
Chapter Ten
Network Performance and Optimization
Introduction
When you come right down to it, the most important responsibility of network administrators is to ensure data availability. When users, customers, or clients need access to network data, it should be ready to go. Many organizations depend on data availability; without it, they could not function.
Two key strategies help ensure data availability: fault tolerance and disaster recovery. To fulfill the role of network administrator, it is essential that you have a clear understanding of how to use these strategies. These strategies and others have a single goal in mind: uptime.
Understanding Uptime
All devices on the network, including routers, cabling, and especially servers, must have one prime underlying trait: availability. Networks play such a vital role in the operation of businesses that their availability must be measured in dollars. The failure of a single desktop PC affects the productivity of a single user. The failure of an entire network affects the productivity of the entire company and potentially of the company’s clients as well. A network failure may have an even larger impact than that as new e-commerce customers look somewhere else for products, and existing customers start to wonder about the reliability of the site.
Every minute that a network is not running can potentially cost an organization money. The exact amount depends on the role that the server performs and the length of time that it is unavailable. For example, if a small departmental server supporting 10 people goes down for 10 minutes, this may not be a big deal. But if the server that runs the company’s e-commerce Web site goes down for an hour, this can cost hundreds of thousands of dollars’ worth of lost orders.
The importance of data availability varies between networks but will dictate to what extent a server/network will implement fault tolerance measures. The projected ability for a network or network component to weather failure is defined as a number or a percentage. The fact that no solution is labeled as providing 100 percent availability indicates that no matter how well we protect our networks, some aspect of the configuration will still, sooner or later, fail.
Assuming we know we can never really obtain 100 percent uptime, what should we aim for? Consider this—if you were responsible for a server system that was available for 99.5 percent of the time, you might be pretty happy. But if you realized that you would also have 43.8 hours of downtime each year—that’s one full work week and a little overtime—you might not be so smug. Table 10.1 compares levels of availability and the resulting potential downtime.
Table 10.1 Levels of Availability and Related Downtime
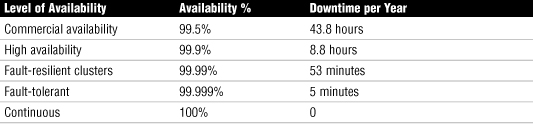
These downtime numbers make it simple to justify spending money on implementing fault-tolerance measures, but remember that to reach the definition of commercial availability, you will need to have a range of measures in place. After the commercial availability level, the strategies that take you to each subsequent level are likely to be increasingly expensive, even though they might be easy to justify.
For example, if you estimate that each hour of server downtime will cost the company $1,000, the reduction of 35 hours of downtime—from 43.8 hours for commercial availability to 8.8 hours for high availability—justifies some serious expenditure on technology. Although this first jump is an easily justifiable one, subsequent levels may not be so easy to sell. Working on the same basis, moving from high availability to fault-resilient clusters equates to less than $10,000, but the equipment, software, and skills required to move to the next level will far exceed this figure. In other words, increasing fault tolerance can represent diminishing returns. As your need to reduce the possibility of downtime increases, so does the investment required to achieve this goal.
The role played by the network administrator in all of this can be somewhat challenging. In some respects, you must function as if you are selling insurance. Informing management of the risks and potential outcomes of downtime can seem a little sensational, but the reality is that the information must be provided if you are to avoid post-event questions about why management was not made aware of the risks. At the same time, a realistic evaluation of exactly the risks presented is needed along with a realistic evaluation of the amount of downtime each failure may bring.
In networking, fault tolerance refers to the capability for a device or system to continue operating in the event of a failure. Fault-tolerant measures are those used to help ensure uptime. Fault tolerance should not be confused with disaster recovery, which is the capability to respond to and recover from catastrophic events with no loss of data and no loss of data availability.
In practical terms, fault tolerance involves ensuring that when network hardware or software fails, users on the network can still access the data and continue working with little or no disruption of service. Developing a strong fault-tolerant system that ensures continual access to data is not easy, and it involves attention to many details.
Today’s business world relies heavily on networks and network servers. If these networks and servers were to fail, many businesses would be unable to function. Thus, every minute a network is not available costs money. The exact amount of money depends on the size of the organization and can range from a mild economic inconvenience to a crippling financial blow. The potential impact of a network failure often dictates the fault tolerance measures an organization implements.
Unfortunately, no fault-tolerance measures can guarantee 100% availability or uptime to network data or services, and fault-tolerance solutions that strive to meet this goal can be expensive. But the costs associated with any fault-tolerance solution must be compared to the costs of losing access to network services and the reconstruction of network data.
Understanding the Risks
Having established that we need to guard against equipment failure, we can now look at which pieces of equipment are more liable to fail than others. Predicating component failure is not an exact science; different companies have different estimates. Combining the estimates around the Internet, Figure 10.1 shows an approximation of what to expect in terms of hardware failure.
Figure 10.1 Server component failures.
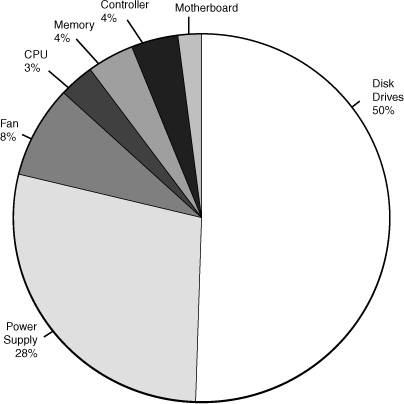
As you can see from the graph, 50 percent of all system downtime can be attributed to hard disk failure. That means that, for instance, a hard disk is more than 12 times more likely to fail than memory is, and 50 times more likely to fail than a motherboard is. With this in mind, it should come as no surprise that hard disks have garnered the most attention when it comes to fault tolerance. Redundant array of inexpensive disks (RAID), which is discussed in detail in this section, is a set of standards that allows servers to cope with the failure of one or more hard disks.
Exam Alert
Moving parts All system components may fail, but those with moving parts, such as the power supply fan, the CPU fans, and hard disk, have a greater chance of failure.
Note
Backup Although this chapter discusses various methods of fault tolerance designed to reduce the susceptibility to server failure and downtime, none of these methods is a substitute for a complete and robust backup strategy. No matter how many of these measures are in place, backing up data to an external medium is still an essential consideration.
In fault tolerance, RAID is only half the story. Each of the other components in the chart can also fail, and to varying degrees, there are measures in place to cope with failures of these components as well. In some cases, the fault tolerance is an elegant solution, and in others, it is a simple case of duplication. This may be having duplicate network cards installed in a system so that one will take over if the other fails. We’ll start our discussion by looking at fault tolerance and RAID before moving on to other fault-tolerance measures.
RAID
RAID is a strategy for implementing fault tolerance, performance, and reliability solutions that prevent data disruption because of hard disk failure or enhance performance over capabilities over a single hard disk. RAID combines multiple hard disks in such a way that more than one disk is responsible for holding data. Instead of using a single large disk, information is written to several smaller disks.
Such a design offers two key advantages. First, the failure of one disk does not, in fault-tolerant RAID configurations, compromise the availability of data. Second, reading (and sometimes writing) to multiple smaller disks is often faster with multiple hard disks than when using one large disk, thus offering a performance boost.
The goals of a RAID solution are clear: Decrease the costs associated with downtime, secure network data, minimize network disruption, and (selfishly) reduce the stress on the network administrator(s). Because a well-designed RAID system can accomplish all these goals, RAID is widely implemented and found in organizations of all sizes.
Several RAID strategies are available, and each has advantages and disadvantages. It is important to know what you are protecting and why before you implement any RAID solution; the particular RAID strategy used depends on many factors, including associated costs, the server’s role, and the level of fault tolerance required. The following sections discuss the characteristics of the various RAID strategies.
Note
RAID or not? Not all RAID solutions are designed for fault tolerance. RAID 0 does not allow any support for fault tolerance but is an implementation used for enhancing performance.
RAID 0
Although it is classified as a RAID level, RAID 0 is, in fact, not fault tolerant. As such, RAID 0 is not recommended for servers that maintain mission-critical data. RAID 0 works by writing to multiple hard drives simultaneously, allowing for faster data throughput. RAID 0 offers a significant performance increase over a single disk, but as with a single disk, all data is lost if any disk in the RAID set fails. With RAID 0 you actually increase your chances of losing data compared to using a single disk because RAID 0 uses multiple hard disks, creating multiple failure points. Essentially, the more disks you use in the RAID 0 array, the more at risk the data is. A minimum of two disks is required to implement a RAID 0 solution.
Exam Alert
RAID 0 For the exam, remember that although RAID 0 is known as a RAID solution, it is not fault tolerant. RAID 0 is used to increase performance by striping data between multiple disks.
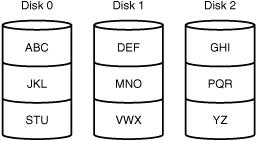
RAID 0 writes data to the disks in the array by using a system called striping. Striping works by dividing the hard disks into stripes and writing the data across the stripes, as shown in Figure 10.2. The striping strategy is also used by RAID 2, RAID 3, RAID 4, and RAID 5.
Figure 10.2 RAID 0 with disk striping.
Advantages of RAID 0
Despite the fact that it is not fault tolerant, RAID 0 is well suited for some environments. The following are some of the advantages of RAID 0:
• Ease of implementation—RAID 0 offers easy setup and configuration.
• Good input/output (I/O) performance—RAID 0 offers a significant increase in performance over a single disk and other RAID solutions by spreading data across multiple disks.
• Minimal hardware requirements—RAID 0 can be implemented with as few as two hard drives, making it a cost-effective solution for some network environments.
Disadvantages of RAID 0
You cannot have the good without the bad. For a number of reasons, a RAID 0 solution may not be appropriate:
• No fault tolerance—Employing a RAID solution that does not offer data protection is a major drawback. This factor alone limits a RAID 0 solution to only a few network environments.
• Increased failure points—A RAID 0 solution has as many failure points as there are hard drives. For instance, if your RAID 0 configuration has five disks and any one of those drives fails, the data on all drives will be lost.
• Limited application—Because of the lack of fault tolerance, a RAID 0 solution is practical for few applications. Quite simply, it’s limited to environments where the performance of I/O outweighs the importance of data availability.
Despite its drawbacks, you might encounter RAID 0.
Exam Alert
Data loss Remember for the Network+ exam, if one disk should fail when using RAID 0, all data will be lost. The more disks added to the RAID 0 array, the greater the chance a disk will fail. The more hard disks added, the more failure points there are.
Recovering from a Failed RAID 0 Array
Anyone relying on a RAID 0 configuration to hold sensitive data is bold. The bottom line is, there is no way to recover from a failed RAID 0 array, short of restoring the data from backups. Both the server and the services it provides to the network are unavailable while you rebuild the drives and the data.
RAID 1
RAID 1 is a fault-tolerant configuration known as disk mirroring. A RAID 1 solution uses two physical disk drives. Whenever a file is saved to the hard disk, a copy of the file is automatically written to the second disk. The second disk is always an exact mirrored copy of the first one. Figure 10.3 illustrates a RAID 1 array.
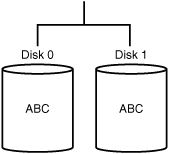
RAID 1 writes the same data to the hard drives simultaneously. The benefits of having a duplicate copy of all saved data are clear, and on the surface, RAID 1 may seem like a very fault-tolerant solution. However, it has a couple drawbacks. First, RAID 1 has high overhead because an entire disk must be used to provide the mirrored copy. Second, a RAID 1 solution is limited to two hard drives, which limits the available storage capacity.
Another RAID strategy that falls under the category of RAID 1 is disk duplexing. Disk duplexing is a mirrored solution that incorporates a second level of fault tolerance by using a separate hard disk controller for each hard drive. Putting the hard disks on separate controllers eliminates the controller as a single point of failure. The likelihood of a failed disk controller is not nearly as high as the likelihood of a failed hard disk, but the more failure points covered, the better. Figure 10.4 shows a disk duplexing configuration.
Figure 10.4 A disk duplexing configuration.
Note
Sizing the mirror Because mirroring involves making a duplicate copy of the data, the volumes used on each disk are the same size. If you set up the mirrored environment with a 500MB volume and a 700MB volume, the result will be only a 500MB volume. The system uses the lowest common amount of free space to construct the mirrored volume.
Advantages of RAID 1
Although it is far from perfect, RAID 1 is widely implemented in many different network environments. The following are a few of the advantages of RAID 1:
• Fault tolerance—RAID 1 is a fault-tolerance solution that maintains a mirrored image of data on a second hard drive in case of failure. Disk duplexing adds extra fault tolerance by using dual hard drive controllers.
• Reduced cost—RAID 1 provides fault tolerance by using only two hard disks, thereby providing a cost-effective method of implementing a fault-tolerance solution.
• Ease of implementation—Implementing a RAID 1 solution is not difficult; it can be set up easily. The procedures and methods for implementing the hardware and software are well documented.
Exam Alert
Data loss RAID 1 uses an exact copy of the data, meaning that if one disk should fail, no data loss occurs when it comes to data transfer rates. RAID 5, however, may lose data when data is being written to multiple disks simultaneously.
Disadvantages of RAID 1
Several factors exclude RAID 1 from being used in many network environments. The following are some of the disadvantages associated with RAID 1:
• Limited disk capacity—Because RAID 1 uses only two hard disks, limited disk space is available for use. With today’s large hard disk capacity, it may not be a problem for most environments.
• High disk space overhead—RAID 1 has 50% overhead—that is, half the hard disk space needs to be used for RAID. So for every megabyte used for other purposes, another is needed for RAID. Even if you purchased two 80GB drives, your network would have only 80GB of storage space. The applications and data storage needs of many of today’s businesses would exceed this limitation quickly.
• Hot-swap support—Some RAID 1 implementations don’t support the capability to hot swap drives, meaning that you might have to shut down the server to replace a damaged hard disk. Many hardware RAID solutions do support hot-swap configurations and are the preferred method.
Exam Alert
Single failure Although disk mirroring is a reliable fault-tolerance method, it provides for only a single disk failure.
Recovering from a Failed RAID 1 Array
RAID 1 can handle the failure of a single drive; if one fails, a complete copy of the data exists on an alternate hard drive. Recovering from a failed RAID 1 array typically involves breaking the mirror set, replacing the failed drive with a working one, and reestablishing the mirror. The data will be automatically rebuilt on the new drive.
The recovery process may cause network disruption while a new hard drive is installed. The server can continue to function with a single drive, but no fault tolerance exists until the RAID 1 array is rebuilt.
It is possible—however unlikely—for multiple drives to fail, and RAID 1 cannot handle such a situation.
RAID 5
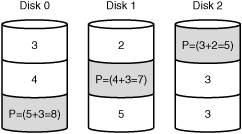
RAID 5 is the preferred hard disk fault-tolerance strategy for most environments; it is trusted to protect the most sensitive data. RAID 5 stripes the data across all the hard drives in the array.
RAID 5 spreads parity information across all the disks in the array. Known as distributed parity, this approach allows the server to continue to function in the event of disk failure. The system can calculate the information missing from the failed drive by using the parity information on the disks. A minimum of three hard drives is required to implement RAID 5, but more drives are recommended, up to 32. When calculating how many drives you will be using in a RAID 5 array, remember that the parity distributed across the drives is equivalent to one disk. Thus, if you have four 10GB hard disks, you will have 30GB of storage space.
You can expect to work with and maintain a RAID 5 array in your network travels. Figure 10.5 shows a RAID 5 array.
Advantages of RAID 5
RAID 5 has become a widely implemented fault-tolerance strategy for several reasons. The following are some of the key advantages of RAID 5:
• Minimal network disruption—When a hard disk crashes in a RAID 5 array, the rest of the drives continue to function with no disruption in data availability. Network users can keep working, and costs associated with network downtime are minimized. Although there is no disruption to data access, the performance of the system decreases until the drive has been replaced.
• Performance—Because RAID 5 can access several drives simultaneously, the read performance over that of a single disk is greatly improved. Increased performance is not necessarily a reason to use a fault-tolerant solution, but it is an added bonus.
• Distributed parity—By writing parity over several disks, RAID 5 avoids the bottleneck of writing parity to a single disk, which occurs with RAID 3 and 4.
Disadvantages of RAID 5
The disadvantages of RAID 5 are few, and the benefits certainly outweigh the costs. The following are the disadvantages of RAID 5:
• Poor write performance—Because parity is distributed across several disks, multiple writes must be performed for every write operation. The severity of this performance lag depends on the application being used, but its impact is minimal enough to make it a factor in only a few environments. Furthermore, the more drives added to the array, the more it will negatively impact write performance.
• Regeneration time—When a hard disk is replaced in a RAID 5 array, the data must be regenerated on it. This process is typically performed automatically and demands extensive system resources.
• Data limitations—RAID 5 that is implemented using software may not be able to include the system or boot partitions in the stripe set, so you must use an alternative method to secure the system and boot partitions. For example, some organizations use RAID 5 for data and a mirrored set to provide fault tolerance for the system and boot partitions. This limitation does not include hardware RAID 5 solutions, which can stripe the system and boot partitions.
Exam Alert
RAID 5 RAID 5 is a common fault tolerant strategy. Ensure you are able to identify both the pros and cons of RAID 5 for the Network+ exam.
Recovering from a RAID 5 Array Failure
RAID 5 ensures data availability even in the event of failed hard disks. A RAID 5 system can still service requests from clients in the event of a failure, by using the parity information from the other disks to identify the data that is now missing because it was on the failed drive.
At some point, you must replace the failed hard disks to rebuild the array. Some systems let you remove the failed hard drive (that is, they are hot swappable) and insert the new one without powering down the server. The new hard disk is configured automatically as part of the existing RAID 5 array, and the rebuilding of data on the new drive occurs automatically. Other systems may require you to power down the server to replace the drive. You must then manually perform the rebuild. Because RAID 5 continues to run after a disk failure, you can schedule a time to replace the damaged drive and minimize the impact on network users.
Note
RAID 6 Like RAID 5, RAID 6 allows fault tolerance by spreading data across multiple disk drives. Building on RAID 5, RAID 6 adds an extra layer of parity increasing data protection and allowing the restoration of data from an array with up to two failed drives.
RAID 10
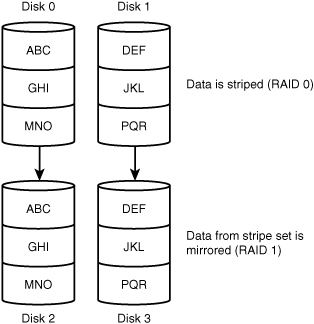
In some server environments, it makes sense to combine RAID levels. One such strategy is RAID 10, which combines RAID 1 and RAID 0. RAID 10 requires four hard disks: two for the data striping and two to provide a mirrored copy of the striped pair.
Note
Implementing RAID 10 There are various ways of implementing RAID 10, depending on how many drives you have available and what the system configuration is.
RAID 10 combines the performance benefits of RAID 0 with the fault-tolerant capability of RAID 1, without requiring the parity calculations. However, RAID 10 also combines the limitations of RAID 0 and RAID 1. Mirroring the drives somewhat reduces the performance capabilities of RAID 0, and the 50% overhead of a RAID 1 solution is still in effect. Even with these limitations, RAID 10 is well suited for many environments, and you might find yourself working with or implementing such a solution. Figure 10.6 shows a possible configuration for a RAID 10 solution.
Figure 10.6 A RAID 10 solution.
Note
What’s in a name? RAID 10 has many names. It’s sometimes referred to as RAID 1/0, RAID 0/1, or RAID 1+0.
Choosing a RAID Level
Deciding whether to use a fault-tolerant solution on a network is the first and most obvious step for you to take when you design a network. The next, less simple, decision is which RAID level to implement. Your first inclination might be to choose the best possible RAID solution, but your budget might dictate otherwise. Consider the following when choosing a specific RAID level:
• Data protection and availability—First and foremost, consider the effect of downtime on the organization. If minutes will cost the organization millions, you need a very strong fault-tolerant solution. On the other hand, if you can go offline for an hour or more and suffer nothing more than an inconvenience, a costly RAID solution might be overkill. Before choosing a RAID solution, be sure what impact data unavailability will have on you and your network.
• Cost—High-end RAID solutions are out of the price range of many organizations. You are left to choose the best solution for the price.
• Capacity—Some organizations’ data needs are measured in megabytes, and other organizations’ needs are measured in gigabytes. Before choosing a RAID solution, you need to know the volume of data. RAID 1, for instance, provides far less space than RAID 5.
• Performance—Speed is an important consideration. With some RAID solutions the network suffers a performance hit, whereas with others performance can be increased over the performance using a single disk. Choosing the correct RAID solution might involve understanding the performance capabilities of each of the different RAID levels.
Table 10.2 summarizes the main characteristics of the various RAID levels.
Table 10.2 RAID Characteristics

Review Break
RAID Level Characteristics
Hardware and Software RAID
After you’ve decided to implement a RAID solution, you must also decide whether to use a software or hardware RAID solution. The decision is not easy, and your budget might again be the deciding factor.
Software RAID is managed by the network operating system or third-party software and as such requires server resources to operate. As a result, the overhead associated with software RAID can affect the performance of the server by taking resource time away from other applications. Some variations of RAID require more from the server than others; for example, RAID 1 is commonly implemented using software RAID because it requires less overhead than RAID 5.
Software RAID has one definite advantage: It’s inexpensive. For example, Linux, Windows 2003/2008, and Mac OS X servers have RAID capability built in, allowing RAID to be implemented at no extra cost, apart from the costs associated with buying multiple disks. These operating systems typically offer support for RAID levels 0, 1, and 5.
Hardware RAID is the way to go if your budget allows. Hardware RAID uses its own specialized controller, which takes the RAID processing requirements away from the server. The server’s resources can thus focus on other applications. Hardware RAID also provides the capability to use cache memory on the RAID controller, further adding to its performance capabilities over software RAID.
Note
Arrays and volumes When discussing RAID, you’ll often encounter the terms array and volume. An array is a group of disks that are part of a single RAID configuration. For example, you would say, “There are two disks in a RAID 1 array.” A volume is a logical disk space within an array. Typically, a volume only refers to data storage and capacity.
Other Fault-Tolerance Measures
Although hard drives represent the single largest failure point in a network, they are not the only failure points. Even the most costly RAID solution cannot save you from a faulty power supply or memory module. To fully address data availability, you must consider all hardware. This section provides a brief overview of some of the other common fault-tolerance measures you can take to further ensure data availability:
• Link redundancy
• Using uninterruptible power supplies (UPSs)
• Using redundant power supplies
• Setting up standby servers and server clusters
• Memory
• Managing processor failures
Link Redundancy
A faulty NIC can disable access to data quickly because a failed NIC effectively isolates a system. Several strategies are used to provide fault tolerance for NICs. Many systems employ a hot spare in the system that can be put to work as soon as the primary NIC fails.
Though a failed network card may not actually stop a system, it may as well. A network system that cannot access the network isn’t much good. Though the chances of a failed network card are relatively low, our attempts to reduce the occurrence of downtime have led to the development of a strategy that provides fault tolerance for network connections.
Through a process called adapter teaming, groups of network cards are configured to act as a single unit. The teaming capability is achieved through software, either as a function of the network card driver or through specific application software. Adapter teaming is not widely implemented in smaller organizations; however, the benefits it offers makes it an important consideration. The result of adapter teaming is increased bandwidth, fault tolerance, and the capability to manage network traffic more effectively. These features are organized into three sections:
• Adapter fault tolerance—The basic configuration allows one network card to be configured as the primary device and others as secondary. If the primary adapter fails, one of the other cards can take its place without the need for intervention. When the original card is replaced, it resumes the role of primary controller.
• Adapter load balancing—Because software controls the network adapters, workloads can be distributed evenly among the cards so that each link is used to a similar degree. This distribution allows for a more responsive server because one card is not overworked while another is underworked.
• Link aggregation—This provides vastly improved performance by allowing more than one network card’s transfer rate to be combined into a single connection. For example, through link aggregation, four 100Mbps network cards can provide a total of 400Mbps transfer rate. Link aggregation requires that both the network adapters and the switch being used support it. In 1999, the IEEE ratified the 802.3ad standard for link aggregation, allowing compatible products to be produced.
Note
Warm swaps Some systems support warm swaps. Warm swapping involves powering down an individual bus slot to change a NIC. Doing so prevents you from having to power down the entire system to replace a NIC.
Using Uninterruptible Power Supplies
No discussion of fault tolerance can be complete without a look at power-related issues and the mechanisms used to combat them. When you’re designing a fault-tolerant system, your planning should definitely include uninterruptible power supplies (UPSs). A UPS serves many functions and is a major part of server consideration and implementation.
On a basic level, a UPS is a box that holds a battery and a built-in charging circuit. During times of good power, the battery is recharged; when the UPS is needed, it’s ready to provide power to the server. Most often, the UPS is required to provide enough power to give the administrator time to shut down the server in an orderly fashion, preventing any potential data loss from a dirty shutdown.
Note
Overloading UPSs One mistake often made by administrators is the overloading of UPSs. UPSs are designed for server systems, and connecting monitors, printers, or other peripheral devices to them reduces their effectiveness.
Why Use a UPS?
Organizations of all shapes and sizes need UPSs as part of their fault-tolerance strategies. A UPS is as important as any other fault-tolerance measure. Three key reasons make a UPS necessary:
• Data availability—The goal of any fault-tolerance measure is data availability. A UPS ensures access to the server in the event of a power failure, or at least as long as it takes to save your file.
• Data loss—Fluctuations in power or a sudden power down can damage the data on the server system. In addition, many servers take full advantage of caching, and a sudden loss of power could cause the loss of all information held in cache.
• Hardware damage—Constant power fluctuations or sudden power downs can damage hardware components within a computer. Damaged hardware can lead to reduced data availability while the hardware is being repaired.
Power Threats
In addition to keeping a server functioning long enough to safely shut it down, a UPS also safeguards a server from inconsistent power. This inconsistent power can take many forms. A UPS protects a system from the following power-related threats:
• Blackout—A total failure of the power supplied to the server.
• Spike—A spike is a short (usually less than a second) but intense increase in voltage. Spikes can do irreparable damage to any kind of equipment, especially computers.
• Surge—Compared to a spike, a surge is a considerably longer (sometimes many seconds) but usually less intense increase in power. Surges can also damage your computer equipment.
• Sag—A sag is a short-term voltage drop (the opposite of a spike). This type of voltage drop can cause a server to reboot.
• Brownout—A brownout is a drop in voltage supply that usually lasts more than a few minutes.
Many of these power-related threats can occur without your knowledge; if you don’t have a UPS, you cannot prepare for them. For the investment, it is worth buying a UPS, if for no other reason than to sleep better at night.
Exam Alert
Power threats Be sure you are able to differentiate between the various power threats before taking the Network+ exam.
Using Redundant Power Supplies
If you work with servers or workstations, you know that from time to time a power supply will fail. When it fails in a workstation, you simply power down the system and replace the power supply. On a server, where downtime is often measured in dollars and cents, powering down to replace a faulty power supply can be a major issue.
You can prepare for a faulty power supply by using redundant, hot-swappable power supplies. As you might expect, such a strategy has associated costs that must be weighed against the importance of continual access to data.
Server and Services Fault Tolerance
In addition to providing fault tolerance for individual hardware components, some organizations go the extra mile to include entire servers in the fault-tolerant design. Such a design keeps servers and the services they provide up and running.
When it comes to server fault tolerance, two key strategies are used: standby servers and server clustering.
Using Standby Servers
In addition to instituting fault-tolerance measures for individual components, many larger organizations use server fault-tolerance measures. In this scenario, if one server fails, a second is fully configured and waiting to take over. Using this configuration, if a server fails, the network services it provided to the network will become available in a short amount of time using the redundant server. The second server is sometimes located in a separate building, in case of fire or flood damage to the location where the first server is kept.
Another strategy used for complete server and network service fault tolerance is server failover. A server failover configuration has two servers wired together, with one acting as the primary server and the other acting as the secondary server. The systems synchronize data between them, ensuring that they are always current with each other. If the secondary server detects that the primary is offline, it switches to failover mode and becomes the primary server for the network. It then is responsible for providing any missing network services. The whole procedure is transparent to the network user, and very little downtime, if any, is experienced.
As you might imagine, the costs associated with having a redundant server are very high. For this reason, few organizations use the failover and standby server measures.
Server Clustering
Continuing our journey into incredibly expensive fault-tolerance strategies, we come to server clustering. For companies that cannot afford even a second of downtime, the costs of server clustering are easily justified.
Server clustering involves grouping several computers into one logical unit. This strategy can, depending on the configuration, provide fault tolerance as well as increased performance and load balancing. Because the servers within the cluster are in constant contact with each other, they are able to detect and compensate for a failing server system. A well-configured server cluster provides failover without any disruption to network users.
The advantages of clustering are obvious. Clustering affords the highest possible availability of data and network services. Clusters are the foundational configuration for the “five nines” level of service—that’s 99.999% uptime, which translates to less than 10 minutes of downtime in a year.
The fundamental downside to server clustering is its cost. Clustering requires a separate network to be constructed between the servers, installation and configuration of additional software, additional hardware, and additional administrative support.
Specifically, server clustering offers the following advantages:
• Increased performance—More servers equals more processing power. The servers in a cluster are able to provide levels of performance beyond the scope of a single system by combining resources and processing power.
• Load balancing—Rather than having individual servers perform specific roles, a cluster can perform a number of roles, assigning the appropriate resources in the best places. This approach maximizes the power of the systems by allocating tasks based on which server in the cluster is best able to service the request.
• Failover—Because the servers in the cluster are in constant contact with each other, they can detect and cope with the failure of an individual system. How transparent the failover is to users will depend on the clustering software, the type of failure, and the capability of the application software being used to cope with the failure.
• Scalability—The capability to add servers to the cluster offers a degree of scalability that is simply not possible in a single-server scenario. It is worth mentioning, though, that clustering on PC platforms is still in its relative infancy, and the number of machines that can be included in a cluster is still limited.
To make server clustering happen, you need certain ingredients: servers, storage devices, network links, and software that makes the cluster work. Various strategies are available.
Preparing for Memory Failures
After memory is installed and confirmed to be working, it generally works error free. Sometimes, however, memory is at the root of system problems. Unfortunately, fault-tolerance strategies for memory are limited. Memory doesn’t support hot swapping, so you have to power down the server during memory replacement. The best you can do is minimize the impact of the failure.
Some environments have spare memory available at all times in case of failure. When memory does fail, a spare is ready to go. Such planning requires considerable forethought, but when you need such a solution, the preparation pays off.
Managing Processor Failures
Processors are hardy, and processor failure is extremely uncommon. In fact, processor failure is so unusual that few organizations include processors in their fault-tolerance designs. Environments that consider processors may have a spare or, more likely, a standby server (discussed previously in this chapter).
Some multiprocessor machines have a built-in safeguard against a single processor failure. In such a machine, the working processor maintains the server while a replacement for the nonfunctioning processor is found.
Disaster Recovery
Besides implementing fault-tolerance measures in a network, you need to consider disaster recovery—the things to do when your carefully implemented fault-tolerance measures fail. Disaster recovery and fault tolerance are two separate entities, and both are equally important. Disaster recovery is defined as measures that allow a network to return to a working state.
Backups and backup strategies are key components of disaster recovery and help ensure the availability of data. The following sections identify the various backup strategies commonly used and why these strategies are such an important part of a network administrator’s role.
Backup Methods
You can choose from several backup methods. Don’t select one at random; choose carefully, to match the needs of your organization.
Exam Alert
Tape cleaning tips Many backup strategies use tapes as the backup media of choice. When backing up to tape, you must periodically clean the tape drive with a cleaning cartridge. If your system is unable to access a tape, you should first try another tape. If that doesn’t work, use a cleaning tape. Remember these tips for the exam.
The backup method you choose will most likely be affected by the amount of time you have available. Many organizations have a time window in which backup procedures must be conducted. Outside that window, the backup procedure can impede the functioning of the network by slowing down the server and the network. Organizations with large amounts of data require more time for a backup than those with small amounts of data. Although both small and large organizations require full backups, the strategy each uses will be different. With that in mind, let’s look at the various backup methods, which include full backups, incremental backups, and differential backups.
Full Backups
If you have time, a full backup is usually the best type of backup. A full backup, also referred to as a normal backup, copies all the files on the hard disk. In case of disaster, the files from a single backup set can be used to restore the entire system.
Despite the advantages of full backups, they are not always a practical solution. Depending on the amount of data that needs to be backed up, the procedure can take a long time. Many administrators try to run full backups in the off hours, to reduce the impact on the network. Today, many networks do not have off hours, making it difficult to find time to squeeze in full backups.
Full backups are often used as the sole backup method in smaller organizations that have only a few gigabytes of data. Larger organizations that utilize hundreds of gigabytes of data storage are unlikely to rely on full backups as their sole backup strategy.
The backup software determines what data has changed since the last full backup, by checking a setting known as the archive bit. When a file is created, moved, or changed, the archive bit is set to indicate that the changed file must be backed up.
Incremental Backups
An incremental backup is much faster than a full backup because only the files that have changed since the last full or incremental backup are included in it. For example, if you do a full backup on Tuesday and an incremental on Thursday, only the files that have changed since Tuesday will be backed up. Because an incremental backup copies less data than a full backup, backup times are significantly reduced.
On the other hand, incremental backups take longer to restore than full backups. When you are restoring from an incremental backup, you need the last full backup tape and each incremental tape done since the last full backup. In addition, these tapes must be restored in order. Suppose that you do a full backup on Friday and incremental backups on Monday, Tuesday, and Wednesday. If the server fails on Thursday, you will need four tapes: Friday’s full backup and the three incremental backups.
Exam Alert
Incremental Incremental backups only back up files that have changed since the last full or incremental backup.
Differential Backups
Many people confuse differential backups and incremental backups, but they are very different from one another. Whereas an incremental backup backs up everything from the last full or incremental backup, a differential backup backs up only the files that have been created or changed since the last full backup.
When restoring from a differential backup, you need only two tapes: the latest full backup and the latest differential. Depending on how dynamic the data is, the differential backup could still take some time. Essentially, differential backups provide the middle ground between incremental and full backups.
Exam Alert
Differential Differential backups only back up files that have been changed or modified since the last full backup.
Note
What to use in a backup cycle In a backup cycle, incremental backups and a differential backup must be combined with a full backup to get a complete copy of the data on a drive.
Exam Alert
Understand the backup types For the Network+ exam, make sure that you understand what is involved in backing up and restoring data for all the backup types (for example, how many tapes are used and in what order they must be restored).
Review Break
A Comparison of Backup Methods
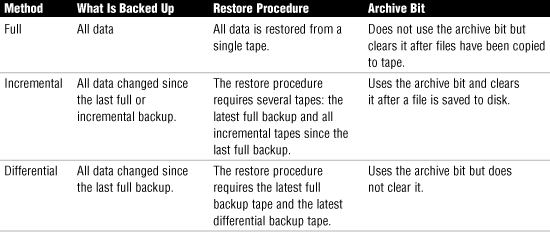
Full backups do not concern themselves with the archive bit because all data is backed up. However, a full backup resets the archive bit after the files have been copied to the tape. Differential backups use the archive bit but do not clear it because the information is needed for the next differential backup. Incremental backups clear the archive bit so that unnecessary files aren’t backed up. Table 10.3 summarizes the characteristics of the different backup methods.
Table 10.3 Comparison of Backup Methods
Exam Alert
Clearing the archive bit On the Network+ exam it is likely that you will be asked to identify what backup methods clear the archive bit from a changed or created file.
Backup Rotation Schedules
You can use a backup rotation schedule in conjunction with a backup method. Organizations use many different rotations, but most are variations on a single popular rotation strategy: the Grandfather-Father-Son (GFS) rotation.
GFS is the most widely used rotation method. It uses separate tapes for monthly, weekly, and daily backups. A common GFS strategy requires 12 tapes. Four tapes are used for daily backups, Monday through Thursday; these are the son tapes. Five tapes are used for weekly backups, perhaps each Friday; these are the father tapes. Finally, three tapes are used for a monthly rotation; these are the grandfather tapes.
Using the GFS rotation, you can retrieve lost information from the previous day, previous week, and several previous months. Adding tapes to the monthly rotation lets you go back even further to retrieve data. Of course, the further back you go, the less current (and perhaps less usable) the information is. More tapes also make the rotation more complex.
Many organizations don’t follow the GFS strategy by the book; instead, they create their own backup regimes. Regardless of the backup strategy used, a well-designed backup rotation is an integral part of system administration and should follow guidelines that allow for several retrieval points.
Offsite Storage
The type of backup to use and the frequency of these backups are critical considerations for any organization. Another backup decision that must be made is how and where backups are to be stored. It is easy to perform a backup and store the tapes onsite, perhaps in a locked room, but backup tape rotation schedules should include a consideration for offsite backup.
Offsite data storage is an important element because it allows backups to be accessed if the original location becomes unavailable. Even though the key feature of backups is its role in guaranteeing the availability of data, it is not without its risks.
For many organizations, backups are often the weak link in the security chain because the item of most value to an organization, and to a criminal, is normally the data. Many security measures can be used to protect data while it is inside a controlled environment. But what happens when it is taken outside that environment?
When a data backup leaves your server environment, the degree of control over that tape and the data on it is diminished. An organization can spend millions of dollars building a state-of-the-art server environment, but if the security of data backups is not fully considered, it is a false sense of security. Here are some precautions that you can take to protect your valuable data when it leaves the server environment:
• Password protection—Tape backup software commonly has a password feature that allows each tape to be password protected. The password must be entered before the tape is restored or viewed.
• Physical locks—Use physically lockable tape cases for transporting the tapes. As well as providing protection against data theft, tape cases also provide a degree of protection against accidental damage.
• Registered couriers—When transferring tapes between sites, use a trusted company employee or a registered secure courier service.
• Secure storage—Ensure that the location at which the tapes are stored is sufficiently secure.
• Verification of data integrity—If possible, when backup tapes reach their destination, they should be checked to ensure that they are the correct tapes and that they contain the correct data.
• Encryption—If facilities exist and the data is deemed sufficiently vital, the use of a data encryption system should be considered.
• Knowledge restriction—Confine knowledge of the backup and storage procedures to only those individuals who need the information.
The safety of backed-up data should be given at least the same considerations as the safety of data held inside your environment. When data leaves your site, it is exposed to a wide range of threats. Securing data when it leaves the site is a major security task for any organization.
Exam Alert
Offsite data To be effective, the data stored offsite must be kept up-to-date. This means that the offsite data should be included in a backup rotation strategy.
Backup Best Practices
When you’re designing a backup strategy, consider some general best practices. These best practices ensure that when you need it, the backup you are depending on will be available:
• Test your backups—After a backup is completed, you have no idea whether the backup was successful and whether you will be able to retrieve needed data from it. Learning this information after your system has crashed is too late. To make sure that the backups work, it is important to periodically restore them.
• Confirm the backup logs—Most backup software generates log files after a backup procedure. After a backup is completed, read the backup logs to look for any documented errors that may have occurred during the backup procedure. Keep in mind that reading the backup-generated logs is no substitute for occasionally testing a restore. A completely unsuccessful backup might generate no documented errors.
• Label the backup cartridges—When you use many tapes in a rotation, label the cartridges to prevent reusing a tape and recording over something you need. The label should include the date of the backup and whether it was a full, incremental, or differential backup.
• Rotate backups offsite—Keeping all the tape backups in the same location as the server can be a problem. If the server location is damaged (by fire or flood, for example), you could lose all the data on the server as well as all your backups. Use an offsite tape rotation scheme to store current copies of backups in a secure offsite location.
• Use new tapes—Over time, tape cartridges can wear out and become unreliable. To combat this problem, periodically introduce new tapes into the tape rotation and destroy the old tapes.
• Password protect the backups—As an added measure of security, it is a good idea to password protect your backups. That way, if they fall into the wrong hands, they are protected by a password.
Tip
Write protection Tape cartridges often use a write-protection tab similar to the ones found on 3.5-inch floppy disks. It is a good idea to write protect a tape cartridge after a backup so that it will not be overwritten accidentally.
Designing an effective backup strategy is one of the most important considerations for a network administrator, and therefore, it is an important topic area for the Network+ exam. Remember that the preservation of data is a foremost consideration when approaching network management.
Hot and Cold Spares
The impact that a failed component has on a system or network depends largely on predisaster preparation and on the recovery strategies used. Hot and cold spares represent a strategy for recovering from failed components.
Hot Spare and Hot Swapping
Hot spares give system administrators the capability to quickly recover from component failure. A hot spare, for example, is widely used by the RAID system to automatically failover to a spare hard drive should one of the other drives in the RAID array fail. A hot spare does not require any manual intervention, rather a redundant drive resides in the system at all times, just waiting to take over if another drive fails. With the RAID array continuing to function, the failed drive can be removed at a later time. Even though hot-spare technology adds an extra level of protection to your system, after a drive has failed and the hot spare has been used, the situation should be remedied as soon as possible.
Hot swapping is the capability to replace a failed component while the system is running. Perhaps the most commonly identified hot-swap component is the hard drive. In certain RAID configurations, when a hard drive crashes, hot swapping allows you to take the failed drive out of the server and install a new one.
The benefits of hot swapping are clear in that it allows a failed component to be recognized and replaced without compromising system availability. Depending on the system’s configuration, the new hardware will normally be recognized automatically by both the current hardware and the operating system. Today, most internal and external RAID subsystems support the hot swapping feature. Some other hot swappable components include power supplies and hard disks.
Cold Spare and Cold Swapping
The term cold spare refers to a component such as a hard disk that resides within a computer system but requires manual intervention in case of component failure. A hot spare engages automatically, but a cold spare may require configuration settings or some other action to engage it. A cold spare configuration typically requires a reboot of the system.
The term cold spare has also been used to refer to a redundant component stored outside the actual system but kept in case of component failure. To replace the failed component with a cold spare, the system would need to be powered down.
Cold swapping refers to replacing components only after the system is completely powered off. This strategy is by far the least attractive for servers because the services provided by the server will be unavailable for the duration of the cold swap procedure. Modern systems have come a long way to ensure that cold swapping is a rare occurrence. For some situations and for some components, however, cold swapping is the only method to replace a failed component.
Note
Warm swapping The term warm swap is sometimes applied to a device that can be replaced while the system is still running but that requires some kind of manual intervention to disable the device before it can be removed. Using a PCI hot plug is technically a warm swap strategy because it requires that the individual PCI slot be powered down before the PCI card is replaced. Of course, a warm swap is not as efficient as a hot swap, but it is far and away better than a cold swap.
Recovery Sites
A disaster recovery plan may include the provision for a recovery site that can be brought quickly into play. These sites fall into three categories: hot, warm, and cold. The need for each of these types of site depends largely on the business you are in and the funds available. Disaster recovery sites represent the ultimate in precautions for organizations that really need it. As a result, they aren’t cheap.
The basic concept of a disaster recovery site is that it can provide a base from which the company can be operated during a disaster. The disaster recovery site is not normally intended to provide a desk for every employee, but is intended more as a means to allow key personnel to continue the core business function.
Cold Site
In general, a cold recovery site is a site that can be up and operational in a relatively short time span, such as a day or two. Provision of services, such as telephone lines and power, is taken care of, and the basic office furniture may be in place, but there is unlikely to be any computer equipment, even though the building may well have a network infrastructure and a room ready to act as a server room. In most cases, cold sites provide the physical location and basic services.
Cold sites are useful if there is some forewarning of a potential problem. Generally, cold sites are used by organizations that can weather the storm for a day or two before they get back up and running. If you are the regional office of a major company, it might be possible to have one of the other divisions take care of business until you are ready to go, but if you are the one and only office in the company, you might need something a little hotter.
Hot Site
For organizations with the dollars and the desire, hot recovery sites represent the ultimate in fault-tolerance strategies. Like cold recovery sites, hot sites are designed to provide only enough facilities to continue the core business function, but hot recovery sites are set up to be ready to go at a moment’s notice.
A hot recovery site includes phone systems with the phone lines already connected. Data networks are also in place, with any necessary routers and switches plugged in and ready to go. Hot sites may have desktop PCs installed and waiting, and server areas replete with the necessary hardware to support business-critical functions. In other words, within moments, the hot site can become a fully functioning element of an organization. Key to this is having network data available and current.
The issue that confronts potential hot recovery site users is simply that of cost. Office space is expensive at the best of times, but having space sitting idle 99.9 percent of the time can seem like a tremendously poor use of money. A popular strategy to get around this problem is to use space provided in a disaster recovery facility, which is basically a building, maintained by a third-party company, in which various businesses rent space. Space is apportioned, usually, on how much each company pays.
Warm Site
Sitting in between the hot and cold recovery sites is the warm site. A warm site typically has computers, but not configured ready to go. This means that data may need to be upgraded or other manual interventions performed before the network is again operational. The time it takes to get a warm site operational lands right in the middle of the other two options, as does the cost.
Exam Alert
Hot, Warm, and Cold A hot site mirrors the organization’s production network and will be able to assume network operations at a moment’s notice. Warm sites have the equipment needed to bring the network to an operational state but require configuration and potential database updates. Warm sites have network data but may not be completely up-to-date. A cold site has the space available with basic service but typically requires equipment and maybe data delivery. Be sure that you can differentiate the three types of recovery sites for the exam.
Network Optimization Strategies
Today’s networks are all about speed. Network users expect data and application delivery quickly; consider how impatient many of us get waiting for web pages to load. Networks, however, are saturated and congested with traffic, making it necessary to have strategies to ensure that we are using bandwidth in the best possible way. These strategies are collectively referred to as quality of service (QoS). QoS strategies include many areas, such as traffic shaping, load balancing, and caching engines. Each of these are discussed in this section.
QoS
Quality of service (QoS) describes the strategies used to manage and increase the flow of network traffic. QoS features allow administrators to predict bandwidth use, monitor that use, and control it to ensure that bandwidth is available to the applications that need it. These applications can generally be broken down into two categories:
• Latency sensitive—These applications need bandwidth for quick delivery where network lag time impacts their effectiveness. This includes voice and video transfer. For example, VoIP would be difficult to use if there was a significant lag time in the conversation.
• Latency insensitive—Controlling bandwidth also involves managing latency insensitive applications. This includes bulk data transfers such as huge backup procedures and FTP transfers.
With bandwidth being limited and networks becoming increasingly congested, it becomes more difficult to deliver latency-sensitive traffic. If network traffic continues to increase and we can’t always increase bandwidth, the choice is to prioritize traffic to ensure timely delivery. This is where QoS comes into play. QoS ensures the delivery of applications, such as video conferencing and VoIP telephony, without adversely affecting network throughput. QoS achieves more efficient use of network resources by differentiating between latency insensitive traffic such as fax data and latency-sensitive streaming media.
One important strategy for QoS is priority queuing. Essentially what happens is that traffic is placed in an order based on its importance on delivery time. All data is given access but the more important and latency sensitive data is given a higher priority.
Exam Alert
Priority queuing Priority queuing is an important concept of QoS. Be sure you understand the function of priority queuing for the Network+ exam.
Latency-Sensitive High-Bandwidth Applications
Many of the applications used on today’s networks require a lot of bandwidth. In fact, the past few years have seen considerable growth of two high-bandwidth applications, VoIP and online or networked video applications. Both of these applications, while gaining in popularity, demand resources and can push network resources to their limit.
Note
High bandwidth CompTIA lists VoIP and video applications as high-bandwidth applications, but there are others. Any application that requires data streaming and is latency sensitive is likely a high-bandwidth application.
Voice over Internet Protocol (VoIP)
VoIP is designed to transfer human voice over the Internet using IP data packets. In operation, VoIP technology digitizes and encapsulates voice in data packets and then converts them back into voice at the destination.
The ability to “chat” over the Internet has been available for a number of years. Users have been using the Internet to communicate among themselves for some time. However, it has only been in the past few years that network bandwidth, protocols, and customer equipment have advanced far enough to become a viable alternative to a public switched telephone network (PSTN). In addition to voice transfer, communicating over the Internet allows users to exchange data with people you are talking with, sending images, graphs, and videos. That is simply not possible with PSTN conversations.
Note
More RTP More information on RTP and other protocols used for real-time communication are found in Chapter 4, “Understanding the TCP/IP Protocol Suite.”
VoIP communication uses a standard called Real-Time Protocol (RTP) for transmitting audio and video packets between systems. RTP packets are typically used inside UDP-IP packets. Recall from Chapter 4 that UDP is a connectionless protocol, whereas TCP is a connection-oriented protocol. UDP does not have the overhead of TCP and therefore can get VoIP data to its destination faster. UDP does not specify an order that packets must arrive at the destination or how long it should take to get there. UDP is a fire-and-forget protocol. This works well because it gets packets to the destination faster and RTP puts the packets in order at the receiving end. UDP ensures a fast continuous flow of data and does not concern itself with guaranteeing the delivery of data packets.
Exam Alert
UDP and RTP VoIP uses both RTP and UDP for maintaining the connection. UDP is preferred over TCP because it does not have error-checking mechanisms and does not guarantee delivery like TCP does.
In addition to latency, another concern with VoIP has been security. Some communications conducted over the Internet can be intercepted, and VoIP is no different. To address these security concerns, RTP was improved upon with the release of Secure RTP (SRTP). Secure RTP provides for encryption, authentication, and integrity of the audio and video packets transmitted between communicating devices.
Video Applications
The popularity of streaming video applications has increased significantly over the past few years. Many users log on to the Internet to watch streaming video, such as missed TV shows, news broadcasts, entertainment videos found on YouTube, and the like. The capability to click a link and in seconds see content streaming from a remote location is quite amazing. There is much that needs to be in place for this content to be displayed in a speedy fashion.
Like VoIP, streaming videos are typically latency sensitive and require protocols built for speed. Streaming video can be sent over UDP or TCP data packets. UDP is faster because TCP has a higher overhead and guarantees data delivery using mechanisms such as timeouts and retries.
Working with transport protocols such as TCP and UDP are underlying real-time protocols. Three protocols associated with real-time streaming video applications are RTP, Real-time Streaming Protocol (RTSP), and the Real-time Transport Control Protocol (RTCP); they were specifically designed to stream media over networks.
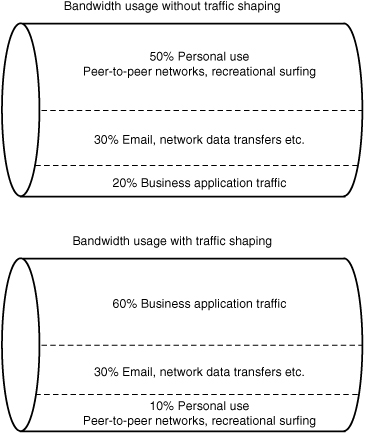
Traffic Shaping
Traffic shaping is a QoS strategy that is designed to enforce prioritization policies on the transmission throughout the network. It is intended to reduce latency by controlling the amount of data that flows into and out of the network. Traffic is categorized, queued, and directed according to network policies.
We can shape and limit network traffic using several strategies. The one chosen depends on the needs of the network and the amount of network traffic. Some common traffic shaping methods include the following:
• Shaping by application—Administrators can configure a traffic shaper by categorizing specific types of network traffic and assigning that category a bandwidth limit. For example, traffic can be categorized using FTP. The rule can specify that no more than 4Mbps be dedicated for FTP traffic. This same principal can apply to Telnet sessions, streaming audio, or any other application coming through the network.
• Shaping network traffic per user—In any network, there are users who use more bandwidth than others. Some of this may be work related, but more often than not, it is personal use. In such a case, it may be necessary to establish traffic shaping on a per-user basis. Traffic shapers allow administrators to delegate a certain bandwidth to a user; for instance, Bob from accounting is allowed no more than 256Kbps. This doesn’t limit what the user can access, just the speed at which that content can be accessed.
• Priority queuing—One important consideration when looking at traffic shaping is determining which traffic is mission critical and which is less so. In addition to setting hard or burstable traffic limits on a per-application or per-user basis, traffic shaping devices can also be used to define the relative importance, or priority, of different types of traffic. For example, in an academic network where teaching and research are most important, recreational uses of the network (such as network games or peer-to-peer file-sharing application traffic) can be allowed bandwidth only when higher priority applications don’t need it.
Some traffic shaping tasks can be done directly on a regular Cisco or Juniper router, just as a router can also be used to do some firewall-like packet filtering tasks. However, specialized traffic shapers, like any specialized devices, can be optimized to specifically and efficiently handle their unique responsibilities. Specialized devices also typically have a “bigger bag of tricks” to draw from when dealing with problems in their special area of expertise. Doing traffic shaping on a dedicated traffic shaping box also avoids loading up routers with other tasks, leaving the router free to focus on doing its job of routing packets as fast as it can. Figure 10.7 shows an example of traffic priority queuing.
Exam Alert
Traffic shaping For the Network+ exam, be sure you are able to identify the function of traffic shaping.
Load Balancing
As the demands placed on an organization’s servers and key systems increases, they have to be able to handle the load. One of the strategies used to help facilitate this is load balancing. In networking terms, load balancing refers to distributing the load between different networked systems. In this way, the demand is shared between multiple CPUs, network links, and hard disks. This configuration increases response time, distributes processing, and ensures optimal resource utilization.
Distributing the load between multiple servers is called a server farm. Server farms are often used to ensure the delivery of Internet services. High-performance websites rely on web server farms, which are essentially a few or even hundreds of computers serving the same content for scalability, reliability, and low-latency access to Internet content. Web server farms are used to reliably deliver a range of Internet services, such as Internet Relay Chat networks, FTP servers, DHCP servers, NNTP servers, and DNS servers.
Exam Alert
Load balancing Load balancing distributes the load between multiple systems helping to ensure reliable delivery of data and Internet services.
Caching Engines
Caching is an important consideration when optimizing network traffic. For example, as we discussed in Chapter 3, “Networking Components and Devices,” proxy servers use caching to limit the number of client requests that go to the Internet; instead, the requests are filled from the proxy servers cache. Recall from Chapter 3 that, when a caching proxy server has answered a request for a web page, the server makes a copy of all or part of that page in its cache. Then, when the page is requested again, the proxy server answers the request from the cache rather than going back out to the Internet. For example, if a client on a network requests the web page www.comptia.org, the proxy server can cache the contents of that web page. When a second client computer on the network attempts to access the same site, that client can grab it from the proxy server cache, and accessing the Internet is not necessary. This greatly reduces the network traffic that has to be filtered to the Internet, a significant gain in terms of network optimization.
When it comes to determining what to cache, an administrator can establish many rules, including the following:
• What websites to cache
• How long the information is cached
• When cached information is updated
• The size of cached information
• What type of content is cached
• Who can access the cache
The rules established for caching vary from network to network depending on the needs of that network. In networks where a large number of people are accessing similar websites, caching can greatly increase network performance. The advantages to properly configured caching are clear: reduced bandwidth and latency and increased throughput. One possible disadvantage of caching is receiving out-of-date files because you are obtaining content from the caching engine and not the website itself.
There are several advantages of using caching strategies. Two of the primary reasons are the following:
• Increasing performance—Caching can store application data close to the user. That is, cached data is stored on local systems rather than a remote web server for example. This allows for faster retrieval of data and less need for repetitive processing and data transportation to a remote server.
Exam Alert
Cached data Caching improves performance because by accessing a cache, servers and systems do not need to re-create and find the same data for multiple user requests.
• Data availability—There may be times when the data or application we are trying to access is unavailable because of failure. For example, a regularly accessed remote website may be down. By having data stored in a cache, it is possible to get that data from the cache. The cache can issue requests from the cache until the failed or unavailable server or database comes back online.
Note
Expiring cache The information stored in a cache must be kept as fresh and current as possible. To do this, some dynamic content must be updated in the cache regularly. Other content that changes more infrequently can be updated less frequently. Cached content updating is managed using expiration policies. The expiration policy determines how long the content in a cache is kept.
Tip
Caching tip Caching features can improve network performance by caching content locally, therefore limiting surges in traffic.
Summary
This chapter explored two important networking concepts: fault tolerance and disaster recovery. Although many people think fault tolerance and disaster recovery are one and the same, they are in fact different, but equally important, concepts.
Fault tolerance usually refers to the measures network administrators use to ensure that data and network services are always available to network users. A strong fault-tolerance strategy does not happen by accident; rather, you must consider many factors when choosing the best fault-tolerance strategies for a specific organization.
Because availability is such a huge issue and server downtime is so costly, most hardware components within a server need to be considered part of a fault-tolerance solution. Hard drives typically receive the most attention because they’re 50% more likely to fail than any other component. The mechanism used to protect against such failures is RAID.
Several RAID levels are available today. The most common are RAID levels 0, 1, and 5. Although RAID 0 is a RAID level, it does not offer any fault tolerance, but it does offer performance improvements over using a single disk. RAID 1 uses disk mirroring to establish fault tolerance but suffers from 50% overhead and limited storage capacity. The RAID level of choice for organizations that can afford it is RAID 5. RAID 5 stripes data and parity information over several disks. The parity information can be used to re-create data in the event that a hard drive in the array fails.
Other fault-tolerance measures include using UPSs, redundant components, and sometimes redundant servers.
Disaster recovery involves having in place measures that can be used when the system goes down. To protect data from disaster, you need backups. Three key types of backups are available: full, incremental, and differential. A full backup makes a copy of all data, an incremental backup makes a copy of the data that has changed since the last full backup or the latest incremental backup, and a differential backup saves everything that has changed since the last full backup.
In addition to backup methods, a backup rotation strategy ensures that data is sufficiently recoverable. The most common backup rotation strategy is the GFS rotation. This type of rotation requires numerous tapes for daily, weekly, and monthly backups.
Real-time applications such as online video and VoIP are gaining in popularity as the protocols and bandwidth needed to support these applications mature. Video and VoIP applications relay on transport protocols, typically UDP, and real-time protocols such as RTP.
The chapter ended by looking at some of the strategies used to optimize the flow of network traffic. This includes QoS, traffic shaping, caching, and load balancing. One form of load balancing is server farms. Server farms distribute the processing and resource load between multiple systems and help ensure the delivery of Internet services.
Key Terms
• QoS
• VoIP
• RTP
• UDP
• TCP
• Uptime
• Hot swap
• RAID
Apply Your Knowledge
Exercise
10.1 Performing a Full Backup
You have recently been employed as the network administrator for a large pharmaceutical company. On your first day of work, you notice that no backup has been performed for more than six months. You immediately decide to perform a full backup and schedule backups to occur at regular intervals.
You use Windows 2003 Server’s Backup Wizard utility to back up a few data files and automate the process to reoccur automatically based on a schedule you construct.
Estimated time: 20 minutes
1. Select Start, All Programs, Accessories, System Tools, Backup. The Backup [Untitled] screen appears.
2. Select the Schedule Jobs tab and click the Add Job button. The Backup Wizard screen appears.
3. Click Next on the Backup Wizard screen.
4. Choose Back Up Selected Files, Drives, or Network Data and click Next.
5. Select the data you want to back up. The window contains a directory of files similar to Windows Explorer, with one added twist: A check box appears next to each directory item. Click the box to select an item to be backed up. Note that if you click a folder, you will back up everything from that point in the directory down.
6. Choose one or two folders that contain a few files. Click Next.
7. Choose the media type to which you want to save your data. In this project, you’ll save your backup to disk, so choose the File in the Backup Media Type drop-down box.
8. If the directory you want to use doesn’t exist, you can create it by clicking the Browse button and navigating to where you want to put the backup file you are about to create. (Click the New Folder icon in the browse window.)
9. Specify the type of backup you want to perform. Choose Normal and click Next.
10. Select Verify Data After Backup if you want the operating system to check to make sure that the backup has been made. Click Next.
11. Choose whether you want to add this backup to the end of any previous backups or whether you want to replace an old backup with this new one. For this project, choose Replace the Data on the Media with This Backup. Click Next.
12. The next window lets you assign Backup Label and Media Label names. Leave the defaults in place and click Next. A Set Account Information dialog box might appear. Windows 2003 allows you to run the job under another account name/password if you want. If you get this choice, enter your administrator account username and password. (The password will be whatever you established when you installed Windows 2000 Server or whatever you changed it to.)
13. The When to Backup screen appears, give the backup job you are creating the name BackupTest and click Set Schedule.
14. The Schedule Job screen appears, and you can schedule when you want the backup job to occur. Set whatever schedule you want and click OK. You return to the When to Backup Screen; click Next.
15. On the Completing the Backup Wizard screen, click Finish to create the job. The backup utility creates the job, and the folders/files you selected will be backed up according to the schedule you selected.
16. You can view the status of the backup job or make changes to it by using the Task Scheduler. To use the Task Scheduler, choose Start, Settings, Control Panel. When the Control Panel opens, double-click the Scheduled Tasks icon. You should see the backup job you just created. You can double-click it to edit the job.
Exam Questions
1. What is the minimum number of disks required for a RAID 5 array?
![]() A. 2
A. 2
![]() B. 5
B. 5
![]() C. 1 physical and 1 logical
C. 1 physical and 1 logical
![]() D. 3
D. 3
2. What RAID level uses disk mirroring to provide fault tolerance?
![]() A. RAID 1
A. RAID 1
![]() B. RAID 0
B. RAID 0
![]() C. RAID 5
C. RAID 5
![]() D. RAID 2
D. RAID 2
3. Which of the following backup methods require the archive bit to be cleared? (Choose the two best answers.)
![]() A. Full
A. Full
![]() B. Incremental
B. Incremental
![]() C. Differential
C. Differential
![]() D. Mirror image
D. Mirror image
4. As network administrator, you have been asked to implement a backup and restore method that requires only a total of two tape sets. Which of the following backup pairs would you use?
![]() A. Full, incremental, and differential
A. Full, incremental, and differential
![]() B. Differential, incremental
B. Differential, incremental
![]() C. Full, differential
C. Full, differential
![]() D. This cannot be done.
D. This cannot be done.
5. You are configuring VoIP for a large organization. As part of the process you are to determine the protocols used with VoIP. Which of the following protocols are you likely to use with VoIP? (Choose the two best answers.)
![]() A. TCP
A. TCP
![]() B. UDP
B. UDP
![]() C. RTP
C. RTP
![]() D. RPT
D. RPT
6. How many hard disks are required to establish a RAID 1 solution?
![]() A. 8
A. 8
![]() B. 4
B. 4
![]() C. 6
C. 6
![]() D. 2
D. 2
7. You are the network administrator for a company that operates from 7 a.m. to 9 p.m. Monday through Friday. Your boss requires that a backup be performed nightly but does not want the backup to interfere with network operations. Full backups have been started at 9:30 p.m. and have taken until 8 a.m. to complete. What strategy would you suggest to correct the backup issue?
![]() A. Weekly full backups, incremental backups on Mondays, and differential backups every other weekday
A. Weekly full backups, incremental backups on Mondays, and differential backups every other weekday
![]() B. Full backup performed on the weekend and incremental backups performed on weekdays
B. Full backup performed on the weekend and incremental backups performed on weekdays
![]() C. Differential backups performed on weekends and a full backup every other weekday evening
C. Differential backups performed on weekends and a full backup every other weekday evening
![]() D. Weekly full backups combined with weekend differential backups
D. Weekly full backups combined with weekend differential backups
8. Which of the following power-related problems is associated with a short-term voltage drop?
![]() A. Surge
A. Surge
![]() B. Brownout
B. Brownout
![]() C. Sag
C. Sag
![]() D. Spike
D. Spike
9. Which of the following fault-tolerant RAID levels offers the best read and write performance?
![]() A. RAID 0
A. RAID 0
![]() B. RAID 1
B. RAID 1
![]() C. RAID 5
C. RAID 5
![]() D. RAID 10
D. RAID 10
10. Which of the following are fault-tolerance measures associated with network adapters? (Choose the two best answers.)
![]() A. Warm swapping
A. Warm swapping
![]() B. Adapter teaming
B. Adapter teaming
![]() C. Packet fragment recovery
C. Packet fragment recovery
![]() D. Secondary I/O recovery
D. Secondary I/O recovery
11. Which of the following devices cannot be implemented in a fault-tolerant configuration?
![]() A. Power supply
A. Power supply
![]() B. Processor
B. Processor
![]() C. NIC
C. NIC
![]() D. Memory
D. Memory
12. What is the storage capacity of a RAID 1 array that uses two 40GB hard disks?
![]() A. 80GB
A. 80GB
![]() B. 40GB minus the parity calculation
B. 40GB minus the parity calculation
![]() C. 40GB
C. 40GB
![]() D. 80GB minus the parity calculation
D. 80GB minus the parity calculation
13. Which of the following are valid reasons to use a UPS? (Choose the three best answers.)
![]() A. Data availability
A. Data availability
![]() B. To prevent damage to hardware
B. To prevent damage to hardware
![]() C. Increased network speeds
C. Increased network speeds
![]() D. To prevent damage to data
D. To prevent damage to data
14. How many tapes are typically used in a GFS tape rotation?
![]() A. 14
A. 14
![]() B. 13
B. 13
![]() C. 12
C. 12
![]() D. 11
D. 11
15. As a network administrator, you have been asked to implement a RAID solution that offers high performance. Fault tolerance is not a concern. Which RAID level are you likely to use?
![]() A. RAID 0
A. RAID 0
![]() B. RAID 1
B. RAID 1
![]() C. RAID 2
C. RAID 2
![]() D. RAID 5
D. RAID 5
![]() E. RAID 10
E. RAID 10
16. Which of the following statements are true of VoIP? (Choose the two best answers.)
![]() A. VoIP is latency sensitive.
A. VoIP is latency sensitive.
![]() B. VoIP is latency insensitive.
B. VoIP is latency insensitive.
![]() C. VoIP typically uses TCP as a transport protocol.
C. VoIP typically uses TCP as a transport protocol.
![]() D. SRTP can be used to help secure VoIP communications.
D. SRTP can be used to help secure VoIP communications.
17. Which of the following recovery sites requires the delivery of computer equipment and an update of all network data?
![]() A. Cold site
A. Cold site
![]() B. Warm site
B. Warm site
![]() C. Hot site
C. Hot site
![]() D. None of the above
D. None of the above
18. Which of the following uses redundant hard disk controllers?
![]() A. Disk duplexing
A. Disk duplexing
![]() B. RAID 0
B. RAID 0
![]() C. Disk duplication
C. Disk duplication
![]() D. RAID 5
D. RAID 5
19. You have installed five 15GB hard disks for your server in a RAID 5 array. How much storage space will be available for data?
![]() A. 75GB
A. 75GB
![]() B. 60GB
B. 60GB
![]() C. 30GB
C. 30GB
![]() D. 45GB
D. 45GB
20. While digging through an old storage closet, you find two 10GB hard disks. What RAID levels could you implement with them? (Choose the two best answers.)
![]() A. RAID 5
A. RAID 5
![]() B. RAID 0
B. RAID 0
![]() C. RAID 10
C. RAID 10
![]() D. RAID 1
D. RAID 1
Answers to Exam Questions
1. D. At least three hard disks are required in a RAID 5 array. None of the other answers are valid. For more information, see the section “RAID 5” in this chapter.
2. A. Disk mirroring is defined by RAID 1. Raid 0 is disk striping, which offers no fault tolerance. RAID 5 is disk striping with parity. RAID 2 is not a commonly implemented RAID level. For more information, see the section “RAID 1” in this chapter.
3. A, B. The archive bit is reset in both a full backup and an incremental backup. Differential backups do not change the status of the archive bit. Mirror image is not an accepted backup type. For more information, see the section “Disaster Recovery” in this chapter.
4. C. A full backup combined with a differential backup requires only two tapes to do a complete restore, assuming that each backup set fits on a single tape. Full and incremental backups might need more than two tapes. Differential and incremental backups must be combined with a full backup to be effective. Answer D is not valid. For more information, see the section “Disaster Recovery” in this chapter.
5. B, C. RTP and UDP are both protocols used with VoIP. UDP is the transport protocol used because it has less overhead and error-checking mechanisms than does TCP. TCP guarantees message delivery, which adds an unnecessary element to real-time applications. RTP is used with UDP to complete the video of VoIP data stream. For more information, see the section “Voice over IP” in this chapter.
6. D. Two disks are required to create a RAID 1 array. All the other answers are invalid. For more information, see the section “RAID 1” in this chapter.
7. B. By making a full backup on the weekend and incremental backups during the week, you should be able to complete the backups without interfering with the normal working hours of the company. All the other answers are invalid. For more information, see the section “Disaster Recovery” in this chapter.
8. C. A sag is a short-term voltage drop. A brownout is also a voltage drop, but it lasts longer than a sag. A surge is an increase in power that lasts a few seconds. A spike is a power increase that lasts a few milliseconds. For more information, see the section “Using Uninterruptible Power Supplies” in this chapter.
9. D. RAID 10 offers the performance advantages of RAID 0 and the fault-tolerance capabilities of RAID 1. RAID 0 is not a fault-tolerant solution. RAID 1 and RAID 5 offer fault tolerance but do not increase performance. For more information, see the section “RAID 10” in this chapter.
10. A, B. In server systems, warm swapping allows network adapters to be swapped out without the server being powered off. Adapter teaming allows multiple NICs to be logically grouped together. If one of the NICs fails, the other NICs in the group can continue to provide network connectivity. Adapters in a team can also be grouped together to increase the available bandwidth. Answers C and D are not valid answers. For more information, see the section “Link Redundancy” in this chapter.
11. D. There is no accepted fault-tolerance strategy for coping with a failed memory module. All the other hardware components listed can be implemented in a fault-tolerant configuration. For more information, see the section “Preparing for Memory Failures” in this chapter.
12. C. A RAID 1 array requires an amount of disk space equivalent to that of the mirrored drive. Therefore, in a RAID 1 array of 80GB, only 40GB will be available for data storage. None of the other answers are valid. For more information, see the section “RAID 1” in this chapter.
13. A, B, D. UPSs can prevent damage to hardware and damage to data caused by fluctuations in the power supply. They can also promote the availability of data by keeping a server running in the event of a power outage. A UPS does not increase the speed of the network. For more information, see the section “Using Uninterruptible Power Supplies” in this chapter.
14. C. The standard GFS rotation uses 12 tapes. None of the other answers are valid. For more information, see the section “Disaster Recovery” in this chapter.
15. A. RAID 0 offers the highest level of performance but does not offer any fault tolerance. If the performance of RAID 0 is required along with fault tolerance, RAID 10 is a better choice. RAID 1 offers fault tolerance but no increase in performance. For more information, see the section “RAID 0” in this chapter.
16. A, D. VoIP is a latency sensitive application. This means that lags in delivery time negatively impact its ability to function properly. VoIP communications can be secured using the secure real-time transfer protocol (SRTP). Answer B is incorrect because VoIP typically uses UDP as a transport protocol and not TCP. For more information, see the section “QoS” in this chapter.
17. A. A cold site provides an alternative location but typically not much more. A cold site often requires the delivery of computer equipment and other services. For more information, see the section “Recovery Sites” in this chapter.
18. A. Disk duplexing is an implementation of RAID 1 (disk mirroring) that places each of the drives on a separate controller. None of the other answers are valid. For more information, see the section “RAID 1” in this chapter.
19. B. In a RAID 5 configuration, a space equivalent to one whole drive is used for the storage of parity information. In this question, this requirement equates to 15GB. Therefore, in a 75GB RAID 5 array, 60GB is available for data storage. None of the other answers are valid. For more information, see the section “Understanding Fault Tolerance” in this chapter.
20. B, D. Both RAID 0 and RAID 1 use two disks. The difference between the two implementations is that RAID 1 offers fault tolerance through disk mirroring, whereas RAID 0 stripes the data across the drives but does not offer any fault tolerance. RAID 5 requires at least three disks, and RAID 10 requires at least four disks if the entire hard disk is to be used. For more information, see the section “Understanding Fault Tolerance” in this chapter.
Suggested Readings and Resources
• Koren, Israel and Mani Krishan. Fault-Tolerant Systems. Morgan Kaufmann, 2007.
• Snedaker, Susan. Business Continuity and Disaster Recovery Planning for IT Professionals. Syngress, 2007.
• Szigeti, Tim. End-to-End QoS Network Design: Quality of Service in LANs, WANs, and VPNs (Networking Technology). Cisco Press, 2004.