
In this chapter
This chapter continues the climb up the learning curve toward the next plateau: understanding directories and information about files.
In this chapter we explore how file information is stored in a directory, how directories themselves are read, created, and removed, what information about files is available, and how to retrieve it. Finally, we explore other ways to update file metadata, such as the owner, group, permissions, and access and modification times.
All Unix systems, including Linux, use the same conceptual design for storing file information on disk. Although there is considerable variation in the implementation of the design, the interface at the C level remains consistent, making it possible to write portable programs that compile and run on many different systems.

Copyright 1997-2004 © J.D. “Illiad” Frazer
Used with permission. http://www.userfriendly.org
We start the discussion by defining some terms.
Partition
Filesystem
A partition (physical or logical) that contains file data and metadata, information about files (as opposed to the file contents, which is information in the files). Such metadata include file ownership, permissions, size, and so on, as well as information for use by the operating system in locating file contents.
You place filesystems “in” partitions (a one-to-one correspondence) by writing standard information in them. This is done with a user-level program, such as
mke2fson GNU/Linux, ornewfson Unix. (The Unixmkfscommand makes partitions but is difficult to use directly.newfscalls it with the correct parameters. If your system is a Unix system, see the newfs(8) and mkfs(8) manpages for the details.)For the most part, GNU/Linux and Unix hide the existence of filesystems and partitions. (Further details are given in Section 8.1, “Mounting and Unmounting Filesystems,” page 228). Everything is accessed by pathnames, without reference to which disk a file lives on. (Contrast this with almost every other commercial operating system, such as OpenVMS, or the default behavior of any Microsoft system.)
Inode
Short for “index node,” initially abbreviated “i-node” and now written “inode.” A small block of information describing everything about a file except the file’s name(s). The number of inodes, and thus the number of unique files per filesystem, is set and made permanent when the filesystem is created. ’
df -i’ can tell you how many inodes you have and how many are used.
Device
In the context of files, filesystems, and file metadata, a unique number representing an in-use (“mounted”) filesystem. The (device, inode) pair uniquely identifies the file: Two different files are guaranteed to have different (device, inode) pairs. This is discussed in more detail later in this chapter.
Directory
Conceptually, each disk block contains either some number of inodes, or file data. The inode, in turn, contains pointers to the blocks that contain the file’s data. See Figure 5.1.
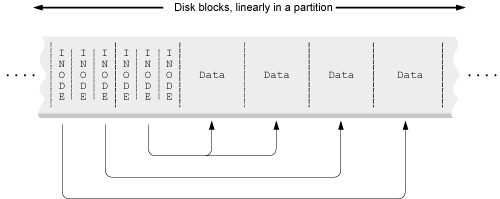
The figure shows all the inode blocks at the front of the partition and the data blocks after them. Early Unix filesystems were indeed organized this way. However, while all modern systems still have inodes and data blocks, the organization has changed for improved efficiency and robustness. The details vary from system to system, and even within GNU/Linux systems there are multiple kinds of filesystems, but the concepts are the same.
Directories make the connection between a filename and an inode. Directory entries contain an inode number and a filename. They also contain additional bookkeeping information that is not of interest to us here. See Figure 5.2.
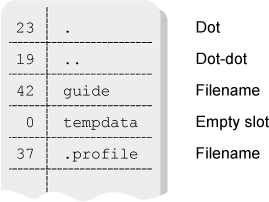
Early Unix systems had two-byte inode numbers and up to 14-byte filenames. Here is the entire content of the V7 /usr/include/sys/dir.h:
#ifndef DIRSIZ
#define DIRSIZ 14
#endif
struct direct
{
ino_t d_ino;
char d_name[DIRSIZ];
};
An ino_t is defined in the V7 <sys/types.h> as ’typedef unsigned int ino_t;’. Since a PDP-11 int is 16 bits, so too is the ino_t. This organization made it easy to read directories directly; since the size of an entry was fixed, the code was simple. (The only thing to watch out for was that a full 14-character d_name was not NUL-terminated.)
Directory content management was also easy for the system. When a file was removed from a directory, the system replaced the inode number with a binary zero, signifying that the “slot” in the directory was unused. New files could then reuse the empty slot. This helped keep the size of directory files themselves reasonable. (By convention, inode number 1 is unused; inode number 2 is always the first usable inode. More details are provided in Section 8.1, “Mounting and Unmounting Filesystems,” page 228.)
Modern systems provide long filenames. Each directory entry is of variable length, with a common limit of 255 bytes for the filename component of the directory. Later on, we show how to read a directory’s contents on a modern system. Modern systems also provide 32-bit (or even 64-bit!) inode numbers.
When a file is created with open() or creat(), the system finds an unused inode and assigns it to the new file. It creates the directory entry for the file, with the file’s name and inode number in it. The -i option to ls shows the inode number:
$ echo hello, world > message Create new file $ ls -il message Show inode number too 228786 -rw-r--r-- 1 arnold devel 13 May 4 15:43 message
Since directory entries associate filenames with inodes, it is possible for one file to have multiple names. Each directory entry referring to the same inode is called a link, or hard link, to the file. Links are created with the ln command. The usage is ’ln oldfile newfile’:
$ ln message msg Create a link $ cat msg Show contents of new name hello, world $ ls -il msg message Show inode numbers 228786 -rw-r--r-- 2 arnold devel 13 May 4 15:43 message 228786 -rw-r--r-- 2 arnold devel 13 May 4 15:43 msg
The output shows that the inode numbers of the two files are the same, and the third field in the long output is now 2. This field is the link count, which reports how many links (directory entries referring to the inode) the file has.
It cannot be emphasized enough: Hard links all refer to the same file. If you change one, you have changed the others:
$ echo "Hi, how ya doin' ?" > msg Change file by new name $ cat message Show contents by old name Hi, how ya doin' ? $ ls -il message msg Show info. Size changed 228786 -rw-r--r-- 2 arnold devel 19 May 4 15:51 message 228786 -rw-r--r-- 2 arnold devel 19 May 4 15:51 msg
Although we’ve created two links to the same file in a single directory, hard links are not restricted to being in the same directory; they can be in any other directory on the same filesystem. (This is discussed a bit more in Section 5.1.6, “Symbolic Links,” page 128.)
Additionally, you can create a link to a file you don’t own as long as you have write permission in the directory in which you’re creating the link. (Such a file retains all the attributes of the original file: the owner, permissions, and so on. This is because it is the original file; it has only acquired an additional name.) User-level code cannot create a hard link to a directory.
Once a link is removed, creating a new file by the same name as the original file creates a new file:
$ rm message Remove old name $ echo "What's happenin?" > message Reuse the name $ ls -il msg message Show information 228794 -rw-r--r-- 1 arnold devel 17 May 4 15:58 message 228786 -rw-r--r-- 1 arnold devel 19 May 4 15:51 msg
Notice that the link counts for both files are now equal to 1.
At the C level, links are created with the link() system call:
#include <unistd.h> POSIX
int link(const char *oldpath, const char *newpath);
The return value is 0 if the link was created successfully, or -1 otherwise, in which case errno reflects the error. An important failure case is one in which newpath already exists. The system won’t remove it for you, since attempting to do so can cause inconsistencies in the filesystem.
The ln program is complicated and large. However, the GNU Coreutils contains a simple link program that just calls link() on its first two arguments. The following example shows the code from link.c, with some irrelevant parts deleted. Line numbers relate to the actual file.
20 /* Implementation overview: 21 22 Simply call the system 'link' function */ 23 ...#include statements omitted for brevity... 34 35 /* The official name of this program (e.g., no 'g' prefix). */ 36 #define PROGRAM_NAME "link" 37 38 #define AUTHORS "Michael Stone" 39 40 /* Name this program was run with. */ 41 char *program_name; 42 43 void 44 usage (int status) 45 { ...omitted for brevity... 62 } 63 64 int 65 main (int argc, char **argv) 66 { 67 program_name = argv[0]; 68 setlocale (LC_ALL, ""); 69 bindtextdomain (PACKAGE, LOCALEDIR); 70 textdomain (PACKAGE); 71 72 atexit (close_stdout); 73 74 parse_long_options (argc, argv, PROGRAM_NAME, GNU_PACKAGE, VERSION, 75 AUTHORS, usage); 76 77 /* The above handles --help and --version. 78 Since there is no other invocation of getopt, handle '--' here. */ 79 if (1 < argc && STREQ (argv[1], "--")) 80 { 81 --argc; 82 ++argv; 83 } 84 85 if (argc < 3) 86 { 87 error (0, 0, _("too few arguments")); 88 usage (EXIT_FAILURE); 89 } 90 91 if (3 < argc) 92 { 93 error (0, 0, _("too many arguments")); 94 usage (EXIT_FAILURE); 95 } 96 97 if (link (argv[1], argv[2]) != 0) 98 error (EXIT_FAILURE, errno, _("cannot create link %s to %s"), 99 quote_n (0, argv[2]), quote_n (1, argv[1])); 100 101 exit (EXIT_SUCCESS); 102 }
Lines 67–75 are typical Coreutils boilerplate, setting up internationalization, the final action upon exit, and parsing the arguments. Lines 79–95 make sure that link is called with only two arguments. The link() system call itself occurs on line 97. (The quote_n() function provides quoting of the arguments in a style suitable for the current locale; the details aren’t important here.)
Rounding off the discussion of links, let’s look at how the ’.’ and ’..’ special names are managed. They are really just hard links. In the first case, ’.’ is a hard link to the directory containing it, and ’..’ is a hard link to the parent directory. The operating system creates these links for you; as mentioned earlier, user-level code cannot create a hard link to a directory. This example illustrates the links:
$ pwd Show current directory /tmp $ ls -ldi /tmp Show its inode number 225345 drwxrwxrwt 14 root root 4096 May 4 16:15 /tmp $ mkdir x Create a new directory $ ls -ldi x And show its inode number 52794 drwxr-xr-x 2 arnold devel 4096 May 4 16:27 x $ ls -ldi x/. x/.. Show. and.. inode numbers 52794 drwxr-xr-x 2 arnold devel 4096 May 4 16:27 x/. 225345 drwxrwxrwt 15 root root 4096 May 4 16:27 x/..
The root’s parent directory (/..) is a special case; we defer discussion of it until Chapter 8, “Filesystems and Directory Walks,” page 227.
Given the way in which directory entries map names to inode numbers, renaming a file is conceptually quite easy:
If the new name for the file names an existing file, remove the existing file first.
Create a new link to the file by the new name.
Remove the old name (link) for the file. (Removing names is discussed in the next section.)
Early versions of the mv command did work this way. However, when done this way, file renaming is not atomic; that is, it doesn’t happen in one uninterruptible operation. And, on a heavily loaded system, a malicious user could take advantage of race conditions,[1] subverting the rename operation and substituting a different file for the original one.
For this reason, 4.2 BSD introduced the rename() system call:
#include <stdio.h> ISO C
int rename(const char *oldpath, const char *newpath);
On Linux systems, the renaming operation is atomic; the manpage states:
If
newpathalready exists it will be atomically replaced ..., so that there is no point at which another process attempting to accessnewpathwill find it missing.If
newpathexists but the operation fails for some reason,renameguarantees to leave an instance ofnewpathin place.However, when overwriting there will probably be a window in which both
oldpathandnewpathrefer to the file being renamed.
As with other system calls, a 0 return indicates success, and a return value of -1 indicates an error.
Removing a file means removing the file’s entry in the directory and decrementing the file’s link count (maintained in the inode). The contents of the file, and the disk blocks holding them, are not freed until the link count reaches zero.
The system call is named unlink():
#include <unistd.h> POSIX
int unlink(const char *pathname);
Given our discussion of file links, the name makes sense; this call removes the given link (directory entry) for the file. It returns 0 on success and -1 on error.
The ability to remove a file requires write permission only for the directory and not for the file itself. This fact can be confusing, particularly for new Linux/Unix users. However, since the operation is one on the directory, this makes sense; it is the directory contents that are being modified, not the file’s contents.[2]
Since the earliest days of Unix, it has been possible to remove open files. Simply call unlink() with the filename after a successful call to open() or creat().
At first glance, this seems to be a strange thing to do. Since the system frees the data blocks when a file’s link count goes to zero, is it even possible to use the open file?
The answer is yes, you can continue to use the open file normally. The system knows that the file is open, and therefore it delays the release of the file’s storage until the last file descriptor on the file is closed. Once the file is completely unused, the storage is freed.
This operation also happens to be a useful one: It is an easy way for a program to get temporary file storage that is guaranteed to be both private and automatically released when no longer needed:
/* Obtaining private temporary storage, error checking omitted for brevity */
int fd;
mode_t mode = O_CREAT|O_EXCL|O_TRUNC|O_RDWR;
fd = open("/tmp/myfile", mode, 0000); Open the file
unlink("/tmp/myfile"); Remove it
...continue to use file...
close(fd); Close file, free storage
The downside to this approach is that it’s also possible for a runaway application to fill up a filesystem with an open but anonymous file, in which case the system administrator has to try to find and kill the process. In olden days, a reboot and filesystem consistency check might have been required; thankfully, this is exceedingly rare on modern systems.
ISO C provides the remove() function for removing files; this is intended to be a general function, usable on any system that supports ISO C, not just Unix and GNU/Linux:
#include <stdio.h> ISO C
int remove(const char *pathname);
While not technically a system call, the return value is in the same vein: 0 on success and -1 on error, with errno reflecting the value.
On GNU/Linux, remove() uses the unlink() system call to remove files, and the rmdir() system call (discussed later in the chapter) to remove directories. (On older GNU/Linux systems not using GLIBC, remove() is an alias for unlink(); this fails on directories. If you have such a system, you should probably upgrade it.)
We started the chapter with a discussion of partitions, filesystems, and inodes. We also saw that directory entries associate names with inode numbers. Because directory entries contain no other information, hard links are restricted to files within the same filesystem. This has to be; there is no way to distinguish inode 2341 on one filesystem from inode 2341 on another filesystem. Here is what happens when we try:
$ mount Show filesystems in use /dev/hda2 on / type ext3 (rw) /dev/hda5 on /d type ext3 (rw) ... $ ls -li /tmp/message Earlier example was on filesystem for / 228786 -rw-r--r-- 2 arnold devel 19 May 4 15:51 /tmp/message $ cat /tmp/message Hi, how ya doin' ? $ /bin/pwd Current directory is on a different filesystem /d/home/arnold $ ln /tmp/message . Attempt the link ln: creating hard link `./message' to `/tmp/message': Invalid cross-device link
Large systems often have many partitions, both on physically attached local disks and on remotely mounted network filesystems. The hard-link restriction to the same filesystem is inconvenient, for example, if some files or directories must be moved to a new location, but old software uses a hard-coded filename for the old location.
To get around this restriction, 4.2 BSD introduced symbolic links. A symbolic link (also referred to as a soft link) is a special kind of file (just as a directory is a special kind of file). The contents of the file are the pathname of the file being “pointed to.” All modern Unix systems, including Linux, provide symbolic links; indeed they are now part of POSIX.
Symbolic links may refer to any file anywhere on the system. They may also refer to directories. This makes it easy to move directories from place to place, with a symbolic link left behind in the original location pointing to the new location.
When processing a filename, the system notices symbolic links and instead performs the action on the pointed-to file or directory. Symbolic links are created with the -s option to ln:
$ /bin/pwd Where are we /d/home/arnold On a different filesystem $ ln -s /tmp/message ./hello Create a symbolic link $ cat hello Use it Hi, how ya doin' ? $ ls -l hello Show information about it lrwxrwxrwx 1 arnold devel 12 May 4 16:41 hello -> /tmp/message
The file pointed to by the link need not exist. The system detects this at runtime and acts appropriately:
$ rm /tmp/message Remove pointed-to file $ cat ./hello Attempt to use it by the soft link cat: ./hello: No such file or directory $ echo hi again > hello Create new file contents $ ls -l /tmp/message Show pointed-to file info ... -rw-r--r-- 1 arnold devel 9 May 4 16:45 /tmp/message $ cat /tmp/message ... and contents hi again
Symbolic links are created with the symlink() system call:
#include <unistd.h> POSIX
int symlink(const char *oldpath, const char *newpath);
The oldpath argument names the pointed-to file or directory, and newpath is the name of the symbolic link to be created. The return value is 0 on success and -1 on error; see your symlink(2) manpage for the possible errno values.
Symbolic links have their disadvantages:
They take up extra disk space, requiring a separate inode and data block. Hard links take up only a directory slot.
They add overhead. The kernel has to work harder to resolve a pathname containing symbolic links.
They can introduce “loops.” Consider the following:
$ rm -f a b Make sure 'a' and 'b' don't exist $ ln -s a b Symlink old file 'a' to new file 'b' $ ln -s b a Symlink old file 'b' to new file 'a' $ cat a What happens? cat: a: Too many levels of symbolic links
The kernel has to be able to detect this case and produce an error message.
They are easy to break. If you move the pointed-to file to a different location or rename it, the symbolic link is no longer valid. This can’t happen with a hard link.
Creating and removing directories is straightforward. The two system calls, not surprisingly, are mkdir() and rmdir(), respectively:
#include <sys/types.h> POSIX #include <sys/stat.h> int mkdir(const char *pathname, mode_t mode); #include <unistd.h> POSIX int rmdir(const char *pathname);
Both return 0 on success and -1 on error, with errno set appropriately. For mkdir(), the mode argument represents the permissions to be applied to the directory. It is completely analogous to the mode arguments for creat() and open() discussed in Section 4.6, “Creating Files,” page 106.
Both functions handle the ’.’ and ’..’ in the directory being created or removed. A directory must be empty before it can be removed; errno is set to ENOTEMPTY if the directory isn’t empty. (In this case, “empty” means the directory contains only ’.’ and ’..’.)
New directories, like all files, are assigned a group ID number. Unfortunately, how this works is complicated. We delay discussion until Section 11.5.1, “Default Group for New Files and Directories,” page 412.
Both functions work one directory level at a time. If /somedir exists and /somedir/sub1 does not, ’mkdir ("/somedir/sub1/sub2/")’ fails. Each component in a long pathname has to be created individually (thus the -p option to mkdir, see mkdir(1)).
Also, if pathname ends with a / character, mkdir() and rmdir() will fail on some systems and succeed on others. The following program, ch05-trymkdir.c, demonstrates both aspects.
1 /* ch05-trymkdir.c --- Demonstrate mkdir() behavior. 2 Courtesy of Nelson H.F. Beebe. */ 3 4 #include <stdio.h> 5 #include <stdlib.h> 6 #include <errno.h> 7 8 #if !defined(EXIT_SUCCESS) 9 #define EXIT_SUCCESS 0 10 #endif 11 12 void do_test(const char *path) 13 { 14 int retcode; 15 16 errno = 0; 17 retcode = mkdir(path, 0755); 18 printf("mkdir("%s") returns %d: errno = %d [%s] ", 19 path, retcode, errno, strerror(errno)); 20 } 21 22 int main(void) 23 { 24 do_test("/tmp/t1/t2/t3/t4"); Attempt creation in subdirs 25 do_test("/tmp/t1/t2/t3"); 26 do_test("/tmp/t1/t2"); 27 do_test("/tmp/t1"); 28 29 do_test("/tmp/u1"); Make subdirs 30 do_test("/tmp/u1/u2"); 31 do_test("/tmp/u1/u2/u3"); 32 do_test("/tmp/u1/u2/u3/u4"); 33 34 do_test("/tmp/v1/"); How is trailing '/' handled? 35 do_test("/tmp/v1/v2/"); 36 do_test("/tmp/v1/v2/v3/"); 37 do_test("/tmp/v1/v2/v3/v4/"); 38 39 return (EXIT_SUCCESS); 40 }
Here are the results under GNU/Linux:
$ ch05-trymkdir
mkdir("/tmp/t1/t2/t3/t4") returns -1: errno = 2 [No such file or directory]
mkdir("/tmp/t1/t2/t3") returns -1: errno = 2 [No such file or directory]
mkdir("/tmp/t1/t2") returns -1: errno = 2 [No such file or directory]
mkdir("/tmp/t1") returns 0: errno = 0 [Success]
mkdir("/tmp/u1") returns 0: errno = 0 [Success]
mkdir("/tmp/u1/u2") returns 0: errno = 0 [Success]
mkdir("/tmp/u1/u2/u3") returns 0: errno = 0 [Success]
mkdir("/tmp/u1/u2/u3/u4") returns 0: errno = 0 [Success]
mkdir("/tmp/v1/") returns 0: errno = 0 [Success]
mkdir("/tmp/v1/v2/") returns 0: errno = 0 [Success]
mkdir("/tmp/v1/v2/v3/") returns 0: errno = 0 [Success]
mkdir("/tmp/v1/v2/v3/v4/") returns 0: errno = 0 [Success]
Note how GNU/Linux accepts a trailing slash. Not all systems do.
On the original Unix systems, reading directory contents was easy. A program opened the directory with open() and read binary struct direct structures directly, 16 bytes at a time. The following fragment of code is from the V7 rmdir program,[3] lines 60–74. It shows the check for the directory being empty.
60 if((fd = open(name,0)) < 0) { 61 fprintf(stderr, "rmdir: %s unreadable ", name); 62 ++Errors; 63 return; 64 } 65 while(read(fd, (char *)&dir, sizeof dir) == sizeof dir) { 66 if(dir.d_ino == 0) continue; 67 if(!strcmp(dir.d_name, ".") || !strcmp(dir.d_name, "..")) 68 continue; 69 fprintf(stderr, "rmdir: %s not empty ", name); 70 ++Errors; 71 close(fd); 72 return; 73 } 74 close(fd);
Line 60 opens the directory for reading (a second argument of 0, equal to O_RDONLY). Line 65 reads the struct direct. Line 66 is the check for an empty directory slot; that is, one with an inode number of 0. Lines 67 and 68 check for ’.’ and ’..’. Upon reaching line 69, we know that some other filename has been seen and, therefore, that the directory isn’t empty.
(The test ’!strcmp(s1, s2)’ is a shorter way of saying ’strcmp(s1, s2) == 0’; that is, testing that the strings are equal. For what it’s worth, we consider the ’!strcmp(s1, s2)’ form to be poor style. As Henry Spencer once said, “strcmp() is not a boolean!”)
When 4.2 BSD introduced a new filesystem format that allowed longer filenames and provided better performance, it also introduced several new functions to provide a directory-reading abstraction. This suite of functions is usable no matter what the underlying filesystem and directory organization are. The basic parts of it are what is standardized by POSIX, and programs using it are portable across GNU/Linux and Unix systems.
Directory entries are represented by a struct dirent (not the same as the V7 struct direct!):
struct dirent {
...
ino_t d_ino; /* XSI extension --- see text */
char d_name[...]; /* See text on the size of this array */
...
};
For portability, POSIX specifies only the d_name field, which is a zero-terminated array of bytes representing the filename part of the directory entry. The size of d_name is not specified by the standard, other than to say that there may be at most NAME_MAX bytes before the terminating zero. (NAME_MAX is defined in <limits.h>.) The XSI extension to POSIX provides for the d_ino inode number field.
In practice, since filenames can be of variable length and NAME_MAX is usually fairly large (like 255), the struct dirent contains additional members that aid in the bookkeeping of variable-length directory entries on disk. These additional members are not relevant for everyday code.
The following functions provide the directory-reading interface:
#include <sys/types.h> POSIX #include <dirent.h> DIR *opendir(const char *name); Open a directory for reading struct dirent *readdir(DIR *dir); Return one struct dirent at a time int closedir(DIR *dir); Close an open directory void rewinddir(DIR *dirp); Return to the front of a directory
The DIR type is analogous to the FILE type in <stdio.h>. It is an opaque type, meaning that application code is not supposed to know what’s inside it; its contents are for use by the other directory routines. If opendir() returns NULL, the named directory could not be opened for reading and errno is set to indicate the error.
Once you have an open DIR * variable, it can be used to retrieve a pointer to a struct dirent representing the next directory entry. readdir() returns NULL upon end-of-file or error.
Finally, closedir() is analogous to the fclose() function in <stdio.h>; it closes the open DIR * variable. The rewinddir() function can be used to start over at the beginning of a directory.
With these routines in hand (or at least in the C library), we can write a simple catdir program that “cats” the contents of a directory. Such a program is presented in ch05-catdir.c:
1 /* ch05-catdir.c --- Demonstrate opendir(), readdir(), closedir(). */ 2 3 #include <stdio.h> /* for printf() etc. */ 4 #include <errno.h> /* for errno */ 5 #include <sys/types.h> /* for system types */ 6 #include <dirent.h> /* for directory functions */ 7 8 char *myname; 9 int process(char *dir); 10 11 /* main --- loop over directory arguments */ 12 13 int main(int argc, char **argv) 14 { 15 int i; 16 int errs = 0; 17 18 myname = argv[0]; 19 20 if (argc == 1) 21 errs = process("."); /* default to current directory */ 22 else 23 for (i = 1; i < argc; i++) 24 errs += process(argv[i]); 25 26 return (errs != 0); 27 }
This program is quite similar to ch04-cat.c (see Section 4.2, “Presenting a Basic Program Structure,” page 84); the main() function is almost identical. The primary difference is that it defaults to using the current directory if there are no arguments (lines 20–21).
29 /* 30 * process --- do something with the directory, in this case, 31 * print inode/name pairs on standard output. 32 * Returns 0 if all ok, 1 otherwise. 33 */ 34 35 int 36 process(char *dir) 37 { 38 DIR *dp; 39 struct dirent *ent; 40 41 if ((dp = opendir(dir)) == NULL) { 42 fprintf(stderr, "%s: %s: cannot open for reading: %s ", 43 myname, dir, strerror(errno)); 44 return 1; 45 } 46 47 errno = 0; 48 while ((ent = readdir(dp)) != NULL) 49 printf("%8ld %s ", ent->d_ino, ent->d_name); 50 51 if (errno != 0) { 52 fprintf(stderr, "%s: %s: reading directory entries: %s ", 53 myname, dir, strerror(errno)); 54 return 1; 55 } 56 57 if (closedir(dp) != 0) { 58 fprintf(stderr, "%s: %s: closedir: %s ", 59 myname, dir, strerror(errno)); 60 return 1; 61 } 62 63 return 0; 64 }
The process() function does all the work, and the majority of it is error-checking code. The heart of the function is lines 48 and 49:
while ((ent = readdir(dp)) != NULL)
printf("%8ld %s
", ent->d_ino, ent->d_name);
This loop reads directory entries, one at a time, until readdir() returns NULL. The loop body prints the inode number and filename of each entry. Here’s what happens when the program is run:
$ ch05-catdir Default to current directory 639063 . 639062 .. 639064 proposal.txt 639012 lightsabers.url 688470 code 638976 progex.texi 639305 texinfo.tex 639007 15-processes.texi 639011 00-preface.texi 639020 18-tty.texi 638980 Makefile 639239 19-i18n.texi ...
The output is not sorted in any way; it represents the linear contents of the directory. (We describe how to sort the directory contents in Section 6.2, “Sorting and Searching Functions,” page 181.)
There are several portability considerations. First, you should not assume that the first two entries returned by readdir() will always be ’.’ and ’..’. Many filesystems use directory organizations that are different from that of the original Unix design, and ’.’ and ’..’ could be in the middle of the directory or possibly not even present.[4]
Second, the POSIX standard is silent about possible values for d_ino. It does say that the returned structures represent directory entries for files; this implies that empty slots are not returned by readdir(), and thus the GNU/Linux readdir() implementation doesn’t bother returning entries when ’d_ino == 0’; it continues to the next valid directory entry.
So, on GNU/Linux and Unix systems at least, it is unlikely that d_ino will ever be zero. However, it is best to avoid using this field entirely if you can.
Finally, some systems use d_fileno instead of d_ino inside the struct dirent. Be aware of this if you have to port directory-reading code to such systems.
Indirect System Calls
“Don’t try this at home, kids!” —Mr. Wizard—
Many system calls, such as open(), read(), and write(), are meant to be called directly from user-level application code: in other words, from code that you, as a GNU/Linux developer, would write.
However, other system calls exist only to make it possible to implement higher-level, standard library functions and should not be called directly. The GNU/Linux getdents() system call is one such; it reads multiple directory entries into a buffer provided by the caller—in this case, the code that implements readdir(). The readdir() code then returns valid directory entries from the buffer, one at a time, refilling the buffer as needed.
These for-library-use-only system calls can be distinguished from for-user-use system calls by their appearance in the manpage. For example, from getdents(2):
NAME
getdents - get directory entries
SYNOPSIS
#include <unistd.h>
#include <linux/types.h>
#include <linux/dirent.h>
#include <linux/unistd.h>
_syscall3(int, getdents, uint, fd, struct dirent *, dirp,
 uint, count);
int getdents(unsigned int fd, struct dirent *dirp, unsigned
int count);
uint, count);
int getdents(unsigned int fd, struct dirent *dirp, unsigned
int count);
Any system call that uses a _syscallX() macro should not be called by application code. (More information on these calls can be found in the intro(2) manpage; you should read that manpage if you haven’t already.)
In the case of getdents(), many other Unix systems have a similar system call; sometimes with the same name, sometimes with a different name. Thus, trying to use these calls would only lead to a massive portability mess anyway; you’re much better off in all cases using readdir(), whose interface is well defined, standard, and portable.
Although we just said that you should only use the d_ino and d_name members of the struct dirent, it’s worth knowing about the d_type member in the BSD and Linux struct dirent. This is an unsigned char value that stores the type of the file named by the directory entry:
struct dirent {
...
ino_t d_ino; /* As before */
char d_name[...]; /* As before */
unsigned char d_type; /* Linux and modern BSD */
...
};
d_type can have any of the values described in Table 5.1.
Table 5.1. Values for d_type
Name | Meaning |
|---|---|
| Block device file. |
| Character device file. |
| Directory. |
| FIFO or named pipe. |
| Symbolic link. |
| Regular file. |
| Socket. |
| Unknown file type. |
| Whiteout entry (BSD systems only). |
Knowing the file’s type just by reading the directory entry is very handy; it can save a possibly expensive stat() system call. (The stat() call is described shortly, in Section 5.4.2, “Retrieving File Information,” page 141.)
Occasionally, it’s useful to mark the current position in a directory in order to be able to return to it later. For example, you might be writing code that traverses a directory tree and wish to recursively enter each subdirectory as you come across it. (How to distinguish files from directories is discussed in the next section.) For this reason, the original BSD interface included two additional routines:
#include <dirent.h> XSI /* Caveat Emptor: POSIX XSI uses long, not off_t, for both functions */ off_t telldir(DIR *dir); Return current position void seekdir(DIR *dir, off_t offset); Move to given position
These routines are similar to the ftell() and fseek() functions in <stdio.h>. They return the current position in a directory and set the current position to a previously retrieved value, respectively.
These routines are included in the XSI part of the POSIX standard, since they make sense only for directories that are implemented with linear storage of directory entries.
Besides the assumptions made about the underlying directory structure, these routines are riskier to use than the simple directory-reading routines. This is because the contents of a directory might be changing dynamically: As files are added to or removed from a directory, the operating system adjusts the contents of the directory. Since directory entries are of variable length, it may be that the absolute offset saved at an earlier time no longer represents the start of a directory entry! Thus, we don’t recommend that you use these functions unless you have to.
Reading a directory to retrieve filenames is only half the battle. Once you have a filename, you need to know how to retrieve the other information associated with a file, such as the file’s type, its permissions, owner, and so on.
Linux (and Unix) supports the following different kinds of file types:
Regular files
Directories
Symbolic links
Devices
Files representing both physical hardware devices and software pseudo-devices. There are two kinds:
Block devices
Character devices
Also known as raw devices. Originally, character devices were those on which I/O happened a few bytes at a time, such as terminals. However, the character device is also used for direct I/O to block devices such as tapes and disks, bypassing the buffer cache.[5] In an ’
ls -l’ listing, they show up with acin the first character of the permissions field.
Also known as FIFOs (“first-in first-out”) files. These special files act like pipes; data written into them by one program can be read by another; no data go to or from the disk. FIFOs are created with the
mkfifocommand; they are discussed in Section 9.3.2, “FIFOs,” page 319. In an ’ls -l’ listing, they show up with a p in the first character of the permissions field.
Sockets
Similar in purpose to named pipes,[6] they are managed with the socket interprocess communication (IPC) system calls and are not otherwise dealt with in this book. In an ’
ls -l’ listing, they show up with ansin the first character of the permissions field.
Three system calls return information about files:
#include <sys/types.h> POSIX
#include <sys/stat.h>
#include <unistd.h>
int stat(const char *file_name, struct stat *buf);
int fstat(int filedes, struct stat *buf);
int lstat(const char *file_name, struct stat *buf);
The stat() function accepts a pathname and returns information about the given file. It follows symbolic links; that is, when applied to a symbolic link, stat() returns information about the pointed-to file, not about the link itself. For those times when you want to know if a file is a symbolic link, use the lstat() function instead; it does not follow symbolic links.
The fstat() function retrieves information about an already open file. It is particularly useful for file descriptors 0, 1, and 2, (standard input, output, and error) which are already open when a process starts up. However, it can be applied to any open file. (An open file descriptor will never relate to a symbolic link; make sure you understand why.)
The value passed in as the second parameter should be the address of a struct stat, declared in <sys/stat.h>. As with the struct dirent, the struct stat contains at least the following members:
struct stat {
...
dev_t st_dev; /* device */
ino_t st_ino; /* inode */
mode_t st_mode; /* type and protection */
nlink_t st_nlink; /* number of hard links */
uid_t st_uid; /* user ID of owner */
gid_t st_gid; /* group ID of owner */
dev_t st_rdev; /* device type (block or character device) */
off_t st_size; /* total size, in bytes */
blksize_t st_blksize; /* blocksize for filesystem I/O */
blkcnt_t st_blocks; /* number of blocks allocated */
time_t st_atime; /* time of last access */
time_t st_mtime; /* time of last modification */
time_t st_ctime; /* time of last inode change */
...
};
(The layout may be different on different architectures.) This structure uses a number of typedef ’d types. Although they are all (typically) integer types, the use of specially defined types allows them to have different sizes on different systems. This keeps user-level code that uses them portable. Here is a fuller description of each field.
st_dev
st_ino
st_mode
st_nlink
st_uid
st_gid
st_rdev
st_size
The logical size of the file. As mentioned in Section 4.5, “Random Access: Moving Around within a File,” page 102, a file may have holes in it, in which case the size may not reflect the true amount of storage space that it occupies.
st_blksize
The “block size” of the file. This represents the preferred size of a data block for I/O to or from the file. This is almost always larger than a physical disk sector. Older Unix systems don’t have this field (or
st_blocks) in thestruct stat. For the Linuxext2andext3filesystems, this value is 4096.
st_blocks
The number of “blocks” used by the file. On Linux, this is in units of 512-byte blocks. On other systems, the size of a block may be different; check your local stat(2) manpage. (This number comes from the
DEV_BSIZEconstant in<sys/param.h>. This constant isn’t standardized, but it is fairly widely used on Unix systems.)The number of blocks may be more than ’
st_size / 512’; besides the data blocks, a filesystem may use additional blocks to store the locations of the data blocks. This is particularly necessary for large files.
st_atime
st_mtime
st_ctime
Note
The st_ctime field is not the file’s “creation time”! There is no such thing in a Linux or Unix system. Some early documentation referred to the st_ctime field as the creation time. This was a misguided effort to simplify the presentation of the file metadata.
The time_t type used for the st_atime, st_mtime, and st_ctime fields represents dates and times. These time-related values are sometimes termed timestamps. Discussion of how to use a time_t value is delayed until Section 6.1, “Times and Dates,” page 166. Similarly, the uid_t and gid_t types represent user and group ID numbers, which are discussed in Section 6.3, “User and Group Names,” page 195. Most of the other types are not of general interest.
The 2.6 and later Linux kernel supplies three additional fields in the struct stat. These provide nanosecond resolution on the file times:
| The nanoseconds component of the file’s access time. |
| The nanoseconds component of the file’s modification time. |
| The nanoseconds component of the file’s inode change time. |
Some other systems also provide such high-resolution time fields, but the member names for the struct stat are not standardized, making it difficult to write portable code that uses these times. (See Section 14.3.2, “Microsecond File Times: utimes(),” page 545, for a related advanced system call.)
Recall that the st_mode field encodes both the file’s type and its permissions. <sys/stat.h> defines a number of macros that determine the file’s type. In particular, these macros return true or false when applied to the st_mode field. The macros correspond to each of the file types described earlier. Assume that the following code has been executed:
struct stat stbuf;
char filename[PATH_MAX]; /* PATH_MAX is from <limits.h> */
...fill in filename with a file name...
if (stat(filename, & stbuf) < 0) {
/* handle error */
}
Once stbuf has been filled in by the system, the following macros can be called, being passed stbuf.st_mode as the argument:
Returns true if
filenameis a regular file.
S_ISDIR(stbuf.st_mode)
Returns true if
filenameis a directory.
S_ISCHR(stbuf.st_mode)
Returns true if
filenameis a character device. Devices are shortly discussed in more detail.
S_ISBLK(stbuf.st_mode)
Returns true if
filenameis a block device.
S_ISFIFO(stbuf.st_mode)
Returns true if
filenameis a FIFO.
S_ISLNK(stbuf.st_mode)
S_ISSOCK(stbuf.st_mode)
Returns true if
filenameis a socket.
Note
It happens that on GNU/Linux, these macros return 1 for true and 0 for false. However, on other systems, it’s possible that they return an arbitrary nonzero value for true, instead of 1. (POSIX specifies only nonzero vs. zero.) Thus, you should always use these macros as standalone tests instead of testing the return value:
if (S_ISREG(stbuf.st_mode)) ... Correct if (S_ISREG(stbuf.st_mode) == 1) ... Incorrect
Along with the macros, <sys/stat.h> provides two sets of bitmasks. One set is for testing permission, and the other set is for testing the type of a file. We saw the permission masks in Section 4.6, “Creating Files,” page 106, when we discussed the mode_t type and values for open() and creat(). The bitmasks, their values for GNU/Linux, and their meanings are described in Table 5.2.
Table 5.2. POSIX file-type and permission bitmasks in <sys/stat.h>
Value | Meaning | |
|---|---|---|
|
| Bitmask for the file type bitfields. |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| Character device. |
|
| FIFO. |
|
| |
|
| |
|
| |
|
| Mask for owner permissions. |
| ||
|
| Owner write permission. |
|
| Owner execute permission. |
|
| |
|
| Group read permission. |
|
| Group write permission. |
|
| Group execute permission. |
|
| |
|
| Other read permission. |
|
| Other write permission. |
|
| Other execute permission. |
Several of these masks serve to isolate the different sets of bits encoded in the st_mode field:
S_IFMTrepresents bits 12–15, which are where the different types of files are encoded.S_IRWXUrepresents bits 6–8, which are the user’s permission (read, write, execute for User).S_IRWXGrepresents bits 3–5, which are the group’s permission (read, write, execute for Group).S_IRWXOrepresents bits 0–2, which are the “other” permission (read, write, execute for Other).
The permission and file type bits are depicted graphically in Figure 5.3.

The file-type masks are standardized primarily for compatibility with older code; they should not be used directly, because such code is less readable than the corresponding macros. It happens that the macros are implemented, logically enough, with the masks, but that’s irrelevant for user-level code.
The POSIX standard explicitly states that no new bitmasks will be standardized in the future and that tests for any additional kinds of file types that may be added will be available only as S_ISxxx() macros.
Because it is meant to apply to non-Unix systems as well as Unix systems, the POSIX standard doesn’t define the meaning for the dev_t type. However, it’s worthwhile to know what’s in a dev_t.
When S_ISBLK(sbuf.st_mode) or S_ISCHR(sbuf.st_mode) is true, then the device information is found in the sbuf.st_rdev field. Otherwise, this field does not contain any useful information.
Traditionally, Unix device files encode a major device number and a minor device number within the dev_t value. The major number distinguishes the device type, such as “disk drive” or “tape drive.” Major numbers also distinguish among different types of devices, such as SCSI disk vs. IDE disk. The minor number distinguishes the unit of that type, for example, the first disk or the second one. You can see these values with ’ls -l’:
$ ls -l /dev/hda /dev/hda? Show numbers for first hard disk brw-rw---- 1 root disk 3, 0 Aug 31 2002 /dev/hda brw-rw---- 1 root disk 3, 1 Aug 31 2002 /dev/hda1 brw-rw---- 1 root disk 3, 2 Aug 31 2002 /dev/hda2 brw-rw---- 1 root disk 3, 3 Aug 31 2002 /dev/hda3 brw-rw---- 1 root disk 3, 4 Aug 31 2002 /dev/hda4 brw-rw---- 1 root disk 3, 5 Aug 31 2002 /dev/hda5 brw-rw---- 1 root disk 3, 6 Aug 31 2002 /dev/hda6 brw-rw---- 1 root disk 3, 7 Aug 31 2002 /dev/hda7 brw-rw---- 1 root disk 3, 8 Aug 31 2002 /dev/hda8 brw-rw---- 1 root disk 3, 9 Aug 31 2002 /dev/hda9 $ ls -l /dev/null Show info for /dev/null, too crw-rw-rw- 1 root root 1, 3 Aug 31 2002 /dev/null
Instead of the file size, ls displays the major and minor numbers. In the case of the hard disk, /dev/hda represents the whole drive. /dev/hda1, /dev/hda2, and so on, represent partitions within the drive. They all share the same major device number (3), but have different minor device numbers.
Note that the disk devices are block devices, whereas /dev/null is a character device. Block devices and character devices are separate entities; even if a character device and a block device share the same major device number, they are not necessarily related.
The major and minor device numbers can be extracted from a dev_t value with the major() and minor() functions defined in <sys/sysmacros.h>:
#include <sys/types.h> Common #include <sys/sysmacros.h> int major(dev_t dev); Major device number int minor(dev_t dev); Minor device number dev_t makedev(int major, int minor); Create a dev_t value
(Some systems implement them as macros.)
The makedev() function goes the other way; it takes separate major and minor values and encodes them into a dev_t value. Its use is otherwise beyond the scope of this book; the morbidly curious should see mknod(2).
The following program, ch05-devnum.c, shows how to use the stat() system call, the file-type test macros, and finally, the major() and minor() macros.
/* ch05-devnum.c --- Demonstrate stat(), major(), minor(). */
#include <stdio.h>
#include <errno.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/sysmacros.h>
int main(int argc, char **argv)
{
struct stat sbuf;
char *devtype;
if (argc != 2) {
fprintf(stderr, "usage: %s path
", argv[0]);
exit(1);
}
if (stat(argv[1], & sbuf) < 0) {
fprintf(stderr, "%s: stat: %s
", argv[1], strerror(errno));
exit(1);
}
if (S_ISCHR(sbuf.st_mode))
devtype = "char";
else if (S_ISBLK(sbuf.st_mode))
devtype = "block";
else {
fprintf(stderr, "%s is not a block or character device
", argv[1]);
exit(1);
}
printf("%s: major: %d, minor: %d
", devtype,
major(sbuf.st_rdev), minor(sbuf.st_rdev));
exit(0);
}
Here is what happens when the program is run:
$ ch05-devnum /tmp Try a nondevice /tmp is not a block or character device $ ch05-devnum /dev/null Character device char: major: 1, minor: 3 $ ch05-devnum /dev/hda2 Block device block: major: 3, minor: 2
Fortunately, the output agrees with that of ls, giving us confidence[7] that we have indeed written correct code.
Reproducing the output of ls is all fine and good, but is it really useful? The answer is yes. Any application that works with file hierarchies must be able to distinguish among all the different types of files. Consider an archiver such as tar or cpio. It would be disastrous if such a program treated a disk device file as a regular file, attempting to read it and store its contents in an archive! Or consider find, which can perform arbitrary actions based on the type and other attributes of files it encounters. (find is a complicated program; see find(1) if you’re not familiar with it.) Or even something as simple as a disk space accounting package has to distinguish regular files from everything else.
In Section 4.4.4, “Example: Unix cat,” page 99, we promised to return to the V7 cat program to review its use of the stat() system call. The first group of lines that used it were these:
31 fstat(fileno(stdout), &statb); 32 statb.st_mode &= S_IFMT; 33 if (statb.st_mode!=S_IFCHR && statb.st_mode!=S_IFBLK) { 34 dev = statb.st_dev; 35 ino = statb.st_ino; 36 }
This code should now make sense. Line 31 calls fstat() on the standard output to fill in the statb structure. Line 32 throws away all the information in statb.st_mode except the file type, by ANDing the mode with the S_IFMT mask. Line 33 checks that the file being used for standard output is not a device file. In that case, the program saves the device and inode numbers in dev and ino. These values are then checked for each input file in lines 50–56:
50 fstat(fileno(fi), &statb); 51 if (statb.st_dev==dev && statb.st_ino==ino) { 52 fprintf(stderr, "cat: input %s is output ", 53 fflg?"-": *argv); 54 fclose(fi); 55 continue; 56 }
If an input file’s st_dev and st_ino values match those of the output file, then cat complains and continues to the next file named on the command line.
The check is done unconditionally, even though dev and ino are set only if the output is not a device file. This works out OK, because of how those variables are declared:
17 int dev, ino = -1;
Since ino is initialized to -1, no valid inode number will ever be equal to it.[8] That dev is not so initialized is sloppy, but not a problem, since the test on line 51 requires that both the device and inode be equal. (A good compiler will complain that dev is used without being initialized: ’gcc -Wall’ does.)
Note also that neither call to fstat() is checked for errors. This too is sloppy, although less so; it is unlikely that fstat() will fail on a valid file descriptor.
The test for input file equals output file is done only for nondevice files. This makes it possible to use cat to copy input from device files to themselves, such as with terminals:
$ tty Print current terminal device name /dev/pts/3 $ cat /dev/pts/3 > /dev/pts/3 Copy keyboard input to screen this is a line of text Type in a line this is a line of text cat repeats it
In general, symbolic links act like hard links; file operations such as open() and stat() apply to the pointed-to file instead of to the symbolic link itself. However, there are times when it really is necessary to work with the symbolic link instead of with the file the link points to.
For this reason, the lstat() system call exists. It behaves exactly like stat(), but if the file being checked happens to be a symbolic link, then the information returned applies to the symbolic link, and not to the pointed-to file. Specifically:
S_ISLNK(sbuf.st_mode)will be true.sbuf.st_sizeis the number of bytes used by the name of the pointed-to file.
We already saw that the symlink() system call creates a symbolic link. But given an existing symbolic link, how can we retrieve the name of the file it points to? (ls obviously can, so we ought to be able to also.)
Opening the link with open() in order to read it with read() won’t work; open() follows the link to the pointed-to file. Symbolic links thus necessitate an additional system call, named readlink():
#include <unistd.h> POSIX
int readlink(const char *path, char *buf, size_t bufsiz);
readlink() places the contents of the symbolic link named by path into the buffer pointed to by buf. No more than bufsiz characters are copied. The return value is the number of characters placed in buf or -l if an error occurred. readlink() does not supply the trailing zero byte.
Note that if the buffer passed in to readlink() is too small, you will lose information; the full name of the pointed-to file won’t be available. To properly use readlink(), your code should do the following:
Make sure that your buffer to hold the link contents is at least ’
sbuf.st_size + 1’ bytes big; the ’+ 1’ is for the trailing zero byte to turn the buffer into a usable C string.Call
readlink(). It doesn’t hurt to verify that the returned value is the same assbuf.st_size.Assign
'�'to the byte after the contents of the link, to make it into a C string.
Code to do all that would look something like this:
/* Error checking omitted for brevity */ int count; char linkfile[PATH_MAX], realfile[PATH_MAX]; /* PATH_MAX is in <limits.h> */ strut stat sbuf; ... fill in linkfile with path to symbolic link of interest... lstat(linkfile, & sbuf); Get stat information if (! S_ISLNK(sbuf.st_mode)) Check that it's a symlink /* not a symbolic link, handle it */ if (sbuf.st_size + 1 > PATH_MAX) Check buffer size /* handle buffer size problems */ count = readlink(linkfile, realfile, PATH_MAX); Read the link if (count != sbuf.st_size) /* something weird going on, handle it */ realfile[count] = '�'; Make it into a C string
This example uses fixed-size buffers for simplicity of presentation. Real code would use malloc() to allocate a buffer of the correct size since the fixed-size arrays might be too small. The file lib/xreadlink.c in the GNU Coreutils does just this. It reads the contents of a symbolic link into storage allocated by malloc(). We show here just the function; most of the file is boilerplate definitions. Line numbers are relative to the start of the file:
55 /* Call readlink to get the symbolic link value of FILENAME. 56 Return a pointer to that NUL-terminated string in malloc'd storage. 57 If readlink fails, return NULL (caller may use errno to diagnose). 58 If realloc fails, or if the link value is longer than SIZE_MAX :-), 59 give a diagnostic and exit. */ 60 61 char * 62 xreadlink (char const *filename) 63 { 64 /* The initial buffer size for the link value. A power of 2 65 detects arithmetic overflow earlier, but is not required. */ 66 size_t buf_size = 128; 67 68 while (1) 69 { 70 char *buffer = xmalloc (buf_size); 71 ssize_t link_length = readlink (filename, buffer, buf_size); 72 73 if (link_length < 0) 74 { 75 int saved_errno = errno; 76 free (buffer); 77 errno = saved_errno; 78 return NULL; 79 } 80 81 if ((size_t) link_length < buf_size) 82 { 83 buffer[link_length] = 0; 84 return buffer; 85 } 86 87 free (buffer); 88 buf_size *= 2; 89 if (SSIZE_MAX < buf_size || (SIZE_MAX / 2 < SSIZE_MAX && buf_size == 0)) 90 xalloc_die (); 91 } 92 }
The function body consists of an infinite loop (lines 68–91), broken at line 84 which returns the allocated buffer. The loop starts by allocating an initial buffer (line 70) and reading the link (line 71). Lines 73–79 handle the error case, saving and restoring errno so that it can be used correctly by the calling code.
Lines 81–85 handle the “success” case, in which the link’s contents’ length is smaller than the buffer size. In this case, the terminating zero is supplied (line 83) and then the buffer returned (line 84), breaking the infinite loop. This ensures that the entire link contents have been placed into the buffer, since readlink() has no way to indicate “insufficient space in buffer.”
Lines 87–88 free the buffer and double the buffer size for the next try at the top of the loop. Lines 89–90 handle the case in which the link’s size is too big: buf_size is greater than SSIZE_MAX, or SSIZE_MAX is larger than the value that can be represented in a signed integer of the same size as used to hold SIZE_MAX and buf_size has wrapped around to zero. (These are unlikely conditions, but strange things do happen.) If either condition is true, the program dies with an error message. Otherwise, the function continues around to the top of the loop to make another try at allocating a buffer and reading the link.
Some further explanation: The ’SIZE_MAX / 2 < SSIZE_MAX’ condition is true only on systems on which ’SIZE_MAX < 2 * SSIZE_MAX’; we don’t know of any, but only on such a system can buf_size wrap around to zero. Since in practice this condition can’t be true, the compiler can optimize away the whole expression, including the following ’buf_size == 0’ test. After reading this code, you might ask, “Why not use lstat() to retrieve the size of the symbolic link, allocate a buffer of the right size with malloc(), and be done?” Well, there are a number of reasons.[9]
lstat()is a system call—it’s best to avoid the overhead of making it since the contents of most symbolic links will fit in the initial buffer size of 128.Calling
lstat()introduces a race condition: The link could change between the execution oflstat()andreadlink(), forcing the need to iterate anyway.Some systems don’t properly fill in the
st_sizemember for symbolic links. (Sad, but true.) In a similar fashion, as we see in Section 8.4.2, “Getting the Current Directory: getcwd(),” page 258, Linux provides special symbolic links under/procwhosest_sizeis zero, but for whichreadlink()does return valid content.
Finally, when the buffer isn’t big enough, xreadlink() uses free() and malloc() with a bigger size, instead of realloc(), to avoid the useless copying that realloc() does. (The comment on line 58 is thus out of date since realloc() isn’t being used; this is fixed in the post-5.0 version of the Coreutils.)
Several additional system calls let you change other file-related information: in particular, the owner and group of a file, the file’s permissions, and the file’s access and modification times.
File ownership and group are changed with three similar system calls:
#include <sys/types.h> POSIX
#include <unistd.h>
int chown(const char *path, uid_t owner, gid_t group);
int fchown(int fd, uid_t owner, gid_t group);
int lchown(const char *path, uid_t owner, gid_t group);
chown() works on a pathname argument, fchown() works on an open file, and lchown() works on symbolic links instead of on the files pointed to by symbolic links. In all other respects, the three calls work identically, returning 0 on success and -1 on error.
It is noteworthy that one system call changes both the owner and group of a file. To change only the owner or only the group, pass in a value of -1 for the ID number that is to be left unchanged.
While you might think that you could pass in the corresponding value from a previously retrieved struct stat for the file or file descriptor, that method is more error prone. There’s a race condition: The owner or group could have changed between the call to stat() and the call to chown().
You might wonder, “Why be able to change ownership of a symbolic link? The permissions and ownership on them don’t matter.” But what happens if a user leaves, but all his files are still needed? It’s necessary to be able to change the ownership on all the person’s files to someone else, including symbolic links.
GNU/Linux systems normally do not permit ordinary (non-root) users to change the ownership of (“give away”) their files. Changing the group to one of the user’s groups is allowed, of course. The restriction on changing owners follows BSD systems, which also have this prohibition. The primary reason is that allowing users to give away files can defeat disk accounting. Consider a scenario like this:
$ mkdir mywork Make a directory $ chmod go-rwx mywork Set permissions to draw------ $ cd mywork Go there $ myprogram > large_data_file Create a large file $ chmod ugo+rw large_data_file Set permissions to -rw-rw-rw- $ chown otherguy large_data_file Give file away to otherguy
In this example, large_data_file now belongs to user otherguy. The original user can continue to read and write the file, because of the permissions. But otherguy will be charged for the disk space it occupies. However, since it’s in a directory that belongs to the original user, which cannot be accessed by otherguy, there is no way for otherguy to remove the file.
Some System V systems do allow users to give away files. (Setuid and setgid files have the corresponding bit removed when the owner is changed.) This can be a particular problem when files are extracted from a .tar or .cpio archive; the extracted files end up belonging to the UID or GID encoded in the archive. On such systems, the tar and cpio programs have options that prevent this, but it’s important to know that chown()’s behavior does vary across systems.
We will see in Section 6.3, “User and Group Names,” page 195, how to relate user and group names to their corresponding numeric values.
After all the discussion in Chapter 4, “Files and File I/O,” page 83, and in this chapter, changing permissions is almost anticlimatic. It’s done with one of two system calls, chmod() and fchmod():
#include <sys/types.h> POSIX
#include <sys/stat.h>
int chmod(const char *path, mode_t mode);
int fchmod(int fildes, mode_t mode);
chmod() works on a pathname argument, and fchmod() works on an open file. (There is no lchmod() call in POSIX, since the system ignores the permission settings on symbolic links. Some systems do have such a call, though.) As with most other system calls, these return 0 on success and -1 on failure. Only the file’s owner or root can change a file’s permissions.
The mode value is created in the same way as for open() and creat(), as discussed in Section 4.6, “Creating Files,” page 106. See also Table 5.2, which lists the permission constants.
The system will not allow setting the setgid bit (S_ISGID) if the group of the file does not match the effective group ID of the process or one of its supplementary groups. (We have not yet discussed these issues in detail; see Section 11.1.1, “Real and Effective IDs,” page 405.) Of course, this check does not apply to root or to code running as root.
The struct stat structure contains three fields of type time_t:
| The time the file was last accessed (read). |
The time the file was last modified (written). | |
The time the file’s inode was last changed (for example, renamed). |
A time_t value represents time in “seconds since the Epoch.” The Epoch is the Beginning of Time for computer systems. GNU/Linux and Unix use Midnight, January 1, 1970 UTC[10] as the Epoch. Microsoft Windows systems use Midnight January 1, 1980 (local time, apparently) as the Epoch.
time_t values are sometimes referred to as timestamps. In Section 6.1, “Times and Dates,” page 166, we look at how these values are obtained and at how they’re used. For now, it’s enough to know what a time_t value is and that it represents seconds since the Epoch.
The utime() system call allows you to change a file’s access and modification timestamps:
#include <sys/types.h> POSIX
#include <utime.h>
int utime(const char *filename, struct utimbuf *buf);
A struct utimbuf looks like this:
struct utimbuf {
time_t actime; /* access time */
time_t modtime; /* modification time */
};
If the call is successful, it returns 0; otherwise, it returns -1. If buf is NULL, then the system sets both the access time and the modification time to the current time.
To change one time but not the other, use the original value from the struct stat. For example:
/* Error checking omitted for brevity */ struct stat sbuf; struct utimbuf ut; time_t now; time(& now); Get current time of day, see next chapter stat("/some/file", & sbuf); Fill in sbuf ut.actime = sbuf.st_atime; Access time unchanged ut.modtime = now - (24 * 60 * 60); Set modtime to 24 hours ago utime("/some/file", & ut); Set the values
About now, you may be asking yourself, “Why would anyone want to change a file’s access and modification times?” Good question.
To answer it, consider the case of a program that creates backup archives, such as tar or cpio. These programs have to read the contents of a file in order to archive them. Reading the file, of course, changes the file’s access time.
However, that file might not have been read by a human in 10 years. Someone doing an ’ls -lu’, which displays the access time (instead of the default modification time), should see that the last time the file was read was 10 years ago. Thus, the backup program should save the original access and modification times, read the file in order to archive it, and then restore the original times with utime().
Similarly, consider the case of an archiving program restoring a file from an archive. The archive stores the file’s original access and modification times. However, when a file is extracted from an archive to a newly created copy on disk, the new file has the current date and time of day for its access and modification times.
However, it’s more useful if the newly created file looks as if it’s the same age as the original file in the archive. Thus, the archiver needs to be able to set the access and modification times to those stored in the archive.
Note
In new code, you may wish to use the utimes() call (note the s in the name), which is described later in the book, in Section 14.3.2, “Microsecond File Times: utimes(),” page 545.
Some older systems don’t set the access and modification times to the current time when the second argument to utime() is NULL. Yet, higher-level code (such as GNU touch) is simpler and more straightforward if it can rely on a single standardized interface.
The GNU Coreutils library thus contains a replacement function for utime() that handles this case, which can then be called by higher-level code. This reflects the “pick the best interface for the job” design principle we described in Section 1.5, “Portability Revisited,” page 19.
The replacement function is in the file lib/utime.c in the Coreutils distribution. The following code is the version from Coreutils 5.0. Line numbers are relative to the start of the file:
24 #include <sys/types.h> 25 26 #ifdef HAVE_UTIME_H 27 # include <utime.h> 28 #endif 29 30 #include "full-write.h" 31 #include "safe-read.h" 32 33 /* Some systems (even some that do have <utime.h>) don't declare this 34 structure anywhere. */ 35 #ifndef HAVE_STRUCT_UTIMBUF 36 struct utimbuf 37 { 38 long actime; 39 long modtime; 40 }; 41 #endif 42 43 /* Emulate utime (file, NULL) for systems (like 4.3BSD) that do not 44 interpret it to set the access and modification times of FILE to 45 the current time. Return 0 if successful, -1 if not. */ 46 47 static int 48 utime_null (const char *file) 49 { 50 #if HAVE_UTIMES_NULL 51 return utimes (file, 0); 52 #else 53 int fd; 54 char c; 55 int status = 0; 56 struct stat sb; 57 58 fd = open (file, O_RDWR); 59 if (fd < 0 60 || fstat (fd, &sb) < 0 61 || safe_read (fd, &c, sizeof c) == SAFE_READ_ERROR 62 || lseek (fd, (off_t) 0, SEEK_SET) < 0 63 || full_write (fd, &c, sizeof c) != sizeof c 64 /* Maybe do this -- it's necessary on SunOS4.1.3 with some combination 65 of patches, but that system doesn't use this code: it has utimes. 66 || fsync (fd) < 0 67 */ 68 || (st.st_size == 0 && ftruncate (fd, st.st_size) < 0) 69 || close (fd) < 0) 70 status = -1; 71 return status; 72 #endif 73 } 74 75 int 76 rpl_utime (const char *file, const struct utimbuf *times) 77 { 78 if (times) 79 return utime (file, times); 80 81 return utime_null (file); 82 }
Lines 33–41 define the struct utimbuf; as the comment says, some systems don’t declare the structure. The utime_null() function does the work. If the utimes() system call is available, it is used. (utimes() is a similar, but more advanced, system call, which is covered in Section 14.3.2, “Microsecond File Times: utimes(),” page 545. It also allows NULL for the second argument, meaning use the current time.)
In the case that the times must be updated manually, the code does the update by first reading a byte from the file, and then writing it back. (The original Unix touch worked this way.) The operations are as follows:
Open the file, line 58.
Call
stat()on the file, line 60.Read one byte, line 61. For our purposes,
safe_read()acts likeread(); it’s explained in Section 10.4.4, “Restartable System Calls,” page 357.Seek back to the front of the file with
lseek(), line 62. This is done to write the just-read byte back on top of itself.Write the byte back, line 63.
full_write()acts likewrite(); it is also covered in Section 10.4.4, “Restartable System Calls,” page 357.If the file is of zero size, use
ftruncate()to set it to zero size (line 68). This doesn’t change the file, but it has the side effect of updating the access and modification times. (ftruncate()was described in Section 4.8, “Setting File Length,” page 114.)Close the file, line 69.
These steps are all done in one long successive chain of tests, inside an if. The tests are set up so that if any operation fails, utime_null() returns -1, like a regular system call. errno is automatically set by the system, for use by higher-level code.
The rpl_utime() function (lines 75–82) is the “replacement utime().” If the second argument is not NULL, then it calls the real utime(). Otherwise, it calls utime_null().
The original Unix systems had only chown() and chmod() system calls. However, on heavily loaded systems, these system calls are subject to race conditions, by which an attacker could arrange to replace with a different file the file whose ownership or permissions were being changed.
However, once a file is opened, race conditions aren’t an issue anymore. A program can use stat() on a pathname to obtain information about the file. If the information is what’s expected, then after the file is opened, fstat() can verify that the file is the same (by comparing the st_dev and st_ino fields of the “before” and “after” struct stat structures).
Once the program knows that the files are the same, the ownership or permissions can then be changed with fchown() or fchmod().
These system calls, as well as lchown(), are of relatively recent vintage;[11] older Unix systems won’t have them, although modern, POSIX-compliant systems do.
There are no corresponding futime() or lutime() functions. In the case of futime(), this is (apparently) because the file timestamps are not critical to system security in the same way that ownership and permissions are. There is no lutime(), since the timestamps are irrelevant for symbolic links.
The file and directory hierarchy as seen by the user is one logical tree, rooted at
/. It is made up of one or more storage partitions, each of which contains a filesystem. Within a filesystem, inodes store information about files (metadata), including the location of file data blocks.Directories make the association between filenames and inodes. Conceptually, directory contents are just sequences of (inode, name) pairs. Each directory entry for a file is called a (hard) link, and files can have many links. Hard links, because they work only by inode number, must all be on the same filesystem. Symbolic (soft) links are pointers to files or directories that work based on filename, not inode number, and thus are not restricted to being on the same filesystem.
Hard links are created with
link(), symbolic links are created withsymlink(), links are removed withunlink(), and files are renamed (possibly being moved to another directory) withrename(). A file’s data blocks are not reclaimed until the link count goes to zero and the last open file descriptor for the file is closed.Directories are created with
mkdir()and removed withrmdir(); a directory must be empty (nothing left but ’.’ and ’..’) before it can be removed. The GNU/Linux version of the ISO Cremove()function callsunlink()orrmdir()as appropriate.Directories are processed with the
opendir(),readdir(),rewinddir(), andclosedir()functions. Astruct direntcontains the inode number and the file’s name. Maximally portable code uses only the filename in thed_namemember. The BSDtelldir()andseekdir()functions for saving and restoring the current position in a directory are widely available but are not as fully portable as the other directory processing functions.File metadata are retrieved with the
stat()family of system calls; thestruct statstructure contains all the information about a file except the filename. (Indeed, since a file may have many names or may even be completely unlinked, it’s not possible to make the name available.)The
S_ISxxx()macros in<sys/stat.h>make it possible to determine a file’s type. Themajor()andminor()functions from<sys/sysmacros.h>make it possible to decode thedev_tvalues that represent block and character devices.Symbolic links can be checked for using
lstat(), and thest_sizefield of thestruct statfor a symbolic link returns the number of bytes needed to hold the name of the pointed-to file. The contents of a symbolic link are read withreadlink(). Care must be taken to get the buffer size correct and to terminate the retrieved filename with a trailing zero byte so that it can be used as a C string.Several miscellaneous system calls update other information: the
chown()family for the owner and group, thechmod()routines for the file permissions, andutime()to change file access and modification times.
Write a routine ’
const char *fmt_mode(mode_t mode)’. The input is amode_tvalue as provided by thest_modefield in thestruct stat; that is, it contains both the permission bits and the file type.The output should be a 10-character string identical to the first field of output from ’
ls -l’. In other words, the first character identifies the file type, and the other nine the permissions.When the
S_ISUIDandS_IXUSRbits are set, use an s instead of anx; if only theI_ISUIDbit is set, use anS. Similarly for theS_ISGIDandS_IXGRPbits. If both theS_ISVTXandS_IXOTHbits are set, uset; forS_ISVTXalone, useT.For simplicity, you may use a
staticbuffer whose contents are overwritten each time the routine is called.Extend
ch05-catdir.cto callstat()on each file name found. Then print the inode number, the result offmt_mode(), the link count, and the file’s name.Extend
ch05-catdir.cfurther such that if a file is a symbolic link, it will also print the name of the pointed-to file.Add an option such that if a filename is that of a subdirectory, the program recursively enters the subdirectory and prints information about the subdirectory’s files (and directories). Only one level of recursion is needed.
If you’re not using a GNU/Linux system, run
ch05-trymkdir(see Section 5.2, “Creating and Removing Directories,” page 130) on your system and compare the results to those we showed.Write the
mkdirprogram. See your local mkdir(1) manpage and implement all its options.In the root directory,
/, both the device and inode numbers for ’.’ and ’..’ are the same. Using this bit of information, write thepwdprogram.The program has to start by finding the name of the current directory by reading the contents of the parent directory. It must then continue, working its way up the filesystem hierarchy, until it reaches the root directory.
Printing the directory name backwards, from the current directory up to the root, is easy. How will your version of
pwdmanage to print the directory name in the correct way, from the root on down?If you wrote
pwdusing recursion, write it again, using iteration. If you used iteration, write it using recursion. Which is better? (Hint: consider very deeply nested directory trees.)Examine the
rpl_utime()function (see Section 5.5.3.1, “Faking utime(file, NULL),” page 159) closely. What resource is not recovered if one of the tests in the middle of theiffails? (Thanks to Geoff Collyer.)(Hard.) Read the chmod(1) manpage. Write code to parse the symbolic options argument, which allows adding, removing, and setting permissions based on user, group, other, and “all.”
Once you believe it works, write your own version of
chmodthat applies the permission specification to each file or directory named on the command line.Which function did you use,
chmod()—oropen()andfchmod()—and why?
[1] A race condition is a situation in which details of timing can produce unintended side effects or bugs. In this case, the directory, for a short period of time, is in an inconsistent state, and it is this inconsistency that introduces the vulnerability.
[2] Indeed, the file’s metadata are changed (the number of links), but that does not affect any other file attribute, nor does it affect the file’s contents. Updating the link count is the only operation on a file that doesn’t involve checking the file’s permissions.
[3] See /usr/src/cmd/rmdir.c in the V7 distribution.
[4] GNU/Linux systems are capable of mounting filesystems from many non-Unix operating systems. Many commercial Unix systems can also mount MS-DOS filesystems. Assumptions about Unix filesystems don’t apply in such cases.
[5] Linux uses the block device for disks exclusively. Other systems use both.
[6] Named pipes and sockets were developed independently by the System V and BSD Unix groups, respectively. As Unix systems reconverged, both kinds of files became universally available.
[7] The technical term is a warm fuzzy.
[8] This statement was true for V7; there are no such guarantees on modern systems.
[9] Thanks to Jim Meyering for explaining the issues.
[10] UTC is a language-independent acronym for Coordinated Universal Time. Older code (and sometimes older people) refer to this as “Greenwich Mean Time” (GMT), which is the time in Greenwich, England. When time zones came into widespread use, Greenwich was chosen as the location to which all other time zones are relative, either behind it or ahead of it.
[11] fchown() and fchmod() were introduced in 4.2 BSD but not picked up for System V until System V Release 4.