
7
Microarchitecture
With contributions from Matthew Watkins
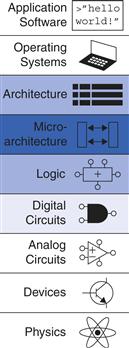
7.1 Introduction
In this chapter, you will learn how to piece together a MIPS microprocessor. Indeed, you will puzzle out three different versions, each with different trade-offs between performance, cost, and complexity.
To the uninitiated, building a microprocessor may seem like black magic. But it is actually relatively straightforward, and by this point you have learned everything you need to know. Specifically, you have learned to design combinational and sequential logic given functional and timing specifications. You are familiar with circuits for arithmetic and memory. And you have learned about the MIPS architecture, which specifies the programmer’s view of the MIPS processor in terms of registers, instructions, and memory.
This chapter covers microarchitecture, which is the connection between logic and architecture. Microarchitecture is the specific arrangement of registers, ALUs, finite state machines (FSMs), memories, and other logic building blocks needed to implement an architecture. A particular architecture, such as MIPS, may have many different microarchitectures, each with different trade-offs of performance, cost, and complexity. They all run the same programs, but their internal designs vary widely. We will design three different microarchitectures in this chapter to illustrate the trade-offs.
This chapter draws heavily on David Patterson and John Hennessy’s classic MIPS designs in their text Computer Organization and Design. They have generously shared their elegant designs, which have the virtue of illustrating a real commercial architecture while being relatively simple and easy to understand.
7.1.1 Architectural State and Instruction Set
Recall that a computer architecture is defined by its instruction set and architectural state. The architectural state for the MIPS processor consists of the program counter and the 32 registers. Any MIPS microarchitecture must contain all of this state. Based on the current architectural state, the processor executes a particular instruction with a particular set of data to produce a new architectural state. Some microarchitectures contain additional nonarchitectural state to either simplify the logic or improve performance; we will point this out as it arises.
David Patterson was the first in his family to graduate from college (UCLA, 1969). He has been a professor of computer science at UC Berkeley since 1977, where he coinvented RISC, the Reduced Instruction Set Computer. In 1984, he developed the SPARC architecture used by Sun Microsystems. He is also the father of RAID (Redundant Array of Inexpensive Disks) and NOW (Network of Workstations).
John Hennessy is president of Stanford University and has been a professor of electrical engineering and computer science there since 1977. He coinvented RISC. He developed the MIPS architecture at Stanford in 1984 and cofounded MIPS Computer Systems. As of 2004, more than 300 million MIPS microprocessors have been sold.
In their copious free time, these two modern paragons write textbooks for recreation and relaxation.
To keep the microarchitectures easy to understand, we consider only a subset of the MIPS instruction set. Specifically, we handle the following instructions:
After building the microarchitectures with these instructions, we extend them to handle addi and j. These particular instructions were chosen because they are sufficient to write many interesting programs. Once you understand how to implement these instructions, you can expand the hardware to handle others.
7.1.2 Design Process
We will divide our microarchitectures into two interacting parts: the datapath and the control. The datapath operates on words of data. It contains structures such as memories, registers, ALUs, and multiplexers. MIPS is a 32-bit architecture, so we will use a 32-bit datapath. The control unit receives the current instruction from the datapath and tells the datapath how to execute that instruction. Specifically, the control unit produces multiplexer select, register enable, and memory write signals to control the operation of the datapath.
A good way to design a complex system is to start with hardware containing the state elements. These elements include the memories and the architectural state (the program counter and registers). Then, add blocks of combinational logic between the state elements to compute the new state based on the current state. The instruction is read from part of memory; load and store instructions then read or write data from another part of memory. Hence, it is often convenient to partition the overall memory into two smaller memories, one containing instructions and the other containing data. Figure 7.1 shows a block diagram with the four state elements: the program counter, register file, and instruction and data memories.
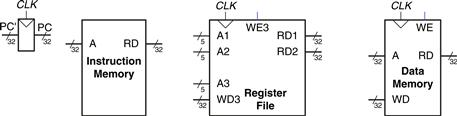
Figure 7.1 State elements of MIPS processor
In Figure 7.1, heavy lines are used to indicate 32-bit data busses. Medium lines are used to indicate narrower busses, such as the 5-bit address busses on the register file. Narrow blue lines are used to indicate control signals, such as the register file write enable. We will use this convention throughout the chapter to avoid cluttering diagrams with bus widths. Also, state elements usually have a reset input to put them into a known state at start-up. Again, to save clutter, this reset is not shown.
The program counter is an ordinary 32-bit register. Its output, PC, points to the current instruction. Its input, PC′, indicates the address of the next instruction.
The instruction memory has a single read port.1 It takes a 32-bit instruction address input, A, and reads the 32-bit data (i.e., instruction) from that address onto the read data output, RD.
The 32-element × 32-bit register file has two read ports and one write port. The read ports take 5-bit address inputs, A1 and A2, each specifying one of 25 = 32 registers as source operands. They read the 32-bit register values onto read data outputs RD1 and RD2, respectively. The write port takes a 5-bit address input, A3; a 32-bit write data input, WD; a write enable input, WE3; and a clock. If the write enable is 1, the register file writes the data into the specified register on the rising edge of the clock.
The data memory has a single read/write port. If the write enable, WE, is 1, it writes data WD into address A on the rising edge of the clock. If the write enable is 0, it reads address A onto RD.
Resetting the PC
At the very least, the program counter must have a reset signal to initialize its value when the processor turns on. MIPS processors initialize the PC to 0xBFC00000 on reset and begin executing code to start up the operating system (OS). The OS then loads an application program at 0x00400000 and begins executing it. For simplicity in this chapter, we will reset the PC to 0x00000000 and place our programs there instead.
The instruction memory, register file, and data memory are all read combinationally. In other words, if the address changes, the new data appears at RD after some propagation delay; no clock is involved. They are written only on the rising edge of the clock. In this fashion, the state of the system is changed only at the clock edge. The address, data, and write enable must setup sometime before the clock edge and must remain stable until a hold time after the clock edge.
Because the state elements change their state only on the rising edge of the clock, they are synchronous sequential circuits. The microprocessor is built of clocked state elements and combinational logic, so it too is a synchronous sequential circuit. Indeed, the processor can be viewed as a giant finite state machine, or as a collection of simpler interacting state machines.
7.1.3 MIPS Microarchitectures
In this chapter, we develop three microarchitectures for the MIPS processor architecture: single-cycle, multicycle, and pipelined. They differ in the way that the state elements are connected together and in the amount of nonarchitectural state.
The single-cycle microarchitecture executes an entire instruction in one cycle. It is easy to explain and has a simple control unit. Because it completes the operation in one cycle, it does not require any nonarchitectural state. However, the cycle time is limited by the slowest instruction.
The multicycle microarchitecture executes instructions in a series of shorter cycles. Simpler instructions execute in fewer cycles than complicated ones. Moreover, the multicycle microarchitecture reduces the hardware cost by reusing expensive hardware blocks such as adders and memories. For example, the adder may be used on several different cycles for several purposes while carrying out a single instruction. The multicycle microprocessor accomplishes this by adding several nonarchitectural registers to hold intermediate results. The multicycle processor executes only one instruction at a time, but each instruction takes multiple clock cycles.
The pipelined microarchitecture applies pipelining to the single-cycle microarchitecture. It therefore can execute several instructions simultaneously, improving the throughput significantly. Pipelining must add logic to handle dependencies between simultaneously executing instructions. It also requires nonarchitectural pipeline registers. The added logic and registers are worthwhile; all commercial high-performance processors use pipelining today.
We explore the details and trade-offs of these three microarchitectures in the subsequent sections. At the end of the chapter, we briefly mention additional techniques that are used to get even more speed in modern high-performance microprocessors.
7.2 Performance Analysis
As we mentioned, a particular processor architecture can have many microarchitectures with different cost and performance trade-offs. The cost depends on the amount of hardware required and the implementation technology. Each year, CMOS processes can pack more transistors on a chip for the same amount of money, and processors take advantage of these additional transistors to deliver more performance. Precise cost calculations require detailed knowledge of the implementation technology, but in general, more gates and more memory mean more dollars. This section lays the foundation for analyzing performance.
There are many ways to measure the performance of a computer system, and marketing departments are infamous for choosing the method that makes their computer look fastest, regardless of whether the measurement has any correlation to real-world performance. For example, Intel and Advanced Micro Devices (AMD) both sell compatible microprocessors conforming to the x86 architecture. Intel Pentium III and Pentium 4 microprocessors were largely advertised according to clock frequency in the late 1990s and early 2000s, because Intel offered higher clock frequencies than its competitors. However, Intel’s main competitor, AMD, sold Athlon microprocessors that executed programs faster than Intel’s chips at the same clock frequency. What is a consumer to do?
The only gimmick-free way to measure performance is by measuring the execution time of a program of interest to you. The computer that executes your program fastest has the highest performance. The next best choice is to measure the total execution time of a collection of programs that are similar to those you plan to run; this may be necessary if you haven’t written your program yet or if somebody else who doesn’t have your program is making the measurements. Such collections of programs are called benchmarks, and the execution times of these programs are commonly published to give some indication of how a processor performs.
The execution time of a program, measured in seconds, is given by Equation 7.1.
![]() (7.1)
(7.1)
The number of instructions in a program depends on the processor architecture. Some architectures have complicated instructions that do more work per instruction, thus reducing the number of instructions in a program. However, these complicated instructions are often slower to execute in hardware. The number of instructions also depends enormously on the cleverness of the programmer. For the purposes of this chapter, we will assume that we are executing known programs on a MIPS processor, so the number of instructions for each program is constant, independent of the microarchitecture.
The number of cycles per instruction, often called CPI, is the number of clock cycles required to execute an average instruction. It is the reciprocal of the throughput (instructions per cycle, or IPC). Different microarchitectures have different CPIs. In this chapter, we will assume we have an ideal memory system that does not affect the CPI. In Chapter 8, we examine how the processor sometimes has to wait for the memory, which increases the CPI.
The number of seconds per cycle is the clock period, Tc. The clock period is determined by the critical path through the logic on the processor. Different microarchitectures have different clock periods. Logic and circuit designs also significantly affect the clock period. For example, a carry-lookahead adder is faster than a ripple-carry adder. Manufacturing advances have historically doubled transistor speeds every 4–6 years, so a microprocessor built today will be much faster than one from last decade, even if the microarchitecture and logic are unchanged.
The challenge of the microarchitect is to choose the design that minimizes the execution time while satisfying constraints on cost and/or power consumption. Because microarchitectural decisions affect both CPI and Tc and are influenced by logic and circuit designs, determining the best choice requires careful analysis.
There are many other factors that affect overall computer performance. For example, the hard disk, the memory, the graphics system, and the network connection may be limiting factors that make processor performance irrelevant. The fastest microprocessor in the world doesn’t help surfing the Internet on a dial-up connection. But these other factors are beyond the scope of this book.
7.3 Single-Cycle Processor
We first design a MIPS microarchitecture that executes instructions in a single cycle. We begin constructing the datapath by connecting the state elements from Figure 7.1 with combinational logic that can execute the various instructions. Control signals determine which specific instruction is carried out by the datapath at any given time. The controller contains combinational logic that generates the appropriate control signals based on the current instruction. We conclude by analyzing the performance of the single-cycle processor.
7.3.1 Single-Cycle Datapath
This section gradually develops the single-cycle datapath, adding one piece at a time to the state elements from Figure 7.1. The new connections are emphasized in black (or blue, for new control signals), while the hardware that has already been studied is shown in gray.
The program counter (PC) register contains the address of the instruction to execute. The first step is to read this instruction from instruction memory. Figure 7.2 shows that the PC is simply connected to the address input of the instruction memory. The instruction memory reads out, or fetches, the 32-bit instruction, labeled Instr.
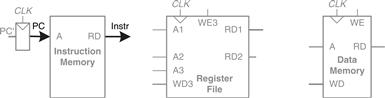
Figure 7.2 Fetch instruction from memory
The processor’s actions depend on the specific instruction that was fetched. First we will work out the datapath connections for the lw instruction. Then we will consider how to generalize the datapath to handle the other instructions.
For a lw instruction, the next step is to read the source register containing the base address. This register is specified in the rs field of the instruction, Instr25:21. These bits of the instruction are connected to the address input of one of the register file read ports, A1, as shown in Figure 7.3. The register file reads the register value onto RD1.
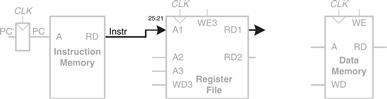
Figure 7.3 Read source operand from register file
The lw instruction also requires an offset. The offset is stored in the immediate field of the instruction, Instr15:0. Because the 16-bit immediate might be either positive or negative, it must be sign-extended to 32 bits, as shown in Figure 7.4. The 32-bit sign-extended value is called SignImm. Recall from Section 1.4.6 that sign extension simply copies the sign bit (most significant bit) of a short input into all of the upper bits of the longer output. Specifically, SignImm15:0 = Instr15:0 and SignImm31:16 = Instr15.
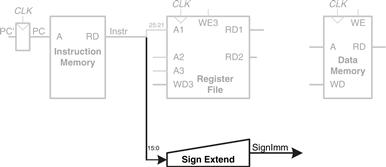
Figure 7.4 Sign-extend the immediate
The processor must add the base address to the offset to find the address to read from memory. Figure 7.5 introduces an ALU to perform this addition. The ALU receives two operands, SrcA and SrcB. SrcA comes from the register file, and SrcB comes from the sign-extended immediate. The ALU can perform many operations, as was described in Section 5.2.4. The 3-bit ALUControl signal specifies the operation. The ALU generates a 32-bit ALUResult and a Zero flag, that indicates whether ALUResult == 0. For a lw instruction, the ALUControl signal should be set to 010 to add the base address and offset. ALUResult is sent to the data memory as the address for the load instruction, as shown in Figure 7.5.
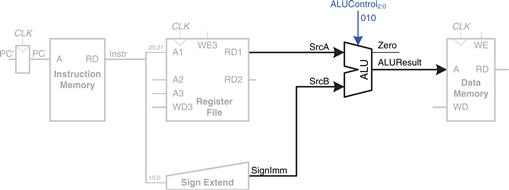
Figure 7.5 Compute memory address
The data is read from the data memory onto the ReadData bus, then written back to the destination register in the register file at the end of the cycle, as shown in Figure 7.6. Port 3 of the register file is the write port. The destination register for the lw instruction is specified in the rt field, Instr20:16, which is connected to the port 3 address input, A3, of the register file. The ReadData bus is connected to the port 3 write data input, WD3, of the register file. A control signal called RegWrite is connected to the port 3 write enable input, WE3, and is asserted during a lw instruction so that the data value is written into the register file. The write takes place on the rising edge of the clock at the end of the cycle.
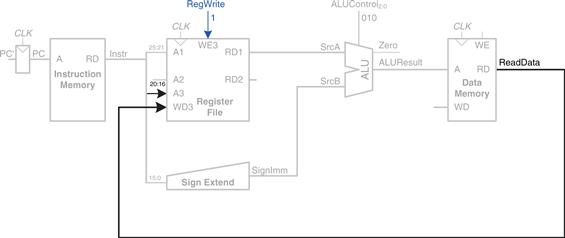
Figure 7.6 Write data back to register file
While the instruction is being executed, the processor must compute the address of the next instruction, PC′. Because instructions are 32 bits = 4 bytes, the next instruction is at PC + 4. Figure 7.7 uses another adder to increment the PC by 4. The new address is written into the program counter on the next rising edge of the clock. This completes the datapath for the lw instruction.
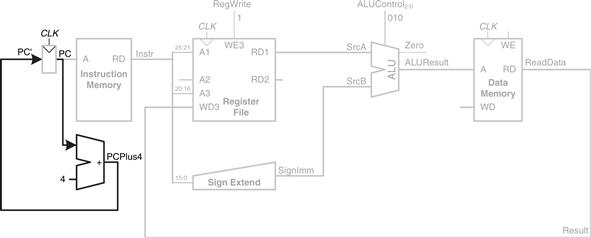
Figure 7.7 Determine address of next instruction for PC
Next, let us extend the datapath to also handle the sw instruction. Like the lw instruction, the sw instruction reads a base address from port 1 of the register file and sign-extends an immediate. The ALU adds the base address to the immediate to find the memory address. All of these functions are already supported by the datapath.
The sw instruction also reads a second register from the register file and writes it to the data memory. Figure 7.8 shows the new connections for this function. The register is specified in the rt field, Instr20:16. These bits of the instruction are connected to the second register file read port, A2. The register value is read onto the RD2 port. It is connected to the write data port of the data memory. The write enable port of the data memory, WE, is controlled by MemWrite. For a sw instruction, MemWrite = 1, to write the data to memory; ALUControl = 010, to add the base address and offset; and RegWrite = 0, because nothing should be written to the register file. Note that data is still read from the address given to the data memory, but that this ReadData is ignored because RegWrite = 0.

Figure 7.8 Write data to memory for sw instruction
Next, consider extending the datapath to handle the R-type instructions add, sub, and, or, and slt. All of these instructions read two registers from the register file, perform some ALU operation on them, and write the result back to a third register file. They differ only in the specific ALU operation. Hence, they can all be handled with the same hardware, using different ALUControl signals.
Figure 7.9 shows the enhanced datapath handling R-type instructions. The register file reads two registers. The ALU performs an operation on these two registers. In Figure 7.8, the ALU always received its SrcB operand from the sign-extended immediate (SignImm). Now, we add a multiplexer to choose SrcB from either the register file RD2 port or SignImm.
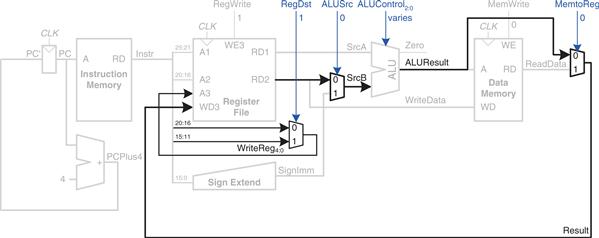
Figure 7.9 Datapath enhancements for R-type instruction
The multiplexer is controlled by a new signal, ALUSrc. ALUSrc is 0 for R-type instructions to choose SrcB from the register file; it is 1 for lw and sw to choose SignImm. This principle of enhancing the datapath’s capabilities by adding a multiplexer to choose inputs from several possibilities is extremely useful. Indeed, we will apply it twice more to complete the handling of R-type instructions.
In Figure 7.8, the register file always got its write data from the data memory. However, R-type instructions write the ALUResult to the register file. Therefore, we add another multiplexer to choose between ReadData and ALUResult. We call its output Result. This multiplexer is controlled by another new signal, MemtoReg. MemtoReg is 0 for R-type instructions to choose Result from the ALUResult; it is 1 for lw to choose ReadData. We don’t care about the value of MemtoReg for sw, because sw does not write to the register file.
Similarly, in Figure 7.8, the register to write was specified by the rt field of the instruction, Instr20:16. However, for R-type instructions, the register is specified by the rd field, Instr15:11. Thus, we add a third multiplexer to choose WriteReg from the appropriate field of the instruction. The multiplexer is controlled by RegDst. RegDst is 1 for R-type instructions to choose WriteReg from the rd field, Instr15:11; it is 0 for lw to choose the rt field, Instr20:16. We don’t care about the value of RegDst for sw, because sw does not write to the register file.
Finally, let us extend the datapath to handle beq. beq compares two registers. If they are equal, it takes the branch by adding the branch offset to the program counter. Recall that the offset is a positive or negative number, stored in the imm field of the instruction, Instr15:0. The offset indicates the number of instructions to branch past. Hence, the immediate must be sign-extended and multiplied by 4 to get the new program counter value: PC′ = PC + 4 + SignImm × 4.
Figure 7.10 shows the datapath modifications. The next PC value for a taken branch, PCBranch, is computed by shifting SignImm left by 2 bits, then adding it to PCPlus4. The left shift by 2 is an easy way to multiply by 4, because a shift by a constant amount involves just wires. The two registers are compared by computing SrcA – SrcB using the ALU. If ALUResult is 0, as indicated by the Zero flag from the ALU, the registers are equal. We add a multiplexer to choose PC′ from either PCPlus4 or PCBranch. PCBranch is selected if the instruction is a branch and the Zero flag is asserted. Hence, Branch is 1 for beq and 0 for other instructions. For beq, ALUControl = 110, so the ALU performs a subtraction. ALUSrc = 0 to choose SrcB from the register file. RegWrite and MemWrite are 0, because a branch does not write to the register file or memory. We don’t care about the values of RegDst and MemtoReg, because the register file is not written.
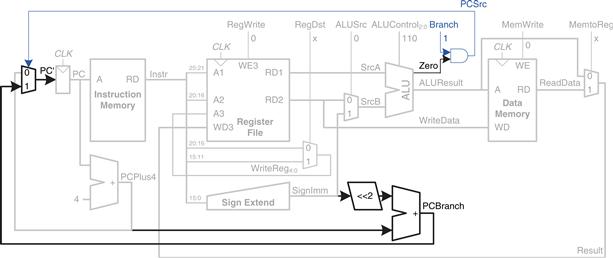
Figure 7.10 Datapath enhancements for beq instruction
This completes the design of the single-cycle MIPS processor datapath. We have illustrated not only the design itself, but also the design process in which the state elements are identified and the combinational logic connecting the state elements is systematically added. In the next section, we consider how to compute the control signals that direct the operation of our datapath.
7.3.2 Single-Cycle Control
The control unit computes the control signals based on the opcode and funct fields of the instruction, Instr31:26 and Instr5:0. Figure 7.11 shows the entire single-cycle MIPS processor with the control unit attached to the datapath.

Figure 7.11 Complete single-cycle MIPS processor
Most of the control information comes from the opcode, but R-type instructions also use the funct field to determine the ALU operation. Thus, we will simplify our design by factoring the control unit into two blocks of combinational logic, as shown in Figure 7.12. The main decoder computes most of the outputs from the opcode. It also determines a 2-bit ALUOp signal. The ALU decoder uses this ALUOp signal in conjunction with the funct field to compute ALUControl. The meaning of the ALUOp signal is given in Table 7.1.
Table 7.1 ALUOp encoding
| ALUOp | Meaning |
| 00 | add |
| 01 | subtract |
| 10 | look at funct field |
| 11 | n/a |
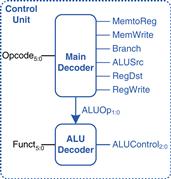
Figure 7.12 Control unit internal structure
Table 7.2 is a truth table for the ALU decoder. Recall that the meanings of the three ALUControl signals were given in Table 5.1. Because ALUOp is never 11, the truth table can use don’t care’s X1 and 1X instead of 01 and 10 to simplify the logic. When ALUOp is 00 or 01, the ALU should add or subtract, respectively. When ALUOp is 10, the decoder examines the funct field to determine the ALUControl. Note that, for the R-type instructions we implement, the first two bits of the funct field are always 10, so we may ignore them to simplify the decoder.
Table 7.2 ALU decoder truth table
| ALUOp | Funct | ALUControl |
| 00 | X | 010 (add) |
| X1 | X | 110 (subtract) |
| 1X | 100000 (add) | 010 (add) |
| 1X | 100010 (sub) | 110 (subtract) |
| 1X | 100100 (and) | 000 (and) |
| 1X | 100101 (or) | 001 (or) |
| 1X | 101010 (slt) | 111 (set less than) |
The control signals for each instruction were described as we built the datapath. Table 7.3 is a truth table for the main decoder that summarizes the control signals as a function of the opcode. All R-type instructions use the same main decoder values; they differ only in the ALU decoder output. Recall that, for instructions that do not write to the register file (e.g., sw and beq), the RegDst and MemtoReg control signals are don’t cares (X); the address and data to the register write port do not matter because RegWrite is not asserted. The logic for the decoder can be designed using your favorite techniques for combinational logic design.
Table 7.3 Main decoder truth table

Example 7.1 Single-Cycle Processor Operation
Determine the values of the control signals and the portions of the datapath that are used when executing an or instruction.
Solution
Figure 7.13 illustrates the control signals and flow of data during execution of the or instruction. The PC points to the memory location holding the instruction, and the instruction memory fetches this instruction.
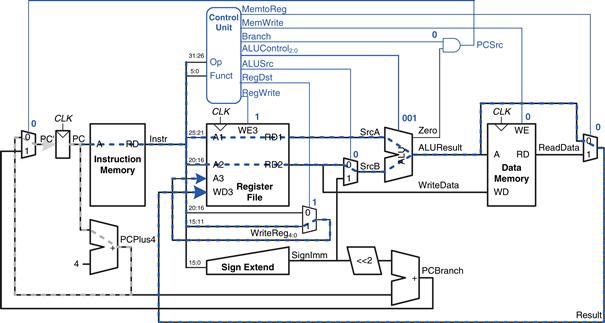
Figure 7.13 Control signals and data flow while executing or instruction
The main flow of data through the register file and ALU is represented with a dashed blue line. The register file reads the two source operands specified by Instr25:21 and Instr20:16. SrcB should come from the second port of the register file (not SignImm), so ALUSrc must be 0. or is an R-type instruction, so ALUOp is 10, indicating that ALUControl should be determined from the funct field to be 001. Result is taken from the ALU, so MemtoReg is 0. The result is written to the register file, so RegWrite is 1. The instruction does not write memory, so MemWrite = 0.
The selection of the destination register is also shown with a dashed blue line. The destination register is specified in the rd field, Instr15:11, so RegDst = 1.
The updating of the PC is shown with the dashed gray line. The instruction is not a branch, so Branch = 0 and, hence, PCSrc is also 0. The PC gets its next value from PCPlus4.
Note that data certainly does flow through the nonhighlighted paths, but that the value of that data is unimportant for this instruction. For example, the immediate is sign-extended and data is read from memory, but these values do not influence the next state of the system.
7.3.3 More Instructions
We have considered a limited subset of the full MIPS instruction set. Adding support for the addi and j instructions illustrates the principle of how to handle new instructions and also gives us a sufficiently rich instruction set to write many interesting programs. We will see that supporting some instructions simply requires enhancing the main decoder, whereas supporting others also requires more hardware in the datapath.
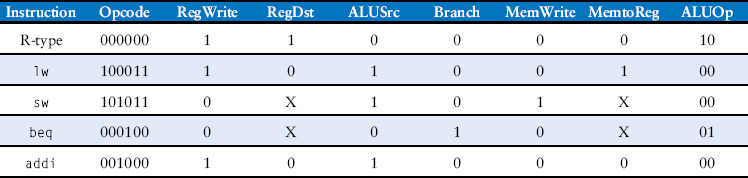
Example 7.2 addi Instruction
The add immediate instruction, addi, adds the value in a register to the immediate and writes the result to another register. The datapath already is capable of this task. Determine the necessary changes to the controller to support addi.
Solution
All we need to do is add a new row to the main decoder truth table showing the control signal values for addi, as given in Table 7.4. The result should be written to the register file, so RegWrite = 1. The destination register is specified in the rt field of the instruction, so RegDst = 0. SrcB comes from the immediate, so ALUSrc = 1. The instruction is not a branch, nor does it write memory, so Branch = MemWrite = 0. The result comes from the ALU, not memory, so MemtoReg = 0. Finally, the ALU should add, so ALUOp = 00.
Table 7.4 Main decoder truth table enhanced to support addi
Example 7.3 j Instruction
The jump instruction, j, writes a new value into the PC. The two least significant bits of the PC are always 0, because the PC is word aligned (i.e., always a multiple of 4). The next 26 bits are taken from the jump address field in Instr25:0. The upper four bits are taken from the old value of the PC.
The existing datapath lacks hardware to compute PC′ in this fashion. Determine the necessary changes to both the datapath and controller to handle j.
Solution
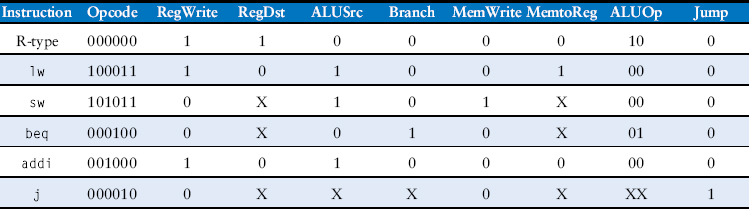
First, we must add hardware to compute the next PC value, PC′, in the case of a j instruction and a multiplexer to select this next PC, as shown in Figure 7.14. The new multiplexer uses the new Jump control signal.
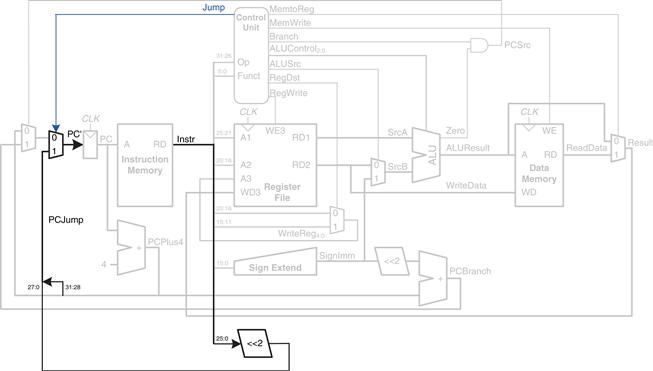
Figure 7.14 Single-cycle MIPS datapath enhanced to support the j instruction
Now we must add a row to the main decoder truth table for the j instruction and a column for the Jump signal, as shown in Table 7.5. The Jump control signal is 1 for the j instruction and 0 for all others. j does not write the register file or memory, so RegWrite = MemWrite = 0. Hence, we don’t care about the computation done in the datapath, and RegDst = ALUSrc = Branch = MemtoReg = ALUOp = X.
Table 7.5 Main decoder truth table enhanced to support j
7.3.4 Performance Analysis
Each instruction in the single-cycle processor takes one clock cycle, so the CPI is 1. The critical path for the lw instruction is shown in Figure 7.15 with a heavy dashed blue line. It starts with the PC loading a new address on the rising edge of the clock. The instruction memory reads the next instruction. The register file reads SrcA. While the register file is reading, the immediate field is sign-extended and selected at the ALUSrc multiplexer to determine SrcB. The ALU adds SrcA and SrcB to find the effective address. The data memory reads from this address. The MemtoReg multiplexer selects ReadData. Finally, Result must setup at the register file before the next rising clock edge, so that it can be properly written. Hence, the cycle time is
![]() (7.2)
(7.2)

Figure 7.15 Critical path for lw instruction
In most implementation technologies, the ALU, memory, and register file accesses are substantially slower than other operations. Therefore, the cycle time simplifies to
![]() (7.3)
(7.3)
The numerical values of these times will depend on the specific implementation technology.
Other instructions have shorter critical paths. For example, R-type instructions do not need to access data memory. However, we are disciplining ourselves to synchronous sequential design, so the clock period is constant and must be long enough to accommodate the slowest instruction.
Example 7.4 Single-Cycle Processor Performance
Ben Bitdiddle is contemplating building the single-cycle MIPS processor in a 65 nm CMOS manufacturing process. He has determined that the logic elements have the delays given in Table 7.6. Help him compute the execution time for a program with 100 billion instructions.
Table 7.6 Delays of circuit elements
| Element | Parameter | Delay (ps) |
| register clk-to-Q | tpcq | 30 |
| register setup | tsetup | 20 |
| multiplexer | tmux | 25 |
| ALU | tALU | 200 |
| memory read | tmem | 250 |
| register file read | tRFread | 150 |
| register file setup | tRFsetup | 20 |
Solution
According to Equation 7.3, the cycle time of the single-cycle processor is Tc1 = 30 + 2(250) + 150 + 200 + 25 + 20 = 925 ps. We use the subscript “1” to distinguish it from subsequent processor designs. According to Equation 7.1, the total execution time is T1 = (100 × 109 instructions) (1 cycle/instruction) (925 × 10−12 s/cycle) = 92.5 seconds.
7.4 Multicycle Processor
The single-cycle processor has three primary weaknesses. First, it requires a clock cycle long enough to support the slowest instruction (lw), even though most instructions are faster. Second, it requires three adders (one in the ALU and two for the PC logic); adders are relatively expensive circuits, especially if they must be fast. And third, it has separate instruction and data memories, which may not be realistic. Most computers have a single large memory that holds both instructions and data and that can be read and written.
The multicycle processor addresses these weaknesses by breaking an instruction into multiple shorter steps. In each short step, the processor can read or write the memory or register file or use the ALU. Different instructions use different numbers of steps, so simpler instructions can complete faster than more complex ones. The processor needs only one adder; this adder is reused for different purposes on various steps. And the processor uses a combined memory for instructions and data. The instruction is fetched from memory on the first step, and data may be read or written on later steps.
We design a multicycle processor following the same procedure we used for the single-cycle processor. First, we construct a datapath by connecting the architectural state elements and memories with combinational logic. But, this time, we also add nonarchitectural state elements to hold intermediate results between the steps. Then we design the controller. The controller produces different signals on different steps during execution of a single instruction, so it is now a finite state machine rather than combinational logic. We again examine how to add new instructions to the processor. Finally, we analyze the performance of the multicycle processor and compare it to the single-cycle processor.
7.4.1 Multicycle Datapath
Again, we begin our design with the memory and architectural state of the MIPS processor, shown in Figure 7.16. In the single-cycle design, we used separate instruction and data memories because we needed to read the instruction memory and read or write the data memory all in one cycle. Now, we choose to use a combined memory for both instructions and data. This is more realistic, and it is feasible because we can read the instruction in one cycle, then read or write the data in a separate cycle. The PC and register file remain unchanged. We gradually build the datapath by adding components to handle each step of each instruction. The new connections are emphasized in black (or blue, for new control signals), whereas the hardware that has already been studied is shown in gray.
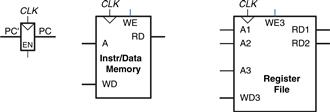
Figure 7.16 State elements with unified instruction/data memory
The PC contains the address of the instruction to execute. The first step is to read this instruction from instruction memory. Figure 7.17 shows that the PC is simply connected to the address input of the instruction memory. The instruction is read and stored in a new nonarchitectural Instruction Register so that it is available for future cycles. The Instruction Register receives an enable signal, called IRWrite, that is asserted when it should be updated with a new instruction.

Figure 7.17 Fetch instruction from memory
As we did with the single-cycle processor, we will work out the datapath connections for the lw instruction. Then we will enhance the datapath to handle the other instructions. For a lw instruction, the next step is to read the source register containing the base address. This register is specified in the rs field of the instruction, Instr25:21. These bits of the instruction are connected to one of the address inputs, A1, of the register file, as shown in Figure 7.18. The register file reads the register onto RD1. This value is stored in another nonarchitectural register, A.
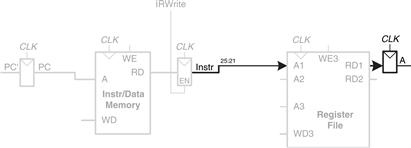
Figure 7.18 Read source operand from register file
The lw instruction also requires an offset. The offset is stored in the immediate field of the instruction, Instr15:0, and must be sign-extended to 32 bits, as shown in Figure 7.19. The 32-bit sign-extended value is called SignImm. To be consistent, we might store SignImm in another nonarchitectural register. However, SignImm is a combinational function of Instr and will not change while the current instruction is being processed, so there is no need to dedicate a register to hold the constant value.
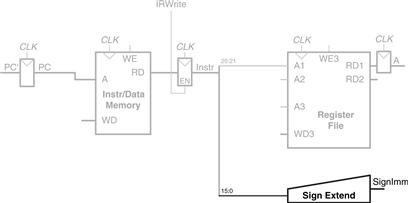
Figure 7.19 Sign-extend the immediate
The address of the load is the sum of the base address and offset. We use an ALU to compute this sum, as shown in Figure 7.20. ALUControl should be set to 010 to perform an addition. ALUResult is stored in a nonarchitectural register called ALUOut.
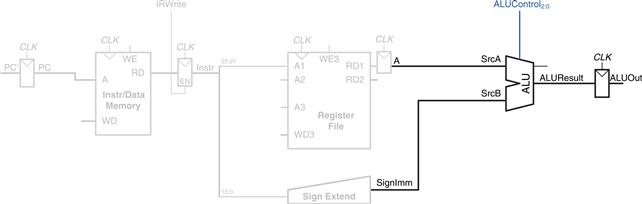
Figure 7.20 Add base address to offset
The next step is to load the data from the calculated address in the memory. We add a multiplexer in front of the memory to choose the memory address, Adr, from either the PC or ALUOut, as shown in Figure 7.21. The multiplexer select signal is called IorD, to indicate either an instruction or data address. The data read from the memory is stored in another nonarchitectural register, called Data. Notice that the address multiplexer permits us to reuse the memory during the lw instruction. On the first step, the address is taken from the PC to fetch the instruction. On a later step, the address is taken from ALUOut to load the data. Hence, IorD must have different values on different steps. In Section 7.4.2, we develop the FSM controller that generates these sequences of control signals.

Figure 7.21 Load data from memory
Finally, the data is written back to the register file, as shown in Figure 7.22. The destination register is specified by the rt field of the instruction, Instr20:16.
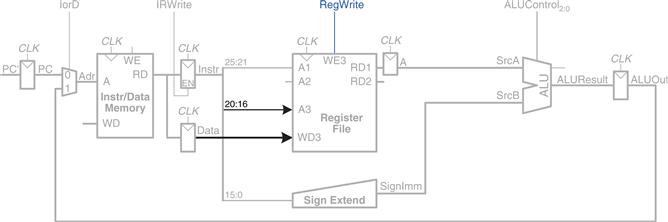
Figure 7.22 Write data back to register file
While all this is happening, the processor must update the program counter by adding 4 to the old PC. In the single-cycle processor, a separate adder was needed. In the multicycle processor, we can use the existing ALU on one of the steps when it is not busy. To do so, we must insert source multiplexers to choose the PC and the constant 4 as ALU inputs, as shown in Figure 7.23. A two-input multiplexer controlled by ALUSrcA chooses either the PC or register A as SrcA. A four-input multiplexer controlled by ALUSrcB chooses either 4 or SignImm as SrcB. We use the other two multiplexer inputs later when we extend the datapath to handle other instructions. (The numbering of inputs to the multiplexer is arbitrary.) To update the PC, the ALU adds SrcA (PC) to SrcB (4), and the result is written into the program counter register. The PCWrite control signal enables the PC register to be written only on certain cycles.
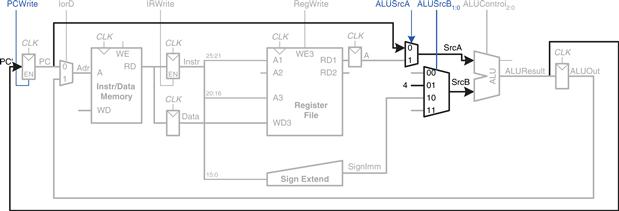
Figure 7.23 Increment PC by 4
This completes the datapath for the lw instruction. Next, let us extend the datapath to also handle the sw instruction. Like the lw instruction, the sw instruction reads a base address from port 1 of the register file and sign-extends the immediate. The ALU adds the base address to the immediate to find the memory address. All of these functions are already supported by existing hardware in the datapath.
The only new feature of sw is that we must read a second register from the register file and write it into the memory, as shown in Figure 7.24. The register is specified in the rt field of the instruction, Instr20:16, which is connected to the second port of the register file. When the register is read, it is stored in a nonarchitectural register, B. On the next step, it is sent to the write data port (WD) of the data memory to be written. The memory receives an additional MemWrite control signal to indicate that the write should occur.
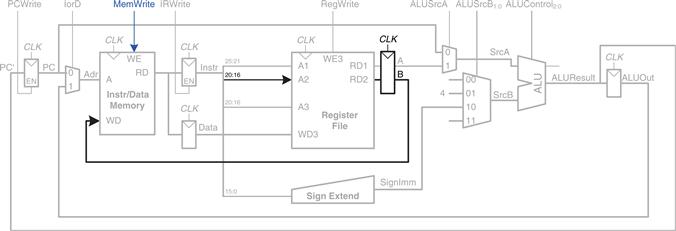
Figure 7.24 Enhanced datapath for sw instruction
For R-type instructions, the instruction is again fetched, and the two source registers are read from the register file. ALUSrcB1:0, the control input of the SrcB multiplexer, is used to choose register B as the second source register for the ALU, as shown in Figure 7.25. The ALU performs the appropriate operation and stores the result in ALUOut. On the next step, ALUOut is written back to the register specified by the rd field of the instruction, Instr15:11. This requires two new multiplexers. The MemtoReg multiplexer selects whether WD3 comes from ALUOut (for R-type instructions) or from Data (for lw). The RegDst instruction selects whether the destination register is specified in the rt or rd field of the instruction.

Figure 7.25 Enhanced datapath for R-type instructions
For the beq instruction, the instruction is again fetched, and the two source registers are read from the register file. To determine whether the registers are equal, the ALU subtracts the registers and, upon a zero result, sets the Zero flag. Meanwhile, the datapath must compute the next value of the PC if the branch is taken: PC′ = PC + 4 + SignImm × 4. In the single-cycle processor, yet another adder was needed to compute the branch address. In the multicycle processor, the ALU can be reused again to save hardware. On one step, the ALU computes PC + 4 and writes it back to the program counter, as was done for other instructions. On another step, the ALU uses this updated PC value to compute PC + SignImm × 4. SignImm is left-shifted by 2 to multiply it by 4, as shown in Figure 7.26. The SrcB multiplexer chooses this value and adds it to the PC. This sum represents the destination of the branch and is stored in ALUOut. A new multiplexer, controlled by PCSrc, chooses what signal should be sent to PC′. The program counter should be written either when PCWrite is asserted or when a branch is taken. A new control signal, Branch, indicates that the beq instruction is being executed. The branch is taken if Zero is also asserted. Hence, the datapath computes a new PC write enable, called PCEn, which is TRUE either when PCWrite is asserted or when both Branch and Zero are asserted.
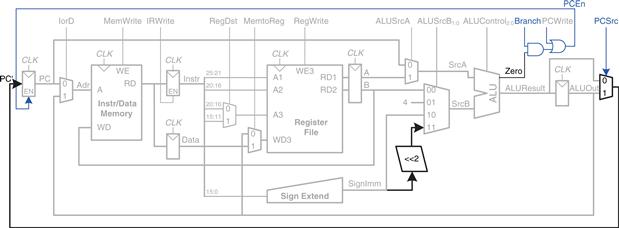
Figure 7.26 Enhanced datapath for beq instruction
This completes the design of the multicycle MIPS processor datapath. The design process is much like that of the single-cycle processor in that hardware is systematically connected between the state elements to handle each instruction. The main difference is that the instruction is executed in several steps. Nonarchitectural registers are inserted to hold the results of each step. In this way, the ALU can be reused several times, saving the cost of extra adders. Similarly, the instructions and data can be stored in one shared memory. In the next section, we develop an FSM controller to deliver the appropriate sequence of control signals to the datapath on each step of each instruction.
7.4.2 Multicycle Control
As in the single-cycle processor, the control unit computes the control signals based on the opcode and funct fields of the instruction, Instr31:26 and Instr5:0. Figure 7.27 shows the entire multicycle MIPS processor with the control unit attached to the datapath. The datapath is shown in black, and the control unit is shown in blue.
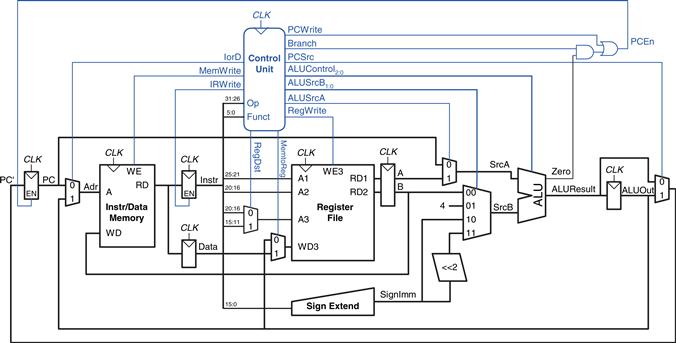
Figure 7.27 Complete multicycle MIPS processor
As in the single-cycle processor, the control unit is partitioned into a main controller and an ALU decoder, as shown in Figure 7.28. The ALU decoder is unchanged and follows the truth table of Table 7.2. Now, however, the main controller is an FSM that applies the proper control signals on the proper cycles or steps. The sequence of control signals depends on the instruction being executed. In the remainder of this section, we will develop the FSM state transition diagram for the main controller.
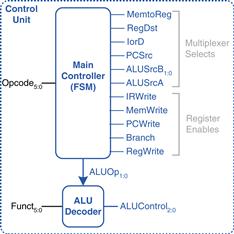
Figure 7.28 Control unit internal structure
The main controller produces multiplexer select and register enable signals for the datapath. The select signals are MemtoReg, RegDst, IorD, PCSrc, ALUSrcB, and ALUSrcA. The enable signals are IRWrite, MemWrite, PCWrite, Branch, and RegWrite.
To keep the following state transition diagrams readable, only the relevant control signals are listed. Select signals are listed only when their value matters; otherwise, they are don’t cares. Enable signals are listed only when they are asserted; otherwise, they are 0.
The first step for any instruction is to fetch the instruction from memory at the address held in the PC. The FSM enters this state on reset. To read memory, IorD = 0, so the address is taken from the PC. IRWrite is asserted to write the instruction into the instruction register, IR. Meanwhile, the PC should be incremented by 4 to point to the next instruction. Because the ALU is not being used for anything else, the processor can use it to compute PC + 4 at the same time that it fetches the instruction. ALUSrcA = 0, so SrcA comes from the PC. ALUSrcB = 01, so SrcB is the constant 4. ALUOp = 00, so the ALU decoder produces ALUControl = 010 to make the ALU add. To update the PC with this new value, PCSrc = 0, and PCWrite is asserted. These control signals are shown in Figure 7.29. The data flow on this step is shown in Figure 7.30, with the instruction fetch shown using the dashed blue line and the PC increment shown using the dashed gray line.
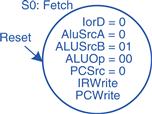
Figure 7.29 Fetch
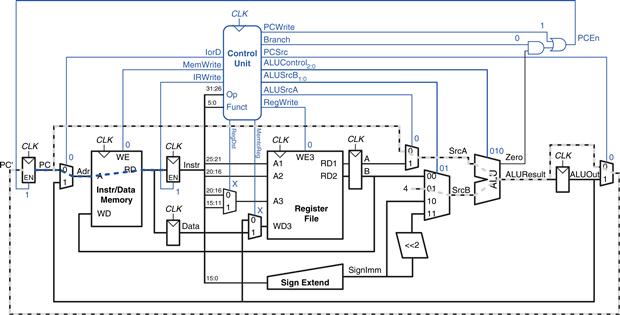
Figure 7.30 Data flow during the fetch step
The next step is to read the register file and decode the instruction. The register file always reads the two sources specified by the rs and rt fields of the instruction. Meanwhile, the immediate is sign-extended. Decoding involves examining the opcode of the instruction to determine what to do next. No control signals are necessary to decode the instruction, but the FSM must wait 1 cycle for the reading and decoding to complete, as shown in Figure 7.31. The new state is highlighted in blue. The data flow is shown in Figure 7.32.
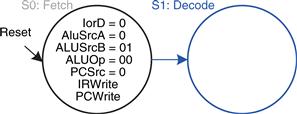
Figure 7.31 Decode
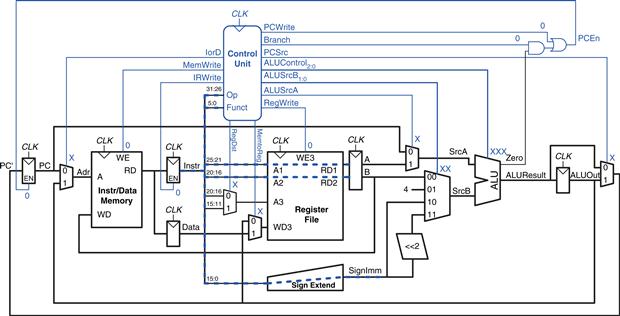
Figure 7.32 Data flow during the decode step
Now the FSM proceeds to one of several possible states, depending on the opcode. If the instruction is a memory load or store (lw or sw), the multicycle processor computes the address by adding the base address to the sign-extended immediate. This requires ALUSrcA = 1 to select register A and ALUSrcB = 10 to select SignImm. ALUOp = 00, so the ALU adds. The effective address is stored in the ALUOut register for use on the next step. This FSM step is shown in Figure 7.33, and the data flow is shown in Figure 7.34.
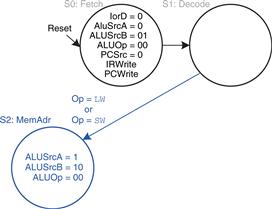
Figure 7.33 Memory address computation
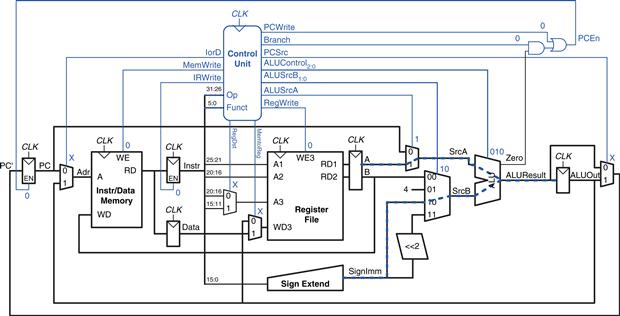
Figure 7.34 Data flow during memory address computation
If the instruction is lw, the multicycle processor must next read data from memory and write it to the register file. These two steps are shown in Figure 7.35. To read from memory, IorD = 1 to select the memory address that was just computed and saved in ALUOut. This address in memory is read and saved in the Data register during step S3. On the next step, S4, Data is written to the register file. MemtoReg = 1 to select Data, and RegDst = 0 to pull the destination register from the rt field of the instruction. RegWrite is asserted to perform the write, completing the lw instruction. Finally, the FSM returns to the initial state, S0, to fetch the next instruction. For these and subsequent steps, try to visualize the data flow on your own.
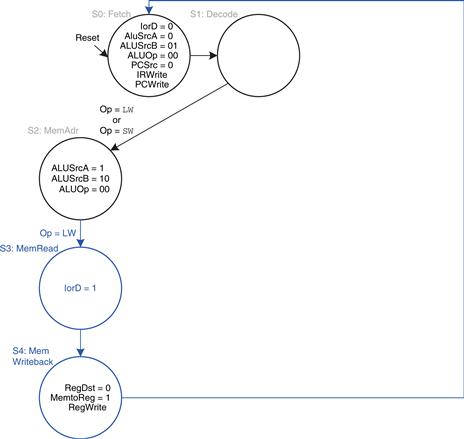
Figure 7.35 Memory read
From state S2, if the instruction is sw, the data read from the second port of the register file is simply written to memory. In state S3, IorD = 1 to select the address computed in S2 and saved in ALUOut. MemWrite is asserted to write the memory. Again, the FSM returns to S0 to fetch the next instruction. The added step is shown in Figure 7.36.
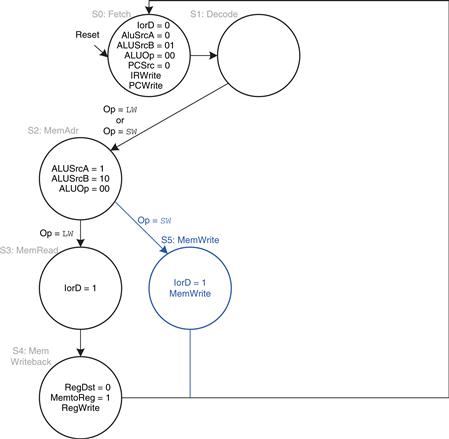
Figure 7.36 Memory write
If the opcode indicates an R-type instruction, the multicycle processor must calculate the result using the ALU and write that result to the register file. Figure 7.37 shows these two steps. In S6, the instruction is executed by selecting the A and B registers (ALUSrcA = 1, ALUSrcB = 00) and performing the ALU operation indicated by the funct field of the instruction. ALUOp = 10 for all R-type instructions. The ALUResult is stored in ALUOut. In S7, ALUOut is written to the register file, RegDst = 1, because the destination register is specified in the rd field of the instruction. MemtoReg = 0 because the write data, WD3, comes from ALUOut. RegWrite is asserted to write the register file.
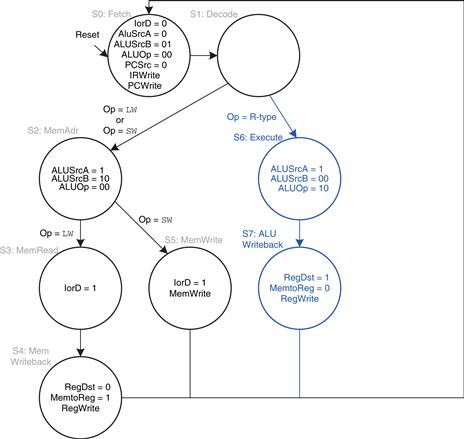
Figure 7.37 Execute R-type operation
For a beq instruction, the processor must calculate the destination address and compare the two source registers to determine whether the branch should be taken. This requires two uses of the ALU and hence might seem to demand two new states. Notice, however, that the ALU was not used during S1 when the registers were being read. The processor might as well use the ALU at that time to compute the destination address by adding the incremented PC, PC + 4, to SignImm × 4, as shown in Figure 7.38 (see page 404). ALUSrcA = 0 to select the incremented PC, ALUSrcB = 11 to select SignImm × 4, and ALUOp = 00 to add. The destination address is stored in ALUOut. If the instruction is not beq, the computed address will not be used in subsequent cycles, but its computation was harmless. In S8, the processor compares the two registers by subtracting them and checking to determine whether the result is 0. If it is, the processor branches to the address that was just computed. ALUSrcA = 1 to select register A; ALUSrcB = 00 to select register B; ALUOp = 01 to subtract; PCSrc = 1 to take the destination address from ALUOut, and Branch = 1 to update the PC with this address if the ALU result is 0.2
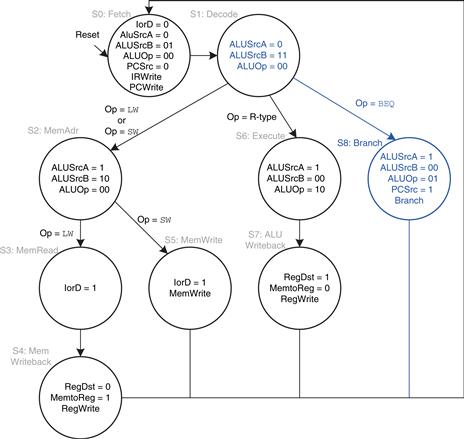
Figure 7.38 Branch
Putting these steps together, Figure 7.39 shows the complete main controller state transition diagram for the multicycle processor (see page 405). Converting it to hardware is a straightforward but tedious task using the techniques of Chapter 3. Better yet, the FSM can be coded in an HDL and synthesized using the techniques of Chapter 4.

Figure 7.39 Complete multicycle control FSM
7.4.3 More Instructions
As we did in Section 7.3.3 for the single-cycle processor, let us now extend the multicycle processor to support the addi and j instructions. The next two examples illustrate the general design process to support new instructions.
Example 7.5 addi Instruction
Modify the multicycle processor to support addi.
Solution
The datapath is already capable of adding registers to immediates, so all we need to do is add new states to the main controller FSM for addi, as shown in Figure 7.40 (see page 406). The states are similar to those for R-type instructions. In S9, register A is added to SignImm (ALUSrcA = 1, ALUSrcB = 10, ALUOp = 00) and the result, ALUResult, is stored in ALUOut. In S10, ALUOut is written to the register specified by the rt field of the instruction (RegDst = 0, MemtoReg = 0, RegWrite asserted). The astute reader may notice that S2 and S9 are identical and could be merged into a single state.
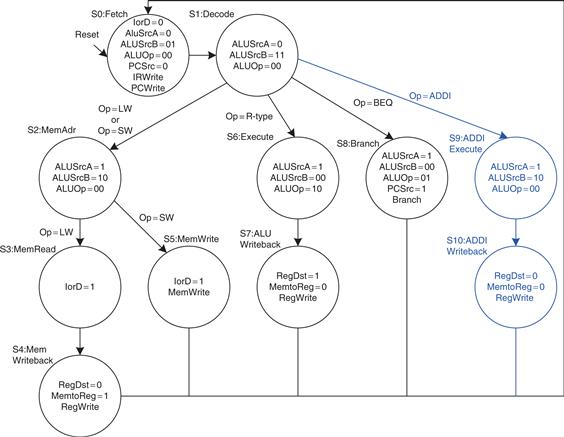
Figure 7.40 Main controller states for addi
Example 7.6 j Instruction
Modify the multicycle processor to support j.
Solution
First, we must modify the datapath to compute the next PC value in the case of a j instruction. Then we add a state to the main controller to handle the instruction.
Figure 7.41 shows the enhanced datapath (see page 407). The jump destination address is formed by left-shifting the 26-bit addr field of the instruction by two bits, then prepending the four most significant bits of the already incremented PC. The PCSrc multiplexer is extended to take this address as a third input.
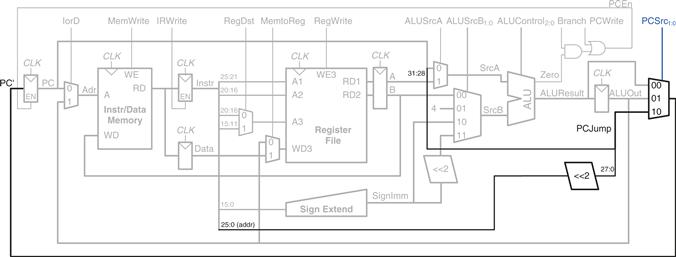
Figure 7.41 Multicycle MIPS datapath enhanced to support the j instruction
Figure 7.42 shows the enhanced main controller (see page 408). The new state, S11, simply selects PC′ as the PCJump value (PCSrc = 10) and writes the PC. Note that the PCSrc select signal is extended to two bits in S0 and S8 as well.
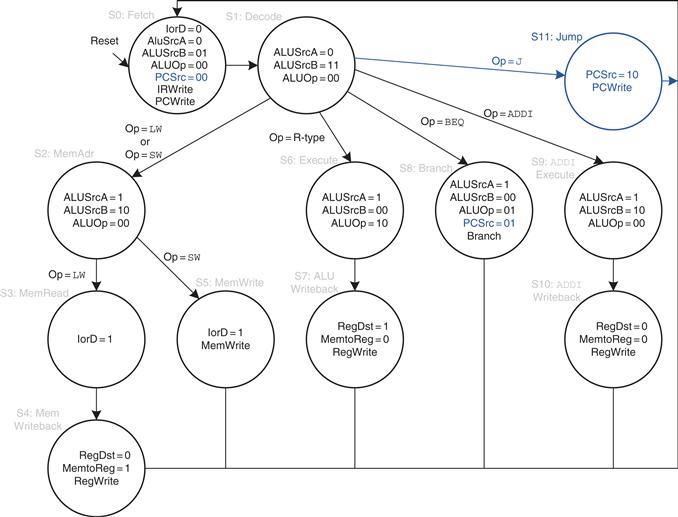
Figure 7.42 Main controller state for j
7.4.4 Performance Analysis
The execution time of an instruction depends on both the number of cycles it uses and the cycle time. Whereas the single-cycle processor performed all instructions in one cycle, the multicycle processor uses varying numbers of cycles for the various instructions. However, the multicycle processor does less work in a single cycle and, thus, has a shorter cycle time.
The multicycle processor requires three cycles for beq and j instructions, four cycles for sw, addi, and R-type instructions, and five cycles for lw instructions. The CPI depends on the relative likelihood that each instruction is used.
Example 7.7 Multicycle Processor CPI
The SPECINT2000 benchmark consists of approximately 25% loads, 10% stores, 11% branches, 2% jumps, and 52% R-type instructions.3 Determine the average CPI for this benchmark.
Solution
The average CPI is the sum over each instruction of the CPI for that instruction multiplied by the fraction of the time that instruction is used. For this benchmark, Average CPI = (0.11 + 0.02)(3) + (0.52 + 0.10)(4) + (0.25)(5) = 4.12. This is better than the worst-case CPI of 5, which would be required if all instructions took the same time.
Recall that we designed the multicycle processor so that each cycle involved one ALU operation, memory access, or register file access. Let us assume that the register file is faster than the memory and that writing memory is faster than reading memory. Examining the datapath reveals two possible critical paths that would limit the cycle time:
![]() (7.4)
(7.4)
The numerical values of these times will depend on the specific implementation technology.
Example 7.8 Processor Performance Comparison
Ben Bitdiddle is wondering whether he would be better off building the multicycle processor instead of the single-cycle processor. For both designs, he plans on using a 65 nm CMOS manufacturing process with the delays given in Table 7.6. Help him compare each processor’s execution time for 100 billion instructions from the SPECINT2000 benchmark (see Example 7.7).
Solution
According to Equation 7.4, the cycle time of the multicycle processor is Tc2 = 30 + 25 + 250 + 20 = 325 ps. Using the CPI of 4.12 from Example 7.7, the total execution time is Τ2 = (100 × 109 instructions)(4.12 cycles/instruction) (325 × 10−12 s/cycle) = 133.9 seconds. According to Example 7.4, the single-cycle processor had a cycle time of Tc1 = 925 ps, a CPI of 1, and a total execution time of 92.5 seconds.
One of the original motivations for building a multicycle processor was to avoid making all instructions take as long as the slowest one. Unfortunately, this example shows that the multicycle processor is slower than the single-cycle processor given the assumptions of CPI and circuit element delays. The fundamental problem is that even though the slowest instruction, lw, was broken into five steps, the multicycle processor cycle time was not nearly improved five-fold. This is partly because not all of the steps are exactly the same length, and partly because the 50-ps sequencing overhead of the register clk-to-Q and setup time must now be paid on every step, not just once for the entire instruction. In general, engineers have learned that it is difficult to exploit the fact that some computations are faster than others unless the differences are large.
Compared with the single-cycle processor, the multicycle processor is likely to be less expensive because it eliminates two adders and combines the instruction and data memories into a single unit. It does, however, require five nonarchitectural registers and additional multiplexers.
7.5 Pipelined Processor
Pipelining, introduced in Section 3.6, is a powerful way to improve the throughput of a digital system. We design a pipelined processor by subdividing the single-cycle processor into five pipeline stages. Thus, five instructions can execute simultaneously, one in each stage. Because each stage has only one-fifth of the entire logic, the clock frequency is almost five times faster. Hence, the latency of each instruction is ideally unchanged, but the throughput is ideally five times better. Microprocessors execute millions or billions of instructions per second, so throughput is more important than latency. Pipelining introduces some overhead, so the throughput will not be quite as high as we might ideally desire, but pipelining nevertheless gives such great advantage for so little cost that all modern high-performance microprocessors are pipelined.
Reading and writing the memory and register file and using the ALU typically constitute the biggest delays in the processor. We choose five pipeline stages so that each stage involves exactly one of these slow steps. Specifically, we call the five stages Fetch, Decode, Execute, Memory, and Writeback. They are similar to the five steps that the multicycle processor used to perform lw. In the Fetch stage, the processor reads the instruction from instruction memory. In the Decode stage, the processor reads the source operands from the register file and decodes the instruction to produce the control signals. In the Execute stage, the processor performs a computation with the ALU. In the Memory stage, the processor reads or writes data memory. Finally, in the Writeback stage, the processor writes the result to the register file, when applicable.
Figure 7.43 shows a timing diagram comparing the single-cycle and pipelined processors. Time is on the horizontal axis, and instructions are on the vertical axis. The diagram assumes the logic element delays from Table 7.6 but ignores the delays of multiplexers and registers. In the single-cycle processor, Figure 7.43(a), the first instruction is read from memory at time 0; next the operands are read from the register file; and then the ALU executes the necessary computation. Finally, the data memory may be accessed, and the result is written back to the register file by 950 ps. The second instruction begins when the first completes. Hence, in this diagram, the single-cycle processor has an instruction latency of 250 + 150 + 200 + 250 + 100 = 950 ps and a throughput of 1 instruction per 950 ps (1.05 billion instructions per second).
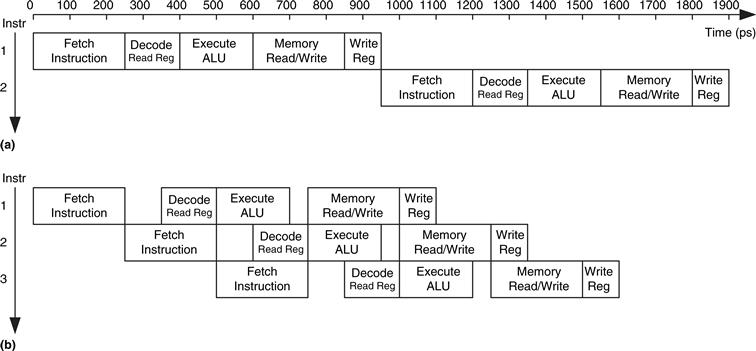
Figure 7.43 Timing diagrams: (a) single-cycle processor, (b) pipelined processor
In the pipelined processor, Figure 7.43(b), the length of a pipeline stage is set at 250 ps by the slowest stage, the memory access (in the Fetch or Memory stage). At time 0, the first instruction is fetched from memory. At 250 ps, the first instruction enters the Decode stage, and a second instruction is fetched. At 500 ps, the first instruction executes, the second instruction enters the Decode stage, and a third instruction is fetched. And so forth, until all the instructions complete. The instruction latency is 5 × 250 = 1250 ps. The throughput is 1 instruction per 250 ps (4 billion instructions per second). Because the stages are not perfectly balanced with equal amounts of logic, the latency is slightly longer for the pipelined than for the single-cycle processor. Similarly, the throughput is not quite five times as great for a five-stage pipeline as for the single-cycle processor. Nevertheless, the throughput advantage is substantial.
Figure 7.44 shows an abstracted view of the pipeline in operation in which each stage is represented pictorially. Each pipeline stage is represented with its major component—instruction memory (IM), register file (RF) read, ALU execution, data memory (DM), and register file writeback—to illustrate the flow of instructions through the pipeline. Reading across a row shows the clock cycles in which a particular instruction is in each stage. For example, the sub instruction is fetched in cycle 3 and executed in cycle 5. Reading down a column shows what the various pipeline stages are doing on a particular cycle. For example, in cycle 6, the or instruction is being fetched from instruction memory, while $s1 is being read from the register file, the ALU is computing $t5 AND $t6, the data memory is idle, and the register file is writing a sum to $s3. Stages are shaded to indicate when they are used. For example, the data memory is used by lw in cycle 4 and by sw in cycle 8. The instruction memory and ALU are used in every cycle. The register file is written by every instruction except sw. In the pipelined processor, the register file is written in the first part of a cycle and read in the second part, as suggested by the shading. This way, data can be written and read back within a single cycle.
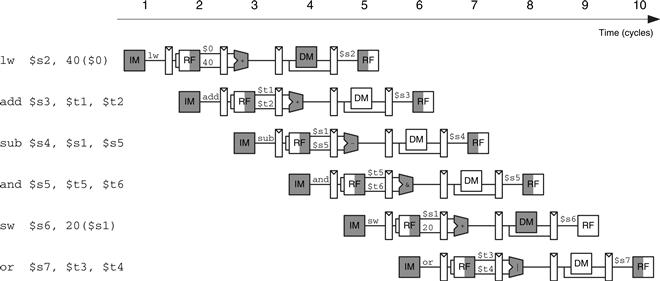
Figure 7.44 Abstract view of pipeline in operation
A central challenge in pipelined systems is handling hazards that occur when the results of one instruction are needed by a subsequent instruction before the former instruction has completed. For example, if the add in Figure 7.44 used $s2 rather than $t2, a hazard would occur because the $s2 register has not been written by the lw by the time it is read by the add. This section explores forwarding, stalls, and flushes as methods to resolve hazards. Finally, this section revisits performance analysis considering sequencing overhead and the impact of hazards.
7.5.1 Pipelined Datapath
The pipelined datapath is formed by chopping the single-cycle datapath into five stages separated by pipeline registers. Figure 7.45(a) shows the single-cycle datapath stretched out to leave room for the pipeline registers. Figure 7.45(b) shows the pipelined datapath formed by inserting four pipeline registers to separate the datapath into five stages. The stages and their boundaries are indicated in blue. Signals are given a suffix (F, D, E, M, or W) to indicate the stage in which they reside.

Figure 7.45 Single-cycle and pipelined datapaths
The register file is peculiar because it is read in the Decode stage and written in the Writeback stage. It is drawn in the Decode stage, but the write address and data come from the Writeback stage. This feedback will lead to pipeline hazards, which are discussed in Section 7.5.3. The register file in the pipelined processor writes on the falling edge of CLK, when WD3 is stable.
One of the subtle but critical issues in pipelining is that all signals associated with a particular instruction must advance through the pipeline in unison. Figure 7.45(b) has an error related to this issue. Can you find it?
The error is in the register file write logic, which should operate in the Writeback stage. The data value comes from ResultW, a Writeback stage signal. But the address comes from WriteRegE, an Execute stage signal. In the pipeline diagram of Figure 7.44, during cycle 5, the result of the lw instruction would be incorrectly written to $s4 rather than $s2.
Figure 7.46 shows a corrected datapath. The WriteReg signal is now pipelined along through the Memory and Writeback stages, so it remains in sync with the rest of the instruction. WriteRegW and ResultW are fed back together to the register file in the Writeback stage.
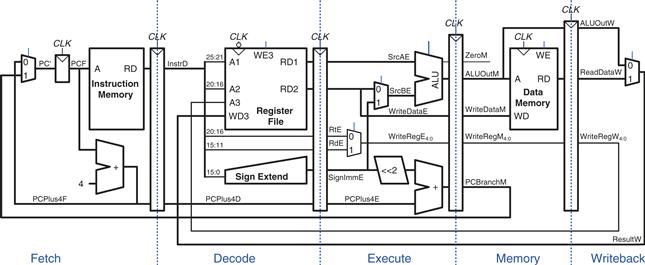
Figure 7.46 Corrected pipelined datapath
The astute reader may notice that the PC′ logic is also problematic, because it might be updated with a Fetch or a Memory stage signal (PCPlus4F or PCBranchM). This control hazard will be fixed in Section 7.5.3.
7.5.2 Pipelined Control
The pipelined processor takes the same control signals as the single-cycle processor and therefore uses the same control unit. The control unit examines the opcode and funct fields of the instruction in the Decode stage to produce the control signals, as was described in Section 7.3.2. These control signals must be pipelined along with the data so that they remain synchronized with the instruction.
The entire pipelined processor with control is shown in Figure 7.47. RegWrite must be pipelined into the Writeback stage before it feeds back to the register file, just as WriteReg was pipelined in Figure 7.46.
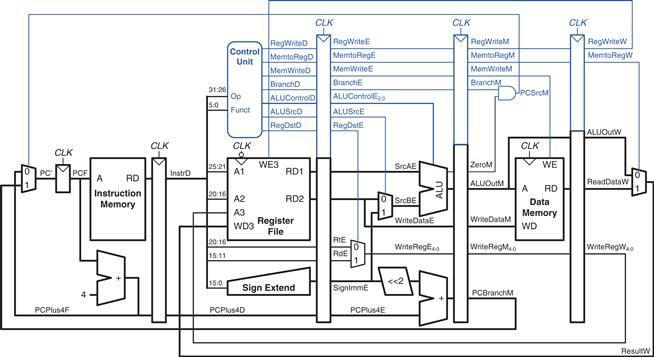
Figure 7.47 Pipelined processor with control
7.5.3 Hazards
In a pipelined system, multiple instructions are handled concurrently. When one instruction is dependent on the results of another that has not yet completed, a hazard occurs.
The register file can be read and written in the same cycle. The write takes place during the first half of the cycle and the read takes place during the second half of the cycle, so a register can be written and read back in the same cycle without introducing a hazard.
Figure 7.48 illustrates hazards that occur when one instruction writes a register ($s0) and subsequent instructions read this register. This is called a read after write (RAW) hazard. The add instruction writes a result into $s0 in the first half of cycle 5. However, the and instruction reads $s0 on cycle 3, obtaining the wrong value. The or instruction reads $s0 on cycle 4, again obtaining the wrong value. The sub instruction reads $s0 in the second half of cycle 5, obtaining the correct value, which was written in the first half of cycle 5. Subsequent instructions also read the correct value of $s0. The diagram shows that hazards may occur in this pipeline when an instruction writes a register and either of the two subsequent instructions read that register. Without special treatment, the pipeline will compute the wrong result.
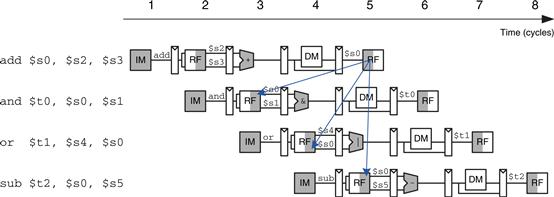
Figure 7.48 Abstract pipeline diagram illustrating hazards
On closer inspection, however, observe that the sum from the add instruction is computed by the ALU in cycle 3 and is not strictly needed by the and instruction until the ALU uses it in cycle 4. In principle, we should be able to forward the result from one instruction to the next to resolve the RAW hazard without slowing down the pipeline. In other situations explored later in this section, we may have to stall the pipeline to give time for a result to be produced before the subsequent instruction uses the result. In any event, something must be done to solve hazards so that the program executes correctly despite the pipelining.
Hazards are classified as data hazards or control hazards. A data hazard occurs when an instruction tries to read a register that has not yet been written back by a previous instruction. A control hazard occurs when the decision of what instruction to fetch next has not been made by the time the fetch takes place. In the remainder of this section, we will enhance the pipelined processor with a hazard unit that detects hazards and handles them appropriately, so that the processor executes the program correctly.
Solving Data Hazards with Forwarding
Some data hazards can be solved by forwarding (also called bypassing) a result from the Memory or Writeback stage to a dependent instruction in the Execute stage. This requires adding multiplexers in front of the ALU to select the operand from either the register file or the Memory or Writeback stage. Figure 7.49 illustrates this principle. In cycle 4, $s0 is forwarded from the Memory stage of the add instruction to the Execute stage of the dependent and instruction. In cycle 5, $s0 is forwarded from the Writeback stage of the add instruction to the Execute stage of the dependent or instruction.
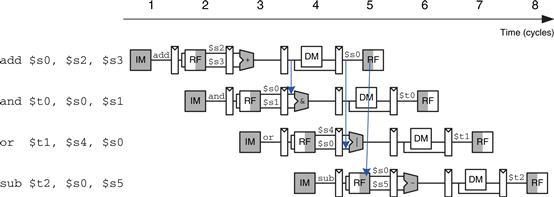
Figure 7.49 Abstract pipeline diagram illustrating forwarding
Forwarding is necessary when an instruction in the Execute stage has a source register matching the destination register of an instruction in the Memory or Writeback stage. Figure 7.50 modifies the pipelined processor to support forwarding. It adds a hazard detection unit and two forwarding multiplexers. The hazard detection unit receives the two source registers from the instruction in the Execute stage and the destination registers from the instructions in the Memory and Writeback stages. It also receives the RegWrite signals from the Memory and Writeback stages to know whether the destination register will actually be written (for example, the sw and beq instructions do not write results to the register file and hence do not need to have their results forwarded). Note that the RegWrite signals are connected by name. In other words, rather than cluttering up the diagram with long wires running from the control signals at the top to the hazard unit at the bottom, the connections are indicated by a short stub of wire labeled with the control signal name to which it is connected.
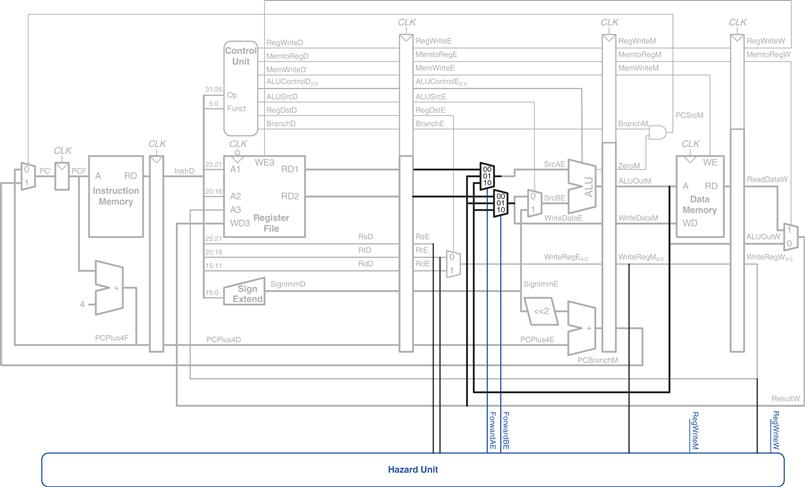
Figure 7.50 Pipelined processor with forwarding to solve hazards
The hazard detection unit computes control signals for the forwarding multiplexers to choose operands from the register file or from the results in the Memory or Writeback stage. It should forward from a stage if that stage will write a destination register and the destination register matches the source register. However, $0 is hardwired to 0 and should never be forwarded. If both the Memory and Writeback stages contain matching destination registers, the Memory stage should have priority, because it contains the more recently executed instruction. In summary, the function of the forwarding logic for SrcA is given below. The forwarding logic for SrcB (ForwardBE) is identical except that it checks rt rather than rs.
if ((rsE != 0) AND (rsE == WriteRegM) AND RegWriteM) then
ForwardAE = 10
else if ((rsE != 0) AND (rsE == WriteRegW) AND RegWriteW) then
ForwardAE = 01
else ForwardAE = 00
Solving Data Hazards with Stalls
Forwarding is sufficient to solve RAW data hazards when the result is computed in the Execute stage of an instruction, because its result can then be forwarded to the Execute stage of the next instruction. Unfortunately, the lw instruction does not finish reading data until the end of the Memory stage, so its result cannot be forwarded to the Execute stage of the next instruction. We say that the lw instruction has a two-cycle latency, because a dependent instruction cannot use its result until two cycles later. Figure 7.51 shows this problem. The lw instruction receives data from memory at the end of cycle 4. But the and instruction needs that data as a source operand at the beginning of cycle 4. There is no way to solve this hazard with forwarding.
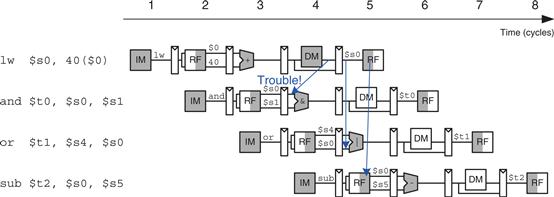
Figure 7.51 Abstract pipeline diagram illustrating trouble forwarding from lw
The alternative solution is to stall the pipeline, holding up operation until the data is available. Figure 7.52 shows stalling the dependent instruction (and) in the Decode stage. and enters the Decode stage in cycle 3 and stalls there through cycle 4. The subsequent instruction (or) must remain in the Fetch stage during both cycles as well, because the Decode stage is full.
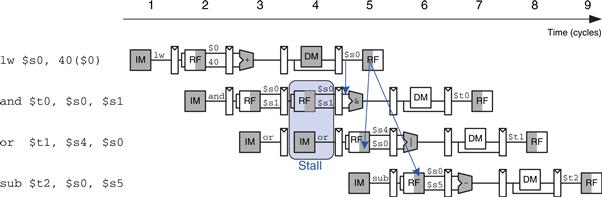
Figure 7.52 Abstract pipeline diagram illustrating stall to solve hazards
In cycle 5, the result can be forwarded from the Writeback stage of lw to the Execute stage of and. In cycle 5, source $s0 of the or instruction is read directly from the register file, with no need for forwarding.
Notice that the Execute stage is unused in cycle 4. Likewise, Memory is unused in Cycle 5 and Writeback is unused in cycle 6. This unused stage propagating through the pipeline is called a bubble, and it behaves like a nop instruction. The bubble is introduced by zeroing out the Execute stage control signals during a Decode stall so that the bubble performs no action and changes no architectural state.
In summary, stalling a stage is performed by disabling the pipeline register, so that the contents do not change. When a stage is stalled, all previous stages must also be stalled, so that no subsequent instructions are lost. The pipeline register directly after the stalled stage must be cleared to prevent bogus information from propagating forward. Stalls degrade performance, so they should only be used when necessary.
Figure 7.53 modifies the pipelined processor to add stalls for lw data dependencies. The hazard unit examines the instruction in the Execute stage. If it is lw and its destination register (rtE) matches either source operand of the instruction in the Decode stage (rsD or rtD), that instruction must be stalled in the Decode stage until the source operand is ready.
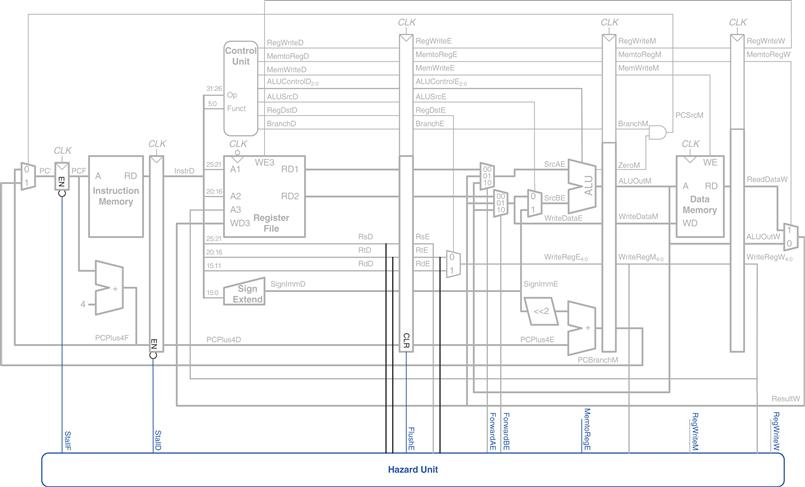
Figure 7.53 Pipelined processor with stalls to solve lw data hazard
Stalls are supported by adding enable inputs (EN) to the Fetch and Decode pipeline registers and a synchronous reset/clear (CLR) input to the Execute pipeline register. When a lw stall occurs, StallD and StallF are asserted to force the Decode and Fetch stage pipeline registers to hold their old values. FlushE is also asserted to clear the contents of the Execute stage pipeline register, introducing a bubble.4
The MemtoReg signal is asserted for the lw instruction. Hence, the logic to compute the stalls and flushes is
lwstall = ((rsD = = rtE) OR (rtD = = rtE)) AND MemtoRegE
StallF = StallD = FlushE = lwstall
Solving Control Hazards
The beq instruction presents a control hazard: the pipelined processor does not know what instruction to fetch next, because the branch decision has not been made by the time the next instruction is fetched.
One mechanism for dealing with the control hazard is to stall the pipeline until the branch decision is made (i.e., PCSrc is computed). Because the decision is made in the Memory stage, the pipeline would have to be stalled for three cycles at every branch. This would severely degrade the system performance.
An alternative is to predict whether the branch will be taken and begin executing instructions based on the prediction. Once the branch decision is available, the processor can throw out the instructions if the prediction was wrong. In particular, suppose that we predict that branches are not taken and simply continue executing the program in order. If the branch should have been taken, the three instructions following the branch must be flushed (discarded) by clearing the pipeline registers for those instructions. These wasted instruction cycles are called the branch misprediction penalty.
Figure 7.54 shows such a scheme, in which a branch from address 20 to address 64 is taken. The branch decision is not made until cycle 4, by which point the and, or, and sub instructions at addresses 24, 28, and 2C have already been fetched. These instructions must be flushed, and the slt instruction is fetched from address 64 in cycle 5. This is somewhat of an improvement, but flushing so many instructions when the branch is taken still degrades performance.
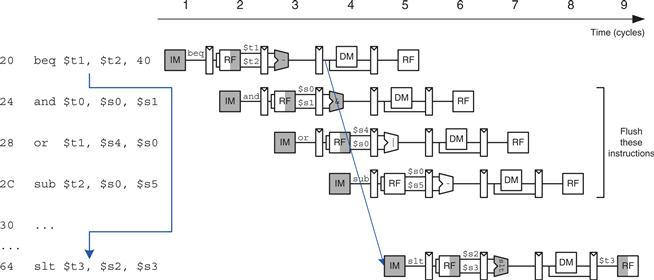
Figure 7.54 Abstract pipeline diagram illustrating flushing when a branch is taken
We could reduce the branch misprediction penalty if the branch decision could be made earlier. Making the decision simply requires comparing the values of two registers. Using a dedicated equality comparator is much faster than performing a subtraction and zero detection. If the comparator is fast enough, it could be moved back into the Decode stage, so that the operands are read from the register file and compared to determine the next PC by the end of the Decode stage.
Figure 7.55 shows the pipeline operation with the early branch decision being made in cycle 2. In cycle 3, the and instruction is flushed and the slt instruction is fetched. Now the branch misprediction penalty is reduced to only one instruction rather than three.

Figure 7.55 Abstract pipeline diagram illustrating earlier branch decision
Figure 7.56 modifies the pipelined processor to move the branch decision earlier and handle control hazards. An equality comparator is added to the Decode stage and the PCSrc AND gate is moved earlier, so that PCSrc can be determined in the Decode stage rather than the Memory stage. The PCBranch adder must also be moved into the Decode stage so that the destination address can be computed in time. The synchronous clear input (CLR) connected to PCSrcD is added to the Decode stage pipeline register so that the incorrectly fetched instruction can be flushed when a branch is taken.
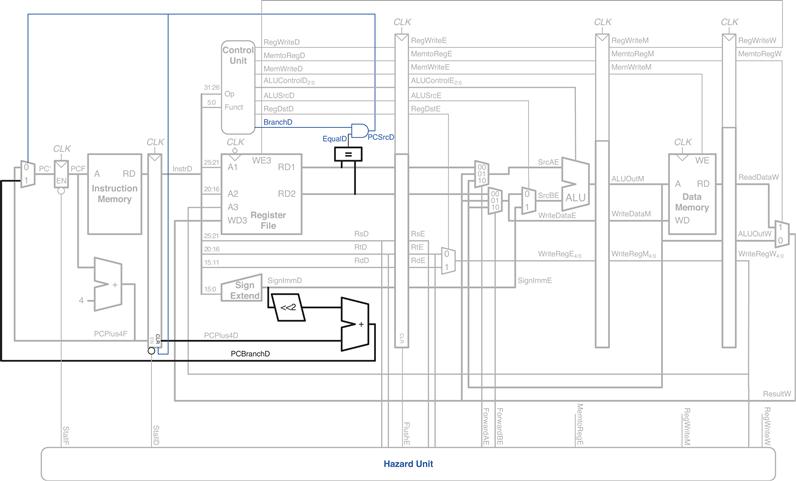
Figure 7.56 Pipelined processor handling branch control hazard
Unfortunately, the early branch decision hardware introduces a new RAW data hazard. Specifically, if one of the source operands for the branch was computed by a previous instruction and has not yet been written into the register file, the branch will read the wrong operand value from the register file. As before, we can solve the data hazard by forwarding the correct value if it is available or by stalling the pipeline until the data is ready.
Figure 7.57 shows the modifications to the pipelined processor needed to handle the Decode stage data dependency. If a result is in the Writeback stage, it will be written in the first half of the cycle and read during the second half, so no hazard exists. If the result of an ALU instruction is in the Memory stage, it can be forwarded to the equality comparator through two new multiplexers. If the result of an ALU instruction is in the Execute stage or the result of a lw instruction is in the Memory stage, the pipeline must be stalled at the Decode stage until the result is ready.
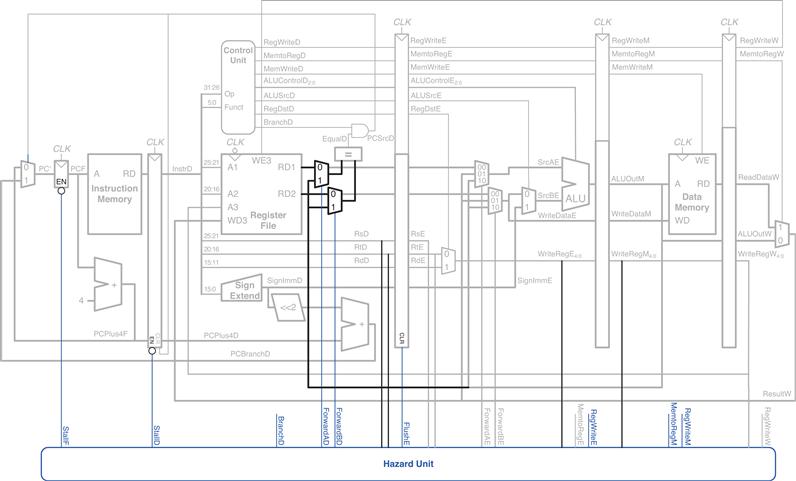
Figure 7.57 Pipelined processor handling data dependencies for branch instructions
The function of the Decode stage forwarding logic is given below.
ForwardAD = (rsD != 0) AND (rsD == WriteRegM) AND RegWriteM
ForwardBD = (rtD != 0) AND (rtD == WriteRegM) AND RegWriteM
The function of the stall detection logic for a branch is given below. The processor must make a branch decision in the Decode stage. If either of the sources of the branch depends on an ALU instruction in the Execute stage or on a lw instruction in the Memory stage, the processor must stall until the sources are ready.
branchstall =
BranchD AND RegWriteE AND (WriteRegE == rsD OR WriteRegE == rtD)
OR
BranchD AND MemtoRegM AND (WriteRegM == rsD OR WriteRegM == rtD)
Now the processor might stall due to either a load or a branch hazard:
StallF = StallD = FlushE = lwstall OR branchstall
Hazard Summary
In summary, RAW data hazards occur when an instruction depends on the result of another instruction that has not yet been written into the register file. The data hazards can be resolved by forwarding if the result is computed soon enough; otherwise, they require stalling the pipeline until the result is available. Control hazards occur when the decision of what instruction to fetch has not been made by the time the next instruction must be fetched. Control hazards are solved by predicting which instruction should be fetched and flushing the pipeline if the prediction is later determined to be wrong. Moving the decision as early as possible minimizes the number of instructions that are flushed on a misprediction. You may have observed by now that one of the challenges of designing a pipelined processor is to understand all the possible interactions between instructions and to discover all the hazards that may exist. Figure 7.58 shows the complete pipelined processor handling all of the hazards.
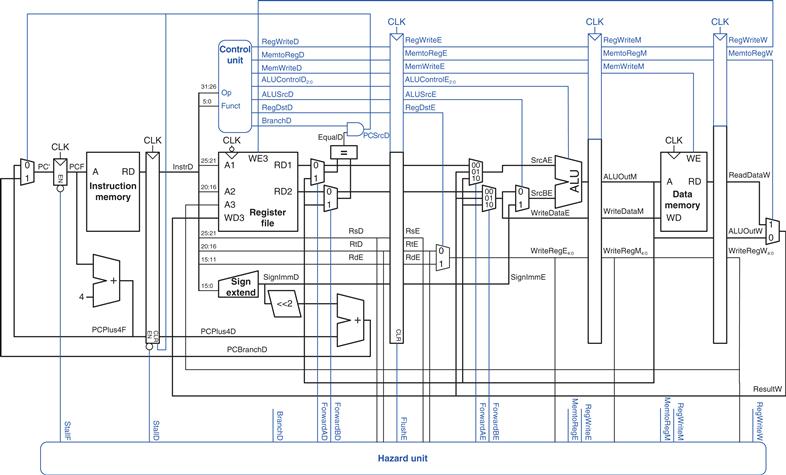
Figure 7.58 Pipelined processor with full hazard handling