
Computers store and retrieve data through supporting peripheral I/O devices. These devices typically include mass-storage devices, such as disk drives, archival-storage devices, and network interfaces. Storage devices such as disks are accessed through I/O controllers that manage the operation of their attached devices according to I/O requests from the CPU.
Many hardware device peculiarities are hidden from the user by high-level kernel facilities, such as the filesystem and socket interfaces. Other such peculiarities are hidden from the bulk of the kernel itself by the I/O system. The I/O system consists of buffer-caching systems, general device-driver code, and drivers for specific hardware devices that must finally address peculiarities of the specific devices. An overview of the entire kernel is shown in Figure 6.1 (on page 216). The bottom third of the figure comprises the various I/O systems.
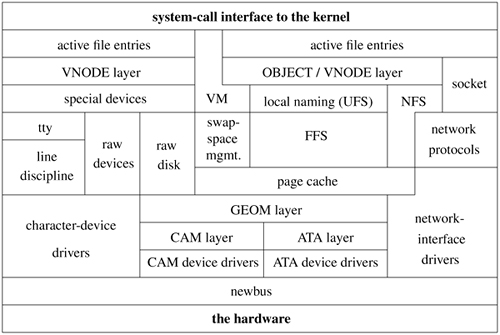
There are three main kinds of I/O in FreeBSD: the character-device interface, the filesystem, and the socket interface with its related network devices. The character interface appears in the filesystem name space and provides unstructured access to the underlying hardware. The network devices do not appear in the filesystem; they are accessible through only the socket interface. Character devices are described in Section 6.2. The filesystem is described in Chapter 8. Sockets are described in Chapter 11.
A character-device interface comes in two styles that depend on the characteristics of the underlying hardware device. For some character-oriented hardware devices, such as terminal multiplexers, the interface is truly character oriented, although higher-level software, such as the terminal driver, may provide a line-oriented interface to applications. However, for block-oriented devices such as disks, a character-device interface is an unstructured or raw interface. For this interface, I/O operations do not go through the filesystem or the page cache; instead, they are made directly between the device and buffers in the application's virtual address space. Consequently, the size of the operations must be a multiple of the underlying block size required by the device, and, on some machines, the application's I/O buffer must be aligned on a suitable boundary.
Internal to the system, I/O devices are accessed through a set of entry points provided by each device's device driver. For a character-device interface, it accesses a cdevsw structure. A cdevsw structure is created for each device as the device is configured either at the time that the system is booted or later when the device is attached to the system.
Devices are identified by a device number that is constructed from a major and a minor device number. The major device number uniquely identifies the type of device (really of the device driver). Historically it was used as the index of the device's entry in the character-device table. FreeBSD 5.2 has no character-device table. As devices are configured, entries are created for the device in the /dev filesystem. Each entry in the /dev filesystem has a direct reference to its corresponding cdevsw entry. FreeBSD 5.2 assigns a unique major device number to each device when it is configured to provide compatibility for applications that look at it. But it is not used internally by the kernel or the device driver.
The minor device number is selected and interpreted solely by the device driver and is used by the driver to identify to which, of potentially many, hardware devices an I/O request refers. For disks, for example, minor device numbers identify a specific controller, disk drive, and partition. The minor device number may also specify a section of a device—for example, a channel of a multiplexed device, or optional handling parameters.
A device driver is divided into three main sections:
- Autoconfiguration and initialization routines
- Routines for servicing I/O requests (the top half)
- Interrupt service routines (the bottom half)
The autoconfiguration portion of a driver is responsible for probing for a hardware device to see whether the latter is present and to initialize the device and any associated software state that is required by the device driver. This portion of the driver is typically called only once, either when the system is initialized or for transient devices when they are connected to the system. Autoconfiguration is described in Section 14.4.
The section of a driver that services I/O requests is invoked because of system calls or by the virtual-memory system. This portion of the device driver executes synchronously in the top half of the kernel and is permitted to block by calling the sleep() routine. We commonly refer to this body of code as the top half of a device driver.
Interrupt service routines are invoked when the system fields an interrupt from a device. Consequently, these routines cannot depend on any per-process state. Historically they did not have a thread context of their own, so they could not block. In FreeBSD 5.2 an interrupt has its own thread context, so it can block if it needs to do so. However, the cost of extra thread switches is sufficiently high that for good performance device drivers should attempt to avoid blocking. We commonly refer to a device driver's interrupt service routines as the bottom half of a device driver.
In addition to these three sections of a device driver, an optional crash-dump routine may be provided. This routine, if present, is invoked when the system recognizes an unrecoverable error and wishes to record the contents of physical memory for use in postmortem analysis. Most device drivers for disk controllers provide a crash-dump routine. The use of the crash-dump routine is described in Section 14.6.
Device drivers typically manage one or more queues of I/O requests in their normal operation. When an input or output request is received by the top half of the driver, it is recorded in a data structure that is placed on a per-device queue for processing. When an input or output operation completes, the device driver receives an interrupt from the controller. The interrupt service routine removes the appropriate request from the device's queue, notifies the requester that the command has completed, and then starts the next request from the queue. The I/O queues are the primary means of communication between the top and bottom halves of a device driver.
Because I/O queues are shared among asynchronous routines, access to the queues must be synchronized. Routines in both the top and bottom half of the device driver must acquire the mutex associated with the queue before manipulating it to avoid corruption from simultaneous modifications (mutexes were described in Section 4.3). For example, a bottom half interrupt might try to remove an entry that had not yet been fully linked in by the top half. Synchronization among multiple processes starting I/O requests is also serialized through the mutex associated with the queue.
Interrupts are generated by devices to signal that an operation has completed or that a change in status has occurred. On receiving a device interrupt, the system schedules the appropriate device-driver interrupt service routine with one or more parameters that identify uniquely the device that requires service. These parameters are needed because device drivers typically support multiple devices of the same type. If the interrupting device's identity were not supplied with each interrupt, the driver would be forced to poll all the potential devices to identify the device that interrupted.
The system arranges for the unit-number parameter to be passed to the interrupt service routine for each device by installing the address of an auxiliary glue routine in the interrupt-vector table. This glue routine, rather than the actual interrupt service routine, is invoked to service the interrupt; it takes the following actions:
- Collects the relevant hardware parameters and places them in the space reserved for them by the device.
- Updates statistics on device interrupts.
- Schedules the interrupt service thread for the device.
- Clears the interrupt-pending flag in the hardware.
- Returns from the interrupt.
Because a glue routine is interposed between the interrupt-vector table and the interrupt service routine, special-purpose instructions that cannot be generated from C, which are needed by the hardware to support interrupts, can be kept out of the device driver. This interposition of a glue routine permits device drivers to be written without assembly language.
Almost all peripherals on the system, except network interfaces, have a character-device interface. A character device usually maps the hardware interface into a byte stream, similar to that of the filesystem. Character devices of this type include terminals (e.g., /dev/tty00), line printers (e.g, /dev/lp0), an interface to physical main memory (/dev/mem), and a bottomless sink for data and an endless source of end-of-file markers (/dev/null). Some of these character devices, such as terminal devices, may display special behavior on line boundaries but in general are still treated as byte streams.
Devices emulating terminals use buffers that are smaller than those used for disks. This buffering system involves small (usually 64-byte) blocks of characters kept in linked lists. Although all free character buffers are kept in a single free list, most device drivers that use them limit the number of characters that can be queued at one time for a single terminal port.
Devices such as high-speed graphics interfaces may have their own buffers or may always do I/O directly into the address space of the user; they too are classed as character devices. Some of these drivers may recognize special types of records and thus be further from the plain byte-stream model.
The character interface for disks is also called the raw device interface; it provides an unstructured interface to the device. Its primary task is to arrange for direct I/O to and from the device. The disk driver handles the asynchronous nature of I/O by maintaining and ordering an active queue of pending transfers. Each entry in the queue specifies whether it is for reading or writing, the main-memory address for the transfer, the device address for the transfer (usually a disk sector number), and the transfer size (in bytes).
All other restrictions of the underlying hardware are passed through the character interface to its clients, making character-device interfaces the furthest from the byte-stream model. Thus, the user process must abide by the sectoring restrictions imposed by the underlying hardware. For magnetic disks, the file offset and transfer size must be a multiple of the sector size. The character interface does not copy the user data into a kernel buffer before putting them on an I/O queue. Instead, it arranges to have the I/O done directly to or from the address space of the process. The size and alignment of the transfer is limited by the physical device. However, the transfer size is not restricted by the maximum size of the internal buffers of the system because these buffers are not used.
The character interface is typically used by only those system utility programs that have an intimate knowledge of the data structures on the disk. The character interface also allows user-level prototyping; for example, the 4.2BSD filesystem implementation was written and largely tested as a user process that used a raw disk interface, before the code was moved into the kernel.
Character devices are described by entries in the cdevsw structure. The entry points in this structure (see Table 6.1 on page 220) are used to support raw access to block-oriented devices such as disk, as well as normal access to character-oriented devices through the terminal driver. Raw devices support a subset of the entry points that correspond to those entry points found in block-oriented devices. The base set of entry points for all device drivers is described in this section; the additional set of entry points for block-oriented devices is given in Section 6.3.

Most raw devices differ from filesystems only in the way that they do I/O. Whereas filesystems read and write data to and from kernel buffers, raw devices transfer data to and from user buffers. Bypassing kernel buffers eliminates the memory-to-memory copy that must be done by filesystems but also denies applications the benefits of data caching. In addition, for devices that support both raw- and filesystem access, applications must take care to preserve consistency between data in the kernel buffers and data written directly to the device. The raw device should be used only when the filesystem is unmounted or mounted readonly. Raw-device access is used by many filesystem utilities, such as the filesystem check program, fsck, and by programs that read and write backup media—for example, tar, dump, and restore.
Because raw devices bypass kernel buffers, they are responsible for managing their own buffer structures. Most devices borrow swap buffers to describe their I/O. The read and write routines use the physio() routine to start a raw I/O operation (see Figure 6.2). The strategy parameter identifies a block-device strategy routine that starts I/O operations on the device. The buffer is used by physio() in constructing the request(s) made to the strategy routine. The device, read-write flag, and uio parameters completely specify the I/O operation that should be done. The maximum transfer size for the device is checked by physio () to adjust the size of each I/O transfer before the latter is passed to the strategy routine. This check allows the transfer to be done in sections according to the maximum transfer size supported by the device.

Raw-device I/O operations request the hardware device to transfer data directly to or from the data buffer in the user program's address space described by the uio parameter. Thus, unlike I/O operations that do direct memory access (DMA) from buffers in the kernel address space, raw I/O operations must check that the user's buffer is accessible by the device and must lock it into memory for the duration of the transfer.
Character-oriented I/O devices are typified by terminal ports, although they also include printers and other character- or line-oriented devices. These devices are usually accessed through the terminal driver, described in Chapter 10. The close tie to the terminal driver has heavily influenced the structure of character device drivers. For example, several entry points in the cdevsw structure exist for communication between the generic terminal handler and the terminal multiplexer hardware drivers.


Disk devices fill a central role in the UNIX kernel and thus have additional features and capabilities beyond those of the typical character device driver. Historically, UNIX provided two interfaces to disks. The first was a character-device interface that provided direct access to the disk in its raw form. This interface is still available in FreeBSD 5.2 and is described in Section 6.2. The second was a block-device interface that converted from the user abstraction of a disk as an array of bytes to the structure imposed by the underlying physical medium. Block devices were accessible directly through appropriate device special files. Block devices were eliminated in FreeBSD 5.2 because they were not needed by any common applications and added considerable complexity to the kernel.
Device drivers for disk devices contain all the usual character device entry points described in Section 6.2. In addition to those entry points there are three entry points that are used only for disk devices:

The kernel provides a generic disksort() routine that can be used by all the disk device drivers to sort I/O requests into a drive's request queue using an elevator sorting algorithm. This algorithm sorts requests in a cyclic, ascending, block order, so that requests can be serviced with minimal one-way scans over the drive. This ordering was originally designed to support the normal read-ahead requested by the filesystem and also to counteract the filesystem's random placement of data on a drive. With the improved placement algorithms in the current filesystem, the effect of the disksort() routine is less noticeable; disksort() produces the largest effect when there are multiple simultaneous users of a drive.
The disksort() algorithm is shown in Figure 6.3. A drive's request queue is made up of two lists of requests ordered by block number. The first is the active list; the second is the next-pass list. The request at the front of the active list shows the current position of the drive. If next-pass list is not empty, it is made up of requests that lie before the current position. Each new request is sorted into either the active or the next-pass list, according to the request's location. When the heads reach the end of the active list, the next-pass list becomes the active list, an empty next-pass list is created, and the drive begins servicing the new active list.

Disk sorting can also be important on machines that have a fast processor but that do not sort requests within the device driver. Here, if a write of several Mbyte is honored in order of queueing, it can block other processes from accessing the disk while it completes. Sorting requests provides some scheduling, which more fairly distributes accesses to the disk controller.
Most modern disk controllers accept several concurrent I/O requests. The controller then sorts these requests to minimize the time needed to service them. If the controller could always manage all outstanding I/O requests, then there would be no need to have the kernel do any sorting. However, most controllers can handle only about 15 outstanding requests. Since a busy system can easily generate bursts of activity that exceed the number that the disk controller can manage simultaneously, disk sorting by the kernel is still necessary.
A disk may be broken up into several partitions, each of which may be used for a separate filesystem or swap area. A disk label contains information about the partition layout and usage including type of filesystem, swap partition, or unused. For the fast filesystem, the partition usage contains enough additional information to enable the filesystem check program (fsck) to locate the alternate superblocks for the filesystem. The disk label also contains any other driver-specific information.
Having labels on each disk means that partition information can be different for each disk and that it carries over when the disk is moved from one system to another. It also means that, when previously unknown types of disks are connected to the system, the system administrator can use them without changing the disk driver, recompiling, and rebooting the system.
The label is located near the beginning of each drive—usually, in block zero. It must be located near the beginning of the disk to enable it to be used in the first-level bootstrap. Most architectures have hardware (or first-level) bootstrap code stored in read-only memory (ROM). When the machine is powered up or the reset button is pressed, the CPU executes the hardware bootstrap code from the ROM. The hardware bootstrap code typically reads the first few sectors on the disk into the main memory, then branches to the address of the first location that it read. The program stored in these first few sectors is the second-level bootstrap. Having the disk label stored in the part of the disk read as part of the hardware bootstrap allows the second-level bootstrap to have the disk-label information. This information gives it the ability to find the root filesystem and hence the files, such as the kernel, needed to bring up FreeBSD. The size and location of the second-level bootstrap are dependent on the requirements of the hardware bootstrap code. Since there is no standard for disk-label formats and the hardware bootstrap code usually understands only the vendor label, it is usually necessary to support both the vendor and the FreeBSD disk labels. Here, the vendor label must be placed where the hardware bootstrap ROM code expects it; the FreeBSD label must be placed out of the way of the vendor label but within the area that is read in by the hardware bootstrap code so that it will be available to the second-level bootstrap.
For example, on the PC architecture, the BIOS expects sector 0 of the disk to contain boot code, a slice table, and a magic number. BIOS slices can be used to break the disk up into several pieces. The BIOS brings in sector 0 and verifies the magic number. The sector 0 boot code then searches the slice table to determine which slice is marked active. This boot code then brings in the operating-system specific bootstrap from the active slice and, if marked bootable, runs it. This operating-system specific bootstrap includes the disk-label described above and the code to interpret it.
For user processes, all I/O is done through descriptors. The user interface to descriptors was described in Section 2.6. This section describes how the kernel manages descriptors and how it provides descriptor services, such as locking and polling.
System calls that refer to open files take a file descriptor as an argument to specify the file. The file descriptor is used by the kernel to index into the descriptor table for the current process (kept in the filedesc structure, a substructure of the process structure for the process) to locate a file entry, or file structure. The relations of these data structures are shown in Figure 6.4.
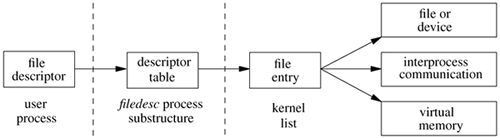
The file entry provides a file type and a pointer to an underlying object for the descriptor. There are six object types supported in FreeBSD:
• For data files, the file entry points to a vnode structure that references a substructure containing the filesystem-specific information described in Chapters 8 and 9. The vnode layer is described in Section 6.5. Special files do not have data blocks allocated on the disk; they are handled by the special-device filesystem that calls appropriate drivers to handle I/O for them.
• For access to interprocess communication including networking, the FreeBSD file entry may reference a socket.
• For unnamed high-speed local communication, the file entry will reference a pipe. Earlier FreeBSD systems used sockets for local communication, but optimized support was added for pipes to improve their performance.
• For named high-speed local communication, the file entry will reference a fifo. As with pipes, optimized support was added for fifo's to improve performance.
• For systems that have cryptographic support in hardware, the descriptor may provide direct access to that hardware.
• To provide notification of kernel events, the descriptor will reference a kqueue.
The virtual-memory system supports the mapping of files into a process's address space. Here, the file descriptor must reference a vnode that will be partially or completely mapped into the user's address space.
The set of file entries is the focus of activity for file descriptors. They contain the information necessary to access the underlying objects and to maintain common information.
The file entry is an object-oriented data structure. Each entry contains a type and an array of function pointers that translate the generic operations on file descriptors into the specific actions associated with their type. The operations that must be implemented for each type are as follows:
• Read from the descriptor
• Write to the descriptor
• Poll the descriptor
• Do ioctl operations on the descriptor
• Collect stat information for the descriptor
• Check to see if there are any kqueue events pending for the descriptor
• Close and possibly deallocate the object associated with the descriptor
Note that there is no open routine defined in the object table. FreeBSD treats descriptors in an object-oriented fashion only after they are created. This approach was taken because the various descriptor types have different characteristics. Generalizing the interface to handle all types of descriptors at open time would have complicated an otherwise simple interface. Vnode descriptors are created by the open system call; socket descriptors are created by the socket system call; fifo descriptors are created by the pipe system call.
Each file entry has a pointer to a data structure that contains information specific to the instance of the underlying object. The data structure is opaque to the routines that manipulate the file entry. A reference to the data structure is passed on each call to a function that implements a file operation. All state associated with an instance of an object must be stored in that instance's data structure; the underlying objects are not permitted to manipulate the file entry themselves.
The read and write system calls do not take an offset in the file as an argument. Instead, each read or write updates the current file offset in the file according to the number of bytes transferred. The offset determines the position in the file for the next read or write. The offset can be set directly by the lseek system call. Since more than one process may open the same file, and each such process needs its own offset for the file, the offset cannot be stored in the per-object data structure. Thus, each open system call allocates a new file entry, and the open file entry contains the offset.
Some semantics associated with all file descriptors are enforced at the descriptor level, before the underlying system call is invoked. These semantics are maintained in a set of flags associated with the descriptor. For example, the flags record whether the descriptor is open for reading, writing, or both reading and writing. If a descriptor is marked as open for reading only, an attempt to write it will be caught by the descriptor code. Thus, the functions defined for doing reading and writing do not need to check the validity of the request; we can implement them knowing that they will never receive an invalid request.
The application-visible flags are described in the next subsection. In addition to the application-visible flags, the flags field also has information on whether the descriptor holds a shared or exclusive lock on the underlying file. The locking primitives could be extended to work on sockets, as well as on files. However, the descriptors for a socket rarely refer to the same file entry. The only way for two processes to share the same socket descriptor is for a parent to share the descriptor with its child by forking or for one process to pass the descriptor to another in a message.
Each file entry has a reference count. A single process may have multiple references to the entry because of calls to the dup or fcntl system calls. Also, file structures are inherited by the child process after a fork, so several different processes may reference the same file entry. Thus, a read or write by either process on the twin descriptors will advance the file offset. This semantic allows two processes to read the same file or to interleave output to the same file. Another process that has independently opened the file will refer to that file through a different file structure with a different file offset. This functionality was the original reason for the existence of the file structure; the file structure provides a place for the file offset between the descriptor and the underlying object.
Each time that a new reference is created, the reference count is incremented. When a descriptor is closed (any one of (1) explicitly with a close, (2) implicitly after an exec because the descriptor has been marked as close-on-exec, or (3) on process exit), the reference count is decremented. When the reference count drops to zero, the file entry is freed.
The close-on-exec flag is kept in the descriptor table rather than in the file entry. This flag is not shared among all the references to the file entry because it is an attribute of the file descriptor itself. The close-on-exec flag is the only piece of information that is kept in the descriptor table rather than being shared in the file entry.
The fcntl system call manipulates the file structure. It can be used to make the following changes to a descriptor:
• Duplicate a descriptor as though by a dup system call.
• Get or set the close-on-exec flag. When a process forks, all the parent's descriptors are duplicated in the child. The child process then execs a new process.
Any of the child's descriptors that were marked close-on-exec are closed. The remaining descriptors are available to the newly executed process.
• Set the no-delay (O_NONBLOCK) flag to put the descriptor into nonblocking mode. In nonblocking mode, if any data are available for a read operation, or if any space is available for a write operation, an immediate partial read or write is done. If no data are available for a read operation, or if a write operation would block, the system call returns an error (EAGAIN) showing that the operation would block, instead of putting the process to sleep. This facility is not implemented for local filesystems in FreeBSD, because local-filesystem I/O is always expected to complete within a few milliseconds.
• Set the synchronous (O_FSYNC) flag to force all writes to the file to be written synchronously to the disk.
• Set the direct (O_DIRECT) flag to request that the kernel attempt to write the data directly from the user application to the disk rather than copying it via kernel buffers.
• Set the append (O_APPEND) flag to force all writes to append data to the end of the file, instead of at the descriptor's current location in the file. This feature is useful when, for example, multiple processes are writing to the same log file.
• Set the asynchronous (O_ASYNC) flag to request that the kernel watch for a change in the status of the descriptor, and arrange to send a signal (SIGIO) when a read or write becomes possible.
• Send a signal to a process when an exception condition arises, such as when urgent data arrive on an interprocess-communication channel.
• Set or get the process identifier or process-group identifier to which the two I/O-related signals in the previous steps should be sent.
• Test or change the status of a lock on a range of bytes within an underlying file. Locking operations are described later in this section.
The implementation of the dup system call is easy. If the process has reached its limit on open files, the kernel returns an error. Otherwise, the kernel scans the current process's descriptor table, starting at descriptor zero, until it finds an unused entry. The kernel allocates the entry to point to the same file entry as does the descriptor being duplicated. The kernel then increments the reference count on the file entry and returns the index of the allocated descriptor-table entry. The fcntl system call provides a similar function, except that it specifies a descriptor from which to start the scan.
Sometimes, a process wants to allocate a specific descriptor-table entry. Such a request is made with the dup2 system call. The process specifies the descriptor-table index into which the duplicated reference should be placed. The kernel implementation is the same as for dup, except that the scan to find a free entry is changed to close the requested entry if that entry is open and then to allocate the entry as before. No action is taken if the new and old descriptors are the same.
The system implements getting or setting the close-on-exec flag via the fcntl system call by making the appropriate change to the flags field of the associated descriptor-table entry. Other attributes that fcntl manipulates operate on the flags in the file entry. However, the implementation of the various flags cannot be handled by the generic code that manages the file entry. Instead, the file flags must be passed through the object interface to the type-specific routines to do the appropriate operation on the underlying object. For example, manipulation of the non-blocking flag for a socket must be done by the socket layer, since only that layer knows whether an operation can block.
The implementation of the ioctl system call is broken into two major levels. The upper level handles the system call itself. The ioctl call includes a descriptor, a command, and pointer to a data area. The command argument encodes what the size is of the data area for the parameters and whether the parameters are input, output, or both input and output. The upper level is responsible for decoding the command argument, allocating a buffer, and copying in any input data. If a return value is to be generated and there is no input, the buffer is zeroed. Finally, the ioctl is dispatched through the file-entry ioctl function, along with the I/O buffer, to the lower-level routine that implements the requested operation.
The lower level does the requested operation. Along with the command argument, it receives a pointer to the I/O buffer. The upper level has already checked for valid memory references, but the lower level may do more precise argument validation because it knows more about the expected nature of the arguments. However, it does not need to copy the arguments in or out of the user process. If the command is successful and produces output, the lower level places the results in the buffer provided by the top level. When the lower level returns, the upper level copies the results to the process.
Historically, UNIX systems did not have the ability to do asynchronous I/O beyond the ability to do background writes to the filesystem. An asynchronous I/O interface was defined by the POSIX.lb-1993 realtime group. Shortly after its ratification, an implementation was added to FreeBSD.
An asynchronous read is started with aio_read; an asynchronous write is started with aio_write. The kernel builds an asynchronous I/O request structure that contains all the information needed to do the requested operation. If the request cannot be immediately satisfied from kernel buffers, the request structure is queued for processing by an asynchronous kernel-based I/O daemon and the system call returns. The next available asynchronous I/O daemon handles the request using the usual kernel synchronous I/O path.
When the daemon finishes the I/O, the asynchronous I/O structure is marked as finished along with a return value or error code. The application uses the aio_error system call to poll to find if the I/O is complete. This call is implemented by checking the status of the asynchronous I/O request structure created by the kernel. If an application gets to the point where it cannot proceed until an I/O completes, it can use the aio_suspend system call to wait until an I/O is done. Here, the application is put to sleep on its asynchronous I/O request structure and is awakened by the asynchronous I/O daemon when the I/O completes. Alternatively, the application can request that a specified signal be sent when the I/O is done.
The aio_return system call gets the return value from the asynchronous request once aio_error, aio_suspend, or the arrival of a completion signal has indicated that the I/O is done. FreeBSD has also added the nonstandard aio_waitcomplete system call that combines the functions of aio_suspend and aio_return into a single operation. For either aio_return or aio_waitcomplete, the return information is copied out to the application from the asynchronous I/O request structure and the asynchronous I/O request structure is then freed.
Early UNIX systems had no provision for locking files. Processes that needed to synchronize access to a file had to use a separate lock file. A process would try to create a lock file. If the creation succeeded, then the process could proceed with its update; if the creation failed, the process would wait and then try again. This mechanism had three drawbacks:
- Processes consumed CPU time by looping over attempts to create locks.
- Locks left lying around because of system crashes had to be removed (normally in a system-startup command script).
- Processes running as the special system-administrator user, the superuser, are always permitted to create files, and so were forced to use a different mechanism.
Although it is possible to work around all these problems, the solutions are not straightforward, so a mechanism for locking files was added in 4.2BSD.
The most general locking schemes allow multiple processes to update a file concurrently. Several of these techniques are discussed in Peterson [1983]. A simpler technique is to serialize access to a file with locks. For standard system applications, a mechanism that locks at the granularity of a file is sufficient. So, 4.2BSD and 4.3BSD provided only a fast, whole-file locking mechanism. The semantics of these locks include allowing locks to be inherited by child processes and releasing locks only on the last close of a file.
Certain applications require the ability to lock pieces of a file. Locking facilities that support a byte-level granularity are well understood. Unfortunately, they are not powerful enough to be used by database systems that require nested hierarchical locks, but are complex enough to require a large and cumbersome implementation compared to the simpler whole-file locks. Because byte-range locks are mandated by the POSIX standard, the developers added them to BSD reluctantly. The semantics of byte-range locks come from the initial implementation of locks in System V, which included releasing all locks held by a process on a file every time a close system call was done on a descriptor referencing that file. The 4.2BSD whole-file locks are removed only on the last close. A problem with the POSIX semantics is that an application can lock a file, then call a library routine that opens, reads, and closes the locked file. Calling the library routine will have the unexpected effect of releasing the locks held by the application. Another problem is that a file must be open for writing to be allowed to get an exclusive lock. A process that does not have permission to open a file for writing cannot get an exclusive lock on that file. To avoid these problems, yet remain POSIX compliant, FreeBSD provides separate interfaces for byte-range locks and whole-file locks. The byte-range locks follow the POSIX semantics; the whole-file locks follow the traditional 4.2BSD semantics. The two types of locks can be used concurrently; they will serialize against each other properly.
Both whole-file locks and byte-range locks use the same implementation; the whole-file locks are implemented as a range lock over an entire file. The kernel handles the other differing semantics between the two implementations by having the byte-range locks be applied to processes, whereas the whole-file locks are applied to descriptors. Because descriptors are shared with child processes, the whole-file locks are inherited. Because the child process gets its own process structure, the byte-range locks are not inherited. The last-close versus every-close semantics are a small bit of special-case code in the close routine that checks whether the underlying object is a process or a descriptor. It releases locks on every call if the lock is associated with a process and only when the reference count drops to zero if the lock is associated with a descriptor.
Locking schemes can be classified according to the extent that they are enforced. A scheme in which locks are enforced for every process without choice is said to use mandatory locks, whereas a scheme in which locks are enforced for only those processes that request them is said to use advisory locks. Clearly, advisory locks are effective only when all programs accessing a file use the locking scheme. With mandatory locks, there must be some override policy implemented in the kernel. With advisory locks, the policy is left to the user programs. In the FreeBSD system, programs with superuser privilege are allowed to override any protection scheme. Because many of the programs that need to use locks must also run as the superuser, 4.2BSD implemented advisory locks rather than creating an additional protection scheme that was inconsistent with the UNIX philosophy or that could not be used by privileged programs. The use of advisory locks carried over to the POSIX specification of byte-range locks and is retained in FreeBSD.
The FreeBSD file-locking facilities allow cooperating programs to apply advisory shared or exclusive locks on ranges of bytes within a file. Only one process may have an exclusive lock on a byte range, whereas multiple shared locks may be present. A shared and an exclusive lock cannot be present on a byte range at the same time. If any lock is requested when another process holds an exclusive lock, or an exclusive lock is requested when another process holds any lock, the lock request will block until the lock can be obtained. Because shared and exclusive locks are only advisory, even if a process has obtained a lock on a file, another process may access the file if it ignores the locking mechanism.
So that there are no races between creating and locking a file, a lock can be requested as part of opening a file. Once a process has opened a file, it can manipulate locks without needing to close and reopen the file. This feature is useful, for example, when a process wishes to apply a shared lock, to read information, to determine whether an update is required, and then to apply an exclusive lock and update the file.
A request for a lock will cause a process to block if the lock cannot be obtained immediately. In certain instances, this blocking is unsatisfactory. For example, a process that wants only to check whether a lock is present would require a separate mechanism to find out this information. Consequently, a process can specify that its locking request should return with an error if a lock cannot be obtained immediately. Being able to request a lock conditionally is useful to daemon processes that wish to service a spooling area. If the first instance of the daemon locks the directory where spooling takes place, later daemon processes can easily check to see whether an active daemon exists. Since locks exist only while the locking processes exist, locks can never be left active after the processes exit or if the system crashes.
The implementation of locks is done on a per-filesystem basis. The implementation for the local filesystems is described in Section 7.5. A network-based filesystem has to coordinate locks with a central lock manager that is usually located on the server exporting the filesystem. Client lock requests must be sent to the lock manager. The lock manager arbitrates among lock requests from processes running on its server and from the various clients to which it is exporting the filesystem. The most complex operation for the lock manager is recovering lock state when a client or server is rebooted or becomes partitioned from the rest of the network. The FreeBSD network-based lock manager is described in Section 9.3.
A process sometimes wants to handle I/O on more than one descriptor. For example, consider a remote login program that wants to read data from the keyboard and to send them through a socket to a remote machine. This program also wants to read data from the socket connected to the remote end and to write them to the screen. If a process makes a read request when there are no data available, it is normally blocked in the kernel until the data become available. In our example, blocking is unacceptable. If the process reads from the keyboard and blocks, it will be unable to read data from the remote end that are destined for the screen. The user does not know what to type until more data arrive from the remote end, so the session deadlocks. Conversely, if the process reads from the remote end when there are no data for the screen, it will block and will be unable to read from the terminal. Again, deadlock would occur if the remote end were waiting for output before sending any data. There is an analogous set of problems to blocking on the writes to the screen or to the remote end. If a user has stopped output to his screen by typing the stop character, the write will block until the user types the start character. In the meantime, the process cannot read from the keyboard to find out that the user wants to flush the output.
FreeBSD provides three mechanisms that permit multiplexing I/O on descriptors: polling I/O, nonblocking I/O, and signal-driven I/O. Polling is done with the select or poll system call, described in the next subsection. Operations on non-blocking descriptors finish immediately, partially complete an input or output operation and return a partial count, or return an error that shows that the operation could not be completed at all. Descriptors that have signaling enabled cause the associated process or process group to be notified when the I/O state of the descriptor changes.
There are four possible alternatives that avoid the blocking problem:
- Set all the descriptors into nonblocking mode. The process can then try operations on each descriptor in turn to find out which descriptors are ready to do I/O. The problem with this busy-waiting approach is that the process must run continuously to discover whether there is any I/O to be done, wasting CPU cycles.
- Enable all descriptors of interest to signal when I/O can be done. The process can then wait for a signal to discover when it is possible to do I/O. The drawback to this approach is that signals are expensive to catch. Hence, signal-driven I/O is impractical for applications that do moderate to large amounts of I/O.
- Have the system provide a method for asking which descriptors are capable of doing I/O. If none of the requested descriptors are ready, the system can put the process to sleep until a descriptor becomes ready. This approach avoids the problem of deadlock because the process will be awakened whenever it is possible to do I/O and will be told which descriptor is ready. The drawback is that the process must do two system calls per operation: one to poll for the descriptor that is ready to do I/O and another to do the operation itself.
- Have the process notify the system of all the descriptors that it is interested in reading and then do a blocking read on that set of descriptors. When the read returns, the process is notified on which descriptor the read completed. The benefit of this approach is that the process does a single system call to specify the set of descriptors, then loops doing only reads [Accetta et al., 1986; Lemon, 2001].
The first approach is available in FreeBSD as nonblocking I/O. It typically is used for output descriptors because the operation typically will not block. Rather than doing a select or poll, which nearly always succeeds, followed immediately by a write, it is more efficient to try the write and revert to using select or poll only during periods when the write returns a blocking error. The second approach is available in FreeBSD as signal-driven I/O. It typically is used for rare events, such as the arrival of out-of-band data on a socket. For such rare events, the cost of handling an occasional signal is lower than that of checking constantly with select or poll to find out whether there are any pending data.
The third approach is available in FreeBSD via the select or poll system call. Although less efficient than the fourth approach, it is a more general interface. In addition to handling reading from multiple descriptors, it handles writes to multiple descriptors, notification of exceptional conditions, and timeout when no I/O is possible.
The select and poll interfaces provide the same information. They differ only in their programming interface. The select interface was first developed in 4.2BSD with the introduction of socket-based interprocess communication. The poll interface was introduced in System V several years later with their competing STREAMS-based interprocess communication. Although STREAMS has fallen into disuse, the poll interface has proven popular enough to be retained. The FreeBSD kernel supports both interfaces.
The select system call is of the form
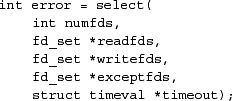
It takes three masks of descriptors to be monitored, corresponding to interest in reading, writing, and exceptional conditions. In addition, it takes a timeout value for returning from select if none of the requested descriptors becomes ready before a specified amount of time has elapsed. The select call returns the same three masks of descriptors after modifying them to show the descriptors that are able to do reading, to do writing, or that have an exceptional condition. If none of the descriptors has become ready in the timeout interval, select returns showing that no descriptors are ready for I/O. If a timeout value is given and a descriptor becomes ready before the specified timeout period, the time that select spends waiting for I/O to become ready is subtracted from the time given.
The poll interface copies in an array of pollfd structures, one array entry for each descriptor of interest. The pollfd structure contains three elements:
• The file descriptor to poll
• A set of flags describing the information being sought
• A set of flags set by the kernel showing the information that was found
The flags specify availability of normal or out-of-band data for reading and the availability of buffer space for normal or out-of-band data writing. The return flags can also specify that an error has occurred on the descriptor, that the descriptor has been disconnected, or that the descriptor is not open. These error conditions are raised by the select call by indicating that the descriptor with the error is ready to do I/O. When the application attempts to do the I/O, the error is returned by the read or write system call. Like the select call, the poll call takes a timeout value to specify the maximum time to wait. If none of the requested descriptors becomes ready before the specified amount of time has elapsed, the poll call returns. If a timeout value is given and a descriptor becomes ready before the specified timeout period, the time that poll spends waiting for I/O to become ready is subtracted from the time given.
The implementation of select is divided into a generic top layer and many deviceor socket-specific bottom pieces. At the top level, select or poll decodes the user's request and then calls the appropriate lower-level poll functions. The select and poll system calls have different top layers to determine the sets of descriptors to be polled but use all the same device- and socket-specific bottom pieces. Only the select top layer will be described here. The poll top layer is implemented in a completely analogous way.
The select top level takes the following steps:
- Copy and validate the descriptor masks for read, write, and exceptional conditions. Doing validation requires checking that each requested descriptor is currently open by the process.
- Set the selecting flag for the thread.
- For each descriptor in each mask, call the device's poll routine. If the descriptor is not able to do the requested I/O operation, the device poll routine is responsible for recording that the thread wants to do I/O. When I/O becomes possible for the descriptor—usually as a result of an interrupt from the underlying device—a notification must be issued for the selecting thread.
- Because the selection process may take a long time, the kernel does not want to block out I/O during the time it takes to poll all the requested descriptors. Instead, the kernel arranges to detect the occurrence of I/O that may affect the status of the descriptors being polled. When such I/O occurs, the select-notification routine, selwakeup(), clears the selecting flag. If the top-level select code finds that the selecting flag for the thread has been cleared while it has been doing the polling, and it has not found any descriptors that are ready to do an operation, then the top level knows that the polling results are incomplete and must be repeated starting at step 2. The other condition that requires the polling to be repeated is a collision. Collisions arise when multiple threads attempt to poll the same descriptor at the same time. Because the poll routines have only enough space to record a single thread identifier, they cannot track multiple threads that need to be awakened when I/O is possible. In such rare instances, all threads that are selecting must be awakened.
- If no descriptors are ready and the select specified a timeout, the kernel posts a timeout for the requested amount of time. The thread goes to sleep, giving the address of the kernel global variable selwait. Normally, a descriptor will become ready and the thread will be notified by selwakeup(). When the thread is awakened, it repeats the polling process and returns the available descriptors. If none of the descriptors become ready before the timer expires, the thread returns with a timed-out error and an empty list of available descriptors. If a timeout value is given and a descriptor becomes ready before the specified timeout period, the time that select spent waiting for I/O to become ready is subtracted from the time given.
Each of the low-level polling routines in the terminal drivers and the network protocols follows roughly the same set of steps. A piece of the poll routine for a terminal driver is shown in Figure 6.5 (on page 238). The steps involved in a device poll routine are as follows:
- The socket or device poll entry is called with one or more of the flags POLLIN, POLLOUT, or POLLRDBAND (exceptional condition). The example in Figure 6.4 shows the POLLIN case; the other cases are similar.
- The poll routine sets flags showing the operations that are possible. In Figure 6.5, it is possible to read a character if the number of unread characters is greater than zero. In addition, if the carrier has dropped, it is possible to get a read error. A return from select does not necessarily mean that there are data to read; rather, it means that a read will not block.
- If the requested operation is not possible, the thread identifier is recorded with the socket or device for later notification. In Figure 6.5, the recording is done by the selrecord() routine. That routine first checks to see whether any thread is recorded for this socket or device. If none is recorded, then the current thread is recorded and the selinfo structure is linked onto the list of events associated with this thread. The second if statement checks for a collision. If the thread recorded with the structure is not ourselves, then a collision has occurred.
- If multiple threads are selecting on the same socket or device, a collision is recorded for the socket or device, because the structure has only enough space for a single thread identifier. In Figure 6.5, a collision occurs when the second if statement in the selrecord() function is true. There is a tty structure containing a selinfo structure for each terminal line (or pseudo-terminal) on the machine. Normally, only one thread at a time is selecting to read from the terminal, so collisions are rare.
Selecting threads must be notified when I/O becomes possible. The steps involved in a status change awakening a thread are as follows:
- The device or socket detects a change in status. Status changes normally occur because of an interrupt (e.g., a character coming in from a keyboard or a packet arriving from the network).
- Selwakeup() is called with a pointer to the selinfo structure used by selrecord() to record the thread identifier and with a flag showing whether a collision occurred.
- If the thread is sleeping on selwait, it is made runnable (or is marked ready, if it is stopped). If the thread is sleeping on some event other than selwait, it is not made runnable. A spurious call to selwakeup() can occur when the thread returns from select to begin processing one descriptor and then another descriptor on which it had been selecting also becomes ready.
- If the thread has its selecting flag set, the flag is cleared so that the kernel will know that its polling results are invalid and must be recomputed.
- If a collision has occurred, all sleepers on selwait are awakened to rescan to see whether one of their descriptors became ready. Awakening all selecting threads is necessary because the selrecord() routine could not record all the threads that needed to be awakened. Hence, it has to wake up all threads that could possibly have been interested. Empirically, collisions occur infrequently. If they were a frequent occurrence, it would be worthwhile to store multiple thread identifiers in the selinfo structure.

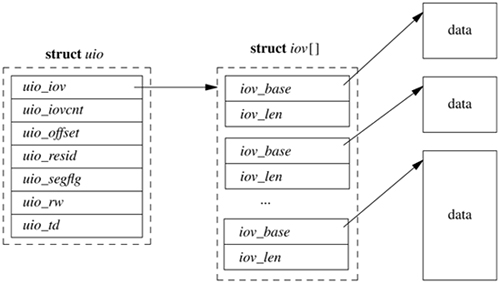
Within the kernel, I/O data are described by an array of vectors. Each I/O vector or iovec has a base address and a length. The I/O vectors are identical to the I/O vectors used by the readv and writev system calls.
The kernel maintains another structure, called a uio structure, that holds additional information about the I/O operation. A sample uio structure is shown in Figure 6.6; it contains the following:
• A pointer to the iovec array
• The number of elements in the iovec array
• The file offset at which the operation should start
• The sum of the lengths of the I/O vectors
• A flag showing whether the source and destination are both within the kernel or whether the source and destination are split between the user and the kernel
• A flag showing whether the data are being copied from the uio structure to the kernel (UIO_WRITE) or from the kernel to the uio structure (UIO_READ)
• A pointer to the thread whose data area is described by the uio structure (the pointer is NULL if the uio structure describes an area within the kernel)
All I/O within the kernel is described with iovec and uio structures. System calls such as read and write that are not passed an iovec create a uio to describe their arguments; this uio structure is passed to the lower levels of the kernel to specify the parameters of an I/O operation. Eventually, the uio structure reaches the part of the kernel responsible for moving the data to or from the process address space: the filesystem, the network, or a device driver. In general, these parts of the kernel do not interpret uio structures directly. Instead, they arrange a kernel buffer to hold the data and then use uiomove() to copy the data to or from the buffer or buffers described by the uio structure. The uiomove() routine is called with a pointer to a kernel data area, a data count, and a uio structure. As it moves data, it updates the counters and pointers of the iovec and uio structures by a corresponding amount. If the kernel buffer is not as large as the areas described by the uio structure, the uio structure will point to the part of the process address space just beyond the location completed most recently. Thus, while servicing a request, the kernel may call uiomove() multiple times, each time giving a pointer to a new kernel buffer for the next block of data.
Character device drivers that do not copy data from the process generally do not interpret the uio structure. Instead, there is one low-level kernel routine that arranges a direct transfer to or from the address space of the process. Here, a separate I/O operation is done for each iovec element, calling back to the driver with one piece at a time.
In early UNIX systems, the file entries directly referenced the local filesystem inode. An inode is a data structure that describes the contents of a file; it is more fully described in Section 8.2. This approach worked fine when there was a single filesystem implementation. However, with the advent of multiple filesystem types, the architecture had to be generalized. The new architecture had to support importing of filesystems from other machines including other machines that were running different operating systems.
One alternative would have been to connect the multiple filesystems into the system as different file types. However, this approach would have required massive restructuring of the internal workings of the system, because current directories, references to executables, and several other interfaces used inodes instead of file entries as their point of reference. Thus, it was easier and more logical to add a new object-oriented layer to the system below the file entry and above the inode. This new layer was first implemented by Sun Microsystems, which called it the virtual-node, or vnode, layer. Interfaces in the system that had referred previously to inodes were changed to reference generic vnodes. A vnode used by a local filesystem would refer to an inode. A vnode used by a remote filesystem would refer to a protocol control block that described the location and naming information necessary to access the remote file.
The vnode is an extensible object-oriented interface. It contains information that is generically useful independent of the underlying filesystem object that it represents. The information stored in a vnode includes the following:
• Flags are used for identifying generic attributes. An example generic attribute is a flag to show that a vnode represents an object that is the root of a filesystem.
• The various reference counts include the number of file entries that are open for reading and/or writing that reference the vnode, the number of file entries that are open for writing that reference the vnode, and the number of pages and buffers that are associated with the vnode.
• A pointer to the mount structure describes the filesystem that contains the object represented by the vnode.
• Various information to do file read-ahead.
• A reference to the vm_object associated with the vnode.
• A reference to state about special devices, sockets, and fifos.
• A mutex to protect the flags and counters within the vnode.
• A lock-manager lock to protect parts of the vnode that may change while it has an I/O operation in progress.
• Fields used by the name cache to track the names associated with the vnode.
• A pointer to the set of vnode operations defined for the object. These operations are described in the next subsection.
• A pointer to private information needed for the underlying object. For the local filesystem, this pointer will reference an inode; for NFS, it will reference an nfsnode.
• The type of the underlying object (e.g., regular file, directory, character device, etc.) is given. The type information is not strictly necessary, since a vnode client could always call a vnode operation to get the type of the underlying object. However, because the type often is needed, the type of underlying objects does not change, and it takes time to call through the vnode interface, the object type is cached in the vnode.
• There are clean and dirty buffers associated with the vnode. Each valid buffer in the system is identified by its associated vnode and the starting offset of its data within the object that the vnode represents. All the buffers that have been modified but have not yet been written back are stored on their vnode dirty-buffer list. All buffers that have not been modified or have been written back since they were last modified are stored on their vnode clean list. Having all the dirty buffers for a vnode grouped onto a single list makes the cost of doing an fsync system call to flush all the dirty blocks associated with a file proportional to the amount of dirty data. In some UNIX systems, the cost is proportional to the smaller of the size of the file or the size of the buffer pool. The list of clean buffers is used to free buffers when a file is deleted. Since the file will never be read again, the kernel can immediately cancel any pending I/O on its dirty buffers and reclaim all its clean and dirty buffers and place them at the head of the buffer free list, ready for immediate reuse.
• A count is kept of the number of buffer write operations in progress. To speed the flushing of dirty data, the kernel does this operation by doing asynchronous writes on all the dirty buffers at once. For local filesystems, this simultaneous push causes all the buffers to be put into the disk queue so that they can be sorted into an optimal order to minimize seeking. For remote filesystems, this simultaneous push causes all the data to be presented to the network at once so that it can maximize their throughput. System calls that cannot return until the data are on stable store (such as fsync) can sleep on the count of pending output operations, waiting for the count to reach zero.
The position of vnodes within the system was shown in Figure 6.1. The vnode itself is connected into several other structures within the kernel, as shown in Figure 6.7. Each mounted filesystem within the kernel is represented by a generic mount structure that includes a pointer to a filesystem-specific control block. All the vnodes associated with a specific mount point are linked together on a list headed by this generic mount structure. Thus, when it is doing a sync system call for a filesystem, the kernel can traverse this list to visit all the files active within that filesystem. Also shown in the figure are the lists of clean and dirty buffers associated with each vnode. Finally, there is a free list that links together all the vnodes in the system that are inactive (not currently referenced). The free list is used when a filesystem needs to allocate a new vnode so that the latter can open a new file; see Section 6.4.
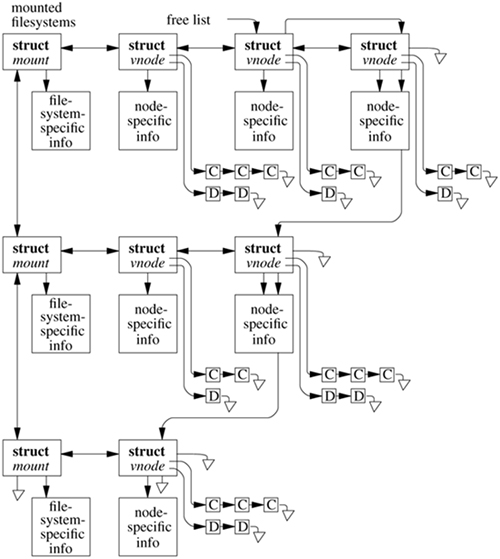
Vnodes are designed as an object-oriented interface. Thus, the kernel manipulates them by passing requests to the underlying object through a set of defined operations. Because of the many varied filesystems that are supported in FreeBSD, the set of operations defined for vnodes is both large and extensible. Unlike the original Sun Microsystems vnode implementation, the one in FreeBSD allows dynamic addition of vnode operations either at system boot time or when a new filesystem is dynamically loaded into the kernel. As part of activating a filesystem, it registers the set of vnode operations that it is able to support. The kernel then builds a table that lists the union of all operations supported by any filesystem. From that table, it builds an operations vector for each filesystem. Supported operations are filled in with the entry point registered by the filesystem. Filesystems may opt to have unsupported operations filled in with either a default routine (typically a routine to bypass the operation to the next lower layer; see Section 6.7) or a routine that returns the characteristic error "operation not supported" [Heidemann & Popek, 1994].
In 4.3BSD, the local filesystem code provided both the semantics of the hierarchical filesystem naming and the details of the on-disk storage management. These functions are only loosely related. To enable experimentation with other disk-storage techniques without having to reproduce the entire naming semantics, 4.4BSD split the naming and storage code into separate modules. The vnode-level operations define a set of hierarchical filesystem operations. Below the naming layer are a separate set of operations defined for storage of variable-sized objects using a flat name space. About 60 percent of the traditional filesystem code became the name-space management, and the remaining 40 percent became the code implementing the on-disk file storage. The 4.4BSD system used this division to support two distinct disk layouts: the traditional fast filesystem and a log-structured filesystem. Support for the log-structured filesystem was dropped in FreeBSD due to lack of anyone willing to maintain it but remains as a primary filesystem in NetBSD. The naming and disk-storage scheme are described in Chapter 8.
The translation of a pathname requires a series of interactions between the vnode interface and the underlying filesystems. The pathname-translation process proceeds as follows:
- The pathname to be translated is copied in from the user process or, for a remote filesystem request, is extracted from the network buffer.
- The starting point of the pathname is determined as either the root directory or the current directory (see Section 2.7). The vnode for the appropriate directory becomes the lookup directory used in the next step.
- The vnode layer calls the filesystem-specific lookup() operation and passes to that operation the remaining components of the pathname and the current lookup directory. Typically, the underlying filesystem will search the lookup directory for the next component of the pathname and will return the resulting vnode (or an error if the name does not exist).
- If an error is returned, the top level returns the error. If the pathname has been exhausted, the pathname lookup is done, and the returned vnode is the result of the lookup. If the pathname has not been exhausted, and the returned vnode is not a directory, then the vnode layer returns the "not a directory" error. If there are no errors, the top layer checks to see whether the returned directory is a mount point for another filesystem. If it is, then the lookup directory becomes the mounted filesystem; otherwise, the lookup directory becomes the vnode returned by the lower layer. The lookup then iterates with step 3.
Although it may seem inefficient to call through the vnode interface for each pathname component, doing so usually is necessary. The reason is that the underlying filesystem does not know which directories are being used as mount points. Since a mount point will redirect the lookup to a new filesystem, it is important that the current filesystem not proceed past a mounted directory. Although it might be possible for a local filesystem to be knowledgeable about which directories are mount points, it is nearly impossible for a server to know which of the directories within its exported filesystems are being used as mount points by its clients. Consequently, the conservative approach of traversing only a single pathname component per lookup() call is used. There are a few instances where a filesystem will know that there are no further mount points in the remaining path, and will traverse the rest of the pathname. An example is crossing into a portal, described in Section 6.7.
The vnode interface has a set of services that the kernel exports from all the filesystems supported under the interface. The first of these is the ability to support the update of generic mount options. These options include the following:

It is not necessary to unmount and remount the filesystem to change these flags; they may be changed while a filesystem is mounted. In addition, a filesystem that is mounted read-only can be upgraded to allow writing. Conversely, a filesystem that allows writing may be downgraded to read-only provided that no files are open for modification. The system administrator can forcibly downgrade the filesystem to read-only by requesting that any files open for writing have their access revoked.
Another service exported from the vnode interface is the ability to get information about a mounted filesystem. The staffs system call returns a buffer that gives the numbers of used and free disk blocks and inodes, along with the filesystem mount point, and the device, location, or program from which the filesystem is mounted. The getfsstat system call returns information about all the mounted filesystems. This interface avoids the need to track the set of mounted filesystems outside the kernel, as is done in many other UNIX variants.
The vnode interface not only supplies an object-oriented interface to the underlying filesystems but also provides a set of management routines that can be used by the client filesystems. These facilities are described in this section.
When the final file-entry reference to a file is closed, the usage count on the vnode drops to zero and the vnode interface calls the inactive() vnode operation. The inactive() call notifies the underlying filesystem that the file is no longer being used. The filesystem will often use this call to write dirty data back to the file but will not typically reclaim the memory holding file data. The filesystem is permitted to cache the file so that the latter can be reactivated quickly (i.e., without disk or network I/O) if the file is reopened.
In addition to the inactive() vnode operation being called when the reference count drops to zero, the vnode is placed on a systemwide free list. Unlike many vendor's vnode implementations, which have a fixed number of vnodes allocated to each filesystem type, the FreeBSD kernel keeps a single systemwide collection of vnodes. When an application opens a file that does not currently have an in-memory vnode, the client filesystem calls the getnewvnode() routine to allocate a new vnode. The kernel maintains two lists of free vnodes: those that have data pages cached in memory and those that do not have any data pages cached in memory. The preference is to reuse vnodes with no cached pages, since the reuse of a vnode with cached pages will cause all the cached pages associated with that vnode to lose their identity. If the vnodes were not classified separately, then an application that walked the filesystem tree doing stat calls on each file that it encountered would eventually flush all the vnodes referencing data pages, thus losing the identity of all the cached pages in the kernel. So when allocating a new vnode, the getnewvnode() routine first checks the front of the free list of vnodes with no cached pages and only if that list is empty does it select from the front of the list of vnodes with cached pages.
Having selected a vnode, the getnewvnode() routine then calls the vnode's reclaim() operation to notify the filesystem currently using that vnode that it is about to be reused. The reclaim() operation writes back any dirty data associated with the underlying object, removes the underlying object from any lists that it is on (such as hash lists used to find it), and frees up any auxiliary storage that was being used by the object. The vnode is then returned for use by the new client filesystem.
The benefit of having a single global vnode table is that the kernel memory dedicated to vnodes is used more efficiently than when several filesystem-specific collections of vnodes are used. Consider a system that is willing to dedicate memory for 1000 vnodes. If the system supports 10 filesystem types, then each filesystem type will get 100 vnodes. If most of the activity moves to a single filesystem (e.g., during the compilation of a kernel located in a local filesystem), all the active files will have to be kept in the 100 vnodes dedicated to that filesystem while the other 900 vnodes sit idle. In a FreeBSD system, all 1000 vnodes could be used for the active filesystem, allowing a much larger set of files to be cached in memory. If the center of activity moved to another filesystem (e.g., compiling a program on an NFS mounted filesystem), the vnodes would migrate from the previously active local filesystem over to the NFS filesystem. Here, too, there would be a much larger set of cached files than if only 100 vnodes were available using a partitioned set of vnodes.
The reclaim() operation is a disassociation of the underlying filesystem object from the vnode itself. This ability, combined with the ability to associate new objects with the vnode, provides functionality with usefulness that goes far beyond simply allowing vnodes to be moved from one filesystem to another. By replacing an existing object with an object from the dead filesystem-a filesystem in which all operations except close fail—the kernel revokes the object. Internally, this revocation of an object is provided by the vgone() routine.
This revocation service is used for session management, where all references to the controlling terminal are revoked when the session leader exits. Revocation works as follows. All open terminal descriptors within the session reference the vnode for the special device representing the session terminal. When vgone() is called on this vnode, the underlying special device is detached from the vnode and is replaced with the dead filesystem. Any further operations on the vnode will result in errors, because the open descriptors no longer reference the terminal. Eventually, all the processes will exit and will close their descriptors, causing the reference count to drop to zero. The inactive() routine for the dead filesystem returns the vnode to the front of the free list for immediate reuse because it will never be possible to get a reference to the vnode again.
The revocation service supports forcible unmounting of filesystems. If the kernel finds an active vnode when unmounting a filesystem, it simply calls the vgone() routine to disassociate the active vnode from the filesystem object. Processes with open files or current directories within the filesystem find that they have simply vanished, as though they had been removed. It is also possible to downgrade a mounted filesystem from read-write to read-only. Instead of access being revoked on every active file within the filesystem, only those files with a nonzero number of references for writing have their access revoked.
Finally, the ability to revoke objects is exported to processes through the revoke system call. This system call can be used to ensure controlled access to a device such as a pseudo-terminal port. First, the ownership of the device is changed to the desired user and the mode is set to owner-access only. Then the device name is revoked to eliminate any interlopers that already had it open. Thereafter, only the new owner is able to open the device.
Name-cache management is another service that is provided by the vnode management routines. The interface provides a facility to add a name and its corresponding vnode, to lookup a name to get the corresponding vnode, and to delete a specific name from the cache. In addition to providing a facility for deleting specific names, the interface also provides an efficient way to invalidate all names that reference a specific vnode. Each vnode has a list that links together all their entries in the name cache. When the references to the vnode are to be deleted, each entry on the list is purged. Each directory vnode also has a second list of all the cache entries for names that are contained within it. When a directory vnode is to be purged, it must delete all the name-cache entries on this second list. A vnode's name-cache entries must be purged each time it is reused by getnewvnode() or when specifically requested by a client (e.g., when a directory is being renamed).
The cache-management routines also allow for negative caching. If a name is looked up in a directory and is not found, that name can be entered in the cache, along with a null pointer for its corresponding vnode. If the name is later looked up, it will be found in the name table, and thus the kernel can avoid scanning the entire directory to determine that the name is not there. If a name is added to a directory, then the name cache must lookup that name and purge it if it finds a negative entry. Negative caching provides a significant performance improvement because of path searching in command shells. When executing a command, many shells will look at each path in turn, looking for the executable. Commonly run executables will be searched for repeatedly in directories in which they do not exist. Negative caching speeds these searches.
Historically, UNIX systems divided the main memory into two main pools. The first was the virtual-memory pool that was used to cache process pages. The second was the buffer pool and was used to cache filesystem data. The main memory was divided between the two pools when the system booted and there was no memory migration between the pools once they were created.
With the addition of the mmap system call, the kernel supported the mapping of files into the address space of a process. If a file is mapped in with the MAP_SHARED attribute, changes made to the mapped file are to be written back to the disk and should show up in read calls done by other processes. Providing these semantics is difficult if there are copies of a file in both the buffer cache and the virtual-memory cache. Thus, FreeBSD merged the buffer cache and the virtual-memory cache into a single-page cache.
As described in Chapter 5, virtual memory is divided into a pool of pages holding the contents of files and a pool of anonymous pages holding the parts of a process that are not backed by a file such as its stack and heap. Pages backed by a file are identified by their vnode and logical block number. Rather than rewrite all the filesystems to lookup pages in the virtual-memory pool, a buffer-cache emulation layer was written. The emulation layer has the same interface as the old buffer-cache routines but works by looking up the requested file pages in the virtual-memory cache. When a filesystem requests a block of a file, the emulation layer calls the virtual-memory system to see if it is in memory. If it is not in memory, the virtual-memory system arranges to have it read. Normally, the pages in the virtual-memory cache are not mapped into the kernel address space. However, a filesystem often needs to inspect the blocks that it requests—for example, if it is a directory or filesystem metadata. Thus, the buffer-cache emulation layer must not only find the requested block but also allocate some kernel address space and map the requested block into it. The filesystem then uses the buffer to read, write, or manipulate the data and when done releases the buffer. On release, the buffer may be held briefly but soon is dissolved by releasing the kernel mapping, dropping the reference count on the virtual-memory pages and releasing the header.
The virtual-memory system does not have any way to describe blocks that are identified as a block associated with a disk. A small remnant of the buffer cache remains to hold these disk blocks that are used to hold filesystem metadata such as superblocks, bitmaps, and inodes.
The internal kernel interface to the buffer-cache emulation layer is simple. The filesystem allocates and fills buffers by calling the bread() routine. Bread() takes a vnode, a logical block number, and a size, and returns a pointer to a locked buffer. The details on how a buffer is created are given in the next subsection. Any other thread that tries to obtain the buffer will be put to sleep until the buffer is released.
A buffer can be released in one of four ways. If the buffer has not been modified, it can simply be released through use of brelse(), which checks for any threads that are waiting for it. If any threads are waiting, they are awakened. Otherwise the buffer is dissolved by returning its contents back to the virtual-memory system, releasing its kernel address-space mapping and releasing the buffer.
If the buffer has been modified, it is called dirty. Dirty buffers must eventually be written back to their filesystem. Three routines are available based on the urgency with which the data must be written. In the typical case, bdwrite() is used. Since the buffer may be modified again soon, it should be marked as dirty but should not be written immediately. After the buffer is marked as dirty, it is returned to the dirty-buffer list and any threads waiting for it are awakened. The heuristic is that, if the buffer will be modified again soon, the I/O would be wasted. Because the buffer is typically held for 20 to 30 seconds before it is written, a thread doing many small writes will not repeatedly access the disk or network.
If a buffer has been filled completely, then it is unlikely to be written again soon, so it should be released with bawrite(). Bawrite() schedules an I/O on the buffer but allows the caller to continue running while the output completes.
The final case is bwrite(), which ensures that the write is complete before proceeding. Because bwrite() can introduce a long latency to the writer, it is used only when a process explicitly requests the behavior (such as the fsync system call), when the operation is critical to ensure the consistency of the filesystem after a system crash, or when a stateless remote filesystem protocol such as NFS is being served. A buffer that is written using bawrite() or bwrite() is placed on the appropriate output queue. When the output completes, the brelse() routine is called to awaken any threads that are waiting for it or, if there is no immediate need for it, to dissolve the buffer.
Some buffers, though clean, may be needed again soon. To avoid the overhead of repeatedly creating and dissolving buffers, the buffer-cache emulation layer provides the bqrelse() routine to let the filesystem notify it that it expects to use the buffer again soon. The bqrelse() routine places the buffer on a clean list rather than dissolving it.
Figure 6.8 shows a snapshot of the buffer pool. A buffer with valid contents is contained on exactly one bufhash hash chain. The kernel uses the hash chains to determine quickly whether a block is in the buffer pool, and if it is, to locate it. A buffer is removed only when its contents become invalid or it is reused for different data. Thus, even if the buffer is in use by one thread, it can still be found by another thread, although it will be locked so that it will not be used until its contents are consistent.
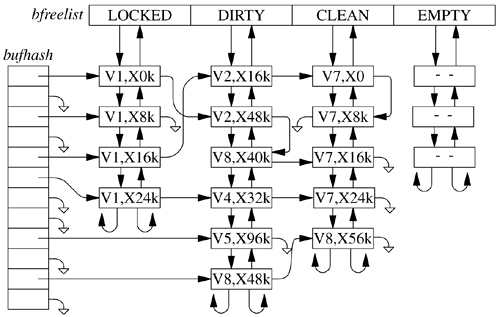
In addition to appearing on the hash list, each unlocked buffer appears on exactly one free list. The first free list is the LOCKED list. Buffers on this list cannot be flushed from the cache. This list was originally intended to hold superblock data; in FreeBSD, it holds only buffers being written in background. In a background write, the contents of a dirty buffer are copied to another anonymous buffer. The anonymous buffer is then written to disk. The original buffer can continue to be used while the anonymous buffer is being written. Background writes are used primarily for fast and continuously changing blocks such as those that hold filesystem allocation bitmaps. If the block holding the bitmap was written normally, it would be locked and unavailable while it waited on the disk queue to be written. Thus, applications trying to write files in the area described by the bitmap would be blocked from running while they waited for the write of the bitmap to finish so that they could update the bitmap. By using background writes for bitmaps, applications are rarely forced to wait to update a bitmap.
The second list is the DIRTY list. Buffers that have been modified, but not yet written to disk, are stored on this list. The DIRTY list is managed using a least-recently used algorithm. When a buffer is found on the DIRTY list, it is removed and used. The buffer is then returned to the end of the DIRTY list. When too many buffers are dirty, the kernel starts the buffer daemon running. The buffer daemon writes buffers starting from the front of the DIRTY list. Thus, buffers written repeatedly will continue to migrate to the end of the DIRTY list and are not likely to be prematurely written or reused for new blocks.
The third free list is the CLEAN list. This list holds blocks that a filesystem is not currently using but that it expects to use soon. The CLEAN list is also managed using a least-recently used algorithm. If a requested block is found on the CLEAN list, it is returned to the end of the list.
The final list is the list of empty buffers—the EMPTY list. The empty buffers are just headers and have no memory associated with them. They are held on this list waiting for another mapping request.
When a new buffer is needed, the kernel first checks to see how much memory is dedicated to the existing buffers. If the memory in use is below its permissible threshold, a new buffer is created from the EMPTY list. Otherwise the oldest buffer is removed from the front of the CLEAN list. If the CLEAN list is empty, the buffer daemon is awakened to clean up and release a buffer from the DIRTY list.
Having looked at the functions and algorithms used to manage the buffer pool, we now turn our attention to the implementation requirements for ensuring the consistency of the data in the buffer pool. Figure 6.9 shows the support routines that implement the interface for getting buffers. The primary interface to getting a buffer is through bread(), which is called with a request for a data block of a specified size for a specified vnode. There is also a related interface, breadn(), that both gets a requested block and starts read-ahead for additional blocks. Bread() first calls getblk() to find out whether the data block is available in an existing buffer. If the block is available in a buffer, getblk() calls bremfree() to take the buffer off whichever free list it is on and to lock it; bread() can then return the buffer to the caller.
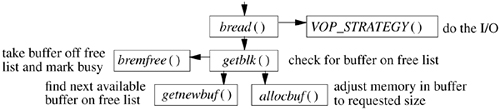
If the block is not already in an existing buffer, getblk() calls getnewbuf() to allocate a new buffer, using the algorithm described in the previous subsection. The new buffer is then passed to allocbuf(), which is responsible for determining how to constitute the contents of the buffer.
The common case is that the buffer is to contain a logical block of a file. Here, allocbuf() must request the needed block from the virtual-memory system. If the virtual-memory system does not already have the needed block, it arranges to get it brought into its page cache. The allocbuf() routine then allocates an appropriately sized piece of kernel address space and requests the virtual-memory system to map the needed file block into that address space. The buffer is then marked filled and returned through getblk() and bread().
The other case is that the buffer is to contain a block of filesystem metadata such as a bitmap or an inode block that is associated with a disk device rather than a file. Because the virtual memory does not (currently) have any way to track such blocks, they can be held in memory only within buffers. Here, allocbuf() must call the kernel malloc() routine to allocate memory to hold the block. The allocbuf() routine then returns the buffer to getblk() and bread() marked busy and unfilled. Noticing that the buffer is unfilled, bread() passes the buffer to the strategy() routine for the underlying filesystem to have the data read in. When the read completes, the buffer is returned.
To maintain the consistency of the filesystem, the kernel must ensure that a disk block is mapped into at most one buffer. If the same disk block were present in two buffers, and both buffers were marked dirty, the system would be unable to determine which buffer had the most current information. Figure 6.10 shows a sample allocation. In the middle of the figure are the blocks on the disk. Above the disk is shown an old buffer containing a 4096-byte fragment for a file that presumably has been removed or shortened. The new buffer is going to be used to hold a 4096-byte fragment for a file that is presumably being created and that will reuse part of the space previously held by the old file. The kernel maintains the consistency by purging old buffers when files are shortened or removed. Whenever a file is removed, the kernel traverses its list of dirty buffers. For each buffer, the kernel cancels its write request and dissolves the buffer so that the buffer cannot be found in the buffer pool again. For a file being partially truncated, only the buffers following the truncation point are invalidated. The system can then allocate the new buffer, knowing that the buffer maps the corresponding disk blocks uniquely.
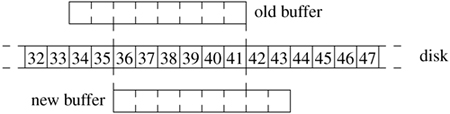
The early vnode interface was simply an object-oriented interface to an underlying filesystem. As the demand grew for new filesystem features, it became desirable to find ways of providing them without having to modify the existing and stable filesystem code. One approach is to provide a mechanism for stacking several filesystems on top of one another other [Rosenthal, 1990]. The stacking ideas were refined and implemented in the 4.4BSD system [Heidemann & Popek, 1994]. The implementation of the stacking has been refined in FreeBSD, but the semantics remain largely unchanged from those found in 4.4BSD. The bottom of a vnode stack tends to be a disk-based filesystem, whereas the layers used above it typically transform their arguments and pass on those arguments to a lower layer.
In all UNIX systems, the mount command takes a special device as a source and maps that device onto a directory mount point in an existing filesystem. When a filesystem is mounted on a directory, the previous contents of the directory are hidden; only the contents of the root of the newly mounted filesystem are visible. To most users, the effect of the series of mount commands done at system startup is the creation of a single seamless filesystem tree.
Stacking also uses the mount command to create new layers. The mount command pushes a new layer onto a vnode stack; an unmount command removes a layer. Like the mounting of a filesystem, a vnode stack is visible to all processes running on the system. The mount command identifies the underlying layer in the stack, creates the new layer, and attaches that layer into the filesystem name space. The new layer can be attached to the same place as the old layer (covering the old layer) or to a different place in the tree (allowing both layers to be visible). An example is shown in the next subsection.
If layers are attached to different places in the name space, then the same file will be visible in multiple places. Access to the file under the name of the new layer's name space will go to the new layer, whereas that under the old layer's name space will go to only the old layer.
When a file access (e.g., an open, read, stat, or close) occurs to a vnode in the stack, that vnode has several options:
• Do the requested operations and return a result.
• Pass the operation without change to the next-lower vnode on the stack. When the operation returns from the lower vnode, it may modify the results or simply return them.
• Modify the operands provided with the request and then pass it to the next-lower vnode. When the operation returns from the lower vnode, it may modify the results, or simply return them.
If an operation is passed to the bottom of the stack without any layer taking action on it, then the interface will return the error "operation not supported."
Vnode interfaces released before 4.4BSD implemented vnode operations as indirect function calls. The requirements that intermediate stack layers bypass operations to lower layers and that new operations can be added into the system at boot or module load time mean that this approach is no longer adequate. Filesystems must be able to bypass operations that may not have been defined at the time that the filesystem was implemented. In addition to passing through the function, the filesystem layer must also pass through the function parameters, which are of unknown type and number.
To resolve these two problems in a clean and portable way, the kernel places the vnode operation name and its arguments into an argument structure. This argument structure is then passed as a single parameter to the vnode operation. Thus, all calls on a vnode operation will always have exactly one parameter, which is the pointer to the argument structure. If the vnode operation is one that is supported by the filesystem, then it will know what the arguments are and how to interpret them. If it is an unknown vnode operation, then the generic bypass routine can call the same operation in the next-lower layer, passing to the operation the same argument structure that it received. In addition, the first argument of every operation is a pointer to the vnode operation description. This description provides to a bypass routine the information about the operation, including the operation's name and the location of the operation's parameters. An example access-check call and its implementation for the UPS filesystem are shown in Figure 6.11. Note that the vop_access_args structure is normally declared in a header file, but here it is declared at the function site to simplify the example.

The simplest filesystem layer is nullfs. It makes no transformations on its arguments, simply passing through all requests that it receives and returning all results that it gets back. Although it provides no useful functionality if it is simply stacked on top of an existing vnode, nullfs can provide a loopback filesystem by mounting the filesystem rooted at its source vnode at some other location in the filesystem tree. The code for nullfs is also an excellent starting point for designers who want to build their own filesystem layers. Examples that could be built include a compression layer or an encryption layer.
A sample vnode stack is shown in Figure 6.12. The figure shows a local filesystem on the bottom of the stack that is being exported from /local via an NFS layer. Clients within the administrative domain of the server can import the /local filesystem directly because they are all presumed to use a common mapping of UIDs to user names.
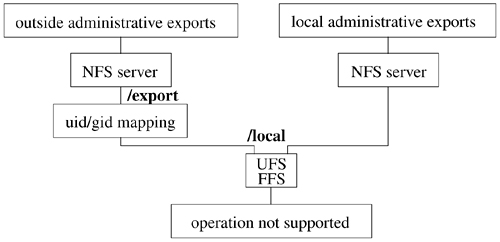
The umapfs filesystem works much like the nullfs filesystem in that it provides a view of the file tree rooted at the /local filesystem on the /export mount point. In addition to providing a copy of the /local filesystem at the /export mount point, it transforms the credentials of each system call made to files within the /export filesystem. The kernel does the transformation using a mapping that was provided as part of the mount system call that created the umapfs layer.
The /export filesystem can be exported to clients from an outside administrative domain that uses different UIDs and GIDs. When an NFS request comes in for the /export filesystem, the umapfs layer modifies the credential from the foreign client by mapping the UIDs used on the foreign client to the corresponding UIDs used on the local system. The requested operation with the modified credential is passed down to the lower layer corresponding to the /local filesystem, where it is processed identically to a local request. When the result is returned to the mapping layer, any returned credentials are mapped inversely so that they are converted from the local UIDs to the outside UIDs, and this result is sent back as the NFS response.
There are three benefits to this approach:
- There is no cost of mapping imposed on the local clients.
- There are no changes required to the local filesystem code or the NFS code to support mapping.
- Each outside domain can have its own mapping. Domains with simple mappings consume small amounts of memory and run quickly; domains with large and complex mappings can be supported without detracting from the performance of simpler environments.
Vnode stacking is an effective approach for adding extensions, such as the umapfs service.
The union filesystem is another example of a middle filesystem layer. Like the nullfs, it does not store data but just provides a name-space transformation. It is loosely modeled on the work on the 3-D filesystem [Korn & Krell, 1989], on the Translucent filesystem [Hendricks, 1990], and on the Automounter [Pendry & Williams, 1994]. The union filesystem takes an existing filesystem and transparently overlays the latter on another filesystem. Unlike most other filesystems, a union mount does not cover up the directory on which the filesystem is mounted. Instead, it shows the logical merger of both directories and allows both directory trees to be accessible simultaneously [Pendry & McKusick, 1995].
A small example of a union-mount stack is shown in Figure 6.13. Here, the bottom layer of the stack is the src filesystem that includes the source for the shell program. Being a simple program, it contains only one source and one header file. The upper layer that has been union mounted on top of src initially contains just the src directory. When the user changes directory into shell, a directory of the same name is created in the top layer. Directories in the top layer corresponding to directories in the lower layer are created only as they are encountered while the top layer is traversed. If the user were to run a recursive traversal of the tree rooted at the top of the union-mount location, the result would be a complete tree of directories matching the underlying filesystem. In our example, the user now types make in the shell directory. The sh executable is created in the upper layer of the union stack. To the user, a directory listing shows the sources and executable all apparently together, as shown on the right in Figure 6.13.
Figure 6.13. A union-mounted filesystem. The /usr/src filesystem is on the bottom, and the /tmp/src filesystem is on the top.
All filesystem layers, except the top one, are treated as though they were readonly. If a file residing in a lower layer is opened for reading, a descriptor is returned for that file. If a file residing in a lower layer is opened for writing, the kernel first copies the entire file to the top layer and then returns a descriptor referencing the copy of the file. The result is that there are two copies of the file: the original unmodified file in the lower layer and the modified copy of the file in the upper layer. When the user does a directory listing, any duplicate names in the lower layer are suppressed. When a file is opened, a descriptor for the file in the uppermost layer in which the name appears is returned. Thus, once a file has been copied to the top layer, instances of the file in lower layers become inaccessible.
The tricky part of the union filesystem is handling the removal of files that reside in a lower layer. Since the lower layers cannot be modified, the only way to remove a file is to hide it by creating a whiteout directory entry in the top layer. A whiteout is an entry in a directory that has no corresponding file; it is distinguished by having an inode number of 1. If the kernel finds a whiteout entry while searching for a name, the lookup is stopped and the "no such file or directory" error is returned. Thus, the file with the same name in a lower layer appears to have been removed. If a file is removed from the top layer, it is necessary to create a whiteout entry for it only if there is a file with the same name in the lower level that would reappear.
When a process creates a file with the same name as a whiteout entry, the whiteout entry is replaced with a regular name that references the new file. Because the new file is being created in the top layer, it will mask out any files with the same name in a lower layer. When a user does a directory listing, white-out entries and the files that they mask usually are not shown. However, there is an option that causes them to appear.
One feature that has long been missing in UNIX systems is the ability to recover files after they have been deleted. For the union filesystem, the kernel can implement file recovery trivially simply by removing the whiteout entry to expose the underlying file. For filesystems that provide file recovery, users can recover files by using a special option to the remove command. Processes can recover files by using the undelete system call.
When a directory whose name appears in a lower layer is removed, a whiteout entry is created just as it would be for a file. However, if the user later attempts to create a directory with the same name as the previously deleted directory, the union filesystem must treat the new directory specially to avoid having the previous contents from the lower-layer directory reappear. When a directory that replaces a whiteout entry is created, the union filesystem sets a flag in the directory metadata to show that this directory should be treated specially. When a directory scan is done, the kernel returns information about only the top-level directory; it suppresses the list of files from the directories of the same name in the lower layers.
The union filesystem can be used for many purposes:
• It allows several different architectures to build from a common source base. The source pool is NFS mounted onto each of several machines. On each host machine, a local filesystem is union mounted on top of the imported source tree. As the build proceeds, the objects and binaries appear in the local filesystem that is layered above the source tree. This approach not only avoids contaminating the source pool with binaries, but also speeds the compilation, because most of the filesystem traffic is on the local filesystem.
• It allows compilation of sources on read-only media such as CD-ROMs. A local filesystem is union mounted above the CD-ROM sources. It is then possible to change into directories on the CD-ROM and to give the appearance of being able to edit and compile in that directory.
• It allows creation of a private source directory. The user creates a source directory in her own work area and then union mounts the system sources underneath that directory. This feature is possible because the restrictions on the mount command have been relaxed. If the sysctl vfs.usermount option has been enabled, any user can do a mount if she owns the directory on which the mount is being done and she has appropriate access permissions on the device or directory being mounted (read permission is required for a read-only mount, read-write permission is required for a read-write mount). Only the user who did the mount or the superuser can unmount a filesystem.
There are several other filesystems included as part of FreeBSD. The portal filesystem mounts a process onto a directory in the file tree. When a pathname that traverses the location of the portal is used, the remainder of the path is passed to the process mounted at that point. The process interprets the path in whatever way it sees fit, then returns a descriptor to the calling process. This descriptor may be for a socket connected to the portal process. If it is, further operations on the descriptor will be passed to the portal process for the latter to interpret. Alternatively, the descriptor may be for a file elsewhere in the filesystem.
Consider a portal process mounted on /dialout used to manage a bank of dialout modems. When a process wanted to connect to an outside number, it would open /dialout/15105551212/28800 to specify that it wanted to dial 1-510-555-1212 at 28800 baud. The portal process would get the final two pathname components. Using the final component, it would determine that it should find an unused 28800-baud modem. It would use the other component as the number to which to place the call. It would then write an accounting record for future billing, and would return the descriptor for the modem to the process.
An interesting use of the portal filesystem is to provide an Internet service directory. For example, with an Internet portal process mounted on /net, an open of /net/tcp/McKusick.COM/smtp returns a TCP socket descriptor to the calling process that is connected to the SMTP server on McKusick.COM. Because access is provided through the normal filesystem, the calling process does not need to be aware of the special functions necessary to create a TCP socket and to establish a TCP connection [Stevens & Pendry, 1995].
There are several filesystems that are designed to provide a convenient interface to kernel information. The procfs filesystem is normally mounted at /proc and provides a view of the running processes in the system. Its primary use is for debugging, but it also provides a convenient interface for collecting information about the processes in the system. A directory listing of /proc produces a numeric list of all the processes in the system. The /proc interface is more fully described in Section 4.9.
The fdesc filesystem is normally mounted on /dev/fd and provides a list of all the active file descriptors for the currently running process. An example where this is useful is specifying to an application that it should read input from its standard input. Here, you can use the pathname /dev/fd/0 instead of having to come up with a special convention, such as using the name - to tell the application to read from its standard input.
The linprocfs emulates a subset of the Linux process filesystem and is normally mounted on /compat/linux/proc. It provides similar information to that provided by the /proc filesystem, but in a format expected by Linux binaries.
Finally there is the cd9660 filesystem. It allows ISO-9660-compliant filesystems, with or without Rock Ridge extensions, to be mounted. The ISO-9660 filesystem format is most commonly used on CD-ROMs.
6.1 Where are the read and write attributes of an open file descriptor stored?
6.2 Why is the close-on-exec bit located in the per-process descriptor table instead of in the system file table?
6.3 Why are the file-table entries reference counted?
6.4 What three shortcomings of lock files are addressed by the FreeBSD descriptor-locking facilities?
6.5 What two problems are raised by mandatory locks?
6.6 Why is the implementation of select split between the descriptor-management code and the lower-level routines?
6.7 Describe how the process selecting flag is used in the implementation of select.
6.8 The syncer daemon starts as part of system boot. Once every second, it does an fsync on any vnodes that it finds that have been dirty for 30 seconds. What problem could arise if this daemon were not run?
6.9 When is a vnode placed on the free list?
6.10 Why must the lookup routine call through the vnode interface once for each component in a pathname?
6.11 Give three reasons for revoking access to a vnode.
6.12 Why are the buffer headers allocated separately from the memory that holds the contents of the buffer?
6.13 Asynchronous I/O is provided through the aio_read and aio_write systems calls rather than through the traditional read and write system calls. What problems arise with providing asynchronous I/O in the existing read-write interface?
*6.14 Why are there both a CLEAN list and a DIRTY list instead of all buffers being managed on one list?
*6.15 If a process reads a large file, the blocks of the file will fill the virtual memory cache completely, flushing out all other contents. All other processes in the system then will have to go to disk for all their filesystem accesses. Write an algorithm to control the purging of the buffer cache.
*6.16 Vnode operation parameters are passed between layers in structures. What alternatives are there to this approach? Explain why your approach is more or less efficient, compared to the current approach, when there are less than five layers in the stack. Also compare the efficiency of your solution when there are more than five layers in the stack.
References
Accetta et al., 1986.
M. Accetta, R. Baron, W. Bolosky, D. Golub, R. Rashid, A. Tevanian, & M. Young, "Mach: A New Kernel Foundation for UNIX Development," USENIX Association Conference Proceedings, pp. 93-113, June 1986.
Heidemann & Popek, 1994.
J. S. Heidemann & G. J. Popek, "File-System Development with Stackable Layers," ACM Transactions on Computer Systems, , no. 1, pp. 58-89, February 1994.
Hendricks, 1990.
D. Hendricks, "A Filesystem for Software Development," USENIX Association Conference Proceedings, pp. 333-340, June 1990.
Korn & Krell, 1989.
D. Korn & E. Krell, "The 3-D File System," USENIX Association Conference Proceedings, pp. 147-156, June 1989.
Lemon, 2001.
J. Lemon, "Kqueue: A Generic and Scalable Event Notification Facility," Proceedings of the Freenix Track at the 2001 Usenix Annual Technical Conference, pp. 141-154, June 2001.
Pendry & McKusick, 1995.
J. Pendry & M. K. McKusick, "Union Mounts in 4.4BSD-Lite," USENIX Association Conference Proceedings, pp. 25-33, January 1995.
Pendry & Williams, 1994.
J. Pendry & N. Williams, "AMD: The 4.4BSD Automounter Reference Manual," in 4.4BSD System Manager's Manual, pp. 13:1-57, O'Reilly & Associates, Inc., Sebastopol, CA, 1994.
Peterson, 1983.
G. Peterson, "Concurrent Reading While Writing," ACM Transactions on Programming Languages and Systems, , no. 1, pp. 46-55, January 1983.