
1: What’s the problem?
Keywords
Defects; RTOS; Embedded Life Cycle; Endianness problem; Coverification; Hard real-time; CodeTest; Priority inversion
Software engineers write code and debug their code. Their platform may be a PC, Apple, Android, Linux, or another standard platform. Electrical engineers design circuits, run simulations, create printed circuit boards, stuff the boards, and then run confidence tests. They will also typically need to debug their designs.
If the software issues and the hardware issues are kept separate from each other, then the bugs that may be found in each domain can be complex and challenging, but are generally bound by the domain in which they reside.
Now, let’s really muddy the water. Let’s bring these two domains together and allow them to interact with each other. Suddenly, we have multiple opportunities for interaction and failures to occur:
- • There is a defect in the software that is independent of the hardware.
- • There is a defect in the hardware that is independent of the software.
- • There is a defect in the system that is only visible when hardware and software are interacting with each other.
- • There is a defect in the system when it must execute an algorithm with a finite window of time.
- • There is a defect in the system when multiple software applications are running concurrently and vying for the limited hardware resources under a control program (real-time operating system, or RTOS).
- • There is a defect in the system that only occurs in rare instances, and we cannot recreate the failure mode.
I’m sure that you, the reader, can add additional instances to this list.
Let’s consider the traditional embedded systems development life cycle model shown below in Fig. 1.1. This model has been presented so many times at every marketing demonstration that it’s fair to question whether it represents reality. Let’s assume for a moment that it does represent how a large fraction of new embedded designs are approached.
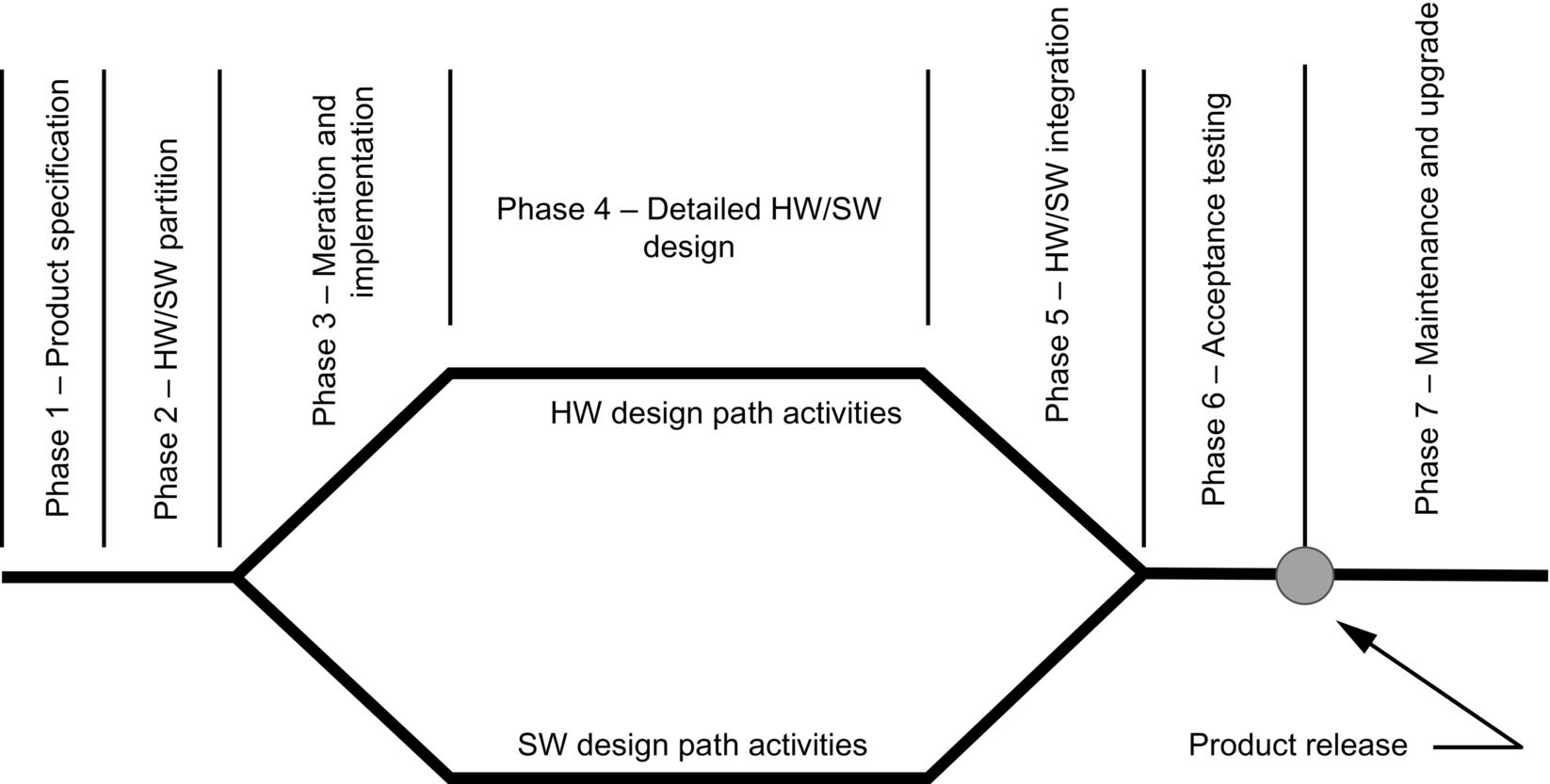
We might assume that everything is fine until we reach phase 3. Here, the software team and the hardware team go their separate ways to design the hardware and the software to the specifications developed during phase 1 and phase 2.
We may certainly question whether defects could have been introduced in these initial two phases that will not become apparent until the specifications are physically implemented.
We’ll ignore that aspect for the moment. Broadly speaking, this bug can be a marketing requirement that, for various reasons, is impossible to achieve. This marketing “bug” is a specification defect. Many will argue that this is not a bug in the true sense of the word, but rather a shortcoming in the product definition phase. However, finding the defect and fixing it can be every bit as challenging and time consuming as finding a bug in hardware timing or software performance.
In the traditional sense, the defects are created in phase 3 and phase 4. The hardware designers work from the specification of what the physical system will be and the software designers work from the sense of how the system must behave and be controlled. Both these dimensions are open to interpretation and there may be ambiguities in how the specification is interpreted by each team or by each individual engineer.
You might argue this won’t happen because the teams are in contact with each other and ambiguities can be discussed and resolved. That’s valid, but suppose that the teams don’t realize an ambiguity exists in the first place.
Here’s a classic example of such a defect. In fact, this is one of the top 10 bugs in computer science. It’s called the Endianness Problem (https://en.wikipedia.org/wiki/Endianness).
This ambiguity occurs because smaller data types such as bytes (8-bits) or words (16-bits) can be stored in memory systems designed to hold larger variable types (32-bits or 64-bits). Because all memory addressing is byte-oriented, a 32-bit long data type can occupy four successive byte addresses.
Let’s assume we have a 32-bit long word at the hexadecimal address 00FFFFF0. Using byte addressing, this long word occupies four memory addresses, 00FFFFF0, c, 00FFFFF2, and 00FFFFF3.a The next long word would begin at byte address 00FFFFF4 and so forth within this long word.
We see in Fig. 1.2 that there are two ways byte addresses may be arranged within the four-byte, 32-bit long word. If we are following the Big Endian convention, then the byte at hexadecimal address 00FFFFF1 would be Byte 2. But if we are following Little Endian convention, then Byte 2 would occupy memory address 00FFFFF2.

Suppose that this memory location was actually a set of memory-mapped hardware registers and writing a byte to a specific address is supposed to cause the hardware to do something. Clearly, if the hardware designer and the software designer have different assumptions about the Endianness of the system and have not explicitly discussed them, then a defect will be created by omission in the formal specification to declare the Endianness of the system.
If you’re lucky, you’ll catch the error in simulation or in a design review. However, the odds are just as likely that you won’t catch the error and the bug will become visible when commands are sent to the wrong portion of the 32-bit hardware register.
Even worse, engineering teams may be geographically separated from each other. I once comanaged a project that was a joint effort between my Hewlett-Packard division, located in Colorado Springs, Colorado, and a semiconductor company’s R&D team located in Herzliya, Israel. Sure, we had regular status meetings via conference calls, but there were many times when the key engineer was not available or we weren’t able to resolve all the issues during the call. Issues fell through the cracks despite our best intentions to keep communicating with each other, and there were several product defects resulting from communications breakdowns.
Unless you are going to design hardware and software through some hybrid model of Extreme Programming (https://en.wikipedia.org/wiki/Extreme_programming) with the hardware designer and software designer sitting together, one writing C code and one writing Verilog HDL code, you can expect that defects will arise that will eventually need to uncovered, analyzed, and repaired.
If the defect is in the hardware, the hardware is an application-specific integrated circuit (ASIC), and the design has gone to fabrication in a silicon foundry, then the cost of fixing the hardware may be prohibitive and the defect will need to be fixed by a software workaround (if possible).
This workaround can cause a chain reaction because in the extreme (Murphy’s Law), the overall system performance is impacted because software ends up doing work that hardware cannot. We’ve fixed the hardware defect, but we’ve introduced a real-time performance defect in the process.
Most of the defects will become apparent during the integration phase of the project when the hardware and software are first brought together. The concept of a hardware/software integration phase is one that is often considered to be either false or misleading. Best practices dictate that the integration of hardware and software should be continuous during the development phase with frequent testing of modules against each other.
One way to implement such a system is to use HW/SW coverification tools, such as Seamless from Mentor Graphics in Beaverton, Oregon. An excellent series of articles [2] provides a good basis for understanding the technology of coverification. Briefly, in coverification, software is continuously tested against the virtual hardware, which exists in a logic simulation. The coverification tools provide the interface between the instruction set simulator (ISS) for the software by creating a bus functional model (BFM) of the processor. The BFM is the glue logic between the ISS and the logic simulator. It accepts the machine level instruction and converts it to the address, data, and status bit activity the processor would execute if it were physically present.
The output side of the BFM plugs into the hardware simulator. This can be a Verilog simulator if the hardware is in an FPGA or an IC model, or a system logic simulator if the rest of the system is made up of discrete logical blocks.
Thus, using a coverification design approach, whether you actually use the coverifications tools, you should expect the integration phase (if it exists at all) to go more smoothly and with fewer bugs to be found and fixed.
When we introduce the third dimension of time constraints and a fourth dimension of real-time multitasking, the opportunity for the introduction of additional defects rises exponentially. Let’s consider one such set of issues, hard real time versus soft real time [3].
In a hard real-time system, a missed deadline is fatal: the system doesn’t work, the plane falls out of the sky, people are killed. Here we have a knife-edge decision to make. Either we fix it or the embedded system is unusable.
What is the best strategy to fix the flaw? Is the processor underpowered? Is the memory system too slow? Should we run a faster clock? Maybe. These are all issues with which the hardware team would grapple. Is software causing the problem? Maybe. Are hardware and software both causing the problems? Very possible. What about the software tools (see below)?
A hard real-time failure is serious because it is unlikely there is a workaround, an easy fix that can get around the flaw. Workarounds fix errors that can’t be fixed any other way, but they never make things better.
Let’s consider the case of a well-known laser printer manufacturer. Their design philosophy was to wring as much performance out of the processor as possible. They had a really good engineer who examined the code that was output from the C compiler and handcrafted it to make it as fast and efficient as possible. This sometimes means rewriting sections of C code in assembly language to eliminate some of the overhead inherent in high-level languages. They realized that if they had a hard real-time failure, the problem had to originate with the hardware because the software was already optimized.
The lesson here is that once you’ve determined the reason your system has hit the performance wall and the cause is hardware, the most likely path to improve performance is to respin the hardware. This may involve:
- • Choosing a faster processor.
- • Running a faster clock with an existing processor.
- • Improving the memory to processor interface.
- • Adding additional custom ASIC hardware.
- • Adding more processors to offload the problem processor.
- • Some combination of the above.
My point is to emphasize the importance of accurate analysis before taking any further action. This would likely involve:
- • Assessing the problem.
- • Analyzing the problem.
- • Deciding on a course of action.
- • Get buy-in (very important).
- • Resolve it.
Here’s another example (Although the problem is a soft real-time issue, which is a topic covered in Chapter 2, it is relevant to our current discussion). A manufacturer of RAID arrays was convinced that their RAID control card required a faster processor. They spoke with their local sales engineer from their current microprocessor vendor and were assured that the new processor coming down the pipe had twice the throughput of their current processor and was code compatible. However, the new processor had a different footprint (pad layout) than their current one, necessitating a redesign of their current version of the RAID controller.
The company went ahead and did a respin of the control board and was devastated to find the throughput improvement was a factor of about 1.15, rather than the 2 × improvement expected. After further analysis, they found the problem was a combination of several poor software architectural decisions; switching to the new processor was not the solution. The company almost went out of business because of their failed analysis.
Let’s move on to look at soft real-time failures. In contrast to a hard real-time failure, a soft real-time failure is one where the system takes longer to complete a task than is desirable or necessary for the product to be competitive in the marketplace. A good example is the laser printer. Let’s assume the marketing specification calls for the printer driver to output 20 pages per minute (20 ppm). The HW/SW integration phase goes smoothly, but the printer’s output is 18 ppm. Clearly, it doesn’t meet specs. The design team (and marketing) must decide whether to fix the bug, which might take weeks or months to correct, or release the product with lower performance and risk being noncompetitive in the marketplace.
This was discussed earlier when we looked at the situation of a defect in a custom IC that caused the correction to be made in software. Software, though very flexible, is not as fast as dedicated hardware, and perhaps this is the root cause of the poor performance. Alternatively, it may be a poorly matched compiler with the chosen microprocessor. When I worked with embedded tools vendors who supported Advance Micro Devices (AMD)-embedded microprocessors, there was a 2:1 performance difference between the lowest performance C compiler and the highest performance C compiler. A 2:1 difference is the same as running the processor at half the normal clock speed.
I was involved in another interesting soft real-time defect situation. My company, Applied Microsystems Corporation (now defunct), created a hardware/software tool called CodeTest. The tool was later sold to Metrowerks when AMC went out of business. CodeTest worked by postprocessing the user’s code and inserting “tags” in various places, such as the entry and exit points of functions. These tags were designed to be low-overhead writes to a specific memory location that could be collected by the hardware portion of the tool.
Unlike a logic analyzer, CodeTest could continuously gather tag data, time stamp it, compress it, and send it to the host computer where the data was being collected; a runtime image of the software execution could be displayed. It was, and still is, a very neat tool for software performance analysis.
Back to the bug. We were demonstrating CodeTest to a telecommunications manufacturer. They had a soft real-time problem they were trying to find. Their product performance was no longer adequate for the market and they were trying to decide if they could upgrade the existing product or if they needed to design a new one.
We set up CodeTest and started to gather statistics. One function seemed to be taking up a lot more of the CPU cycles than any other function and no one on the software team would admit to being the one who developed the code.
After some searching, the company’s engineers discovered that the function was written by an intern who was doing some board testing and wrote a high-priority test function that blinked a light on the back of one of the PC boards in the device. This code was never intended to be part of the released product code but somehow was added to the code build for the released product.
Once the code image was repaired and the errant function was removed, the telecomm manufacturer’s product was back in business. We lost a sale, but they bought us a nice dinner instead. How do we categorize this bug? It was certainly a soft real-time defect, but the root cause was the company’s source code control and build system. However, it is unlikely that without CodeTest, the engineers would have gained the insight they needed to see the product defect and fix it.
Once we add multitasking into the mix via an RTOS (real-time operating system), the possibility of system defects becomes even more likely. Before we discuss RTOS and defects, a few words about the way an RTOS operates are in order. Any computer operating system generally has the same purpose. It wants every independent application running concurrently to be well isolated from every other application and, for any individual application, it should appear to have all the systems resources available to it all the time. It makes writing programs infinitely easier for any processor doing more than a few simple concurrent tasks.
I’m writing this book on a laptop computer running Windows 10 as its operating system. If you count the number of programs that I have open, plus all the software running in the background, there are more than 30 applications all running at the same time. Well, sort of running at the same time. Windows is mostly a round-robin operating system. Every active program gets a time slice and there is an internal timer that allocates time slices for each application. These time slices are generally fast enough so that all the programs appear to be running simultaneously, though only oneb application is actually running at a time. Round-robin operating systems are perfectly acceptable and desirable for desktop or laptop computers, but are totally inadequate for real-time systems because real-time systems have time applications that require prioritizing CPU cycles based on the criticality of their time constraints. A task with a hypercritical time window can’t wait until its next turn in the queue. It must preempt all other less-critical tasks and run as soon as it needs to run.
A real-time operating system is a priority-driven O/S. The more important tasks have priority over the less-critical tasks. If a lower priority task is running while the higher priority task wakes up and needs to run, the lower priority task is temporarily put in suspension while the higher priority task takes over and runs to completion, or is preempted by an even higher priority task.
What might go wrong? One of the simplest defects is CPU starvation. The CPU is so heavily loaded that a low priority task is basically starved of CPU availability and never gets to run to completion. If you want to see a manifestation of this phenomenon, although not quite the same thing, try running Windows 10 on a computer with less than 4 GB of memory installed.
You’ll see delays when you move the mouse or strike a key on the keyboard as the processor struggles to give all the programs the time they require. Because there is so little memory installed, the hard drive, which is 10,000 × slower than RAM, must take over and hold the programs as they are being swapped in and out of memory.
Another classic defect involving an RTOS is called priority inversion. Suppose a low priority task has requested a system resource under control of the RTOS and has been granted the use of the resource. This could be a timer, a communications channel, a block of memory, etc. Suddenly, a high-priority task wakes up and needs the use of the resource. While it is possible for a higher priority task to preempt a lower priority task, when system resources are involved, this becomes more problematic. The lower priority task must relinquish the resource as soon as possible, but it can’t immediately relinquish the resource because that could leave the resource in a metastable state.
Thus, the RTOS waits until the resource is free before turning it over to the waiting task. In the interim, a medium priority task that does not require the resource is able to preempt the lower priority task and run. This is priority inversion. The highest priority task has been preempted by a lower priority task. In other words, the two priorities have been inverted.
The most famous of these system failures occurred on the Mars Pathfinder Mission in 1997. The Sojourner vehicle stopped communication with the Jet Propulsion Lab in Pasadena and began to exhibit systematic resets that wiped out all the data collected that day.
The story was recounted in a famous Dr. Dobbs interview with Glenn Reeves, the Flight Software Cognizant Engineer for the Attitude and Information Management Subsystem, Mars Pathfinder Mission [4]. The title of this article says it all:
REALLY REMOTE Debugging: A Conversation with Glenn Reeves
Quoting Glenn Reeves:
In less than 18 hours, we were able to repeat the problem, isolate it to an interaction of the pipe() and diagnose it as a priority inversion problem, and identify the most likely fix.
The point of this remarkable story is that even after your hardware and operational software are running correctly, the new dimension added by the introduction of a resource control and scheduling program (an RTOS) can lead to yet another opportunity for defects to be introduced into your system.
One way to avoid this cross-coupling problem is to partition the problem among multiple independent processors. Ganssle [5] discusses this as an approach to improve productivity and defeat the productivity reduction caused by large programs and the need to maintain communications among many programmers.
It may seem counterintuitive at first, as engineers are trying to optimize our designs, but throwing transistorsc at a problem may be the easiest way to design a multitasking embedded system without resorting to a real-time operating system. Not every design lends itself to this approach, but many do. Look at today’s automobiles. Each one is a mobile computer network with nearly 100 unique microprocessors and microcontrollers. Many of these processors have just one task to perform.
My favorite automobile example is the luxury car with a unique capability. If a driver closes the door from the inside when all of the other doors and windows are closed, a single itty-bitty microcontroller in each door will crack open the window just as the door is about to shut. As soon as the door is shut, the window goes back up. It happens in seconds.
The purpose of this processor is to avoid the air pressure burst on the driver’s ear when the door is shut. Cool, yes, but why do this? Because we can. I could design a circuit using a programmable logic array or discrete components and replicate this circuit, but the solution would not be as simple as a 4-bit microcontroller costing less than $0.10 USD and probably requiring fewer than 100 lines of assembly code.
As we wrap up this chapter, it is instructive to reflect on what I’ve tried to say here and its relationship to designing embedded systems. Due to the often-chaotic state of software development, a great deal has been written about methods for designing software (less so about designing hardware). A systematic method of specifying, coding, and testing software should be an engineering discipline and not an art form.
So, why write a book about finding and fixing bugs when the whole idea is to design hardware and software that is bug-free in the first place?
Here’s what I’ve concluded:
- • We’re still not a place where, for whatever reason, software and hardware can be designed without the introduction of defects.
- • Electrical engineering, computer science, and computer engineering students, by and large, have never been taught a systematic process for finding and fixing defects.
- • Tools and techniques for finding and fixing bugs often go unused because engineers don’t know they exist or don’t make the effort to learn the tool.
- • Some combination of the above.
In the next chapter, we’ll tackle the first problem. You know you have a problem, so how do you find it and fix it?