
In this chapter
8.1 Mounting and Unmounting Filesystems page 228
8.2 Files for Filesystem Administration page 238
8.3 Retrieving Per-Filesystem Information page 244
8.4 Moving Around in the File Hierarchy page 256
8.5 Walking a File Tree: GNU
dupage 2698.6 Changing the Root Directory:
chroot()page 2768.7 Summary page 277
Exercises page 278
This chapter completes the discussion of Linux (and Unix) filesystems and directories. We first describe how a disk partition containing a filesystem is added to (and removed from) the logical filesystem namespace, such that in general a user need neither know nor care where a file is physically located, along with the APIs for working with filesystems.
We then describe how to move around within the hierarchical file namespace, how to retrieve the full pathname of the current working directory, and how to easily process arbitrary directory hierarchies (trees), using the nftw() function. Finally, we describe the specialized but important chroot() system call.
The unified hierarchical file namespace is a great strength of the Linux/Unix design. This section looks at how administrative files, commands, and the operating system cooperate to build the namespace from separate physical devices that contain file data and metadata.
Chapter 5, “Directories and File Metadata,” page 117, introduced inodes for file metadata and described how directory entries link filenames to inodes. It also described partitions and filesystems, and you saw that hard links are restricted to working within a single filesystem because directories contain only inode numbers and inode numbers are not unique across the entire set of in-use filesystems.
Besides inodes and data blocks, filesystems also contain one or more copies of the superblock. This is a special disk block that describes the filesystem; its information is updated as the filesystem itself changes. For example, it contains counts of free and used inodes, free and used blocks, and other information. It also includes a magic number: a unique special value in a special location that identifies the type of the filesystem. (We’ll see how this is relevant, shortly.)
Making a partition that contains a filesystem available for use is called mounting the filesystem. Removing a filesystem from use is called, not surprisingly, unmounting the filesystem.
These two jobs are accomplished with the mount and umount [sic] programs, named for the corresponding system calls. Every Unix system’s mount() system call has a different interface. Because mounting and unmounting are considered implementation issues, POSIX purposely does not standardize these system calls.
You mount a filesystem onto a directory; such a directory is referred to as the filesystem’s mount point. By convention the directory should be empty, but nothing enforces this. However, if the mount point is not empty, all of its contents become completely inaccessible while a filesystem is mounted on it.[1]
The kernel maintains a unique number, known as the device number, that identifies each mounted partition. For this reason, it is the (device, inode) pair that together uniquely identifies a file; when the struct stat structures for two filenames indicate that both numbers are the same, you can be sure that they do refer to the same file.
As mentioned earlier, user-level software places the inode structures and other metadata onto a disk partition, thereby creating the filesystem. This same software creates an initial root directory for the filesystem. Thus, we have to make a distinction between “the root directory named /,” which is the topmost directory in the hierarchical filename namespace, and “the root directory of a filesystem,” which is each filesystem’s individual topmost directory. The / directory is also the “root directory” of the “root filesystem.”
For reasons described in the sidebar, a filesystem’s root directory always has inode number 2 (although this is not formally standardized). Since there can be multiple filesystems, each one’s root directory has the same inode number, 2. When resolving a pathname, the kernel knows where each filesystem is mounted and arranges for the mount point’s name to refer to the root directory of the mounted filesystem. Furthermore, ’..’ in the root of a mounted filesystem is made to refer to the parent directory of the mount point.
Figure 8.1 shows two filesystems: one for the root directory, and one for /usr, before /usr is mounted. Figure 8.2 shows the situation after /usr is mounted.

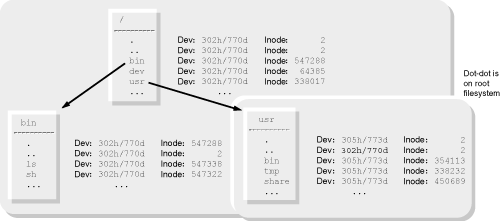
The / directory, the root of the entire logical hierarchy, is special in an additional way: /. and /.. refer to the same directory; this is not true of any other directory on the system. (Thus, after something like ’cd /../../../..’, you’re still in /.) This behavior is implemented in a simple fashion: Both /. and /.. are hard links to the filesystem’s root directory. (You can see this in both Figure 8.1 and Figure 8.2.) Every filesystem works this way, but the kernel treats / specially and does not treat as a special case the ’..’ directory for the filesystem mounted on /.
Note
The discussion in this section is specific to Linux. However, most modern Unix systems have similar features. We encourage you to explore your system’s documentation.
Historically, V7 Unix supported only a single filesystem type; every partition’s metadata and directory organization were structured the same way. 4.1 BSD used a filesystem with the same structure as that of V7, but with a 1024-byte block size instead of a 512-byte one. 4.2 BSD introduced the “BSD Fast Filesystem,” which dramatically changed the layout of inodes and data on disk and enabled the use of much larger block sizes. (In general, using larger contiguous blocks of data provides better throughput, especially for file reads.)
Through 4.3 BSD and System V Release 2 in the early and mid-1980s, Unix systems continued to support just one filesystem type. To switch a computer from one filesystem to another,[2] you had to first back up each filesystem to archival media (9-track tape), upgrade the system, and then restore the data.
In the mid-1980s, Sun Microsystems developed a kernel architecture that made it possible to use multiple filesystem architectures at the same time. This design was implemented for their SunOS operating system, primarily to support Sun’s Network File System (NFS). However, as a consequence it was also possible to support multiple on-disk architectures. System V Release 3 used a similar architecture to support the Remote File System (RFS), but it continued to support only one on-disk architecture.[3] (RFS was never widely used and is now only a historical footnote.)
Sun’s general design became popular and widely implemented in commercial Unix systems, including System V Release 4. Linux and BSD systems use a variant of this design to support multiple on-disk filesystem formats. In particular, it’s common for all Unix variants on Intel x86 hardware to be able to mount MS-DOS/Windows FAT filesystems, including those supplying long filenames, as well as ISO 9660-formatted CD-ROMs.
Linux has several native (that is, on-disk) filesystems. The most popular are the ext2 and ext3 filesystems. Many more filesystem types are available, however. You can find information about most of them in the /usr/src/linux/Documentation/filesystems/ directory (if you have kernel source installed). Table 8.1 lists the various filesystem names, with brief descriptions of each. The abbreviation “RW” means “read/write” and “RO” means “read only.”
Table 8.1. Supported in-kernel Linux filesystems (kernel 2.4.x)
Name | Support | Description |
|---|---|---|
| RW | The Andrew File System. |
RW | Acorn Advanced Disc Filing System. | |
RO, RW | Amiga Fast File System. Read only vs. read/write depends upon the version of the filesystem. | |
| RW | Filesystem for interacting with the automounter daemon. |
RO | BeOS Filesystem. Marked as alpha software. | |
RW | SCO UnixWare Boot Filesystem. | |
RW | Special filesystem for running interpreters on compiled files (for example, Java files). | |
RW | A filesystem developed for SGI’s Unix variant named Irix. | |
RW | An experimental distributed filesystem developed at CMU. | |
RO | A small filesystem for storing files in ROM. | |
RW | A way to dynamically provide device files for | |
RW | Special filesystem for pseudo-ttys. | |
RW | The Second Extended Filesystem. This is the default GNU/Linux filesystem, although some distributions now use | |
| RW | The |
RW | Apple Mac OS Hierarchical File System. | |
RW | The OS/2 High Performance File System. | |
RW | An experimental distributed filesystem for working while disconnected. See the InterMezzo web site ( | |
| RW | Journaled Flash Filesystem (for embedded systems). |
RW | Journaled Flash Filesystem 2 (also for embedded systems). | |
| RO | The ISO 9660 CD-ROM filesystem. The Rock Ridge extensions are also supported, making a CD-ROM that uses them look like a normal (but read-only) filesystem. |
RW | IBM’s Journaled File System for Linux. | |
RW | Novell’s NCP protocol for NetWare; a remote filesystem client. | |
RO | Support for Windows NTFS filesystem. | |
RO | A | |
RW | Access to per-process and kernel information. | |
RW | The QNX4 (a small, real-time operating system) filesystem. | |
RW | A filesystem for creating RAM disks. | |
RW | An advanced journaling filesystem. | |
RO | A filesystem for creating simple read-only RAM disks. | |
RW | Client support for SMB filesystems (Windows file shares). | |
RW | The System V Release 2, Xenix, Minix, and Coherent filesystems. | |
| RW | A ramdisk filesystem, supporting dynamic growth. |
RO | The UDF filesystem format used by DVD-ROMs. | |
RO, RW | The BSD Fast Filesystem; read/write for modern systems. | |
| RW | An extension to |
RW | A special filesystem for working with USB devices. The original name was | |
RW | All variants of MS-DOS/Windows FAT filesystems. | |
RW | The Veritas VxFS journaling filesystem. | |
RW | A high-performance journaling filesystem developed by SGI for Linux. See the XFS web site ( |
Not all of these filesystems are supported by the mount command; see mount(8) for the list of those that are supported.
Journaling is a technique, pioneered in database systems, for improving the performance of file updates, in such a way that filesystem recovery in the event of a crash can be done both correctly and quickly. As of this writing, several different journaling filesystems are available and competing for prominence in the GNU/Linux world. ext3 is one such; it has the advantage of being upwardly compatible with existing ext2 filesystems, and it’s easy to convert a filesystem back and forth between the two types. (See tune2fs(8).) ReiserFS and XFS also have strong followings.
The fat, msdos, umsdos, and vfat filesystems all share common code. In general, you should use vfat to mount Windows FAT-32 (or other FAT-xx) partitions, and umsdos if you wish to use a FAT partition as the root filesystem for your GNU/Linux system.
The Coherent, MINIX, original System V, and Xenix filesystems all have similar on-disk structures. The sysv filesystem type supports all of them; the four names coherent, minix, sysv, and xenix are aliases one for the other. The coherent and xenix names will eventually be removed.
The BSD Fast Filesystem has evolved somewhat over the years. The ufs filesystem supports read/write operation for the version from 4.4 BSD, which is the basis for the three widely used BSD operating systems: FreeBSD, NetBSD, and OpenBSD. It also supports read/write operation for Sun’s Solaris filesystem, for both SPARC and Intel x86 systems. The original BSD format and that from the NeXTStep operating system are supported read-only.
The “RO” designations for befs and ntfs mean that filesystems of those types can be mounted and read but files cannot be written on them or removed from them. (This may change with time; check your system’s documentation.) The cramfs, iso9660, romfs, and udf filesystems are marked “RO” because the underlying media are inherently read-only.
Two filesystem types no longer exist: ext, which was the original Extended Filesystem, and xiafs, which extended the original MINIX filesystem for longer names and larger file sizes. xiafs and ext2 came out approximately simultaneously, but ext2 eventually became the dominant filesystem.[4]
The mount command mounts filesystems, splicing their contents into the system file hierarchy at their mount points. Under GNU/Linux, it is somewhat complicated since it has to deal with all the known filesystem types and their options. Normally, only root can run mount, although it’s possible to make exceptions for certain cases, as is discussed later in the chapter.
You specify the filesystem type with the -t option:
mount [ options ] device mount-point
For example (# is the root prompt):
# mount -t iso9660 /dev/cdrom /mnt/cdrom Mount CD-ROM # mount -t vfat /dev/fd0 /mnt/floppy Mount MS-DOS floppy # mount -t nfs files.example.com:/ /mnt/files Mount NFS filesystem
You can use ’-t auto’ to force mount to guess the filesystem type. This usually works, although if you know for sure what kind of filesystem you have, it helps to supply the type and avoid the chance that mount will guess incorrectly. mount does this guessing by default, so ’-t auto’ isn’t strictly necessary.
GNU/Linux systems provide a special kind of mounting by means of the loopback device. In this way, a filesystem image contained in a regular file can be mounted as if it were an actual disk device. This capability is very useful, for example, with CD-ROM images. It allows you to create one and try it out, without having to burn it to a writable CD and mount the CD. The following example uses the first CD image from the Red Hat 9 distribution of GNU/Linux:
# ls -l shrike-i386-disc1.iso Examine CD image file -rw-r--r-- 1 arnold devel 668991488 Apr 11 05:13 shrike-i386-discl.iso # mount -t iso9660 -o ro, loop shrike-i386-disc1.iso /mnt/cdrom Mount it on /mnt/cdrom # cd /mnt/cdrom Go there # ls Look at files autorun README.it RELEASE-NOTES-fr.html dosutils README.ja RELEASE-NOTES.html EULA README.ko RELEASE-NOTES-it.html GPL README.pt RELEASE-NOTES-ja.html images README.pt_BR RELEASE-NOTES-ko.html isolinux README.zh_CN RELEASE-NOTES-pt_BR.html README README.zh_TW RELEASE-NOTES-pt.html README-Accessibility RedHat RELEASE-NOTES-zh_CN.html README.de RELEASE-NOTES RELEASE-NOTES-zh_TW.html README.es RELEASE-NOTES-de.html RPM-GPG-KEY README.fr RELEASE-NOTES-es.html TRANS.TBL # cd Change out # umount /mnt/cdrom Unmount
Being able to mount an ISO 9660 image this way is particularly helpful when you are testing scripts that make CD images. You can create an image in a regular file, mount it, and verify that it’s arranged correctly. Then, once you’re sure it’s correct, you can copy the image to a writable CD (“burn” the CD). The loopback facility is useful for mounting floppy disk images, too.
The umount command unmounts a filesystem, removing its contents from the system file hierarchy. The usage is as follows:
umount file-or-device
The filesystem being unmounted must not be busy. This means that there aren’t any processes with open files on the filesystem and that no process has a directory on the filesystem as its current working directory:
$ mount Show what's mounted /dev/hda2 on / type ext3 (rw) / is on a real device none on /proc type proc (rw) usbdevfs on /proc/bus/usb type usbdevfs (rw) /dev/hda5 on /d type ext3 (rw) So is /d none on /dev/pts type devpts (rw,gid=5,mode=620) none on /dev/shm type tmpfs (rw) none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw) $ su Switch to superuser Password: Password does not echo # cd /d Make /d the current directory # umount /d Try to unmount /d umount: /d: device is busy Doesn't work; it's still in use # cd / Change out of /d # umount /d Try to unmount /d again # Silence is golden: unmount worked
The /etc/fstab file[5] lists filesystems that can be mounted. Most are automatically mounted when the system boots. The format is as follows:
device mount-point fs-type options dump-freq fsck-pass
(The dump-freq and fsck-pass are administrative features that aren’t relevant to the current discussion.) For example, on our system, the file looks like this:
$ cat /etc/fstab # device mount-point type options freq passno /dev/hda3 / ext3 defaults 1 1 Root filesystem /dev/hda5 /d ext3 defaults 1 2 none /dev/pts devpts gid=5,mode=620 0 0 none /proc proc defaults 0 0 none /dev/shm tmpfs defaults 0 0 # Windows partition: /dev/hda1 /win vfat noauto, defaults, user, uid=2076, gid=10 0 0 /dev/hda3 swap swap defaults 0 0 /dev/cdrom /mnt/cdrom iso9660 noauto, owner, ro 0 0 World mountable /dev/fd0 /mnt/floppy auto noauto, owner 0 0 Floppy, same
Comments beginning with # are allowed. Discussion of the various options is provided shortly, in Section 8.2.1, “Using Mount Options,” page 239.
This same file format is used for /etc/mtab, which is where mount writes information about filesystems as they are mounted; umount removes information from that file when a filesystem is unmounted:
$ cat /etc/mtab
/dev/hda2 / ext3 rw 0 0
none /proc proc rw 0 0
usbdevfs /proc/bus/usb usbdevfs rw 0 0
/dev/hda5 /d ext3 rw 0 0
none /dev/pts devpts rw, gid=5,mode=620 0 0
none /dev/shm tmpfs rw 0 0
none /proc/sys/fs/binfmt_misc binfmt_misc rw 0 0
/dev/hda1 /win vfat rw, noexec, nosuid, nodev, uid=2076, gid=10, user=arnold 0 0
The kernel makes (almost) the same information available in /proc/mounts, in the same format:
$ cat /proc/mounts
rootfs / rootfs rw 0 0
/dev/root / ext3 rw 0 0
/proc /proc proc rw 0 0
usbdevfs /proc/bus/usb usbdevfs rw 0 0
/dev/hda5 /d ext3 rw 0 0
none /dev/pts devpts rw 0 0
none /dev/shm tmpfs rw 0 0
none /proc/sys/fs/binfmt_misc binfmt_misc rw 0 0
/dev/hda1 /win vfat rw,nosuid,nodev,noexec 0 0
Note that /etc/mtab has some information that /proc/mounts doesn’t. (For example, see the line for the /win mount point.) On the flip side, it’s possible (using ’mount -f’) to put entries into /etc/mtab that aren’t real (this practice has its uses, see mount(8)). To sum up, /proc/mounts always describes what is really mounted; however, /etc/mtab contains information about mount options that /proc/mounts doesn’t. Thus, to get the full picture, you may have to read both files.
The mount command supports options that control what operations the kernel will or will not allow for the filesystem. There are a fair number of these. Only two are really useful on the command line:
ro
loop
Use the loopback device for treating a regular file as a filesystem. We showed an example of this earlier (see Section 8.1.3, “Mounting Filesystems: mount,” page 236).
Options are passed with the -o command-line option and can be grouped, separated by commas. For example, here is the command line used earlier:
mount -t iso9660 -o ro, loop shrike-i386-disc1.iso /mnt/cdrom
The rest of the options are intended for use in /etc/fstab (although they can also be used on the command line). The following list provides the ones we think are most important for day-to-day use.
auto, noauto
Filesystems marked
autoare to be mounted when the system boots through ’mount -a’ (mount all filesystems).noautofilesystems must be mounted manually. Such filesystems still appear in/etc/fstabalong with the other filesystems. (See, for example, the entry for/winin our/etc/fstabfile, shown previously.)
defaults
Use the default options
rw, suid, dev, exec, auto, nouser, andasync. (asyncis an advanced option that increases I/O throughput.)
dev, nodev
Allow (don’t allow) the use of character or block device files on the filesystem.
Allow (don’t allow) execution of binary executables on the filesystem.
Allow (don’t allow) any user to mount this filesystem. This is useful for CD-ROMs; even if you’re on a single-user workstation, it’s convenient to not have to switch to
rootjust to mount a CD. Only the user who mounted the filesystem can unmount it.userimplies thenoexec, nosuid, andnodevoptions.
suid, nosuid
Support (don’t support) the setuid and setgid bits on executables on the filesystem.
rw
Mount the filesystem read-write.
The nodev, noexec, and nosuid options are particularly valuable for security on floppy-disk and CD-ROM filesystems. Consider a student environment in which students are allowed to mount their own floppies or CDs. It’s trivial to craft a filesystem with a setuid -root shell or a world-writable device file for the hard disk that could let an enterprising user change permissions on system files.
Each filesystem has additional options specific to it. One important option for ext2 and ext3 is the grpid option. We defer discussion of this option until Section 11.5.1, “Default Group for New Files and Directories,” page 412. The details for all supported filesystems can be found in the mount(8) manpage.
As a concrete example, reconsider the line for the Windows partition on our system:
# device mount-point type options freq passno /dev/hda1 /win vfat noauto, defaults, user, uid=2076, gid=10 0 0
The noauto option prevents the Windows partition from being mounted at boot time. The defaults option is the same as rw, suid, dev, exec, async. The user option allows us to mount the filesystem without being root. The uid= and gid= options force the files in /win to belong to us as a regular user so that we don’t need to be root when working on that partition.
Any of /etc/fstab, /etc/mtab, and /proc/mounts can be read programmatically with the getmntent() suite of routines:
#include <stdio.h> GLIBC
#include <mntent.h>
FILE *setmntent (const char *filename, const char *type);
struct mntent *getmntent (FILE *filep);
int addmntent (FILE *filep, const struct mntent *mnt);
int endmntent (FILE *filep);
char *hasmntopt (const struct mntent *mnt, const char *opt);
setmntent() opens the file containing mount point entries. The filename argument is the file to open. The type argument is like the second argument to fopen(), indicating read, write, or read/write access. (Consider the mount command, which has to add an entry to /etc/mtab for each filesystem it mounts, and umount, which has to remove one.) The returned value of type FILE * is then used with the rest of the routines.
getmntent() reads through the file, returning a pointer to a static struct mntent, which is filled in with the appropriate values. This static storage is overwritten on each call. It returns NULL when there are no more entries. (This is similar to the routines for reading the password and group files; see Section 6.3, “User and Group Names,” page 195.)
addmntent() is called to add more information to the end of the open file; it’s intended for use by mount.
endmntent() closes the open file; call it when you’re done processing. Don’t just call fclose(); other internal data structures associated with the FILE * variable may need to be cleaned up.
hasmntopt() is a more specialized function. It scans the struct mntent passed as the first parameter for a mount option matching the second argument. If the option is found, it returns the address of the matching substring. Otherwise, it returns NULL.
The fields in the struct mntent correspond directly to the fields in the /etc/fstab file. It looks like this:
struct mntent {
char *mnt_fsname; /* Device or server for filesystem. */
char *mnt_dir; /* Directory mounted on. */
char *mnt_type; /* Type of filesystem: ufs, nfs, etc. */
char *mnt_opts; /* Comma-separated options for fs. */
int mnt_freq; /* Dump frequency (in days). */
int mnt_passno; /* Pass number for 'fsck'. */
};
The normal paradigm for working with mounted filesystems is to write an outer loop that reads /etc/mtab, processing one struct mntent at a time. Our first example, ch08-mounted.c, does exactly that:
1 /* ch08-mounted.c --- print a list of mounted filesystems */ 2 3 /* NOTE: GNU/Linux specific! */ 4 5 #include <stdio.h> 6 #include <errno.h> 7 #include <mntent.h> /* for getmntent(), et al. */ 8 #include <unistd.h> /* for getopt() */ 9 10 void process(const char *filename); 11 void print_mount(const struct mntent *fs); 12 13 char *myname; 14 15 /* main --- process options */ 16 17 int main(int argc, char **argv) 18 { 19 int c; 20 char *file = "/etc/mtab" /* default file to read */ 21 22 myname = argv[0]; 23 while ((c = getopt(argc, argv, "f:")) != -1) { 24 switch (c) { 25 case 'f': 26 file = optarg; 27 break; 28 default: 29 fprintf(stderr, "usage: %s [-f fstab-file] ", argv[0]); 30 exit(1); 31 } 32 } 33 34 process(file); 35 return 0; 36 } 37 38 /* process --- read struct mntent structures from file */ 39 40 void process(const char *filename) 41 { 42 FILE *fp; 43 struct mntent *fs; 44 45 fp = setmntent(filename, "r"); /* read only */ 46 if (fp == NULL) { 47 fprintf(stderr, "%s: %s: could not open: %s/n", 48 myname, filename, strerror(errno)); 49 exit(1); 50 } 51 52 while ((fs = getmntent(fp)) != NULL) 53 print_mount(fs); 54 55 endmntent(fp); 56 } 57 58 /* print_mount --- print a single mount entry */ 59 60 void print_mount(const struct mntent *fs) 61 { 62 printf("%s %s %s %s %d %d " 63 fs->mnt_fsname, 64 fs->mnt_dir, 65 fs->mnt_type, 66 fs->mnt_opts, 67 fs->mnt_freq, 68 fs->mnt_passno); 69 }
Unlike most of the programs that we’ve seen up to now, this one is Linux specific. Many Unix systems have similar routines, but they’re not guaranteed to be identical.
By default, ch08-mounted reads /etc/mtab, printing the information about each mounted filesystem. The -f option allows you to specify a different file to read, such as /proc/mounts or even /etc/fstab.
The main() function processes the command line (lines 23–32) and calls process() on the named file. (This program follows our standard boilerplate.)
process(), in turn, opens the file (line 45), and loops over each returned filesystem (lines 52–53). When done, it closes the file (line 55).
The print_mount() function prints the information in the struct mntent. The output ends up being much the same as that of ’cat /etc/mtab’:
$ ch08-mounted Run the program /dev/hda2 / ext3 rw 0 0 none /proc proc rw 0 0 usbdevfs /proc/bus/usb usbdevfs rw 0 0 /dev/hda5 /d ext3 rw 0 0 none /dev/pts devpts rw,gid=5,mode=620 0 0 none /dev/shm tmpfs rw 0 0 none /proc/sys/fs/binfmt_misc binfmt_misc rw 0 0 /dev/hda1 /win vfat rw,noexec,nosuid,nodev,uid=2076,gid=10,user=arnold 0 0
Printing per-filesystem information is all fine and good, but it’s not exciting. Once we know that a particular mount point represents a filesystem, we want information about the filesystem. This allows us to do things like print the information retrieved by df and ’df -i’:
$ df Show free/used space Filesystem 1k-blocks Used Available Use% Mounted on /dev/hda2 6198436 4940316 943248 84% / /dev/hda5 61431520 27618536 30692360 48% /d none 256616 0 256616 0% /dev/shm /dev/hda1 8369532 2784700 5584832 34% /win $ df -i Show free/used inodes Filesystem Inodes IUsed IFree IUse% Mounted on /dev/hda2 788704 233216 555488 30% / /dev/hda5 7815168 503243 7311925 7% /d none 64154 1 64153 1% /dev/shm /dev/hda1 0 0 0 - /win
Early Unix systems had only one kind of filesystem. For them, it was sufficient if df read the superblock of each mounted filesystem, extracted the relevant statistics, and formatted them nicely for printing. (The superblock was typically the second block in the filesystem; the first was the boot block, to hold bootstrapping code.)
However, in the modern world, such an approach would be untenable. POSIX provides an XSI extension to access this information. The main function is called statvfs(). (The “vfs” part comes from the underlying SunOS technology, later used in System V Release 4, called a virtual filesystem.) There are two functions:
#include <sys/types.h> XSI
#include <sys/statvfs.h>
int statvfs (const char *path, struct statvfs *buf);
int fstatvfs (int fd, struct statvfs *buf);
statvfs() uses a pathname for any file; it returns information about the filesystem containing the file. fstatvfs() accepts an open file descriptor as its first argument; here too, the information returned is about the filesystem containing the open file. The struct statvfs contains the following members:
struct statvfs {
unsigned long int f_bsize; Block size
unsigned long int f_frsize; Fragment size ("fundamental block size")
fsblkcnt_t f_blocks; Total number of blocks
fsblkcnt_t f_bfree; Total number of free blocks
fsblkcnt_t f_bavail; Number of available blocks (≤f_bfree)
fsfilcnt_t f_files; Total number of inodes
fsfilcnt_t f_ffree; Total number of free inodes
fsfilcnt_t f_favail; Number of available inodes (≤f_files)
unsigned long int f_fsid; Filesystem ID
unsigned long int f_flag; Flags: ST_RDONLY and/or ST_NOSUID
unsigned long int f_namemax; Maximum filename length
};
The information it contains is enough to write df:
unsigned long int f_bsize
The block size is the preferred size for doing I/O. The filesystem attempts to keep at least f_bsize bytes worth of data in contiguous sectors on disk. (A sector is the smallest amount of addressable data on the disk. Typically, a disk sector is 512 bytes.)
unsigned long int f_frsize
Some filesystems (such as the BSD Fast Filesystem) distinguish between blocks and fragments of blocks. Small files whose total size is smaller than a block reside in some number of fragments. This avoids wasting disk space (at the admitted cost of more complexity in the kernel code). The fragment size is chosen at the time the filesystem is created.
fsblkcnt_t f_blocks
The total number of blocks (in units of f_bsize) in the filesystem.
fsblkcnt_t f_bfree
The total number of free blocks in the filesystem.
fsblkcnt_t f_bavail
The number of blocks that may actually be used. Some filesystems reserve a percentage of the filesystem’s blocks for use by the superuser, in case the filesystem fills up. Modern systems reserve around 5 percent, although this number can be changed by an administrator. (See tune2fs(8) on a GNU/Linux system, and tunefs(8) on Unix systems.)
fsfilcnt_t f_files
The total number of inodes (“file serial numbers”, in POSIX parlance) on the filesystem. This number is usually initialized and made permanent when the filesystem is created.
fsfilcnt_t f_ffree
The total number of free inodes.
fsfilcnt_t f_favail
The number of inodes that may actually be used. Some percentage of the inodes are reserved for the superuser, just as for blocks.
unsigned long int f_fsid
The filesystem ID. POSIX doesn’t specify what this represents, and it’s not used under Linux.
unsigned long int f_flag
Flags giving information about the filesystem. POSIX specifies two: ST_RDONLY, for a read-only filesystem (such as a CD-ROM), and ST_NOSUID, which disallows the use of the setuid and setgid permission bits on executables. GNU/Linux systems provide additional flags: They are listed in Table 8.2.
Table 8.2. GLIBC values for f_flag
POSIX | Meaning | |
|---|---|---|
| Enforce mandatory locking (see Section 14.2, page 531). | |
| ||
| Disallow access through device files. | |
| Don’t update the access time field of directories. | |
| Disallow execution of binaries. | |
| ✓ | |
| ✓ | |
| All writes are synchronous (see Section 4.6.3, page 110). |
The maximum length of a filename. This refers to each individual component in a pathname; in other words, the maximum length for a directory entry.
The fsblkcnt_t and fsfilcnt_t types are defined in <sys/types.h>. They are typically unsigned long, but on modern systems, they may be even be a 64-bit type, since disks have gotten very large. The following program, ch08-statvfs.c, shows how to use statvfs():
1 /* ch08-statvfs.c --- demonstrate statvfs */ 2 3 /* NOTE: GNU/Linux specific! */ 4 5 #include <stdio.h> 6 #include <errno.h> 7 #include <mntent.h> /* for getmntent(), et al. */ 8 #include <unistd.h> /* for getopt() */ 9 #include <sys/types.h> 10 #include <sys/statvfs.h> 11 12 void process(const char *filename); 13 void do_statvfs(const struct mntent *fs); 14 15 int errors = 0; 16 char *myname; 17 18 /* main --- process options */ 19 20 int main(int argc, char **argv) 21 { 22 int c; 23 char *file = "/etc/mtab"; /* default file to read */ 24 25 myname = argv[0]; 26 while ((c = getopt(argc, argv, "f:")) != -1) { 27 switch (c) { 28 case 'f': 29 file = optarg; 30 break; 31 default: 32 fprintf(stderr, "usage: %s [-f fstab-file] ", argv[0]); 33 exit(1); 34 } 35 } 36 37 process(file); 38 return(errors != 0); 39 } 40 41 /* process --- read struct mntent structures from file */ 42 43 void process(const char *filename) 44 { 45 FILE *fp; 46 struct mntent *fs; 47 48 fp = setmntent(filename, "r"); /* read only */ 49 if (fp == NULL) { 50 fprintf(stderr, "%s: %s: could not open: %s ", 51 myname, filename, strerror(errno)); 52 exit(1); 53 } 54 55 while ((fs = getmntent(fp)) != NULL) 56 do_statvfs(fs); 57 58 endmntent(fp); 59 }
Lines 1–59 are essentially the same as ch08-mounted.c.main() handles the command line, and process() loops over each mounted filesystem. do_statvfs() does the real work, printing the struct statvfs for each interesting filesystem.
61 /* do_statvfs --- Use statvfs and print info */ 62 63 void do_statvfs(const struct mntent *fs) 64 { 65 struct statvfs vfs; 66 67 if (fs->mnt_fsname[0] != '/') /* skip nonreal filesystems */ 68 return; 69 70 if (statvfs(fs->mnt_dir, & vfs) != 0) { 71 fprintf(stderr, "%s: %s: statvfs failed: %s ", 72 myname, fs->mnt_dir, strerror(errno)); 73 errors++; 74 return; 75 } 76 77 printf("%s, mounted on %s: ", fs->mnt_dir, fs->mnt_fsname); 78 printf(" f_bsize: %ld ", (long) vfs.f_bsize); 79 printf(" f_frsize: %ld ", (long) vfs.f_frsize); 80 printf(" f_blocks: %lu ", (unsigned long) vfs.f_blocks); 81 printf(" f_bfree: %lu ", (unsigned long) vfs.f_bfree); 82 printf(" f_bavail: %lu ", (unsigned long) vfs.f_bavail); 83 printf(" f_files: %lu ", (unsigned long) vfs.f_files); 84 printf(" f_ffree: %lu ", (unsigned long) vfs.f_ffree); 85 printf(" f_favail: %lu ", (unsigned long) vfs.f_favail); 86 printf(" f_fsid: %#lx ", (unsigned long) vfs.f_fsid); 87 88 printf(" f_flag: "); 89 if (vfs.f_flag == 0) 90 printf("(none) "); 91 else { 92 if ((vfs.f_flag & ST_RDONLY) != 0) 93 printf("ST_RDONLY "); 94 if ((vfs.f_flag & ST_NOSUID) != 0) 95 printf("ST_NOSUID"); 96 printf(" "); 97 } 98 99 printf(" f_namemax: %#ld ", (long) vfs.f_namemax); 100 }
Lines 67–68 skip filesystems that are not based on a real disk device. This means that filesystems like /proc or /dev/pts are ignored. (Admittedly, this check is a heuristic, but it works: In /etc/mtab mounted devices are listed by the full device pathname: for example, /dev/hda1.) Line 70 calls statvfs() with appropriate error checking, and lines 77–99 print the information.
Lines 89–96 deal with flags: single bits of information that are or are not present. See the sidebar for a discussion of how flag bits are used in C code. Here is the output of ch08-statvfs:
$ ch08-statvfs Run the program /, mounted on /dev/hda2: Results for ext2 filesystem f_bsize: 4096 f_frsize: 4096 f_blocks: 1549609 f_bfree: 316663 f_bavail: 237945 f_files: 788704 f_ffree: 555482 f_favail: 555482 f_fsid: 0 f_flag: (none) f_namemax: 255 ... /win, mounted on /dev/hda1: Results for vfat filesystem f_bsize: 4096 f_frsize: 4096 f_blocks: 2092383 f_bfree: 1391952 f_bavail: 1391952 f_files: 0 f_ffree: 0 f_favail: 0 f_fsid: 0 f_flag: ST_NOSUID f_namemax: 260
As of this writing, for GLIBC 2.3.2 and earlier, GNU df doesn’t use statvfs(). This is because the code reads /etc/mtab, and calls stat() for each mounted filesystem, to find the one on which the device number matches that of the file (or file descriptor) argument. It needs to find the filesystem in order to read the mount options so that it can set the f_flag bits. The problem is that stat() on a remotely mounted filesystem whose server is not available can hang indefinitely, thus causing df to hang as well. This problem has since been fixed in GLIBC, but df won’t change for a while so that it can continue to work on older systems.
Note
Although POSIX specifies statvfs() and fstatvfs(), not all systems support them or support them correctly. Many systems (including Linux, as described shortly), have their own system calls that provide similar information. GNU df uses a library routine to acquire filesystem information; the source file for that routine is full of #ifdefs for a plethora of different systems. With time, the portability situation should improve.
Bit Flags
A common technique, applicable in many cases, is to have a set of flag values; when a flag is set (that is, true), a certain fact is true or a certain condition applies. Flag values are defined with either #defined symbolic constants or enums. In this chapter, the nftw() API (described later) also uses flags. There are only two flags for the struct statvfs field f_flag:
#define ST_RDONLY 1 /* read-only filesystem */Sample definitions #define ST_NOSUID 2 /* setuid/setgid not allowed */
Physically, each symbolic constant represents a different bit position within the f_flag value. Logically, each value represents a separate bit of state information; that is, some fact or condition that is or isn’t true for this particular instance of a struct statvfs.
Flags are set, tested, and cleared with the C bitwise operators. For example, statvfs() would set these flags, using the bitwise OR operator:
int statvfs (const char *path, struct statvfs *vfs)
{
... fill in most of *vfs...
vfs->f_flag = 0; Make sure it starts
out as zero
if (filesystem is read-only)
vfs->f_flag |= ST_RDONLY; Add the ST_RDONLY flag
if (filesystem disallows setuid)
vfs->f_flag | = ST_NOSUID; Add the ST_NOSUID flag
...rest of routine...
}
The bitwise AND operator tests whether a flag is set, and a combination of the bitwise AND and COMPLEMENT operators clears a flag:
if ((vfs.f_flag & ST_RDONLY) != 0) True if ST_RDONLY
The bitwise operators are daunting if you’ve not used them before. However, the example code just shown represents common C idioms. Study each operation carefully; perhaps draw yourself a few pictures showing how these operators work. Once you understand them, you can train yourself to recognize these operators as high-level operations for managing flag values instead of treating them as low-level bit manipulations.
The reason to use flag values is that they provide considerable savings in data space. The single unsigned long field lets you store at least 32 separate bits of information. GLIBC (as of this writing) defines 11 different flags for the f_flag field.[*] If you used a separate char field for each flag, that would use 11 bytes instead of just the four used by the unsigned long. If you had 32 flags, that would be 32 bytes instead of just four!
The statfs() and fstatfs() system calls are Linux specific. Their declarations are as follows:
#include <sys/types.h> GLIBC
#include <sys/vfs.h>
int statfs(const char *path, struct statfs *buf);
int fstatfs(int fd, struct statfs *buf);
As with statvfs() and fstatvfs(), the two versions work on a filename or an open file descriptor, respectively. The struct statfs looks like this:
struct statfs {
long f_type; /* type of filesystem */
long f_bsize; /* optimal transfer block size */
long f_blocks; /* total data blocks in filesystem */
long f_bfree; /* free blocks in fs */
long f_bavail; /* free blocks avail to nonsuperuser */
long f_files; /* total file nodes in file system */
long f_ffree; /* free file nodes in fs */
fsid_t f_fsid; /* filesystem id */
long f_namelen; /* maximum length of filenames */
long f_spare[6]; /* spare for later */
};
The fields are analogous to those in the struct statvfs. At least through GLIBC 2.3.2, the POSIX statvfs() and fstatvfs() functions are wrappers around statfs() and fstatfs(), respectively, copying the values from one kind of struct to the other.
The advantage to using statfs() or fstatfs() is that they are system calls. The kernel returns the information directly. Since there is no f_flag field with mount options, it’s not necessary to look at every mounted filesystem to find the right one. (In other words, in order to fill in the mount options, statvfs() must examine each mounted filesystem to find the one containing the file named by path or fd.statfs() doesn’t need to do that, since it doesn’t provide information about the mount options.)
There are two disadvantages to using these calls. First, they are Linux specific. Second, some of the information in the struct statvfs isn’t in the struct statfs; most noticeably, the mount flags (f_flag) and the number of available inodes (f_favail). (Thus, the Linux statvfs() has to find mount options from other sources, such as /etc/mtab, and it “fakes” the information for the struct statvfs fields for which real information isn’t available.)
One field in the struct statfs deserves special note. This is the f_type field, which indicates the type of the filesystem. The value is the filesystem’s magic number, extracted from the superblock. The statfs(2) manpage provides a list of commonly used filesystems and their magic numbers, which we use in ch08-statfs.c. (Alas, there is no separate #include file.)
1 /* ch08-statfs.c --- demonstrate Linux statfs */ 2 3 /* NOTE: GNU/Linux specific! */ 4 5 #include <stdio.h> 6 #include <errno.h> 7 #include <mntent.h> /* for getmntent(), et al. */ 8 #include <unistd.h> /* for getopt() */ 9 #include <sys/types.h> 10 #include <sys/vfs.h> 11 12 /* Defines taken from statfs(2) man page: */ 13 #define AFFS_SUPER_MAGIC 0xADFF 14 #define EFS_SUPER_MAGIC 0x00414A53 15 #define EXT_SUPER_MAGIC 0x137D 16 #define EXT2_OLD_SUPER_MAGIC 0xEF51 17 #define EXT2_SUPER_MAGIC 0xEF53 18 #define HPFS_SUPER_MAGIC 0xF995E849 19 #define ISOFS_SUPER_MAGIC 0x9660 20 #define MINIX_SUPER_MAGIC 0x137F /* orig. minix */ 21 #define MINIX_SUPER_MAGIC2 0x138F /* 30-char minix */ 22 #define MINIX2_SUPER_MAGIC 0x2468 /* minix V2 */ 23 #define MINIX2_SUPER_MAGIC2 0x2478 /* minix V2, 30 char names */ 24 #define MSDOS_SUPER_MAGIC 0x4d44 25 #define NCP_SUPER_MAGIC 0x564c 26 #define NFS_SUPER_MAGIC 0x6969 27 #define PROC_SUPER_MAGIC 0x9fa0 28 #define SMB_SUPER_MAGIC 0x517B 29 #define XENIX_SUPER_MAGIC 0x012FF7B4 30 #define SYSV4_SUPER_MAGIC 0x012FF7B5 31 #define SYSV2_SUPER_MAGIC 0x012FF7B6 32 #define COH_SUPER_MAGIC 0x012FF7B7 33 #define UFS_MAGIC 0x00011954 34 #define XFS_SUPER_MAGIC 0x58465342 35 #define _XIAFS_SUPER_MAGIC 0x012FD16D 36 37 void process (const char *filename); 38 void do_statfs(const struct mntent *fs); 39 40 int errors = 0; 41 char *myname; 42 ... main() is unchanged, process() is almost identical... 85 86 /* type2str --- convert fs type to printable string, from statfs(2) */ 87 88 const char *type2str(long type) 89 { 90 static struct fsname { 91 long type; 92 const char *name; 93 } table[] = { 94 { AFFS_SUPER_MAGIC, "AFFS" }, 95 { COH_SUPER_MAGIC, "COH" }, 96 { EXT2_OLD_SUPER_MAGIC, "OLD EXT2" }, 97 { EXT2_SUPER_MAGIC, "EXT2" }, 98 { HPFS_SUPER_MAGIC, "HPFS" }, 99 { ISOFS_SUPER_MAGIC, "ISOFS" }, 100 { MINIX2_SUPER_MAGIC, "MINIX V2" }, 101 { MINIX2_SUPER_MAGIC2, "MINIX V2 30 char" }, 102 { MINIX_SUPER_MAGIC, "MINIX" }, 103 { MINIX_SUPER_MAGIC2, "MINIX 30 char" }, 104 { MSDOS_SUPER_MAGIC, "MSDOS" }, 105 { NCP_SUPER_MAGIC, "NCP" }, 106 { NFS_SUPER_MAGIC, "NFS" }, 107 { PROC_SUPER_MAGIC, "PROC" }, 108 { SMB_SUPER_MAGIC, "SMB" }, 109 { SYSV2_SUPER_MAGIC, "SYSV2" }, 110 { SYSV4_SUPER_MAGIC, "SYSV4" }, 111 { UFS_MAGIC, "UFS" }, 112 { XENIX_SUPER_MAGIC, "XENIX" }, 113 { _XIAFS_SUPER_MAGIC, "XIAFS" }, 114 { 0, NULL }, 115 }; 116 static char unknown [100]; 117 int i; 118 119 for (i = 0; table[i].type ! = 0; i++) 120 if (table[i].type == type) 121 return table[i].name; 122 123 sprintf (unknown, "unknown type: %#x", type); 124 return unknown; 125 } 126 127 /* do_statfs --- Use statfs and print info */ 128 129 void do_statfs (const struct mntent *fs) 130 { 131 struct statfs vfs; 132 133 if (fs->mnt_fsname[0] != '/') /* skip nonreal filesystems */ 134 return; 135 136 if (statfs(fs->mnt_dir, & vfs) != 0) { 137 fprintf(stderr, "%s: %s: statfs failed: %s ", 138 myname, fs->mnt_dir, strerror(errno)); 139 errors++; 140 return; 141 } 142 143 printf("s, mounted on %s;/n", fs->mnt_dir, fs->mnt_fsname); 144 145 printf(" f_type: %s ", type2str(vfs.f_type)); 146 printf(" f_bsize: %ld ", vfs.f_bsize); 147 printf(" f_blocks: %ld ", vfs.f_blocks); 148 printf(" f_bfree: %ld ", vfs.f_bfree); 149 printf(" f_bavail: %ld ", vfs.f_bavail); 150 printf(" f_files: %ld ", vfs.f_files); 151 printf(" f_ffree: %ld ", vfs.f_ffree); 152 printf(" f_namelen: %ld ", vfs.f_namelen); 153 }
To save space, we’ve omitted main(), which is unchanged from the other programs presented earlier, and we’ve also omitted process(), which now calls do_statfs() instead of do_statvfs().
Lines 13–35 contain the list of filesystem magic numbers from the statfs(2) manpage. Although the numbers could be retrieved from kernel source code header files, such retrieval is painful (we tried), and the presentation here is easier to follow. Lines 86–125 define type2str(), which converts the magic number to a printable string. It does a simple linear search on a table of (value, string) pairs. In the (unlikely) event that the magic number isn’t in the table, types2str() creates an “unknown type” message and returns that (lines 123–124).
do_statfs() (lines 129–153) prints the information from the struct statfs. The f_fsid member is omitted since fsid_t is an opaque type. The code is straightforward; line 145 uses type2str() to print the filesystem type. As for the similar program using statvfs(), this function ignores filesystems that aren’t on local devices (lines 133–134). Here is the output on our system:
$ ch08-statfs Run the Program /, mounted on /dev/hda2: Results for ext2 filesystem f_type: EXT2 f_bsize: 4096 f_blocks: 1549609 f_bfree: 316664 f_bavail: 237946 f_files: 788704 f_ffree: 555483 f_namelen: 255 ... /win, mounted on /dev/hda1: Results for vfat filesystem f_type: MSDOS f_bsize: 4096 f_blocks: 2092383 f_bfree: 1391952 f_bavail: 1391952 f_files: 0 f_ffree: 0 f_namelen: 260
In conclusion, whether to use statvfs() or statfs() in your own code depends on your requirements. As described in the previous section, GNU df doesn’t use statvfs() under GNU/Linux and in general tends to use each Unix system’s unique “get filesystem info” system call. Although this works, it isn’t pretty. On the other hand, sometimes you have no choice: for example, the GLIBC problems we mentioned above. In this case, there is no perfect solution.
Several system calls and standard library functions let you change your current directory and determine the full pathname of the current directory. More complicated functions let you perform arbitrary actions for every filesystem object in a directory hierarchy.
In Section 1.2, “The Linux/Unix Process Model,” page 10, we said:
Each process has a current working directory. Each new process inherits its current directory from the process that started it (its parent). Two functions let you change to another directory:
#include <unistd.h> int chdir (const char *path); POSIX int fchdir (int fd); XSI
The chdir() function takes a string naming a directory, whereas fchdir() expects a file descriptor that was opened on a directory with open().[6] Both return 0 on success and -1 on error (with errno set appropriately). Typically, if open() on a directory succeeded, then fchdir() will also succeed, unless someone changed the permissions on the directory between the calls. (fchdir() is a relatively new function; older Unix systems won’t have it.)
These functions are almost trivial to use. The following program, ch08-chdir.c, demonstrates both functions. It also demonstrates that fchdir() can fail if the permissions on the open directory don’t include search (execute) permission:
1 /* ch08-chdir.c --- demonstrate chdir() and fchdir(). 2 Error checking omitted for brevity */ 3 4 #include <stdio.h> 5 #include <fcntl.h> 6 #include <unistd.h> 7 #include <sys/types.h> 8 #include <sys/stat.h> 9 10 int main(void) 11 { 12 int fd; 13 struct stat sbuf; 14 15 fd = open(“.”, O_RDONLY); /* open directory for reading */ 16 fstat(fd, & sbuf); /* obtain info, need original permissions */ 17 chdir(“..”); /* ’cd ..’ */ 18 fchmod(fd, 0); /* zap permissions on original directory */ 19 20 if (fchdir(fd) < 0) /* try to ’cd’ back, should fail */ 21 perror(“fchdir back”); 22 23 fchmod(fd, sbuf.st_mode & 07777); /* restore original permissions */ 24 close(fd); /* all done */ 25 26 return 0; 27 }
Line 15 opens the current directory. Line 16 calls fstat() on the open directory so that we have a copy of its permissions. Line 17 uses chdir() to move up a level in the file hierarchy. Line 18 does the dirty work, turning off all permissions on the original directory.
Lines 20–21 attempt to change back to the original directory. It is expected to fail, since the current permissions don’t allow it. Line 23 restores the original permissions. The ’sbuf.st_mode & 07777’ retrieves the low-order 12 permission bits; these are the regular 9 rwxrwxrwx bits, and the setuid, setgid, and “sticky” bits, which we discuss in Chapter 11, “Permissions and User and Group ID Numbers,” page 403. Finally, line 24 cleans up by closing the open file descriptor. Here’s what happens when the program runs:
$ ls -ld. Show current permissions drwxr-xr-x 2 arnold devel 4096 Sep 9 16:42. $ ch08-chdir Run the program fchdir back: Permission denied Fails as expected $ ls -ld. Look at permissions again drwxr-xr-x 2 arnold devel 4096 Sep 9 16:42. Everything is back as it was
The aptly named getcwd() function retrieves the absolute pathname of the current working directory:
#include <unistd.h> POSIX
char *getcwd(char *buf, size_t size);
The function fills in buf with the pathname; it expects buf to have size bytes. Upon success, it returns its first argument. Otherwise, if it needs more than size bytes, it returns NULL and sets errno to ERANGE. The intent is that if ERANGE happens, you should try to allocate a larger buffer (with malloc() or realloc()) and try again.
If any of the directory components leading to the current directory are not readable or searchable, then getcwd() can fail and errno will be EACCES. The following simple program demonstrates its use:
/* ch08-getcwd.c --- demonstrate getcwd().
Error checking omitted for brevity */
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
int main(void)
{
char buf[PATH_MAX];
char *cp;
cp = getcwd(buf, sizeof(buf));
printf("Current dir: %s
", buf);
printf("Changing to ..
");
chdir(".."); /* 'cd ..' */
cp = getcwd(buf, sizeof(buf));
printf("Current dir is now: %s
", buf);
return 0;
}
This simple program prints the current directory, changes to the parent directory, and then prints the new current directory. (cp isn’t really needed here, but in a real program it would be used for error checking.) When run, it produces the following output:
$ ch08-getcwd
Current dir: /home/arnold/work/prenhall/progex/code/ch08
Changing to ..
Current dir is now: /home/arnold/work/prenhall/progex/code
>Formally, if the buf argument is NULL, the behavior of getcwd() is undefined. In this case, the GLIBC version of getcwd() will call malloc() for you, allocating a buffer of size size. Going even further out of its way to be helpful, if size is 0, then the buffer it allocates will be “big enough” to hold the returned pathname. In either case, you should call free() on the returned pointer when you’re done with the buffer.
The GLIBC behavior is helpful, but it’s not portable. For code that has to work across platforms, you can write a replacement function that provides the same functionality while having your replacement function call getcwd() directly if on a GLIBC system.
GNU/Linux systems provide the file /proc/self/cwd. This file is a symbolic link to the current directory:
$ cd /tmp Change directory someplace $ ls -l /proc/self/cwd Look at the file lrwxrwxrwx 1 arnold devel 0 Sep 9 17:29 /proc/self/cwd -> /tmp $ cd Change to home directory $ ls -l /proc/self/cwd Look at it again lrwxrwxrwx 1 arnold devel 0 Sep 9 17:30 /proc/self/cwd -> /home/arnold
This is convenient at the shell level but presents a problem at the programmatic level. In particular, the size of the file is zero! (This is because it’s a file in /proc, which the kernel fakes; it’s not a real file living on disk.)
Why is the zero size a problem? If you remember from Section 5.4.5, “Working with Symbolic Links,” page 151, lstat() on a symbolic link returns the number of characters in the name of the linked-to file in the st_size field of the struct stat. This number can then be used to allocate a buffer of the appropriate size for use with readlink(). That won’t work here, since the size is zero. You have to use (or allocate) a buffer that you guess is big enough. However, since readlink() does not fill in any more characters than you provide, you can’t tell whether or not the buffer is big enough; readlink() does not fail when there isn’t enough room. (See the Coreutils xreadlink() function in Section 5.4.5, “Working with Symbolic Links,” page 151, which solves the problem.)
In addition to getcwd(), GLIBC has several other nonportable routines. These save you the trouble of managing buffers and provide compatibility with older BSD systems. For the details, see getcwd(3).
A common programming task is to process entire directory hierarchies: doing something for every file and every directory and subdirectory in an entire tree. Consider, for example, du, which prints disk usage information, ’chown -R’, which recursively changes ownership, or the find program, which finds files matching certain criteria.
At this point, you know enough to write your own code to manually open and read directories, call stat() (or lstat()) for each entry, and recursively process subdirectories. However, such code is challenging to get right; it’s possible to run out of file descriptors if you leave parent directories open while processing subdirectories; you have to decide whether to process symbolic links as themselves or as the files they point to; you have to be able to deal with directories that aren’t readable or searchable, and so on. It’s also painful to have to write the same code over and over again if you need it for multiple applications.
To obviate the problems, System V introduced the ftw() (“file tree walk”) function. ftw() did all the work to “walk” a file tree (hierarchy). You supplied it with a pointer to a function, and it called the function for every file object it encountered. Your function could then process each filesystem object as it saw fit.
Over time, it became clear that the ftw() interface didn’t quite do the full job;[7] for example, originally it didn’t support symbolic links. For this reason, nftw() (“new ftw()” [sic]) was added to the X/Open Portability Guide; it’s now part of POSIX. Here’s the prototype:
#include <ftw.h> XSI int nftw(const char *dir, Starting point int (*fn) (const char *file, Function pointer to const struct stat *sb, function of four arguments int flag, struct FTW *s), int depth, int flags); Max open fds, flags
And here are the arguments:
const char *dir
A string naming the starting point of the hierarchy to process.
int (*fn) (const char *file, const struct stat *sb, int flag, struct FTW *s)
A pointer to a function with the given arguments. This function is called for every object in the hierarchy. Details below.
int depth
This argument is misnamed. To avoid running out of file descriptors,
nftw()keeps no more thandepthsimultaneously open directories. This does not preventnftw()from processing hierarchies that are more thandepthlevels deep; but smaller values fordepthmean thatnftw()has to do more work.
flags
A set of flags, bitwise OR’d, that direct how
nftw()should process the hierarchy.
The nftw() interface has two disjoint sets of flags. One set controls nftw() itself (the flags argument to nftw()). The other set is passed to the user-supplied function that nftw() calls (the flag argument to (*fn)()). However, the interface is confusing, because both sets of flags use names starting with the prefix ’FTW_’. We’ll do our best to keep this clear as we go. Table 8.3 presents the flags that control nftw().
Table 8.3. Control flags for nftw()
Flag | Meaning |
|---|---|
| When set, change to each directory before opening it. This action is more efficient, but the calling application has to be prepared to be in a different directory when |
| When set, do a “depth-first search.” This means that all of the files and subdirectories in a directory are processed before the directory itself is processed. |
| When set, stay within the same mounted filesystem. This is a more specialized option. |
| When set, do not follow symbolic links. |
FTW_CHDIR provides greater efficiency; when processing deep file hierarchies, the kernel doesn’t have to process full pathnames over and over again when doing a stat() or opening a directory. The time savings on large hierarchies can be quite noticeable.[8]
FTW_DEPTH may or may not be what you need; for some applications it’s just right. Consider ’chmod -R u-rx .’. This removes read and execute permission for the owner of all files and subdirectories in the current directory. If this permission change is applied to a directory before it’s applied to the directory’s contents, any subsequent attempt to process the contents will fail! Thus, it should be applied after the contents have been processed.[9] The GNU/Linux nftw(3) manpage notes for FTW_PHYS that “this is what you want”. This lets you process symbolic links as themselves, which is usually what’s necessary. (Consider du; it should count the link’s space separately from that of the linked-to file.)
As nftw() runs, it calls a function to which you supply a pointer. (Such functions are termed callback functions since they are “called back” from library code.) The callback function receives four arguments:
const char *file
The name of the current file (directory, symbolic link, etc.) being processed.
const struct stat *sb
A pointer to a
struct statfor the file.
int flag
One of several flag values (described below) indicating what kind of file this is or whether an error was encountered for the object.
struct FTW *s
The flag parameter has one of the values listed in Table 8.4.
Table 8.4. Flag values for nftw() callback function
Flag | Meaning |
|---|---|
| Object is a regular file. |
| Object is a directory. |
| Object is a directory that wasn’t readable. |
| Object is a symbolic link. |
| Object is not a symbolic link, and |
| Object is a directory whose children have already been processed. This can only happen if |
| Object is a symbolic link pointing to a nonexistent file. This can only happen if |
The struct FTW *s provides additional information that can be useful. s->base acts as an index into file; file is the full pathname of the object being processed (relative to the starting point). ’file + s->base’ points to the first character of the filename component of the file.
s->level indicates the current depth in the hierarchy; the original starting point is considered to be at level 0.
The callback function should return 0 if all is well. Any nonzero return causes nftw() to stop its processing and to return the same nonzero value. The manpage notes that the callback function should stop processing only by using its return value so that nftw() has a chance to clean up: that is, free any dynamic storage, close open file descriptors, and so on. The callback function should not use longjmp() unless the program will immediately exit.( longjmp() is an advanced function, which we describe in Section 12.5, “Nonlocal Gotos,” page 446.) The recommended technique for handling errors is to set a global variable indicating that there were problems, return 0 from the callback, and deal with the failures once nftw() has completed traversing the file hierarchy. (GNU du does this, as we see shortly.)
Let’s tie all this together with an example program. ch08-nftw.c processes each file or directory named on the command line, running nftw() on it. The function that processes each file prints the filename and type with indentation, showing the hierarchical position of each file. For a change, we show the results first, and then we show and discuss the program:
$ pwd Where we are /home/arnold/work/prenhall/progex $ code/ch08/ch08-nftw code Walk the 'code' directory code (directory) Top-level directory ch02 (directory) Subdirectories one level indented ch02-printenv.c (file) Files in subdirs two levels indented ch03 (directory) ch03-memaddr.c (file) ch04 (directory) ch04-holes.c (file) ch04-cat.c (file) ch04-maxfds.c (file) v7cat.c (file) ...
Here’s the program itself:
1 /* ch08-nftw.c --- demonstrate nftw() */ 2 3 #define _XOPEN_SOURCE 1 /* Required under GLIBC for nftw() */ 4 #define _XOPEN_SOURCE_EXTENDED 1 /* Same */ 5 6 #include <stdio.h> 7 #include <errno.h> 8 #include <getopt.h> 9 #include <ftw.h> /* gets <sys/types.h> and <sys/stat.h> for us */ 10 #include <limits.h> /* for PATH_MAX */ 11 #include <unistd.h> /* for getdtablesize(), getcwd() declarations */ 12 13 #define SPARE_FDS 5 /* fds for use by other functions, see text */ 14 15 extern int process (const char *file, const struct stat *sb, 16 int flag, struct FTW *s); 17 18 /* usage --- print message and die */ 19 20 void usage (const char *name) 21 { 22 fprintf(stderr, "usage: %s [-c] directory ... ", name); 23 exit(1); 24 } 25 26 /* main --- call nftw() on each command-line argument */ 27 28 int main(int argc, char **argv) 29 { 30 int i, c, nfds; 31 int errors = 0; 32 int flags = FTW_PHYS; 33 char start[PATH_MAX], finish[PATH_MAX]; 34 35 while ((c = getopt (argc, argv, "c")) != -1) { 36 switch (c) { 37 case 'c': 38 flags |= FTW_CHDIR; 39 break; 40 default: 41 usage(argv[0]); 42 break; 43 } 44 } 45 46 if (optind == argc) 47 usage (argv[0]); 48 49 getcwd(start, sizeof start); 50 51 nfds = getdtablesize() - SPARE_FDS; /* leave some spare descriptors */ 52 for (i = optind; i < argc; i++) { 53 if (nftw(argv[i], process, nfds, flags) != 0) { 54 fprintf(stderr, "%s: %s: stopped early ", 55 argv[0], argv[i]); 56 errors++; 57 } 58 } 59 60 if ((flags & FTW_CHDIR) != 0) { 61 getcwd(finish, sizeof finish); 62 printf("Starting dir: %s ", start); 63 printf("Finishing dir: %s ", finish); 64 } 65 66 return (errors != 0); 67 }
Lines 3–11 include header files. Through at least GLIBC 2.3.2, the #defines for _XOPEN_SOURCE and _XOPEN_SOURCE_EXTENDED are necessary before any header file inclusion. They make it possible to get the declarations and flag values that nftw() provides over and above those of ftw(). This is specific to GLIBC. The need for it will eventually disappear as GLIBC becomes fully compliant with the 2001 POSIX standard.
Lines 35–44 process options. The -c option adds the FTW_CHDIR flag to the nftw() flags. This is an experiment to see if you can end up somewhere different from where you started. It seems that if nftw() fails, you can; otherwise, you end up back where you were. (POSIX doesn’t document this explicitly, but the intent seems to be that you do end up back where you started. The standard does say that the callback function should not change the current directory.)
Line 49 saves the starting directory for later use, using getcwd().
Line 51 computes the number of file descriptors nftw() can use. We don’t want it to use all available file descriptors in case the callback function wants to open files too. The computation uses getdtablesize() (see Section 4.4.1, “Understanding File Descriptors,” page 92) to retrieve the maximum available number and subtracts SPARE_FDS, which was defined earlier, on line 13.
This procedure warrants more explanation. In the normal case, at least three descriptors are already used for standard input, standard output, and standard error. nftw() needs some number of file descriptors for opening and reading directories; under the hood, opendir() uses open() to open a directory for reading. If the callback function also needs to open files, we have to prevent nftw() from using up all available file descriptors with open directories. We do this by subtracting some number from the maximum available. For this example, we chose five, but if the callback function needs to open files, a larger number should be used. (nftw() knows how to recover when it runs out of file descriptors; we don’t have to worry about that case.)
Lines 52–58 are the main loop over the arguments; lines 53–57 check for errors; when they occur, the code prints a diagnostic and increments the errors variable.
Lines 60–64 are part of the experiment for FTW_CHDIR, printing the starting and finishing directories if -c was used.
The function of real interest is process(); this is the callback function that processes each file. It uses the basic template for an nftw() callback function, which is a switch statement on the flag value:
69 /* process --- print out each file at the right level */ 70 71 int process(const char *file, const struct stat *sb, 72 int flag, struct FTW *s) 73 { 74 int retval = 0; 75 const char *name = file + s->base; 76 77 printf("%*s", s->level * 4, ""); /* indent over */ 78 79 switch (flag) { 80 case FTW_F: 81 printf("%s (file) ", name); 82 break; 83 case FTW_D: 84 printf("%s (directory) ", name); 85 break; 86 case FTW_DNR: 87 printf("%s (unreadable directory) ", name); 88 break; 89 case FTW_SL: 90 printf("%s (symbolic link) ", name); 91 break; 92 case FTW_NS: 93 printf("%s (stat failed): %s ", name, strerror(errno)); 94 break; 95 case FTW_DP: 96 case FTW_SLN: 97 printf("%s: FTW_DP or FTW_SLN: can't happen! ", name); 98 retval = 1; 99 break; 100 default: 101 printf("%s: unknown flag %d: can't happen! ", name, flag); 102 retval = 1; 103 break; 104 } 105 106 return retval; 107 }
Line 75 uses ’file + s->base’ to get at the name part of the full pathname. This pointer value is saved in the name variable for reuse throughout the function.
Line 77 produces the right amount of indentation, using a nice trick. Using %*s, printf() takes the field width from the first argument. This is computed dynamically as ’level * 4’. The string to be printed is “ ”, the null string. The end result is that printf() produces the right amount of space for us, without our having to run a loop.
Lines 79–104 are the switch statement. In this case, it doesn’t do anything terribly interesting except print the file’s name and its type (file, directory, etc.).
Although this program doesn’t use the struct stat, it should be clear that you could do anything you need to in the callback function.
Note
Jim Meyering, the maintainer of the GNU Coreutils, notes that the nftw() design isn’t perfect, because of its recursive nature. (It calls itself recursively when processing subdirectories.) If a directory hierarchy gets really deep, in the 20,000–40,000 level range(!), nftw() can run out of stack space, killing the program. There are other problems related to nftw()’s design as well. The post-5.0 version of the GNU Coreutils fixes this by using the BSD fts() suite of routines (see fts(3)).
The GNU version of du in the GNU Coreutils uses nftw() to traverse one or more file hierarchies, gathering and producing statistics concerning the amount of disk space used. It has a large number of options that control its behavior with respect to symbolic links, output format of numbers, and so on. This makes the code harder to decipher than a simpler version would be. (However, we’re not going to let that stop us.) Here is a summary of du’s options, which will be helpful shortly when we look at the code:
$ du --help Usage: du [OPTION] ... [FILE] ... Summarize disk usage of each FILE, recursively for directories. Mandatory arguments to long options are mandatory for short options too. -a, --all write counts for all files, not just directories --apparent-size print apparent sizes, rather than disk usage; although the apparent size is usually smaller, it may be larger due to holes in ('sparse') files, internal fragmentation, indirect blocks, and the like -B, --block-size=SIZE use SIZE-byte blocks -b, --bytes equivalent to '--apparent-size --block-size=1' -c, --total produce a grand total -D, --dereference-args dereference FILEs that are symbolic links -h, --human-readable print sizes in human readable format (e.g., 1K 234M 2G) -H, --si likewise, but use powers of 1000 not 1024 -k like --block-size=1K -l, --count-links count sizes many times if hard linked -L, --dereference dereference all symbolic links -S, --separate-dirs do not include size of subdirectories -s, --summarize display only a total for each argument -x, --one-file-system skip directories on different filesystems -X FILE, --exclude-from=FILE Exclude files that match any pattern in FILE. --exclude=PATTERN Exclude files that match PATTERN. --max-depth=N print the total for a directory (or file, with --all) only if it is N or fewer levels below the command line argument; --max-depth=0 is the same as --summarize --help display this help and exit --version output version information and exit SIZE may be (or may be an integer optionally followed by) one of following: kB 1000, K 1024, MB 1,000,000, M 1,048,576, and so on for G, T, P, E, Z, Y. Report bugs to <[email protected]>.
To complicate matters further, du uses a private version of nftw() that has some extensions. First, there are additional flag values for the callback function:
FTW_DCHP
This value signifies that
nftw()could not execute ’chdir(“..”)’.
FTW_DCH
This value signifies that
nftw()could not usechdir()to change into a directory itself.
FTW_DPRE
The private nftw() also adds a new member, int skip, to the struct FTW. If the current object is a directory and the callback function sets the skip field to nonzero, nftw() will not process that directory any further. (The callback function should set skip this way when the flag is FTW_DPRE; doing it for FTW_DP is too late.)
With that explanation under our belt, here is the process_file() function from du.c. Line numbers are relative to the start of the function:
1 /* This function is called once for every file system object that nftw 2 encounters. nftw does a depth-first traversal. This function knows 3 that and accumulates per-directory totals based on changes in 4 the depth of the current entry. */ 5 6 static int 7 process_file (const char *file, const struct stat *sb, int file_type, 8 struct FTW *info) 9 { 10 uintmax_t size; 11 uintmax_t size_to_print; 12 static int first_call = 1; 13 static size_t prev_level; 14 static size_t n_alloc; 15 static uintmax_t *sum_ent; 16 static uintmax_t *sum_subdir; 17 int print = 1; 18 19 /* Always define info->skip before returning. */ 20 info->skip = excluded_filename (exclude, file + info->base); For --exclude
This function does a lot since it has to implement all of du’s options. Line 17 sets print to true (1); the default is to print information about each file. Later code sets it to false (0) if necessary.
Line 20 sets info->skip based on the --exclude option. Note that this excludes subdirectories if a directory matches the pattern for --exclude.
22 switch (file_type) 23 { 24 case FTW_NS: 25 error (0, errno, _("cannot access %s"), quote (file)); 26 G_fail = 1; Set global var for later 27 return 0; Return 0 to keep going 28 29 case FTW_DCHP: 30 error (0, errno, _("cannot change to parent of directory %s"), 31 quote (file)); 32 G_fail = 1; 33 return 0; 34 35 case FTW_DCH: 36 /* Don't return just yet, since although nftw couldn't chdir into the 37 directory, it was able to stat it, so we do have a size. */ 38 error (0, errno, _("cannot change to directory %s"), quote (file)); 39 G_fail = 1; 40 break; 41 42 case FTW_DNR: 43 /* Don't return just yet, since although nftw couldn't read the 44 directory, it was able to stat it, so we do have a size. */ 45 error (0, errno, _("cannot read directory %s"), quote (file)); 46 G_fail = 1; 47 break; 48 49 default: 50 break; 51 } 52 53 /* If this is the first (pre-order) encounter with a directory, 54 return right away. */ 55 if (file_type == FTW_DPRE) 56 return 0;
Lines 22–51 are the standard switch statement. Errors for which there’s no size information set the global variable G_fail to 1 and return 0 to keep going (see lines 24–27 and 29–33). Errors for which there is a size also set G_fail but then break out of the switch in order to handle the statistics (see lines 35–40 and 42–47).
Lines 55–56 return early if this is the first time a directory is encountered.
58 /* If the file is being excluded or if it has already been counted 59 via a hard link, then don't let it contribute to the sums. */ 60 if (info->skip 61 || (!opt_count_all 62 && 1 < sb->st_nlink 63 && hash_ins (sb->st__ino, sb->st_dev))) 64 { 65 /* Note that we must not simply return here. 66 We still have to update prev_level and maybe propagate 67 some sums up the hierarchy. */ 68 size = 0; 69 print = 0; 70 } 71 else 72 { 73 size = (apparent_size 74 ? sb->st_size 75 : ST_NBLOCKS (*sb) * ST_NBLOCKSIZE); 76 }
Now it starts to get interesting. By default, du counts the space used by hard-linked files just once. The --count-links option causes it to count each link’s space; the variable opt_count_all is true when --count-links is supplied. To keep track of links, du maintains a hash table[10] of already seen (device, inode) pairs.
Lines 60–63 test whether a file should not be counted, either because it was excluded (info->skip is true, line 60) or because --count-links was not supplied (line 61) and the file has multiple links (line 62) and the file is already in the hash table (line 63). In this case, the size is set to 0, so that it doesn’t add to the running totals, and print is also set to false (lines 68–69).
If none of those conditions hold, the size is computed either according to the size in the struct stat or the number of disk blocks (lines 73–75). This decision is based on the apparent_size variable, which is set if the --apparent-size option is used.
78 if (first_call) 79 { 80 n_alloc = info->level + 10; Allocate arrays 81 sum_ent = XCALLOC (uintmax_t, n_alloc); 82 sum_subdir = XCALLOC (uintmax_t
Lines 78–97 manage the dynamic memory used to hold file size statistics. first_call is a static variable (line 12) that is true the first time process_file() is called. In this case, calloc() is called (through a wrapper macro on lines 81–82; this was discussed in Section 3.2.1.8, “Example: Reading Arbitrarily Long Lines” page 67). The rest of the time, first_call is false, and realloc() is used (again, through a wrapper macro, lines 91–96).
Line 99 sets size_to_print to size; this variable may be updated depending on whether it has to include the sizes of any children. Although size could have been reused, the separate variable makes the code easier to read.
101 if (! first_call) 102 { 103 if ((size_t) info->level == prev_level) 104 { 105 /* This is usually the most common case. Do nothing. */ 106 } 107 else if ((size_t) info-> level > prev_level) 108 { 109 /* Descending the hierarchy. 110 Clear the accumulators for *all* levels between prev_level 111 and the current one. The depth may change dramatically, 112 e.g., from 1 to 10. */ 113 int i; 114 for (i = prev_level + 1; i <= info->level; i++) 115 sum_ent[i] = sum_subdir[i] = 0; 116 } 117 else /* info->level < prev_level */ 118 { 119 /* Ascending the hierarchy. 120 nftw processes a directory only after all entries in that 121 directory have been processed. When the depth decreases, 122 propagate sums from the children (prev_level) to the parent. 123 Here, the current level is always one smaller than the 124 previous one. */ 125 assert ((size_t) info->level == prev_level - 1); 126 size_to_print += sum_ent[prev_level]; 127 if (!opt_separate_dirs) 128 size_to_print += sum_subdir[prev_level]; 129 sum_subdir[info->level] += (sum_ent[prev_level] 130 + sum_subdir[prev_level]); 131 } 132 }
Lines 101–132 compare the current level to the previous one. There are three possible cases.
The levels are the same.
In this case, there’s no need to worry about child statistics. (Lines 103–106.)
The current level is higher than the previous level.
In this case, we’ve gone down the hierarchy, and the statistics must be reset (lines 107–116). The term “accumulator” in the comment is apt: each element accumulates the total disk space used at that level. (In the early days of computing, CPU registers were often termed “accumulators”.)
The current level is lower than the previous level.
In this case, we’ve finished processing all the children in a directory and have just moved back up to the parent directory (lines 117–131). The code updates the totals, including
size_to_print.
134 prev_level = info->level; Set static variables 135 first_call = 0; 136 137 /* Let the size of a directory entry contribute to the total for the 138 containing directory, unless --separate-dirs (-S) is specified. */ 139 if ( ! (opt_separate_dirs && IS_FTW_DIR_TYPE (file_type))) 140 sum_ent[info->level] += size; 141 142 /* Even if this directory is unreadable or we can't chdir into it, 143 do let its size contribute to the total, ... */ 144 tot_size += size; 145 146 /* ... but don't print out a total for it, since without the size(s) 147 of any potential entries, it could be very misleading. */ 148 if (file_type == FTW_DNR || file_type == FTW_DCH) 149 return 0; 150 151 /* If we're not counting an entry, e.g., because it's a hard link 152 to a file we've already counted (and --count-links), then don't 153 print a line for it. */ 154 if (!print) 155 return 0;
Lines 134–135 set the static variables prev_level and first_call so that they’ll have the correct values for a subsequent call to process_file(), ensuring that all the previous code works correctly.
Lines 137–144 adjust statistics on the basis of options and the file type. The comments and code are fairly straightforward. Lines 146–155 quit early if the information should not be printed.
157 /* FIXME: This looks suspiciously like it could be simplified. */ 158 if ((IS_FTW_DIR_TYPE (file_type) && 159 (info->level <= max_depth || info->level == 0)) 160 || ((opt_all && info->level <= max_depth) || info->level == 0)) 161 { 162 print_only_size (size_to_print); 163 fputc (' ', stdout); 164 if (arg_length) 165 { 166 /* Print the file name, but without the `.' or `/.' 167 directory suffix that we may have added in main. */ 168 /* Print everything before the part we appended. */ 169 fwrite (file, arg_length, 1, stdout); 170 /* Print everything after what we appended. */ 171 fputs (file + arg_length + suffix_length 172 + (file[arg_length + suffix_length] == '/'), stdout); 173 } 174 else 175 { 176 fputs (file, stdout); 177 } 178 fputc (' ', stdout); 179 fflush (stdout); 180 } 181 182 return 0; 183 }
The condition on lines 158–160 is confusing, and the comment on line 157 notes this. The condition states: ’If (1a) the file is a directory and (lb) the level is less than the maximum to print (the --max-depth and max_depth variable) or the level is zero, or (2a) all files should be printed and the level is less than the maximum to print, or (2b) the level is zero,” then print the file. (Yow! The post-5.0 version of du uses a slightly less complicated condition for this case.)
Lines 162–179 do the printing. Lines 162–163 print the size and a TAB character. Lines 164–173 handle a special case. This is explained later on in du.c, on lines 524–529 of the file:
524 /* When dereferencing only command line arguments, we're using 525 nftw's FTW_PHYS flag, so a symlink-to-directory specified on 526 the command line wouldn't normally be dereferenced. To work 527 around that, we incur the overhead of appending `/.' (or `.') 528 now, and later removing it each time we output the name of 529 a derived file or directory name. */
In this case, arg_length is true, so lines 164–173 have to print out the original name, not the modified one. Otherwise, lines 174–117 can print the name as it is.
Whew! That’s a lot of code. We find this to be on the upper end of the complexity spectrum, at least as far as what can be easily presented in a book of this nature. However, it demonstrates that real-world code is often complex. The best way to manage such complexity is with clearly named variables and detailed comments. du.c is good in that respect; we were able to extract the code and examine it fairly easily, without having to show all 735 lines of the program!
The current working directory, set with chdir() (see Section 8.4.1, “Changing Directory: chdir() and fchdir(),” page 256), is an attribute of the process, just like the set of open files. It is also inherited by new processes.
Less well known is that every process also has a current root directory. It is this directory to which the pathname / refers. Most of the time, a process’s root and the system root directories are identical. However, the superuser can change the root directory, with the (you guessed it) chroot() system call:
#include <unistd.h> Common
int chroot(const char *path);
The return value is 0 upon success and -1 upon error.
As the GNU/Linux chroot(2) manpage points out, changing the root directory does not change the current directory: Programs that must make sure that they stay underneath the new root directory must also execute chdir() afterwards:
if (chroot("/new/root") < 0) Set new root directory
/* handle error */
if (chdir("/some/dir") < 0) Pathnames now relative to new root
/* handle error */
The chroot() system call is used most often for daemons—background programs that must run in a special, contained environment. For example, consider an Internet FTP daemon that allows anonymous FTP (connection by anyone, from anywhere, without a regular username and password). Obviously, such a connection should not be able to see all the files on the whole system. Instead, the FTP daemon does a chroot() to a special directory with just enough structure to allow it to function. (For example, its own /bin/ls for listing files, its own copy of the C runtime library if it’s shared, and possibly its own copy of /etc/passwd and /etc/group to show a limited set of user and group names.)
POSIX doesn’t standardize this system call, although GNU/Linux and all Unix systems support it. (It’s been around since V7.) It is specialized, but when you need it, it’s very handy.
Filesystems are collections of free, inode, metadata, and data blocks, organized in a specific fashion. Filesystems correspond one-to-one with the (physical or logical) partitions in which they are made. Each filesystem has its own root directory; by convention the root directory always has inode number
2.The
mountcommand mounts a filesystem, grafting it onto the logical hierarchical file namespace. Theumountcommand detaches a filesystem. The kernel arranges for /. and /.. to be the same; the root directory of the entire namespace is its own parent. In all other cases, the kernel arranges for ’..’ in the root of a mounted filesystem to point to the parent directory of the mount point.Modern Unix systems support multiple types of filesystems. In particular, Sun’s Network File System (NFS) is universally supported, as is the ISO 9660 standard format for CD-ROMs, and MS-DOS FAT partitions are supported on all Unix systems that run on Intel x86 hardware. To our knowledge, Linux supports the largest number of different filesystems—well over 30! Many are specialized, but many others are for general use, including at least four different journaling filesystems.
The
/etc/fstabfile lists each system’s partitions, their mount points, and any relevant mount options./etc/mtablists those filesystems that are currently mounted, as does/proc/mountson GNU/Linux systems. Theloopoption to mount is particularly useful under GNU/Linux for mounting filesystem images contained in regular files, such as CD-ROM images. Other options are useful for security and for mounting foreign filesystems, such as Windowsvfatfilesystems.The
/etc/fstab-format files can be read with thegetmntent()suite of routines. The GNU/Linux format is shared with several other commercial Unix variants, most notably Sun’s Solaris.The
statvfs()andfstatvfs()functions are standardized by POSIX for retrieving filesystem information, such as the number of free and used disk blocks, the number of free and used inodes, and so on. Linux has its own system calls for retrieving similar information:statfs()andfstatfs().chdir()andfchdir()let a process change its current directory.getcwd()retrieves the absolute pathname of the current directory. These three functions are straightforward to use.The
nftw()function centralizes the task of “walking a file tree” that is, visiting every filesystem object (file, device, symbolic link, directory) in an entire directory hierarchy. Different flags control its behavior. The programmer then has to provide a callback function that receives each file’s name, astruct statfor the file, the file’s type, and information about the file’s name and level in the hierarchy. This function can then do whatever is necessary for each file. The Coreutils 5.0 version of GNUduuses an extended version ofnftw()to do its job.Finally, the
chroot()system call changes a process’s current root directory. This is a specialized but important facility, which is particularly useful for certain daemon-style programs.
Examine the mount(2) manpage under GNU/Linux and on as many other different Unix systems as you have access to. How do the system calls differ?
Enhance
ch08-statvfs.cto take an option giving an open integer file descriptor; it should usefstatvfs()to retrieve filesystem information.Enhance
ch08-statvfs.cto not ignore NFS-mounted filesystems. Such filesystems have a device of the formserver.example.com:/big/disk.Modify
ch08-statfs.c(the one that uses the Linux-specificstatfs()call) to produce output that looks like that fromdf.Add a
-ioption to the program you wrote for the previous exercise to produce output like that of ’df -i’.Using
opendir(), readdir(),stat() or fstat(), dirfd(),andfchdir(), write your own version ofgetcwd(). How will you compute the total size the buffer needs to be? How will you move through the directory hierarchy?Enhance your version of
getcwd()to allocate a buffer for the caller if the first argument isNULL.Can you use
nftw()to writegetcwd()? If not, why not?Using
nftw(), write your own version ofchownthat accepts a-Roption to recursively process entire directory trees. Make sure that without-R, ’chownuser directory’ does not recurse. How will you test it?The BSD
fts()(“file tree stream”) suite of routines provides a different way to process directory hierarchies. It has a somewhat heftier API, in terms of both the number of functions and thestructit makes available to the user-level function that calls it. These functions are available as a standard part of GLIBC.Read the fts(3) manpage. (It may help you to print it and have it handy.) Rewrite your private version of
chownto usefts().Look at the find(1) manpage. If you were to try to write
findfrom scratch, which file tree suite would you prefer,nftw()orfts()?Why?
[1] GNU/Linux and Solaris allow you to mount one file on top of another; this has advanced uses, which we don’t otherwise discuss.
[2] For example, consider upgrading a VAX 11/780 from 4.1 BSD to 4.2 BSD.
[3] System V Release 3 supported two different block sizes: 512 bytes and 1024 bytes, but otherwise the disk organization was the same.
[5] On GNU/Linux and most systems. Solaris and some systems based on System V Release 4 use /etc/vfstab, possibly with a different format.
[*] See /usr/include/bits/statvfs.h on a GNU/Linux system.
[6] On GNU/Linux and BSD systems, you can apply the dirfd() function to a DIR * pointer to obtain the underlying file descriptor; see the GNU/Linux dirfd(3) manpage.
[7] POSIX standardizes the ftw() interface to support existing code, and GNU/Linux and commercial Unix systems continue to supply it. However, since it’s underpowered, we don’t otherwise discuss it. See ftw(3) if you’re interested.
[8] Some older GLIBC versions have problems with FTW_CHDIR. This is not true for GLIBC 2.3.2 and later, and it’s unlikely that you’ll encounter problems.
[9] Why anyone would want to make such a change, we don’t know, but the “you asked for it, you got it” philosophy applies here too!
[10] A hash table is a data structure that allows quick retrieval of stored information; the details are beyond the scope of this book.