
CHAPTER 11
Security in the Cloud
In this chapter, you will learn about
• Data security
• Network security
• Endpoint protection
• Access control
This chapter covers the concepts of security in the cloud as they apply to data both in motion across networks and at rest in storage, as well as the controlled access to information in both states. Our security coverage begins with some high-level best practices and then delves into the details of the mechanisms and technologies required to deliver against those practices. Some of these technologies include encryption (data confidentiality) and digital signatures (data integrity) and their supporting systems.
Access control is the process of determining who should be able to view, modify, or delete information. Controlling access to network resources such as files, folders, databases, and web applications requires effective access control techniques.
Data Security
Data security encompasses data as it traverses a network, as well as stored data or data at rest. Data security is concerned with data confidentiality (encryption), ensuring that only authorized parties can access data, and data integrity (digital signatures), ensuring that data is tamper-free and comes from a trusted party. These can be implemented alongside a public key infrastructure (PKI). Encryption is also used to create secure connections between locations in a technique called tunneling. These control mechanisms can be used separately or together for the utmost security, and this section will explore them in detail in the following sections:
• Encryption
• Public key infrastructure
• Encryption protocols
• Tunneling protocols
• Ciphers
• Storage security
• Protected backups
Encryption
Encryption is the process of making data unreadable to anyone except those who have the correct decryption key. Encryption is performed by changing the bits that make up the data by running them through an encryption algorithm. The algorithm uses a mathematical formula and a unique key or a key pair to take readable data and turn it into encrypted data that is unreadable. To help you better understand encryption, this section will first explain a few encryption terms. These include obfuscation, plaintext, and ciphertext. We will then talk through how encryption is employed for data in two different states: data at rest and data in transit.
Obfuscation
Obfuscation is the practice of using some defined pattern to mask sensitive data. This pattern can be a substitution pattern, a shuffling of characters, or a patterned removal of selected characters. Obfuscation is more secure than plaintext but can be reverse-engineered if a malicious entity were willing to spend the time to decode it.
Plaintext
Before data is encrypted, it is called plaintext. When an unencrypted e-mail message (i.e., an e-mail in plaintext form) is transmitted across a network, a third party can intercept and read that message in its entirety.
Ciphertext
Ciphers are mathematical algorithms used to encrypt data. Applying an encryption algorithm (cipher) and a value to make the encryption unique (key) against plaintext results in ciphertext; it is the encrypted version of the originating plaintext.
Encryption at Rest
Encrypting data when stored on a media such as a hard drive, USB drive, or DVD is known as encryption at rest. Don’t forget that whenever data is stored in the cloud, it is stored on some media in the CSP’s data center, so this is considered data at rest. Some of the options for encrypting data at rest include encrypting the storage, file system, operating system, database, or files and folders.
• Storage Storage encryption is implemented at the hardware level through self-encrypting drives.
• File system File system encryption is performed by software and managed by the storage controller.
• Operating system Operating system encryption is similar to file system encryption in that it is performed by software, but it is managed with built-in tools in the operating system. Some examples include BitLocker from Microsoft or FileVault from Apple.
• Database Database encryption encrypts data within rows or columns within a database. For example, you could encrypt the Social Security number field, or you could have certain records encrypted instead, such as encrypting only records marked top secret.
• Files and folders File and folder encryption is implemented by software. It can be selectively performed on a single file, a group of files, or one or more folders. Some file and folder encryption methods are built into operating systems, but the majority of options are available as software that is installed on the machine. If you move encrypted files or folders to another machine, you will need to install the software first and then provide the decryption key before the data can be accessed.
Encryption in Transit
Data does not always remain on storage. It must also be protected when it travels from one machine to another. Data that is being transferred is referred to as data in transit. Several methods are used to encrypt data in transit, including LAN encryption, browser encryption, and API endpoint encryption.
• LAN encryption Data can be encrypted over the local network via protocols such as IPSec. This helps protect data traversing the network from being observed by others on the network.
• Browser encryption Browser encryption encrypts a browser session between the client and server using protocols such as SSL or TLS. Encrypted browser connections use a certificate, and their URLs are prefaced with https://.
• API endpoint encryption API endpoint encryption protects data traveling between clients and the API endpoint. The encryption is performed using SSL or TLS.
Public Key Infrastructure
A PKI is a hierarchy of trusted security certificates. These security certificates (also called X.509 certificates or PKI certificates) are issued to users, applications, or computing devices. PKI certificates are primarily used in two ways. The first is to encrypt and decrypt data. The second is as a digital identity, to sign and verify an entity’s integrity such as a computer, user, website, application, or code.
Each certificate contains a unique, mathematically related public and private key pair. When the certificate is issued, it has an expiration date; certificates must be renewed before the expiration date. Otherwise, they are not usable.
To help you better understand encryption and PKI, this section is divided into the following topics:
• Certificate management
• Cryptographic key
• Key management
• Symmetric encryption
• Asymmetric encryption
• Digital signatures
• Secret management
Certificate Management
Certificate management is the set of processes to issue, renew, store, authenticate, and revoke digital certificates. It is an integral part of a PKI. It consists of several elements, including a root certificate authority (CA), subordinate CAs, and the systems that receive certificates.
The root CA exists at the top of the PKI hierarchy. The root CA can issue, revoke, and renew all security certificates. Under it reside either user, application, and device certificates or subordinate certificate authorities. Computers are configured by default to trust several root certificate authorities. These authorities can issue certificates to other certificate servers, known as subordinate CAs. You can also set up an internal CA hierarchy for issuing internal certificates.
When a CA grants a certificate to a subordinate CA, it gives them the right to issue certificates for a specific domain. Subordinate CAs can issue, revoke, and renew certificates for the scope of operations provided in their mandate from the CA above them in the hierarchy.
A large enterprise, for example, Acme, might have a CA named Acme-CA. For each of its three U.S. regions, Acme might create subordinate CAs called West, East, and Central. These regions could be further divided into sections by creating subordinate CAs from each of those, one for production and one for development. Such a subordinate CA configuration would allow the cloud operations and development personnel in each of the three regions to control their own user and device PKI certificates without controlling resources from other areas or departments. This hierarchy is shown in Figure 11-1.
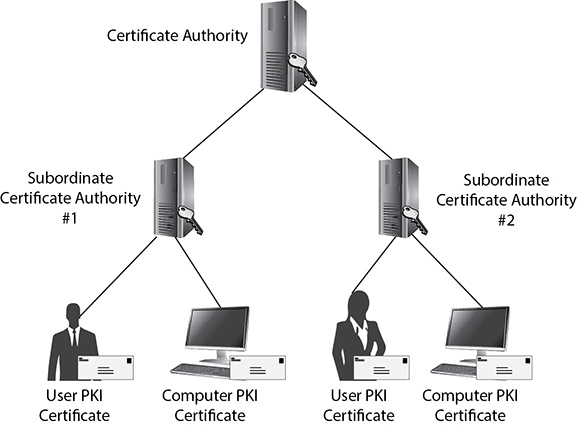
Figure 11-1 Illustration of a public key infrastructure hierarchy
Certificates have a defined expiration date, but some need to be deactivated before their expiration. In such cases, administrators can revoke the certificate. Revoking a certificate places the certificate on the certificate revocation list (CRL). Computers check the CRL to verify that a certificate is not on the list when they validate a certificate.
Companies can issue their own certificates without being part of the trusted certificate chain leading back to a trusted certificate authority. This is often performed for authentication or encryption on a domain. Computers in the domain can be configured to trust the domain certificate authority. The certificate authority then issues certificates to the machines on the domain to authenticate each other. However, suppose a company tries to use certificates generated on its own domain for use over the Internet. In that case, those outside the organization will not trust the certificates assigned to the sites. They will receive warnings or errors in displaying the page.
Cryptographic Key
Many people can own the same lock model, while each has its own unique key that opens that specific lock. The same is valid for cryptography. Multiple people can each use the same cryptographic algorithm, but they will each use a unique cryptographic key, or key for short, so that one person cannot decrypt the data of another.
Let’s continue with the lock example. Some locks have more tumblers than others, and this makes them harder to pick. Similarly, some keys are longer than others. Longer keys result in more unique ciphertext, and this makes the resulting ciphertext harder to break. Keys are used for data at rest (stored data) and data in motion (transmission data).
Key Exchange Keys are generated and distributed as part of the encryption process, or they are configured before encryption begins. Keys that are generated as part of the encryption process are said to be created in-band. The key generation and exchange process occurs during the negotiation phase of communication. Similarly, systems that encrypt stored data will need to generate a key when encrypting the data if one has not been provided before encryption.
The other approach is to provide keys before engaging in encrypted communication or encryption. For transmission partners, keys are generated out-of-band, meaning that they are created separately and distributed to transmission partners before communication starts. Such a key is known as a pre-shared key (PSK).
Software or tools that encrypt stored data may be provided with a key upon installation or configuration, and then this key will be used in the encryption process. Some systems use a PSK to encrypt unique keys generated for each file, backup job, or volume. This allows a different key to be used for discrete portions of data, but these keys do not all have to be provided beforehand. Without such a process, new jobs or drives would require more administrative involvement before being encrypted.
Distributed Key Generation Multiple devices can work together to create a key in a process known as distributed key generation. Distributed key generation makes it harder for the system to be corrupted because there is no single device responsible for the key. An attacker would need to compromise several systems. This is the method blockchain uses to create keys for Bitcoin and the many other services that depend on the blockchain.
Elliptic Curve Cryptography Elliptic curve cryptography (ECC) is a cryptographic function that allows for smaller keys to be used through the use of a finite-field algebraic structure of elliptic curves. The math behind it is a bit complex, but the simple description is that ECC uses a curve rather than large prime number factors to provide the same security as those with larger keys. Also, a key using ECC of the same length as one using prime number factors would be considered a stronger key.
Key Management
However they are provided, each key must be documented and protected so that data can be decrypted when needed. This is performed through a key management system (KMS).
Key Management System Organizations can deploy a KMS to manage the process of issuing, validating, distributing, and revoking cryptographic keys so that keys are stored and managed in a single place. Cloud KMSs include such systems as AWS KMS, Microsoft Azure Key Vault, Google Cloud KMS, and Oracle Key Manager.
Symmetric Encryption
Encrypting data requires a passphrase or key. Symmetric encryption, also called private key encryption, uses a single key that encrypts and decrypts data. Think of it as locking and unlocking a door using the same key. The key must be kept safe, since anybody with it in their possession can unlock the door. Symmetric encryption is used to encrypt files, secure some VPN solutions, and encrypt Wi-Fi networks, just to name a few examples.
To see symmetric encryption in action, let’s consider a situation where a user, Stacey, encrypts a file on a hard disk:
1. Stacey flags the file to be encrypted.
2. The file encryption software uses a configured symmetric key (or passphrase) to encrypt the file contents. The key might be stored in a file or on a smartcard, or the user might be prompted for the passphrase at the time.
3. This same symmetric key (or passphrase) is used when the file is decrypted.
Encrypting files on a single computer is easy with symmetric encryption, but when other parties that need the symmetric key are involved (e.g., when connecting to a VPN using symmetric encryption), it becomes problematic: How do we securely get the symmetric key to all parties? We could transmit the key to the other parties via e-mail or text message, but we would already need to have a way to encrypt this transmission in the first place. For this reason, symmetric encryption does not scale well.
Asymmetric Encryption
Asymmetric encryption uses two different keys to secure data: a public key and a private key. This key pair is stored with a PKI certificate (which itself can be stored as a file), in a user account database, or on a smartcard. Using two mathematically related keys is what PKI is all about: a hierarchy of trusted certificates, each with its own unique public and private key pairs.
The public key can be freely shared, but the private key must be accessible only by the certificate owner. Both the public and private keys can be exported to a certificate file or just the public key by itself. Keys are exported to exchange with others for secure communications or to use as a backup. If the private key is stored in a file, the file should be password protected.
The recipient’s public key is required to encrypt transmissions to them. Bear in mind that the recipient could be a user, an application, or a computer. The recipient then uses their mathematically related private key to decrypt the message.
Consider an example, shown in Figure 11-2, where user Roman sends user Trinity an encrypted e-mail message using a PKI, or asymmetric encryption:
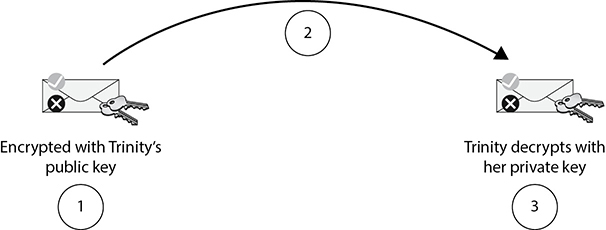
Figure 11-2 Sending an encrypted e-mail message
1. Roman flags an e-mail message for encryption. His e-mail software needs Trinity’s public key. PKI encryption uses the recipient’s public key to encrypt. If Roman cannot get Trinity’s public key, he cannot encrypt a message to her.
2. Roman’s e-mail software encrypts and sends the message. Anybody intercepting the e-mail message will be unable to decipher the message content.
3. Trinity opens the e-mail message using her e-mail program. Because the message is encrypted with her public key, only her mathematically related private key can decrypt the message.
Unlike symmetric encryption, PKI scales well. There is no need to find a safe way to distribute secret keys because only the public keys need to be accessible by others, and public keys do not have to be kept secret.
Cloud providers use asymmetric encryption for communication between VMs. For example, AWS generates key pairs for authentication to Windows cloud-based VMs. AWS stores the public key, and you must download and safeguard the private key.
Digital Signatures
A PKI allows us to trust the integrity of data by way of digital signatures. When data is digitally signed, a mathematical hashing function is applied to the message’s data, which results in what is called a message digest or hash. The PKI private key of the signer is then used to encrypt the hash: this is the digital signature.
Notice that the message content has not been secured; for that, encryption is required. Other parties needing to trust the digitally signed data use the mathematically related public key of the signer to validate the hash. Remember that public keys can be freely distributed to anyone without compromising security.
As an example of the digital signature at work, consider user Ana, who is sending user Zoey a high-priority e-mail message that Zoey must trust really did come from Ana:
1. Ana creates the e-mail message and flags it to be digitally signed.
2. Ana’s e-mail program uses her PKI private key to encrypt the generated message hash.
3. The e-mail message is sent to Zoey, but it is not encrypted in this example, only signed.
4. Zoey’s e-mail program verifies Ana’s digital signature using Ana’s mathematically related public key; if Zoey does not have Ana’s public key, she cannot verify Ana’s digital signature.
Using a public key to verify a digital signature is valid because only the related private key could have created that unique signature. Hence, the message had to have come from that party. This is referred to as nonrepudiation. If the message is tampered with along the way, the signature is invalidated. Again, unlike symmetric encryption, there is no need to safely transmit secret keys; public keys are designed to be publicly available.
For the utmost security, data can be encrypted and digitally signed, whether it is transmitted data or data at rest (stored).

EXAM TIP Data confidentiality is achieved with encryption. Data authentication and integrity are achieved with digital signatures.
Secret Management
Secrets in the cloud must also be managed. Secrets include things like API keys, passwords, and other sensitive data that your applications need to securely access. Secret management includes provisioning secrets, providing access to authorized entities, rotating secrets, and auditing. The major cloud vendors each have their tools for secret management. For example, you can manage secrets in Google’s cloud using Google’s Secret Manager.
Encryption Protocols
Many methods can be used to secure and verify the authenticity of data. These methods are called encryption protocols, and each is designed for specific purposes, such as encryption for confidentiality and digital signatures for data authenticity and verification (also known as nonrepudiation).
IPSec
Internet Protocol Security (IPSec) secures IP traffic using encryption and digital signatures. PKI certificates, symmetric keys, and other methods can be used to implement this type of security. IPSec is flexible because it is not application-specific. If IPSec secures the communication between hosts, it can encrypt and sign network traffic regardless of the application generating the traffic. IPSec can be used as both an encryption protocol and a tunneling protocol, discussed in the next section.
SSL/TLS
Unlike IPSec, Secure Sockets Layer (SSL) or Transport Layer Security (TLS) is used to secure the communication of specially configured applications. Like IPSec, encryption and authentication (signatures) are used to accomplish this level of security. TLS is SSL’s successor.
Most computer people associate SSL/TLS with secure web servers. However, SSL/TLS can be applied to any network software that supports it, such as Simple Mail Transfer Protocol (SMTP) e-mail servers and Lightweight Directory Access Protocol (LDAP) directory servers. SSL and TLS rely on PKI certificates to obtain the keys required for encryption, decryption, and authentication. Take note that some secured communication, such as connecting to a secured website using Hypertext Transfer Protocol Secure (HTTPS), uses public and private key pairs (asymmetric) to encrypt a session-specific key (symmetric). Most public cloud services are accessed over HTTPS.
Tunneling Protocols
Tunneling is the use of encapsulation and encryption to create a secure connection between devices so that intermediary devices cannot read the traffic and so that devices communicating over the tunnel are connected as if on a local network. Tunneling creates a secure way for devices to protect the confidentiality of communications over less secure networks such as the Internet. This is a great way to extend an on-premises network into the public cloud.
Encapsulation is the packaging of data within another piece of data. Encapsulation is a normal function of network devices as data moves through the TCP/IP layers. For example, layer 3 IP packets are encapsulated inside layer 2 Ethernet frames. Tunneling encapsulates one IP packet destined for the recipient into another IP packet, treating the encapsulated packet simply as data to be transmitted. The reverse encapsulation process is de-encapsulation, where the original IP packet is reassembled from the data received by a tunnel endpoint.
The nodes that form encapsulation, de-encapsulation, encryption, and decryption of data in the tunnel are called tunnel endpoints. Tunnel endpoints transmit the first packets of encapsulated data that will traverse the intermediary network.
Not all tunneling protocols encrypt the data that is transmitted through them, but all do encapsulate. Suppose connectivity that seems local is all you are looking for. In that case, a protocol that does not encrypt could work because it will operate faster without having to perform encryption on the data. However, for most tunneling uses, encryption is a necessity because traffic is routed over an unsecured network. Without encryption, any node along the route could reassemble the data contained in the packets.
Tunneling consumes more network bandwidth and can result in lower speeds for connections over the tunnel because rather than transmitting the packets themselves, network devices must take the entire packet, including header information, and package that into multiple packets that traverse from node to node until they reach their destination and are reassembled into the original packets that were sent.
Tunneling protocols are network protocols that enable tunneling between devices or sites. They consist of GRE, IPSec, PPTP, and L2TP. Table 11-1 compares each of these tunneling protocols.

Table 11-1 Tunneling Protocols Compared
GRE
Generic Routing Encapsulation (GRE) is a lightweight, flexible tunneling protocol. GRE works with multiple protocols over IP versions 4 and 6. It is not considered a secure tunneling protocol because it does not use encryption. GRE has an optional key field that can be used for authentication using checksum authentication or keyword authentication.
IPSec
IPSec is a tunneling and encryption protocol. Its encryption features were mentioned previously in this chapter. IPSec tunneling secures IP traffic using Encapsulating Security Protocol (ESP) to encrypt the data tunneled over it using PKI certificates or asymmetric keys. Keys are exchanged using the Internet Security Agreement Key Management Protocol (ISAKMP) and Oakley protocol and a security association (SA) so that endpoints can negotiate security settings and exchange encryption keys.
IPSec also offers authentication through the Authentication Header (AH) protocol. The main disadvantage of IPSec is that it encrypts the data of the original IP packet but replicates the original packet’s IP header information, so intermediary devices know the final destination within the tunnel instead of just knowing the tunnel endpoint. IPSec functions in this way because it offers end-to-end encryption, meaning that the data is encrypted not from the endpoint to endpoint, but from the original source to the final destination.
PPTP
Point-to-Point Tunneling Protocol (PPTP) is a tunneling protocol that uses GRE and Point-to-Point Protocol (PPP) to transport data. PPTP has a very flexible configuration for authentication and encryption, so various implementations can utilize a variety of authentication and encryption protocols. PPP or GRE frames can be encrypted, compressed, or both. The primary benefit of PPTP is its speed and its native support in Microsoft Windows.
The most widely used variation of PPTP is used in Microsoft VPN connections. These connections use PAP, CHAP, MS-CHAP version 1, or MS-CHAP version 2 for authentication. At the time of this publication, weaknesses have been found in most of these protocols. The only secure implementation currently available for PPTP is Extensible Authentication Protocol Transport Layer Security (EAP-TLS) or Protected Extensible Authentication Protocol (PEAP).
PPTP data is encrypted using the Microsoft Point-to-Point Encryption (MPPE) protocol. MPPE uses RC4 key lengths of 128 bits, 56 bits, and 40 bits. Negotiation of keys is performed using the Compression Control Protocol (CCP). At the time of this publication, weaknesses in the RC4 protocol make PPTP implementations insecure because data can be decrypted using current toolsets.
L2TP
Layer 2 Tunneling Protocol (L2TP) offers improvements over PPTP. L2TP does not offer built-in encryption but can be combined with IPSec to provide encryption and authentication using ESP and AH. However, L2TP is CPU intensive when encryption is used because data must be encapsulated twice, once with L2TP and another time with IPSec.
L2TP is a flexible tunneling protocol, allowing a variety of protocols to be encrypted through it. L2TP has been used to encrypt and tunnel IP, Asynchronous Transfer Mode (ATM), and Frame Relay data.
Ciphers
Recall that plaintext fed to an encryption algorithm results in ciphertext. “Cipher” is synonymous with “encryption algorithm,” whether the algorithm is symmetric (same key) or asymmetric (different paired keys). There are two categories of ciphers: block ciphers and stream ciphers. Table 11-2 lists some of the more common ciphers.
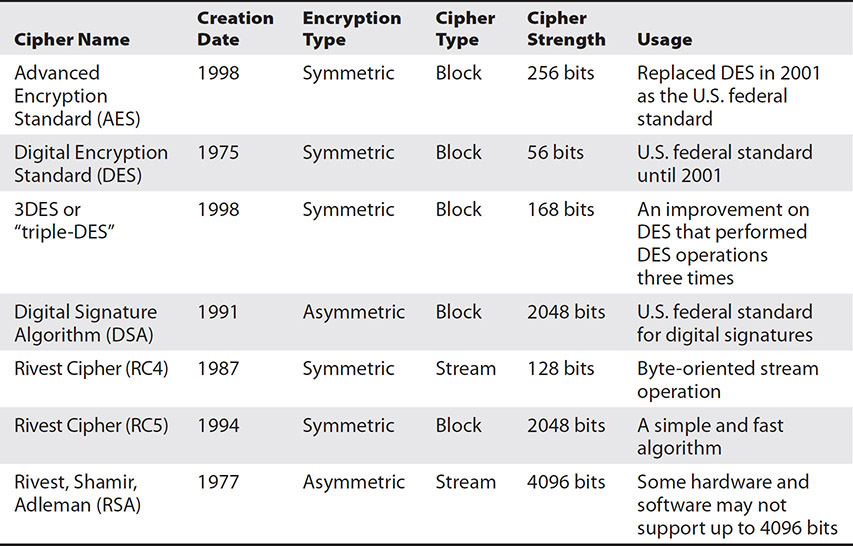
Table 11-2 Common Block and Stream Ciphers
Block Ciphers
Designed to encrypt chunks or blocks of data, block ciphers convert plaintext to ciphertext in bulk as opposed to one data bit at a time, either using a fixed secret key or by generating keys from each encrypted block. A 128-bit block cipher produces a 128-bit block of ciphertext. This type of cipher is best applied to fixed-length segments of data, such as fixed-length network packets or files stored on a disk.
Some block ciphers include DES, AES, RC5, DSA, and 3DES. Each of these ciphers is shown in Table 11-2.
DES Data Encryption Standard (DES) is a symmetric block cipher that uses block sizes of 64 bits and 16 rounds of encryption. 3DES, or “triple-DES,” encrypts data with DES three times using three keys. It is marginally better than DES and managed to extend the life of DES for a short time. DES and 3DES are now outdated protocols. They were succeeded by AES in 2001 as the new standard for government encryption.
AES Advanced Encryption Standard (AES) is a symmetric block cipher that uses a 128-bit block and variable key sizes of 128, 192, and 256 bits. It performs 10 to 14 rounds of encryption depending on the key size used. AES replaces DES as the new standard for government encryption.
RC5 Rivest Cipher 5 (RC5) is a symmetric block cipher used to encrypt and decrypt data. It is named for its creator, Ron Rivest. RC5 is a block cipher that uses symmetric keys for encryption. RC5 replaces RC4 and supports a cipher strength of up to 2048 bits. RC5 uses 1 to 255 rounds of encryption.
DSA The digital signature algorithm (DSA) is an asymmetric block cipher used for message or data signing and verification. DSA creates keys of variable lengths and can create per-user keys. DSA is accepted as a federal information processing standard in FIPS 186. DSA has a maximum cipher strength of 2048 bits and was created in 1991.
Stream Ciphers
Unlike block ciphers that work on a chunk of data at a time, stream ciphers convert plaintext into ciphertext one binary bit at a time. Stream ciphers are considerably faster than block ciphers. Stream ciphers are best suited when an unknown or variable amount of data needs to be encrypted, such as variable-length network transmissions. Some stream ciphers include RC4 and RSA, shown in Table 11-2.
RC4 Rivest Cipher 4 (RC4) is a symmetric stream cipher used to encrypt and decrypt data. RC4 uses symmetric keys up to 128 bits in length for encryption. It is named for its creator, Ron Rivest.
TKIP Temporal Key Integrity Protocol (TKIP) is a protocol specified in IEEE 802.11i that enhances the WEP/RC4 encryption in wireless networks. It was created in 2002. TKIP takes a PSK called the secret root key and combines it with a unique random or pseudorandom value called an initialization vector. TKIP also tracks the order of pieces of encrypted data using a sequence counter. This helps protect against an attack where the previous ciphertext is provided to a system to perform a transaction twice in what is known as a replay attack. Lastly, TKIP uses an integrity checking function called the message integrity code (MIC) to verify ciphertext in the communication stream.
RSA Rivest, Shamir, Adleman (RSA) is an asymmetric stream cipher used to encrypt and decrypt data. It is named after its three creators, Ron Rivest, Adi Shamir, and Leonard Adleman, and was created in 1977. RSA uses asymmetric key pairs up to 4096 bits in length for encryption.
EXAM TIP Stream ciphers are faster than block ciphers.
Storage Security
Storage security is concerned with the security of data at rest or when it is stored on a cloud system. There are a large number of cloud services specifically dedicated to the storage of data, such as Dropbox, Google Drive, Amazon Drive, Microsoft OneDrive, and SpiderOak. For these services, storage is the business. For other cloud services, storage is one of the core building blocks on which the cloud service is architected, and it is important to implement effective security at this level.
From the cloud consumer perspective, storage security is built into the product offering, so cloud consumers do not need to implement these controls. It is, however, still important to understand cloud security controls to ensure that the cloud service meets organizational security and technology stipulations, contractual agreements, and regulatory requirements. Storage security is vital when setting up a private cloud or when providing cloud services to others, since storage is the underlying component behind cloud systems.
Granular Storage Resource Controls
Based on the storage technology utilized in the cloud system, security mechanisms can be put in place to limit access to resources over the network. This is important when setting up a private cloud or working for a cloud provider, since storage is the underlying component behind cloud systems. When using a storage area network (SAN), two techniques for limiting resource access are LUN masking and zoning. See Chapter 3 if you need a review on SANs and LUNs.
• LUN masking LUN masking allows access to resources, namely storage logical unit numbers (LUNs), to be limited by the utilization of a LUN mask either at the host bus adapter or the switch level.
• Zoning SANs can also utilize zoning, which is a practice of limiting access to LUNs that are attached to the storage controller.
LUN masking and zoning can be used in combination. Storage security is best implemented in layers, with data having to pass multiple checks before arriving at its intended target. All the possible security mechanisms, from software to operating system to storage system, should be implemented and configured to architect the most secure storage solution possible.
Securing Storage Resources
Data is the most valuable component of any cloud system. It is the reason that companies invest in these large, expensive infrastructures or services: to make certain that their users have access to the data they need to drive their business.
Storage is such a critical resource to the users of cloud models that special care must be taken with its security to make sure resources are available and accurate and accessible for users who have been authorized for access.
Digital and Information Rights Management
Digital rights management (DRM) is a set of technologies that enforces specific usage limitations on data, such as preventing a document from being printed or e-mailed or photos from being downloaded from a phone app. DRM is typically associated with consumer applications.
Similarly, information rights management (IRM) is a set of technologies that enforces specific usage limitations on data throughout enterprise systems, including cloud and distributed systems.
Protected Backups
Backups are copies of live data that are maintained in case something happens that makes the live data set inaccessible. Because it is a copy of valuable data, it needs to have the same protections afforded to it that the live data employs. It should be encrypted, password-protected, and kept physically locked away from unauthorized access. See Chapter 13 for more information on backups and backup strategies.
Network Security
Network security is the practice of protecting the usability, reliability, integrity, and safety of a network infrastructure and also the data traveling along it. As it does in many other areas, security in cloud computing has similarities to traditional computing models. If deployed without evaluating security, cloud systems may deliver against their functional requirements. Still, they will likely have many gaps that could lead to a compromised system.
Security systems are designed to protect the network against certain types of threats. One solution alone will not fully protect the company because attackers have multiple avenues for exploitation. Security systems should be used in conjunction with one another to protect against these avenues and to provide layers of security. If an attacker passes by one layer, he will not be able to exploit the network without bypassing another layer and so forth. Security systems will only overlap in some places, so having 20 security systems does not mean that the organization has 20 layers.
The security systems mentioned here, and many others, can exist either as networking/security hardware that is installed in a data center or as virtual appliances that are placed in hypervisors in much the same way as servers. Cloud environments can deploy virtual appliances to their networks easily with this method. Virtual appliances were covered in the “Component Updates” section of Chapter 10. The following sections cover the following important network security controls:
• Segmentation
• Firewalls
• Distributed denial of service (DDoS) protection
• Packet capture
• Intrusion prevention systems (IPSs)/intrusion detection systems (IDSs)
• Packet broker
• Network access control (NAC)
• APIs
Segmentation
Remember the phrase “don’t put all of your eggs in one basket”? If you drop the basket, all the eggs are broken. Some networks today are like that basket. We call these flat networks. As you can see in Figure 11-3, they have all their computers, servers, and devices on one network, so when one device is compromised, all are placed at risk.

Figure 11-3 Flat network
Segmentation can also have a performance impact. Have you ever tried to have a conversation in a full open room? It is very noisy and hard to talk. However, if you divide that room into many smaller spaces, talking becomes much easier. Similarly, if you divide the network into smaller sections, each one receives less communication. Thus each machine will be less burdened processing traffic that is not intended for it.
To segment a network, you will need to define a distinct subnet for the network and place a device capable of routing between the networks. Such devices include most commonly routers, firewalls, and layer 3 switches. You will then need to define the network segments using a protocol such as VLAN, VXLAN, NVGRE, STT, and GENEVE. These protocols were discussed in detail in Chapter 4. Figure 11-4 shows a network that is segmented into different networks for various purposes. This improves security because analytics data is not directly accessible to web servers, and development data cannot affect virtual desktops. Each segment is kept separate from the others, using a firewall to govern acceptable traffic flows between the segments.
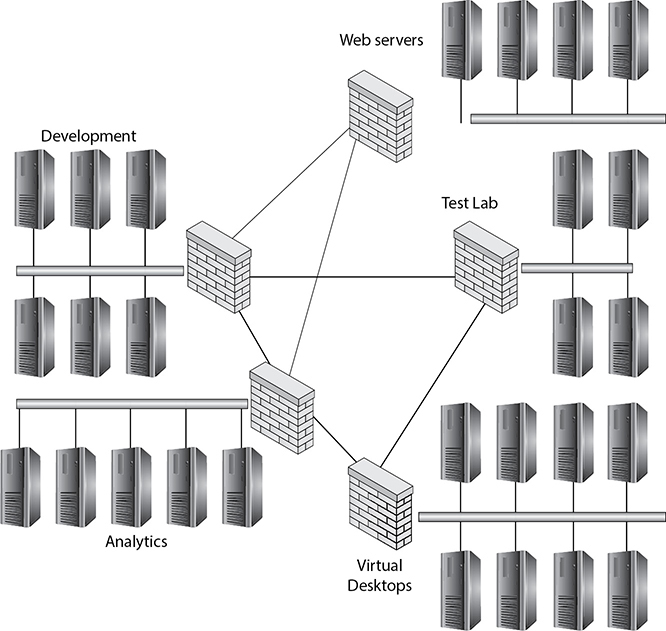
Figure 11-4 Segmented network

NOTE A layer 3 device is one that is capable of routing packets. Layer 3 comes from the OSI network model.
Firewall
A firewall is used to control traffic. Firewalls operate at OSI layer 3 or above, meaning that, at a minimum, they can analyze packets and implement filtering on packets based on the information contained in the packet header, such as source and destination IP addresses, lengths, and sizes. However, most firewalls operate at a much higher level.
Firewalls in a cloud environment are typically virtual appliances or software services offered to cloud consumers. Common public cloud providers offer layer 4 firewalls such as the Azure Network Security Group (NSG) and AWS EC2 Security Group. These are implemented simply by configuring them on an administrative dashboard.
Some firewall capabilities include the following:
• NAT/PAT Network address translation (NAT) consolidates the addresses needed for each internal device to a single valid public IP address, allowing all of the organization’s employees to access the Internet using a single public IP address.
Firewalls can be configured with multiple IP addresses, and NAT can be used to translate external IP addresses to internal IP addresses so that the host’s actual IP address is hidden from the outside world.
Port address translation (PAT) allows for the mapping of private IP addresses to public IP addresses, as well as for mapping multiple devices on a network to a single public IP address. PAT enables the sharing of a single public IP address between multiple clients trying to access the Internet. Each external-facing service has a port associated with it, and the PAT service knows which ones map to which internal servers. It repackages the data received on the outside network to the inside network, addressing it to the destination server. PAT makes this determination based on the port the data was sent to.
• Port/service The firewall can be configured to filter out traffic that is not addressed to an open port. For example, the firewall may be configured to allow traffic to HTTPS, port 443, and SMTP, port 25. If it receives data for HTTP on port 80, it will drop the packet.
• DMZ A demilitarized zone (DMZ) is a network segment that allows some level of access to its resources from the public Internet. DMZs are configured with ACLs that enforce specific security rules to allow only the traffic required for those DMZ systems. Externally facing web servers, remote access servers, or Internet file sharing systems are often housed in a DMZ.
• Screened subnet A screened subnet is a network segmentation technique that uses multiple networks to segment Internet-facing systems from internal systems. It is accomplished with multiple routers or firewalls or by using a triple-homed firewall (one with three interfaces). A typical scenario is to place public-facing web servers in a DMZ. ACLs are then defined to allow web traffic to the web servers but not anywhere else. The web servers may need to connect back to a database server on an internal cloud segment, so ACLs allow the web servers in the DMZ to talk to the database server in the internal cloud segment, but connections from the outside would not be able to talk to the database server directly. Similarly, other internal machines on the internal segment could not be contacted directly from outside resources.
• Stateful packet inspection Stateful packet inspection evaluates whether a session has been created for a packet before it will accept it. This is similar to how an accounts receivable department looks to see if they issued a purchase order before paying an invoice. If there is no purchase order, no check is sent. If the firewall sees that an inside computer has established a connection with a handshake (SYN packet, then SYN + ACK, then ACK packet) with the target system, it allows the traffic to flow back to the inside machine that initiated the connection. Otherwise, the packets are dropped. Unfortunately, stateful firewalls can be subjected to SYN-based DDoS attacks, so DDoS mitigation controls are advised when using stateful packet inspection.
• Stateless The cheaper alternative to a stateful firewall is the stateless firewall. This type of firewall does not analyze packets with as much rigor as the stateful firewall. Stateless firewalls do less processing of the traffic flowing through them, so they can achieve better performance.
• IP spoofing detection Spoofing is the modification of the sending IP address in a packet to obscure the data transmission origin. Attackers will sometimes try to send data to a device to make it seem like the data came from another device on the local network. They spoof the sending IP address and give it some local address. Spoofing is the modification of the source IP address to obfuscate the original source. However, the firewall knows which addresses it has internally because they are contained in its routing table. If it sees data with a sender address from outside the network, it knows that data is spoofed.
Spoofing is not limited to local addresses. Spoofing is often used in e-mail phishing to make e-mails appear as if they originated from a company’s servers when they actually came from an attacker. Spoofing is also used in man-in-the-middle attacks so that data is routed through a middleman.
WAF
One specialized type of firewall is called a web application firewall (WAF). A WAF is a device that screens traffic intended for web applications. WAFs understand common web application attacks such as cross-site scripting (XSS) and SQL injection and can inspect traffic at the OSI model’s application layer.
Cloud Access Security Broker
Organizations may choose to have a third-party screen traffic for cloud or on-premises systems. A cloud access security broker (CASB) is an on-premises or cloud service that operates as the gateway between users and cloud systems.
CASBs are configured with policies to determine what type of access is allowed to cloud services. The CASB screens incoming traffic for malicious content and anomalous behavior and prevents that traffic from being delivered to the cloud systems it services. A CASB can also be used as an on-premises proxy so that local user access is limited to specific cloud apps only.
Ingress and Egress Traffic Filtering
Firewalls filter traffic. This filtering is performed on both ingress and egress traffic. Ingress traffic flows from the outside to the inside, while egress traffic flows from the inside out. Some filtering methods include access control lists (ACLs), whitelisting, and blacklisting.
Cloud firewalls perform filtering with ACLs to a large extent. ACLs are made up of a series of access control entries (ACEs). Each ACE specifies the access rights of an individual principal or entity. An ACL comprises one or more ACEs.
The firewall processes the ACL in order from the first ACE to the last ACE. For example, the first ACE would say “allow traffic over HTTP to the web server.” The second ACE would say “allow SMTP traffic to the e-mail server,” and the third ACE would say “deny all traffic.” If the firewall receives DNS traffic, it will go through the rules in order. ACE 1 is not matched because this is not HTTP traffic. ACE 2 is not matched because this is not SMTP traffic. ACE 3 is matched because it is anything else, so the firewall drops the packet. In the real world, ACLs are much more complex.
Another method of ingress and egress filtering is whitelisting and blacklisting. Whitelisting, also known as an allow list, denies all traffic unless it is on the whitelist. A company might have a system set up for remote access by employees from their homes. They could require users to provide them with their home IP address and then whitelist that address so the users can connect. If a connection request is received by an IP address that is not on the whitelist, it will be rejected.
The opposite approach is to blacklist, also known as a deny list. You could pull down a list of known bad sites or IP addresses from a public blacklist and instruct the firewall to drop any packets from these systems.
EXAM TIP When a technology has multiple terms, be sure to memorize both so that you will be ready no matter which one is used on the test.
DDoS Protection
DDoS is an attack that targets a single system simultaneously from multiple compromised systems to make that system unavailable. The attack is distributed because it uses thousands or millions of machines that could be spread worldwide. The attack denies services or disrupts availability by overwhelming the system so that it cannot respond to legitimate connection requests.
Cloud firewalls or CASBs can often prevent DDoS traffic from reaching organizational cloud servers because the cloud vendor or CASB has the necessary bandwidth to withstand a DDoS attack. However, some DDoS attacks have been performed using the Mirai botnet that overwhelmed several of the world’s largest networks.
Packet Capture
Packet capture devices collect the traffic traveling over a link, such as a firewall, to be analyzed later. Packet capture can be used to replay the traffic at a point in time for troubleshooting or investigation of a threat. Some monitoring systems automatically gather packet captures when certain events are triggered.
Network Flow
Network flow tools provide visibility into network traffic, where it is going, and how much traffic flows to the various network nodes. It is a useful tool for discovering congestion on the network or troubleshooting excessive network errors or dropped packets. You can also use network flows to identify abnormal traffic patterns that may be indicative of an attack.
IDS/IPS
An intrusion detection system (IDS) or an intrusion prevention system (IPS) looks at traffic to identify malicious traffic. IDSs and IPSs do this through two methods: signatures and heuristics. IDSs or IPSs in a cloud environment are typically virtual appliances or software services offered to cloud consumers. Azure and AWS have built-in IDS/IPS solutions in their environments that can be licensed and enabled as software configurations. They can also utilize third-party cloud solutions that are supported by the cloud provider. For example, in the AWS or Azure marketplace, you can deploy IDS/IPS solutions from companies like Alert Logic, Trend Micro, or McAfee.
Signatures are descriptions of what malicious data looks like. IDSs and IPSs review the data that passes through them and take action if the system finds data that matches a signature. The second screening method used is heuristics, which looks for patterns that appear malicious, such as many failed authentication attempts. Heuristics operates off an understanding of what constitutes normal on the network. A baseline is configured and periodically updated so the IDS or IPS understands what to expect from the network traffic. Anything else is an anomaly, and the device will take action.
So far, we have only said that these devices take action. IDSs and IPSs differ in how they react to the things they find. An IDS sends alerts and logs suspicious traffic but does not block the traffic. An IPS can send alerts and record log entries on activities observed. IPS can also block, queue, or quarantine the traffic. An IPS can be generically referred to as intrusion detection and prevention (IDP). This term is used in the same way that IPS is used.
In the cloud, firewalls and IDS/IPS functionality can be achieved with cloud-specific configuration settings or by deploying a virtual appliance from the cloud provider marketplace. IDSs and IPSs need to be in a position to collect network data. There are three types: network-based, host-based, and hybrid configurations.
Network-Based
A network-based IDS (NIDS) or IPS (NIPS) is placed next to a firewall or built into a perimeter firewall. A firewall is an ideal place because it processes all traffic going between the inside network and the outside. If the NIPS is a separate device, it will need to have the traffic forwarded to it and then relay back instructions, or it will need to be the first device to screen the information.
Host-Based
The second type of IDS or IPS is the host-based IDS (HIDS) or IPS (HIPS). These devices reside on endpoints such as cloud servers or a cloud virtual desktop infrastructure (VDI). A NIDS or NIPS can collect a lot of data, but it does not see everything because not all data passes through the perimeter. Consider malware that has infected a machine. It may reach out to other computers on the network without touching the perimeter device. A HIDS or HIPS would be able to identify this traffic when a NIDS or NIPS would not.
Hybrid
You can choose to implement both a host-based and network-based IDS or IPS. They will still operate independently but also send data to a collection point so that the data between the devices can be correlated to produce better intelligence on what is expected and abnormal. This is known as a hybrid IDS or IPS configuration.
Packet Broker
As you can imagine, all these tools, monitoring systems, packet capture devices, network flow, and IDSs/IPSs are receiving traffic from network devices. Some of this traffic is redundant and sent to multiple devices, while other traffic is unique to the system. It can be challenging for administrators to manage all these services that need to collect data as the network changes or when new systems are provisioned.
The packet broker is positioned between the network and the tools collecting data to manage and optimize the flow of data to those devices. Packet brokers combine traffic coming from multiple sources to more efficiently transmit the data to recipients. They can also filter network traffic using specific criteria for each recipient service so that services do not receive data that they will not ultimately use. This improves network performance overall and eases the management complexity of the systems.
APIs
Application programming interfaces (APIs) are used to expose functions of an application or cloud service to other programs and services. APIs allow for expansion of the original application’s scope. They are used to integrate multiple applications together as part of an organization’s cloud or security operations.
A vendor will create an API for its application and then release documentation so that developers and integrators know how to utilize that API. For example, Office 365, a cloud-based productivity suite that includes an e-mail application, has an API for importing and exporting contacts. Salesforce, a cloud-based customer relationship management (CRM) application, could integrate with Office 365 through that API so that contacts could be updated based on interactions in the CRM tool.
Effects of Cloud Service Models on Security Implementation
Cloud technologies have streamlined many aspects of security, but they have added their own complexities as well. Many security functions that were once performed in-house have now been delegated to the CSP, but this results in reduced visibility and control for the organization. They have to place a level of trust in the CSP.
In the cloud, companies may not need to provision their own security technologies. Rather, they use a self-service portal where they can simply select the systems they want deployed, and the CSP automates the process on their behalf. Similarly, consumers can browse through solutions in cloud marketplaces and begin using those systems almost immediately. These systems still need to be configured, but there is still far less work to go through than required in a traditional data center model.
Endpoint Protection
Vendors have created a vast number of applications to solve many endpoint security challenges, and many security applications are available as cloud services on your endpoints. IT administrators and security teams have many tools at their disposal. There are systems they can deploy to implement security or vendor applications. Each of these systems must be compatible with existing systems and services.
The following sections cover important endpoint security controls:
• Host-based firewall
• Antivirus/antimalware
• Endpoint detection and response
• Data loss prevention
• Hardening
• Application whitelisting
We will wrap this section up with a discussion on the impact security tools have on systems and services.
Host-Based Firewall
Firewalls often exist on the perimeter of the network, where they can screen the data that is going to and coming from the Internet. There is also a type of firewall called the host-based firewall that resides on an endpoint to screen the data that is received by the endpoint. If a device is not running as a web server, there is no reason for it to process web traffic. Web traffic sent to it is either malicious or sent by mistake, so it is either a waste of time to look at it or, more likely, a threat. The host-based firewall drops this traffic before it can do harm to the device.
Host-based firewalls can be configured based on policy so that many machines can use the same configuration. Chapter 10 covered how to automate configuring firewalls with scripting. You can also use Windows group policies to configure the Windows Defender firewall that comes with Windows.
Many antivirus vendors bundle a host-based firewall with their products, and these can be managed with a central management application or cloud portal if the licensing for that application or portal has been purchased.
Antivirus/Antimalware
Antivirus or antimalware looks at actions on a system to identify malicious activity. Antivirus or antimalware does this through the same two methods used by an IDS/IPS: signatures and heuristics. The terms antivirus and antimalware are used interchangeably. Both antivirus and antimalware software detect viruses, trojans, bots, worms, and malicious cookies. Some antivirus or antimalware software also identifies adware, spyware, and potentially unwanted applications.
Signatures are descriptions of what malicious actions look like. Antivirus and antimalware review the data in memory and scan data on the disk or disks plugged into them and take action if they find data that matches a signature.
The second screening method used is heuristics, which looks for patterns that appear malicious, such as a user-mode process trying to access kernel-mode memory addresses. Just as with the IDS and IPS, antivirus or antimalware heuristics operate off an understanding of what constitutes normal on the device. A baseline is configured and periodically updated so the antivirus or antimalware understands what to expect from the network traffic. Anything else is an anomaly, and the device will take action.
Many antivirus and antimalware vendors have a central management application or cloud portal option that can be purchased. These tools or portals are very valuable for ease of administration. Each antivirus or antimalware client reports into the portal, and administrators can view all machines in a set of dashboards. Dashboards, like the one shown in Figure 11-5, display things like machines with outdated signatures, number of viruses detected, virus detection rates, virus types, items in quarantine, number of files scanned, and much more.
Figure 11-5 Antivirus central administration dashboard
These administration tools usually allow administrators to deploy antivirus or antimalware software to endpoints without walking to each machine.
Some antivirus and antimalware tools come with other services bundled in. These include host-based firewalls, data loss prevention, password vaults, e-mail scanners, web scanners, and other features.
Endpoint Detection and Response
Endpoint detection and response (EDR) is a system that resides on endpoints to continually collect data from them for real-time analysis. EDR automates elements of the incident response analysis by applying policy rules and workflow to events that are triggered along the way. This helps guard against more advanced threats that would typically evade the perimeter defenses and standard antivirus scans. Some primary functions of an EDR include:
• Collecting endpoint data based on established policy rules
• Identifying threat patterns in the collected data
• Performing workflow when events occur
• Collecting and preserving evidence of threats for forensic analysis and investigation
Data Loss Prevention
Data loss prevention (DLP) systems enforce policies for data flow and on managed devices. Data may be identified through tags that are embedded into documents or from searches performed on the data. Searches commonly use regular expressions to identify information of specific types, such as Social Security numbers, credit card numbers, or health records.
DLP policies define how the data can and cannot be used, and they can be used to enforce protections, such as encryption, on the data. For example, you could configure DLP to allow personally identifiable information (PII) to be e-mailed to others within the organization, but not to outside domain names. Department of Defense (DoD) contractors will often use DLP to ensure that data tagged as Controlled Unclassified Information (CUI) cannot be transferred to a computer unless it is on the whitelist. Cloud DLP solutions can enforce policies throughout their ecosystem. For example, Microsoft’s DLP for Office 365 extends to e-mail, SharePoint, Teams, and OneDrive.
Exercise 11-1: Creating a DLP Policy for Office 365
In this exercise, we will create a DLP policy for Office 365 for U.S. Social Security numbers, taxpayer ID numbers, and passport numbers. This DLP policy will prevent the data from being shared with anyone outside the organization. Furthermore, it will send a notification to the user and data owners that this activity is prohibited.
1. Log into your Office 365 portal.
2. Select Admin at the bottom of the apps list on the left:
3. Expand the Data Loss Prevention section and select Policy. The Policy screen will now show the policies you have defined.
4. Select the Create A Policy button to start the DLP policy wizard.
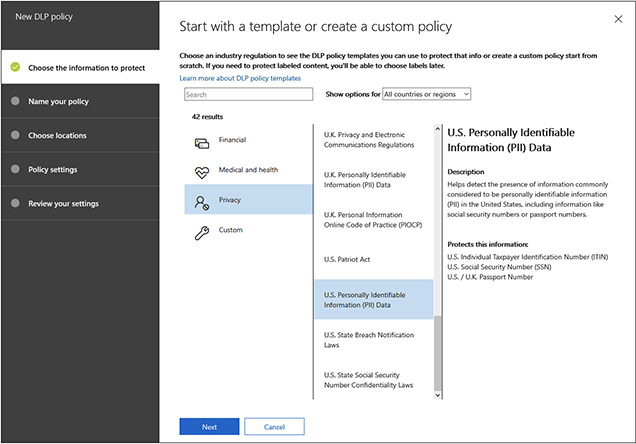
5. We will first choose the information that the policy will be focused on. In this case, we want to protect U.S. PII, including Social Security numbers, taxpayer ID numbers, and passport numbers. Select Privacy and then scroll down and select U.S. Personally Identifiable Information (PII) Data, as shown here:
6. Click Next.
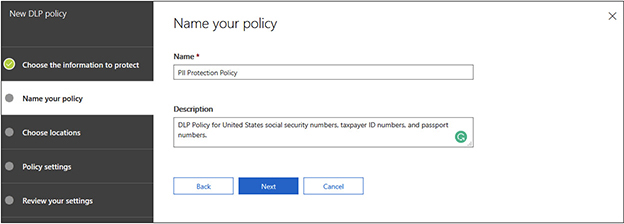
7. Enter a name and a description of the policy. In this example, we called the policy “PII Protection Policy” and gave it a short description, as shown in the following illustration. Click Next when finished.
8. You can now select the scope of the policy. Microsoft lets you enforce the policy throughout the Office 365 ecosystem, including e-mail, Teams, OneDrive, and SharePoint, or you can select only some of those locations. By default, all locations are enabled, as shown next. In this example, we will enforce protection on all locations, so you just need to click Next.
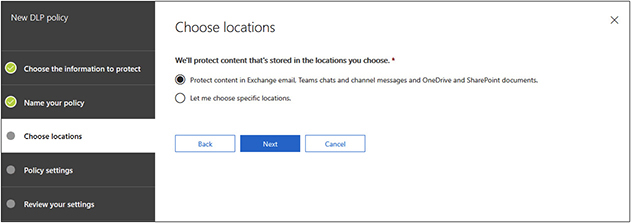
9. Select Use Advanced Settings and then click Next.
10. The advanced settings give you options for what to do when someone tries to share a small number of files and a large number of files, as shown next. In this case, we will only apply one policy for whenever someone tries to share a document containing PII, so select Delete Rule under Low Volume Of Content Detected U.S. PII.
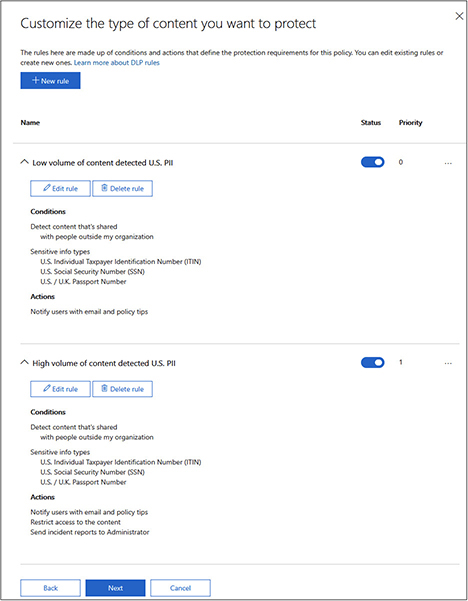
11. Select Yes in the dialog box that confirms whether you want to delete the object.
12. Click Edit Rule under High Volume Of Content Detected U.S. PII.
13. Change the name from “High volume of content detected U.S. PII” to “Content detected: U.S. PII.”
14. Under Content Contains, change the instance count min from 10 to 1 for each of the information types by clicking on the 10 and changing it to a 1. When you are done, the section should look like this:
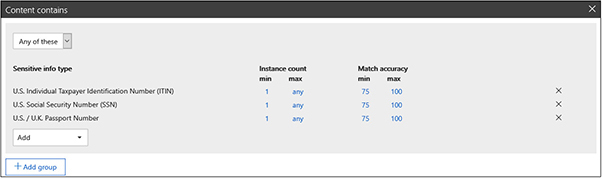
15. The Content Is Shared section is set to With People Outside My Organization by default. Leave this setting as is because we are looking for when users try to send such information outside the organization.
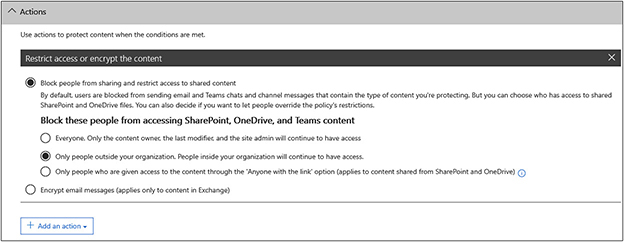
16. Under Actions, leave the default settings, as shown next. These include blocking people from sharing the content and enabling restrictions only for those outside the organization.
17. Scroll down to the User Notifications section and review the options. We will leave them at their default, but this is where you can change it to send notifications of the event to a custom list of people, such as a compliance person, internal audit, or the SOC team.
18. Under User Overrides, toggle the switch to Off so that users who see the tip cannot override the policy. The settings for steps 17 and 18 are shown here:
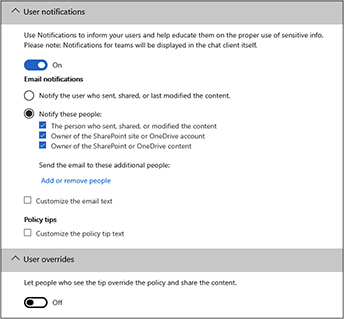
19. At the bottom, click Save. This will bring you back to the policy settings step in the wizard.
20. Click Next.
21. On the last page, you are given a choice to test the policy out first, turn it on right away, or leave it off and turn it on later. DLP can have a significant impact on operations, so it is best to test the policy first before deploying it. You might choose to leave it off and turn it on later if you plan to enable it in downtime but want to get it configured ahead of time. For this example, select I’d Like To Test It Out First, as shown next, and then click Next.
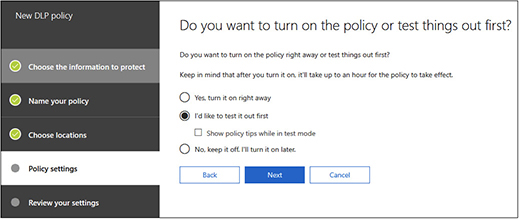
22. Click Create to create your policy in test mode. The policy will now show up on the policy screen.
NAC
NAC manages access to network resources based on policies. NAC can block computers from a network or connect them to networks based on their settings. It can screen computers before allowing their connection to the network. Computers are denied access unless they meet all the security requirements. Security requirements can include some of the following:
• Patch level
• Operating system type
• Antivirus signature version
• IDS/IPS signature version
• Host-based firewall status
• Geolocation
In some cases, the NAC system will provide limited access to systems that do not meet compliance with the policy to update their virus signatures or apply patches. Once they remediate the issues, they are allowed regular access.
The other use of NAC is to connect systems to resources based on their settings and organizational policy. NAC can automatically place Linux machines on a dedicated Linux network and Macs on another network. A popular use of NAC is to automatically place mobile phones on their own network so that their traffic is isolated from other computing devices. It can also be used to segment BYOD or IoT from other networks.
Hardening
The hardening of computer systems and networks, whether they are on-premises or in the cloud, involves ensuring that the host and guest computers are configured in such a way that it reduces the risk of attack from either internal or external sources. While the specific configuration steps for hardening vary from one system to another, the basic concepts involved are largely similar, regardless of the technologies that are being hardened. Some of these central hardening concepts are as follows:
• Remove all software and services that are not needed on the system Most operating systems and all preloaded systems run applications and services that are not required by all configurations as part of their default. Systems deployed from standard cloud templates may contain services that are not required for your specific use case. These additional services and applications add to the attack surface of any given system and thus should be removed.
• Maintain firmware and patch levels Security holes are continually discovered in both software and firmware, and vendors release patches as quickly as they can to respond to those discoveries. Enterprises, as well as cloud providers, need to apply these patches to be protected from the patched vulnerabilities.
• Control account access Unused accounts should be either disabled or removed entirely from systems. The remaining accounts should be audited to make sure they are necessary and that they only have access to the resources they require. Default accounts should be disabled or renamed. If hackers are looking to gain unauthorized access to a system and guess the username, they already have half of the necessary information to log into that system.
For the same reason, all default passwords associated with any system or cloud service should be changed. In addition to security threats from malicious users who are attempting to access unauthorized systems or data, security administrators must beware of the danger from a well-meaning employee who unknowingly accesses resources that shouldn’t be made available to them or, worse yet, deletes data that he or she did not intend to remove.
• Implement the principle of least privilege (POLP) POLP dictates that users are given only the amount of access they need to carry out their duties and no additional privileges above that for anything else. Protecting against potential insider threats and protecting cloud consumers in a multitenant environment require that privileged user management be implemented and that security policies follow the POLP.
• Disable unnecessary network ports As with software and service hardening, only the required network ports should be enabled to and from servers and cloud services to reduce the attack surface.
• Deploy antivirus or antimalware software Antivirus or antimalware software should be deployed to all systems that support it. The most secure approach to virus defense is one in which any malicious traffic must pass through multiple layers of detection before reaching its potential targets, such as filtering at the perimeter, through e-mail gateways, and then on endpoints such as cloud servers or end-user machines.
• Configure logging Logging should be enabled on all systems so that if an intrusion is attempted, it can be identified and mitigated or, at the very least, investigated. Cloud logging options can be leveraged to archive logs automatically, conserving space on servers and ensuring that data is available if needed. See Chapter 10 for more information on log automation.
• Limit physical access If a malicious user has physical access to a network resource, they may have more options for gaining access to that resource. Because of this, limitations that can be applied to physical access should be utilized. Some examples of physical access deterrents are locks on server room doors, network cabinets, and the network devices themselves. Additionally, servers need to be secured at the BIOS level with a password so that malicious users cannot boot to secondary drives and bypass operating system security.
• Scan for vulnerabilities Once the security configuration steps have been defined and implemented for a system, a vulnerability assessment should be performed using a third-party tool or service provider to make certain no security gaps were missed. Penetration testing can validate whether vulnerabilities are exploitable and whether other security controls are mitigating the vulnerability. Vulnerability scanning and penetration testing are discussed later in this chapter.
• Deploy a host-based firewall Software firewalls should be deployed to the hosts and guests that will support them. These software firewalls can be configured with ACLs and protection tools in the same fashion as hardware firewalls.
• Deactivate default accounts Many systems come provisioned with accounts that are used to initially set up the software or device. The usernames and passwords of such accounts are well known to attackers, so it is best to deactivate these default accounts. Deactivation is better than just changing the password because attackers still know the default username, which gives them one piece of the puzzle even if the password is changed.
• Disable weak protocols and ciphers Weak protocols and ciphers are those that can be broken or compromised. As computers get more powerful and as vulnerabilities are discovered in existing protocols, those are flagged as weak, and companies should stop using them. Computer systems may support several ciphers or encryption protocols. They will use the highest one that both sender and receiver support, so any enabled protocol can potentially be used.
• Single function Systems should perform a single function so that it will be easier to limit the services, open ports, and software that must be updated.
• Hardened baselines Ensure that the baselined systems and templates used to create new machines are hardened so that security vulnerabilities are not introduced into the environment when new devices are provisioned.
Application Whitelisting
Application whitelisting allows a company to restrict the applications that can be installed on a machine to only those that have been approved for use. Many applications are available to users, but a myriad of deployed applications can make it difficult for administrators to keep those applications up to date and ensure that they are sufficiently tested when changes are made.
For this reason, companies typically restrict applications to the ones that they have approved and placed on a whitelist. These applications are tested when new changes are rolled out, and administrators stay informed when new versions are released or when vulnerabilities are identified for those applications.
Impact of Security Tools to Systems and Services
Security tools can affect the systems they are installed on. Antivirus software could flag some legitimate applications as malicious or require additional steps to log on to tools. Security tools can take up a large amount of CPU or memory resources. Logging tools utilize a large amount of storage. Since cloud resource utilization often determines how much the cloud consumer is charged, resource utilization directly affects the bottom line.
Some security tools do not play well together. For example, it is never a good idea to install multiple antivirus tools on the same machine. Each tool will interpret the other tool as malicious because they each are scanning large numbers of files and trying to read memory. Some security tools may accidentally flag other security tools as malicious and cause problems running those tools. If this happens, whitelist the application in the security tool that blocks it. Some security tools can cause issues with backup jobs because the tools create locks when scanning files and folders that the backup job must wait for or try to snapshot.
Access Control
Access control is the process of determining who or what should be able to view, modify, or delete information. Controlling access to network resources such as files, folders, databases, and web applications relies upon effective access control techniques. Access control is accomplished by authenticating and authorizing both users and hosts.
Authentication means that an entity can prove that it is who or what it claims to be. Authorization means that an entity has access to all of the resources it is supposed to have access to and no access to the resources it is not supposed to have access to.
Authorization is the set of processes that determine who a claimant is and what they are allowed to do. These processes also log activity for later auditing. They are sometimes referred to as AAA, which stands for authentication, authorization, and accounting.
This section includes coverage of the following access control concepts:
• Identification
• Authentication
• Authorization
• Access control methodologies
• Multifactor authentication
• Single sign-on (SSO)
• Federation
Identification
Identification is the process of claiming an identity. In the medieval days, a guard would ask, “Who goes there?” if a stranger approached the gate, in response to which the stranger would reply, “Eric Vanderburg.” Of course, the guard would not just take the stranger’s word for it, and neither should a computer when a user or service tries to connect to it or log on. The next step is authentication.
Authentication
Authentication is the process of determining who or what is requesting access to a resource. When you log on to a computer, you present credentials that validate your identity to the computer, much like a driver’s license or passport identifies your identity to a police officer or customs officer. And just as the police officer or customs officer compares the photo on the ID to your face, the computer will compare the credentials you offer with the information on hand to determine if you are who you claim to be. However, the computer may trust that you are who you say you are, but that doesn’t necessarily mean that you are allowed to be there. The next step is to determine if the user identity is allowed access to the resource.
Authorization
Authorization determines if the authenticated individual should have the requested access to the resource. For example, after this book is published, if I go to a club to celebrate, bypass the line, and present my credentials to the bouncer, he or she will compare my name to a list of authorized individuals. If the club owner is a huge fan of this book, she might have put my name on the list, in which case, I will be granted access to the club. If not, the bouncer will tell me to get lost. Computer systems compare the identity to the resource ACL to determine if the user can access the resource.
ACLs define the level of access, such as read-only (RO), modify (M), or full control (FC). Read-only access allows a user to view the data but not make changes to it. Modify allows the user to read the data and change it. Full control allows the user to read data, change it, delete it, or change the permissions on it.
Organizations should implement approval procedures and access policies along with authorization techniques. Approval and access policy are discussed next.
EXAM TIP Devices may exchange authorization data using the Security Assertion Markup Language (SAML).
Approval
Approval is an audit of the authorization function. In the bouncer example, imagine that the bouncer is a fan of this book, not the owner. A supervisor who is watching over a group of club staff members, including the bouncer, sees the bouncer letting us into the club and decides to check the list to verify that Eric Vanderburg is on it. If the supervisor finds that I am not on the list or sees my name written in with the bouncer’s handwriting, sanctions are soon to follow, and I might not be welcome there anymore.
When implemented in the computer setting, approval would see a connection from a new user who is on the ACL. Since the user has not logged in before, a second authentication would occur, such as sending a text to the user’s phone or an e-mail to their inbox. The user would enter the code from the text or e-mail to prove that they know the password from the first authentication and have access to the phone or e-mail. In future attempts, the approval step would not be needed since the user has logged in before. The concept of approval operates on a level of trust, which can be changed depending on organizational preferences. One company could decide that approval will take place not just for new connections but the lesser of every fifth time someone logs in or every two weeks. Implementations are quite flexible.
Access Policy
Access policy is the governing activities that establish authorization levels. Access policy determines who should have access to what. Access policy requires at least three roles. The first is the authorizer. This is the person or group that can define who has access. The second is the implementer. This is the person or group that assigns access based on an authorization. The third role is the auditor. This person or group reviews existing access to verify that each access granted is authorized.
Here is how an access policy plays out on the job: The organization typically defines access based on a job role. In this example, human resources (HR) is the authorizer, IT is the implementer, and audit is the auditor. When a new person is hired for a job in marketing, HR will notify IT of the new hire, their name, start date, and that they are in marketing. IT would then grant them access to the systems that others in marketing have access to. This is typically accomplished by creating the user account and then adding that account to an appropriate group.
Auditors will routinely review group memberships to determine if they match what has been defined by HR. Any inconsistencies would be brought to the attention of management. Access policies have a lifetime. Access is not provided forever, and at some point, access rights are revoked. In this example, HR would notify IT to revoke access, and IT would disable or remove the account when employees are terminated. On the next audit cycle, the auditor would verify that the account had been disabled.
Single Sign-On
As individuals, we have all had to remember multiple usernames and passwords for various software at work or even at home for multiple websites. Wouldn’t it be great if we logged in only once and had access to everything without being prompted to log in again? This is what SSO is all about!
SSO can take the operating system, VPN, or web browser authentication credentials and present them to the relying party transparently, so the user does not even know it is happening. Modern Windows operating systems use the credential locker as a password vault to store varying types of credentials to facilitate SSO. Enterprise SSO solutions such as the open-source Shibboleth tool or Microsoft Active Directory Federation Services (ADFS) let cloud personnel implement SSO on a large scale. Cloud providers normally offer identity federation services to cloud customers.
The problem with SSO is that different software and websites may use other authentication mechanisms. This makes implementing SSO in a large environment difficult.
Federation
Federation uses SSO to authorize access for users or devices to potentially many very different protected network resources, such as file servers, websites, and database applications. The protected resources could exist within a single organization or between multiple organizations.
For business-to-business (B2B) relationships, such as between a cloud customer and a cloud provider, a federation allows the cloud customer to retain their own on-premises user accounts and passwords that can be used to access cloud services from the provider. This way, the user does not have to remember a username and password for the cloud services as well as for the local network. Federation also allows cloud providers to rent on-demand computing resources from other cloud providers to service their clients’ needs.
Here is a typical B2B federation scenario (see Figure 11-6):

Figure 11-6 An example of a B2B federation at work
1. User Bob in company A attempts to access an application on the web application server 1 in company B.
2. If Bob is not already authenticated, the web application server in company B redirects Bob to the federation server in company B for authentication.
3. Since Bob’s user account does not exist in company B, the federation server in company B sends an authentication redirect to Bob.
4. Bob is redirected to the company A federation server and gets authenticated since this is where his user account exists.
5. The company A federation server returns a digitally signed authentication token to Bob.
6. Bob presents the authentication token to the application on the web application server 1 and is authorized to use the application.
Access Control Protocols
Access control protocols are used to send authentication challenges and responses to and from resources and authenticators. Some common access control protocols include Kerberos, LDAP, and SAML.
Kerberos
Kerberos is an authentication protocol that uses tickets to validate whether an entity can access a resource. A Kerberos system consists of the following elements:
• Authentication Server (AS) Clients send their credentials to the AS to verify them and then forward user information to the KDC.
• Key Distribution Center (KDC) The KDC issues a TGT (discussed next) to clients after receiving identifying information from an AS for a client. These TGTs expire after a period of time and must be renewed.
• Ticket Granting Ticket (TGT) The TGT is provided by the KDC. It can be used to get a session key from a TGS.
• Ticket Granting Service (TGS) This service is associated with a resource. Clients request access to the resource by sending their TGT to the resource TGS’s Service Principal Name (SPN).
Kerberos has been implemented by Microsoft Windows, macOS, FreeBSD, Linux, and other systems. It uses UDP port 88.
Lightweight Directory Access Protocol
LDAP is an open protocol that is used to query a database of authentication credentials. This database is known as a directory. Many systems have been based on LDAP, as this protocol has been around since 1993. Microsoft’s Active Directory is based on LDAP.
An LDAP directory consists of entries that each has attributes. The directory schema defines which attributes will be associated with each type of entry. Each entry must have a unique identifier so that it can be singularly referenced within the directory. This unique identifier is called its distinguished name. Suppose we had an entry for a user in the directory. In that case, some of its attributes could include username, password, first name, last name, department, e-mail address, and phone number. Figure 11-7 shows a user account entry in Microsoft Active Directory for a service account.
Figure 11-7 User account in Microsoft Active Directory
LDAP communicates over port 389 on TCP and UDP and port 636 over SSL/TLS.
Security Assertion Markup Language
SAML is an authentication protocol that is used primarily for federated access and SSO. SAML allows identity providers, such as Azure Active Directory or Identity Access Management (IAM) solutions, to send a SAML assertion to service providers. SAML assertions inform the provider that the user is who they say they are and that they have access to the selected resource. SAML assertions are formatted in Extensible Markup Language (XML), hence the ML part of the SAML acronym.
Access Control Methodologies
Several methodologies can be used to assign permissions to users so that they can use network resources. These methods include mandatory access control (MAC), discretionary access control (DAC), and nondiscretionary access control (NDAC). NDAC consists of role-based access control (RBAC) and task-based access control (TBAC). RBAC, MAC, and DAC are compared in Table 11-3.

Table 11-3 Comparison of Access Control Methods
As systems become more complex and distributed, the policies, procedures, and technologies required to control access privileges, roles, and rights of users across a heterogeneous enterprise can be centralized in an identity and access management (IAM) system.
Mandatory Access Control
The word mandatory is used to describe this access control model because permissions to resources are controlled or mandated by the operating system (OS) or application, which looks at the requesting party and their attributes to determine whether access should be granted. These decisions are based on configured policies that are enforced by the OS or application.
With mandatory access control (MAC), data is labeled or classified, so only those parties with specific attributes can access it. For example, perhaps only full-time employees can access a particular portion of an intranet web portal. Alternatively, perhaps only human resources employees can access files classified as confidential.
Discretionary Access Control
With the DAC methodology, the power to grant or deny user permissions to resources lies not with the OS or an application, but rather with the data owner. Protected resources might be files on a file server or items in a specific web application.

TIP Most network environments use both DAC and RBAC; the data custodian can give permissions to the resource by adding a group to the ACL.
There are no security labels or classifications with DAC; instead, each protected resource has an ACL that determines access. For example, we might add user RayLee with read and write permissions to the ACL of a specific folder on a file server so that she can access that data.
Nondiscretionary Access Control
With the NDAC methodology, access control decisions are based on organizational rules and cannot be modified by (at the discretion of) nonprivileged users. NDAC scales well because access control rules are not resource-specific and can be applied across the board to new resources such as servers, computers, cloud services, and storage as those systems are provisioned.
NDAC has been implemented in the RBAC and TBAC methodologies. RBAC is by far the most popular, but both are discussed in this section. RBAC relies on group or role memberships to determine access, while TBAC relies on the task that is being performed to make access decisions.
Role-Based Access Control For many years, IT administrators, and now cloud administrators, have found it easier to manage permissions to resources by using groups or roles. This is the premise of RBAC. A group or role has one or more members and that group or role is assigned permissions to a resource.
Permissions are granted either implicitly or explicitly. Any user placed into that group or role inherits its permissions; this is known as implicit inheritance. Giving permissions to individual users is considered an explicit permission assignment. Explicit permission assignment does not scale as well in larger organizations as RBAC does. RBAC is implemented in different ways depending on where it is being performed. Solutions such as IAM can manage identity across an enterprise, including on-premises and cloud systems. However, these systems tie into locally defined groups to assign generalized IAM groups to the local groups. IAM can significantly improve the time it takes to provision or remove users or change their roles across an enterprise.
Sometimes, cloud vendors define the groups or roles in RBAC through an IAM solution such as AWS IAM. RBAC can also be applied at the operating system level, as in a Microsoft Windows Active Directory group. RBAC can be used at the application level, as in the case of Microsoft SharePoint Server roles. In the cloud, roles may be defined by the cloud provider if cloud consumers are not using provider IAM solutions.
To illustrate how cloud-based RBAC would be implemented using an IAM solution, consider the following commands. AWS IAM can be managed through the web GUI or via the CLI. These commands can be used in the AWS IAM CLI. This first command creates a group called managers:
aws iam create-group --group-name Managers
The following command assigns the administrator policy to the managers group. AWS IAM has policies that package together a set of permissions to perform tasks. The administrator policy provides full access to AWS.
aws iam attach-group-policy --group-name Managers --policy-arn
arn:aws:iam::aws:policy/AdministratorAccess
We can then create a user named EricVanderburg with the following command:
aws iam create-user --user-name EricVanderburg
Last, we add the user EricVanderburg to the managers group with this command:
aws iam add-user-to-group --username EricVanderburg --group-name Managers
Task-Based Access Control The TBAC methodology is a dynamic method of providing access to resources. It differs significantly from the other NDAC methodology, RBAC, in that it is not based on subjects and objects (users and resources).
TBAC was created around the concept of least privilege. In other models, a user might have the ability to access a reporting system, but they use that system only once a month. For the majority of each month, the user has more access than they require. In TBAC, users have no access to resources by default and are only provided access when they perform a task requiring it, and access is not retained after the task is complete.
TBAC systems provide access just as it is needed, and it is usually associated with workflows or transactions. TBAC can also be efficient because tasks and their required access can be defined when new processes are defined, and they are independent of who performs them or how many times they are performed.
Multifactor Authentication
Authentication means proving who (or what) you are. Authentication can be done with the standard username and password combination or with a variety of other methods.
Some environments use a combination of the five authentication mechanisms (listed next), known as multifactor authentication (MFA). Possessing a debit card, along with knowledge of the PIN, comprises multifactor authentication. Combining these authentication methods is considered much more secure than single-factor authentication. These are the five categories of authentication that can be combined in multifactor authentication scenarios:
• Something you know Knowing your username and password is by far the most common. Knowing your first pet’s name or the PIN for your credit card or your mother’s maiden name all fall into this category.
• Something you have Most of us have used a debit or credit card to make a purchase. We must physically have the card in our possession. For VPN authentication, a user would be given a hardware token with a changing numeric code synced with the VPN server. For cloud authentication, users could employ a mobile device authenticator app with a changing numeric code in addition to their username and password.
• Something you do This measures how an individual performs a routine task to validate their identity. Handwriting analysis can determine if the user writes their name the same way, or the user could be asked to count to 10, and the computer would determine if this is the way they normally count to 10 with the appropriate pauses and inflection points.
• Someplace you are Geolocation is often used as an authentication method along with other methods. The organization may allow employees to access certain systems when they are in the workplace or facility but not from home. Traveling employees might be able to access some resources in the country but not when traveling internationally.
• Something you are This is where biometric authentication kicks in. Your fingerprints, your voice, your facial structure, the capillary pattern in your retinas—these are unique to you. Of course, voice impersonators could reproduce your voice, so some methods are more secure than others.
EXAM TIP Knowing both a username and password is not considered multifactor authentication because they are both “something you know.”
Chapter Review
This chapter focused on data security, network security, and access control, all of which are of interest to cloud personnel. Assessing the network is only effective when comparing your results with an established baseline of typical configuration and activity. Auditing a network is best done by a third party, and you may be required to use only accredited auditors that conform to industry standards such as NIST or ISO 27000 and compliance requirements like HIPAA, GDPR, or PCI. All computing equipment must be patched and hardened to minimize the potential for compromise.
An understanding of data security measures and access control methods is also important for the exam. Data security must be in place both for data as it traverses a network and for stored data. Encrypting data prevents unauthorized access to the data, while digital signatures verify the authenticity of the data. Various encryption protocols are used to accomplish these objectives. The various access control models discussed in this chapter include role-based access control, mandatory access control, and discretionary access control.
Questions
The following questions will help you gauge your understanding of the material in this chapter. Read all the answers carefully because there might be more than one correct answer. Choose the best response(s) for each question.
1. You are invited to join an IT meeting where the merits and pitfalls of cloud computing are being debated. Your manager conveys her concerns about data confidentiality for cloud storage. What can be done to secure data stored in the cloud?
A. Encrypt the data.
B. Digitally sign the data.
C. Use a stream cipher.
D. Change default passwords.
2. Which of the following works best to encrypt variable-length data?
A. Block cipher
B. Symmetric cipher
C. Asymmetric cipher
D. Stream cipher
3. With PKI, which key is used to validate a digital signature?
A. Private key
B. Public key
C. Secret key
D. Signing key
4. Which of the following is related to nonrepudiation?
A. Block cipher
B. PKI
C. Symmetric encryption
D. Stream cipher
5. Which service does a firewall use to segment traffic into different zones?
A. DMZ
B. ACL
C. Port/service
D. NAT/PAT
6. Which device would be used in front of a cloud application to prevent web application attacks such as cross-site scripting (XSS) and SQL injection?
A. IAM
B. DLP
C. WAF
D. IDS/IPS
7. Which best practice configures host computers so that they are not vulnerable to attack?
A. Vulnerability assessment
B. Penetration test
C. Hardening
D. PKI
8. Which device would be used to identify potentially malicious activity on a network?
A. IAM
B. DLP
C. WAF
D. IDS/IPS
9. Sean configures a web application to allow content managers to upload files to the website. What type of access control model is Sean using?
A. DAC
B. MAC
C. RBAC
D. GBAC
10. You are the administrator of a Windows network. When creating a new user account, you specify a security clearance level of top secret so that the user can access classified files. What type of access control method is being used?
A. DAC
B. MAC
C. RBAC
D. GBAC
11. John is architecting access control for a custom application. He would like to implement a nondiscretionary access control method that does not rely upon roles. Which method would meet John’s criteria?
A. RBAC
B. MAC
C. TBAC
D. DAC
Answers
1. A. Encrypting data at rest protects the data from those not in possession of a decryption key.
2. D. Stream ciphers encrypt data, usually a bit at a time, so this works well for data that is not a fixed length.
3. B. The public key of the signer is used to validate a digital signature.
4. B. PKI is related to nonrepudiation, which means that a verified digital signature proves the message came from the listed party. This is true because only the private key of the signing party could have created the validated signature.
5. A. A demilitarized zone (DMZ) is a segment that has specific security rules on it. DMZs are created to segment traffic.
6. C. A web application firewall (WAF) is a specialized type of firewall that screens traffic intended for web applications. WAFs understand common web application attacks such as XSS and SQL injection and can inspect traffic at the application layer of the OSI model.
7. C. Hardening configures systems such that they are protected from compromise.
8. D. IDS/IPS technologies look at traffic to identify malicious traffic.
9. C. Sean is using a role (content managers) to control who can upload files to the website. This is role-based access control (RBAC).
10. B. Mandatory access control (MAC) uses attributes or labels (such as “top secret”) that enable computer systems to determine who should have access to what.
11. C. Task-based access control uses tasks instead of roles to determine the level and extent of access.