
In this chapter
12.1 Assertion Statements:
assert()page 42812.2 Low-Level Memory: The
memXXX()Functions page 43212.3 Temporary Files page 436
12.4 Committing Suicide:
abort()page 44512.5 Nonlocal Gotos page 446
12.6 Pseudorandom Numbers page 454
12.7 Metacharacter Expansions page 461
12.8 Regular Expressions page 471
12.9 Suggested Reading page 480
12.10 Summary page 481
Exercises page 482
Chapter 6, “General Library Interfaces — Part 1,” page 165, presented the first set of general-purpose library APIs. In a sense, those APIs support working with the fundamental objects that Linux and Unix systems manage: the time of day, users and groups for files, and sorting and searching.
This chapter is more eclectic; the APIs covered here are not particularly related to each other. However, all are useful for day-to-day Linux/Unix programming. Our presentation moves from simpler, more general APIs to more complicated and more specialized ones.
An assertion is a statement you make about the state of your program at certain points in time during its execution. The use of assertions for programming was originally developed by C.A.R. Hoare.[1] The general idea is part of “program verification”: That as you design and develop a program, you can show that it’s correct by making carefully reasoned statements about the effects of your program’s code. Often, such statements are made about invariants—facts about the program’s state that are supposed to remain true throughout the execution of a chunk of code.
Assertions are particularly useful for describing two kinds of invariants: preconditions and postconditions: conditions that must hold true before and after, respectively, the execution of a code segment. A simple example of preconditions and postconditions is linear search:
/* lsearch --- return index in array of value, or -1 if not found */
int lsearch(int *array, size_t size, int value)
{
size_t i;
/* precondition: array != NULL */
/* precondition: size > 0 */
for (i = 0; i < size; i++)
if (array[i] == value)
return i;
/* postcondition: i == size */
return -1;
}
This example states the conditions using comments. But wouldn’t it be better to be able to test the conditions by using code? This is the job of the assert() macro:
#include <assert.h> ISO C void assert(scalar expression);
When the scalar expression is false, the assert() macro prints a diagnostic message and exits the program (with the abort() function; see Section 12.4, “Committing Suicide: abort(),” page 445). ch12-assert.c provides the lsearch() function again, this time with assertions and a main() function:
1 /* ch12-assert.c --- demonstrate assertions */ 2 3 #include <stdio.h> 4 #include <assert.h> 5 6 /* lsearch --- return index in array of value, or -1 if not found */ 7 8 int lsearch(int *array, size_t size, int value) 9 { 10 size_t i; 11 12 assert(array != NULL); 13 assert(size > 0); 14 for (i = 0; i < size; i++) 15 if (array[i] == value) 16 return i; 17 18 assert(i == size); 19 20 return -1; 21 } 22 23 /* main --- test out assertions */ 24 25 int main(void) 26 { 27 #define NELEMS 4 28 static int array[NELEMS] = { 1, 17, 42, 91 }; 29 int index; 30 31 index = lsearch(array, NELEMS, 21); 32 assert(index == -1); 33 34 index = lsearch(array, NELEMS, 17); 35 assert(index == 1); 36 37 index = lsearch(NULL, NELEMS, 10); /* won't return */ 38 39 printf("index = %d ", index); 40 41 return 0; 42 }
When compiled and run, the assertion on line 12 “fires:”
$ ch12-assert Run the program ch12-assert: ch12-assert.c:12: lsearch: Assertion `array != ((void *)0)' failed. Aborted (core dumped)
The message from assert() varies from system to system. For GLIBC on GNU/Linux, the message includes the program name, the source code filename and line number, the function name, and then the text of the failed assertion. (In this case, the symbolic constant NULL shows up as its macro expansion, ’((void *)0)’.)
The ’Aborted (core dumped)’ message means that ch12-assert created a core file; that is, a snapshot of the process’s address space right before it died.[2] This file can be used later, with a debugger; see Section 15.3, “GDB Basics,” page 570. Core file creation is a purposeful side effect of assert(); the assumption is that something went drastically wrong, and you’ll want to examine the process with a debugger to determine what.
You can disable assertions by compiling your program with the command-line option `-DNDEBUG’. When this macro is defined before <assert.h> is included, the assert() macro expands into code that does nothing. For example:
$ gcc -DNDEBUG=1 ch12-assert.c -o ch12-assert Compile with -DNDEBUG $ ch12-assert Run it Segmentation fault (core dumped) What happened?
Here, we got a real core dump! We know that assertions were disabled; there’s no “failed assertion” message. So what happened? Consider line 15 of lsearch(), when called from line 37 of main(). In this case, the array variable is NULL. Accessing memory through a NULL pointer is an error. (Technically, the various standards leave as “undefined” what happens when you dereference a NULL pointer. Most modern systems do what GNU/Linux does; they kill the process by sending it a SIGSEGV signal; this in turn produces a core dump. This process is described in Chapter 10, “Signals,” page 347.)
This case raises an important point about assertions. Frequently, programmers mistakenly use assertions instead of runtime error checking. In our case, the test for ’array != NULL’ should be a runtime check:
if (array == NULL)
return -1;
The test for ’size > 0’ (line 13) is less problematic; if size is 0 or less than 0, the loop never executes and lsearch() (correctly) returns -1. (In truth, this assertion isn’t needed because the code correctly handles the case in which ’size <= 0’.)
The logic behind turning off assertions is that the extra checking can slow program performance and that therefore they should be disabled for the production version of a program. C.A.R. Hoare[3] made this observation, however:
Finally, it is absurd to make elaborate security checks on debugging runs, when no trust is put in the results, and then remove them in production runs, when an erroneous result could be expensive or disastrous. What would we think of a sailing enthusiast who wears his lifejacket when training on dry land, but takes it off as soon as he goes to sea?
Given these sentiments, our recommendation is to use assertions thoughtfully: First, for any given assertion, consider whether it should instead be a runtime check. Second, place your assertions carefully so that you won’t mind leaving assertion checking enabled, even in the production version of your program.
Finally, we’ll note the following, from the “BUGS” section of the GNU/Linux assert(3) manpage:
assert()is implemented as a macro; if the expression tested has side effects, program behavior will be different depending on whetherNDEBUGis defined. This may create Heisenbugs which go away when debugging is turned on.
Heisenberg’s famous Uncertainty Principle from physics indicates that the more precisely you can determine a particle’s velocity, the less precisely you can determine its position, and vice versa. In layman’s terms, it states that the mere act of observing the particle affects it.
A similar phenomenon occurs in programming, not related to particle physics: The act of compiling a program for debugging, or running it with debugging enabled can change the program’s behavior. In particular, the original bug can disappear. Such a bug is known colloquially as a heisenbug.
The manpage is warning us against putting expressions with side effects into assert() calls:
assert(*p++ == ' '),
The side-effect here is that the p pointer is incremented as part of the test. When NDEBUG is defined, the expression argument disappears from the source code; it’s never executed. This can lead to an unexpected failure. However, as soon as assertions are reenabled in preparation for debugging, things start working again! Such problems are painful to track down.
Several functions provide low-level services for working with arbitrary blocks of memory. Their names all start with the prefix ’mem’:
#include <string.h> ISO C
void *memset(void *buf, int val, size_t count);
void *memcpy(void *dest, const void *src, size_t count);
void *memmove(void *dest, const void *src, size_t count);
void *memccpy(void *dest, const void *src, int val, size_t count);
int memcmp(const void *buf1, const void *buf2, size_t count);
void *memchr(const void *buf, int val, size_t count);
The memset() function copies the value val (treated as an unsigned char) into the first count bytes of buf. It is particularly useful for zeroing out blocks of dynamic memory:
void *p = malloc(count);
if (p != NULL)
memset(p, 0, count);
However, memset() can be used on any kind of memory, not just dynamic memory. The return value is the first argument: buf.
Three functions copy one block of memory to another. The first two differ in their handling of overlapping memory areas; the third copies memory but stops upon seeing a particular value.
void *memcpy(void *dest, const void *src, size_t count)
This is the simplest function. It copies
countbytes fromsrctodest. It does not handle overlapping memory areas. It returnsdest.
void *memmove(void *dest, const void *src, size_t count)
Similar to
memcpy(), it also copiescountbytes fromsrctodest. However, it does handle overlapping memory areas. It returnsdest.
void *memccpy(void *dest, const void *src, int val, size_t count)
This copies bytes from
srctodeststopping either after copyingvalintodestor after copyingcountbytes. If it foundval, it returns a pointer to the position indestjust beyond wherevalwas placed. Otherwise, it returnsNULL.
Now, what’s the issue with overlapping memory? Consider Figure 12.1.
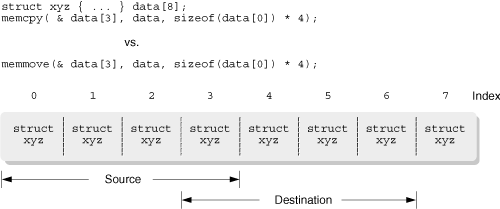
The goal is to copy the four instances of struct xyz in data[0] through data[3] into data[3] through data[6].data[3] is the problem here; a byte-by-byte copy moving forward in memory from data[0] will clobber data[3] before it can be safely copied into data[6]! (It’s also possible to come up with a scenario where a backwards copy through memory destroys overlapping data.)
The memcpy() function was the original System V API for copying blocks of memory; its behavior for overlapping blocks of memory wasn’t particularly defined one way or the other. For the 1989 C standard, the committee felt that this lack of defined behavior was a problem; thus they invented memmove(). For historical compatibility, memcpy() was left alone, with the behavior for overlapping memory specifically stated as undefined, and memmove() was invented to provide a routine that would correctly deal with problem cases.
Which one should you use in your own code? For a library function that has no knowledge of the memory areas being passed into it, you should use memmove(). That way, you’re guaranteed that there won’t be any problems with overlapping areas. For application-level code that “knows” that two areas don’t overlap, it’s safe to use memcpy().
For both memcpy() and memmove() (as for strcpy()), the destination buffer is the first argument and the source is the second one. To remember this, note that the order is the same as for an assignment statement:
dest = src;
(Many systems have manpages that don’t help, providing the prototype as ’void *memcpy(void *buf1, void *buf2, size_t n)’ and relying on the prose to explain which is which. Fortunately, the GNU/Linux manpage uses better names.)
The memcmp() function compares count bytes from two arbitrary buffers of data. Its return value is like strcmp(): negative, zero, or positive if the first buffer is less than, equal to, or greater than the second one.
You may be wondering “Why not use strcmp() for such comparisons?” The difference between the two functions is that memcmp() doesn’t care about zero bytes (the ’�’ string terminator). Thus, memcmp() is the function to use when you need to compare arbitrary binary data.
Another advantage to memcmp() is that it’s faster than the typical C implementation:
/* memcmp --- example C implementation, NOT for real use */
int memcmp(const void *buf1, const void *buf2, size_t count)
{
const unsigned char *cp1 = (const unsigned char *) buf1;
const unsigned char *cp2 = (const unsigned char *) buf2;
int diff;
while (count-- != 0) {
diff = *cp1++ - *cp2++;
if (diff != 0)
return diff;
}
return 0;
}
The speed can be due to special “block memory compare” instructions that many architectures support or to comparisons in units larger than bytes. (This latter operation is tricky and is best left to the library’s author.)
For these reasons, you should always use your library’s version of memcmp() instead of rolling your own. Chances are excellent that the library author knows the machine better than you do.
The memchr() function is similar to the strchr() function: It returns the location of a particular value within an arbitrary buffer. As for memcmp() vs. strcmp(), the principal reason to use memchr() is that you have arbitrary binary data.
GNU wc uses memchr() when counting only lines and bytes,[4] and this allows wc to be quite fast. From wc.c in the GNU Coreutils:
257 else if (!count_chars && !count_complicated) 258 { 259 /* Use a separate loop when counting only lines or lines and bytes -- 260 but not chars or words. */ 261 while ((bytes_read = safe_read (fd, buf, BUFFER_SIZE)) > 0) 262 { 263 register char *p = buf; 264 265 if (bytes_read == SAFE_READ_ERROR) 266 { 267 error (0, errno, "%s", file); 268 exit_status = 1; 269 break; 270 } 271 272 while ((p = memchr (p, ' ', (buf + bytes_read) - p))) 273 { 274 ++p; 275 ++lines; 276 } 277 bytes += bytes_read; 278 } 279 }
The outer loop (lines 261–278) reads data blocks from the input file. The inner loop (lines 272–276) uses memchr() to find and count newline characters. The complicated expression ’(buf + bytes_read) - p’ resolves to the number of bytes left between the current value of p and the end of the buffer.
The comment on lines 259–260 needs some explanation. Briefly, modern systems can use characters that occupy more than one byte in memory and on disk. (This is discussed in a little more detail in Section 13.4, “Can You Spell That for Me, Please?,” page 521.) Thus, wc has to use different code if it’s distinguishing characters from bytes: This code deals with the counting-bytes case.
A temporary file is exactly what it sounds like: A file that while a program runs, holds data that isn’t needed once the program exits. An excellent example is the sort program. sort reads standard input if no files are named on the command line or if you use ’-’ as the filename. Yet sort has to read all of its input data before it can output the sorted results. (Think about this a bit and you’ll see that it’s true.) While standard input is being read, the data must be stored somewhere until sort can sort it; this is the perfect use for a temporary file. sort also uses temporary files for storing intermediate sorted results.
Amazingly, there are five different functions for creating temporary files. Three of them work by creating strings representing (supposedly) unique filenames. As we’ll see, these should generally be avoided. The other two work by creating and opening the temporary file; these functions are preferred.
There are three functions whose purpose is to create the name of a unique, nonexistent file. Once you have such a filename, you can use it to create a temporary file. Since the name is unique, you’re “guaranteed” exclusive use of the file. Here are the function declarations:
#include <stdio.h> char *tmpnam(char *s); ISO C char *tempnam(const char *dir, const char *pfx); XSI char *mktemp(char *template); ISO C
The functions all provide different variations of the same theme: They fill in or create a buffer with the path of a unique temporary filename. The file is unique in that the created name doesn’t exist as of the time the functions create the name and return it. The functions work as follows:
char *tmpnam(char *s)
Generates a unique filename. If
sis notNULL, it should be at leastL_tmpnambytes in size and the unique name is copied into it. IfsisNULL, the name is generated in an internalstaticbuffer that can be overwritten on subsequent calls. The directory prefix of the path will beP_tmpdir. BothP_tmpdirandL_tmpnamare defined in<stdio.h>.
char *tempnam(const char *dir, const char *pfx)
Like
tmpnam(), lets you specify the directory prefix. IfdirisNULL, P_tmpdiris used. Thepfxargument, if notNULL, specifies up to five characters to use as the leading characters of the filename.tempnam()allocates storage for the filenames it generates. The returned pointer can be used later withfree()(and should be if you wish to avoid memory leaks).
Generates unique filenames based on a template. The last six characters of
templatemust be ’XXXXXX’; these characters are replaced with a unique suffix.
Note
The template argument to mktemp() is overwritten in place. Thus, it should not be a string constant. Many pre-Standard C compilers put string constants into the data segment, along with regular global variables. Although defined as constants in the source code, they were writable; thus, code like the following was not uncommon:
/* Old-style code: don't do this. */
char *tfile = mktemp("/tmp/myprogXXXXXX");
... use tfile ...
On modern systems, such code will likely fail; string constants nowadays find themselves in read-only segments of memory.
Using these functions is quite straightforward. The file ch12-mktemp.c demonstrates mktemp(); changes to use the other functions are not difficult:
1 /* ch12-mktemp.c --- demonstrate naive use of mktemp(). 2 Error checking omitted for brevity */ 3 4 #include <stdio.h> 5 #include <fcntl.h> /* for open flags */ 6 #include <limits.h> /* for PATH_MAX */ 7 8 int main(void) 9 { 10 static char template[] = "/tmp/myfileXXXXXX"; 11 char fname[PATH_MAX]; 12 static char mesg[] = 13 "Here's lookin' at you, kid! "; /* beats "hello, world" */ 14 int fd; 15 16 strcpy(fname, template); 17 mktemp(fname); 18 19 /* RACE CONDITION WINDOW OPENS */ 20 21 printf("Filename is %s ", fname); 22 23 /* RACE CONDITION WINDOW LASTS TO HERE */ 24 25 fd = open(fname, O_CREAT|o_RDWR|O_TRUNC, 0600); 26 write(fd, mesg, strlen(mesg)); 27 close(fd); 28 29 /* unlink(fname); */ 30 31 return 0; 32 }
The template variable (line 10) defines the filename template; the ’XXXXXX’ will be replaced with a unique value. Line 16 copies the template into fname, which isn’t const: It can be modified. Line 18 calls mktemp() to generate the filename, and line 21 prints it so we can see what it is. (We explain the comments on lines 19 and 23 shortly.)
Line 25 opens the file, creating it if necessary. Line 26 writes the message in mesg, and line 27 closes the file. In a program in which the file should be removed when we’re done with it, line 29 would not be commented out. (Sometimes, a temporary file should not be unlinked; for example, if the file will be renamed once it’s completely written.) We’ve commented it out so that we can run this program and look at the file afterwards. Here’s what happens when the program runs:
$ ch12-mktemp Run the program Filename is /tmp/myfileQES4WA Filename printed $ cat /tmp/myfileQES4WA Here's lookin' at you, kid! Contents are what we expect $ ls -l /tmp/myfileQES4WA So are owner and permissions -rw------- 1 arnold devel 28 Sep 18 09:27 /tmp/myfileQES4WA $ rm /tmp/myfileQES4WA Remove it $ ch12-mktemp Is same filename reused? Filename is /tmp/myfileic7xCy No. That's good $ cat /tmp/myfileic7xCy Check contents again Here's lookin' at you, kid! $ ls -l /tmp/myfileic7xCy Check owner and permissions again -rw------- 1 arnold devel 28 Sep 18 09:28 /tmp/myfileic7xCy
Everything seems to be working fine. mktemp() gives back a unique name, ch12-mktemp creates the file with the right permissions, and the contents are what’s expected. So what’s the problem with all of these functions?
Historically, mktemp() used a simple, predictable algorithm to generate the replacement characters for the ’XXXXXX’ in the template. Furthermore, the interval between the time the filename is generated and the time the file itself is created creates a race condition.
How? Well, Linux and Unix systems use time slicing, a technique that shares the processor among all the executing processes. This means that, although a program appears to be running all the time, in actuality, there are times when processes are sleeping, that is, waiting to run on the processor.
Now, consider a professor’s program for tracking student grades. Both the professor and a malicious student are using a heavily loaded, multiuser system at the same time.
The professor’s program uses mktemp() to create temporary files, and the student, having in the past watched the grading program create and remove temporary files, has figured out the algorithm that mktemp() uses. (The GLIBC version doesn’t have this problem, but not all systems use GLIBC!) Figure 12.2 illustrates the race condition and how the student takes advantage of it.
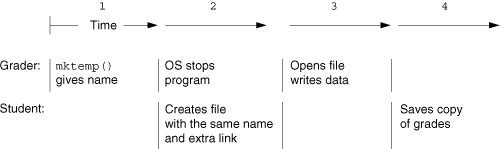
The grading program uses
mktemp()to generate a filename. Upon return frommktemp(), the race condition window is now open (line 19 inch12-mktemp.c).The kernel stops the grader so that other programs on the system can run. This happens before the call to
open().While the grader is stopped, the student creates the file with the same name
mktemp()returned to the grader program. (Remember, the algorithm was easy to figure out.) The student creates the file with an extra link to it, so that when the grading program unlinks the file, it will still be available for perusal.The grader program now opens the file and writes data to it. The student created the file with
-rw-rw-rw-permissions, so this isn’t a problem.When the grader program is finished, it unlinks the temporary file. However, the student still has a copy. For example, there may be a profit opportunity to sell classmates their grades in advance.
Our example is simplistic; besides just stealing the grade data, a clever (if immoral) student might be able to change the data in place. If the professor doesn’t double-check his program’s results, no one would be the wiser.
Note
We do not recommend doing any of this! If you are a student, don’t try any of this. First and foremost, it is unethical. Second, it’s likely to get you kicked out of school. Third, your professors are probably not so naive as to have used mktemp() to code their programs. The example is for illustration only!
For the reasons given, and others, all three functions described in this section should never be used. They exist in POSIX and in GLIBC only to support old programs that were written before the dangers of these routines were understood. To this end, GNU/Linux systems generate a warning at link time:
$ cc ch12-mktemp.c -o ch12-mktemp Compile the program /tmp/cc1XCvD9.o(.text+0x35) : In function 'main': : the use of 'mktemp' is dangerous, better use 'mkstemp'
(We cover mkstemp() in the next subsection.)
Should your system not have mkstemp(), think about how you might use these interfaces to simulate it. (See also “Exercises” for Chapter 12, page 482, at the end of the chapter.)
There are two functions that don’t have race condition problems. One is intended for use with the <stdio.h> library:
#include <stdio.h> ISO C
FILE *tmpfile(void);
The second function is for use with the file-descriptor-based system calls:
#include <stdlib.h> XSI
int mkstemp(char *template);
tmpfile() returns a FILE * value representing a unique, open temporary file. The file is opened in "w+b" mode. The w+ means “open for reading and writing, truncate the file first,” and the b means binary mode, not text mode. (There’s no difference on a GNU/Linux or Unix system, but there is on other systems.) The file is automatically deleted when the file pointer is closed; there is no way to get to the file’s name to save its contents. The program in ch12-tmpfile.c demonstrates tmpfile():
/* ch12-tmpfile.c --- demonstrate tmpfile().
Error checking omitted for brevity */
#include <stdio.h>
int main(void)
{
static char mesg[] =
"Here's lookin' at you, kid!"; /* beats "hello, world" */
FILE *fp;
char buf[BUFSIZ];
fp = tmpfile(); /* Get temp file */
fprintf(fp, "%s", mesg); /* Write to it */
fflush(fp); /* Force it out */
rewind(fp); /* Move to front */
fgets(buf, sizeof buf, fp); /* Read contents */
printf("Got back <%s>
", buf); /* Print retrieved data */
fclose(fp); /* Close file, goes away */
return 0; /* All done */
}
The returned FILE * value is no different from any other FILE * returned by fopen(). When run, the results are what’s expected:
$ ch12-tmpfile
Got back <Here's lookin' at you, kid!>
We saw earlier that the GLIBC authors recommend the use of mkstemp() function:
$ cc ch12-mktemp.c -o ch12-mktemp Compile the program /tmp/cc1XCvD9.o(.text+0x35): In function 'main': : the use of 'mktemp' is dangerous, better use 'mkstemp'
This function is similar to mktemp() in that it takes a filename ending in ’XXXXXX’ and replaces those characters with a unique suffix to create a unique filename. However, it goes one step further. It creates and opens the file. The file is created with mode 0600 (that is, -rw-------). Thus, only the user running the program can access the file.
Furthermore, and this is what makes mkstemp() more secure, the file is created using the O_EXCL flag, which guarantees that the file doesn’t exist and keeps anyone else from opening the file.
The return value is an open file descriptor that can be used for reading and writing. The pathname now stored in the buffer passed to mkstemp() should be used to remove the file when you’re done. This is all demonstrated in ch12-mkstemp.c, which is a straightforward modification of ch12-tmpfile.c:
/* ch12-mkstemp.c --- demonstrate mkstemp().
Error checking omitted for brevity */
#include <stdio.h>
#include <fcntl.h> /* for open flags */
#include <limits.h> /* for PATH_MAX */
int main(void)
{
static char template[] = "/tmp/myfileXXXXXX";
char fname[PATH_MAX];
static char mesg[] =
"Here's lookin' at you, kid!
"; /* beats "hello, world" */
int fd;
char buf[BUFSIZ];
int n;
strcpy(fname, template); /* Copy template */
fd = mkstemp(fname); /* Create and open temp file */
printf("Filename is %s
", fname); /* Print it for information */
write(fd, mesg, strlen(mesg)); /* Write something to file */
lseek(fd, 0L, SEEK_SET); /* Rewind to front */
n = read(fd, buf, sizeof(buf)); /* Read data back; NOT '�' terminated! */
printf("Got back: %.*s", n, buf); /* Print it out for verification */
close(fd); /* Close file */
unlink(fname); /* Remove it */
return 0;
}
When run, the results are as expected:
$ ch12-mkstemp
Filename is /tmp/myfileuXFW1N
Got back: Here's lookin' at you, kid!
Many standard utilities pay attention to the TMPDIR environment variable, using the directory it names as the place in which to put their temporary files. If TMPDIR isn’t set, then the default directory for temporary files is usually /tmp, although most modern systems have a /var/tmp directory as well. /tmp is usually cleared of all files and directories by administrative shell scripts at system startup.
Many GNU/Linux systems provide a directory /dev/shm that uses the tmpfs filesystem type:
$ df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda2 6198436 5136020 747544 88% /
/dev/hda5 61431520 27720248 30590648 48% /d
none 256616 0 256616 0% /dev/shm
The tmpfs filesystem type provides a RAM disk: a portion of memory used as if it were a disk. Furthermore, the tmpfs filesystem uses the Linux kernel’s virtual memory mechanisms to allow it to grow beyond a fixed size limit. If you have lots of RAM in your system, this approach can provide a noticeable speedup. To test performance we started with the /usr/share/dict/linux.words file, which is a sorted list of correctly spelled words, one per line. We then randomized this file so that it was no longer sorted and created a larger file containing 500 copies of the random version of the file:
$ ls -l /tmp/randwords.big Show size -rw-r--r-- 1 arnold devel 204652500 Sep 18 16:02 /tmp/randwords.big $ wc -l /tmp/randwords.big How many words? 22713500 /tmp/randwords.big Over 22 million!
We then sorted the file, first using the default /tmp directory, and then with TMPDIR set to /dev/shm:[5]
$ time sort /tmp/randwords.big > /dev/null Use real files real 1m32.566s user 1m23.137s sys 0m1.740s $ time TMPDIR=/dev/shm sort /tmp/randwords.big > /dev/null Use RAM disk real 1m28.257s user 1m18.469s sys 0m1.602s
Interestingly, using the RAM disk was only marginally faster than using regular files. (On some further tests, it was actually slower!) We conjecture that the kernel’s buffer cache (see Section 4.6.2, “Creating Files with creat(),” page 109) comes into the picture, quite effectively speeding up file I/O.[6]
The RAM disk has a significant disadvantage: It is limited by the amount of swap space configured on your system.[7] When we tried to sort a file containing 1,000 copies of the randomized words file, the RAM disk ran out of room, whereas the regular sort finished successfully.
Using TMPDIR for your own programs is straightforward. We offer the following outline:
const char template[] = "myprog.XXXXXX";
char *tmpdir, *tfile;
size_t count;
int fd;
if ((tmpdir = getenv("TMPDIR")) == NULL) Use TMPDIR value if there
tmpdir = "/tmp"; Otherwise, default to /tmp
count = strlen(tmpdir) + strlen(template) + 2; Compute size of filename
tfile = (char *) malloc(count); Allocate space for it
if (tfile == NULL) Check for error
/* recover */
sprintf(tfile, "%s/%s", tmpdir, template); Create final template
fd = mkstemp(tfile); Create and open file
... use tempfile via fd ...
close(fd); Clean up
unlink(tfile);
free(tfile);
Depending on your application’s needs, you may wish to unlink the file immediately after opening it instead of doing so as part of the cleanup.
There are times when a program just can’t continue. Generally, the best thing to do is to generate an error message and call exit(). However, particularly for errors that are likely to be programming problems, it’s helpful to not just exit but also to produce a core dump, which saves the state of the running program in a file for later examination with a debugger. This is the job of the abort() function:
#include <stdlib.h> ISO C
void abort(void);
The abort() function sends a SIGABRT signal to the process itself. This happens even if SIGABRT is blocked or ignored. The normal action for SIGABRT, which is to produce a core dump, then takes place.
An example of abort() in action is the assert() macro described at the beginning of this chapter. When assert() finds that its expression is false, it prints an error message and then calls abort() to dump core.
According to the C standard, it is implementation defined whether or not abort() does any cleanup actions. Under GNU/Linux it does: All <stdio.h> FILE * streams are closed before the program exits. Note, however, that nothing is done for open files that use the file descriptor-based system calls. (Nothing needs to be done if all that are open are files or pipes. Although we don’t discuss it, file descriptors are also used for network connections, and not closing them cleanly is poor practice.)
“Go directly to jail. Do not pass GO. Do not collect $200.” | ||
| --Monopoly | ||
You undoubtedly know what a goto is: a transfer of control flow to a label somewhere else within the current function. goto statements, when used sparingly, can contribute to the readability and correctness of a function. (For example, when all error checks use a goto to a label at the end of a function, such as clean_up, the code at that label then cleans things up [closing files, etc.] and returns.) When used poorly, goto statements can lead to so-called spaghetti code, the logic of which becomes impossible to follow.
The goto statement is constrained by the C language to jump to a label within the current function. Many languages in the Algol family, such as Pascal, allow a goto to “jump out” of a nested function into an earlier calling function. However in C, there is no way, within the syntax of the language itself, to jump to a location in a different function, even a calling one. Such a jump is termed a nonlocal goto.
Why is a nonlocal goto useful? Consider an interactive program that reads commands and processes them. Suppose the user starts a long-running task, gets frustrated or changes his mind about doing the task, and then presses CTRL-C to generate a SIGINT signal. When the signal handler runs, it can jump back to the start of the main read-commands-and-process-them loop. The ed line editor provides a straightforward example of this:
$ ed -p '>' sayings Start ed, use '>' as prompt sayings: No such file or directory > a Append text Hello, world Don't panic ^C Generate SIGINT ? The "one size fits all" error message > 1, $p ed returns to command loop Hello, world '1,$p' prints all the lines Don't panic > w Save file 25 > q All done
Internally, ed sets up a return point before the command loop, and the signal handler then does a nonlocal goto back to the return point.
Nonlocal gotos are accomplished with the setjmp() and longjmp() functions. These functions come in two flavors. The traditional routines are defined by the ISO C standard:
#include <setjmp.h> ISO C
int setjmp(jmp_buf env);
void longjmp(jmp_buf env, int val);
The jmp_buf type is typedef’d in <setjmp.h>. setjmp() saves the current “environment” in env. env is typically a global or file-level static variable so that it can be used from a called function. This environment includes whatever information is necessary for jumping to the location at which setjmp() is called. The contents of a jmp_buf are by nature machine dependent; thus, jmp_buf is an opaque type: something you use without knowing what’s inside it.
setjmp() returns 0 when it is called to save the current environment in a jmp_buf. It returns nonzero when a nonlocal jump is made using the environment:
jmp_buf command_loop; At global level ...then in main()... if (setjmp (command_loop) == 0) State saved OK, proceed on ; else We get here via nonlocal goto printf("? "); ed's famous message ...now start command loop...
longjmp() makes the jump. The first parameter is a jmp_buf that must have been initialized by setjmp(). The second is an integer nonzero value that setjmp() returns in the original environment. This is so that code such as that just shown can distinguish between setting the environment and arriving by way of a nonlocal jump.
The C standard states that even if longjmp() is called with a second argument of 0, setjmp() still returns nonzero. In such a case, it instead returns 1.
The ability to pass an integer value and have that come back from the return of setjmp() is useful; it lets user-level code distinguish the reason for the jump. For instance, gawk uses this capability to handle the break and continue statements inside loops. (The awk language is deliberately similar to C in its syntax for loops, with while, do-while, and for loops, and break and continue.) The use of setjmp() looks like this (from eval.c in the gawk 3.1.3 distribution):
507 case Node_K_while: 508 PUSH_BINDING(loop_tag_stack, loop_tag, loop_tag_valid); 509 510 stable_tree = tree; 511 while (eval_condition(stable_tree->lnode)) { 512 INCREMENT(stable_tree->exec_count); 513 switch (setjmp(loop_tag)) { 514 case 0: /* normal non-jump */ 515 (void) interpret (stable_tree->rnode); 516 break; 517 case TAG_CONTINUE: /* continue statement */ 518 break; 519 case TAG_BREAK: /* break statement */ 520 RESTORE_BINDING(loop_tag_stack, loop_tag, loop_tag_valid); 521 return 1; 522 default: 523 cant_happen(); 524 } 525 } 526 RESTORE_BINDING(loop_tag_stack, loop_tag, loop_tag_valid); 527 break;
This code fragment represents a while loop. Line 508 manages nested loops by means of a stack of saved jmp_buf variables. Lines 511–524 run the while loop (using a C while loop!). Line 511 tests the loop’s condition. If it’s true, line 513 does a switch on the setjmp() return value. If it’s 0 (lines 514–516), then line 515 runs the statement’s body. However, when setjmp() returns either TAG_BREAK or TAG_CONTINUE, the switch statement handles them appropriately (lines 517–518 and 519–521, respectively).
An awk-level break statement passes TAG_BREAK to longjmp(), and the awk-level continue passes TAG_CONTINUE. Again, from eval.c, with some irrelevant details omitted:
657 case Node_K_break: 658 INCREMENT(tree->exec_count); ... 675 longjmp(loop_tag, TAG_BREAK); 676 break; 677 678 case Node_K_continue: 679 INCREMENT(tree->exec_count); ... 696 longjmp(loop_tag, TAG_CONTINUE); 697 break;
You can think of setjmp() as placing the label, and longjmp() as the goto, with the extra advantage of being able to tell where the code “came from” (by the return value).
For historical reasons that would most likely bore you to tears, the 1999 C standard is silent about the effect of setjmp() and longjmp() on the state of a process’s signals, and POSIX states explicitly that their effect on the process signal mask (see Section 10.6, “POSIX Signals,” page 367) is undefined.
In other words, if a program changes its process signal mask between the first call to setjmp() and a call to longjmp(), what is the state of the process signal mask after the longjmp()? Is it the mask in effect when setjmp() was first called? Or is it the current mask? POSIX says explicitly “there’s no way to know.”
To make handling of the process signal mask explicit, POSIX introduced two additional functions and one typedef:
#include <setjmp.h> POSIX int sigsetjmp(sigjmp_buf env, int savesigs); Note: sigjmp_buf, not jmp_buf! void siglongjmp(sigjmp_buf env, int val);
The main difference is the savesigs argument to sigsetjmp(). If nonzero, then the current set of blocked signals is saved in env, along with the rest of the environment that would be saved by setjmp(). A siglongjmp() with an env where savesigs was true restores the saved process signal mask.
Note
POSIX is also clear that if savesigs is zero (false), it’s undefined whether the process signal mask is saved and restored, just like setjmp() / longjmp(). This in turn implies that if you’re going to use ’sigsetjmp (env, 0)’ you may as well not bother: The whole point is to have control over saving and restoring the process signal mask!
There are several technical caveats to be aware of:
First, because the environment saving and restoring can be messy, machine-dependent tasks, setjmp() and longjmp() are allowed to be macros.
Second, the C standard limits the use of setjmp() to the following situations:
As the sole controlling expression of a loop or condition statement (
if, switch).As one operand of a comparison expression (==, <, etc.), with the other operand as an integer constant. The comparison expression can be the sole controlling expression of a loop or condition statement.
As the operand of the unary ! operator, with the resulting expression being the sole controlling expression of a loop or condition statement.
As the entire expression of an expression statement, possibly cast to
void. For example:(void) setjmp(buf);
Third, if you wish to change a local variable in the function that calls setjmp(), after the call, and you want that variable to maintain its most recently assigned value after a longjmp(), you must declare the variable to be volatile. Otherwise, any non-volatile local variables changed after setjmp() was initially called have indeterminate values. (Note that the jmp_buf variable itself need not be declared volatile.) For example:
1 /* ch12-setjmp.c --- demonstrate setjmp()/longjmp() and volatile. */ 2 3 #include <stdio.h> 4 #include <setjmp.h> 5 6 jmp_buf env; 7 8 /* comeback --- do a longjmp */ 9 10 void comeback(void) 11 { 12 longjmp(env, 1); 13 printf("This line is never printed "); 14 } 15 16 /* main --- call setjmp, fiddle with vars, print values */ 17 18 int main(void) 19 { 20 int i = 5; 21 volatile int j = 6; 22 23 if (setjmp(env) == 0) { /* first time */ 24 i++; 25 j++; 26 printf("first time: i = %d, j = %d ", i, j); 27 comeback(); 28 } else /* second time */ 29 printf("second time: i = %d, j = %d ", i, j); 30 31 return 0; 32 }
In this example, only j (line 21) is guaranteed to maintain its value for the second call to printf(). The value of i (line 20), according to the 1999 C standard, is indeterminate. It may be 6, it may be 5, or it may even be something else!
Fourth, as described in Section 12.5.2, “Handling Signal Masks: sigsetjmp() and siglongjmp(),” page 449, the 1999 C standard makes no statement about the effect, if any, of setjmp() and longjmp() on the state of the program’s signals. If that’s important, you have to use sigsetjmp() and siglongjmp() instead.
Fifth, these routines provide amazing potential for memory leaks! Consider a program in which main() calls setjmp() and then calls several nested functions, each of which allocates dynamic memory with malloc(). If the most deeply nested function does a longjmp() back into main(), the pointers to the dynamic memory are lost. Consider ch12-memleak.c:
1 /* ch12-memleak.c --- demonstrate memory leaks with setjmp()/longjmp(). */ 2 3 #include <stdio.h> 4 #include <malloc.h> /* for definition of ptrdiff_t on GLIBC */ 5 #include <setjmp.h> 6 #include <unistd.h> 7 8 jmp_buf env; 9 10 void f1(void), f2(void); 11 12 /* main --- leak memory with setjmp() and longjmp() */ 13 14 int main(void) 15 { 16 char *start_break; 17 char *current_break; 18 ptrdiff_t diff; 19 20 start_break = sbrk((ptrdiff_t) 0); 21 22 if (setjmp(env) == 0) /* first time */ 23 printf("setjmp called "); 24 25 current_break = sbrk((ptrdiff_t) 0); 26 27 diff = current_break - start_break; 28 printf("memsize = %ld ", (long) diff); 29 30 f1(); 31 32 return 0; 33 } 34 35 /* f1 --- allocate some memory, make a nested call */ 36 37 void f1(void) 38 { 39 char *p = malloc(1024); 40 41 f2(); 42 } 43 44 /* f2 --- allocate some memory, make longjmp */ 45 46 void f2(void) 47 { 48 char *p = malloc(1024); 49 50 longjmp(env, 1); 51 }
This program sets up an infinite loop, using setjmp() and longjmp(). Line 20 uses sbrk() (see Section 3.2.3, “System Calls: brk() and sbrk(),” page 75) to find the current start of the heap, and then line 22 calls setjmp(). Line 25 gets the current start of the heap; this location changes each time through since the code is entered repeatedly by longjmp(). Lines 27–28 compute how much memory has been allocated and print the amount. Here’s what happens when it runs:
$ ch12-memleak Run the program setjmp called memsize = 0 memsize = 6372 memsize = 6372 memsize = 6372 memsize = 10468 memsize = 10468 memsize = 14564 memsize = 14564 memsize = 18660 memsize = 18660 ...
The program leaks memory like a sieve. It runs until interrupted from the keyboard or until it runs out of memory (at which point it produces a massive core dump).
Functions f1() and f2() each allocate memory, and f2() does the longjmp() back to main() (line 51). Once that happens, the local pointers (lines 41 and 49) to the allocated memory are gone! Such memory leaks can be difficult to track down because they are often for small amounts of memory, and as such, they can go unnoticed literally for years.[8]
This code is clearly pathological, but it’s intended to illustrate our point: setjmp() and longjmp() can lead to hard-to-find memory leaks. Suppose that f1() called free() correctly. It would then be far from obvious that the memory would never be freed. In a larger, more realistic program, in which longjmp() might be called only by an if, such a leak becomes even harder to find.
In the presence of setjmp() and longjmp(), dynamic memory must thus be managed by global variables, and you must have code that detects entry with longjmp() (by checking the setjmp() return value). Such code should then clean up any dynamically allocated memory that’s no longer needed.
Sixth, longjmp() and siglongjmp() should not be used from any functions registered with atexit() (see Section 9.1.5.3, “Exiting Functions,” page 302).
Seventh, setjmp() and longjmp() can be costly operations on machines with lots of registers.
Given all of these issues, you should take a hard look at your program’s design. If you don’t need to use setjmp() and longjmp(), then you’re probably better off not doing so. However, if their use is the best way to structure your program, then go ahead and use them, but do so carefully.
Many applications need sequences of random numbers. For example, game programs that simulate rolling a die, dealing cards, or turning the wheels on a slot machine need to be able to pick one of a set of possible values at random. (Consider the fortune program, which has a large collection of pithy sayings; it prints a different one “at random” each time it’s called.) Many cryptographic algorithms also require “high quality” random numbers. This section describes different ways to get sequences of random numbers.
Note
The nature of randomness, generation of random numbers, and the “quality” of random numbers are all broad topics, beyond the scope of this book. We provide an introduction to the available APIs, but that’s about all we can do. See Section 12.9, “Suggested Reading,” page 480, for other sources of more detailed information.
Computers, by design, are deterministic. The same calculation, with the same inputs, should produce the same outputs, every time. Thus, they are not good at generating truly random numbers, that is, sequences of numbers in which each number in the sequence is completely independent of the number (or numbers) that came before it. Instead, the kinds of numbers usually dealt with at the programmatic level are called pseudorandom numbers. That is, within any given sequence, the numbers appear to be independent of each other, but the sequence as a whole is repeatable. (This repeatability can be an asset; it provides determinism for the program as a whole.)
Many methods of producing pseudorandom number sequences work by performing the same calculation each time on a starting, or seed, value. The stored seed value is then updated for use next time. APIs provide a way to specify a new seed. Each initial seed produces the same sequence of pseudorandom numbers, although different seeds (should) produce different sequences.
Standard C defines two related functions for pseudorandom numbers:
#include <stdlib.h> ISO C
int rand(void);
void srand(unsigned int seed);
rand() returns a pseudorandom number between 0 and RAND_MAX (inclusive, as far as we can tell from the C99 standard) each time it’s called. The constant RAND_MAX must be at least 32,767; it can be larger.
srand() seeds the random number generator with seed. If srand() is never called by the application, rand() behaves as if the initial seed were 1.
The following program, ch12-rand.c, uses rand() to print die faces.
1 /* ch12-rand.c --- generate die rolls, using rand(). */ 2 3 #include <stdio.h> 4 #include <stdlib.h> 5 6 char *die_faces[] = { /* ASCII graphics rule! */ 7 " ", 8 " * ", /* 1 */ 9 " ", 10 11 " ", 12 " * * ", /* 2 */ 13 " ", 14 15 " ", 16 " * * * ", /* 3 */ 17 " ", 18 19 " * * ", 20 " ", /* 4 */ 21 " * * ", 22 23 " * * ", 24 " * ", /* 5 */ 25 " * * ", 26 27 " * * * ", 28 " ", /* 6 */ 29 " * * * ", 30 }; 31 32 /* main --- print N different die faces */ 33 34 int main(int argc, char **argv) 35 { 36 int nfaces; 37 int i, j, k; 38 39 if (argc != 2) { 40 fprintf(stderr, "usage: %s number-die-faces ", argv[0]); 41 exit(1); 42 } 43 44 nfaces = atoi(argv[1]); 45 46 if (nfaces <= 0) { 47 fprintf(stderr, "usage: %s number-die-faces ", argv[0]); 48 fprintf(stderr, " Use a positive number! "); 49 exit(1); 50 } 51 52 for (i = 1; i <= nfaces; i++) { 53 j = rand() % 6; /* force to range 0 <= j <= 5 */ 54 printf("+-------+ "); 55 for (k = 0; k < 3; k++) 56 printf("|%s| ", die_faces[(j * 3) + k]); 57 printf("+-------+ "); 58 } 59 60 return 0; 61 }
This program uses simple ASCII graphics to print out the semblance of a die face. You call it with the number of die faces to print. This is computed on line 44 with atoi(). (In general, atoi() should be avoided for production code since it does no error or overflow checking nor does it do any input validation.)
The key line is line 53, which converts the rand() return value into a number between zero and five, using the remainder operator, %. The value `j * 3’ acts a starting index into the die_faces array for the three strings that make up each die’s face. Lines 54 and 57 print out surrounding top and bottom lines, and the loop on lines 55 and 56 prints the face itself. When run, it produces output like the following:
$ ch12-rand 2 Print two dice +-------+ | | | * * | | | +-------+ +-------+ | * * | | * | | * * | +-------+
The rand() interface dates back to V7 and the PDP-11. In particular, on many systems the result is only a 16-bit number, which severely limits the range of numbers that can be returned. Furthermore, the algorithm it used is considered “weak” by modern standards. (The GLIBC version of rand() doesn’t have these problems, but portable code needs to be written with the awareness that rand() isn’t the best API to use.)
ch12-rand.c uses a simple technique to obtain a value within a certain range: the % operator. This technique uses the low bits of the returned value (just as in decimal division, where the remainder of dividing by 10 or 100 uses the lowest one or two decimal digits). It turns out that the historical rand() generator did a better job of producing random values in the middle and higher-order bits than in the lower bits. Thus, if you must use rand(), try to avoid the lower bits. The GNU/Linux rand(3) manpage cites Numerical Recipes in C,[9] which recommends this technique:
j = 1+(int) (10.0*rand()/(RAND_MAX+1.0)); /* for a number between 1 and 10 */
4.3 BSD introduced random() and its partner functions. These functions use a much better random number generator, which returns a 31-bit value. They are now an XSI extension standardized by POSIX:
#include <stdlib.h> XSI
long random(void);
void srandom(unsigned int seed);
char *initstate(unsigned int seed, char *state, size_t n);
char *setstate(char *state);
The first two functions correspond closely to rand() and srand() and can be used similarly. However, instead of a single seed value that produces the sequence of pseudorandom numbers, these functions use a seed value along with a state array: an array of bytes that holds state information for calculating the pseudorandom numbers. The last two functions let you manage the state array.
long random(void);
void srandom(unsigned int seed);
char *initstate(unsigned int seed, char *state, size_t n);
Initializes the
statearray with information for use in generating random numbers.seedis the seed value to use, as forsrandom(), andnis the number of bytes in thestatearray.nshould be one of the values8, 32, 64, 128, or256. Larger values produce better sequences of random numbers. Values less than8causerandom()to use a simple random number generator similar to that ofrand(). Values larger than8that are not equal to a value in the list are rounded down to the nearest appropriate value.
char *setstate(char *state);
Sets the internal state to the
statearray, which must have been initialized byinitstate(). This lets you switch back and forth between different states at will, providing multiple random number generators.
If initstate() and setstate() are never called, random() uses an internal state array of size 128.
The state array is opaque; you initialize it with initstate() and pass it to the random() function with setstate(), but you don’t otherwise need to look inside it. If you use initstate() and setstate(), you don’t have to also call srandom(), since the seed is included in the state information. ch12-random.c uses these routines instead of rand(). It also uses a common technique, which is to seed the random number generator with the time of day, added to the PID.
1 /* ch12-random.c --- generate die rolls, using random(). */ 2 3 #include <stdio.h> 4 #include <stdlib.h> 5 #include <sys/types.h> 6 #include <unistd.h> 7 8 char *die_faces[] = { /* ASCII graphics rule! */ ... as before ... 32 }; 33 34 /* main --- print N different die faces */ 35 36 int main(int argc, char **argv) 37 { 38 int nfaces; 39 int i, j, k; 40 char state[256]; 41 time_t now; 42 ... check args, compute nfaces, as before ... 55 56 (void) time(& now); /* seed with time of day and PID */ 57 (void) initstate((unsigned int) (now + getpid()), state, sizeof state); 58 (void) setstate(state); 59 60 for (i = 1; i <= nfaces; i++) { 61 j = random() % 6; /* force to range 0 <= j <= 5 */ 62 printf("+-------+ "); 63 for (k = 0; k < 3; k++) 64 printf("|%s| ", die_faces[(j * 3) + k]); 65 printf("+-------+ "); 66 } 67 68 return 0; 69 }
Including the PID as part of the seed value guarantees that you’ll get different results, even when two programs are started within the same second.
Because it produces a higher-quality sequence of random numbers, random() is preferred over rand(), and GNU/Linux and all modern Unix systems support it.
Both rand() and srandom() are pseudorandom number generators. Their output, for the same seed, is a reproducible sequence of numbers. Some applications, like cryptography, require their random numbers to be (more) truly random. To this end, the Linux kernel, as well as various BSD and commercial Unix systems, provide special device files that provide access to an “entropy pool” of random bits that the kernel collects from physical devices and other sources. From the random(4) manpage:
/dev/random
[Bytes read from this file are] within the estimated number of bits of noise in the entropy pool.
/dev/randomshould be suitable for uses that need high quality randomness such as one-time pad or key generation. When the entropy pool is empty, reads to/dev/randomwill block until additional environmental noise is gathered.
/dev/urandom
[This device will] return as many bytes as are requested. As a result, if there is not sufficient entropy in the entropy pool, the returned values are theoretically vulnerable to a cryptographic attack on the algorithms used by the driver. Knowledge of how to do this is not available in the current non-classified literature, but it is theoretically possible that such an attack may exist. If this is a concern in your application, use
/dev/randominstead.
For most applications, reading from /dev/urandom should be good enough. If you’re going to be writing high-quality cryptographic algorithms, you should read up on cryptography and randomness first; don’t rely on the cursory presentation here! Here’s our die rolling program, once more, using /dev/urandom:
1 /* ch12-devrandom.c --- generate die rolls, using /dev/urandom. */ 2 3 #include <stdio.h> 4 #include <fcntl.h> 5 #include <stdlib.h> 6 7 char *die_faces[] = { /* ASCII graphics rule! */ ... as before ... 31 }; 32 33 /* myrandom --- return data from /dev/urandom as unsigned long */ 34 35 unsigned long myrandom(void) 36 { 37 static int fd = -1; 38 unsigned long data; 39 40 if (fd == -1) 41 fd = open("/dev/urandom", O_RDONLY); 42 43 if (fd == -1 || read(fd, & data, sizeof data) <= 0) 44 return random(); /* fall back */ 45 46 return data; 47 } 48 49 /* main --- print N different die faces */ 50 51 int main(int argc, char **argv) 52 { 53 int nfaces; 54 int i, j, k; 55 ... check args, compute nfaces, as before ... 68 69 for (i = 1; i <= nfaces; i++) { 70 j = myrandom() % 6; /* force to range 0 <= j <= 5 */ 71 printf("+-------+ "); 72 for (k = 0; k < 3; k++) 73 printf("|%s| ", die_faces[(j * 3) + k]); 74 printf("+-------+ "); 75 putchar(' '), 76 } 77 78 return 0; 79 }
Lines 35–47 provide a function-call interface to /dev/urandom, reading an unsigned long’s worth of data each time. The cost is one file descriptor that remains open throughout the program’s life.
Three sets of functions, of increasing complexity, provide the ability to match shell wildcard patterns. Many programs need such library functions. One example is find: ’find . -name '*.c' -print’. Another is the --exclude option in many programs that accepts a wildcard pattern of files to exclude from some action or other. This section looks at each set of functions in turn.
We start with the fnmatch() (“filename match”) function:
#include <fnmatch.h> POSIX
int fnmatch(const char *pattern, const char *string, int flags);
This function matches string against pattern, which is a regular shell wildcard pattern. The flags value (described shortly) modifies the function’s behavior. The return value is 0 if string matches pattern, FNM_NOMATCH if it doesn’t, and a nonzero value if an error occurred. Unfortunately, POSIX doesn’t define any specific errors; thus, you can only tell that something went wrong, but not what.
The flags variable is the bitwise-OR of one or more of the flags listed in Table 12.1.
Table 12.1. Flag values for fnmatch()
Flag name | GLIBC only | Meaning |
|---|---|---|
| ✓ | Do case-insensitive matching. |
| ✓ | This is a GNU synonym for |
| ✓ | This is a flag for internal use by GLIBC; don’t use it in your programs. See fnmatch(3) for the details. |
| Backslash is an ordinary character, not an escape character. | |
| Slash in | |
| A leading period in |
fnmatch() works with strings from any source; strings to be matched need not be actual filenames. In practice though, you would use fnmatch() from code that reads a directory with readdir() (see Section 5.3.1, “Basic Directory Reading,” page 133):
struct dirent dp;
DIR *dir;
char pattern[100];
... fill pattern, open directory, check for errors ...
while ((dp = readdir(dir)) != NULL) {
if (fnmatch(pattern, dir->d_name, FNM_PERIOD) == 0)
/* filename matches pattern */
else
continue; /* doesn't match */
}
GNU ls uses fnmatch() to implement its --ignore option. You can provide multiple patterns to ignore (with multiple options). ls tests each filename against all the patterns. It does this with the file_interesting() function in ls.c:
2269 /* Return nonzero if the file in `next' should be listed. */ 2270 2271 static int 2272 file_interesting (const struct dirent *next) 2273 { 2274 register struct ignore_pattern *ignore; 2275 2276 for (ignore = ignore_patterns; ignore; ignore = ignore->next) 2277 if (fnmatch (ignore->pattern, next->d_name, FNM_PERIOD) == 0) 2278 return 0; 2279 2280 if (really_all_files 2281 || next->d_name[0] != `.' 2282 || (all_files 2283 && next->d_name[1] != `�' 2284 && (next->d_name[1] != `.' || next->d_name[2] != `�'))) 2285 return 1; 2286 2287 return 0; 2288 }
The loop on lines 2276–2278 tests the filename against the list of patterns for files to ignore. If any of the patterns matches, the file is not interesting and file_interesting() returns false (that is, 0).
The all_files variable corresponds to the -A option, which shows files whose names begin with a period but that aren’t `.’ and `..’. The really_all_files variable corresponds to the -a option, which implies -A, and also shows `.’ and `..’. Given this information, the condition on lines 2280–2284 can be represented with the following pseudocode:
if ( show every file, no matter what its name (-a) OR the first character of the name isn't a period OR ( show dot files (-A) AND there are multiple characters in the filename AND ( the second character isn't a period OR the third character doesn't end the name))) return TRUE;
Note
fnmatch() can be an expensive function if it’s used in a locale that uses a multibyte character set. We discuss multibyte character sets in Section 13.4, “Can You Spell That for Me, Please?,” page 521.
The glob() and globfree() functions are more elaborate than fnmatch():
#include <glob.h> POSIX
int glob(const char *pattern, int flags,
int (*errfunc) (const char *epath, int eerrno),
glob_t *pglob);
void globfree(glob_t *pglob);
The glob() function does directory scanning and wildcard matching, returning a list of all pathnames that match the pattern. Wildcards can be included at multiple points in the pathame, not just for the last component (for example, `/usr/*/*.so’). The arguments are as follows:
const char *pattern
The pattern to expand.
int flags
Flags that control
glob()’s behavior, described shortly.
int (*errfunc) (const char *epath, int eerrno)
A pointer to a function to use for reporting errors. This value may be
NULL. If it’s not, and if (*errfunc)()returns nonzero or ifGLOB_ERRis set inflags, thenglob()stops processing.The arguments to (
*errfunc)()are the pathname that caused a problem and the value oferrnoset byopendir(), readdir(), orstat().
A pointer to a
glob_tstructure used to hold the results.
The glob_t structure holds the list of pathnames that glob() produces:
typedef struct { POSIX
size_t gl_pathc; Count of paths matched so far
char **gl_pathv; List of matched pathnames
size_t gl_offs; Slots to reserve in gl_pathv
} glob_t;
size_t gl_pathc
The number of paths that were matched.
char **gl_pathv
An array of matched pathnames.
gl_pathv[gl_pathc]is alwaysNULL.
size_t gl_offs
“Reserved slots” in
gl_pathv. The idea is to reserve slots at the front ofgl_pathvfor the application to fill in later, such as with a command name and options. The list can then be passed directly toexecv()orexecvp()(see Section 9.1.4, “Starting New Programs: The exec() Family,” page 293). Reserved slots are set toNULL. For all this to work,GLOB_DOOFFSmust be set inflags.
Table 12.2 lists the standard flags for glob().
Table 12.2. Flags for glob()
Flag name | Meaning |
|---|---|
| Append current call’s results to those of a previous call. |
| Reserve |
| Append a |
| If the pattern doesn’t match any filename, return it unchanged. |
| Treat backslash as a literal character. This makes it impossible to escape wildcard metacharacters. |
| Don’t sort the results; the default is to sort them. |
The GLIBC version of the glob_t structure contains additional members:
typedef struct { GLIBC
/* POSIX components: */
size_t gl_pathc; Count of paths matched so far
char **gl_pathv; List of matched pathnames
size_t gl_offs; Slots to reserve in gl_pathv
/* GLIBC components: */
int gl_flags; Copy of flags, additional GLIBC flags
void (*gl_closedir) (DIR *); Private version of closedir()
struct dirent *(*gl_readdir) (DIR *); Private version of readdir()
DIR *(*gl_opendir) (const char *); Private version of opendir()
int (*gl_lstat) (const char *, struct stat *); Private version of lstat()
int (*gl_stat) (const char *, struct stat *); Private version of stat()
} glob_t;
The members are as follows:
int gl_flags
Copy of
flags. Also includesGLOB_MAGCHARifpatternincluded any metacharacters.
void (*gl_closedir) (DIR *)
struct dirent *(*gl_readdir) (DIR *)
Pointer to alternative version of
readdir().
DIR *(*gl_opendir) (const char *)
Pointer to alternative version of
opendir().
int (*gl_lstat) (const char *, struct stat *)
Pointer to alternative version of
lstat().
int (*gl_stat) (const char *, struct stat *)
Pointer to alternative version of
stat().
The pointers to private versions of the standard functions are mainly for use in implementing GLIBC; it is highly unlikely that you will ever need to use them. Because GLIBC provides the gl_flags field and additional flag values, the manpage and Info manual document the rest of the GLIBC glob_t structure. Table 12.3 lists the additional flags.
Table 12.3. Additional GLIBC flags for glob()
Meaning | |
|---|---|
| Use alternative functions for directory access (see text). |
| Perform |
| Set in |
| Return the pattern if it doesn’t contain metacharacters. |
| If possible, only match directories. See text. |
| Allow metacharacters like * and ? to match a leading period. |
| Do shell-style tilde expansions. |
Like |
The GLOB_ONLYDIR flag functions as a hint to the implementation that the caller is only interested in directories. Its primary use is by other functions within GLIBC, and a caller still has to be prepared to handle nondirectory files. You should not use it in your programs.
glob() can be called more than once: The first call should not have the GLOB_APPEND flag set, and all subsequent calls must have it set. You cannot change gl_offs between calls, and if you modify any values in gl_pathv or gl_pathc, you must restore them before making a subsequent call to glob().
The ability to call glob() multiple times allows you to build up the results in a single list. This is quite useful; it approaches the power of the shell’s wildcard expansion facility, but at the C programming level.
glob() returns 0 if there were no problems or one of the values in Table 12.4 if there were.
Table 12.4. glob() return values
Constant | Meaning |
|---|---|
| Scanning stopped early because |
| No filenames matched |
| There was a problem allocating dynamic memory. |
globfree() releases all the memory that glob() dynamically allocated. The following program, ch12-glob.c, demonstrates glob():
1 /* ch12-glob.c --- demonstrate glob(). */ 2 3 #include <stdio.h> 4 #include <errno.h> 5 #include <glob.h> 6 7 char *myname; 8 9 /* globerr --- print error message for glob() */ 10 11 int globerr (const char *path, int eerrno) 12 { 13 fprintf(stderr, "%s: %s: %s ", myname, path, strerror(eerrno)); 14 return 0; /* let glob() keep going */ 15 } 16 17 /* main() --- expand command-line wildcards and print results */ 18 19 int main(int argc, char **argv) 20 { 21 int i; 22 int flags = 0; 23 glob_t results; 24 int ret; 25 26 if (argc == 1) { 27 fprintf(stderr, "usage: %s wildcard ... ", argv[0]); 28 exit(1); 29 } 30 31 myname = argv[0]; /* for globerr() */ 32 33 for (i = 1; i < argc; i++) { 34 flags |= (i > 1 ? GLOB_APPEND : 0); 35 ret = glob(argv[i], flags, globerr, & results); 36 if (ret != 0) { 37 fprintf(stderr, "%s: problem with %s (%s), stopping early ", 38 myname, argv[i], 39 /* ugly: */ (ret == GLOB_ABORTED ? "filesystem problem" : 40 ret == GLOB_NOMATCH ? "no match of pattern" : 41 ret == GLOB_NOSPACE ? "no dynamic memory" : 42 "unknown problem")); 43 break; 44 } 45 } 46 47 for (i = 0; i < results.gl_pathc; i++) 48 printf("%s ", results.gl_pathv[i]); 49 50 globfree(& results); 51 return 0; 52 }
Line 7 defines myname, which points to the program’s name; this variable is for error messages from globerr(), defined on lines 11–15.
Lines 33–45 are the heart of the program. They loop over the patterns given on the command line, calling glob() on each one to append its results to the list. Most of the loop is error handling (lines 36–44). Lines 47–48 print the resulting list, and lines 50–51 clean up and return.
Lines 39–41 aren’t pretty; a separate function that converts the integer constant to a string should be used; we’ve done it this way primarily to save space. Code like this is tolerable in a small program, but a larger program should use a function.
If you think about all the work going on under the hood (opening and reading directories, matching patterns, dynamic allocation to grow the list, sorting the list), you can start to appreciate how much glob() does for you! Here are some results:
$ ch12-glob `/usr/lib/x*.so' `../../*.texi'
/usr/lib/xchat-autob5.so
/usr/lib/xchat-autogb.so
../../00-preface.texi
../../01-intro.texi
../../02-cmdline.texi
../../03-memory.texi
...
Note that we have to quote the arguments to keep the shell from doing the expansion!
Many members of the POSIX committee felt that glob() didn’t do enough: They wanted a library routine capable of doing everything the shell can do: tilde expansion (`echo ~arnold’), shell variable expansion (`echo $HOME’), and command substitution (`echo $(cd ; pwd)’). Many others felt that glob() wasn’t the right function for this purpose. To “satisfy” everyone, POSIX supplies an additional two functions that do everything:
#include <wordexp.h> POSIX
int wordexp(const char *words, wordexp_t *pwordexp, int flags);
void wordfree(wordexp_t *wordexp);
These functions work similarly to glob() and globfree(), but on a wordexp_t structure:
typedef struct {
size_t we_wordc; Count of words matched
char **we_wordv; List of expanded words
size_t we_offs; Slots to reserve in we_wordv
} wordexp_t;
The members are completely analogous to those of the glob_t described earlier; we won't repeat the whole description here.
As with glob(), several flags control wordexp()'s behavior. The flags are listed in Table 12.5.
Table 12.5. Flags for wordexp()
Constant | Meaning |
|---|---|
| Append current call's results to those of a previous call. |
| Reserve |
| Don't allow command substitution. |
| Reuse the storage already pointed to by |
| Don't be silent about errors during expansion. |
| Cause undefined shell variables to produce an error. |
The return value is 0 if everything went well or one of the values in Table 12.6 if not.
Table 12.6. wordexp() error return values
Constant | Meaning |
|---|---|
| A metacharacter (one of newline, |
| A variable was undefined and |
| Command substitution was attempted and |
| There was a problem allocating dynamic memory. |
| There was a shell syntax error. |
We leave it to you as an exercise (see later) to modify ch12-glob.c to use wordexp() and wordfree(). Here’s our version in action:
$ ch12-wordexp `echo $HOME' Shell variable expansion echo /home/arnold $ ch12-wordexp `echo $HOME/*.gz' Variables and wildcards echo /home/arnold/48000.wav.gz /home/arnold/ipmasq-HOWTO.tar.gz /home/arnold/rc.firewall-examples.tar.gz $ ch12-wordexp `echo ~arnold' Tilde expansion echo /home/arnold $ ch12-wordexp `echo ~arnold/.p*' Tilde and wildcards echo /home/arnold/.postitnotes /home/arnold/.procmailrc /home/arnold/.profile $ ch12-wordexp "echo `~arnold/.p*'" Quoting works echo ~arnold/.p*
A regular expression is a way to describe patterns of text to be matched. If you’ve used GNU/Linux or Unix for any time at all, you’re undoubtedly familiar with regular expressions: They are a fundamental part of the Unix programmer’s toolbox. They are integral to such everyday programs as grep, egrep, sed, awk, Perl, and the ed, vi, vim, and Emacs editors. If you’re not at all familiar with regular expressions, we suggest you take a detour to some of the books or URLs named in Section 12.9, “Suggested Reading,” page 480.
POSIX defines two flavors of regular expressions: basic and extended. Programs such as grep, sed, and the ed line editor use basic regular expressions. Programs such as egrep and awk use extended regular expressions. The following functions give you the ability to use either flavor in your programs:
#include <sys/types.h> POSIX
#include <regex.h>
int regcomp(regex_t *preg, const char *regex, int cflags);
int regexec(const regex_t *preg, const char *string, size_t nmatch,
regmatch_t pmatch[], int eflags);
size_t regerror(int errcode, const regex_t *preg,
char *errbuf, size_t errbuf_size);
void regfree(regex_t *preg);
To do regular expression matching, you must first compile a string version of the regular expression. Compilation converts the regular expression into an internal form. The compiled form is then executed against a string to see whether it matches the original regular expression. The functions are as follows:
int regcomp(regex_t *preg, const char *regex, int cflags)
Compiles the regular expression
regexinto the internal form, storing it in theregex_tstructure pointed to bypreg. cflagscontrols how the compilation is done; its value is0or the bitwise OR of one or more of the flags in Table 12.7.
Table 12.7. Flags for regcomp()
Constant | Meaning |
|---|---|
| Use extended regular expressions. The default is basic regular expressions. |
| Matches with |
| Operators that can match any character don’t match newline. |
| Subpattern start and end information isn’t needed (see text). |
int regexec(const regex_t *preg, const char *string, size_t nmatch, regmatch_t pmatch[], int eflags)
Executes the compiled regular expression in
*pregagainst the stringstring.eflagscontrols how the execution is done; its value is0or the bitwise OR of one or more of the flags in Table 12.8. We discuss the other arguments shortly.
Table 12.8. Flags for regexec()
Constant | Meaning |
|---|---|
| Don’t allow the ^ (beginning of line) operator to match. |
| Don’t allow the |
size_t regerror(int errcode, const regex_t *preg, char *errbuf, size_t errbuf_size)
void regfree(regex_t *preg)
The <regex.h> header file defines a number of flags. Some are for use with regcomp(); others are for use with regexec(). However, they all start with the prefix ’REG_’. Table 12.7 lists the flags for regular expression compilation with regcomp().
The flags for regular expression matching with regexec() are given in Table 12.8.
The REG_NEWLINE, REG_NOTBOL, and REG_NOTEOL flags interact with each other. It’s a little complicated, so we take it one step at a time.
When
REG_NEWLINEis not included incflags, the newline character acts like an ordinary character. The ’.’ (match any character) metacharacter can match it, as can complemented character lists (’[^...]’). Also,$does not match immediately before an embedded newline, and^does not match immediately after one.When
REG_NOTBOLis set ineflags, the^operator does not match the beginning of the string. This is useful when thestringparameter is the address of a character in the middle of the text being matched.Similarly, when
REG_NOTEOLis set ineflags, the$operator does not match the end of the string.When
REG_NEWLINEis included incflags, then:Newline is not matched by ’.’ or by a complemented character list.
The
^operator always matches immediately following an embedded newline, no matter the setting ofREG_BOL.The
$operator always matches immediately before an embedded newline, no matter the setting ofREG_EOL.
When you’re doing line-at-a-time I/O, such as by grep, you can leave REG_NEWLINE out of cflags. If you have multiple lines in a buffer and want to treat each one as a separate string, with ^ and $ matching within them, then you should include REG_NEWLINE.
The regex_t structure is mostly opaque. It has one member that user-level code can examine; the rest is for internal use by the regular expression routines:
typedef struct {
...internal stuff here...
size_t re_nsub;
...internal stuff here...
} regex_t;
The regmatch_t structure has at least two members for use by user-level code:
typedef struct {
...possible internal stuff here...
regoff_t rm_so; Byte offset to start of substring
regoff_t rm_eo; Byte offset to first character after substring end
...possible internal stuff here...
} regmatch_t;
Both the re_nsub field and the regmatch_t structure are for subexpression matching. Consider an extended regular expression such as:
[[:space:]]+([[:digit:]]+)[[:space:]]+([[:alpha:]])+
The two parenthesized subexpressions can each match one or more characters. Furthermore, the text matching each subexpression can start and end at arbitrary positions within the string.
regcomp() sets the re_nsub field to the number of parenthesized subexpressions in the regular expression. regexec() fills in the pmatch array of regmatch_t structures with the start and ending byte offsets of the text that matched the corresponding subexpressions. Together, these data allow you to do text substitution—deletion of matched text or replacement of matched text with other text, just as in your favorite text editor.
pmatch[0] describes the portion of string that matched the entire regular expression. pmatch[1] through pmatch[preg->re_nsub] describe the portions that matched each parenthesized subexpression. (Thus, subexpressions are numbered from 1.) Unused elements in the pmatch array have their rm_so and rm_eo elements set to -1.
regexec() fills in no more than nmatch - 1 elements of pmatch; you should thus ensure that there are at least as many elements (plus 1) as in preg->re_nsub.
Finally, the REG_NOSUB flag for regcomp() indicates that starting and ending information isn’t necessary. You should use this flag when you don’t need the information; it can potentially improve the performance of regexec(), making a significant difference.
In other words, if all you need to know is “did it match?” then include REG_NOSUB. However, if you also need to know “where is the matching text?” then omit it.
Finally, both regcomp() and regexec() return 0 if they were successful or a specific error code if not. The error codes are listed in Table 12.9.
Table 12.9. Error codes for regcomp() and regexec()
Constant | Meaning |
|---|---|
| The contents of ’{...}’ are invalid. |
| The regular expression is invalid. |
| A ?, +, or * is not preceded by valid regular expression. |
| Braces (’{...}’) are not balanced correctly. |
Square brackets (’[...]’) are not balanced correctly. | |
The pattern used an invalid collating element. | |
| The pattern used an invalid character class. |
| The pattern has a trailing character. |
| Grouping parentheses (’(...)’ or ’(...)’) are not balanced correctly. |
The endpoint in a range expression is invalid. | |
| The function ran out of memory. |
| The digit in ’ |
|
|
To demonstrate the regular expression routines, ch12-grep.c provides a basic reimplementation of the standard grep program, which searches files for a pattern. Our version uses basic regular expressions by default. It accepts a -E option to use extended regular expressions instead and a -i option to ignore case. Like the real grep, if no files are provided on the command line, our grep reads standard input, and as in the real grep, a filename of ’-’ can be used to mean standard input. (This technique is useful for searching standard input along with other files.) Here’s the program:
1 /* ch12-grep.c --- Simple version of grep using POSIX R.E. functions. */ 2 3 #define _GNU_SOURCE 1 /* for getline() */ 4 #include <stdio.h> 5 #include <errno.h> 6 #include <regex.h> 7 #include <unistd.h> 8 #include <sys/types.h> 9 10 char *myname; /* for error messages */ 11 int ignore_case = 0; /* -i option: ignore case */ 12 int extended = 0; /* -E option: use extended RE's */ 13 int errors = 0; /* number of errors */ 14 15 regex_t pattern; /* pattern to match */ 16 17 void compile_pattern(const char *pat); 18 void process(const char *name, FILE *fp); 19 void usage(void);
Lines 10–15 declare the program’s global variables. The first set (lines 10–13) are for options and error messages. Line 15 declares pattern, which holds the compiled pattern. Lines 17–19 declare the program’s other functions.
21 /* main --- process options, open files */ 22 23 int main(int argc, char **argv) 24 { 25 int c; 26 int i; 27 FILE *fp; 28 29 myname = argv[0]; 30 while ((c = getopt(argc, argv, ":iE")) != -1) { 31 switch (c) { 32 case ’i’: 33 ignore_case = 1; 34 break; 35 case ’E’: 36 extended = 1; 37 break; 38 case ’?’: 39 usage(); 40 break; 41 } 42 } 43 44 if (optind == argc) /* sanity check */ 45 usage(); 46 47 compile_pattern(argv[optind]); /* compile the pattern */ 48 if (errors) /* compile failed */ 49 return 1; 50 else 51 optind++;
Line 29 sets myname, and lines 30–45 parse the options. Lines 47–51 compile the regular expression, placing the results into pattern.compile_pattern() increments errors if there was a problem. (Coupling the functions by means of a global variable like this is generally considered bad form. It’s OK for a small program such as this one, but such coupling can become a problem in larger programs.) If there was no problem, line 51 increments optind so that the remaining arguments are the files to be processed.
53 if (optind == argc) /* no files, default to stdin */ 54 process("standard input", stdin); 55 else { 56 /* loop over files */ 57 for (i = optind; i < argc; i++) { 58 if (strcmp(argv[i], "-") == 0) 59 process("standard input", stdin); 60 else if ((fp = fopen(argv[i], "r")) != NULL) { 61 process(argv[i], fp); 62 fclose(fp); 63 } else { 64 fprintf(stderr, "%s: %s: could not open: %s ", 65 argv[0], argv[i], strerror(errno)); 66 errors++; 67 } 68 } 69 } 70 71 regfree(& pattern); 72 return errors != 0; 73 }
Lines 53–69 process the files, searching for lines that match the pattern. Lines 53–54 handle the case in which no files are provided: The program reads standard input. Otherwise, lines 57–68 loop over the files. Line 58 handles the special casing of ’-’ to mean standard input, lines 60–62 handle regular files, and lines 63–67 handle problems.
75 /* compile_pattern --- compile the pattern */ 76 77 void compile_pattern(const char *pat) 78 { 79 int flags = REG_NOSUB; /* don't need where-matched info */ 80 int ret; 81 #define MSGBUFSIZE 512 /* arbitrary */ 82 char error[MSGBUFSIZE]; 83 84 if (ignore_case) 85 flags |= REG_ICASE; 86 if (extended) 87 flags |= REG_EXTENDED; 88 89 ret = regcomp(& pattern, pat, flags); 90 if (ret != 0) { 91 (void) regerror(ret, & pattern, error, sizeof error); 92 fprintf(stderr, "%s: pattern '%s': %s ", myname, pat, error); 93 errors++; 94 } 95 }
Lines 75–95 define the compile_pattern() function. It first sets flags to REG_NOSUB since all we need to know is “did a line match?” and not “where in the line is the matching text?”.
Lines 84–85 add additional flags in accordance with the command-line options. Line 89 compiles the pattern, and lines 90–94 report any problems.
97 /* process --- read lines of text and match against the pattern */ 98 99 void process(const char *name, FILE *fp) 100 { 101 char *buf = NULL; 102 size_t size = 0; 103 char error[MSGBUFSIZE]; 104 int ret; 105 106 while (getline(& buf, &size, fp) != -1) { 107 ret = regexec(& pattern, buf, 0, NULL, 0); 108 if (ret != 0) { 109 if (ret != REG_NOMATCH) { 110 (void) regerror(ret, & pattern, error, sizeof error); 111 fprintf(stderr, "%s: file %s: %s ", myname, name, error); 112 free(buf); 113 errors++; 114 return; 115 } 116 } else 117 printf("%s: %s", name, buf); /* print matching lines */ 119 } 119 free(buf); 120 }
Lines 97–120 define process(), which reads the file and does the regular expression match. The outer loop (lines 106–119) reads input lines. We use getline() (see Section 3.2.1.9, “GLIBC Only: Reading Entire Lines: getline() and getdelim(),” page 73) to avoid line-length problems. Line 107 calls regexec(). A nonzero return indicates either failure to match or some other error. Thus, lines 109–115 check for REG_NOMATCH and print an error only if some other problem occurred—failure to match isn’t an error.
If the return value was 0, the line matched the pattern and thus line 117 prints the filename and matching line.
122 /* usage --- print usage message and exit */ 123 124 void usage(void) 125 { 126 fprintf(stderr, "usage: %s [-i] [-E] pattern [ files ... ] ", myname); 127 exit(1); 128 }
The usage() function prints a usage message and exits. It’s called when invalid options are provided or if no pattern is provided (lines 38–40 and 44–45).
That’s it! A modest, yet useful version of grep, in under 130 lines of code.
Programming Pearls, 2nd edition, by Jon Louis Bentley. Addison-Wesley, Reading, Massachusetts, USA, 2000. ISBN: 0-201-65788-0. See also this book’s web site.[10]
Program design with assertions is one of the fundamental themes in the book.
Building Secure Software: How to Avoid Security Problems the Right Way, by John Viega and Gary McGraw. Addison-Wesley, Reading, Massachusetts, USA, 2001. ISBN: 0-201-72152-X.
Race conditions are only one of many issues to worry about when you are writing secure software. Random numbers are another. This book covers both, among other things. (We mentioned it in the previous chapter.)
The Art of Computer Programming: Volume 2: Seminumerical Algorithms, 3rd edition, by Donald E. Knuth. Addison-Wesley, Reading, Massachusetts, USA, 1998. ISBN: 0-201-89684-2. See also the book’s web site.[11]
Random Number Generation and Monte Carlo Methods, 2nd edition, by James E. Gentle. Springer-Verlag, Berlin, Germany, 2003. ISBN: 0-387-00178-6.
This book has wide coverage of the methods for generating and testing pseudorandom numbers. While it still requires background in mathematics and statistics, the level is not as high as that in Knuth’s book. (Thanks to Nelson H.F. Beebe for the pointer to this reference.)
sed & awk, 2nd edition, by Dale Dougherty and Arnold Robbins. O’Reilly and Associates, Sebastopol, California, USA, 1997. ISBN: 1-56592-225-5.
This book gently introduces regular expressions and text processing, starting with
grep, and moving on to the more powerfulsedandawktools.Mastering Regular Expressions, 2nd edition, by Jeffrey E.F. Friedl. O’Reilly and Associates, Sebastopol, California, USA, 2002. ISBN: 0-59600-289-0.
Regular expressions are an important part of Unix. For learning how to chop, slice, and dice text using regular expressions, we recommend this book.
The online manual for GNU
grepalso explains regular expressions. On a GNU/Linux system, you can use ’info grep’ to look at the local copy. Or use a web browser to read the GNU Project’s online documentation forgrep.[12]
Assertions provide a way to make statements about the expected state of a program. They are a useful design and debugging tool and should generally be left in production code. Be careful, however, not to confuse assertions with runtime checks for possible failure conditions.
The
memXXX()functions provide analogues to the better-knownstrXXX()functions. Their greatest value is that they can work on binary data; zero bytes are no different from other bytes. Of particular note ismemcpy()vs.memmove()and the handling of overlapping copies.Temporary files are useful in many applications. The
tmpfile()andmkstemp()APIs are the preferred way to create temporary files while avoiding race conditions and their security implications. Many programs use theTMPDIRenvironment variable to specify the location for their temporary files, with a meaningful default (usually/tmp) if that variable isn’t defined. This is a good convention, one you should adopt for your own programs.The
abort()function sends aSIGABRTto the calling process. The effect is to kill the process and create a core dump, presumably for debugging.setjmp()andlongjmp()provide a nonlocal goto. This is a powerful facility that must be used with care.sigsetjmp()andsiglongjmp()save and restore the process signal mask when a program does a nonlocal jump. The problems with nonlocal gotos sometimes outweigh their benefits; thus, use these routines only if there isn’t a better way to structure your application.Random numbers are useful in a variety of applications. Most software uses pseudorandom numbers—sequences of numbers that appear random but that can be reproduced by starting with the same seed each time.
rand()andsrand()are the original API, standardized by the C language. On many systems,rand()uses a subpar algorithm.random()andsrandom()use a better algorithm, are included in the POSIX standard, and are preferred overrand()andsrand(). Use the/dev/randomand/dev/urandomspecial files (a) if they’re available and (b) if you need high-quality random numbers.Three APIs provide increasingly powerful facilities for metacharacter expansion (wildcarding).
fnmatch()is the simplest, returning true/false as a given string does or doesn’t match a shell wildcard pattern.glob()works its way through the filesystem, returning a list of pathnames that match a given wildcard. When the standardglob()functionality is all that’s needed, it should be used. While the GLIBC version ofglob()has some extensions, portable programs needing the extra power should usewordexp()instead. (Programs that will only run on GNU/Linux systems should feel free to use the full power of the GLIBCglob()).wordexp()not only does whatglob()does, but it also does full shell word expansion, including tilde expansion, shell variable expansion, and command substitution.
The
regcomp()andregexec()functions give you access to POSIX basic and extended regular expressions. By using one or the other, you can make your program behave identically to the standard utilities, making it much easier for programmers familiar with GNU/Linux and Unix to use your program.
Use
read()andmemcmp()to write a simple version of thecmpprogram that compares two files. Your version need not support any options.Use the
<stdio.h> getc()macro and direct comparison of each read character to write another version ofcmpthat compares two files. Compare the performance of this version against the one you wrote for the previous exercise.(Medium.) Consider the
<stdio.h> fgets()and GLIBCgetline()functions. Wouldmemccpy()be useful for implementing them? Sketch a possible implementation offgets()using it.(Hard.) Find the source to the GLIBC version of
memcmp(). This should be on one of the source code CD-ROMs in your GNU/Linux distribution, or you can find it by a Web search. Examine the code, and explain it.Test your memory. How does
tmpfile()arrange for the file to be deleted when the file pointer is closed?Using
mkstemp()andfdopen()and any other functions or system calls you think necessary, write your own version oftmpfile(). Test it too.Describe the advantages and disadvantages of using
unlink()on the filename created bymkstemp()immediately aftermkstemp()returns.Write your own version of
mkstemp(), usingmktemp()andopen(). How can you make the same guarantees about uniqueness thatmkstemp()does?Programs using
mkstemp()should arrange to clean up the file when they exit. (Assume that the file is not immediately unlinked after opening, for whatever reason.) This includes the case in which a terminating signal could arrive. So, as part of a signal catcher, the file should be removed. How do you do this?(Hard.) Even with the first-cut signal-handling cleanup, there’s still a race condition. There’s a small window between the time
mkstemp()creates the temporary file and the time its name is returned and recorded (for use by the signal handling function) in a variable. If an uncaught signal is delivered in that window, the program dies and leaves behind the temporary file. How do you close that window? (Thanks to Jim Meyering.)Try compiling and running
ch12-setjmp.con as many different systems with as many different compilers as you have access to. Try compiling with and without different levels of optimizations. What variations in behavior, if any, did you see?Look at the file
/usr/src/libc/gen/sleep.cin the V7 Unix source distribution. It implements thesleep()function described in Section 10.8.1, “Alarm Clocks: sleep(), alarm(), and SIGALRM,” page 382. Print it, and annotate it in the style of our examples to explain how it works.On a GNU/Linux or System V Unix system, look at the lrand48(3) manpage. Does this interface look easier or harder to use than
random()?Take
ch08-nftw.cfrom Section 8.4.3, “Walking a Hierarchy: nftw(),” page 260, and add a--exclude=patoption. Files matching the pattern should not be printed.(Hard.) Why would GLIBC need pointers to private versions of the standard directory and
stat()calls? Can’t it just call them directly?Modify
ch12-glob.cto use thewordexp()API. Experiment with it by doing some of the extra things it provides. Be sure to quote your command-line arguments so thatwordexp()is really doing all the work!The standard
grepprints the filename only when more than one file is provided on the command line. Makech12-grep.cperform the same way.Look at the grep(1) manpage. Add the standard
-e, -s, and-voptions toch12-grep.c.Write a simple substitution program:
subst [-g] pattern replacement [ files ... ]
It should read lines of text from the named
filesor from standard input if no files are given. It should search each line for a match ofpattern. If it finds one, it should replace it withreplacement.With
-g, it should replace not just the first match but all matches on the line.
[1] In his 1981 ACM Turing Award lecture, however, Dr. Hoare states that Alan Turing himself promoted this idea.
[2] As mentioned in Section 10.2, “Signal Actions,” page 348, some GNU/Linux distributions disable creation of core files. To reenable them, put the line ’ulimit -S -c unlimited’ into your ~/.profile file.
[3] “Hints On Programming Language Design”, C.A.R. Hoare. Stanford University Computer Science Technical Report CS-73-403 (ftp://reports.stanford.edu/pub/cstr/reports/cs/tr/73/403/CS-TR-73-403.pdf), December, 1973.
[4] See wc(1). wc counts lines, words, and characters.
[5] This use of /dev/shm is really an abuse of it; it’s intended for use in implementing shared memory, not for use as a RAM disk. Nevertheless, it’s helpful for illustrating our point.
[6] Our system has 512 megabytes of RAM, which to old fogies like the author seems like a lot. However, RAM prices have fallen, and systems with one or more gigabytes of RAM are not uncommon, at least for software developers.
[7] Swap space consists of one or more dedicated chunks of disk, used to hold the parts of executing processes that are not currently in memory.
[8] We had such a leak in gawk. Fortunately, it’s fixed.
[9] Numerical Recipes in C: The Art of Scientific Computing, 2nd edition, by William H. Press, Brian P. Flannery, Saul A. Teukolsky, and William T. Vetterling. Cambridge University Press, USA, 1993. ISBN: 0-521-43108-5.
[*] See /usr/source/s1/glob.c in the V6 distribution.