud provider would expose so their customers can programmatically access resources. Most, if not all, cloud providers in every service model will expose both an API and a web interface for customers. The functionality of these exposed APIs will, of course, be vendor-dependent. Some IaaS providers may offer all functionality through their APIs, while an SaaS provider may allow you to create a new record, but not modify a record, for example. This leads us to another interesting Amazon-related observation. When Amazon created Amazon Web Services, only API access was available for consumer access; there was no web interface. I think this is the exact opposite of what you would expect to come first when a company launches a product for mass consumption. But when you think about it, it shows just how valuable Amazon considers APIs for itself and for everyone else.
Now that you know about the different API deployments, let’s move on to the different “standards” that are popular for open APIs. The two dominant ones are REST and SOAP. I’ll cover each one separately, giving appropriate consideration for both.
First up is Representational State Transfer (REST). REST isn’t actually a standard; it’s considered an architectural style, and that’s why I put quotes around the word “standards.” You’ll never see a “REST 2.0,” for example. REST is stateless (meaning it doesn’t retain session information) and depends on other standards (such as HTTP, URI, JSON, and XML) to do its job. Every REST call uses an HTTP method. The following table lists the methods and a high-level overview of what each does:

So what does REST look like in action? The following examples show how you would get a list of your server instances from three major IaaS providers.
NOTE These examples don’t address the authentication or authorization processes that will need to be performed. API authentication is discussed later in this chapter.
AWS Example:
![]()
Microsoft Azure Example:
![]()
Google Cloud Example:
![]()
You have probably noticed something here—they’re all different! You have to consult the API reference guide for any provider you want to work with. Each will expose functionality differently.
NOTE For all the details you could ever want to know about web APIs and REST, look up Roy Fielding’s dissertation, “Architectural Styles and the Design of Network-based Software Architectures.” I’m just highlighting key facts about APIs as background information.
Now how about terminating (deleting) an instance? Here are some examples.
AWS Example:
![]()
Microsoft Azure Example:

Google Cloud Example:
![]()
Now that you have an idea of how easy it is to execute commands in the REST API, I hope you have an appreciation for how easy it would be for anyone with administrative control of the management plane to programmatically destroy everything in your environment within seconds. They would just need to create a simple script that lists all instances and then issue a terminate command for each one listed. One last thing before we move on: Do you notice how all of the API requests are using HTTPS? This is the thing about REST. It uses other standards. If you want your requests to be secure, you need to use HTTPS, because security isn’t baked into REST. This is very different from the SOAP API.
Simple Object Access Protocol (SOAP) is a standard and a protocol. It’s often said that REST is like a postcard and SOAP is like an envelope. Unlike REST, SOAP has security included inside it, as well as other features, but there is more overhead associated with SOAP than with REST as a result. As such, the use cases for SOAP are more for internal enterprise purposes with high security requirements. Cloud providers often won’t expose a SOAP API to customers, and any that did likely don’t anymore. For example, Amazon Web Services (AWS) used to have a SOAP API for Elastic Compute Cloud (EC2), but the company deprecated (removed) it back in 2015. At the end of the day, you’re most likely going to run into REST APIs if you’re dealing with anything web-related.
Quite often, APIs can be used in a programming language of your choice. For example, if you want to make a Python script that would create an instance in AWS, you can use the AWS Boto3 Software Development Kit (SDK). The following offers an example of such a script:

TIP Using a vendor’s API is always best if you really want to understand how a particular provider works. The web interface usually hides a lot of functionality.
I would like to conclude this backgrounder with the concept of an API gateway. The API gateway serves as the single interface with which a requesting machine will connect to one or multiple APIs behind it and will deliver a seamless experience for customers. The API gateway is beneficial from a security perspective because it can inspect incoming requests for threat protection (such as denial of service, code injection attacks, and so on) and can be used to support authentication and authorization services. This is particularly true with delegated authorization with microservices (covered in Chapter 12).
Accessing the Management Plane
The management plane is often accessible via multiple methods. In general, you can expect to have access to command-line interface (CLI) tools, a web interface, or APIs. Think of the API as being the engine that runs everything. Whether you use the web interface, the CLI, or any SDK, you’re likely having your request translated to the provider API, and that, in turn, is executed at the provider.
As mentioned earlier, if you really want to see under the hood regarding what a provider allows, using the API will often show what you’re looking for. You can generally consider that anything available via the web console will also be available via the API. If something is exposed via an API, it can be accessed programmatically. And if it can be accessed programmatically, it can be automated. A provider may offer some functionality to either method first, but these encounters should be rare with any established provider. I would take it as a safe bet that “beta” functionality will be exposed via the API first, but, personally, I’m not a big fan of using anything “beta” in a production environment.
When you’re considering these different access methods from a security perspective, be aware that quite often different credentials will be involved. For example, when you’re connecting via the web browser, standard credentials such as a username and password are generally used. These credential sets can be stored within the cloud provider’s environment, or you can use identity federation to keep the credentials on your side and not on the provider’s side. (Federation is covered in Chapter 12.)
Aside from the web browser access, accessing via the API generally uses either HTTP request signing or the OAuth protocol (discussed in Chapter 12). Some providers will use an access key and secret access key as the credentials as part of authenticating and signing REST requests. The access key itself acts like your username, and the secret access key is like your password. Behind the scenes, the secret access key is used to sign the request.
The key (see what I did there?) is that you understand that the management plane can be accessed by a variety of means and will likely use different methods to authenticate access. How are these credentials being used and secured? Let’s move on to that part.
Securing the Management Plane
When you first register or sign up with a cloud provider, you will create an initial account that is considered the master account (some providers may call this the root account, which is a terrible name considering UNIX has been using it for decades). This account needs to be tightly locked down and used only to establish proper identity and access management. Here is some guidance regarding the creation and securing of this initial master account:
1. Create the account using a unique corporate e-mail address (for example, [email protected]). This e-mail address will be the user ID for the master account and may serve as the way your provider will engage with your company. This account should never be created by someone using their personal e-mail address, or even their own corporate e-mail address.
2. Set up a distribution list for this master account e-mail. This will prevent several problems (for example, the original creator leaves the company and all e-mails wind up in /dev/null [a UNIX term for a garbage bin], or someone vital doesn’t see an urgent message from the provider).
3. Establish a strong password that meets your security policy at the very least, and establish multifactor authentication (MFA) for this account based on a hardware MFA device. How you do this will vary based on the provider you are working with, but many, if not all, providers will support the time-based one-time password (TOTP), a temporary passcode generated by an algorithm that uses the current time of day as one of its authentication factors. Other providers may support a newer MFA method, Universal 2nd Factor (U2F), which is considered by many to be a safer MFA method than TOTP.
NOTE You can also use a “virtual” TOTP such as Google Authenticator, but given the fact that you’re going to be storing the MFA device for safekeeping, a virtual MFA device may not make the most sense in an enterprise scenario.
Once the account, password, and MFA for the master account are set, you need to set up a new super-admin account you can use to access the management plane. Once that’s done, you should write down the master account logon ID and password, put them in an envelope along with the MFA device, and lock these in a safe. From this point forward, the master account should be used only in emergencies, and all activity performed should use appropriate accounts.
NOTE There are three possible “factors” involved in MFA: something you know (such as a password), something you have (such as a smart card), and something you are (biometrics such as fingerprints or retina scans).
To secure the management plane properly, you need two things: a solid plan of who is allowed to do what (entitlements) and a provider that has a robust identity and access management (IAM) system that supports identification, authentication, and authorization with appropriate granularity. This granularity will enable you to implement a least-privilege approach to restrict who is permitted to perform specific actions in your cloud environment.
NOTE IAM is discussed further in Chapter 12, but don’t bother jumping there just yet.
The Importance of Least Privilege and MFA
It’s really important that you take a least-privilege approach regarding who can access and manage the cloud environment. This doesn’t apply only to user accounts; it also applies to IAM roles. Why do I focus on least privileges? Consider the following example: A major bank was compromised by essentially allowing a role to list the contents of an object storage bucket (covered in Chapter 11). Huh? Yes…it’s true. A role having access to list the contents of an object storage bucket led to an attacker being able to identify files that he accessed and downloaded. These files contained personally identifiable information (PII) data on millions of clients. Had the role’s permissions been to read a known filename but not list the filename contents, the bank’s data may not have been compromised—or, at the very least, it would have been a whole lot harder for the attacker to find the PII data.
EXAM TIP Seriously, implement least privileges. If you are asked about appropriate permissions, the answer will always be related to the principle of least privilege.
This is an extreme example, but at a basic framework level, what does your organization do to handle access within its internal network? Does everyone have an administrator account that they use on a day-to-day basis? If they do, put down this book and get that fixed right away! That’s not likely the case, however. In most organizations, users are given only the appropriate permissions to do their jobs and nothing more. Storage administrators should have access to manage and configure storage, and server admins may be granted the ability to create instances but not terminate them. You can’t go wrong by always assuming a credential will be compromised and locking it down to minimize potential impact (which is, of course, a control to minimize risk).
You will encounter two main sets of credentials in cloud environments of all types: usernames and passwords for web console logins, and access keys for programmatic access. Access keys are considered a “permanent credential.” I have two warnings about using access keys in a cloud environment:
• Access keys (and secret keys) should never be included in any script. These are, after all, clear-text credentials. I’m sure you don’t use hard-coded clear-text passwords in scripts, so why would it be alright to do it with a different kind of credential? If the access key is kept in a script and that script is pushed to a public software repository such as GitHub, it can take minutes for a malicious actor to discover those credentials.
• Access keys should be avoided if at all possible in favor of “temporary credentials.” Temporary credentials use what some providers call “IAM roles.” In the temporary credential model, cloud user accounts are given minimal credentials, and role inheritance is used to elevate privileges so programs can execute successfully.
In addition to establishing accounts with least privilege as a paramount factor, you need to strongly consider the use of MFA for all accounts, not just the master account. The use of MFA (especially U2F) has demonstrable success in thwarting account takeovers. For example, Google implemented U2F with security keys internally in 2017. Guess how many of their 85,000 employees have been successfully phished since? Zero. Nada. Zilch. I think that’s pretty impressive. Consider that this is an internal network and not a publicly available management plane—do you think the use of MFA for all management plane access would improve security across the board? I do. MFA should be implemented in any cloud environment; it’s just as important for SaaS as it is for Platform as a Service (PaaS) and IaaS.
Management Plane Security When Building or Providing a Cloud Service
So far we have been looking at what the customer can do to secure their use of the management plane. What should the provider focus on when building the management plane, and what should customers be inspecting prior to using a provider? The following offers some considerations:
• Perimeter security How has the provider implemented controls to protect its network from attacks, both lower-level network defenses and the application stack, for both web consoles and API gateways?
• Customer authentication Does the provider allow use of MFA? What types of MFA are supported, and what systems in the provider’s environment can use MFA? Does the provider support cryptographically secure methods of authentication such as OAuth or HTTP request signing?
• Internal authentication and credential passing How does the provider allow for access within the environment? Do they support temporary credentials through the implementation of IAM roles, for example?
• Authorization and entitlements How granular are the permissions that customers can use to support least privilege? Does the provider simply grant anyone logging on with administrative privileges? If so, you won’t be able to create job-specific permissions, and that’s not a good thing because any account compromise can be devastating.
• Logging, monitoring, and alerting This is a critical consideration. How can you collect artifacts of compliance if you have no ability to log failed and successful logins, or to log what actions are taken by particular IAM accounts? The ability to log actions can lead to discovery of malicious actions, and if appropriate orchestration is possible in the environment, this can be used to support event-driven security (covered in Chapter 10) to lower response times to seconds instead of hours thanks to automated response capabilities.
Business Continuity and Disaster Recovery in the Cloud
BCP/DR in a cloud environment differs from BCP/DR in a traditional IT world, because the cloud environment offers a pay-as-you-go model. Every decision you make has an associated cost and likely additional complexity. Let’s consider an IaaS example: Implementing BCP/DR in a single region is often easier and less costly than implementing BCP/DR in multiple regions. Providers may charge additional fees to copy data from one region to another, and you may need to create region-specific scripts to reflect changes in asset IDs. Then there are the jurisdictional challenges, as discussed in previous chapters, and how they may impact BCP/DR legally.
BCP/DR Backgrounder
Business continuity planning and disaster recovery are often considered one and the same, but they really aren’t the same things. They do, however, work together in support of a company’s recovery and resiliency planning (commonly used for BCP/DR in many companies). This backgrounder covers some of the more important aspects of both.
NOTE Recovery of a system doesn’t necessarily mean 100 percent recovery. It could mean getting the system back up to 60 percent capacity, or it could involve creating a brand new system (or a new normal, if you will).
BCP is about continuing business operations, even if the organization is in a crippled state while DR steps are undertaken. BCP is not just focused on the IT systems in a company; it includes determining which systems are critical to operations, determining acceptable downtimes or losses, and applying appropriate mechanisms to meet those targets. DR is a part of a recovery and resiliency function that focuses on recovering from an incident, and it is generally IT-system focused. I like to differentiate the two by saying that BCP is about the people and operations, while DR is about technology. The two work together as part of a recovery and resiliency plan for your company, which needs appropriate policies, procedures, measurements, and, of course, testing to ensure that the plan addresses business requirements.
NOTE Consider a Sony example to demonstrate the difference between BCP and DR. When the company was completely compromised in 2014, business continuity consisted of using a phone tree, where executives would use cell phones to call one another down the chain to communicate status updates; using Gmail for e-mail; using manual machines to cut paychecks; and using repurposed Blackberry smartphones that were stored in a closet somewhere. These BCP stopgaps kept the business operating while it restored systems as part of its DR. Disaster recovery, in the meantime, consisted of rebuilding all the systems compromised during the attack.
Before doing anything BCP/DR related, you must first identify the critical systems that need to be addressed. Not all systems have the same value to the organization, right? If your payroll system goes down, do you really expect employees to work for free until the system can be recovered? Or consider the loss of a graphics program used for new promotions. Is that program as important as payroll? Determining critical systems requires analyses, including business impact analysis (BIA), threat analysis, and impact scenarios.
Two calculations need to be performed as part of the BIA: the recovery time objective (RTO) and the recovery point objective (RPO). The RTO is simply the acceptable amount of time required to restore function and is usually measured in hours or days. You could have two RTOs: one for partial capacity and another for full capacity. The RPO is the acceptable amount of recent data loss that would be tolerated. It can also be measured in hours or days, or it may be measured in minutes for critical systems. The RPO can be used to drive the mandatory backup routines for a system. If, for example, you perform backups once a day, then in the event of an incident, you might be able to afford to lose up to a day’s worth of data. If the RPO is set to one hour, how are you going to meet that requirement with a once-daily backup at 2 A.M.?
RTO and RPO also determine the costs associated with appropriate recovery and resiliency as a whole. So if you want a very low RTO and RPO of five minutes, you’re going to need more systems to support real-time replication (as an example), and it’s going to cost you way more than if you required only a two-week recovery. Proper assessment will drive acceptable investments in DR capabilities to meet appropriate recovery times at an acceptable cost. Figure 6-1 shows this process graphically.
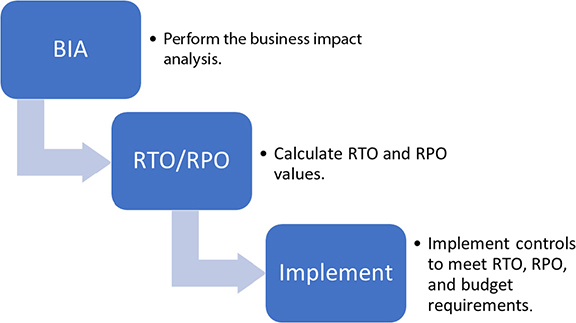
Figure 6-1 BIA and the RTO/RPO process
Finally, you need to understand the different types of site recovery options. In a traditional data center environment, you need to consider the potential loss of the data center itself. Where are you going to rebuild your systems? Although this consideration is completely transformed if you use the cloud, I’ll cover the different site recovery options in cold sites, warm sites, and hot sites here, because these have significant cost differences and support the RTO/RPO.
• Cold site Offers the lowest cost and longest downtime. Space in an alternative processing environment is available to host servers, but there is little at this location as far as equipment is concerned. For example, you may have a contract with a co-location provider and have power, cooling, network connectivity, and other core requirements addressed, but there won’t be any server hardware immediately available.
• Warm site Offers moderate cost and moderate downtime. In this scenario, the facilities and the hardware are available, and the applications may be installed (but data is re-created from backup media). Obviously, costs are higher than those at a cold site because you need to have multiple hardware systems in place for both production and DR purposes.
• Hot site Offers the highest cost and least downtime. The site has all hardware, software, data, and people ready to cut over at a moment’s notice. The trick here is the continuous replication of data from the data center to the hot site.
Let’s apply this information to the cloud environment by looking at how the cloud changes business continuity and disaster recovery plans.
Architecting for Failure
If you fail to plan, you plan to fail. BCP/DR in the cloud is like everything else we’ve covered in this book, in that it involves a shared responsibility. The provider gives you the tools for DR, but you need to perform the BIA to understand the critical systems and implement appropriately to meet recovery objectives. That’s what architecting for failure is all about.
The really fascinating aspect of DR in a cloud environment is that there’s no longer the concept of a cold, warm, or hot site to deal with. Some companies refer to DR sites in the cloud (IaaS, most appropriately) as a “pilot light” site. If a site is properly planned and continuously tested, you can go from nothing to a completely available site in minutes through the beauty of infrastructure as code (IaC). IaC, which is covered in Chapter 10, is essentially the creation (and maintenance) of a script that uses templates that will build anything you want, ranging from networking to systems. Using IaC, you have the ability not only to rebuild a virtual infrastructure programmatically in minutes instead of hours, but you also remove the potential of human error that is often introduced when people are under pressure and trying to do things as quickly as possible.
Service models do have a significant impact on BCP and DR in the cloud, based on the good old security responsibility sharing model. Let’s consider the various service models and how BCP/DR may be impacted:
• IaaS DR options in IaaS range from running everything in a single data center, to using IaC to build an infrastructure very quickly and restoring data from snapshots, to building a secondary hot site in a different geographical region while data is continuously copied from one region to another. How do you determine what is appropriate?
• PaaS How do you store your data and application code within a provider’s environment? Did you bake encryption into your application, or are you relying on the provider for that service? The answer directly impacts your lock-in potential with a provider. (Vendor lock-in refers to the inability to move from one environment to another without significant effort on the customer side.) Finally, how do you export this data if a provider goes out of business or is sold to another company?
• SaaS In SaaS, your BCP/DR plans may be as simple as exporting data on a regular basis. When considering SaaS, however, consider data availability. Make sure your provider allows you to export data in a common format at acceptable times to support your RTO/RPO requirements. For example, imagine you have an RTO of one hour, but the provider allows you to export data only once a week. How are you going to meet your RTO if the provider goes bankrupt and stops communicating with you, the latest export is five days old, and data is stored in a proprietary format? How portable is data that can be used only with provider tools when those tools are unavailable?
Business Continuity Within the Cloud Provider
I’m going to get this somewhat controversial statement out of the way now: do not use multiple cloud providers as part of your IaaS BCP/DR planning. Before you slam the book shut, let me justify my statement. Building a single IaaS environment properly is hard enough on its own. Securing the metastructure of additional providers to the same level is much harder. First, every provider needs to expose controls (and how they do so will likely differ from how your primary CSP does it, if at all). Then you need the people who are experts in the target CSP to implement required controls. Do you really think there’s a mass of people out there who know everything there is to know about the security of a single provider, let alone two or three, and that have the time to double or triple their efforts to secure all of them? It’s not just about the data. In fact, I would say copying the data from one provider to another is the easy part; you must consider the entire logical model of the cloud and all the layers to understand what’s at stake:
• Metastructure As you know, this is your entire virtual infrastructure. Creating a properly secured environment is a challenge on its own. Why would you want to do it all over again in a different environment that may not even offer the same controls? Oh, and remember you have to manage multiple environments continuously so there’s no configuration drift between the two. I think that’s just crazy talk. Sure, there’s IaC, but as you saw earlier in the API backgrounder section, all the commands are different, so you can’t use one script from one vendor in another vendor’s environment. The metastructure makes a properly secured and maintained multicloud failover approach to DR unrealistic for most companies. This is a leading reason why the CSA Guidance includes a section specifically dealing with business continuity within the cloud provider. Get that done properly before considering using multiple providers.
• Software defined infrastructure Software defined infrastructure (SDI) enables you to define and implement an infrastructure through software orchestration, which can help greatly with recovery efforts. This capability is leveraged by using IaC, as you will learn in Chapter 10.
• Infrastructure Your provider will likely make multiple regions available for you to leverage as part of your BCP/DR plans. Having geo-redundancy is a very viable approach and may be warranted (or even mandated) depending on the criticality of particular systems and/or data. Even the biggest cloud providers have experienced times when entire regions became unavailable. When considering geo-redundancy, you need to understand what services are available across different portions of the provider’s infrastructure (not all services may be available in all regions, for example) and the costs associated with copying data from one region to another. You also need to consider items that must be addressed when moving something from one region to another (such as copying of images and resulting resource IDs changes).
• Infostructure If you plan on implementing real-time replication of data—not just from one server instance to another, but from one side of North America to the other, for example—you must consider latency and continuously test it.
• Applistructure The applistructure includes the full range of everything included in an application. If everything required for an application is self-contained in a single server, it will be much easier to move than if, for example, your application is tied into other services supplied by the cloud provider. Containers, microservices, and serverless computing are great examples of application code leveraging other services.
By taking all of this into account, you can see why accepting the risk of downtime is a viable option according to CSA Guidance. If you determine that downtime is acceptable, you need to make sure that your systems will fail gracefully. For example, if a customer-facing web page is unavailable, it may be a good idea to add DNS redirection to point to a page displaying that you are aware of the issue and are working on it, rather than presenting some generic “server error 500” message.
One last thing to consider is provider guidance on your DR plans. It might be great to say, “We’ll just fail over from Region A to Region B in the event of failure, and we test that every month,” but I want to highlight a problem with this plan by using a comparison. You know those fire evacuation drills your company has on a quarterly basis? Let’s say you work in an office tower with 30 floors and your company occupies a full floor. As you go through your drill, it takes everyone 15 minutes to evacuate the building. Awesome. But what would happen if there were an actual emergency and all 30 floors were evacuating at once? Think it’s still going to take 15 minutes to get your people out of the building? Not very likely, right? Well, what if you are located in a region with six data centers and a total capacity of, say, six million virtual CPUs (vCPUs), and your target DR region has two data centers and a total capacity of two million vCPUs. What do you think is going to happen if you experience a failover in one or more regions? It’s a game of musical chairs, but the music just stopped, and everyone with the same plans as yours are kicking off their DR processes. It’s just a matter of time until capacity is reached and chaos ensues. So talk to your particular vendor about your DR plans. You may have to purchase capacity reservations, have reserved instances, or take other steps as part of DR planning to guarantee space in the target region.
Chaos Engineering
Chaos engineering is the disciplined approach to experimenting on a system to build confidence in its ability to withstand turbulent and unexpected conditions in production. One leading company not only adopted chaos engineering but created an entire suite of chaos engineering tools and open sourced it to the world: Netflix. As part of its continuous testing of business continuity, Netflix will literally degrade portions of its cloud to determine whether systems are recovering and performing as expected. The company does this in production, not in development.
You may be thinking right now that the Netflix technical leadership is crazy, and there’s no way you would ever take this approach. When you think hard about it, though, it makes sense. This approach forces Netflix developers and engineers to assume failure and build for it from the start. In any organization, this process can help address DR, because failure is already addressed as part of design. In a way, you can consider chaos engineering as continuous resiliency testing.
Business Continuity for Loss of the Cloud Provider
The potential for a provider’s entire environment being unavailable obviously depends on the provider itself. This scenario is extremely rare for leading IaaS providers, however. In fact, the only time I can recall that an entire IaaS provider became unavailable was the Microsoft Azure outage of 2012, when a leap-year bug brought everything down for about nine hours. Amazon and Google have had outages, but these have impacted particular regions, not the entire infrastructure across all regions.
Of course, the minimal risk of a major IaaS failing is one thing, but the failure of PaaS and SaaS are another. In fact, it’s not that rare for a PaaS or SaaS provider to go out of business or be sold to another provider that may not meet contractual obligations or that change the terms and conditions on you with little advance notice. With that in mind, you should be aware of a few important terms if you are considering moving data or applications from one cloud provider to another:
• Interoperability The ability for system components to work together to deliver a service.
• Portability The ability to move from one environment to another with minimal changes required.
• Lock-In Providers can lock in clients not just from a contractual perspective but from a technical one as well—for example, by not supporting the exporting of data in a common format (which, as you may recall from our legal discussion, may impact admissibility of evidence as well).
TIP When thinking of SaaS portability specifically, remember that this is essentially a custom application. If you’ve ever been involved with migrating from Lotus Notes to Microsoft Exchange, for instance, you know all too well the difficulties that can be encountered during application migration, and SaaS migration is no different. Before you adopt a particular SaaS vendor for production use, you should understand how you can get your data exported and what format that data will be in.
Continuity for Private Cloud and Providers
If you are responsible for your company’s private cloud, all aspects of BCP and DR apply, from the facilities up to the applications and data stored. You could determine that a public cloud is the best secondary site, or you could have a traditional spare site that is cold, warm, or hot. As always, plan and test, test, test.
If you are a cloud service provider, the importance of BCP/DR is highly critical—to the point at which the viability of the company as a whole can depend on proper BCP/DR capabilities. You could, for example, lose your business as a result of inappropriate BCP/DR capabilities. Or, if your system is perceived as being undependable by prospective clients, they won’t use your service. If you break service level agreements, you could face penalties. Or if your DR includes failing over to a different jurisdiction, you may be breaking contractual obligations and even potentially data residency laws.
Chapter Review
This chapter covered the importance of APIs, the role of both web consoles and APIs when accessing the management plane, and the use of the IAM functionality supplied by the provider to secure the management plane. This chapter also covered some background information on business continuity planning and disaster recovery and the need for proper planning and architecture of DR in the cloud to meet business requirements.
In preparation for your CCSK exam, you should be comfortable with the following concepts:
• Master accounts should use MFA and be treated as emergency access only.
• Establish accounts using a least-privilege approach.
• All accounts should use MFA when possible to access the management plane.
• Ensure that strong perimeter security exists for API gateways and web consoles.
• BCP and DR are risk-based activities. Remember that not all systems are equally important to business continuity.
• Always architect for failure with regard to BCP and DR.
• Remember that downtime is always an option.
• When considering BCP/DR, consider the entire logical stack.
• Using multiple providers as part of DR can be very difficult, if not impossible, from a metastructure perspective. Strongly consider failover within a single provider before contemplating adding another provider.
• Understand the importance of portability and how it is impacted in BCP/DR.
Questions
1. What level of privileges should be assigned to a user account with access to the metastructure?
A. Read-only
B. Administrative access
C. Least privileges required to perform a job
D. Administrative access only to the system the user is using
2. How should the master account be used in a cloud environment?
A. It should be treated as any other privileged account.
B. The password for the account should be shared only through encrypted e-mail.
C. It should be used only to terminate instances.
D. It should have MFA assigned and be locked in a safe.
3. What layers of the logical stack should be considered as part of BCP/DR?
A. Infostructure
B. Metastructure
C. Infrastructure
D. All layers of the logical model
4. How should BCP/DR be architected in the cloud?
A. Architect for failure.
B. Architect using a single cloud provider.
C. Architect using multiple cloud providers.
D. Architect using real-time replication for all data.
5. What is meant by “lock-in”?
A. Lock-in applies when you are contractually unable to export your data.
B. Exporting data out of a provider would require significant effort.
C. Data exported can be used only with the original provider’s services.
D. All of the above are correct.
6. Which of the following needs to be part of business continuity planning by the customer?
A. Determining how to guarantee availability in the DR region by discussing your DR plans with the vendor
B. Determining how the IaaS provider will fix any availability issues in your application
C. Using contracts to ensure that DR does not result in a different jurisdiction being used to store and process data
D. Implementing chaos engineering
7. What is infrastructure as code (IaC)?
A. IaC uses templates to build your virtual network infrastructure.
B. IaC uses templates to build an entire virtual infrastructure, ranging from networking through to systems.
C. IaC is a ticketing system through which additional instances are requested from the provider.
D. IaC is a ticketing system through which limit increases are requested from the provider.
8. What is the release cycle for new functionality?
A. API functionality is released first, followed by CLI, followed by web console.
B. CLI functionality is released first, followed by API, followed by web console.
C. Web console and API functionality are released first, followed by CLI.
D. The method used to expose new capabilities is determined by the provider.
9. Alice wants to update, but not replace, a file via a REST API. What method should Alice use?
A. GET
B. POST
C. PUT
D. PATCH
10. Which of the following introduces the most complexity when considering a multicloud approach to BCP/DR?
A. Applistructure
B. Metastructure
C. Infrastructure
D. Infostructure
Answers
1. C. Least privileges should always be used. None of the other answers is applicable.
2. D. The master account should have a hardware MFA device assigned, and the credentials along with the MFA device should be locked in a safe to be used only in the event of an emergency.
3. D. All layers of the logical model should be considered for BCP/DR.
4. A. You should always architect for failure when dealing with BCP/DR.
5. D. Lock-in occurs when you cannot easily change providers and export data. It can be addressed only through strong due diligence processes for adopting cloud service providers.
6. A. You need to consult your vendor to determine guaranteed availability in the region. Not all regions have the same amount of capacity and may be over-subscribed in the event of failure in another region. An IaaS provider will not address issues with your own applications. Although data residency regulations may be critical to some companies in certain lines of business, not all companies will face this issue, so C is not the best answer. Chaos engineering may not be for everyone.
7. B. The best answer is that IaC uses templates to build an entire virtual infrastructure, ranging from networking through to systems. Using IaC, you can not only build an entire infrastructure, including server instances based off configured images, but some IaaS providers go so far as supporting the configuration of servers at boot time. It is not a ticketing system.
8. D. Connection and functionality exposed to customers are always dependent on the provider. They may expose new functionalities in many different ways.
9. D. Alice should use the PATCH method to update, but not replace, a file. The PUT method creates a new file. POST is similar to PATCH, but a POST will update and delete the file.
10. B. The metastructure introduces the most complexity when considering a multicloud approach to BCP/DR.