
CHAPTER 2
IT Governance and Management
This chapter discusses the following topics:
• IT governance structure
• Human resources management
• IT policies, standards, processes, and procedures
• Management practices
• IT resource investment, use, and allocation practices
• IT contracting and contract management strategies and practices
• Risk management practices
• Monitoring and assurance
• Business continuity planning
This chapter covers CISA Domain 2, “Governance and Management of IT.” The topics in this chapter represent 16 percent of the CISA examination.
IT governance should be the wellspring from which all other IT activities flow.
Properly implemented, governance is a process whereby senior management exerts strategic control over business functions through policies, objectives, delegation of authority, and monitoring. Governance is management’s control over all other IT processes to ensure that IT processes continue to effectively meet the organization’s business objectives.
Organizations usually establish governance through an IT steering committee that is responsible for setting long-term IT strategy, and by making changes to ensure that IT processes continue to support IT strategy and the organization’s needs. This is accomplished through the development and enforcement of IT policies, requirements, and standards.
IT governance typically focuses on several key processes, such as personnel management, sourcing, change management, financial management, quality management, security management, and performance optimization. Another key component is the establishment of an effective organization structure and clear statements of roles and responsibilities. An effective governance program will use a balanced scorecard or other means to monitor these and other key processes, and through a process of continuous improvement, IT processes will be changed to remain effective and to support ongoing business needs.
IT Governance Practices for Executives and Boards of Directors
Governance starts at the top.
Whether the organization has a board of directors, council members, commissioners, or some other top-level governing body, governance begins with the establishment of top-level objectives and policies that are translated into more actions, policies, processes, procedures, and other activities downward through each level in the organization.
This section describes governance practices recommended for IT organizations, including a strategy-developing committee, measurement via the balanced scorecard, and security management.

NOTE Governance is not merely an IT practice. Rather, governance is practiced in the business apart from IT, to facilitate management’s control over business operations.
IT Governance
The purpose of IT governance is to align the IT organization with the needs of the business. The term IT governance refers to a collection of top-down activities intended to control the IT organization from a strategic perspective to ensure that the IT organization supports the business. Some of the artifacts and activities that flow out of healthy IT governance include
• Policy At its minimum, IT policy should directly reflect the mission, objectives, and goals of the overall organization.
• Priorities The priorities in the IT organization should flow directly from the organization’s mission, objectives, and goals. Whatever is most important to the organization as a whole should be important to IT as well.
• Standards The technologies, protocols, and practices used by IT should be a reflection of the organization’s needs. On their own, standards help to drive a consistent approach to solving business challenges; the choice of standards should facilitate solutions that meet the organization’s needs in a cost-effective and secure manner.
• Vendor management The suppliers that IT selects should reflect IT priorities, standards, and practices.
• Program and project management IT programs and projects should be organized and performed in a consistent manner that reflects IT priorities and supports the business.
While IT governance contains the elements just described, strategic planning is also a key component of governance. Strategy is discussed in the next section.
IT Governance Frameworks
While every organization may have its unique missions, objectives, business models, tolerance for risk, and so on, organizations need not invent governance frameworks from scratch to manage their IT objectives. Several good frameworks can be adapted to meet organizations’ needs, including:
• COBIT This is an IT management framework developed by the IT Governance Institute and ISACA. COBIT’s five domains are Evaluate, Direct, and Monitor; Align, Plan, and Organize; Build, Acquire, and Implement; Deliver, Service, and Support; and Monitor, Evaluate, and Assess.
• ISO/IEC 27001 This is the well-known international standard for top-down information security management. In the context of IT security governance, what’s important here is the requirements in ISO/IEC 27001, not the controls that appear in its appendix.
• ITIL Formerly an acronym for IT Infrastructure Library, ITIL is a framework of processes for IT service delivery. ITIL was originally sponsored by the UK Office of Government Commerce in order to improve its IT management processes, and is now owned by AXELOS. The international standard, ISO/IEC 20000, is adapted from ITIL.
• ISO/IEC 38500 This is an international standard on corporate governance of information technology, suitable for small and large organizations in the public or private sector.
These and other frameworks are discussed in greater detail in Appendix B.
IT Strategy Committee
In organizations where IT provides significant value, the board of directors should have an IT strategy committee. This group will advise the board of directors on strategies to enable better IT support of the organization’s overall strategy and objectives.
The IT strategy committee can meet with the organization’s top IT executives to impart the board’s wishes directly to them. This works best as a two-way conversation, where IT executives can inform the strategy committee of their status on major initiatives, as well as on challenges and risks. This ongoing dialogue can take place as often as needed, usually once or twice per year.
Readers should note that this suggestion of the IT strategy committee communicating with IT management is not an attempt to circumvent communications through intermediate layers of management. Those individuals should be included in this conversation as well.
The Balanced Scorecard
The balanced scorecard (BSC) is a management tool that is used to measure the performance and effectiveness of an organization. The balanced scorecard is used to determine how well an organization can fulfill its mission and strategic objectives, and how well it is aligned with overall organizational objectives.
In the balanced scorecard, management defines key performance indicators in each of four perspectives:
• Financial Key financial items measured include the cost of strategic initiatives, support costs of key applications, and capital investment.
• Customer Key measurements include the satisfaction rate with various customer-facing aspects of the organization.
• Internal processes Measurements of key activities include the number of projects and the effectiveness of key internal workings of the organization.
• Innovation and learning Human-oriented measurements include turnover, illness, internal promotions, and training.
Each organization’s balanced scorecard will represent a unique set of measurements that reflects the organization’s type of business, business model, and style of management.
The balanced scorecard methodology of greatest interest to readers of this book is the standard IT balanced scorecard, discussed in the next section.
The Standard IT Balanced Scorecard
The balanced scorecard should be used to measure overall organizational effectiveness and progress. A similar scorecard, the standard IT balanced scorecard (IT-BSC), can be used to specifically measure IT organization performance and results.
Like the balanced scorecard, the standard IT balanced scorecard has four perspectives:
• Business contribution Key indicators here are the perception of IT department effectiveness and value as seen from other (non-IT) corporate executives.
• User Key measurements include end-user satisfaction rate with IT systems and the IT support organization. Satisfaction rates of external users should be included if the IT department builds or supports externally facing applications or systems.
• Operational excellence Key measurements include the number of support cases, amount of unscheduled downtime, and defects reported.
• Innovation This includes the rate at which the IT organization utilizes newer technologies to increase IT value and the amount of training made available to IT staff.
The IT balanced scorecard should flow directly out of the organization’s overall balanced scorecard. This will ensure that IT will align itself with corporate objectives. While the perspectives between the overall BSC and the IT-BSC vary, the approach for each is similar, and the results for the IT-BSC can “roll up” to the organization’s overall BSC.
Information Security Governance
Security governance is the collection of management activities that establishes key roles and responsibilities, identifies and treats risks to key assets, and measures key security processes. Depending upon the structure of the organization and its business purpose, information security governance may be included in IT governance, or security governance may stand on its own (but if so, it should still be linked to IT governance so that these two activities are kept in sync).
The main roles and responsibilities for security should be
• Board of directors The board is responsible for establishing the tone for risk appetite and risk management in the organization. To the extent that the board of directors establishes business and IT security, so, too, should the board consider risk and security in that strategy.
• Steering committee The security steering committee should establish the operational strategy for security and risk management in the organization. This includes setting strategic and tactical roles and responsibilities in more detail than was done by the board of directors. The security strategy should be in harmony with the strategy for IT and the business overall. The steering committee should also ratify security policy and other strategic policies and processes developed by the chief information security officer (CISO).
• Chief information security officer (CISO) The CISO should be responsible for developing security policy; conducting risk assessments; developing processes for vulnerability management, incident management, identity and access management, security awareness and training, and compliance management; and informing the steering committee and board of directors of incidents and new or changed risks. In some organizations, this is known as the chief information risk officer (CIRO).
NOTE Some organizations may employ a chief security officer (CSO) who is responsible for logical security as described in the CISO role, as well as physical security, including workplace and personnel safety, physical access control, and investigations.
• Chief information officer (CIO) The CIO is responsible for overall management of the IT organization, including IT strategy, development, operations, and service desk. In some organizations the CISO or other top-ranking security individual reports to the CIO, while in other organizations they are peers.
• Management Every manager in the organization should be at least partially responsible for the conduct of their employees. This approach helps to establish a chain of accountability from the top of the organization, all the way down to individual employees.
• All employees Every employee in the organization should be required to comply with the organization’s security policy, as well as with security requirements and processes. All senior and executive management should demonstrably comply with these policies as an example for others.
Security governance is not only for the identification and enforcement of applicable laws, regulations, and other legal requirements, but also for the fulfillment of goals and objectives, as well as management of policies and processes.
Security governance should also make it clear that compliance with policies is a condition of employment; employees who fail to comply with policy are subject to discipline or termination of employment.
Reasons for Security Governance
Organizations are dependent on their information systems. This has progressed to the point where organizations—including those whose products or services are not information-related—are completely dependent on the integrity and availability of their information systems to continue operations. Security governance, then, is needed to ensure that security-related incidents do not threaten critical systems and their support of the ongoing viability of the organization.
Security Governance Activities and Results
Within an effective security governance program, the organization’s management will see to it that information systems necessary to support business operations will be adequately protected. Some of the activities that will take place include
• Risk management Management will make sure that risk assessments will be performed to identify risks in information systems. Follow-up actions will be carried out that will reduce the risk of system failure and compromise.
• Process improvement Management will ensure that key changes will be made to business processes that will result in security improvements.
• Incident response Management will put incident response procedures into place that will help to avoid incidents, reduce the impact and probability of incidents, and improve response to incidents so that their impact on the organization is minimized.
• Improved compliance Management will be sure to identify all applicable laws, regulations, and standards and carry out activities to confirm that the organization is able to attain and maintain compliance.
• Business continuity and disaster recovery planning Management will define objectives and allocate resources for the development of business continuity and disaster recovery plans.
• Effectiveness measurement Management will establish processes to measure key security events such as incidents, policy changes and violations, audits, and training.
• Resource management The allocation of manpower, budget, and other resources to meet security objectives is monitored by management.
• Improved IT governance An effective security governance program will result in better strategic decisions in the IT organization that keep risks at an acceptably low level.
These and other governance activities are carried out through scripted interactions among key business and IT executives at regular intervals. Meetings will include a discussion of effectiveness measurements, recent incidents, recent audits, and risk assessments. Other discussions may include such things as changes to the business, recent business results, and any anticipated business events such as mergers or acquisitions.
Two key results of an effective security governance program are
• Increased trust Customers, suppliers, and partners trust the organization to a greater degree when they see that security is managed effectively.
• Improved reputation The business community, including customers, investors, and regulators, will hold the organization in higher regard.
IT Strategic Planning
In a methodical and organized way, a good strategic planning process answers the question of what to do, often in a way that takes longer to answer than it does to ask. While IT organizations require personnel who perform the day-to-day work of supporting systems and applications, some IT personnel need to spend at least part of their time developing plans for what the IT organization will be doing two, three, or more years in the future.
Strategic planning needs to be part of a formal, iterative planning process, not an ad hoc, chaotic activity. Specific roles and responsibilities for planning need to be established, and those individuals must carry out planning roles as they would any other responsibility. A part of the struggle with the process of planning stems from the fact that strategic planning is partly a creative endeavor that includes analysis of reliable information about future technologies and practices, as well as long-term strategic plans for the organization itself. In a nutshell, the key question is In five years, when the organization will be performing specific activities in a particular manner, how will IT systems support those activities?
But it’s more than just understanding how IT will support future business activities. Innovations in IT may help to shape what activities will take place, or at least how they will take place. On a more down-to-earth level, IT strategic planning is about the ability to provide the capability and capacity for IT services that will match the levels of and the types of business activities that the organization expects to achieve at certain points in the future. In other words, if organization strategic planning predicts specific transaction volumes (as well as new types of transactions) at specific points in the future, then the job of IT strategic planning will be to ensure that cost-effective IT systems of sufficient processing capacity will be up and running to support those features and workloads.
Discussion of new business activities, as well as the projected volume of current activities at certain times in the future, is most often discussed by a steering committee.
The IT Steering Committee
A steering committee is a body of senior managers or executives that meets from time to time to discuss high-level and long-term issues in the organization. An IT steering committee will typically discuss the future states of the organization and how the IT organization will meet the organization’s needs. A steering committee will typically consist of senior-level IT managers as well as key customers or constituents. This provider-customer dialogue will help to ensure that IT, as the organization’s technology service arm, will fully understand the future vision of the business (in business terms) and be able to support future business activities in terms of capacity, cost-effectiveness, and the ability to support new activities that do not yet exist.
NOTE The role of the IT steering committee also serves as the body for assessing results of recent initiatives and major projects to gain a high-level understanding of past performance in order to shape future activities. The committee also needs to consider industry trends and practices, risks as defined by internal risk assessments, and current IT capabilities.
The role of the IT steering committee is depicted in Figure 2-1.
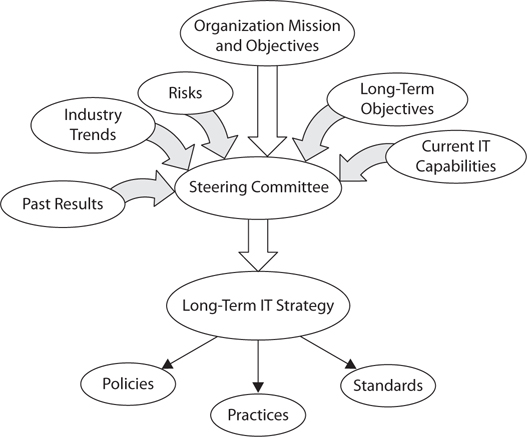
Figure 2-1 The IT steering committee synthesizes a future strategy using several inputs.
A steering committee’s mission, objectives, roles, and responsibilities should be formally defined in a written charter. Steering committee meetings should be documented and published.
The steering committee needs to meet regularly to consider strategic issues and make decisions that translate into actions, tasks, and projects in IT and elsewhere.
Not all organizations have an IT steering committee. The role is sometimes filled by key senior staff members, with or without an official charter. And in some organizations, the role is not filled at all, and as a result the IT organization is directionless.
Policies, Processes, Procedures, and Standards
Policies, processes, procedures, and standards define IT organizational behavior and uses of technology. They are part of the written record that defines how the IT organization performs the services that support the organization.
Policy documents should be developed and ratified by IT management. Policies state only what must be done (or not done) in an IT organization. They should not state how something must be done (or not done). That way, a policy document will be durable—meaning it may last many years with only minor edits from time to time.
IT policies typically cover many topics, including:
• Roles and responsibilities This will range from general to specific, usually by describing each major role and responsibility in the IT department and then specifying which position is responsible for it. IT policies will also make general statements about responsibilities that all IT employees will share.
• Development practices IT policy should define the processes used to develop and implement software for the organization. Typically, IT policy will require a formal development methodology that includes a number of specific ingredients, such as quality review and the inclusion of security requirements and testing.
• Operational practices IT policy defines the high-level processes that constitute IT’s operations. This will include service desk, backups, system monitoring, metrics, and other day-to-day IT activities.
• IT processes, documents, and records IT policy will define other important IT processes, including incident management, project management, vulnerability management, and support operations. IT policy should also define how and where documents such as procedures and records will be managed and stored.
IT policy, like any other organization policy, is generally focused on what should be done and on what parties are responsible for different activities. However, policy generally steers clear of describing how these activities should be performed. That, instead, is the role of procedures and standards, discussed later in this section.
The relationship between policies, processes, procedures, and standards is shown in Figure 2-2.
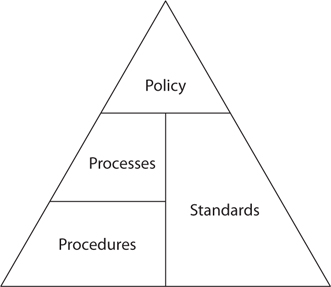
Figure 2-2 Policies, processes, procedures, and standards
Information Security Policy
Security policy defines how an organization will protect its important assets. Like IT policy, information security policy defines several fundamental principles and activities:
• Roles and responsibilities Security policy should define specific roles and responsibilities, including the roles of specific positions in the organization as well as the responsibilities of all staff members.
• Risk management Security policy should define how the organization identifies and treats risks. An organization should perform periodic risk assessments and risk analysis, which will lead to decisions about risk treatment for specific risks that are identified.
• Security processes Security policy should define important security processes, such as vulnerability management and incident management, and incorporate security in other business processes, such as software development and acquisition, vendor selection and management, and employee screening and hiring.
• Acceptable use Security policy should define the types of activities that are acceptable and those that are not.
The best practice for information security policy is the definition of a top-down, management-driven information security program that performs periodic risk assessments to identify and focus on the most important risks in the organization. Roles and responsibilities define who is responsible for carrying out these activities. Executive management should have visibility and decision-making power, particularly in the areas of policy review and risk treatment.
It is generally accepted that security policy and security management should be separate from IT policy and IT management. This permits the security organization function to operate outside of IT, thereby permitting security to be objective and independent of IT. This puts security in a better position to be able to objectively assess IT systems and processes without fear of direct reprisal.
Privacy Policy
One of the most important policies an organization will develop that is related to information security is a privacy policy. A privacy policy describes how the organization will treat information that is considered private because it is related to a private citizen. A privacy policy defines two broad activities in this regard:
• Protecting private information An organization that is required to collect, store, or transmit private information is duty-bound to protect this information so that it is not disclosed to unauthorized parties. This part of a privacy policy will describe what information is obtained and how it is protected.
• Handling private information Aside from the actual protection of private information, some organizations may, in the course of their business activities, transmit some or all of this information to other parts of the organization or to other organizations. A privacy policy is typically forthright about this internal handling and the transmittals to other parties. Further, a privacy policy describes how the information is used by the organization and by other organizations to which it is transmitted. The privacy policy typically describes how a private citizen may confirm whether his or her private information is stored by the organization, whether it is accurate, and how the citizen can arrange for its removal if he or she wishes.
NOTE Many countries have privacy laws that require an organization to have a privacy policy and to enact safeguards to protect private information.
Data Classification Policy
A data classification policy defines degrees of sensitivity for various types of information used in the organization. A typical data classification policy will define two or more (but rarely more than five) data classification levels. For example:
• Top Secret
• Secret
• Sensitive
• Public
Along with defining levels of classification, a data classification policy will define policies and procedures for handling of information in various settings at these levels. For instance, a data classification policy will state the conditions at each level in which sensitive information may be e-mailed, faxed, stored, transmitted, or shipped. Note that some methods for handling may be forbidden—such as e-mailing a top-secret document.

EXAM TIP While the CISO is responsible for establishing the organization’s data classification policy, it is usually the responsibility of a document owner to correctly classify and mark a document. It is then the responsibility of any party that uses a document to handle it according to its classification level. All personnel who work with the document are responsible for handling it according to the classification policy.
System Classification Policy
A data classification policy may specify levels of security for systems storing classified information. A system classification policy will establish levels of system security that correspond to levels of data classification. Such a policy will help the organization to be more deliberate in its system hardening standards so that the most sensitive information will be stored only on systems with the highest levels of hardening (often, those higher levels of hardening are more costly and time consuming to manage; otherwise, an organization might just make all of its systems as secure).
Site Classification Policy
A site classification policy defines levels of security for an organization’s work sites. This policy sets levels of physical security that corresponds to one or more factors:
• Criticality of staff that works at the site
• Criticality or value of business processes performed at the site
• Value of assets located at the site
• Sensitivity or value of data stored or processed at the site
• Siting risks associated with a site (human-made or natural hazards)
Based on the classification of a site, an organization may have additional security controls, such as video surveillance, guards, fences, visitor controls, and so on. Just as it does not make sense to protect all data at a single level, it also is sensible to have the right level of physical security at each site according to the information, equipment, or activity that takes place there.
Access Control Policy
An access control policy defines the need for specific processes and procedures related to the granting, review, and revocation of access to systems and work areas. This policy will state which roles are permitted to manage access controls, what levels of approval are required for access requests, how often access reviews will take place, and what access control records will be kept.
Often, there will be linkage between a data classification policy and an access control policy, since access controls protecting the most sensitive information may be stricter than access controls protecting less sensitive information.
Mobile Device Policy
A mobile device policy defines the use of mobile devices and personally owned devices in the context of business operations and access to business information and information systems. This policy will state the types of devices that may be permitted, the rules and conditions of their use, and responsibilities of device owners and users.
Social Media Policy
A social media policy defines employees’ use of social media. Generally, this encompasses online behavior and employees’ online representations of their personal and professional conduct. Components in a social media policy may include
• Personal social media Policy may limit the posting of content that could put the employee or the organization in a bad light.
• Professional social media Policy may address or restrict how employees describe their positions and activities in the workplace.
• Disclosure of company information Policy may restrict the types of information that employees are permitted to disclose to the public.
While organizations generally don’t try to restrict employees’ use of social media, organizations use social media policy to reaffirm their ownership of official information about the organization.
Other Policies
Organizations may have additional technology-related policies, including:
• Equipment control and use Policy may address the appropriate use of IT and other equipment, and perhaps includes cases where equipment is assigned to employee use in the field.
• Data destruction Policy defines acceptable and required methods for the disposal of information when no longer needed.
• Moonlighting Policy addresses matters regarding outside employment, such as employees who have a second job or perform volunteer work.
Processes and Procedures
Process and procedure documents, sometimes called SOPs (standard operating procedures), describe in step-by-step detail how IT processes and tasks are performed. Formal procedure documents ensure that tasks are performed consistently and correctly, even when performed by different IT staff members.
In addition to the actual steps in support of a process or task, a procedure document needs to contain several pieces of metadata:
• Document (or process) ownership The document should contain the name of the person or department responsible for its review, revision, and publication.
• Document revision information The procedure document should contain the name of the person who wrote the document and the person who made the most recent changes to the document. The document should also include the name or location where the official copy of the document may be found.
• Review and approval The document should include the name of the manager who last reviewed the procedure document, as well as the name of the manager (or higher) who approved the document.
• Dependencies The document should specify which other procedures are related to this procedure. This includes those procedures that are dependent upon this procedure, and the procedures that this one depends on. For example, a document that describes the database backup process will depend on database management and maintenance documents; documents on media handling will depend on this document.
IT process and procedure documents are not meant to be a replacement for vendor task documentation. For instance, an IT department does not necessarily need to create a document that describes the steps for operating a data storage device when the device vendor’s instructions are available and sufficient. Also, IT procedure documents need not be remedial and include every specific keystroke and mouse click: they can usually assume that the reader has experience in the subject area and only needs to know how things are done in this organization. For example, a procedure document that includes a step that involves the modification of a configuration file does not need to include instructions on how to operate a text editor.

TIP An IT department should maintain a catalog of its procedure documents to facilitate convenient document management. This will permit IT management to better understand which documents are in its catalog and when each was last reviewed and updated.
Standards
IT standards are official, management-approved statements that define the technologies, protocols, suppliers, and methods that are used by an IT organization. Standards help to drive consistency into the IT organization, which will make the organization more cost-efficient and cost-effective.
An IT organization will have different types of standards, including:
• Technology standards These standards specify what software and hardware technologies or products are used by the IT organization. Examples include operating system, database management system, application server, storage systems, backup media, and so on.
• Protocol standards These standards specify the protocols that are used by the organization. For instance, an IT organization may opt to use Transmission Control Protocol/Information Protocol (TCP/IP) v6 for its internal networks, Cisco gateway routing protocols (GRP), Transport Layer Security (TLS) for secure transmission of data, Secure Shell (SSH) for device management, and so forth.
• Supplier standards This defines which suppliers and vendors are used for various types of supplies and services. Using established suppliers can help the IT organization through specially negotiated discounts and other arrangements.
• Methodology standards This refers to practices used in various processes, including software development, system administration, network engineering, and end-user support.
• Configuration standards This refers to specific detailed configurations that are to be applied to servers, database management systems, end-user workstations, network devices, and so on. This enables users, developers, and technical administrative personnel to be more comfortable with IT systems because the systems will be consistent with each other. This helps to reduce unscheduled downtime and to improve quality.
• Architecture standards This refers to technology architecture at the database, system, or network level. An organization may develop reference architectures for use in various standard settings. For instance, a large retail organization may develop specific network diagrams to be used in every retail location, down to the colors of wires to use and how equipment is situated on racks or shelves.
TIP Standards enable the IT organization to be simpler, leaner, and more efficient. IT organizations with effective standards will have fewer types of hardware and software to support, which reduces the number of technologies that must be managed by the organization. An organization that standardizes on one operating system, one database management system, and one server platform need only build expertise in those technologies. This enables the IT organization to manage and support the environment more effectively than if many different technologies were in use.
Applicable Laws, Regulations, and Standards
Organizations need to identify all of the laws, regulations, and standards that are applicable to their operations. As information technology has become more critical for organizations in many industry sectors, many nations and local governments have enacted new laws and regulations concerning the processing and protection of information.
The board of directors, strategy committee, or chief legal counsel should appoint an executive to be responsible for identifying all potentially applicable laws and regulations, who should then consult with inside or outside legal counsel to determine their scope and applicability.
Once applicable laws and regulations have been identified, the organization then needs to determine how they affect
• Enterprise architecture Laws and regulations may require that organizations put specific IT components or configurations into place that affect the organization’s enterprise architecture.
• Controls Laws and regulations may require that additional controls be enacted or existing controls changed.
• Processes Laws and regulations may require that the organization perform certain tasks that may affect processes.
• Personnel Laws and regulations may require that certain personnel possess specific qualifications, certifications, or licenses.
Many factors will determine whether specific laws are applicable to an organization, including:
• Type of data that is stored, processed, or transmitted by the organization’s systems
• Industry sector
• Location of stored, processed, or transmitted data
• Location of the owner(s) of stored, processed, or transmitted data
Organizations may also be required to comply with specific standards. For example, organizations that process, store, or transmit credit card numbers may be required to comply with the Payment Card Industry Data Security Standard (PCI-DSS), even though there may be no laws requiring organizations to do so.
Risk Management
Organizations need to understand the internal activities, practices, and systems, as well as external threats, that are introducing risk into their operations. The span of activities that seek, identify, and manage these risks is known as risk management. Like many other processes, risk management is a life cycle activity that has no beginning and no end. It’s a continuous and phased set of activities that includes the examination of processes, records, systems, and external phenomena in order to identify risks. This is continued by an analysis that examines a range of solutions for reducing or eliminating risks, followed by formal decision-making that brings about a resolution to risks.
Risk management needs to support overall business objectives. This support will include the adoption of a risk appetite that reflects the organization’s overall approach to risk. For instance, if the organization is a conservative financial institution, then that organization’s risk management program will probably adopt a position of being risk averse. Similarly, a high-tech startup organization that, by its very nature, is comfortable with overall business risk will probably be less averse to risks identified in its risk management program.
Regardless of its overall risk appetite, when an organization identifies risks, the organization can take one of four possible actions:
• Accept The organization accepts the risk as-is.
• Mitigate (or Reduce) The organization takes action to reduce the level of risk.
• Transfer (or Share) The organization shares the risk with another entity, usually an insurance company.
• Avoid The organization discontinues the activity associated with the risk.
These alternatives are known as risk treatments. Often, a particular risk will be treated with a blended solution that consists of two or more of the actions just listed.
This section dives into the details of risk management, risk analysis, and risk treatment.
The Risk Management Program
An organization that operates a risk management program should establish principles that will enable the program to succeed. These may include
• Objectives The risk management program must have a specific purpose; otherwise, it will be difficult to determine whether the program is successful. Example objectives include reducing the number of industrial accidents, reducing the cost of insurance premiums, or reducing the number of stolen assets. If objectives are measurable and specific, then the individuals who are responsible for the risk management program can focus on its objectives in order to achieve the best possible outcome.
• Scope Management must determine the scope of the risk management program. This is a fairly delicate undertaking because of the many interdependencies found in IT systems and business processes. However, in an organization with several distinct operations or business units (BUs), a risk management program could be isolated to one or more operational arms or BUs. In such a case, where there are dependencies on other services in the organization, those dependencies can be treated like an external service provider (or customer).
• Authority The risk management program is being started at the request of one or more executives in the organization. It is important to know who these individuals are and their level of commitment to the program.
• Roles and responsibilities This defines specific job titles, together with their respective roles and responsibilities in the risk management program. In a risk management program with several individuals, it should be clear which individuals or job titles are responsible for which activities in the program.
• Resources The risk management program, like other activities in the business, requires resources to operate. This will include a budget for salaries as well as for workstations, software licenses, and possibly travel.
• Policies, processes, procedures, and records The various risk management activities, such as asset identification, risk analysis, and risk treatment, along with some general activities like recordkeeping, should be written down.
NOTE An organization’s risk management program should be documented in a charter. A charter is a formal document that defines and describes a business program, and becomes a part of the organization’s record.
The risk management life cycle is depicted in Figure 2-3.
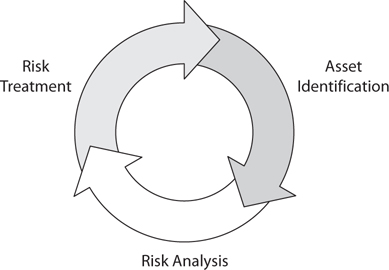
Figure 2-3 The risk management life cycle
The Risk Management Process
Risk management is a life cycle set of activities used to identify, analyze, and treat risks. These activities are methodical and, as mentioned in the previous section, should be documented so that they will be performed consistently and in support of the program’s charter and objectives.
The risk management process is a part of a larger risk framework, such as ISACA’s Risk IT Framework, whose components are
• Risk Governance This includes integration with the organization’s enterprise risk management (ERM), the establishment and maintenance of a common risk view, and the ensurance that business decisions include the consideration of risk.
• Risk Evaluation This includes asset identification, risk analysis, and the maintenance of a risk profile.
• Risk Response This includes the management and articulation of risks, and response to events.
CISA candidates are not required to memorize the Risk IT Framework, but familiarity with its principles are important.
Asset Identification
The risk management program’s main objective (whether formally stated or not) is the protection of the organization’s assets. These assets may be tangible or intangible, physical, logical, or virtual. Some examples of assets include
• Buildings and property These assets include structures and other improvements.
• Equipment This can include machinery, vehicles, and office equipment such as copiers and fax machines.
• IT equipment This includes computers, printers, scanners, tape libraries (the devices that create backup tapes, not the tapes themselves), storage systems, network devices, and phone systems.
• Supplies and materials These can include office supplies as well as materials that are used in manufacturing.
• Records These include business records, such as contracts, video surveillance tapes, visitor logs, and far more.
• Information This includes data in software applications, documents, e-mail messages, and files of every kind on workstations and servers.
• Intellectual property This includes an organization’s designs, architectures, software source code, processes, and procedures.
• Personnel In a real sense, an organization’s personnel are the organization. Without its staff, the organization cannot perform or sustain its processes.
• Reputation One of the intangible characteristics of an organization, reputation is the individual and collective opinion about an organization in the eyes of its customers, competitors, shareholders, and the community.
• Brand equity Similar to reputation, this is the perceived or actual market value of an individual brand of product or service that is produced by the organization.
Grouping Assets For risk management purposes, an electronic inventory of assets will be useful in the risk management life cycle. It is not always necessary to list each individual asset: often, it is acceptable to instead list classes or groups of assets as a single asset entity for risk management purposes. For instance, a single entry for laptop computers may be preferred over listing every laptop computer; this is because the risks for all laptop computers are roughly the same (ignoring behavior differences among individual employees or employees in specific departments). This eliminates the need to list them individually.
Similarly, groups of IT servers, network devices, and other equipment can be named instead of all of the individual servers and devices, again because the risks for each of them will usually be similar. However, one reason to create multiple entries for servers might be their physical location or their purpose: servers in one location may have different risks than servers in another location, and servers containing high-value information will have different risks than servers that do not contain high-value information.
Sources of Asset Data An organization that is undergoing its initial risk-management cycle may need to build its asset database from scratch. Management will need to determine where this initial asset data will come from. Some choices include
• Financial system asset inventory An organization that keeps all of its assets on the books will have a wealth of asset inventory information. However, it may not be entirely useful: asset lists often do not include the location or purpose of the asset and whether it is still in use. Correlating a financial asset inventory to assets in actual use may consume more effort than the other methods for creating the initial asset. However, for organizations that have a relatively small number of highly valued assets (for instance, a rock crusher in a gold mine or a mainframe computer), knowing the precise financial value of an asset is highly useful because the actual depreciated value of the asset is used in the risk analysis phase of risk management. Knowing the depreciated value of other assets is also useful, as this will figure into the risk treatment choices that will be identified later on.
TIP Financial records that indicate the value of an asset do not include the value of information stored on (or processed by) the asset.
• Interviews Discussions with key personnel for purposes of identifying assets are usually the best approach. However, to be effective, several people usually need to be interviewed to be sure to include all relevant assets.
• IT systems portfolio A well-managed IT organization will have formal documents and records for its major applications. While this information may not encompass every single IT asset in the organization, it can provide information on the assets supporting individual applications or geographic locations.
• Online data An organization with a large number of IT assets (systems, network devices, and so on) can sometimes utilize the capability of local online data to identify those assets. For instance, a systems or network management system often includes a list of managed assets, which can be a good starting point when creating the initial asset list.
• Asset management system Larger organizations may find it more cost effective to use an asset management application dedicated to this purpose, rather than rely on lists of assets from other sources.
Collecting and Organizing Asset Data It is rarely possible to take (or create) a list of assets from a single source. Rather, more than one source of information is often needed to be sure that the risk management program has identified at least the important, in-scope assets that it needs to worry about.
NOTE As a part of IT governance, management needs to determine which person or group is responsible for maintaining an asset inventory.
It is usually useful to organize or classify assets. This will help to get the assets under study into smaller chunks that can be analyzed more effectively. There is no single way to organize assets, but a few ideas include
• Geography A widely dispersed organization may want to classify its assets according to their location. This will aid risk managers during the risk analysis phase, since many risks are geographic-centric, particularly natural hazards. Mitigation of risks is often geography based: for instance, it’s easier to make sense of building a fence around one data center than putting up fences around buildings in every location.
• Business process Because some organizations rank the criticality of their individual business processes, it can be useful to group assets according to the business processes that they support. This helps the risk analysis and risk treatment phases, because assets supporting individual processes can be associated with business criticality and treated appropriately.
• Organizational unit In larger organizations, it may be easier to classify assets according to the organizational unit they support.
• Sensitivity Usually ascribed to information, sensitivity relates to the nature and content of that information. Sensitivity usually applies in two ways: to an individual, where the information is considered personal or private, and to an organization, where the information may be considered a trade secret. Sometimes sensitivity is somewhat subjective and arbitrary, but often it is defined in laws and regulations.
• Regulation For organizations that are required to follow government or private regulation regarding the processing and protection of information, it will be useful to include data points that indicate whether specific assets are considered in scope for specific regulations. This is important because some regulations specify how assets should be protected, so it’s useful to be aware of this during risk analysis and risk treatment.
There is no need to choose which of these three methods will be used to classify assets. Instead, an IT analyst should collect several points of metadata about each asset (including location, process supported, and organizational unit supported). This will enable the risk manager to sort and filter the list of assets in various ways to better understand which assets are in a given location or which ones support a particular process or part of the business.
TIP Organizations should consider managing information about assets in a fixed-assets application.
Risk Analysis
Risk analysis is the activity in a risk management program where individual risks are identified. A risk consists of the intersection of threats, vulnerabilities, probabilities, and impact. In its simplest terms, risk is described in the following formula:
Risk = Probability × Impact
This equation implies that risk is always used in quantitative terms, but risk is equally used in qualitative risk analysis.
Other definitions of risk include
• The combination of the probability of an event and its consequence (source: ISACA Cybersecurity Fundamentals Glossary)
• The probable frequency and probable magnitude of future loss (source: “An Introduction to Factor Analysis of Information Risk (FAIR),” Risk Management Insight, LLC)
• The potential that a given threat will exploit vulnerabilities of an asset or group of assets and thereby cause harm to the organization (source: ISO/IEC 27005)
These definitions convey essentially the same message: the amount of risk is directly proportional to the probability of occurrence and the impact that a risk would have if realized.
A risk analysis consists of identifying threats and their impact of realization against each asset. This usually also includes a vulnerability analysis, where assets are studied to determine whether they are vulnerable to identified threats. The sheer number of assets may make this task appear daunting; however, threat and vulnerability analyses can usually be performed against groups of assets. For instance, when identifying natural and human-made threats against assets, it often makes sense to perform a single threat analysis against all of the assets that reside in a given location. After all, the odds of a volcanic eruption are the same for any of the servers in the room—the threat need not be called out separately for each asset.
Threat Analysis The usual first step in a risk analysis is to identify threats against an asset or group of assets. A threat is an event that, if realized, would bring harm to an asset and, hence, to the organization. A typical approach is to list all of the threats that have some realistic opportunity of occurrence; those threats that are highly unlikely to occur can be left out. For instance, the listing of meteorites, tsunamis in landlocked regions, and wars in typically peaceful regions will just add clutter to a risk analysis.
A more reasonable approach in a threat analysis is to identify all of the threats that a reasonable person would believe could occur, even if the probability is low. For example, include flooding when a facility is located near a river, hurricanes for an organization located along the southern or eastern coast (and inland for some distance) of the United States, or a terrorist attack in practically every major city in the world. All of these would be considered reasonable in a threat analysis.
It is important to include the entire range of both natural and human-made threats. The full list could approach or even exceed 100 separate threats. The categories of possible threats include
• Severe storms This may include tornadoes, hurricanes, windstorms, ice storms, and blizzards.
• Earth movement This includes earthquakes, landslides, avalanches, volcanoes, and tsunamis.
• Flooding This can include both natural and human-made situations.
• Disease This includes sickness outbreaks and pandemics, as well as quarantines that result.
• Fire This includes forest fires, range fires, and structure fires, all of which may be natural or human-caused.
• Labor This includes work stoppages, sick-outs, protests, and strikes.
• Violence This includes riots, looting, terrorism, and war.
• Malware This includes all kinds of viruses, worms, Trojan horses, root kits, and associated malicious software.
• Hacking attack This includes automated attacks (think of an Internet worm that is on the loose) as well as targeted attacks by employees, former employees, or criminals.
• Hardware failures This includes any kind of failure of IT equipment or related environmental equipment failures, such as heating, ventilation, and air conditioning (HVAC).
• Software failures This can include any software problem that precipitates a disaster. Examples are the software bug that caused a significant power blackout in the U.S. Northeast in 2003 and the Nest home thermostat bug in 2016.
• Utilities This includes electric power failures, water supply failures, and natural gas outages, as well as communications outages.
• Transportation This may include airplane crashes, railroad derailments, ship collisions, and highway accidents.
• Hazardous materials This includes chemical spills. The primary threat here is direct damage by hazardous substances, casualties, and forced evacuations.
• Criminal This includes extortion, embezzlement, theft, vandalism, sabotage, and hacker intrusion. Note that company insiders can play a role in these activities.
• Errors This includes mistakes made by personnel that result in disaster situations.
Alongside each threat that is identified, the risk analyst assigns a probability or frequency of occurrence. This may be a numeric value, expressed as a probability of one occurrence within a calendar year. For example, if the risk of a flood is 1 in 100, it would be expressed as 0.01, or 1 percent. Probability can also be expressed as a ranking; for example, Low, Medium, and High; or on a numeric probability scale from 1 to 5 (where 5 can be either highest or lowest probability).
An approach for completing a threat analysis is to
• Perform a geographic threat analysis for each location This will provide an analysis on the probability of each type of threat against all assets in each location.
• Perform a logical threat analysis for each type of asset This provides information on all of the logical (that is, not physical) threats that can occur to each asset type. For example, the risk of malware on all assets of one type is probably the same, regardless of their location.
• Perform a threat analysis for each highly valued asset This will help to identify any unique threats that may have appeared in the geographic or logical threat analysis, but with different probabilities of occurrence.
Threat Forecasting Data Is Sparse
One of the biggest problems with information security–related risk management is the lack of reliable data on the probability of many types of threats. While the probability of some natural threats can sometimes be obtained from local disaster response agencies, the probabilities of most other threats are difficult to accurately predict.
The difficulty in predicting security events sits in stark contrast to volumes of available data related to automobile and airplane accidents, as well as human life expectancy. In these cases, insurance companies have been accumulating statistics on these events for decades, and the variables (for instance, tobacco and alcohol use) are well known. On the topic of cyber-related risk, there is a general lack of reliable data, and the factors that influence risk are not well known from a statistical perspective. It is for this reason that risk analysis still relies on educated guesses for the probabilities of most events. But given the recent surge in popularity for cyber insurance, the availability and quality of cyber-attack risk factors may soon be determined.
Vulnerability Identification A vulnerability is a weakness or absence of a protective control that makes the probability of one or more threats more likely. A vulnerability analysis is an examination of an asset in order to discover weaknesses that could lead to a higher-than-normal rate of occurrence or potency of a threat.
Examples of vulnerabilities include
• Missing or inoperative antivirus software
• Outdated and unsupported software in use
• Missing security patches
• Weak password settings
• Missing or incomplete audit logs
• Inadequate monitoring of event logs
• Weak or defective application session management
• Building entrances that permit tailgating
In a vulnerability analysis, the risk manager needs to examine the asset itself as well as all of the protective measures that are—or should be—in place to protect the asset from relevant threats.
Vulnerabilities can be ranked by severity. Vulnerabilities are indicators that show the effectiveness (or ineffectiveness) of protective measures. For example, an antivirus program on a server that updates its virus signatures once per week might be ranked as a medium vulnerability, whereas the complete absence (or malfunction) of an antivirus program on the same server might be ranked as a high vulnerability. Severity is an indication of the likelihood that a given threat might be realized. This is different from impact, which is discussed later in this section.
TIP A vulnerability, and its ranking, should not be influenced by the probability that a threat will be realized. Instead, a vulnerability ranking should depend on whether the threat will actually bring about harm to the asset. Also, the ranking of a vulnerability should not be influenced by the value of the asset or the impact of a realized threat. These factors are covered separately in risk management.
Probability Analysis For any given threat and asset, the probability that the threat will actually be realized needs to be estimated. This is often easier said than done, as there is a lack of reliable data on security incidents. A risk manager still will need to perform some research and develop a best guess based on available data.
Impact Analysis A threat, when actually realized, will have some effect on the organization. Impact analysis is the study of estimating the impact of specific threats on specific assets.
In impact analysis, it is necessary to understand the relationship between an asset and the business processes and activities that the asset supports. The purpose of impact analysis is to identify the impact on business operations or business processes. This is because risk management is not an abstract identification of abstract risks, but instead a search for risks that have real impact on business operations.
In an impact analysis, the impact can be expressed as a rating such as H-M-L (High-Medium-Low) or as a numeric scale, and it can also be expressed in financial terms. But what is also vitally important in an impact analysis is the inclusion of a statement of impact for each threat. Example statements of impact include “inability to process customer support calls” and “inability for customers to view payment history.” Statements such as “inability to authenticate users” may be technically accurate, but they do not identify the business impact.
NOTE Because of the additional time required to quantify and develop statements of impact, impact analysis is usually performed only on the highest-ranked threats on the most critical assets.
Qualitative Risk Analysis A qualitative risk analysis is an in-depth examination of in-scope assets with a detailed study of threats (and their probability of occurrence), vulnerabilities (and their severity), and statements of impact. The threats, vulnerabilities, and impact are all expressed in qualitative terms such as High-Medium-Low or in quasi-numeric terms such as a 1–5 numeric scale.
The purpose of qualitative risk analysis is to identify the most critical risks in the organization based on these rankings.
Qualitative risk analysis does not get to the issue of “how much does a given threat cost my business if it is realized?”—nor does it mean to. The value in a qualitative risk analysis is the ability to quickly identify the most critical risks without the additional burden of identifying precise financial impacts.
The individual(s) performing risk analysis may wish to include threat-vulnerability pairing as well as asset-threat pairing. These are techniques that may help a risk analyst better understand the probability or impact of specific threats.
NOTE Organizations that do need to perform quantitative risk analysis often begin with qualitative risk analysis to determine the highest-ranked risks that warrant the additional effort of quantitative analysis.
Quantitative Risk Analysis Quantitative risk analysis is a risk analysis approach that uses numeric methods to measure risk. The advantage of quantitative risk analysis is the statements of risk in terms that can be easily compared with the known value of their respective assets. In other words, risks are expressed in the same units of measure as most organizations’ primary unit of measure: financial.
Despite this, quantitative risk analysis must still be regarded as an effort to develop estimates, not exact figures. Partly this is because risk analysis is a measure of events that may occur, not a measure of events that do occur.
Standard quantitative risk analysis involves the development of several figures:
• Asset value (AV) This is the value of the asset, which is usually (but not necessarily) the asset’s replacement value.
• Exposure factor (EF) This is the financial loss that results from the realization of a threat, expressed as a percentage of the asset’s total value. Most threats do not completely eliminate the asset’s value; instead, they reduce its value. For example, if a construction company’s $120,000 earth mover is destroyed in a fire, the equipment will still have salvage value, even if that is only 10 percent of the asset’s value. In this case the EF would be 90 percent. Note that different threats will have different impacts on EF because the realization of different threats will cause varying amounts of damage to assets.
• Single loss expectancy (SLE) This value represents the financial loss when a threat is realized one time. SLE is defined as AV × EF. Note that different threats have a varied impact on EF, so those threats will also have the same multiplicative effect on SLE.
• Annualized rate of occurrence (ARO) This is an estimate of the number of times that a threat will occur per year. If the probability of the threat is 1 in 50, then ARO is expressed as 0.02. However, if the threat is estimated to occur four times per year, then ARO is 4.0. Like EF and SLE, ARO will vary by threat.
• Annualized loss expectancy (ALE) This is the expected annualized loss of asset value due to threat realization. ALE is defined as SLE × ARO.
ALE is based upon the verifiable values AV, EF, and SLE, but because ARO is only an estimate, ALE is only as good as ARO. Depending upon the value of the asset, the risk manager may need to take extra care to develop the best possible estimate for ARO, based upon whatever data is available. Sources for estimates include
• History of event losses in the organization
• History of similar losses in other organizations
• History of dissimilar losses
• Best estimates based on available data
TIP When performing a quantitative risk analysis for a given asset, the ALE for all threats can be added together. The sum of all ALEs is the annualized loss expectancy for the total array of threats. A particularly high sum of ALEs would mean that a given asset is confronted with a lot of significant threats that are more likely to occur. But in terms of risk treatment, ALEs are better off left as separate and associated with their respective threats.
Developing Mitigation Strategies An important part of risk analysis is the investigation of potential solutions for reducing or eliminating risk. This involves understanding specific threats and their impact (EF) and likelihood of occurrence (ARO). Once a given asset and threat combination has been baselined (that is, the existing asset, threats, and controls have been analyzed to understand the threats as they exist right now), the risk analyst can then apply various hypothetical means for reducing risk, documenting each one in terms of its impact on EF and ARO.
For example, suppose a risk analysis identifies the threat of attack on a public web server. Specific EF and ARO figures have been identified for a range of individual threats. Now the risk analyst applies a range of fixes (on paper), such as an application firewall, an intrusion prevention system, and a patch management tool. Each solution will have a specific and unique impact on EF and ARO (these are all estimates, of course, just like the estimates of EF and ARO on the initial conditions); some will have better EF and ARO figures than others. Each solution should also be rated in terms of cost (financial or H-M-L) and effort to implement (financial or H-M-L).
NOTE Developing mitigation strategies is the first step in risk treatment, where various solutions are put forward, each with its cost and impact on risk.
While security analysts may have the responsibility for documenting vulnerabilities, threats, and risks, it is senior management’s responsibility (through the security steering committee) to formally approve the treatment of risk. Risk treatment is discussed later in this chapter.
Risk Analysis and Disaster Recovery Planning Disaster recovery planning (DRP) and business continuity planning (BCP) utilize risk analysis to identify risks that are related to application resilience and the impact of disasters. The risk analysis performed for DRP and BCP is the same risk analysis that is discussed in this chapter—the methods and approach are the same, although the overall objectives are somewhat different.
Business continuity planning is discussed in depth later in this chapter. Disaster recovery planning is discussed in detail in Chapter 5.
High-Impact Events The risk manager is likely to identify one or more high-impact events during the risk analysis. These events, which may be significant enough to threaten the very viability of the organization, require risk treatment that warrants executive management visibility and belongs in the categories of business continuity planning and disaster recovery planning. These topics are discussed in detail later in this chapter.
Risk Treatment
When risks to assets have been identified through qualitative or quantitative risk analysis, the next step in risk management is to decide what to do about the identified risks. In the risk analysis, one or more potential solutions may have been examined, along with their cost to implement and their impact on risk. In risk treatment, a decision about whether to proceed with any of the proposed solutions (or others) is needed.
Risk treatment pits available resources against the need to reduce risk. In an enterprise environment, not all risks can be mitigated or eliminated because there are not enough resources to treat them all. Instead, a strategy for choosing the best combination of solutions that will reduce risk by the greatest possible margin is needed. For this reason, risk treatment is often more effective when all the risks and solutions are considered together, instead of each one separately. Then they can be compared and prioritized.
When risk treatment is performed at the enterprise level, risk analysts and technology architects can devise ways to bring about the greatest possible reduction in risk. This can be achieved through the implementation of solutions that will reduce many risks for many assets at once. For example, a firewall can reduce risks from many threats on many assets; this will be more effective than individual solutions for each asset.
So far I have been talking about risk mitigation as if it were the only option available when handling risk. Rather, you have four primary ways to treat risk: mitigation, transfer, avoidance, and acceptance. And there is always some leftover risk, called residual risk. These four approaches are discussed here.
Risk Mitigation
Risk mitigation, or risk reduction, involves the implementation of some solution that will reduce an identified risk. For instance, the risk of advanced malware being introduced onto a server can be mitigated with advanced malware prevention software or a network-based intrusion prevention system. Either of these solutions would constitute mitigation of this risk on a given asset.
An organization usually makes a decision to implement some form of risk mitigation only after performing some cost analysis to determine whether the reduction of risk is worth the expenditure of risk mitigation.
Risk Transfer
Risk transfer, or sharing, means that some or all of the risk is being transferred to some external entity, such as an insurance company or business partner. When an organization purchases an insurance policy to protect an asset against damage or loss, the insurance company is assuming part of the risk in exchange for payment of insurance premiums.
The details of a cyber-insurance policy need to be carefully examined to be sure that any specific risk is transferrable to the policy. Cyber-insurance policies typically have exclusions that limit or deny payment of benefits in certain situations.
Risk Avoidance
In risk avoidance, the organization abandons the activity altogether, effectively taking the asset out of service so that the threat is no longer present. In another scenario, they may decide that the risk of pursuing a given business activity is too great, so they may decide to avoid that particular activity.
NOTE Organizations do not often back away completely from an activity because of identified risks. Generally, this avenue is taken only when the risk of loss is great and when the perceived probability of occurrence is high.
Risk Acceptance
Risk acceptance occurs when management is willing to accept an identified risk as-is, with no effort taken to reduce it. Risk acceptance also takes place (sometimes implicitly) for residual risk, after other forms of risk treatment have been applied.
Residual Risk
Residual risk is the risk that is left over from the original risk after some of the risk has been removed through mitigation or transfer. For instance, if a particular threat had a probability of 10 percent before risk treatment and 1 percent after risk treatment, the residual risk is that 1 percent left over. This is best illustrated by the following formula:
Original Risk – Mitigated Risk – Transferred Risk = Residual Risk
It is unusual for risk treatment to eliminate risk altogether; rather, various controls are implemented that remove some of the risk. Often, management implicitly accepts the leftover risk; however, it’s a good idea to make that acceptance of residual risk more formal by documenting the acceptance in a risk management log or a decision log.
Compliance Risk: The Risk Management Trump Card
Organizations that perform risk management are generally aware of the laws, regulations, and standards they are required to follow. For instance, U.S.-based banks, brokerages, and insurance companies are required to comply with the Gramm Leach Bliley Act (GLBA), and organizations that store, process, or transmit credit card numbers are required to comply with PCI-DSS (Payment Card Industry Data Security Standard).
GLBA, PCI-DSS, and other regulations often state in specific terms what controls are required in an organization’s IT systems. This brings to light the matter of compliance risk. Sometimes, the risk associated with a specific control (or lack of a control) may be rated as a low risk, either because the probability of a risk event is low or because the impact of the event is low. However, if a given law, regulation, or standard requires that the control be enacted anyway, then the organization must consider the compliance risk. The risk of noncompliance may result in fines or other sanctions against the organization, which may (or may not) have consequences greater than the actual risk.
The end result of this is that organizations often implement specific security controls because they are required by laws, regulations, or standards—not because their risk analysis would otherwise compel them to.
IT Management Practices
The primary services in the IT organization typically are development, operations, and support. These primary activities require the support of a second layer of activities that together support the delivery of primary IT services to the organization. The second layer of IT management practices consists of the following:
• Personnel management
• Sourcing
• Third-party service delivery management
• Change management
• Financial management
• Quality management
• Portfolio management
• Controls management
• Security management
• Performance and capacity management
Some of these activities the IT organization undertakes itself, while some are usually performed by other parts of the organization. For instance, most of the personnel management functions are typically carried out by a human resources department. This is another essential reason for the existence of an organization-wide IT steering committee that is represented by other departments such as human resources. This enables the entire spectrum of IT management to be centrally controlled even when other departments perform some IT management functions.
Personnel Management
Personnel management encompasses many activities related to the status of employment, training, and the acceptance and management of policy. These personnel management activities ensure that the individuals who are hired into the organization are suitably vetted, trained, and equipped to perform their functions. It is important that they are provided with the organization’s key policies so that their behavior and decisions will reflect the organization’s needs.
Hiring
The purpose of the employee hiring process is to ensure that the organization hires persons who are qualified to perform their stated job duties and that their personal, professional, and educational histories are appropriate. The hiring process includes several activities necessary to ensure that candidates being considered are suitable.
Background Verification Various studies suggest that 30 to 80 percent of employment candidates exaggerate their education and experience on their résumé, and some candidates commit outright fraud by providing false information about their education or prior positions. Because of this, employers need to perform their own background investigation on an employment candidate to obtain an independent assessment of the candidate’s true background.
Employers should examine the following parts of a candidate’s background prior to hiring:
• Employment background The employer should check at least two years back, although five to seven years is needed for mid- or senior-level personnel.
• Education background The employer should confirm whether the candidate has earned any of the degrees or diplomas listed on their résumé. There are many “diploma mills,” enterprises that will print a fake college diploma for a fee.
• Military service background If the candidate served in any branch of the military, then this must be verified to confirm whether the candidate served at all and whether they received relevant training and work experience, and whether their discharge was honorable or otherwise.
• Professional licenses and certifications If a position requires licenses or certifications, these need to be confirmed, including whether the candidate is in good standing with the organizations that manage those licenses and certifications.
• Criminal background The employer needs to investigate whether the candidate has a criminal record. In countries with a national criminal registry like the National Crime Information Center (NCIC) in the United States, this is simpler than in countries that have no nationwide criminal records database. Some industrialized countries do not permit criminal background checks, believe it or not.
• Credit background Where permitted by law, the employer may wish to examine a candidate’s credit and financial history. There are two principal reasons for this type of check: first, a good credit history indicates the candidate is responsible, while a poor credit history may be an indication of irresponsibility or poor choices (although in many cases a candidate’s credit background is not entirely his or her own doing); second, a candidate with excessive debt and a poor credit history may be considered a risk for embezzlement, fraud, or theft.
• Terrorist association Some employers wish to know whether a candidate has documented ties with terrorist organizations. In the United States, an employer can request verification of whether a candidate is on one of several lists of individuals and organizations with whom U.S. citizens are prohibited from doing business. Lists are maintained by the Office of Foreign Assets Control (OFAC), a department of the U.S. Treasury, and also by the U.S. Bureau of Industry and Security.
• References The employer may wish to contact two or more personal and professional references—people who know the candidate and will vouch for his or her background, work history, and character.
TIP In many jurisdictions, employment candidates are required to sign a consent form that will allow the employer (or a third-party agent acting on behalf of the employer) to perform the background check.
Employers also frequently research a candidate’s background through word-of-mouth inquiries, Internet searches, and social media. Much useful information can be obtained that can help an employer corroborate information provided by a candidate.
Background checks are a prudent business practice to identify and reduce risk. In many industries they are a common practice or even required by law. And in addition to performing a background check at the time of hire, many organizations perform them annually for employees in high-risk or high-value positions.
Employee Policy Manuals Sometimes known as an employee handbook, an employee policy manual is a formal statement of the terms of employment, facts about the organization, benefits, compensation, conduct, and other policies.
Employee handbooks are often the cornerstone of corporate policy. A thorough employee handbook usually will cover a wide swath of territory, including the following topics:
• Welcome This welcomes a new employee into the organization, often in an upbeat letter that makes the new employee glad to have joined the organization. This may also include a brief history of the organization.
• Policies These are the most important policies in the organization, which include security, privacy, code of conduct (ethics), and acceptable use of resources. In the United States and other countries, the handbook may also include antiharassment and other workplace behavior policies.
• Compensation This describes when and how employees are compensated.
• Benefits This describes company benefit programs.
• Work hours This discusses work hours and basic expectations for when employees are expected to report to work and how many hours per week they are expected to work.
• Dress code This provides a description and guidelines for required attire in the workplace.
• Performance review This describes the performance review policy and program that is used to periodically evaluate each employee’s performance.
• Promotions This describes the criteria used by the organization to consider promotions for employees.
• Time off This describes compensated and uncompensated time off, including holidays, vacation, illness, disability, bereavement, sabbaticals, military duty, and leaves of absence.
• Security This discusses basic expectations on the topics of physical security and information security, as well as expectations for how employees are expected to handle confidential and sensitive information.
• Regulation If the organization is subject to regulation, this may be mentioned in the employee handbook so that employees will be aware of this and conduct themselves accordingly.
• Safety This discusses workplace safety, which may cover evacuation procedures, emergency procedures, permitted and prohibited items and substances (for example, weapons, alcoholic beverages, other substances and items), procedures for working with hazardous substances, and procedures for operating equipment and machinery.
• Conduct This covers basic expectations for workplace conduct, both with fellow employees and with customers, vendors, business partners, and other third parties.
• Discipline Organizations that have a disciplinary process usually describe its highlights in the employee handbook.
NOTE Employees are often required to sign a statement that affirms their understanding of and compliance with the employee handbook. Many organizations require that employees sign a new copy of the statement on an annual basis, even if the employee handbook has not changed. This helps to affirm for employees the importance of policies contained in the employee handbook.
Initial Access Provisioning New employees may need access to office locations, computers, networks, and/or applications to perform their required duties. This will necessitate the provisioning of one or more building access and computer or network user accounts that they will use to perform their work-related tasks.
An access-provisioning process should be used to determine the access privileges that a new employee should be given. A template of job titles and access privileges should be set up in advance so that management can easily determine which access privileges any new employee will receive. But even with such a plan, each new employee’s manager should still formally request these privileges be set up for new employees.
Job Descriptions A job description is a formal document that describes the roles, responsibilities, and experience required. Each position in an organization, from chief executive officer to office clerk, should have a formal job description.
Job descriptions should also state that employees are required to support company policies, including but not limited to security and privacy, code of conduct, and acceptable use policies. By listing these in a job description, an employer is stating that all employees are expected to comply with these and other policies.
NOTE Employers usually are required to include several boilerplate items or statements (such as equal opportunity clauses) in job descriptions to conform to local labor and workplace safety laws.
Employee Development
Once hired into the organization, employees will require training in the organization’s policies and practices so that their contribution will be effective and further the organization’s goals. Regular evaluation will help employees to focus their long-term efforts on personal and organization goals and objectives.
Training To be effective, employees need to receive periodic training. This includes
• Skills training This covers the need to learn how to use tools and equipment properly. In some cases, employees are required to receive training and prove competency before they are permitted to use some tools and equipment. Sometimes this is required by law.
• Practices and techniques Employees need to understand how the organization uses its tools and equipment for its specific use.
• Policies Organizations often impart information about their policies in the context of training. This helps the organization make sure that employees comprehend the material.
Performance Evaluation Many organizations utilize a performance evaluation process that is used to examine each employee’s performance against a set of expectations and objectives. A performance evaluation program also helps to shape employees’ behavior over the long term and helps them to reflect on how their effort contributes toward the organization’s overall objectives. A performance evaluation is frequently used to determine whether (and by how much) an employee’s compensation should be increased.
Career Path In many cultures, employees feel that they can be successful if they understand how they can advance within the organization. A career path program can achieve this by helping employees understand what skills are required for other positions in the organization and how they can strive toward positions that they desire in the future.
Mandatory Vacations
Some organizations, particularly those that deal with high-risk or high-value activities, enact mandatory vacations of one week or longer for some or all employees. This practice can accomplish three objectives:
• Cross-training An absence of one week or longer will force management to cross-train other employees so that the organization is less reliant upon specific individuals.
• Audit A minimum absence gives the organization an opportunity to audit the absent employee’s work to make sure that the employee is not involved in any undesired behavior.
• Reduced risk Knowing that they will be away from their day-to-day activities for at least one or two contiguous weeks each year, employees are less apt to partake in prohibited activities that could be discovered by colleagues or auditors during their absence.
Termination
When an employee leaves an organization, several actions need to take place:
• Physical access to all work areas must be immediately revoked. Depending upon the sensitivity of work activities in the organization, the employee may also need to be escorted out of the work area and have his or her personal belongings gathered by others and delivered to the departed employee’s residence.
• Each of the employee’s computer and network access accounts needs to be locked. The purpose of this is to protect the integrity of business information by permitting only authorized employees to access it. Locking computer accounts also prevents other employees from accessing information using the former employee’s credentials.

CAUTION The issue of whether a former employee’s account should be removed or merely locked depends upon the nature of the application or system. In some cases, the record of actions taken by employees (such as an audit log) depends upon the existence of the employee’s ID on the system; if a former employee’s ID is removed, then those audit records may not properly reference who is associated with them.
If the organization chooses to lock rather than remove computer or network accounts for terminated employees, those accounts must be locked or restricted in a way that positively prohibits any further access. For instance, merely changing the passwords of terminated accounts to “locked” would be considered a highly unsafe practice in the event that anyone discovers the password. If changing the account’s password is the only way to lock it, then a long and highly random password must be used and then forgotten so that even the account administrator cannot use it.
NOTE In some jurisdictions, employers may be required to permit former employees to be able to access their compensation and tax records.
Transfers and Reassignments
In many organizations, employees will move from position to position over time. These position changes are not always upward through a career path, but are instead lateral moves from one type of work to another.
Unless an organization is very careful about its access management processes and procedures, employees who transfer and are promoted tend to accumulate access privileges. This happens because a transferring employee’s old privileges are not revoked even though those privileges are no longer needed. Over a period of years, an employee who is transferred or promoted can accumulate many excessive privileges that can indicate significant risk should the individual choose to perform functions in the applications that they are no longer officially authorized to use. This phenomenon is sometimes known as “accumulation of privileges” or “privilege creep.”
Privilege creep happens frequently in companies’ accounting departments. An individual, for example, can move from role to role in the accounting department, all the while accumulating privileges that eventually result in the ability for that employee to defraud his or her employer by requesting, approving, and disbursing payments to themselves or their accomplices. Similarly, this can occur in an IT department when an employee transfers from the operations department to the software development department (which is a common career path). Unless the IT department deliberately removes the transferring employee’s prior privileges, it will end up with an employee who is a developer with access to production systems—a red flag to auditors who examine roles and responsibilities.
Sourcing
The term sourcing refers to the choices that organizations make when selecting the personnel who will perform functions and where those functions will be performed.
The options include whose personnel will perform tasks:
• Insourced The organization hires employees to perform work. These workers can be full time, part time, or temporary.
• Outsourced The organization utilizes contractors or consultants to perform work.
• Hybrid The organization can utilize a combination of insourced and outsourced workers.
Next, the options include where personnel will perform tasks:
• On-site Personnel work in the organization’s work site(s).
• Off-site, local Personnel are not located on-site, but are near the organization’s premises, usually in or near the same community.
• Off-site, remote Personnel are in the same country, but not near the organization’s premises.
• Offshore Personnel are located in a different country.
NOTE Organizations are often able to work out different combinations of whether personnel are insourced or outsourced and where they perform their work. For instance, an organization can open its own office in a foreign country and hire employees to work there; this would be an example of offshore insourcing. Similarly, an organization can use contractors to perform work on-site; this is on-site outsourcing.
Insourcing
Insourcing, which is the practice of hiring employees for long-term work, is discussed earlier in this chapter in the “Personnel Management” section.
Outsourcing
Outsourcing is the practice of using contractors or consultants to perform work for the organization. An organization will make a decision to outsource a task, activity, or project for a wide variety of reasons:
• Project duration An organization may require personnel only for a specific project, such as the development of or migration to a new application. Often, an organization will opt to use contractors or consultants when it cannot justify hiring permanent workers.
• Skills An organization may require personnel with certain hard-to-find skills but not need them on a full-time basis. Persons with certain skills may command a higher salary than the organization is willing to pay, and the organization may not have sufficient work to keep such a worker interested in permanent employment with the organization.
• Variable demand Organizations may experience seasonal increases and decreases of demand for certain workers. Organizations often cannot justify hiring full-time employees for peak demand capacity, when at other times those workers will not have enough work to keep them busy and productive. Instead, organizations will usually staff for average demand and augment staff with contractors for peak demand.
• High turnover Some positions, such as IT helpdesk and call center, are inherently high-turnover positions that are costly to replace and train. Instead, an organization may opt to outsource some or all of the personnel in these positions.
• Focus on core activities An organization may wish to concentrate on hiring for positions related to its core purpose and to outsource functions that are considered “overhead.” For instance, an organization that produces computer hardware products may elect to outsource its IT computer support department so that it can focus on its product development and support.
• Financial A decision to outsource may be primarily financial. Usually an organization seeking to reduce costs of software development and other activities will outsource and off-shore these activities to service organizations located in other countries.
• Complete time coverage An organization that needs to have personnel available around the clock may choose to outsource part of that function to work centers in other time zones.
An organization that chooses to hire employees only in its core service areas can outsource many of its noncore functions, including these:
• IT helpdesk and support This is often a high-turnover function, as well as variable in demand, making this a good candidate for outsourcing.
• Software development An organization that lacks development and programming skills can elect to have contractors or consultants perform this work.
• Software maintenance An organization may wish to keep its developers and analysts focused on new software development projects and to leave maintenance of existing software to contractors.
• Customer support An organization may choose to outsource its telephone and online support to personnel or organizations in countries with lower labor costs.
TIP Although outsourcing decisions appear, on the surface, to be economically motivated, some of the other reasons stated earlier may be even more important in some organizations. For example, the flexibility afforded by outsourcing may help to make an organization more agile, which may improve quality or increase efficiency over longer periods.
Outsourcing Benefits Organizations that are considering outsourcing need to carefully weigh the benefits and the costs in order to determine whether the effort to outsource will result in measurable improvement in their processing, service delivery, or finances. In the 1990s, when many organizations rushed to outsource development and support functions to operations in other countries, they did so with unrealistic short-term gains in mind and without adequately considering all of the real costs of outsourcing. This is not to say that outsourcing is bad, but that many organizations made outsourcing decisions without fully understanding it.
Outsourcing can bring many benefits:
• Available skills and experience Organizations that may have trouble attracting persons with specialized skills often turn to outsourcing firms whose highly skilled personnel can ply their trade in a variety of client organizations.
• Economies of scale Often, specialized outsourcing firms can achieve better economies of scale through discipline and mature practices that organizations are unable to achieve.
• Objectivity Some functions are better done by outsiders. Personnel in an organization may have trouble being objective about some activities such as process improvement and requirements definition. Also, auditors frequently must be from an outside firm in order to achieve sufficient objectivity and independence.
• Reduced costs When outsourcing is done with offshore personnel, an organization may be able to lower its operating costs and improve its competitive market position, usually through currency exchange rates and differences in the standards of living in headquarters versus offshore countries.
When an organization is making an outsourcing decision, it needs to consider these advantages together with risks that are discussed in the next section.
Risks Associated with Outsourcing While outsourcing can bring many tangible and intangible benefits to an organization, it is not without certain risks and disadvantages. Naturally, when an organization employs outsiders to perform some of its functions, it relinquishes some control. The risks of outsourcing include these:
• Higher-than-expected costs Reduced costs were the main driver for offshore outsourcing in the 1990s. However, many organizations failed to fully anticipate the operational realities. For instance, when outsourcing to overseas operations, IT personnel back in U.S.-based organizations had to make many more expensive trips than expected. Also, changes in international currency exchange rates can transform this year’s bargain into next year’s high cost.
• Poor quality The outsourced work product may be lower than was produced when the function was performed in-house.
• Poor performance The outsourced service may not perform as expected. The capacity of networks or IT systems used by the outsourcing firm may cause processing delays or longer-than-acceptable response times.
• Loss of control An organization that is accustomed to being in control of its workers may feel loss of control. Making small adjustments to processes and procedures may be more time-consuming or increase costs.
• Employee integrity and background It may be decidedly more difficult to determine the integrity of employees in an outsourced situation, particularly when the outsourcing is taking place offshore. Some countries, even where outsourcing is popular, lack nationwide criminal background checks and other means for making a solid determination on an employee’s background.
• Loss of competitive advantage If the services performed by the outsourcing firm are not flexible enough to meet the organization’s needs, this can result in the organization losing some of its competitive advantage. For example, an organization outsources its corporate messaging (e-mail and other messaging) to a service provider. Later, the organization wishes to enhance its customer communication by integrating its service application with e-mail. The e-mail service provider may be unable or unwilling to provide the necessary integration, which will result in the organization losing a competitive advantage.
• Errors and omissions The organization performing outsourcing services may make serious errors or fail to perform essential tasks. For instance, an outsourcing service may suffer a data security breach that may result in the loss or disclosure of sensitive information. This can be a disastrous event when it occurs within an organization’s four walls, but when it happens in an outsourced part of the business, the organization may find that the lack of control will make it difficult to take the proper steps to contain and remedy the incident. If an outsourcing firm has a security breach or other similar incident, it may be putting itself first and only secondarily watching out for the interests of its customers.
• Vendor failure The failure of the organization to provide outsourcing services may result in increased costs and delays in service or product delivery.
• Differing mission and goals An organization’s employees are going to be loyal to its mission and objectives. However, the employees in an outsourced organization usually have little or no interest in the hiring organization’s interests; instead, they will be loyal to the outsourcing provider’s values, which may at times be in direct conflict. For example, an outsourcing organization may place emphasis on maximizing billable hours, while the hiring organization emphasizes efficiency. These two objectives conflict with each other.
• Difficult recourse If an organization is dissatisfied with the performance or quality of its outsourced operation, contract provisions may not sufficiently facilitate any remedy. If the outsourced operation is in a foreign country, applying remediation in the court system may also be futile.
• Lowered employee morale If part of an organization chooses to outsource, those employees who remain may be upset because some of their colleagues may have lost their jobs as a result of the outsourcing. Further, remaining employees may feel that their own jobs may soon be outsourced or eliminated. They may also feel that their organization is more interested in saving money than in taking care of its employees. Personnel who have lost their jobs may vent their anger at the organization through a variety of harmful actions that may threaten assets or other workers.
• Audit and compliance An organization that outsources a part of its operation that is in-scope for applicable laws and regulation may find it more challenging to perform audits and achieve compliance. Audit costs may rise, as auditors need to visit the outsourced work centers. Requiring the outsourced organization to make changes to achieve compliance may be difficult or expensive.
• Applicable laws Laws, regulations, and standards in headquarters and offshore countries may impose requirements on the protection of information that may complicate business operations or enterprise architecture.
• Cross-border data transfer Governments around the world are paying attention to the flow of data, particularly the sensitive data of its citizens. Many countries have passed laws that attempt to exert control over data about its citizens when it is transferred out of their jurisdiction.
• Time zone differences Communications will suffer when an organization outsources some of its operations to offshore organizations that are several time zones distant. It will be more difficult to schedule telephone conferences when there is very little overlap between workers in each time zone. It will take more time to communicate important issues and to make changes.
• Language and cultural differences When outsourcing crosses language and cultural barriers, it can result in less-than-optimal communication and results. The outsourcing customer will express its needs through its own language and culture, but the outsourcing provider will hear those needs through its own language and culture. Both sides may be thinking or saying, “They don’t understand what we want” and “We don’t understand what they want.” This can result in unexpected differences in work products produced by the outsourcing firm. Delays in project completion or delivery of goods and services can occur as a result.
CAUTION Some of the risks associated with outsourcing are intangible or may lie outside the bounds of legal remedies. For instance, language and time zone differences may introduce delays in communication, adding friction to the business relationship in a way that may not be easily measurable.
Mitigating Outsourcing Risk The only means of exchange between an outsourcing provider and its customer organization are money and reputation. In other words, the only leverage that an organization has against its outsourcing provider is the withholding of payment and communicating the quality (or lack therein) of the outsourcing provider to other organizations. This is especially true if the outsourcing crosses national boundaries. Therefore, an organization that is considering outsourcing must carefully consider how it will enforce contract terms so that it receives the goods and services that it is expecting.
Many of the risks of outsourcing can be remedied through contract provisions. Some of the remedies are
• Service level agreement (SLA) The contract should provide details on every avenue of work performance and communication, including escalations and problem management.
• Quality Depending upon the product or service, this may translate into an error or defect rate, a customer satisfaction rate, or system performance.
• Security policy and controls Whether the outsourcing firm is safeguarding the organization’s intellectual property, keeping business secrets, or protecting information about its employees or customers, the contract should spell out the details of the security controls that it expects the outsourcing firm to perform. The organization should also require periodic third-party audits and the results of those audits. The contract should contain a “right to audit” clause that allows the outsourcing organization to examine the work premises, records, and work papers on demand.
• Business continuity The contract should require the outsourcing firm to have reasonable measures and safeguards in place to ensure resilience of operations and the ability to continue operations with minimum disruption in the event of a disaster.
• Employee integrity The contract should define how the outsourcing firm will vet its employees’ backgrounds so that it is not inadvertently hiring individuals with a criminal history and so employees’ claimed education and work experience are genuine.
• Ownership of intellectual property If the outsourcing firm is producing software or other designs, the contract must define ownership of those work products and whether the outsourcing firm may reuse any of those work products for other engagements.
• Roles and responsibilities The contract should specify in detail the roles and responsibilities of each party so that each will know what is expected of them.
• Schedule The contract must specify when and how many items of work products should be produced.
• Regulation The contract should require both parties to conform to all applicable laws and regulations, including but not limited to intellectual property, data protection, and workplace safety.
• Warranty The contract should specify terms of warranty for the workmanship and quality of all work products so that there can be no ambiguity regarding the quality of goods or services performed.
• Dispute and resolution The contract should contain provisions that define the process for handling and resolving disputes.
• Payment The contract should specify how and when the outsourcing provider will be paid. Compensation should be tied not only to the quantity but also to the quality of work performed. The contract should include incentive provisions for additional payment when specific schedule, quantity, or quality targets are exceeded. The contract should also contain financial penalties that are enacted when SLA, quality, security, audit, or schedule targets are missed.
The terms of an outsourcing contract should adequately reward the outsourcing firm for a job well done, which should include the prospect of earning additional contracts as well as referrals that will help it to earn outsourcing contracts from other customers.
Outsourcing Governance You cannot outsource accountability. Outsourcing is a convenient way to transfer some operations to an external organization, thereby allowing the outsourcing organization to be more agile and to improve focus on core competencies. While senior managers can transfer these activities to external organizations and even specify rewards for good performance and penalties for substandard performance, those senior managers are still ultimately accountable for the delivery of these services, whether they are outsourced or performed by internal staff.
In the context of outsourcing, the role of governance must be expanded to include the aggregation of activities that control the work performed by external organizations. Governance activities may include
• Contracts The overall business relationship between the organization and its service providers should be defined in detailed legal agreements. The terms of legal agreements should define the work to be done (in general), the expectations of all parties, service levels, quality, the terms of compensation, and remedies in case expectations fail to be met. Appropriate levels of management must approve the content in contracts.
• Work orders Sometimes called statements of work (SOWs), work orders describe in greater detail the work that is to be performed. While contracts are expected to change seldom, work orders operate in short-term intervals and are specific to currently delivered goods or services. Like contracts themselves, work orders should include precise statements regarding work output, timeliness, quality, and remedies.
• Service level agreements These are documents that specify service levels in terms of the quantity of work, quality, timeliness, and remedies for shortfalls in quality or quantity.
• Change management A formal method is needed so that changes in delivery specifications can be formally controlled.
• Security If the service provider has access to the organization’s records or other intellectual property, the organization will require that specific security controls be in place. In higher risk situations, the organization will want to periodically validate that the service provider’s security controls are effective.
• Quality Minimum standards for quality should be expressed in detail so that both service provider and customer have a common understanding of the quality of work to be performed.
• Metrics Often, the outsourcing organization will want to actively measure various aspects of the outsourced activity in order to have short-term visibility into work output as well as the ability to understand long-term trends.
• Audits The outsourcing organization may require that audits of the outsourced work be performed. These audits may be performed by a competent third party (such as a public accounting firm performing an SSAE 16, ISAE 3402, SOC 1, or SOC 2 audit), an independent security consulting firm, or by the customer. Often, an outsourcing organization will negotiate a “right to audit” clause in the contract, but will only exercise this if they suspect irregularities or issues related to the work performed.
Depending on the nature of specific outsourcing arrangements, the activities just listed may be combined or performed separately.
Benchmarking Benchmarking measures a process in order to compare its performance and quality with the same process in other organizations. The purpose is to discover opportunities for improvement that may result in lower cost, fewer resources, and higher quality.
In the context of outsourcing, benchmarking can be used to measure the performance of an outsourced process with the same process as performed by other outsourcing firms, as well as to compare it with the same process as performed internally by other organizations. The objective is the same: to learn whether a particular outsourcing solution is performing effectively and efficiently. Benchmarking is discussed in further detail in Chapter 4.
Third-Party Service Delivery Management
Service delivery management is the institution of controls and metrics to ensure that services are performed properly and with a minimum of incidents and defects. When activities are transferred to a service provider, service delivery management has some added dimensions and considerations.
When service delivery management is used to manage an external service provider, the service provider must be required to maintain detailed measurements of its work output. The organization utilizing an external service provider needs to also maintain detailed records of work received, as well as to perform its own defect management controls in order to ensure that the work performed by the service provider meets quality standards. Problems and incidents encountered by the organization should be documented and transmitted to the service provider in order to improve quality.
These activities should be included in the SLA or in the contract in order to ensure that the customer will be able to impose financial penalties or other leverage onto the service provider in order to improve quality while maintaining minimum work output.
Service delivery standards related to IT service management are defined in the international standard ISO/IEC 20000:2011. Relevant controls from this standard can be used to impose a standard method for managing service delivery by the service provider.
SaaS, IaaS, and PaaS Considerations
Organizations such as SaaS (Software as a Service), IaaS (Infrastructure as a Service), and PaaS (Platform as a Service) provide cloud-based application or computing resources to clients that cannot justify building their own.
SaaS is an arrangement where an organization obtains a software application for use by its employees, where the software application is hosted by the software provider, as opposed to the customer organization.
IaaS is an arrangement where an organization rents IT infrastructure from a service provider.
PaaS is a service that allows organizations to deploy applications without having to deal with underlying infrastructure such as servers and database management systems.
The primary advantages of using SaaS, IaaS, and PaaS as opposed to self-hosting are
• Capital savings The SaaS/IaaS/PaaS provider makes its software, infrastructure, or platform resources available to its customers on its own servers, thereby eliminating the need to purchase dedicated hardware and software.
• Labor savings The SaaS/IaaS/PaaS provider performs many administration functions, including typical administrative tasks such as applying software or operating system patches, performance and capacity management, software upgrades, and troubleshooting.
CAUTION An organization that is considering a SaaS, IaaS, or PaaS provider for one of its environments will need to ensure that the provider has adequate controls in place to protect the organization’s data. In particular, the provider should have controls in place that will prevent one customer from being able to view the data associated with a different customer.
An organization can consider a SaaS/IaaS/PaaS provider to be similar to other service providers. Generally, methods used to determine the integrity and quality of a service provider would be the same as used with other service providers.
Change Management
Change management is a business process that is used to control changes made to an IT environment. A formal change management process consists of several steps that are carried out for each change:
• Request
• Review
• Approve
• Perform
• Verify
• Back out (when verification of a successful change fails)
Each step in change management includes recordkeeping. Change management is covered in detail in Chapter 4.
Financial Management
Sound financial management is critical in any organization. Because IT is a cost-intensive activity, it is imperative that the organization be well managed, with short-term and long-term budget planning, and that it track actual spending.
One area where senior management needs to make strategic financial decisions in IT is the manner in which it acquires software applications. At the steering committee level, IT organizations need to carefully weigh “make versus buy” with its primary applications. This typically falls into three alternatives:
• Develop the application The organization develops the application using in-house or contracted software developers, designers, and analysts.
• Purchase the application The organization licenses the application from a software vendor and installs it on servers that it leases or purchases.
• Rent the application This generally refers to the cloud computing or SaaS model, where the cloud/application service provider hosts the application on its own premises (or on an Internet data center) and the organization using the software pays either a fixed fee or an on-demand fee. The organization will have no capital cost for servers and little or no development cost (except, possibly, for interfaces to other applications).
The choice that an organization makes is not just about the finances, but is also concerned with the degree of control that the organization requires.
IT financial management is about not only applications, but also the other services that an IT organization provides. Other functions such as service desk, PC build and support, e-mail, and network services can likewise be insourced or outsourced, each with financial and other implications.
NOTE Many larger organizations employ a “chargeback” feature for the delivery of IT services. This is a method where an IT organization charges (usually through budget transfers but occasionally through real funds) for the services that it provides. The advantage to chargeback is that the customers of the IT organization are required to budget for IT services and are less likely to make frivolous requests of IT, since every activity has a cost associated with it. Chargeback may also force an IT organization to be more competitive, as chargeback may invite IT’s customers to acquire services from outside organizations and not from the internal IT organization. Chargeback can thus be viewed as outsourcing to the internal IT organization.
Quality Management
Quality management refers to the methods by which business processes are controlled, monitored, and managed to bring about continuous improvement. The scope of a quality management system in an IT organization may cover any or all of the following activities:
• Software development
• Software acquisition
• Service desk
• IT operations
• Security
The components that are required to build and operate a quality management system are
• Documented processes Each process that is part of a quality management system must be fully documented. This means that all of the tasks, notifications, records, and data flows must be fully described in formal process documents that are themselves controlled.
• Key measurements Each process under quality management must have some key measurement points so that management will be able to understand the frequency and effort expended for the process. Measurement goes beyond simply tallying and must include methods for recognizing, classifying, and measuring incidents, events, problems, and defects.
• Management review of key measurements Key measurements need to be regularly analyzed and included in status reports that provide meaningful information to various levels of management. This enables management to understand how key processes are performing and whether they are meeting management’s expectations.
• Audits Processes in a quality management system should be periodically measured by internal or external auditors to ensure that they are being operated properly. These auditors need to be sufficiently independent of the processes and of management itself so that they can objectively evaluate processes.
• Process changes When key measurements suggest that changes to a process are needed, a business or process analyst will make changes to the design of a process. Examples of process changes include the addition of data fields in a change request process, the addition of security requirements to the software development process, or a new method for communicating passwords to the users of newly created user accounts.
TIP An organization should document and measure its quality management processes, just as it does with all of the processes under its observation and control. This will help to confirm whether the quality management system itself is effective.
ISO/IEC 9000
Established in the 1980s, ISO/IEC 9000 remains the world’s standard for quality management systems. The ISO/IEC 9001, 9002, 9003, and 9004 standards have been superseded by the single ISO/IEC 9001:2015 Quality Management System standard.
Organizations that implement the ISO/IEC 9001:2015 standard can voluntarily undergo regular external audits by an accredited firm to earn an ISO/IEC 9001:2015 certification. Over one million ISO/IEC 9001 certificates have been issued to organizations around the world since 1978.
ISO/IEC 9000 began as a manufacturing product quality standard. While many manufacturing firms are certified to ISO/IEC 9000, the standard is growing in popularity among service providers and software development organizations.
ISO/IEC 20000
Many IT organizations have adopted the IT Infrastructure Library (ITIL) of IT service management processes as a standard framework for IT processes. Organizations that desire a certification can be evaluated by an accredited external audit firm to the ISO/IEC 20000 IT Service Management standard. ISO/IEC 20000 supersedes the earlier BS 15000 standard.
The ITIL framework consists of 26 processes in five volumes:
• Service Strategy
• Service Design
• Service Transition
• Service Operation
• Continual Service Improvement
ITIL’s processes are interrelated and together constitute an effective framework for IT’s primary function: delivering valuable services to enable key organization processes.
Portfolio Management
Portfolio management refers to the systematic management of IT projects, investments, and activities. The purpose of portfolio management is to measure the value derived from IT projects, investments, and activities and to periodically make adjustments to maximize that value for the organization.
The principles of IT portfolio management are similar to those of financial investment portfolio management. All of the activities in IT are treated like investments, with a careful look at the value they bring to the organization.
Mature organizations that practice IT portfolio management typically develop three portfolios:
• Project Portfolio
• Infrastructure Portfolio
• Application Portfolio
The items in these portfolios are measured, examined, and scrutinized for their continuing contribution to, and alignment with, the organization’s mission and main objectives. Management can make periodic adjustments to the level of resources associated with IT projects and activities in order to maximize value to the organization.
ISACA’s Val IT (IT Value Delivery) framework is one such IT portfolio management framework, and is now a part of COBIT 5. More information can be found at www.isaca.org/valit.
Controls Management
IT organizations employ controls to assure specific outcomes within business processes, IT systems, and personnel. Better organizations adopt one of several standard frameworks of controls, and then periodically assess risk and control performance, resulting in changes to controls, as well as the addition or removal of controls.
Controls are generally enacted as a result of one or more of the following:
• Policies Controls can be established to assure compliance to policy and to measure its effectiveness.
• Regulations Organizations often establish controls in order to ensure compliance to regulations.
• Requirements Legal or operational requirements, such as terms and conditions in contracts with customers or suppliers, compel an organization to enact controls in order to assure compliance.
• Risks An internal or external risk assessment may compel an organization to enact controls in order to reduce risks to acceptable levels.
It is not enough for organizations to develop and implement controls. To measure their effectiveness, organizations need to periodically examine controls to see if they are operating properly and ensuring their intended outcomes. The entire discipline of internal and external audit is brought to bear on the subject of control examination and effectiveness. The process and practice of audits is explored in detail in Chapter 3 and Appendix A.
Well-known control frameworks include
• COBIT 5 Developed by ISACA, COBIT 5 is a general-purpose IT controls framework.
• NIST 800-53 Developed by the U.S. Department of Commerce, NIST 800-53 is a comprehensive set of security controls that are required for U.S. government information systems. This framework has been adopted by many nongovernment organizations as well.
• ISO/IEC 20000 This is the international standard with its roots in the IT Infrastructure Library (ITIL), the framework of IT service management.
• ISO/IEC 27002 This is the international standard framework of IT security controls, and widely adopted worldwide.
• PCI-DSS (Payment Card Industry Data Security Standard) This is the IT security controls framework required for systems and networks that store, process, or transmit credit card data.
• HIPAA (Health Insurance Portability and Accountability Act) Security Rule This is the framework of controls required for organizations that store, process, or transmit electronic patient health information (ePHI).
As an integral part of information security and IT audit, controls are also discussed in Chapters 3, 4, 5, and 6.
Security Management
Security management refers to several key activities that work together to identify risks and risk treatment for the organization’s assets. In most organizations these activities include
• Security governance Security governance is the practice of setting organization security policy and then taking steps to ensure that policy is followed. Security governance also is involved with the management and continuous improvement of other key security activities discussed in this section.
• Risk assessment This is the practice of identifying key assets in use by the organization and identifying vulnerabilities in, and threats against, each asset. This is followed by the development of risk treatment strategies that attempt to mitigate, transfer, avoid, or accept identified risks.
• Incident management This practice is concerned with the planned response to security incidents when they occur in the organization. An incident is defined as a violation of security policy; such an incident may be minor (such as a user choosing an easily guessed password) or major (such as a hacking attack and theft of sensitive information). Some of the aspects of incident management include computer forensics (the preservation of evidence that could be used in later legal action) and the involvement of regulatory authorities and law enforcement.
• Vulnerability management This is the practice of proactively identifying vulnerabilities in IT systems, as well as in business processes, that could be exploited to the detriment of the organization. Activities that take place in vulnerability management include security scanning, vulnerability assessment, code review, patch management, and reviewing threat intelligence and risk advisories issued by software vendors and security organizations.
• Identity and access management These practices are used to control which persons and groups may have access to which organization applications, assets, systems, workplaces, and functions. Identity management is the activity of managing the identity and access history of each employee, contractor, temporary worker, supplier worker, and, optionally, customer. These records are then used as the basis for controlling which workplaces, applications, IT systems, and business functions each person is permitted to use.
• Compliance management Security management should be responsible for knowing which laws, regulations, standards, requirements, and legal contracts the organization is required to comply with. Verification of compliance may involve internal or external audits and other activities to confirm that the organization is in compliance with all of these legal and other requirements.
• Third-party risk This is the practice of identifying and managing risks associated with third-party organizations that store, process, or transmit sensitive information. Activities include up-front due diligence and periodic assessment of critical control effectiveness.
• Business continuity and disaster recovery planning These practices allow the organization to develop response plans in the event that a disaster should occur that would otherwise threaten the ongoing viability of the organization. Business continuity and disaster recovery planning is covered in detail later in this chapter.
Control frameworks for security management include
• ISO/IEC 27001 requirements The first half of the ISO/IEC 27001 standard contains a set of requirements that describe a scalable and flexible Information Security Management System (ISMS) that is based on a life cycle of risk assessment, controls examination, and controls development, with an overarching theme of executive oversight and control.
• U.S. Cybersecurity Framework Developed as a result of the Presidential Executive Order 13636, the U.S. National Institute for Standards and Technology (NIST) developed the Framework for Improving Critical Infrastructure Cybersecurity, which is a life cycle methodology of risk assessment and mitigation.
Performance and Capacity Management
Performance optimization is concerned with the continual improvement of IT processes and systems. This set of activities is concerned not only with financial efficiency, but also with the time and resources required to perform common IT functions. The primary objective of IT performance optimization is to ensure that the organization is getting the maximum benefit from IT services for the lowest possible expenditure of resources.
An organization that measures process performance is more apt to recognize opportunities for making improvements to business processes. Organizations that reach a level of process maturity that includes measurement and feedback will be able to adopt a culture of continuous improvement. Then, management can track improvement opportunities and assign resources accordingly.
Performance optimization is considered a rather mature approach to the management of IT processes and systems. It requires mature processes with key controls and measurement points, and is one of the natural results of effective quality management. An organization that is not already monitoring and managing its processes is probably not ready to undertake performance optimization. See the earlier section “Quality Management” for more information on this perspective.
Performance optimization is a complicated undertaking because IT systems and processes usually change frequently over time; it can be difficult to attribute specific changes in systems or processes to changes in performance metrics.
Maturity models such as Capability Maturity Model Integration (CMMI) can be used to determine the level of an organization’s processes. CMMI focuses on whether an organization’s processes have a level of maturity associated with measurement and continuous improvement.
The COBIT framework also contains facilities to identify and measure key performance indicators (KPIs), with the aim of enabling continuous improvement to processes and technology. The COBIT framework contains 37 key IT processes, along with the means for any individual organization to determine how much (and what kind of) control is appropriate for each organization, based upon its business objectives and how IT supports them.
A typical organization will not have the same level of maturity across all of its departments and processes. Instead, some processes and departments will be more mature than others, often by a wide variance.
Benchmarking
An organization may wish to benchmark its key processes. Benchmarking is a process of performing a detailed comparison of a business process (or system, or almost any other aspect of an organization) with that in other organizations. This will help an organization better understand how similar organizations are solving similar business problems, which could lead the organization to enact process improvements on its own.
Organization Structure and Responsibilities
Organizations require structure to distribute responsibility to groups of people with specific skills and knowledge. The structure of an organization is called an organization chart (org chart). Figure 2-4 shows a typical IT organization chart.
Figure 2-4 Typical IT organization chart
Organizing and maintaining an organization structure requires that many factors be taken into account. In most organizations, the org chart is a living structure that changes from time to time, based upon several conditions, including:
• Short- and long-term objectives Organizations sometimes move departments from one executive to another so that departments that were once far from each other (in terms of the org chart structure) will be near each other. This provides new opportunities for developing synergies and partnerships that did not exist before the reorganization. These organizational changes are usually performed to help an organization meet new objectives that were less important before and that require new partnerships and teamwork.
• Market conditions Changes in market positions can cause an organization to realign its internal structure in order to strengthen itself. For example, if a competitor lowers its prices based on a new sourcing strategy, an organization may need to respond by changing its organizational structure in order to put experienced executives in charge of specific activities.
• Regulations New laws, regulations, or standards may induce an organization to change its organizational structure. For instance, an organization that becomes highly regulated may elect to move its security and compliance group away from IT and place it under the legal department, since compliance has much more to do with legal compliance than industry standards.
• Attrition and available talent When someone leaves the organization or moves to another position within the organization, particularly in positions of leadership, a space opens in the org chart that often cannot be filled right away. Instead, senior management will temporarily change the structure of the organization by moving the leaderless department under the control of someone else. Often, the decisions of how to change the organization will depend upon the talent and experience of existing leaders, in addition to each leader’s workload and other factors. For example, if the director of IT program management leaves the organization, the existing department could temporarily be placed under the IT operations department, in this case, because the director of IT operations used to run IT program management. Senior management can see how that arrangement works out and later decide whether to replace the director of IT program management position or do something else.
TIP Many organizations use formal succession planning as a way of preparing for unexpected changes in the organization, especially terminations and resignations. A succession plan helps the organization to temporarily fill an absent position until a long-term replacement can be found.
This structure serves as a top-down and bottom-up conduit of communication. Figure 2-5 depicts the communication and control that an organization provides.
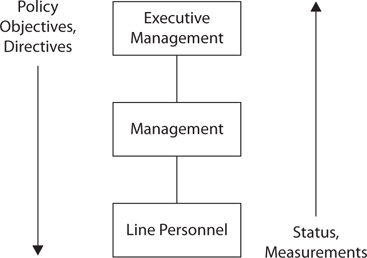
Figure 2-5 Communication and control flow upward and downward in an organization.
Roles and Responsibilities
The topic of roles and responsibilities is multidimensional: it encompasses positions and relationships on the organization chart, it defines specific job titles and duties, and it denotes generic expectations and responsibilities regarding the use and protection of assets.
Individual Roles and Responsibilities
Several roles and responsibilities fall upon all individuals throughout the organization:
• Board of directors The organization’s governing body is legally responsible for overseeing the organization’s activities, as well as the selection, support, and review of the chief executive. In private industry, directors are composed of the organization’s senior executives as well as executives from other firms, including firms with a significant investment in the organization. In government, directors are often elected.
• Executive management The most senior managers and executives in an organization are responsible for developing the organization’s mission, objectives, and goals, as well as policy. Executives are responsible for enacting security policy, which defines (among other things) the protection of assets.
• Owner An owner is an individual (usually but not necessarily a manager) who is the designated owner-steward of an asset. Depending upon the organization’s security policy, an owner may be responsible for the maintenance and integrity of the asset, as well as for deciding who is permitted to access the asset. If the asset is information, the owner may be responsible for determining who can access and make changes to the information.
• Manager A manager is, in the general sense, responsible for obtaining policies and procedures and making them available to their staff members. They should also, to some extent, be responsible for their staff members’ behavior.
• User Users are individuals (at any level of the organization) who use assets in the performance of their job duties. Each user is responsible for how he or she uses the asset, and does not permit others to access the asset in his or her name. Users are responsible for performing their duties lawfully and for conforming to organization policies.
These generic roles and responsibilities should apply all across the org chart to include every person in the organization. Persons in these roles may be full-time or part-time employees, or they may be temporary workers such as contractors and consultants.
TIP The roles and responsibilities of executives, owners, managers, and users should be formally defined in an organization’s security policy.
Job Titles and Job Descriptions
A job title is a label that is assigned to a job description. A job title denotes a position in the organization that has a given set of responsibilities and that requires a certain level and focus of education and prior experience. A job description is a list of those responsibilities and required education and experience.
EXAM TIP The CISA exam may present questions that address proper procedures for the audit of a specified job title. When considering your response, you should consider the job role assigned with the specific title rather than focusing on the title itself. Questions that address job titles are intended to examine understanding of their related roles—an example being the Network Management role associated with the Network Engineer title.
An organization that has a program of career advancement may have a set of career paths or career ladders that are models showing how employees may advance. For each job title, a career path will show the possible avenues of advancement to other job titles and the experience required to reach those other job titles.
Job titles in IT have matured and are quite consistent across organizations. This consistency helps organizations in several ways:
• Recruiting When the organization needs to find someone to fill an open position, the use of standard job titles will help prospective candidates more easily find positions that match their criteria.
• Compensation baselining Because of the chronic shortage of talented IT workers, organizations are forced to be more competitive when trying to attract new workers. To remain competitive, many organizations periodically undertake a regional compensation analysis to better understand the levels of compensation paid to IT workers in other organizations. The use of standard job titles makes the task of comparing compensation far easier.
• Career advancement When an organization uses job titles that are consistent in the industry, IT workers have a better understanding of the functions of positions within their own organizations and can more easily plan how they can advance.
The remainder of this section includes many IT job titles with a short description (not a full job description by any measure) of the function of that position.
Virtually all organizations also include titles that denote the level of experience, leadership, or span of control in an organization. These titles may include executive vice president, senior vice president, vice president, executive director, senior director, director, general manager, senior manager, manager, and supervisor. Larger organizations will use more of these, and possibly additional titles such as district manager, group manager, or area manager.
Executive Management Executive managers are the chief leaders and policymakers in an organization. They set objectives and work directly with the organization’s most senior management to help make decisions affecting the future strategy of the organization:
• CIO (chief information officer) This is the title of the topmost leader in a larger IT organization.
• CTO (chief technical officer) This position is usually responsible for an organization’s overall technology strategy. Depending upon the purpose of the organization, this position may be separate from IT.
• CRO (chief risk officer) This position is responsible for all aspects of risk, including information risk, business risk, compliance risk, and market risk. This role is separate from IT.
• CSO (chief security officer) This position is responsible for all aspects of security, including information security, physical security, and possibly executive protection (protecting the safety of senior executives). This role is separate from IT.
• CISO (chief information security officer) This position is responsible for all aspects of data-related security. This usually includes incident management, disaster recovery, vulnerability management, and compliance. This role is usually separate from IT.
• CPO (chief privacy officer) This position is responsible for the protection and use of personal information. This position is found in organizations that collect and store sensitive information for large numbers of persons.
Software Development Positions in software development are involved in the design, development, and testing of software applications:
• Systems architect This position is usually responsible for the overall information systems architecture in the organization. This may or may not include overall data architecture as well as interfaces to external organizations.
• Systems analyst A systems analyst is involved with the design of applications, including changes in an application’s original design. This position may develop technical requirements, program design, and software test plans. In cases where organizations license applications developed by other companies, systems analysts design interfaces to other applications.
• Software engineer/developer This position develops application software. Depending upon the level of experience, persons in this position may also design programs or applications. In organizations that utilize purchased application software, developers often create custom interfaces, application customizations, and custom reports.
• Software tester This position tests changes in programs made by software engineers/developers.
Data Management Positions in data management are responsible for developing and implementing database designs and for maintaining databases:
• Data manager This position is responsible for data architecture and data management in larger organizations.
• Big data architect This position develops data models and data analytics for large, complex data sets.
• Database architect This position develops logical and physical designs of data models for applications. With sufficient experience, this person may also design an organization’s overall data architecture.
• Database administrator (DBA) This position builds and maintains databases designed by the database architect and those databases that are included as a part of purchased applications. The DBA monitors databases, tunes them for performance and efficiency, and troubleshoots problems.
• Database analyst This position performs tasks that are junior to the database administrator, carrying out routine data maintenance and monitoring tasks.
EXAM TIP The roles of data manager, big data architect, database architect, database administrator, and database analyst are distinct from the data owner. The former are IT department roles for managing data technology, whereas the latter role governs the business use of data in information systems.
Network Management Positions in network management are responsible for designing, building, monitoring, and maintaining voice and data communications networks, including connections to outside business partners and the Internet:
• Network architect This position designs data and voice networks, and designs changes and upgrades to networks as needed to meet new organization objectives.
• Network engineer This position implements, configures, and maintains network devices such as routers, switches, firewalls, and gateways.
• Network administrator This position performs routine tasks in the network such as making configuration changes and monitoring event logs.
• Telecom engineer This position works with telecommunications technologies such as telecomm services, data circuits, phone systems, conferencing systems, and voicemail systems.
Systems Management Positions in systems management are responsible for architecture, design, building, and maintenance of servers and operating systems. This may include desktop operating systems as well.
• Systems architect This position is responsible for the overall architecture of systems (usually servers), which includes both the internal architecture of a system and the relationship between systems. This position is usually also responsible for the design of services such as authentication, e-mail, and time synchronization.
• Systems engineer This position is responsible for designing, building, and maintaining servers and server operating systems.
• Storage engineer This position is responsible for designing, building, and maintaining storage subsystems.
• Systems administrator This position is responsible for performing maintenance and configuration operations on systems.
Operations Positions in operations are responsible for day-to-day operational tasks that may include networks, servers, databases, and applications:
• Operations manager This position is responsible for overall operations that are carried out by others. Responsibilities will include establishing operations shift schedules.
• Operations analyst This position may be responsible for the development of operational procedures; examining the health of networks, systems, and databases; setting and monitoring the operations schedule; and maintaining operations records.
• Controls analyst This position is responsible for monitoring batch jobs, data entry work, and other tasks to make sure that they are operating correctly.
• Systems operator This position is responsible for monitoring systems and networks, performing backup tasks, running batch jobs, printing reports, and other operational tasks.
• Data entry This position is responsible for keying batches of data from hardcopy or other sources.
• Media manager This position is responsible for maintaining and tracking the use and whereabouts of backup tapes and other media.
Security Operations Positions in security operations are responsible for designing, building, and monitoring security systems and security controls to ensure the confidentiality, integrity, and availability of information systems:
• Security architect This position is responsible for the design of security controls and systems such as authentication, audit logging, intrusion detection systems, intrusion prevention systems, and firewalls.
• Security engineer This position is responsible for designing, building, and maintaining security services and systems that are designed by the security architect.
• Security analyst This position is responsible for examining logs from firewalls, intrusion detection systems, and audit logs from systems and applications. This position may also be responsible for issuing security advisories to others in IT.
• Access administrator This position is responsible for accepting approved requests for user access management changes and performing the necessary changes at the network, system, database, or application level. Often, this position is carried out by personnel in network and systems management functions; only in larger organizations is user account management performed in security or even in a separate user access department.
• Security auditor This position is responsible for performing internal audits of IT controls to ensure that they are being operated properly.
CAUTION The security auditor position needs to be carefully placed in the organization so that persons in this role can be objective and independent from the departments they audit.
Service Desk Positions at the service desk are responsible for providing frontline support services to IT and IT’s customers:
• Service desk manager This position serves as a liaison between end users and the IT service desk department.
• Helpdesk analyst This position is responsible for providing frontline user support services to personnel in the organization.
• Technical support analyst This position is responsible for providing technical support services to other IT personnel, and perhaps also to IT customers.
Quality Assurance Positions in quality assurance are responsible for developing IT processes and standards and for measuring IT systems and processes to confirm their accuracy:
• QA manager This position is responsible for facilitating quality improvement activities throughout the IT organization.
• QC manager This position is responsible for quality control through the testing of IT systems and applications to confirm whether they are free of defects.
Other Roles Other roles in IT organizations include
• Vendor manager This position is responsible for maintaining business relationships with external vendors, measuring their performance, and handling business issues.
• Project manager This position is responsible for creating project plans and managing IT projects.
Segregation of Duties
Information systems often process large volumes of information that is often highly valuable or sensitive. Measures need to be taken in IT organizations to ensure that individuals do not possess sufficient privileges to carry out potentially harmful actions on their own. Checks and balances are needed so that high-value and high-sensitivity activities involve the coordination of two or more authorized individuals. The concept of segregation of duties (SOD), sometimes known as separation of duties, ensures that single individuals do not possess excess privileges that could result in unauthorized activities such as fraud or the manipulation, exposure, or compromise of sensitive data.
The concept of segregation of duties has been long established in organization accounting departments where, for instance, separate individuals or groups are responsible for the creation of vendors, the request for payments, and the remittance of payments. Since accounting personnel frequently handle checks, currency, and other payment instruments, the principles and practices of segregation of duties controls in accounting departments are the norm.
IT departments are lagging behind somewhat, since the functions in IT are less often involved in direct monetary activities, except in certain industries, such as banking. But thanks to financial scandals in the 1980s and 1990s that involved the illicit manipulation of financial records and the emergence of new laws such as Sarbanes-Oxley, the need for full and formal IT-level segregation of duties is now well recognized.
CAUTION At its most basic form, the rule of segregation of duties specifies that no single individual should be permitted or be able to perform high-value, high-sensitivity, or high-risk actions. Instead, two or more parties must be required to perform these functions.
Segregation of Duties Controls
Preventive and detective controls should be put into place to manage segregation of duties matters. In many organizations, both the preventive and detective controls will be manual, particularly when it comes to unwanted combinations of access between different applications. However, in some transaction-related situations, controls can be automated, although they may still require intervention by others.
Some examples of segregation of duties controls include
• Transaction authorization Information systems can be programmed or configured to require two (or more) persons to approve certain transactions. Many of us see this in retail establishments where a manager is required to approve a large transaction or a refund. In IT applications, transactions meeting certain criteria (for example, exceeding normally accepted limits or conditions) may require a manager’s approval to be able to proceed.
• Split custody of high-value assets Assets of high importance or value can be protected using various means of split custody. For example, a password to an encryption key that protects a highly valued asset can be split in two halves—one half assigned to two persons, and the other half assigned to two persons—so that no single individual knows the entire password. Banks do this for central vaults, where a vault combination is split into two or more pieces so that two or more are required to open it.
• Workflow Applications that are workflow-enabled can use a second (or third) level of approval before certain high-value or high-sensitivity activities can take place. For example, a workflow application that is used to provision user accounts can include extra management approval steps in requests for administrative privileges.
• Periodic reviews IT or internal audit personnel can periodically review user access rights to identify whether any segregation of duties issues exist. The access privileges for each worker can be compared against a segregation of duties control matrix. Table 2-1 shows an example matrix.
Table 2-1 Example Segregation of Duties Matrix Identifies Forbidden Combinations of Privileges
When SOD issues are encountered during a segregation of duties review, management will need to decide how to mitigate the matter. The choices for mitigating an SOD issue include
• Reduce access privileges Management can reduce individual user privileges so that the conflict no longer exists.
• Introduce a new control If management has determined that the person needs to retain privileges that are viewed as a conflict, then new preventive or detective controls need to be introduced that will prevent or detect unwanted activities. Examples of mitigating controls include increased logging to record the actions of personnel, improved exception reporting to identify possible issues, reconciliations of data sets, and external reviews of high-risk controls.
TIP An organization should periodically review its SOD matrix, particularly if new roles or high-value applications are added or changed.
Business Continuity Planning
Business continuity planning (BCP) is undertaken to reduce risks related to the onset of disasters and other disruptive events. BCP activities identify risks and mitigate those risks through changes or enhancements in technology or business processes so that the impact of disasters is reduced and the time to recovery is lessened. The primary objective of BCP is to improve the chances that the organization will survive a disaster without incurring costly or even fatal damage to its most critical activities.
The activities of BCP development scale for any size organization. BCP has the unfortunate reputation of existing only in the stratospheric, thin air of the largest and wealthiest organizations. This misunderstanding hurts the majority of organizations that are too timid to begin any kind of BCP efforts at all because they believe that these activities are too costly and disruptive. The fact is that any size organization, from a one-person home office to a multinational conglomerate, can successfully undertake BCP projects that will bring about immediate benefits as well as take some of the sting out of disruptive events that do occur.
Organizations can benefit from BCP projects, even if a disaster never occurs. The steps in the BCP development process usually bring immediate benefit in the form of process and technology improvements that increase the resilience, integrity, and efficiency of those processes and systems.
EXAM TIP Business continuity planning is closely related to disaster recovery planning—both are concerned with the recovery of business operations after a disaster. Business continuity planning is discussed in this chapter, while disaster recovery planning is discussed in Chapter 5.
Disasters
I always tried to turn every disaster into an opportunity –John D. Rockefeller
In a business context, disasters are unexpected and unplanned events that result in the disruption of business operations. A disaster could be a regional event spread over a wide geographic area, or it could occur within the confines of a single room. The impact of a disaster will also vary, from a complete interruption of all company operations to merely a slowdown. (The question invariably comes up: when is a disaster a disaster? This is somewhat subjective, like asking, “When is a person sick?” Is it when he or she is too ill to report to work, or if he or she just has a sniffle and a scratchy throat? I’ll discuss disaster declaration later in this chapter.)
Types of Disasters
BCP professionals broadly classify disasters as natural or human-made, although the origin of a disaster does not figure very much into how we respond to it. Let’s examine the types of disasters.
Natural Disasters Natural disasters are those phenomena that occur in the natural world with little or no assistance from mankind. They are a result of the natural processes that occur in, on, and above the earth.
Examples of natural disasters include
• Earthquakes Sudden movements of the earth with the capacity to damage buildings, houses, roads, bridges, and dams; to precipitate landslides and avalanches; and to induce flooding and other secondary events.
• Volcanoes Eruptions of magma, pyroclastic flows, steam, ash, and flying rocks that can cause significant damage over wide geographic regions. Some volcanoes, such as Kilauea in Hawaii, produce a nearly continuous and predictable outpouring of lava in a limited area, whereas the Mount St. Helens eruption in 1980 caused an ash fall over thousands of square miles that brought many metropolitan areas to a standstill for days and also blocked rivers and damaged roads. Figure 2-6 shows a volcanic eruption as seen from space.

Figure 2-6 Mount Etna volcano in Sicily
• Landslides Sudden downhill movements of earth, usually down steep slopes, can bury buildings, houses, roads, and public utilities and cause secondary (although still disastrous) effects such as the rerouting of rivers.
• Avalanches Sudden downward flows of snow, rocks, and debris on a mountainside. A slab avalanche consists of the movement of a large, stiff layer of compacted snow. A loose snow avalanche occurs when the accumulated snowpack exceeds its shear strength. A power snow avalanche is the largest type and can travel in excess of 200 mph and exceed 10 million tons of material. All types can damage buildings, houses, roads, and utilities, resulting in direct or indirect damage affecting businesses.
• Wildfires Fires in forests, chaparral, and grasslands are part of the natural order. However, fires can also damage buildings and equipment and cause injury and death.
• Tropical cyclones The largest and most violent storms are known in various parts of the world as hurricanes, typhoons, tropical cyclones, tropical storms, and cyclones. Tropical cyclones consist of strong winds that can reach 190 mph, heavy rains, and storm surge that can raise the level of the ocean by as much as 20 feet, all of which can result in widespread coastal flooding and damage to buildings, houses, roads, and utilities and significant loss of life.
• Tornadoes These violent rotating columns of air can cause catastrophic damage to buildings, houses, roads, and utilities when they reach the ground. Most tornadoes can have wind speeds from 40 to 110 mph and travel along the ground for a few miles. Some tornadoes can exceed 300 mph and travel for dozens of miles.
• Windstorms While generally less intense than hurricanes and tornadoes, windstorms can nonetheless cause widespread damage, including damage to buildings, roads, and utilities. Widespread electric power outages are common, as windstorms can uproot trees that can fall into overhead power lines.
• Lightning Atmospheric discharges of electricity that occur during thunderstorms, but also during dust storms and volcanic eruptions. Lightning can start fires and also damage buildings and power transmission systems, causing power outages.
• Ice storms Ice storms occur when rain falls through a layer of colder air, causing raindrops to freeze onto whatever surface they strike. They can cause widespread power outages when ice forms on power lines and the resulting weight causes those power lines to collapse. A notable example is the Great Ice Storm of 1998 in eastern Canada, which resulted in millions being without power for as long as two weeks and in the virtual immobilization of the cities of Montreal and Ottawa.
• Hail This form of precipitation consists of ice chunks ranging from 5mm to 150mm in diameter. An example of a damaging hailstorm is the April 1999 storm in Sydney, Australia, where hailstones up to 9.5cm in diameter damaged 40,000 vehicles, 20,000 properties, 25 airplanes, and caused one direct fatality. The storm caused $1.5 billion in damage.
• Flooding Standing or moving water spills out of its banks and flows into and through buildings and causes significant damage to roads, buildings, and utilities. Flooding can be a result of locally heavy rains, heavy snow melt, a dam or levee break, tropical cyclone storm surge, or an avalanche or landslide that displaces lake or river water.
• Tsunamis A series of waves that usually result from the sudden vertical displacement of a lake bed or ocean floor, but can also be caused by landslides, asteroids, or explosions. A tsunami wave can be barely noticeable in open, deep water, but as it approaches a shoreline, the wave can grow to a height of 50 feet or more. Recent notable examples are the 2004 Indian Ocean tsunami and the 2011 Japan tsunami. Coastline damage from the Japan tsunami is shown in Figure 2-7.

Figure 2-7 Damage to structures caused by the 2011 Japan tsunami
• Pandemic The spread of infectious disease over a wide geographic region, even worldwide. Pandemics have regularly occurred throughout history and are likely to continue occurring, despite advances in sanitation and immunology. A pandemic is the rapid spread of any type of disease, including typhoid, tuberculosis, bubonic plague, or influenza. Pandemics in the 20th century include the 1918–1920 Spanish flu, the 1956–1958 Asian flu, the 1968–1969 Hong Kong “swine” flu, and the 2009–2010 swine flu pandemics. Figure 2-8 shows an auditorium that was converted into a hospital during the 1918–1920 pandemic.
Figure 2-8 An auditorium was used as a temporary hospital during the 1918 flu pandemic.
• Extraterrestrial impacts This category includes meteorites and other objects that may fall from the sky from way, way up. Sure, these events are extremely rare, and most organizations don’t even include these events in their risk analysis, but I’ve included it here for the sake of rounding out the types of natural events.
Human-Made Disasters Human-made disasters are those events that are directly or indirectly caused by human activity through action or inaction. The results of human-made disasters are similar to natural disasters: localized or widespread damage to businesses that results in potentially lengthy interruptions in operations.
Examples of human-made disasters include
• Civil disturbances These can take on many forms, including protests; demonstrations; riots; strikes; work slowdowns and stoppages; looting; and resulting actions such as curfews, evacuations, or lockdowns.
• Utility outages Failures in electric, natural gas, district heating, water, communications, and other utilities. These can be caused by equipment failures, sabotage, or natural events such as landslides or flooding.
• Service outages Failures in IT equipment, software programs, and online services. These can be caused by hardware failures, software bugs, or misconfiguration.
• Materials shortages Interruptions in the supply of food, fuel, supplies, and materials can have a ripple effect on businesses and the services that support them. Readers who are old enough to remember the petroleum shortages of the mid-1970s know what this is all about; Figure 2-9 shows a line at a gas station during a 1970s-era gasoline shortage. Shortages can result in spikes in the price of commodities, which is almost as damaging as not having any supply at all.

Figure 2-9 Citizens wait in long lines to buy fuel during a gas shortage.
• Fires As contrasted to wildfires, here I mean fires that originate in or involve buildings, equipment, and materials.
• Hazardous materials spills Many created or refined substances can be dangerous if they escape their confines. Examples include petroleum substances, gases, pesticides and herbicides, medical substances, and radioactive substances.
• Transportation accidents This broad category includes plane crashes, railroad derailment, bridge collapse, and the like.
• Terrorism and war Whether they are actions of a nation, nation-state, or group, terrorism and war can have devastating but usually localized effects in cities and regions. Often, terrorism and war precipitate secondary effects such as materials shortages and utility outages.
• Security events The actions of a lone hacker or a team of organized cyber-criminals can bring down one system, one network, or many networks, which could result in widespread interruption in services. The hackers’ activities can directly result in an outage, or an organization can voluntarily (although reluctantly) shut down an affected service or network in order to contain the incident.
NOTE It is important to remember that real disasters are usually complex events that involve more than just one type of damaging event. For instance, an earthquake directly damages buildings and equipment, but can also cause fires and utility outages. A hurricane also brings flooding, utility outages, and sometimes even hazardous materials events and civil disturbances such as looting.
How Disasters Affect Organizations
Disasters have a wide variety of effects on an organization that are discussed in this section. Many disasters have direct effects, but sometimes it is the secondary effects of a disaster event that are most significant from the perspective of ongoing business operations.
A risk analysis is a part of the BCP process (discussed in the next section in this chapter) that will identify the ways in which disasters are likely to affect a particular organization. It is during the risk analysis when the primary, secondary, and downstream effects of likely disaster scenarios need to be identified and considered. Whoever is performing this risk analysis will need to have a broad understanding of the interdependencies of business processes and IT systems, as well as the ways in which a disaster will affect ongoing business operations. Similarly, those personnel who are developing contingency and recovery plans also need to be familiar with these effects so that those plans will adequately serve the organization’s needs.
Disasters, by our definition, interrupt business operations in some measurable way. An event that has the appearance of a disaster may occur, but if it doesn’t affect a particular organization, then we would say that no disaster occurred, at least for that particular organization.
It would be shortsighted to say that a disaster only affects operations. Rather, it is appropriate to understand the longer-term effects that a disaster has on the organization’s image, brand, reputation, and ongoing financial viability. The factors affecting image, brand, and reputation have as much to do with how the organization communicates to its customers, suppliers, and shareholders, as with how the organization actually handles a disaster in progress.
Some of the ways that a disaster affects an organization’s operations include
• Direct damage Events like earthquakes, floods, and fires directly damage an organization’s buildings, equipment, or records. The damage may be severe enough that no salvageable items remain, or it may be less severe, where some equipment and buildings may be salvageable or repairable.
• Utility interruption Even if an organization’s buildings and equipment are undamaged, a disaster may affect utilities such as power, natural gas, or water, which can incapacitate some or all business operations. Significant delays in refuse collection can result in unsanitary conditions.
• Transportation A disaster may damage or render transportation systems such as roads, railroads, shipping, or air transport unusable for a period. Damaged transportation systems will interrupt supply lines and personnel.
• Services and supplier shortage Even if a disaster does not have a direct effect on an organization, critical suppliers affected by a disaster can have an undesirable effect on business operations. For instance, a regional baker that cannot produce and ship bread to its corporate customers will soon result in sandwich shops without a critical resource.
• Staff availability A community-wide or regional disaster that affects businesses is likely to also affect homes and families. Depending upon the nature of a disaster, employees will place a higher priority on the safety and comfort of family members. Also, workers may not be able or willing to travel to work if transportation systems are affected or if there is a significant materials shortage. Employees may also be unwilling to travel to work if they fear for their personal safety or that of their families.
• Customer availability Various types of disasters may force or dissuade customers from traveling to business locations to conduct business. Many of the factors that keep employees away may also keep customers away.
CAUTION The kinds of secondary and tertiary effects that a disaster has on a particular organization depend entirely upon its unique set of circumstances that constitute its specific critical needs. A risk analysis should be performed to identify these specific factors.
The Business Continuity Planning Process
The proper way to plan for disaster preparedness is to first know what kinds of disasters are likely and their possible effects on the organization. That is, plan first, act later.
The business continuity planning process is a life cycle process. In other words, business continuity planning (and disaster recovery planning) is not a one-time event or activity. It’s a set of activities that result in the ongoing preparedness for disaster that continually adapts to changing business conditions and that continually improves.
The elements of the BCP process life cycle are
• Develop BCP policy
• Conduct business impact analysis (BIA)
• Perform criticality analysis
• Establish recovery targets
• Develop recovery and continuity strategies and plans
• Test recovery and continuity plans and procedures
• Train personnel
• Maintain strategies, plans, and procedures through periodic reviews and updates
The BCP life cycle is shown in Figure 2-10. The details of this life cycle are described in detail in this chapter.
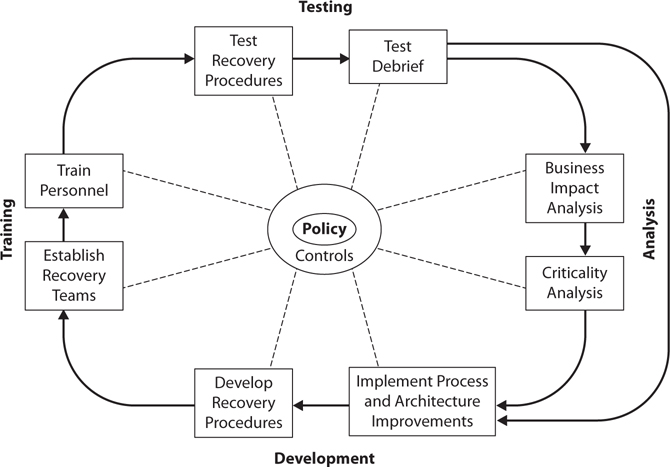
Figure 2-10 The BCP process life cycle
BCP Policy
A formal BCP effort must, like any strategic activity, flow from the existence of a formal policy and be included in the overall governance model that is the topic of this chapter. BCP should be an integral part of the IT control framework, not lie outside of it. Therefore, BCP policy should include or cite specific controls that ensure that key activities in the BCP life cycle are performed appropriately.
BCP policy should also define the scope of the BCP strategy. This means that the specific business processes (or departments or divisions within an organization) that are included in the BCP effort must be defined. Sometimes the scope will include a geographic boundary. In larger organizations, it is possible to “bite off more than you can chew” and define too large a scope for a BCP project, so limiting scope to a smaller, more manageable portion of the organization can be a good approach.
BCP and COBIT 5 Controls The specific COBIT 5 controls that are involved with BCP are contained within DSS04—Ensure continuous service. DSS04 has eight specific controls that constitute the entire BCP life cycle:
• Define the business continuity policy, objectives and scope
• Maintain a continuity strategy
• Develop and implement a business continuity response
• Exercise, test and review the BCP
• Review, maintain and improve the continuity plan
• Conduct continuity plan training
• Manage backup arrangements
• Conduct post-resumption review
These controls are discussed in this chapter and also in COBIT 5.
Business Impact Analysis
The objective of the business impact analysis (BIA) is to identify the impact that different scenarios will have on ongoing business operations. The BIA is one of several steps of critical, detailed analysis that must be carried out before the development of continuity or recovery plans and procedures.
Inventory Key Processes and Systems The first step in a BIA is the collection of key business processes and IT systems. Within the overall scope of the BCP project, the objective here is to establish a detailed list of all identifiable processes and systems. The usual approach is the development of a questionnaire or intake form that would be circulated to key personnel in end-user departments and also within IT. A sample intake form is shown in Figure 2-11.
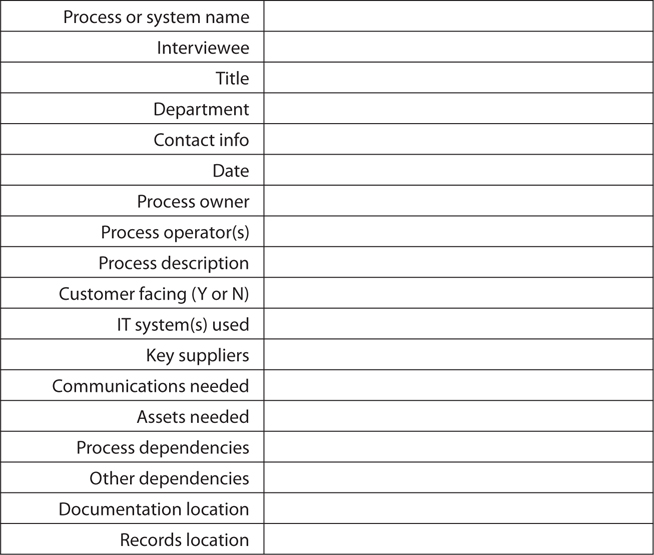
Figure 2-11 BIA sample intake form for gathering data about key processes
Typically, the information that is gathered on intake forms is transferred to a multi-columned spreadsheet, where information on all of the organization’s in-scope processes can be viewed together. This will become even more useful in subsequent phases of the BCP project, such as the criticality analysis.
TIP Use of an intake form is not the only accepted approach when gathering information about critical processes and systems. It’s also acceptable to conduct one-on-one interviews or group interviews with key users and IT personnel to identify critical processes and systems. I recommend the use of an intake form (whether paper-based or electronic), even if the interviewer uses it him-/herself as a framework for note-taking.
Planning Precedes Action
IT personnel are often eager to get to the fun and meaty part of a project. Developers are anxious to begin coding before design; system administrators are eager to build systems before they are scoped and designed; and BCP personnel fervently desire to begin designing more robust system architectures and to tinker with replication and backup capabilities before key facts are known. In the case of business continuity and disaster recovery planning, completion of the BIA and other analyses is critical, as the analyses help to define the systems and processes most needed before getting to the fun part.
Statements of Impact When processes and systems are being inventoried and cataloged, it is also vitally important to obtain one or more statements of impact for each process and system. A statement of impact is a qualitative or quantitative description of the impact on the business if the process or system were incapacitated for a time.
For IT systems, you might capture the number of users and the names of departments or functions that are affected by the unavailability of a specific IT system. Include the geography of affected users and functions if that is appropriate. Example statements of impact for IT systems might include
• Three thousand users in France and Italy will be unable to access customer records.
• All users in North America will be unable to read or send e-mail.
Statements of impact for business processes might cite the business functions that would be affected. Some example statements of impact include
• Accounts payable and accounts receivable functions will be unable to process.
• Legal department will be unable to access contracts and addendums.
Statements of impact for revenue-generating and revenue-supporting business functions could quantify financial impact per unit of time (be sure to use the same units of time for all functions so that they can be easily compared with one another). Some examples include
• Inability to place orders for appliances will cost at the rate of $12,000 per hour.
• Delays in payments will cost $45,000 per day in interest charges.
As statements of impact are gathered, it might make sense to create several columns in the main worksheet so that like units (names of functions, numbers of users, financial figures) can be sorted and ranked later on.
When the BIA is completed, you’ll have the following information about each process and system:
• Name of the system or process
• Who is responsible for it
• A description of its function
• Dependencies on systems
• Dependencies on suppliers
• Dependencies on key employees
• Quantified statements of impact in terms of revenue, users affected, and/or functions impacted
You’re almost home.
Criticality Analysis
When all of the BIA information has been collected and charted, the criticality analysis (CA) can be performed.
The criticality analysis is a study of each system and process, a consideration of the impact on the organization if it is incapacitated, the likelihood of incapacitation, and the estimated cost of mitigating the risk or impact of incapacitation. In other words, it’s a somewhat special type of a risk analysis that focuses on key processes and systems.
The criticality analysis needs to include, or reference, a threat analysis. A threat analysis is a risk analysis that identifies every threat that has a reasonable probability of occurrence, plus one or more mitigating controls or compensating controls, and new probabilities of occurrence with those mitigating/compensating controls in place. In case you’re having a little trouble imagining what this looks like (I’m writing the book and I’m having trouble seeing this!), take a look at Table 2-2, which is a lightweight example of what I’m talking about.
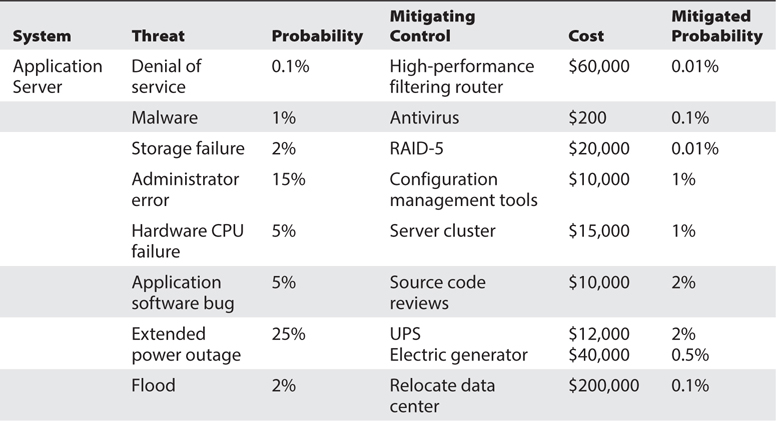
Table 2-2 Example Threat Analysis Identifies Threats and Controls for Critical Systems and Processes
In the preceding threat analysis, notice the following:
• Multiple threats are listed for a single asset. In the preceding example, I mentioned just eight threats. For all the threats but one, I listed only a single mitigating control. For the extended power outage threat, I listed two mitigating controls.
• Cost of downtime wasn’t listed. For systems or processes where you have a cost per unit of time for downtime, you’ll need to include it here, along with some calculations to show the payback for each control.
• Some mitigating controls can benefit more than one system. That may not have been obvious in this example, but in the case of a UPS (uninterruptible power supply) and electric generator, many systems can benefit, so the cost for these mitigating controls can be allocated across many systems, thereby lowering the cost for each system. Another example is a high-availability storage area network (SAN) located in two different geographic areas; while initially expensive, many applications can use the SAN for storage, and all will benefit from replication to the counterpart storage system.
• Threat probabilities are arbitrary. In Table 2-2, the probabilities were for a single occurrence in an entire year, so, for example, 5 percent means the threat will be realized once every 20 years.
• The length of outage was not included. You may need to include this also, particularly if you are quantifying downtime per hour or other unit of time.
It is probably becoming obvious that a threat analysis, and the corresponding criticality analysis, can get complicated. The rule here should be this: the complexity of the threat and criticality analyses should be proportional to the value of the assets (or revenue, or both). For example, in a company where application downtime is measured in thousands of dollars per minute, it’s probably worth taking a few weeks or even months to work out all of the likely scenarios and a variety of mitigating controls, and to work out which ones are the most cost-effective. On the other hand, for a system or business process where the impact of an outage is far less costly, a good deal less time might be spent on the supporting threat and criticality analysis.
EXAM TIP Test-takers should ensure that any question dealing with BIA and CA places the business impact analysis first. Without this analysis, criticality analysis is impossible to evaluate in terms of likelihood or cost-effectiveness in mitigation strategies. The BIA identifies strategic resources and provides a value to their recovery and operation, which is, in turn, consumed in the criticality analysis phase. If presented with a question identifying BCP at a particular stage, make sure that any answers you select facilitate the BIA and then the CA before moving on toward objectives and strategies.
Determine Maximum Tolerable Downtime
The next step for each critical process is the establishment of a metric called maximum tolerable downtime (MTD). This is a theoretical period of time, measured from the onset of a disaster, after which the organization’s very survival is at risk. Establishing MTD for each critical process is an important step that aids in the establishment of key recovery targets, discussed in the next section.
Establishing Key Recovery Targets
When the cost or impact of downtime has been established and the cost and benefit of mitigating controls has been considered, some key targets can be established for each critical process. The two key targets are recovery time objective and recovery point objective. These objectives determine how quickly key systems and processes are made available after the onset of a disaster and the maximum tolerable data loss that results from the disaster. The two key recovery targets are
• Recovery time objective (RTO) This refers to the maximum period that elapses from the onset of a disaster until the resumption of service.
• Recovery point objective (RPO) This refers to the maximum data loss from the onset of a disaster.
Once these objectives are known, the disaster recovery (DR) team can begin to build system recovery capabilities and procedures that will help the organization to economically realize these targets. This is discussed in detail in Chapter 5.
Developing Continuity Plans
In the previous section, I discussed the notion of establishing recovery targets and the development of architectures, processes, and procedures. The processes and procedures are related to the normal operation of those new technologies as they will be operated in normal day-to-day operations. When those processes and procedures have been completed, then the disaster recovery plans and procedures (those actions that will take place during and immediately after a disaster) can be developed.
For example, an organization has established RPO and RTO targets for its critical applications. These targets necessitated the development of server clusters and storage area networks with replication. While implementing those new technologies, the organization developed the operations processes and procedures in support of those new technologies that would be carried out every day during normal business operations. As a separate activity, the organization would then develop the procedures to be performed when a disaster strikes the primary operations center for those applications; those procedures would include all of the steps that must be taken so that the applications can continue operating in an alternate location.
The procedures for operating critical applications during a disaster are a small part of the entire body of procedures that must be developed. Several other sets of procedures must also be developed, including:
• Personnel safety procedures
• Disaster declaration procedures
• Responsibilities
• Contact information
• Recovery procedures
• Continuing operations
• Restoration procedures
All of these are required so that an organization will be adequately prepared in the event a disaster occurs.
Personnel Safety Procedures
When a disaster strikes, measures to ensure the safety of personnel need to be taken immediately. If the disaster has occurred or is about to occur to a building, personnel may need to be evacuated as soon as possible. Arguably, however, in some situations evacuation is exactly the wrong thing to do; for example, if a hurricane or tornado is bearing down on a facility, then the building itself may be the best shelter for personnel, even if it incurs some damage. The point here is that personnel safety procedures need to be carefully developed, and possibly more than one set of procedures will be needed, depending on the event.
TIP The highest priority in any disaster or emergency situation is the safety of human life.
Personnel safety procedures need to take many factors into account, including:
• Ensuring that all personnel are familiar with evacuation and sheltering procedures
• Ensuring that visitors will know how to evacuate the premises and the location of sheltering areas
• Posting signs and placards that indicate emergency evacuation routes and gathering areas outside of the building
• Emergency lighting to aid in evacuation or sheltering in place
• Fire extinguishment equipment (portable fire extinguishers and so on)
• The ability to communicate with public safety and law enforcement authorities, including in situations where communications and electric power have been cut off and when all personnel are outside of the building
• Care for injured personnel
• CPR and emergency first-aid training
• Safety personnel who can assist in the evacuation of injured and disabled persons
• The ability to account for visitors and other nonemployees
• Emergency shelter in extreme weather conditions
• Emergency food and drinking water
• Periodic tests to ensure that evacuation procedures will be adequate in the event of a real emergency
Local emergency management organizations may have additional information available that can assist an organization with its emergency personnel safety procedures.
Disaster Declaration Procedures
Disaster response procedures are initiated when a disaster is declared. However, there needs to be a procedure for the declaration itself so that there will be little doubt as to the conditions that must be present.
Why is a disaster declaration procedure required? Primarily because it’s not always clear whether a situation is a real disaster. Sure, a 7.5 earthquake or a major fire is a disaster, but overcooking popcorn in the microwave that sets off a building’s fire alarm system might not be. Many “in between” situations may or may not be disasters. A disaster declaration procedure must state some basic conditions that will help determine whether a disaster should be declared.
Further, who has the authority to declare a disaster? What if senior management personnel frequently travel and may not be around? Who else can declare a disaster? And, finally, what does it mean to declare a disaster—and what happens next? The following points constitute the primary items that organizations need to consider for their disaster declaration procedure.
Form a Core Team To be effective and workable, a core team of personnel needs to be established, all of whom will be familiar with the disaster declaration procedure, as well as the actions that must take place once a disaster has been declared. This core team should consist of middle and upper managers who are familiar with business operations, particularly those that are critical. This core team must be large enough so that a requisite few of them are on hand when a disaster strikes. In organizations that have second shifts, third shifts, and weekend work, some of the core team members should be those in supervisory positions during those off-hours times. However, some of the core team members can be personnel who work “business hours” and are not on-site all of the time.
Declaration Criteria The declaration procedure must contain some tangible criteria that a core team member can consult to guide him or her down the “Is this a disaster?” decision path.
The criteria for declaring a disaster should be related to the availability and viability of ongoing critical business operations. Some example criteria include any one or more of the following:
• Forced evacuation of a building containing or supporting critical operations that is likely to last for more than four hours
• Hardware, software, or network failures that result in a critical IT system being incapacitated or unavailable for more than four hours
• Any security incident that results in a critical IT system being incapacitated for more than four hours (security incidents could involve malware, break-in, attack, sabotage, and so on)
• Any event causing employee absenteeism or supplier shortages that, in turn, results in one or more critical business processes being incapacitated for more than eight hours
• Any event causing a communications failure that results in critical IT systems being unreachable for more than four hours
The preceding examples are a mostly complete list of criteria for many organizations. The periods will vary from organization to organization. For instance, a large, pure-online business such as Salesforce.com would probably declare a disaster if its main websites were unavailable for more than a few minutes. But in an organization where computers are far less critical, an outage of four hours might not be considered a disaster.
Pulling the Trigger When disaster declaration criteria are met, the disaster should be declared. The procedure for disaster declaration could permit any single core team member to declare the disaster, but it may be better to have two or more core team members agree on whether a disaster should be declared. Whether an organization should use a single-person declaration or a group of two or more is each organization’s choice.
All core team members empowered to declare a disaster should have the procedure on hand at all times. In most cases, the criteria should fit on a small, laminated wallet card that each team member can have with him or her or nearby at all times. For organizations that use the consensus method for declaring a disaster, the wallet card should include the names and contact numbers for other core team members so that each will have a way of contacting others.
Next Steps Declaring a disaster will trigger the start of one or more other response procedures, but not necessarily all of them. For instance, if a disaster is declared because of a serious computer or software malfunction, there is no need to evacuate the building. While this example may be obvious, not all instances will be this clear. Either the disaster declaration procedure itself or each of the subsequent response procedures should contain criteria that will help determine which response procedures should be enacted.
False Alarms Probably the most common cause of personnel not declaring a disaster is the fear that a real disaster is not taking place. Core team members empowered with declaring a disaster should not necessarily hesitate. Instead, core team members could convene with additional core team members to reach a firm decision, provided this can be done quickly.
If a disaster has been declared and later it is clear that a disaster has been averted (or did not exist in the first place), the disaster can simply be called off and declared to be over. Response personnel can be contacted and told to cease response activities and return to their normal activities.
TIP Depending on the level of effort that takes place in the opening minutes and hours of disaster response, the consequences of declaring a disaster when none exists may be significant, or not. In the spirit of continuous improvement, any organization that has had a few false alarms should seek to improve their disaster declaration criteria. Well-trained and experienced personnel can usually reduce the frequency of false alarms.
Responsibilities
During a disaster, many important tasks must be performed to evacuate or shelter personnel, assess damage, recover critical processes and systems, and carry out many other functions that are critical to the survival of the enterprise.
About 20 different responsibilities are described here. In a large organization, each responsibility may be staffed with a team of two, three, or many individuals. In small organizations, a few people may incur many responsibilities each, switching from role to role as the situation warrants.
All of these roles will be staffed by people who are available to fill them. It is important to remember that many of the “ideal” persons to fill each role will be unavailable during a disaster for several reasons, including:
• Injured, ill, or deceased Some regional disasters will inflict widespread casualties that will include some proportion of response personnel. Those who are injured, ill (in the case of a pandemic, for instance, or who are recovering from a sickness or surgery when the disaster occurs), or who are killed by the disaster are clearly not going to be showing up to help out.
• Caring for family members Some types of disasters may cause widespread injury or require mass evacuation. In some of these situations, many personnel will be caring for family members whose immediate needs for safety will take priority over the needs of the workplace.
• Unavailable transportation Some types of disasters include localized or widespread damage to transportation infrastructure, which may result in many persons who are willing to be on-site to help with emergency operations being unable to travel to the work site.
• Out of the area Some disaster response personnel may be away on business travel or on vacation and be unable to respond. However, some persons being away may actually be opportunities in disguise; unaffected by the physical impact of the disaster, they may be able to help out in other ways, such as communications with suppliers, customers, or other personnel.
• Communications Some types of disasters, particularly those that are localized (versus widespread and obvious to an observer), require that disaster response personnel be contacted and asked to help. If a disaster strikes after hours, some personnel may be unreachable if they are engaged in any activity where they do not have a mobile phone with them or are out of range.
• Fear Some types of disasters (such as pandemic, terrorist attack, flood, and so on) may instill fear for safety on the part of response personnel who will disregard the call to help and stay away from the work site.
NOTE Response personnel in all disciplines and responsibilities will need to be able to piece together whatever functionality they are called on to do, using whatever resources are available—this is part art form and part science. While response and contingency plans may make certain assumptions, personnel may find themselves with fewer resources than planned, requiring them to do the best they can with the resources available.
Each function will be working with personnel in many other functions, often working with unfamiliar persons. An entire response and recovery operation may be operating almost like a brand-new organization in unfamiliar settings and with an entirely new set of rules. In typical organizations, teams work well when team members are familiar with, and trust, one another. In a response and recovery operation, the stress level is much higher because the stakes—company survival—are higher, and often the teams are composed of persons who have little experience with each other and these new roles. This will cause additional stress that will bring out the best and worst in people, as illustrated in Figure 2-12.

Figure 2-12 Stress is compounded by the pressure of disaster recovery and the formation of new teams in times of chaos.
Emergency Response These are the “first responders” during a disaster. Top priorities include evacuation or sheltering of personnel, first aid, triage of injured personnel, and possibly firefighting.
Command and Control (Emergency Management) During disaster response operations, someone has to be in charge. In a disaster, resources may be scarce, and many matters vie for attention. Someone needs to fill the role of decision maker to keep disaster response activities moving and to handle situations that arise. This role may need to be rotated among various personnel, particularly in smaller organizations, to counteract fatigue.
TIP Although the first person on the scene may be the person in charge initially, that will definitely change as qualified assigned personnel show up and take charge and as the nature of the disaster and response solidifies. The leadership roles may then be passed among key personnel already designated to be in charge.
Scribe It’s vital that one or more persons continually document the important events during disaster response operations. From decisions to discussions to status to roll call, these events must be written down so that the details of disaster response can be pieced together afterward. This will help the organization better understand how disaster response unfolded, how decisions were made, and who performed which actions, all of which will help the organization be better prepared for future events.
Internal Communications In many disaster scenarios, personnel may be stripped of many or all of their normal means of communication, such as desk phone, voicemail, e-mail, smartphone, and instant messaging. Yet never are communications as vital as during a disaster, when nothing is going according to plan. Internal communications are needed so that status on various activities can be sent to command and control, and so that priorities and orders can be sent to disaster response personnel.
External Communications People outside of the organization need to know what’s going on when a disaster strikes. There’s a potentially long list of parties who want or need to know the status of business operations during and after a disaster, including:
• Customers
• Suppliers
• Partners
• Shareholders
• Neighbors
• Regulators
• Media
• Law enforcement and public safety authorities
These different audiences need different messages, as well as messages in different forms.
Legal and Compliance Several needs may arise during a disaster that require the attention of inside or outside legal counsel. Disasters present unique situations that need legal assistance, such as:
• Interpretation of regulations
• Interpretation of contracts with suppliers and customers
• Management of matters of liability to other parties
TIP Typical legal matters need to be resolved before the onset of a disaster, with this information included in disaster response procedures, since legal staff members may be unavailable during the disaster.
Damage Assessment Whether a disaster is a physically violent event, such as an earthquake or volcano, or instead involves no physical manifestation, such as a serious security incident, one or more experts are needed who can examine affected assets and accurately assess the damage. Because most organizations own many different types of assets (from buildings to equipment to information), qualified experts are needed to assess each asset type involved. It is not necessary to call upon all available experts, only those whose expertise matches the type of event that has occurred.
Some expertise may go well beyond the skills present in an organization, such as a building structural engineer who can assess potential earthquake damage. In such cases it may be sensible to retain the services of an outside engineer who will respond and provide an assessment on whether a building is safe to occupy after a disaster. In fact, it may make sense to retain more than one, in case they themselves are affected by a disaster.
Salvage Disasters destroy assets that the organization uses to make products or perform services. When a disaster occurs, someone (either a qualified employee or an outside expert) needs to examine assets to determine which are salvageable; then a salvage team needs to perform the actual salvage operation at a pace that meets the organization’s needs.
In some cases, salvage may be a critical-path activity, where critical processes are paralyzed until salvage and repairs to critically needed machinery can be performed. In other cases, the salvage operation is performed on inventory of finished goods, raw materials, and other items so that business operations can be resumed. Occasionally, when it is obvious that damaged equipment or materials are a total loss, the salvage effort is one of selling the damaged items or materials to some organization that wants them.
Assessment of damage to assets may be a high priority when an organization will be filing an insurance claim. Insurance may be a primary source of funding for the organization’s recovery effort.
CAUTION Salvage operations may be a critical-path activity or one that can be carried out well after the disaster. To the greatest extent possible, this should be decided in advance. Otherwise, the command-and-control function will need to decide the priority of salvage operations.
Physical Security After a disaster, the organization’s usual physical security controls may be compromised. For instance, fencing, walls, and barricades could be damaged, or video surveillance systems may be disabled or have no electric power. These and other failures could lead to increased risk of loss or damage to assets and personnel until those controls can be fixed. Also, security controls in temporary quarters such as hot/warm/cold sites and temporary work centers may be below those in primary locations.
Supplies During emergency and recovery operations, personnel will require supplies of many kinds, from drinking water, writing tablets, and pens to smartphones, portable generators, and extension cords. This function may also be responsible for ordering replacement assets such as servers and network equipment for a cold site.
Transportation When workers are operating from a temporary location and/or if regional or local transportation systems have been compromised, many arrangements for all kinds of transportation may be required to support emergency operations. These can include transportation of replacement workers, equipment, or supplies by truck, car, rail, sea, or air. This function could also be responsible for arranging for temporary lodging for personnel.
Network This technology function is responsible for damage assessment to the organization’s voice and data networks, building/configuring networks for emergency operations, or both. This function may require extensive coordination with external telecommunications service providers, who, by the way, may be suffering the effects of a local or regional disaster as well.
Network Services This function is responsible for network-centric services such as Domain Name System (DNS), Simple Network Management Protocol (SNMP), network routing, and authentication.
Systems This is the function that is responsible for building, loading, and configuring the servers and systems that support critical services, applications, databases, and other functions. Personnel may have other resources such as virtualization technology to enable additional flexibility.
Database Management Systems For critical applications that rely upon database management systems, this function is responsible for building databases on recovery systems and for restoring or recovering data from backup media, replication volumes, or e-vaults onto recovery systems. Database personnel will need to work with systems, network, and applications personnel to ensure that databases are operating properly and are available as needed.
Data and Records This function is responsible for access to and re-creation of electronic and paper business records. This is a business function that supports critical business processes and works with database management personnel and, if necessary, works with data-entry personnel to rekey lost data.
Applications This function is responsible for recovering application functionality on application servers. This may include reloading application software; performing configuration; provisioning roles and user accounts; and connecting the application to databases, network services, and other application integration issues.
Access Management This function is responsible for creating and managing user accounts for network, system, and application access. Personnel with this responsibility may be especially susceptible to social engineering and be tempted to create user accounts without proper authority or approval.
Information Security and Privacy Personnel in this capacity are responsible for ensuring that proper security controls are being carried out during recovery and emergency operations. They will be expected to identify risks associated with emergency operations and to require remedies to reduce risks.
Security personnel will also be responsible for enforcing privacy controls so that employee and customer personal data will not be compromised, even as business operations are affected by the disaster.
Off-Site Storage This function is responsible for managing the effort of retrieving backup media from off-site storage facilities and for protecting that media in transit to the scene of recovery operations. If recovery operations take place over an extended period (more than a couple of days), data at the recovery site will need to be backed up and sent to an off-site media storage facility to protect that information should a disaster occur at the hot/warm/cold site (and what bad luck that would be!).
User Hardware In many organizations, little productive work gets done when employees don’t have their workstations, printers, scanners, copiers, and other office equipment. Thus, a function is required to provide, configure, and support the variety of office equipment required by end users working in temporary or alternate locations. This function, like most others, will have to work with many others to ensure that workstations and other equipment are able to communicate with applications and services as needed to support critical processes.
Training During emergency operations, when response personnel and users are working in new locations (and often on new or different equipment and software), some of these personnel may need training so that their productivity can be quickly restored. Training personnel will need to be familiar with many disaster response and recovery procedures so that they can help people in those roles understand what is expected of them. This function will also need to be able to dispense emergency operations procedures to these personnel.
Restoration This function comes into play when IT is ready to migrate applications running on hot/warm/cold site systems back to the original (or replacement) processing center.
Contract Information This function is responsible for understanding and interpreting legal contracts. Most organizations are a party to one or more legal contracts that require them to perform specific activities, provide specific services, and communicate status if service levels have changed. These contracts may or may not have provisions for activities and services during disasters, including communications regarding any changes in service levels.
This function is vital not only during the disaster planning stages but also during actual disaster response. Customers, suppliers, regulators, and other parties need to be informed according to specific contract terms.
Recovery Procedures
Recovery procedures are the instructions that key personnel use to bootstrap services (such as IT systems and other business-enabling technologies) that support the critical business functions identified in the BIA and CA. The recovery procedures should work hand in hand with the technologies that may have been added to IT systems to make them more resilient.
An example would be useful here. A fictitious company, Acme Rocket Boots, determines that its order-entry business function is highly critical to the ongoing viability of the business and sets recovery objectives to ensure that order entry would be continued within no more than 48 hours after a disaster.
Acme determines that it needs to invest in storage, backup, and replication technologies to make a 48-hour recovery possible. Without these investments, IT systems supporting order-entry would be down for at least ten days until they could be rebuilt from scratch. Acme cannot justify the purchase of systems and software to facilitate an auto-failover of the order-entry application to hot-site DR servers; instead, the recovery procedure would require that the database be rebuilt from replicated data on cloud-based servers. Other tasks, such as installing recent patches, would also be necessary to make recovery servers ready for production use. All of the tasks required to make the systems ready constitute the body of recovery procedures needed to support the business order-entry function.
This example is, of course, a gross oversimplification. Actual recovery procedures could take dozens of pages of documentation, and procedures would also be necessary for network components, end-user workstations, network services, and other supporting IT services required by the order-entry application. And those are the procedures needed just to get the application running again. More procedures would be needed to keep the applications running properly in the recovery environment.
Continuing Operations
Procedures for continuing operations have more to do with business processes than they do with IT systems. However, the two are related, since the procedures for continuing critical business processes have to fit hand in hand with the procedures for operating supporting IT systems that may also (but not necessarily) be operating in a recovery or emergency mode.
Let me clarify that last statement. It is entirely conceivable that a disaster could strike an organization with critical business processes that operate in one city but that are supported by IT systems located in another city. A disaster could strike the city with the critical business function, which means that personnel might have to continue operating that business function in another location, on the original, fully featured IT application. It is also possible that a disaster could strike the city with the IT application, forcing it into an emergency/recovery mode in an alternate location, while users of the application are operating in a business-as-usual mode. And, of course, a disaster could strike both locations (or a disaster could strike in one location where both the critical business function and its supporting IT applications reside), throwing both the critical business function and its supporting IT applications into emergency mode. Any organization’s reality could be even more complex than this: just add dependencies on external application service providers, applications with custom interfaces, or critical business functions that operate in multiple cities. If you wondered why disaster recovery and business continuity planning were so complicated, perhaps your appreciation has grown just now.
Restoration Procedures
When a disaster has occurred, IT operations need to temporarily take up residence in an alternate processing site while repairs are performed on the original processing site. Once those repairs are completed, IT operations would need to be transitioned back to the main (or replacement) processing facility. You should expect that the procedures for this transition would also be documented (and tested—testing is discussed later in this chapter).
NOTE Transitioning applications back to the original processing site is not necessarily just a second iteration of the initial move to the hot/warm/cold site. Far from it: the recovery site may have been a skeleton (in capacity, functionality, or both) of its original self. The objective is not necessarily to move the functionality at the recovery site back to the original site, but to restore the original functionality to the original site.
Let’s look at an example. To continue the Acme Rocket Boots example: their order-entry application at the DR site had only basic, not extended, functions. For instance, customers could not look at order history, and they could not place custom orders; they could only order off-the-shelf products. But when the application is moved back to the primary processing facility, the history of orders accumulated on the DR application needs to be merged into the main order history database, which was not a part of the DR plan.
Considerations for Continuity and Recovery Plans
A considerable amount of detailed planning and logistics must go into continuity and recovery plans if they are to be effective.
Availability of Key Personnel An organization cannot depend upon every member of its regular expert workforce to be available in a disaster. As discussed earlier in this chapter in more detail, personnel may be unavailable for a number of reasons, including:
• Injury, illness, or death
• Caring for family members
• Unavailable transportation
• Damaged transportation infrastructure
• Being out of the area
• Lack of communications
• Fear, related to the disaster and its effects
TIP An organization must develop thorough and accurate recovery and continuity documentation as well as cross-training and plan testing. When a disaster strikes, an organization has one chance to survive, and it depends upon how well the available personnel are able to follow recovery and continuity procedures and to keep critical processes functioning properly.
Emergency Supplies The onset of a disaster may cause personnel to be stranded at a work location, possibly for several days. This can be caused by a number of reasons, including inclement weather that makes travel dangerous or a transportation infrastructure that is damaged or blocked with debris.
Emergency supplies should be laid up at a work location and made available to personnel stranded there, regardless of whether they are supporting a recovery effort or not (it’s also possible that severe weather or a natural or human-made event could make transportation dangerous or impossible).
A disaster can also prompt employees to report to a work location (at the primary location or at an alternate site) where they may remain for days at a time, even around the clock if necessary. A situation like this may make the need for emergency supplies less critical, but it still may be beneficial to the recovery effort to make supplies available to support recovery personnel.
An organization stocking emergency supplies at a work location should consider including:
• Drinking water
• Food rations
• First-aid supplies
• Blankets
• Flashlights
• Battery or crank-powered radio
Local emergency response authorities may recommend other supplies be kept at a work location as well.
Communications Communications within organizations, as well as with customers, suppliers, partners, shareholders, regulators, and others, is vital under normal business conditions. During a disaster and subsequent recovery and restoration operations, such communications are more important than ever, while many of the usual means for communications may be impaired.
Identifying Critical Personnel A successful disaster recovery operation requires available personnel who are located near company operations centers. While the primary response personnel may consist of the individuals and teams responsible for day-to-day corporate operations, others need to be identified. In a disaster, some personnel will be unavailable for many reasons (discussed earlier in this chapter).
Key personnel, as well as their backup persons, need to be identified. Backup personnel can consist of other employees who have familiarity with specific technologies, such as operating system, database, and network administration, and who can cover for primary personnel if needed. Sure, it would be desirable for these backup personnel also to be trained in specific recovery operations, but at the very least, if these personnel have access to specific detailed recovery procedures, having them on a call list is probably better than having no available personnel during a disaster.
Identifying Critical Suppliers, Customers, and Other Parties Besides employees, many other parties need to be notified in the event of a disaster. Outside parties need to be aware of the disaster, as well as of basic changes in business conditions.
In a regional disaster such as a hurricane or earthquake, nearby parties will certainly be aware of the disaster and that your organization is involved in it somehow. However, those parties may not be aware of the status of business operations immediately after the disaster: a regional event’s effects can range from complete destruction of buildings and equipment to no damage at all and business-as-usual conditions. Unless key parties are notified of the status, they may have no other way to know for sure.
Parties that need to be contacted may include
• Key suppliers This may include electric and gas utilities, fuel delivery, and materials delivery. In a disaster, an organization will often need to impart special instructions to one or more suppliers, requesting delivery of extra supplies or temporary cessation of deliveries.
• Key customers Many organizations have key customers whose relationships are valued above most others. These customers may depend on a steady delivery of products and services that are critical to their own operations; in a disaster, those customers may have a dire need to know whether such deliveries will be able to continue or not and under what circumstances.
• Public safety Police, fire, and other public safety authorities may need to be contacted, not only for emergency operations such as firefighting, but also for any required inspections or other services. It is important that “business office” telephone numbers for these agencies be included on contact lists, as 911 and other emergency lines may be flooded by calls from others.
• Insurance adjusters Most organizations rely on insurance companies to protect their assets from damage or loss in a disaster. Because insurance adjustment funds are often a key part of continuing business operations in an emergency, it’s important to be able to reach insurers as soon as possible after a disaster has occurred.
• Regulators In some industries, organizations are required to notify regulators of certain types of disasters. While regulators obviously may be aware of noteworthy regional disasters, they may not immediately know an event’s specific effects on an organization. Further, some types of disasters are highly localized and may not be newsworthy, even in a local city.
• Media Media outlets such as newspapers and television stations may need to be notified as a means of quickly reaching the community or region with information about the effects of a disaster on organizations.
• Shareholders Organizations are usually obliged to notify their shareholders of any disastrous event that affects business operations. This may be the case whether the organization is publicly or privately held.
The persons or teams responsible for communicating with these outside parties will need to have all of the individuals and organizations included in a list of parties to contact. This information should all be included in emergency response procedures.
Setting Up Call Trees Disaster response procedures need to include a call tree. This is a method where the first personnel involved in a disaster begin notifying others in the organization, informing them of the developing disaster and enlisting their assistance.
Just as the branches of a tree originate at the trunk and are repeatedly subdivided, a call tree is most effective when each person in the tree can make just a few phone calls. Not only will the notification of important personnel proceed more quickly, but each person will not be overburdened with many calls.
Remember, in a disaster a significant portion of personnel may be unavailable or unreachable. Therefore, a call tree should be structured so that there is sufficient flexibility as well as assurance that all critical personnel will be contacted. Figure 2-13 shows an example call tree.
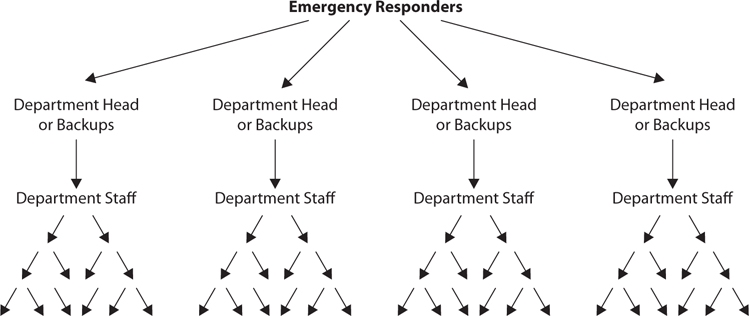
Figure 2-13 Example call tree structure
An organization can also use an automated outcalling system to notify critical personnel of a disaster. Such a system can play a prerecorded message or request that personnel call an information number to hear a prerecorded message. Most outcalling systems keep a log of which personnel have been successfully reached.
An automated calling system should not be located in the same geographic region. If it were, a regional disaster could damage the system or make it unavailable during a disaster. The system should be Internet accessible so that response personnel can access it to determine which personnel have been notified, and to make any needed changes before or during a disaster.
Wallet Cards Wallet cards containing emergency contact information should be prepared for core team personnel for the organization, as well as for members in each department who would be actively involved in disaster response. Wallet cards are advantageous, because most personnel will have their wallet, pocketbook, or purse nearby at all times, even when away from home, running errands, traveling, or on vacation. Information on the wallet card should include contact information for fellow team members, a few of the key disaster response personnel, and any conference bridges or emergency call-in numbers that are set up. An example wallet card is shown in Figure 2-14.

Figure 2-14 Example laminated wallet card for core team participants with emergency contact information and disaster declaration criteria
Transportation Some types of disasters may make certain modes of transportation unavailable or unsafe. Widespread natural disasters, such as earthquakes, volcanoes, hurricanes, and floods, can immobilize virtually every form of transportation, including highways, railroads, boats, and airplanes. Other types of disasters may impede one or more types of transportation, which could result in overwhelming demand for the available modes. High volumes of emergency supplies may be needed during and after a disaster, but damaged transportation infrastructure often makes the delivery of those supplies difficult.
Components of a Business Continuity Plan
The complete set of business continuity plan documents will include the following:
• Supporting project documents These will include the documents created at the beginning of the business continuity project, including the project charter, project plan, statement of scope, and statement of support from executives.
• Analysis documents These include the:
• Business impact analysis (BIA)
• Threat assessment and risk assessment
• Criticality analysis
• Documents defining recovery targets such as recovery time objective (RTO) and recovery point objective (RPO)
• Response documents These are all the documents that describe the required action of personnel when a disaster strikes, plus documents containing information required by those same personnel. Examples of these documents include
• Business recovery (or resumption) plan This describes the activities required to recover and resume critical business processes and activities.
• Occupant emergency plan (OEP) This describes activities required to safely care for occupants in a business location during a disaster. This will include both evacuation procedures and sheltering procedures, each of which might be required, depending upon the type of disaster that occurs.
• Emergency communications plan This describes the types of communications imparted to many parties, including emergency response personnel, employees in general, customers, suppliers, regulators, public safety organizations, shareholders, and the public.
• Contact lists These contain names and contact information for emergency response personnel as well as for critical suppliers, customers, and other parties.
• Disaster recovery plan This describes the activities required to restore critical IT systems and other critical assets, whether in alternate or primary locations.
• Continuity of operations plan (COOP) This describes the activities required to continue critical and strategic business functions at an alternate site.
• Security incident response plan (SIRP) This describes the steps required to deal with a security incident that could reach disaster-like proportions.
• Test and review documents This is the entire collection of documents related to tests of all of the different types of business continuity plans, as well as reviews and revisions to documents.
Testing Recovery Plans
It’s surprising what you can accomplish when no one is concerned about who gets the credit.
–Ronald Reagan
Business continuity and disaster recovery plans may look elegant and even ingenious on paper, but their true business value is unknown until their worth is proven through testing.
The process of testing DR and BC plans uncovers flaws not only in the plans, but also in the systems and processes that they are designed to protect. For example, testing a system recovery procedure might point out the absence of a critically needed hardware component, or a recovery procedure might contain a syntax or grammatical error that misleads the recovery team member and results in recovery delays. Testing is designed to uncover these types of issues.
Testing Recovery and Continuity Plans
Recovery and continuity plans need to be tested to prove their viability. Without testing, an organization has no way of really knowing whether its plans are effective. With ineffective plans, an organization has a far smaller chance of surviving a disaster.
Recovery and continuity plans have built-in obsolescence—not by design, but by virtue of the fact that technology and business processes in most organizations are undergoing constant change and improvement. Thus, it is imperative that newly developed or updated plans be tested as soon as possible to ensure their effectiveness.
Types of tests range from lightweight and unobtrusive to intense and disruptive. The types of tests are
• Document review
• Walkthrough
• Simulation
• Parallel test
• Cutover test
These tests are described in more detail in this section.
TIP Usually, an organization will perform the less intensive tests first to identify the most obvious flaws and follow with tests that require more effort.
Test Preparation
Each type of test requires advance preparation and recordkeeping. Preparation will consist of several activities, including:
• Participants The organization needs to identify personnel who will participate in an upcoming test. It is important to identify all relevant skill groups and department stakeholders so that the test will include a full slate of contributors.
• Schedule The availability of each participant needs to be confirmed so that the test will include participation from all stakeholders.
• Facilities For all but the document review test, proper facilities need to be identified and set up. This might consist of a large conference room or training room. If the test will take place over several hours, one or more meals and/or refreshments may be needed as well.
• Scripting The simulation test requires some scripting, usually in the form of one or more documents that describe a developing scenario and related circumstances. Scenario scripting can make parallel and cutover tests more interesting and valuable, but this can be considered optional.
• Recordkeeping For all of the tests except the document review, one or more persons need to take good notes that can be collected and organized after the test is completed.
• Contingency plan The cutover test involves the cessation of processing on primary systems and the resumption of processing on recovery systems. This is the highest-risk plan, and things can go wrong. A contingency plan to get primary systems running again in case something goes wrong during the test needs to be developed.
These preparation activities are shown in Table 2-3.
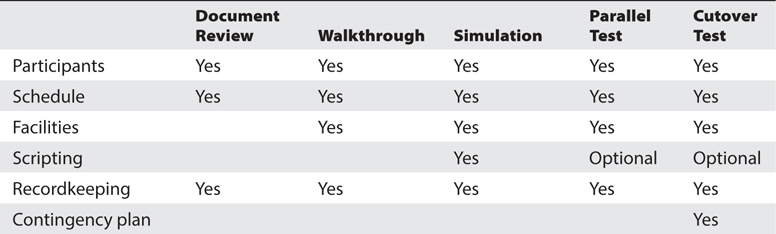
Table 2-3 Preparation Activities Required for Each Type of DR/BC Test
The various types of tests are discussed next.
Document Review A document review test is a review of some or all disaster recovery and business continuity plans, procedures, and other documentation. Individuals typically review these documents on their own, at their own pace, but within whatever time constraints or deadlines that may have been established.
The purpose of a document review test is to review the accuracy and completeness of document content. Reviewers should read each document with a critical eye, point out any errors, and annotate the document with questions or comments that can be sent back to the document’s author(s), who can make any necessary changes.
If significant changes are needed in one or more documents, the project team may want to include a second round of document review before moving on to more resource-intensive tests.
The owner or document manager for the organization’s business continuity and disaster recovery planning project should document which persons review which documents, and perhaps even include the review copies or annotations. This practice will create a more complete record of the activities related to the development and testing of important BCP planning and response documents. It will also help to capture the true cost and effort of the development and testing of BCP capabilities in the organization.
Walkthrough A walkthrough is similar to a document review: it’s a review of just the BCP documents. However, where a document review is carried out by individuals working on their own, a walkthrough is performed by an entire group of individuals in a live discussion.
A walkthrough is usually facilitated by a leader who guides the participants page by page through each document. The leader may read sections of the document aloud, describe various scenarios where information in a section might be relevant, and take comments and questions from participants.
A walkthrough is likely to take considerably more time than a document review. One participant’s question on some minor point in the document could spark a worthwhile and lively discussion that could last a few minutes to an hour. The group leader or another person will need to take careful notes in the event that any deficiencies are found in any of the documents, as well as issues to be handled after the walkthrough. The leader will also need to be able to control the pace of the review so that the group does not get unnecessarily hung up on minor points. Some discussions will need to be cut short or tabled for a later time or for an offline conversation among interested parties.
Even if major revisions are needed in recovery documents, it probably will be infeasible to conduct another walkthrough with updated documents. However, follow-up document reviews are probably warranted to ensure that they were updated appropriately, at least in the opinion of the walkthrough participants.
CAUTION Participants in the walkthrough should carefully consider that the potential audience for recovery procedures may be persons who are not as familiar as they are with systems and processes. They need to remember that the ideal personnel may not be available during a real disaster. Participants also need to realize that the skill level of recovery personnel might be a little below that of the experts who operate systems and processes in normal circumstances. Finally, walkthrough participants need to remember that systems and processes undergo almost continuous change, which could render some parts of the recovery documentation obsolete or incorrect all too soon.
Simulation A simulation is a test of disaster recovery and business continuity procedures where the participants take part in a “mock disaster” to add some realism to the process of thinking their way through procedures in emergency response documents.
A simulation could be an elaborate and choreographed walkthrough test where a facilitator reads from a script and describes a series of unfolding events in a disaster such as a hurricane or an earthquake. This type of simulation might almost be viewed as “playacting,” where the script is the set of emergency response documentation. By stimulating the imagination of simulation participants, it’s possible for participants to really imagine that a disaster is taking place, which may help them to better understand what real disaster conditions might be like. It will help tremendously if the facilitator has actually experienced one or more disaster scenarios so that he or she can add more realism when describing events.
To make the simulation more credible and valuable, the scenario that is chosen should be one that has a reasonable chance of actually occurring in the local area. Good choices would include an earthquake in San Francisco or Los Angeles, a volcanic eruption in Seattle, or an avalanche in Switzerland. A poor choice would be a hurricane or tsunami in central Asia, because these events would not ever occur there.
A simulation can also go a few steps further. For instance, the simulation can take place at an established emergency operations center, the same place where emergency command and control would operate in a real disaster. Also, the facilitator could change some of the participants’ roles to simulate the real absence of certain key personnel to see how remaining personnel might conduct themselves in a real emergency.
TIP The facilitator of a simulation is limited only by his or her own imagination when organizing a simulation. One important fact to remember, though, is that a simulation does not actually affect any live or DR systems—it’s all as pretend as the make-believe cardboard television sets and computers found in furniture stores.
Parallel Test A parallel test is an actual test of disaster recovery and/or business continuity response plans and their supporting IT systems. The purpose of a parallel test is to evaluate the ability of personnel to follow directives in emergency response plans—to actually set up the DR business processing or data processing capability. In a parallel test, personnel are actually setting up the IT systems that would be used in an actual disaster and operating those IT systems with real business transactions to find out if the IT systems perform the processing correctly.
The outcome of a parallel test is threefold:
• It evaluates the accuracy of emergency response procedures.
• It evaluates the ability of personnel to correctly follow the emergency response procedures.
• It evaluates the ability of IT systems and other supporting apparatus to process real business transactions properly.
A parallel test is called a parallel test because live production systems continue to operate and the backup IT systems are processing business transactions in parallel to see if they process them the same as the live production systems do.
Setting up a valid parallel test is complicated in many cases. In effect, you need to insert a logical “Y cable” into the business process flow so that the information flow will split and flow both to production systems (without interfering with their operation) and to the backup systems. Results of transactions need to be compared. Personnel need to be able to determine whether the backup systems would be able to output correct data without actually having them do so. In many complex environments, you would not want the DR system to actually feed information back into a live environment, because that might cause duplicate events to occur someplace else in the organization (or with customers, suppliers, or other parties). For instance, in a travel reservations system, you would not want a DR system to actually book travel, because that would cost real money and consume available space on an airline or other mode of transportation. But it would be important to know whether the DR system would be able to perform those functions. Somewhere along the line, it will be necessary to “unplug” the DR system from the rest of the environment and manually examine results to see if they appear to be correct.
Organizations that do wish to see if their backup/DR systems can manage a real workload can perform a cutover test, which is discussed next.
Cutover Test A cutover test is the most intrusive type of disaster recovery test. It will also provide the most reliable results in terms of answering the question of whether backup systems have the capacity and correct functionality to shoulder the real workload properly.
The consequences of a failed cutover test, however, might resemble an actual disaster: if any part of the cutover test fails, then real, live business processes will be going without the support of IT applications as though a real outage or disaster were in progress. But even a failure like this would show you that “no, the backup systems won’t work in the event a real disaster were to happen later today.”
In some respects, a cutover test is easier to perform than a parallel test. A parallel test is a little trickier, since business information is required to flow to the production system and to the backup system, which means that some artificial component has been somehow inserted into the environment. However, with a cutover test, business processing does take place on the backup systems only, which can often be achieved through a simple configuration someplace in the network or the systems layer of the environment.
TIP Not all organizations perform cutover tests because they take a lot of resources to set up and are risky. Many organizations find that a parallel test is sufficient to tell whether backup systems are accurate, and the risk of an embarrassing incident is almost zero with a parallel test.
Documenting Test Results
Every type and every iteration of DR plan testing needs to be documented. It’s not enough to say, “We did the test on September 10, 2015, and it worked.” First of all, no test goes perfectly—opportunities for improvement are always identified. But the most important part of testing is to discover what parts of the test still need work so that those parts of the plan can be fixed before the next test (or a real disaster).
As with any well-organized project, success is in the details. The road to success is littered with big and little mistakes, and all of the things that are identified in every sort of DR test need to be detailed so that the next iteration of the test will give better results.
Recording and comparing detailed test results from one test to the next will also help the organization to measure progress. By this I mean that the quality of emergency response plans should steadily improve from year to year. Simple mistakes of the past should not be repeated, and the only failures in future tests should be in new and novel parts of the environment that weren’t well thought out to begin with. And even these should diminish over time.
Improving Recovery and Continuity Plans
Every test of recovery and response plans should include a debrief or review so that participants can discuss the outcome of the test: what went well, what went wrong, and how things should be done differently next time. All of this information should be collected by someone who will be responsible for making changes to relevant documents. The updated documents should be circulated among the test participants who can confirm whether their discussion and ideas are properly reflected in the document.
Training Personnel
The value and usefulness of a high-quality set of disaster response and continuity plans and procedures will be greatly diminished if those responsible for carrying out the procedures are unfamiliar with them.
A person cannot learn to ride a bicycle by reading even the most detailed how-to instructions on the subject, so it’s equally unrealistic to expect personnel to be able to properly carry out disaster response procedures if they are inexperienced in those procedures.
Several forms of training can be made available for the personnel who are expected to be available if a disaster strikes, including:
• Document review Personnel can carefully read through procedure documents to become familiar with the nature of the recovery procedures. But as mentioned earlier, this alone may be insufficient.
• Participation in walkthroughs People who are familiar with specific processes and systems that are the subject of walkthroughs should participate in them. Exposing personnel to the walkthrough process will not only help to improve the walkthrough and recovery procedures, but will also be a learning experience for participants.
• Participation in simulations Taking part in simulations will similarly benefit the participants by giving them the experience of thinking through a disaster.
• Participation in parallel and cutover tests Other than experiencing an actual disaster and its recovery operations, no experience is quite like participating in parallel and cutover tests. Here, participants will gain actual hands-on experience with critical business processes and IT environments by performing the actual procedures that they would in the event of a disaster. When a disaster strikes, those participants can draw upon their memory of having performed those procedures in the past, instead of just the memory of having read the procedures.
You can see that all of the levels of tests that need to be performed to verify the quality of response plans are also training opportunities for personnel. The development and testing of disaster-related plans and procedures provide a continuous learning experience for all of the personnel involved.
Making Plans Available to Personnel When Needed
When a disaster strikes, often one of the effects is no access to even the most critical IT systems. Given a 40-hour workweek, there is roughly a 25 percent likelihood that critical personnel will be at the business location when a disaster strikes (at least the violent type of disaster that strikes with no warning, such as an earthquake—other types of disasters, such as hurricanes, may afford the organization a little bit of time to anticipate the disaster’s impact). The point is that chances are very good that the personnel who are available to respond may be unable to access the procedures and other information that they will need, unless special measures are taken.
CAUTION Complete BCP documentation often contains details of key systems, operating procedures, recovery strategies, and even vendor and model identification of in-place equipment. This information can be misused if available to unauthorized personnel, so the mechanism selected for ensuring availability must include planning to exclude inadvertent disclosure.
There are several ways that response and recovery procedures can be made available to personnel during a disaster, including:
• Hard copy While many have grown accustomed to the paperless office, disaster recovery and response documentation is one type of information that should be available in hardcopy form. Copies, even multiple copies, should be available for each responder, with a copy at the workplace and another at home, and possibly even a set in the responder’s vehicle.
• Soft copy Traditionally, softcopy documentation is kept on file servers, but as you might expect, those file servers might be unavailable in a disaster. Soft copies should be available on responders’ portable devices (laptops, tablets, and smartphones). An organization can also consider issuing documentation on memory sticks and cards. Depending upon the type of disaster, it can be difficult to know what resources will be available to access documentation, so making it available in more than one form will ensure that at least one copy of it will be available to the personnel who need access to it.
• Alternate work/processing site Organizations that utilize a hot/warm/cold site for the recovery of critical operations can maintain hard copies and/or soft copies of recovery documentation there. This makes perfect sense; personnel working at an alternate processing or work site will need to know what to do, and having those procedures on-site will facilitate their work.
• Online Soft copies of recovery documentation can be archived on an Internet-based site that includes the ability to store data. Almost any type of online service that includes authentication and the ability to upload documents could be suitable for this purpose.
• Wallet cards It’s unreasonable to expect to publish recovery documentation on a laminated wallet card, but those cards could be used to store the contact information for core response team members as well as a few other pieces of information, such as conference bridge codes, passwords to online repositories of documentation, and so on. An example wallet card appears earlier in this chapter, in Figure 2-14.
Maintaining Recovery and Continuity Plans
Business processes and technology undergo almost continuous change in most organizations. A business continuity plan that is developed and tested is liable to be outdated within months and obsolete within a year. If much more than a year passes, a DR plan in some organizations may approach uselessness. This section discusses how organizations need to keep their DR plans up to date and relevant.
A typical organization needs to establish a schedule whereby the principal DR documents will be reviewed. Depending on the rate of change, this could be as frequently as quarterly or as seldom as every two years.
Further, every change, however insignificant, in business processes and information systems should include a step to review, and possibly update, relevant DR documents. That is, a review of, and possibly changes to, relevant DR documents should be a required step in every business process engineering or information systems change process, and a key component of the organization’s information system development life cycle (SDLC). If this is done faithfully, then you would expect that the annual review of DR documents would conclude that few (if any) changes were required, although it is still a good practice to perform a periodic review, just to be sure.
Periodic testing of DR documents and plans, discussed in detail in the preceding section, is another vital activity. Testing validates the accuracy and relevance of DR documents, and any issues or exceptions in the testing process should precipitate updates to appropriate documents.
Sources for Best Practices
It is unnecessary to begin business continuity planning and disaster recovery planning by first inventing a practice or methodology. Business continuity planning and disaster recovery planning are advanced professions with several professional associations, professional certifications, international standards, and publications. Any or all of these are, or can lead to, sources of practices, processes, and methodologies:
• U.S. National Institute of Standards and Technology (NIST) This is a branch of the U.S. Department of Commerce that is responsible for developing business and technology standards for the federal government. The quality of the standards developed by NIST is exceedingly high, and as a result many private organizations all over the world are adopting them. The NIST website is found at www.nist.gov.
• Business Continuity Institute (BCI) This is a membership organization dedicated to the advancement of business continuity management. BCI has over 8,000 members in almost 100 countries. Its website is found at www.thebci.org. BCI holds several events around the world, prints a professional journal, and has developed a professional certification, the Certificate of the BCI (CBCI).
• U.S. National Fire Protection Agency (NFPA) NFPA has developed a pre-incident planning standard, NFPA 1620, which addresses the protection, construction, and features of buildings and other structures. It also requires the development of pre-incident plans that emergency responders can use to deal with fires and other emergencies. The NFPA website can be found at www.nfpa.org.
• U.S. Federal Emergency Management Agency (FEMA) FEMA is a part of the Department of Homeland Security (DHS) and is responsible for emergency disaster relief planning information and services. FEMA’s most visible activities are its relief operations in the wake of hurricanes and floods in the United States. Its website can be found at www.fema.gov.
• Disaster Recovery Institute International (DRI International) This is a professional membership organization that provides education and professional certifications for disaster recovery planning professionals. Its website is found at www.drii.org. Its certifications include
• Associate Business Continuity Professional (ABCP)
• Certified Business Continuity Vendor (CBCV)
• Certified Functional Continuity Professional (CFCP)
• Certified Business Continuity Professional (CBCP)
• Master Business Continuity Professional (MBCP)
• Business Continuity Management Institute (BCM Institute) This is a professional association that specializes in education and professional certification. BCM Institute is a co-organizer of the World Continuity Congress, an annual conference that is dedicated to business continuity and disaster recovery planning. Its website can be found at www.bcm-institute.org. Certifications offered by BCM Institute include
• Business Continuity Certified Expert (BCCE)
• Business Continuity Certified Specialist (BCCS)
• Business Continuity Certified Planner (BCCP)
• Disaster Recovery Certified Expert (DRCE)
• Disaster Recovery Certified Specialist (DRCS)
Auditing IT Governance
IT governance is more about business processes than it is about technology. This will make audits of IT governance rely more on interviews and documentation reviews than on inspections of information systems. Effective or ineffective IT governance is discernible in interviews of IT personnel as well as of business customers and end users.
EXAM TIP Governance questions on the exam will consider ISACA’s COBIT strategies as the standard, but will be generic enough in nature to ensure that an understanding of other common IT governance methods will remain applicable to the test-taker. Focus here on the measures and instruments used to validate the governance model.
Problems in IT governance will manifest themselves through a variety of symptoms:
• Discontentment among staff or end users Burned-out or overworked IT staff, low IT morale, high turnover, and malaise among end users about IT-supported systems can indicate an IT department that lacks maturity and is falling behind on its methodology or is applying Band-Aid fixes to systems.
• Poor system performance Excessive incidents of unscheduled downtime, a large backlog of support tasks, and long wait times indicate a lack of attention to the quality of applications.
• Nonstandard hardware or software A mix of hardware or software technologies among applications or end-user systems may indicate a lack of technology standards or the failure to enforce standards that are already in place.
• Project dysfunction An IT department suffering from late projects, aborted projects, and budget-busting projects indicates a lack of program and project management discipline.
• Highly critical personnel A disproportionate overreliance on a few IT personnel indicates that responsibilities are not fairly apportioned over the entire IT staff. This may be a result of a lack of training, unqualified personnel, or high turnover.
Auditing Documentation and Records
The heart of an IT audit is the examination of documentation and records. They tell the story of IT control, planning, and day-to-day operations. When auditing IT governance, the IS (information systems) auditor will need to review many documents:
• IT charter, strategy, and planning These documents will indicate management’s commitment to IT strategic planning as a formally required activity. Other documents that should be sought include IT steering committee meeting agendas, minutes, and decision logs.
• IT organization chart and job descriptions These documents give an indication of the organization’s level of maturity regarding the classification of employees and their specific responsibilities. An org chart also depicts the hierarchy of management and control. Job description documents describe detailed responsibilities for each position in the IT organization. An IS auditor’s interviews should include some inquiry into the actual skills and experience of IT personnel to see whether they correspond to their respective job descriptions.
• HR/IT employee performance review process The IS auditor should review the process and procedures used for employee performance reviews. In particular, the IS auditor should view actual performance goals and review documents to see how well individual employees’ goals align with IT department objectives. Further, any performance problems identified in performance reviews can be compared with documents that describe the outcomes of key IT projects.
• HR promotion policy It will be helpful for the IS auditor to determine whether the organization has a policy (written or not) of promoting from within. In other words, when positions become available, does the organization first look within its ranks for potential candidates, or are new hires typically outsiders? This will influence both employee morale and the overall effectiveness of the IT organization.
• HR manuals Documents such as the employee handbook, corporate policies, and HR procedures related to hiring, performance evaluation, and termination should exist; reflect regular management reviews; and reflect practices that meet the organization’s business needs.
• Life cycle processes and procedures Processes such as the software development life cycle and change management should reflect the needs of IT governance. The IS auditor should request records from the SDLC (specifically, documents that describe specific changes to IT systems and supporting infrastructure) and change management process to see how changes mandated at the steering group level are carried out.
• IT operations procedures IT operations process documents for activities such as service desk, monitoring, and computer and network operations should exist. The IS auditor should request records for these activities to determine whether these processes are active.
• IT procurement process An IT organization needs to take a consistent and effective approach to the procurement process. The process should reflect management attention to requirements development, bidding, vendor selection, and due diligence so that any supplier risks are identified and mitigated in the procurement phase and reflected in the service agreement contract. The goods and services provided by suppliers should be required to adhere to the organization’s IT policies, processes, and standards; exceptions should be handled in an exception process. Records should exist that reflect ongoing attention to this process.
• Quality management documents An IT organization that is committed to quality and improvement will have documents and records to support this objective.
• Business continuity and disaster recovery documents These include documents such as the business impact assessment, critical assessment, and statements of impact, as well as evidence of periodic updates to recovery documentation and regular testing.
Another indication of a healthy governance system is evidence of regular review and update of all of these documents. Often this is found in each document’s modification history, but it may also be present in a separate document management system.
Like any other facets of an audit, the IS auditor needs to conduct several interviews and walkthroughs to gain a level of confidence that these documents reflect the actual management and operations of an IT organization. These interviews should include staff from all levels of management, as well as key end users who can also attest to IT’s organization and commitment to its governance program and the maturity of its processes.
NOTE The IS auditor should also review the processes related to the regular review and update of IT governance documents. Regular reviews attest to active management involvement in IT governance. The lack of recent reviews might suggest that management began a governance program but has subsequently lost interest in it.
Auditing Contracts
The IS auditor who is examining IT governance needs to examine the service agreements between the organization and its key IT-related suppliers. Contracts should contain several items:
• Service levels Contracts should contain a section on acceptable service levels and the process followed when service interruptions occur. Service outages should include an escalation path so that management can obtain information from appropriate levels of the supplier’s management team.
• Quality levels Contracts should contain specifications on the quality of goods or services delivered, as well as remedies when quality standards are not met.
• Right to audit Contracts should include a right-to-audit clause that permits the organization to examine the supplier’s premises and records upon reasonable notice.
• Third-party audits Contracts should include provisions that require the supplier to undergo appropriate and regular audits. Audit reports from these audits should be available upon request, including remediation plans for any significant findings found in the audit reports.
• Conformance to security policies Suppliers should be required to provide goods or services that can meet the organization’s security policies. For instance, if the organization’s security policy requires specific password-quality standards, then the goods or services from suppliers should be able to meet those standards.
• Protection and use of sensitive information Contracts should include detailed statements that describe how the organization’s sensitive information will be protected and used. This is primarily relevant in an online, SaaS (Software as a Service), or ASP (application service provider) model where some of the organization’s data will reside on systems or networks that are under the control of a supplier. The contract should include details that describe how the supplier tests its controls to ensure that they are still effective. Third-party audits of these controls may also be warranted, depending upon the sensitivity of the information in question.
• Compliance with laws and regulations Contracts should require that the supplier conform to all relevant laws and regulations. This should include laws and regulations that the organization itself is required to comply with; in other words, compliance with laws and regulations should flow to and include suppliers. For example, if a health-care organization is required to comply with HIPAA (Health Insurance Portability and Accountability Act, a U.S. law that requires specific protections of patient health-care information when in electronic form), any suppliers that store or manage the organization’s health-care–related information must be required to also be in compliance with HIPAA regulations.
• Incident notification Contracts should contain specific language that describes how incidents are handled and how the organization is notified of incidents. This includes not only service changes and interruptions, but also security incidents. The supplier should be required to notify the organization within a specific period, and also provide periodic updates as needed.
• Source code escrow If the supplier is a software organization that uses proprietary software as a means for providing services, the supplier should be required to regularly deposit its software source code into a software escrow. A software escrow firm is a third-party organization that will place software into a vault and release it to customer organizations in the event of the failure of the supplier’s business.
• Liabilities Contracts should clearly state which parties are liable for which actions and activities. They should further specify the remedies available should any party fail to perform adequately.
• Termination terms Contracts should contain reasonable provisions that describe the actions taken if the business relationship is terminated.
NOTE While the IS auditor may not be required to understand the nuances of legal contracts, the auditor should look for these sections in contracts with key suppliers. The IS auditor should also look for other contractual provisions in supplier contracts that are specific to any unique or highly critical needs that are provided by a supplier.
Auditing Outsourcing
When an auditor is auditing an organization’s key processes and systems, those processes and systems that are outsourced require just as much (if not more) scrutiny than if they were performed by the organization’s own staff using its own assets. However, it may be difficult to audit the services provided by a third-party supplier, for several reasons:
• Distance The supplier may be located in a remote region, and travel to the supplier’s location may be costly.
• Lack of audit contract terms The organization may not have a clause in its contract with the supplier that requires cooperation with auditors. While it may be said that the organization should have negotiated a right-to-audit clause, this point may be moot at the time of the audit.
• Lack of cooperation The supplier might not cooperate with the organization’s auditors. Noncooperation takes many forms, including taking excessive time to return inquiries and providing incomplete or inadequate records. An audit report may include one or more findings (nonconformities) related to the lack of cooperation; this may provide sufficient leverage to force the supplier to improve its cooperation or for the organization to look for a new supplier.
An ideal situation is one where a supplier undergoes regular third-party audits that are relevant to the services provided and where the supplier makes those audit results available on request.
Auditing Business Continuity Planning
Audits of an organization’s business continuity plan are especially difficult because it is impossible to prove whether the plans will work unless there is a real disaster.
The IT auditor has quite a task when it comes to auditing an organization’s business continuity. The lion’s share of the audit results hinges on the quality of documentation and walkthroughs with key personnel.
As is typical with most audit activities, an audit of an organization’s BC program is a top-down analysis of key business objectives and a review of documentation and interviews to determine whether the BC strategy and program details support those key business objectives. This approach is depicted in Figure 2-15.
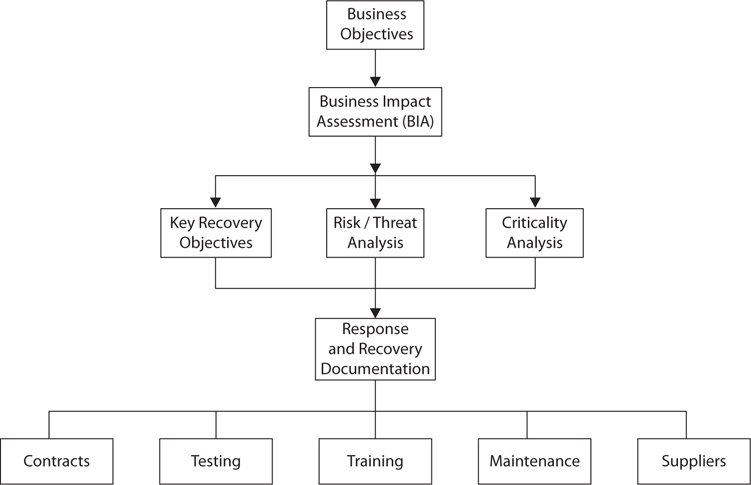
Figure 2-15 Top-down approach to an audit of business continuity
The objectives of an audit of business continuity planning should include the following activities:
• Obtain documentation that describes current business strategies and objectives. Obtain high-level documentation (for example, strategy, charter, objectives) for the BC program, and determine whether the BC program supports business strategies and objectives.
• Obtain the most recent BIA and accompanying threat analysis, risk analysis, and criticality analysis. Determine whether these documents are current, complete, and support the BC strategy. Also determine whether the scope of these documents covers those activities considered strategic according to high-level business objectives. Finally, determine whether the methods in these documents represent good practices for these activities.
• Determine whether key personnel are ready to respond during a disaster by reviewing test plans and training plans and results. Find out where emergency procedures are stored and whether key personnel have access to them.
• Verify whether there is a process for the regular review and update of BC documentation. Evaluate the process’s effectiveness by reviewing records to see how frequently documents are being reviewed.
These activities are described in more detail in the following sections.
Auditing Business Continuity Plans
The bulk of an organization’s business continuity plan lies in its documentation, so it should be of little surprise that the bulk of the audit effort will lie in the examination of this documentation. The following steps will help the auditor to determine the effectiveness of the organization’s BC plans:
• Obtain a copy of business continuity documentation, including response procedures, contact lists, and communication plans.
• Examine samples of distributed copies of BC documentation, and determine whether they are up to date. These samples can be obtained during interviews of key response personnel, which are covered in this procedure.
• Determine whether all documents are clear and easy to understand, not just for primary responders, but for alternate personnel who may have specific relevant skills but less familiarity with the organization’s critical applications.
• Examine documentation related to the declaration of a disaster and the initiation of disaster response. Determine whether the methods for declaration are likely to be effective in a disaster scenario.
• Obtain emergency contact information, and contact some of the personnel to see whether the contact information is accurate and up to date. Also determine whether all response personnel are still employed in the organization and are in the same or similar roles in support of disaster response efforts.
• Contact some or all of the response personnel who are listed in emergency contact lists. Interview them and see how well they understand their disaster response responsibilities and whether they are familiar with disaster response procedures. Ask each interviewee if they have a copy of these procedures. See if their copies are current.
• Determine whether a process exists for the formal review and update of business continuity documentation. Examine records to see how frequently, and how recently, documents have been reviewed and updated.
• Determine whether response personnel receive any formal or informal training on response and recovery procedures. Determine whether personnel are required to receive training and whether any records are kept that show which personnel received training and at what time.
Reviewing Prior Test Results and Action Plans
Effectiveness of business continuity plans relies, to a great degree, on the results and outcomes of tests. An IS auditor needs to carefully examine these tests to determine their effectiveness and to what degree they are used to improve procedures and to train personnel. The following procedure will help the IS auditor to determine the effectiveness of business continuity testing:
• Determine whether there is a strategy for testing business continuity procedures. Obtain records for past tests and a plan for future tests. Determine whether prior tests and planned tests are adequate for establishing the effectiveness of response and recovery procedures.
• Examine records for tests that have been performed over the past year or two. Determine the types of tests that were performed. Obtain a list of participants for each test. Compare the participants to lists of key recovery personnel. Examine test work papers to determine the level of participation by key recovery personnel.
• Determine whether there is a formal process for recording test results and for using those results to make improvements in plans and procedures. Examine work papers and records to determine the types of changes that were recommended in prior tests. Examine BC documents to see whether these changes were made as expected.
• Considering the types of tests that were performed, determine the adequacy of testing as an indicator of the effectiveness of the BC program. Did the organization only perform document reviews and walkthroughs, for example, or did the organization also perform parallel or cutover tests?
• If tests have been performed for two years or more, determine whether there’s a trend showing continuous improvement in response and recovery procedures.
• If the organization performs parallel tests, determine whether tests are designed in a way that effectively determines the actual readiness of standby systems. Also determine whether parallel tests measure the capacity of standby systems or merely their ability to process correctly but at a lower level of performance.
Interviewing Key Personnel
The knowledge and experience of key personnel are vital to the success of any disaster response operation. Interviews will help the IT auditor determine whether key personnel are prepared and trained to respond during a disaster. The following procedure will guide the IT auditor in interviews:
• Obtain the name, title, tenure, and full contact information for each person interviewed.
• Ask the interviewee to summarize his or her professional experience and training and current responsibilities in the organization.
• Ask the interviewee whether he or she is familiar with the organization’s business continuity and disaster recovery programs.
• Determine whether the interviewee is among the key response personnel expected to respond during a disaster.
• Ask the interviewee if he or she has been issued a copy of any response or recovery procedures. If so, ask to see those procedures; determine whether they are current versions. Ask if the interviewee has additional sets of procedures in any other locations (residence, for example).
• Ask the interviewee if he or she has received any training. Request evidence of this training (certificate, calendar entry, and so on).
• Ask the interviewee if he or she has participated in any tests or evaluations of recovery and response procedures. Ask the interviewee whether he or she felt the tests were effective, whether management takes the tests seriously, and whether any deficiencies in tests resulted in any improvements to test procedures or other documents.
Reviewing Service Provider Contracts
No organization is an island. Every organization has critical suppliers without which it could not carry out its critical functions. The ability to recover from a disaster also frequently requires the support of one or more service providers or suppliers. The IT auditor should examine contracts for all critical suppliers and consider the following guidelines:
• Does the contract support the organization’s requirements for delivery of services and supplies, even in the event of a local or regional disaster?
• Determine whether the service provider has its own disaster recovery capabilities that will ensure its ability to deliver critical services during a disaster.
• Determine the recourse available should the supplier be unable to provide goods or services during a disaster.
Reviewing Insurance Coverage
The IT auditor should examine the organization’s insurance policies related to the loss of property and assets supporting critical business processes. Insurance coverage should cover the actual cost of recovery, or a lesser amount if the organization’s executive management has accepted a lower amount. The IT auditor should obtain documentation that includes cost estimates for various disaster recovery scenarios, including equipment replacement, business interruption, and the cost of performing business functions and operating IT systems in alternate sites. These cost estimates should be compared with the value of insurance policies.
Visiting Media Storage and Alternate Processing Sites
The IT auditor should identify and visit remote sites used for storage of backup media and alternate processing. This will permit the auditor to confirm their existence, verify features and functions of these sites to see if they correspond to details in continuity and recovery plans, and to discover any risks.
Summary
IT governance is the top-down management and control of an IT organization. Governance is usually undertaken through a steering committee that consists of executives from throughout the organization. The steering committee is responsible for setting overall strategic direction and policy, ensuring that IT strategy is in alignment with the organization’s strategy and objectives. The wishes of the steering committee are carried out through projects and tasks that steer the IT organization toward strategic objectives. The steering committee can monitor IT progress through a balanced scorecard.
The IT steering committee is responsible for IT strategic planning. The IT steering committee will develop and approve IT policies, and appoint managers to develop and maintain processes, procedures, and standards, all of which should align with each other and with the organization’s overall strategy.
Security governance is accomplished using the same means as IT governance: it begins with board-level involvement that sets the tone for risk appetite and is carried out through the chief information security officer (CISO) or chief information risk officer (CIRO), who develops security and privacy policies, as well as strategic security programs, including incident management, vulnerability management, and identity and access management.
Risk management is the practice of identifying key assets and the vulnerabilities they may possess and the threats that may harm them if permitted. This is accomplished through a risk assessment that identifies assets, threats, and vulnerabilities in detail, and is followed by specific risk treatment strategies used to mitigate, transfer, avoid, or accept risks. A risk assessment may be qualitative, where threats and risks are labeled on scales such as “high,” “medium,” and “low”; or it may be quantitative, where risks are expressed in financial terms.
Key management practices will help ensure that the IT organization will operate effectively. These practices include personnel management, which encompasses the hiring, development, and evaluation of employees, as well as onboarding and offboarding processes, and development of the employee handbook and other policies. Another key practice area is sourcing, which is the management of determining where and by whom key business processes will be performed; the basic choices are insourced or outsourced and on-site or off-site. The third key practice area is change management, the formal process whereby changes are applied to IT environments in a way that reduces risk and ensures highest reliability. The next practice area is financial management, a key area, given that IT organizations are cost-intensive and require planning and analysis to guarantee the best use of financial resources. Another practice area is quality management, where processes are carefully measured and managed so that they may be continuously improved over time. Another practice is portfolio management, which is the systematic management of IT projects, investments, and activities. The next key practice is controls management, which is the life cycle of activities related to the creation, measurement, and improvement of controls. The next practice area is security management, which encompasses several activities, including risk assessments, incident management, vulnerability management, access and identity management, compliance management, business continuity planning, and performance and capacity management.
The IT organization should have a formal management and reporting structure, as well as established roles and responsibilities, and written job descriptions. Roles and responsibilities should address the need for segregation of duties to ensure that high-value and high-risk tasks are carried out by two or more persons and recorded.
Natural and human-made disasters can damage business facilities, assets, and information systems, thus threatening the viability of the organization by halting its critical processes. Even without direct effects, many secondary or indirect effects from a disaster such as crippled transportation systems, damaged communications systems, and damaged public utilities can seriously harm an organization. The development of business continuity plans helps an organization to be better prepared to act when a disaster strikes. A vital part of this preparation is the development of alternative means for continuing the most critical activities, usually in alternative locations that are not damaged by a disaster.
There is an accepted methodology to business continuity and disaster recovery planning, which begins with the development of a business continuity planning policy, a statement of the goals and objectives of a planning effort. This is followed by a BIA, a study of the organization’s business processes to determine which are the most critical to the organization’s ongoing viability. For each critical process, a statement of impact is developed, which is a brief description of the effect on the organization if the process is incapacitated for any significant period. The statement of impact can be qualitative or quantitative.
A criticality analysis is performed next, where all in-scope business processes are ranked in order of criticality. Ranking can be strictly quantitative, qualitative, or even subjective. The maximum tolerable downtime (MTD) is established for each critical business process. This drives the development of recovery targets.
Next, recovery targets for each critical business process are developed. The key targets are RTO and RPO. These targets specify time to system restoration and maximum data loss, respectively. When these targets have been established, the project team can develop plans that include changes to technical architecture as well as business processes that will help achieve these established recovery objectives.
Continuity plans are then developed. These consist of procedures for personnel safety and disaster declaration, together with definitions of responsibilities, contact information for key personnel, and procedures for recovery, continuity of operations, and restoration of assets.
The effectiveness of business continuity plans can only be determined by testing. There are five types of tests: document review, walkthrough, simulation, parallel test, and cutover test. These five tests represent progressively more complex (and risky) means for testing procedures and IT systems to determine whether they will be able to actually support critical business processes in a real disaster. The parallel test involves the use of backup IT systems in a way that enables them to process real business transactions while primary systems continue to perform the organization’s real work. The cutover test actually transitions business data processing to backup IT systems, where they will process actual business workload for a period.
Response personnel need to be carefully chosen from available staff to ensure that sufficient numbers of personnel will be available in a real disaster. Some personnel may be unable to respond for a variety of reasons that are related to the disaster itself. As a result, some of the personnel who respond in an actual disaster may not be as familiar with the systems and procedures required to recover and maintain them. This makes training and accurate procedures critical for effective disaster recovery.
Recovery and continuity plans need to be periodically updated to reflect changes in information systems, and distributed to or made available to response and recovery personnel.
The IS auditor who is auditing IT governance and risk management needs to examine organization policies, processes, and records that reflect active involvement by steering committees, management, and staff. The IS auditor must determine whether the IT organization is operating in alignment with overall organization objectives and according to the wishes of executive management.
Auditing an organization’s business continuity capabilities involves the examination of BCP policies, plans, and procedures, as well as contracts and technical architectures. The IT auditor also needs to interview response personnel to gauge their readiness and to visit off-site media storage and alternate processing sites to identify risks present there.
Notes
• IT executives and the board of directors are responsible for imposing an IT governance model encompassing IT strategy, information security, and formal enterprise architectural mandates.
• Strategic planning is accomplished by the steering committee, addressing the near-term and long-term requirements aligning business objectives and technology strategies.
• Policies, procedures, and standards allow validation of business practices against acceptable measures of regulatory compliance, performance, and standard operational guidelines.
• Risk management involves the identification of potential risks and the appropriate responses for each risk based on impact assessment using qualitative and/or quantitative measures for an enterprise-wide risk management strategy.
• Assigned IT management roles ensure that resource allocation, enterprise performance, and operational capabilities coordinate with business requirements by validating alignment with standards and procedures for change management and compliance with sourcing, financial, quality, and security controls.
• Formal organizational structure ensures alignment between operational roles and responsibilities within the enterprise, where a separation of duties ensures individual accountability and validation of policy alignment between coordinated team members.
• Business continuity planning ensures business recovery following a disaster. Business continuity focuses on maintaining service availability with the least disruption to standard operating parameters during an event, while disaster recovery focuses on post-event recovery and restoration of services.
• The BCP process encompasses a life cycle beginning with the initial BCP policy, followed by business impact and criticality analysis to evaluate risk and impact factors. Recovery targets facilitate the development of strategies for continuity and recovery, which then must be tested and conveyed to operation personnel through training and exercise. Post-implementation maintenance includes periodic reviews and updates as part of the enterprise continuous-improvement process.
• The business impact analysis (BIA) measures the impact on enterprise operation posed by various identified areas of risk. The output of the BIA is used in the criticality analysis (CA), which measures the impact of each risk against its likelihood and the cost of mitigation. Maximum tolerable downtime (MTD) metrics are established for each critical process.
• The output of the BIA, CA, and MTD activities are used when establishing recovery time objectives (RTOs) and recovery point objectives (RPOs), which can then be measured against relative cost scenarios for each identified risk and mitigation option.
• RTOs and RPOs are fed into the disaster recovery process so that staff can develop resilient and recoverable IT architectures supporting critical business processes.
• BC plans must be tested to validate effectiveness through document review, walkthrough, simulation, parallel testing, or cutover testing practices. Regular testing must take place to ensure new objectives and procedures meet the requirements of a living enterprise environment. Participation in these tests provides familiarity and training for engaged operational staff members, raising understanding and awareness of requirements and responsibilities.
• Regular audit of the IT governance process ensures alignment with regulatory and business mandates in the evolving enterprise by ensuring all documentation, contracts, and sourcing policies are reviewed and updated to meet changes in the living enterprise.
Questions
1. IT governance is most concerned with:
A. Security policy
B. IT policy
C. IT strategy
D. IT executive compensation
2. One of the advantages of outsourcing is
A. It permits the organization to focus on core competencies.
B. It results in reduced costs.
C. It provides greater control over work performed by the outsourcing agency.
D. It eliminates segregation of duties issues.
3. An external IS auditor has discovered a segregation of duties issue in a high-value process. What is the best action for the auditor to take?
A. Implement a preventive control.
B. Implement a detective control.
C. Implement a compensating control.
D. Document the matter in the audit report.
4. An organization has chosen to open a business office in another country where labor costs are lower and has hired workers to perform business functions there. This organization has
A. Outsourced the function
B. Outsourced the function offshore
C. Insourced the function on-site
D. Insourced the function at a remote location
5. What is the purpose of a criticality analysis?
A. Determine feasible recovery targets.
B. Determine which staff members are the most critical.
C. Determine which business processes are the most critical.
D. Determine maximum tolerable downtime.
6. An organization needs to better understand whether one of its key business processes is effective. What action should the organization consider?
A. Audit the process.
B. Benchmark the process.
C. Outsource the process.
D. Offshore the process.
7. Annualized loss expectancy (ALE) is defined as:
A. Single loss expectancy (SLE) times annualized rate of occurrence (ARO)
B. Exposure factor (EF) times the annualized rate of occurrence (ARO)
C. Single loss expectancy (SLE) times the exposure factor (EF)
D. Asset value (AV) times the single loss expectancy (SLE)
8. A quantitative risk analysis is more difficult to perform because:
A. It is difficult to get accurate figures on the impact of a realized threat.
B. It is difficult to get accurate figures on the frequency of specific threats.
C. It is difficult to get accurate figures on the value of assets.
D. It is difficult to calculate the annualized loss expectancy of a specific threat.
9. A collection of servers that is designed to operate as a single logical server is known as a:
A. Cluster
B. Grid
C. Cloud
D. Replicant
10. The purpose of a balanced scorecard is to:
A. Measure the efficiency of an IT organization
B. Evaluate the performance of individual employees
C. Benchmark a process in the organization against peer organizations
D. Measure organizational performance and effectiveness against strategic goals
11. An organization has discovered that some of its employees have criminal records. What is the best course of action for the organization to take?
A. Terminate the employees with criminal records.
B. Immediately perform background checks, including criminal history, on all existing employees.
C. Immediately perform background checks, including criminal history, on all new employees.
D. Immediately perform background checks on those employees with criminal records.
12. The options for risk treatment are
A. Risk mitigation, risk reduction, and risk acceptance
B. Risk mitigation, risk reduction, risk transfer, and risk acceptance
C. Risk mitigation, risk avoidance, risk transfer, and risk acceptance
D. Risk mitigation, risk avoidance, risk transfer, and risk conveyance
13. An IS auditor is examining the IT standards document for an organization that was last reviewed two years earlier. The best course of action for the IS auditor is
A. Locate the IT policy document and see how frequently IT standards should be reviewed.
B. Compare the standards with current practices and make a determination of adequacy.
C. Report that IT standards are not being reviewed often enough.
D. Report that IT standards are adequate.
14. The most important step in the process of outsourcing a business function is
A. Developing a business case
B. Measuring the cost savings
C. Measuring the change in risk
D. Performing due diligence on the external service provider
15. An organization has published a new security policy. What is the best course of action for the organization to undertake to ensure that all employees will support the policy?
A. The company CEO should send an e-mail to all employees, instructing them to support the policy.
B. The company should provide training on the new security policy.
C. The company should publish the policy on an internal website.
D. The company should require all employees to sign a statement agreeing to support the policy.
Answers
1. C. IT governance is the mechanism through which IT strategy is established, controlled, and monitored through the balanced scorecard. Long-term and other strategic decisions are made in the context of IT governance.
2. A. Outsourcing is an opportunity for the organization to focus on its core competencies. When an organization outsources a business function, it no longer needs to be concerned about training employees in that function. Outsourcing does not always reduce costs, because cost reduction is not always the primary purpose for outsourcing in the first place.
3. D. The external auditor can only document the finding in the audit report. An external auditor is not in a position to implement controls.
4. D. An organization that opens a business office in another country and staffs the office with its own employees is not outsourcing, but is insourcing. Outsourcing is the practice of using contract labor, which is clearly not the case in this example. In this case, the insourcing is taking place at a remote location.
5. C. A criticality analysis is used to determine which business processes are the most critical by ranking them in order of criticality.
6. B. An organization that needs to better understand whether a key process is effective should consider benchmarking the process. This will help the organization better understand whether its approach is similar to that of other organizations.
7. A. Annualized loss expectancy (ALE) is the annual expected loss to an asset. It is calculated as the single loss expectancy (SLE—the financial loss experienced when the loss is realized one time) times the annualized rate of occurrence (ARO—the number of times that the organization expects the loss to occur).
8. B. The most difficult part of a quantitative risk analysis is determining the probability that a threat will actually be realized. It is relatively easy to determine the value of an asset and the impact of a threat event.
9. A. A server cluster is a collection of two or more servers that is designed to appear as a single server.
10. D. The balanced scorecard is a tool that is used to quantify the performance of an organization against strategic objectives. The focus of a balanced scorecard is financial, customer, internal processes, and innovation/learning.
11. B. An organization that has discovered that some employees have criminal records should have background checks performed on all existing employees, and also begin instituting background checks (which should include criminal history) for all new employees. It is not necessarily required to terminate these employees; the specific criminal offenses may not warrant termination.
12. C. The options for risk treatment are the actions that management will take when a risk has been identified. The options are risk mitigation (where the risk is reduced), risk avoidance (where the activity is discontinued), risk transfer (where the risk is transferred to an insurance company), and risk acceptance (where management agrees to accept the risk as-is).
13. C. IT standards that have not been reviewed for two years are out of date. If the IS auditor finds an IT policy that says that IT standards can be reviewed every two years, then there is a problem with IT policy as well; two years is far too long between reviews of IT standards.
14. A. Development of a business case is the most important step when considering the outsourcing of a business function. The other items (measuring cost savings and changes in risk, and performing due diligence on service providers) are parts of development of a business case.
15. D. All employees should be required to sign a statement agreeing to support the policy. The other actions are important but less effective.