
Chapter 1
Introduction
A compiler is a translator that translates programs written in one language to another language, that is, translates a high-level language program into a functionally equivalent low-level language program that can be understood and later executed by a computer. Designing an effective compiler for a computer system is also one of the most complex areas of system development.
CHAPTER OUTLINE
Compiler construction is a broad field. The demand for compilers will always remain as long as there are programming languages. In early compilers, little was understood about the underlying principles and techniques and all tasks were done by hand. Hence, compilers were messy and complex systems. As programming languages started evolving rapidly, more compilers were in demand; so people realized the importance of compilers and started understanding the principles and introduced new tools for designing a compiler.
In early days, much of the effort in compilation was focused on how to implement high-level language constructs. Then, for a long time, the main emphasis was on improving the efficiency of generated codes. These topics remain important even today, but many new technologies have caused them to become more specialized. Compiler writing techniques can be used to construct translators for a wide variety of languages. The process of compilation is introduced in this chapter. The importance of a compiler in a typical language-processing system and the challenges in designing a compiler are discussed in detail. The design phases of a compiler along with the modern compiler tools are explained.
1.1 What Is a Compiler?
The software that accepts text in some language as input and produces text in another language as output while preserving the actual meaning of the original text is called a translator. The input language is called the source language; the output language is called the target or object language. A compiler is basically a translator. It translates a source program written in some high-level programming language such as Pascal/C/C++ into machine language for computers, such as the Intel Pentium IV/AMD processor machine, as shown in Figure 1.1. The generated machine code can be used for execution as many times as needed. In addition to this, a compiler even reports about errors in the source program.
1.1.1 History
In the early days of computers, programmers had to be exceptionally skilled since all the coding was done in machine language. Machine language code is written in binary bit patterns (or hexadecimal patterns). With the evolution of assembly language, programming was made simpler. These languages used mnemonics, which has a close resemblance with symbolic instructions and executable machine codes. A programmer must pay attention to far more detail and must have complete knowledge of the processor in use.
Toward the end of the 1950s, machine-independent languages were introduced. These languages had a high level of abstraction. Typically, a single high-level instruction is translated into several (sometimes dozens or in rare cases even hundreds) executable machine language instructions. Grace Murray Hopper conceptualized the first translator for the A-0 programming language from his experimental studies. This was coined as a compiler in the early 1950s. John Backus at IBM took 18 man years to introduce the first complete compiler for FORTRAN in 1957.
In many application domains, the idea of using a higher-level language quickly caught on for various reasons.
- High-level programming languages are much easier to learn and understand. No background knowledge in hardware is necessary.
- They can be easily debugged.
- They are relatively machine independent.
- While writing programs, programmers need not consider the internal structure of a system.
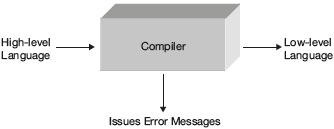
Figure 1.1 Compiler Input and Output
- High-level languages (HLL) offer more powerful control and data structure facilities than low-level languages.
- High-level languages allow faster development than in assembly language, even with highly skilled programmers. Development time increases and it becomes 10 to 100 times faster.
- Programs written in high-level languages are much easier and less expensive to maintain than similar programs written in assembly language or low-level languages.
Computers only understand machine language. As people started writing programs in high-level languages, to translate them into machine understandable form, compilers were invented. Hence, knowledge of compilers became the basic necessity for any programmer.
Initially compilers were written in the assembly language. In 1962, Tim Hart and Mike Levin at MIT created the first self-hosting compiler for Lisp. A self-hosting compiler is capable of compiling its own source code in a high-level language. The initial C compiler was written in C at AT & T Bell labs. Since the 1970s, it has become common practice to implement a compiler in the language it compiles. Building a self-hosting compiler is a bootstrapping problem.
1.1.2 What Is the Challenge?
The complexity of compilers is increasing day by day because of the increasing complexity of computer architectures and expanding functionality supported by newer programming languages.
So to design a compiler, the main challenge lies with variations in issues like:
- Programming languages (e.g., FORTRAN, C++, Java)
- Programming paradigms (e.g., object-oriented, functional, logic)
- Computer architectures (e.g., MIPS, SPARC, Intel, alpha)
- Operating systems (e.g., Linux, Solaris, Windows)
Qualities of a Compiler (in the order of importance)
- The compiler itself must be bug-free.
- It must generate the correct machine code.
- The generated machine code must run fast.
- The compiler itself must run fast (compilation time must be proportional to program size).
- The compiler must be portable (i.e., modular, supporting separate compilation).
- It must print good diagnostics and error messages.
- The generated code must work well with existing debuggers.
- The compiler must have consistent and predictable optimization.
Building a compiler requires knowledge of
- Programming languages (parameter passing techniques supported, scope of variables, memory allocation techniques supported, etc.)
- Theory (automata, context-free languages, grammars, etc.)
- Algorithms and data structures (hash tables, graph algorithms, dynamic programming, etc.)
- Computer architecture (assembly programming)
- Software engineering.
The first compiler was built for FORTRAN at IBM in the 1950s. It took nearly 18 man years to do this. Today, with automated tools, we can build a simple compiler in just a few months. Crafting an efficient and a reliable compiler is always a challenging task.
1.2 Compiler vs. Interpreter
An interpreter is another way of implementing a programming language. An interpreter works similar to a compiler in most of the phases like Lexical, Syntax, and Semantic. This analysis is performed for each single statement and when the statement is error free, instead of generating the corresponding code, that statement is executed and the result of execution is displayed. In an interpreter, since every time the program has to be processed for and has to be checked for errors, it is slower than the compiler program. Writing an interpreter program is a simpler task than writing a compiler program because a compiler processes the program as a whole, whereas an interpreter processes a program one line at a time. If speed is not a constraint, an interpreter can be moved on to any machine easily.
An interpreter first reads the source program line by line, written in a high-level programming language; it also reads the data for this program; then it runs or executes the program directly against the data to produce results. This is shown in Figure 1.2. It does not produce machine code or object code. One example is the Unix shell interpreter, which runs operating system commands interactively.
Some languages, like Java, combine both compiler and interpreter. The Java program was first compiled by a compiler to produce a byte code. This byte code is interpreted while execution. In some systems, the compiler may generate a syntax tree and syntax tree may be interpreted directly. The choice of compiler and interpreter depends on the compromise made on speed and space. The compiled code is bigger than the syntax tree, but the running speed is less for the compiled code than for the syntax tree.
The interpreter is a good choice, if the program has to be modified while testing. It starts to run the program quickly and works on the representation that is close to the source code. When an error occurs, it displays informative messages and allows users to correct the errors immediately.
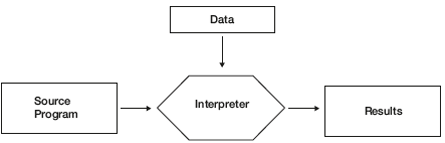
Figure 1.2 Interpreter
Note that both interpreters and compilers (like any other program) are written in some high-level programming language (which may be different from the language they accept) and they are translated into machine code. For example, a Java interpreter can be completely written in C or C++ or even in Java. Because an interpreter does not generate machine code as output for the input source code, it is machine independent.
- C, C++, Fortran, Pascal, C#
- Usually compiled
- Basic, JavaScript, Lisp, LOGO, Perl, Python, SMALL TALK, APL
- Usually interpreted
Generally a compiler is faster than an interpreter because interpreter reads and interprets each statement in a program as many times as the number of evaluations of the statement. For example, when a for/while loop is interpreted, the statements inside the body of the loop will be analyzed and evaluated on every iteration. Some languages, such as Java and Lisp, are provided with both an interpreter and a compiler. Java programs are generally compiled and interpreted. Java compiler (javac) converts programs written in java, that is, Java classes with .java extension into byte-code files with .class extension. The Java Virtual Machine, which is known as JVM is a java interpreter. It may internally compile the byte code into machine code or interpret the byte code directly and then execute the resulting code.
Advantages of Interpreters
- If a program is simple and is to be executed once, an interpreter is preferred.
For example, let us suppose that there is a program with 5000 statements. For a test run, only 50 lines need to be visited. The time taken by a compiler and then an interpreter to run the program is as follows:
Compiler → 5000 tc + 50 te
Interpreter → 50 ti
where tc is time taken to compile, te is time taken for execution, and ti is time taken for interpreting.
Hence, if it is single execution, an interpreter is preferred to a compiler.
To execute a database, OS commands interpreter is preferred to a compiler. - Interpreters can be made portable than compilers.
To understand the portability of an interpreter, consider the following scenario. Assume that we are writing an interpreter in some high-level language (like Java), which supports portability. Whatever you write using that language is portable. Hence, the interpreter is also portable. However, if a compiler is written in the same language, then it is not portable. Because the output of a compiler (whatever may be the implementation language) is always machine language, it runs only on a specific machine.
- Certain language features are supported by interpreters.
For example, consider a language feature like dynamic types. In SNOBOL, the type of a variable is dependent on a value that is assigned to it anytime.
If x = 20, then x is of the integer type.
If x = 2.5, then x is real type.
If x = “hai,” then x is literal type.
In languages like FORTRAN, the variables are assigned the type based on first character. If variable name starts with i, j, k, l, m, n, it is treated as an integer and otherwise as real. All compilers do not support dynamic types but can be supported by interpreters.
Therefore, in the above situation, we prefer an interpreter rather than a compiler.
Compilers and interpreters are not the only examples of translators. There are many other translators. Here are a few more examples:
Table 1.1 List of translators
|
Translator
|
Source code
|
Target code
|
|---|---|---|
|
Text editors |
English text |
Meaningful sentence |
|
LEX |
Regular expression |
A scanner |
|
YACC |
SDT |
Parser generator |
|
Javac compiler |
Java |
Java byte code |
|
Cross compiler |
Java |
C++ code |
|
Database query optimizer |
SQL |
Query evaluation plan |
|
Text formater |
LaTeX |
PostScript |
This book discusses the design of a compiler for programs in high-level languages. But the same techniques can also be applied to design interpreters.
1.3 Typical Language-Processing System
To understand the importance of a compiler, let us take a typical language-processing system shown in Figure 1.3. Given a high-level language program, let us see how we get the executable code. In addition to a compiler, other programs (translators) are needed to generate an executable code. The different software required in this process are shown below in the figure. The first translator needed here is the preprocessor.
1.3.1 Preprocessor
A source program may be divided into modules stored in separate files and may consist of macros. A preprocessor produces input to a compiler. A preprocessor processes the source code before the compilation and produces a code that can be more efficiently used by the compiler. It is not necessary to consider a preprocessor as part of a compiler as preprocessing requires a complete pass. It cannot be included as part of a single pass compiler.
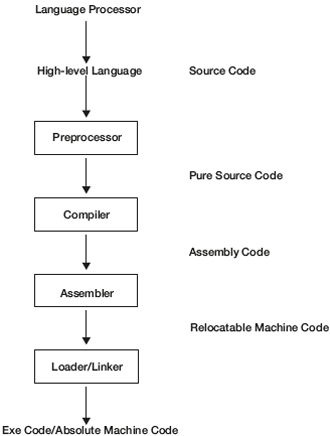
Figure 1.3 Typical Language Processing System
A preprocessor performs the following functions:
- Macro processing: Macros are shorthands for longer constructs. A macro processor has to deal with two types of statements—macro definition and macro expansion. Macro definitions have the name of the macro and a body defining the macro. They contain formal parameters. During the expansion of the macro, these formal parameters are substituted for the actual parameters. All macros (i.e., #define statements) are identified and substituted with their respective values.
- File inclusion: Code from all files is appended in text while preserving line numbers from individual files.
- Rational preprocessor: They augment older languages with modern flow of control and data-structuring facilities.
- Language extensions: A preprocessor can add new functionalities to extend the language by built-in macros—for example, adding database query facilities to the language.

Figure 1.4 Preprocessor Example
Figure 1.4 shows an example of a code before and after preprocessing.
If the C language program is an input for a preprocessor, then it produces the output as a C program where there are no #includes and macros, that is, a C program with only C statements (pure HLL). This phase/translator is not mandatory for every high-level language program. For example, if the source code is a Pascal program, preprocessing is not required. This is an optional phase. So the output of this translator is a pure HLL program.
Compiler: To convert any high-level language to machine code, one translator is mandatory and that is nothing but a compiler. A compiler is a translator that converts a high-level language to a low-level language (e.g., assembly code or machine code).
Assembler: Assembly code is a mnemonic version of machine code in which names rather than binary values for machine instructions and memory addresses are used. An assembler needs to assign memory locations or addresses to symbols/identifiers. It should use these addresses in generating the target language, that is, the machine language. The assembler should ensure that the same address must be used for all the occurrences of a given identifier and no two identifiers are assigned with the same address. A simple mechanism to accomplish this is to make two passes over the input. During the first pass whenever a new identifier is encountered, assign an address to it. Store the identifier along with the address in a symbol table. During the second pass, whenever an identifier is seen, then its address is retrieved from the symbol table and that value is used in the generated machine code.
Consider the following example:
Example 1: Consider the following C code for adding two numbers:
main()
{
int x,y,z;
scanf(“%d, %d”,&x,&y);
z=x+y;
}
The equivalent assembly code for adding two numbers is as follows:
.BEGIN
IN X
LOAD X
IN Y
ADD Y
STORE Z
HALT
.END
X: .DATA 0
Y: .DATA 0
Z: .DATA 0
Assembler is a translator that converts assembly code to machine code. Machine code is of two types. One is absolute machine code and other is relocatable machine code. The machine code with actual memory addresses is called the absolute machine code. Generally, the assembler produces the machine code with relative addresses, which is called the relocatable machine code since it needs to be relocated in memory for execution.
The equivalent machine relocatable code for adding two numbers is as follows:
|
Address |
Machine |
Code |
|
0000 |
1101 |
0110 |
|
0001 |
0000 |
0110 |
|
0010 |
1101 |
0111 |
|
0011 |
0011 |
0111 |
|
0100 |
0001 |
1000 |
|
0101 |
1111 |
0000 |
|
0110 |
0000 |
0000 |
|
0111 |
0000 |
0000 |
|
1000 |
0000 |
0000 |
1.3.2 Loader/Linker
To convert the relocatable machine code to the executable code, one more translator is required and this is called the loader/linker.
A loader/linker or link editor is a translator that takes one or more object modules generated by a compiler and combines them into a single executable program called the exe code.
The terms loader and linker are used synonymsly on Unix environments. This program is known as a linkage editor in IBM mainframe OS. However, in some operating systems, the same program handles both the tasks of object linking and physical loading of a program. Some systems use linking for the former and loading for the latter. The definitions of linking and loading are as follows:
Linking: This is a process where a linker takes several object files and libraries as input and produces one executable object file shown in Figure 1.5. It retrieves from the input files (and combines them in the executable code) the code of all the procedures that are referenced and resolves all external references to actual machine addresses. The libraries include language-specific libraries, operating system libraries, and user-defined libraries.
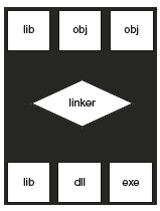
Figure 1.5 Linker
Loading: This is a process where a loader loads an executable file into memory, initializes the registers, heap, data, etc., and starts the execution of the program.
If we look at the design of all these translators, designing a preprocessor or assembler or loader/linker is simple. It can be taken up as a one-month project. But among all, the most complex translator is the compiler. The design of the first FORTRAN compiler took 18 man years. The complexity of the design of a compiler mainly depends on the source language. Currently, many automated tools are available. With modern compiler tools like YACC (yet another compiler compiler), LEX (lexical analyzer), and data flow engines, the design of a compiler is made easy.
1.4 Design Phases
Designing a compiler is a complex task; the design is divided into simpler subtasks called “phases.” A phase converts one form of representation to another form. The task of a compiler can be divided into six phases as shown in Figure 1.6.
1.4.1 The Lexical Analysis
Lexical analyzer is also called scanner. The scanner groups the input stream of characters into a stream of tokens and constructs a symbol table, which is used later for contextual analysis. The tokens in any high-level language can include
- keywords,
- identifiers,
- operators,
- constants: numeric, character and special characters
- comments,
- punctuation symbols.
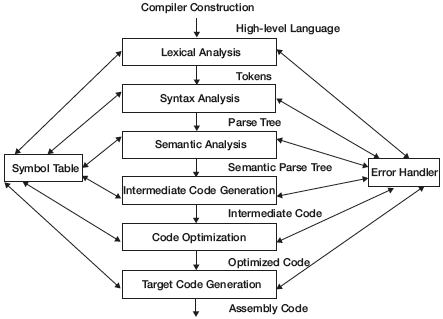
Figure 1.6 Phases of a Compiler
The lexical analyzer groups input stream of characters into logical units called tokens. The input to the lexical analysis is a character stream and the output is a stream of tokens. The lexical analysis is shown in Figure 1.7. Regular expressions are used to define the rules for recognizing the tokens by a scanner (or lexical analyzer). The scanner is implemented as a finite state automata. Automated scanner generators tools are Lex and Flex. Flex is a faster version of Lex.
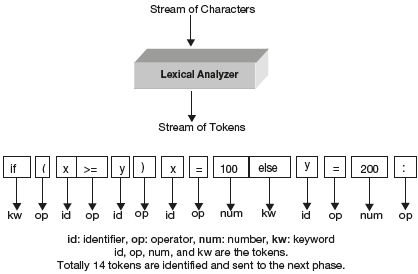
Figure 1.7 Lexical Analysis
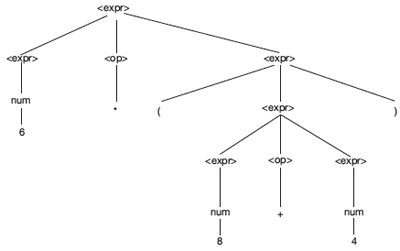
Figure 1.8 Parser tree for 6 * (8 + 4)
Ex: If (x > = y) x = 100 else y = 200;
Syntax Analysis: Syntax Analyzer checks the syntax of a given statement. This is also called parser. The parser groups stream of tokens into a hierarchical structure called the parse tree. In order to check the syntax, first the standard syntax of all such statements is to be known. Generally the syntax rules for any HLL are given by context-free grammars (CFG) or Backus-Naur Form (BNF). The CFG, which describes all assignment statements with arithmetic expressions, is as follows:
Example 2: To check the syntax of the statement 6 × (8 + 4)
CFG is
Expr → Expr op Expr
| (expr)
| num
op → + | - | * | /
Using this grammar, the syntax of the given statement is verified by deriving the statement from grammar. This is shown in Figure 1.8.
So the output of the parser is a parse tree representation of the program. The parser is generally implemented as a push-down automaton.
Many automated tools are available for designing parsers. YACC and Bison are widely used tools. They are used for generating bottom-up parsers in C language. Bison is a faster version of YACC.
Semantic Analysis: Checks are performed to ensure that parts of a program fit together meaningfully. The semantic analyzer checks semantics, that is, whether the language constructs are meaningful.
For example, given a statement A + B, let us see how a parser and a semantic analyzer work.
On seeing the above expression, parsers look at binary addition and check whether two operands are present. The presence of two operands confirms that the syntax is right. However, it does not recognize the operand type, whether it is A or B. Even if A is an array and B is a function, it says that the syntax is right. It is the semantic analyzer that checks whether the two operands are type-compatible or not. Static type checking is the basic function of the semantic analyzer. The output of the semantic analysis phase is an annotated parse tree. Attribute grammars are used to describe the semantics of a program.
This phase is often combined with the syntax analysis. During parsing, information concerning variables and other objects is stored in a symbol table. This information is used to perform the context-sensitive checking in the semantic analysis phase.
1.4.2 Intermediate Code Generator
This phase converts the hierarchical representation of source text, that is, this phase converts the parse tree into a linear representation called Intermediate Representation (IR) of the program. A well-designed intermediate representation of source text facilitates the independence of the analysis and syntheses (front- and back-end) phases. Intermediate representations may be the assembly language or an abstract syntax tree.
An intermediate language/code is often used by many compilers for analyzing and optimizing the source program. Intermediate language should have two important properties: (a) it should be simple and easy to generate and (b) it should be easy to translate to the target program.
IR can be represented in different ways: (1) as a syntax tree, (2) as a directed acyclic graph (DAG), (3) as a postfix notation, and (4) as a three-address code.
Example of IR in three-address code is as follows:
temp1 = int2float(sqr(t));
temp2 = g * temp1;
temp3 = 0.5 * temp2;
dist = temp3;
The main purpose of IR is to make target code generation easier.
1.4.3 Code Optimizer
Compile time code optimization involves static analysis of the intermediate code to remove extraneous operations. The main goal of a code optimizer is to improve the efficiency. Hence, it always tries to reduce the number of instructions. Once the number of instructions is reduced, the code runs faster and occupies less space.
Examples of code optimizations are as follows:
Constant folding
I := 4 + J – 5; can be optimized as I := J – 1;
or
I = 3; J = I + 2; can be optimized as I = 3; J = 5
INPUT SALES;
SVALUE := SALES * ( PRICE + TAX );
OUTPUT := SVALUE;
COUNT := COUNT + 1;
end;
can be optimized as
T :=PRICE + TAX;
while (COUNT < MAX) do
INPUT SALES;
SVALUE := SALES * T;
OUTPUT := SVALUE;
COUNT := COUNT + 1;
end;
Common sub-expression elimination
From:
A := 100 * (B + C);
D := 200 + 8 * (B + C);
E := A * (B + C);
can be optimized as:
TEMP := B + C;
A := 100 * TEMP;
D := 200 + 8 * TEMP;
E := A * TEMP;
E := A * TEMP;
Strength reduction
2 * x can be optimized as x + x
2 * x can be optimized as shift left x
Mathematical identities
a * b + a * c can be optimized as a*(b + c)
a - b can be optimized as a + (-b)
1.4.4 Target Code Generator
The code generator’s main function is to translate the intermediate representation of the source code to the target machine code. The machine code may be an executable binary or assembly code, or another high-level language. To design a target code generator, the designer should have the complete knowledge about the target machine. Producing low-level code requires familiarity with machine-level issues such as
- data handling
- machine instruction syntax
- variable allocation
- program layout
- registers
- instruction set
This phase takes each IR statement and generates an equivalent machine instruction.
For the following source text
if (x <= 3) then y := 2 * x;
else y := 5;
The target code generated is
Address |
Instruction | |
10 |
CMP x 3 |
|
11 |
JG 14 |
|
12 |
MUL 2 x temp |
|
13 |
JMP 16 |
|
14 |
MOV y 5 |
To design a compiler, all the above phases are necessary; additionally, two more routines are also important. They are symbol table manager and error handler.
1.4.5 Symbol Table Manager and Error Handler
In addition to passing the data from one phase to other, additional information acquired during a phase may be needed by a later phase. The symbol table manager is used to store the record for each identifier, procedure encountered in the source program with relevant attributes. The attributes of identifier can be name, token, type, address, and so on. For procedures, a record is stored in the symbol table with attributes like return type, number of parameters, type of each parameter, and so on. Whenever any phase encounters new information, records are stored in the symbol table and whenever any phase requires any information, records are retrieved from the symbol table. Syntax analyzer stores the type of information; this is later used by the semantic analyzer for type checking.
The error handler is used to report and recover from errors encountered in the source program. A good compiler should not stop on seeing the very first error. Each phase may encounter errors, so to deal with errors and to continue further, error handlers are required in each phase.
The process of compilation can be viewed in the analysis and synthesis model shown in Figure 1.9.
Two-Stage Model of Compilation
- Analysis: The analysis part of compiler analyses breaks up the source program into constituent pieces and creates an intermediate representation of source text.
Figure 1.9 Phases of a Compiler Compilation
- Synthesis: Synthesis part of compiler constructs the desired target machine code from the intermediate representation.
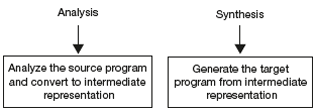
Most compilers are designed as two-stage systems. The first stage focuses on analyzing the source program and transforming it into intermediate representation. This is also called the front end of the system. The second stage focuses on the synthesis part where the intermediate code is converted to the target code.
The two-pass model simplifies the design of the compiler and helps in generating a new compiler for a new source language or to a new target machine with ease. The front end is designed with a focus on the source language to check for errors and generate a common intermediate representation that is error free to the back end. The back end can be designed to take the intermediate code that may be from any source language and generate the target code that is efficient and correct. Both front end and back end can use the common optimizer, which works on intermediate representation.
Analysis of the Source Program
Analysis deals with analyzing the source program and preparing the intermediate form.
- Lexical Analysis
- Syntax Analysis
- Semantic Analysis
Synthesis
Synthesis concerns issues involving generating code in the target language. It usually consists of the following phases:
- Intermediate code generation
- Code optimization
- Final code generation
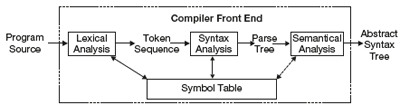
1.4.6 Compiler Front End
The compiler front end shown in Figure 1.10 consists of multiple phases, each provided by the formal language theory:
- Lexical analysis—breaking the source code text into small pieces called tokens, each representing a single atomic unit of the language, for instance, a keyword, identifier, or symbol name. The tokens are specified typically as regular expressions. From a regular expression, a finite state machine is constructed. This machine can be used to recognize tokens. This phase is also called scanner or lexical analysis.
Figure 1.10 The Front End of a Compiler
- Syntax analysis—Syntax analyzer checks the syntactic structures of the source code. It focuses only on the form or structure. In other words, it identifies the order of tokens and builds hierarchical structure called parse tree. This phase is also called parsing.
- Semantic analysis is to recognize the meaning of programming constructs and start to prepare for output. In that phase, static type checking is done and most of the compilers show these semantic errors as incompatible types.
- Intermediate representation—source program is transformed to an equivalent of the original program called intermediate representation (IR). This IR makes the target code generation easier. Intermediate code can be a data structure (typically a tree or graph) or an intermediate language.
1.4.7 Compiler Back End
Compiler front end alone is necessary for a few applications like language verification tools. A real compiler carries the intermediate code produced by the front end to the back end, which produces a functional equivalent program in the output language. This is done in multiple steps.
- Compiler—The process of collecting program information from the intermediate representation of the source code is called compiler analysis. Typical analysis includes variable u-d (use-define) and d-u (define-use) chains, alias analysis, dependency analysis, and so on. The best possible way for any compiler optimization is an accurate variable analysis. During the analysis phase call graph and control flow graph are usually built.
- Optimization—The optimizer optimizes the code. It transforms the intermediate language representation into functionally equivalent faster and smaller code.
- Code generation—This is the transformation from intermediate code to the target/machine code. This involves the proper usage of registers, memory, and resources and proper selection of the machine instructions and addressing modes that reduce the running cost.
Prerequisite for any compiler optimization is compiler analysis and they tightly work together. The dependency of compiler front end and back end is shown in Figure 1.11(a).
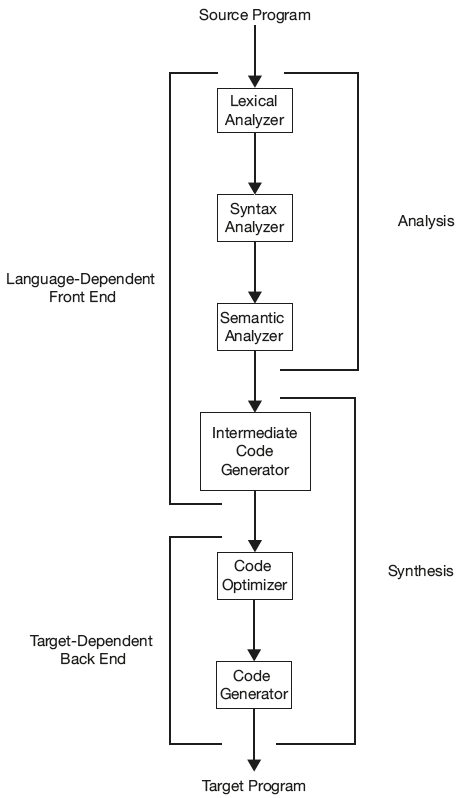
Figure 1.11(a) Compiler Front End and Back End
Example 3: Compiler phases:
Int a,b,c;
Real d;
– – –
a = b * c + d
output of each phase is shown below in Figure 1.11(b).
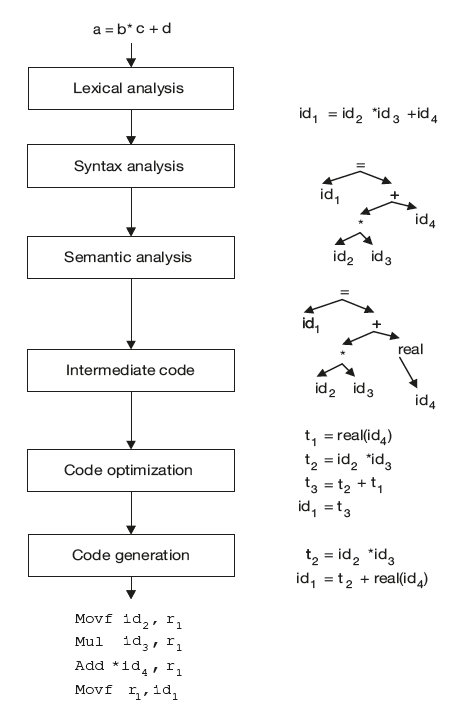
Figure 1.11(b) Result of Each Phase
1.5 Design of Passes
Reading the source text once is called a pass. All translators are designed in passes.
For example, the assembler is designed in two passes. Suppose there is a program as follows:
Add R1,R2
Jmp L
– – – – – –
– – – – – –
L:
– – – – – –
Here Jmp L cannot be translated in first pass as address of L is not known. It is defined later. This is called forward reference problem. Because of this forward reference, the assembler is designed in two passes. In the first pass, the assembler collects all the labels and stores their addresses in the symbol table. In the second pass, the assembler completes the translation to machine code.
The assembler can be designed even in one pass. The process is to scan the input text line by line and translate. If the statement is seen with a forward reference, store it in some table-“not_yet_assembled” and continue with next statement. While doing so, if any label is seen, store it in the symbol table. At the end, since all the labels are available in the table, take each statement in the “not_yet_assembled” table and translate. But the problem here is if every statement has a forward reference, the size of the table becomes a problem. This is the reason why generally the assembler is designed in two passes.
A macro processor or loader is also designed in two passes.
Coming to the compiler, if we want to complete all the phases in one pass, it requires too much of space. This is the reason why a compiler is designed in two passes. Lexical analysis to intermediate code generation, that is, lexical analysis, syntax analysis, semantic analysis, and intermediate code generation is carried out in the first pass and target code generation and optimization in the second pass. This is how we can group phases into passes.
1.6 Retargeting
Creating more and more compilers for the same source language but for different machines is called retargeting. Retargetable compiler, also called cross compiler, is a compiler that can be modified easily to generate code for different architecture. The code generated is less efficient.
For example: If there is a C compiler that produces code for poor machine T800, 8 bit processor machine, then we want a compiler for a better machine, that is, i860–64 bit processor machine. To design a C compiler for i860, we do not have to start the design from lexical analysis. As front end is independent of target machine and completely dependent on source language, take the front end of T800 and design the back end for i860 machine. Add these two to get the C compiler for i860. This is the advantage of retargeting.
Typically the design of a compiler divides the functionality so that the code generation is separate from parsing and semantic checking. Polymorphism in the code-generating section is used in the design and implementation of a re-targetable compiler, so that a code can be generated for a processor of any type.
Examples of retargetable compilers:
- GCC
- lcc
- vbcc
1.7 Bootstrapping
A compiler is a complex program and it is not desirable to use the assembly language for its development. Rather, a high-level language is used for writing compilers.
The process by which a simple language is used to translate a more complicated program, which in turn may handle an even more complicated program and so on, is known as bootstrapping. Using the facilities offered by a language to compile itself is the essence of bootstrapping.
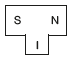
1.7.1 T-diagram
For bootstrapping purposes, a compiler is characterized by three languages: the source language that it compiles (S), the target language it generates code for (N), and the implementation/host language (I). This characteristic can be represented by using a diagram known as the T-diagram.
A compiler may run on one machine and produce code for another machine. Such a compiler is called a cross compiler.
Suppose we write a cross compiler in S in implementation language I to generate code for machine N, i.e., we create S I N. If an existing compiler for I runs on machine M and generates code for M, it is characterized by I M M. If S I N runs on I M M, we get a compiler S M N, that is, a compiler from S to N runs on M. This is illustrated by putting T-Diagrams together as shown in Figure 1.12.
Note that the implementation language I of the source compiler and the source language of the running compiler must be the same.
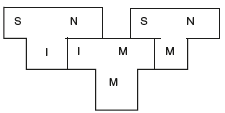
Figure 1.12 Cross Compiler
Example 4: Suppose we have a Pascal translator written in C, which takes pascal code and produces C as output.
If we want to have the same Pascal compiler in C++, then run the Pascal compiler under the C compiler, which produces C++ as output. Implementation language can be any language like Java. Once we run the Pascal compiler under the C compiler, we get Pascal compiler in C++. This is shown as a T diagram in Figure 1.13.
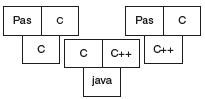
Figure 1.13 Pascal Compiler in C++
1.7.2 Advantages of Bootstrapping
- It builds up a compiler for larger and larger subsets of a language.
Suppose we write a compiler LNN for language L in L to generate code for machine N. Development takes place on machine M, where an existing compiler LLM for L runs and generates code for M. By first compiling LLM with LNN, we obtain a cross compiler LNM that runs on N, but produces code for M.
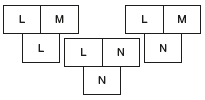
The compiler LNM can be compiler second time, this time using generated cross compiler. The result of second compilation is a compiler LMM that runs on N and generates code for M.
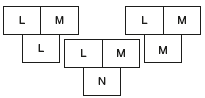
The two steps can be combined as shown in the figure below.
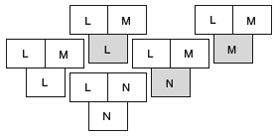
- Using bootstrapping an optimizing compiler can optimize itself.
Suppose all development is done on machine Q. We have SSQ, a good optimizing compiler for language S written in S for machine Q. We want SQQ a good optimizing compiler for S written in Q.
We create SQ#Q#, a quick and dirty compiler for S on Q that not only generates poor code but also takes a long time to do so. (Q# indicates poor implementation in Q. SQ#Q# is a poor implementation of the compiler that generates poor code.) However, we can use the compiler SQ#Q# to obtain a good compiler for S in two steps shown in the following T diagram.
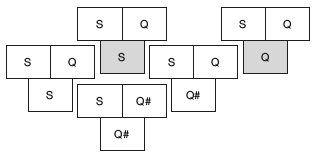
Example 5:
Let us see how the process of bootstrapping gives us a clean implementation of Pascal. A fresh compiler was written in 1972 for CDC 6000 series machines by revising Pascal. In the following diagram, O represents “old Pascal “ and P represents “revised Pascal.”
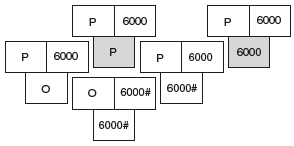
A compiler for revised Pascal language was written in old Pascal and translated into CDC as 6000#, that is, P6000#6000#. The old compiler did not generate efficient code. Therefore, the compiler speed of 6000#, that is, P6000#6000# was rather moderate and its storage requirements were high. Revisions to Pascal were small enough that compiler P06000 and run through the inefficient compiler P6000#6000#. This gives a clean implementation of a compiler for the required language.
1.8 Compiler Design Tools
Many automated tools are available to design and enhance the performance of a compiler. Some of them are as follows:
- Automatic Parser Generators
With the help of CFG, these generators produce syntax analyzers (parse tree). Out of all phases of a compiler, the most complex is parsing. In old compilers, syntax analysis consumed not only a fraction of the running time of a compiler but also a large fraction of the intellectual effort of writing a compiler.
For example, YACC, Bison
- Scanner Generators
These generators automatically generate lexical analyzers (the stream of tokens), normally from a specification based on regular expression.
For example, Lex, Flex
- Syntax-Directed Translation Engines
These engines take the parse tree as input and produce intermediate code with the three-address format.
- Automatic Code Generators
These take a collection of rules that define the translation of each operation of the intermediate language for the target machine.
- Data-Flow Engines
To perform good code optimization, we need to understand how information flows across different parts of a program. The “data flow engines” gather the information about how values are transmitted from one part to other parts of the program. This is very useful for good code optimization.
- Global Optimizers
Global optimizer is language and compiler independent. It can be retargeted and it supports a number of architectures. It is useful if you need a back end for the compiler that handles code optimization,
These are the various compiler construction tools, which are widely used.
1.9 Modern Compilers—Design Need for Compilers
A compiler is one of the most important system software that translates the programs written in high-level language to low-level language. Most of the techniques are for procedure-oriented languages like C, Pascal and so on. Researchers are working in the direction of generating compilers for new paradigms of the language and generating an efficient code in terms of execution time, power consumption, and space requirement. Modern compilers have to be designed with different orientation as the languages are object based or object oriented. It becomes essential for the compiler designer to focus on the following issues:
- Focus on essential traditional and advanced techniques common to all language paradigms
- Consider programming types—procedural, object oriented, functional, logic and distributed languages
- Understand different optimizing techniques and tools available
- Understand various computer architectures and formats
1.10 Application of Compiler Design Principles
The important component of programming is language processing. Many application software and systems software require structured input. Few examples are databases (query language processing), OS (command line processing), Equation editors, XML- and html-based systems, typesetting systems like Troff, Latex, editors like vi, Emacs, Awk, Sed, Form processing, extracting information automatically from forms. If input of any application has a structure, then language processing can be done on the input. The whole spectrum of the language-processing technology is used by compilers.
By studying the complete structure of compilers and how various parts are composed together to get a compiler, one can become confident of using the language-processing technology for various software developments. This knowledge helps to design, develop, understand, modify/enhance, and maintain compilers for (even complex!) programming languages.
Solved Problems
- Show the output of each phase of compiler on the following input.
int gcd(int a, int b)
{
while (a != b) {
if (a > b) a =b;
else b =a;
}
return a;
}
Solution:
The first phase: Lexical Analysis Gives Tokens
Input to LA:
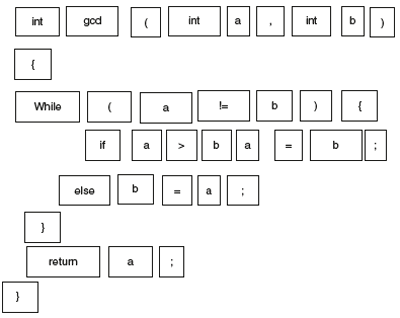
A stream of tokens. Whitespace, comments are removed.
The second phase: Syntax Analysis Gives the Syntax Tree
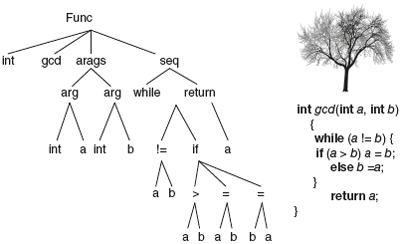
Abstract syntax tree built from parsing rules.
The third phase: Semantic Analysis Resolves Symbols
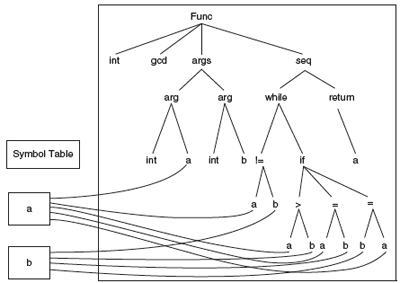
Translation into Three-Address Code
If (a !=b) go to L1
go to Last
L1: if a > b goto L2
goto L3
L2: a=b
goto Last
L3: b=a
Last: goto calling program
Code optimization phase also will have the same output as there is no scope for any optimization. Now target code generator generates instructions as follows:
Translation into Target Code
mov a, R0 |
% Load a from stack |
|
mov b, R1 |
% Load b from stack |
|
cmp, !=, R0,R1 |
|
|
jmp .L1 |
% while (a != b) |
|
jne .L5 |
% if (a < b) |
|
subl %edx,%eax |
% a =b |
|
jmp .L8 |
|
|
.L5: subl %eax,%edx |
% b =a |
|
jmp .L8 |
|
|
.L3: leave |
% Restore SP, BP |
|
ret |
|
Idealized assembly language with infinite registers
Summary
- A compiler is a program that translates a source program written in some high-level programming language (such as C++) into machine code.
- An interpreter reads source text line by line and executes without producing machine code.
- A preprocessor processes the source code before compilation and produces a code that can be more efficiently used by the compiler.
- An assembler is a translator that converts assembly code to machine code.
- A loader/linker or link editor is a program that takes one or more objects generated by a compiler and combines them into a single executable program.
- A phase is one which converts one form of representation to another form.
- The task of a compiler can be divided into six phases—lexical analysis, parsing, semantic analysis, intermediate code generation, code optimization, target code generation.
- The lexical analyzer or scanner groups the input stream (of characters) into a stream of tokens.
- The parser groups tokens into hierarchical structure called the parse tree.
- The semantic analyzer checks semantics, that is, whether the language constructs are meaningful.
- Intermediate Code Generator converts hierarchical representation of source text, that is, parse tree into a linear representation called intermediate representation (IR) of the program.
- Intermediate Code Generator can be represented in different ways (1) as a syntax tree, (2) DAG (directed acyclic graph), (3) postfix notation, and (4) Tree address code.
- Code optimizer tries to improve the efficiency of the code.
- Target code generator takes each IR statement and generates equivalent machine instruction.
- The symbol table manager is used to store record for each identifier and for every procedure encountered in the source program with relevant attributes.
- The error handler is used to report and recover from errors encountered in the source.
- A retargetable compiler is a compiler that can relatively easily be modified to generate code for different CPU architectures.
- A compiler that runs on one machine and produces code for another machine is called a cross compiler.
Fill in the Blanks
- A compiler is a translator that converts source program to __________.
- __________ reads source text line by line and executes the source text without producing machine code.
- A preprocessor processes the __________ and produces a code that can be more efficiently used by the compiler.
- An assembler is a translator that converts assembly code to __________.
- __________ is a program that takes one or more objects generated by a compiler and combines them into a single executable program.
- A phase is one that converts __________.
- The task of a compiler can be divided into __________ phases.
- The lexical analyzer or scanner groups the input stream into __________.
- The parser groups tokens into a hierarchical structure called the __________.
- The semantic analyzer checks __________.
- Intermediate Code Generator can be represented in a tree form as __________.
- __________ is an optional phase in a compiler.
- Information in the symbol table is filled by __________ phases.
- The error handler is used to report and recover from errors encountered in the source. It is required in the __________ phase.
- A retargetable compiler is a compiler that can easily be modified to generate code for __________.
- A compiler that runs on one machine and produces code for another machine is called __________.
Objective Question Bank
- * Consider line number three of the following C program.
int main()
{ int I,N;
fro(I=0; I<N; I++);
}
Identify the compiler response about this line while creating the object module.
- No compilation error
- only lexical error
- only syntactic error
- both lexical and syntactic errors.
- Output of an interpreter is
- HLL
- Exe code
- assembly code
- machine code
- Syntax analyzer verifies syntax and produces
- syntax tree
- parse tree
- DAG
- none
- Intermediate Code Generator prepares IR as
- polish notation
- dependency graph
- parse tree
- all
- Cross compiler uses which technique?
- backtracking
- bootstrapping
- reverse engg
- forward engg
- Retargeting is useful for creating compilers for more and more
- CPU architectures
- high-level languages
- assembly languages
- none
- Code optimization can be performed on
- source text
- IR
- assembly code
- all
- Assembler can be designed in
- one pass
- two pass
- many pass
- all
- YACC is
- scanner
- parser generator
- Intermediate Code Generator
- none
- Lex is a
- scanner
- parser generator
- Intermediate Code Generator
- none
Exercises
- Explain the difference between a compiler and an interpreter.
- What is the difference between pass and a phase? Explain the design of a compiler with phases.
- Explain the different translators required for converting a high-level language to an executable code.
- Give the output of each phase of compiler for the following source text for (i = 0; i < 10; i++) a = a + 10;
- What is a cross compiler? What is the advantage of the bootstrapping technique with compilers?
- What is retargeting? What is its use?
- Give the output of each phase of compiler for the following source text: while (i < 10) a = a + 10;
- What are the tools available for compiler construction?
- Explain the analysis and synthesis model of a compiler.
- What is the front end and the back end of a compiler? Explain them in detail.
Key for Fill in the Blanks
- machine code
- Interpreter
- source code before the compilation
- machine code
- Link edit or
- one form of representation to another form
- 6
- a stream of tokens
- parse tree
- semantics
- DAG, Syntax tree
- Code optimizer
- all
- all
- different CPU architectures
- cross compiler
Key for Objective Question Bank
- c
- b
- b
- a
- b
- a
- a
- d
- b
- a