
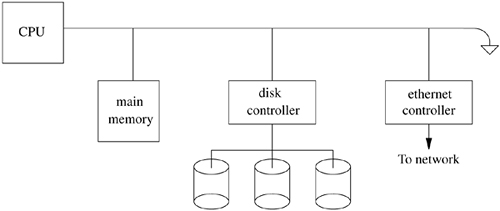
A central component of any operating system is the memory-management system. As the name implies, memory-management facilities are responsible for the management of memory resources available on a machine. These resources are typically layered in a hierarchical fashion, with memory-access times inversely related to their proximity to the CPU (see Figure 5.1 on page 136). The primary memory system is main memory; the next level of storage is secondary storage or backing storage. Main-memory systems usually are constructed from random-access memories, whereas secondary stores are placed on moving-head disk drives. In certain workstation environments, the common two-level hierarchy is becoming a three-level hierarchy, with the addition of file-server machines or network-attached storage connected to a workstation via a local-area network [Gingell, Moran, & Shannon, 1987].
In a multiprogrammed environment, it is critical for the operating system to share available memory resources effectively among the processes. The operation of any memory-management policy is directly related to the memory required for a process to execute. That is, if a process must reside entirely in main memory for it to execute, then a memory-management system must be oriented toward allocating large units of memory. On the other hand, if a process can execute when it is only partially resident in main memory, then memory-management policies are likely to be substantially different. Memory-management facilities usually try to optimize the number of runnable processes that are resident in main memory. This goal must be considered with the goals of the process scheduler (Chapter 4) so that conflicts that can adversely affect overall system performance are avoided.
Although the availability of secondary storage permits more processes to exist than can be resident in main memory, it also requires additional algorithms that can be complicated. Space management typically requires algorithms and policies different from those used for main memory, and a policy must be devised for deciding when to move processes between main memory and secondary storage.
Each process operates on a virtual machine that is defined by the architecture of the underlying hardware on which it executes. We are interested in only those machines that include the notion of a virtual address space. A virtual address space is a range of memory locations that a process references independently of the physical memory present in the system. In other words, the virtual address space of a process is independent of the physical address space of the CPU. For a machine to support virtual memory, we also require that the whole of a process's virtual address space does not need to be resident in main memory for that process to execute.
References to the virtual address space—virtual addresses—are translated by hardware into references to physical memory. This operation, termed address translation, permits programs to be loaded into memory at any location without requiring position-dependent addresses in the program to be changed. This relocation of position-dependent addressing is possible because the addresses known to the program do not change. Address translation and virtual addressing are also important in efficient sharing of a CPU, because position independence usually permits context switching to be done quickly.
Most machine architectures provide a contiguous virtual address space for processes. Some machine architectures, however, choose to partition visibly a process's virtual address space into regions termed segments [Intel, 1984]. Such segments usually must be physically contiguous in main memory and must begin at fixed addresses. We shall be concerned with only those systems that do not visibly segment their virtual address space. This use of the word segment is not the same as its earlier use in Section 3.5, when we were describing FreeBSD process segments, such as text and data segments.
When multiple processes are coresident in main memory, we must protect the physical memory associated with each process's virtual address space to ensure that one process cannot alter the contents of another process's virtual address space. This protection is implemented in hardware and is usually tightly coupled with the implementation of address translation. Consequently, the two operations usually are defined and implemented together as hardware termed the memory-management unit.
Virtual memory can be implemented in many ways, some of which are software based, such as overlays. Most effective virtual-memory schemes are, however, hardware based. In these schemes, the virtual address space is divided into fixed-sized units, termed pages, as shown in Figure 5.2. Virtual-memory references are resolved by the address-translation unit to a page in main memory and an offset within that page. Hardware protection is applied by the memory-management unit on a page-by-page basis.
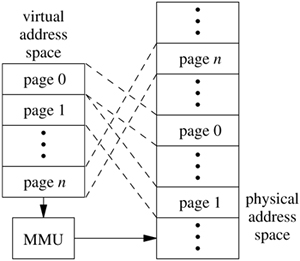
Some systems provide a two-tiered virtual-memory system in which pages are grouped into segments [Organick, 1975]. In these systems, protection is usually at the segment level. In the remainder of this chapter, we shall be concerned with only those virtual-memory systems that are page based.
Address translation provides the implementation of virtual memory by decoupling the virtual address space of a process from the physical address space of the CPU. Each page of virtual memory is marked as resident or nonresident in main memory. If a process references a location in virtual memory that is not resident, a hardware trap termed a page fault is generated. The servicing of page faults, or paging, permits processes to execute even if they are only partially resident in main memory.
Coffman & Denning [1973] characterize paging systems by three important policies:
- When the system loads pages into memory—the fetch policy
- Where the system places pages in memory—the placement policy
- How the system selects pages to be removed from main memory when pages are unavailable for a placement request—the replacement policy
The performance of modern computers is heavily dependent on one or more highspeed caches to reduce the need to access the much slower main memory. The placement policy should ensure that contiguous pages in virtual memory make the best use of the processor cache. FreeBSD uses a coloring algorithm to ensure good placement. Under a pure demand-paging system, a demand-fetch policy is used, in which only the missing page is fetched, and replacements occur only when main memory is full. Consequently, the performance of a pure demand-paging system depends on only the system's replacement policy. In practice, paging systems do not implement a pure demand-paging algorithm. Instead, the fetch policy often is altered to do prepaging—fetching pages of memory other than the one that caused the page fault—and the replacement policy is invoked before main memory is full.
The replacement policy is the most critical aspect of any paging system. There is a wide range of algorithms from which we can select in designing a replacement strategy for a paging system. Much research has been carried out in evaluating the performance of different page-replacement algorithms [Bansal & Modha, 2004; Belady, 1966; King, 1971; Marshall, 1979].
A process's paging behavior for a given input is described in terms of the pages referenced over the time of the process's execution. This sequence of pages, termed a reference string, represents the behavior of the process at discrete times during the process's lifetime. Corresponding to the sampled references that constitute a process's reference string are real-time values that reflect whether the associated references resulted in a page fault. A useful measure of a process's behavior is the fault rate, which is the number of page faults encountered during processing of a reference string, normalized by the length of the reference string.
Page-replacement algorithms typically are evaluated in terms of their effectiveness on reference strings that have been collected from execution of real programs. Formal analysis can also be used, although it is difficult to do unless many restrictions are applied to the execution environment. The most common metric used in measuring the effectiveness of a page-replacement algorithm is the fault rate.
Page-replacement algorithms are defined by the criteria that they use for selecting pages to be reclaimed. For example, the optimal replacement policy [Denning, 1970] states that the "best" choice of a page to replace is the one with the longest expected time until its next reference. Clearly, this policy is not applicable to dynamic systems, as it requires a priori knowledge of the paging characteristics of a process. The policy is useful for evaluation purposes, however, as it provides a yardstick for comparing the performance of other page-replacement algorithms.
Practical page-replacement algorithms require a certain amount of state information that the system uses in selecting replacement pages. This state typically includes the reference pattern of a process, sampled at discrete time intervals. On some systems, this information can be expensive to collect [Babaoglu & Joy, 1981]. As a result, the "best" page-replacement algorithm may not be the most efficient.
The working-set model assumes that processes exhibit a slowly changing locality of reference. For a period of time, a process operates in a set of subroutines or loops, causing all its memory references to refer to a fixed subset of its address space, termed the working set. The process periodically changes its working set, abandoning certain areas of memory and beginning to access new ones. After a period of transition, the process defines a new set of pages as its working set. In general, if the system can provide the process with enough pages to hold that process's working set, the process will experience a low page-fault rate. If the system cannot provide the process with enough pages for the working set, the process will run slowly and will have a high page-fault rate.
Precise calculation of the working set of a process is impossible without a priori knowledge of that process's memory-reference pattern. However, the working set can be approximated by various means. One method of approximation is to track the number of pages held by a process and that process's page-fault rate. If the page-fault rate increases above a high watermark, the working set is assumed to have increased, and the number of pages held by the process is allowed to grow. Conversely, if the page-fault rate drops below a low watermark, the working set is assumed to have decreased, and the number of pages held by the process is reduced.
Swapping is the term used to describe a memory-management policy in which entire processes are moved to and from secondary storage when main memory is in short supply. Swap-based memory-management systems usually are less complicated than are demand-paged systems, since there is less bookkeeping to do. However, pure swapping systems typically are less effective than are paging systems, since the degree of multiprogramming is lowered by the requirement that processes be fully resident to execute. Swapping is sometimes combined with paging in a two-tiered scheme, whereby paging satisfies memory demands until a severe memory shortfall requires drastic action, in which case swapping is used.
In this chapter, a portion of secondary storage that is used for paging or swapping is termed a swap area or swap space. The hardware devices on which these areas reside are termed swap devices.
There are several advantages to the use of virtual memory on computers capable of supporting this facility properly. Virtual memory allows large programs to be run on machines with main-memory configurations that are smaller than the program size. On machines with a moderate amount of memory, it allows more programs to be resident in main memory to compete for CPU time, as the programs do not need to be completely resident. When programs use sections of their program or data space for some time, leaving other sections unused, the unused sections do not need to be present. Also, the use of virtual memory allows programs to start up faster, since they generally require only a small section to be loaded before they begin processing arguments and determining what actions to take. Other parts of a program may not be needed at all during individual runs. As a program runs, additional sections of its program and data spaces are paged in on demand (demand paging). Finally, there are many algorithms that are more easily programmed by sparse use of a large address space than by careful packing of data structures into a small area. Such techniques are too expensive for use without virtual memory, but they may run much faster when that facility is available, without using an inordinate amount of physical memory.
On the other hand, the use of virtual memory can degrade performance. It is more efficient to load a program all at one time than to load it entirely in small sections on demand. There is a finite cost for each operation, including saving and restoring state and determining which page must be loaded, so some systems use demand paging for only those programs that are larger than some minimum size.
Nearly all versions of UNIX have required some form of memory-management hardware to support transparent multiprogramming. To protect processes from modification by other processes, the memory-management hardware must prevent programs from changing their own address mapping. The FreeBSD kernel runs in a privileged mode (kernel mode or system mode) in which memory mapping can be controlled, whereas processes run in an unprivileged mode (user mode). There are several additional architectural requirements for support of virtual memory. The CPU must distinguish between resident and nonresident portions of the address space, must suspend programs when they refer to nonresident addresses, and must resume programs' operation once the operating system has placed the required section in memory. Because the CPU may discover missing data at various times during the execution of an instruction, it must provide a mechanism to save the machine state so that the instruction can be continued or restarted later. The CPU may implement restarting by saving enough state when an instruction begins that the state can be restored when a fault is discovered. Alternatively, instructions could delay any modifications or side effects until after any faults would be discovered so that the instruction execution does not need to back up before restarting. On some computers, instruction backup requires the assistance of the operating system.
Most machines designed to support demand-paged virtual memory include hardware support for the collection of information on program references to memory. When the system selects a page for replacement, it must save the contents of that page if they have been modified since the page was brought into memory. The hardware usually maintains a per-page flag showing whether the page has been modified. Many machines also include a flag recording any access to a page for use by the replacement algorithm.
The FreeBSD virtual-memory system is based on the Mach 2.0 virtual-memory system [Tevanian, 1987], with updates from Mach 2.5 and Mach 3.0. The Mach virtual-memory system was adopted because it features efficient support for sharing and a clean separation of machine-independent and machine-dependent features, as well as multiprocessor support. None of the original Mach system-call interface remains. It has been replaced with the interface first proposed for 4.2BSD that has been widely adopted by the UNIX industry; the FreeBSD interface is described in Section 5.5.
The virtual-memory system implements protected address spaces into which can be mapped data sources (objects) such as files or private, anonymous pieces of swap space. Physical memory is used as a cache of recently used pages from these objects and is managed by a global page-replacement algorithm.
The virtual address space of most architectures is divided into two parts. For FreeBSD running on 32-bit architectures, the top 1 Gbyte of the address space is reserved for use by the kernel. Systems with many small processes making heavy use of kernel facilities such as networking can be configured to use the top 2 Gbyte for the kernel. The remaining address space is available for use by processes. A traditional UNIX layout is shown in Figure 5.3 (on page 142). Here, the kernel and its associated data structures reside at the top of the address space. The initial text and data areas of the user process start at or near the beginning of memory. Typically, the first 4 or 8 Kbyte of memory are kept off-limits to the process. The reason for this restriction is to ease program debugging; indirecting through a null pointer will cause an invalid address fault instead of reading or writing the program text. Memory allocations made by the running process using the malloc() library routine (or the sbrk system call) are done on the heap that starts immediately following the data area and grows to higher addresses. The argument vector and environment vectors are at the top of the user portion of the address space. The user's stack starts just below these vectors and grows to lower addresses. Subject to only administrative limits, the stack and heap can each grow until they meet. At that point, a process running on a 32-bit machine will be using nearly 3 Gbyte of address space.
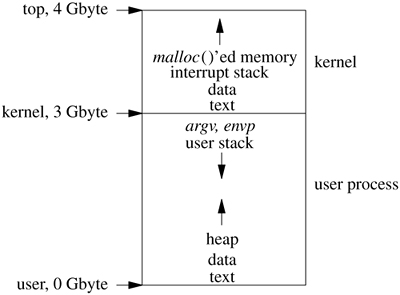
In FreeBSD and other modern UNIX systems that support the mmap system call, address-space usage is less structured. Shared library implementations may place text or data arbitrarily, rendering the notion of predefined regions obsolete. For compatibility, FreeBSD still supports the sbrk call that malloc() uses to provide a contiguous heap region, and the stack region is automatically grown to its size limit. By default, shared libraries are placed just below the run-time configured maximum stack area.
At any time, the currently executing process is mapped into the virtual address space. When the system decides to context switch to another process, it must save the information about the current-process address mapping, then load the address mapping for the new process to be run. The details of this address-map switching are architecture dependent. Some architectures need to change only a few memory-mapping registers that point to the base, and to give the length of memory-resident page tables. Other architectures store the page-table descriptors in special high-speed static RAM. Switching these maps may require dumping and reloading hundreds of map entries.
Both the kernel and user processes use the same basic data structures for the management of their virtual memory. The data structures used to manage virtual memory are as follows:

In the remainder of this section, we describe briefly how all these data structures fit together. The remainder of this chapter describes the details of the structures and how the structures are used.
Figure 5.4 shows a typical process address space and associated data structures. The vmspace structure encapsulates the virtual-memory state of a particular process, including the machine-dependent and machine-independent data structures, as well as statistics. The machine-dependent pmap structure is opaque to all but the lowest level of the system and contains all information necessary to manage the memory-management hardware. This pmap layer is the subject of Section 5.13 and is ignored for the remainder of the current discussion. The machine-independent data structures include the address space that is represented by a vm_map structure. The vm_map contains a linked list of vm_map_entry structures, hints for speeding up lookups during memory allocation and page-fault handling, and a pointer to the associated machine-dependent pmap structure contained in the vmspace. A vm_map_entry structure describes a virtually contiguous range of addresses that have the same protection and inheritance attributes. Every vm_map_entry points to a chain of vm_object structures that describes sources of data (objects) that are mapped at the indicated address range. At the tail of the chain is the original mapped data object, usually representing a persistent data source, such as a file. Interposed between that object and the map entry are one or more transient shadow objects that represent modified copies of the original data. These shadow objects are discussed in detail in Section 5.5.
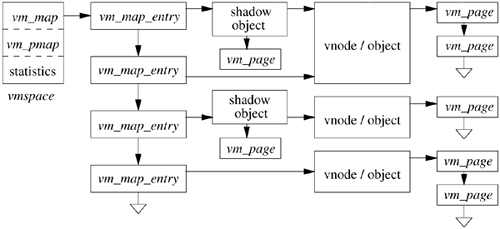
Each vm_object structure contains a linked list of vm_page structures representing the physical-memory cache of the object, as well as the type of and a pointer to the pager structure that contains information on how to page in or page out data from its backing store. There is a vm_page structure allocated for every page of physical memory managed by the virtual-memory system, where a page here may be a collection of multiple, contiguous hardware pages that will be treated by the machine-dependent layer as though they were a single unit. The structure also contains the status of the page (e.g., modified or referenced) and links for various paging queues. A vm_page structure is most commonly and quickly found through a global hash list that is keyed by the object and logical page within that object whose contents are held by the page.
All structures contain the necessary interlocks for multithreading in a multiprocessor environment. The locking is fine grained, with at least one lock per instance of a data structure. Many of the structures contain multiple locks to protect individual fields.
There are two ways in which the kernel's memory can be organized. The most common is for the kernel to be permanently mapped into the high part of every process address space. In this model, switching from one process to another does not affect the kernel portion of the address space. The alternative organization is to switch between having the kernel occupy the whole address space and mapping the currently running process into the address space. Having the kernel permanently mapped does reduce the amount of address space available to a large process (and the kernel), but it also reduces the cost of data copying. Many system calls require data to be transferred between the currently running user process and the kernel. With the kernel permanently mapped, the data can be copied via the efficient block-copy instructions. If the kernel is alternately mapped with the process, data copying requires the use of special instructions that copy to and from the previously mapped address space. These instructions are usually a factor of 2 slower than the standard block-copy instructions. Since up to one-third of the kernel time is spent in copying between the kernel and user processes, slowing this operation by a factor of 2 significantly slows system throughput.
Although the kernel is able to freely read and write the address space of the user process, the converse is not true. The kernel's range of virtual address space is marked inaccessible to all user processes. Writing is restricted so user processes cannot tamper with the kernel's data structures. Reading is restricted so user processes cannot watch sensitive kernel data structures, such as the terminal input queues, that include such things as users typing their passwords.
Usually, the hardware dictates which organization can be used. All the architectures supported by FreeBSD map the kernel into the top of the address space.
When the system boots, the first task that the kernel must do is to set up data structures to describe and manage its address space. Like any process, the kernel has a vm_map with a corresponding set of vm_map_entry structures that describe the use of a range of addresses. Submaps are a special kernel-only construct used to isolate and constrain address-space allocation for kernel subsystems. One use is in subsystems that require contiguous pieces of the kernel address space. To avoid intermixing of unrelated allocations within an address range, that range is covered by a submap, and only the appropriate subsystem can allocate from that map. For example, several network buffer (mbuf) manipulation macros use address arithmetic to generate unique indices, thus requiring the network buffer region to be contiguous. Parts of the kernel may also require addresses with particular alignments or even specific addresses. Both can be ensured by use of submaps. Finally, submaps can be used to limit statically the amount of address space and hence the physical memory consumed by a subsystem.
A typical layout of the kernel map is shown in Figure 5.5. The kernel's address space is described by the vm_map structure shown in the upperleft corner of the figure. Pieces of the address space are described by the vm_map_entry structures that are linked in ascending address order from K0 to K8 on the vm_map structure. Here, the kernel text, initialized data, uninitialized data, and initially allocated data structures reside in the range K0 to Kl and are represented by the first vm_map_entry. The next vm_map_entry is associated with the address range from K2 to K6. This piece of the kernel address space is being managed via a submap headed by the referenced vm_map structure. This submap currently has two parts of its address space used: the address range K2 to K3, and the address range K4 to K5. These two submaps represent the kernel malloc arena and the network buffer arena, respectively. The final part of the kernel address space is being managed in the kernel's main map, the address range K7 to K8 representing the kernel I/O staging area.
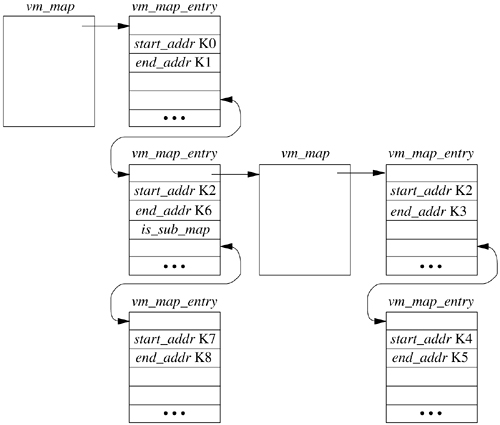
The virtual-memory system implements a set of primitive functions for allocating and freeing the page-aligned, page-rounded virtual-memory ranges that the kernel uses. These ranges may be allocated either from the main kernel-address map or from a submap. The allocation routines take a map and size as parameters but do not take an address. Thus, specific addresses within a map cannot be selected. There are different allocation routines for obtaining nonpageable and pageable memory ranges.
A nonpageable, or wired, range has physical memory assigned at the time of the call, and this memory is not subject to replacement by the pageout daemon. Wired pages must never cause a page fault that might result in a blocking operation. Wired memory is allocated with kmem_alloc() and kmem_malloc(). Kmem_alloc() returns zero-filled memory and may block if insufficient physical memory is available to honor the request. It will return a failure only if no address space is available in the indicated map. Kmem_malloc() is a variant of kmem_alloc() used by only the general allocator, malloc(), described in the next subsection. This routine has a nonblocking option that protects callers against inadvertently blocking on kernel data structures; it will fail if insufficient physical memory is available to fill the requested range. This nonblocking option allocates memory at interrupt time and during other critical sections of code. In general, wired memory should be allocated via the general-purpose kernel allocator. Kmem_alloc() should be used only to allocate memory from specific kernel submaps.
Pageable kernel virtual memory can be allocated with kmem_alloc_pageable() and kmem_alloc_wait(). A pageable range has physical memory allocated on demand, and this memory can be written out to backing store by the pageout daemon as part of the latter's normal replacement policy. Kmem_alloc_pageable() will return an error if insufficient address space is available for the desired allocation; kmem_alloc_wait() will block until space is available. Currently, pageable kernel memory is used only for temporary storage of exec arguments.
Kmem_free() deallocates kernel wired memory and pageable memory allocated with kmem_alloc_pageable(). Kmem_free_wakeup() should be used with kmem_alloc_wait() because it wakes up any processes waiting for address space in the specified map.
The kernel also provides a generalized nonpageable memory-allocation and freeing mechanism that can handle requests with arbitrary alignment or size, as well as allocate memory at interrupt time. So it is the preferred way to allocate kernel memory other than large, fixed-size structures that are better handled by the zone allocator described in the next subsection. This mechanism has an interface similar to that of the well-known memory allocator provided for applications programmers through the C library routines malloc() and free(). Like the C library interface, the allocation routine takes a parameter specifying the size of memory that is needed. The range of sizes for memory requests are not constrained. The free routine takes a pointer to the storage being freed, but it does not require the size of the piece of memory being freed.
Often, the kernel needs a memory allocation for the duration of a single system call. In a user process, such short-term memory would be allocated on the run-time stack. Because the kernel has a limited run-time stack, it is not feasible to allocate even moderate blocks of memory on it. Consequently, such memory must be allocated dynamically. For example, when the system must translate a pathname, it must allocate a 1-Kbyte buffer to hold the name. Other blocks of memory must be more persistent than a single system call and have to be allocated from dynamic memory. Examples include protocol control blocks that remain throughout the duration of a network connection.
The design specification for a kernel memory allocator is similar, but not identical, to the design criteria for a user-level memory allocator. One criterion for a memory allocator is that it make good use of the physical memory. Use of memory is measured by the amount of memory needed to hold a set of allocations at any point in time. Percentage utilization is expressed as
Here, requested is the sum of the memory that has been requested and not yet freed; required is the amount of memory that has been allocated for the pool from which the requests are filled. An allocator requires more memory than requested because of fragmentation and a need to have a ready supply of free memory for future requests. A perfect memory allocator would have a utilization of 100 percent. In practice, a 50 percent utilization is considered good [Korn & Vo, 1985].
Good memory utilization in the kernel is more important than in user processes. Because user processes run in virtual memory, unused parts of their address space can be paged out. Thus, pages in the process address space that are part of the required pool that are not being requested do not need to tie up physical memory. Since the kernel malloc arena is not paged, all pages in the required pool are held by the kernel and cannot be used for other purposes. To keep the kernel-utilization percentage as high as possible, the kernel should release unused memory in the required pool rather than hold it, as is typically done with user processes. Because the kernel can manipulate its own page maps directly, freeing unused memory is fast; a user process must do a system call to free memory.
The most important criterion for a kernel memory allocator is that it be fast. A slow memory allocator will degrade the system performance because memory allocation is done frequently. Speed of allocation is more critical when executing in the kernel than it is in user code because the kernel must allocate many data structures that user processes can allocate cheaply on their run-time stack. In addition, the kernel represents the platform on which all user processes run, and if it is slow, it will degrade the performance of every process that is running.
Another problem with a slow memory allocator is that programmers of frequently used kernel interfaces will think that they cannot afford to use the memory allocator as their primary one. Instead, they will build their own memory allocator on top of the original by maintaining their own pool of memory blocks. Multiple allocators reduce the efficiency with which memory is used. The kernel ends up with many different free lists of memory instead of a single free list from which all allocations can be drawn. For example, consider the case of two subsystems that need memory. If they have their own free lists, the amount of memory tied up in the two lists will be the sum of the greatest amount of memory that each of the two subsystems has ever used. If they share a free list, the amount of memory tied up in the free list may be as low as the greatest amount of memory that either subsystem used. As the number of subsystems grows, the savings from having a single free list grow.
The kernel memory allocator uses a hybrid strategy. Small allocations are done using a power-of-2 list strategy. Using the zone allocator (described in the next subsection), the kernel creates a set of zones with one for each power-of-two between 16 and the page size. The allocation simply requests a block of memory from the appropriate zone. Usually, the zone will have an available piece of memory that it can return. Only if every piece of memory in the zone is in use will the zone allocator have to do a full allocation. When forced to do an additional allocation, it allocates an entire page and carves it up into the appropriate-sized pieces. This strategy speeds future allocations because several pieces of memory become available as a result of the call into the allocator.
Freeing a small block also is fast. The memory is simply returned to the zone from which it came.
Because of the inefficiency of power-of-2 allocation strategies for large allocations, the allocation method for large blocks is based on allocating pieces of memory in multiples of pages. The algorithm switches to the slower but more memory-efficient strategy for allocation sizes larger than a page. This value is chosen because the power-of-2 algorithm yields sizes of 1, 2, 4, 8, . . ., n pages, whereas the large block algorithm that allocates in multiples of pages yields sizes of 1, 2, 3, 4,. . ., n pages. Thus, for allocations of greater than one page, the large block algorithm will use less than or equal to the number of pages used by the power-of-2 algorithm, so the threshold between the large and small allocators is set at one page.
Large allocations are first rounded up to be a multiple of the page size. The allocator then uses a "first-fit" algorithm to find space in the kernel address arena set aside for dynamic allocations. On a machine with a 4-Kbyte page size, a request for a 20-Kbyte piece of memory will use exactly five pages of memory, rather than the eight pages used with the power-of-2 allocation strategy. When a large piece of memory is freed, the memory pages are returned to the free-memory pool and the vm_map_entry structure is deleted from the submap, effectively coalescing the freed piece with any adjacent free space.
Because the size is not specified when a block of memory is freed, the allocator must keep track of the sizes of the pieces that it has handed out. Many allocators increase the allocation request by a few bytes to create space to store the size of the block in a header just before the allocation. However, this strategy doubles the memory requirement for allocations that request a power-of-2-sized block. Therefore, instead of storing the size of each piece of memory with the piece itself, the zone allocator associates the size information with the memory page. Locating the allocation size outside of the allocated block improved utilization far more than expected. The reason is that many allocations in the kernel are for blocks of memory whose size is exactly a power of 2. The size of these requests would be nearly doubled if the more typical strategy were used. Now they can be accommodated with no wasted memory.
The allocator can be called both from the top half of the kernel that is willing to wait for memory to become available and from the interrupt routines in the bottom half of the kernel that cannot wait for memory to become available. Clients show their willingness (and ability) to wait with a flag to the allocation routine. For clients that are willing to wait, the allocator guarantees that their request will succeed. Thus, these clients do not need to check the return value from the allocator. If memory is unavailable and the client cannot wait, the allocator returns a null pointer. These clients must be prepared to cope with this (typically infrequent) condition (usually by giving up and hoping to succeed later). The details of the kernel memory allocator are further described in McKusick & Karels [1988].
Some commonly allocated items in the kernel such as process, thread, vnode, and control-block structures are not well handled by the general purpose malloc interface. These structures share several characteristics:
• They tend to be large and hence wasteful of space. For example, the process structure is about 550 bytes, which when rounded up to a power-of-2 size requires 1024 bytes of memory.
• They tend to be common. Because they are individually wasteful of space, collectively they waste too much space compared to a denser representation.
• They are often linked together in long lists. If the allocation of each structure begins on a page boundary, then the list pointers will all be at the same offset from the beginning of the page. When traversing these structures, the linkage pointers will all be located on the same hardware cache line, causing each step along the list to produce a cache miss, making the list-traversal slow.
• These structures often contain many lists and locks that must be initialized before use. If there is a dedicated pool of memory for each structure, then these substructures need to be initialized only when the pool is first created rather than after every allocation.
For these reasons, FreeBSD provides a zone allocator (sometimes referred to as a slab allocator). The zone allocator provides an efficient interface for managing a collection of items of the same size and type [Bonwick, 1994; Bonwick & Adams, 2001]. The creation of separate zones runs counter to the desire to keep all memory in a single pool to maximize utilization efficiency. However, the benefits from segregating memory for the small set of structures for which the zone allocator is appropriate outweighs the efficiency gains from keeping them in the general pool. The zone allocator minimizes the impact of the separate pools by freeing memory from a zone based on a reduction in demand for objects from the zone and when notified of a memory shortage by the pageout daemon.
A zone is an extensible collection of items of identical size. The zone allocator keeps track of the active and free items and provides functions for allocating items from the zone and for releasing them back to make them available for later use. Memory is allocated to the zone as necessary.
Items in the pool are type stable. The memory in the pool will not be used for any other purpose. A structure in the pool need only be initialized on its first use. Later uses may assume that the initialized values will retain their contents as of the previous free. A callback is provided before memory is freed from the zone to allow any persistent state to be cleaned up.
A new zone is created with the uma_zcreate() function. It must specify the size of the items to be allocated and register two sets of functions. The first set is called whenever an item is allocated or freed from the zone. They typically track the number of allocated items. The second set is called whenever memory is allocated or freed from the zone. They provide hooks for initializing or destroying substructures within the items such as locks or mutexes when they are first allocated or are about to be freed.
Items are allocated with uma_zalloc(), which takes a zone identifier returned by uma_zcreate(). Items are freed with uma_zfree(), which takes a zone identifier and a pointer to the item to be freed. No size is needed when allocating or freeing, since the item size was set when the zone was created.
To aid performance on multiprocessor systems, a zone may be backed by pages from the per-CPU caches of each of the processors for objects that are likely to have processor affinity. For example, if a particular process is likely to be run on the same CPU, then it would be sensible to allocate its structure from the cache for that CPU.
The zone allocator provides the uma_zone_set_max() function to set the upper limit of items in the zone. The limit on the total number of items in the zone includes the allocated and free items, including the items in the per-CPU caches. On multiprocessor systems, it may not be possible to allocate a new item for a particular CPU because the limit has been hit and all the free items are in the caches of the other CPUs.
As we have already seen, a process requires a process entry and a kernel stack. The next major resource that must be allocated is its virtual memory. The initial virtual-memory requirements are defined by the header in the process's executable. These requirements include the space needed for the program text, the initialized data, the uninitialized data, and the run-time stack. During the initial startup of the program, the kernel will build the data structures necessary to describe these four areas. Most programs need to allocate additional memory. The kernel typically provides this additional memory by expanding the uninitialized data area.
Most FreeBSD programs use shared libraries. The header for the executable will describe the libraries that it needs (usually the C library, and possibly others). The kernel is not responsible for locating and mapping these libraries during the initial execution of the program. Finding, mapping, and creating the dynamic linkages to these libraries is handled by the user-level startup code prepended to the file being executed. This startup code usually runs before control is passed to the main entry point of the program [Gingell et al., 1987].
The initial layout of the address space for a process is shown in Figure 5.6 (on page 152). As discussed in Section 5.2, the address space for a process is described by that process's vmspace structure. The contents of the address space are defined by a list of vm_map_entry structures, each structure describing a region of virtual address space that resides between a start and an end address. A region describes a range of memory that is being treated in the same way. For example, the text of a program is a region that is read-only and is demand paged from the file on disk that contains it. Thus, the vm_map_entry also contains the protection mode to be applied to the region that it describes. Each vm_map_entry structure also has a pointer to the object that provides the initial data for the region. The object also stores the modified contents either transiently, when memory is being reclaimed, or more permanently, when the region is no longer needed. Finally, each vm_map_entry structure has an offset that describes where within the object the mapping begins.
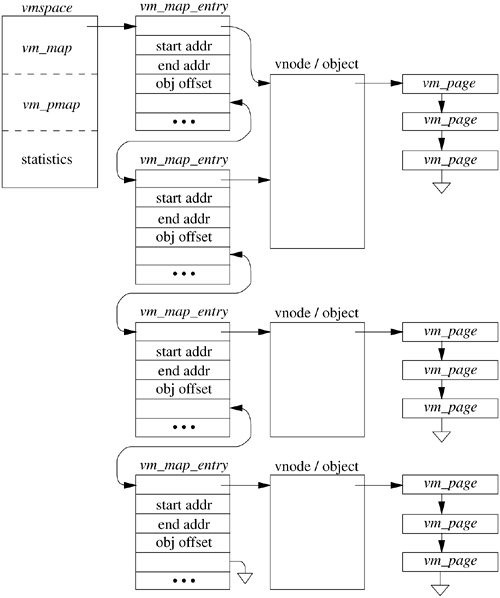
The example shown in Figure 5.6 represents a process just after it has started execution. The first two map entries both point to the same object; here, that object is the executable. The executable consists of two parts: the text of the program that resides at the beginning of the file and the initialized data area that follows at the end of the text. Thus, the first vm_map_entry describes a read-only region that maps the text of the program. The second vm_map_entry describes the copy-on-write region that maps the initialized data of the program that follows the program text in the file (copy-on-write is described in Section 5.6). The offset field in the entry reflects this different starting location. The third and fourth vm_map_entry structures describe the uninitialized data and stack areas, respectively. Both of these areas are represented by anonymous objects. An anonymous object provides a zero-filled page on first use and arranges to store modified pages in the swap area if memory becomes tight. Anonymous objects are described in more detail later in this section.
When a process attempts to access a piece of its address space that is not currently resident, a page fault occurs. The page-fault handler in the kernel is presented with the virtual address that caused the fault and the type of access that was attempted (read or write). The fault is handled with the following four steps:
- Find the vmspace structure for the faulting process; from that structure, find the head of the vm_map_entry list.
- Traverse the vm_map_entry list, starting at the entry indicated by the map hint; for each entry, check whether the faulting address falls within its start and end address range. If the kernel reaches the end of the list without finding any valid region, the faulting address is not within any valid part of the address space for the process, so send the process a segment fault signal.
- Having found a vm_map_entry that contains the faulting address, convert that address to an offset within the underlying object. Calculate the offset within the object as

Subtract off the start address to give the offset into the region mapped by the vm_map_entry. Add in the object offset to give the absolute offset of the page within the object.
- Present the absolute object offset to the underlying object, which allocates a vm_page structure and uses its pager to fill the page. The object then returns a pointer to the vm_page structure, which is mapped into the faulting location in the process address space.
Once the appropriate page has been mapped into the faulting location, the page-fault handler returns and reexecutes the faulting instruction.
Objects are used to hold information about either a file or about an area of anonymous memory. Whether a file is mapped by a single process in the system or by many processes in the system, it will always be represented by a single object. Thus, the object is responsible for maintaining all the state about those pages of a file that are resident. All references to that file will be described by vm_map_entry structures that reference the same object. An object never stores the same page of a file in more than one physical-memory page, so all mappings will get a consistent view of the file.
An object stores the following information:
• A list of the pages for that object that are currently resident in main memory; a page may be mapped into multiple address spaces, but it is always claimed by exactly one object
• A count of the number of vm_map_entry structures or other objects that reference the object
• The size of the file or anonymous area described by the object
• The number of memory-resident pages held by the object
• Pointer to shadow objects (described in Section 5.5)
• The type of pager for the object; the pager is responsible for providing the data to fill a page and for providing a place to store the page when it has been modified (pagers are covered in Section 5.10)
There are three types of objects in the system:
• Named objects represent files; they may also represent hardware devices that are able to provide mapped memory such as frame buffers.
• Anonymous objects represent areas of memory that are zero filled on first use; they are abandoned when they are no longer needed.
• Shadow objects hold private copies of pages that have been modified; they are abandoned when they are no longer referenced.
These objects are often referred to as "internal" objects in the source code. The type of an object is defined by the type of pager that that object uses to fulfill page-fault requests.
A named object uses either the device pager, if it maps a hardware device, or the vnode pager, if it is backed by a file in the filesystem. The device pager services a page fault by returning the appropriate address for the device being mapped. Since the device memory is separate from the main memory on the machine, it will never be selected by the pageout daemon. Thus, the device pager never has to handle a pageout request.
The vnode pager provides an interface to objects that represent files in the filesystem. The vnode pager keeps a reference to a vnode that represents the file being mapped in the object. The vnode pager services a pagein request by doing a read on the vnode; it services a pageout request by doing a write to the vnode. Thus, the file itself stores the modified pages. In cases where it is not appropriate to modify the file directly, such as an executable that does not want to modify its initialized data pages, the kernel must interpose an anonymous shadow object between the vm_map_entry and the object representing the file; see Section 5.5.
Anonymous objects use the swap pager. An anonymous object services pagein requests by getting a page of memory from the free list and zeroing that page. When a pageout request is made for a page for the first time, the swap pager is responsible for finding an unused page in the swap area, writing the contents of the page to that space, and recording where that page is stored. If a pagein request comes for a page that had been previously paged out, the swap pager is responsible for finding where it stored that page and reading back the contents into a free page in memory. A later pageout request for that page will cause the page to be written out to the previously allocated location.
Shadow objects also use the swap pager. They work just like anonymous objects, except that the swap pager provides their initial pages by copying existing pages in response to copy-on-write faults instead of by zero-filling pages.
Further details on the pagers are given in Section 5.10.
Each virtual-memory object has a pager type, pager handle, and pager private data associated with it. Objects that map files have a vnode-pager type associated with them. The handle for the vnode-pager type is a pointer to the vnode on which to do the I/O, and the private data is the size of the vnode at the time that the mapping was done. Every vnode that maps a file has an object associated with it. When a fault occurs for a file that is mapped into memory, the object associated with the file can be checked to see whether the faulted page is resident. If the page is resident, it can be used. If the page is not resident, a new page is allocated, and the vnode pager is requested to fill the new page.
Caching in the virtual-memory system is identified by an object that is associated with a file or region that it represents. Each object contains pages that are the cached contents of its associated file or region. Objects are reclaimed as soon as their reference count drops to zero. Pages associated with reclaimed objects are moved to the free list. Objects that represent anonymous memory are reclaimed as part of cleaning up a process as it exits. However, objects that refer to files are persistent. When the reference count on a vnode drops to zero, it is stored on a least-recently used (LRU) list known as the vnode cache; see Section 6.6. The vnode does not release its object until the vnode is reclaimed and reused for another file. Unless there is pressure on the memory, the object associated with the vnode will retain its pages. If the vnode is reactivated and a page fault occurs before the associated page is freed, that page can be reattached rather than being reread from disk.
This cache is similar to the text cache found in earlier versions of BSD in that it provides performance improvements for short-running but frequently executed programs. Frequently executed programs include those used to list the contents of directories, show system status, or perform the intermediate steps involved in compiling a program. For example, consider a typical application that is made up of multiple source files. Each of several compiler steps must be run on each file in turn. The first time that the compiler is run, the executable files associated with its various components are read in from the disk. For each file compiled thereafter, the previously created executable files are found, as well as any previously read header files, alleviating the need to reload them from disk each time.
When the system is first booted, the kernel looks through the physical memory on the machine to find out how many pages are available. After the physical memory that will be dedicated to the kernel itself has been deducted, all the remaining pages of physical memory are described by vm_page structures. These vm_page structures are all initially placed on the memory free list. As the system starts running and processes begin to execute, they generate page faults. Each page fault is matched to the object that covers the faulting piece of address space. The first time that a piece of an object is faulted, it must allocate a page from the free list and must initialize that page either by zero-filling it or by reading its contents from the filesystem. That page then becomes associated with the object. Thus, each object has its current set of vm_page structures linked to it. A page can be associated with at most one object at a time. Although a file may be mapped into several processes at once, all those mappings reference the same object. Having a single object for each file ensures that all processes will reference the same physical pages.
If memory becomes scarce, the paging daemon will search for pages that have not been used actively. Before these pages can be used by a new object, they must be removed from all the processes that currently have them mapped, and any modified contents must be saved by the object that owns them. Once cleaned, the pages can be removed from the object that owns them and can be placed on the free list for reuse. The details of the paging system are described in Section 5.12.
In Section 5.4, we explained how the address space of a process is organized. This section shows the additional data structures needed to support shared address space between processes. Traditionally, the address space of each process was completely isolated from the address space of all other processes running on the system. The only exception was read-only sharing of program text. All interprocess communication was done through well-defined channels that passed through the kernel: pipes, sockets, files, and special devices. The benefit of this isolated approach is that, no matter how badly a process destroys its own address space, it cannot affect the address space of any other process running on the system. Each process can precisely control when data are sent or received; it can also precisely identify the locations within its address space that are read or written. The drawback of this approach is that all interprocess communication requires at least two system calls: one from the sending process and one from the receiving process. For high volumes of interprocess communication, especially when small packets of data are being exchanged, the overhead of the system calls dominates the communications cost.
Shared memory provides a way to reduce interprocess-communication costs dramatically. Two or more processes that wish to communicate map the same piece of read-write memory into their address space. Once all the processes have mapped the memory into their address space, any changes to that piece of memory are visible to all the other processes, without any intervention by the kernel. Thus, interprocess communication can be achieved without any system-call overhead other than the cost of the initial mapping. The drawback to this approach is that, if a process that has the memory mapped corrupts the data structures in that memory, all the other processes mapping that memory also are corrupted. In addition, there is the complexity faced by the application developer who must develop data structures to control access to the shared memory and must cope with the race conditions inherent in manipulating and controlling such data structures that are being accessed concurrently.
Some UNIX variants have a kernel-based semaphore mechanism to provide the needed serialization of access to the shared memory. However, both getting and setting such semaphores require system calls. The overhead of using such semaphores is comparable to that of using the traditional interprocess-communication methods. Unfortunately, these semaphores have all the complexity of shared memory, yet confer little of its speed advantage. The primary reason to introduce the complexity of shared memory is for the commensurate speed gain. If this gain is to be obtained, most of the data-structure locking needs to be done in the shared memory segment itself. The kernel-based semaphores should be used for only those rare cases where there is contention for a lock and one process must wait. Consequently, modern interfaces, such as POSIX Pthreads, are designed such that the semaphores can be located in the shared memory region. The common case of setting or clearing an uncontested semaphore can be done by the user process, without calling the kernel. There are two cases where a process must do a system call. If a process tries to set an already locked semaphore, it must call the kernel to block until the semaphore is available. This system call has little effect on performance because the lock is contested, so it is impossible to proceed, and the kernel must be invoked to do a context switch anyway. If a process clears a semaphore that is wanted by another process, it must call the kernel to awaken that process. Since most locks are uncontested, the applications can run at full speed without kernel intervention.
When two processes wish to create an area of shared memory, they must have some way to name the piece of memory that they wish to share, and they must be able to describe its size and initial contents. The system interface describing an area of shared memory accomplishes all these goals by using files as the basis for describing a shared memory segment. A process creates a shared memory segment by using

to map the file referenced by descriptor fd starting at file offset offset into its address space starting at address and continuing for length bytes with access permission protection. The flags parameter allows a process to specify whether it wants to make a shared or private mapping. Changes made to a shared mapping are written back to the file and are visible to other processes. Changes made to a private mapping are not written back to the file and are not visible to other processes. Two processes that wish to share a piece of memory request a shared mapping of the same file into their address space. Thus, the existing and well-understood filesystem name space identifies shared objects. The contents of the file are used as the initial value of the memory segment. All changes made to the mapping are reflected back into the contents of the file, so long-term state can be maintained in the shared memory region, even across invocations of the sharing processes.
Some applications want to use shared memory purely as a short-term interprocess-communication mechanism. They need an area of memory that is initially zeroed and whose contents are abandoned when they are done using it. Such processes neither want to pay the relatively high startup cost associated with paging in the contents of a file to initialize a shared memory segment nor to pay the shutdown costs of writing modified pages back to the file when they are done with the memory. Although FreeBSD does provide the limited and quirky naming scheme of the System V shmem interface as a rendezvous mechanism for such short-term shared memory, the designers ultimately decided that all naming of memory objects for mmap should use the filesystem name space. To provide an efficient mechanism for short-term shared memory, they created a virtual-memory-resident filesystem for transient objects. Unless memory is in high demand, files created in the virtual-memory-resident filesystem reside entirely in memory. Thus, both the initial paging and later write-back costs are eliminated. Typically, a virtual-memory-resident filesystem is mounted on /tmp. Two processes wishing to create a transient area of shared memory create a file in /tmp that they can then both map into their address space.
When a mapping is no longer needed, it can be removed using
munmap(caddr_t address, size_t length);
The munmap system call removes any mappings that exist in the address space, starting at address and continuing for length bytes. There are no constraints between previous mappings and a later munmap. The specified range may be a subset of a previous mmap, or it may encompass an area that contains many mmap'ed files. When a process exits, the system does an implied munmap over its entire address space.
During its initial mapping, a process can set the protections on a page to allow reading, writing, and/or execution. The process can change these protections later by using
mprotect(caddr_t address, int length, int protection);
This feature can be used by debuggers when they are trying to track down a memory-corruption bug. By disabling writing on the page containing the data structure that is being corrupted, the debugger can trap all writes to the page and verify that they are correct before allowing them to occur.
Traditionally, programming for real-time systems has been done with specially written operating systems. In the interests of reducing the costs of real-time applications and of using the skills of the large body of UNIX programmers, companies developing real-time applications have expressed increased interest in using UNIX-based systems for writing these applications. Two fundamental requirements of a real-time system are guaranteed maximum latencies and predictable execution times. Predictable execution time is difficult to provide in a virtual-memory-based system, since a page fault may occur at any point in the execution of a program, resulting in a potentially large delay while the faulting page is retrieved from the disk or network. To avoid paging delays, the system allows a process to force its pages to be resident, and not paged out, by using
mlock(caddr_t address, size_t length);
As long as the process limits its accesses to the locked area of its address space, it can be sure that it will not be delayed by page faults. To prevent a single process from acquiring all the physical memory on the machine to the detriment of all other processes, the system imposes a resource limit to control the amount of memory that may be locked. Typically, this limit is set to no more than one-third of the physical memory, and it may be set to zero by a system administrator that does not want random processes to be able to monopolize system resources.
When a process has finished with its time-critical use of an mlock'ed region, it can release the pages using
munlock(caddr_t address, size_t length);
After the munlock call, the pages in the specified address range are still accessible, but they may be paged out if memory is needed and they are not accessed.
An application may need to ensure that certain records are committed to disk without forcing the writing of all the dirty pages of a file done by the fsync system call. For example, a database program may want to commit a single piece of metadata without writing back all the dirty blocks in its database file. A process does this selective synchronization using
msync(caddr_t address, int length);
Only those modified pages within the specified address range are written back to the filesystem. The msync system call has no effect on anonymous regions.
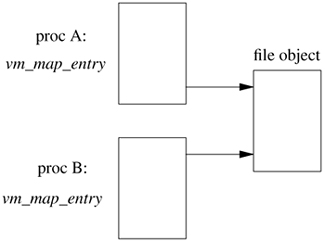
When multiple processes map the same file into their address space, the system must ensure that all the processes view the same set of memory pages. As shown in Section 5.4, each file that is being used actively by a client of the virtual-memory system is represented by an object. Each mapping that a process has to a piece of a file is described by a vm_map_entry structure. An example of two processes mapping the same file into their address space is shown in Figure 5.7. When a page fault occurs in one of these processes, the process's vm_map_entry references the object to find the appropriate page. Since all mappings reference the same object, the processes will all get references to the same set of physical memory, thus ensuring that changes made by one process will be visible in the address spaces of the other processes as well.
A process may request a private mapping of a file. A private mapping has two main effects:
- Changes made to the memory mapping the file are not reflected back into the mapped file.
- Changes made to the memory mapping the file are not visible to other processes mapping the file.
An example of the use of a private mapping would be during program debugging. The debugger will request a private mapping of the program text so that, when it sets a breakpoint, the modification is not written back into the executable stored on the disk and is not visible to the other (presumably nondebugging) processes executing the program.
The kernel uses shadow objects to prevent changes made by a process from being reflected back to the underlying object. The use of a shadow object is shown in Figure 5.8. When the initial private mapping is requested, the file object is mapped into the requesting-process address space, with copy-on-write semantics. If the process attempts to write a page of the object, a page fault occurs and traps into the kernel. The kernel makes a copy of the page to be modified and hangs it from the shadow object. In this example, process A has modified page 0 of the file object. The kernel has copied page 0 to the shadow object that is being used to provide the private mapping for process A.
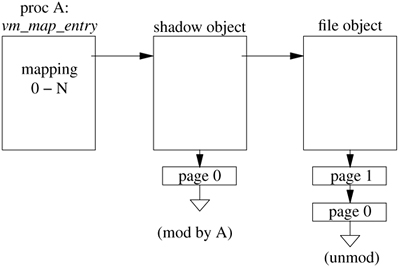
If free memory is limited, it would be better simply to move the modified page from the file object to the shadow object. The move would reduce the immediate demand on the free memory, because a new page would not have to be allocated. The drawback to this optimization is that, if there is a later access to the file object by some other process, the kernel will have to allocate a new page. The kernel will also have to pay the cost of doing an I/O operation to reload the page contents. In FreeBSD, the virtual-memory system never moves the page rather than copying it.
When a page fault for the private mapping occurs, the kernel traverses the list of objects headed by the vm_map_entry, looking for the faulted page. The first object in the chain that has the desired page is the one that is used. If the search gets to the final object on the chain without finding the desired page, then the page is requested from that final object. Thus, pages on a shadow object will be used in preference to the same pages in the file object itself. The details of page-fault handling are given in Section 5.11.
When a process removes a mapping from its address space (either explicitly from an munmap request or implicitly when the address space is freed on process exit), pages held by its shadow object are not written back to the file object. The shadow-object pages are simply placed back on the memory free list for immediate reuse.
When a process forks, it does not want changes to its private mappings made after it forked to be visible in its child; similarly, the child does not want its changes to be visible in its parent. The result is that each process needs to create a shadow object if it continues to make changes in a private mapping. When process A in Figure 5.8 forks, a set of shadow-object chains is created, as shown in Figure 5.9 (on page 162). In this example, process A modified page 0 before it forked and then later modified page 1. Its modified version of page 1 hangs off its new shadow object, so those modifications will not be visible to its child. Similarly, its child has modified page 0. If the child were to modify page 0 in the original shadow object, that change would be visible in its parent. Thus, the child process must make a new copy of page 0 in its own shadow object.
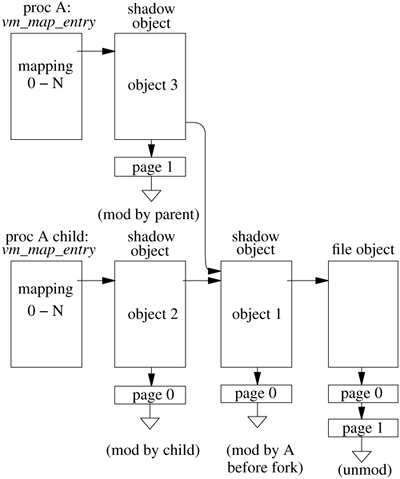
If the system runs short of memory, the kernel may need to reclaim inactive memory held in a shadow object. The kernel assigns to the swap pager the task of backing the shadow object. The swap pager sets up data structures (described in Section 5.10) that can describe the entire contents of the shadow object. It then allocates enough swap space to hold the requested shadow pages and writes them to that area. These pages can then be freed for other uses. If a later page fault requests a swapped-out page, then a new page of memory is allocated and its contents are reloaded with an I/O from the swap area.
When a process with a private mapping removes that mapping either explicitly with an munmap system call or implicitly by exiting, its parent or child process may be left with a chain of shadow objects. Usually, these chains of shadow objects can be collapsed into a single shadow object, often freeing up memory as part of the collapse. Consider what happens when process A exits in Figure 5.9. First, shadow object 3 can be freed along with its associated page of memory. This deallocation leaves shadow objects 1 and 2 in a chain with no intervening references. Thus, these two objects can be collapsed into a single shadow object. Since they both contain a copy of page 0, and since only the page 0 in shadow object 2 can be accessed by the remaining child process, the page 0 in shadow object 1 can be freed along with shadow object 1 itself.
If the child of process A were to exit, then shadow object 2 and the associated page of memory could be freed. Shadow objects 1 and 3 would then be in a chain that would be eligible for collapse. Here, there are no common pages, so object 3 would retain its own page 1 and acquire page 0 from shadow object 1. Object 1 would then be freed. In addition to merging the pages from the two objects, the collapse operation requires a similar merger of any swap space that has been allocated by the two objects. If page 2 had been copied to object 3 and page 4 had been copied to object 1, but these pages were later reclaimed, the pager for object 3 would hold a swap block for page 2, and the pager for object 1 would hold a swap block for page 4. Before freeing object 1, its swap block for page 4 would have to be moved over to object 3.
A performance problem can arise if either a process or its children repeatedly fork. Without some intervention, they can create long chains of shadow objects. If the processes are long-lived, the system does not get an opportunity to collapse these shadow-object chains. Traversing these long chains of shadow objects to resolve page faults is time consuming, and many inaccessible pages can build up forcing the system to needlessly page them out to reclaim them.
One alternative would be to calculate the number of live references to a page after each copy-on-write fault. When only one live reference remained, the page could be moved to the shadow object that still referenced it. When all the pages had been moved out of a shadow object, it could be removed from the chain. For example, in Figure 5.9, when the child of process A wrote to page 0, a copy of page 0 was made in shadow object 2. At that point, the only live reference to page 0 in object 1 was from process A. Thus, the page 0 in object 1 could be moved to object 3. That would leave object 1 with no pages, so it could be reclaimed leaving objects 2 and 3 pointing at the file object directly. Unfortunately, this strategy would add considerable overhead to the page-fault handling routine which would noticeably slow the overall performance of the system. So FreeBSD does not make this optimization.
FreeBSD uses a lower-cost heuristic to reduce the length of shadow chains. When taking a copy-on-write fault, it checks to see whether the object taking the fault completely shadows the object below it in the chain. When it achieves complete coverage, it can bypass that object and reference the next object down the chain. The removal of its reference has the same effect as if it had exited and allowed the normal shadow chain collapse to be done with the sole remaining reference to the object. For example, in Figure 5.9, when the child of process A wrote to page 0, a copy of page 0 was made in shadow object 2. At that point object 2 completely shadows object 1, so object 2 can drop its reference to object 1 and point to the file object directly. With only one reference to object 1, the collapse of object 3 and object 1 will happen as already described. The cost of determining whether one object completely covers the object below it is much easier than tracking live references. Thus, this approach is used by FreeBSD.
This heuristic works well in practice. Even with the heavily forking parent or child processes found in many network servers, shadow-chain depth generally stabilizes at a depth of about three to four levels.
When a process makes read accesses to a private mapping of an object, it continues to see changes made to that object by other processes that are writing to the object through the filesystem or that have a shared mapping to the object. When a process makes a write access to a private mapping of an object, a snapshot of the corresponding page of the object is made and is stored in the shadow object, and the modification is made to that snapshot. Thus, further changes to that page made by other processes that are writing to the page through the filesystem or that have a shared mapping to the object are no longer visible. However, changes to unmodified pages of the object continue to be visible. This mix of changing and unchanging parts of the file can be confusing.
To provide a more consistent view of a file, a process may want to take a snapshot of the file at the time that it is initially privately mapped. Historically, both Mach and 4.4BSD provided a copy object whose effect was to take a snapshot of an object at the time that the private mapping was set up. The copy object tracked changes to an object by other processes and kept original copies of any pages that changed. None of the other UNIX vendors implemented copy objects, and there are no major applications that depend on them. The copy-object code in the virtual-memory system was large and complex, and it noticeably slowed virtual-memory performance. Consequently, copy objects were deemed unnecessary and were removed from FreeBSD as part of the early cleanup and performance work done on the virtual-memory system. Applications that want to get a snapshot of a file can do so by reading it into their address space or by making a copy of it in the filesystem and then referring to the copy.
Processes are created with a fork system call. The fork is usually followed shortly thereafter by an exec system call that overlays the virtual address space of the child process with the contents of an executable image that resides in the filesystem. The process then executes until it terminates by exiting, either voluntarily or involuntarily, by receiving a signal. In Sections 5.6 to 5.9, we trace the management of the memory resources used at each step in this cycle.
A fork system call duplicates the address space of an existing process, creating an identical child process. The fork set of system calls is the only way that new processes are created in FreeBSD. Fork duplicates all the resources of the original process and copies that process's address space.
The virtual-memory resources of the process that must be allocated for the child include the process structure and its associated substructures, and the user structure and kernel stack. In addition, the kernel must reserve storage (either memory, filesystem space, or swap space) used to back the process. The general outline of the implementation of a fork is as follows:
• Reserve virtual address space for the child process.
• Allocate a process entry and thread structure for the child process, and fill it in.
• Copy to the child the parent's process group, credentials, file descriptors, limits, and signal actions.
• Allocate a new user structure and kernel stack, copying the current ones to initialize them.
• Allocate a vmspace structure.
• Duplicate the address space, by creating copies of the parent vm_map_entry structures marked copy-on-write.
• Arrange for the child process to return 0, to distinguish its return value from the new PID that is returned to the parent process.
The allocation and initialization of the process structure, and the arrangement of the return value, were covered in Chapter 4. The remainder of this section discusses the other steps involved in duplicating a process.
The first resource to be reserved when an address space is duplicated is the required virtual address space. To avoid running out of memory resources, the kernel must ensure that it does not promise to provide more virtual memory than it is able to deliver. The total virtual memory that can be provided by the system is limited to the amount of physical memory available for paging plus the amount of swap space that is provided. A few pages are held in reserve to stage I/O between the swap area and main memory.
The reason for this restriction is to ensure that processes get synchronous notification of memory limitations. Specifically, a process should get an error back from a system call (such as sbrk, fork, or mmap) if there are insufficient resources to allocate the needed virtual memory. If the kernel promises more virtual memory than it can support, it can deadlock trying to service a page fault. Trouble arises when it has no free pages to service the fault and no available swap space to save an active page. Here, the kernel has no choice but to send a kill signal to the process unfortunate enough to be page faulting. Such asynchronous notification of insufficient memory resources is unacceptable.
Excluded from this limit are those parts of the address space that are mapped read-only, such as the program text. Any pages that are being used for a read-only part of the address space can be reclaimed for another use without being saved because their contents can be refilled from the original source. Also excluded from this limit are parts of the address space that map shared files. The kernel can reclaim any pages that are being used for a shared mapping after writing their contents back to the filesystem from which they are mapped. Here, the filesystem is being used as an extension of the swap area. Finally, any piece of memory that is used by more than one process (such as an area of anonymous memory being shared by several processes) needs to be counted only once toward the virtual-memory limit.
The limit on the amount of virtual address space that can be allocated causes problems for applications that want to allocate a large piece of address space but want to use the piece only sparsely. For example, a process may wish to make a private mapping of a large database from which it will access only a small part. Because the kernel has no way to guarantee that the access will be sparse, it takes the pessimistic view that the entire file will be modified and denies the request. One extension that many BSD-derived systems have made to the mmap system call is to add a flag that tells the kernel that the process is prepared to accept asynchronous faults in the mapping. Such a mapping would be permitted to use up to the amount of virtual memory that had not been promised to other processes. If the process then modifies more of the file than this available memory, or if the limit is reduced by other processes allocating promised memory, the kernel can then send a segmentation-fault or a more specific out-of-memory signal to the process. On receiving the signal, the process must munmap an unneeded part of the file to release resources back to the system. The process must ensure that the code, stack, and data structures needed to handle the segment-fault signal do not reside in the part of the address space that is subject to such faults.
Tracking the outstanding virtual memory accurately and determining when to limit further allocation is a complex task. Because most processes use only about half of their virtual address space, limiting outstanding virtual memory to the sum of process address spaces is needlessly conservative. However, allowing greater allocation runs the risk of running out of virtual-memory resources. Although FreeBSD calculates the outstanding-memory load, it does not enforce any total memory limit so it can be made to promise more than it can deliver. When memory resources run out, it picks a process to kill favoring processes with large memory use. An important future enhancement will be to develop a heuristic for determining when virtual-memory resources are in danger of running out and need to be limited.
The next step in fork is to allocate and initialize a new process structure. This operation must be done before the address space of the current process is duplicated because it records state in the process structure. From the time that the process structure is allocated until all the needed resources are allocated, the parent process is locked against swapping to avoid deadlock. The child is in an inconsistent state and cannot yet run or be swapped, so the parent is needed to complete the copy of its address space. To ensure that the child process is ignored by the scheduler, the kernel sets the process's state to NEW during the entire fork procedure.
Historically, the fork system call operated by copying the entire address space of the parent process. When large processes fork, copying the entire user address space is expensive. All the pages that are on secondary storage must be read back into memory to be copied. If there is not enough free memory for both complete copies of the process, this memory shortage will cause the system to begin paging to create enough memory to do the copy (see Section 5.12). The copy operation may result in parts of the parent and child processes being paged out, as well as the paging out of parts of unrelated processes.
The technique used by FreeBSD to create processes without this overhead is called copy-on-write. Rather than copy each page of a parent process, both the child and parent processes resulting from a fork are given references to the same physical pages. The page tables are changed to prevent either process from modifying a shared page. Instead, when a process attempts to modify a page, the kernel is entered with a protection fault. On discovering that the fault was caused by an attempt to modify a shared page, the kernel simply copies the page and changes the protection field for the page to allow modification once again. Only pages modified by one of the processes need to be copied. Because processes that fork typically overlay the child process with a new image with exec shortly thereafter, this technique significantly improves the performance of fork.
The next step in fork is to traverse the list of vm_map_entry structures in the parent and to create a corresponding entry in the child. Each entry must be analyzed and the appropriate action taken:
• If the entry maps a read-only or shared region, the child can take a reference to it.
• If the entry maps a privately mapped region (such as the data area or stack), the child must create a copy-on-write mapping of the region. The parent must be converted to a copy-on-write mapping of the region. If either process later tries to write the region, it will create a shadow map to hold the modified pages.
Map entries for a process are never merged (simplified). Only entries for the kernel map itself can be merged. The kernel-map entries need to be simplified so that excess growth is avoided. It might be worthwhile to do such a merge of the map entries for a process when it forks, especially for large or long-running processes.
With the virtual-memory resources allocated, the system sets up the kernel- and user-mode state of the new process, including the hardware memory-management registers, user structure, and stack. It then clears the NEW flag and places the process's thread on the run queue; the new process can then begin execution.
When a process (such as a shell) wishes to start another program, it will generally fork, do a few simple operations such as redirecting I/O descriptors and changing signal actions, and then start the new program with an exec. In the meantime, the parent shell suspends itself with wait until the new program completes. For such operations, it is not necessary for both parent and child to run simultaneously, and therefore only one copy of the address space is required. This frequently occurring set of system calls led to the implementation of the vfork system call. Although it is extremely efficient, vfork has peculiar semantics and is generally considered to be an architectural blemish.
The implementation of vfork will always be more efficient than the copy-on-write implementation because the kernel avoids copying the address space for the child. Instead, the kernel simply passes the parent's address space to the child and suspends the parent. The child process does not need to allocate any virtual-memory structures, receiving the vmspace structure and all its pieces from its parent. The child process returns from the vfork system call with the parent still suspended. The child does the usual activities in preparation for starting a new program, then calls exec. Now the address space is passed back to the parent process, rather than being abandoned, as in a normal exec. Alternatively, if the child process encounters an error and is unable to execute the new program, it will exit. Again, the address space is passed back to the parent instead of being abandoned.
With vfork, the entries describing the address space do not need to be copied, and the page-table entries do not need to be marked and then cleared of copy-on-write. Vfork is likely to remain more efficient than copy-on-write or other schemes that must duplicate the process's virtual address space. The architectural quirk of the vfork call is that the child process may modify the contents and even the size of the parent's address space while the child has control. Although modification of the parent's address space is bad programming practice, some programs have been known to take advantage of this quirk.
The exec system call was described in Sections 2.4 and 3.1; it replaces the address space of a process with the contents of a new program obtained from an executable file. During an exec, the target executable image is validated and then the arguments and environment are copied from the current process image into a temporary area of pageable kernel virtual memory.
To do an exec, the system must allocate resources to hold the new contents of the virtual address space, set up the mapping for this address space to reference the new image, and release the resources being used for the existing virtual memory.
The first step is to reserve memory resources for the new executable image. The algorithm for the calculation of the amount of virtual address space that must be reserved was described in Section 5.6. For an executable that is not being debugged (and hence will not have its text space modified), a space reservation must be made for only the data and stack space of the new executable. Exec does this reservation without first releasing the currently assigned space, because the system must be able to continue running the old executable until it is sure that it will be able to run the new one. If the system released the current space and the memory reservation failed, the exec would be unable to return to the original process. Once the reservation is made, the address space and virtual-memory resources of the current process are then freed as though the process were exiting; this mechanism is described in Section 5.9.
Now the process has only a user structure and kernel stack. The kernel now allocates a new vmspace structure and creates the list of four vm_map_entry structures:
- A copy-on-write, fill-from-file entry maps the text segment. A copy-on-write mapping is used, rather than a read-only one, to allow active text segments to have debugging breakpoints set without affecting other users of the binary. In FreeBSD, some legacy code in the kernel debugging interface disallows the setting of break points in binaries being used by more than one process. This legacy code prevents the use of the copy-on-write feature and requires that the text be mapped read-only.
- A private (copy-on-write), fill-from-file entry maps the initialized data segment.
- An anonymous zero-fill-on-demand entry maps the uninitialized data segment.
- An anonymous zero-fill-on-demand entry maps the stack segment.
No further operations are needed to create a new address space during an exec system call; the remainder of the work involves copying the arguments and environment out to the top of the new stack. Initial values are set for the registers: The program counter is set to the entry point, and the stack pointer is set to point to the argument vector. The new process image is then ready to run.
Once a process begins execution, it has several ways to manipulate its address space. The system has always allowed processes to expand their uninitialized data area (usually done with the malloc() library routine). The stack is grown on an as-needed basis. The FreeBSD system also allows a process to map files and devices into arbitrary parts of its address space and to change the protection of various parts of its address space, as described in Section 5.5. This section describes how these address-space manipulations are done.
A process can change its size during execution by explicitly requesting more data space with the sbrk system call. Also, the stack segment will be expanded automatically if a protection fault is encountered because of an attempt to grow the stack below the end of the stack region. In either case, the size of the process address space must be changed. The size of the request is always rounded up to a multiple of page size. New pages are marked fill-with-zeros, since there are no contents initially associated with new sections of the address space.
The first step of enlarging a process's size is to check whether the new size would violate the size limit for the process segment involved. If the new size is in range, the following steps are taken to enlarge the data area:
- Verify that the virtual-memory resources are available.
- Verify that the address space of the requested size immediately following the current end of the data area is not already mapped.
- If the existing vm_map_entry is the only reference to the swap object, increment the vm_map_entry's ending address by the requested size and increase the size of the swap object by the same amount. If the swap object has two or more references (as it would after a process forked), a new vm_map_entry must be created with a starting address immediately following the end of the previous fixed-sized entry. Its ending address is calculated to give it the size of the request. It will be backed by a new swap object. Until this process forks again, the new entry and its swap object will be able to continue growing.
If the change is to reduce the size of the data segment, the operation is easy: Any memory allocated to the pages that will no longer be part of the address space is freed. The ending address of the vm_map_entry is reduced by the size. If the requested size reduction is bigger than the range defined by the vm_map_entry, the entire entry is freed, and the remaining reduction is applied to the vm_map_entry that precedes it. This algorithm is applied until the entire reduction has been made. Future references to these addresses will result in protection faults, as access is disallowed when the address range has been deallocated.
The mmap system call requests that a file be mapped into an address space. The system call may request either that the mapping be done at a particular address or that the kernel pick an unused area. If the request is for a particular address range, the kernel first checks to see whether that part of the address space is already in use. If it is in use, the kernel first does an munmap of the existing mapping, then proceeds with the new mapping.
The kernel implements the mmap system call by traversing the list of vm_map_entry structures for the process. The various overlap conditions to consider are shown in Figure 5.10. The five cases are as follows:
- The new mapping exactly overlaps an existing mapping. The old mapping is deallocated as described in Section 5.9. The new mapping is created in its place as described in the paragraph following this list.
- The new mapping is a subset of the existing mapping. The existing mapping is split into three pieces (two pieces if the new mapping begins at the beginning or ends at the end of the existing mapping). The existing vm_map_entry structure is augmented with one or two additional vm_map_entry structures: one mapping the remaining part of the existing mapping before the new mapping, and one mapping the remaining part of the existing mapping following the new mapping. Its overlapped piece is replaced by the new mapping, as described in the paragraph following this list.
- The new mapping is a superset of an existing mapping. The old mapping is deallocated as described in Section 5.9, and a new mapping is created as described in the paragraph following this list.
- The new mapping starts partway into and extends past the end of an existing mapping. The existing mapping has its length reduced by the size of the unmapped area. Its overlapped piece is replaced by the new mapping, as described in the paragraph following this list.
- The new mapping extends into the beginning of an existing mapping. The existing mapping has its starting address incremented and its length reduced by the size of the covered area. Its overlapped piece is replaced by the new mapping, as described in the paragraph following this list.
In addition to these five basic types of overlap, a new mapping request may span several existing mappings. Specifically, a new request may be composed of zero or one of type 4, mzero to many of type 3, and zero or one of type 5. When a mapping is shortened, any shadow pages associated with it are released, because they are no longer needed.
Once the address space is zero filled, the kernel creates a new vm_map_entry to describe the new address range. If the object being mapped is already being mapped by another process, the new entry gets a reference to the existing object. This reference is obtained in the same way, as described in Section 5.6, when a new process is being created and needs to map each of the regions in its parent. If this request is a mapping of a file, then the kernel sets the new vm_map_entry to reference its object.
If this is a mapping to an anonymous region, then a new swap object must be created. First, a new object is allocated with a pager type of swap (pagers are described in Section 5.10). The vm_map_entry is then set to reference the object.
A process may change the protections associated with a region of its virtual memory by using the mprotect system call. The size of the region to be protected may be as small as a single page. Because the kernel depends on the hardware to enforce the access permissions, the granularity of the protection is limited by the underlying hardware. A region may be set for any combination of read, write, and execute permissions. Many architectures do not distinguish between read and execute permissions; on such architectures, the execute permission is treated as read permission.
The kernel implements the mprotect system call by finding the existing vm_map_entry structure or structures that cover the region specified by the call. If the existing permissions are the same as the request, then no further action is required. Otherwise, the new permissions are compared to the maximum protection value associated with the vm_map_entry. The maximum value is set at mmap time and reflects the maximum value allowed by the underlying file. If the new permissions are valid, one or more new vm_map_entry structures have to be set up to describe the new protections. The set of overlap conditions that must be handled is similar to that described in the previous subsection. Instead of replacing the object underlying the new vm_map_entry structures, these vm_map_entry structures still reference the same object; the difference is that they grant different access permissions to it.
The final change in process state that relates to the operation of the virtual-memory system is exit; this system call terminates a process, as described in Chapter 4. The part of exit that is discussed here is the release of the virtual-memory resources of the process. There are two sets of virtual-memory resources that need to be freed:
- The user portions of the address space, both memory and swap space
- The user structure and kernel stack
The first set of resources is freed in exit. The second set of resources is freed in wait. The release of the second set of resources is delayed because the kernel stack must be used until the process relinquishes the processor for the final time.
The first step—freeing the user address space—is identical to the one that occurs during exec to free the old address space. The free operation proceeds entry by entry through the list of vm_map_entry structures associated with the address space. The first step in freeing an entry is to traverse its list of shadow objects. If the entry is the last reference to a shadow object, then any memory or swap space that is associated with the object can be freed. In addition, the machine-dependent routines are called to unmap and free up any page table or data structures that are associated with the object. If the shadow object is still referenced by other vm_map_entry structures, its resources cannot be freed, but the kernel still needs to call the machine-dependent routines to unmap and free the resources associated with the current process mapping. Finally, if the underlying object referenced by the vm_map_entry is losing its last reference, then that object is a candidate for deallocation. If it is an object that will never have any chance of a future reuse (such as an anonymous object associated with a stack or uninitialized data area), then its resources are freed as though it were a shadow object. However, if the object is associated with a vnode (e.g., it maps a file such as an executable), the object will persist until the vnode is reused for another purpose. Until the vnode is reused, the object and its associated pages will be available for reuse by newly executing processes or by processes mapping in a file.
With all its resources free, the exiting process finishes detaching itself from its process group and notifies its parent that it is done. The process has now become a zombie process—one with no resources. Its parent will collect its exit status with a wait call. Because the process structure, user structure, and kernel stack are allocated using the zone allocator, they will normally be retained for future use by another process rather than being broken down and their memory pages reclaimed. Thus, there is nothing for the virtual-memory system to do when wait is called: All virtual-memory resources of a process are removed when exit is done. On wait, the system just returns the process status to the caller, releases the process structure, user structure, and kernel stack back to the zone allocator, and frees the space in which the resource-usage information was kept.
The pager interface provides the mechanism by which data are moved between backing store and physical memory. The FreeBSD pager interface is an evolution of the interface present in Mach 2.0 as evolved by 4.4BSD. The interface is page based, with all data requests made in multiples of the software page size. Vm_page structures are passed around as descriptors providing the backing-store offset and physical-memory address of the desired data. This interface should not be confused with the Mach 3.0 external paging interface [Young, 1989], where pagers are typically user applications outside the kernel and are invoked via asynchronous remote procedure calls using the Mach interprocess-communication mechanism. The FreeBSD interface is internal in the sense that the pagers are compiled into the kernel and pager routines are invoked via simple function calls.
Each virtual-memory object has a pager type, pager handle, and pager private data associated with it. Conceptually, the pager describes a logically contiguous piece of backing store, such as a chunk of swap space or a disk file. The pager type identifies the pager responsible for supplying the contents of pages within the object. Each pager registers a set of functions that define its operations. These function sets are stored in an array indexed by pager type. When the kernel needs to do a pager operation, it uses the pager type to index into the array of pager functions and then selects the routine that it needs such as getting or putting pages. For example,
(*pagertab[object->type]->pgo_putpages)
(object, vmpage, count, flags, rtvals);
pushes count pages starting with page vmpage from object.
A pager type is specified when an object is created to map a file, device, or piece of anonymous memory into a process address space. The pager manages the object throughout its lifetime. When a page fault occurs for a virtual address mapping a particular object, the fault-handling code allocates a vm_page structure and converts the faulting address to an offset within the object. This offset is recorded in the vm_page structure, and the page is added to the list of pages cached by the object. The page frame and object are then passed to the underlying pager routine. The pager routine is responsible for filling the vm_page structure with the appropriate initial value for that offset of the object that it represents.
The pager is also responsible for saving the contents of a dirty page if the system decides to push out the latter to backing store. When the pageout daemon decides that a particular page is no longer needed, it requests the object that owns the page to free the page. The object first passes the page with the associated logical offset to the underlying pager to be saved for future use. The pager is responsible for finding an appropriate place to save the page, doing any I/O necessary for the save, and then notifying the object that the page is being freed. When it is done, the pager marks the page as clean so that the pageout daemon can move the vm_page structure to the cache or free list for future use.
There are seven routines associated with each pager type; see Table 5.1. The pgo_init() routine is called at boot time to do any one-time type-specific initializations, such as allocating a pool of private pager structures. The pgo_alloc() routine associates a pager with an object as part of the creation of the object. The pgo_dealloc() routine disassociates a pager from an object as part of the destruction of the object. Objects are created either by the mmap system call or internally as part of the creation of a process as part of the fork or exec system calls.

Pgo_getpages() is called to return one or more pages of data from a pager. The main use of this routine is by the page-fault handler. Pgo_putpages() writes back one or more pages of data. This routine is called by the pageout daemon to write back one or more pages asynchronously, and by msync to write back one or more pages synchronously or asynchronously. Both the get and put routines are called with an array of vm_page structures and a count indicating the affected pages.
The pgo_haspage() routine queries a pager to see whether it has data at a particular backing-store offset. This routine is used in the clustering code of the page-fault handler to determine whether pages on either side of a faulted page can be read in as part of a single I/O operation. It is also used when collapsing objects to determine if the allocated pages of a shadow object completely obscure the allocated pages of the object that it shadows.
The four types of pagers supported by the system are described in the next four subsections.
The vnode pager handles objects that map files in a filesystem. Whenever a file is opened either explicitly by open or implicitly by exec, the system must find an existing vnode that represents it or, if there is no existing vnode for the file, allocate a new vnode for it. Part of allocating a new vnode is to allocate an object to hold the pages of the file and to associate the vnode pager with the object. The object handle is set to point to the vnode and the private data stores the size of the file. Any time the vnode changes size, the object is informed by a call to vnode_pager_setsize().
When a pagein request is received by the vnode-pager pgo_getpages() routine, it is passed an array of physical pages, the size of the array, and the index into the array of the page that is required. Only the required page must be read, but the pgo_getpages() routine is encouraged to provide as many of the others as it can easily read at the same time. For example, if the required page is in the middle of the block of a file, the filesystem will usually read the entire file block since the file block can be read with a single I/O operation. The larger read will fill in the required page along with the pages surrounding it. The I/O is done using a physical-I/O buffer that maps the pages to be read into the kernel address space long enough for the pager to call the device-driver strategy routine to load the pages with the file contents. Once the pages are filled, the kernel mapping can be dropped, the physical-I/O buffer can be released, and the pages can be returned.
When the vnode pager is asked to save a page to be freed, it simply arranges to write the page back to the part of the file from which the page came. The request is made with the pgo_getpages() routine, which is passed an array of physical pages, the size of the array, and the index into the array of the page that must be written. Only the required page must be written, but the pgo_putpages() routine is encouraged to write as many of the others as it can easily handle at the same time. The filesystem will write out all the pages that are in the same filesystem block as the required page. As with the pgo_getpages() routine, the pages are mapped into the kernel only long enough to do the write operation.
If a file is being privately mapped, then modified pages cannot be written back to the filesystem. Such private mapping must use a shadow object with a swap pager for all pages that are modified. Thus, a privately mapped object will never be asked to save any dirty pages to the underlying file.
Historically, the BSD kernel had separate caches for the filesystems and the virtual memory. FreeBSD has eliminated the filesystem buffer cache by replacing it with the virtual-memory cache. Each vnode has an object associated with it, and the blocks of the file are stored in the pages associated with the object. The file data is accessed using the same pages whether they are mapped into an address space or accessed via read and write. An added benefit of this design is that the filesystem cache is no longer limited by the address space in the kernel that can be dedicated to it. Absent other demands on the system memory, it can all be dedicated to caching filesystem data.
The device pager handles objects representing memory-mapped hardware devices. Memory-mapped devices provide an interface that looks like a piece of memory. An example of a memory-mapped device is a frame buffer, which presents a range of memory addresses with one word per pixel on the screen. The kernel provides access to memory-mapped devices by mapping the device memory into a process's address space. The process can then access that memory without further operating-system intervention. Writing to a word of the frame-buffer memory causes the corresponding pixel to take on the appropriate color and brightness.
The device pager is fundamentally different from the other three pagers in that it does not fill provided physical-memory pages with data. Instead, it creates and manages its own vm_page structures, each of which describes a page of the device space. The head of the list of these pages is kept in the pager private-data area of the object. This approach makes device memory look like wired physical memory. Thus, no special code should be needed in the remainder of the virtual-memory system to handle device memory.
When a device is first mapped, the device-pager allocation routine will validate the desired range by calling the device d_mmap () routine. If the device allows the requested access for all pages in the range, an empty page list is created in the private-data area of the object that manages the device mapping. The device-pager allocation routine does not create vm_page structures immediately—they are created individually by the pgo_getpages() routine as they are referenced. The reason for this late allocation is that some devices export a large memory range in which either not all pages are valid or the pages may not be accessed for common operations. Complete allocation of vm_page structures for these sparsely accessed devices would be wasteful.
The first access to a device page will cause a page fault and will invoke the device-pager pgo_getpages() routine. The device pager creates a vm_page structure, initializes the latter with the appropriate object offset and a physical address returned by the device d_mmap() routine, and flags the page as fictitious. This vm_page structure is added to the list of all such allocated pages for the object. Since the fault code has no special knowledge of the device pager, it has preallocated a physical-memory page to fill and has associated that vm_page structure with the object. The device-pager routine removes that vm_page structure from the object, returns the structure to the free list, and inserts its own vm_page structure in the same place.
The device-pager pgo_putpages() routine expects never to be called and will panic if it is. This behavior is based on the assumption that device-pager pages are never entered into any of the paging queues and hence will never be seen by the pageout daemon. However, it is possible to msync a range of device memory. This operation brings up an exception to the higher-level virtual-memory system's ignorance of device memory: The object page-cleaning routine will skip pages that are flagged as fictitious.
Finally, when a device is unmapped, the device-pager deallocation routine is invoked. This routine deallocates all the vm_page structures that it allocated.
The physical-memory pager handles objects that contain nonpagable memory. Their only use is for the System V shared-memory interface, which can be configured to use nonpagable memory instead of the default swappable memory.
The first access to a physical-memory-pager page will cause a page fault and will invoke the pgo_getpages() routine. Like the swap pager, the physical-memory pager zero-fills pages when they are first faulted. Unlike the swap pager, the page is marked as unmanaged so that it will not be considered for replacement by the page-out daemon. Marking its pages unmanaged makes the memory for the physical-memory pager look like wired physical memory. Thus, no special code is needed in the remainder of the virtual-memory system to handle physical-memory-pager memory.
The pgo_putpages() routine of the physical-memory-pager does not expect to be called, and it panics if it is. This behavior is based on the assumption that physical-memory-pager pages are never entered into any of the paging queues and hence will never be seen by the pageout daemon. However, it is possible to msync a range of device memory. This operation brings up an exception to the higher-level virtual-memory system's ignorance of physical-memory-pager memory: The object page-cleaning routine will skip pages that are flagged as unmanaged.
Finally, when an object using a physical-memory-pager is freed, all its pages have their unmanaged flag cleared and are released back to the list of free pages.
The term swap pager refers to two functionally different pagers. In the most common use, swap pager refers to the pager that is used by objects that map anonymous memory. This pager has sometimes been referred to as the default pager because it is the pager that is used if no other pager has been requested. It provides what is commonly known as swap space: nonpersistent backing store that is zero filled on first reference. When an anonymous object is first created, it is assigned the default pager. The default pager allocates no resources and provides no storage backing. The default pager handles page faults (pgo_getpage()) by zero filling and page queries (pgo_haspage()) as not held. The expectation is that free memory will be plentiful enough that it will not be necessary to swap out any pages. The object will simply create zero-filled pages during the process lifetime that can all be returned to the free list when the process exits. When an object is freed with the default pager, no pager cleanup is required, since no pager resources were allocated.
However, on the first request by the pageout daemon to remove an active page from an anonymous object, the default pager replaces itself with the swap pager. The role of the swap pager is swap-space management: figuring out where to store dirty pages and how to find dirty pages when they are needed again. Shadow objects require that these operations be efficient. A typical shadow object is sparsely populated: It may cover a large range of pages, but only those pages that have been modified will be in the shadow object's backing store. In addition, long chains of shadow objects may require numerous pager queries to locate the correct copy of an object page to satisfy a page fault. Hence, determining whether a pager contains a particular page needs to be fast, preferably requiring no I/O operations. A final requirement of the swap pager is that it can do asynchronous writeback of dirty pages. This requirement is necessitated by the pageout daemon, which is a single-threaded process. If the pageout daemon blocked waiting for a page-clean operation to complete before starting the next operation, it is unlikely that it could keep enough memory free in times of heavy memory demand.
In theory, any pager that meets these criteria can be used as the swap pager. In Mach 2.0, the vnode pager was used as the swap pager. Special paging files could be created in any filesystem and registered with the kernel. The swap pager would then suballocate pieces of the files to back particular anonymous objects. One obvious advantage of using the vnode pager is that swap space can be expanded by the addition of more swap files or the extension of existing ones dynamically (i.e., without rebooting or reconfiguring of the kernel). The main disadvantage is that the filesystem does not provide as much bandwidth as direct access to the disk.
The desire to provide the highest possible disk bandwidth led to the creation of a special raw-partition pager to use as the swap pager for FreeBSD. Previous versions of BSD also used dedicated disk partitions, commonly known as swap partitions, so this partition pager became the swap pager. The remainder of this section describes how the swap pager is implemented and how it provides the necessary capabilities for backing anonymous objects.
In 4.4BSD, the swap pager preallocated a fixed-sized structure to describe the object. For a large object the structure would be large even if only a few pages of the object were pushed to backing store. Worse, the size of the object was frozen at the time of allocation. Thus, if the anonymous area continued to grow (such as the stack or heap of a process), a new object had to be created to describe the expanded area. On a system that was short of memory, the result was that a large process could acquire many anonymous objects. Changing the swap pager to handle growing objects dramatically reduced this object proliferation. Other problems with the 4.4BSD swap pager were that its simplistic management of the swap space led to fragmentation, slow allocation under load, and deadlocks brought on by its need to allocate kernel memory during periods of shortage. For all these reasons, the swap pager was completely rewritten in FreeBSD 4.0.
Swap space tends to be sparsely allocated. On average, a process only accesses about half of its allocated address space during its lifetime. Thus, only about half the pages in an object ever come into existence. Unless the machine is under heavy memory pressure and the process is long-lived, most of the pages in the object that do come into existence will never be pushed to backing store. So the new swap pager replaced the old fixed-size block map for each object with a method that allocates a structure for each set of swap blocks that gets allocated. Each structure can track a set of up to 32 contiguous swap blocks. A large object with two pages swapped out will use at most two of these structures, and only one if the two swapped pages are close to each other (as they often are). The amount of memory required to track swap space for an object is proportional to the number of pages that have been pushed to swap rather than to the size of the object. The size of the object is no longer frozen when its first page is swapped out, since any pages that are part of its larger size can be accommodated.
The structures that track swap space usage are kept in a global hash table managed by the swap pager. While it might seem logical to store the structures separately on lists associated with the object of which they are a part, the single global hash table has two important advantages:
- It ensures a short time to determine whether a page of an object has been pushed to swap. If the structures were linked onto a list headed by the object, then objects with many swapped pages would require the traversal of a long list. The long list could be shortened by creating a hash table for every object, but that would require much more memory than simply allocating a single large hash table that could be used by all objects.
- It allows operations that need to scan all the allocated swap blocks to have a centralized place to find them rather than needing to scan all the anonymous objects in the system. An example is the swapoff system call that removes a swap partition from use. It needs to page in all the blocks from the device that is to be taken out of service.
The free space in the swap area is managed with a bitmap with one bit for each page-sized block of swap space. The bitmap for the entire swap area is allocated when the swap space is first added to the system. This initial allocation avoids the need to allocate kernel memory during critical low-memory swapping operations. Although when it is first allocated the bitmap requires more space than the block list needed when first allocated, its size does not change with use, whereas the block list grew to a size bigger than the bitmap as the swap area became fragmented. The system tends to swap when it is low on memory. To avoid potential deadlocks, kernel memory should not be allocated at such times.
Doing a linear scan of the swap-block bitmaps to find free space would be unacceptably slow. Thus, the bitmap is organized in a radix-tree structure with free-space hinting in the radix-node structures. The use of radix-tree structures makes swap-space allocation and release a constant-time operation. To reduce fragmentation, the radix tree can allocate large contiguous chunks at once, skipping over smaller fragmented chunks.
A future improvement would be to keep track of the different-sized free areas as swap allocations are done similarly to the way that the filesystem tracks the different sizes of free space. This free-space information would increase the probability of doing contiguous allocation and improve locality of reference.
Swap blocks are allocated at the time that swap out is done. They are freed when the page is brought back in and becomes dirty or the object is freed.
The swap pager is responsible for managing the I/O associated with the pgo_putpages() request. Once it identifies the set of pages within the pgo_putpages() request that it will be able to write, it must allocate a buffer and have those pages mapped into it. Because the swap pager does not synchronously wait while the I/O is done, it does not regain control after the I/O operation completes. Therefore, it marks the buffer with a callback flag and sets the routine for the callback to be swp_pager_async_iodone().
When the push completes, swp_pager_async_iodone() is called. Each written page is marked as clean, has its busy bit cleared, and calls the vm_page_io_finish() routine to notify the pageout daemon that the write has completed and to awaken any processes waiting for it. The swap pager then unmaps the pages from the buffer and releases it. A count of pageouts-in-progress is kept for the pager associated with each object; this count is decremented when the pageout completes, and, if the count goes to zero, a wakeup() is issued. This operation is done so that an object that is deallocating a swap pager can wait for the completion of all page-out operations before freeing the pager's references to the associated swap space.
Because the number of swap buffers is constant, the swap pager must take care to ensure that it does not use more than its fair share. Once this limit is reached, the pgo_putpages() operations blocks until one of the swap pager's outstanding writes completes. This unexpected blocking of the pageout daemon is an unfortunate side effect of pushing the buffer management down into the pagers. Any single pager hitting its buffer limit stops the pageout daemon. While the page-out daemon might want to do additional I/O operations using other I/O resources such as the network, it is prevented from doing so. Worse, the failure of any single pager can deadlock the system by preventing the pageout daemon from running.
When the memory-management hardware detects an invalid virtual address, it generates a trap to the system. This page-fault trap can occur for several reasons. Most BSD programs are created in a format that permits the executable image to be paged into main memory directly from the filesystem. When a program in a demand-paged format is first run, the kernel marks as invalid the pages for the text and initialized-data regions of the executing process. The text and initialized data regions share an object that provides fill-on-demand from the filesystem. As part of mapping in the object, the kernel traverses the list of pages associated with the object and marks them as resident and copy-on-write in the newly created process. For a heavily used executable with most of its pages already resident, this prepaging reduces many of its initial page faults. As missing pages of the text or initialized-data region are first referenced, or write attempts are made on pages in the initialized-data region, page faults occur.
Page faults can also occur when a process first references a page in the uninitialized-data region of a program. Here, the anonymous object managing the region automatically allocates memory to the process and initializes the newly assigned page to zero. The idle process fills part of its time by zeroing out pages on the free list so that the system does not have to do the zero fill when servicing the first reference to a page for an anonymous object. Other types of page faults arise when previously resident pages have been reclaimed by the system in response to a memory shortage.
The handling of page faults is done with the vm_fault() routine; this routine services all page faults. Each time vm_fault() is invoked, it is provided the virtual address that caused the fault. The first action of vm_fault() is to traverse the vm_map_entry list of the faulting process to find the entry associated with the fault. The routine then computes the logical page within the underlying object and traverses the list of objects to find or create the needed page. Once the page has been found, vm_fault() must call the machine-dependent layer to validate the faulted page and return to restart the process.
The details of calculating the address within the object are described in Section 5.4. Having computed the offset within the object and determined the object's protection and object list from the vm_map_entry, the kernel is ready to find or create the associated page. The page-fault-handling algorithm is shown in Figure 5.11. In the following overview, the lettered points are references to the tags down the left side of the code.


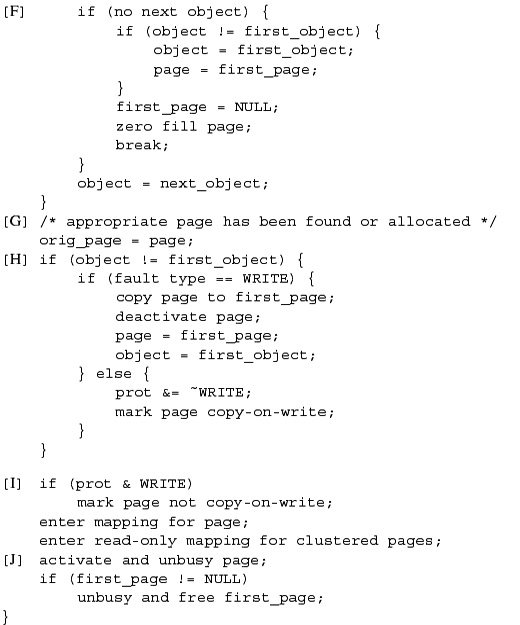
A. The loop traverses the list of shadow, anonymous, and file objects until it either finds an object that holds the sought-after page or reaches the final object in the list. If no page is found, the final object will be requested to produce it.
B. An object with the desired page has been found. If the page is busy, another process may be in the middle of faulting it in, so this process is blocked until the page is no longer busy. Since many things could have happened to the affected object while the process was blocked, it must restart the entire fault-handling algorithm. If the page was not busy, the algorithm exits the loop with the page.
C. Anonymous objects (such as those used to represent shadow objects) do not upgrade from the default pager to the swap pager until the first time that they need to push a page to backing store. Thus, if an object has a pager other than the default pager, then there is a chance that the page previously existed but was paged out. If the object has a nondefault pager, then the kernel needs to allocate a page to give to the pager to be filled (see D). The special case for the object being the first object is to avoid a race condition with two processes trying to get the same page. The first process through will create the sought-after page in the first object but keep it marked as busy. When the second process tries to fault the same page, it will find the page created by the first process and block on it (see B). When the first process completes the pagein processing, it will unlock the first page, causing the second process to awaken, retry the fault, and find the page created by the first process.
D. Before calling the pager, check to see if any of the eight pages on either side of the faulting page are eligible to be brought in at the same time. To be eligible, a page must be part of the object and neither already in memory nor part of another I/O operation. The pager is given the range of possible pages and told which one is the required page. It must return the required page if it holds a copy of it. The other pages are produced only if they are held by the object and can be easily read at the same time. If the required page is present in the file or swap area, the pager will bring it back into the newly allocated page. If the pagein succeeds, then the sought-after page has been found. If the page never existed, then the pagein request will fail. Unless this object is the first, the page is freed and the search continues. If this object is the first, the page is not freed, so it will act as a block to further searches by other processes (as described in C).
E. If the kernel created a page in the first object but did not use that page, it will have to remember that page so it can free the page when the pagein is done (see J).
F. If the search has reached the end of the object list and has not found the page, then the fault is on an anonymous object chain, and the first object in the list will handle the page fault using the page allocated in C. The first_page entry is set to NULL to show that it does not need to be freed, if the idle process has not already done so the page is zero filled, and the loop is exited.
G. The search exits the loop with page as the page that has been found or allocated and initialized, and object as the owner of that page. The page has been filled with the correct data at this point.
H. If the object providing the page is not the first object, then this mapping must be private, with the first object being a shadow object of the object providing the page. If pagein is handling a write fault, then the contents of the page that it has found have to be copied to the page that it allocated for the first object. Having made the copy, it can release the object and page from which the copy came, since the first object and first page will be used to finish the page-fault service. If pagein is handling a read fault, it can use the page that it found, but it has to mark the page copy-on-write to avoid the page being modified in the future.
I. If pagein is handling a write fault, then it has made any copies that were necessary, so it can safely make the page writable. As any pages around the required page that were brought into memory as part of the clustering were not copied, they are mapped read-only so that if a write is done on one of them, the full page-fault analysis will be done and a copy made at that time if it is necessary to do so.
J. As the page and possibly the first_page are released, any processes waiting for that page of the object will get a chance to run to get their own references.
Note that the page and object locking has been elided in Figure 5.11 to simplify the explanation.
Because the speed of CPUs has increased far more rapidly than the speed of main memory, most machines today require the use of a memory cache to allow the CPU to operate near its full potential.
Code that describes the operation of a hardware cache is given in Figure 5.12. An actual cache is entirely implemented in hardware, so the loop shown in Figure 5.12 would really be done by parallel comparisons rather than iteratively. Historically most machines had a direct-mapped cache. With a direct-mapped cache, an access to byte N followed by an access to byte N + (CACHELINES × LINESIZE) would cause the cached data for byte N to be lost. Most modern caches are either 2-way set associative or 4-way set associative. The 4-way set associative cache allows access of four different memory regions that overlap the same cache memory without destroying the previously cached data. But on the fifth access at that offset, an earlier cached value is lost.
There are several cache-design choices that require cooperation with the virtual-memory system. The design option with the biggest effect is whether the cache uses virtual or physical addressing. A physically addressed cache takes the address from the CPU, runs it through the MMU to get the address of the physical page, then uses this physical address to find out whether the requested memory location is available in the cache. Although a translation lookaside buffer (described in Section 5.13) significantly reduces the average latency of the translation, there is still a delay in going through the MMU. A virtually addressed cache uses the virtual address as that address comes from the CPU to find out whether the requested memory location is available in the cache. The virtual-address cache is faster than the physical-address cache because it avoids the time to run the address through the MMU. However, the virtual-address cache must be flushed completely after each context switch, because virtual addresses from one process are indistinguishable from the virtual addresses of another process. By contrast, a physical-address cache needs to flush only a few individual entries when their associated physical page is reassigned. In a system with many short-running processes, a virtual-address cache gets flushed so frequently that it is seldom useful.
Figure 5.12. Hardware-cache algorithm. Key: LINESIZE—Number of bytes in each cache line, typically 64 or 128 bytes; CACHELINES—Number of lines in the cache, 8192 is a typical size; SETSIZE—1 for a direct mapped cache, 2 for 2-way set associative, or 4 for 4-way set associative.

A further refinement to the virtual-address cache is to add a process tag to the key field for each cache line. At each context switch, the kernel loads a hardware context register with the tag assigned to the process. Each time an entry is recorded in the cache, both the virtual address and the process tag that faulted it are recorded in the key field of the cache line. The cache looks up the virtual address as before, but when it finds an entry, it compares the tag associated with that entry to the hardware context register. If they match, the cached value is returned. If they do not match, the correct value and current process tag replace the old cached value. When this technique is used, the cache does not need to be flushed completely at each context switch, since multiple processes can have entries in the cache. The drawback is that the kernel must manage the process tags. Usually, there are fewer tags (8 to 16) than there are processes. The kernel must assign the tags to the active set of processes. When an old process drops out of the active set to allow a new one to enter, the kernel must flush the cache entries associated with the tag that it is about to reuse.
A final consideration is a write-through versus a write-back cache. A write-through cache writes the data back to main memory at the same time as it is writing to the cache, forcing the CPU to wait for the memory access to conclude.
A write-back cache writes the data to only the cache, delaying the memory write until an explicit request or until the cache entry is reused. The write-back cache allows the CPU to resume execution more quickly and permits multiple writes to the same cache block to be consolidated into a single memory write. However, the writes must be forced any time it is necessary for the data to be visible to other CPUs on a multiprocessor.
Page coloring is a performance optimization designed to ensure that accesses to contiguous pages in virtual memory make the best use of a physical-address cache. The Intel architecture uses a physical-address cache referred to as the L1 cache. The performance of the system is closely tied to the percentage of memory references that can be serviced by the L1 cache because the L1 cache operates at the processor frequency. A miss in the L1 cache requires a few cycles of processor delay to wait for data in the L2 cache, or tens of cycles to wait for the dynamic RAM that stores the main memory.
A process on FreeBSD is running with a virtual-address space, not a physical-address space. The physical pages underlying the virtual-address space are rarely contiguous. In the worst case, two consecutive virtual pages could be stored in two physical pages backed by the same location in the L1 cache. Consider a process running on a CPU with a 1 Mbyte physical cache. If the process has its first virtual page mapped at physical page 1 Mbyte and its second virtual page mapped at physical page 2 Mbyte, despite maintaining locality of reference between its two consecutive virtual pages, the process unintentionally keeps missing the L1 cache. The effect is mitigated somewhat with multiway set-associative caches, but it is still problematic.
The role of the page-coloring algorithm is to ensure that consecutive pages in virtual memory will be contiguous from the point of view of the cache. Instead of assigning random physical pages to virtual addresses, page coloring assigns cache-contiguous physical pages to virtual addresses. Two physical pages are cache-contiguous if they hit consecutive pages in the cache. These pages may be far apart in physical memory. Figure 5.13 shows a sample assignment of pages to a process. In Figure 5.13, the cache holds 4 pages and page 10 of physical memory is assigned to page 0 of the process's virtual memory. Physical-memory page 10 is color 2 of the cache (10 modulo 4 equals 2). The page coloring code has assigned page 15 of physical memory to page 1 of the process's virtual memory as it has color 3. The page-coloring code attempts to avoid assigning pages 6 or 14 because they map over the same cache memory as page 10 and would result in nonoptimal caching, whereas any of pages 7, 11, or 15 are optimal, since they all follow the cache memory used for page 10.
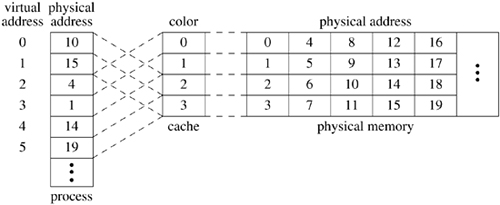
Page coloring is implemented by creating as many free lists as there are pages in the cache. Each of the pages in the cache is assigned a color. A machine with 1 Mbyte of cache and 4 Kbyte pages would have 256 cache pages—hence 256 colors. At system startup, each vm_page records its color in the L1 cache. When a page is freed, it is put onto the free list corresponding to its color. When an object is created, it is assigned a starting color. To ensure that demand for colors is moderately balanced, the starting color to be used for the next object is updated by the smaller of the size of the object or a third of the size of the L1 cache. When a page fault occurs on an object, its preferred color for the new page is calculated by adding the faulting logical-page number of the object to the starting color of the object modulo the number of colors. A page is taken from the free list of that color if it is available. Otherwise colors furthest away from the requested color are checked until an available page is found. A page furthest away is used because the algorithm wants to minimize the possibility of having a cache collision with a neighboring page in the virtual address space. For example, if a next-higher-colored page were used, it would likely collide with the page that the algorithm would select for the next-higher virtual address.
Page coloring makes virtual memory as deterministic as physical memory from the perspective of cache performance. Thus, programs can be written under the assumption that the characteristics of the underlying hardware cache are the same for their virtual address space as they would be if the program had been run directly in a physical-address space.
The service of page faults and other demands for memory may be satisfied from the free list for some time, but eventually memory must be reclaimed for reuse. Some pages are reclaimed when processes exit. On systems with a large amount of memory and low memory demand, exiting processes may provide enough free memory to fill demand. This case arises when there is enough memory for the kernel and for all pages that have ever been used by any current process. Obviously, many computers do not have enough main memory to retain all pages in memory. Thus, it eventually becomes necessary to move some pages to secondary storage—back to the filesystem and to the swap space. Bringing in a page is demand driven. For paging it out, however, there is no immediate indication when a page is no longer needed by a process. The kernel must implement some strategy for deciding which pages to move out of memory so that it can replace these pages with the ones that are currently needed in memory. Ideally, the strategy will choose pages for replacement that will not be needed soon. An approximation to this strategy is to find pages that have not been used actively or recently.
The 4.4BSD system implemented demand paging with a page-replacement algorithm that approximated global least-recently used [Easton & Franaszek, 1979]. In FreeBSD, the one-bit use field for each page has been augmented with an activity counter to approximate global least-actively used. Both these algorithms are examples of a global replacement algorithm: one in which the choice of a page for replacement is made according to systemwide criteria. A local replacement algorithm would choose a process for which to replace a page and then chose a page based on per-process criteria. Although the algorithm in FreeBSD is similar in nature to that in 4.4BSD, its implementation is considerably different.
The kernel scans physical memory on a regular basis, considering pages for replacement. The use of a systemwide list of pages forces all processes to compete for memory on an equal basis. Note that it is also consistent with the way that FreeBSD treats other resources provided by the system. A common alternative to allowing all processes to compete equally for memory is to partition memory into multiple independent areas, each localized to a collection of processes that compete with one another for memory. This scheme is used, for example, by the VMS operating system [Kenah & Bate, 1984]. With this scheme, system administrators can guarantee that a process, or collection of processes, will always have a minimal percentage of memory. Unfortunately, this scheme can be difficult to administer. Allocating too small a number of pages to a partition can result in underutilization of memory and excessive I/O activity to secondary-storage devices, whereas setting the number too high can result in excessive swapping [Lazowska & Kelsey, 1978].
The kernel divides the main memory into five lists:
- Wired: Wired pages are locked in memory and cannot be paged out. Typically, these pages are being used by the kernel or the physical-memory pager, or they have been locked down with mlock. In addition, all the pages being used to hold the user structure and thread stacks of loaded (i.e., not swapped-out) processes are also wired. Wired pages cannot be paged out.
- Active: Active pages are being used by one or more regions of virtual memory. Although the kernel can page them out, doing so is likely to cause an active process to fault them back again.
- Inactive: Inactive pages have contents that are still known, but they are not usually part of any active region. If the contents of the page are dirty, the contents must be written to backing store before the page can be reused. Once the page has been cleaned, it is moved to the cache list. If the system becomes short of memory, the pageout daemon may try to move active pages to the inactive list in the hopes of finding pages that are not really in use. The selection criteria that are used by the pageout daemon to select pages to move from the active list to the inactive list are described later in this section. When the free-memory and cache lists drop too low, the pageout daemon traverses the inactive list to create more cache and free pages.
- Cache: Cache pages have contents that are still known, but they are not usually part of any active region. If they are mapped into an active region, they must be marked read-only so that any write attempt will cause them to be moved off the cache list. They are similar to inactive pages except that they are not dirty, either because they are unmodified, since they were paged in, or because they have been written to their backing store. They can be moved to the free list when needed.
- Free: Free pages have no useful contents and will be used to fulfill new page-fault requests. The idle process attempts to keep about 75 percent of the pages on the free list zeroed so that they do not have to be zeroed while servicing an anonymous-region page fault. Pages with unknown contents are placed at the front of the free list. Zeroed pages are placed at the end of the free list. The idle process takes pages from the front of the free list, zeros them, marks them as having been zeroed, and puts them on the end of the free list. Page faults that will be filling a page take one from the front of the free list. Page faults that need a zero-filled page take one from the end of the free list. If marked as zeroed, it does not have to be zeroed during the fault service.
The pages of main memory that can be used by user processes are those on the active, inactive, cache, and free lists. Requests for new pages are taken first from the free list if it has pages available otherwise from the cache list. The cache and free lists are subdivided into separate lists organized by page color.
Ideally, the kernel would maintain a working set for each process in the system. It would then know how much memory to provide to each process to minimize the latter's page-fault behavior. The FreeBSD virtual-memory system does not use the working-set model because it lacks accurate information about the reference pattern of a process. It does track the number of pages held by a process via the resident-set size, but it does not know which of the resident pages constitute the working set. In 4.3BSD, the count of resident pages was used in making decisions on whether there was enough memory for a process to be swapped in when that process wanted to run. This feature was not carried over to the FreeBSD virtual-memory system. Because it worked well during periods of high memory demand, this feature should be incorporated in future FreeBSD systems.
The memory-allocation needs of processes compete constantly, through the page-fault handler, with the overall system goal of maintaining a minimum threshold of pages in the inactive, cache, and free lists. As the system operates, it monitors main-memory utilization and attempts to run the pageout daemon frequently enough to keep the amount of inactive, cache, and free memory at or above the minimum threshold shown in Table 5.2. When the page-allocation routine, vm_page_alloc(), determines that more memory is needed, it awakens the pageout daemon.
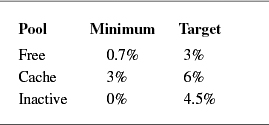
The number of pages to be reclaimed by the pageout daemon is a function of the memory needs of the system. As more memory is needed by the system, more pages are scanned. This scanning causes the number of pages freed to increase. The pageout daemon determines the memory needed by comparing the number of available-memory pages against several parameters that are calculated during system startup. The desired values for the paging parameters are communicated to the pageout daemon through global variables that may be viewed or changed with sysctl. Likewise, the pageout daemon records its progress in global counters that may be viewed or reset with sysctl. Progress is measured by the number of pages scanned over each interval that it runs.
The goal of the pageout daemon is to maintain the inactive, cache, and free queues between the minimum and target thresholds shown in Table 5.2. The pageout daemon achieves this goal by moving pages from more active queues to less active queues to reach the indicated ranges. It moves pages from the cache list to the free list to maintain the free list minimum. It moves pages from the inactive list to the cache list to keep the cache list near its target. It moves pages from the active list to the inactive list to maintain the inactive list near its target.
Page replacement is done by the pageout daemon (process 2). The paging policy of the pageout daemon is embodied in the vm_pageout() and vm_pageout_scan() routines. When the pageout daemon reclaims pages that have been modified, it is responsible for writing them to the swap area. Thus, the pageout daemon must be able to use normal kernel-synchronization mechanisms, such as sleep(). It therefore runs as a separate process, with its own process structure and kernel stack. Like init, the pageout daemon is created by an internal fork operation during system startup (see Section 14.4); unlike init, however, it remains in kernel mode after the fork. The pageout daemon simply enters vm_pageout() and never returns. Unlike some other users of the disk I/O routines, the pageout process needs to do its disk operations asynchronously so that it can continue scanning in parallel with disk writes.
Historically, the pages were handled using a least-recently used algorithm. The drawback to this algorithm is that a sudden burst of memory activity can flush many useful pages from the cache. To mitigate this behavior, FreeBSD uses a least-actively used algorithm to preserve pages that have a history of usage so that they will be favored over the once-used pages brought in during a period of high memory demand.
When a page is first brought into memory it is given an initial usage count of three. Further usage information is gathered by the pageout daemon during its periodic scans of memory. As each page of memory is scanned, its reference bit is checked. If the bit is set, it is cleared and the usage counter for the page is incremented (up to a limit of 64) by the number of references to the page. If the reference bit is clear, the usage counter is decremented. When the usage counter reaches zero, the page is moved from the active list to the inactive list. Pages that are repeatedly used build up large usage counts that will cause them to remain on the active list much longer than pages that are used just once.
The goal of the pageout daemon is to keep the number of pages on the inactive, cache, and free lists within their desired ranges. Whenever an operation that uses pages causes the amount of free memory to fall below the minimum thresholds, the pageout daemon is awakened. The pageout-handling algorithm is shown in Figure 5.14 (on pages 192-193). In the following overview, the lettered points are references to the tags down the left side of the code.
A. The pageout daemon calculates the number of pages that need to be moved from the inactive list to the cache list. As some will later be moved to the free list, enough pages must moved to the cache list to leave its minimum level after the free list has been filled. To avoid saturating the I/O system, the pageout daemon limits the number of I/O operations that it will start concurrently.
B. Scan the inactive list until the desired number of pages are moved. Skip over busy pages, since they are likely being paged out and can be moved later when they are clean.
C. If we find a page that is part of an object that has started being used, then it has been moved to the inactive list prematurely. So update its usage count and move it back to the active list. Pages with no associated object have no useful contents and are moved to the free list. Pages that are clean can be moved to the cache list.
D. Dirty pages need to be paged out, but flushing a page is extremely expensive compared to freeing a clean page. Thus, dirty pages are given extra time on the inactive queue by cycling them through the queue twice before being flushed. They cycle through the list once more while being cleaned. This extra time on the inactive queue will reduce unnecessary I/O caused by prematurely paging out an active page. The clustering checks for up to eight dirty pages on either side of the selected page. The pager is only required to write the selected page. However, it may write as many of the clustered dirty pages as it finds convenient. The scanning of the inactive list stops if the number of pageouts in progress hits its limit. In 4.4BSD, the I/O completions were handled by the pageout daemon. FreeBSD requires that pagers track their own I/O operations including the appropriate updating of the written pages. The written-page update at I/O completion does not move the page from the inactive list to the cache list. Rather, the page remains on the inactive list until it is eventually moved to the cache list during a future pass of the pageout daemon.



E. The pageout daemon calculates the number of pages that need to be moved from the active list to the inactive list. As some will eventually need to be moved to the cache and free lists, enough pages must be moved to the inactive list to leave it at its target level after the cache and free lists have been filled.
F. Scan the active list until the desired number of pages are moved. Skip over busy pages as they are likely being actively used. If we find a page that is part of an active object, update its usage count and move it to the end of the active list.
G. The page is not active, so decrement its usage count. If its usage is still above zero, move it to the end of the active list. Otherwise, move it to the inactive list if it is dirty or the cache list if it is clean.
H. Calculate the number of pages that need to be moved to the free list. It only fills the free list to its minimum level. It prefers to keep pages on the cache list since they can be reclaimed if their object or file is reactivated. Once on the free list the identity of a page is lost. Thus, the pageout daemon delays moving pages to the free list until just before they are expected to be needed.
I. If the page-count targets have not been met, the swap-out daemon is started (see next subsection) to try to clear additional memory.
J. The FreeBSD 5.2 kernel does not impose any limits on the amount of virtual memory that it will grant. If it finds that it has nearly filled its memory and swap space, it avoids going into deadlock by killing off the largest process. One day virtual-memory accounting and limits will be added to the system so as to avoid this crude resource-control mechanism.
Note that the page and object locking has been elided in Figure 5.14 to simplify the explanation.
Although swapping is generally avoided, there are several times when it is used in FreeBSD to address a serious memory shortage. Swapping is done in FreeBSD when any of the following occurs:
• The system becomes so short of memory that the paging process cannot free memory fast enough to satisfy the demand. For example, a memory shortfall may happen when multiple large processes are run on a machine lacking enough memory for the minimum working sets of the processes.
• Processes are completely inactive for more than 10 seconds. Otherwise, such processes would retain a few pages of memory associated with their user structure and thread stacks.
Swap operations completely remove a process from main memory, including the process page tables, the pages of the data and the stack segments that are not already in swap space, and the user structure and thread stacks.
Process swapping is invoked only when paging is unable to keep up with memory needs or when short-term memory needs warrant swapping a process. In general, the swap-scheduling mechanism does not do well under heavy load; system performance is much better when memory scheduling can be done by the page-replacement algorithm than when the swap algorithm is used.
Swap out is driven by the swap-out daemon, vmdaemon (process 3). The swap-out policy of the vmdaemon is embodied in the vm_daemon() routine. If the pageout daemon can find any processes that have been sleeping for more than 10 seconds (swap_idle_threshold2, the cutoff for considering the time sleeping to be "a long time"), it will swap out the one sleeping for the longest time. Such processes have the least likelihood of making good use of the memory that they occupy; thus, they are swapped out even if they are small. If none of these processes are available, the pageout daemon will swap out a process that has been sleeping for as briefly as 2 seconds (swap_idle_thresholdl). These criteria attempt to avoid swapping entirely until the pageout daemon is clearly unable to keep enough memory free.
In 4.4BSD, if memory was still desperately low, the swap-out daemon would select to swap out the runnable process that had been resident the longest. Once swapping of runnable processes had begun, the processes eligible for swapping would take turns in memory so that no process was frozen out entirely. The FreeBSD swap-out daemon will not select a runnable processes to swap out. So, if the set of runnable processes do not fit in memory, the machine will effectively deadlock. Current machines have enough memory that this condition does not arise. If it does, the 4.4BSD algorithm will need to be restored.
The mechanics of doing a swap out are simple. The swapped-in process flag P_INMEM is cleared to show that the process is not resident in memory. The PS_SWAPPINGOUT flag is set while the swap out is being done so that neither a second swap out nor a swap in is attempted at the same time. If a runnable process is to be swapped (which currently never happens), it needs to be removed from the runnable process queue. The user structure of the process and the kernel stack of its threads are then marked as pageable, which allows the user structure and stack pages, along with any other remaining pages for the process, to be paged out via the standard pageout mechanism. The swapped-out process cannot be run until after it is swapped back into memory.
Swap-in operations are done by the swapping process, swapper (process 0). This process is the first one created by the system when the latter is started. The swap-in policy of the swapper is embodied in the scheduler() routine. This routine swaps processes back in when memory is available and they are ready to run. At any time, the swapper is in one of three states:
- Idle: No swapped-out processes are ready to be run. Idle is the normal state.
- Swapping in: At least one runnable process is swapped out, and scheduler() attempts to find memory for it.
- Swapping out: The system is short of memory, or there is not enough memory to swap in a process. Under these circumstances, scheduler() awakens the pageout daemon to free pages and to swap out other processes until the memory shortage abates.
If more than one swapped-out process is runnable, the first task of the swapper is to decide which process to swap in. This decision may affect the decision whether to swap out another process. Each swapped-out process is assigned a priority based on
• The length of time it has been swapped out
• Its nice value
• The amount of time it was asleep since it last ran
In general, the process that has been swapped out longest or was swapped out because it had slept for a long time before being swapped will be brought in first. Once a process is selected, the swapper checks to see whether there is enough memory free to swap in the process. Historically, the system required as much memory to be available as was occupied by the process before that process was swapped. Under FreeBSD, this requirement was reduced to a requirement that the number of pages on the free and cache lists be at least equal to the minimum free-memory threshold. If there is enough memory available, the process is brought back into memory. The user structure is swapped in immediately, but the process loads the rest of its working set by demand paging from the backing store. Thus, not all the memory that is needed by the process is used immediately. Earlier BSD systems tracked the anticipated demand and would only swap in runnable processes as free memory became available to fulfill their expected needs. FreeBSD allows all swapped-out runnable processes to be swapped in as soon as there is enough memory to load their user structure and thread stacks.
The procedure for swap in of a process is the reverse of that for swap out:
- Memory is allocated for the user structure and the kernel stack of each of its threads, and they are read back from swap space.
- The process is marked as resident, and its runnable threads are returned to the run queue (i.e., those threads that are not stopped or sleeping).
After the swap in completes, the process is ready to run like any other, except that it has no resident pages. It will bring in the pages that it needs by faulting them.
Everything discussed in this chapter up to this section has been part of the machine-independent data structures and algorithms. These parts of the virtual-memory system require little change when FreeBSD is ported to a new architecture. This section will describe the machine-dependent parts of the virtual-memory system; the parts of the virtual-memory system that must be written as part of a port of FreeBSD to a new architecture. The machine-dependent parts of the virtual-memory system control the hardware memory-management unit (MMU). The MMU implements address translation and access control when virtual memory is mapped onto physical memory.
One common MMU design uses memory-resident forward-mapped page tables. These page tables are large contiguous arrays indexed by the virtual address. There is one element, or page-table entry, in the array for each virtual page in the address space. This element contains the physical page to which the virtual page is mapped, as well as access permissions, status bits telling whether the page has been referenced or modified, and a bit showing whether the entry contains valid information. For a 4-Gbyte address space with 4-Kbyte virtual pages and a 32-bit page-table entry, 1 million entries, or 4 Mbyte, would be needed to describe an entire address space. Since most processes use little of their address space, most of the entries would be invalid, and allocating 4 Mbyte of physical memory per process would be wasteful. Thus, most page-table structures are hierarchical, using two or more levels of mapping. With a hierarchical structure, different portions of the virtual address are used to index the various levels of the page tables. The intermediate levels of the table contain the addresses of the next lower level of the page table. The kernel can mark as unused large contiguous regions of an address space by inserting invalid entries at the higher levels of the page table, eliminating the need for invalid page descriptors for each individual unused virtual page.
This hierarchical page-table structure requires the hardware to make frequent memory references to translate a virtual address. To speed the translation process, most page-table-based MMUs also have a small, fast, fully associative hardware cache of recent address translations, a structure known commonly as a translation lookaside buffer (TLB). When a memory reference is translated, the TLB is first consulted and, only if a valid entry is not found there, the page-table structure for the current process is traversed. Because most programs exhibit spatial locality in their memory-access patterns, the TLB does not need to be large; many are as small as 128 entries.
As address spaces grew beyond 32 to 48 and, more recently, 64 bits, simple indexed data structures become unwieldy, with three or more levels of tables required to handle address translation. A response to this page-table growth is the inverted page table, also known as the reverse-mapped page table. In an inverted page table, the hardware still maintains a memory-resident table, but that table contains one entry per physical page and is indexed by physical address instead of by virtual address. An entry contains the virtual address to which the physical page is currently mapped, as well as protection and status attributes. The hardware does virtual-to-physical address translation by computing a hash function on the virtual address to select an entry in the table. The system handles collisions by linking together table entries and making a linear search of this chain until it finds the matching virtual address.
The advantages of an inverted page table are that the size of the table is proportional to the amount of physical memory and that only one global table is needed, rather than one table per process. A disadvantage to this approach is that there can be only one virtual address mapped to any given physical page at any one time. This limitation makes virtual-address aliasing—having multiple virtual addresses for the same physical page—difficult to handle. As it is with the forward-mapped page table, a hardware TLB is typically used to speed the translation process.
A final common MMU organization consists of just a TLB. This architecture is the simplest hardware design. It gives the software maximum flexibility by allowing the latter to manage translation information in whatever structure it desires.
Often, a port to another architecture with a similar memory-management organization can be used as a starting point for a new port. The PC architecture uses the typical two-level page-table organization shown in Figure 5.15. An address space is broken into 4-Kbyte virtual pages, with each page identified by a 32-bit entry in the page table. Each page-table entry contains the physical page number assigned to the virtual page, the access permissions allowed, modify and reference information, and a bit showing that the entry contains valid information. The 4 Mbyte of page-table entries are likewise divided into 4-Kbyte page-table pages, each of which is described by a single 32-bit entry in the directory table. Directory-table entries are nearly identical to page-table entries: They contain access bits, modify and reference bits, a valid bit, and the physical page number of the page-table page described. One 4-Kbyte page—1024 directory-table entries—covers the maximum-sized 4-Gbyte address space. The CR3 hardware register contains the physical address of the directory table for the currently active process.
Figure 5.15. Two-level page-table organization. Key: V—page-valid bit; M—page-modified bit; R—page-referenced bit; ACC—page-access permissions.
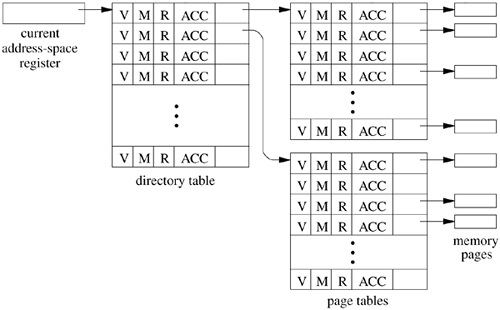
In Figure 5.15, translation of a virtual address to a physical address during a CPU access proceeds as follows:
- The 10 most significant bits of the virtual address are used to index into the active directory table.
- If the selected directory-table entry is valid and the access permissions grant the access being made, the next 10 bits of the virtual address are used to index into the page-table page referenced by the directory-table entry.
- If the selected page-table entry is valid and the access permissions match, the final 12 bits of the virtual address are combined with the physical page referenced by the page-table entry to form the physical address of the access.
The machine-dependent code describes how the physical mapping is done between the user-processes and kernel virtual addresses and the physical addresses of the main memory. This mapping function includes management of access rights in addition to address translation. In FreeBSD, the physical-mapping (pmap) module manages machine-dependent translation and access tables that are used either directly or indirectly by the memory-management hardware. For example, on the PC, the pmap maintains the memory-resident directory and page tables for each process, as well as for the kernel. The machine-dependent state required to describe the translation and access rights of a single page is often referred to as a mapping or mapping structure.
The FreeBSD pmap interface is nearly identical to that in Mach 3.0 and it shares many design characteristics. The pmap module is intended to be logically independent of the higher levels of the virtual-memory system. The interface deals strictly in machine-independent page-aligned virtual and physical addresses and in machine-independent protections. The machine-independent page size may be a multiple of the architecture-supported page size. Thus, pmap operations must be able to affect more than one physical page per logical page. The machine-independent protection is a simple encoding of read, write, and execute permission bits. The pmap must map all possible combinations into valid architecture-specific values.
A process's pmap is considered to be a cache of mapping information kept in a machine-dependent format. As such, it does not need to contain complete state for all valid mappings. Mapping state is the responsibility of the machine-independent layer. With one exception, the pmap module may throw away mapping state at its discretion to reclaim resources. The exception is wired mappings, which should never cause a fault that reaches the machine-independent vm_fault() routine. Thus, state for wired mappings must be retained in the pmap until it is removed explicitly.
In general, pmap routines may act either on a set of mappings defined by a virtual address range or on all mappings for a particular physical address. Being able to act on individual or all virtual mappings for a physical page requires that the mapping information maintained by the pmap module be easily found by both virtual and physical address. For architectures such as the PC that support memory-resident page tables, the virtual-to-physical, or forward lookup, may be a simple emulation of the hardware page-table traversal. Physical-to-virtual, or reverse, lookup uses a list of pv_entry structures, described in the next subsection, to find all the page-table entries referencing a page. The list may contain multiple entries only if virtual-address aliasing is allowed.
There are two strategies that can be used for management of pmap memory resources, such as user-directory or page-table memory. The traditional and easiest approach is for the pmap module to manage its own memory. Under this strategy, the pmap module can grab a fixed amount of wired physical memory at system boot time, map that memory into the kernel's address space, and allocate pieces of the memory as needed for its own data structures. The primary benefit is that this approach isolates the pmap module's memory needs from those of the rest of the system and limits the pmap module's dependencies on other parts of the system. This design is consistent with a layered model of the virtual-memory system in which the pmap is the lowest, and hence self-sufficient, layer.
The disadvantage is that this approach requires the duplication of many of the memory-management functions. The pmap module has its own memory allocator and deallocator for its private heap—a heap that is statically sized and cannot be adjusted for varying systemwide memory demands. For an architecture with memory-resident page tables, it must keep track of noncontiguous chunks of processes' page tables, because a process may populate its address space sparsely. Handling this requirement entails duplicating much of the standard list-management code, such as that used by the vm_map code.
An alternative approach, used by the PC, is to use the higher-level virtual-memory code recursively to manage some pmap resources. Here, the 4-Kbyte directory table for each user process is mapped into the address space of the kernel as part of setting up the process and remains resident until the process exits. While a process is running, its page-table entries are mapped into a virtually contiguous 4-Mbyte array of page-table entries in the kernel's address space. This organization leads to an obscure memory-saving optimization exploited in the PC pmap module where the kernel's page-table page describing the 4-Mbyte user page-table range can double as the user's directory table. The kernel also maintains alternate maps to hold individual page-table pages of other nonrunning processes if it needs to access their address space.
Using the same page-allocation routines as all the other parts of the system ensures that physical memory is allocated only when needed and from the systemwide free-memory pool. Page tables and other pmap resources also can be allocated from pageable kernel memory. This approach easily and efficiently supports large sparse address spaces, including the kernel's own address space.
The primary drawback is that this approach violates the independent nature of the interface. In particular, the recursive structure leads to deadlock problems with global multiprocessor spin locks that can be held while the kernel is calling a pmap routine.
The pmap data structures are contained in the machine-dependent include directory in the file pmap.h. Most of the code for these routines is in the machine-dependent source directory in the file pmap.c. The main tasks of the pmap module are these:
• System initialization and startup (pmap_bootstrap(), pmap_init(), pmap_growkernel())
• Allocation and deallocation of mappings of physical to virtual pages (pmap_enter(), pmap_remove(), pmap_qenter(), pmap_qremove())
• Change of access protections and other attributes of mappings (pmap_change_wiring(), pmap_page_protect(), pmap_protect())
• Maintenance of physical page-usage information (pmap_clear_modify(), pmap_clear_reference(), pmap_is_modified(), pmap_ts_referenced())
• Initialization of physical pages (pmap_copy_page(), pmap_zero_page())
• Management of internal data structures (pmap_pinit(), pmap_release())
Each of these tasks is described in the following subsections.
The first step in starting up the system is for the loader to bring the kernel image from a disk or the network into the physical memory of the machine. The kernel load image looks much like that of any other process; it contains a text segment, an initialized data segment, and an uninitialized data segment. The loader places the kernel contiguously into the beginning of physical memory. Unlike a user process that is demand paged into memory, the text and data for the kernel are read into memory in their entirety. Following these two segments, the loader zeros an area of memory equal to the size of the kernel's uninitialized memory segment. After loading the kernel, the loader passes control to the starting address given in the kernel executable image. When the kernel begins executing, it is executing with the MMU turned off. Consequently, all addressing is done using the direct physical addresses.
The first task undertaken by the kernel is to set up the kernel pmap, and any other data structures that are necessary to describe the kernel's virtual address space. On the PC, the initial setup includes allocating and initializing the directory and page tables that map the statically loaded kernel image and memory-mapped I/O address space, allocating a fixed amount of memory for kernel page-table pages, allocating and initializing the user structure and kernel stack for the initial process, reserving special areas of the kernel's address space, and initializing assorted critical pmap-internal data structures. When done, it is possible to enable the MMU. Once the MMU is enabled, the kernel begins running in the context of process zero.
Once the kernel is running in its virtual address space, it proceeds to initialize the rest of the system. It determines the size of the physical memory, then calls pmap_bootstrap() and vm_page_startup() to set up the initial pmap data structures, to allocate the vm_page structures, and to create a small, fixed-size pool of memory, which the kernel memory allocators can use so that they can begin responding to memory allocation requests. Next it makes a call to set up the machine-independent portion of the virtual-memory system. It concludes with a call to pmap_init(), which allocates all resources necessary to manage multiple user address spaces and synchronizes the higher-level kernel virtual-memory data structures with the kernel pmap.
Pmap_init() allocates a minimal amount of wired memory to use for kernel page-table pages. The page-table space is expanded dynamically by the pmap_growkernel() routine as it is needed while the kernel is running. Once allocated it is never freed. The limit on the size of the kernel's address space is selected at boot time. On the PC, the kernel is typically given a maximum of 1 Gbyte of address space.
In 4.4BSD, the memory managed by the buffer cache was separate from the memory managed by the virtual-memory system. Since all the virtual-memory pages were used to map process regions, it was sensible to create an inverted page table. This table was an array of pv_entry structures. Each pv_entry described a single address translation and included the virtual address, a pointer to the associated pmap structure for that virtual address, a link for chaining together multiple entries mapping this physical address, and additional information specific to entries mapping page-table pages. Building a dedicated table was sensible, since all valid pages were referenced by a pmap, yet few had multiple mappings.
With the merger of the buffer cache into the virtual-memory system in FreeBSD, many pages of memory are used to cache file data that is not mapped into any process address space. Thus, preallocating a table of pv_entry structures is wasteful, since many of them would go unused. So, FreeBSD allocates pv_entry structures on demand as pages are mapped into a process address space.
Figure 5.16 shows the pv_entry references for a set of pages that have a single mapping. The purpose of the pv_entry structures is to identify the address space that has the page mapped. The machine-dependent part of each vm_page structure contains the head of list of pv_entry structures and a count of the number of entries on the list. In Figure 5.16, the object is using pages 5, 18, and 79. The list heads in the machine-dependent structures of these vm_page structures would each point to a single pv_entry structure labelled in the figure with the number of the vm_page structure that references them. Not shown in Figure 5.16 is that each physical map structure also maintains a list of all the pv_entry structures that reference it.
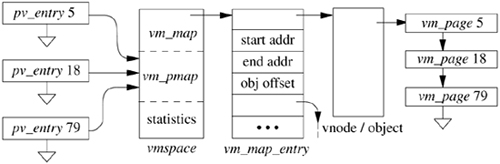
Each pv_entry can reference only one physical map. When an object becomes shared between two or more processes, each physical page of memory becomes mapped into two or more sets of page tables. To track these multiple references, the pmap module must create chains of pv_entry structures, as shown in Figure 5.17. Copy-on-write is an example of the need to find all the mappings of a page as it requires that the page tables be set to read-only in all the processes sharing the object. The pmap module can implement this request by walking the list of pages associated with the object to be made copy-on-write. For each page, it traverses that page's list of pv_entry structures. It then makes the appropriate change to the page-table entry associated with each pv_entry structure.
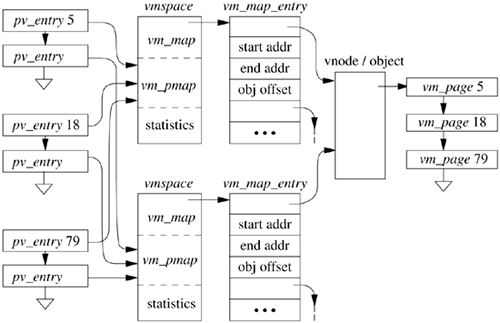
A system with many shared objects can require many pv_entry structures, which can use an unreasonable amount of the kernel memory. The alternative would be to keep a list associated with each object of all the vm_map_entry structures that reference it. When it becomes necessary to modify the mapping of all the references to the page, the kernel could traverse this list checking the address space associated with each vm_map_entry to see if it held a reference to the page. For each page found, it could make the appropriate update.
The pv_entry structures consume more memory but reduce the time to do a common operation. For example, consider a system running a thousand processes that all share a common library. Without the pv_entry list, the cost to change a page to copy-on-write would require checking all thousand processes. With the pv_entry list, only those processes using the page would need to be inspected.
The primary responsibility of the pmap module is validating (allocating) and invalidating (deallocating) mappings of physical pages to virtual addresses. The physical pages represent cached portions of an object that is providing data from a file or an anonymous memory region. A physical page is bound to a virtual address because that object is being mapped into a process's address space either explicitly by mmap or implicitly by fork or exec. Physical-to-virtual address mappings are not created at the time that the object is mapped; instead, their creation is delayed until the first reference to a particular page is made. At that point, an access fault will occur, and pmap_enter() will be called. Pmap_enter(), is responsible for any required side effects associated with creation of a new mapping. Such side effects are largely the result of entering a second translation for an already mapped physical page—for example, as the result of a copy-on-write operation. Typically, this operation requires flushing uniprocessor or multiprocessor TLB or cache entries to maintain consistency.
In addition to its use to create new mappings, pmap_enter() may also be called to modify the wiring or protection attributes of an existing mapping or to rebind an existing mapping for a virtual address to a new physical address. The kernel can handle changing attributes by calling the appropriate interface routine, described in the next subsection. Changing the target physical address of a mapping is simply a matter of first removing the old mapping and then handling it like any other new mapping request.
Pmap_enter() is the only routine that cannot lose state or delay its action. When called, it must create a mapping as requested, and it must validate that mapping before returning to the caller. On the PC, pmap_enter() must first check whether a page-table entry exists for the requested address. If a physical page has not yet been allocated to the process page-table at the location required for the new mapping, a zeroed page is allocated, wired, and inserted into the directory table of the process.
After ensuring that all page-table resources exist for the mapping being entered, pmap_enter() validates or modifies the requested mapping as follows:
- Check to see whether a mapping structure already exists for this virtual-to-physical address translation. If one does, the call must be one to change the protection or wiring attributes of the mapping; it is handled as described in the next subsection.
- Otherwise, if a mapping exists for this virtual address but it references a different physical address, that mapping is removed.
- The hold count on a page-table page is incremented each time a new page reference is added and decremented each time an old page reference is removed. When the last valid page is removed, the hold count drops to zero, the page is unwired, and the page-table page is freed because it contains no useful information.
- A page-table entry is created and validated, with cache and TLB entries flushed as necessary.
- If the physical address is outside the range managed by the pmap module (e.g., a frame-buffer page), no pv_entry structure is needed. Otherwise, for the case of a new mapping for a physical page that is mapped into an address space, a pv_entry structure is created.
- For machines with a virtually-indexed cache, a check is made to see whether this physical page already has other mappings. If it does, all mappings may need to be marked cache inhibited, to avoid cache inconsistencies.
When an object is unmapped from an address space, either explicitly by munmap or implicitly on process exit, the pmap module is invoked to invalidate and remove the mappings for all physical pages caching data for the object. Unlike pmap_enter(), pmap_remove() can be called with a virtual-address range encompassing more than one mapping. Hence, the kernel does the unmapping by looping over all virtual pages in the range, ignoring those for which there is no mapping and removing those for which there is one.
Pmap_remove() on the PC is simple. It loops over the specified address range, invalidating individual page mappings. Since pmap_remove() can be called with large sparsely allocated regions, such as an entire process virtual address range, it needs to skip efficiently invalid entries within the range. It skips invalid entries by first checking the directory-table entry for a particular address and, if an entry is invalid, skipping to the next 4-Mbyte boundary. When all page mappings have been invalidated, any necessary global cache flushing is done.
To invalidate a single mapping, the kernel locates and marks as invalid the appropriate page-table entry. The reference and modify bits for the page are saved in the page's vm_page structure for future retrieval. If this mapping was a user mapping, the hold count for the page-table page is decremented. When the count reaches zero, the page-table page can be reclaimed because it contains no more valid mappings. When a user page-table page is removed from the kernel's address space (i.e., as a result of removal of the final valid user mapping from that page), the process's directory table must be updated. The kernel does this update by invalidating the appropriate directory-table entry. If the physical address from the mapping is outside the managed range, nothing more is done. Otherwise, the pv_entry structure is found and is deallocated.
The pmap_qenter() and pmap_qremove() are faster versions of the pmap_enter() and pmap_remove() functions that can be used by the kernel to quickly create and remove temporary mappings. They can only be used on non-pageable mappings in the address space of the kernel. For example, the buffer-cache management routines use these routines to map file pages into kernel memory so that they can be read or written by the filesystem.
An important role of the pmap module is to manipulate the hardware access protections for pages. These manipulations may be applied to all mappings covered by a virtual-address range within a pmap via pmap_protect(), or they may be applied to all mappings of a particular physical page across pmaps via pmap_page_protect(). There are two features common to both calls. First, either form may be called with a protection value of VM_PROT_NONE to remove a range of virtual addresses or to remove all mappings for a particular physical page. Second, these routines should never add write permission to the affected mappings. Thus, calls including VM_PROT_WRITE should make no changes. This restriction is necessary for the copy-on-write mechanism to function properly. The request to make the page writable is made only in the vm_map_entry structure. When a later write attempt on the page is made by the process, a page fault will occur. The page-fault handler will inspect the vm_map_entry and determine that the write should be permitted. If it is a copy-on-write page, the fault handler will make any necessary copies before calling pmap_enter() to enable writing on the page. Thus, write permission on a page is added only via calls to pmap_enter().
Pmap_protect() is used primarily by the mprotect system call to change the protection for a region of process address space. The strategy is similar to that of pmap_remove(): Loop over all virtual pages in the range and apply the change to all valid mappings that are found. Invalid mappings are left alone.
For the PC, pmap_protect() first checks for the special cases. If the requested permission is VM_PROT_NONE, it calls pmap_remove() to handle the revocation of all access permission. If VM_PROT_WRITE is included, it just returns immediately. For a normal protection value, pmap_remove() loops over the given address range, skipping invalid mappings. For valid mappings, the page-table entry is looked up, and, if the new protection value differs from the current value, the entry is modified and any TLB and cache flushing done. As occurs with pmap_remove(), any global cache actions are delayed until the entire range has been modified.
Pmap_page_protect() is used internally by the virtual-memory system for two purposes. It is called to set read-only permission when a copy-on-write operation is set up (e.g., during fork). It also removes all access permissions before doing page replacement to force all references to a page to block pending the completion of its operation. In Mach, this routine used to be two separate routines—pmap_clear_ptes() and pmap_remove_all()—and many pmap modules implement pmap_page_protect() as a call to one or the other of these functions, depending on the protection argument.
In the PC implementation of pmap_page_protect(), if VM_PROT_WRITE is requested, it returns without doing anything. The addition of write enable must be done on a page-by-page basis by the page-fault handling routine as described for pmap_protect(). Otherwise, it traverses the list of pv_entry structures for this page, invalidating the individual mappings as described in the previous subsection. As occurs with pmap_protect(), the entry is checked to ensure that it is changing before expensive TLB and cache flushes are done. Note that TLB and cache flushing differ from those for pmap_remove(), since they must invalidate entries from multiple process contexts, rather than invalidating multiple entries from a single process context.
Pmap_change_wiring() is called to wire or unwire a single machine-independent virtual page within a pmap. As described in the previous subsection, wiring informs the pmap module that a mapping should not cause a hardware fault that reaches the machine-independent vm_fault() code. Wiring is typically a software attribute that has no effect on the hardware MMU state: It simply tells the pmap not to throw away state about the mapping. As such, if a pmap module never discards state, then it is not strictly necessary for the module even to track the wired status of pages. The only side effect of not tracking wiring information in the pmap is that the mlock system call cannot be completely implemented without a wired page-count statistic.
The PC pmap implementation maintains wiring information. An unused bit in the page-table-entry structure records a page's wired status. Pmap_change_wiring() sets or clears this bit when it is invoked with a valid virtual address. Since the wired bit is ignored by the hardware, there is no need to modify the TLB or cache when the bit is changed.
The machine-independent page-management code needs to be able to get basic information about the usage and modification of pages from the underlying hardware. The pmap module facilitates the collection of this information without requiring the machine-independent code to understand the details of the mapping tables by providing a set of interfaces to query and clear the reference and modify bits. The pageout daemon can call vm_page_test_dirty() to determine whether a page is dirty. If the page is dirty, the pageout daemon can write it to backing store and then call pmap_clear_modify() to clear the modify bit. Similarly, when the pageout daemon pages out or inactivates a page, it uses pmap_clear_reference() to clear the reference bit for the page. When it wants to update the active count for a page, it uses pmap_ts_referenced() to count the number of uses of the page since it was last scanned.
One important feature of the query routines is that they should return valid information even if there are currently no mappings for the page in question. Thus, referenced and modified information cannot just be gathered from the hardware-maintained bits of the various page-table or TLB entries; rather, there must be a place where the information is retained when a mapping is removed.
For the PC, the modified information for a page is stored in the dirty field of its vm_page structure. Initially cleared, the information is updated whenever a mapping for a page is considered for removal. The vm_page_test_dirty() routine first checks the dirty field and, if the bit is set, returns TRUE immediately. Since this attribute array contains only past information, it still needs to check status bits in the page-table entries for currently valid mappings of the page. This information is checked by calling the pmap_is_modified() routine, which immediately returns FALSE if it is not passed a managed physical page. Otherwise, pmap_is_modified() traverses the pv_entry structures associated with the physical page, examining the modified bit for the pv_entry's associated page-table entry. It can return TRUE as soon as it encounters a set bit or FALSE if the bit is not set in any page-table entry.
The referenced information for a page is stored in the act_count field and as a flag of its vm_page structure. Initially cleared, the information is updated periodically by the pageout daemon. As it scans memory, the pageout daemon calls the pmap_ts_referenced() routine to collect a count of references to the page. The pmap_ts_referenced() routine returns zero if it is not passed a managed physical page. Otherwise, it traverses the pv_entry structures associated with the physical page, examining and clearing the referenced bit for the pv_entry's associated page-table entry. It returns the number of referenced bits that it found.
The clear routines also return immediately if they are not passed a managed physical page. Otherwise, the referenced or modified bit is cleared in the attribute array, and they loop over all pv_entry structures associated with the physical page, clearing the hardware-maintained page-table-entry bits. This final step may involve TLB or cache flushes along the way or afterward.
Two interfaces are provided to allow the higher-level virtual-memory routines to initialize physical memory. Pmap_zero_page() takes a physical address and fills the page with zeros. Pmap_copy_page() takes two physical addresses and copies the contents of the first page to the second page. Since both take physical addresses, the pmap module will most likely have to first map those pages into the kernel's address space before it can access them.
The PC implementation has a pair of global kernel virtual addresses reserved for zeroing and copying pages. Pmap_zero_page() maps the specified physical address into the reserved virtual address, calls bzero() to clear the page, and then removes the temporary mapping with the single translation-invalidation primitive used by pmap_remove(). Similarly, pmap_copy_page() creates mappings for both physical addresses, uses bcopy() to make the copy, and then removes both mappings.
The remaining pmap interface routines are used for management and synchronization of internal data structures. Pmap_pinit() creates an instance of the machine-dependent pmap structure. It is used by the vmspace_fork() and vmspace_exec() routines when creating new address spaces during a fork or exec. Pmap_release() deallocates the pmap's resources. It is used by the vmspace_free() routine when cleaning up a vmspace when a process exits.
5.1 What does it mean for a machine to support virtual memory? What four hardware facilities are typically required for a machine to support virtual memory?
5.2 What is the relationship between paging and swapping on a demand-paged virtual-memory system? Explain whether it is desirable to provide both mechanisms in the same system. Can you suggest an alternative to providing both mechanisms?
5.3 What three policies characterize paging systems?
5.4 What is copy-on-write? In most UNIX applications, the fork system call is followed almost immediately by an exec system call. Why does this behavior make it particularly attractive to use copy-on-write in implementing fork?
5.5 Explain why the vfork system call will always be more efficient than a clever implementation of the fork system call.
5.6 When a process exits, all its pages may not be placed immediately on the memory free list. Explain this behavior.
5.7 Why does the kernel have both the traditional malloc() and free() interface and the zone allocator? Explain when each type of interface is useful.
5.8 What is the purpose of page coloring? On what sort of hardware is it needed?
5.9 What purpose does the pageout-daemon process serve in the virtual-memory system?
5.10 What is clustering? Where is it used in the virtual-memory system?
5.11 Why is the historic use of the sticky bit to lock a process image in memory no longer useful in FreeBSD?
5.12 Give two reasons for swapping to be initiated.
*5.13 The 4.3BSD virtual-memory system had a text cache that retained the identity of text pages from one execution of a program to the next. How does the caching of vnode objects in FreeBSD improve on the performance of the 4.3BSD text cache?
**5.14 FreeBSD reduces the length of shadow chains by checking at each copy-on-write fault whether the object taking the fault completely shadows the object below it in the chain. If it does, a collapse can be done. One alternative would be to calculate the number of live references to a page after each copy-on-write fault and if only one reference remains, to move that page to the object that references it. When the last page is removed, the chain can be collapsed. Implement this algorithm and compare its cost to the current algorithm.
**5.15 The pv_entry structures could be replaced by keeping a list associated with each object of all the vm_map_entry structures that reference it. If each vm_map_entry structure had only a single list pointer in it, only the final object would be able to reference it. Shadow objects would have to find their final object to find their referencing vm_map_entry structure. Implement an algorithm to find all the references to the pages of a shadow object using this scheme. Compare its cost with that of the current algorithm using pv_entry structures.
**5.16 Port the code from 4.3BSD that would forcibly swap out runnable processes when the paging rate gets too high. Run three or more processes that each have a working set of 40 percent of the available memory. Compare the performance of this benchmark using the 4.3BSD algorithm and the current algorithm.
References
Babao
![]() lu & Joy, 1981. Ö. Babao
lu & Joy, 1981. Ö. Babao
![]() lu & W. N. Joy, "Converting a Swap-Based System to Do Paging in an Architecture Lacking Page-Referenced Bits," Proceedings of the Eighth Symposium on Operating Systems Principles, pp. 78-86, December 1981.
lu & W. N. Joy, "Converting a Swap-Based System to Do Paging in an Architecture Lacking Page-Referenced Bits," Proceedings of the Eighth Symposium on Operating Systems Principles, pp. 78-86, December 1981.
Bansal & Modha, 2004.
S. Bansal & D. Modha, "CAR: Clock with Adaptive Replacement," Proceedings of the Third Usenix Conference on File and Storage Technologies, pp. 187-200, April 2004.
Belady, 1966.
L. A. Belady, "A Study of Replacement Algorithms for Virtual Storage Systems," IBM Systems Journal, , no. 2, pp. 78-101, 1966.
Bonwick, 1994.
J. Bonwick, "The Slab Allocator: An Object-Caching Kernel Memory Allocator," Proceedings of the 1994 Usenix Annual Technical Conference, pp. 87-98, June 1994.
Bonwick & Adams, 2001. J. Bonwick & J. Adams, "Magazines and Vmem: Extending the Slab Allocator to Many CPUs and Arbitrary Resources," Proceedings of the 2001 Usenix Annual Technical Conference, pp. 15-34, June 2001.
Coffman & Denning, 1973.
E. G. Coffman,Jr. & P. J. Denning, Operating Systems Theory, p. 243, Prentice-Hall, Englewood Cliffs, NJ, 1973.
Denning, 1970.
P. J. Denning, "Virtual Memory," Computer Surveys, , no. 3, pp. 153-190, September 1970.
Easton & Franaszek, 1979.
M. C. Easton & P. A. Franaszek, "Use Bit Scanning in Replacement Decisions," IEEE Transactions on Computing, , no. 2, pp. 133-141, February 1979.
Gingell et al., 1987.
R. Gingell, M. Lee, X. Dang, & M. Weeks, "Shared Libraries in SunOS," USENIX Association Conference Proceedings, pp. 131-146, June 1987.
Gingell, Moran, & Shannon, 1987.
R. Gingell, J. Moran, & W. Shannon, "Virtual Memory Architecture in SunOS," USENIX Association Conference Proceedings, pp. 81-94, June 1987.
Intel, 1984. , "Introduction to the iAPX 286," Order Number 210308, Intel Corporation, Santa Clara, CA, 1984.
Kenah & Bate, 1984.
L. J. Kenah & S. F. Bate, VAX/VMS Internals and Data Structures, Digital Press, Bedford, MA, 1984.
King, 1971.
W. F. King, "Analysis of Demand Paging Algorithms," IFIP, pp. 485-490, North Holland, Amsterdam, 1971.
Korn & Vo, 1985.
D. Korn & K. Vo, "In Search of a Better Malloc," USENIX Association Conference Proceedings, pp. 489-506, June 1985.
Lazowska & Kelsey, 1978.
E. D. Lazowska & J. M. Kelsey, "Notes on Tuning VAX/VMS.," Technical Report 78-12-01, Department of Computer Science, University of Washington, Seattle, WA, December 1978.
Marshall, 1979.
W. T. Marshall, "A Unified Approach to the Evaluation of a Class of `Working Set Like' Replacement Algorithms," PhD Thesis, Department of Computer Engineering, Case Western Reserve University, Cleveland, OH, May 1979.
McKusick & Karels, 1988.
M. K. McKusick & M. Karels, "Design of a General Purpose MemoryAllocator for the 4.3BSD UNIX Kernel," USENIX Association Conference Proceedings, pp. 295-304, June 1988.
Organick, 1975.
E. I. Organick, The Multics System: An Examination of Its Structure, MIT Press, Cambridge, MA, 1975.