
7.5.4 More Instructions
Supporting new instructions in the pipelined processor is much like supporting them in the single-cycle processor. However, new instructions may introduce hazards that must be detected and solved.
In particular, supporting addi and j instructions in the pipelined processor requires enhancing the controller, exactly as was described in Section 7.3.3, and adding a jump multiplexer to the datapath after the branch multiplexer. Like a branch, the jump takes place in the Decode stage, so the subsequent instruction in the Fetch stage must be flushed. Designing this flush logic is left as Exercise 7.35.
7.5.5 Performance Analysis
The pipelined processor ideally would have a CPI of 1, because a new instruction is issued every cycle. However, a stall or a flush wastes a cycle, so the CPI is slightly higher and depends on the specific program being executed.
Example 7.9 Pipelined Processor CPI
The SPECINT2000 benchmark considered in Example 7.7 consists of approximately 25% loads, 10% stores, 11% branches, 2% jumps, and 52% R-type instructions. Assume that 40% of the loads are immediately followed by an instruction that uses the result, requiring a stall, and that one quarter of the branches are mispredicted, requiring a flush. Assume that jumps always flush the subsequent instruction. Ignore other hazards. Compute the average CPI of the pipelined processor.
Solution
The average CPI is the sum over each instruction of the CPI for that instruction multiplied by the fraction of time that instruction is used. Loads take one clock cycle when there is no dependency and two cycles when the processor must stall for a dependency, so they have a CPI of (0.6)(1) + (0.4)(2) = 1.4. Branches take one clock cycle when they are predicted properly and two when they are not, so they have a CPI of (0.75)(1) + (0.25)(2) = 1.25. Jumps always have a CPI of 2. All other instructions have a CPI of 1. Hence, for this benchmark, Average CPI = (0.25)(1.4) + (0.1)(1) + (0.11)(1.25) + (0.02)(2) + (0.52)(1) = 1.15.
We can determine the cycle time by considering the critical path in each of the five pipeline stages shown in Figure 7.58. Recall that the register file is written in the first half of the Writeback cycle and read in the second half of the Decode cycle. Therefore, the cycle time of the Decode and Writeback stages is twice the time necessary to do the half-cycle of work.
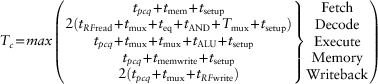 (7.5)
(7.5)
Example 7.10 Processor Performance Comparison
Ben Bitdiddle needs to compare the pipelined processor performance to that of the single-cycle and multicycle processors considered in Example 7.8. Most of the logic delays were given in Table 7.6. The other element delays are 40 ps for an equality comparator, 15 ps for an AND gate, 100 ps for a register file write, and 220 ps for a memory write. Help Ben compare the execution time of 100 billion instructions from the SPECINT2000 benchmark for each processor.
Solution
According to Equation 7.5, the cycle time of the pipelined processor is Tc3 = max[30 + 250 + 20, 2(150 + 25 + 40 + 15 + 25 + 20), 30 + 25 + 25 + 200 + 20, 30 + 220 + 20, 2(30 + 25 + 100)] = 550 ps. According to Equation 7.1, the total execution time is T3 = (100 × 109 instructions)(1.15 cycles/instruction)(550 × 10−12 s/cycle) = 63.3 seconds. This compares to 92.5 seconds for the single-cycle processor and 133.9 seconds for the multicycle processor.
The pipelined processor is substantially faster than the others. However, its advantage over the single-cycle processor is nowhere near the fivefold speedup one might hope to get from a five-stage pipeline. The pipeline hazards introduce a small CPI penalty. More significantly, the sequencing overhead (clk-to-Q and setup times) of the registers applies to every pipeline stage, not just once to the overall datapath. Sequencing overhead limits the benefits one can hope to achieve from pipelining.
The careful reader might observe that the Decode stage is substantially slower than the others, because the register file read and branch comparison must both happen in half a cycle. Perhaps moving the branch comparison to the Decode stage was not such a good idea. If branches were resolved in the Execute stage instead, the CPI would increase slightly, because a mispredict would flush two instructions, but the cycle time would decrease substantially, giving an overall speedup.
The pipelined processor is similar in hardware requirements to the single-cycle processor, but it adds a substantial number of pipeline registers, along with multiplexers and control logic to resolve hazards.
7.6 HDL Representation*
This section presents HDL code for the single-cycle MIPS processor supporting all of the instructions discussed in this chapter, including addi and j. The code illustrates good coding practices for a moderately complex system. HDL code for the multicycle processor and pipelined processor are left to Exercises 7.25 and 7.40.
In this section, the instruction and data memories are separated from the main processor and connected by address and data busses. This is more realistic, because most real processors have external memory. It also illustrates how the processor can communicate with the outside world.
The processor is composed of a datapath and a controller. The controller, in turn, is composed of the main decoder and the ALU decoder. Figure 7.59 shows a block diagram of the single-cycle MIPS processor interfaced to external memories.

Figure 7.59 MIPS single-cycle processor interfaced to external memory
The HDL code is partitioned into several sections. Section 7.6.1 provides HDL for the single-cycle processor datapath and controller. Section 7.6.2 presents the generic building blocks, such as registers and multiplexers, that are used by any microarchitecture. Section 7.6.3 introduces the testbench and external memories. The HDL is available in electronic form on this book’s website (see the preface).
7.6.1 Single-Cycle Processor
The main modules of the single-cycle MIPS processor module are given in the following HDL examples.
HDL Example 7.1 Single-Cycle MIPS Processor
SystemVerilog
module mips(input logic clk, reset,
output logic [31:0] pc,
input logic [31:0] instr,
output logic memwrite,
output logic [31:0] aluout, writedata,
input logic [31:0] readdata);
logic memtoreg, alusrc, regdst,
regwrite, jump, pcsrc, zero;
logic [2:0] alucontrol;
controller c(instr[31:26], instr[5:0], zero, memtoreg, memwrite, pcsrc, alusrc, regdst, regwrite, jump, alucontrol);
datapath dp(clk, reset, memtoreg, pcsrc,
alusrc, regdst, regwrite, jump,
alucontrol,
zero, pc, instr,
aluout, writedata, readdata);
endmodule
VHDL
library IEEE; use IEEE.STD_LOGIC_1164.all;
entity mips is –– single cycle MIPS processor
port(clk, reset: in STD_LOGIC;
pc: out STD_LOGIC_VECTOR(31 downto 0);
instr: in STD_LOGIC_VECTOR(31 downto 0);
memwrite: out STD_LOGIC;
aluout, writedata: out STD_LOGIC_VECTOR(31 downto 0);
readdata: in STD_LOGIC_VECTOR(31 downto 0));
end;
architecture struct of mips is
component controller
port(op, funct: in STD_LOGIC_VECTOR(5 downto 0);
zero: in STD_LOGIC;
memtoreg, memwrite: out STD_LOGIC;
pcsrc, alusrc: out STD_LOGIC;
regdst, regwrite: out STD_LOGIC;
jump: out STD_LOGIC;
alucontrol: out STD_LOGIC_VECTOR(2 downto 0));
end component;
component datapath
port(clk, reset: in STD_LOGIC;
memtoreg, pcsrc: in STD_LOGIC;
alusrc, regdst: in STD_LOGIC;
regwrite, jump: in STD_LOGIC;
alucontrol: in STD_LOGIC_VECTOR(2 downto 0);
zero: out STD_LOGIC;
pc: buffer STD_LOGIC_VECTOR(31 downto 0);
instr: in STD_LOGIC_VECTOR(31 downto 0);
aluout, writedata: buffer STD_LOGIC_VECTOR(31 downto 0);
readdata: in STD_LOGIC_VECTOR(31 downto 0));
end component;
signal memtoreg, alusrc, regdst, regwrite, jump, pcsrc: STD_LOGIC;
signal zero: STD_LOGIC;
signal alucontrol: STD_LOGIC_VECTOR(2 downto 0);
begin
cont: controller port map(instr(31 downto 26), instr(5 downto 0), zero, memtoreg, memwrite, pcsrc, alusrc, regdst, regwrite, jump, alucontrol);
dp: datapath port map(clk, reset, memtoreg, pcsrc, alusrc, regdst, regwrite, jump, alucontrol, zero, pc, instr, aluout, writedata, readdata);
end;
HDL Example 7.2 Controller
SystemVerilog
module controller(input logic [5:0] op, funct,
input logic zero,
output logic memtoreg, memwrite,
output logic pcsrc, alusrc,
output logic regdst, regwrite,
output logic jump,
output logic [2:0] alucontrol);
logic [1:0] aluop;
logic branch;
maindec md(op, memtoreg, memwrite, branch, alusrc, regdst, regwrite, jump, aluop);
aludec ad(funct, aluop, alucontrol);
assign pcsrc = branch & zero;
endmodule
VHDL
library IEEE; use IEEE.STD_LOGIC_1164.all;
entity controller is –– single cycle control decoder
port(op, funct: in STD_LOGIC_VECTOR(5 downto 0);
zero: in STD_LOGIC;
memtoreg, memwrite: out STD_LOGIC;
pcsrc, alusrc: out STD_LOGIC;
regdst, regwrite: out STD_LOGIC;
jump: out STD_LOGIC;
alucontrol: out STD_LOGIC_VECTOR(2 downto 0));
end;
architecture struct of controller is
component maindec
port(op: in STD_LOGIC_VECTOR(5 downto 0);
memtoreg, memwrite: out STD_LOGIC;
branch, alusrc: out STD_LOGIC;
regdst, regwrite: out STD_LOGIC;
jump: out STD_LOGIC;
aluop: out STD_LOGIC_VECTOR(1 downto 0));
end component;
component aludec
port(funct: in STD_LOGIC_VECTOR(5 downto 0);
aluop: in STD_LOGIC_VECTOR(1 downto 0);
alucontrol: out STD_LOGIC_VECTOR(2 downto 0));
end component;
signal aluop: STD_LOGIC_VECTOR(1 downto 0);
signal branch: STD_LOGIC;
begin
md: maindec port map(op, memtoreg, memwrite, branch, alusrc, regdst, regwrite, jump, aluop);
ad: aludec port map(funct, aluop, alucontrol);
pcsrc <= branch and zero;
end;
HDL Example 7.3 Main Decoder
SystemVerilog
module maindec(input logic [5:0] op,
output logic memtoreg, memwrite,
output logic branch, alusrc,
output logic regdst, regwrite,
output logic jump,
output logic [1:0] aluop);
logic [8:0] controls;
assign {regwrite, regdst, alusrc, branch, memwrite,
memtoreg, jump, aluop} = controls;
always_comb
case(op)
6’b000000: controls <= 9’b110000010; // RTYPE
6’b100011: controls <= 9’b101001000; // LW
6’b101011: controls <= 9’b001010000; // SW
6’b000100: controls <= 9’b000100001; // BEQ
6’b001000: controls <= 9’b101000000; // ADDI
6’b000010: controls <= 9’b000000100; // J
default: controls <= 9’bxxxxxxxxx; // illegal op
endcase
endmodule
VHDL
library IEEE; use IEEE.STD_LOGIC_1164.all;
entity maindec is –– main control decoder
port(op: in STD_LOGIC_VECTOR(5 downto 0);
memtoreg, memwrite: out STD_LOGIC;
branch, alusrc: out STD_LOGIC;
regdst, regwrite: out STD_LOGIC;
jump: out STD_LOGIC;
aluop: out STD_LOGIC_VECTOR(1 downto 0));
end;
architecture behave of maindec is
signal controls: STD_LOGIC_VECTOR(8 downto 0);
begin
process(all) begin
case op is
when "000000" => controls <= "110000010"; –– RTYPE
when "100011" => controls <= "101001000"; –– LW
when "101011" => controls <= "001010000"; –– SW
when "000100" => controls <= "000100001"; –– BEQ
when "001000" => controls <= "101000000"; –– ADDI
when "000010" => controls <= "000000100"; –– J
when others => controls <= "–––––––––"; –– illegal op
end case;
end process;
(regwrite, regdst, alusrc, branch, memwrite, memtoreg, jump, aluop(1 downto 0)) <= controls;
end;
HDL Example 7.4 ALU Decoder
SystemVerilog
module aludec(input logic [5:0] funct,
input logic [1:0] aluop,
output logic [2:0] alucontrol);
always_comb
case(aluop)
2’b00: alucontrol <= 3’b010; // add (for lw/sw/addi)
2’b01: alucontrol <= 3’b110; // sub (for beq)
default: case(funct) // R-type instructions
6’b100000: alucontrol <= 3’b010; // add
6’b100010: alucontrol <= 3’b110; // sub
6’b100100: alucontrol <= 3’b000; // and
6’b100101: alucontrol <= 3’b001; // or
6’b101010: alucontrol <= 3’b111; // slt
default: alucontrol <= 3’bxxx; // ???
endcase
endcase
endmodule
VHDL
library IEEE; use IEEE.STD_LOGIC_1164.all;
entity aludec is –– ALU control decoder
port(funct: in STD_LOGIC_VECTOR(5 downto 0);
aluop: in STD_LOGIC_VECTOR(1 downto 0);
alucontrol: out STD_LOGIC_VECTOR(2 downto 0));
end;
architecture behave of aludec is
begin
process(all) begin
case aluop is
when "00" => alucontrol <= "010"; –– add (for 1w/sw/addi)
when "01" => alucontrol <= "110"; –– sub (for beq)
when others => case funct is –– R-type instructions
when "100000" => alucontrol <= "010"; –– add
when "100010" => alucontrol <= "110"; –– sub
when "100100" => alucontrol <= "000"; –– and
when "100101" => alucontrol <= "001"; –– or
when "101010" => alucontrol <= "111"; –– slt
when others => alucontrol <= "–––"; –– ???
end case;
end case;
end process;
end;
HDL Example 7.5 Datapath
SystemVerilog
module datapath(input logic clk, reset,
input logic memtoreg, pcsrc,
input logic alusrc, regdst,
input logic regwrite, jump,
input logic [2:0] alucontrol,
output logic zero,
output logic [31:0] pc,
input logic [31:0] instr,
output logic [31:0] aluout, writedata,
input logic [31:0] readdata);
logic [4:0] writereg;
logic [31:0] pcnext, pcnextbr, pcplus4, pcbranch;
logic [31:0] signimm, signimmsh;
logic [31:0] srca, srcb;
logic [31:0] result;
// next PC logic
flopr #(32) pcreg(clk, reset, pcnext, pc);
adder pcadd1(pc, 32'b100, pcplus4);
sl2 immsh(signimm, signimmsh);
adder pcadd2(pcplus4, signimmsh, pcbranch);
mux2 #(32) pcbrmux(pcplus4, pcbranch, pcsrc, pcnextbr);
mux2 #(32) pcmux(pcnextbr, {pcplus4[31:28], instr[25:0], 2'b00}, jump, pcnext);
// register file logic
regfile rf(clk, regwrite, instr[25:21], instr[20:16], writereg, result, srca, writedata);
mux2 #(5) wrmux(instr[20:16], instr[15:11], regdst, writereg);
mux2 #(32) resmux(aluout, readdata, memtoreg, result);
signext se(instr[15:0], signimm);
// ALU logic
mux2 #(32) srcbmux(writedata, signimm, alusrc, srcb);
alu alu(srca, srcb, alucontrol, aluout, zero);
endmodule
VHDL
library IEEE; use IEEE.STD_LOGIC_1164.all;
use IEEE.STD_LOGIC_ARITH.all;
entity datapath is -- MIPS datapath
port(clk, reset: in STD_LOGIC;
memtoreg, pcsrc: in STD_LOGIC;
alusrc, regdst: in STD_LOGIC;
regwrite, jump: in STD_LOGIC;
alucontrol: in STD_LOGIC_VECTOR(2 downto 0);
zero: out STD_LOGIC;
pc: buffer STD_LOGIC_VECTOR(31 downto 0);
instr: in STD_LOGIC_VECTOR(31 downto 0);
aluout, writedata: buffer STD_LOGIC_VECTOR(31 downto 0);
readdata: in STD_LOGIC_VECTOR(31 downto 0));
end;
architecture struct of datapath is
component alu
port(a, b: in STD_LOGIC_VECTOR(31 downto 0);
alucontrol: in STD_LOGIC_VECTOR(2 downto 0);
result: buffer STD_LOGIC_VECTOR(31 downto 0);
zero: out STD_LOGIC);
end component;
component regfile
port(clk: in STD_LOGIC;
we3: in STD_LOGIC;
ra1, ra2, wa3: in STD_LOGIC_VECTOR(4 downto 0);
wd3: in STD_LOGIC_VECTOR(31 downto 0);
rd1, rd2: out STD_LOGIC_VECTOR(31 downto 0));
end component;
component adder
port(a, b: in STD_LOGIC_VECTOR(31 downto 0);
y: out STD_LOGIC_VECTOR(31 downto 0));
end component;
component sl2
port(a: in STD_LOGIC_VECTOR(31 downto 0);
y: out STD_LOGIC_VECTOR(31 downto 0));
end component;
component signext
port(a: in STD_LOGIC_VECTOR(15 downto 0);
y: out STD_LOGIC_VECTOR(31 downto 0));
end component;
component flopr generic(width: integer);
port(clk, reset: in STD_LOGIC;
d: in STD_LOGIC_VECTOR(width-1 downto 0);
q: out STD_LOGIC_VECTOR(width-1 downto 0));
end component;
component mux2 generic(width: integer);
port(d0, d1: in STD_LOGIC_VECTOR(width-1 downto 0);
s: in STD_LOGIC;
y: out STD_LOGIC_VECTOR(width-1 downto 0));
end component;
signal writereg: STD_LOGIC_VECTOR(4 downto 0);
signal pcjump, pcnext, pcnextbr, pcplus4,
pcbranch: STD_LOGIC_VECTOR(31 downto 0);
signal signimm, signimmsh: STD_LOGIC_VECTOR(31 downto 0);
signal srca, srcb, result: STD_LOGIC_VECTOR(31 downto 0);
begin
-- next PC logic
pcjump <= pcplus4(31 downto 28) & instr(25 downto 0) & "00";
pcreg: flopr generic map(32) port map(clk, reset, pcnext, pc);
pcadd1: adder port map(pc, X"00000004", pcplus4);
immsh: sl2 port map(signimm, signimmsh);
pcadd2: adder port map(pcplus4, signimmsh, pcbranch);
pcbrmux: mux2 generic map(32) port map(pcplus4, pcbranch, pcsrc, pcnextbr);
pcmux: mux2 generic map(32) port map(pcnextbr, pcjump, jump, pcnext);
-- register file logic
rf: regfile port map(clk, regwrite, instr(25 downto 21), instr(20 downto 16), writereg, result, srca, writedata);
wrmux: mux2 generic map(5) port map(instr(20 downto 16),
instr(15 downto 11), regdst, writereg);
resmux: mux2 generic map(32) port map(aluout, readdata, memtoreg, result);
se: signext port map(instr(15 downto 0), signimm);
-- ALU logic
srcbmux: mux2 generic map(32) port map(writedata, signimm, alusrc, srcb);
mainalu: alu port map(srca, srcb, alucontrol, aluout, zero);
end;
7.6.2 Generic Building Blocks
This section contains generic building blocks that may be useful in any MIPS microarchitecture, including a register file, adder, left shift unit, sign-extension unit, resettable flip-flop, and multiplexer. The HDL for the ALU is left to Exercise 5.9.
HDL Example 7.6 Register File
SystemVerilog
module regfile(input logic clk,
input logic we3,
input logic [4:0] ra1, ra2, wa3,
input logic [31:0] wd3,
output logic [31:0] rd1, rd2);
logic [31:0] rf[31:0];
// three ported register file
// read two ports combinationally
// write third port on rising edge of clk
// register 0 hardwired to 0
// note: for pipelined processor, write third port
// on falling edge of clk
always_ff @(posedge clk)
if (we3) rf[wa3] <= wd3;
assign rd1 = (ra1 ! = 0) ? rf[ra1] : 0;
assign rd2 = (ra2 ! = 0) ? rf[ra2] : 0;
endmodule
VHDL
library IEEE; use IEEE.STD_LOGIC_1164.all;
use IEEE.NUMERIC_STD_UNSIGNED.all;
entity regfile is –– three-port register file
port(clk: in STD_LOGIC;
we3: in STD_LOGIC;
ra1, ra2, wa3: in STD_LOGIC_VECTOR(4 downto 0);
wd3: in STD_LOGIC_VECTOR(31 downto 0);
rd1, rd2: out STD_LOGIC_VECTOR(31 downto 0));
end;
architecture behave of regfile is
type ramtype is array (31 downto 0) of STD_LOGIC_VECTOR(31 downto 0);
signal mem: ramtype;
begin
–– three-ported register file
–– read two ports combinationally
–– write third port on rising edge of clk
–– register 0 hardwired to 0
–– note: for pipelined processor, write third port
–– on falling edge of clk
process(clk) begin
if rising_edge(clk) then
if we3 = ‘1’ then mem(to_integer(wa3)) <= wd3;
end if;
end if;
end process;
process(all) begin
if (to_integer(ra1) = 0) then rd1 <= X"00000000";
–– register 0 holds 0
else rd1 <= mem(to_integer(ra1));
end if;
if (to_integer(ra2) = 0) then rd2 <= X"00000000";
else rd2 <= mem(to_integer(ra2));
end if;
end process;
end;
HDL Example 7.7 Adder
SystemVerilog
module adder(input logic [31:0] a, b,
output logic [31:0] y);
assign y = a + b;
endmodule
VHDL
library IEEE; use IEEE.STD_LOGIC_1164.all;
use IEEE.NUMERIC_STD_UNSIGNED.all;
entity adder is –– adder
port(a, b: in STD_LOGIC_VECTOR(31 downto 0);
y: out STD_LOGIC_VECTOR(31 downto 0));
end;
architecture behave of adder is
begin
y <= a + b;
end;
HDL Example 7.8 Left Shift (Multiply by 4)
SystemVerilog
module sl2(input logic [31:0] a,
output logic [31:0] y);
// shift left by 2
assign y = {a[29:0], 2’b00};
endmodule
VHDL
library IEEE; use IEEE.STD_LOGIC_1164.all;
entity sl2 is –– shift left by 2
port(a: in STD_LOGIC_VECTOR(31 downto 0);
y: out STD_LOGIC_VECTOR(31 downto 0));
end;
architecture behave of sl2 is
begin
y <= a(29 downto 0) & "00";
end;
HDL Example 7.9 Sign Extension
SystemVerilog
module signext(input logic [15:0] a,
output logic [31:0] y);
assign y = {{16{a[15]}}, a};
endmodule
VHDL
library IEEE; use IEEE.STD_LOGIC_1164.all;
entity signext is –– sign extender
port(a: in STD_LOGIC_VECTOR(15 downto 0);
y: out STD_LOGIC_VECTOR(31 downto 0));
end;
architecture behave of signext is
begin
y <= X"ffff" & a when a(15) else X"0000" & a;
end;
HDL Example 7.10 Resettable Flip-Flop
SystemVerilog
module flopr #(parameter WIDTH = 8)
(input logic clk, reset,
input logic [WIDTH-1:0] d,
output logic [WIDTH-1:0] q);
always_ff @(posedge clk, posedge reset)
if (reset) q <= 0;
else q <= d;
endmodule
VHDL
library IEEE; use IEEE.STD_LOGIC_1164.all;
use IEEE.STD_LOGIC_ARITH.all;
entity flopr is –– flip-flop with synchronous reset
generic (width: integer);
port(clk, reset: in STD_LOGIC;
d: in STD_LOGIC_VECTOR(width-1 downto 0);
q: out STD_LOGIC_VECTOR(width-1 downto 0));
end;
architecture asynchronous of flopr is
begin
process(clk, reset) begin
if reset then q <= (others => ‘0’);
elsif rising_edge(clk) then
q <= d;
end if;
end process;
end;
HDL Example 7.11 2:1 Multiplexer
SystemVerilog
module mux2 #(parameter WIDTH = 8)
(input logic [WIDTH-1:0] d0, d1,
input logic s,
output logic [WIDTH-1:0] y);
assign y = s ? d1 : d0;
endmodule
VHDL
library IEEE; use IEEE.STD_LOGIC_1164.all;
entity mux2 is –– two-input multiplexer
generic(width: integer := 8);
port(d0, d1: in STD_LOGIC_VECTOR(width-1 downto 0);
s: in STD_LOGIC;
y: out STD_LOGIC_VECTOR(width-1 downto 0));
end;
architecture behave of mux2 is
begin
y <= d1 when s else d0;
end;
7.6.3 Testbench
The MIPS testbench loads a program into the memories. The program in Figure 7.60 exercises all of the instructions by performing a computation that should produce the correct answer only if all of the instructions are functioning properly. Specifically, the program will write the value 7 to address 84 if it runs correctly, and is unlikely to do so if the hardware is buggy. This is an example of ad hoc testing.
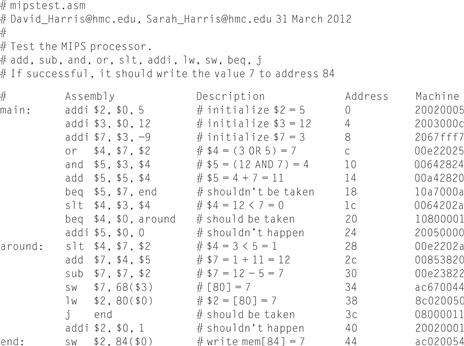
Figure 7.60 Assembly and machine code for MIPS test program
The machine code is stored in a hexadecimal file called memfile.dat (see Figure 7.61), which is loaded by the testbench during simulation. The file consists of the machine code for the instructions, one instruction per line.
![]()
Figure 7.61 Contents of memfile.dat
The testbench, top-level MIPS module, and external memory HDL code are given in the following examples. The memories in this example hold 64 words each.
HDL Example 7.12 Mips Testbench
SystemVerilog
module testbench();
logic clk;
logic reset;
logic [31:0] writedata, dataadr;
logic memwrite;
// instantiate device to be tested
top dut (clk, reset, writedata, dataadr, memwrite);
// initialize test
initial
begin
reset <= 1; # 22; reset <= 0;
end
// generate clock to sequence tests
always
begin
clk <= 1; # 5; clk <= 0; # 5;
end
// check results
always @(negedge clk)
begin
if (memwrite) begin
if (dataadr = = = 84 & writedata = = = 7) begin
$display("Simulation succeeded");
$stop;
end else if (dataadr != = 80) begin
$display("Simulation failed");
$stop;
end
end
end
endmodule
VHDL
library IEEE;
use IEEE.STD_LOGIC_1164.all; use IEEE.NUMERIC_STD_UNSIGNED.all;
entity testbench is
end;
architecture test of testbench is
component top
port(clk, reset: in STD_LOGIC;
writedata, dataadr: out STD_LOGIC_VECTOR(31 downto 0);
memwrite: out STD_LOGIC);
end component;
signal writedata, dataadr: STD_LOGIC_VECTOR(31 downto 0);
signal clk, reset, memwrite: STD_LOGIC;
begin
–– instantiate device to be tested
dut: top port map(clk, reset, writedata, dataadr, memwrite);
–– Generate clock with 10 ns period
process begin
clk <= ‘1’;
wait for 5 ns;
clk <= ‘0’;
wait for 5 ns;
end process;
–– Generate reset for first two clock cycles
process begin
reset <= ‘1’;
wait for 22 ns;
reset <= ‘0’;
wait;
end process;
–– check that 7 gets written to address 84 at end of program
process(clk) begin
if (clk’event and clk = ‘0’ and memwrite = ‘1’) then
if (to_integer(dataadr) = 84 and to_integer (writedata) = 7) then
report "NO ERRORS: Simulation succeeded" severity failure;
elsif (dataadr /= 80) then
report "Simulation failed" severity failure;
end if;
end if;
end process;
end;
HDL Example 7.13 Mips Top-Level Module
SystemVerilog
module top(input logic clk, reset,
output logic [31:0] writedata, dataadr,
output logic memwrite);
logic [31:0] pc, instr, readdata;
// instantiate processor and memories
mips mips(clk, reset, pc, instr, memwrite, dataadr, writedata, readdata);
imem imem(pc[7:2], instr);
dmem dmem(clk, memwrite, dataadr, writedata, readdata);
endmodule
VHDL
library IEEE;
use IEEE.STD_LOGIC_1164.all; use IEEE.NUMERIC_STD_UNSIGNED.all;
entity top is –– top-level design for testing
port(clk, reset: in STD_LOGIC;
writedata, dataadr: buffer STD_LOGIC_VECTOR(31 downto 0);
memwrite: buffer STD_LOGIC);
end;
architecture test of top is
component mips
port(clk, reset: in STD_LOGIC;
pc: out STD_LOGIC_VECTOR(31 downto 0);
instr: in STD_LOGIC_VECTOR(31 downto 0);
memwrite: out STD_LOGIC;
aluout, writedata: out STD_LOGIC_VECTOR(31 downto 0);
readdata: in STD_LOGIC_VECTOR(31 downto 0));
end component;
component imem
port(a: in STD_LOGIC_VECTOR(5 downto 0);
rd: out STD_LOGIC_VECTOR(31 downto 0));
end component;
component dmem
port(clk, we: in STD_LOGIC;
a, wd: in STD_LOGIC_VECTOR(31 downto 0);
rd: out STD_LOGIC_VECTOR(31 downto 0));
end component;
signal pc, instr,
readdata: STD_LOGIC_VECTOR(31 downto 0);
begin
–– instantiate processor and memories
mips1: mips port map(clk, reset, pc, instr, memwrite,
dataadr, writedata, readdata);
imem1: imem port map(pc(7 downto 2), instr);
dmem1: dmem port map(clk, memwrite, dataadr, writedata, readdata);
end;
HDL Example 7.14 Mips Data Memory
SystemVerilog
module dmem(input logic clk, we,
input logic [31:0] a, wd,
output logic [31:0] rd);
logic [31:0] RAM[63:0];
assign rd = RAM[a[31:2]]; // word aligned
always_ff @(posedge clk)
if (we) RAM[a[31:2]] <= wd;
endmodule
VHDL
library IEEE;
use IEEE.STD_LOGIC_1164.all; use STD.TEXTIO.all;
use IEEE.NUMERIC_STD_UNSIGNED.all;
entity dmem is –– data memory
port(clk, we: in STD_LOGIC;
a, wd: in STD_LOGIC_VECTOR (31 downto 0);
rd: out STD_LOGIC_VECTOR (31 downto 0));
end;
architecture behave of dmem is
begin
process is
type ramtype is array (63 downto 0) of STD_LOGIC_VECTOR(31 downto 0);
variable mem: ramtype;
begin
–– read or write memory
loop
if rising_edge(clk) then
if (we = ’1’) then mem (to_integer(a(7 downto 2))):= wd;
end if;
end if;
rd <= mem (to_integer(a (7 downto 2)));
wait on clk, a;
end loop;
end process;
end;
HDL Example 7.15 Mips Instruction Memory
SystemVerilog
module imem(input logic [5:0] a,
output logic [31:0] rd);
logic [31:0] RAM[63:0];
initial
$readmemh("memfile.dat", RAM);
assign rd = RAM[a]; // word aligned
endmodule
VHDL
library IEEE;
use IEEE.STD_LOGIC_1164.all; use STD.TEXTIO.all;
use IEEE.NUMERIC_STD_UNSIGNED.all;
entity imem is –– instruction memory
port(a: in STD_LOGIC_VECTOR(5 downto 0);
rd: out STD_LOGIC_VECTOR(31 downto 0));
end;
architecture behave of imem is
begin
process is
file mem_file: TEXT;
variable L: line;
variable ch: character;
variable i, index, result: integer;
type ramtype is array (63 downto 0) of STD_LOGIC_VECTOR(31 downto 0);
variable mem: ramtype;
begin
–– initialize memory from file
for i in 0 to 63 loop –– set all contents low
mem(i) := (others => ’0’);
end loop;
index := 0;
FILE_OPEN (mem_file, "C:/docs/DDCA2e/hdl/memfile.dat", READ_MODE);
while not endfile(mem_file) loop
readline(mem_file, L);
result := 0;
for i in 1 to 8 loop
read (L, ch);
if ’0’ <= ch and ch <= ’9’ then
result := character'pos(ch) - character'pos('0'),
elsif ’a’ <= ch and ch <= ’f’ then
result := character'pos(ch) - character'pos('a')+10;
else report "Format error on line" & integer’ image(index) severity error;
end if;
mem(index)(35-i*4 downto 32-i*4) := to_std_logic_vector(result,4);
end loop;
index := index + 1;
end loop;
–– read memory
loop
rd <= mem(to_integer(a));
wait on a;
end loop;
end process;
end;
7.7 Exceptions*
Section 6.7.2 introduced exceptions, which cause unplanned changes in the flow of a program. In this section, we enhance the multicycle processor to support two types of exceptions: undefined instructions and arithmetic overflow. Supporting exceptions in other microarchitectures follows similar principles.
As described in Section 6.7.2, when an exception takes place, the processor copies the PC to the EPC register and stores a code in the Cause register indicating the source of the exception. Exception causes include 0x28 for undefined instructions and 0x30 for overflow (see Table 6.7). The processor then jumps to the exception handler at memory address 0x80000180. The exception handler is code that responds to the exception. It is part of the operating system.
Also as discussed in Section 6.7.2, the exception registers are part of Coprocessor 0, a portion of the MIPS processor that is used for system functions. Coprocessor 0 defines up to 32 special-purpose registers, including Cause and EPC. The exception handler may use the mfc0 (move from coprocessor 0) instruction to copy these special-purpose registers into a general-purpose register in the register file; the Cause register is Coprocessor 0 register 13, and EPC is register 14.
To handle exceptions, we must add EPC and Cause registers to the datapath and extend the PCSrc multiplexer to accept the exception handler address, as shown in Figure 7.62. The two new registers have write enables, EPCWrite and CauseWrite, to store the PC and exception cause when an exception takes place. The cause is generated by a multiplexer that selects the appropriate code for the exception. The ALU must also generate an overflow signal, as was discussed in Section 5.2.4.5

Figure 7.62 Datapath supporting overflow and undefined instruction exceptions
To support the mfc0 instruction, we also add a way to select the Coprocessor 0 registers and write them to the register file, as shown in Figure 7.63. The mfc0 instruction specifies the Coprocessor 0 register by Instr15:11; in this diagram, only the Cause and EPC registers are supported. We add another input to the MemtoReg multiplexer to select the value from Coprocessor 0.

Figure 7.63 Datapath supporting mfcO
The modified controller is shown in Figure 7.64. The controller receives the overflow flag from the ALU. It generates three new control signals: one to write the EPC, a second to write the Cause register, and a third to select the Cause. It also includes two new states to support the two exceptions and another state to handle mfc0.
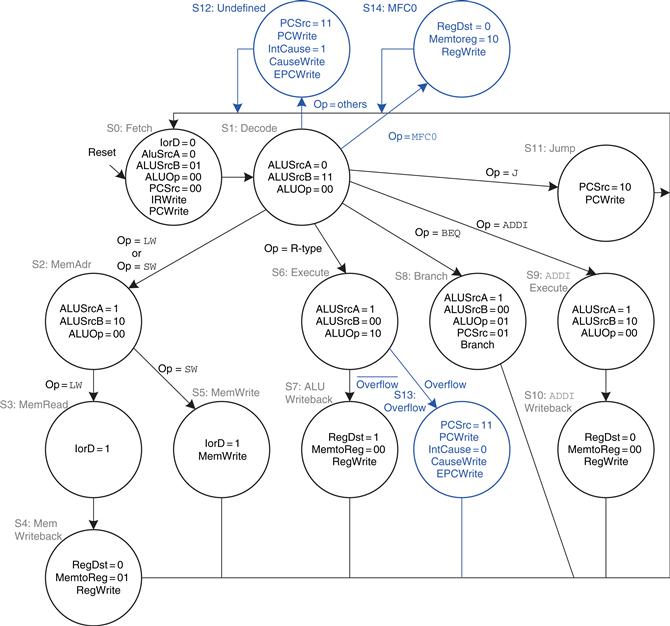
Figure 7.64 Controller supporting exceptions and mfc0
If the controller receives an undefined instruction (one that it does not know how to handle), it proceeds to S12, saves the PC in EPC, writes 0x28 to the Cause register, and jumps to the exception handler. Similarly, if the controller detects arithmetic overflow on an add or sub instruction, it proceeds to S13, saves the PC in EPC, writes 0x30 in the Cause register, and jumps to the exception handler. Note that, when an exception occurs, the instruction is discarded and the register file is not written. When a mfc0 instruction is decoded, the processor goes to S14 and writes the appropriate Coprocessor 0 register to the main register file.
7.8 Advanced Microarchitecture*
High-performance microprocessors use a wide variety of techniques to run programs faster. Recall that the time required to run a program is proportional to the period of the clock and to the number of clock cycles per instruction (CPI). Thus, to increase performance we would like to speed up the clock and/or reduce the CPI. This section surveys some existing speedup techniques. The implementation details become quite complex, so we will focus on the concepts. Hennessy & Patterson’s Computer Architecture text is a definitive reference if you want to fully understand the details.
Every 2 to 3 years, advances in CMOS manufacturing reduce transistor dimensions by 30% in each direction, doubling the number of transistors that can fit on a chip. A manufacturing process is characterized by its feature size, which indicates the smallest transistor that can be reliably built. Smaller transistors are faster and generally consume less power. Thus, even if the microarchitecture does not change, the clock frequency can increase because all the gates are faster. Moreover, smaller transistors enable placing more transistors on a chip. Microarchitects use the additional transistors to build more complicated processors or to put more processors on a chip. Unfortunately, power consumption increases with the number of transistors and the speed at which they operate (see Section 1.8). Power consumption is now an essential concern. Microprocessor designers have a challenging task juggling the trade-offs among speed, power, and cost for chips with billions of transistors in some of the most complex systems that humans have ever built.
7.8.1 Deep Pipelines
Aside from advances in manufacturing, the easiest way to speed up the clock is to chop the pipeline into more stages. Each stage contains less logic, so it can run faster. This chapter has considered a classic five-stage pipeline, but 10 to 20 stages are now commonly used.
The maximum number of pipeline stages is limited by pipeline hazards, sequencing overhead, and cost. Longer pipelines introduce more dependencies. Some of the dependencies can be solved by forwarding, but others require stalls, which increase the CPI. The pipeline registers between each stage have sequencing overhead from their setup time and clk-to-Q delay (as well as clock skew). This sequencing overhead makes adding more pipeline stages give diminishing returns. Finally, adding more stages increases the cost because of the extra pipeline registers and hardware required to handle hazards.
Example 7.11 Deep Pipelines
Consider building a pipelined processor by chopping up the single-cycle processor into N stages (N ≥ 5). The single-cycle processor has a propagation delay of 875 ps through the combinational logic. The sequencing overhead of a register is 50 ps. Assume that the combinational delay can be arbitrarily divided into any number of stages and that pipeline hazard logic does not increase the delay. The five-stage pipeline in Example 7.9 has a CPI of 1.15. Assume that each additional stage increases the CPI by 0.1 because of branch mispredictions and other pipeline hazards. How many pipeline stages should be used to make the processor execute programs as fast as possible?
Solution
If the 875 ps combinational logic delay is divided into N stages and each stage also pays 50 ps of sequencing overhead for its pipeline register, the cycle time is Tc = (875/N + 50) ps. The CPI is 1.15 + 0.1(N – 5). The time per instruction, or instruction time, is the product of the cycle time and the CPI. Figure 7.65 plots the cycle time and instruction time versus the number of stages. The instruction time has a minimum of 227 ps at N = 11 stages. This minimum is only slightly better than the 245 ps per instruction achieved with a six-stage pipeline.

Figure 7.65 Cycle time and instruction time versus the number of pipeline stages
In the late 1990s and early 2000s, microprocessors were marketed largely based on clock frequency (1/Tc). This pushed microprocessors to use very deep pipelines (20 to 31 stages on the Pentium 4) to maximize the clock frequency, even if the benefits for overall performance were questionable. Power is proportional to clock frequency and also increases with the number of pipeline registers, so now that power consumption is so important, pipeline depths are decreasing.
7.8.2 Branch Prediction
An ideal pipelined processor would have a CPI of 1. The branch misprediction penalty is a major reason for increased CPI. As pipelines get deeper, branches are resolved later in the pipeline. Thus, the branch misprediction penalty gets larger, because all the instructions issued after the mispredicted branch must be flushed. To address this problem, most pipelined processors use a branch predictor to guess whether the branch should be taken. Recall that our pipeline from Section 7.5.3 simply predicted that branches are never taken.
Some branches occur when a program reaches the end of a loop (e.g., a for or while statement) and branches back to repeat the loop. Loops tend to be executed many times, so these backward branches are usually taken. The simplest form of branch prediction checks the direction of the branch and predicts that backward branches should be taken. This is called static branch prediction, because it does not depend on the history of the program.
Forward branches are difficult to predict without knowing more about the specific program. Therefore, most processors use dynamic branch predictors, which use the history of program execution to guess whether a branch should be taken. Dynamic branch predictors maintain a table of the last several hundred (or thousand) branch instructions that the processor has executed. The table, sometimes called a branch target buffer, includes the destination of the branch and a history of whether the branch was taken.
To see the operation of dynamic branch predictors, consider the following loop code from Code Example 6.20. The loop repeats 10 times, and the beq out of the loop is taken only on the last time.
add $s1, $0, $0 # sum = 0
addi $s0, $0, 0 # i = 0
addi $t0, $0, 10 # $t0 = 10
for:
beq $s0, $t0, done # if i = = 10, branch to done
add $s1, $s1, $s0 # sum = sum + i
addi $s0, $s0, 1 # increment i
j for
done:
A one-bit dynamic branch predictor remembers whether the branch was taken the last time and predicts that it will do the same thing the next time. While the loop is repeating, it remembers that the beq was not taken last time and predicts that it should not be taken next time. This is a correct prediction until the last branch of the loop, when the branch does get taken. Unfortunately, if the loop is run again, the branch predictor remembers that the last branch was taken. Therefore, it incorrectly predicts that the branch should be taken when the loop is first run again. In summary, a 1-bit branch predictor mispredicts the first and last branches of a loop.
A scalar processor acts on one piece of data at a time. A vector processor acts on several pieces of data with a single instruction. A superscalar processor issues several instructions at a time, each of which operates on one piece of data.
Our MIPS pipelined processor is a scalar processor. Vector processors were popular for supercomputers in the 1980s and 1990s because they efficiently handled the long vectors of data common in scientific computations. Modern high-performance microprocessors are superscalar, because issuing several independent instructions is more flexible than processing vectors.
However, modern processors also include hardware to handle short vectors of data that are common in multimedia and graphics applications. These are called single instruction multiple data (SIMD) units.
A 2-bit dynamic branch predictor solves this problem by having four states: strongly taken, weakly taken, weakly not taken, and strongly not taken, as shown in Figure 7.66. When the loop is repeating, it enters the “strongly not taken” state and predicts that the branch should not be taken next time. This is correct until the last branch of the loop, which is taken and moves the predictor to the “weakly not taken” state. When the loop is first run again, the branch predictor correctly predicts that the branch should not be taken and reenters the “strongly not taken” state. In summary, a 2-bit branch predictor mispredicts only the last branch of a loop.

Figure 7.66 2-bit branch predictor state transition diagram
As one can imagine, branch predictors may be used to track even more history of the program to increase the accuracy of predictions. Good branch predictors achieve better than 90% accuracy on typical programs.
The branch predictor operates in the Fetch stage of the pipeline so that it can determine which instruction to execute on the next cycle. When it predicts that the branch should be taken, the processor fetches the next instruction from the branch destination stored in the branch target buffer. By keeping track of both branch and jump destinations in the branch target buffer, the processor can also avoid flushing the pipeline during jump instructions.
7.8.3 Superscalar Processor
A superscalar processor contains multiple copies of the datapath hardware to execute multiple instructions simultaneously. Figure 7.67 shows a block diagram of a two-way superscalar processor that fetches and executes two instructions per cycle. The datapath fetches two instructions at a time from the instruction memory. It has a six-ported register file to read four source operands and write two results back in each cycle. It also contains two ALUs and a two-ported data memory to execute the two instructions at the same time.
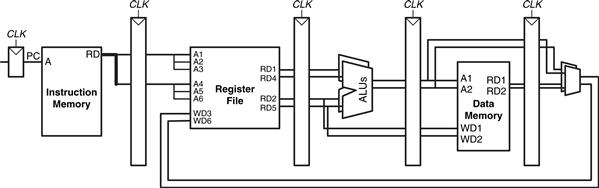
Figure 7.67 Superscalar datapath
Figure 7.68 shows a pipeline diagram illustrating the two-way superscalar processor executing two instructions on each cycle. For this program, the processor has a CPI of 0.5. Designers commonly refer to the reciprocal of the CPI as the instructions per cycle, or IPC. This processor has an IPC of 2 on this program.

Figure 7.68 Abstract view of a superscalar pipeline in operation
Executing many instructions simultaneously is difficult because of dependencies. For example, Figure 7.69 shows a pipeline diagram running a program with data dependencies. The dependencies in the code are shown in blue. The add instruction is dependent on $t0, which is produced by the lw instruction, so it cannot be issued at the same time as lw. Indeed, the add instruction stalls for yet another cycle so that lw can forward $t0 to add in cycle 5. The other dependencies (between sub and and based on $t0, and between or and sw based on $t3) are handled by forwarding results produced in one cycle to be consumed in the next. This program, also given below, requires five cycles to issue six instructions, for an IPC of 1.17.
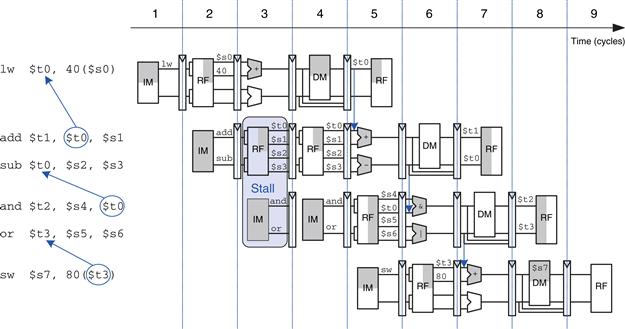
Figure 7.69 Program with data dependencies
lw $t0, 40($s0)
add $t1, $t0, $s1
sub $t0, $s2, $s3
and $t2, $s4, $t0
or $t3, $s5, $s6
sw $s7, 80($t3)
Recall that parallelism comes in temporal and spatial forms. Pipelining is a case of temporal parallelism. Multiple execution units is a case of spatial parallelism. Superscalar processors exploit both forms of parallelism to squeeze out performance far exceeding that of our single-cycle and multicycle processors.
Commercial processors may be three-, four-, or even six-way superscalar. They must handle control hazards such as branches as well as data hazards. Unfortunately, real programs have many dependencies, so wide superscalar processors rarely fully utilize all of the execution units. Moreover, the large number of execution units and complex forwarding networks consume vast amounts of circuitry and power.
7.8.4 Out-of-Order Processor
To cope with the problem of dependencies, an out-of-order processor looks ahead across many instructions to issue, or begin executing, independent instructions as rapidly as possible. The instructions can be issued in a different order than that written by the programmer, as long as dependencies are honored so that the program produces the intended result.
Consider running the same program from Figure 7.69 on a two-way superscalar out-of-order processor. The processor can issue up to two instructions per cycle from anywhere in the program, as long as dependencies are observed. Figure 7.70 shows the data dependencies and the operation of the processor. The classifications of dependencies as RAW and WAR will be discussed shortly. The constraints on issuing instructions are described below.
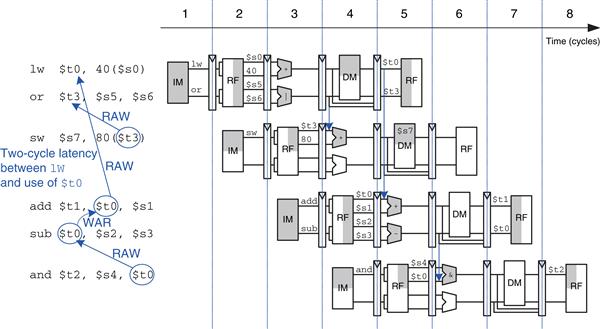
Figure 7.70 Out-of-order execution of a program with dependencies
– The add, sub, and and instructions are dependent on lw by way of $t0, so they cannot issue yet. However, the or instruction is independent, so it also issues.
– Remember that there is a two-cycle latency between when a lw instruction issues and when a dependent instruction can use its result, so add cannot issue yet because of the $t0 dependence. sub writes $t0, so it cannot issue before add, lest add receive the wrong value of $t0. and is dependent on sub.
– Only the sw instruction issues.
– On cycle 3, $t0 is available, so add issues. sub issues simultaneously, because it will not write $t0 until after add consumes $t0.
– The and instruction issues. $t0 is forwarded from sub to and.
The out-of-order processor issues the six instructions in four cycles, for an IPC of 1.5.
The dependence of add on lw by way of $t0 is a read after write (RAW) hazard. add must not read $t0 until after lw has written it. This is the type of dependency we are accustomed to handling in the pipelined processor. It inherently limits the speed at which the program can run, even if infinitely many execution units are available. Similarly, the dependence of sw on or by way of $t3 and of and on sub by way of $t0 are RAW dependencies.
The dependence between sub and add by way of $t0 is called a write after read (WAR) hazard or an antidependence. sub must not write $t0 before add reads $t0, so that add receives the correct value according to the original order of the program. WAR hazards could not occur in the simple MIPS pipeline, but they may happen in an out-of-order processor if the dependent instruction (in this case, sub) is moved too early.
A WAR hazard is not essential to the operation of the program. It is merely an artifact of the programmer’s choice to use the same register for two unrelated instructions. If the sub instruction had written $t4 instead of $t0, the dependency would disappear and sub could be issued before add. The MIPS architecture only has 32 registers, so sometimes the programmer is forced to reuse a register and introduce a hazard just because all the other registers are in use.
A third type of hazard, not shown in the program, is called write after write (WAW) or an output dependence. A WAW hazard occurs if an instruction attempts to write a register after a subsequent instruction has already written it. The hazard would result in the wrong value being written to the register. For example, in the following program, add and sub both write $t0. The final value in $t0 should come from sub according to the order of the program. If an out-of-order processor attempted to execute sub first, a WAW hazard would occur.
add $t0, $s1, $s2
sub $t0, $s3, $s4
WAW hazards are not essential either; again, they are artifacts caused by the programmer’s using the same register for two unrelated instructions. If the sub instruction were issued first, the program could eliminate the WAW hazard by discarding the result of the add instead of writing it to $t0. This is called squashing the add.6
Out-of-order processors use a table to keep track of instructions waiting to issue. The table, sometimes called a scoreboard, contains information about the dependencies. The size of the table determines how many instructions can be considered for issue. On each cycle, the processor examines the table and issues as many instructions as it can, limited by the dependencies and by the number of execution units (e.g., ALUs, memory ports) that are available.
The instruction level parallelism (ILP) is the number of instructions that can be executed simultaneously for a particular program and microarchitecture. Theoretical studies have shown that the ILP can be quite large for out-of-order microarchitectures with perfect branch predictors and enormous numbers of execution units. However, practical processors seldom achieve an ILP greater than 2 or 3, even with six-way superscalar datapaths with out-of-order execution.
7.8.5 Register Renaming
Out-of-order processors use a technique called register renaming to eliminate WAR hazards. Register renaming adds some nonarchitectural renaming registers to the processor. For example, a MIPS processor might add 20 renaming registers, called $r0-$r19. The programmer cannot use these registers directly, because they are not part of the architecture. However, the processor is free to use them to eliminate hazards.
For example, in the previous section, a WAR hazard occurred between the sub and add instructions based on reusing $t0. The out-of-order processor could rename $t0 to $r0 for the sub instruction. Then sub could be executed sooner, because $r0 has no dependency on the add instruction. The processor keeps a table of which registers were renamed so that it can consistently rename registers in subsequent dependent instructions. In this example, $t0 must also be renamed to $r0 in the and instruction, because it refers to the result of sub.
Figure 7.71 shows the same program from Figure 7.70 executing on an out-of-order processor with register renaming. $t0 is renamed to $r0 in sub and and to eliminate the WAR hazard. The constraints on issuing instructions are described below.
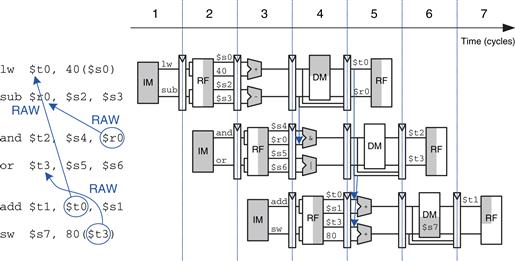
Figure 7.71 Out-of-order execution of a program using register renaming
– The add instruction is dependent on lw by way of $t0, so it cannot issue yet. However, the sub instruction is independent now that its destination has been renamed to $r0, so sub also issues.
– Remember that there is a two-cycle latency between when a lw issues and when a dependent instruction can use its result, so add cannot issue yet because of the $t0 dependence.
– The and instruction is dependent on sub, so it can issue. $r0 is forwarded from sub to and.
– The or instruction is independent, so it also issues.
– On cycle 3, $t0 is available, so add issues. $t3 is also available, so sw issues.
The out-of-order processor with register renaming issues the six instructions in three cycles, for an IPC of 2.
7.8.6 Single Instruction Multiple Data
The term SIMD (pronounced “sim-dee”) stands for single instruction multiple data, in which a single instruction acts on multiple pieces of data in parallel. A common application of SIMD is to perform many short arithmetic operations at once, especially for graphics processing. This is also called packed arithmetic.
For example, a 32-bit microprocessor might pack four 8-bit data elements into one 32-bit word. Packed add and subtract instructions operate on all four data elements within the word in parallel. Figure 7.72 shows a packed 8-bit addition summing four pairs of 8-bit numbers to produce four results. The word could also be divided into two 16-bit elements. Performing packed arithmetic requires modifying the ALU to eliminate carries between the smaller data elements. For example, a carry out of a0 + b0 should not affect the result of a1 + b1.

Figure 7.72 Packed arithmetic: four simultaneous 8-bit additions
Short data elements often appear in graphics processing. For example, a pixel in a digital photo may use 8 bits to store each of the red, green, and blue color components. Using an entire 32-bit word to process one of these components wastes the upper 24 bits. When the components from four adjacent pixels are packed into a 32-bit word, the processing can be performed four times faster.
SIMD instructions are even more helpful for 64-bit architectures, which can pack eight 8-bit elements, four 16-bit elements, or two 32-bit elements into a single 64-bit word. SIMD instructions are also used for floating-point computations; for example, four 32-bit single-precision floating-point values can be packed into a single 128-bit word.
7.8.7 Multithreading
Because the ILP of real programs tends to be fairly low, adding more execution units to a superscalar or out-of-order processor gives diminishing returns. Another problem, discussed in Chapter 8, is that memory is much slower than the processor. Most loads and stores access a smaller and faster memory, called a cache. However, when the instructions or data are not available in the cache, the processor may stall for 100 or more cycles while retrieving the information from the main memory. Multithreading is a technique that helps keep a processor with many execution units busy even if the ILP of a program is low or the program is stalled waiting for memory.
To explain multithreading, we need to define a few new terms. A program running on a computer is called a process. Computers can run multiple processes simultaneously; for example, you can play music on a PC while surfing the web and running a virus checker. Each process consists of one or more threads that also run simultaneously. For example, a word processor may have one thread handling the user typing, a second thread spell-checking the document while the user works, and a third thread printing the document. In this way, the user does not have to wait, for example, for a document to finish printing before being able to type again. The degree to which a process can be split into multiple threads that can run simultaneously defines its level of thread level parallelism (TLP).
In a conventional processor, the threads only give the illusion of running simultaneously. The threads actually take turns being executed on the processor under control of the OS. When one thread’s turn ends, the OS saves its architectural state, loads the architectural state of the next thread, and starts executing that next thread. This procedure is called context switching. As long as the processor switches through all the threads fast enough, the user perceives all of the threads as running at the same time.
A multithreaded processor contains more than one copy of its architectural state, so that more than one thread can be active at a time. For example, if we extended a MIPS processor to have four program counters and 128 registers, four threads could be available at one time. If one thread stalls while waiting for data from main memory, the processor could context switch to another thread without any delay, because the program counter and registers are already available. Moreover, if one thread lacks sufficient parallelism to keep all the execution units busy, another thread could issue instructions to the idle units.
Multithreading does not improve the performance of an individual thread, because it does not increase the ILP. However, it does improve the overall throughput of the processor, because multiple threads can use processor resources that would have been idle when executing a single thread. Multithreading is also relatively inexpensive to implement, because it replicates only the PC and register file, not the execution units and memories.
7.8.8 Homogeneous Multiprocessors
A multiprocessor system consists of multiple processors and a method for communication between the processors. A common form of multiprocessing in computer systems is homogeneous multiprocessing, also called symmetric multiprocessing (SMP), in which two or more identical processors share a single main memory.
Scientists searching for signs of extraterrestrial intelligence use the world’s largest clustered multiprocessors to analyze radio telescope data for patterns that might be signs of life in other solar systems. The cluster consists of personal computers owned by more than 3.8 million volunteers around the world.
When a computer in the cluster is idle, it fetches a piece of the data from a centralized server, analyzes the data, and sends the results back to the server. You can volunteer your computer’s idle time for the cluster by visiting setiathome.berkeley.edu.
The multiple processors may be separate chips or multiple cores on the same chip. Modern processors have enormous numbers of transistors available. Using them to increase the pipeline depth or to add more execution units to a superscalar processor gives little performance benefit and is wasteful of power. Around the year 2005, computer architects made a major shift to building multiple copies of the processor on the same chip; these copies are called cores.
Multiprocessors can be used to run more threads simultaneously or to run a particular thread faster. Running more threads simultaneously is easy; the threads are simply divided up among the processors. Unfortunately typical PC users need to run only a small number of threads at any given time. Running a particular thread faster is much more challenging. The programmer must divide the existing thread into multiple threads to execute on each processor. This becomes tricky when the processors need to communicate with each other. One of the major challenges for computer designers and programmers is to effectively use large numbers of processor cores.
Other forms of multiprocessing include heterogeneous multiprocessing and clusters. Heterogeneous multiprocessors, also called asymmetric multiprocessors, use separate specialized microprocessors for separate tasks and are discussed next. In clustered multiprocessing, each processor has its own local memory system. Clustering can also refer to a group of PCs connected together on the network running software to jointly solve a large problem.
7.8.9 Heterogeneous Multiprocessors
The homogeneous multiprocessors described in Section 7.8.8 have a number of advantages. They are relatively simple to design because the processor can be designed once and then replicated multiple times to increase performance. Programming for and executing code on a homogeneous multiprocessor is also relatively straightforward because any program can run on any processor in the system and achieve approximately the same performance.
Unfortunately, continuing to add more and more cores is not guaranteed to provide continued performance improvement. As of 2012, consumer applications employed only 2–3 threads on average at any given time, and a typical consumer might be expected to have a couple of applications actually computing simultaneously. While this is enough to keep dual- and quad-core systems busy, unless programs start incorporating significantly more parallelism, continuing to add more cores beyond this point will provide diminishing benefits. As an added issue, because general purpose processors are designed to provide good average performance they are generally not the most power efficient option for performing a given operation. This energy inefficiency is especially important in highly power-constrained portable environments.
Heterogeneous multiprocessors aim to address these issues by incorporating different types of cores and/or specialized hardware in a single system. Each application uses those resources that provide the best performance, or power-performance ratio, for that application. Because transistors are fairly plentiful these days, the fact that not every application will make use of every piece of hardware is of minimal concern. Heterogeneous systems can take a number of forms. A heterogeneous system can incorporate cores with different microarchitectures that have different power, performance, and area tradeoffs. For example, a system could include both simple single-issue in-order cores and more complex superscalar out-of-order cores. Applications that can make efficient use of the higher performing, but more power hungry, out-of-order cores have that option available to them, while other applications that do not use the added computation effectively can use the more energy efficient in-order cores.
In such a system, the cores may all use the same ISA, which allows an application to run on any of the cores, or may employ different ISAs, which can allow further tailoring of a core to a given task. IBM’s Cell Broadband Engine is an example of the latter. The Cell incorporates a single dual-issue in-order power processor element (PPE) with eight synergistic processor elements (SPEs). The SPEs use a new ISA, the SPU ISA, that is tailored to power efficiency for computationally intensive workloads. Although multiple programming paradigms are possible, the general idea is that the PPE handles most control and management decisions, such as dividing the workload among the SPEs, while the SPEs handle the majority of the computation. The heterogeneous nature of the Cell allows it to provide far higher computational performance for a given power and area than would be possible using traditional Power processors.
Other heterogeneous systems can include a mix of traditional cores and specialized hardware. Floating-point coprocessors are an early example of this. In early microprocessors, there was not space for floating-point hardware on the main chip. Users interested in floating-point performance could add a separate chip that provided dedicated floating-point support. Today’s microprocessors include one or more floating-point units on chip and are now beginning to include other types of specialized hardware. AMD and Intel both have processors that incorporate a graphics processing unit (GPU) or FPGA and one or more traditional x86 cores on the same chip. AMD’s Fusion line and Intel’s Sandy Bridge are the first set of devices to incorporate a processor and GPU in the same die. Intel’s E600 (Stellarton) series chips, released in early 2011, pair an Atom processor with an Altera FPGA, again on the same die. At a chip level, a cell phone contains both a conventional processor to handle user interaction, such as managing the phone book, processing websites and playing games, and a digital signal processor (DSP) with specialized instructions to decipher wireless data in real time. In power constrained environments, these types of integrated, specialized hardware provide better power-performance tradeoffs than performing the same operation on a standard core.
Heterogeneous systems are not without their drawbacks. They add complexity, both in terms of designing the different heterogeneous elements and in terms of the additional programming effort to decide when and how to make use of the varying resources. In the end, homogeneous and heterogeneous systems will both likely have their places. Homogeneous multiprocessors are good for situations, like large data centers, that have lots of thread level parallelism available. Heterogeneous systems are good for cases that have more varying workloads and limited parallelism.
Synergistic Processor Unit (SPU) ISA
The SPU ISA is designed to provide the same performance as general purpose processors at half the area and power for certain sets of workloads. Specifically, the SPU ISA targets graphics, stream processing, and other highly computational workloads, such as game physics and other system modeling. To achieve the desired performance, power, and area goals, the ISA incorporates a number of features, including 128-bit SIMD execution, software-managed memory, and a large register file. In software-managed memory the programmer is explicitly responsible for moving data into and out of local memory, as opposed to the caches of common processors, which bring data in automatically. If used correctly, this can both save power and improve performance because necessary data is brought in ahead of time and only when needed. The large register file helps avoid register starvation without the need for expensive register renaming.
7.9 Real-World Perspective: x86 Microarchitecture*
Section 6.8 introduced the x86 architecture used in almost all PCs. This section tracks the evolution of x86 processors through progressively faster and more complicated microarchitectures. The same principles we have applied to the MIPS microarchitectures are used in x86.
Intel invented the first single-chip microprocessor, the 4-bit 4004, in 1971 as a flexible controller for a line of calculators. It contained 2300 transistors manufactured on a 12-mm2 sliver of silicon in a process with a 10-μm feature size and operated at 750 kHz. A photograph of the chip taken under a microscope is shown in Figure 7.73.

Figure 7.73 4004 microprocessor chip
In places, columns of four similar-looking structures are visible, as one would expect in a 4-bit microprocessor. Around the periphery are bond wires, which are used to connect the chip to its package and the circuit board.
The 4004 inspired the 8-bit 8008, then the 8080, which eventually evolved into the 16-bit 8086 in 1978 and the 80286 in 1982. In 1985, Intel introduced the 80386, which extended the 8086 architecture to 32 bits and defined the x86 architecture. Table 7.7 summarizes major Intel x86 microprocessors. In the 40 years since the 4004, transistor feature size has shrunk 160-fold, the number of transistors on a chip has increased by five orders of magnitude, and the operating frequency has increased by almost four orders of magnitude. No other field of engineering has made such astonishing progress in such a short time.
Table 7.7 Evolution of Intel x86 microprocessors

The 80386 is a multicycle processor. The major components are labeled on the chip photograph in Figure 7.74. The 32-bit datapath is clearly visible on the left. Each of the columns processes one bit of data. Some of the control signals are generated using a microcode PLA that steps through the various states of the control FSM. The memory management unit in the upper right controls access to the external memory.

Figure 7.74 80386 microprocessor chip
The 80486, shown in Figure 7.75, dramatically improved performance using pipelining. The datapath is again clearly visible, along with the control logic and microcode PLA. The 80486 added an on-chip floating-point unit; previous Intel processors either sent floating-point instructions to a separate coprocessor or emulated them in software. The 80486 was too fast for external memory to keep up, so it incorporated an 8-KB cache onto the chip to hold the most commonly used instructions and data. Chapter 8 describes caches in more detail and revisits the cache systems on Intel x86 processors.

Figure 7.75 80486 microprocessor chip
The Pentium processor, shown in Figure 7.76, is a superscalar processor capable of executing two instructions simultaneously. Intel switched to the name Pentium instead of 80586 because AMD was becoming a serious competitor selling interchangeable 80486 chips, and part numbers cannot be trademarked. The Pentium uses separate instruction and data caches. It also uses a branch predictor to reduce the performance penalty for branches.

Figure 7.76 Pentium microprocessor chip
The Pentium Pro, Pentium II, and Pentium III processors all share a common out-of-order microarchitecture, code-named P6. The complex x86 instructions are broken down into one or more micro-ops similar to MIPS instructions. The micro-ops are then executed on a fast out-of-order execution core with an 11-stage pipeline. Figure 7.77 shows the Pentium III. The 32-bit datapath is called the Integer Execution Unit (IEU). The floating-point datapath is called the Floating Point Unit (FPU). The processor also has a SIMD unit to perform packed operations on short integer and floating-point data. A larger portion of the chip is dedicated to issuing instructions out-of-order than to actually executing the instructions. The instruction and data caches have grown to 16 KB each. The Pentium III also has a larger but slower 256-KB second-level cache on the same chip.

Figure 7.77 Pentium III microprocessor chip
By the late 1990s, processors were marketed largely on clock speed. The Pentium 4 is another out-of-order processor with a very deep pipeline to achieve extremely high clock frequencies. It started with 20 stages, and later versions adopted 31 stages to achieve frequencies greater than 3 GHz. The chip, shown in Figure 7.78, packs in 42 to 178 million transistors (depending on the cache size), so even the major execution units are difficult to see on the photograph. Decoding three x86 instructions per cycle is impossible at such high clock frequencies because the instruction encodings are so complex and irregular. Instead, the processor predecodes the instructions into simpler micro-ops, then stores the micro-ops in a memory called a trace cache. Later versions of the Pentium 4 also perform multithreading to increase the throughput of multiple threads.

Figure 7.78 Pentium 4 microprocessor chip
The Pentium 4’s reliance on deep pipelines and high clock speed led to extremely high power consumption, sometimes more than 100 W. This is unacceptable in laptops and makes cooling of desktops expensive.
Intel discovered that the older P6 architecture could achieve comparable performance at much lower clock speed and power. The Pentium M uses an enhanced version of the P6 out-of-order microarchitecture with 32-KB instruction and data caches and a 1- to 2-MB second-level cache. The Core Duo is a multicore processor based on two Pentium M cores connected to a shared 2-MB second-level cache. The individual functional units in Figure 7.79 are difficult to see, but the two cores and the large cache are clearly visible.

Figure 7.79 Core Duo microprocessor chip
In 2009, Intel introduced a new microarchitecture code-named Nehalem that streamlines the initial Core microarchitecture. These processors, including the Core i3, i5, and i7 series, extend the instruction set to 64 bits. They offer from 2 to 6 cores, 3–15 MB of third-level cache, and a built-in memory controller. Some models include built-in graphics processors, also called graphics accelerators. Some support “TurboBoost” to improve the performance of single-threaded code by turning off the unused cores and raising the voltage and clock frequency of the boosted core. Some offer “hyperthreading,” Intel’s term for 2-way multithreading that doubles the number of cores from the user’s perspective. Figure 7.80 shows a Core i7 die with four cores and 8 MB of shared L3 cache.
Figure 7.80 Core i7 microprocessor chip
Source: http://www.intel.com/pressroom/archive/releases/2008/20081117comp_sm.htm. Courtesy Intel
7.10 Summary
This chapter has described three ways to build MIPS processors, each with different performance and cost trade-offs. We find this topic almost magical: how can such a seemingly complicated device as a microprocessor actually be simple enough to fit in a half-page schematic? Moreover, the inner workings, so mysterious to the uninitiated, are actually reasonably straightforward.
The MIPS microarchitectures have drawn together almost every topic covered in the text so far. Piecing together the microarchitecture puzzle illustrates the principles introduced in previous chapters, including the design of combinational and sequential circuits, covered in Chapters 2 and 3; the application of many of the building blocks described in Chapter 5; and the implementation of the MIPS architecture, introduced in Chapter 6. The MIPS microarchitectures can be described in a few pages of HDL, using the techniques from Chapter 4.
Building the microarchitectures has also heavily used our techniques for managing complexity. The microarchitectural abstraction forms the link between the logic and architecture abstractions, forming the crux of this book on digital design and computer architecture. We also use the abstractions of block diagrams and HDL to succinctly describe the arrangement of components. The microarchitectures exploit regularity and modularity, reusing a library of common building blocks such as ALUs, memories, multiplexers, and registers. Hierarchy is used in numerous ways. The microarchitectures are partitioned into the datapath and control units. Each of these units is built from logic blocks, which can be built from gates, which in turn can be built from transistors using the techniques developed in the first five chapters.
This chapter has compared single-cycle, multicycle, and pipelined microarchitectures for the MIPS processor. All three microarchitectures implement the same subset of the MIPS instruction set and have the same architectural state. The single-cycle processor is the most straightforward and has a CPI of 1.
The multicycle processor uses a variable number of shorter steps to execute instructions. It thus can reuse the ALU, rather than requiring several adders. However, it does require several nonarchitectural registers to store results between steps. The multicycle design in principle could be faster, because not all instructions must be equally long. In practice, it is generally slower, because it is limited by the slowest steps and by the sequencing overhead in each step.
The pipelined processor divides the single-cycle processor into five relatively fast pipeline stages. It adds pipeline registers between the stages to separate the five instructions that are simultaneously executing. It nominally has a CPI of 1, but hazards force stalls or flushes that increase the CPI slightly. Hazard resolution also costs some extra hardware and design complexity. The clock period ideally could be five times shorter than that of the single-cycle processor. In practice, it is not that short, because it is limited by the slowest stage and by the sequencing overhead in each stage. Nevertheless, pipelining provides substantial performance benefits. All modern high-performance microprocessors use pipelining today.
Although the microarchitectures in this chapter implement only a subset of the MIPS architecture, we have seen that supporting more instructions involves straightforward enhancements of the datapath and controller. Supporting exceptions also requires simple modifications.
A major limitation of this chapter is that we have assumed an ideal memory system that is fast and large enough to store the entire program and data. In reality, large fast memories are prohibitively expensive. The next chapter shows how to get most of the benefits of a large fast memory with a small fast memory that holds the most commonly used information and one or more larger but slower memories that hold the rest of the information.
Exercises
Exercise 7.1 Suppose that one of the following control signals in the single-cycle MIPS processor has a stuck-at-0 fault, meaning that the signal is always 0, regardless of its intended value. What instructions would malfunction? Why?
Exercise 7.2 Repeat Exercise 7.1, assuming that the signal has a stuck-at-1 fault.
Exercise 7.3 Modify the single-cycle MIPS processor to implement one of the following instructions. See Appendix B for a definition of the instructions. Mark up a copy of Figure 7.11 to indicate the changes to the datapath. Name any new control signals. Mark up a copy of Table 7.8 to show the changes to the main decoder. Describe any other changes that are required.
Table 7.8 Main decoder truth table to mark up with changes

Exercise 7.4 Repeat Exercise 7.3 for the following MIPS instructions.
Exercise 7.5 Many processor architectures have a load with postincrement instruction, which updates the index register to point to the next memory word after completing the load. lwinc $rt, imm($rs) is equivalent to the following two instructions:
lw $rt, imm($rs)
addi $rs, $rs, 4
Repeat Exercise 7.3 for the lwinc instruction. Is it possible to add the instruction without modifying the register file?
Exercise 7.6 Add a single-precision floating-point unit to the single-cycle MIPS processor to handle add.s, sub.s, and mul.s. Assume that you have single-precision floating-point adder and multiplier units available. Explain what changes must be made to the datapath and the controller.
Exercise 7.7 Your friend is a crack circuit designer. She has offered to redesign one of the units in the single-cycle MIPS processor to have half the delay. Using the delays from Table 7.6, which unit should she work on to obtain the greatest speedup of the overall processor, and what would the cycle time of the improved machine be?
Exercise 7.8 Consider the delays given in Table 7.6. Ben Bitdiddle builds a prefix adder that reduces the ALU delay by 20 ps. If the other element delays stay the same, find the new cycle time of the single-cycle MIPS processor and determine how long it takes to execute a benchmark with 100 billion instructions.
Exercise 7.9 Suppose one of the following control signals in the multicycle MIPS processor has a stuck-at-0 fault, meaning that the signal is always 0, regardless of its intended value. What instructions would malfunction? Why?
Exercise 7.10 Repeat Exercise 7.9, assuming that the signal has a stuck-at-1 fault.
Exercise 7.11 Modify the HDL code for the single-cycle MIPS processor, given in Section 7.6.1, to handle one of the new instructions from Exercise 7.3. Enhance the testbench, given in Section 7.6.3, to test the new instruction.
Exercise 7.12 Repeat Exercise 7.11 for the new instructions from Exercise 7.4.
Exercise 7.13 Modify the multicycle MIPS processor to implement one of the following instructions. See Appendix B for a definition of the instructions. Mark up a copy of Figure 7.27 to indicate the changes to the datapath. Name any new control signals. Mark up a copy of Figure 7.39 to show the changes to the controller FSM. Describe any other changes that are required.
Exercise 7.14 Repeat Exercise 7.13 for the following MIPS instructions.
Exercise 7.15 Repeat Exercise 7.5 for the multicycle MIPS processor. Show the changes to the multicycle datapath and control FSM. Is it possible to add the instruction without modifying the register file?
Exercise 7.16 Repeat Exercise 7.6 for the multicycle MIPS processor.
Exercise 7.17 Suppose that the floating-point adder and multiplier from Exercise 7.16 each take two cycles to operate. In other words, the inputs are applied at the beginning of one cycle, and the output is available in the second cycle. How does your answer to Exercise 7.16 change?
Exercise 7.18 Your friend, the crack circuit designer, has offered to redesign one of the units in the multicycle MIPS processor to be much faster. Using the delays from Table 7.6, which unit should she work on to obtain the greatest speedup of the overall processor? How fast should it be? (Making it faster than necessary is a waste of your friend’s effort.) What is the cycle time of the improved processor?
Exercise 7.19 Repeat Exercise 7.8 for the multicycle processor. Assume the instruction mix of Example 7.7.
Exercise 7.20 Suppose the multicycle MIPS processor has the component delays given in Table 7.6. Alyssa P. Hacker designs a new register file that has 40% less power but twice as much delay. Should she switch to the slower but lower power register file for her multicycle processor design?
Exercise 7.21 Goliath Corp claims to have a patent on a three-ported register file. Rather than fighting Goliath in court, Ben Bitdiddle designs a new register file that has only a single read/write port (like the combined instruction and data memory). Redesign the MIPS multicycle datapath and controller to use his new register file.
Exercise 7.22 What is the CPI of the redesigned multicycle MIPS processor from Exercise 7.21? Use the instruction mix from Example 7.7.
Exercise 7.23 How many cycles are required to run the following program on the multicycle MIPS processor? What is the CPI of this program?
addi $s0, $0, done # result = 5
while:
beq $s0, $0, done # if result > 0, execute while block
addi $s0, $s0, -1 # while block: result = result-1
j while
done:
Exercise 7.24 Repeat Exercise 7.23 for the following program.
add $s0, $0, $0 # i = 0
add $s1, $0, $0 # sum = 0
addi $t0, $0, 10 # $t0 = 10
loop:
slt $t1, $s0, $t0 # if (i < 10), $t1 = 1, else $t1 = 0
beq $t1, $0,done # if $t1 == 0 (i > = 10), branch to done
add $s1, $s1, $s0 # sum = sum + i
addi $s0, $s0, 1 # increment i
j loop
done:
Exercise 7.25 Write HDL code for the multicycle MIPS processor. The processor should be compatible with the following top-level module. The mem module is used to hold both instructions and data. Test your processor using the testbench from Section 7.6.3.
module top(inputlogic clk, reset,
output logic [31:0] writedata, adr,
output logic memwrite);
logic [31:0] readdata;
// instantiate processor and memories
mips mips(clk, reset, adr, writedata, memwrite, readdata);
mem mem(clk, memwrite, adr, writedata, readdata);
endmodule
module mem(input logic clk, we,
input logic [31:0] a, wd,
output logic [31:0] rd);
logic [31:0] RAM[63:0];
initial
begin
$readmemh("memfile.dat", RAM);
end
assign rd = RAM[a[31:2]]; // word aligned
always @(posedge clk)
if (we)
RAM[a[31:2]] <= wd;
endmodule
Exercise 7.26 Extend your HDL code for the multicycle MIPS processor from Exercise 7.25 to handle one of the new instructions from Exercise 7.13. Enhance the testbench to test the new instruction.
Exercise 7.27 Repeat Exercise 7.26 for one of the new instructions from Exercise 7.14.
Exercise 7.28 The pipelined MIPS processor is running the following program. Which registers are being written, and which are being read on the fifth cycle?
addi $s1, $s2, 5
sub $t0, $t1, $t2
lw $t3, 15($s1)
sw $t5, 72($t0)
or $t2, $s4, $s5
Exercise 7.29 Repeat Exercise 7.28 for the following MIPS program. Recall that the pipelined MIPS processor has a hazard unit.
add $s0, $t0, $t1
sub $s1, $t2, $t3
and $s2, $s0, $s1
or $s3, $t4, $t5
slt $s4, $s2, $s3
Exercise 7.30 Using a diagram similar to Figure 7.52, show the forwarding and stalls needed to execute the following instructions on the pipelined MIPS processor.
add $t0, $s0, $s1
sub $t0, $t0, $s2
Iw $t1, 60($t0)
and $t2, $t1, $t0
Exercise 7.31 Repeat Exercise 7.30 for the following instructions.
add $t0, $s0, $s1
Iw $t1, 60($s2)
sub $t2, $t0, $s3
and $t3, $t1, $t0
Exercise 7.32 How many cycles are required for the pipelined MIPS processor to issue all of the instructions for the program in Exercise 7.23? What is the CPI of the processor on this program?
Exercise 7.33 Repeat Exercise 7.32 for the instructions of the program in Exercise 7.24.
Exercise 7.34 Explain how to extend the pipelined MIPS processor to handle the addi instruction.
Exercise 7.35 Explain how to extend the pipelined processor to handle the j instruction. Give particular attention to how the pipeline is flushed when a jump takes place.
Exercise 7.36 Examples 7.9 and 7.10 point out that the pipelined MIPS processor performance might be better if branches take place during the Execute stage rather than the Decode stage. Show how to modify the pipelined processor from Figure 7.58 to branch in the Execute stage. How do the stall and flush signals change? Redo Examples 7.9 and 7.10 to find the new CPI, cycle time, and overall time to execute the program.
Exercise 7.37 Your friend, the crack circuit designer, has offered to redesign one of the units in the pipelined MIPS processor to be much faster. Using the delays from Table 7.6 and Example 7.10, which unit should she work on to obtain the greatest speedup of the overall processor? How fast should it be? (Making it faster than necessary is a waste of your friend’s effort.) What is the cycle time of the improved processor?
Exercise 7.38 Consider the delays from Table 7.6 and Example 7.10. Now suppose that the ALU were 20% faster. Would the cycle time of the pipelined MIPS processor change? What if the ALU were 20% slower?
Exercise 7.39 Suppose the MIPS pipelined processor is divided into 10 stages of 400 ps each, including sequencing overhead. Assume the instruction mix of Example 7.7. Also assume that 50% of the loads are immediately followed by an instruction that uses the result, requiring six stalls, and that 30% of the branches are mispredicted. The target address of a branch or jump instruction is not computed until the end of the second stage. Calculate the average CPI and execution time of computing 100 billion instructions from the SPECINT2000 benchmark for this 10-stage pipelined processor.
Exercise 7.40 Write HDL code for the pipelined MIPS processor. The processor should be compatible with the top-level module from HDL Example 7.13. It should support all of the instructions described in this chapter, including addi and j (see Exercises 7.34 and 7.35). Test your design using the testbench from HDL Example 7.12.
Exercise 7.41 Design the hazard unit shown in Figure 7.58 for the pipelined MIPS processor. Use an HDL to implement your design. Sketch the hardware that a synthesis tool might generate from your HDL.
Exercise 7.42 A nonmaskable interrupt (NMI) is triggered by an input pin to the processor. When the pin is asserted, the current instruction should finish, then the processor should set the Cause register to 0 and take an exception. Show how to modify the multicycle processor in Figures 7.63 and 7.64 to handle nonmaskable interrupts.
Interview Questions
The following exercises present questions that have been asked at interviews for digital design jobs.
Question 7.1 Explain the advantages of pipelined microprocessors.
Question 7.2 If additional pipeline stages allow a processor to go faster, why don’t processors have 100 pipeline stages?
Question 7.3 Describe what a hazard is in a microprocessor and explain ways in which it can be resolved. What are the pros and cons of each way?
Question 7.4 Describe the concept of a superscalar processor and its pros and cons.
1 This is an oversimplification used to treat the instruction memory as a ROM; in most real processors, the instruction memory must be writable so that the OS can load a new program into memory. The multicycle microarchitecture described in Section 7.4 is more realistic in that it uses a combined memory for instructions and data that can be both read and written.
2 Now we see why the PCSrc multiplexer is necessary to choose PC′ from either ALUResult (in S0) or ALUOut (in S8).
3 Data from Patterson and Hennessy, Computer Organization and Design, 4th Edition, Morgan Kaufmann, 2011.
4 Strictly speaking, only the register designations (RsE, RtE, and RdE) and the control signals that might update memory or architectural state (RegWrite, MemWrite, and Branch) need to be cleared; as long as these signals are cleared, the bubble can contain random data that has no effect.
5 Strictly speaking, the ALU should assert overflow only for add and sub, not for other ALU instructions.
6 You might wonder why the add needs to be issued at all. The reason is that out-of-order processors must guarantee that all of the same exceptions occur that would have occurred if the program had been executed in its original order. The add potentially may produce an overflow exception, so it must be issued to check for the exception, even though the result can be discarded.