

Tabular Data Storage
Data models are built upon a method of storing data called tabular storage. We must understand this way of storing data to understand data models. Tabular data storage can also be called relational data storage. For examples, I showed Luke the bus schedule, phone book, and a spreadsheet I named Person. Tabular data storage in the physical data model consists of tables which contain columns and rows:
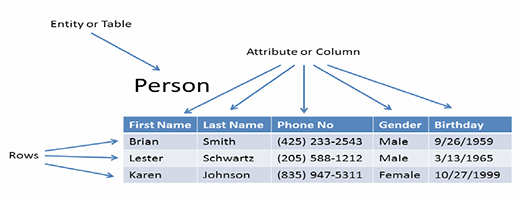
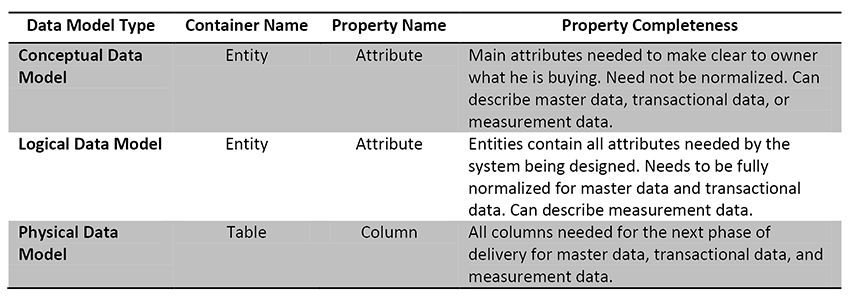
Tables and columns are referred to by different terms based on the type of data model being produced. While the idea is the same for all types of data models, the physical model uses the terms table and column. Conceptual, logical, and physical will be defined shortly. Here are the names and completeness required for each data model type:
Luke seemed to get the tabular idea and wanted to understand more about the conceptual versus the logical data model. This would require Luke to understand the notion of abstraction. I was worried that abstraction would be out of his grasp at age nine, but we gave it a try.
Luke jumped onto Wikipedia.org and looked up abstraction:
Abstraction is a process by which higher concepts are derived from the usage and classification of literal (“real” or “concrete”) concepts. “An abstraction” is the product of this process: a concept that acts as a super-categorical noun for all subordinate concepts, and connects any related concepts as a group, field, or category.
Of course, this definition left both of us more confused than we were originally. I tried a simpler approach. Things can be modeled specifically or they can be modeled with generality. When models are specific, they are clear, obvious, and easily understood. When models are generalized, they are unclear, hidden, and hard to understand.
Sounds like an easy decision between which abstraction style to choose, right? Wait, there is catch: specific models are more susceptible to data structure change while generalized models are less susceptible to data structure change.
On the other hand, generalized models may be more complex to process against because you always have to find the data you need—it’s not explicitly laid out for you. The cost of change in computing systems is way too high in most businesses. I tried some simple examples. I had Luke create a general abstraction that covered all the things in my list of specifics. I started with obvious examples to solidify his confidence.

Yes Luke, this is correct. Now let’s try a harder one:

Correct again. Now let’s try a really hard one:

This was mostly correct, but to lead him toward a new data model abstraction, I added one more thing to his abstraction of “Ball.” I called it “Sport”. Technically the first example of leather ball, rubber ball and plastic ball requires the abstraction of ball as well as the abstraction of material type. Now he understood that to abstract some sets of specific things, you may need two or more general things to fully cover the specific things:

This was an excellent answer and showed that Luke was grasping abstraction much better than I imagined for his first lesson. Next one:

Another correct answer; Luke was on an abstraction roll!

This was wrong since the specific thing and the general thing cannot be the same, and “Tree” is in both. I was fishing for a recursive abstraction and had him try again. He said “Plant.” Not a bad abstraction, but think about the “Rank” entity that helped “Soldier” to be a complete abstraction. Can you think of a helper generalization that can help “Plant” cover the large and small pieces of the tree? Luke came up with the entity “Chunk,” and then immediately changed it to “Plant Part Type,” Both answers solved the problem. Next one:

Luke got this one right since his dad had spent 16 years working at Boeing Airplane Company and we had toured the factory several times. Now it was time to look at real data models and apply the principles from our abstraction game.
Key Points
- Models are abstractions of the real world things around us. Models themselves can be designed with various degrees of abstraction, from high to low.
- Low amounts of abstraction in a model yield a clear, obvious, and easily understood model. Business owners get value from these models since they can have a clear understanding of what it is they are buying. These models, unfortunately, require re-design and re-structuring when the business changes.
- High amounts of abstraction in a model yield a model that is hard to understand. Business owners do not get great value from these models. However, these models are easy to change when the business changes, so they are valuable for the computing system designers and builders.
We had just spent an afternoon with our neighbors Anne and Julia, playing badminton until dark. It had been lots of fun, so I launched into this explanation of abstraction using badminton as the scope statement. The conceptual data model would be designed with specificity (low amount of abstraction) and the logical data model would be designed with generality (high amount of abstraction).
An entity is a person, place, thing, or event that exists within the scope of the project being modeled. What are the entities for our new software project called badminton?
Conceptual Data Model
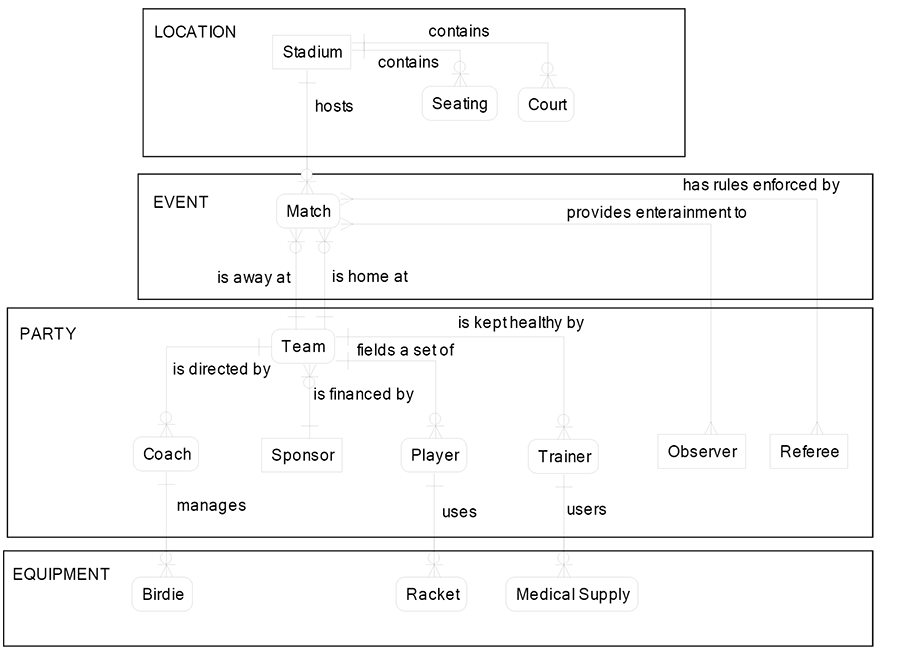
Conceptual data model entities should be designed with specificity and obvious clarity. Again, this is called a “low level of abstraction data design.” This design approach is clear to business owners and does not require them to understand the data values that reside inside of entities. This approach is good for conceptual data models but is bad for logical and physical data models. When the rules of the business change, the CDM will often require data model redesign. It is acceptable to modify the structure of the CDM when new business requirements arise since we don’t have thousands of lines of code needing to be changed when the CDM changes.
Changing the structure of the information system logical and physical data models is usually not acceptable since changes to the system data structures can trigger costly recoding and retesting of thousands of lines of code in the system. The symbols and notation below will be explained in detail later. Since CDM and LDM have design principles at the entity/relationship level, I will leave out most of the attributes for this exercise. The attribute design principles will be covered later in the book under normalization. The following page contains the badminton CDM.
The subject areas are the large boxes:
Location: The place where matches are played and where teams practice.
Event: The matches played between two teams.
Party: The people involved in badminton and their roles.
Equipment: The items managed by each team.
Here is a description of each relationship:
- Badminton is played in a stadium that hosts matches.
- Each stadium contains seating sections for observers and courts where the teams play.
- Each match is between two teams, one home team and one away team.
- The match has rules enforced by a referee.
- Each match provides entertainment to the observers, who pay to watch the game.
- Teams are financed by their sponsor.
- Teams are given direction by their coaches.
- Teams field a set of players to engage in matches.
- The coaches manage the birdies for each match.
- The players use their rackets for each match.
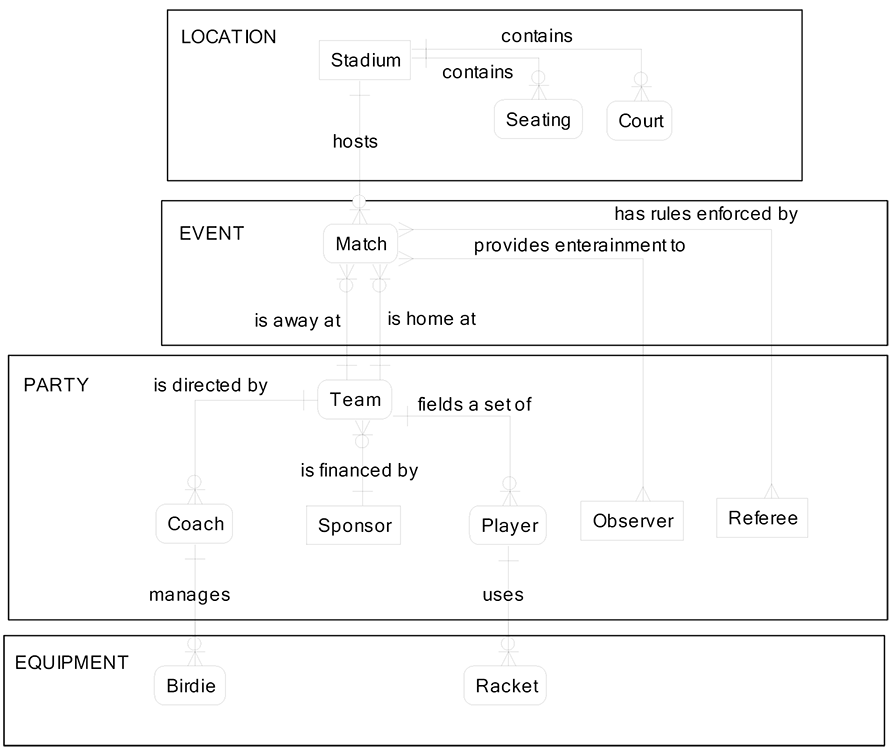
Here is a description of each entity:
- Location
- Stadium–the place where matches are held
- Seating–the place where spectators sit to watch the matches
- Court–the place where the players engage in the match
- Event
- Match–two badminton teams playing at a specific time and place
- Party
- Sponsor–the organization that manages the finances
- Team–the collection of players who compete in matches
- Coach–the people who manage the team
- Player–the athletes who play the matches
- Referee–the person who enforces the rules
- Observer–the people who purchase tickets and watch the matches
- Equipment
- Birdie–the object that the players hit with the racket
- Racket–the instrument that strikes the birdie
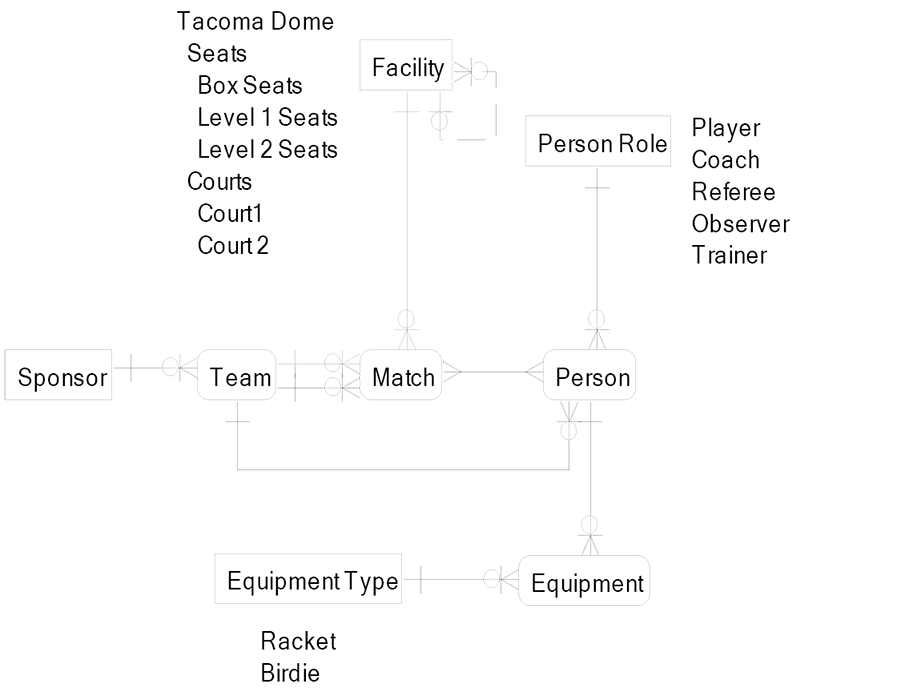
Logical Data Model
Logical data model entities should be designed with generality. This is called a “high level of abstraction data design.” The LDM on the next page is a transformation of the CDM above. We have transformed the low-abstraction CDM to become a high-abstraction LDM.
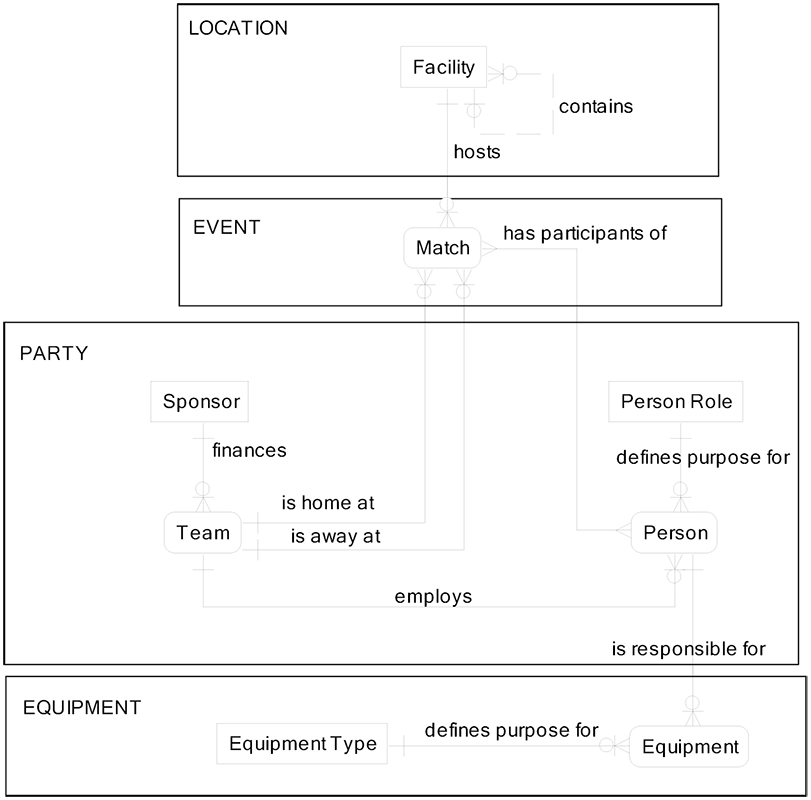
Here is a description of each relationship:
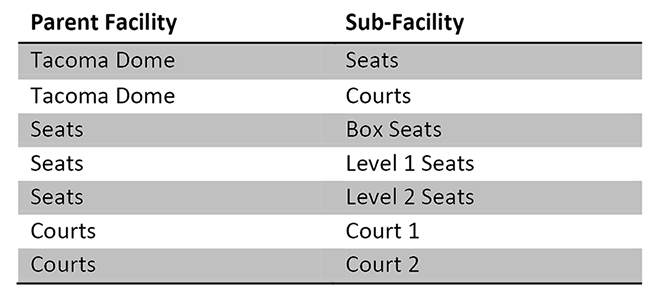
- A facility contains internal structures (seating, courts), which may themselves contain smaller internal structures.
- The facility is the host for each match.
- At a match there is one home team and one away team that will compete.
- A sponsor manages the finances for the team by collecting ticket revenue and paying the team’s expenses.
- Each person has a purpose in a match.
- The team employs a group of people.
- Each person has equipment that they must manage.
- Equipment types define the purpose for each piece of equipment.
Here is a description of each entity:
- Location
- Facility–the building and the internal structures used for matches. Internal structures may contain smaller structures
- Event
- Match–the event where two teams compete
- Party
- Sponsor–the organization that manages the finances
- Team–the collection of players who compete in matches
- Person–an individual who participates on the team
- Person Role–the purpose for a person who participates on the team
- Equipment
- Equipment–the things used by the team to engage in matches
- Equipment Type–the function of each piece of equipment
This LDM design requires an understanding of the rows of data within some key master data entities such as Equipment Type. The only way to know that we are tracking birdies and rackets is to look inside of the Equipment Type entity to see the values. This approach is good for logical and physical data models since it is less susceptible to costly computing change when the rules of the business change.
The technique used to transform the Badminton CDM into the Badminton LDM is abstraction, as we are merging diverse and specific entities from the CDM into a smaller set of less diverse and more generalized entities in the LDM that can handle business changes without altering the data structure.
The sample data values in the diagram below show the main rows of master data needed to understand the meaning of the LDM.
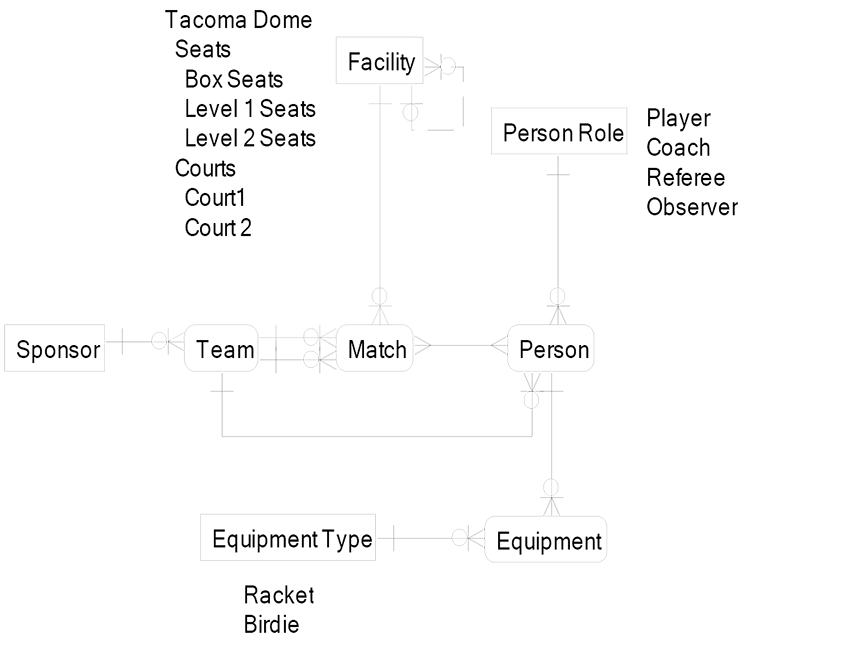
The facility entity has a relationship to itself. This means that a facility may have sub-facilities.
After a long silence, Luke asked what happens when we need to change things due to people changing their minds about how to run a badminton team. Well, let us imagine that a change happens in our aspect of the world called “badminton.”
The boss announces that next quarter all teams will have trainers to manage medical issues with the players. He had recently been sued by a player who had hurt his leg but continued to play and now is permanently in pain. The cost of the trainer will be nothing compared to the cost of losing a law suit. The trainers will have medical supplies that are used to treat the players for problems they experience in the games. Our CDM (low abstraction) design will have to change schema structure (this is okay) by adding two entities Trainer and Medical Supply. On the facing page the top model is the badminton conceptual data model after making this change.
The LDM is a general (high abstraction) data model, so it will remain stable across the boss’ new change. We will merely need to add rows to the database represented by the LDM. This is a quick, easy, and cheap way to change the data model and the database. Add a row of data to Person Role for Trainer and add a row of data to Equipment Type for Medical Supply.
Now the LDM and the related physical data model are ready to start recording new trainer and medical supply information. Here is the badminton logical data model after making this change.
Luke finally saw the value of abstraction when he understood that changing the data structure would impact lots of code and be costly to implement, while changing the rows of data was fast, cheap, and easy. Later, we will discuss how over-abstraction in the logical model can lead to confusion and problems.
Then, quite to my surprise, Luke got a perplexed look on his face and asked how my abstracted logical data model handles the fact that birdies have a feather count and rackets have a string tension? Luke observed that the CDM had separate entities for Birdie and Racket and that each of these entities had their own separate attributes. He asked where these attributes belong in the LDM, and how we keep people from recording string tension on a birdie and keep people from recording feather count on a racket.
I was floored and had to reevaluate Luke’s ability to listen, understand, and analyze. He had just turned 10 years old the week before, but I never expected this response. Sometimes I forget that children have more functional neurons in their brains than we adults. Getting those neurons to infer sophisticated paradoxes from an LDM is rare, so I attributed this epiphany to his intelligence and my teaching ability. Now I was in recovery mode and had to scramble to avoid embarrassment. First, I explained an entity called Attribute and described how this is used to handle the attributes that are specific to different types of equipment. The entity Attribute is a red flag for potential over-abstraction. Next, I pointed out that there are attributes that all types of equipment have in common, such as:
- Equipment Id
- Asset Tag Number
- Equipment Name
- Purchase Date
- Purchase Price
- Condition Category
These attributes are characteristics of the entity Equipment and belong in that entity. Now some attributes apply specifically to certain types of equipment, like the birdie attribute of feather count and the racket attribute of string tension. In this case, we need an entity to allow our information system to maintain a rapid and cost-effective capability to change as business needs change and to ensure that each type of Equipment has the proper set of attributes. I quickly got into my data modeling tool and pounded out a model to illustrate this design principle. See the model below.
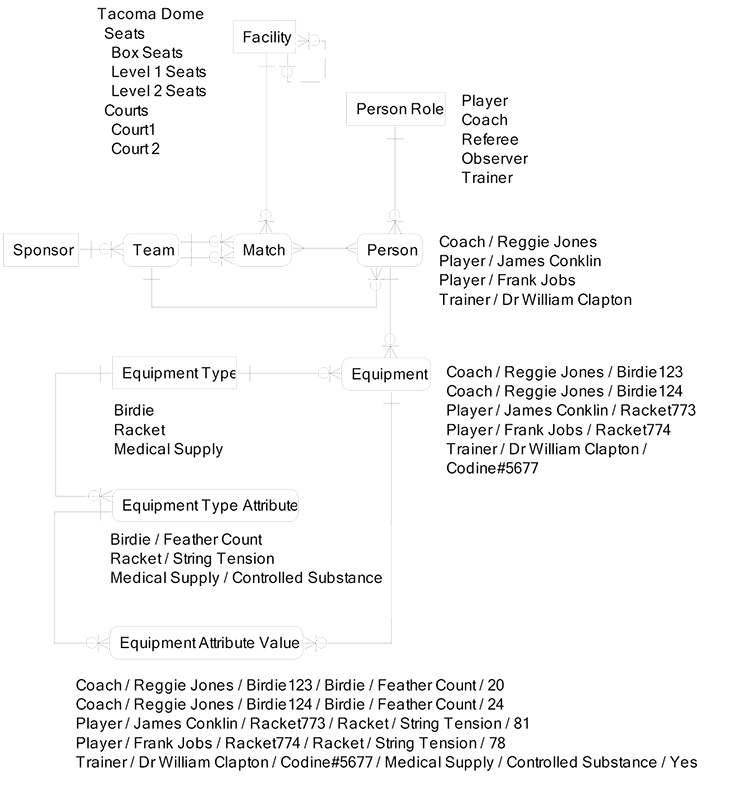
I added entities for Equipment Type Attribute to store the attributes unique to each Equipment Type and added Equipment Attribute Value to store the actual data contents for each Equipment Type Attribute. That is, the Equipment Type Attribute entity provides a list of the attributes that are valid for each type of equipment, while the Equipment Attribute Value entity contains the actual values for each person’s piece of equipment.
Luke looked at it for a few minutes and agreed that this solved the problem he was thinking about, and he thanked me. I breathed a sigh of relief to know that my barely 10-year-old son had not out-data-modeled his 62-year-old dad.
Key Points
- Conceptual models are oriented to business owners and should be easily consumed by a broad group of business participants.
- Concepts are grouped into subject areas (large box around entities), and require structural redesign when business rules change.
- Logical models are oriented to information technology professionals, and should be structurally stable across business changes.
- Some selected group of business participants should understand the logical models. These business participants should not control content unless the logical model fails to fully support the conceptual model.
Abstraction can be overdone, resulting in confusion in the logical model and poor system performance in the physical model. Abstraction can also be underdone, as we have noted previously, resulting in costly and time consuming changes to system code. Luke was dismayed to find out that abstraction, his recently acquired idea for doing good things, could be a bad thing when used in the extreme. I started out with a clearly ridiculous example of over-abstraction to entertain Luke:
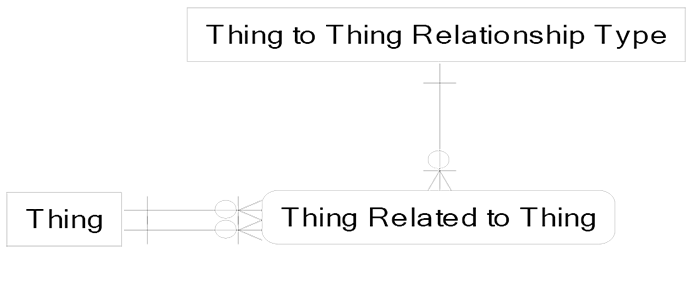
If this is our logical data model, we will have a problem being clear about when we are talking about persons and roles versus when we are talking about medical equipment and medical equipment types. This over-abstraction makes the normal amount of confusion on IT projects become an epidemic of severe confusion and rampant miscommunication. If this is our physical data model, we will have a problem with referential integrity and performance optimization.
If we have three tables in our database that match the diagram above, when the Thing called customer gets related to the Thing called order, the referential integrity between them and the transactional unit of work that records them must be coded by the developer. Further, the optimization of how to efficiently access customer and order data must be coded by the developer, and recoded when indexes change.
Luke asked about physical models, and since I would be the physical data modeler for the computing system running his lemon business, I felt obliged to respond briefly. If the CDM and LDM are done properly, the PDM, or physical data model, is relatively easy. The PDM design criteria vary from database product to database product since each product has different strengths and weaknesses. You must have a physical database designer who knows the technical strengths and weaknesses of the database product used to implement the PDM. Single server database systems, which execute instructions sequentially on one machine, are very different from the massively parallel processing database systems that are used for big data. Database systems that can only scale up (buy a larger server to get more performance) are very different from database systems that can scale out (add more servers to get more performance).
When I consider that Luke may well have another 90 years to interact with various database technologies, I can’t imagine the capacity and features that he will have when he is an old man like his dad is today. I imagine Luke as a retired curmudgeon who queries big data using brainwaves and gets the answers injected directly into his brain. I also imagine him defining the semantics of data with the same CDM and LDM principles that he is learning today.
Key Points
- Physical database technology will change every day, and over a period of years will become unrecognizable to guys like yours truly, “dinosaur dad” (Luke’s moniker for me).
- But the mental process for designing information systems has been stable for over 50 years now, so learning CDM, LDM, and value chain should be valuable for another 50 years or so.
- Abstraction can be a good thing, but it can also be a bad thing. Especially in the PDM, over-abstraction can cost more than it saves.