

Security
In this chapter, you will learn how to
• Control access to storage resources
• Explain how encryption is used to protect the confidentiality of data
• Manage the visibility of storage used on the network or fabric
Chapter 7 discussed how the widespread availability of networks, infrastructure, and applications has lulled us as consumers into a false sense of security. In fact, these systems are double-edged swords. On one hand, they are marvelous innovations that simplify our lives by allowing us to complete complex transactions from a variety of devices. On the other, they are potentially dangerous portals for cybercrime. Many trust their most personal transactions—prescriptions, medical appointments, banking, dating, and so on—to the vacuous cloud, never once considering the potential harm unauthorized access to these resources poses.
Network providers, designers, and managers are faced with an equally daunting task of providing an environment for safe and secure transaction processing. Modern networks are characterized as a complex hybridization of digital, analog, wired, and wireless multiplatform/protocol technologies. The adoption of global standards and policies has been the primary catalyst for the high degree of global interoperability we enjoy. Yet it is these very factors that contribute to and are likely predictors that any network and its attached resources are potential targets for breach.
While the news and other information resources provide daily accounts of hacking, identity theft, and cyberterrorism, some of the most common vulnerabilities exist at a basic level. For example, most banks and other applications such as home security systems require a PIN based on a standard number of digits; most ATM PINs are four digits. A random number generator or freeware designed specifically for the task can easily decode the PIN, allowing for unauthorized access.
Complexity is perhaps the major challenge we face in providing security for physical assets, storage, data, infrastructure, and other system resources of a given network. For example, when a birthday approaches and you decide to look for a gift online, the choices are staggering! Free shipping, comparative shopping apps, and competitive pricing all mean you can select a deal from anywhere around the world and have it delivered to your doorstep in a matter of days. Behind the “point, click, buy” phenomenon are systems that gather data from around the world—product information, pricing, availability, shipping options, and so on. Once an item has been selected, it may be provisioned or sourced from a different provider than the site from which it was ordered. “Pick and pack” information is sent to highly automated warehouse operations and passed onto other entities in the supply chain.
The ordered item is then taken off the available or in-stock list, automatically updating the innumerable sites that have offered it for sale. When a threshold has been reached for the amount of the item that needs to be on hand, another application seeks providers, compares prices, and generates an order for more. A great deal of this is automated and has put buying power back into the hands of the consumer. This short narrative does not begin to describe all of the steps and interconnected events the purchase triggered. What it illustrates is the potential for risk and vulnerability.
Many separate systems are interconnected. Each interface—terminal, kiosk, device or portal, database, node, storage, infrastructure, or application—is a potential point of entry into the system. What is even more problematic is the varying degree of network management and security that characterizes these networks. Since networks evolve, they are composed of both legacy and new innovations that also vary in terms of their associated vulnerability for unauthorized access. Each domain within the network may have differing security policies and protection systems in place.
Mobility and cloud networks have allowed us to share information and data seamlessly across a variety of devices. Both have added yet another layer of complexity to the task of controlling who has access to these resources. Tasks such as intrusion detection, data loss prevention, and network access control can be tricky when the access points—tablets, cell phones, laptops, and automobile navigation and info systems—are in motion. This chapter will examine in both practical and technical terms the elements and challenges related to providing network security.
Access Control
Access control is the selective restriction of access to physical or logical entry points and any attached storage or associated resources. Accessing network attached storage (NAS) may be done by directly logging onto the NAS, by using transaction processing, or by using an application that queries the NAS. In this regard, determining whether the requesting party (human or machine) has the right or permission to access a resource is the most fundamental step in providing security for storage. Access control is based on authentication and authorization.
Authentication
Authentication is the mechanism used to establish that the user, application, or device is who or what it claims it is. Access to a resource begins by presenting credentials to an authenticator to determine who you are. Physical authenticators will send the information to a control panel, which is a highly reliable processor. The control panel then compares the information it received to the information in its access control list. When the information matches, the system can grant or prevent access based on the information it contained in its database.
 EXAM TIP The term physical describes direct access to a site, system, or piece of equipment such that it can be touched, seen, or otherwise interacted with.
EXAM TIP The term physical describes direct access to a site, system, or piece of equipment such that it can be touched, seen, or otherwise interacted with.Users can be authenticated based on one or more of the following factors:
• Something you are Fingerprint, iris scan, handwriting analysis
• Something you know Password, passphrase, PIN
• Something you have Access card, badge, key
Users can interact with a system directly with physical access, or they can interact remotely. Authentication types differ based on this type of access, and the security controls used for physical (sometimes called local) and remote access differ.
Physical Authentication
Physical access is a term used in computer security that refers to the extent to which information assets or the sites that house them can be physically interacted with, such as touched, walked through, or seen. Physical access control is used to determine who has permission to access the resource, the time or interval such resources may be accessed, and which locations may be used.
Physical access controls have become more complex, beginning with simple locks and keys, guards, and hidden stashes. These controls have been enhanced and augmented through electromechanical, electromagnetic, and optical access control mechanisms. Today, even more sophisticated electronic or computer-based access to physical resources is provided by biometrics, such as fingerprint, voice, retinal identification, radio frequency identification (RFID), and other high-tech scanning techniques. These are combined with cameras that have footage that can be archived to alternate sites and encrypted, as well as thermal, laser, and other sensors to detect entry into a facility.
Authentication methods for physical access include checking a badge, employee ID, or state-issued ID or using an authenticator such as a key card reader, PIN code pad, or a biometric scanner.
Remote Authentication
When users connect to a device remotely, such as connecting from a computer at home to a network server or connecting a workstation in the office to a NAS in the server room, they send credentials electronically to prove that they are who they say they are. These credentials usually include a username and password, but could also include digital certificates, a number generated from a token, or a PIN code.
Authorization
The next phase of access control is authorization. Once a system has determined who you are, it needs to determine what access you should have, if any. The fact that you are who you say you are means nothing if that person is not authorized to access the information or system. Authorization determines the scope, span, and extent of rights or privileges the requesting entity is entitled to. This is handled through permissions.
There are different kinds of authorization, called permissions, that can be granted. This access can be limited to a file, folder, or logical volume. An administrator, or someone with the special permission to grant access to other users, sets all the necessary access rights that others receive. The type of access that will be assigned will vary depending on need and the sensitivity of the data or application.
• Full control This allows the user the maximum amount of control; read, write, and delete are the basic type of access at this level. More complex tasks allowed at this level may include the ability to rename and change the attributes of a file. Full control also grants the ability to assign or revoke privileges to or from others.
• Read-write The user’s access is limited in comparison to full control, granting the ability to read, change, or edit (write) a resource or change how and where the resource is stored.
• Read-only This allows a logical volume (LV), file, or folder to be accessed and viewed but not modified.
• Deny This is used to prevent access to the storage resource. For example, one department in an organization may ban a separate department from accessing a certain folder in a drive because of the sensitive nature of the files contained within them. Deny permissions override other permissions.
Permission can be used to provide a range of access choices to a file or database, individual, or group. For example, a group is working on a project where they need both read and write access to certain files. An administrator will give each member of the group the ability to modify files in the system. However, another group may also need access to those files, but in this case, they only need to see the changes made and don’t need to modify anything. Ultimately, the system administrator determines the extent of permissions that are granted to users.
On a Unix-like system, permissions are managed in three distinct classes. These classes are known as user, group, and others. A user owns files and directories. It is the owner who determines the owner class of a file or directory. A group is assigned files and directories, which define its group class. The owner of the file may be part of the group. The other class refers to the permissions given to users who are not the owner or member of the group.
Access Control List
An access control list (ACL) is a list of permissions that are attached to an object or file. An ACL specifies which users or system processes are allowed to interact with objects, as well as specifying allowable operations for such objects. ACLs are organized like a table with entries as rows. Entries in an ACL specify an action, a subject, and an operation. For example, if a file has an ACL that contains “grant Blake, delete,” this means that Blake has been given permission to delete the file. In the same scenario, “deny Aisha read” means that Aisha cannot read the file. In an ACL-based security model, when a subject requests an operation to be performed on an object, the operating system checks the ACL for an applicable entry first to decide whether the operation requested is authorized.
The following list includes a few of the types of systems that use ACLs:
• File system ACLs This is a data structure that contains entries specifying the individual or group rights to a specific object, including programs, processes, or files. Every object that is accessible is assigned an identifier to its ACL. The privileges or permissions given determine whether a user can read from, write to, or execute an object. In some implementations, an ACL controls the permission rights of a group to a certain object.
• Access control entries (ACEs) ACLs are like a table with each row containing a user principal, typically represented by a unique identifier and its assigned permissions. These records, rows, or entries are called access control entries.
• Networking ACLs Some proprietary computer hardware has an ACL whose rules are applied to port numbers or IP addresses that are available on a host or other layer 3 device, each with a list of hosts or networks that are permitted to use the service.
• SQL implementations Structured Query Language (SQL) and relational database systems have ACLs with Data Control Language (DCL) statements ported into them to control access to databases, tables, views, and stored procedures. SQL uses GRANT to provide access to an entity, while REVOKE is used to deny access.
File Permissions
File permissions are the permissions assigned at the file system level. A file system has permissions associated with each file and folder, but the permission type can differ between file system types. Not all file systems support permissions. For example, FAT and FAT32 do not support file permissions, so everyone can access the files on the system once they are logged onto the computer. Some example file permissions are
• Read permission Allows a given user the right to read a file. When this permission is set for a directory, a user is granted the ability to read the names of files in the directory, but cannot perform any actions on the directory.
• Write permission Allows the user the ability to modify a file. When this is set for a directory, a user has the ability to modify entries in it, which means that users can create, delete, and rename files in a directory.
• Execute permission Grants the user the ability to execute a file or program that accesses the file. This kind of permission can be set for executable programs such as shell scripts so that the operating system can run them.
Share Permissions
Shared access means that a computer resource is made available from one host to other hosts on a computer network. Programs that can be shared include computer programs, data, storage devices, and printers. Sharing through a network is made possible by inter-process communication over a network.
A shared resource is a device or piece of information on a computer that can be accessed remotely from another computer. Typically, this is done through a local area network or an enterprise intranet. A shared resource is also called a shared disk or mounted disk. Depending on the object being shared, it is also referred to as a shared drive volume, shared folder, shared file, shared document, shared printer, or shared scanner. Permissions are also assigned to shares. The share permissions determine who on the network can interact with the files. When a user is logged on locally to a machine, the only permissions that apply are the file permissions, but when a user accesses a file on a share, both the share and file permissions are applied, and the most restrictive permission wins. In many cases, administrators will control access to files using file permissions so that security is consistent whether a user is local or remote to the data. In this case, share permissions are often assigned as full control to everyone. This does not mean everyone has full control of the files because access is still determined by the sum of both permission sets. For example, the marketing share has full control assigned to everyone in the group. The file permissions on the marketing folder grant the sales group read-only access.
Bob is a member of the sales group, and he can access the marketing share from his computer, but he cannot change or delete files from the share even though he has full control share permissions because the more restrictive read-only file permissions have priority. This can work the opposite way as well. If full control was granted at the file level but read-only was granted at the share level, users would still only have read-only access when accessing the files over the network share.
Share permissions are important when a file system does not support a particular set of file permissions such as the File Allocation Table (FAT) file system. In this case, since there are no file permissions, the share permissions are the only ones that are evaluated when users request access. There may be instances when a NAS appliance provides administrators with only share permissions but file permissions are managed by the appliance, usually with full control assigned to files created in shared folders. Share permissions alone are used to determine file access and prevent administrators from modifying system data and other protected areas.
The sharing of resources over a network is made possible through protocols such as the Network File System Protocol (NFS) and the Common Internet File System (CIFS), described in Chapter 2. The features of these protocols are provided next as each relates to their security features:
• NFS3 NFS is a protocol used for sharing files over a network. It is used on Unix and Linux systems and carries little overhead. The first NFS version was specified by Sun Microsystems in 1984 and was used only within the company. Version 2 of the protocol saw widespread use as a file system protocol. The protocol was designed to have little overhead characterized by its stateless design and User Datagram Protocol (UDP) transport mechanism. NFS3 references entities in the ACE as users@domain.
• NFS4 NFS version 4 runs only on top of Transmission Control Protocol (TCP). In NFS version 4, finer-grained access control is allowed than in NFS version 3.
• CIFS CIFS operates as an application-layer network protocol that is mainly used for providing shared access to files on Microsoft Windows networks. CIFS shares associate users and groups to the CIFS ACL by using a security identifier (SID) in the ACE as compared to NFS’s use of user@domain. This is a string of alphanumeric characters that uniquely identifies the user or group in the namespace, such as a domain or a local machine, depending on the scope of the account.
CIFS makes use of the client-server networking model. A client program makes a request of a server program (which is usually in another computer) for access to a file or to pass a message to a program that runs in the server computer. The server takes the requested action and returns a response. CIFS uses sessions, which allows for connections to be restored automatically in the case of a connection failure.
Some NAS systems may define their own permissions that roughly emulate the permissions mentioned previously. For example, Figure 8-1 shows the share permissions assignment screen for a Hitachi NAS product. Here, View permission is equivalent to read, Modify is equivalent to read-write, and Admin is equivalent to full control.
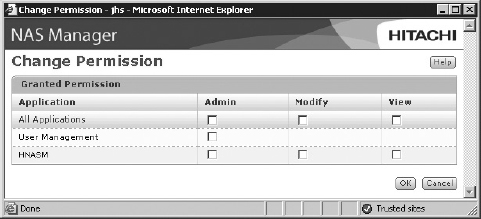
Figure 8-1 NAS permission configuration
Permissions Best Practices
The following are some practical approaches to follow in establishing permissions:
• Apply permissions to groups instead of individual users. Assign permissions to individual users, set up permissions for a group, and then assign users to that group. This strategy adds flexibility in adding or modifying permissions. A user can be added to one or more groups to gain access to permissions on many different servers. Applying permissions to folders can be inefficient because a folder may contain a large number of files. Assigning permissions to an individual or group as previously described is a more efficient means of updating or managing permissions.
For example, say there was a NAS share that had more than 100 million files in it. An administrator needed to make a change to the permissions and add another group. After 30 minutes, the administrator became concerned about the time it was taking to accomplish the task. The size of the NAS share was the culprit. In fact, the operation took 28 hours. While this is an anomaly because most environments will not have 100 million files, enterprises expect permission management to be done in real time with negligible time required. The following bullets discuss some of the basic rules of thumb in providing baseline access control through permissions:
• Give users least privilege. The term least privilege refers to the minimum permissions that will allow a user to perform their tasks. If a user needs to access files but will never need to change them, that user should be assigned read-only access. Granting ubiquitous rights or privileges to users minimizes the task of managing permissions. However, full access can result in accidental or intentional compromise of data and files.
• Classify and organize data. Place data with similar security requirements in the same folder or share. Do not mix highly confidential data that only a few people need access to with data that many people have access to because this will mean that the larger group of people will need to have access to the share to do their work, but they will also have access to the highly confidential data. It pays to organize the data up front so that a consistent and easy-to-understand and manage permission set can be put in place.
• Use deny permissions sparingly. Deny permissions always override allow permissions, so if a user is denied read but they are allowed full access, they will not have access to the files because the read deny takes precedence over the allow permission. Failure to properly document deny permissions can be problematic. For example, Bob is a manager of the marketing department. Marketing users have access to a share called corporate_docs, which contains a folder called marketing and a folder called finance. The marketing group is assigned full control to the corporate_docs share, and deny full control has been applied to the finance folder underneath. Another group called managers has full control on the finance folder. Bob is a member of the marketing and managers group, but he is unable to access the finance folder because the deny permissions associated with the marketing group override the permissions granted by the management group. It is better to separate resources so that permissions are simply not applied for a user or group. This way, if access is needed later, it can be granted without first removing deny permissions.
Interoperability
Interoperability refers to the ability of systems and devices to exchange and interpret shared data without the need for additional assistance. For two systems to be called interoperable, both of them should be able to exchange data and then present that data in a manner that can be understood by a user. Over the years, interoperability has become an element of increasing importance for information technology products. This is because the concept of “the network is the computer” is becoming a reality. It is for this reason that the term is widely used in product marketing descriptions. Compatibility is an integral component of interoperability. A product is considered compatible with a standard but interoperable with other products that meet the same standard.
There are two approaches for products to achieve interoperability with other products. The first is to implement systems that have complied with published interface standards. If both systems comply with the same standard, they should have a level of interoperability, but you may need to make configuration changes as documented in their manuals to get some features to work between platforms. One good example of this approach to interoperability is the set of standards that were developed for the World Wide Web (WWW). These standards include protocols such as Transmission Control Protocol/Internet Protocol (TCP/IP), Hypertext Transfer Protocol (HTTP), and Hypertext Markup Language (HTML).
The second approach is to use a broker of services that can convert the interface of one product into the interface of another product when needed. These often come packaged as a gateway appliance that sits between two systems to translate. Specifications such as the Common Object Request Broker (CORBA) and Object Request Broker (ORB) are used in some such systems.
Encryption
Encryption is based on the science of cryptography, which has been used for a long time to keep information protected. Before the dawn of the digital age, the biggest users of cryptography were governments for military purposes. In fact, the practice of encrypting information extends back to antiquity when Spartan generals sent and received encrypted messages through the scytale rod that would be wound around a message to decipher it and to the substitution of letters used by the Romans in the Caesar cipher.
These days, cryptography relies primarily on computers because a human-based code can be cracked by computers, which can try all possibly combinations of numbers quickly. Ciphers—specific codes that involve substitutions or transpositions of letters and numbers—are better known these days as algorithms. Substitutions place a specific character or characters in place of another character or block of characters, and transpositions switch the order of characters or blocks of characters. These algorithms serve as guides for encryption and provide a way to create a message and give a certain range of possible combinations. A key is what is used to decipher the encrypted data by explaining how the algorithm was implemented. Many people can use a master combination lock; however, each is different in that they assign a combination to the lock. This combination is the key, and it determines how the lock is implemented to provide security.
Encryption works by scrambling data so that it appears as gibberish to those who are unauthorized to view it. It is the process of taking all the data that one system or device is sending to another and encoding it into a form that only the other device or system can decode.
Computer encryption systems belong to the following categories:
• Symmetric-key encryption Two systems or devices using this kind of encryption should have the same key. Symmetric encryption is much faster to implement than asymmetric encryption. An example of where symmetric encryption is used is with wireless networking in your home—you specify the password (key) on the router, and that same key must be used on each wireless client.
• Asymmetric encryption Asymmetric-key encryption or public-key encryption uses two different keys at once, a combination of both a private key and a public key. The private key is kept secret on the device or user, while the public key is made available to others who want to communicate in a secure manner with the device. Messages encoded with the public key can be decrypted only by the associated private key, which is retained only by the authorized recipient. Asymmetric encryption also provides a way to verify that data was sent by a party. If data can be decrypted with a user’s public key, then it must have been encrypted with the user’s private key, and this can confirm that the message originated from the owner of the private key.
• Using file encryption File encryption is typically used for data at rest. However, it can be applicable to data in motion when the data is encrypted first before being sent.
Encryption Keys
Encryption is a security form that converts information, images, programs, and other data into an unreadable cipher by applying a set of complex algorithms to the original material. These algorithms are the ones responsible for transferring the data into streams or blocks of random alphanumeric characters. Unencrypted text is called plain text, and encrypted text is called cipher text. An encryption key is a piece of information that makes the encryption or decryption process unique. For example, a door can be locked or unlocked, and many doors can use the same model of lock. Each lock is unique because it has only one key that can lock or unlock it. Similarly, two communication sessions can use the same software and encryption algorithms, but one session would not be able to read the data from another session because they use different keys.
Most encryption algorithms alone cannot function without a key except in certain cases when the developer of an algorithm specifically designs it without a key. The combination of an algorithm and a unique key allows it to vary the mathematical process used to encrypt data so that the two copies of the same plain text encrypted with the same algorithm but different keys will result in very different cipher text.
Lots of encryption schemes are available; however, some are more vulnerable to attack or exploitation than others. There are simple algorithms that can easily be decoded because of the widespread availability of powerful computers and decryption tools. For this reason, it is important to utilize up-to-date encryption algorithms.
A symmetric type of encryption uses a single password to serve as both encryptor and decryptor. With the encryption key, a user can mount the drive and work in an unencrypted state and then switch over and return the drive to a cipher when a job is complete. Algorithms provide a secure means of protecting data. One of the weaknesses of a symmetric encryption program is that a single key should be shared, which presents opportunities for it to be leaked or stolen. This is why the constant changing of the key is required to improve security.
Asymmetric encryption schemes use very highly secure algorithms that have different ways of encrypting and decrypting information. The software makes use of two keys, which are known as the key pair. One is the public key, which can be shared freely and given to anyone. It can be used to encrypt data that can be read only by the one holding the private key, and it can also decrypt message digests encrypted with a private key, which is commonly done to verify that a message was sent by an individual. The term nonrepudiation is often used to describe this action where the private key is used to encrypt. Since the sender is validated by their use of their private key, they cannot deny or “repudiate” that they sent the message.
Whereas the public key is made available to anyone, the private key is not shared. The private key is the one needed to decrypt messages that have been encrypted with the associated public key or to encrypt message digests to verify the identity of the sender. Widespread use of asymmetric encryption software allows for encrypted web sessions such as banking or shopping over HTTPS.
Systems are often implemented using asymmetric encryption to set up a session where symmetric keys are then exchanged. These keys are changed periodically. This allows for the connection to be secure since the key material was exchanged in an encrypted channel, but the overhead of using asymmetric encryption the entire time is avoided, and the keys used are changed often to avoid the potential of keys being deciphered and used during the communication stream.
When securing data, it is important to understand the state the data is in. Data can be either at rest or in motion. At-rest data is present on a storage device but not being accessed. Data in motion is data that is being transmitted across a medium such as network or computer system so that it can be worked with. Data is secured quite differently depending on whether it is at rest or in motion.
Data at Rest
Data at rest is a term that refers to all data that is in computer storage. This excludes data that is traversing a network or is temporarily residing in computer memory that needs to be read or updated. Data at rest can be archival or reference files that are rarely or never changed. Data at rest can also refer to data that is subject to regular but not constant change.
Examples of data at rest include some of the following:
• Files on the hard drive of a laptop
• Files that are stored on external backup media
• Files that are located on a storage area network (SAN) LUN
• Files that are on the servers of an offsite backup service provider
Protecting data at rest is a major concern for all types of organizations, including in the private sector, in the public sector, and in education. Many types of data are subject to regulatory oversight or mandates. Hence, encryption is used to protect data at rest by preventing unauthorized access. Some methods used to encrypt data at rest include disk encryption, file encryption, and tape encryption.
Disk Encryption
Disk encryption refers to the technology that is used to protect information on a logical volume (LV) by converting it into code that is unreadable and cannot be easily deciphered by those who are unauthorized to access or view it. Disk encryption makes use of disk encryption software or hardware to encrypt each bit of data that is present on a disk or disk volume so that unauthorized access is prevented on data storage.
Full disk encryption (FDE) is a term that is used to signify that everything on a disk is encrypted, and this includes programs that can encrypt bootable operating system partitions. This type of encryption is at the hardware level. It works by automatically converting data on a hard drive into a form that is not easy to understand by those who don’t have access to data. An advantage of FDE is that it doesn’t require special attention on the part of a user once they initially unlock a system or device.
In FDE, volumes containing the data are automatically encrypted once the system is shut down and decrypted when the user logs into the system. One of the disadvantages of FDE is that the process of encrypting/decrypting slows down data access at certain times, especially when virtual memory is being heavily accessed. Also, if a system is left unattended and not locked or the machine is not shut down, an unauthorized individual can access the data unencrypted.
Windows systems can utilize the built-in FDE system known as BitLocker. Even though BitLocker services are available for Windows 7 and newer editions, Windows 7 Home and Professional users cannot use the functionality. BitLocker encryption is available in 128-bit or 256-bit mode. The difference between these modes is in the amount of data that is uniquely used to generate cipher-text blocks. The larger the blocks, the harder it is to detect patterns in the encryption and to break encryption keys.
BitLocker secures files irrespective of the users associated with it, which means that all the users with administrative credentials can turn on/off this feature. BitLocker uses a special microchip, called Trusted Platform Module (TPM), which is hardwired to the motherboard of machines that require all advanced encryption features. Moreover, only administrators have the right to turn on/off BitLocker advanced encryption features. BitLocker keys prevent the operating system itself from booting from a different computer.
An enhancement to BitLocker is BitLocker to Go, which can be used to encrypt files and folders in removable hard drives such as USB drives, thumb drives, and so on. The major factor that you need to consider is BitLocker cannot be enforced while the operating system is running. Since BitLocker can be used only for avoiding offline attacks, you need to rely on standard operating system security techniques to protect your computer while it is running. The major attacks on your system during its running time may be from malicious users trying to access the machine either locally or using a remote connection. Either way, your operating system should be configured with strict user access permissions and a password policy by which such attacks can be mitigated. As another example of FDE, FileVault 2 encrypts the entire OS X startup volume. Users who are authorized have their information loaded on a separate nonencrypted boot volume. In systems that use a master boot record (MBR), a part of the disk remains nonencrypted. There are some hardware-based full-disk encryption systems that encrypt an entire boot disk, including the MBR. While Windows uses BitLocker and EFS encryption technologies, Apple Mac OS uses FileVault. FileVault can be used in encrypting the entire drive for privacy. FileVault version 1 requires Mac OS 10.3 Panther, Mac OS 10.4 Tiger, Mac OS 10.5 Leopard, or Mac OS 10.6 Snow Leopard. FileVault 1 encrypted a user’s home directory, but it did not encrypt the entire drive. Users create a password that is used to decrypt the files. If this password is lost, a recovery key may be used as well to decrypt the files.
FileVault 2 expands the functionality of FileVault by using the Advanced Encryption Standard (AES) 256-bit keys. It can also be used to encrypt the entire drive. FileVault 2 uses significantly more CPU than FileVault, and decryption can be performed with a password or recovery key similar to FileVault. FileVault 2 requires Mac OS 10.7 Lion, Mac OS 10.8 Mountain Lion, or Mac OS 10.9 Mavericks to be installed in the system.
Enabling or disabling FileVault is an easy task because you simply need to navigate to the System Preferences page and click Security And Privacy. Click the FileVault tab on the Security and Privacy page to enable/disable the services. There may be situations when multiple user accounts are available in a system. In such cases, administrators need to decide which users are allowed to unlock the encrypted drive. Only those users who are given permission to unlock the drive can access the system. Thus, users who do not have permission to unlock cannot log in to the system. Only after authorized users unlock the drive will other users be able to use the system.
Once the users are assigned permissions for unlocking the drive, a recovery key is displayed, which comes in handy when users forget the password for unlocking the drive. The recovery key can be used in such situations to unlock the drive and set a new password. It is advisable that the recovery key be stored externally in secure places rather than storing the key in the system itself because when the system is locked, the recovery key will also be encrypted and cannot be accessed when you forget the password. The recovery key can also be stored with Apple in the cloud. You will be given an option for storing the recovery key with Apple once it is displayed. If you prefer to store the key with Apple, you will need to answer three secret questions. The answers you provide for the questions will be used for encrypting the recovery key that is sent to Apple. The only way by which you can retrieve the key from Apple is by answering the questions.
FDE is useful for laptops and other small computing devices that are prone to getting lost or stolen. On a corporate level, a storage administrator needs to enforce a strong password policy and provide an encryption key backup process in the event that an employee forgets their password or unexpectedly leaves the company if only one key is used to encrypt the entire hard drive. Many systems allow for a user key and a recovery or administrative key to be created to decrypt the data. This way, data can be recovered if an employee leaves, falls ill, forgets the password, or dies.
File Encryption
File encryption refers to the technology that is used to protect information on a file or folder basis. Similar to disk encryption, it works by converting it into code that is unreadable and cannot be easily deciphered by those who are unauthorized to access or view it.
Encrypting File System (EFS) is relatively simpler than BitLocker, but it can be used to encrypt individual files on the user level. Only a check box needs to be selected in order to turn on encryption. The check box is available in the file and folder properties. Users can also assign the ability to decrypt a file for various other users. The files are ready to use once they are opened. When the check box is unselected, the file becomes decrypted, and any user can access them. There is an alternative for such Windows users where files can be decrypted using the Cipher.exe command at the command prompt. An encrypted file can also be modified and copied to the local system. The EFS certificates can also be exported and stored as backup files in case the decryption key is lost.
EFS uses individual accounts and permissions while encrypting files. Users can encrypt only those files that belong to them. EFS does not require any additional hardware to work, and it is compatible with most machines. EFS does not require administrative permissions to enable or disable encryption on files and folders. Individual users can encrypt their files if needed, but only their files. EFS security keys are stored in the operating system unless EFS is used in domain mode where some key material is stored on the network and some on the local machine, requiring both to decrypt files.
Tape Encryption
Tape-based encryption offers a lot of advantages for storage administrators. Encrypting data on the tape uses hardware on the drive itself, which means that encryption is fast. With a really fast encryption, the backup server is not congested, and the backup process won’t be slowed down. Administrators can also send encrypted files offsite using tape encryption with the knowledge that the content in the tape is secure and helps them meet regulatory obligations.
Tape-based encryption is also able to achieve a measure of standardization and interoperability in the form of Linear Tape-Open (LTO-4). This is because organizations can upgrade their LTO-3 tape systems to LTO-4 while also maintaining backward compatibility with existing LTO-3 tape cartridges. This is discussed in more detail in Chapter 4.
Data in Motion
Data in motion refers to information that is being transmitted over a network or in transit. For example, when sending an e-mail, that e-mail is considered data in motion from the moment it is sent until it is received. Other than sending mail, the following are also considered data in motion:
• Data being backed up from a laptop or personal computer onto a central server
• Uploading and downloading files to file-hosting sites
• Data sent and received through the process of logging onto services
• Copying files over the network
• Sending e-mail
• HTML files sent when browsing the Internet
Alteration and interception are the biggest threats to data in motion. Important data such as usernames and passwords are typical examples of those that should not be transmitted over a network without the protection of encryption because they could be intercepted by someone else and used in malicious ways. When unprotected data is intercepted, it can be used by others to impersonate or gain access to sensitive information. Encryption of a network session using a VPN (discussed later in this section) is important for data that traverses less secure zones because it helps ensure a higher security level for data in motion. Data in motion is vulnerable to attackers who may be in between the sender and the receiver because those who want to attack do not need to be near the computer where the data is stored in order to gain access to it. Even private networks are susceptible to this through malware that could be resident on a network machine. Attackers just need to be somewhere “along the path” to tap into the data. VPNs are important in protecting data along the path of communications so that those in between the communication cannot decipher the protected communication.
There are two ways to use encryption in protecting data in motion:
• Using an encrypted connection Files sent over an encrypted connection such as an encrypted tunnel will be automatically encrypted while in transit. Even files that were encrypted prior to being sent will get encrypted again while being sent. Examples of encrypted connections include Internet Protocol Security (IPSec) and virtual private networks (VPNs), both discussed later in this chapter, and Secure Shell (SSH) and Secure Sockets Layer (SSL), discussed in Chapter 6.
• Using file encryption File encryption is typically used for data at rest. However, it can be applicable to data in motion when data is encrypted first before being sent.
Network Encryption
Network encryption is also known as network-layer or network-level encryption. The network and transport layers of the Open Systems Interconnection (OSI) reference model are the ones responsible for connectivity and routing between two end points. Network encryption is a network security process that applies crypto services at the network layer (layer 3) or transport layer (layer 4), which is above the data link layer (layer 2) but below the application layer (layer 7). With the use of existing network services and application software, network encryption is invisible to the end user and operates independently of any other encryption process being used. Data is encrypted only during transit. Data exists as plain text on the originating device or system and receiving hosts.
Network encryption is implemented through IPsec, which is a set of open Internet Engineering Task Force (IETF) standards that, when used in conjunction, creates a framework for private communication over IP networks. End users and applications do not need to be altered in any form because IPSec works through the network architecture by encrypting the payload or data section of IP packets. IPSec-encrypted packets do not encrypt the header of the packet containing the source and destination address, so they are easily routed through any IP network.
IPSec
IPSec is a protocol suite for securing Internet Protocol (IP) communications by authenticating and encrypting each IP packet of a communication session. There are a number of protocols being used by IPSec for establishing mutual authentication between agents at the beginning of the session and negotiating cryptographic keys to be used during the session. These include Authentication Header (AH), which protects against replay attacks and ensures sender identity and data integrity; Encapsulating Security Payload (ESP), which provides confidentiality and integrity for data packets; and Security Association (SA), which provides the framework for how AH and ESP exchange keys and interact with other layers of the communication.
IPSec can be used in protecting data flows between a pair of hosts, between a pair of security gateways, or between a security gateway and a host. IPSec is an end-to-end security scheme that operates in the Internet layer of the Internet Protocol suite. Other Internet security systems that are in widespread use, including Transport Layer Security (TLS) and Secure Shell (SSH), operate in the upper layers of the Transmission Control Protocol/Internet Protocol (TCP/IP) model. IPSec protects any application traffic across an IP network. Applications do not have to be designed specifically to use IPSec.
IPSec can operate in transport mode or tunnel mode. In transport mode, the packet is encrypted, but the packet cannot be used with Network Address Translation (NAT) because the intermediary devices cannot read the packet information. In tunnel mode, the packet is encrypted and then encapsulated into another packet that has source and destination information in it. This packet can be read and can be easily routed across an internetwork, including across NAT.
VPN
A VPN is an encrypted session between two devices such as two routers or firewalls or between a VPN server and a VPN client such as a remote laptop. Devices connecting through the VPN appear to be on the same network, and they will send data to each other using local network addresses. The VPN encapsulates this data within encrypted packets that are delivered through the intermediary networks and then decrypted at the other end and dropped onto the network unencrypted so that they can be delivered to their destination, as shown in Figure 8-2.
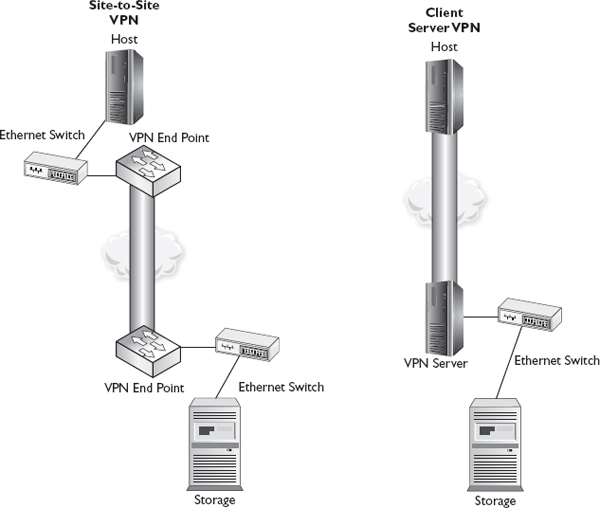
Figure 8-2 Virtual private network
Popular VPN protocols include Secure Socket Tunneling Protocol (SSTP), Point to Point Tunneling Protocol (PPTP), and Layer 2 Tunneling Protocol (L2TP) using IPSec.
Host Encryption
Encrypting data at the host level provides similar benefits and trade-offs to application-based encryption. There are opportunities to classify data at the host level on a less granular basis. When encryption is performed at the host level, data can be of variable record length. Just like an application-based approach, the encryption solution can add information to the encryption payload to allow for the inclusion of a digital signature or cryptographic authentication. By having this, a “man-in-the-middle” is prevented from substituting bad packets for the good encrypted packets.
Backed-up data can be secured using host-based encryption. One of the cons of host-based encryption schemes is that they are harder to manage if there is a lot of data to encrypt without a centrally managed system.
Storage Visibility
One way of controlling access to storage resources is limiting their visibility on the storage network. Some methods of limiting this visibility include LUN security, zoning, iSCSI security, and storage segmentation.
LUN Security
A logical unit number (LUN) is a unique identifier that references a logical volume by a protocol that is associated with a SCSI, iSCSI, Fibre Channel (FC), or similar interface. LUNs are central to the management of block storage arrays that are shared over a storage area network.
LUN Masking
LUN masking is an authorization process that makes a LUN available to some hosts, as well as unavailable to others. Many storage controllers support LUN masking. When LUN masking is implemented at the storage control level, the controller enforces access policies on the device. As a result, having LUN masking implemented at the storage control level is more secure. When it is implemented in this level, LUN masking protects data integrity since multiple nonclustered servers accessing the same disk do not corrupt the data. Without LUN masking, corruption would occur when two systems access the same LUN simultaneously.
EXAM TIP LUN masking is implemented on the storage device such as a storage array, and it limits which WWNs can see the LUN.For example, Windows servers attached to a storage area network can, on certain occasions, corrupt non-Windows (Unix, Linux, and NetWare) volumes on the storage area network by attempting to write Windows volume labels to them. When LUN masking is implemented at the storage control level, the attempt to write volume labels is prevented. This is made possible because the other LUNs are hidden from the Windows server, and it does not realize that the other LUNs exist. LUN masking is a constraint added to LUN zoning to make sure that only the devices that are authorized to access a specific server can access the corresponding port. It subdivides access to a given port, which is why several LUNs are accessed through one port; the server masks can be set to limit each of the server’s access to the right LUNs.
LUN Sharing
A LUN can be shared between two or more servers. This is accomplished through clustering or time sharing. Clustering is used when one or more computers are configured to take over the operations of another computer. The disks that are used in these operations must be available to the cluster members in the case of a failure, but only one member will access the disk at a point in time. Time sharing allows a device to access a LUN and then release it for use by another device. This is often used for backing up data. A copy of data can be created to another LUN, which is then allocated to the backup device temporarily.
An important question to be asked about LUN sharing is whether a LUN can be used (read-write) by two or more servers along with an application at the same time and still be able to maintain data integrity. The answer is yes if some form of volume or file synchronization software is used such as a clustered volume manager, a clustered file system, a network file system using NFS or CIFS, or a clustered application. Without the use of some form of software on the servers or a NAS device, there is no way to coordinate access to change data blocks and maintain data integrity.
Host Based
Host-based LUN masking implements the control at the end points or hosts. The visibility of LUNs is restricted at the host bus adapter (HBA). The security benefits of LUN masking implemented at the HBA level are limited since it is possible to forge source identification information such as worldwide name (WWN), media access control (MAC), or Internet Protocol (IP) addresses in a process known as spoofing.
Storage Based
Storage-based LUN masking implemented on the storage device will enforce security when access is requested to storage resources on the controller. This is generally seen as more secure since changes in access require access to the storage device. Figure 8-3 shows the configuration screen for assigning LUNs to a host group called 001:Bear.
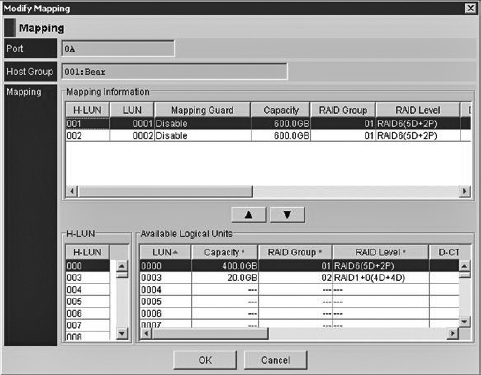
Figure 8-3 Storage-based LUN masking
Load Balancing
Load balancing is a method used in computer networking to distribute workloads across multiple computing resources such as computers, a computer cluster, network links, central processing units, or disk drives. The aim of load balancing is to optimize the use of resources, maximize throughput, minimize response time, and avoid the overload of any one of the available resources. Making use of multiple components with load balancing instead of a single component can increase its reliability through redundancy. Load balancing is also usually provided by a dedicated software or hardware such as a multilayer switch or a Domain Name System server process.
Load balancing can also be used to ensure the continuation of a service after the failure of one or more of its components. The components are monitored continually, and when they begin to become unresponsive, the load balancer is informed, and it no longer sends traffic to the component. When a component becomes active or comes back online, the load balancer starts to route traffic to it again. For this to work, there should be at least one component that is in excess of the capacity of the server.
When servers are load balanced, LUN masking and sharing must be implemented identically on both servers, and the storage controller must know that this is a clustered resource. This is often a setting when creating the LUN share.
Zoning
In a SAN, zoning is used to specify access to certain devices on the network. In essence, zoning allows an administrator to control who can see what in a SAN. A zone is a logical grouping of ports that can communicate with each other. A zone alias is a collection of zone members. The zone alias can be added to one or more zones.
The use of zoning minimizes the risk of data corruption by limiting access to authorized devices. Zoning also helps prevent the unauthorized modification of logical volumes by preventing other nodes from seeing the LUN or mounting it. Although it provides certain benefits, zoning can complicate the scaling process if the number of users and servers in a SAN increases in a significant manner in a short period because storage administrators will need to create zones for each device and storage array pair.
Port Zoning
Zoning can be applied to the switch port where the HBA of the device is connected using port zoning. Port zoning restricts the traffic flow based on the specific switch that a device is connected to. When a device is moved, that device will lose access to the LUNs that have been assigned to it in the port zone. If a different device is the one connected to a particular port, it will be able to gain access to the LUNs that the previous host had access to.
Zone Set
Zone set refers to zones that belong to a single storage area network. A zone set can be activated or deactivated as a single entity across all switches in the fabric. A zone set can contain one or more zones, and a zone can be a member of more than one zone set.
WWN Zoning
Worldwide name (WWN) zoning is another kind of zoning that restricts access through the device’s WWN. A WWN, introduced in Chapter 3, is an 8-byte (64-bit) or 16-byte (128-bit) unique identifier on a Fibre Channel network. Devices may display the WWN in a variety of formats. The WWN is typically represented by 16 or 32 hexadecimal characters similar to Ethernet MAC addresses. WWN zoning is also referred to as name zoning.
EXAM TIP The WWN is on the host, and the port the host is connected to can be moved, and access is still preserved. By connecting a new device to a port that was previously used by a WWN zone device, it will not allow access to the resources that the previous device occupied.Just to review from Chapter 3 before I use these terms again, a worldwide node name (WWNN) is a WWN that is assigned to an FC device such as a switch or director during manufacturing. WWNNs are encoded into the hardware and cannot be changed. A worldwide port name (WWPN) is a WWN that is used to uniquely identify ports on an FC network. These ports are generated by software on the device and are based on the WWNN.
There are two kinds of zoning: hard zoning and soft zoning. With hard zoning, every device is assigned to a particular zone and the assigned places do not change. In soft zoning, device assignments can be changed by the storage administrator, as well as accommodate variations in the demands on different servers in the network.
Hard Zoning
Hard zoning restricts the communication that runs across a fabric. Only specifically allowed devices are allowed to communicate with each other. All other connections are refused. Hard zoning requires an efficient hardware implementation in the fabric switches but is much more secure the soft zoning.
Soft Zoning
Soft zoning restricts only the fabric name service. It is “security by obscurity” because devices lack only the information on where resources are, but they could connect to those resources if they guessed the information. Soft zoning shows only an allowed subset of devices. When a server looks at the content of the fabric, it will see only the devices that have been made visible to it. However, it can still attempt to contact any device on the network by address. Soft zoning is much easier to implement, but it is not as secure as hard zoning.
Zoning Best Practices
There are several best practices when it comes to zoning, which include the following:
• Always implement zoning even if LUN masking is used.
• Make use of WWPN identification for zoning for both security and operational consistency.
• All zones should make use of frame-based hardware enforcement, and the best way to do this is to use WWPN identification exclusively for all zoning configurations.
• Zoning aliases and names should be only as long as they need to be. This allows for maximum scaling, especially with really large fabrics.
• Use single initiator zoning with separate zones for tape and disk traffic when an HBA is carrying both kinds of traffic.
iSCSI Security
Internet Small Computer System Interface (iSCSI) is a storage protocol that operates over IP and Ethernet networks. iSCSI uses Challenge Handshake Authentication Protocol (CHAP) for authentication, but this protocol is vulnerable to dictionary attacks so it should not be relied upon in the field. This is also an optional setting, and it is not enabled by default.
The iSCSI iQN is a node name given to iSCSI initiators. The iQN is formatted with “iqn” first and then the date when the naming authority began owning the domain and the reverse domain name of the naming authority. For example, the iQN for a device called NYMail in the Tropics.com domain for a naming authority that took effect in May 2012 would look like this:
iSCSI traffic is sent without encryption, so the data and the source and destination, iQN, and authentication information are sent in the clear. Nodes on the same network can retrieve this information and potentially retrieve data not intended for them. At a minimum, iSCSI traffic should be segmented onto its own VLAN away from normal Ethernet traffic. Also, consider using IPSec to encrypt iSCSI data between initiators and targets.
iSCSI and iSNS Security
Internet Storage Name Service (iSNS) is a protocol that allows for initiators to discover iSCSI targets. iSNS can retain target information for iSCSI attached devices in iSNS databases. iSNS databases can reside on iSCSI switches or on software-based iSNS databases such as those bundled in Linux, Solaris, and Microsoft Windows servers. iSNS databases can be distributed among many iSCSI switches to allow for larger scalability. iSNS servers on targets register their resources and state changes with SNS databases, which initiators, running iSNS clients, can query to find available targets.
iSCSI security when using iSNS for discovery is provided through simple trust. This makes it vulnerable to spoofing. A device can change its iQN to match another device in order to access that device’s LUNs, or a rogue iSNS server could be set up to issue incorrect data to targets and initiators, allowing for unauthorized connections.
iSCSI VLANs
It is common to use a virtual local area network to separate iSCSI traffic on Ethernet switches from computer network traffic. VLANs are created by assigning a VLAN ID to each Ethernet switch that will contain ports in the VLAN. Each port is then associated with the VLAN ID. These ports will not be able to communicate with ports that have a different VLAN ID unless a router is used to route between the VLANs. iSCSI traffic can be isolated from the rest of the network with VLANs; this protects iSCSI traffic from being observed by other hosts on the network, and it isolates the iSCSI network cards from broadcast traffic originating from the computer network. Ports used to connect Ethernet switches need to be configured as trunk ports in order to send VLAN traffic to another Ethernet switch. These trunk ports tag the traffic with a VLAN ID so that the receiving Ethernet switch will know which VLAN to place the traffic on when it arrives.
Discovery Domains
Discovery domains (DDs) are similar to zones in that they determine which parties can communicate with each other. Members of a DD set can query initiators and targets of other members through iSNS. DDs contain targets and initiators that are allowed to connect to one another. Initiators can belong to many DDs so that they can connect to multiple resources. Initiators and targets do not belong to any zones by default, so new initiators are prevented from connecting to resources, and newly provisioned targets are prevented from being accessed until they are placed into a zone. DDs need to be configured manually by storage administrators to enable communication between targets and initiators. iSCSI targets and initiators belong to a default DD unless otherwise specified. This means that all devices will be able to view each other unless DDs are configured.
EXAM TIP As a reminder, initiators are iSCSI devices that connect to resources, and targets are the resources initiators connect to.DD are created with an ID and a symbolic name. Here is an example of how DDs might be configured. Database1 needs to connect to three drives that exist on a storage array called DBStorage. A DD could be created called DBStorage-Database1 with both devices in the domain. This would allow Database1 to talk to DBStorage. If another server called Database 2 wants to talk to DBStorage, a second DD could be created called DBStorage-Database2 with DBStorage and Database2 in the domain. In this way, Database2 and Database1 can map resources on DBStorage, but they cannot map resources on each other through iSNS. Avoid creating a single DD with all targets and initiators in it. This may seem like a simple way to allow connections to devices, but it removes the ability to restrict target access for initiators, and it will increase the amount of administrative traffic on the iSCSI network, which can lead to longer logon times and diminished iSCSI performance.
Storage Segmentation
SAN segmentation involves separating different fabrics logically. While multiple Fibre Channel fabrics can be connected, they are logically isolated in a way that shows their own autonomy and namespaces. Having this kind of scenario also allows the administrator to not have to worry about the management of traffic that is crossing different fabrics. In other words, SAN segmentation is similar to how a LAN is segmented.
Storage systems can use virtualization concepts as a tool to enable better functionality and more advanced features within storage systems, as well as across them. Storage systems make use of special hardware and software along with disk drives in order to provide fast and reliable storage for computing and data processing. Storage systems are complex and can be thought of as a computer with a special purpose designed to provide storage capacity, as well as advanced data protection features. Disk drives are just one element within a storage system, together with hardware and special-purpose embedded software within the system.
Storage systems are able to provide either block-accessed storage or file-accessed storage. Block access is delivered through protocols such as Fibre Channel, iSCSI, and SAS, and storage is represented as a logical volume. The NFS and CIFS protocols are used to provide file access, and storage is represented as a share on the network. In a storage system, two kinds of virtualization can be deployed:
• Block virtualization The abstraction—meaning, separation—of logical storage (partition) from physical storage so that it can be accessed without regard to physical storage or heterogeneous structure. This kind of separation gives the administrators of a storage system a great amount of flexibility in how they should manage it for end users.
• File virtualization Addresses the NAS challenges by eliminating the dependencies between the data that is accessed at the file level and the physical location of the files. This provides opportunities for optimizing the use of the storage and also allows nondisruptive file migrations to be performed.
Chapter Summary
This chapter provided both practical and technical elements related to providing a safe and secure environment for data and associated resources. The ubiquity of storage networks, their complexity, and their high degree of interoperability have inextricably linked the economies of countries around the globe. These same characteristics can be problematic because they may also make these critical resources vulnerable to unauthorized access. System access was discussed within the context of how devices authenticate or prove they are who they say they are, how devices are authorized, and how systems interoperate.
Authentication relies upon credentials that an entity presents to an authenticator to be validated. These credentials can include one or a combination of factors such as something you are (fingerprint), something you know (password), or something you have (key).
Authorization determines whether the authenticated user has the right or permission to access this resource and what level of access they have. Levels of access include
• Full control Allows the user the maximum amount of control—read, write, and delete are the basic type of access at this level. More complex tasks allowed at this level may include the ability to rename, change the attributes of, or change access levels for others.
• Read-write The user’s access is limited in comparison to full control, granting the ability to read, change, or edit (write), or change how and where the resource is stored.
• Read-only Allows an LV, file, or folder to be accessed and viewed but not modified.
• Deny Is used to prevent access to the storage resource. For example, one department in an organization may ban a separate department from accessing a certain folder in a drive because of the sensitive nature of the files contained within it.
An access control list is a list of permissions that are attached to an object or file. An ACL specifies which users or system processes are allowed to interact with objects, as well as specifying allowable operations for such objects.
Permissions can be assigned at two levels, file or share. File permissions are enforced through the file system, and they apply whether the user is local to the machine or remote. Share permissions are enforced through the network-sharing protocol such as CIFS or NFS. These permissions apply only to users who access the data remotely over the share. The more restrictive of the two permissions is the one that applies, so a user who has full control share permission but only read file permission will be able to only read files.
It is important for systems to be able to communicate with one another and to enforce the security settings throughout the communication stream. This can be difficult when components from many vendors are utilized together, but standards make this process a bit easier. Consider using components that comply with the same standard in order to make interoperability easier. If this is not possible, consider using a broker, either hardware or software, that will translate between two incompatible systems.
Encryption is a popular way of securing data. Encryption uses a mathematical formula called an algorithm to perform substitutions and transpositions on data. Substitutions place a specific character or characters in place of another character or block of characters, and transpositions switch the order of characters or blocks of characters. The cipher text is made unique by use of a key that determines how the algorithm will be applied to the data. Asymmetric algorithms use a private key to encrypt the data, which can be decrypted only by the associated public key, whereas symmetric algorithms utilize the same key for encryption and decryption.
Data can be encrypted when it is at rest or in motion. Data at rest refers to all data that is in computer storage. Data in motion refers to information that is being transmitted over a network or in transit. Alteration and interception are the biggest threats to data in motion. Usernames and passwords are typical examples of important data that should not be transmitted over a network without the protection of encryption because the data could be intercepted by someone else and used in malicious ways. When unprotected data is intercepted, it can be used by others to impersonate or gain access to sensitive information.
Full-disk encryption is one option for securing data at rest. This encrypts an entire hard drive so that it cannot be read until an entity is authenticated. The main disadvantage to this is that it treats all data on the drive the same, and once the drive is unlocked, all the data on the drive is available. It is up to the entity (user or service) to log off when not using the disk for it to remain safe. Another form of data at rest is backup tapes. These backup tapes can also be encrypted to protect archival data.
Data in motion over the network can be encrypted using protocols such as IPSec. IPSec can be used in protecting data flows between a pair of hosts, between a pair of security gateways, or between a security gateway and a host. IPSec is an end-to-end security scheme that operates in the Internet layer of the Internet Protocol suite.
Storage must be visible in order to be used. Visibility is also a way of protecting data by making it available to only the hosts that need it. LUN masking and sharing are ways to protect visibility of storage resources. LUN masking is an authorization process that makes a LUN available to some hosts, as well as unavailable to others.
In a storage area network, zoning is used to specify access to certain devices on the network. In essence, zoning allows an administrator to control who can see what in a SAN. A zone is a logical grouping of ports that can communicate with each other. A zone alias is a collection of zone members. It can be added to one or more zones.
Internet Small Computer System Interface uses a similar technology called discovery domains. DDs are similar to zones in that they determine which parties can communicate with each other. Members of a DD set can query initiators and targets of other members through Internet Storage Name Service, a protocol that allows for initiators to discover iSCSI targets.
DDs contain targets and imitators that are allowed to connect to one another. Initiators can belong to many DDs so that they can connect to multiple resources. Initiators and targets do not belong to any zones by default, so new initiators are prevented from connecting to resources, and newly provisioned targets are prevented from being accessed until they are placed into a zone.
iSCSI uses Challenge Handshake Authentication Protocol for authentication, but this protocol is vulnerable to dictionary attacks. The iSCSI iQN is a node name given to iSCSI initiators. The iQN is formatted with “iqn” first and then the date when the naming authority began owning the domain and the reverse domain name of the naming authority. iSCSI traffic is sent without encryption, so the data and the source and destination, iQN, and authentication information are all sent in the clear. Nodes on the same network can retrieve this information and potentially retrieve data not intended for them. For this reason, it is common to use a virtual VLAN to separate iSCSI traffic on Ethernet switches from computer network traffic.
Chapter Review Questions
1. A security audit of your storage network infrastructure results in a recommendation for using multiple authentication methods. You currently use a password for accessing the storage array management console, and your system is not compatible with biometrics. What could you use in addition to the password to satisfy the security requirement?
A. Something you know
B. Something you value
C. Something you are
D. Something you have
2. A Macintosh user will be traveling to a foreign country, and they are concerned about the data on their hard drive being read if it is stolen. They have heard about full-disk encryption, so they ask you for a recommendation. Which technology should they use?
A. EFS
B. BitLocker
C. FileVault
D. IPSec
3. A user needs to change the name of a file on a NAS. Which authorization level will provide the least permissions necessary?
A. Read
B. Read and write
C. Full control
D. Read, deny full control
4. How are access control lists (ACLs) organized?
A. Hierarchal tree
B. Relational database
C. XML
D. Table
5. Randy is a member of the helpdesk and San Francisco groups. The helpdesk group has full control share permissions on the IT policies share. The helpdesk group also has full control file permissions over all files and folders on the server that hosts the IT policies share. The San Francisco group has deny file permission on the folder above the IT policies share. Randy attempts to access the IT policies share, but it returns an error saying “access denied.” What must be done to allow Randy full control access?
A. Grant Randy full control share and file permissions to the IT policies folder and share.
B. Add Randy to the administrators group.
C. Remove Randy from the San Francisco group.
D. Remove Randy from all groups.
6. Two new users join the company, and Tom, the storage administrator, creates accounts for both on the NAS and assigns them read permission to the DATA share. Cindy notifies Tom that this is not a best practice. How could Tom perform the task differently to adhere to best practices?
A. Create a group and assign read permission to the DATA share for the group. Add new users who need access to DATA to that group.
B. Write a script that adds read permission to accounts in a list. When new users are hired, simply add them to the list and run the script.
C. Grant all users full control over the DATA share so that permissions do not need to be applied to individual users.
D. Utilize a central authentication mechanism to control permissions for the NAS.
7. Which of the following is an example of data in motion?
A. Files on a server
B. Files transferred over FTP
C. Files archived to tape
D. Files on a thumb drive in your pocket
8. Asymmetric encryption requires what?
A. Interfaces to a central authenticator
B. Homogeneous systems
C. Virtualization
D. Public and private keys
9. You have been tasked with implementing LUN masking on your storage network. Where should you enforce LUN masking security?
A. The server or device where the LUN resides
B. The device accessing the LUN
C. The network devices in between source and destination
D. The iSNS server
10. Which trait of iSCSI is a possible security concern?
A. iSCSI uses encapsulated packets over unsecure networks.
B. iSCSI does not authenticate requests for management information.
C. iSCSI traffic is unencrypted by default.
D. iSCSI packets are easily corrupted.
Chapter Review Answers
1. D is correct. Something you have such as a token device could be used along with the password to authenticate and satisfy the mutual authentication security requirement.
A, B, and C are incorrect. A is incorrect because you are already using a password, which is something you know. B is incorrect because something you value is not a way to authenticate. C is incorrect because something you are requires biometrics, which is not supported on the system.
2. C is correct. FileVault can be used for full-disk encryption on Macintosh computers.
A, B, and D are incorrect. A is incorrect because EFS is used for file-based encryption. B is incorrect because BitLocker is used with Windows computers. D is incorrect because IPSec is used for encrypting data in motion, not data at rest.
3. B is correct. Read and write would provide the necessary permissions.
A, C, and D are incorrect. A would only allow the user to see the file and open it but not change it. C would provide more than required, and D would not allow any access.
4. D is correct. ACLs are organized like a table with entries as rows.
A, B, and C are incorrect. ACLs are not organized in a hierarchical tree, relational database, or using XML.
5. C is correct. Removing Randy from the San Francisco group will remove the deny permission associated with the San Francisco group, allowing him to access the data. Since deny permission overrides allow, this was preventing Randy from accessing the share.
A, B, and D are incorrect. A is incorrect because Randy already has full control by being a member of the helpdesk group, but the deny from his other membership is overriding it. B is incorrect because the administrators group would still not override the deny from the San Francisco group. D is incorrect because removing Randy from all groups would not allow him to access the share at all.
6. A is correct. Create a group and assign read permission to the DATA share for the group. Add new users who need access to DATA to that group. It is a best practice to assign permissions to groups rather than individual users. Group membership can be easily changed rather than making individual permission changes on potentially many different shares or systems.
B, C, and D are incorrect. B is incorrect because the script would only work for the current permission set. If additional permissions are needed in the future, the script would need to be updated and then executed against all the appropriate users again. C is incorrect because full control for all users would give many users more access than they need. D is incorrect because a central authentication mechanism for the NAS would still only manage the NAS. The same group, however, could be used on many different devices.
7. B is correct. Files transferred over FTP would be an example of data in motion because these files are being transferred over the network. They are moving, whereas all the other options are stationary.
A, C, and D are incorrect. A is incorrect because files on a server is an example of data at rest. The files do not move when they reside on the server. C is incorrect because files archived to tape stay on the tape. While the tape may be transported somewhere else, the files themselves stay put. D is incorrect because the files reside on the thumb drive and do not move on their own from the drive to another location. The drive may be physically transported somewhere else, but the file still exist on the thumb drive.
8. D is correct. Public and private keys are required for asymmetric encryption.
A, B, and C are incorrect. A is incorrect because a central authenticator is not necessary. However, a trusted key repository is needed. B is incorrect because systems can be heterogeneous as long as the same encryption protocols are supported. C is incorrect because virtualization is not required for asymmetric encryption. Asymmetric encryption can operate on both virtualized and non-virtualized systems.
9. A is correct. The server or device where the LUN resides would enforce the security.
B, C, and D are incorrect. B is incorrect because storage-based LUN masking enforces the mask on the device where the LUN resides. C is incorrect because, as the term says, it is storage based so it resides on the storage, not the network. D is incorrect because the iSNS server does not enforce security. It simply makes devices aware of targets.
10. C is correct. iSCSI traffic is unencrypted by default.
A, B, and D are incorrect. A is incorrect because iSCSI does not encapsulate packets. Other protocols such as IPSec can be used to encapsulate packets, and encapsulation increases security, so this would be a good feature if it existed. B is incorrect because iSCSI does not have a mechanism for authenticating management requests. D is incorrect because iSCSI traffic is no more easily corrupted than other IP traffic.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.