
Count vectorization and Term Frequency-Inverse Document Frequency (TTF-IDF) are two different strategies to convert a bag of words into a feature vector suitable for input to a machine learning algorithm.
Count vectorization takes our set of words and creates a vector where each element represents one word in the corpus vocabulary. Naturally, the number of unique words in a set of documents might be quite large, and many documents may not contain any instances of a word present in the corpus. When this is the case, it's often very wise to use sparse matrices to represent these types of word vectors. When a word is present one or more times, the count vectorizer will simply count the number of times that word appears in the document and place that count in the position representing the word.
Using a count vectorizer, an entire corpus can be represented as a two-dimensional matrix, where each row is a document, each column is a word, and each element is then the count of that word in the document.
Let's walk through a quick example before moving on. Imagine a corpus with two documents like this:
docA = "the cat sat on my face" docB = "the dog sat on my bed"
The corpus vocabulary is:
{'bed', 'cat', 'dog', 'face', 'my', 'on', 'sat', 'the'}
And so if we were to create a count embedding for this corpus, it would look like this:
| bed | cat | dog | face | my | on | sat | the | |
| doc 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| doc 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 |
That's count vectorization. It's the simplest vectorization technique in our toolbox.
The problem with count vectorization is that we use many words that just don't have much meaning at all. In fact, the most commonly used word in the English language (the) makes up 7% of the words we speak, which is double the frequency of the next most popular word (of). The distribution of words in a language is a power law distribution, which is the basis for something called Zipf's law (https://en.wikipedia.org/wiki/Zipf%27s_law). If we construct our document matrix out of counts, we end up with numbers that don't contain much information, unless our goal was to see who uses the most often.
A better strategy is to weight the word based on its relative importance in the document. To do that we can use something called the TF-IDF.
The TF-IDF score of a word is:
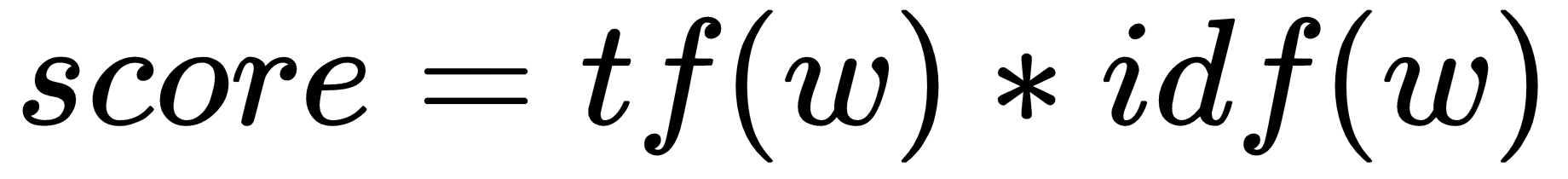
In this formula:

And n this formula:

If we were to compute the TF-IDF matrix for the same corpus, it would look like this:
| bed | cat | dog | face | my | on | sat | the | |
| doc 0 | 0 | 0.116 | 0 | 0.116 | 0 | 0 | 0 | 0 |
| doc 1 | 0.116 | 0 | 0.116 | 0 | 0 | 0 | 0 | 0 |
As you might notice, by weighting the words by their term frequency * inverse document frequency, we have canceled out the words that appear in all documents, which amplifies the words that are different. Document 0 is all about cats and faces, whereas document 1 is all about dogs and beds. This is exactly what we want for many classifiers.