
18. Loading Custom Data Formats into Cascalog
In the prior chapter we did some data-munging to get our data into a more acceptable format prior to loading into Cascalog. What if we could modify Cascalog to read the file directly? We’ll do that now.
Assumptions
In this chapter we assume the following:
![]() You have Leiningen set up.
You have Leiningen set up.
![]() You have read the previous Cascalog chapters.
You have read the previous Cascalog chapters.
Benefits
The benefit of this chapter is understanding and applying the Cascalog and Hadoop framework sufficiently to write your own custom data format reader.
The Recipe—Code
To load custom data directly, we need to create new instances of the Hadoop classes that read from a stream of data. We want our stream reader to stop and start at sentence ends.
1. Create a new Leiningen project cascalog-sentence-reader in your projects directory, and change to that directory:
lein new cascalog-sentence-reader
cd cascalog-sentence-reader
2. Change the project.clj to be the following:
(defproject cascalog-sentence-reader "0.1.0-SNAPSHOT"
:description "Sentence stream reader"
:source-paths ["src/clj"]
:java-source-paths ["src/java" "test/java"]
:junit ["test/java"]
:main cascalog-sentence-reader.max-length
:uberjar-name "sentence-reader.jar"
:dependencies [[org.clojure/clojure "1.5.1"]
[org.apache.hadoop/hadoop-core "0.20.2"]
[org.apache.hadoop/hadoop-common "0.22.0"]
[junit/junit "4.6"]
[cascalog/cascalog-core "2.0.0"]
[cascalog/cascalog-more-taps "2.0.0"]])
3. Now as this contains significant Java code, if you run into trouble it may be helpful to debug it as a Maven project in Eclipse. If you need to debug the Java code in this project (and hopefully you won’t), create the Maven pom.xml by running the following command:
lein pom
4. First we’ll set up our test data:
mkdir data
cp ../cascalog-pre-format/data/AdventuresOfHuckleBerryFinn.txt data
5. Create the following directory structures:
src/java/cascalogSentenceReader
src/clj/cascalog_sentence_reader
Delete the directory structure:
src/cascalog_sentence_reader
6. Next we’ll make the classes. Create the file src/java/cascalogSentenceReader/SentenceReaderAlgorithm.java with the following contents:
package cascalogSentenceReader;
import static java.lang.Character.isLowerCase;
import java.io.BufferedReader;
import java.io.IOException;
public class SentenceReaderAlgorithm {
private boolean isNextCharTerminatorFollowedBySpaceAndNBS(BufferedReader
br, char d) throws IOException {
// can't reuse code because of single mark method (need it to be
// recursive)
br.mark(3);
// assumption that EOF already tested
char a = ((char) br.read());
if (a == d) {
char b = ((char) br.read());
if (b == 'u0020') {// regular space
int cint = br.read();
char c = ((char) cint);
if (c == 'u00A0') { // non-breaking space
//br.reset();
return true;
} else {
br.reset();
return false;
}
} else {
br.reset();
return false;
}
} else {
br.reset();
return false;
}
}
private boolean isNextCharTerminatorFollowedBySpace(BufferedReader br,
char c)
throws IOException {
br.mark(2);
char a = ((char) br.read());
if (a == c) {
char b = ((char) br.read());
if (b == 'u0020') {// regular space
return true;
} else {
br.reset();
return false;
}
} else {
br.reset();
return false;
}
}
private boolean isNextCharTerminator(BufferedReader br, char c) throws
IOException {
return isNextCharTerminatorFollowedBySpaceAndNBS(br, c)
|| isNextCharTerminatorFollowedBySpace(br, c);
}
public boolean isNextCharEOF(BufferedReader br) throws IOException {
// flag the reset point
br.mark(1);
if (br.read() == -1) {
br.reset();
return true;
} else {
br.reset();
return false;
}
}
private boolean isNextCharLowercase(BufferedReader br) throws IOException
{
br.mark(1);
if (isLowerCase( ((char) br.read()))) {
br.reset();
return true;
}
else {
br.reset();
return false;
}
}
private boolean isNextTwoCharsLineFeedNewlineWithNoTrailingLowerCase(
BufferedReader br) throws IOException {
br.mark(3);
if (((char) br.read()) == '
')
if (((char) br.read()) == '
')
if (!isNextCharLowercase(br))
return true;
else {
br.reset();
return false;
}
else {
br.reset();
return false;
}
else {
br.reset();
return false;
}
}
private boolean isNextCharNewlineWithNoTrailingLowerCase(BufferedReader
br)
throws IOException {
br.mark(2);
if (((char) br.read()) == '
')
if (!isNextCharLowercase(br))
return true;
else {
br.reset();
return false;
}
else {
br.reset();
return false;
}
}
private boolean isNextTwoCharsSpaceNBS(BufferedReader br) throws
IOException {
br.mark(2);
if (((char) br.read()) == 'u0020')
if (((char) br.read()) == 'u00A0')
return true;
else {
br.reset();
return false;
}
else {
br.reset();
return false;
}
}
private boolean isNextTwoCharsLineFeedNewline(BufferedReader br) throws
IOException {
br.mark(2);
if (((char) br.read()) == '
')
if (((char) br.read()) == '
')
return true;
else {
br.reset();
return false;
}
else {
br.reset();
return false;
}
}
public String readSentence(BufferedReader br) throws IOException {
String result = "";
while (true) {
// Handle termination condition
if (isNextCharTerminator(br, '.') ) {
result += ".";
break;
}
if (isNextCharTerminator(br, '?') ) {
result += "?";
break;
}
if (isNextCharEOF(br)
|| isNextTwoCharsLineFeedNewlineWithNoTrailingLowerCase
(br)
|| isNextCharNewlineWithNoTrailingLowerCase(br)
)
break;
if (!isNextTwoCharsSpaceNBS(br) )
result += (char) br.read();
if (isNextTwoCharsLineFeedNewline(br))
result += " ";
}
//trim whitespace
result = result.replaceAll("u00A0", "");
result = result.replaceAll("u00C2", "");
result = result.replaceAll(""+Character.toChars(239)[0],"");
result = result.replaceAll(""+Character.toChars(187)[0],"");
result = result.replaceAll(""+Character.toChars(191)[0],"");
//put m-dashes back in
result = result.replaceAll(""+Character.toChars(151)[0]," - ");
return result;
}
}
7. Next create the file src/java/cascalogSentenceReader/SentenceRecordReader.java with the following contents:
package cascalogSentenceReader;
import java.io.BufferedReader;
import java.io.DataInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.charset.Charset;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapred.RecordReader;
public class SentenceRecordReader implements RecordReader<Text,
BytesWritable> {
private FileSplit fileSplit;
private Configuration conf;
private boolean processed = false;
private Path file;
private FSDataInputStream fsdis = null;
private BufferedReader brz;
public SentenceRecordReader(FileSplit fileSplit, Configuration conf) {
this.fileSplit = fileSplit;
this.conf = conf;
file = fileSplit.getPath();
FileSystem fs;
try {
fs = file.getFileSystem(conf);
fsdis = fs.open(file);
DataInputStream dis = //new DataInputStream(fstream);
new DataInputStream(fsdis);
brz = new BufferedReader(new InputStreamReader(//in,
dis,
Charset.forName("ISO-8859-1")));
} catch (IOException e) {
e.printStackTrace();
}
}
public boolean next(Text key, BytesWritable value) throws IOException {
if (!processed) {
String fileName = file.getName();
SentenceReaderAlgorithm sra = new SentenceReaderAlgorithm();
try {
String sentence = sra.readSentence(brz);
byte[] contents = new byte[(int) sentence.length()];
contents = sentence.getBytes();
key.set(sentence);
value.set(contents, 0, contents.length);
} catch (Exception e) {
e.printStackTrace();
} finally {
}
processed = sra.isNextCharEOF(brz);
return true;
}
return false;
}
public Text createKey() {
return new Text();
}
public BytesWritable createValue() {
return new BytesWritable();
}
public long getPos() throws IOException {
return processed ? fileSplit.getLength() : 0;
}
public float getProgress() throws IOException {
return processed ? 1.0f : 0.0f;
}
public void close() throws IOException {
fsdis.close();
}
}
8. Next create the file src/java/cascalogSentenceReader/SentenceInputFormat.java with the following contents:
package cascalogSentenceReader;
import java.io.IOException;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapred.InputSplit;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.RecordReader;
import org.apache.hadoop.mapred.Reporter;
public class SentenceInputFormat extends FileInputFormat {
@Override
public RecordReader getRecordReader(InputSplit input, JobConf job,
Reporter reporter) throws IOException {
reporter.setStatus(input.toString());
return new SentenceRecordReader((FileSplit) input, job);
}
protected boolean isSplitable(FileSystem fs, Path file) {
return false;
}
}
9. Next create the file src/java/cascalogSentenceReader/SentenceFileCascading.java with the following contents:
package cascalogSentenceReader;
import java.io.IOException;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.RecordReader;
import cascading.flow.FlowProcess;
import cascading.scheme.Scheme;
import cascading.scheme.SinkCall;
import cascading.scheme.SourceCall;
import cascading.tap.Tap;
import cascading.tuple.Fields;
import cascading.tuple.Tuple;
public class SentenceFileCascading
extends
Scheme<JobConf, RecordReader, OutputCollector, Object[], Object[]> {
public SentenceFileCascading(Fields fields) {
super(fields);
}
@Override
public void sink(FlowProcess<JobConf> arg0,
SinkCall<Object[], OutputCollector> arg1)
throws IOException {
throw new UnsupportedOperationException("Not supported yet.");
}
@Override
public void sinkConfInit(FlowProcess<JobConf> arg0,
Tap<JobConf,RecordReader,OutputCollector> arg1, JobConf arg2) {
throw new UnsupportedOperationException("Not supported yet.");
}
@Override
public void sourcePrepare(FlowProcess<JobConf> flowProcess,
SourceCall<Object[], RecordReader> sourceCall) {
sourceCall.setContext(new Object[2]);
sourceCall.getContext()[0] = sourceCall.getInput().createKey();
sourceCall.getContext()[1] = sourceCall.getInput().createValue();
}
@Override
public boolean source(FlowProcess<JobConf> arg0,
SourceCall<Object[], RecordReader> sourceCall) throws
IOException {
Text key = (Text) sourceCall.getContext()[0];
BytesWritable value = (BytesWritable) sourceCall.getContext()[1];
boolean result = sourceCall.getInput().next(key, value);
if (!result)
return false;
sourceCall.getIncomingEntry()
.setTuple(new Tuple(key.toString(), value));
return true;
}
@Override
public void sourceConfInit(FlowProcess<JobConf> arg0,
Tap<JobConf,RecordReader,OutputCollector> arg1, JobConf conf) {
conf.setInputFormat(SentenceInputFormat.class);
}
}
10. Now we’ll set up our Cascalog calling files. Create a new file src/clj/cascalog_sentence_reader/max_length.clj with the following contents:
(ns cascalog-sentence-reader.max-length
(:require [cascalog.cascading.util :as util]
[cascalog.logic [vars :as v] [ops :as c]]
[clojure.string :as s :refer [join]]
[cascalog.api :refer :all]
[cascalog.cascading.io :refer [get-bytes]]
[cascalog.more-taps :refer [hfs-delimited]])
(:import [cascalogSentenceReader SentenceFileCascading]
[cascading.tuple Fields])
(:gen-class))
(defn sentence-file
"Custom scheme for dealing with entire files."
[field-names]
(SentenceFileCascading. (util/fields field-names)))
(defn hfs-sentencefile
"Subquery to return distinct files in the supplied directory. Files
will be returned as 2-tuples, formatted as '<filename, file>' The
filename is a text object, while the entire, unchopped file is
encoded as a Hadoop `BytesWritable` object."
[path & opts]
(let [scheme (-> (:outfields (apply array-map opts) Fields/ALL)
(sentence-file))]
(apply hfs-tap scheme path opts)))
(defmapcatfn split [line]
"reads in a line of string and splits it by regex"
(s/split line #"[[]\(),.)s]+"))
(defn -main [in out & args]
(let [; define subquery for average
counts (<- [ ?word-count ?sentence]
((hfs-sentencefile in :skip-header? false) ?sentence _)
(split ?sentence :> ?word-dirty)
(c/count ?word-count))]
(?<- (hfs-delimited out)
[ ?mymax ]
(counts ?vals ?sentence)
(c/max ?vals :> ?mymax))))
(defn -main-get-sentence [in out & args]
(let [counts (<- [?word-count ?sentence]
((hfs-sentencefile in :skip-header? false) ?sentence _)
(split ?sentence :> ?word-dirty)
(c/count ?word-count))]
(?<- (hfs-delimited out) [ ?word-count ?sentence]
((c/first-n counts 1
:sort ["?word-count"]
:reverse true)
?word-count ?sentence))))
11. Create a new file src/clj/cascalog_sentence_reader/max_sentence.clj with the following contents:
(ns cascalog-sentence-reader.max-sentence
(:require [cascalog.cascading.util :as util]
[cascalog.logic [vars :as v] [ops :as c]]
[clojure.string :as s :refer [join]]
[cascalog.api :refer :all]
[cascalog.cascading.io :refer [get-bytes]]
[cascalog.more-taps :refer [hfs-delimited]])
(:import [cascalogSentenceReader SentenceFileCascading]
[cascading.tuple Fields])
(:gen-class))
(defn sentence-file
"Custom scheme for dealing with entire files."
[field-names]
(SentenceFileCascading. (util/fields field-names)))
(defn hfs-sentencefile
"Subquery to return distinct files in the supplied directory. Files
will be returned as 2-tuples, formatted as '<filename, file>' The
filename is a text object, while the entire, unchopped file is
encoded as a Hadoop 'BytesWritable' object."
[path & opts]
(let [scheme (-> (:outfields (apply array-map opts) Fields/ALL)
(sentence-file))]
(apply hfs-tap scheme path opts)))
(defmapcatfn split [line]
"reads in a line of string and splits it by regex"
(s/split line #"[[]\(),.)s]+"))
(defn -main [in out & args]
(let [counts (<- [?word-count ?sentence]
((hfs-sentencefile in :skip-header? false) ?sentence _)
(split ?sentence :> ?word-dirty)
(c/count ?word-count))]
(?<- (hfs-delimited out) [ ?word-count ?sentence]
((c/first-n counts 1
:sort ["?word-count"]
:reverse true)
?word-count ?sentence))))
Testing the Recipe
Test the recipe by following these steps:
1. Build it and run it with the following command:
lein uberjar
2. Now run it with the following commands:
rm -rf output
hadoop jar target/sentence-reader.jar data/AdventuresOfHuckleBerryFinn.txt
output/max
3. Then look at the output. Run the command
cat output/max/part-00000
You should see the following:
269
So the longest sentence in the file has 269 words (this book does have a number of rambling monologues).
4. Now we’ll find out what that sentence was. In the file project.clj, modify the :main method to comment out the max-length namespace and uncomment the max-sentence namespace so it looks like the following:
;;:main cascalog-sentence-reader.max-length
main cascalog-sentence-reader.max-sentence
Now repeat the build steps above (especially deleting the output directory).
lein uberjar
rm -rf output
hadoop jar target/sentence-reader.jar data/AdventuresOfHuckleBerryFinn.txt
output/max
5. To view the output, run the following command:
cat output/max/part-00000
This shows the file output/max/part-00000:
269 The first thing to see, looking away over the water, was a kind of
dull line - that was the woods on t'other side; you couldn't make nothing
else out; then a pale place in the sky; then more paleness spreading around;
then the river softened up away off, and warn't black any more, but gray; you
could see little dark spots drifting along ever so far away - trading scows,
and such things; and long black streaks - rafts; sometimes you could hear a
sweep screaking; or jumbled up voices, it was so still, and sounds come so
far; and by and by you could see a streak on the water which you know by the
look of the streak that there's a snag there in a swift current which breaks
on it and makes that streak look that way; and you see the mist curl up off
of the water, and the east reddens up, and the river, and you make out a
log-cabin in the edge of the woods, away on the bank on t'other side of the
river, being a woodyard, likely, and piled by them cheats so you can throw a
dog through it anywheres; then the nice breeze springs up, and comes fanning
you from over there, so cool and fresh and sweet to smell on account of the
woods and the flowers; but sometimes not that way, because they've left
dead fish laying around, gars and such, and they do get pretty rank; and
next you've got the full day, and everything smiling in the sun, and the
song-birds just going it!
You can see this is the longest sentence in the book. So without needing to do a pre-parsing step, we can read a custom data file format that doesn’t fit into a line-delimited standard.
Notes on the Solution
Now from a purist point of view, the Cascalog reader could be done in Clojure. However, we have provided a pragmatic solution that is easy to debug and has greater support online. We’ll start by writing a stream reader to read sentences.
Now we’ll look at a class diagram of the Java classes we’ve created. Take a look at Figure 18.1.
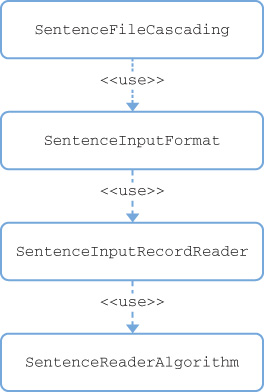
The first class, SentenceFileCascading, follows the Tap pattern that Cascading uses to read files. The second and third classes, SentenceInputFormat and SentenceInputRecordReader, follow the Hadoop patterns for reading files. The fourth class, SentenceReaderAlgorithm, is our sentence stream reader implementation from the previous section. So let’s implement it!
At the last step, where we changed the :main key in the project.clj, the particular change is here (hfs-delimited out) [ ?word-count ?sentence] so we output both a word count and the sentence.