
Figure 16-5: Workflow for combining parallel and serial microtasks.
Chapter 16
Combining Microtasks and Preparing Workflow
In This Chapter
![]() Understanding parallel and serial tasks
Understanding parallel and serial tasks
![]() Checking for errors
Checking for errors
![]() Bringing together parallel and serial tasks
Bringing together parallel and serial tasks
![]() Making decisions in workflow
Making decisions in workflow
Microtasking takes some effort, there’s no doubt about it. You have to design your tasks, upload them to a microtask market, let the crowd do its work, check the results and then download the work that meets your standards. (See Chapter 8 for a discussion of how to microtask.) With all this to do, you could be forgiven for wanting to keep your microtasking job as simple as possible. After all, why would you want to make it more complicated? Well, of course you should keep your microtasks as simple as possible, but sometimes the very simplest microtasks aren’t the best. Simple microtasks may be easy to design and easy to start, but they can only do simple things.
Checking the results of microtasks can take real effort. You have to review each task to be sure that the work’s done properly. When you’ve uploaded a large number of tasks, you quickly learn that checking the results of each microtask takes a lot of time and isn’t always feasible. Microtasks have a way of expanding. You start by doing 10, but soon you’re doing 100 tasks, and before you know it you’re doing 1,000. You can probably check 10 microtasks and maybe even check 100, but when you’re running 1,000, you can’t check them all.
To check for errors in microtasks or to get microtasks to do complicated things, you need a process called workflow, where the work flows from one task to the next. Workflow is a very powerful tool. With it, you can get microtasks to do things that you might not have imagined were possible (see the sidebar, Using microtasks to see the big picture).
 Using microtasks to see the big picture
Using microtasks to see the big picture
The crowdsourcing company Tagasauris came from a simple idea, an idea that originally didn’t involve workflow. The founders of Tagasauris wanted to use crowdsourcing to write descriptions of photographs. However, the company founders knew that naïve approaches to the problem wouldn’t work. ‘You can’t assume that the crowd will always produce useful results,’ explains Todd Carter, CEO of the firm. ‘And you can’t duplicate the work, because the way one member of the crowd describes an image can be very different from the way another member of the crowd describes the same image.’
In the end, the company developed a complex workflow to prepare descriptions. ‘We adopted the policy of trying to use the best kind of labour for each task of the process,’ Carter says. ‘We use software to recognise faces, one set of microtaskers to identify details, another to draft parts of the description, and macrotaskers to curate parts of the process.’ All of these steps are held together with a sophisticated workflow. It may sound complicated, but it works. The workflow uses the crowd to create clear descriptions of images and to create those descriptions quickly and inexpensively.
Workflow can be challenging to create. You have to design and test many different microtasks and then work out how to combine them. To help, in this chapter you find out about the basic ideas of workflow. You discover new ways of dividing complicated jobs into small tasks, and clever methods of combining the results. At the end of the chapter, I look at how you might be able to use workflow to handle real problems in crowdsourcing.
Discerning the Difference between Parallel and Serial Microtasks
To understand the nature of workflow, you first need to understand the different kinds of microtask. (If you want to know the basics of microtasking, head first to Chapter 8.) Microtasks come in two principal varieties: parallel tasks and serial tasks. (Technically, a third variety exists called a recursive task, but it’s yet to find any practical application, so I won’t go into that one here.) In addition to these two approaches, you can combine them in many different ways (see the section Combining parallel and serial tasks later in this chapter).
Doing the job all at once: Parallel tasks
Parallel microtasks are the simplest form of microtask. You start with a large problem that you can divide into tiny tasks which you give to the crowd. For these tasks, everyone in the crowd gets the same set of instructions. Each crowd member is doing the same thing but with different data. Each member is trying to transcribe a different business card or characterise a different tweet or recognise faces in a different photograph. One set of instructions. Many people. Different data. No concern about which data is processed first and which is processed last. These things describe parallel microtasks.
 In the computer world, parallel microtasks are known as single instruction multiple data tasks, or SIMD tasks.
In the computer world, parallel microtasks are known as single instruction multiple data tasks, or SIMD tasks.
Figure 16-1 shows how parallel microtasks work. You have a single job that you can divide into identical tasks. You give the tasks to the crowd. The crowd completes the tasks and returns them to you. You reassemble the tasks into a complete job.
For a simple example of parallel microtasks, say you receive 1,000 audio logs every day that you need to transcribe. These audio logs come from security guards who are protecting various buildings and businesses around your city. Most of your guards can’t write well and some are illiterate, so you ask them to record the events that occur on their shift with a small audio recorder. You need to transcribe those 1,000 audio files into written texts, one text for each file.
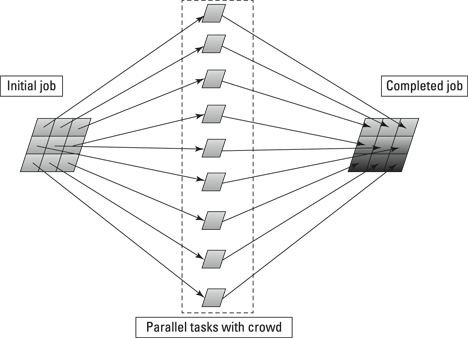
Figure 16-1: Parallel microtasks.
Each audio file contains some standard information: the date and time of the shift, the name of the guard, the location of the property, the state of the property when the guard arrived, anything unusual that happened during the hours of the shift, and the state of the property at the end of the shift. That information’s followed by a list of any events and details that the guard believes to be important: a door left open, a person knocking on the door, a box of files left on the floor.
The simplest way of handling these transcription tasks is to make them into 1,000 parallel microtasks. You upload the audio files to a crowdsourcing platform and let the crowd transcribe the six elements of information from each one. You don’t care which file is transcribed first and which is transcribed last. Eventually, they will all be done, and you can then use the results.
 If you use this simple version of crowdsourcing, you’ll discover what many crowdsourcers have found – that when you give microtasks to the crowd, you don’t always get back what you hope to get back. Some members of the crowd do the work properly, but some don’t. Some misinterpret the instructions. Some don’t understand what they hear. Some fail to do the job properly for other reasons. When the job’s finished, some of your files aren’t properly transcribed, and without checking each one you can’t easily tell which ones have been done correctly and which ones haven’t. That’s where serial microtasking comes in handy. With serial microtasking, you can get results that are often more reliable.
If you use this simple version of crowdsourcing, you’ll discover what many crowdsourcers have found – that when you give microtasks to the crowd, you don’t always get back what you hope to get back. Some members of the crowd do the work properly, but some don’t. Some misinterpret the instructions. Some don’t understand what they hear. Some fail to do the job properly for other reasons. When the job’s finished, some of your files aren’t properly transcribed, and without checking each one you can’t easily tell which ones have been done correctly and which ones haven’t. That’s where serial microtasking comes in handy. With serial microtasking, you can get results that are often more reliable.
Putting one thing after another: Serial tasks
Serial microtasking tasks are like the stages of an assembly line. You take a complicated task and break it into little steps that you perform in order – in series. You begin by asking the crowd to do the first step. Next, you ask it to do the second, and then the third, and so on until the crowd finishes all the steps. Figure 16-2 shows the steps of a serial task, a task that performs six independent steps on a single object.
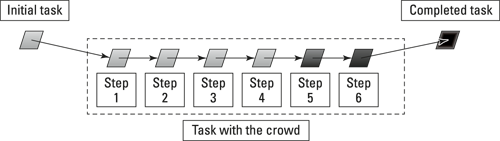
Figure 16-2: A single serial task.
If you take the example of the 1,000 audio logs I used in the preceding section, you could divide this transcription job into an assembly line with six steps:
1. Transcribe the date and time of the shift.
2. Transcribe the name of the guard.
3. Transcribe the location of the property.
4. Transcribe the state of the property at the start of the shift.
5. Transcribe the events that happened during the shift.
6. Transcribe the state of the property at the end of the shift.
You can create various different kinds of serial microtask to transcribe these audio files. In one way of transcribing files with serial microtasks, you first take one audio file, give it to the crowd and ask a crowdworker to transcribe the date and time of the shift. Secondly, you give that same audio file to another worker and ask that worker to transcribe the name of the guard. Next, you give the file to a third crowdworker, who you ask to transcribe the location of the property. You continue this process through the fourth, fifth and sixth steps.
Do you see what you’ve done there? You’ve divided the transcription job into six new microtasks, but you’ve not accrued any actual benefits from doing the work in serial. If anything, you’ve made your life more complicated. Whereas you once had to manage just one kind of microtask, you now have to manage six.
However, you can tweak these six microtasks just a little bit and get tasks that are crowd corrected. You get a crowd-corrected microtask by asking each worker to both do something new and to check all the work that’s been done before. If the worker sees a mistake in the earlier work, she should correct it. Making this change gives you six new microtasks:
1. Transcribe the date and time of the shift.
2. Transcribe the name of the guard, check the results from step 1 and correct any mistakes.
3. Transcribe the location of the property, check the results from steps 1 and 2 and correct any mistakes.
4. Transcribe the state of the property at the start of the shift, check the results from steps 1, 2 and 3 and correct any mistakes.
5. Transcribe the events that happened during the shift, check the results from steps 1, 2, 3 and 4 and correct any mistakes.
6. Transcribe the state of the property at the end of the shift, check all the information already transcribed and correct any mistakes.
These new tasks have to be done in a fixed order. A crowdworker can’t do the second task until the first task is complete, or the third task until the second is done. Furthermore, each task requires a little more work than its predecessors. The first task doesn’t require any checking of previous work, whereas the second task requires a check of the work of the first task as well as doing some transcription, and the third task requires a check of the work of the first and second tasks as well as doing a little transcription. (Figure 16-3 shows how this job is divided into serial tasks for each audio file.)
 When you create serial tasks, you often ask the crowd to do more work for some tasks than for others, so offering larger payments for the more complicated tasks than for the simpler tasks is a good idea. Otherwise, workers may not complete the more complicated tasks as quickly, and your tasks will stall in the crowdmarket.
When you create serial tasks, you often ask the crowd to do more work for some tasks than for others, so offering larger payments for the more complicated tasks than for the simpler tasks is a good idea. Otherwise, workers may not complete the more complicated tasks as quickly, and your tasks will stall in the crowdmarket.
 The difference between serial and parallel tasks is that serial tasks need to be done in a specific order. If you divide a job into six serial tasks, you have data that moves through your crowd in six waves. On each piece of the data, a member of the crowd has to do the first step of the process before someone can do the second step. Then a crowdworker has to do the second step before someone does the third.
The difference between serial and parallel tasks is that serial tasks need to be done in a specific order. If you divide a job into six serial tasks, you have data that moves through your crowd in six waves. On each piece of the data, a member of the crowd has to do the first step of the process before someone can do the second step. Then a crowdworker has to do the second step before someone does the third.
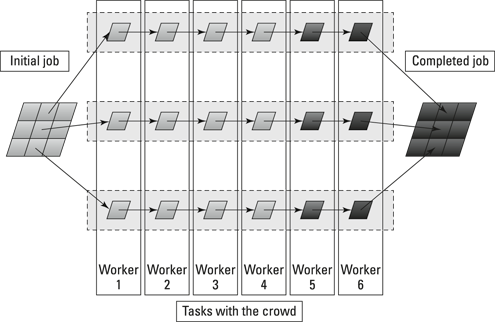
Figure 16-3: Serial tasks with the crowd.
The crowd doesn’t see serial microtasks from the same perspective as you do. In fact, the workers may not be aware that they’re doing serial microtasks. For them, each step in the process is a microtask. Because they can see several steps, workers understand that you’re offering several different kinds of microtask. However, they may not be aware that the different microtasks are connected.
Some members of the crowd may look at each microtask and try each one. Others may look at only one and concentrate on it. Each member of the crowd chooses which of the steps she’d like to do, but the crowdsourcing platform ensures that the different steps are done in the proper order. No one attempts to do step 2 before step 1’s been completed.
In the computer world, serial tasks may be known as pipeline tasks.
Minimising Error
Workflow is a powerful tool where you take the results from one microtask and combine them with the output of a second, third or even a fourth microtask to produce a complicated result. You can use workflow for many different reasons, but it’s an especially useful way of minimising the effects of errors, mistakes, goofs, typos, misunderstandings and even sabotage in microtasks.
Appreciating the value of serial tasks
At first, serial tasks may not look too appealing. They tend to be more expensive than parallel tasks, take more time and be more trouble.
Take the example of transcribing audio files that I cover in the preceding section. If your 1,000 audio files are small, you can create 1,000 parallel microtasks by asking a member of the crowd to transcribe each one. However, if you create six serial tasks for each audio file, you suddenly have 6,000 tasks on your hands. And while you may not pay the same amount for each of these serial tasks as you would for one of the parallel tasks, you’ll still probably pay more than one-sixth of the price of each parallel task. Suppose that you pay $1 (£0.63) for each transcription done by a single parallel task and you pay $0.25 (£0.16) for each serial task. To complete all the transcriptions, you’ll pay $1,000 (£630) if you do it with the parallel tasks or $1,500 (£945) if you do it with the serial tasks. So not only do you pay more money, but you have to do more work, too. You have to follow each audio file as it goes from crowdworker to crowdworker.
So, you may ask why do serial tasks at all. The answer is that you choose serial tasks because they offer a better way than parallel tasks of finding errors in the work. Sure, they take more time, more money and more effort, but they product more reliable results.
Among the six workers processing each audio file, for example, each worker both adds a little bit of information and checks previous workers’ results. If one worker spots an error, she can correct the mistake before she sends it forward to the next step. When the job reaches the last step, it’s been checked by each of the workers along the way.
Duplicating parallel tasks
Despite the benefits they bring, serial tasks can still seem like a lot of work. Because of this, many people instead try to weed out errors in microtasks by using another technique – duplicating parallel tasks and checking the results.
Duplicating parallel tasks works like this: suppose you have 1,000 audio files that you want to transcribe. You create a microtask for each audio file and send the tasks to the crowd. When the crowd has transcribed the files, you duplicate the process; you have the crowd transcribe the files a second time. You then compare the results of the two stages. If the results agree, the files are properly transcribed. If they disagree, someone in the crowd has made a mistake, so you then send the audio file to the crowd again and ask for a third transcription. If that third transcription agrees with one of the other two, you decide that majority rules. Two transcriptions that agree beats one that doesn’t agree, so you accept as correct the two transcriptions that agree.
Duplicating parallel tasks does have the benefit of being a simpler alternative to doing serial tasks, but it does have drawbacks of its own. It doesn’t guarantee perfect results, for one. Two crowdworkers can agree and still be wrong. Think about it for a moment. The audio file might have a voice that speaks with an unfamiliar accent or uses a word in an unusual way. When they listen to the file, both workers may misunderstand the words in the same way. They agree, but both are wrong. (For more on this blunder, see Chapter 23.)
Duplication also involves more work than you may at first think. If you transcribe 1,000 audio files with parallel workflow and duplicate all the microtasks, you expect to do at least 2,000 individual microtasks. The exact number you do depends on the percentage of mistakes you see in the work. If 10 per cent of the transcriptions contain errors, you expect to do roughly 2,222 microtasks. (Of the original 2,000 transcriptions, 200 have an error and don’t match. Of those 200, you find 20 with an error when they’re re-transcribed. Of those 20, you find a final 2 with errors in the transcription.)
When you duplicate work in order to detect errors, you achieve the best results if each crowd worker does the task in a different way. If the workers use different instructions, they’re less likely to make the same errors. If the crowd is transcribing audio files, for example, you may have one group complete the transcriptions with parallel tasks and another group do it as serial tasks. If the results of the two kinds of tasks agree, you can be more confident that you have the right transcriptions.
Working through an Example: Devising Workflow and Making Decisions in Mechanical Turk
When you use workflow in microtasking, you take a large job and break it into a combination of parallel tasks, serial tasks and computer programs. You use workflow in order to bring the power of human intelligence to large, complex jobs.
Workflow is most important for large microtasking jobs – for the jobs you can’t check yourself or assemble a trusted team to check. If you’re doing microtasking jobs that are small and can be checked relatively easily, you may not need to worry much about workflow.
No matter whether you use parallel or serial microtasks – or a combination of both – an important component of workflow is decision making. When you make a decision in a workflow, you review the results of one microtask with a computer program and automatically decide which microtask should be done next.
In the preceding section on duplicating parallel tasks, my example uses workflow to compare the results of two duplicate tasks. If the two tasks produce identical results, the workflow notifies the crowdsourcer that the tasks have been done properly. If the two tasks produce different results, the workflow creates a new task and sends it to the crowd. When the crowd finishes this task, the workflow checks the result with the results of the two tasks completed earlier. If the results from two of the tasks agree, the workflow notifies the crowdsourcer that the work has been done properly.
Of course, this process may continue for a long time. If no two of the three results agree, the workflow creates a fourth task and again sends it to the crowd. The workflow continues this process until it finds that the results of two tasks agree.
Figure 16-4 gives you a diagram that illustrates this workflow. It shows how the workflow sends the tasks to the crowd, makes a decision and sends the final result to you.
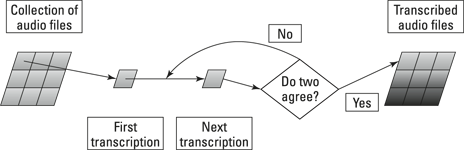
Figure 16-4: Workflow decision making.
When you create workflow, you’re actually creating a form of program – a program that controls your microtasks. (If you need to know more about programming, you might look at Beginning Programming with Java For Dummies by Barry Burd (Wiley).) This workflow sends the microtasks to the crowd and retrieves the results. Like a program, it can examine the results of microtasks in order to determine how those results should be processed. The workflow can create new tasks from those results and send those tasks to the crowd, or it can feed those results into a real computer program. In my example, such a program might put the transcribed sentences into a certain order or it might count the number of times that certain words appear in the transcripts.
See Chapter 8 for an introduction to Amazon’s Mechanical Turk. Mechanical Turk is a general-purpose microtasking crowdsourcing platform that enables you to create your own workflow and to create rules to govern your decision-making process. You do this by writing a program to run on your own computer. That program sends commands to Mechanical Turk to create microtasks, send those microtasks to the market and recover the results of the microtasks after the crowd has done its work.
Fortunately, Mechanical Turk and most other microtasking crowdmarkets let you develop your workflow in a test environment, which it calls a sandbox. The sandbox looks like a standard crowdsourcing platform but is a private one that only you can see. In the sandbox, you can test your workflow. The crowd won’t see your tasks, but you can look at the tasks as they would appear on the real platform.
To create a workflow in Mechanical Turk, your first step is to go to the Mechanical Turk website (www.mturk.com) to create a requestor account. This enables you to post microtasks and to deposit funds that cover the costs of your tasks and the Mechanical Turk fees. When you've done that, you can return to your own computer and create your workflow.
Here, I give you just an overview of how to create workflow in Mechanical Turk. To get the finer details of how to create and manage workflow in Mechanical Turk, read the Amazon Mechanical Turk Developer Guide and the Amazon Mechanical Turk API Reference. (An API is an application programming interface.) You can find both documents at http://aws.amazon.com/documentation/mturk. These documents describe in detail the commands – the operations you can send to Mechanical Turk from your workflow – and the information that you have to give them in order to create the workflow you want. The documents also point to where you can learn to use these commands with specific programming languages.
When you create workflow for Mechanical Turk or any microtask platform, you regularly use five commands. Those five commands create microtasks, send the tasks to the microtask market (in this example, Mechanical Turk), review the results of those tasks, and accept or reject them. In Mechanical Turk, those five commands are:
![]()
CreateHIT: creates a single microtask
![]()
GetReviewableHITs: retrieves the microtasks that have been done by the crowd
![]()
ApproveAssignment: approves a microtask and pays the worker
![]()
RejectAssignment: rejects the microtask and doesn't pay the worker
![]()
GetAssignmentforHIT: gets the results for a microtask
In Mechanical Turk, microtasks are called Human Intelligence Tasks or HITs.
Starting with parallel tasks
To create a single microtask, parallel or serial, you use the command CreateHIT when writing your program. To create 1,000 parallel microtasks for the audio transcription job example (see the earlier section Doing the job all at once: Parallel tasks), you invoke the CreateHIT command 1,000 times and give it a different audio file each time.
With the CreateHIT command, you can easily duplicate your microtasks and have multiple crowdworkers transcribe your file. When you invoke the command, you simply tell it that you want to duplicate the work, and specify the number of times you want it duplicated. Again, following the audio file example, you tell Mechanical Turk that you want each of the 1,000 microtasks to be done twice.
The programming commands GetReviewableHITs and GetAssignmentforHIT give you a way to compare the results of duplicate microtasks. The first command gives you a list of microtasks that are completed. The second command gives you the results for each microtask. You can then compare the results of the two duplicate tasks. If the results are the same, you can decide that the tasks have been done well. If they differ, you can create a new microtask, again using CreateHIT, to resolve the difference.
Mechanical Turk enables you to both automatically duplicate microtasks and compare the results. You automatically compare results by telling CreateHIT that you want to duplicate those tasks three times, and you review the results with a Simple Majority HIT Review Policy. Mechanical Turk will then carry out all your microtasks three times and give you the results whenever at least two of the three duplicate results agree.
Advancing to serial tasks
You can perform serial tasks in Mechanical Turk, although you need to do a little extra work. The audio file transcription example consists of six different tasks in its serial form. Each task transcribes a new part of the file. After the first task, each subsequent task asks the crowdworker to review and correct the work that’s been done already. (You can see the list of tasks in the section Putting one thing after another: Serial tasks.)
Using CreateHIT, you can create 1,000 microtasks that do the first step of the serial process, and then give these tasks a name such as Step 1. When the Step 1 tasks are done, you can recover the results using GetReviewableHITs and GetAssignmentforHIT. With those results, you create the next step of the process. Using CreateHIT, you create 1,000 new tasks called Step 2. When those tasks are done you proceed to create microtasks for the next steps of the process until you've completed all six steps.
Combining parallel and serial tasks
When you’ve got to grips with handling both serial and parallel microtasks with workflow, you can combine them to create a highly reliable way of doing work. For example, you can take each audio file in the transcription job example, transcribe it with both a parallel microtask and six serial microtasks, and compare the results of the two approaches. If the results from the two different approaches agree, you can be certain that the results of the microtasking are reliable. Figure 16-5 shows the workflow for this process.
Figure 16-5: Workflow for combining parallel and serial microtasks.
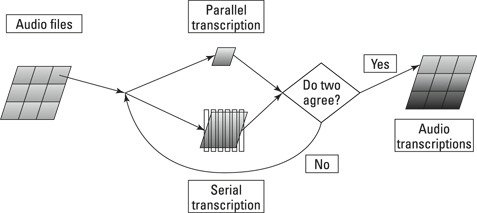
This form of microtasking is more reliable than the simple approach that I describe in Chapter 8, simply because the different crowdworkers are unlikely to make the same mistakes.
Going for Gold: The Many Benefits of Workflow
Microtasking with workflow is a difficult and complex form of crowdsourcing. It’s not for first-time crowdsourcers or individuals who know little about programming.
Still, workflow turns microtasking into a very powerful form of crowdsourcing. It enables you to combine different kinds of skills and different approaches to work on a single job, to improve the ability of the crowd to tag images or transcribe text, to improve the quality of data searches, and even to edit articles and reports. It also enables you to improve the reliability of work through a process known as the Gold Standard.
The Gold Standard evaluates the quality of work being done as the crowd handles your microtasks. When you adopt the Gold Standard, you create special microtasks that have known answers and give them to the workers in the middle of your existing job. The workers don’t know that these microtasks are any different from the others or in any way special. They just take on these tasks like any other task and are paid for the work just the same. Therefore, by using these tasks you should be able to capture the reliability of each worker.
If the members of the crowd do the Gold Standard tasks correctly, you can be confident that they are doing all of your work well.
If the crowd isn’t doing the Gold Standard tasks properly, you should feel concerned that the results of the work being produced aren’t reliable. From looking at the results of these specific tasks, you may be able to identify some workers who aren’t producing good results and exclude them from your job.
Mechanical Turk makes it easy for you to implement Gold Standard questions. When you use the CreateHIT command, you can specify that you're creating Gold Standard questions by using what Mechanical Turk calls an Assignment Review Policy. When it uses this policy, Mechanical Turk compares the correct answers to the question with those given by the crowd and marks those that are wrong. Using workflow, you can then exclude unreliable workers form your jobs.
Many of the other companies that offer crowdsourcing services also use Gold Standard questions to improve the reliability of the results.