
CHAPTER 5
IT Service Delivery and Infrastructure
This chapter discusses the following topics:
• Information systems operations
• Information systems hardware
• Information systems architecture and software
• Network infrastructure, technologies, models, and protocols
• Disaster recovery planning
• Auditing infrastructure, operations, and disaster recovery planning
This chapter discusses CISA Domain 4, “Information Systems Operations, Maintenance, and Service Management.” The topics in this chapter represent 20 percent of the CISA examination.
IT organizations are effective if their operations are effective. Management needs to be in control of information systems operations, which means that all aspects of operations need to be measured, those measurements and reports reviewed, and management-directed changes carried out to ensure continuous improvement.
IT organizations are service organizations—their existence is to serve the organization and support its business processes. IT’s service management operations need to be well designed, adequately measured, and reviewed by management.
In addition to being familiar with IT business processes, IS auditors need to have a keen understanding of the workings of computer hardware, operating systems, and network communications technology. This knowledge will help the auditor to better understand many aspects of service management and operations.
Information Systems Operations
IS operations is the term that encompasses the day-to-day control of the information systems, applications, and infrastructure that support organizational objectives and processes. IS operations is composed of several sets of activities, which include management and control of operations:
• IT service management
• IT operations and exception handling
• Software program library management
• Quality assurance
• Security management
• Media control
• Data management
These activities are discussed in detail in the remainder of this section, following a brief overview describing how IS operations need to be managed and controlled.
Management and Control of Operations
All of the activities that take place in an IT department should be managed and controlled. This means that all actions and activities performed by operations personnel should be a part of a procedure, process, or project that has been approved by management. Processes, procedures, and projects should have sufficient recordkeeping so that management can understand the status of these activities.
Management is ultimately responsible for all activities that take place in an IS operations department. The primary high-level management activities that govern IS operations are
• Development of processes and procedures Every repetitive activity performed by any operations personnel should be documented in the form of a process or procedure. This means that documents that describe each step of every process and procedure need to be developed, reviewed, approved by management, and made available to operations staff.
• Development of standards From the way that operations performs tasks to the brands and technologies used, standards drive consistency in everything that IS operations does.
• Resource allocation Management is responsible for allocating resources that support IS operations, including manpower, technology, and budget. Resource allocation should align with the organization’s mission, goals, and objectives.
• Process management All IS operations processes should be measured and managed. This will ensure that processes are being performed properly, accurately, and within time and budget targets.
IT Service Management
IT service management (ITSM) is the set of activities that ensures the delivery of IT services is efficient and effective, through active management and the continuous improvement of processes.
ITSM consists of several distinct activities:
• Service desk
• Incident management
• Change management
• Configuration management
• Release management
• Service-level management
• Financial management
• Capacity management
• Service continuity management
• Availability management
Each of these activities is described in detail in this section.
ITSM is defined in the IT Infrastructure Library (ITIL) process framework, a well-recognized standard. The content of ITIL is managed by AXELOS. IT service management processes can be audited and registered to the ISO/IEC 20000:2011 standard, the international standard for ITSM.
Service Desk
Often known as the helpdesk or call center, the IT service desk function handles incidents and service requests on behalf of customers by acting as a single point of contact. The service desk performs end-to-end management of incidents and service requests (at least from the perspective of the customer) and also is responsible for communicating status reports to the customer.
The service desk can also serve as a collection point for other ITSM processes, such as change management, configuration management, service-level management, availability management, and other ITSM functions.
Incident Management
ITIL defines an incident as “An unplanned interruption to an IT service or reduction in the quality of an IT service. Failure of a configuration item that has not yet affected service is also an incident—for example, failure of one disk from a mirror set.”
Thus, an incident may be any of the following:
• Service outage
• Service slowdown
• Software bug
Regardless of the cause, incidents are a result of failures or errors in any component or layer in IT infrastructure.
In ITIL terminology, if the incident has been seen before and its root cause is known, this is a known error. If the service desk is able to access the catalog of known errors, this may result in more rapid resolution of incidents, resulting in less downtime and inconvenience. The change management and configuration management processes are used to make modifications to the system in order to fix it temporarily or permanently.
IT Infrastructure Library, Not Just for the UK
While ITIL may have its roots in the UK, it has very much become an international standard. Partly this is due to ITIL being adopted by the International Organization for Standardization (ISO)/International Electrotechnical Commission (IEC), in the ISO/IEC 20000 standard, and partly because IT management practices are becoming more standardized and mature.
If the root cause of the incident is not known, the incident may be escalated to a problem, which is discussed in the next section.
Problem Management
When several incidents have occurred that appear to have the same or a similar root cause, a problem is occurring. ITIL defines a problem as “a cause of one or more incidents.”
The overall objective of problem management is the reduction in the number and severity of incidents.
Problem management can also include some proactive measures, including system monitoring to measure system health and capacity management that will help management to forestall capacity-related incidents.
Examples of problems include
• A server that has exhausted available resources that result in similar, multiple errors (which, in ITSM terms, are known as incidents)
• A software bug in a service that is noticed by and affecting many users
• A chronically congested network that causes the communications between many IT components to fail
Similar to incidents, when the root cause of a problem has been identified, the change management and configuration management processes will be enacted to make temporary and permanent fixes.
Change Management
Change management is the set of processes that ensures all changes performed in an IT environment are controlled and performed consistently. ITIL defines change management as follows: “The goal of the change management process is to ensure that standardized methods and procedures are used for efficient and prompt handling of all changes, in order to minimize the impact of change-related incidents upon service quality, and consequently improve the day-to-day operations of the organization.”
The main purpose of change management is to ensure that all proposed changes to an IT environment are vetted for suitability and risk, and to ensure that changes will not interfere with each other or with other planned or unplanned activities. In order to be effective, each stakeholder should review all changes so that every perspective of each change is properly reviewed.
A typical change management process is a formal “waterfall” process that includes the following steps:
• Proposal or request The person or group performing the change announces the proposed change. Typically, a change proposal contains a description of the change, the change procedure, the IT components that are expected to be affected by the change, a verification procedure to ensure that the change was applied properly, a back-out procedure in the event the change cannot be applied (or failed verification), and the results of tests that were performed in a test environment. The proposal should be distributed to all stakeholders several days prior to its review.
• Review This is typically a meeting or discussion about the proposed change, where the personnel who will be performing the change can discuss the change and answer any of the stakeholders’ questions. Since the change proposal was sent out earlier, each stakeholder should have had an opportunity to read about the proposed change in advance of the review. Stakeholders can discuss any aspect of the change during the review. The stakeholders may agree to approve the change, or they may request that it be deferred or that some aspect of the proposed change be altered.
• Approval When a change has been formally approved in the review step, the person or group responsible for change management recordkeeping will record the approval, including the names of the individuals who consented to the change. If, however, a change has been deferred or denied, the person or group that proposed the change will need to make alterations to the proposed change so that it will be acceptable, or they can withdraw the change altogether.
• Implementation The actual change is implemented per the procedure described in the change proposal. Here, the personnel identified as the change implementers perform the actual change to the IT system(s) identified in the approved change procedure.
• Verification After the implementers have completed the change, they will perform the verification procedure to make sure that the change was implemented correctly and that it produces the desired result. Generally, the verification procedure will include one or more steps that include the gathering of evidence (and directions for confirming correct vs. incorrect change) that shows the change is correct. This evidence will be filed with other records related to the change, and may be useful in the future if there is any problem with the system where this change is suspected as a part of the root cause.
• Post-change review Some or all changes in an IT organization will be reviewed after the change is implemented. In this activity, the personnel who made the change discuss the change with other stakeholders in order to learn more about the change and whether any updates to future changes may be needed.
These activities should be part of a change control board, a group of stakeholders from IT and every group that is affected by changes in IT applications and supporting infrastructure.

NOTE The change management process is similar to the system development life cycle (SDLC) in that it consists of activities that systematically enact changes to an IT environment.
Change Management Records Most or all of the activities related to a change should include updates to business records so that all of the facts related to each change are captured for future reference. In even the smallest IT organization, there are too many changes taking place over time to expect that anyone will be able to recall facts about each change later on. Records that are related to each change serve as a permanent record.
Emergency Changes While most changes can be planned in advance using the change management process described here, there are times when IT systems need to be changed right away. Most change management processes include a process for emergency changes that details most of the steps in the nonemergency change management process, but they are performed out of order. The steps for emergency changes are
• Emergency approval When an emergency situation arises, the staff members attending to the emergency should still seek management approval for the proposed change. This approval may be done by phone, in person, or in writing (typically e-mail). If the approval was by phone or in person, e-mail or other follow-up is usually performed. Certain members of management should be designated in advance who can approve these emergency changes.
• Implementation The staff members perform the change.
• Verification Staff members verify that the change produced the expected result. This may involve other staff members from other departments or end users.
• Review The emergency change is formally reviewed. This review may be performed alongside nonemergency changes with the change control board, the same group of individuals who discuss nonemergency changes.
Like nonemergency changes, emergency changes should have a full set of records available for future reference.
Linkage to Problem and Incident Management Often, changes are made as a result of an incident or problem. Emergency and nonemergency changes should reference specific incidents or problems so that those incidents and problems may be properly closed once verification of their resolution has been completed.
Configuration Management
Configuration management (CM) is the process of recording the configuration of IT systems. Each configuration setting is known in ITSM parlance as a configuration item (CI). CIs usually include the following:
• Hardware complement This includes the hardware specifications of each system (e.g., CPU speed, amount of memory, firmware version, adaptors, and peripherals).
• Hardware configuration Settings at the hardware level may include boot settings, adaptor configuration, and firmware settings.
• Operating system version and configuration This includes versions, patches, and many operating system configuration items that have an impact on system performance and functionality.
• Software versions and configuration Software components such as database management systems, application servers, and integration interfaces often have many configuration settings of their own.
Organizations that have many IT systems may automate the CM function with tools that are used to automatically record and change configuration settings. These tools help to streamline IT operations and make it easier for IT systems to be more consistent with one another. The database of system configurations is called a configuration management database (CMDB).
Linkage to Problem and Incident Management An intelligent problem and incident management system is able to access the CMDB to help IT personnel determine whether incidents and problems are related to specific configurations. This can be an invaluable aid to those who are seeking to determine a problem’s root cause.
Linkage to Change Management Many configuration management tools are able to automatically detect configuration changes that are made to a system. With some change and configuration management systems, it is possible to correlate changes detected by a configuration management system with changes approved in the change management process. Further, many changes that are approved by the change management process can be performed by configuration management tools, which can be used to push changes out to managed systems.
Release Management
Release management is the ITIL term used to describe the portion of the SDLC where changes in applications are made available to end users. Release management is used to control the changes that are made to software programs, applications, and environments.
The release process is used for several types of changes to a system, including:
• Incidents and problem resolution Casually known as bug fixes, these types of changes are done in response to an incident or problem, where it has been determined that a change to application software is the appropriate remedy.
• Enhancements New functions in an application are created and implemented. These enhancements may have been requested by customers, or they may be a part of the long-range vision on the part of the designers of the software program.
• Subsystem patches and changes Changes in lower layers in an application environment may require a level of testing that is similar to what is used when changes are made to the application itself. Examples of changes are patches, service packs, and version upgrades to operating systems, database management systems, application servers, and middleware.
The release process is a sequential process. That is, each change that is proposed to a software program will be taken through each step in the release management process. In many applications, changes are usually assembled into a “package” for process efficiency purposes: it is more effective to discuss and manage groups of changes than it would be to manage individual changes.
The steps in a typical release process are preceded by typical SDLC process steps, which are
• Feasibility Study Activities that seek to determine the expected benefits of a program, project, or change to a system.
• Requirements Definition Each software change is described in terms of a feature description and requirements. The feature description is a high-level description of a change to software that may explain the change in business terms. Requirements are the detailed statements that describe a change in enough detail for a developer to make changes and additions to application code that will provide the desired functionality. Often, end users will be involved in the development of requirements so that they may verify that the proposed software change is really what they desire.
• Design After requirements have been developed, a programmer/analyst or application designer will create a formal design. For an existing software application, this will usually involve changes to existing design documents and diagrams, but for new applications, these will need to be created from scratch or copied from similar designs and modified. Regardless, the design will have a sufficient level of detail to permit a programmer or software engineer to complete development without having to discern the meaning of requirements or design.
• Development When requirements and design have been completed, reviewed, and approved, programmers or software engineers begin development. This involves actual coding in the chosen computer language with approved development tools, as well as the creation or update to ancillary components, such as a database design or application programming interface (API). Developers will often perform their own unit testing, where they test individual modules and sections of the application code to make sure that it works properly.
• Testing When the developers have finished coding and unit testing, a more formal and comprehensive test phase is performed. Here, analysts, dedicated software testers, and perhaps end users will test all of the new and changed functionality to confirm whether it is performing according to requirements. Depending on the nature of the changes, some amount of regression testing is also performed; this means that functions that were confirmed to be working properly in prior releases are tested again to make sure that they continue to work as expected. Testing is performed according to formal, written test plans that are designed to confirm that every requirement is fulfilled. Formal test scripts are used, and the results of all tests should be recorded and archived. The testing that users perform is usually called user acceptance testing (UAT). Often, automated test tools are used, which can make testing more accurate and efficient. After testing is completed, a formal review and approval are required before the process is allowed to continue.
• Implementation When testing has been completed the software is implemented on production systems. Here, developers hand off the completed software to operations personnel, who install it according to instructions created by developers. This could also involve the use of tools to make changes to data and database design, to accommodate changes in the software. When changes are completed and tested, the release itself is carried out with these last two steps:
• Release preparation When UAT and regression testing have been completed, reviewed, and approved, a release management team will begin to prepare the new or changed software for release. Depending upon the complexity of the application and of the change itself, release preparation may involve not only software installation but also the installation or change to database design, and perhaps even changes to customer data. Hence, the software release may involve the development and testing of data conversion tools and other programs that are required so that the new or changed software will operate properly. As with testing and other phases, full records of testing and implementation of release preparation details need to be captured and archived.
• Release deployment When release preparation is completed (and perhaps reviewed and approved), the release is installed on the target system(s). Personnel deploying the release will follow the release procedure, which may involve the use of tools that will make changes to the target system at the operating system, database, or other level; any required data manipulation or migration; and the installation of the actual software. The release procedure will also include verification steps that will be used to confirm the correct installation of all components.
• Post-Implementation After the software has been implemented, a post-implementation review takes place to examine matters of system adequacy, security, ROI, and any issues encountered during implementation.
Utilizing a Gate Process Many organizations utilize a “gate process” approach in their release management process. This means that each step of the process undergoes formal review and approval before the next step is allowed to begin. For example, a formal design review will be performed and attended by end users, personnel who created requirements and feature description documents, developers, and management. If the design is approved, development may begin. But if there are questions or concerns raised in the design review, the design may need to be modified and reviewed again before development is allowed to begin.
Agile processes utilize gates as well, although the flow of Agile processes is often parallel rather than sequential. The concept of formal reviews is the same, regardless of the SDLC process in use.
Service-Level Management
Service-level management is composed of the set of activities that confirms whether IS operations is providing adequate service to its customers. This is achieved through continuous monitoring and periodic review of IT service delivery.
An IT department often plays two different roles in service-level management. As a provider of service to its own customers, the IT department will measure and manage the services that it provides directly. Also, many IT departments directly or indirectly manage services that are provided by external service providers. Thus, many IT departments are both service provider and customer, and often the two are interrelated. This is depicted in Figure 5-1.

Figure 5-1 The different perspectives of the delivery of IT services
Financial Management
Financial management for IT services consists of several activities, including:
• Budgeting
• Capital investment
• Project accounting and project return on investment (ROI)
IT financial management is the portion of IT management that takes into account the financial value of IT services that support organizational objectives.
Capacity Management
Capacity management is a set of activities that confirms there is sufficient capacity in IT systems and IT processes to meet service needs. Primarily, an IT system or process has sufficient capacity if its performance falls within an acceptable range, as specified in service-level agreements (SLAs).
Capacity management is not just a concern for current needs; capacity management must also be concerned about meeting future needs. This is attained through several activities, including:
• Periodic measurements Systems and processes need to be regularly measured so that trends in usage can be used to predict future capacity needs.
• Considering planned changes Planned changes to processes and IT systems may have an impact on predicted workload.
• Understanding long-term strategies Changes in the organization, including IT systems, business processes, and organizational objectives, may have an impact on workloads, requiring more (or less) capacity than would be extrapolated through simpler trend analysis.
• Changes in technology Several factors may influence capacity plans, including the expectation that computing and network technologies will deliver better performance in the future and that trends in the usage of technology may influence how end users use technology.
Linkage to Financial Management One of the work products of capacity management is a projection for the acquisition of additional computer or network hardware to meet future capacity needs. This information needs to be made a part of budgeting and spending management processes.
Linkage to Service-Level Management If there are insufficient resources to handle workloads, capacity issues may result in violations to SLAs. Systems and processes that are overburdened will take longer to respond. In some cases, systems may stop responding altogether.
Linkage to Incident and Problem Management Systems with severe capacity issues may take excessive time to respond to user requests. In some cases, systems may malfunction or users may give up. Often, users will call the service desk, resulting in the logging of incidents and problems.
Service Continuity Management
Service continuity management is the set of activities that is concerned with the ability of the organization to continue providing services, primarily in the event that a natural or manmade disaster has occurred. Service continuity management is ITIL parlance for the more common terms business continuity planning and disaster recovery planning.
Business continuity is discussed later in this chapter. Disaster recovery planning is discussed in Chapter 2.
Availability Management
The goal of availability management is to sustain IT service availability in support of organizational objectives and processes. The availability of IT systems is governed by:
• Effective change management When changes to systems and infrastructure are properly vetted through a change management process, changes are less likely to result in unanticipated downtime.
• Effective application testing When changes to applications are made according to a set of formal requirements, review, and testing, the application is less likely to fail and become unavailable.
• Resilient architecture When the overall architecture of an application environment is designed from the beginning to be highly reliable, it will be more resilient and more tolerant of individual faults and component failures.
• Serviceable components When the individual components of an application environment can be effectively serviced by third-party service organizations, those components will be less likely to fail unexpectedly.
NOTE Organizations typically measure availability as a percentage of uptime of an application or service.
IT Operations and Exception Handling
Effective IT operations requires that IT personnel understand and properly carry out operational tasks according to established processes and procedures. Personnel must also be trained to recognize exceptions and errors, and respond to them accordingly. The tasks that may be included in IT operations include
• Running jobs according to the job schedule
• Monitoring jobs and allocating resources to jobs based on priority
• Restarting failed jobs and processes
• Facilitating backup jobs by loading or changing backup media
• Monitoring systems, applications, and networks for availability and adequate performance
• Performing after-hours maintenance activities such as equipment cleaning and system restarts
IT organizations often employ a production schedule, which is a list of activities or tasks that are carried out periodically (daily, weekly, monthly, quarterly, and so on). These activities consist of system-borne activities such as backups, as well as human-performed activities such as access reviews. Scheduled activities in systems may be automatically scheduled or manually invoked.
Larger organizations may have a network operations center (NOC) and perhaps also a security operations center (SOC), staffed by personnel who monitor activities in the organization’s security devices, networks, systems, and applications. Often these activities are outsourced to a managed security service provider (MSSP).
Exceptions and errors that occur within the context of IT operations are typically handled according to ITSM incident management and problem management processes, which were discussed in the preceding section.
Monitoring
Information systems, applications, and supporting infrastructure must be monitored to ensure that they continue to operate as required.
Monitoring tools and programs enable IT operations staff to detect when software or hardware components are not operating as planned. The IT operations staff must also make direct observations in order to detect some problems. The types of errors that should be detected and reported include
• System errors
• Program errors
• Communications errors
• Operator errors
Simply put, any event that represents unexpected or abnormal activity should be recorded so that management and customers may become aware of it. This requires that incident and problem management processes be developed. Incident and problem management are discussed in detail in the earlier section, “IT Service Management.”
NOTE IT business processes also need to be monitored. Process monitoring is discussed in Chapters 2 and 3.
Security Monitoring
Many organizations perform several types of security monitoring, as a part of their overall strategy to prevent and respond to security incidents. The types of monitoring that an organization may perform include
• Firewall exceptions
• Intrusion prevention system (IPS) alerts
• Data loss prevention (DLP) system alerts
• User access management system alerts
• Network anomaly (netflow) system alerts
• Web filtering system alerts
• Endpoint management system alerts
• Vendor security advisories
• Third-party security advisories
• Work center access system alerts
• Video surveillance system alerts
End-User Computing
A critical portion of an IT organization’s function is the services it renders to organization personnel to facilitate their access and use of IT systems and applications. Several operational models for supporting end-user computing are used, including:
• Organization-provided hardware and software The organization provides all computing devices (typically, laptop or desktop computers, and also perhaps mobile computing devices such as tablets or smartphones) and software.
• Personnel-provided hardware and software The organization provides network infrastructure and instructions on how end users may configure their computing devices to access the organization’s IT applications and systems. Some organizations provide a stipend to its personnel to pay for all or part of the costs of end-user computers.
• Hybrid models Many organizations employ a hybrid of the organization and personnel models. Often, an organization provides laptop or desktop computers, and employees are permitted to access e-mail and some organization applications via personally owned devices such as home computers, tablets, and smartphones.
Usually the organization will employ enterprise management tools to facilitate efficient and consistent management of end-user computers. Typically, end-user computers are “locked down,” which limits the amount of and types of configuration changes that end users may perform on their devices, including:
• Operating system configuration
• Patch installation
• Software program installation
• Use of external data storage devices
Such restrictions may be viewed by end users as an inconvenience. However, these restrictions not only help to ensure greater security of end-user devices and the entire organization’s IT environment, but also promote greater consistency, which leads to reduced support costs.
Software Program Library Management
The software program library is the facility that is used to store and manage access to an organization’s application source and object code.
In most organizations, application source code is highly sensitive. It may be considered intellectual property, and it may contain information such as algorithms, encryption keys, and other sensitive information that should be accessed by as few persons as possible. In a very real sense, application source code should be considered information and be treated as such through the organization’s security policy and data classification policy.
A software program library often exists as an information system with a user interface and several functions, including:
• Access and authorization controls The program library should uniquely identify all individuals who attempt to access the program library and authenticate them with means that are commensurate with the sensitivity of the application. The program library should be able to manage different roles or levels of access so that each person is able to perform only the functions that they are authorized to perform. Also, the program library should be able to restrict access to different modules or applications stored within it; for example, source code that is more sensitive (such as the code related to access control or data encryption) should be accessible by fewer personnel than less sensitive source code.
• Program checkout This means that an authorized user is able to access some portion of application source code, presumably to make a modification or perform analysis. Checkout permits the user to make a copy of the source code module that might be stored elsewhere on the program library or on another computer. Often, checkout is only permitted upon management approval, or it may be integrated with a defect tracking system so that a developer is able to check out a piece of source code only if there is a defect in that program that has been assigned to her. When source code is checked out, the program library typically “locks” that section of source code so that another developer is not able to also check it out—this prevents a “collision” where two developers are making changes to the same section of code at the same time.
• Program check-in This function allows an authorized user to return a section of application source code to the program library. A program library will usually only permit the person who checked out a section of code to check it back in. If the user who is checking in the code section made modifications to it, the program library will process those changes and may perform a number of additional functions, including version control and code scanning. If the section of code being checked in was locked, the program library will either automatically unlock it or ask the user whether it should remain locked.
• Version control This function allows the program library to manage changes to the source code by tracking the changes that are made to it each time it is checked in. Each time a source code module is modified, a “version number” is incremented. This gives the program library the ability to recall any prior version of a source code module at any time in the future. This can be useful during program troubleshooting or investigations into a particular programmer’s actions.
• Code analysis Some program library systems are able to perform different types of code analysis when source code is checked in. This may include a security scan that will examine the code for vulnerabilities or a scan that will determine whether the checked-in module complies with the organization’s coding policies and standards.
These controls enable an organization to have a high degree of control over the integrity and, hence, quality and security, of its software applications.
Quality Assurance
The purpose of quality assurance (QA) is to ensure that changes to software applications, operating system configuration, network device configuration, and other information systems components are performed properly. Primarily, this is carried out through independent verification of work.
QA can be carried out within most IT processes, including but not limited to:
• Software development
• Change management
• Configuration management
• Service management
• Incident management
• Problem management
As a result of QA activities, improvements in accuracy and efficiency are sought and processes and systems are changed.
Security Management
Information security management is the collection of high-level activities that ensures that an organization’s information security program is adequate and operating properly. An information security management program usually consists of several activities:
• Development of security policy, processes, procedures, and standards
• Risk assessment and risk management
• Vulnerability management
• Incident management
• Security awareness training
These topics are discussed in detail in Chapters 2 and 6.
Media Control
Security standards and privacy laws have highlighted the need for formal processes to ensure the proper management of digital media, including its protection, as well as destruction of data that is no longer needed. These processes are usually a part of data retention and data purging procedures so that data that is needed is adequately protected with physical and logical security controls, and data that is no longer needed is effectively erased. Procedures related to the disposal of media that is no longer needed now include steps to erase data on that media or make the data on that media irretrievable in some other way.
Media that should be considered in scope for media management and destruction policies and procedures includes
• Backup media
• Virtual tape libraries
• Optical media
• Hard drives and solid-state drives
• Flash memory in computers, network devices, disk drives, workstations, mobile devices, and portable USB storage devices
• Hard drives in printers, copiers, and scanners
• Hard copy
Policies and procedures for media sanitization need to be included in service provider contracts, as well as recordkeeping to track the destruction of media over time.
Media control is closely related to data management, discussed in the next subsection.
Data Management
Data management is the set of activities related to the acquisition, processing, storage, use, and disposal of data.
Arguably the most important activity in data management is planning. Like most human endeavors, data management activities have far better outcomes when planning precedes action. Mainly this is related to data architecture, which is the set of activities related to the design of databases and the flows of information between databases, systems, and organizations.
Data Life Cycle
The data life cycle is the set of activities that take place throughout the use of data in an organization. The phases of the data life cycle are
• Planning Prior to the creation or acquisition of data, organizations need to understand its structure, its sensitivity and value, its use, and its eventual destruction.
• Design This is the actual process of creating the structure and protection of data. Typical activities at this stage include the creation of a database schema and configuration of physical and logical storage systems that will store databases.
• Build/acquire This is the phase where data is created, or imported from another system.
• Operations This is the phase where data is processed, shared, and used.
• Monitoring This includes examination of the data itself, as well as activities related to the access and use of data, to ensure that the data retains its quality and that it is protected from misuse and harm.
• Archival This is related to any long-term storage of data for legal or historical purposes.
• Disposal This is related to the discarding or erasure process that takes place at the end of the useful life of a set of data.
NOTE DAMA International is a professional organization for people in the data management profession. Information is available at www.dama.org.
Data Quality Management
Data quality management encompasses several activities to ensure the confidentiality, integrity, and completeness of data. Activities in data quality management include
• Application controls Measures to ensure that applications enforce the integrity and completeness of data. This topic is covered in Chapter 4.
• Systems development Measures to ensure that applications that are developed or acquired enforce the integrity and completeness of data. This topic is covered in Chapter 4.
• Systems integrity Measures to ensure that information systems enforce the confidentiality and integrity of data. This topic is covered in Chapter 6.
Information Systems Hardware
Hardware is the elemental basis of information systems. It consists of circuit boards containing microprocessors and memory, and other components connected through circuitry, such as hard disk drives or solid-state drives, and peripherals, such as keyboards, printers, monitors, and network connections.
IS auditors need to understand at least the basic concepts of computer hardware architecture, maintenance, and monitoring so that they can properly assess an organization’s use and care of information systems hardware. A lack of knowledge in this area could result in the auditor overlooking or failing to understand important aspects of an organization’s operations.
Computer Usage
Computers are manufactured for a variety of purposes and contexts, and are used for many different purposes. They can be classified by their capacity, throughput, size, use, or the operating system or software that they use.
Types of Computers
From a business perspective, computers are classified according to their size and portability. In this regard, the types of computers are
• Supercomputer These are the largest computers in terms of the number and/or power of their central processing units (CPUs). Supercomputers are generally employed for scientific applications such as weather and climate forecasting, seismology, and other computer-intensive applications.
• Mainframe These are the business workhorse computers that are designed to run large, complex applications that operate on enormous databases or support vast numbers of users. When computing began, mainframes were the only kind of computer; most of the other types were derived from the mainframe.
• Midrange These computers are not as large and powerful as mainframe computers, but are larger or more powerful than small servers. There are no hard distinctions between these sizes of computers, but only vague, rough guidelines.
• Server If mainframe computers are the largest business servers, then the ordinary server is the smallest. In terms of its hardware complement and physical appearance, a server can be indistinguishable from a user’s desktop computer.
• Blade server This is a style of hardware design where servers are modules that plug in to a cabinet. Each module contains all of the internal components of a stand-alone computer. The cabinet itself will contain power supplies and network connectors.
• Appliance This is a type of computer that typically comes with one or more tools or applications preinstalled. The term “appliance” is used to connote the fact that little or no maintenance is required on the system.
• Desktop This is a computer that is used by an individual worker. Its size makes it fairly easy to move from place to place, but it is not considered portable. The desktop computers of today are more powerful in many ways than the mainframe computers of a few decades ago. Desktop computers used to be called microcomputers, but the term is seldom used now.
• Laptop/notebook This computer is portable in every sense of the word. It is self-contained, is equipped with a battery, and folds for storage and transport. Functionally, desktop and laptop computers are nearly identical: they may run the same operating system and programs.
• Mobile These computers come in the form of smartphones, tablet computers, and netbook computers.
• Embedded These are computers built into products such as televisions, automobiles, and many other industrial and consumer devices.
Uses for Computers
Aside from the sizes and types of computers discussed in the previous section, computers may also be used for several reasons, including:
• Application server This is a computer—usually a mainframe, midrange, or server—that runs application-server software. An application server contains one or more application programs that run on behalf of users. Data used by an application server may be stored on a database server.
• Web server This is a server that runs a web server program to make web pages available to users. A web server will usually contain both the web server software and the content (“pages”) that are requested by and sent to users’ web browser programs. A web server can also be linked to an application server or database server to permit the display of business information, such as filling out order forms, viewing reports, and so on.
• Database server Also a mainframe, midrange, or small server, a database server runs specialized database management software that controls the storage and processing of large amounts of data that resides in one or more databases.
• Gateway A server that performs some manner of data transformation—for instance, converting messages from one format to another—between two applications.
• File server This computer is used to provide a central location for the storage of commonly used files. File servers may be used by application servers or by a user community.
• Print server In an environment that uses shared printers, a print server is typically used to receive print requests from users or applications and store them temporarily until they are ready to be printed.
• Production server/test server The terms production server and test server denote whether a server supports actual business use (a production server) or is a separate server that can be used to test new programs or configurations (a test server). Most organizations will have at least one test server for every type of production server so that any new programs, configurations, patches, or settings can be tested on a test server, where there will be little or no risk of disrupting actual business operations.
• Thick client A thick client is a user’s computer (of the desktop or laptop variety) that contains a fully functional operating system and application programs. Purists will argue that a thick client is only a thick client if the system contains one or more software application client programs. This is a reasonable distinction between a thick client and a workstation, described later.
• Thin client A thin client is a user’s workstation that contains a minimal operating system and little or no data storage. Thin-client computers are often used in businesses where users run only application programs that can be executed on central servers and display data shown on the thin client’s screen. A thin client may be a desktop or laptop computer with thin-client software, or it may be a specialized computer with no local storage other than flash memory.
• Workstation A user’s laptop or desktop computer. For example, a PC running the Windows operating system and using Microsoft Office word processor and spreadsheet programs, a Firefox browser, and Winamp media player would be considered a workstation.
• Mobile device A user’s smartphone, tablet computer, or netbook computer.
NOTE For the most part, computers are designed for general use in mind so that they may perform any of the functions listed here.
Computer Hardware Architecture
Computers made since the 1960s share common characteristics in their hardware architecture. They have one or more central processing units, a bus (or more than one), main memory, and secondary storage. They also have some means for communicating with other computers or with humans, usually through communications adaptors.
This section describes computer hardware in detail.
Mobile Devices, the New and Disruptive Endpoint
Much is said about endpoints being the weak link in IT infrastructure. But historically speaking, these proclamations are more about laptop computers, which, for the most part, can be well managed by enterprises.
Mobile devices are a different matter entirely. They are turning all of the rules about endpoint computing on their head. Principally:
• End users choose which models to purchase and own them outright.
• End users can install any application they choose.
• Mobile devices can be easily connected to corporate e-mail without any help (or consent) from the IT department.
• There are few, if any, anti-malware or other anti-tampering tools available.
• Mobile devices are easily lost and more easily broken into than laptop computers.
• Mobile device manufacturers have published application interfaces, thereby enabling the creation of malware that can steal data and alter operation of the device.
IS auditors need to understand how organizations are addressing the mobile device dilemma.
Central Processing Unit
The central processing unit, or CPU, is the main hardware component of a computer system. The CPU is the component that executes instructions in computer programs.
Each CPU has an arithmetic logic unit (ALU), a control unit, and a small amount of memory. The memory in a CPU is usually in the form of registers, which are memory locations where arithmetic values are stored.
The CPU in modern computers is wholly contained in a single large-scale integration integrated circuit (LSI IC), more commonly known as a microprocessor. A CPU is attached to a computer circuit board (often called a motherboard on a personal computer) by soldering or a plug-in socket. A CPU on a motherboard is shown in Figure 5-2.

Figure 5-2 A CPU that is plugged into a computer circuit board (Image courtesy of Fir0002/Flagstaffotos)
CPU Architectures A number of architectures dominate the design of CPUs. Two primary architectures that are widely used commercially are
• CISC (complex instruction set computer) This CPU design has a comprehensive instruction set, and many instructions can be performed in a single cycle. This design philosophy claims superior performance over RISC. Well-known CISC CPUs include Intel x86, VAX, PDP-11, Motorola 68000, and System/360.
• RISC (reduced instruction set computer) This CPU design uses a smaller instruction set (meaning fewer instructions in its “vocabulary”), with the idea that a small instruction set will lead to a simpler microprocessor design and better computer performance. Well-known RISC CPUs include Alpha, MIPS, PowerPC, and SPARC. None of these is produced today.
Another aspect of CPUs that is often discussed is the power requirements. Typically, the CPUs that are used for laptop computers and mobile devices are known as low-power CPUs, while other CPUs are used in desktop, server, and mainframe systems, where performance and speed are more important considerations than power consumption.
Computer CPU Architectures Early computers had a single CPU. However, it became clear that many computing tasks could be performed more efficiently if computers had more than one CPU to perform them. Some of the ways that computers have implemented CPUs are
• Single CPU In this design, the computer has a single CPU. This simplest design is still prevalent, particularly among small servers and personal computers.
• Multiple CPUs A computer design can accommodate multiple CPUs, from as few as 2 to as many as 128 or more. There are two designs for multi-CPU computers: symmetric and asymmetric. In the symmetric design, all CPUs are equal in terms of how the overall computer’s architecture uses them. In the asymmetric design, one CPU is the “master.” Virtually all multi-CPU computers made today are symmetric.
• Multicore CPUs A change in the design of CPUs themselves has led to multicore CPUs, in which two or more central processors occupy a single CPU chip. The benefit of multicore design is the ability for software code to be executed in parallel, leading to improved performance. Many newer servers and personal computers are equipped with multicore CPUs, and some are equipped with multiple multicore CPUs.
Bus
A bus is an internal component in a computer that provides the means for the computer’s other components to communicate with each other. A computer’s bus connects the CPU with its main and secondary storage, as well as to external devices.
Most computers also utilize electrical connectors that permit the addition of small circuit boards that may contain additional memory, a communications device or adaptor (for example, a network adaptor or a modem), a storage controller (for example, a SCSI [Small Computer Systems Interface] or ATA [AT Attachment] disk controller), or an additional CPU.
Several industry standards for computer buses have been developed. Notable standards include
• Universal Serial Bus (USB) This standard is used to connect external peripherals such as external storage devices, printers, and mobile devices. USB operates at data rates up to 5.0 Gbit/sec. USB is discussed in more detail later in this chapter.
• Serial ATA (SATA) This standard is used mainly to connect mass storage devices such as hard disk drives, optical drives, and solid-state drives.
• PCI Express (PCIe) This bus standard replaced older standards such as PCI and PCI-X, and employs data rates from 250 Mbyte/sec to 31 Gbyte/sec.
• Thunderbolt This hardware interface standard is a combination of PCI Express and DisplayPort (DP) in a single serial signal.
• PC Card Formerly known as PCMCIA, the PC Card bus is prevalent in laptop computers, and is commonly used for the addition of specialized communication devices.
• ExpressCard Also developed by the PCMCIA, this bus standard replaces the PC Card standard.
It is not uncommon for a computer to have more than one bus. For instance, many PCs have an additional bus that is known as a front-side bus (FSB), which connects the CPU to a memory controller hub, as well as a high-speed graphics bus, a memory bus, and the low pin count (LPC) bus that is used for low-speed peripherals such as parallel and serial ports, keyboard, and mouse.
Main Storage
A computer’s main storage is used for short-term storage of information. Main storage is usually implemented with electronic components such as random access memory (RAM), which is relatively expensive but also relatively fast in terms of accessibility and transfer rate.
A computer uses its main storage for several purposes:
• Operating system The computer’s running operating system uses main storage to store information about running programs, open files, logged-in users, in-use devices, active processes, and so on.
• Buffers Operating systems and programs will set aside a portion of memory as a “scratch pad” that can be used to temporarily store information retrieved from hard disks or information that is being sent to a printer or other device. Buffers are also used by network adaptors to temporarily store incoming and outgoing information.
• Storage of program code Any program that the computer is currently executing will be stored in main storage so that the CPU can quickly access and read any portion of the program as needed. Note that the program in main storage is only a working copy of the program, used by the computer to quickly reference instructions in the program.
• Storage of program variables When a program is being run, it will store intermediate results of calculations and other temporary data. This information is stored in main storage, where the program can quickly reference portions of it as needed.
Main storage is typically volatile. This means that the information stored in main storage should be considered temporary. If electric power were suddenly removed from the computer, the contents of main storage would vanish and would not be easily recovered, if at all.
Different technologies are used in computers for main storage:
• DRAM (dynamic RAM) The most common form of semiconductor memory, data is stored in capacitors that require periodic refreshing to keep them charged—hence the term dynamic.
• SRAM (static RAM) Another form of semiconductor memory that does not require periodic refresh cycles like DRAM.
A typical semiconductor memory module is shown in Figure 5-3.

Figure 5-3 Typical RAM module for a laptop, workstation, or server (Image courtesy of Sassospicco)
Secondary Storage
Secondary storage is the permanent storage used by a computer system. Unlike primary storage (which is usually implemented in volatile RAM modules), secondary storage is persistent and can last many years.
This type of storage is usually implemented using hard disk drives or solid-state drives ranging in capacity from megabytes to terabytes.
Secondary storage represents an economic and performance tradeoff from primary storage. It is usually far slower than primary storage, but the unit cost for storage is far less costly. At the time of this writing, the price paid for about 16GB of RAM could also purchase a 2TB hard disk drive, which makes RAM (primary) storage more than 1,000 times more expensive than hard disk (secondary) storage. A hard disk drive from a desktop computer is shown in Figure 5-4.

Figure 5-4 Typical computer hard disk drive (Image courtesy of Robert Jacek Tomczak)
A computer uses secondary storage for several purposes:
• Program storage The programs that the computer executes are contained in secondary storage. When a computer begins to execute a program, it makes a working copy of the program in primary storage.
• Data storage Information read into, created by, or used by computer programs is often stored in secondary storage. Secondary storage is usually used when information is needed for use at a later time.
• Computer operating system The set of programs and device drivers that are used to control and manage the use of the computer is stored in secondary storage.
• Temporary files Many computer programs need to store information for temporary use that may exceed the capacity of main memory. Secondary storage is often used for this purpose. For example, a user wishes to print a data file onto a nearby laser printer; software on the computer will transform the stored data file into a format that is used by the laser printer to make a readable copy of the file; this “print file” is stored in secondary storage temporarily until the printer has completed printing the file for the user, and then the file is deleted.
• Virtual memory This is a technique for creating a main memory space that is physically larger than the actual available main memory. Virtual memory (which should not be confused with virtualization) is discussed in detail later in this chapter in the section “Computer Operating Systems.”
While secondary storage is usually implemented with hard disk drives, many newer systems use semiconductor flash memory in devices called solid-state drives. Flash is a nonvolatile semiconductor memory that can be rewritten and requires no electric power to preserve stored data.
While secondary storage technology is persistent and highly reliable, hard disk drives and even solid-state drives (SSDs) are known to fail from time to time. For this reason, important data in secondary storage is often copied to other storage devices, either on the same computer or on a different computer, or it is copied onto computer backup tapes that are designed to store large amounts of data for long periods at low cost. This practice of data backup is discussed at length in the section “Information Systems Operations” earlier in this chapter.
Firmware
Firmware is special-purpose storage that is used to store the instructions needed to start a computer system. Typically, firmware consists of low-level computer instructions that are used to control the various hardware components in a computer system and to load and execute components of the operating system from secondary storage. This process of system initialization is known as an initial program load (IPL) or bootstrap (or just “boot”).
Read-only memory (ROM) technology is often used to store a computer’s firmware. Several available ROM technologies are in use, including:
• ROM (read-only memory) The earliest forms of ROM are considered permanent and can never be modified. The permanency of ROM makes it secure, but it can be difficult to carry out field upgrades. For this reason ROM is not often used.
• PROM (programmable read-only memory) This is also a permanent and unchangeable form of storage. A PROM chip can be programmed only once, and must be replaced if the firmware needs to be updated.
• EPROM (erasable programmable read-only memory) This type of memory can be written to with a special programming device and then erased and rewritten at a later time. EPROM chips are erased by shining ultraviolet (UV) light through a quartz window on the chip; the quartz window is usually covered with a foil label, although sometimes an EPROM chip does not have a window at all, which effectively makes it a PROM device.
• EEPROM (electrically erasable programmable read-only memory) This is similar to EPROM, except that no UV light source is required to erase and reprogram the EEPROM chip; instead, signals from the computer in which the EEPROM chip is stored can be used to reprogram or update the EEPROM. Thus, EEPROM was one of the first types of firmware that could be updated by the computer on which it was installed.
• Flash This memory is erasable, reprogrammable, and functionally similar to EEPROM, in that the contents of flash memory can be altered by the computer that it is installed in. Flash memory is the technology used in popular portable storage devices such as USB memory devices, Secure Digital (SD) cards, Compact Flash, and Memory Stick.
A well-known use for firmware is the ROM-based BIOS (basic input/output system) on IBM and Intel-based personal computers.
I/O and Networking
Regardless of their specific purpose, computers nearly always must have some means for accepting input data from some external source, as well as for sending output data to some external destination. Whether this input and output are continuous or infrequent, computers usually have one or more methods for transferring data. These methods include
• Input/output (I/O) devices Most computers have external connectors to permit the attachment of devices such as keyboards, mice, monitors, scanners, printers, and cameras. The electrical signal and connector-type standards include PS/2 (for keyboards and mice), USB, parallel, serial, and Thunderbolt. Some types of computers lack these external connectors; instead, special adaptor cards can be plugged into a computer’s bus connector. Early computers required reprogramming and/or reconfiguration when external devices were connected, but newer computers are designed to automatically recognize when an external device is connected or disconnected, and will adjust automatically.
• Networking A computer can be connected to a local or wide area data network. Then, one of a multitude of means for inbound and outbound data transfer can be configured that will use the networking capability. Some computers will have built-in connectors or adaptors, but others will require the addition of internal or external adaptors that plug into bus connectors such as PC Card, ExpressCard, or PCI.
Multicomputer Architectures
Organizations that use several computers have a lot of available choices. Not so long ago, organizations that required several servers would purchase individual server computers. Now there are choices that can help to improve performance and reduce capital, including:
• Blade computers This architecture consists of a main chassis component that is equipped with a central power supply, cooling, network, and console connectors, with several slots that are fitted with individual CPU modules. The advantage of blade architecture is the lower-than-usual unit cost for each server module, since it consists of only a circuit board. The costs of power supply, cooling, and so on, are amortized among all of the blades. A typical blade system is shown in Figure 5-5.

Figure 5-5 Blade computer architecture (Image courtesy of Robert Kloosterhuis)
• Grid computing The term grid computing is used to describe a large number of loosely coupled computers that are used to solve a common task. Computers in a grid may be in close proximity to each other or scattered over a wide geographic area. Grid computing is a viable alternative to supercomputers for solving computationally intensive problems.
• Server clusters A cluster is a tightly coupled collection of computers that is used to solve a common task. In a cluster, one or more servers actively perform tasks, while zero or more computers may be in a “standby” state, ready to assume active duty should the need arise. Clusters usually give the appearance of a single computer to the perspective of outside systems. Clusters usually operate in one of two modes: active-active and active-passive. In active-active mode, all servers perform tasks; in active-passive mode, some servers are in a standby state, waiting to become active in an event called a failover, which usually occurs when one of the active servers has become incapacitated.
These options give organizations the freedom to develop a computer architecture that will meet their needs in terms of performance, availability, flexibility, and cost.
Virtualization Architectures
Virtualization refers to the set of technologies that permits two or more running operating systems (of the same type, or different types) to reside on a single physical computer. Virtualization technology permits organizations to use its computing resources more efficiently.
Before I explain the benefits of virtualization, I should first state one of the principles of computer infrastructure management. It is a sound practice to use a server for one single purpose. Using a single server for multiple purposes can introduce a number of problems, including:
• Tools or applications that reside on a single computer may interfere with one another.
• Tools or applications that reside on a single computer may interact with each other or compete for common resources.
• A tool or application on a server could, although rarely, cause the entire server to stop running; on a server with multiple tools or applications, this could cause the other tools and applications to stop functioning.
Prior to virtualization, the most stable configuration for running many applications and tools was to run each on a separate server. This would, however, result in a highly inefficient use of computers and of capital, as most computers with a single operating system spend much of their time in an idle state.
Virtualization permits IT departments to run many applications or tools on a single physical server, each within its own respective operating system, thereby making more efficient use of computers (not to mention electric power and data center space). Virtualization software emulates computer hardware so that an operating system running in a virtualized environment does not know that it is actually running on a virtual machine. Virtualization software, known as a hypervisor, includes resource allocation configuration settings so that each guest (a running operating system) will have a specific amount of memory, hard disk space, and other peripherals available for its use. Virtualization also facilitates the sharing of peripheral devices such as network connectors so that many guests can use an individual network connector, although each will have its own unique IP address.
Virtualization software provides security by isolating each running operating system and preventing it from accessing or interfering with others. This is similar to the concept of process isolation within a running operating system, where a process is not permitted to access resources used by other processes.
A server with running virtual machines is depicted in Figure 5-6.

Figure 5-6 Virtualization
Many security issues need to be considered in a virtualization environment, including:
• Access control Access to virtualization management and monitoring functions should be restricted to those personnel who require it.
• Resource allocation A virtualization environment needs to be carefully configured so that each virtual machine is given the resources that it requires to function correctly and perform adequately.
• Logging and monitoring Virtual environments need to be carefully monitored so that any sign of security compromise will be quickly recognized and acted on.
• Hardening Virtual environments need to be configured so that only necessary services and features are enabled, and all unnecessary services and features are either disabled or removed.
• Vulnerability management Virtualization environments need to be monitored as closely as operating systems and other software so that the IT organization is aware of newly discovered security vulnerabilities and available patches.
Hardware Maintenance
In comparison to computer hardware systems that were manufactured through the 1980s, today’s computer hardware requires little or no preventive or periodic maintenance.
Computer hardware maintenance is limited to periodic checks to ensure that the computer is free of dirt and moisture. From time to time, a systems engineer will need to open a computer system cabinet and inspect it for accumulation of dust and dirt, and she may need to remove this debris with a vacuum cleaner or filtered compressed air. Depending on the cleanliness of the surrounding environment, inspection and cleaning may be needed as often as every few months or as seldom as every few years.
Maintenance may also be carried out by third-party service organizations that specialize in computer maintenance.
When it is required, hardware maintenance is an activity that should be monitored. Qualified service organizations should be hired to perform maintenance at appropriate intervals. If periodic maintenance is required, management should establish a service availability plan that includes planned downtime when such operations take place.
Automated hardware monitoring tools can provide information that will help determine whether maintenance is needed. Automated monitoring is discussed in the next section.
Hardware Monitoring
Automated hardware monitoring tools can be used to keep a continuous watch on the health and utilization of server and network hardware. In an environment with many servers, this capability can be centralized so that the health of many servers and network devices can be monitored using a single monitoring program.
Hardware monitoring capabilities may vary among different makes of computer systems, but can include any or all of the following:
• CPU Monitoring will indicate whether the system’s CPU is operating properly and whether its temperature is within normal range.
• Power supply Monitoring will show whether the power supply is operating properly, including input voltage, output voltage and current, cooling fans, and temperature.
• Internal components Monitoring will specify whether other internal components such as storage devices, memory, chipsets, controllers, adaptors, and cooling fans are operating properly and within normal temperature ranges.
• Resource utilization Monitoring will measure the amount of resources in use, including CPU, memory, disk storage, and network utilization.
• Asset management Many monitoring systems can track the assets that are present in the environment, giving management an electronic asset inventory capability.
• External environment Monitoring is usually considered incomplete unless the surrounding environment is also monitored. This usually includes temperature, humidity, the presence of water, and vibration in locales where earthquakes are common. Monitoring can also include video surveillance and access door alarms.
Centralized monitoring environments typically utilize the local area network for transmitting information from systems to a central console. Many monitoring consoles have the ability to send alert messages to the personnel who manage the systems being monitored. Often, reports can show monitoring statistics over time so that personnel can identify trends that could be indications of impending failure.
NOTE Hardware monitoring is often included in network device and network traffic monitoring that is performed by personnel in a network operations center (NOC).
Information Systems Architecture and Software
This section discusses computer operating systems, data communications, file systems, database management systems, media management systems, and utility software.
Computer Operating Systems
Computer operating systems (which are generally known as operating systems, or OSs) are large, general-purpose programs that are used to control computer hardware and facilitate the use of software applications. Operating systems perform the following functions:
• Access to peripheral devices The operating system controls and manages access to all devices and adaptors that are connected to the computer. This includes storage devices, display devices, and communications adaptors.
• Storage management The operating system provides for the orderly storage of information on storage hardware. For example, operating systems provide file system management for the storage of files and directories on solid-state drives or hard drives.
• Process management Operating systems facilitate the existence of multiple processes, some of which will be computer applications and tools. Operating systems ensure that each process has private memory space and is protected from interference and eavesdropping by other processes.
• Resource allocation Operating systems facilitate the sharing of resources on a computer such as memory, communications, and display devices.
• Communication Operating systems facilitate communications with users via peripheral devices and also with other computers through networking. Operating systems typically have drivers and tools to facilitate network communications.
• Security Operating systems restrict access to protected resources through process, user, and device authentication.
Examples of popular operating systems include Solaris, Linux, Mac OS X, Android, iOS, and Microsoft Windows.
The traditional context of the relationship between operating systems and computer hardware is this: One copy of a computer operating system runs on a computer at any given time. Virtualization, however, has changed all of that. Virtualization is discussed earlier in this chapter.
Server Clustering
Using special software, a group of two or more computers can be configured to operate as a cluster. This means that the group of computers will appear as a single computer for the purpose of providing services. Within the cluster, one computer will be active and the other computer(s) will be in passive mode; if the active computer should experience a hardware or software failure and crash, the passive computer(s) will transition to active mode and continue to provide service. This is known as active-passive mode. The transition is called a failover.
Clusters can also operate in active-active mode, where all computers in the cluster provide service; in the event of the failure of one computer in the cluster, the remaining computer(s) will continue providing service.
Grid Computing
Grid computing is a technique used to distribute a problem or task to several computers at the same time, taking advantage of the processing power of each, in order to solve the problem or complete the task in less time. Grid computing is a form of distributed computing, but in grid computing, the computers are coupled more loosely and the number of computers participating in the solution of a problem can be dynamically expanded or contracted at will.
Cloud Computing
Cloud computing refers to dynamically scalable and usually virtualized computing resources that are provided as a service. Cloud computing services may be rented or leased so that an organization can have scalable application environments without the need for supporting hardware or a data center. Or, cloud computing may include networking, computing, and even application services in a Software-as-a-Service (SaaS) or Platform-as-a-Service (PaaS) model. Cloud computing is discussed in more detail in Chapter 4.
Data Communications Software
The prevalence of network-centric computing has resulted in networking capabilities being included with virtually every computer and being built in to virtually every computer operating system. Almost without exception, computer operating systems include the ability for the computer to connect with networks based on the TCP/IP suite of protocols, enabling the computer to communicate on a home network, enterprise business network, or the global Internet.
Data communications is discussed in greater detail later in this chapter in the section “Network Infrastructure.”
File Systems
A file system is a logical structure that facilitates the storage of data on a digital storage medium such as a hard drive, solid-state drive, CD/DVD-ROM, or flash memory device. The structure of the file system facilitates the creation, modification, expansion and contraction, and deletion of data files. A file system may also be used to enforce access controls to regulate which users or processes are permitted to access, alter, or create files in a file system.
It can also be said that a file system is a special-purpose database designed for the storage and management of files.
Modern file systems employ a storage hierarchy that consists of two main elements:
• Directories A directory is a structure that is used to store files. A file system may contain one or more directories, each of which may contain files and subdirectories. The topmost directory in a file system is usually called the “root” directory. A file system may exist as a hierarchy of information, in the same way that a building can contain several file rooms, each of which contains several file cabinets, which contain drawers that contain dividers, folders, and documents. Directories are sometimes called folders in some computing environments.
• Files A file is a sequence of zero or more characters that are stored as a whole. A file may be a document, spreadsheet, image, sound file, computer program, or data that is used by a program. A file can be small as zero characters in length (an empty file) or as large as many gigabytes (trillions of characters). A file occupies units of storage on storage media (which could be a hard disk, solid-state drive, or flash memory device, for example) that may be called blocks or sectors; however, the file system hides these underlying details from the user so that the file may be known simply by its name, the directory in which it resides, and its contents.
Well-known file systems in use today include
• FAT (File Allocation Table) This file system has been used in MS-DOS and early versions of Microsoft Windows, and commonly used on removable storage devices such as flash drives. Versions of FAT include FAT12, FAT16, and FAT32. FAT is often used as the file system on portable media devices such as flash drives. FAT does not support security access controls, including specifying access permissions to files and directories.
• NTFS (NT File System) This is used in newer versions of Windows, including desktop and server editions. NTFS supports file- and directory-based access control and file system journaling (the process of recording changes made to a file system; this aids in file system recovery).
• EXT3 This is a journaled file system used by the Linux operating system.
• HFS (Hierarchical File System) This is the file system used on computers running the Apple Mac OS X operating system.
• ISO/IEC 9660 This is a file system used by CD-ROM and DVD-ROM media.
• UDF (Universal Disk Format) This is an optical media file system that is considered a replacement for ISO/IEC 9660. UDF is widely used on rewritable optical media.
Database Management Systems
A database management system, or DBMS, is a software program or collection of programs that facilitates the storage and retrieval of potentially large amounts of structured information. A DBMS contains methods for inserting, updating, and removing data; these functions can be used by computer programs and software applications. A DBMS also usually contains authentication and access control, thereby permitting control over which users may access what data.
Database Management System Organization
Most database management systems employ a data definition language (DDL) that is used to define the structure of the data contained in a database. The DDL defines the types of data stored in the database, as well as relationships between different portions of that data.
Database management systems employ some sort of a data dictionary (DD) or directory system (DS) that is used to store information about the internal structure of databases stored in the DBMS.
To better understand how they relate to each other, the DDL can be thought of as the instructions for building a database’s structure and data relationships; the DD or DS is where the database’s structure and relationships are stored and used by the DBMS.
Database management systems also employ a data manipulation language (DML) that is used to insert, delete, and update data in a database. SQL is a popular DML that is used in the Oracle and SQL Server database management systems.
Database Management System Structure
There are three principal types of DBMSs in use today: relational, object, and hierarchical. Each is described in this section.
Relational Database Management Systems Relational database management systems (RDBMSs) represent the most popular model used for database management systems. A relational database permits the design of a structured, logical representation of information.
Many relational databases are accessed and updated through the SQL (Structured Query Language) computer language. Standardized in ISO/IEC and ANSI standards, SQL is used in many popular relational database management system products, including Oracle Database, Microsoft SQL Server, MySQL, and IBM DB2.
RDBMS Basic Concepts A relational database consists of one or more tables. A table can be thought of as a simple list of records, like lines in a data file. The records in a table are often called rows. The different data items that appear in each row are usually called fields.
A table often has a primary key. This is simply one of the table’s fields whose values are unique in the table. For example, a table of healthcare patient names can include each patient’s patient identification number, which can be made the primary key for the table.
One or more indexes can be built for a table. An index facilitates rapid searching for specific records in a table based upon the value of one of the fields other than the primary key. For instance, a table that contains a list of assets that includes their serial numbers can have an index of the table’s serial numbers. This will permit a rapid search for a record containing a specific serial number; without the index, RDBMS software would have to sequentially examine every record in the table until the desired records were found.
One of the most powerful features of a relational database is the use of foreign keys. A foreign key is a field in a record in one table that can reference a primary key in another table. For example, a table that lists sales orders includes fields that are foreign keys, each of which references records in other tables. This is shown in Figure 5-7.

Figure 5-7 Fields in a sales order table point to records in other tables
Relational databases enforce referential integrity. This means that the database will not permit a program (or user) to delete a row from a table if there are records in other tables whose foreign keys reference the row to be deleted. The database instead will return an error code that will signal to the requesting program that there are rows in other tables that would be “stranded” if the row was deleted. Using the example in Figure 5-7, a relational database will not permit a program to delete salesperson #2 or #4 since there are records in the sales order table that reference those rows.
The power of relational databases comes from their design and from the SQL language. Queries are used to find one or more records from a table using the SELECT statement. An example statement is
![]()
One powerful feature in relational databases is a special query called a join, where records from two or more tables are searched in a single query. An example join query is

This query will produce a list of salespersons and the number of orders they have sold.
Relational Database Security Relational databases in commercial applications need to have some security features. Three primary security features are
• Access controls Most relational databases have access controls at the table and field levels. This means that a database can permit or deny a user the ability to read data from or write data to a specific table or even a specific field. In order to enforce access controls, the database needs to authenticate users so that it knows the identity of each user making access requests. Database management systems employ a data control language (DCL) to control access to data in a database.
• Encryption Sensitive data such as financial or medical records may need to be encrypted. Some relational databases provide field-level database encryption that permits a user or application to specify certain fields that should be encrypted. Encryption protects the data by making it difficult to read if an intruder is able to obtain the contents of the database by some illicit means.
• Audit logging Database management systems provide audit logging features that permit an administrator or auditor to view some or all activities that take place in a database. Audit logging can show precisely the activities that take place, including details of database changes and the person who made those changes. The audit logs themselves can be protected so that they resist tampering, which can make it difficult for someone to make changes to data and erase their tracks.
Database administrators can also create views, which are virtual tables created via stored queries. Views can simplify viewing data by aggregating or filtering data. They can improve security by exposing only certain records or fields to users.
Object Database Management Systems An object database (or object database management system, ODBMS) is a database where information is represented as objects that are used in object-oriented programming languages. Object-oriented databases are used for data that does not require static or predefined attributes, such as a fixed-length field or defined data structure. The data can even be of varying types. The data that is contained in an object-oriented database is unpredictable in nature.
Unlike the clean separation between programs and data in the relational database model, object databases make database objects appear as programming language objects. Both the data and the programming method are contained in an object. Object databases are really just the mechanisms used to store data that is inherently part of the basic object-oriented programming model. Thus, when a data object is accessed, the data object itself will contain functions (methods), negating the requirement for a query language like SQL.
Object databases are not widely used commercially. They are limited to a few applications requiring high-performance processing on complex data.
Relational databases are starting to look a little more like object databases through the addition of object-oriented interfaces and functions; object-oriented databases are starting to look a little more like relational databases through query languages such as Object Query Language (OQL).
Hierarchical Database Management Systems A hierarchical database is so named because its data model is a top-down hierarchy, with parent records and one or more child records in its design. The dominant hierarchical database management system product in use today is IBM’s IMS (Information Management System) that runs on mainframes in nearly all of the larger organizations in the world.
A network database is similar to a hierarchical database, extended somewhat to permit lateral data relationships (like the addition of “cousins” to the parent and child records). Figure 5-8 illustrates hierarchical and network databases.

Figure 5-8 Hierarchical and network databases
Media Management Systems
Information systems may employ automated tape management systems (TMSs) or disk management systems (DMSs) that track the tape and disk volumes that are needed for application processing.
Disk and tape management systems instruct system operators to mount specific media volumes when they are needed. These systems reduce operator error by requesting specific volumes and rejecting incorrect volumes that do not contain the required data.
TMSs and DMSs are most often found as a component of a computer backup system. Most commercial backup systems track which tape or disk volumes contain which backed-up files and databases. Coupled with automatic volume recognition (usually through barcode readers), backup systems maintain an extensive catalog of the entire collection of backup media and their contents. When data needs to be restored, the backup software (or the TMS or DMS) will specify which media volume should be mounted, verify that the correct media is available, and then restore the desired data as directed.
Significant reductions in the cost of storage, together with the trend toward cloud computing and cloud storage, have resulted in few new installations of TMSs and DMSs. Still, many organizations utilize these today, and IS auditors must be familiar with their function and operation.
Utility Software
Utility software is a term that represents the broad class of programs that support the development or use of networks, information systems, operating systems, and applications. Utility software is most often used by IT specialists whose responsibilities include some aspect of system development, support, or operations. End users, on the other hand, most often use software applications instead of utilities.
Utility software can be classified into the following categories:
• Software and data design This includes program and data modeling tools that are used to design new applications or to model existing applications.
• Software development These programs are used to facilitate the actual coding of an application (or another utility). Development tools can provide a wide variety of functions, including program language syntax checking, compilation, debugging, and testing.
• Software testing Apart from unit testing that may be present in a development environment, dedicated software testing tools perform extensive testing of software functions. Automated testing tools can contain entire suites of test cases that are run against an application program, with the results stored for future reference.
• Security testing This refers to several different types of software tools that are used to determine the security of software applications, operating systems, DBMSs, and networks. One type of security testing tool examines an application’s source code, looking for potential security vulnerabilities. Another type of security testing tool runs the application program and inputs different forms of data to see if the application contains vulnerabilities in the way that it handles this data. Other security testing tools examine operating system and DBMS configuration settings. Still others send specially crafted network messages to a target system to see what types of vulnerabilities might exist that could be exploited by an intruder or hacker.
• Data management These utilities are used to manipulate, list, transform, query, compare, encrypt, decrypt, import, or export data. They may also test the integrity of data (for instance, examining an index in a relational database or the integrity of a file system) and possibly make repairs.
• System health These utilities are used to assess the health of an operating system by examining configuration settings; verifying the versions of the kernel, drivers, and utilities; and making performance measurements and tuning changes.
• Network These utilities are used to examine the network in order to discover other systems connected to it, determine network configuration, and listen to network traffic.
Utilities and Security
Because some utilities are used to observe or make changes to access controls or security, organizations should limit the use of utilities to those personnel whose responsibilities include their use. All other personnel should not be permitted to use them.
Because many utilities are readily available, simply posting a policy will not prevent their use. Instead, strict access controls should be established so that unauthorized users who do obtain utilities would derive little or no use from them. These controls are typically implemented through one of two methods:
• Remove local administrator privileges from end users on their workstations so that they are unable to install software packages or change the configuration of their workstations’ operating systems.
• Employ software whitelisting software that prohibits all but strictly permitted software programs from running on users’ workstations.
Software Licensing
The majority of organizations purchase many software components in support of their software applications. For example, organizations often purchase operating systems, software development tools, database management systems, web servers, network management tools, office automation systems, and security tools. Organizations need to be aware of the licensing terms and conditions for each of the software products that they lease or purchase.
To be effective, an organization should centralize its records and expertise in software licensing to avoid licensing issues that could lead to unwanted and potentially embarrassing legal actions. Some of the ways that an organization can organize and control its software usage include
• Develop policy The organization should develop policies that define acceptable and unacceptable uses of software.
• Centralize procurement This can help to funnel purchasing through a group or department that can help to manage and control software acquisition and use.
• Implement software metering Automated tools that are installed on each computer (including user workstations) can alert IT of every software program that is installed and run in the organization. This can help to raise awareness of any new software programs that are being used, as well as the numbers of copies of programs installed and in use.
• Implement concurrent licensing The organization can use dynamic license management that controls the number of persons who are able to use a program simultaneously. This can help reduce costs for expensive programs used infrequently by many employees.
• Review software contracts The person or group with responsibility for managing software licensing should be aware of the terms and conditions of use.
Digital Rights Management
The Internet has provided a means for easily distributing content to large numbers of people. This ability, however, sometimes runs afoul of legal copyright protection afforded to the owners of copyrighted work. This encompasses software programs as well as documents and media.
Organizations also are faced with the problem of limiting the distribution of documents for privacy or intellectual property protection. For example, an organization may publish a technical whitepaper describing its services, and desires that only its current customers be able to view the whitepaper.
Digital rights management (DRM) is a set of emerging technologies that permits the owner of digital information (such as documents) to control access to that information, even after it is no longer contained in the owner’s environment. In some instances, these technologies are implemented in system hardware (such as electronic book readers), and in other cases they are implemented in software.
Whether implemented in hardware or software, the program or device displaying information will first examine the file being displayed to determine whether the information should be displayed or not. Some of the characteristics that the owner of a file may be able to set include
• Expiration The owner of a file may be able to set an expiration date, after which time the file cannot be viewed or used.
• Registration The owner of a file may be able to require anyone viewing the file to register themselves in a reliable way (such as through e-mail address verification).
• Authentication The owner of a file may be able to require that persons viewing a file first authenticate themselves.
Network Infrastructure
Networks are used to transport data from one computer to another, either within an organization or between them. Network infrastructure is the collection of devices and cabling that facilitates network communications among an organization’s systems, as well as between the organization’s systems and those belonging to other organizations. This section describes the following network infrastructure topics:
• Enterprise architecture
• Network architecture
• Network-based services
• Network models
• Network technologies
• Local area networks
• Wide area networks
• Wireless networks
• The TCP/IP suite of protocols
• The global Internet
• Network management
• Networked applications
Enterprise Architecture
There are two distinct facets related to the term enterprise architecture. The first is the overall set of infrastructure that facilitates access to applications and information: the networks, whether wired or wireless, local or wide area, together with resilience, access controls, and monitoring; the systems with their applications and tools; and the data and where it is stored, transmitted, and processed. The second facet is the ongoing activity carried out by one or more persons with titles such as Enterprise Network Architect, Enterprise Data Architect, Enterprise Systems Engineer, or Enterprise Security Architect, any and all of whom are concerned with “big picture” aspects of the organization and its mission, objectives, and goals, and whether the organization’s infrastructure as a whole contributes to their fulfillment.
Enterprise architecture, done correctly, requires standards: consistent ways of doing things, and consistency in the components that are used and how those components are configured.
The goals of enterprise architecture include
• Scalability Enterprise architects should design the whole enterprise and its components so that systems, networks, and storage can be easily expanded where needed.
• Agility The overall design of the organization’s infrastructure should be flexible enough to meet new goals and objectives.
• Transparency High-level and detailed diagrams should be readily available and up to date. There should be no secrets.
• Consistency The organization’s infrastructure should reflect consistency through the use of common components and configurations. This makes troubleshooting and upkeep more effective when engineers are familiar with micro architectures, components, and configurations. For example, an organization with retail stores or branch offices should employ identical architectures in each of those locations; this makes support and troubleshooting easier because engineers don’t first need to figure out how a local network is configured—they’re all the same, or nearly so.
• Repeatability Consistency brings repeatability. In an organization with retail stores or branch offices, for instance, additions or changes are “cookie cutter” instead of time-consuming “one-off” efforts.
• Efficiency Repeatability and consistency yield efficiency. Upgrades, expansion, and configuration changes are consistent and repeatable. Troubleshooting takes less time.
• Resilience Enterprise architects need to understand where resilience is required, so that infrastructure will be continuously available even in the event of the failure of individual components, or in cases of maintenance.
The challenge facing many organizations is the temptation to cut corners and deviate from (or never implement) standard architectures. Short-term gains are almost sure to be smaller than long-term inefficiencies realized later. Vision and discipline are required to attain, and maintain, a consistent and effective enterprise architecture.
Network Architecture
The term network architecture has several meanings, all of which comprise the overall design of an organization’s network communications. An organization’s network architecture, like other aspects of its information technology, should support the organization’s mission, goals, and objectives.
The facets of network architecture include
• Physical network architecture This part of network architecture is concerned with the physical locations of network equipment and media. This includes, for instance, the design of a network cable plant (also known by the term structured cabling), as well as the locations and types of network devices. An organization’s physical network architecture may be expressed in several layers. A high-level architecture may depict global physical locations or regions and their interconnectivity, while an in-building architecture will be highly specific regarding the types of cabling and locations of equipment.
• Logical network architecture This part of network architecture is concerned with the depiction of network communications at a local, campus, regional, and global level. Here, the network architecture will include several related layers, including representations of network protocols, device addressing, traffic routing, security zones, and the utilization of carrier services.
• Data flow architecture This part of network architecture is closely related to application and data architecture. Here, the flow of data is shown as connections among applications, systems, users, partners, and suppliers. Data flow can be depicted in nongeographic terms, although representations of data flow at local, campus, regional, and global levels are also needed, since geographic distance is often inversely proportional to capacity and throughput.
• Network standards and services This part of network architecture is more involved with the services that are used on the network and less with the geographic and spatial characteristics of the network. Services and standards need to be established in several layers, including cable types, addressing standards, routing protocols, network management protocols, utility protocols (such as Domain Name System [DNS], Network Time Protocol [NTP], file sharing, printing, e-mail, remote access, and many more), and application data interchange protocols, such as SOA (Service-Oriented Architecture), SOAP (Simple Object Access Protocol), and XML (eXtensible Markup Language).
Types of Networks
Computer networks can be classified in a number of different ways. The primary method of classification is based on the size of a network. By size, we refer not necessarily to the number of nodes or stations on the network, but to its physical or geographic size. These types are (from smallest to largest):
• Personal area network (PAN) Arguably the newest type of network, a personal area network is generally used by a single individual. Its reach ranges from a few centimeters up to three meters, and is used to connect peripherals and communication devices for use by an individual.
• Local area network (LAN) The original type of network, a local area network connects computers and devices together in a small building or a residence. The typical maximum size of a LAN is 100 meters, which is the maximum cable length for popular network technologies such as Ethernet.
• Campus area network (CAN) A campus area network is a term that connotes the interconnection of LANs for an organization that has buildings in close proximity.
• Metropolitan area network (MAN) A network that spans a city or regional area is sometimes known as a metropolitan area network. Usually, this type of network consists of two or more in-building LANs in multiple locations that are connected by telecommunications circuits (e.g., Multiprotocol Label Switching [MPLS], T-1, Frame Relay, or dark fiber) or private network connections over the global Internet.
• Wide area network (WAN) A wide area network is a network whose size ranges from regional to international. An organization with multiple locations across vast distances will connect its locations together with dedicated telecommunications connections or protected connections over the Internet. It is noted that an organization will also call a single point-to-point connection between two distant locations a “WAN connection.”
The classifications discussed here are not rigid, nor do they impose restrictions on the use of any specific technology from one to the next. Instead, they are simply a set of terms that allow professionals to speak easily about the geographic extent of their networks with easily understood terms.
The relative scale of these network terms is depicted in Figure 5-9.

Figure 5-9 A comparison of network sizes
Network-Based Services
Network-based services are the protocols and utilities that facilitate system- and network-based resource utilization. In a literal sense, many of these services operate on servers; they are called network-based services because they facilitate or utilize various kinds of network communication.
Some of these services are
• E-mail E-mail servers collect, store, and transmit e-mail messages from person to person. They accept incoming e-mail messages from other users on the Internet, and likewise send e-mail messages over the Internet to e-mail servers that accept and store e-mail messages for distant recipients.
• Print Print servers act as aggregation points for network-based printers in an organization. When users print a document, their workstation sends it to a specific printer queue on a print server. If other users are also sending documents to the same printer, the print server will store them temporarily until the printer is able to print them.
• File storage File servers provide centralized storage of files for use among groups of users. Often, centralized file storage is configured so that files stored on remote servers logically appear to be stored locally on user workstations.
• Directory These services provide centralized management of resource information. Examples include DNS, which provides translation between resource name and IP address, and Lightweight Directory Access Protocol (LDAP), which provides directory information for users and resources, and is often used as a central database of user IDs and passwords. An example of an LDAP-based directory service is Active Directory, which is the Microsoft implementation of and extensions to LDAP.
• Remote access Network- and server-based services within an organization’s network are protected from Internet access by firewalls and other means. This makes them available only to users whose workstations are physically connected to the enterprise network. Remote access permits an authorized user to remotely access network-based services from anywhere on the Internet via an encrypted “tunnel” that logically connects the user to the enterprise network as though they were physically there. These are known as virtual private networks (VPNs), and are typically encrypted to prevent any eavesdropper from being able to view the contents of a user’s network communication.
• Terminal emulation In many organizations with mainframe computers, PCs have replaced “green screen” and other types of mainframe-centric terminals. Terminal emulation software on PCs allows them to function like those older mainframe terminals.
• Virtual workstation Many organizations implement a virtual desktop infrastructure (VDI), wherein its workstations run operating systems that are actually stored on central servers. This simplifies the administration of those user operating systems since they are centrally stored.
• Time synchronization It is a well-known fact among systems engineers that the time clocks built in to most computers are not very accurate (some are, in fact, notoriously inaccurate). Distributed applications and network services have made accurate “timestamping” increasingly important. Time synchronization protocols allow an organization’s time server system to make sure that all other servers and workstation time clocks are synchronized. And the time server itself will synchronize with one of several reliable Internet-based time servers, GPS-equipped time servers, or time servers that are attached to international standard atomic clocks.
• Network connectivity and authentication Many organizations have adopted one of several available methods that authenticate users and workstations before logically connecting them to the enterprise network. This helps to prevent nonorganization-owned or noncompliant workstations from being able to connect to an internal network, which is a potential security threat. Users or workstations that are unable to authenticate are connected to a “quarantine” network where users can obtain information about the steps they need to take to get connected to enterprise resources. Network-based authentication can even quickly examine an organization workstation, checking it for proper security settings (anti-malware, firewall, security patches, security configuration, and so on), and allow it to connect logically only if the workstation is configured properly. Various protocols and technologies that are used to connect, verify, and authenticate devices to a network include Dynamic Host Configuration Protocol (DHCP), 802.1X, and network access control (NAC).
• Web security Most organizations have a vested interest in having some level of control over the choice of Internet websites that their employees choose to visit. Websites that serve no business purpose (for example, online gambling, porn, and online games) can be blocked so that employees cannot access them. Further, many Internet websites (even legitimate ones) host malware that can be automatically downloaded to user workstations. Web security appliances can examine incoming content for malware, in much the same way that a workstation checks incoming files for viruses.
• Anti-malware Malware (viruses, worms, Trojan horses, and so on) remains a significant threat to organizations. Antivirus software (and now, increasingly, anti-spyware and anti-rootkit software) on each workstation is still an important line of defense. Because of the complexity of anti-malware, many organizations have opted to implement centralized management and control. Using a central anti-malware console, security engineers can quickly spot workstations whose anti-malware is not functioning, and they can force new anti-malware updates to all user workstations. They can even force user workstations to commence an immediate whole-disk scan for malware if an outbreak has started. Centralized anti-malware consoles can also receive virus infection alerts from workstations and keep centralized statistics on virus updates and outbreaks, giving security engineers a vital “big picture” status.
• Network management Larger organizations with too many servers and network devices to administer manually often turn to network management systems. These systems serve as a collection point for all alerts and error messages from vital servers and network devices. They can also be used to centrally configure network devices, making wide-scale configuration changes possible by a small team of engineers working in a NOC. Network management systems also measure network performance, throughput, latency, and outages, giving network engineers vital information on the health of the enterprise network.
Network Models
Network models are the archetype of the actual designs of network protocols. While a model is often a simplistic depiction of a more complicated reality, the OSI and TCP/IP network models accurately illustrate what is actually happening in a network. It is fairly difficult to actually see the components of the network in action; the models help us to understand how they work.
The purpose of developing these models was to build consensus among the various manufacturers of network components (from programs to software drivers to network devices and cabling) in order to improve interoperability between different types of computers. In essence, it was a move toward networks with “interchangeable parts” that would facilitate data communications on a global scale.
The two dominant network models that are used to illustrate networks are OSI and TCP/IP. Both are described in this section.
The OSI Network Model
The first widely accepted network model is the Open Systems Interconnection model, known as the OSI model. The OSI model was developed by the International Organization for Standardization (ISO) and the International Telecommunications Union (ITU). The working groups that developed the OSI model ignored the existence of the TCP/IP model, which was gaining in popularity around the world and has become the de facto world standard.
The OSI model consists of seven layers. Messages that are sent on an OSI network are encapsulated; a message that is constructed at layer 7 is placed inside of layer 6, which is then placed inside of layer 5, and so on. This is not figurative—this encapsulation literally takes place and can be viewed using tools that show the detailed contents of packets on a network. Encapsulation is illustrated in Figure 5-10.

Figure 5-10 Encapsulation of packets in the OSI network model
The layers of the OSI model are, from bottom to top:
• Physical
• Data link
• Transport
• Session
• Presentation
• Application
Because it is difficult for many people to memorize a list such as this, there are some memory aids to help remember the sequence of these layers. Some of these aids are
• Please Do Not Throw Sausage Pizza Away
• Please Do Not Touch Steve’s Pet Alligator
• All People Seem To Need Data Processing
• All People Standing Totally Naked Don’t Perspire
The layers of the OSI model are explained in more detail in the remainder of this section.
OSI Layer 1: Physical The physical layer in the OSI model is concerned with electrical and physical specifications for devices. This includes communications cabling, voltage levels, and connectors, as well as some of the basic specifications for devices that would connect to networks. At the physical layer, networks are little more than electric signals flowing in wires or radio frequency airwaves.
At the physical layer, data exists merely as bits; there are no frames, packets, or message here. The physical layer also addresses the modulation of digital information into voltage and current levels in the physical medium.
Examples of OSI physical layer standards include
• Cabling 10BASE-T, 100BASE-TX, 1000BASE-X, twinax, and fiber optics, which are standards for physical network cabling.
• Communications RS-232, RS-449, and V.35, which are standards for sending serial data between computers.
• Telecommunications T1, E1, SONET (Synchronous Optical Networking), DSL (Digital Subscriber Line), and DOCSIS (Data Over Cable Service Interface Specification), which are standards for common carrier communications networks for voice and data.
• Wireless communications 802.11a PHY (meaning the physical layer component of 802.11) and other wireless local area network (WLAN) airlink standards.
• Wireless telecommunications LTE (Long Term Evolution), WiMAX (Worldwide Interoperability for Microwave Access), CDMA (Code Division Multiple Access), W-CDMA, CDMA2000, TDMA (Time Division Multiple Access), and UMTS (Universal Mobile Telecommunications Service), which are airlink standards for wireless communications between cell phones and base stations (these standards also include some OSI layer 2 features).
OSI Layer 2: Data Link The data link layer in the OSI model focuses on the method of transferring data from one station on a network to another station on the same network. In the data link layer, information is arranged into frames and transported across the medium. Error correction is usually implemented as collision detection, as well as the confirmation that a frame has arrived intact at its destination, usually through the use of a checksum.
The data link layer is concerned only with communications on a local area network. At the data link layer, there are no routers (or routing protocols). Instead, the data link layer should be thought of as a collection of locally connected computers to a single physical medium. Data link layer standards and protocols are only concerned with getting a frame from one computer to another on that local network.
Examples of data link layer standards include
• LAN protocols Ethernet, Token Ring, ATM (Asynchronous Transfer Mode), FDDI (Fiber Distributed Data Interface), and Fibre Channel are protocols that are used to assemble a stream of data into frames for transport over a physical medium (the physical layer) from one station to another on a local area network. These protocols include error correction, primarily through collision detection; collision avoidance; synchronous timing; or tokens.
• 802.11 MAC/LLC This is the data link portion of the well-known Wi-Fi (wireless LAN) protocols.
• Common carrier packet networks MPLS, Frame Relay, and X.25 are packet-oriented standards for network services provided by telecommunications carriers. Organizations that required point-to-point communications with various locations would often obtain an MPLS or Frame Relay connection from a local telecommunications provider. X.25 has been all but replaced by Frame Relay, and now Frame Relay is being replaced by MPLS.
• ARP (Address Resolution Protocol) This protocol is used when one station needs to communicate with another and the initiating station does not know the receiving station’s network link layer (hardware) address. ARP is prevalent in TCP/IP networks, but is used in other network types as well.
• PPP and SLIP These are protocols that are used to transport TCP/IP packets over point-to-point serial connections (usually RS-232). SLIP is now obsolete, and PPP is generally seen only in remote access connections that utilize dial-up services.
• Tunneling PPTP (Point-to-Point Tunneling Protocol), L2TP (Layer 2 Tunneling Protocol), and other tunneling protocols were developed as a way to extend TCP/IP (among others) from a centralized network to a branch network or a remote workstation, usually over a dial-up connection.
In the data link layer, stations on the network must have an address. Ethernet and Token Ring, for instance, use MAC (Media Access Control) addresses, which are considered hardware addresses. Most other multistation protocols also utilize some form of addressing for each device on the network.
OSI Layer 3: Network The purpose of the OSI network layer is the delivery of messages from one station to another via one or more networks. The network layer can process messages of any length, and will “fragment” messages so that they are able to fit into packets that the network is able to transport.
The network layer is the layer that is concerned with the interconnection of networks and the packet routing between networks. Network devices called routers are used to connect networks together. Routers are physically connected to two or more logical networks, and are configured with (or have some ability to learn) the network settings for each network. Using this information, routers are able to make routing decisions that will enable them to forward packets to the correct network, moving them closer to their ultimate destination.
Examples of protocols at the network layer include
• IP (Internet Protocol) This is the network layer protocol used in the TCP/IP suite of protocols. IP is concerned with the delivery of packets from one station to another, whether the stations are on the same network or on different networks. IP has the IP address scheme for assigning addresses to stations on a network; this is entirely separate from link layer (hardware) addressing such as Ethernet’s MAC addressing. IP is the basis for the global Internet.
• IPsec (Internet Protocol Security) This is a protocol used to authenticate, encapsulate, and encrypt IP traffic between networks. This protocol is often used for VPNs facilitating secure remote access.
• ICMP (Internet Control Message Protocol) This is a communications diagnostics protocol that is also a part of the TCP/IP suite of protocols. One of its primary uses is the transmission of error messages from one station to another; these error messages are usually related to problems encountered when attempting to send packets from one station to another.
• IGMP (Internet Group Management Protocol) This is a protocol used to organize multicast group memberships between routers. IGMP is a part of the multicast protocol family.
• AppleTalk This is the original suite of protocols developed by Apple Computer for networking the Apple brand of computers. The suite of protocols includes the transmission of messages from one computer over interconnected networks, as well as routing protocols. AppleTalk has since been deprecated in favor of TCP/IP.
OSI Layer 4: Transport The transport layer in the OSI model is primarily concerned with the reliability of data transfer between systems. The transport layer manages the following characteristics of data communications:
• Connection orientation At the transport layer, communications between two stations can take place in the context of a connection. Here, two stations will initiate a unique, logical context (called a connection) under which they can exchange messages until at a later time the stations agree to end the connection. Stations can have two or more unique connections established concurrently; each is uniquely identified.
• Guaranteed delivery Protocols at the transport layer can track individual packets in order to guarantee delivery. For example, the TCP protocol uses something like a return receipt for each transported packet to confirm that each sent packet was successfully received by the destination.
• Order of delivery The transport layer includes protocols that are able to track the order in which packets are delivered. Typically, each transported packet will have a serialized number that the receiving system will use to make sure that packets on the receiving system are delivered in proper order. When coupled with guaranteed delivery, a receiving system can request retransmission of any missing packets, ensuring that none are lost.
The protocols at the transport layer are doing the heavy lifting by ensuring the integrity and completeness of messages that flow from system to system. The ability for data communications to take place over the vast worldwide network that is the global Internet is made possible by the characteristics of protocols in the transport layer.
Examples of transport layer protocols include
• TCP (Transmission Control Protocol) This is the “TCP” in the TCP/IP protocol suite. TCP is connection-oriented due to the formal establishment (three-way handshake) and maintenance (sequence numbers and acknowledgments) of a connection, using flags to indicate connection state. When a system sends a TCP packet to another system on a specific port, that port number helps the operating system direct the message to a specific program. For example, port 25 is used for inbound e-mail, ports 20 and 21 are used for FTP (File Transfer Protocol), and ports 80 and 443 are used for HTTP (Hypertext Transfer Protocol) and HTTPS (HTTP Secure), respectively. Hundreds of preassigned port numbers are the subject of Internet standards. TCP employs guaranteed delivery and guaranteed order of delivery.
• UDP (User Datagram Protocol) This is the other principal protocol used by TCP/IP in the OSI transport layer. Unlike TCP, UDP is a lighter-weight protocol that lacks connection orientation, order of delivery, and guaranteed delivery. UDP consequently has less computing and network overhead, which makes it ideal for some protocols that are less sensitive to occasional packet loss. Examples of protocols that use UDP are DNS (Domain Name System), TFTP (Trivial File Transfer Protocol), and VoIP (Voice over IP). Like TCP, UDP also employs port numbers so that incoming packets on a computer can be delivered to the right program or process. Sometimes UDP is called “unreliable data protocol,” a memory aid that is a reference to the protocol’s lack of guaranteed delivery.
The TCP/IP suite of protocols is described in more detail later in this chapter.
OSI Layer 5: Session The session layer in the OSI model is used to control connections that are established between applications on the same, or different, systems. This involves connection establishment, termination, and recovery.
In the OSI model, connection control takes place in the session layer. This means that the concept of the establishment of a logical connection between systems is a session layer function. However, the TCP protocol—which is generally thought of as a transport layer protocol—handles this on its own.
Examples of session layer protocols include
• Interprocess communications Sockets and named pipes are some of the ways that processes on a system (or on different systems) exchange information.
• SIP (Session Initiation Protocol) SIP is the protocol used to set up and tear down VoIP and other communications connections.
• RPC (Remote Procedure Call) This is another interprocess communication technology that permits an application to execute a subroutine or procedure on another computer.
• NetBIOS (Network Basic Input/Output System) This permits applications to communicate with one another using the legacy NetBIOS API.
OSI Layer 6: Presentation The presentation layer in the OSI model is used to translate or transform data from lower layers (session, transport, and so on) into formats that the application layer can work with. Examples of presentation layer functions include
• Character set translation Programs or filters are sometimes needed to translate character sets between ASCII and EBCDIC, for instance.
• Encryption/decryption Communications may be encrypted if data is to be transported across unsecure networks. Example protocols are SSL (Secure Sockets Layer), TLS (Transport Layer Security), and MIME (Multipurpose Internet Mail Extensions).
• Codecs Protocols such as MPEG (Moving Picture Experts Group) use codecs to encode/decode or to compress/decompress audio and video data streams.
OSI Layer 7: Application The application layer in the OSI model contains programs that communicate directly with the end user. This includes utilities that are packaged with operating systems, as well as tools and software applications.
Examples of application layer protocols include
• Utility protocols DNS, SNMP (Simple Network Management Protocol), DHCP, and NTP
• Messaging protocols SMTP (Simple Mail Transfer Protocol), NNTP (Network News Transfer Protocol), HTTP, X.400, and X.500
• Data transfer protocols NFS (Network File System) and FTP
• Interactive protocols Telnet, SSH (Secure Shell)
End-user applications that communicate over networks do so via OSI layer 7.
OSI: A Model That Has Never Been Implemented—or Has It?
The OSI network model is a distinguished tool for teaching the concepts of network encapsulation and the functions taking place at each layer. However, the problem is that no actual, living network protocol environments have ever been built that contain all of the layers of the OSI model, and it is becoming increasingly apparent that none ever will. The world’s dominant network standard, TCP/IP, is a layered protocol stack that consists of four layers, and it’s not likely that TCP/IP’s model will ever be increased to seven layers.
As the OSI model was being developed and socialized by ISO (and is now defined by ISO/IEC 7498-1), the rival TCP/IP model was quickly becoming the world’s standard for data network communications. OSI has been relegated to a teaching tool, and the model itself is more of an interesting museum piece that represents an idea that never came to fruition.
There is a different and equally valid point of view regarding implementation of the OSI model: it can be said that all of the modern encapsulated network protocols—TCP/IP, IPX/SPX (Internetwork Packet Exchange/Sequenced Packet Exchange), AppleTalk, and Token Ring—are implementations, albeit incomplete, of the OSI model. This is a topic for technology philosophers and historians to take up.
The TCP/IP Network Model
The TCP/IP network model is one of the basic design characteristics of the TCP/IP suite of protocols. The network model consists of four “layers,” where each layer is used to manage some aspect of the transmission, routing, or delivery of data over a network. In a layered model, a layer receives services from the next lowest layer and provides services to the next higher layer.
Like OSI, the TCP/IP network model utilizes encapsulation. This means that a message created by an application program is encapsulated within a transport layer message, which in turn is encapsulated within an Internet layer message, which is encapsulated in a link layer message, which is delivered to a network adaptor for delivery across a physical network medium. This encapsulation is depicted in Figure 5-11.

Figure 5-11 Encapsulation in the TCP/IP network model
The layers of the TCP/IP model, from bottom to top, are
• Link
• Internet
• Transport
• Application
These layers are discussed in detail in this section.
One of the primary purposes of the layered model (in both the OSI and TCP/IP models) is to permit abstraction. This means that each layer need be concerned only with its own delivery characteristics, while permitting other layers to manage their own matters. For instance, order of delivery is managed by the transport layer; at the Internet and link layers, order of delivery is irrelevant. Also, the link layer is concerned with just getting a message from one station to another and with collisions and the basic integrity of the message as it is transported from one device to another; but the link layer has no concept of a logical connection or with order of delivery, which are addressed by higher layers.
TCP/IP Link Layer The link layer is the lowest layer in the TCP/IP model. Its purpose is the delivery of messages (usually called frames) from one station to another on a local network. Being the lowest layer of the TCP/IP model, the link layer provides services to the transport layer.
The link layer is the physical layer of the network, and is usually implemented in the form of hardware network adaptors. TCP/IP can be implemented on top of any viable physical medium that has the capacity to transmit frames from one station to another. Examples of physical media used for TCP/IP include those from standards such as Ethernet, ATM, USB, Wi-Fi, GPRS (General Packet Radio Service), DSL, ISDN (Integrated Services Digital Network), and fiber optics.
The link layer is only concerned with the delivery of messages from one station to another on a local network. At this layer, there is no concept of neighboring networks or of routing; these are handled at higher layers in the model.
TCP/IP Internet Layer The Internet layer of the TCP/IP model is the foundation layer of TCP/IP. The purpose of this layer is the delivery of messages (called packets) from one station to another on the same network or on different networks. The Internet layer receives services from the link layer and provides services to the transport layer.
At this layer, the delivery of messages from one station to another is not guaranteed. Instead, the Internet layer makes only a best effort to deliver messages. The Internet layer also does not concern itself with the order of delivery of messages. Concerns such as these are addressed at the transport layer.
The primary protocol that has been implemented in the Internet layer is known as IP (Internet Protocol). IP is the building block for nearly all other protocols and message types in TCP/IP. One other protocol is common in the Internet layer: ICMP (Internet Control Message Protocol), a diagnostic protocol that is used to send error messages and other diagnostic messages over networks.
At the Internet layer, there are two types of devices: hosts and routers. Hosts are computers that could be functioning as servers or workstations. They communicate by creating messages that they send on the network. Routers are computers that forward packets from one network to another. In the early Internet, routers really were computers like others, with some additional configurations that they used to forward packets between networks.
The relationship between hosts and routers is depicted in Figure 5-12.

Figure 5-12 Hosts and routers at the Internet layer
TCP/IP Transport Layer The transport layer in the TCP/IP model consists of two main packet transport protocols, TCP and UDP, as well as a few other protocols that were developed after the initial design of TCP/IP. The transport layer receives services from the Internet layer and provides services to the application layer.
Several features are available at the transport layer for packet delivery, including
• Reliable delivery This involves two characteristics: integrity of the packet contents and guaranteed delivery. The TCP protocol includes these two features that ensure confirmation that a packet sent from one station will be delivered to its destination and that the contents of the packet will not be altered along the way.
• Connection orientation This involves the establishment of a persistent logical “connection” between two stations. This is particularly useful when a station is communicating on many simultaneous “conversations” from one or more source stations. When a connection is established, the requesting system communicates on an arbitrary source port, to the destination system on standard ports (e.g., HTTP port 80, DNS port 53, etc.). The two stations will negotiate and agree on arbitrary high-numbered ports (channels) that will make each established connection unique.
• Order of delivery The order of delivery of packets can be guaranteed to match the order in which they were sent. This is implemented through the use of sequence numbers, which are used by the receiving system to deliver packets in the correct order to the receiving process.
• Flow control This means that the delivery of packets from one station to another will not overrun the destination station. For example, the transfer of a large file from a faster system to a slower system could overrun the slower system, unless the latter has a way to periodically pause the transfer (flow control) so that it can keep up with the inbound messages.
• Port number A message on one station may be sent to a specific port number on a destination station. A port number essentially signifies the type of message that is being sent. A “listener” program can be set up on a destination system to listen on a preassigned port, and then will process messages received on that port number. The primary advantage of port numbers is that a destination system does not need to examine the contents of a message in order to discern its type; instead, the port number defines the purpose. There are many standard port numbers established, including 23 = Telnet, 25 = e-mail, 53 = Domain Name System, 80 = HTTP, and so on.
It should be noted that not all transport layer protocols utilize all of these features. For instance, UDP utilizes flow control but none of the other features listed.
TCP/IP Application Layer The application layer is the topmost layer of the TCP/IP model. This layer interfaces directly with applications and application services. The application layer receives services from the transport layer and may communicate directly with end users.
Application layer programs include DNS, SNMP, DHCP, NTP, SMTP, NNTP, HTTP, HTTPS, NFS, FTP, and Telnet.
The TCP/IP and OSI Models The TCP/IP model was not designed to conform to the seven-layer OSI network model. However, the models are similar in their use of encapsulation and abstraction, and some layers between the two models are similar. Figure 5-13 shows the TCP/IP and OSI models side by side and how the layers in one model correspond to the other.

Figure 5-13 The TCP/IP and OSI network models side by side
EXAM TIP Mapping TCP/IP and OSI models to each other has no practical purpose except to understand their similarities and differences. There is not unanimous agreement on the mapping of the models. It is easy to argue for some small differences in the way that they are conjoined.
Network Technologies
Many network technologies have been developed over the past several decades. Some, like Ethernet, DSL, and TCP/IP, are found practically everywhere, while other technologies, such as ISDN, Frame Relay, and AppleTalk, have had shorter lifespans.
The IS auditor needs to be familiar with network technologies, architectures, protocols, and media so that he may examine an organization’s network architecture and operation. The following sections describe network technologies at a level of detail that should be sufficient for most auditing needs:
• Local Area Networks This section discusses local area network topologies, cabling, and transport protocols (including Ethernet, ATM, Token Ring, USB, and FDDI).
• Wide Area Networks This section discusses wide area networks, including transport protocols MPLS, SONET, T-Carrier, Frame Relay, ISDN, and X.25.
• Wireless Networks This section discusses wireless network standards Wi-Fi, Bluetooth, Wireless USB, NFC, and IrDA.
• TCP/IP Protocols and Devices This section discusses TCP/IP protocols in the link layer, Internet layer, transport layer, and application layer.
• The Global Internet This section discusses global Internet addressing, DNS, routing, and applications.
• Network Management This section discusses the business function, plus the tools and protocols used to manage networks.
• Networked Applications This section discusses the techniques used to build network-based applications.
Local Area Networks
Local area networks (LANs) are networks that exist within a relatively small area, such as a floor in a building, a lab, storefront, office, or residence. Because of signaling limitations, a LAN is usually several hundred feet in length or less.
Physical Network Topology
Wired LANs are transported over network cabling that runs throughout a building. Network cabling is set up in one of three physical topologies:
• Star In a star topology, a separate cable is run from a central location to each computer. This is the way that most networks are wired today. The central location might be a wiring closet or a computer room, where all of the cables from each computer would converge at one location and be connected to network equipment such as a switch or hub.
• Ring A ring topology consists of cabling that runs from one computer to the next. Early Token Ring and Ethernet networks were often wired this way. Where the network cable was attached to a computer, a “T” connector was used: one part connected to the computer itself, and the other two connectors were attached to the network cabling.
• Bus A bus topology consists of a central cable, with connectors along its length that would facilitate “branch” cables that would be connected to individual computers. Like the ring topology, this was used in early networks but is seldom used today.
These three topologies are depicted in Figure 5-14.

Figure 5-14 Network physical topologies: star, ring, and bus
It should be noted that the logical function and physical topology of a network might vary. For instance, a Token Ring network may resemble a physical star (with all stations connected to a central device), but it will function logically as a ring. An Ethernet network functions as a bus, but may be wired as a star, bus, or ring, depending on the type of cabling used (and, as indicated earlier, star topology is prevalent). The point is that logical function and physical topology often differ from each other.
Cabling Types
Several types of cables have been used in local area networks over the past several decades. This section will focus on the types in use today, but will mention those that have been used in the past, which may still be in use in some organizations.
Twisted-Pair Cable Twisted-pair cabling is a thin cable that contains four pairs of insulated copper conductors, all surrounded by a protective jacket. Several varieties of twisted-pair cabling are suitable for various physical environments and provide various network bandwidth capabilities.
Because network transmissions can be subject to interference, network cabling may include shielding that protects the conductors from interference. Some of these types are
• Shielded twisted pair (U/FTP or STP) This type of cable includes a thin metal shield that protects each pair of conductors from electromagnetic interference (EMI), making it more resistant to interference.
• Screened unshielded twisted pair (S/UTP) Also known as foiled twisted pair (FTP), this type of cable has a thin metal shield that protects the conductors from EMI.
• Screened shielded twisted pair (S/STP or S/FTP) This type of cable includes a thin layer of metal shielding surrounding each twisted pair of conductors, plus an outer shield that protects all of the conductors together. This is all covered by a protective jacket.
• Unshielded twisted pair (UTP) This type of cable has no shielding and consists only of the four pairs of twisted conductors and the outer protective jacket.
The abbreviations for twisted-pair cable have recently changed in compliance with international standard ISO/IEC 11801, “Information technology — Generic cabling for customer premises.” The new standard takes the form X/YTP, where X denotes whether the entire cable has shielding, and Y indicates whether individual pairs in the cable are shielded. Table 5-1 shows the old and new names and their meanings. The old names are likely going to be in common use for many years, as office buildings and residences around the world are wired with twisted-pair cabling that is labeled with the old names; this wiring is likely going to last for decades in many locations.

Table 5-1 Old and New Twisted-Pair Cabling Abbreviations and Meaning
Twisted-pair network cabling is also available with different capacity ratings to meet various bandwidth requirements. The common ratings include
• Category 3 This is the oldest still-recognized twisted-pair cabling standard, capable of transporting 10Mbit Ethernet up to 100 m (328 ft). The 100BASE-T4 standard permitted up to 100Mbit Ethernet over Cat-3 cable by using all four pairs of conductors. Category 3 cable is no longer installed, but is still found in older networks.
• Category 5 Known as “Cat-5,” this cabling grade has been in common use since the mid-1990s, and is suitable for 10Mbit, 100Mbit, and 1000Mbit (1Gbit) Ethernet over distances up to 100 m (328 ft.). Category 5 cable is typically made from 24-gauge copper wire with three twists per inch. A newer grade called Category 5e has better performance for Gigabit Ethernet networks.
• Category 6 This is the cabling standard for Gigabit Ethernet networks. Cat-6 cabling greatly resembles Cat-5 cabling, but Cat-6 has more stringent specifications for crosstalk and noise. Cat-6 cable is typically made from 23-gauge copper. Category 6 cabling is “backward compatible” with Category 5 and 5e cabling, which means that Cat-6 cables can be used for 10Mbit and 100Mbit Ethernet networks as well as 1000Mbit (1Gbit).
• Category 7 This cable standard has been developed to permit 10Gbit Ethernet over 100 m of cabling. Cat-7 cabling is almost always made from S/FTP cabling to provide maximum resistance to EMI. A newer grade known as Category 7a is designed to have telephone, cable TV, and 1GB networking in the same cable. This newer grade is still under development.
• Category 8 This is a new cable standard that is still under development, designed for high-speed networking.
Twisted-pair cable ratings are usually printed on the outer jacket of the cable. Figure 5-15 shows a short length of Category 5 cable with the rating and other information stamped on it.
Figure 5-15 Category 5 twisted-pair cable (Image courtesy of Rebecca Steele)
Fiber Optic Cable Fiber optic cable is the transmission medium for fiber optic communications, which is the method of transmitting information using pulses of light instead of electric signals through metal cabling. The advantages of fiber optic cable are its much higher bandwidth, lower loss, and compact size. Because communications over fiber optic cable are based on light instead of electric current, they are immune from EMI.
In local area networks, multimode-type fiber optic cable can carry signals up to 10 Gbit/sec up to 600 m (and distances up to a few kilometers at lower bandwidths), sufficient for interconnecting buildings in a campus-type environment. For longer distances, single-mode–type fiber optic cable is used, usually by telecommunications carriers for interconnecting cities for voice and data communications.
Compared to twisted-pair and other network cable types, fiber optic cable is relatively fragile and must be treated with care. It can never be pinched, bent, or twisted—doing so will break the internal fibers. For this reason, fiber optic cabling is usually limited to data centers requiring high bandwidths between systems, where network engineers will carefully route fiber optic cabling from device to device, using guides and channels that will prevent the cable from being damaged. But the advantage of fiber optic cabling is its high capacity and freedom from EMI.
Figures 5-16 and 5-17 show fiber optic cable and connectors.
Figure 5-16 Fiber optic cable with its connector removed to reveal its interior (Image courtesy of Harout S. Hedeshian)

Figure 5-17 Connectors link fiber optic cable to network equipment. (Image courtesy of Stephane Tsacas)
Other Types of Network Cable Twisted-pair and fiber optic cable are the primary local area network cable types. However, older types of cable have been used and are still found in many installations, including:
• Coaxial Coaxial cable consists of a solid inner conductor that is surrounded by an insulating jacket, surrounded by a metallic shield. A plastic jacket protects the shield. Coaxial cables were used in early Ethernet networks with cable types such as 10BASE5 and 10BASE2. Twist-lock or threaded connectors were used to connect coaxial cable to computers or network devices. A typical coaxial cable is shown in Figure 5-18.

Figure 5-18 Coaxial cable (Image courtesy of Fdominec)
• Serial Point-to-point network connections can be established over USB or RS-232 serial cables. In the case of serial lines, in the 1980s, many organizations used central computers and user terminals that communicated over RS-232 serial cabling. At that time these existing cable plants made the adoption of SLIP (Serial Line Internet Protocol) popular for connecting workstations and minicomputers to central computers using existing cabling. SLIP is all but obsolete now, although USB is still growing in popularity.
Network Transport Protocols
Many protocols, or standards, have been developed to facilitate data communications over network cabling. Ethernet, ATM, Token Ring, USB, and FDDI protocols are described in detail in the following sections.
Ethernet
Ethernet is the dominant standard used in LANs. It uses a frame-based protocol, which means that data transmitted over an Ethernet-based network is placed into a “frame” that has places for source and destination addresses as well as contents.
Shared Medium Ethernet is a “broadcast” or “shared medium” type of protocol. This means that a frame that is sent from one station on a network to another station may be physically received by all stations that are connected to the network medium. When each station receives the frame, the station will examine the destination address of the frame to determine whether the frame is intended for that or another station. If the frame is destined for another station, the station will simply ignore the frame and do nothing. The destination station will accept the frame and deliver it to the operating system for processing.
Collision Detection Ethernet networks are asynchronous—a station that needs to transmit a frame may do so at any time. However, Ethernet also employs a “collision detection” mechanism whereby a station that wishes to broadcast a frame will begin transmitting and also listen to the network to see if any other stations are transmitting at the same time. If another station is transmitting, the station that wishes to transmit will “back off” and wait for a short interval and then try again (in a 10Mbit Ethernet, the station will wait for 9.6 microseconds). If a collision (two stations transmitting at the same time) does occur, both transmitting stations will stop, wait a short interval (the length of the interval is based on a randomly generated number), and then try again. The use of a random number as a part of the “back off” algorithm ensures that each station has a statistically equal chance to transmit its frames on the network.
Ethernet Addressing On an Ethernet network, each station on the network has a unique address called a Media Access Control (MAC) address, expressed as a six-byte hexadecimal value. A typical address is displayed in a notation separated by colons or dashes, such as F0:E3:67:AB:98:02.
The Ethernet standard dictates that no two devices in the entire world will have the same MAC address; this is established through the issuance of ranges of MAC addresses that are allocated to each manufacturer of Ethernet devices. Typically, each manufacturer will be issued a range, which consists of the first three bytes of the MAC address; the manufacturer will then assign consecutive values for the last three bytes to each device that it produces.
For example, a company is issued the value A0-66-01 (called its Organizationally Unique Identifier, or OUI). The devices that the company produces will have that value as the first three bytes of its MAC address and assign three additional bytes to each device that it produces, giving addresses such as A0-66-01-FF-01-01, A0-66-01-FF-01-02, A0-66-01-FF-01-03, and so on. This will guarantee that no two devices in the world will have the same address.
Ethernet Frame Format An Ethernet frame consists of a header segment, a data segment, and a checksum. The header segment contains the destination MAC address, the source MAC address, and a two-byte Ethernet type field. The data segment ranges from 46 to 1,500 bytes in length. The checksum field is four bytes in length and is a CRC (cyclic redundancy check) checksum of the entire frame. An Ethernet frame is shown in Figure 5-19.
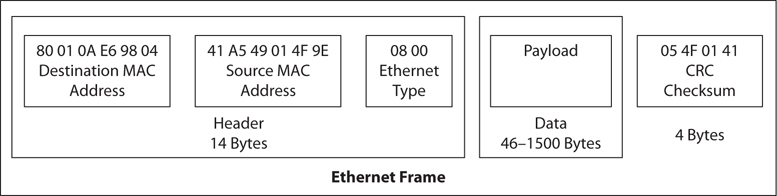
Figure 5-19 An Ethernet frame consists of a header, data, and checksum
Network Devices Network devices must not only facilitate the transmission of frames on Ethernet networks, but support all other network standards as well. These devices include
• Network adaptor A network adaptor, commonly known as a network interface card (NIC), is a device that is directly connected to a computer’s bus and contains one or more connectors to which an Ethernet network cable may be connected. Often, a computer’s NIC is integrated with the computer’s motherboard, but a NIC may also be a separate circuit card that is plugged into a bus connector.
• Hub Organizations came to realize that ring and bus topology networks were problematic with regard to cable failures. This gave rise to the star topology as a preferred network architecture, because a cable problem would affect only one station instead of many or all stations. A multiport repeater would be used to connect all of the devices to the network. Over time, this device became known as a hub. Like repeaters, Ethernet hubs propagate packets to all stations on the network.
• Gateway A gateway is a device that acts as a protocol converter, or performs some other type of transformation of messages.
• Repeater A repeater is a device that receives and retransmits the signal on an Ethernet network. Repeaters are useful for situations in which cable lengths exceed 100 m, or to interconnect two or more Ethernet networks. A disadvantage of repeaters is that they propagate collisions and other network anomalies onto all parts of the network. Repeaters as stand-alone devices are seldom used in Ethernet networks today; more modern devices have absorbed their functions.
• Bridge A bridge is a device that is used to interconnect Ethernet networks. For example, an organization may have an Ethernet network on each floor of a multistory building; a bridge can be used to interconnect each of the separate Ethernet segments. A bridge is similar to a repeater, except that a bridge does not propagate errors such as collisions, but instead only propagates well-formed packets. Bridges also, as stand-alone devices, are seldom seen in today’s Ethernet networks.
• Switch An Ethernet switch is similar to a hub, but with one important difference: a switch will listen to traffic and learn the MAC address(es) associated with each port (connector) and will send packets only to destination ports. The result is potentially greater network throughput, because each station on the network will be receiving only the frames that are specifically addressed to it. When only one station is connected to each port on an Ethernet switch, theoretically, collisions will never occur.
Devices such as routers, layer 3 switches, layer 4 switches, and layer 4-7 switches are discussed in the section, “TCP/IP Protocols and Devices,” later this chapter.
ATM
ATM, or Asynchronous Transfer Mode, is a link-layer network protocol developed in the 1980s in response to the need to unify telecommunications and computer networks. ATM has been a dominant protocol in the core networks of telecommunications carriers, although IP is becoming more dominant.
Messages (called cells) on an ATM network are transmitted in synchronization with a network-based time clock. Stations on an Ethernet, on the other hand, transmit as needed, provided the network is quiet at the moment.
ATM cells are fixed at a length of 53 bytes (5-byte header and 48-byte payload). This small frame size improves performance by reducing jitter, which is a key characteristic of networks that are carrying streaming media such as VoIP or video.
ATM is a connection-oriented link-layer protocol. This means that two devices on an ATM network that wish to communicate with each other will establish a connection through a virtual circuit. A connection also establishes a Quality of Service (QoS) setting for the connection that defines the priority and sensitivity of the connection.
Cells that are transmitted from one station to another are transported through one or more ATM switches. The path that a cell takes is established at the time that the virtual circuit is established. An ATM switch is used even when two stations on the same local area network are communicating with each other.
Like Ethernet, ATM can be used to transport TCP/IP messages. TCP/IP packets that are larger than 48 bytes in length are transmitted over ATM in pieces and reassembled at the destination.
Token Ring
Token Ring is a local area network protocol that was developed by IBM in the 1980s. Historically, Token Ring was prevalent in organizations that had IBM mainframe or midrange computer systems. However, as TCP/IP and Ethernet grew in popularity, Token Ring declined and it is rarely found today.
Token Ring networks operate through the passage of a three-byte token frame from station to station on the network. If a station has information that it needs to send to another station on the network, it must first receive the token; then it can place a frame on the network that includes the token and the message for the destination station. When the token frame reaches the destination station, the destination station will remove the message from the token frame and then pass an empty token (or a frame containing the token and a message for another station) to the next station on the network.
Token Ring Devices The principal Token Ring device is the multistation access unit, or MAU. A MAU is a device that contains several Token Ring cable connectors and connects network cables from the MAU to each station on the network. A typical MAU contains as many as eight connectors; if a Token Ring network is to contain more than eight stations, MAUs can be connected together using their ring in/ring out connectors. Figure 5-20 shows small and large Token Ring networks.
Figure 5-20 Token Ring network topologies
Token Ring Design Considerations The design of Token Ring technology makes collisions impossible, since no station can transmit unless it possesses the token. A disadvantage of this design occurs if the station with the token encounters a malfunction that causes it to not propagate the token. This results in a momentary pause until the network goes into a recovery mode and regenerates a token.
Universal Serial Bus
Universal Serial Bus, or USB, is not typically considered a network technology, but rather a workstation bus technology. This is primarily because USB is used to connect peripherals such as mice, keyboards, storage devices, printers, scanners, cameras, and network adaptors. However, the USB specification indeed contains full networking capabilities, which makes use of those small USB hubs possible.
USB data rates are shown in Table 5-2.

Table 5-2 USB Data Rates
Cable length for USB is restricted to five meters. The maximum number of devices on a USB network is 127.
One of the valuable characteristics of USB technology is the ability to “hot plug” devices. This means that USB devices can be connected and disconnected without the need to power down the workstation they are connected to. This is achieved primarily through the design specification for devices and device drivers that tolerate plugging and unplugging. This does not mean, however, that all types of USB devices may be plugged and unplugged at will. USB mass storage devices, for instance, should be logically “dismounted” in order to ensure the integrity of the file system on the device.
FDDI
Fiber Distributed Data Interface, or FDDI, is a local area network technology whose range can extend up to 200 km over optical fiber. FDDI is a “dual ring” technology that utilizes redundant network cabling and counter-rotating tokens, which together make FDDI highly resilient. Each ring has a 100 Mbit/sec data rate, making the entire network capable of 200 Mbit/sec.
FDDI has been largely superseded by 100 Mbit/sec and 1 Gbit/sec Ethernet, and is no longer often seen in commercial networks.
Wide Area Networks
Wide area networks, commonly known as WANs, are those networks that extend for miles to thousands of miles between stations. The term WAN is generally used in two ways: to connote an organization’s entire regional or global data network, and as the label for the long-distance network connections used to join individual networks together. In the second usage, the terms “WAN link” and “WAN connection” are used.
Wide Area Transmission Modes
Before discussing specific WAN protocols, it is important to understand the basics of message transmission techniques used in wide area networks.
The basic problem of wide area communications is the need to efficiently route communications from many different endpoints to many destinations, without constructing dedicated connections between all possible communication sources and destinations. Instead, some scheme for sharing a common communication medium is needed. These methods are
• Circuit-switched Here, a dedicated, end-to-end communications channel is established that lasts for the duration of a connection. The best-known example of circuit-switched technology is the old public-switched telephone network, where a telephone call from one telephone to another occupied a dedicated circuit that was assigned at the onset of the call and used until the call was finished.
• Packet-switched Communications between endpoints takes place over a stream of packets, which are routed through switches until they reach their destination. Frame Relay and the TCP/IP Internet are good examples of packet-switched networks. And while landline telephone calls still have the appearance of being circuit-switched, telephone conversations are actually converted into packets for transmission through the core of a telecommunications network.
• Message-switched Each message is switched to its destination when a communications path is available. An example of message switching is the transmission of individual e-mail messages between servers on the Internet.
• Virtual circuit A logical communications channel is established between two endpoints on a packet-switched network. This communications channel may be known as a permanent virtual circuit (PVC) or a switched virtual circuit (SVC). Virtual circuits are used in Frame Relay networks. VPNs can also be thought of as virtual circuits.
Wide Area Network Protocols
This section describes several well-known protocols used in wide area networks.
MPLS Multiprotocol Label Switching, or MPLS, is a variable-length, packet-switched network technology. In an MPLS network, each packet has one or more labels affixed to it that contain information that helps MPLS routers to make packet-forwarding decisions, without having to examine the contents of the packet itself (for an IP address, for instance).
MPLS can be used to carry many types of traffic, including Ethernet, ATM, SONET, and IP. It is often used to trunk voice and data networks over WAN connections between business locations in an enterprise network. One of the strengths of MPLS is its QoS properties, which facilitate the rapid transfer of packets using time-sensitive protocols such as VoIP and H.323.
MPLS employs two types of devices: label edge routers (LERs) and label switch routers (LSRs). Label edge routers are used at the boundaries of an MPLS network; LERs push a label onto incoming packets that enter the network. LSRs make packet-forwarding decisions based upon the value of the label. When a packet leaves the MPLS network, another LER pops the label off the packet and forwards it out of the MPLS network.
SONET Synchronous Optical Networking, or SONET, is a class of telecommunications network transport technologies transmitted over fiber optic networks. It is a multiplexed network technology that can be used to transport voice and data communications at very high speeds over long distances.
SONET networks are almost exclusively built and operated by telecommunications network providers, who sell voice and data connectivity services to businesses. Often, the endpoint equipment for SONET networks provides connectivity using a native technology such as MPLS, Ethernet, or T-1.
Telecommunications service providers often encapsulate older services, such as DS0, DS-1, T-1, and Frame Relay, over SONET networks.
The data rates available in SONET networks are shown in Table 5-3. Rates are expressed using the term Optical Carrier Level, abbreviated OC.

Table 5-3 SONET OC Levels
T-Carrier The term T-Carrier refers to a class of multiplexed telecommunications carrier network technologies developed to transport voice and data communications over long distances using copper cabling.
The basic service in T-Carrier technology is known as DS-0, which is used to transport a single voice or data circuit. The data rate for a DS-0 is 64 Kbit/sec. Another basic T-Carrier service is the DS-1, also known as T-1. DS-1 contains 24 channels, each a DS-0. The total speed of a DS-1 is 1,544 Kbit/sec. There are additional services, all of which are shown, together with their respective data rates and channels, in Table 5-4. These services are unique to North America.

Table 5-4 T-Carrier Data Rates and Channels in North America
In Europe, T-Carrier circuits are known instead as E-1 and E-3, which multiplex 32 and 512 64 Kbit/sec circuits, respectively. The European E-Carrier standards are based on multiples of 32 circuits, whereas North American standards are based on multiples of 24 circuits. Otherwise, there isn’t much practical difference between them. E-Carrier services are shown in Table 5-5.
Table 5-5 E-Carrier Services
T-Carrier and E-Carrier protocols are synchronous, which means that packets transported on a T-Carrier and E-Carrier network are transmitted according to the pulses of a centralized clock that is usually controlled by the telecommunications carrier. This is contrasted with Ethernet, which is asynchronous, meaning a station on an Ethernet may transmit a frame at any time of its choosing (provided the network is not busy at that exact moment).
Organizations that use T-Carrier or E-Carrier services to carry data can utilize individual DS-0 channels (which are the same speed as a dial-up connection) or an entire T-1 (or E-1) circuit without multiplexing. This enables use of the entire 1,544 Kbit/sec (T-1) or 2,048 Kbit/sec (E-1) as a single resource.
Frame Relay Frame Relay is a carrier-based, packet-switched network technology. It is most often used to connect remote data networks to a centralized network; for example, a retail store chain might use Frame Relay to connect each of its retail store LANs to the corporate LAN.
Frame Relay is often more economical than dedicated DS-0 or DS-1/T-1 circuits. By their nature, Frame Relay backbone networks are shared, in the sense that they transport packets for many customers.
Connections between locations using Frame Relay are made via a permanent virtual circuit (PVC), which is not unlike a VPN, except that the payload is not encrypted. For purposes of security and privacy, PVCs are generally considered private, like a T-1 circuit.
Frame Relay has all but superseded the older X.25 services, discussed shortly. However, MPLS is rapidly overtaking Frame Relay.
ISDN ISDN, or Integrated Services Digital Network, is best described as a digital version of the public-switched telephone network. In many regions of the United States, ISDN was the first “high-speed” Internet access available for residential and small business subscribers.
A subscriber with ISDN service will have a digital modem with one connection to a digital ISDN voice telephone and one connection (typically Ethernet) to a computer. The speed of the computer connection in this configuration is 64 Kbits/sec. Alternatively, the ISDN modem could be configured in a “bonded” state with no voice telephone and only a computer connection at 128 Kbits/sec. Both of these configurations use a BRI (basic rate interface) type of connection.
Higher speeds are also available, up to 1,544 Kbits/sec, and are known as a PRI (primary rate interface) type of connection.
ISDN utilizes a separate, but similar, environment where an ISDN modem “dials” a phone number, similar to dial-up Internet service.
X.25 X.25 is an early packet network technology used for long-distance data communications, typically between business locations. It usually connects slow-speed serial communications devices such as terminals. At each location, an X.25 PAD (packet assembler-disassembler) device connects local devices to the X.25 network. The PAD would be configured to send outgoing packets to specific destinations over the X.25 network.
X.25 contained no authentication or encryption, and has been largely replaced by the newer Frame Relay and MPLS technologies discussed earlier in this section.
Wide Area Network Devices
This section describes devices used to connect wide area network components to each other and to an organization’s internal network.
Modem A modulator-demodulator unit, also known as a modem, is a device used to connect a telecommunications carrier network to a computer or a local area network. Early modems consisted of an analog telephone connector for connecting to the public telephone network, and a serial port for connecting to a computer. Later versions connect to ISDN, cable, and DSL networks and an Ethernet port for connecting to a single computer or a LAN.
Multiplexor A multiplexor is a device that connects several separate signals and combines them into a single data stream. There are four basic types of multiplexing:
• Time division Separate signals are combined into a pattern where each individual signal occupies a separate dedicated timeslot.
• Asynchronous time division multiplexing Separate signals are allocated into timeslots of varying sizes depending on need.
• Frequency division multiplexing Separate signals are combined into a single stream where each separate signal occupies a nonoverlapping frequency.
• Statistical multiplexing Separate signals are inserted into available timeslots. This is different from time division multiplexing, where input signals are assigned to timeslots. In statistical multiplexing, input signals are dynamically assigned to available timeslots.
Channel Service Unit/Digital Service Unit Also known as a CSU/DSU, a channel service unit/digital service unit is a device that is used to connect a telecommunications circuit (typically a T-1 line) to a device such as a router. A CSU/DSU is essentially a modem for T-1 and similar telecomm technologies.
WAN Switch WAN switch is a general term that encompasses several types of wide area network switching devices, including ATM switches, Frame Relay switches, MPLS switches, and ISDN switches. See the respective sections on these technologies earlier in this chapter.
Router A router is a device used to connect two or more logical local (occupying the same subnet) networks together. In the context of wide area networks, a router would be used to connect two or more wide area networks to each other.
See also the discussion of routers in the “TCP/IP Protocols and Devices” section later in this chapter.
Wireless Networks
Several types of wireless technologies are available to organizations that wish to implement data communications without constructing or maintaining a wiring plant. Furthermore, wireless networks permit devices to move from place to place, even outside of buildings, facilitating highly flexible and convenient means for high-speed communications.
The technologies discussed in this section are the type that an organization would set up on its own, without any services required from a telecommunications service provider.
Wi-Fi
Wi-Fi is the popular term used to describe several similar standards developed around the IEEE 802.11i/a/b/n/ac/ad standards. Wi-Fi, or WLAN, permits computers to communicate with each other wirelessly at high speeds over moderate distances from each other. The term “Wi-Fi” is a trademark of the Wi-Fi Alliance for certifying products as compatible with IEEE 802.11 standards. The generic term describing networks based on IEEE 802.11 standards is wireless LAN, or WLAN, although this term is not often used.
Wi-Fi Standards The various Wi-Fi standards are outlined in Table 5-6.

Table 5-6 Comparison of Wi-Fi Standards
Wi-Fi Security Wi-Fi networks can be configured with several security features that protect the privacy as well as the availability of the Wi-Fi network. Available features include
• Authentication Individual stations that wish to connect with a Wi-Fi network can be required to provide an encryption key. Furthermore, the user may be required to provide a user ID and password. Without this information, a station is unable to connect to the Wi-Fi network and communicate with it. Wi-Fi access points can contain a list of user IDs and passwords, or they can be configured to utilize a network-based authentication service such as RADIUS, LDAP, or Active Directory. Use of the latter generally makes more sense for organizations that wish to centralize user authentication information; this also makes access simpler for employees, who do not need to remember yet another user ID and password.
• Access control A Wi-Fi network can be configured to permit only stations with known MAC addresses to connect to it. Any station without a permitted address will not be able to connect.
• Encryption A Wi-Fi network can use encryption to protect traffic from interception through over-the-air eavesdropping. It can encrypt with the WEP (Wired Equivalent Privacy; now deprecated and should not be used), WPA (Wi-Fi Protected Access), or WPA2 method. A Wi-Fi network can also be configured to not use encryption, in which case another station may be able to eavesdrop on any communications on the wireless network. When a Wi-Fi network uses encryption, only the airlink communications are encrypted; network traffic from the Wi-Fi access point to other networks will not be encrypted.
• Network identifier A Wi-Fi access point is configured with a service set identifier (SSID) that identifies the network. For organizations that provide network access only for their own personnel, it is recommended that the SSID not be set to a value that makes the ownership or identity of the access point obvious. Using a company name, for instance, is not a good idea. Instead, a word—even a random set of characters—that does not relate to the organization’s identity should be used. The reason for this is that the SSID will not itself identify the owner of the network, which could, in some circumstances, invite outsiders to attempt to access it. An exception to this is a “public hotspot” used to provide free network access, where the SSID will clearly identify the establishment providing access.
• Broadcast A Wi-Fi access point can be configured to broadcast its SSID, making it easier for users to discover and connect to the network. However, broadcasting SSIDs also alerts outsiders to the presence of the network, which can compromise network security by encouraging someone to attempt to connect to it. However, turning off the SSID broadcast does not make the network absolutely secure: a determined intruder can obtain tools that will allow him to discover the presence of a Wi-Fi network that does not broadcast its SSID.
• Signal strength The transmit signal strength of a Wi-Fi access point can be configured so that radio signals from the access point do not significantly exceed the service area. Often, signal strength of access points will be set to maximum, which provides persons outside the physical premises with a strong signal. Instead, transmit signal strength should be turned down so that as little signal as possible leaves the physical premises. This is a challenge in shared-space office buildings, however, and thus cannot be used as a Wi-Fi network’s only security control.

CAUTION Because a Wi-Fi network utilizes radio signals, an untrusted outsider is able to intercept those signals, which could provide enough information for that outsider to penetrate the network. It is for this reason that all of the controls discussed in this section should be utilized in order to provide an effective defense-in-depth security protection.
WiMAX
WiMAX (Worldwide Interoperability for Microwave Access) is a set of wireless telecommunications protocols that provides data throughput from 30 Mbit/sec to 1 Gbit/sec. WiMAX is an implementation of the IEEE 802.16 standard.
WiMAX networks were in service in the 2000s, but have been largely discontinued in favor of LTE.
LTE
LTE (Long Term Evolution) is a telecommunications standard for wireless voice and data communications for smartphones, mobile devices, and wireless broadband modems. LTE is a shared-medium technology that provides data rates up to 300 Mbit/sec.
Bluetooth
Bluetooth is a short-range airlink standard for data communications between computer peripherals and low power consumption devices. Designed as a replacement for short-range cabling, Bluetooth also provides security via authentication and encryption.
Applications using Bluetooth include
• Mobile phone earsets
• In-car audio for smartphones
• Data transfer between smartphones and computers
• Music player headphones
• Computer mice, keyboards, and other low-power and low-speed peripherals
• Printers and scanners
Bluetooth is a lower-power standard, which supports the use of very small devices, such as mobile phone earsets. The standard includes one-time authentication of devices using a process called “pairing.” Communications over Bluetooth can also be encrypted so that any eavesdropping is made ineffective. Data rates range from 1 to 24 Mbit/sec.
Wireless USB
Wireless USB (WUSB) is a short-range, high-bandwidth wireless protocol used for personal area networks (PANs). Data rates range from 110 to 480 Mbit/sec. WUSB is typically used to connect computer peripherals that would otherwise be connected with cables.
WUSB can be thought of as a competitor to Bluetooth, and due to Bluetooth’s success, WUSB is not widely used.
NFC
Near-Field Communications, or NFC, is a standard of extremely short-distance radio frequencies that are commonly used for merchant payment applications. The typical maximum range for NFC is 10 cm (4 in).
NFC supports two types of communications: active-active and active-passive. In active-active mode, the base station and the wireless node electronically transmit messages over the NFC airlink. In active-passive mode, the wireless node has no active power supply and instead behaves more like an RFID (radio frequency identification) card. Throughput rates range from 106 to 848 kbit/sec.
Common applications of NFC include merchant payments using a mobile phone or credit card–sized card, and advanced building access control systems.
IrDA
IrDA stands for Infrared Data Association, which is the organization that has developed technical standards for point-to-point data communications using infrared light. IrDA has been used for communications between devices such as laptop computers, PDAs, and printers.
IrDA is not considered a secure protocol: there is no authentication or encryption of IrDA-based communications.
Bluetooth and USB have largely replaced IrDA, and few IrDA-capable devices are now sold.
TCP/IP Protocols and Devices
TCP/IP, the technology that the Internet is built upon, contains many protocols. This section discusses many of the well-known protocols, layer by layer. First, link layer protocols are discussed, followed by Internet layer protocols, then transport layer protocols, and finally application layer protocols. This is followed by a discussion of network devices that are used to build TCP/IP networks.
Link Layer Protocols
The link layer (sometimes referred to as the network access layer) is the lowest logical layer in the TCP/IP protocol suite. Several protocols have been implemented as link layer protocols, including:
• ARP (Address Resolution Protocol) This protocol is used when a station on a network needs to find another station’s MAC when it knows its Internet layer (IP) address. Basically, a station sends a broadcast on a local network, asking, in effect, “What station on this network has IP address xx.xx.xx.xx?” If any station on the network does have this IP address, it responds to the sender. When the sending station receives the reply, the receiving station’s MAC address is contained in the reply, and the sending station can now send messages to the destination station since it knows its MAC address. Another type of ARP message is known as a gratuitous ARP message that informs other stations on the network of the station’s IP and MAC addresses, regardless of whether it was requested to do so or not. Gratuitous ARP messages can be used in network attacks and are often blocked by the switch.
• RARP (Reverse Address Resolution Protocol) This protocol is used by a station that needs to know its own Internet layer (IP) address. A station sends a broadcast on a local network, asking, “This is my MAC address (xx.xx.xx.xx.xx.xx). What is my IP address supposed to be?” If a station configured to respond to RARP requests exists on the network, it will respond to the querying station with an assigned IP address. RARP has been largely superseded by BOOTP (Bootstrap Protocol) and later by DHCP.
• OSPF (Open Shortest Path First) This is a routing protocol that is implemented in the TCP/IP Internet layer. The purpose and function of routing protocols are discussed in detail later in this section.
• L2TP (Layer 2 Tunneling Protocol) This is a tunneling protocol that is implemented in the link layer. The purpose and function of tunneling protocols are discussed later in this section.
• PPP (Point-to-Point Protocol) This packet-oriented protocol is used mainly over point-to-point physical connections such as RS-232 or HSSI (High-Speed Serial Interface) between computers.
• Media Access Control (MAC) This is the underlying communications standard used by various media such as Ethernet, DSL, MPLS, and ISDN.
Internet Layer Protocols
Internet layer protocols are the fundamental building blocks of TCP/IP. The Internet layer is the bottom-most layer where a frame or packet is uniquely TCP/IP.
Protocols in the TCP/IP Internet layer include
• IP
• ICMP
• IGMP
• IPsec
IP IP is the principal protocol used by TCP/IP at the Internet layer. The main transport layer protocols (discussed in the next section), TCP and UDP, are built on IP.
The purpose of IP is to transport messages over internetworked networks. IP is the workhorse of the TCP/IP protocol suite: most communications used on the Internet are built on it.
Characteristics of IP include
• IP addressing At the IP layer, nodes on networks have unique addresses. IP addressing is discussed in detail later in this section.
• Best-effort delivery IP does not guarantee that a packet will reach its intended destination.
• Connectionless Each packet is individual and not related to any other packet.
• Out-of-order packet delivery No assurances for order of delivery are addressed by IP. Packets may arrive out of order at their destination.
Higher-layer protocols such as TCP address reliability, connections, and order of delivery.
Multicast Multicast is a method for sending IP packets to multiple stations in a one-to-many fashion. This allows a sender to send a single packet to any number of receivers. Multicast uses the IP network range 224.0.0.0/24 for originating multicast traffic.
Network infrastructure such as switches and routers take care of the task of receiving individual multicast packets and relaying them to all receivers.
The list of receivers for any given multicast is maintained in multicast groups. Group membership can change in real time without involvement from the originator of the multicast traffic. The protocol used to manage group membership is known as Internet Group Management Protocol (IGMP).
ICMP ICMP is used by systems for diagnostic purposes. Primarily, ICMP messages are automatically issued whenever there are problems with IP communications between two stations. For example, if one station attempts to send a message to another station, and a router on the network knows that there is no existing route to the destination station, the router will send an ICMP Type 3, Code 1 “No route to host” diagnostic packet back to the sending station to inform it that the destination station is not reachable.
ICMP message types are shown in Table 5-7.
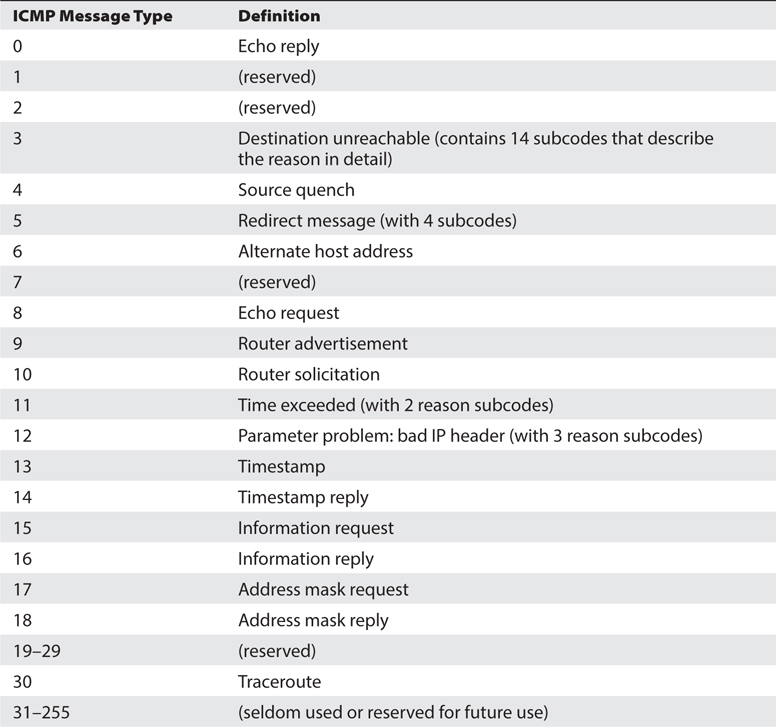
Table 5-7 ICMP Message Types
The well-known “ping” command uses the ICMP 8 Echo Request packet type. If the target station is reachable, it will respond with ICMP 1 Echo Reply packets. The ping command is used to determine whether a particular system is reachable from another system over a TCP/IP network.
IGMP IGMP provides a type of communications called multicast. Multicast is discussed earlier in this section.
IPsec Internet Protocol Security, usually known as IPsec, is a suite of protocols that is used to secure IP-based communication. The security that IPsec provides is in the form of authentication and encryption.
IPsec authentication is used to confirm the identity of a station on a network. This is used to prevent a rogue system from easily masquerading as another, real system. Authentication is achieved through the establishment of a security association (SA) between two nodes, which permits the transmission of data from the originating node to the destination node. If the two nodes need to send messages in both directions, two SAs need to be established. The Internet Key Exchange (IKE) protocol is used to set up associations.
IPsec has two primary modes of operation:
• Transport mode Only the payload of an incoming packet is authenticated or encrypted. The original IP header is left intact. The original headers are protected with hashes; if the headers are altered, the hashes will fail and an error will occur.
• Tunnel mode Each entire incoming packet is encapsulated within an IPsec packet. The entire incoming packet can be encrypted, which protects the packet against eavesdropping. This mode is often used for protecting network traffic that traverses the Internet, thereby creating a VPN between two nodes, between two networks, or between a remote node and a network. IPsec tunnel mode is shown in Figure 5-21.

Figure 5-21 IPsec tunnel mode protects all traffic between two remote networks.
Internet Layer Node Addressing: IPv4
In order to specify the source and destination of messages, TCP/IP utilizes a numeric address scheme. In the TCP/IP protocol, a station’s address is known as an “IP address.” On a given network, no two stations will have the same IP address; this uniqueness permits any station to communicate directly with any other station.
The TCP/IP IP address scheme also includes something called a subnet mask, which permits a station to determine whether any particular IP address resides on the same subnetwork. Furthermore, an IP address plan usually includes a default gateway, a station on the network that is able to forward messages to stations on other networks.
IP Addresses and Subnets The notation of an IP address is four sets of integers, separated by periods. The value of each integer may range from 0 through 255; hence, each integer is an eight-bit value. A typical IP address is 141.204.13.240. The entire IP address is 32 bits in length.
Each station on a network is assigned a unique IP address. Uniqueness permits any station to send messages to any other station; the station only needs to know the IP address of a destination station.
A larger organization may have hundreds, thousands, or even tens of thousands of stations on many networks. Typically, a network is the interconnection of computers within a single building, or even one part of a building. Within a larger building or collection of buildings, the individual networks are called subnetworks, or subnets. Those subnets are joined together by network devices such as routers or switches; they function as gateways between networks.
Subnet Mask A subnet mask is a numeric value that determines which portion of an IP address is used to identify the network and which portion is used to identify a station on the network.
For example, an organization has the network 141.204.13. On this network the organization can have up to 256 stations, numbered 0 through 255. Example station IP addresses on the network are 141.204.13.5, 141.204.13.15, and 141.204.13.200.
A subnet mask actually works at the bit level. A “1” signifies that a bit in the same position in an IP address is the network identifier, while a “0” signifies that a bit in the same position is part of the station’s address. In the previous example, where the first three numbers in the IP address signify the network, the subnet mask would be 255.255.255.0. This is illustrated in Figure 5-22.

Figure 5-22 A subnet mask denotes which part of an IP address signifies a network and which part signifies a station on the network.
Default Gateway Networks are usually interconnected so that a station on one network is able to communicate with a station on any other connected network (subject to any security restrictions). When a station wishes to send a packet to another station, the sending station will examine its own network ID (by comparing its IP address to the subnet mask) and compare that to the IP address of the destination. If the destination station is on the same network, the station may simply send the packet directly to the destination station.
If, however, the destination station is on a different network, the sending station cannot send the packet to it directly. Instead, the sending station will send the packet to a node called the default gateway—usually a router that has knowledge of neighboring and distant networks and is capable of forwarding packets to their destination. Any network that is interconnected to other networks will have a default gateway, which is where all packets for “other” networks are sent. The default gateway will forward the packet closer to its ultimate destination. A default gateway can be thought of as “the way out of this network to other networks.”
For example, a station at IP address 141.204.13.15 wishes to send a packet to a station at IP address 141.204.21.110. The sending station’s subnet mask is 255.255.255.0, which means it is on network 141.204.13. This is a different network from 141.204.21.110, so the sending station will send the packet instead to the default gateway at 141.204.13.1, a router that can forward the packet to 141.204.21.110.
When the packet reaches a router that is connected to the 141.204.21 network, that router can send the packet directly to the destination station, which is on the same network as the router.
Classful Networks The original plan for subnets and subnet masks allowed for the network/node address boundary to align with the decimals in IP addresses. This was expressed in several classes of networks, shown in Table 5-8.

Table 5-8 Classes of Networks
The matter of the shortage of usable IP addresses in the global Internet is related to classful networks. This is discussed later in this chapter in the section, “The Global Internet.”
Classless Networks It became clear that the rigidity of Class A, Class B, and Class C networks as the only ways to create subnets was wasteful. For instance, the smallest subnet available was a Class C network with its 256 available addresses. If a given subnet had only one station on it, the other 255 addresses were wasted and unused. This situation gave rise to classless networks, where subnet masks could divide networks at any arbitrary boundary.
Classless networks don’t have names like the classful networks’ Class A, Class B, and Class C. Instead, they just have subnet masks that help to serve the purpose of preserving IP addresses and allocating them more efficiently.
Table 5-9 shows some example subnet masks that can be used to allocate IP addresses to smaller networks.

Table 5-9 Classless Network Subnet Masks
A more rapid way of expressing an IP address with its accompanying subnet mask has been developed, where the number of bits in the subnet mask follows the IP address after a slash. For example, the IP address 141.204.13.15/26 means the subnet mask is the first 26 bits (in binary) of the IP address, or 255.255.255.192. This is easier than expressing the IP address and subnet mask separately.
Virtual Networks (VLANs) In the preceding discussions of IP addresses and subnets, the classic design of TCP/IP LANs specifies that LANs are physically separate. Each LAN will have its own physical cabling and devices.
Virtual networks, known as VLANs, are logically separate networks that occupy the same physical network. VLANs are made possible through advanced configuration of network devices, including switches and routers.
The primary advantage of VLAN technology is the cost savings realized through the use of fewer network cables and devices. Another advantage of VLAN technology is the ability to divide a single network into logically separate networks, thereby creating smaller broadcast domains and reducing the potential for information leakage.
The main disadvantage is that, while they are logically separate, VLANs occupy a single physical medium: traffic on one VLAN has the potential to disrupt traffic on other VLANs, since they must share the physical network.
Special IP Addresses Other IP addresses are used in IP that have not been discussed thus far. These other addresses and their functions are
• Loopback The IP address 127.0.0.1 (or any other address in the entire 127 address block) is a special “loopback” address that is analogous to earlier technologies where a physical loopback plug would be connected to a network connector in order to confirm communications within a system or device. The 127.0.0.1 loopback address serves the same function. If a system attempts to connect to a system at IP address 127.0.0.1, it is essentially communicating with itself. A system that is able to connect to itself through its loopback address is testing its IP drivers within the operating system; during network troubleshooting, it is common to issue a “ping 127.0.0.1” or similar command to verify whether the computer’s IP software is functioning correctly.
• Broadcast The highest numeric IP address in an IP subnet is called its broadcast address. When a packet is sent to a network’s broadcast address, all active stations on the network will logically receive and potentially act on the incoming message. For example, in the network 141.204.13/24, the broadcast address is 141.204.13.255. Any packet sent to that address would be sent to all stations. A ping command sent to a network’s broadcast address will cause all stations to respond with an echo reply.
Internet Layer Node Addressing: IPv6
The design of the IP, known as IPv4, had a number of shortcomings, namely in the total number of available IP addresses for use in the global Internet. The new IP, known as IPv6, takes care of the problem of available addresses, as well as other matters.
The total number of IP addresses available in IPv4 is 232, or 4,294,967,296 addresses. Because IP was originally designed prior to the proliferation of network-enabled devices, over 4 billion available IP addresses seemed more than sufficient to meet world demand. The number of IP addresses available in IPv6 is 2128, or about 3.4 × 1038 addresses.
Many new network-enabled devices support IPv6, which is enabling organizations to slowly migrate their networks. However, it is expected that IPv4 will be with us for many years. Network devices today support “dual stack” networks where IPv4 and IPv6 coexist on the same network medium.
The format of an IPv6 address is eight groups of four hexadecimal digits, separated by colons. For example:
![]()
Unlike IPv4 with its various schemes of subnetting, the standard size of an IPv6 subnet is 64 bits. Protocols for assigning addresses to individual nodes such as stateless address autoconfiguration generally work with /64 networks.
Transport Layer Protocols
The two principal protocols in TCP/IP’s transport layer are TCP and UDP. The majority of Internet communications are based on these. This section explores TCP and UDP in detail.
TCP and UDP support the two primary types of Internet-based communication: that which requires highly reliable and ordered message delivery, and that which has a high tolerance for lost messages. TCP and UDP are uniquely designed for these two scenarios.
TCP TCP is a highly reliable messaging protocol that is used in situations where high-integrity messaging is required. The main characteristics of TCP-based network traffic are
• Unique connections TCP utilizes what is known as a connection between two stations. TCP supports several concurrent connections between any two stations.
• Guaranteed message integrity TCP performs checks on the sent and received segments to ensure that the segments arrived at their destination fully intact. If the checksum indicates that the segment was altered in transit, TCP will handle retransmission.
• Guaranteed delivery TCP guarantees message delivery. This means that if an application sends a message to another application over an established TCP connection and the function sending the message receives a “success” code from the operating system, then the message was successfully delivered to the destination system. This is contrasted with the message delivery used by UDP that is discussed later in this section.
• Guaranteed delivery sequence Segments sent using TCP include sequence numbers so that the destination system can assemble arriving segments into the correct order. This guarantees that an application receiving segments from a sending application over TCP can be confident that segments are arriving in the same order in which they were sent.
UDP UDP is a lightweight messaging protocol used in situations where speed and low overhead are more important than guaranteed delivery and delivery sequence.
Unlike the connection-oriented TCP, UDP is “connectionless.” This means that UDP does not need to set up a connection between sending and receiving systems before datagrams can be sent; instead, the sending system just sends its datagrams to the destination system. Like TCP, datagrams can be sent to a specific port number on a destination system.
UDP does nothing to assure order of delivery. Hence, it is entirely possible that datagrams may arrive at the destination system out of order. In practice, this is a rarity, but the point is that UDP does not make any effort to reassemble datagrams into their original order upon arrival.
Protocol Data Units (PDUs)
In the telecommunications and network industry, there are discrete terms that are used to signify the messages that are created at various layers of encapsulated protocols such as TCP/IP. These terms include

Frequently, the term packet is used to signify messages at every layer, although it is useful to know the specific terms used for each.
Furthermore, not only does UDP not guarantee the sequence of delivery, but it also does not even guarantee that the destination system will receive a datagram. In UDP, when an application sends a message to a target system, the “success” error code returned by the operating system only means that the datagram was sent. The sending system receives no confirmation that the datagram was received by the destination system.
Application Layer Protocols
Scores of protocols have been developed for the TCP/IP application layer. Several are discussed in this section; they are grouped by the type of service that they provide.
File Transfer Protocols
• FTP (File Transfer Protocol) An early and still widely used protocol for batch transfer of files or entire directories from one system to another. FTP is supported by most modern operating systems, including Unix, OS X, and Windows. One drawback of FTP is that the login credentials (and all data) are transmitted unencrypted, which means that anyone eavesdropping on network communications can easily intercept them and use them later.
• FTPS (File Transfer Protocol Secure, or FTP-SSL) This is an extension to the FTP protocol where authentication and file transfer are encrypted using SSL or TLS.
• SFTP (SSH File Transfer Protocol) This is an extension to the FTP protocol where authentication and file transfer are encrypted using SSH.
• SCP (Secure Copy) This is a file transfer protocol that is similar to rcp (remote copy) but which is protected using SSH.
• rcp (remote copy) This is an early Unix-based file transfer protocol that is used to copy files or directories from system to system. The main drawback with rcp is the lack of encryption of credentials or transferred data.
Messaging Protocols
• SMTP (Simple Mail Transfer Protocol) This is the protocol used to transport virtually all e-mail over the Internet. SMTP is used to route e-mail messages from their source over the Internet to a destination e-mail server. It is an early protocol that lacks authentication and encryption. It is partly for this reason that people should consider their e-mail to be nonprivate.
• SMTPS (Simple Mail Transfer Protocol Secure) This is a security-enhanced version of SMTP that incorporates TLS. It is sometimes known as “SMTP over TLS.”
• POP (Post Office Protocol) This is a protocol used by an end-user e-mail program to retrieve messages from an e-mail server. POP is not particularly secure because user credentials and messages are transported without encryption.
• IMAP (Internet Message Access Protocol) Like POP, this is a protocol used by an end-user program to retrieve e-mail messages from an e-mail server.
• NNTP (Network News Transport Protocol) This is the protocol used to transport Usenet news throughout the Internet, and from news servers to end users using news-reading programs. Usenet news has been largely deprecated by web-based applications.
File and Directory Sharing Protocols
• NFS (Network File System) This protocol was developed in order to make a disk-based resource on another computer appear as a logical volume on a local computer. The NFS protocol transmits the disk requests and replies over the network.
• RPC (Remote Procedure Call) This protocol is used to permit a running process to make a procedure call to a process running on another computer. RPC supports a variety of functions that permit various types of client-server computing.
Session Protocols
• Telnet This is an early protocol that is used to establish a command-line session on a remote computer. Telnet does not encrypt user credentials as they are transmitted over the network.
• rlogin This is an early Unix-based protocol used to establish a command-line session on a remote system. Like Telnet, rlogin does not encrypt authentication or session contents.
• SSH (Secure Shell) This protocol provides a secure channel between two computers whereby all communications between them are encrypted. SSH can also be used as a tunnel to encapsulate and thereby protect other protocols.
• HTTP (Hypertext Transfer Protocol) This protocol is used to transmit webpage contents from web servers to users who are using web browsers.
• HTTPS (Hypertext Transfer Protocol Secure) This is similar to HTTP in its use for transporting data between web servers and browsers. HTTPS is not a separate protocol, but instead is the instance where HTTP is encrypted with SSL or TLS.
• RDP (Remote Desktop Protocol) This proprietary protocol from Microsoft is used to establish a graphical console interface to another computer.
Management Protocols
• SNMP (Simple Network Management Protocol) This protocol is used by network devices and systems to transmit management messages indicating a need for administrative attention. SNMP is used to monitor networks and their components; SNMP messages are generated when events warrant attention by network engineers or system engineers. In larger organizations, SNMP messages are collected by a network management system that displays the network topology and devices that require attention.
• NTP (Network Time Protocol) This protocol is used to synchronize the time-of-day clocks on systems with time-reference standards. The use of NTP is vital because the time clocks in computers often drift (run too fast or too slow), and it is important for all computers’ time clocks in an organization to be precisely the same so that complex events can be more easily correlated.
Directory Services Protocols
• DNS (Domain Name System) This is a vital Internet-based service that is used to translate domain names (such as www.isecbooks.com) into IP addresses. A call to a DNS server is a prerequisite for system-to-system communications where one system wishes to establish a communications session with another system and where it only knows the domain name for the target system.
• LDAP (Lightweight Directory Access Protocol) This protocol is used as a directory service for people and computing resources. LDAP is frequently used as an enterprise authentication and computing resource service. Microsoft Active Directory is an adaptation of LDAP.
• X.500 This protocol is a functional predecessor to LDAP that provides directory services.
TCP/IP Network Devices
Network devices are required to facilitate the transmission of packets among TCP/IP networks. These devices include
• Router This device is used to connect two or more separate TCP/IP networks to each other. A router typically has two or more network interface connectors, each of which is connected to a separate network. A router that is used to connect LANs is typically equipped with Ethernet interfaces, while a router used to connect LANs with WANs will have one or more Ethernet connectors and one or more connectors for WAN protocols such as T-1 or MPLS. A router may also have an access control list (ACL) that the router uses to determine whether packets passing through it should be permitted to proceed to their destination.
• Firewall This device is used to control which network packets are permitted to cross network boundaries. Typically, a firewall will block or permit packets to pass based on their source IP address, destination IP address, and protocol. Firewalls are typically used at an organization’s network boundary to protect it from unwanted network traffic from the Internet, but still permit traffic to the organization’s e-mail and web servers, for instance.
• Application firewall This device is used to control packets being sent to an application server, blocking those that contain unwanted or malicious content. An application firewall can help to protect a web server from attacks such as SQL injection or buffer overflow.
• Proxy server This device is typically used to control end-user access to websites on the Internet. A proxy server typically controls access according to policy.
• Layer 3 switch This device routes packets between different VLANs. Functionally, this is the same as a router; a router performs network routing using software running on a microprocessor, while a layer 3 switch performs this routing using a dedicated application-specific integrated circuit (ASIC), giving it much better performance than a router.
• Layer 4 switch This device is used to route packets to destinations based on TCP and UDP port numbers.
• Layer 4-7 switch Also known as a content switch, web switch, or application switch, this device is used to route packets to destinations based on their internal content. Layer 4-7 switches can be used to intelligently route incoming network traffic to various servers based on policy, performance, or availability.
Interestingly, the names of layer 3, layer 4, and layer 4-7 switches are based on their OSI network model layers even though these are TCP network devices.
Other network devices such as hubs, switches, and gateways are discussed in the section, “Ethernet,” earlier in this chapter.
Software-Defined Networking
Software-defined networking (SDN) is the term that represents a new class of capabilities where network infrastructure is created, configured, and managed in the context of virtualization. In SDN, routers, firewalls, switches, and other network devices are no longer physical devices but software programs that run in virtualized environments.
SDN gives organizations greater agility with regard to their network infrastructure: instead of procuring additional network devices as network infrastructure needs grow and change, virtual network devices are instantiated and deployed immediately.
Organizations and groups of organizations are developing SDN standards, such as OpenFlow, to build consistent practices to SDN.
The Global Internet
The TCP/IP networks owned by businesses, government, military, and educational institutions are interconnected; collectively this is known as the global Internet—or just the Internet. It is in the context of the global Internet that TCP/IP topics such as node addressing, routing, domain naming, and other matters are most relevant.
IP Addressing
The allocation of routable IP addresses is coordinated through a central governing body known as the Internet Assigned Numbers Authority (IANA). This coordination is necessary so that duplicate addresses are not allocated, which would cause confusion and unreachable systems.
The original IP address allocation scheme appears in Table 5-10.

Table 5-10 Internet IP Address Allocation
When the TCP/IP protocol was established, the entire IP address space (that is, the entire range of possible addresses from 1.1.1.1 through 255.255.255.255) appeared to be far more than would ever be needed. However, it soon became apparent that the original IP address allocation scheme was woefully inadequate. This led to the establishment of ranges for private networks and rules for their use. Private address ranges are listed in Table 5-11.

Table 5-11 Private Address Ranges
Availability of a sufficient number of publicly routable IP addresses has been addressed with IPv6. See the sidebar on IPv6 earlier in this chapter.
NOTE The number of available addresses does not take network IDs and broadcast addresses into account, which will make the number of actual addresses lower. This will vary, based upon how networks are subnetted.
The private addresses listed in Table 5-11 are not “routable.” This means that no router on the Internet is permitted to forward a packet with any IP address within any of the private address ranges. These IP addresses are intended for use wholly within organizations to facilitate communication among internal systems. When any system with a private address needs to communicate with a system on the Internet, its communication is required to pass through a gateway that will translate the internal IP address to a public routable IP address. The NAT (Network Address Translation) protocol is often used for this purpose.
Domain Name System
The Internet utilizes a centrally coordinated domain name registration system known as the Domain Name System (DNS). Several independent domain registrars are licensed to issue new domain names to individuals and corporations in exchange for modest fees. These domain registrars often also provide DNS services on behalf of each domain name’s owner.
New and changed domain names are periodically uploaded to the Internet’s “root” DNS servers, enabling users to access services by referring to domain names such as www.newsite.com.
Network Routing
Routers used by Internet service providers (ISPs) receive and forward IP traffic to and from any of the millions of systems that are connected to the Internet. These big routers exchange information on the whereabouts of all publicly reachable networks in large “routing tables” that contain rules about the topology of the Internet and the addresses and locations of networks. Internet routers exchange this information through the use of routing protocols, which are “out of band” messages that contain updates to the topology and IP addressing of the Internet. Some of these protocols are
• BGP (Border Gateway Protocol)
• OSPF (Open Shortest Path First)
• IGRP (Interior Gateway Routing Protocol)
• EIGRP (Enhanced Interior Gateway Routing Protocol)
• IS-IS (Intermediate System to Intermediate System)
• RIP (Routing Information Protocol; this is one of the earliest protocols and no longer used for Internet routing)
Organizations with several internal networks also use one or more of these routing protocols so that their routers can keep track of the changing topology and addressing of its network.
Global Internet Applications
Applications are what make the Internet popular. From electronic banking to e-commerce, entertainment, news, television, and movies, applications on the Internet have made it possible for people anywhere to view or receive virtually any kind of information and content.
The World Wide Web The World Wide Web is the term that encompasses all of the world’s web servers, which are accessible from workstations of many types that use web browser programs. Requests to web servers, and content returned to browsers, are issued using HTTP and HTTPS. Content sent to browsers consists primarily of text written in HTML, as well as rich text, including images and dynamic content.
The World Wide Web rapidly gained in popularity because information and applications could be accessed from anywhere without any special software. Readily available tools simplified the publication of many types of data to the Web.
The most critical service that supports the World Wide Web is DNS. This service translates server domain names into IP addresses. For example, if a user wants to visit www.mheducation.com, the operating system running the user’s browser will make a request to a local DNS server for the IP address corresponding to www.mheducation.com. After the DNS server responds with the server’s IP address, the user’s browser can issue a request to the server (at www.mheducation.com) and then receive content from the server.
Web servers can act as application servers. Authenticated users can receive menus, data entry screens and forms, query results, and reports, all written in HTML, all with only web browser software.
E-mail Electronic mail was one of the Internet’s first applications. E-mail existed before the Internet, but it was implemented on the Internet as a way to send messages not only within organizations but also between them. The SMTP and POP protocols were developed and adopted early on, and are still widely used today. SMTP remains the backbone of Internet e-mail transport. Organizations increasingly are using SMTPS to protect the contents of e-mail messages.
Instant Messaging It makes good sense that e-mail, while far more rapid than postal-delivered letters, can still be slow at times. Instant messaging (IM), originally developed on DEC PDP-11 computers in the 1970s and on Unix in the early 1980s, was adapted to the Internet in the early 1990s. Instant messaging, like all other Internet applications, is based on the TCP/IP protocol suite and enables people all over the world to communicate in real time via text, voice, and video.
Network Tunneling Tunneling refers to a number of protocols that permit communications between two endpoints to be encapsulated in a logical “tunnel.” Often, a tunnel is used to protect communications containing sensitive data that is transported over public networks such as the Internet. Packets in a tunnel can be encrypted, which hides the true endpoint IP addresses as well as the message contents from any intermediate system that may eavesdrop on those communications. Tunnels are frequently called virtual private networks (VPNs), because they provide both security (through encryption and authentication) and abstraction (by hiding the details of the path between systems).
VPNs are frequently used for end-user remote access into an organization’s network. When an end user wishes to connect to an organization’s internal network, the network will establish a session with a VPN server and provide authentication credentials. An encrypted tunnel will then be established that gives the end user the appearance of being connected to the internal network.
Network Management
Network management is the function of ensuring that a data network continues to support business objectives. The activities that take place include monitoring network devices, identifying problems, and applying remedies as needed to restore network operations.
The purpose of network management is the continued reliable operation of an organization’s data network. A properly functioning data network, in turn, supports business applications that support critical business processes.
Network Management Tools
Network management requires tools that are used to monitor, troubleshoot, and maintain data networks. This permits an IT organization to ensure the continuous operation of its data network so that it has sufficient capacity and capability to support applications and services vital to the organization’s ongoing business operations.
The tools that are used to fulfill this mission include
• Network management systems These are software applications that collect network management messages that are sent from network devices and systems. These messages alert the management system that certain conditions exist on the device, some of which may require intervention. Some network management systems also contain the means for network administrators and engineers to diagnose and correct conditions that require attention.
• Network management reports Network management systems generally have the ability to generate reports showing key metrics such as network availability, utilization, response time, and downtime. Reports from helpdesk systems or incident management systems also help to better understand the health of an organization’s networks.
• Network management agents Agents are small software modules that reside on managed network devices and other systems. These agents monitor operations on the device or system and transmit messages to a centralized network management system when needed.
• Incident management systems These systems are general-purpose ticketing engines that capture and track individual incidents and report on an organization’s timely response to them. Often, network management systems and incident management systems can be integrated together so that conditions requiring attention in the network can automatically create a ticket that will be used to track the course of the incident until it is closed.
• Sniffers A sniffer is a software program that can be installed on a network-attached system, or a separate hard device, used to capture and analyze network traffic.
• Security incident and event management (SIEM) system A SIEM (pronounced “sim”) is a system that collects, correlates, analyzes, reports on, and creates actionable alerts based on the individual error and event messages generated by the systems and devices in an environment.
Organizations employing network management tools often implement a network operations center, or NOC, staffed with personnel who monitor and manage network devices and services.
Networked Applications
Other than simple end-user tools on a business workstation, business applications are rarely installed and used within the context of an individual computer. Instead, many applications are centrally installed and used by people in many locations. Data networks facilitate the communications between central servers and business workstations. The two types of applications discussed in this section are client-server and web-based. Middleware is sometimes used in client-server applications.
Client-Server
Client-server applications are a prior-generation technology used to build high-performance business applications. They consist of one or more central application servers, database servers, and business workstations. The central application servers contain some business logic, primarily the instructions to receive and respond to requests sent from workstations. The remainder of the business logic will reside on each business workstation; primarily this is the logic used to display forms and reports for the user.
When a user is using a client-server application, he or she is typically selecting functions to input, view, or change information. When inputting information, application logic on the business workstation will request, analyze, and accept the information and then transmit it to the central application server for further processing and storage. When viewing information, a user will typically select a viewing function with, perhaps, criteria specifying which information they wish to view. Business logic on the workstation will validate this information and then send a request to the central application server, which, in turn, will respond with information that is then sent back to the workstation and transformed for easy viewing.
The promise of client-server applications was improved performance by removing all application display logic from the central computer and placing that logic on each individual workstation. This scheme succeeded in principle but failed in practice for two principal reasons:
• Network performance Client-server applications often overburdened the organization’s data network, and application performance failed when many people were using it at once. A typical example is a database query issued by a workstation that results in thousands of records being returned to the workstation over the network.
• Workstation software updates Keeping the central application software and the software modules on each workstation in sync proved to be problematic. Often, updates required that all workstations be upgraded at the same time. Invariably, some workstations are down (powered down by end users or taken home if they are laptop computers) and unavailable for updates.
Organizations that did implement full-scale client-server applications were often dissatisfied with the results. And at nearly the same time, the World Wide Web was invented and soon proved to be a promising alternative.
Client-server application design has enjoyed a revival with the advent of smartphone and tablet applications, called “apps,” which are often designed as client-server.
Web-Based Applications
With client-server applications declining in favor, web-based applications were the only way forward. The primary characteristics of web-based applications that make them highly favorable include
• Centralized business logic All business logic resides on one or more centralized servers. There are no longer issues related to pushing software updates to workstations since they run web browsers that rarely require updating.
• Lightweight and universal display logic Display logic, such as forms, lists, and other application controls, is easily written in HTML, a simple markup language that displays well on workstations without any application logic on the workstation.
• Lightweight network requirements Unlike client-server applications that would often send large amounts of data from the centralized server to the workstation, web applications send only display data to workstations.
• Workstations requiring few, if any, updates Workstations require only browser software. Updates to applications themselves are entirely server-based.
• Fewer compatibility issues Instead of requiring a narrow choice of workstations, web-based applications can run on nearly every kind of workstation, including Unix, Windows, Mac OS X, or Linux.
Middleware
Middleware is a component used in some client-server or web-based application environments to control the processing of communications or transactions. Middleware manages the interaction between major components in larger application environments.
Some of the common types of middleware include
• Transaction processing (TP) monitors A TP monitor manages transactions between application servers and database servers in order to ensure the integrity of business transactions and a collection of database servers.
• RPC gateways These systems facilitate communications through the suite of RPC protocols between various components of an application environment.
• Object request broker (ORB) gateways An ORB gateway facilitates the execution of transactions across complex, multiserver application environments that use CORBA (Common Object Request Broker Architecture) or Microsoft COM/DCOM technologies.
• Message servers These systems store and forward transactions between systems and ensure the eventual delivery of transactions to the right systems.
Middleware is typically used in a large, complex application environment, particularly when there are multiple technologies (operating systems, databases, and languages) in use. Middleware can be thought of as “glue” that helps the application environment operate more smoothly.
Disaster Recovery Planning
Disaster recovery planning (DRP) is undertaken to reduce risks related to the onset of disasters and other events.
Disaster recovery planning is closely related to business continuity planning (BCP). The groundwork for DRP begins in BCP activities such as the business impact analysis, criticality analysis, establishment of recovery objectives, and testing. The outputs from these activities are the key inputs to DRP:
• The business impact analysis and criticality analysis help to prioritize which business processes (and, therefore, which IT systems) are the most important.
• Key recovery targets specify how quickly specific IT applications are to be recovered. This guides DRP personnel as they develop new IT architectures that make IT systems compliant with those objectives.
• Testing of DRP plans can be performed in coordination with tests of BCP plans to more accurately simulate real disasters and disaster response.
Business continuity planning is discussed in detail in Chapter 2.
Disaster Response Teams’ Roles and Responsibilities
Disaster recovery plans need to specify the teams that are required for disaster response, as well as each team’s roles and responsibilities. Table 5-12 describes several teams and their roles.

Table 5-12 Disaster Response Teams’ Roles and Responsibilities
NOTE Some of the roles in Table 5-12 may overlap with responsibilities defined in the organization’s business continuity plan. DR and BC planners will need to work together to ensure that the organization’s overall response to disaster is appropriate and does not overlook vital functions.
Because of variations in organizations’ disaster response plans, some of these teams will not be needed in some organizations.
Recovery Objectives
During the business impact analysis and criticality analysis phases of a BC/DR project, the speed with which each business activity (with its underlying IT systems) needs to be restored after a disaster is determined.
Recovery Time Objective (RTO)
Recovery time objective (RTO) is the period from the onset of an outage until the resumption of service. RTO is usually measured in hours or days. Each process and system in the BIA should have an RTO value.
RTO does not mean that the system (or process) has been recovered to 100 percent of its former capacity. Far from it—in an emergency situation, management may determine that a DR (disaster recovery) server in another city with, say, 60 percent of the capacity of the original server is adequate. That said, an organization could establish two RTO targets, one for partial capacity and one for full capacity.
NOTE For a given organization, it’s probably best to use one unit of measure for recovery objectives for all systems. That will help to avoid any errors that would occur during a rank-ordering of systems so that two days does not appear to be a shorter period than four hours.
Further, a system that has been recovered in a disaster situation might not have 100 percent of its functionality. For instance, an application that lets users view transactions that are more than two years old may, in a recovery situation, only contain 30 days’ worth of data. Again, such a decision is usually the result of a careful analysis of the cost of recovering different features and functions in an application environment. In a larger, complex environment, some features might be considered critical, while others are less so.
CAUTION Senior management should be involved in any discussion related to recovery system specifications in terms of capacity, integrity, or functionality.
Recovery Point Objective (RPO)
A recovery point objective (RPO) is the period for which recent data will be irretrievably lost in a disaster. Like RTO, RPO is usually measured in hours or days. However, for critical transaction systems, RPO could even be measured in minutes or seconds.
RPO is usually expressed as a worst-case figure; for instance, the transaction processing system RPO will be two hours or less.
The value of a system’s RPO is usually a direct result of the frequency of data backup or replication. For example, if an application server is backed up once per day, the RPO is going to be at least 24 hours (or one day, whichever way you like to express it). Maybe it will take three days to rebuild the server, but once data is restored from backup tape, no more than the last 24 hours of transactions are lost. In this case, the RTO is three days and the RPO is one day.
Publishing RTO and RPO Figures
If the storage system for an application takes a snapshot every hour, the RPO could be one hour, unless the storage system itself was damaged in a disaster. If the snapshot is replicated to another storage system four times per day, then the RPO might be better expressed as six to eight hours.
The last example brings up an interesting point. There might not be one golden RPO figure for a given system. Instead, the severity of a disrupting event or a disaster will dictate the time to get systems running again (RTO) with a certain amount of data loss (RPO). Here are some examples:
• A server’s CPU or memory fails and is replaced and restarted in two hours. No data is lost. The RTO is two hours and the RPO is zero.
• The storage system supporting an application suffers a hardware failure that results in the loss of all data. Data is recovered from a snapshot on another server taken every six hours. The RPO is six hours in this case.
• The database in a transaction application is corrupted and must be recovered. Backups are taken twice per day. The RPO is 12 hours. However, it takes 10 hours to rebuild indexes on the database, so the RTO is closer to 22 to 24 hours, since the application cannot be returned to service until indexes are available.
NOTE When publishing RTO and RPO figures to customers, it’s best to publish the worst-case figures: “If our data center burns to the ground, our RTO is X hours and the RPO is Y hours.” Saying it that way would be simpler than publishing a chart that shows RPO and RTO figures for various types of disasters.
Pricing RTO and RPO Capabilities
Generally speaking, the shorter the RTO or RPO for a given system, the more expensive it will be to achieve the target. Table 5-13 depicts a range of RTOs along with the technologies needed to achieve them and their relative cost.

Table 5-13 The Lower the Recovery Time Objective (RTO), the Higher the Cost to Achieve It
The BCP project team needs to understand the relationship between the time required to recover an application and the cost required to recover the application within that time. A shorter recovery time is more expensive, and this relationship is not linear. This means that reducing RPO from three days to six hours may mean that the equipment and software investment might double, or it might increase eightfold. There are so many factors involved in the supporting infrastructure for a given application that the BCP project team has to just knuckle down and develop the cost for a few different RTO and RPO figures.
The business value of the application itself is the primary driver in determining the amount of investment that senior management is willing to make to reach any arbitrary RTO and RPO figures. This business value may be measured in local currency if the application supports revenue. However, the loss of an application during a disaster may harm the organization’s reputation. Again, management will have to make a decision on how much it will be willing to invest in DR capabilities that bring RTO and RPO figures down to a certain level. Figure 5-23 illustrates these relationships.

Figure 5-23 Aim for the sweet spot and balance the costs of downtime and recovery.
Developing Recovery Strategies
When management has chosen specific RPO and RTO targets for a given system or process, the BCP project team can now roll up its sleeves and devise some ways to meet these targets. This section discusses the technologies and logistics associated with various recovery strategies. This will help the project team to decide which types of strategies are best suited for their organization.
Developing recovery strategies to meet specific recovery targets is an iterative process. The project team will develop a strategy to reach specific targets for a specific cost; senior management could well decide that the cost is too high and that they are willing to increase RPO and/or RTO targets accordingly. Similarly, the project team could also discover that it is less costly to achieve specific RPO and RTO targets, and management could respond by lowering those targets. This is illustrated in Figure 5-24.

Figure 5-24 Recovery objective development flowchart
Site Recovery Options
In a worst-case disaster scenario, the site where information systems reside is partially or completely destroyed. In most cases, the organization cannot afford to wait for the damaged or destroyed facility to be restored, as this could take weeks or months. If an organization can take that long to recover an application, you’d have to wonder whether it is needed at all. The assumption has got to be that in a disaster scenario, critical applications will be recovered in another location. This other location is called a recovery site. There are two dimensions to the process of choosing a recovery site: the first is the speed at which the application will be recovered at the recovery site; the second is the location of the recovery site itself. Both are discussed here.
As you might expect, speed costs. If a system is to be recovered within a few minutes or hours, the costs will be much higher than if the system can be recovered in five days.
Various types of facilities are available for rapid or not-too-rapid recovery. These facilities are called hot sites, warm sites, and cold sites. As the names might suggest, hot sites permit rapid recovery, while cold sites provide a much slower recovery. The costs associated with these are somewhat proportional as well, as illustrated in Table 5-14.

Table 5-14 Relative Costs of Recovery Sites
The details about each type of site are discussed in the remainder of this section.
Hot Sites A hot site is an alternate processing center where backup systems are already running and in some state of near-readiness to assume production workload. The systems at a hot site most likely have application software and database management software already loaded and running, perhaps even at the same patch levels as the systems in the primary processing center.
A hot site is the best choice for systems whose RTO targets range from zero to several hours, perhaps as long as 24 hours.
A hot site may consist of leased rack space (or even a cage for larger installations) at a colocation center. If the organization has its own processing centers, then a hot site for a given system would consist of the required rack space to house the recovery systems. Recovery servers will be installed and running, with the same version and patch level for the operating system, database management system (if used), and application software.
Systems at a hot site require the same level of administration and maintenance as the primary systems. When patches or configuration changes are made to primary systems, they should be made to hot-site systems at the same time or very shortly afterward.
Because systems at a hot site need to be at or very near a state of readiness, a strategy needs to be developed regarding a method for keeping the data on hot standby systems current. This is discussed in detail in the later section, “Recovery and Resilience Technologies.”
Systems at a hot site should have full network connectivity. A method for quickly directing network traffic toward the recovery servers needs to be worked out in advance so that a switchover can be accomplished. This is also discussed in the “Recovery and Resilience Technologies” section.
When setting up a hot site, the organization will need to send one or more technical staff members to the site to set up systems. But once the systems are operating, much or all of the system- and database-level administration can be performed remotely. However, in a disaster scenario, the organization may need to send the administrative staff to the site for day-to-day management of the systems. This means that workspace for these personnel needs to be identified so that they can perform their duties during the recovery operation.
NOTE Hot-site planning needs to consider work (desk) space for on-site personnel. Some colocation centers provide limited work areas, but these areas are often shared and often have little privacy for phone discussions. Also, transportation, hotel, and dining accommodations need to be arranged, possibly in advance, if the hot site is in a different city from the primary site.
Warm Sites A warm site is an alternate processing center where recovery systems are present, but at a lower state of readiness than recovery systems at a hot site. For example, while the same version of the operating system may be running on the warm site system, it may be a few patch levels behind primary systems. The same could be said about the versions and patch levels of database management systems (if used) and application software: they may be present, but they’re not as up-to-date.
A warm site is appropriate for an organization whose RTO figures range from roughly one to seven days. In a disaster scenario, recovery teams would travel to the warm site and work to get the recovery systems to a state of production readiness and to get systems up-to-date with patches and configuration changes to bring the systems into a state of complete readiness.
A warm site is also used when the organization is willing to take the time necessary to recover data from tape or other backup media. Depending upon the size of the database(s), this recovery task can take several hours to a few days.
The primary advantage of a warm site is that its costs are lower than for a hot site, particularly in the effort required to keep the recovery system up-to-date. The site may not require expensive data replication technology, but instead data can be recovered from backup media.
Cold Sites A cold site is an alternate processing center where the degree of readiness for recovery systems is low. At the very least, a cold site is nothing more than an empty rack, or just allocated space on a computer room floor. It’s just an address in someone’s data center or colocation site where computers can be set up and used at some future date.
Often, there is little or no equipment at a cold site. When a disaster or other highly disruptive event occurs in which the outage is expected to exceed 7 to 14 days, the organization will order computers from a manufacturer, or perhaps have computers shipped from some other business location, so that they can arrive at the cold site soon after the disaster event has begun. Then personnel would travel to the site and set up the computers, operating systems, databases, network equipment, and so on, and get applications running within several days.
The advantage of a cold site is its low cost. The main disadvantage is the cost, time, and effort required to bring it to operational readiness in a short period. But for some organizations, a cold site is exactly what is needed.
Table 5-15 shows a comparison of hot, warm, and cold recovery sites and a few characteristics of each.

Table 5-15 Detailed Comparison of Cold, Warm, and Hot Sites
Mobile Sites A mobile site is a portable recovery center that can be delivered to almost any location in the world. A viable alternative to a fixed location recovery site, a mobile site can be transported by semi truck, and may even have its own generator, communications, and cooling capabilities.
APC and SunGuard have mobile sites installed in semi truck trailers. Oracle has mobile sites that can include a configurable selection of servers and workstations, all housed in shipping containers that can be shipped by truck, rail, ship, or air to any location in the world.
Cloud Sites Organizations are increasingly using cloud hosting services as their recovery sites. Such sites charge for the utilization of servers and devices in virtual environments. Hence, capital costs for recovery sites is near zero and operational costs come into play as recovery sites are used.
As organizations become accustomed to building recovery sites in the cloud, they are with increasing frequency moving their primary processing sites to the cloud as well.
Reciprocal Sites A reciprocal recovery site is a data center that is operated by another company. Two or more organizations with similar processing needs will draw up a legal contract that obligates one or more of the organizations to temporarily house another party’s systems in the event of a disaster.
Often, a reciprocal agreement pledges not only floor space in a data center, but also the use of the reciprocal partner’s computer system. This type of arrangement is less common, but is still used by organizations that use mainframe computers and other high-cost systems.
NOTE With the wide use of Internet colocation centers, reciprocal sites have fallen out of favor. Still, they may be ideal for organizations with mainframe computers that are otherwise too expensive to deploy to a cold or warm site.
Geographic Site Selection An important factor in the process of recovery site selection is the location of the recovery site. The distance between the main processing site and the recovery site is vital and may figure heavily into the viability and success of a recovery operation.
A recovery site should not be located in the same geographic region as the primary site. A recovery site in the same region may be involved in the same regional disaster as the primary site and may be unavailable for use or be suffering from the same problems present at the primary site.
By “geographic region” I mean a location that will likely experience the effects of the same regional disaster that affects the primary site. No arbitrarily chosen distance (such as 100 miles) guarantees sufficient separation. In some locales, 50 miles is plenty of distance; in other places, 300 miles is too close—it all depends on the nature of disasters that are likely to occur in these areas. Information on regional disasters should be available from local disaster preparedness authorities or from local disaster recovery experts.
Considerations When Using Third-Party Disaster Recovery Sites
Since most organizations cannot afford to implement their own secondary processing site, the only other option is to use a disaster recovery site that is owned by a third party. This could be a colocation center, a disaster services center, or a cloud-based infrastructure service provider. An organization considering such a site needs to ensure that its services contract addresses the following:
• Disaster definition The definition of disaster needs to be broad enough to meet the organization’s requirements.
• Equipment configuration IT equipment must be configured as needed to support critical applications during a disaster.
• Availability of equipment during a disaster IT equipment needs to actually be available during a disaster. The organization needs to know how the disaster service provider will allocate equipment if many of its customers suffer a disaster simultaneously.
• Customer priorities The organization needs to know whether the disaster services provider has any customers (government or military, for example) whose priorities may exceed their own.
• Data communications There must be sufficient bandwidth and capacity for the organization plus other customers who may be operating at the disaster provider’s center at the same time.
• Testing The organization needs to know what testing it is permitted to perform on the service provider’s systems so that the ability to recover from a disaster can be tested in advance.
• Right to audit The organization should have a “right to audit” clause in its contract so that it can verity the presence and effectiveness of all key controls in place at the recovery facility.
• Security and environmental controls The organization needs to know what security and environmental controls are in place at the disaster recovery facility.
Acquiring Additional Hardware
Many organizations elect to acquire their own server, storage, and network hardware for disaster recovery purposes. The way that an organization will need to go about acquiring hardware will depend on its high-level recovery strategy:
• Cold site An organization will need to be able to purchase hardware as soon as the disaster occurs.
• Warm site An organization probably will need to purchase hardware in advance of the disaster, but it may be able to purchase hardware when the disaster occurs. The choice taken will depend on the recovery time objective.
• Hot site An organization will need to purchase its recovery hardware in advance of the disaster.
• Cloud An organization will not need to purchase hardware, as this is provided by the cloud infrastructure provider.
Pros and cons to these strategies are listed in Table 5-16. Warm site strategy is not listed, since an organization could purchase hardware either in advance of the disaster or when it occurs. But because cold, hot, and cloud sites are deterministic, they are included in the table.

Table 5-16 Hardware Acquisition Pros and Cons for Cold, Hot, and Cloud Recovery Sites
The main reason for choosing a cloud hosting provider is the elimination of capital costs. The cloud hosting provider provides all hardware, and charges organizations when the hardware is used.
The primary business reason for not choosing a hot site is the high capital cost required to purchase disaster recovery equipment that may never be used. One way around this obstacle is to put those recovery systems to work every day. For example, recovery systems could be used for development or testing of the same applications that are used in production. This way, systems that are purchased for recovery purposes are being well utilized for other purposes, and they’ll be ready in case a disaster occurs.
When a disaster occurs, the organization will be less concerned about development and testing, and more concerned about keeping critical production applications running. It will be a small sacrifice to forgo development or testing (or whatever low-criticality functions are using the DR hardware) during a disaster.
Recovery and Resilience Technologies
Once recovery targets have been established, the next major task is the survey and selection of technologies to enable recovery time and recovery point objectives to be met. The important factors when considering each technology are
• Does the technology help the information system achieve the RTO and RPO targets?
• Does the cost of the technology meet or exceed budget constraints?
• Can the technology be used to benefit other information systems (thereby lowering the cost for each system)?
• Does the technology fit well into the organization’s current IT operations?
• Will operations staff require specialized training on the technology used for recovery?
• Does the technology contribute to the simplicity of the overall IT architecture, or does it complicate it unnecessarily?
These questions are designed to help determine whether a specific technology is a good fit, from a technology perspective as well as from process and operational perspectives.
RAID Redundant Array of Independent Disks (RAID) is a family of technologies that is used to improve the reliability, performance, or size of disk-based storage systems. From a disaster recovery or systems resilience perspective, the feature of RAID that is of particular interest is the reliability. RAID is used to create virtual disk volumes over an array (pun intended) of disk storage devices and can be configured so that the failure of any individual disk drive in the array will not affect the availability of data on the disk array.
RAID is usually implemented on a hardware device called a disk array, which is a chassis in which several hard disks can be installed and connected to a server. The individual disk drives can usually be “hot swapped” in the chassis while the array is still operating. When the array is configured with RAID, a failure of a single disk drive will have no effect on the disk array’s availability to the server to which it is connected. A system operator can be alerted to the disk’s failure, and the defective disk drive can be removed and replaced while the array is still fully operational.
There are several options for RAID configuration, called levels:
• RAID-0 This is known as a striped volume, where a disk volume splits data evenly across two or more disks in order to improve performance.
• RAID-1 This creates a mirror, where data written to one disk in the array is also written to a second disk in the array. RAID-1 makes the volume more reliable, through the preservation of data, even when one disk in the array fails.
• RAID-4 This level of RAID employs data striping at the block level by adding a dedicated parity disk. The parity disk permits the rebuilding of data in the event one of the other disks fails.
• RAID-5 This is similar to RAID-4 block-level striping, except that the parity data is distributed evenly across all of the disks instead of dedicated on one disk. Like RAID-4, RAID-5 allows for the failure of one disk without losing information.
• RAID-6 This is an extension of RAID-5, where two parity blocks are used instead of a single parity block. The advantage of RAID-6 is that it can withstand the failure of any two disk drives in the array, instead of a single disk, as is the case with RAID-5.
NOTE Several nonstandard RAID levels have been developed by various hardware and software companies. Some of these are extensions of RAID standards, while others are entirely different.
Storage systems are hardware devices that are entirely separate from servers—their only purpose is to store a large amount of data and to be highly reliable through the use of redundant components and the use of one or more RAID levels. Storage systems generally come in two forms:
• Storage area network (SAN) This is a stand-alone storage system that can be configured to contain several virtual volumes and to connect to several servers through fiber optic cables. The servers’ operating systems will often consider this storage to be “local,” as though it consisted of one or more hard disks present in the server’s own chassis.
• Network attached storage (NAS) This is a stand-alone storage system that contains one or more virtual volumes. Servers access these volumes over the network using the NFS or Server Message Block/Common Internet File System (SMB/CIFS) protocols, common on Unix and Windows operating systems, respectively.
Replication Replication is an activity where data that is written to a storage system is also copied over a network to another storage system. The result is the presence of up-to-date data that exists on two or more storage systems, each of which could be located in a different geographic region.
Replication can be handled in several ways and at different levels in the technology stack:
• Disk storage system Data-write operations that take place in a disk storage system (such as a SAN or NAS) can be transmitted over a network to another disk storage system, where the same data will be written to the other disk storage system.
• Operating system The operating system can control replication so that updates to a particular file system can be transmitted to another server where those updates will be applied locally on that other server.
• Database management system The database management system (DBMS) can manage replication by sending transactions to a DBMS on another server.
• Transaction management system The transaction management system (TMS) can manage replication by sending transactions to a counterpart TMS located elsewhere.
• Application The application can write its transactions to two different storage systems. This method is not often used.
• Virtualization Virtual machine images can be replicated to recovery sites to speed the recovery of applications.
Replication can take place from one system to another system, called primary-backup replication. This is the typical setup when data on an application server is sent to a distant storage system for data recovery or disaster recovery purposes.
Replication can also be bidirectional, between two active servers, called multiprimary or multimaster. This method is more complicated, because simultaneous transactions on different servers could conflict with one another (such as two reservation agents trying to book a passenger in the same seat on an airline flight). Some form of concurrent transaction control would be required, such as a distributed lock manager.
In terms of the speed and integrity of replicated information, there are two types of replication:
• Synchronous replication Writing data to a local and to a remote storage system is performed as a single operation, guaranteeing that data on the remote storage system is identical to data on the local storage system. Synchronous replication incurs a performance penalty, as the speed of the entire transaction is slowed to the rate of the remote transaction.
• Asynchronous replication Writing data to the remote storage system is not kept in sync with updates on the local storage system. Instead, there may be a time lag, and you have no guarantee that data on the remote system is identical to that on the local storage system. However, performance is improved, because transactions are considered complete when they have been written to the local storage system only. Bursts of local updates to data will take a finite period to replicate to the remote server, subject to the available bandwidth of the network connection between the local and remote storage systems.
NOTE Replication is often used for applications where the RTO is smaller than the time necessary to recover data from backup media. For example, if a critical application’s RTO is established to be two hours, then recovery from backup tape is probably not a viable option, unless backups are performed every two hours. While more expensive than recovery from backup media, replication ensures that up-to-date information is present on a remote storage system that can be put online in a short period.
Server Clusters A cluster is a collection of two or more servers that appear as a single server resource. Clusters are often the technology of choice for applications that require a high degree of availability and a very small RTO, measured in minutes.
When an application is implemented on a cluster, even if one of the servers in the cluster fails, the other server (or servers) in the cluster will continue to run the application, usually with no user awareness that such a failure occurred.
There are two typical configurations for clusters, active/active and active/passive. In active/active mode, all servers in the cluster are running and servicing application requests. This is often used in high-volume applications where many servers are required to service the application workload.
In active/passive mode, one or more servers in the cluster are active and servicing application requests, while one or more servers in the cluster are in a “standby” mode; they can service application requests, but won’t do so unless one of the active servers fails or goes offline for any reason. When an active server goes offline and a standby server takes over, this event is called a failover.
A typical server cluster architecture is shown in Figure 5-25.

Figure 5-25 Application and database server clusters
A server cluster is typically implemented in a single physical location such as a data center. However, a cluster can also be implemented where great distances separate the servers in the cluster. This type of cluster is called a geographic cluster, or geo-cluster. Servers in a geo-cluster are connected through a WAN connection. A typical geographic cluster architecture is shown in Figure 5-26.

Figure 5-26 Geographic cluster with data replication
Network Connectivity and Services An overall application environment that is required to be resilient and have recoverability must have those characteristics present within the network that supports it. A highly resilient application architecture that includes clustering and replication would be of little value if it had only a single network connection that was a single point of failure.
An application that requires high availability and resilience may require one or more of the following in the supporting network:
• Redundant network connections These may include multiple network adapters on a server, but also a fully redundant network architecture with multiple switches, routers, load balancers, and firewalls. This could also include physically diverse network provider connections, where network service provider feeds enter the building from two different directions.
• Redundant network services Certain network services are vital to the continued operation of applications, such as DNS (the function of translating server names like www.mcgraw-hill.com into an IP address), NTP (used to synchronize computer time clocks), SMTP, SNMP, authentication services, and perhaps others. These services are usually operated on servers, which may require clustering and/or replication of their own so that the application will be able to continue functioning in the event of a disaster.
Developing Recovery Plans
A disaster recovery planning effort starts with the initial phases of the business continuity planning (BCP) project: the business impact analysis (BIA) and criticality analysis (CA) lead to the establishment of recovery objectives that determine how quickly critical business processes need to be back up and running.
With this information, the DR team can determine what additional data processing equipment is needed (if any) and establish a roadmap for acquiring that equipment.
The other major component in the DR project is the development of recovery plans. These are the process and procedure documents that will be triggered when a disaster has been declared. These processes and procedures will instruct response personnel how to establish and operate business processes and IT systems after a disaster has occurred. It’s not enough to have all of the technology ready if personnel don’t know what to do.
Most DR plans are going to have common components, which are
• Disaster declaration procedure This needs to include criteria for how a disaster is determined and who has the authority to declare a disaster.
• Roles and responsibilities DR plans need to specify what activities need to be performed and specify which persons or teams are best equipped to perform them.
• Emergency contact lists Response personnel need contact information for other personnel so that they may establish and maintain communications as the disaster unfolds and recovery operations begin. These contact lists should contain several different ways of contacting personnel, since some disasters have an adverse impact on regional telecommunications infrastructure.
• System recovery procedures These are the detailed steps for getting recovery systems up and running. These procedures will include a lot of detail describing obtaining data, configuring servers and network devices, confirming that the application and business information is healthy, and starting business applications.
• System operations procedures These are detailed steps for operating critical IT systems while they are in recovery mode. These detailed procedures are needed because the systems in recovery mode may need to be operated differently than their production counterparts; further, they may need to be operated by personnel who have not been doing this before.
• System restoration procedures These are the detailed steps to restore IT operations back to the original production systems.
NOTE Business continuity and disaster recovery plans work together to get critical business functions operating again after a disaster. Because of this, BC and DR teams need to work closely when developing their respective response procedures to make sure that all activities are covered, but without unnecessary overlap.
DR plans need to take into account the likely disaster scenarios that may occur to an organization. Understanding these scenarios can help the DR team take a more pragmatic approach when creating response procedures. The added benefit is that not all disasters result in the entire loss of a computing facility. Most are more limited in their scope, although all of them can still result in a complete inability to continue operations. Some of these scenarios are
• Complete loss of network connectivity
• Sustained electric power outage
• Loss of a key system (this could be a server, storage system, or network device)
• Extensive data corruption or data loss
These scenarios are probably more likely to occur than a catastrophe such as a major earthquake or hurricane (depending on where your data center is located).
Data Backup and Recovery
Disasters and other disruptive events can damage information and information systems. It’s essential that fresh copies of this information exist elsewhere and in a form that enables IT personnel to easily load this information into alternative systems so that processing can resume as quickly as possible.
CAUTION Testing backups is important; testing recoverability is critical. In other words, performing backups is only valuable to the extent that backed-up data can be recovered at a future time.
Backup to Tape and Other Media
In organizations still utilizing their own IT infrastructure, tape backup is just about as ubiquitous as power cords. From a disaster recovery perspective, however, the issue probably is not whether the organization has tape backup, but whether its current backup capabilities are adequate in the context of disaster recovery. An organization’s backup capability may need to be upgraded if:
• The current backup system is difficult to manage.
• Whole-system restoration takes too long.
• The system lacks flexibility with regard to disaster recovery (for instance, how difficult it would be to recover information onto a different type of system).
• The technology is old or outdated.
• Confidence in the backup technology is low.
Many organizations may consider tape backup as a means for restoring files or databases when errors have occurred, and they may have confidence in their backup system for that purpose. However, the organization may have somewhat less confidence in their backup system and its ability to recover all of their critical systems accurately and in a timely manner.
While tape has been the default medium since the 1960s, using hard drives as a backup medium is growing in popularity: hard disk transfer rates are far higher, and disk is a random-access medium, whereas tape is a sequential-access medium. A virtual tape library (VTL) is a type of data storage technology that sets up a disk-based storage system with the appearance of tape storage, permitting existing backup software to continue to back data up to “tape,” which is really just more disk storage.
E-vaulting is another viable option for system backup. E-vaulting permits organizations to back up their systems and data to an off-site location, which could be a storage system in another data center or a third-party service provider. This accomplishes two important objectives: reliable backup and off-site storage of backup data.
Backup Schemes
There are three main schemes for backing up data; they are the full, incremental, and differential backups. Each is explained here.
• Full backup This is a complete copy of a data set.
• Incremental backup This is a copy of all data that has changed since the last full or incremental backup.
• Differential backup This is a copy of all data that has changed since the last full backup.
The precise nature of the data to be backed up will determine which combination of backup schemes is appropriate for the organization. Some of the considerations for choosing an overall scheme include
• Criticality of the data set
• Size of the data set
• Frequency of change of the data set
• Performance requirements and the impact of backup jobs
• Recovery requirements
An organization that is creating a backup scheme usually starts with the most common scheme, which is a full backup once per week and an incremental or differential backup every day. However, as stated previously, various factors will influence the design of the final backup scheme. Some examples include
• A small data set could be backed up more than once a week, while an especially large data set might be backed up less often.
• A more rapid recovery requirement may induce the organization to perform differential backups instead of incremental backups.
• If a full backup takes a long time to complete, it should probably be performed during times of lower demand or system utilization.
Backup Media Rotation
Organizations will typically want to retain backup media for as long as possible in order to provide a greater array of choices for data recovery. However, the desire to maintain a large library of backup media will be countered by the high cost of media and the space required to store it. And while legal or statutory requirements may dictate that backup media be kept for some minimum period, the organization may be able to creatively find ways to comply with such requirements without retaining several generations of such media.
Some example backup media rotation schemes are discussed here.
First In First Out (FIFO) In this scheme, there is no specific requirement for retaining any backup media for long periods (e.g., one year or more). The method in the FIFO rotation scheme specifies that the oldest available backup tape is the next one to be used.
The advantage of this scheme is its simplicity. However, there is a significant disadvantage: any corruption of backed-up data needs to be discovered quickly (within the period of media rotation), or else no valid set of data can be recovered. Hence, only low-criticality data without any lengthy retention requirements should be backed up using this scheme.
Grandfather-Father-Son The most common backup media rotation scheme, grandfather-father-son creates a hierarchical set of backup media that provides for greater retention of backed-up data that is still economically feasible.
In the most common form of this scheme, full backups are performed once per week and incremental or differential backups are performed daily.
Daily backup tapes used on Monday are not used again until the following Monday. Backup tapes used on Tuesday, Wednesday, Thursday, Friday, and Saturday are handled in the same way.
Full backup tapes created on Sunday are kept longer. Tapes used on the first Sunday of the month are not used again until the first Sunday of the following month. Similarly, tapes used on the second Sunday are not reused until the second Sunday of the following month, and so on for each week’s tapes for Sunday.
For even longer retention, for example, tapes created on the first Sunday of the first month of each calendar quarter can be retained until the first Sunday of the first month of the next quarter. Backup media can be kept for even longer if needed.
Towers of Hanoi The Towers of Hanoi backup media retention scheme is complex but results in a more efficient scheme for producing a more lengthy retention of some backups. Patterned after the Towers of Hanoi puzzle, the scheme is most easily understood visually, as in Figure 5-27 in a five-level scheme.

Figure 5-27 Towers of Hanoi backup media rotation scheme
Backup Media Storage
Backup media that remains in the same location as backed-up systems is adequate for data recovery purposes, but completely inadequate for disaster recovery purposes: any event that physically damages information systems (such as fire, smoke, flood, hazardous chemical spill, and so on) is likely to also damage backup media. To provide disaster recovery protection, backup media must be stored off-site in a secure location. Selection of this storage location is as important as the selection of a primary business location: in the event of a disaster, the survival of the organization may depend upon the protection measures in place at the off-site storage location.

EXAM TIP CISA exam questions relating to off-site backups may include details for safeguarding data during transport and storage, mechanisms for access during restoration procedures, media aging and retention, or other details that may aid you during the exam. Watch for question details involving the type of media, geo-locality (distance, shared disaster spectrum [such as a shared coastline], and so on) of the off-site storage area and the primary site, or access controls during transport and at the storage site, including environmental controls and security safeguards.
The criteria for selection of an off-site media storage facility are similar to the criteria for selection of a hot/warm/cold recovery site discussed earlier in this chapter. If a media storage location is too close to the primary processing site, then it is more likely to be involved in the same regional disaster, which could result in damage to backup media. However, if the media storage location is too far away, then it might take too long for a delivery of backup media, which would result in a recovery operation that runs unacceptably long.
Another location consideration is the proximity of the media storage location and the hot/warm/cold recovery site. If a hot site is being used, then chances are there is some other near-real-time means (such as replication) for data to get to the hot site. But a warm or cold site may be relying on the arrival of backup media from the off-site media storage facility, so it might make sense for the off-site facility to be near the recovery site.
An important factor when considering off-site media storage is the method of delivery to and from the storage location. Chances are that the backup media is being transported by a courier or a shipping company. It is vital that the backup media arrive safely and intact, and that the opportunities for interception or loss be reduced as much as possible. Not only can a lost backup tape make recovery more difficult, but it can also cause an embarrassing security incident if knowledge of the loss were to become public. From a confidentiality/integrity perspective, encryption of backup tapes is a good idea, although this digresses somewhat from disaster recovery (concerned primarily with availability). Backup media encryption is discussed in Chapter 6.
NOTE The requirements for off-site storage are a little less critical than for a hot/warm/cold recovery site. All you have to do is be able to get your backup media out of that facility. This can occur even if there is a regional power outage, for instance.
Backup media that must be kept on-site should be stored in locked cabinets or storerooms that are separate from the rooms where backups are performed. This will help to preserve backup media if a relatively small fire breaks out in the room containing computers that are backed up.
Backup Media Records and Destruction
To ensure the ability of restoring data from backup media, organizations need to have meticulous records that list all backup volumes in place, where they are located, and which data elements are backed up on them. Without these records, it may prove impossible for an organization to recover data from its backup media library.
Protecting Sensitive Backup Media with Encryption
Information security and data privacy laws are expanding data protection requirements by requiring encryption of backup media in many cases. This is a sensible safeguard, especially for organizations that utilize off-site backup media storage. There is a risk of loss of backup media when it is being transported back and forth from an organization’s primary data center and the backup media offsite storage facility.
Laws and regulations may specify maximum periods that specific information may be retained. Organizations need to have good records management that helps them track which business records are on which backup media volumes. When it is time for an organization to stop retaining a specific set of data, those responsible for the backup media library need to identify the backup volumes that can be recycled. If the data on the backup media is sensitive, the backup volume may need to be erased prior to use. Any backup media that is being discarded needs to be destroyed so that no other party can possibly recover data on the volume. Records of this destruction need to be kept.
Testing DR Plans
Disaster response plans need to be accurate and complete if they are going to result in a successful recovery. It is recommended that recovery and response plans be thoroughly tested.
The types of recovery tests are
• Document review
• Walkthrough
• Simulation
• Parallel test
• Cutover test
These test methods are described in detail in Chapter 2.
Auditing IT Infrastructure and Operations
Auditing infrastructure and operations requires considerable technical expertise in order for the auditor to fully understand the technology that she is examining. Lacking technical knowledge, interviewed subjects may offer explanations that can evade vital facts that the auditor should be aware of. Auditors need to have familiarity with hardware, operating systems, database management systems, networks, IT operations, monitoring, and disaster recovery planning.
Auditing Information Systems Hardware
Auditing hardware requires attention to several key factors and activities, including:
• Standards The auditor should examine hardware procurement standards that specify the types of systems that the organization uses. These standards should be periodically reviewed and updated. A sample of recent purchases should be examined to see whether standards are being followed. The scope of this activity should include servers, workstations, network devices, and other hardware used by IT.
• Maintenance Maintenance requirements and records should be examined to see whether any required maintenance is being performed. If service contracts are used, these should be examined to ensure that all critical systems are covered.
• Capacity The auditor should examine capacity management and planning processes, procedures, and records. This will help the auditor to understand whether the organization monitors its systems’ capacity and does any planning for future expansion.
• Change management Change management processes and records should be examined to see whether hardware changes are being performed in a life cycle process. All changes that are made should be requested and reviewed in advance, approved by management, and recorded.
• Configuration management The auditor should examine configuration management records to see whether the IT organization is tracking the configuration of its systems in a centralized and systematic manner.
Auditing Operating Systems
Auditing operating systems requires attention to many different details, including:
• Standards The auditor should examine written standards to see if they are complete and up-to-date. He or she should then examine a sampling of servers and workstations to see whether they comply with the organization’s written standards.
• Maintenance and support Business records should be examined to see whether the operating systems running on servers or workstations are covered by maintenance or support contracts.
• Change management The auditor should examine operating system change management processes and records to see whether changes are being performed in a systematic manner. All changes that are made should be requested and reviewed in advance, approved by management, and recorded.
• Configuration management Operating systems are enormously complex; in all but the smallest organizations, configuration management tools should be used to ensure consistency of configuration among systems. The auditor should examine configuration management processes, tools, and recordkeeping.
• Security management The auditor should examine security configurations on a sample of servers and workstations, and determine whether they are “hardened” or resemble manufacturer default configurations. This determination should be made in light of the relative risk of various selected systems. An examination should include patch management and administrative access.
Auditing File Systems
File systems containing business information must be examined to ensure that they are properly configured. An examination should include
• Capacity File systems must have adequate capacity to store all of the currently required information, plus room for future growth. The auditor should examine any file storage capacity management tools, processes, and records.
• Access control Files and directories should be accessible only by personnel with a business need. Records of access requests should be examined to see if they correspond to the access permissions observed.
Auditing Database Management Systems
Database management systems (DBMSs) are as complex as operating systems. This complexity requires considerable auditor scrutiny in several areas, including:
• Configuration management The configuration of DBMSs should be centrally controlled and tracked in larger organizations to ensure consistency among systems. Individual DBMSs and configuration management records should be compared.
• Change management Databases are used to store not only information, but also software in many cases. The auditor should examine DBMS change management processes and records to see whether changes are being performed in a consistent, systematic manner. All changes that are made should be requested and reviewed in advance, approved by management, tested, implemented, and recorded. Changes to software should be examined in coordination with an audit of the organization’s software development life cycle.
• Capacity management The availability and integrity of supported business processes requires sufficient capacity in all underlying databases. The auditor should examine procedures and records related to capacity management to see whether management ensures sufficient capacity for business data.
• Security management Access controls determine which users and systems are able to access and update data. The auditor should examine access control configurations, access requests, and access logs.
Auditing Network Infrastructure
The IS auditor needs to perform a detailed study of the organization’s network infrastructure and underlying management processes. An auditor’s scrutiny should include
• Enterprise architecture The auditor should examine enterprise architecture documents. There should be overall and detailed schematics and standards.
• Network architecture The auditor should examine network architecture documents. These should include schematics, topology and design, data flow, routing, and addressing.
• Security architecture Security architecture documents should be examined, including critical and sensitive data flows, network security zones, access control devices and systems, security countermeasures, intrusion detection systems, firewalls, screening routers, gateways, anti-malware, and security monitoring.
• Standards The auditor should examine standards documents and determine whether they are reasonable and current. Selected devices and equipment should be examined to see whether they conform to these standards.
• Change management All changes to network devices and services should be governed by a change management process. The auditor should review change management procedures and records, and examine a sample of devices and systems to ensure that changes are being performed within change management policy.
• Capacity management The auditor should determine how the organization measures network capacity, whether capacity management procedures and records exist, and how capacity management affects network operations.
• Configuration management The auditor should determine whether any configuration management standards, procedures, and records exist and are used. He or she should examine the configuration of a sampling of devices to see whether configurations are consistent from device to device.
• Administrative access management Access management procedures, records, and configurations should be examined to see whether only authorized persons are able to access and manage network devices and services.
• Network components The auditor should examine several components and their configuration to determine how well the organization has constructed its network infrastructure to support business objectives.
• Log management The auditor should determine whether administrative activities performed on network devices and services are logged. He should examine the configuration of logs to see if they can be altered. The logs themselves should be examined to determine whether any unauthorized activities are taking place.
• User access management Often, network-based services provide organization-wide user access controls. The auditor should examine these centralized services to see whether they conform to written security standards. Examination should include user ID convention, password controls, inactivity locking, user account provisioning, user account termination, and password reset procedures.
Auditing Network Operating Controls
The IS auditor needs to examine network operations in order to determine whether the organization is operating its network effectively. Examinations should include
• Network operating procedures The auditor should examine procedures for normal activities for all network devices and services. These activities will include login, startup, shutdown, upgrade, and configuration changes.
• Restart procedures Procedures for restarting the entire network (and portions of it for larger organizations) should exist and be tested periodically. A network restart would be needed in the event of a massive power failure, network failure, or significant upgrade.
• Troubleshooting procedures The auditor should examine network troubleshooting procedures for all significant network components. Procedures that are specific to the organization’s network help network engineers and analysts quickly locate problems and reduce downtime.
• Security controls Operational security controls should be examined, including administrator authentication, administrator access control, logging of administrator actions, protection of device configuration data, security configuration reviews, and protection of audit logs.
• Change management All changes to network components and services should follow a formal change management life cycle, including request, review, approval by management, testing in a separate environment, implementation, verification, and complete recordkeeping. The auditor should examine change management policy, procedures, and records.
Auditing IT Operations
Auditing IT operations involves examining the processes used to build, maintain, update, and repair computing hardware, operating systems, and network devices. Audits will cover processes, procedures, and records, as well as examinations of information systems.
Auditing Computer Operations
The auditor should examine computer operational processes, including:
• System configuration standards The auditor should examine configuration standards that specify the detailed configuration settings for each type of system that is used in the organization.
• System build procedures The auditor should examine the procedures used to install and configure the operating system.
• System recovery procedures The procedures that are used to recover systems from various types of failures should be examined. Usually, this will include reinstalling and configuring the operating system, restoring software and data from backup, and verifying system recovery.
• System update procedures The auditor should examine procedures used for making changes to systems, including configuration changes and component upgrades.
• Patch management The auditor should examine the procedures for receiving security advisories, risk analysis, and decisions regarding when new security patches should be implemented. Procedures should also include testing, implementation, and verification.
• Daily tasks Daily and weekly operating procedures for systems should be examined, which may include data backup, log review, log file cycling, review of performance logs, and system capacity checks.
• Backup The auditor should examine procedures and records for file and database backup, backup verification, recovery testing, backup media control and inventory, and off-site media storage.
• Media control Media control procedures should be examined, which includes backup media retirement procedures, disk media retirement procedures, media custody, and off-site storage.
• Monitoring Computer monitoring is discussed in detail later in this section.
Auditing File Management
The IS auditor should examine file management policies and procedures, including:
• File system standards The auditor should examine file system standards that specify file system architecture, directory naming standards, and technical settings that govern disk utilization and performance.
• Access controls The auditor should examine file system access control policy and procedures, the configuration settings that control which users and processes are able to access directories and files, and log files that record access control events such as permission changes and attempted file accesses.
• Capacity management The settings and controls used to manage the capacity of file systems should be examined. This should include logs that show file system utilization, procedures for adding capacity, and records of capacity-related events.
• Version control In file systems and data repositories that contain documents under version control, the auditor should examine version control configuration settings, file update procedures, and file recovery procedures and records.
Auditing Data Entry
The IS auditor should examine data entry standards and operations, including:
• Data entry procedures This may include document control, input procedures, and error recovery procedures.
• Input verification This may include automatic and manual controls used to ensure that data has been entered properly into forms.
• Batch verification This may include automatic and manual controls used to calculate and verify batches of records that are input.
• Correction procedures This may include controls and procedures used to correct individual forms and batches when errors occur.
Auditing Lights-Out Operations
A lights-out operation is any production IT environment, such as computers in a data center, that runs without on-site operator intervention. The term “lights out” means that the computers can be in a room with the lights out since no personnel are present to attend to them.
Audit activities of a lights-out operation will primarily fall into the other categories of audits discussed in this chapter, plus a few specific activities, including:
• Remote administration procedures
• Remote monitoring procedures
Auditing Problem Management Operations
The auditor should examine the organization’s problem management operations, including:
• Problem management policy and processes The auditor should examine policy and procedure documents that describe how problem management is supposed to be performed.
• Problem management records A sampling of problems and incidents should be examined to see whether problems are being properly managed.
• Problem management timelines The time spent on each problem should be examined to see whether resolution falls within the SLA.
• Problem management reports The auditor should examine management reports to ensure that management is aware of all problems.
• Problem resolution The auditor should examine a sample of problems to see which ones required changes in other processes. The other process documents should be examined to see if they were changed. The auditor also should examine records to see if fixes were verified by another party.
• Problem recurrence The auditor should examine problem records to make sure that the same problems are not coming up over and over again.
Auditing Monitoring Operations
The IS auditor needs to audit system monitoring operations to ensure that it is effective, including:
• Monitoring plan The auditor should review any monitoring plan documents that describe the organization’s monitoring program, tools, and processes.
• Problem log Monitoring problem logs should be reviewed to see what kinds of problems are being recorded. The auditor should see whether all devices and systems are represented in problem logs.
• Preventive maintenance The auditor should examine monitoring results, monitoring plan, and preventive maintenance records, and determine whether the level of preventive maintenance is adequate and effective.
• Management review and action Any monitoring reports, meeting minutes, and decision logs should be examined to see whether management is reviewing monitoring reports and whether management actions are being carried out.
Auditing Procurement
The auditor should examine hardware and software procurement processes, procedures, and records to determine whether any of the following activities are being performed:
• Requirements definition All stakeholders (both technical and business, as appropriate) need to develop functional, technical, and security requirements. Each requirement needs to be approved and used to apply scrutiny to candidate products and services. Each candidate supplier’s responses need to be scored on their merits regarding their ability to meet requirements. This entire process needs to be transparent and documented. Auditors will need to examine procurement policies, procedures, and records from selected procurement projects.
• Feasibility studies Many requests for service will require an objective feasibility study that will be designed to identify the economic and business benefits that may be derived from the requested service. Auditors need to examine selected feasibility study documents as well as policy and procedure documents for performing feasibility projects.
Auditing Disaster Recovery Planning
The objectives of an audit of disaster recovery planning should include the following activities:
• Determine the effectiveness of planning and recovery documentation by examining previous test results.
• Evaluate the methods used to store critical information off-site (which may consist of off-site storage, alternate data centers, or e-vaulting). Examine environmental and physical security controls in any off-site or alternate sites and determine their effectiveness. Note whether off-site or alternate site locations are within the same geographic region—which could mean that both the primary and alternate sites may be involved in common disaster scenarios.
Auditing Disaster Recovery Plans
The following steps will help the auditor to determine the effectiveness of the organization’s disaster recovery plans:
• Obtain a copy of disaster recovery documentation, including response procedures, contact lists, and communication plans.
• Examine samples of distributed copies of DR documentation, and determine whether they are up-to-date. These samples can be obtained during interviews of key response personnel, which are covered in this procedure.
• Determine whether all documents are clear and easy to understand, not just for primary responders, but for alternate personnel who may have specific relevant skills but less familiarity with the organization’s critical applications.
• Obtain contact information for off-site storage providers, hot-site facilities, and critical suppliers. Determine whether these organizations are still providing services to the organization. Call some of the contacts to determine the accuracy of the documented contact information.
• For organizations using third-party recovery sites such as cloud infrastructure providers, obtain contracts that define organization and cloud provider obligations, service levels, and security controls.
• Obtain logical and physical architecture diagrams for key IT applications that support critical business processes. Determine whether BC documentation includes recovery procedures for all components that support those IT applications. See whether documentation includes recovery for end users and administrators for the applications.
• If the organization uses a hot site, examine one or more systems to determine whether they have the proper versions of software, patches, and configurations. Examine procedures and records related to the tasks in support of keeping standby systems current. Determine whether these procedures are effective.
• If the organization has a warm site, examine the procedures used to bring standby systems into operational readiness. Examine warm-site systems to see whether they are in a state where readiness procedures will likely be successful.
• If the organization has a cold site, examine all documentation related to the acquisition of replacement systems and other components. Determine whether the procedures and documentation are likely to result in systems capable of hosting critical IT applications and within the period required to meet key recovery objectives.
• If the organization uses a cloud service provider’s service as a recovery site, examine the procedures used to bring cloud-based systems to operational readiness. Examine procedures and configurations to see whether they are likely to successfully support the organization during a disaster.
• Determine whether any documentation exists regarding the relocation of key personnel to the hot/warm/cold processing site. See whether the documentation specifies which personnel are to be relocated and what accommodations and supporting logistics are provided. Determine the effectiveness of these relocation plans.
• Determine whether backup and off-site (or e-vaulting) storage procedures are being followed. Examine systems to ensure that critical IT applications are being backed up and that proper media are being stored off-site (or that the proper data is being e-vaulted). Determine whether data recovery tests are ever performed and, if so, whether results of those tests are documented and problems are properly dealt with.
• Evaluate procedures for transitioning processing from the alternate processing facility back to the primary processing facility. Determine whether these procedures are complete and effective.
• Determine whether a process exists for the formal review and update of business continuity documentation. Examine records to see how frequently, and how recently, documents have been reviewed and updated. Determine whether this is sufficient and effective by interviewing key personnel to understand whether significant changes to applications, systems, networks, or processes are reflected in recovery and response documentation.
• Determine whether response personnel receive any formal or informal training on response and recovery procedures. Determine whether personnel are required to receive training, and whether any records are kept that show which personnel received training and at what time.
• Examine the organization’s change control process. Determine whether the process includes any steps or procedures that require personnel to determine whether any change has an impact on disaster recovery documentation or procedures.
Reviewing Prior Disaster Recovery Test Results and Action Plans
The effectiveness of disaster recovery plans relies on the results and outcomes of tests. The IS auditor needs to examine these plans and activities to determine their effectiveness. The following will help the IS auditor audit disaster recovery testing:
• Determine whether there is a strategy for testing business continuity procedures. Obtain records for past tests and a plan for future tests.
• Examine records for tests that have been performed over the past year or two. Determine the types of tests that were performed. Obtain a list of participants for each test. Compare the participants to lists of key recovery personnel. Examine test work papers to determine the level of participation by key recovery personnel.
• Determine whether there is a formal process for recording test results and for using those results to make improvements in plans and procedures. Examine work papers and records to determine the types of changes that were recommended in prior tests. Examine BC documents to see whether these changes were made as expected.
• Considering the types of tests that were performed, determine the adequacy of testing as an indicator of the effectiveness of the DR program. Did the organization only perform document reviews and walkthroughs, for example, or did the organization also perform parallel or cutover tests?
• If tests have been performed for two years or more, determine whether there’s a trend showing continuous improvement in response and recovery procedures.
• If the organization performs parallel tests, determine whether tests are designed in a way that effectively determines the actual readiness of standby systems. Also determine whether parallel tests measure the capacity of standby systems or merely their ability to process correctly but at a lower level of performance.
• Determine whether any tests included the retrieval of backup data from off-site storage or e-vaulting facilities.
Evaluating Off-Site Storage
Storage of critical data and other supporting information is a key component in any organization’s business continuity plan. Because some types of disasters can completely destroy a business location, including its vital records, it is imperative that all critical information is backed up and copies moved to an off-site storage facility. The following procedure will help the IS auditor determine the effectiveness of off-site storage:
• Obtain the location of the off-site storage or e-vaulting facility. Determine whether the facility is located in the same geographic region as the organization’s primary processing facility.
• If possible, visit the off-site storage facility. Examine its physical security controls as well as its safeguards to prevent damage to stored information in a disaster. Consider the entire spectrum of physical and logical access controls. Examine procedures and records related to the storage and return of backup media, and of other information that the organization may store there. If it is not possible to visit the off-site storage facility, obtain copies of audits or other attestations of controls effectiveness.
• Take an inventory of backup media and other information stored at the facility. Compare this inventory with a list of critical business processes and supporting IT systems to determine whether all relevant information is, in fact, stored at the off-site storage facility.
• Determine how often the organization performs its own inventory of the off-site facility, and whether steps to correct deficiencies are documented and remedied.
• Examine contracts, terms, and conditions for off-site storage providers or e-vaulting facilities, if applicable. Determine whether data can be recovered to the original processing center and to alternate processing centers within a period that will ensure that disaster recovery can be completed within recovery time objectives.
• Determine whether the appropriate personnel have current access codes for off-site storage or e-vaulting facilities, and whether they have the ability to recover data from those facilities.
• Determine what information, in addition to backup data, exists at the off-site storage facility. Information stored off-site should include architecture diagrams, design documentation, operations procedures, and configuration information for all logical and physical layers of technology and facilities supporting critical IT applications, operations documentation, and application source code.
• Obtain information related to the manner in which backup media and copies of records are transported to and from the off-site storage or e-vaulting facility. Determine whether controls protecting transported information are adequate.
• Obtain records supporting the transport of backup media and records to and from the off-site storage facility. Examine samples of records and determine whether they match other records such as backup logs.
Evaluating Alternative Processing Facilities
The IS auditor needs to examine alternate processing facilities to determine whether they are sufficient to support the organization’s business continuity and disaster recovery plans. The following procedure will help the IS auditor determine whether an alternate processing facility will be effective:
• Obtain addresses and other location information for alternate processing facilities. These will include hot sites, warm sites, cold sites, cloud-based services, and alternate processing centers owned or operated by the organization.
• Determine whether alternate facilities are located within the same geographic region as the primary processing facility and the probability that the alternate facility will be adversely affected by a disaster that strikes the primary facility.
• Perform a threat analysis on the alternate processing site. Determine which threats and hazards pose a significant risk to the organization and its ability to effectively carry out operations during a disaster.
• Determine the types of natural and man-made events likely to take place at the alternate processing facility. Determine whether there are adequate controls to mitigate the effect of these events.
• Examine all environmental controls and determine their adequacy. This should include environmental controls (HVAC), power supply, uninterruptible power supply (UPS), power distribution units (PDUs), and electric generators. Also examine fire detection and suppression systems, including smoke detectors, pull stations, fire extinguishers, sprinklers, and inert gas suppression systems.
• If the alternate processing facility is a separate organization, obtain the legal contract and all exhibits. Examine these documents and determine whether the contract and exhibits support the organization’s recovery and testing requirements.
NOTE Cloud-based service providers often do not permit on-site visits. Instead, they may have one or more external audit report available through standard audits such as SSAE16, ISAE3402, SOC1, SOC2, or PCI. Auditors will need to determine whether any such external audit reports may be relied upon, and whether there are any controls that are not covered by such external audits.
Summary
All activities in the IT department should be managed, controlled, and monitored. Activities performed by operations personnel should be a part of a procedure or process that is approved by management. Processes, procedures, and projects should have sufficient recordkeeping to facilitate measurements.
IT operations should be structured in a service management model that is aligned with the IT Infrastructure Library (ITIL) or the COBIT framework of processes. These frameworks ensure that comprehensive coverage of activities is likely to be taking place in most IT organizations.
IS auditors need to have a thorough understanding of information systems hardware and software and how they work to support business objectives. This includes knowing how computer hardware functions; how operating systems are installed, configured, and operated; how end users’ workstations are provisioned, managed, and used; and how software applications operate. Because newer technologies are not always implemented properly at first, IS auditors need to understand technologies such as virtualization, virtual desktops, software-defined networking, and mobile devices to ensure that the organization is not incurring unnecessary risk through their use.
Network management tools and systems help management understand a network’s utilization, capacity, and problems. Network management should be a part of a larger infrastructure monitoring strategy.
During a disaster recovery planning project, once acceptable architectures and process changes have been determined, the organization sets out to make investments in these areas to bring its systems and processes closer to the recovery objectives. Procedures for recovering systems and processes are also developed at this time, as well as procedures for other aspects of disaster response, such as emergency communications plans and evacuation plans.
Some of the investment in IT system resilience may involve the establishment of an alternate processing site, where IT systems can be resumed in support of critical business processes. There are several types of alternate sites, including a hot site, where IT systems are in a continual state of near-readiness and can assume production workload within an hour or two; a warm site, where IT systems are present but require several hours to a day of preparation; a cold site, where no systems are present but must be acquired, which may require several days of preparation before those replacement systems are ready to support business processes; and a cloud-based site, in which virtual machines are provided on an on-demand basis, and where the organization will establish a hot, warm, or cold capability therein.
Some of the technologies that may be introduced in IT systems to improve recovery targets include RAID, a technology that improves the reliability of disk storage systems; replication, a technique for copying data in near–real time to an alternate (and usually distant) storage system; and clustering, a technology where several servers (including some that can be located in another region) act as one logical server, enabling processing to continue even if one or more servers are incapacitated or unreachable.
Notes
• All IT activities should be a part of a documented process, procedure, or project.
• Key systems, applications, and infrastructure should be monitored to ensure that they continue to operate properly in their support of key business processes.
• Software program libraries should be controlled with access and authorization controls, check out and check in, version control, and code analysis.
• Media sanitization procedures ensure that data leakage will not result from discarded data storage media.
• Mobile devices such as tablet computers and smartphones are the new endpoints. Lacking mature enterprise management controls and anti-malware tools, and being small enough to easily lose, mobile devices are a popular attack vector. The IS auditor needs to understand how the organization addresses these matters.
• It is as important to understand the internal architecture of computers as it is to understand how computers can be combined together to form clusters and multitier application environments.
• Automated monitoring of computing and network infrastructure includes monitoring of internal components such as CPU, power supply, memory, and storage. Monitoring also includes resource utilization such as CPU, memory, disk storage, and network. The external environment, including temperature, humidity, water, and vibration, should also be monitored.
• Software license management ensures that the organization will remain in compliance with its software license agreements and avoid costly and embarrassing legal trouble. Automated tools can help monitor the installation and use of licensed software.
• While it has never been implemented in its pure form, it is still important to understand the concepts of the seven-layer OSI data model. Terms from the model are used by IT specialists; for instance, layer 4 switches are a type of network device that routes packets based on their OSI layer 4 characteristics.
• IS auditors need to understand the TCP/IP model and TCP/IP’s common protocols well enough to be able to identify risks and control weaknesses.
• A network’s logical architecture (star, ring, and bus) often does not match its physical architecture (star, ring, bus).
• A key place to examine on a network is its boundary. Edge devices such as firewalls, routers, wireless access points, and gateways contain configurations that control inbound and outbound traffic. Mistakes here can be costly.
• Most of the older and less secure TCP/IP protocols such as Telnet, FTP, and RCP have been superseded by newer protocols such as SSH, SFTP, and FTPS.
• Business continuity planning ensures business recovery following a disaster. Business continuity focuses on maintaining service availability with the least disruption to standard operating parameters during an event, while disaster recovery focuses on post-event recovery and restoration of services.
• Organizations are increasingly turning to the cloud for their alternate processing sites. IS auditors need to understand how cloud-based infrastructure is procured, protected, and managed.
• Once recovery objectives have been identified, strategies can be developed to meet each objective. Many solutions may include redundant (hot, warm, or cold) alternate sites, redundant service operation or storage in high-availability or distributed-cluster environments, alternative network access strategies, and backup/recovery strategies structured to meet identified recovery time and recovery point requirements.
Questions
1. A web application is displaying information incorrectly and many users have contacted the IT service desk. This matter should be considered a(n):
A. Incident
B. Problem
C. Bug
D. Outage
2. An IT organization is experiencing many cases of unexpected downtime that are caused by unauthorized changes to application code and operating system configuration. Which process should the IT organization implement to reduce downtime?
A. Configuration management
B. Incident management
C. Change management
D. Problem management
3. An IT organization manages hundreds of servers, databases, and applications, and is having difficulty tracking changes to the configuration of these systems. What process should be implemented to remedy this?
A. Configuration management
B. Change management
C. Problem management
D. Incident management
4. A computer’s CPU, memory, and peripherals are connected to each other through a:
A. Kernel
B. FireWire
C. Pipeline
D. Bus
5. A database administrator has been asked to configure a database management system so that it records all changes made by users. What should the database administrator implement?
A. Audit logging
B. Triggers
C. Stored procedures
D. Journaling
6. The layers of the TCP/IP reference model are
A. Link, Internet, transport, application
B. Physical, link, Internet, transport, application
C. Link, transport, Internet, application
D. Physical, data link, network, transport, session, presentation, application
7. The purpose of the Internet layer in the TCP/IP model is
A. Encapsulation
B. Packet delivery on a local network
C. Packet delivery on a local or remote network
D. Order of delivery and flow control
8. The purpose of the DHCP protocol is
A. Control flow on a congested network
B. Query a station to discover its IP address
C. Assign an IP address to a station
D. Assign an Ethernet MAC address to a station
9. An IS auditor is examining a wireless (Wi-Fi) network and has determined that the network uses WEP encryption. What action should the auditor take?
A. Recommend that encryption be changed to WPA
B. Recommend that encryption be changed to EAP
C. Request documentation for the key management process
D. Request documentation for the authentication process
10. 126.0.0.1 is an example of a:
A. MAC address
B. Loopback address
C. Class A address
D. Subnet mask
11. What is the most important consideration when selecting a hot site?
A. Time zone
B. Geographic location in relation to the primary site
C. Proximity to major transportation
D. Natural hazards
12. An organization has established a recovery point objective of 14 days for its most critical business applications. Which recovery strategy would be the best choice?
A. Mobile site
B. Warm site
C. Hot site
D. Cold site
13. What technology should an organization use for its application servers to provide continuous service to users?
A. Dual power supplies
B. Server clustering
C. Dual network feeds
D. Transaction monitoring
14. An organization currently stores its backup media in a cabinet next to the computers being backed up. A consultant told the organization to store backup media at an offsite storage facility. What risk did the consultant most likely have in mind when he made this recommendation?
A. A disaster that damages computer systems can also damage backup media.
B. Backup media rotation may result in loss of data backed up several weeks in the past.
C. Corruption of online data will require rapid data recovery from off-site storage.
D. Physical controls at the data processing site are insufficient.
15. Which of the following statements about virtual server hardening is true?
A. The configuration of the host operating system will automatically flow to each guest operating system.
B. Each guest virtual machine needs to be hardened separately.
C. Guest operating systems do not need to be hardened because they are protected by the hypervisor.
D. Virtual servers do not need to be hardened because they do not run directly on computer hardware.
Answers
1. B.A problem is defined as a condition that is the result of multiple incidents that exhibit common symptoms. In this example, many users are experiencing the effects of the application error.
2. C.Change management is the process of managing change through a life cycle process that consists of request, review, approve, implement, and verify.
3. A.Configuration management is the process (often supplemented with automated tools) of tracking configuration changes to systems and system components such as databases and applications.
4. D.A computer’s bus connects all of the computer’s internal components together, including its CPU, main memory, secondary memory, and peripheral devices.
5. A.The database administrator should implement audit logging. This will cause the database to record every change that is made to it.
6. A.The layers of the TCP/IP model are (from lowest to highest) link, Internet, transport, and application.
7. C.The purpose of the Internet layer in the TCP/IP model is the delivery of packets from one station to another, on the same network or on a different network.
8. C.The DHCP protocol is used to assign IP addresses to computers on a network.
9. A.The WEP protocol has been seriously compromised and should be replaced with WPA or WPA2 encryption.
10. C.Class A addresses are in the range 0.0.0.0 to 127.255.255.255. The address 126.0.0.1 falls into this range.
11. B. An important selection criterion for a hot site is the geographic location in relation to the primary site. If they are too close together, then a single disaster event may involve both locations.
12. D.An organization that has a 14-day recovery time objective (RTO) can use a cold site for its recovery strategy. Fourteen days is enough time for most organizations to acquire hardware and recover applications.
13. B.An organization that wishes its application servers to be continuously available to its users needs to employ server clustering. This enables at least one server to always be available to service user requests.
14. A.The primary reason for employing off-site backup media storage is to mitigate the effects of a disaster that could otherwise destroy computer systems and their backup media.
15. B.In a virtualization environment, each guest operating system needs to be hardened, no different from operating systems running directly on server (or workstation) hardware.