
In this chapter
As we said in Chapter 1, “Introduction,” page 3, if you were to summarize Unix (and thus Linux) in three words, they would have to be “files and processes.” Now that we’ve seen how to work with files and directories, it’s time to look at the rest of the story: processes. In particular, we examine how processes are created and managed, how they interact with open files, and how they can communicate with each other. Subsequent chapters examine signals—a coarse way for one process (or the kernel) to let another know that some event has occurred—and permission checking.
In this chapter the picture begins to get more complicated. In particular, to be fairly complete, we must mention things that aren’t covered until later in the chapter or later in the book. In such cases, we provide forward references, but you should be able to get the gist of each section without looking ahead.
Unlike many predecessor and successor operating systems, process creation in Unix was intended to be (and is) cheap. Furthermore, Unix separated the idea of “create a new process” from that of “run a given program in a process.” This was an elegant design decision, one that simplifies many operations.
The first step in starting a new program is calling fork():
#include <sys/types.h> POSIX
#include <unistd.h>
pid_t fork(void);
Using fork() is simple. Before the call, one process, which we term the parent, is running. When fork() returns, there are two processes: the parent and the child.
Here is the key: The two processes both run the same program. The two processes can distinguish themselves based on the return value from fork():
Negative
If there is an error,
fork()returns-1, and no new process is created. The original process continues running.
Zero
In the child,
fork()returns0.
Positive
In the parent,
fork()returns the positive process identification number (PID) of the child.
Boilerplate code for creating a child process looks like this:
pid_t child;
if ((child = fork()) < 0)
/* handle error */
else if (child == 0)
/* this is the new process */
else
/* this is the original parent process */
The pid_t is a signed integer type for holding PID values. It is most likely a plain int, but it makes code more self-documenting and should be used instead of int.
In Unix parlance, besides being the name of a system call, the word “fork” is both a verb and a noun. We might say that “one process forks another,” and that “after the fork, two processes are running.” (Think “fork in a road” and not “fork, knife and spoon.”)
The child “inherits” identical copies of a large number of attributes from the parent. Many of these attributes are specialized and irrelevant here. Thus, the following list in purposely incomplete. The following attributes are the relevant ones:
The environment; see Section 2.4, “The Environment,” page 40.
All open files and open directories; see Section 4.4.1, “Understanding File Descriptors,” page 92, and see Section 5.3.1, “Basic Directory Reading,” page 133.
The umask setting; see Section 4.6, “Creating Files,” page 106.
The current working directory; see Section 8.4.1, “Changing Directory: chdir() and fchdir(),” page 256.
The root directory; see Section 8.6, “Changing the Root Directory: chroot(),” page 276.
The current priority (a.k.a. “nice value”; we discuss this shortly; see Section 9.1.3, “Setting Process Priority: nice(),” page 291).
The controlling terminal. This is the terminal device (physical console or terminalemulator window) that is allowed to send signals to a process (such as CTRL-Z to stop running jobs). This is discussed later, in Section 9.2.1, “Job Control Overview,” page 312.
The process signal mask and all current signal dispositions (not discussed yet; see Chapter 10, “Signals,” page 347).
The real, effective, and saved set-user and set-group IDs and the supplemental group set (not discussed yet; see Chapter 11, “Permissions and User and Group ID Numbers,” page 403).
Besides the
fork()return value, the two processes differ in the following ways:Each one has a unique process ID and parent process ID (PID and PPID). These are described in Section 9.1.2, “Identifying a Process:
getpid()andgetppid,” page 289.The child’s PID will not equal that of any existing process group ID (see Section 9.2, “Process Groups,” page 312).
The accumulated CPU times for the child process and its future children are initialized to zero. (This makes sense; after all, it is a brand-new process.)
Any signals that were pending in the parent are cleared in the child, as are any pending alarms or timers. (We haven’t covered these topics yet; see Chapter 10, “Signals,” page 347, and see Section 14.3.3, “Interval Timers: setitimer() and getitimer(),” page 546.)
File locks held by the parent are not duplicated in the child (also not discussed yet; see Section 14.2, “Locking Files,” page 531).
The attributes that the child inherits from the parent are all set to the same values they had in the parent at the time of the fork(). From then on, though, the two processes proceed on their merry ways, (mostly) independent of each other. For example, if the child changes directory, the parent’s directory is not affected. Similarly, if the child changes its environment, the parent’s environment is not changed.
Open files are a significant exception to this rule. Open file descriptors are shared, and an action by one process on a shared file descriptor affects the state of the file for the other process as well. This is best understood after study of Figure 9.1.
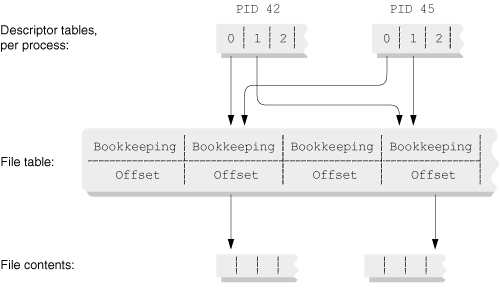
The figure displays the kernel’s internal data structures. The key data structure is the file table. Each element refers to an open file. Besides other bookkeeping data, the file table maintains the current position (read/write offset) in the file. This is adjusted either automatically each time a file is read or written or directly with lseek() (see Section 4.5, “Random Access: Moving Around within a File,” page 102).
The file descriptor returned by open () or creat() acts as an index into a per-process array of pointers into the file table. This per-process array won’t be any larger than the value returned by getdtablesize() (see Section 4.4.1, “Understanding File Descriptors,” page 92).
Figure 9.1 shows two processes sharing standard input and standard output; for each, both point to the same entries in the file table. Thus, when process 45 (the child) does a read(), the shared offset is updated; the next time process 42 (the parent) does a read(), it starts at the position where process 45’s read() finished.
This can be seen easily at the shell level:
$ cat data Show demo data file contents line 1 line 2 line 3 line 4 $ ls -1 test1 ; cat test1 Mode and contents of test program -rwxr-xr-x 1 arnold devel 93 Oct 20 22:11 test1 #! /bin/sh read line ; echo p: $line Read a line in parent shell, print it ( read line ; echo c: $line ) Read a line in child shell, print it read line ; echo p: $line Read a line in parent shell, print it $ test1 < data Run the program p: line 1 Parent starts at beginning c: line 2 Child picks up where parent left off p: line 3 Parent picks up where child left off
The first executable line of test1 reads a line from standard input, changing the offset in the file. The second line of test1 runs the commands enclosed between the parentheses in a subshell. This is a separate shell process created—you guessed it—with fork(). The child subshell inherits standard input from the parent, including the current file offset. This process reads a line and updates the shared offset into the file. When the third line, back in the parent shell, reads the file, it starts where the child left off.
Although the read command is built into the shell, things work the same way with external commands. Some early Unix systems had a line command that read one line of input (one character at a time!) for use within shell scripts; if the file offset weren’t shared, it would be impossible to use such a command in a loop.
File descriptor sharing and inheritance play a pivotal role in shell I/O redirection; the system calls and their semantics make the shell-level primitives straightforward to implement in C, as we see later in the chapter.
The fact that multiple file descriptors can point at the same open file has an important consequence: A file is not closed until all its file descriptors are closed.
We see later in the chapter that multiple descriptors for the same file can exist not only across processes but even within the same process; this rule is particularly important for working with pipes.
If you need to know if two descriptors are open on the same file, you can use fstat() (see Section 5.4.2, “Retrieving File Information,” page 141) on the two descriptors with two different struct stat structures. If the corresponding st_dev and st_ino fields are equal, they’re the same file.
We complete the discussion of file descriptor manipulation and the file descriptor table later in the chapter.
Each process has a unique process ID number (the PID). Two system calls provide the current PID and the PID of the parent process:
#include <sys/types.h> POSIX
#include <unistd.h>
pid_t getpid(void);
pid_t getppid(void);
The functions are about as simple as they come:
| Returns the PID of the current process. |
| Returns the parent’s PID. |
PID values are unique; by definition there cannot be two running processes with the same PID. PIDs usually increase in value, in that a child process generally has a higher PID than its parent. On many systems, however, PID values wrap around; when the system maximum value for PIDs is exceeded, the next process created will have the lowest unused PID number. (Nothing in POSIX requires this behavior, and some systems assign unused PID numbers randomly.)
If the parent dies or exits, the child is given a new parent, init. In this case, the new parent PID will be 1, which is init’s PID. Such a child is termed an orphan. The following program, ch09-reparent.c, demonstrates this. This is also the first example we’ve seen of fork() in action:
1 /* ch09-reparent.c --- show that getppid() can change values */ 2 3 #include <stdio.h> 4 #include <errno.h> 5 #include <sys/types.h> 6 #include <unistd.h> 7 8 /* main --- do the work */ 9 10 int main(int argc, char **argv) 11 { 12 pid_t pid, old_ppid, new_ppid; 13 pid_t child, parent; 14 15 parent = getpid(); /* before fork() */ 16 17 if ((child = fork()) < 0) { 18 fprintf(stderr, "%s: fork of child failed: %s ", 19 argv[0], strerror(errno)); 20 exit(1); 21 } else if (child == 0) { 22 old_ppid = getppid() ; 23 sleep(2); /* see Chapter 10 */ 24 new_ppid = getppid(); 25 } else { 26 sleep(1); 27 exit(0); /*parent exits after fork() */ 28 } 29 30 /* only the child executes this */ 31 printf("Original parent: %d ", parent); 32 printf("Child: %d ", getpid()); 33 printf("Child's old ppid: %d ", old_ppid); 34 printf("Child's new ppid: %d ", new_ppid); 35 36 exit(0); 37 }
Line 15 retrieves the PID of the initial process, using getpid() Lines 17—20 fork the child, checking for an error return.
Lines 21–24 are executed by the child: Line 22 retrieves the PPID. Line 23 suspends the process for two seconds (see Section 10.8.1, “Alarm Clocks: sleep(), alarm(), and SIGALRM,” page 382, for information about sleep() and then line 24 retrieves the PPID again.
Lines 25–27 run in the parent. Line 26 delays the parent for one second, giving the child enough time to make the first getppid() call. Line 27 then exits the parent.
Line 31–34 print the values. Note that the parent variable, which was set before the fork, still maintains its value in the child. After forking, the two processes have identical but independent copies of their address spaces. Here’s what happens when the program runs:
$ ch09-reparent Run the program $ Original parent: 6582 Program finishes: shell prompts and child prints Child: 6583 Child's old ppid: 6582 Child's new ppid: 1
Remember that the two programs execute in parallel. This is depicted graphically in Figure 9.2.

Note
The use of sleep() to have one process outlive another works most of the time. However, occasionally it fails, leading to hard-to-reproduce and hard-to-find bugs. The only way to guarantee correct behavior is explicit synchronization with wait() or waitpid(), which are described further on in the chapter (see Section 9.1.6.1, “Using POSIX Functions: wait() and waitpid(),” page 306).
As processes run, the kernel dynamically changes each process’s priority. As in life, higher-priority items get attention before lower-priority ones. In brief, each process is allotted a small amount of time in which to run, called its time slice. When the time slice finishes, if the current process is still the one with the highest priority, it is allowed to continue running.
Linux, like Unix, provides preemptive multitasking. This means that the kernel can preempt a process (pause it) if it’s time to let another process run. Processes that have been running a lot (for example, compute-intensive processes) have their priority lowered at the end of their time slice, to let other processes have a chance at the processor. Similarly, processes that have been idle while waiting for I/O (such as an interactive text editor) are given a higher priority so that they can respond to the I/O when it happens. In short, the kernel makes sure that all processes, averaged over time, get their “fair share” of the CPU. Raising and lowering priorities are part of this process.
Designing a good process scheduler for the kernel is an art; the nitty-gritty details are beyond the scope of this book. However, a process can influence the kernel’s priority assignment algorithm by way of its nice value.
The nice value is an indication of “how nice” the process is willing to be toward other processes. Thus, higher nice values indicate increasingly more patient processes; that is, ones that are increasingly nice toward others, lowering their priority with respect to that of other processes.
A negative nice value, on the other hand, indicates that a process wishes to be “less nice” towards others. Such a process is more selfish, wanting more CPU time for itself.[1] Fortunately, while users can increase their nice value (be more nice), only root can decrease the nice value (be less nice).
The nice value is only one factor in the equation used by the kernel to compute the priority; the nice value is not the priority itself, which varies over time, based on the process’s behavior and the state of other processes in the system. To change the nice value, use the nice() system call:
#include <unistd.h> XSI
int nice(int inc);
The default nice value is 0. The allowed range for nice values is -20 to 19. This takes some getting used to. The more negative the value, the higher the process’s priority: -20 is the highest priority (least nice), and 19 is the lowest priority (most nice).
The inc argument is the increment by which to change the nice value. Use ’nice (0)’ to retrieve the current value without changing it. If the result of ’current_nice_value + inc’ would be outside the range -20 to 19, the system forces the result to be inside the range.
The return value is the new nice value or -1 if there was an error. Since -1 is also a valid nice value, when calling nice() you must explicitly set errno to zero first, and then check it afterwards to see if there was a problem:
int niceval;
int inc = /* whatever */;
errno = 0;
if ((niceval = nice(inc)) < 0 && errno != 0) {
fprintf(stderr, "nice(%d) failed: %s
", inc, strerror(errno));
/* other recovery */
}
This example can fail if inc has a negative value and the process is not running as root.
The nice value range of -20, to 19 that Linux uses is historical; it dates back at least as far as V7. POSIX expresses the situation in more indirect language, which allows for implementation flexibility while maintaining historical compatibility. It also makes the standard harder to read and understand, but then, that’s why you’re reading this book. So, here’s how POSIX describes it.
First, the process’s nice value as maintained by the system ranges from 0 to ’(2 * NZERO) - 1’. The constant NZERO is defined in <limits.h> and must be at least 20. This gives us the range 0–39.
Second, as we described, the sum of the current nice value and the incr increment is forced into this range.
Finally, the return value from nice() is the process nice value minus NZERO. With an NZERO value of 20, this gives us the original -20 to 19 range that we initially described.
The upshot is that nice()’s return value actually ranges from ’-NZERO’ to ’NZERO-1’, and it’s best to write your code in terms of that symbolic constant. However, practically speaking, you’re unlikely to find a system where NZERO is not 20.
Once a new process is running (through fork()), the next step is to start a different program running in the process. There are multiple functions that serve different purposes:
#include <unistd.h> POSIX int execve(const char *filename, char *const argv[], System call char *const envp[]); int execl(const char *path, const char *arg, ...); Wrappers int execlp(const char *file, const char *arg, ...); int execle(const char *path, const char *arg, ..., char *const envp[]); int execv(const char *path, char *const argv[]); int execvp(const char *file, char *const argv[]);
We refer to these functions as the “exec() family.” There is no function named exec(); instead we use this function name to mean any of the above listed functions. As with fork(), “exec” is used in Unix parlance as a verb, meaning to execute (run) a program, and as a noun.
The simplest function to explain is execve(). It is also the underlying system call. The others are wrapper functions, as is explained shortly.
int execve(const char *filename, char *const argv[], char *const envp[])
filenameis the name of the program to execute. It may be a full or relative pathname. The file must be in an executable format that the kernel understands. Modern systems uses the ELF (Extensible Linking Format) executable format. GNU/Linux understands ELF and several others. Interpreted scripts can be executed withexecve()if they use the ’#!’ special first line that names the interpreter to use. (Scripts that don’t start with ’#!’ will fail.) Section 1.1.3, “Executable Files,”, page 7, provides an example use of ’#!’.argvis a standard C argument list—an array of character pointers to argument strings, including the value to use forargv[0], terminated with aNULLpointer.envpis the environment to use for the new process, with the same layout as theenvironglobal variable (see Section 2.4, “The Environment”, page 40). In the new program, this environment becomes the initial value ofenviron.
A call to exec() should not return. If it does, there was a problem. Most commonly, either the requested program doesn’t exist, or it exists but it isn’t executable (ENOENT and EACCES for errno, respectively). Many more things can go wrong; see the execve(2) manpage.
Assuming that the call succeeds, the current contents of the process’s address space are thrown away. (The kernel does arrange to save the argv and envp data in a safe place first.) The kernel loads the executable code for the new program, along with any global and static variables. Next, the kernel initializes the environment with that passed to execve(), and then it calls the new program’s main() routine with the argv array passed to execve(). It counts the number of arguments and passes that value to main() in argc.
At that point, the new program is running. It doesn’t know (and can’t find out) what program was running in the process before it. Note that the process ID does not change. Many other attributes remain in place across the exec; we cover this in more detail shortly.
In a loose analogy, exec() is to a process what life roles are to a person. At different times during the day, a single person might function as parent, spouse, friend, student or worker, store customer, and so on. Yet it is the same underlying person performing the different roles. So too, the process—its PID, open files, current directory, etc.—doesn’t change, while the particular job it’s doing—the program run with exec() —can.
Five additional functions, acting as wrappers, provide more convenient interfaces to execve(). The first group all take a list of arguments, each one passed as an explicit function parameter:
int execl(const char *path, const char *arg, ...).
The first argument,
path, is the pathname of the file to execute. Subsequent arguments, starting witharg, are the individual elements to be placed inargv. As before,argv[0]must be explicitly included. You must pass a terminatingNULLpointer as the final argument so thatexecl()can tell where the argument list ends. The new program inherits whatever environment is in the current program’senvironvariable.
int execlp(const char *file, const char *arg, ...)
This function is like
execl(), but it simulates the shell’s command searching mechanism, looking forfilein each directory named in thePATHenvironment variable. Iffilecontains a / character, this search is not done. IfPATHisn’t present in the environment,execlp()uses a default path. On GNU/Linux, the default is “:/bin:/usr/bin” but it may be different on other systems. (Note that the leading colon inPATHmeans that the current directory is searched first.)Furthermore, if the file is found and has execute permission but cannot be exec’d because it isn’t in a known executable format,
execlp()assumes that the program is a shell script, and execs the shell with the filename as an argument.
int execle(const char *path, const char *arg, ..., char *const envp[])
This function is also like
execl(), but it accepts an additional argument,envp, which becomes the new program’s environment. As withexecl(), you must supply the terminatingNULLpointer to end the argument list, beforeenvp.
The second group of wrapper functions accepts an argv style array:
int execv(const char *path, char *const argv [])
This function is like
execve(), but the new program inherits whatever environment is in the current program’senvironvariable.
int execvp(const char *file, char *const argv[])
This function is like
execv(), but it does the samePATHsearch thatexeclp()does. It also does the same falling back to exec’ing the shell if the found file cannot be executed directly.
Table 9.1 summarizes the six exec() functions.
Table 9.1. Alphabetical exec() family summary
Function | Path search | Uses environ | Purpose |
|---|---|---|---|
| ✓ | Execute arg list. | |
| Execute arg list with environment. | ||
| ✓ | ✓ | Execute arg list by path search. |
| ✓ | Execute with | |
| Execute with | ||
| ✓ | ✓ | Execute with |
The execlp() and execvp() functions are best avoided unless you know that the PATH environment variable contains a reasonable list of directories.
Until now, we have always treated argv[0] as the program name. We know that it may or may not contain a / character, depending on how the program is invoked; if it does, then that’s usually a good clue as to the pathname used to invoke the program.
However, as should be clear by now, argv[0] being the filename is only a convention. There’s nothing stopping you from passing an arbitrary string to the exec’d program for argv [0]. The following program, ch09-run.c, demonstrates passing an arbitrary string:
1 /* ch09-run.c --- run a program with a different name and any arguments */ 2 3 #include <stdio.h> 4 #include <errno.h> 5 #include <unistd.h> 6 7 /* main --- adjust argv and run named program */ 8 9 int main(int argc, char **argv) 10 { 11 char *path; 12 13 if (argc < 3) { 14 fprintf(stderr, "usage: %s path arg0 [ arg ... ] ", argv[0]); 15 exit(1); 16 } 17 18 path = argv[1]; 19 20 execv(path, argv + 2); /* skip argv[0] and argv[1] */ 21 22 fprintf(stderr, "%s: execv() failed: %s ", argv[0], 23 strerror(errno)); 24 exit(1); 25 }
The first argument is the pathname of the program to run and the second is the new name for the program (which most utilities ignore, other than for error messages); any other arguments are passed on to the program being exec’d.
Lines 13–16 do error checking. Line 18 saves the path in path. Line 20 does the exec; if lines 22–23 run, it’s because there was a problem. Here’s what happens when we run the program:
$ ch09-run /bin/grep whoami foo Run grep a line Input line doesn't match a line with foo in it Input line that does match a line with foo in it It's printed ^D EOF $ ch09-run nonexistent-program foo bar Demonstrate failure ch09-run: execv() failed: No such file or directory
This next example is a bit bizarre: we have ch09-run run itself, passing ’foo’ as the program name. Since there aren’t enough arguments for the second run, it prints the usage message and exits:
$ ch09-run ./ch09-run foo
usage: foo path arg0 [ arg ... ]
While not very useful, ch09-run clearly shows that argv[0] need not have any relationship to the file that is actually run.
In System III (circa 1980), the cp, In, and mv commands were one executable file, with three links by those names in /bin. The program would examine argv[0] and decide what it should do. This saved a modest amount of disk space, at the expense of complicating the source code and forcing the program to choose a default action if invoked by an unrecognized name. (Some current commercial Unix systems continue this practice!) Without stating an explicit reason, the GNU Coding Standards recommends that a program not base its behavior upon its name. One reason we see is that administrators often install the GNU version of a utility alongside the standard ones on commercial Unix systems, using a g prefix: gmake, gawk, and so on. If such programs expect only the standard names, they’ll fail when run with a different name.
Also, today, disk space is cheap; if two almost identical programs can be built from the same source code, it’s better to do it that way, using #ifdef or what-have-you. For example, grep and egrep share considerable code, but the GNU version builds two separate executables.
As with fork(), a number of attributes remain in place after a program does an exec:
All open files and open directories; see Section 4.4.1, “Understanding File Descriptors,” page 92, and see Section 5.3.1, “Basic Directory Reading”, page 133. (This doesn’t include files marked close-on-exec, as described later in the chapter; see Section 9.4.3.1, “The Close-on-exec Flag,” page 329.)
The umask setting; see Section 4.6, “Creating Files,” page 106.
The current working directory; see Section 8.4.1, “Changing Directory: chdir() and fchdir(),” page 256.
The root directory; see Section 8.6, “Changing the Root Directory: chroot(),” page 276.
The current nice value.
The process ID and parent process ID.
The process group ID; see Section 9.2, “Process Groups,” page 312.
The session ID and the controlling terminal; for both, see Section 9.2.1, “Job Control Overview,” page 312.
The process signal mask and any pending signals, as well as any unexpired alarms or timers (not discussed yet; see Chapter 10, “Signals,” page 347).
The real user ID and group IDs and the supplemental group set. The effective user and group IDs (and thus the saved set-user and set-group IDs) can be set by the setuid and setgid bits on the file being exec’d. (None of this has been discussed yet; see Chapter 11, “Permissions and User and Group ID Numbers,” page 403).
File locks remain in place (also not discussed yet; see Section 14.2, “Locking Files,” page 531).
Accumulated CPU times for the process and its children don’t change.
After an exec, signal disposition changes; see Section 10.9, “Signals Across fork() and exec(),” page 398, for more information.
All open files and directories remain open and available after the exec. This is how programs inherit standard input, output, and error: They’re in place when the program starts up.
Most of the time, when you fork and exec a separate program, you don’t want it to inherit anything but file descriptors 0,1 and 2. In this case, you can manually close all other open files in the child, after the fork but before the exec. Alternatively, you can mark a file descriptor to be automatically closed by the system upon an exec; this latter option is discussed later in the chapter (see Section 9.4.3.1, “The Close-on-exec Flag,” page 329).
Process termination involves two steps: The process exits, passing an exit status to the system, and the parent process recovers the information.
The exit status (also known variously as the exit value, return code, and return value) is an 8-bit value that the parent can recover when the child exits (in Unix parlance, “when the child dies”). By convention, an exit status of 0 means that the program ran with no problems. Any nonzero exit status indicates some sort of failure; the program determines the values to use and their meanings, if any. (For example, grep uses 0 to mean that it matched the pattern at least once, 1 to mean that it did not match the pattern at all, and 2 to mean that an error occurred.) This exit status is available at the shell level (for Bourne-style shells) in the special variable $?.
The C standard defines two constants, which are all you should use for strict portability to non-POSIX systems:
EXIT_SUCCESS
EXIT_FAILURE
In practice, using only these values is rather constraining. Instead, you should pick a small set of return codes, document their meanings, and use them. (For example, 1 for command-line option and argument errors, 2 for I/O errors, 3 for bad data errors, and so on.) For readability, it pays to use #defined constants or an enum for them. Having too large a list of errors makes using them cumbersome; most of the time the invoking program (or user) only cares about zero vs. nonzero.
When the binary success/failure distinction is adequate, the pedantic programmer uses EXIT_SUCCESS and EXIT_FAILURE. Our own style is more idiomatic, using the explicit constants 0 or 1 with return and exit(). This is so common that it is learned early on and quickly becomes second nature. However, you should make youR own decision for your own projects.
Note
Only the least-significant eight bits of the value are available to the parent process. Thus, you should use values in the range 0–255. As we’ll see shortly, 126 and 127 have a conventional meaning (above and beyond plain “unsuccessful”), to which your programs should adhere.
Since only the least-significant eight bits matter, you should never use a negative exit status. When the last eight bits are retrieved from small negative numbers, they become large positive values! (For example, -1 becomes 255, and -5 becomes 251.) We have seen C programming books that get this wrong—don’t be misled.
A program can terminate voluntarily in one of two ways: by using one of the functions described next or by returning from main(). (A third, more drastic, way, is described later, in Section 12.4, “Committing Suicide: abort(),” page 445.) In the latter case, you should use an explicit return value instead of falling off the end of the function:
/* Good: */ /* Bad: */
int main(int argc, char **argv) int main(int argc, char **argv)
{ {
/* code here */ /* code here */
return 0; /* ?? What does main() return ?? */
} }
The 1999 C standard indicates that when main() returns by falling off the end, the behavior is as if it had returned 0. (This is also true for C++; however, the 1989 C standard leaves this case purposely undefined.) In all cases, it’s poor practice to rely on this behavior; one day you may be programming for a system with meager C runtime support or an embedded system, or somewhere else where it will make a difference. (In general, falling off the end of any non-void function is a bad idea; it can only lead to buggy code.)
The value returned from main() is automatically passed back to the system, from which the parent can recover it later. We describe how in Section 9.1.6.1, “Using POSIX Functions: wait() and waitpid(),” page 306.
The other way to voluntarily terminate a program is by calling an exiting function. The C standard defines the following functions:
#include <stdlib.h> ISO C
void exit(int status);
void _Exit(int status);
int atexit(void (*function) (void));
The functions work as follows:
void exit(int status)
This function terminates the program.
statusis passed to the system for recovery by the parent. Before the program exits,exit()calls all functions registered withatexit(), flushes and closes all open<stdio.h> FILE* streams, and removes any temporary files created withtmpfile()(see Section 12.3.2, “Creating and Opening Temporary Files (Good),” page 441). When the process exits, the kernel closes any remaining open files (those opened byopen(), creat(), or file descriptor inheritance), frees up its address space, and releases any other resources it may have been using.exit()never returns.
void _Exit(int status)
This function is essentially identical to the POSIX
_exit()function; we delay discussion of it for a short while.
int atexit(void (*function) (void))
functionis a pointer to a callback function to be called at program exit.exit()invokes the callback function before it closes files and terminates. The idea is that an application can provide one or more cleanup functions to be run before finally shutting down. Providing a function is called registering it. (Callback functions fornftw()were described in Section 8.4.3.2, “The nftw() Callback Function,” page 263; it’s the same idea here, althoughatexit()invokes each registered function only once.)atexit()returns0on success or-1on error, and setserrnoappropriately.
The following program does no useful work, but it does demonstrate how atexit() works:
/* ch09-atexit.c --- demonstrate atexit().
Error checking omitted for brevity. */
/*
* The callback functions here just answer roll call.
* In a real application, they would do more.
*/
void callback1(void) { printf("callback1 called
"); }
void callback2(void) { printf("callback2 called
"); }
void callback3(void) { printf("callback3 called
"); }
/* main --- register functions and then exit */
int main(int argc, char **argv)
{
printf("registering callback1
"); atexit(callback1);
printf("registering callback2
"); atexit(callback2);
printf("registering callback3
"); atexit(callback3);
printf("exiting now
");
exit(0);
}
Here’s what happens when it’s run:
$ ch09-atexit registering callback1 Main program runs registering callback2 registering callback3 exiting now callback3 called Callback functions run in reverse order callback2 called callback1 called
As the example demonstrates, functions registered with atexit() run in the reverse order in which they were registered: most recent one first. (This is also termed last-in first-out, abbreviated LIFO.)
POSIX defines the _exit() function. Unlike exit(), which invokes callback functions and does <stdio.h> cleanup, _exit() is the “die immediately” function:
#include <unistd.h> POSIX
void _exit(int status);
The status is given to the system, just as for exit(), but the process terminates immediately. The kernel still does the usual cleanup: All open files are closed, the memory used by the address space is released, and any other resources the process was using are also released.
In practice, the ISO C _Exit() function is identical to _exit(). The C standard says it’s implementation defined as to whether _Exit() calls functions registered with atexit() and closes open files. For GLIBC systems, it does not, behaving like _exit().
The time to use _exit() is when an exec fails in a forked child. In this case, you don’t want to use regular exit(), since that flushes any buffered data held by FILE* streams. When the parent later flushes its copies of the buffers, the buffered data ends up being written twice; obviously this is not good.
For example, suppose you wish to run a shell command and do the fork and exec yourself. Such code would look like this:
char *shellcommand = "...";
pid_t child;
if ((child = fork()) == 0) { /* child */
execl("/bin/sh", "sh", "-c", shellcommand, NULL);
_exit(errno == ENOENT ? 127 : 126);
}
/* parent continues */
The errno test and exit values follow conventions used by the POSIX shell. If a requested program doesn’t exist (ENOENT—no entry for it in a directory), then the exit value is 127. Otherwise, the file exists but couldn’t be exec’d for some other reason, so the exit status is 126. It’s a good idea to follow this convention in your own programs too.
Briefly, to make good use of exit() and atexit(), you should do the following:
Define a small set of exit status values that your program will use to communicate information to its caller. Use
#definedconstants or anenumfor them in your code.Decide if having callback functions for use with
atexit()makes sense. If it does, register them inmain()at the appropriate point; for example, after parsing options, and after initializing whatever data structures the callback functions are supposed to clean up. Remember that the functions are called in LIFO (last-in first-out) order.Use
exit()everywhere to exit from the program when something goes wrong, and exiting is the correct action to take. Use the error codes that you defined.An exception is
main(), for which you can usereturnif you wish. Our own style is generally to useexit()when there are problems and ’return 0’ at the end ofmain()if everything has gone well.Use
_exit() or _Exit()in a child process ifexec()fails.
When a process dies, the normal course of action is for the kernel to release all its resources. The kernel does retain the dead process’s exit status, as well as information about the resources it used during its lifetime, and the PID continues to be counted as being in use. Such a dead process is termed a zombie.
The parent process, be it the original parent or init, can recover the child’s exit status. Or, by use of BSD functions that aren’t standardized by POSIX, the exit status together with the resource usage information can be recovered. Status recovery is done by waiting for the process to die: This is also known as reaping the process.[2]
There is considerable interaction between the mechanisms that wait for children to die and the signal mechanisms we haven’t described yet. Which one to describe first is a bit of a chicken-and-egg problem; we’ve chosen to talk about the child-waiting mechanisms first, and Chapter 10, “Signals,” page 347, provides the full story on signals.
For now, it’s enough to understand that a signal is a way to notify a process that some event has occurred. Processes can generate signals that get sent to themselves, or signals can be sent externally by other processes or by a user at a terminal. For example, CTRL-C sends an “interrupt” signal, and CTRL-Z sends a job control “stop” signal.
By default, many signals, such as the interrupt signal, cause the receiving process to die. Others, such as the job control signals, cause it to change state. The child waiting mechanisms can determine whether a process suffered death-by-signal, and, if so, which signal it was. The same is true for processes stopping and, on some systems, when a process continues.
The original V7 system call was wait(). The newer POSIX call, based on BSD functionality, is waitpid(). The function declarations are:
#include <sys/types.h> POSIX
#include <sys/wait.h>
pid_t wait (int *status);
pid_t waitpid (pid_t pid, int *status, int options);
wait() waits for any child process to die; the information as to how it died is returned in *status. (We discuss how to interpret *status shortly.) The return value is the PID of the process that died or -1 if an error occurred.
If there is no child process, wait() returns -1 with errno set to ECHILD (no child process). Otherwise, it waits for the first child to die or for a signal to come in.
The waitpid() function lets you wait for a specific child process to exit. It provides considerable flexibility and is the preferred function to use. It too returns the PID of the process that died or -1 if an error occurred. The arguments are as follows:
pid_t pid
The value specifies which child to wait for, both by real
pidand by process group.The
pidvalue has the following meanings:
int *status
This is the same as for
wait().<sys/wait.h>defines various macros that interpret the value in*status, which we describe soon.
int options
This should be either 0 or the bitwise OR of one or more of the following flags:
WNOHANG
WUNTRACED
WCONTINUED
Multiple macros work on the filled-in *status value to determine what happened. They tend to come in pairs: one macro to determine if something occurred, and if that macro is true, one or more macros that retrieve the details. The macros are as follows:
WIFEXITED (status)
This macro is nonzero (true) if the process exited (as opposed to changing state).
WEXITSTATUS (status)
WIFSIGNALED (status)
This macro is nonzero if the process suffered death-by-signal.
WTERMSIG (status)
WIFSTOPPED (status)
This macro is nonzero if the process was stopped.
WSTOPSIG (status)
This macro provides the signal number that stopped the process. (Several signals can stop a process.) You should use this macro only if
WIFSTOPPED (status)is true. Job control signals are discussed in Section 10.8.2, “Job Control Signals,” page 383.
WIFCONTINUED (status)
(XSI.) This macro is nonzero if the process was continued. There is no corresponding
WCONTSIG()macro, since only one signal can cause a process to continue.Note that this macro is an XSI extension. In particular, it is not available on GNU/Linux. Therefore, if you wish to use it, bracket your code inside ’
#ifdef WIFCONTINUED... #endif’.
WCOREDUMP (status)
(Common.) This macro is nonzero if the process dumped core. A core dump is the memory image of a running process created when the process terminates. It is intended for use later for debugging. Unix systems name the file
core, whereas GNU/Linux systems usecore.pid, wherepidis the process ID of the process that died. Certain signals terminate a process and produce a core dump automatically.Note that this macro is nonstandard. GNU/Linux, Solaris, and BSD systems support it, but some other Unix systems do not. Thus, here too, if you wish to use it, bracket your code inside ’
#ifdef WCOREDUMP ... #endif’.
Most programs don’t care why a child process died; they merely care that it died, perhaps noting if it exited successfully or not. The GNU Coreutils install program demonstrates such straightforward use of fork(), execlp(), and wait(). The -s option causes install to run the strip program on the binary executable being installed. (strip removes debugging and other information from an executable file. This can save considerable space, relatively speaking. On modern systems with multi-gigabyte disk drives, it’s rarely necessary to strip executables upon installation.) Here is the strip() function from install.c:
513 /* Strip the symbol table from the file PATH. 514 We could dig the magic number out of the file first to 515 determine whether to strip it, but the header files and 516 magic numbers vary so much from system to system that making 517 it portable would be very difficult. Not worth the effort. */ 518 519 static void 520 strip (const char *path) 521 { 522 int status; 523 pid_t pid = fork(); 524 525 switch (pid) 526 { 527 case -1: 528 error (EXIT_FAILURE, errno, _("fork system call failed")); 529 break; 530 case 0: /* Child. */ 531 execlp ("strip", "strip", path, NULL); 532 error (EXIT_FAILURE, errno, _("cannot run strip")); 533 break; 534 default: /* Parent. */ 535 /* Parent process. */ 536 while (pid != wait (&status)) /* Wait for kid to finish. */ 537 /* Do nothing. */; 538 if (status) 539 error (EXIT_FAILURE, 0, _("strip failed")); 540 break; 541 } 542 }
Line 523 calls fork(). The switch statement then takes the correct action for error return (lines 527–529), child process (lines 530–533), and parent process (lines 534–539).
The idiom on lines 536–537 is common; it waits until the specific child of interest exits. wait()’s return value is the PID of the reaped child. This is compared with that of the forked child. status is unused other than to see if it’s nonzero (line 538), in which case the child exited unsuccessfully. (The test, while correct, is coarse but simple. A test like ’if (WIFEXITED(status) && WEXITSTATUS(status) != 0)’ would be more pedantically correct.)
From the description and code presented so far, it may appear that parent programs must choose a specific point to wait for any child processes to die, possibly polling in a loop (as install.c does), waiting for all children. In Section 10.8.3, “Parental Supervision: Three Different Strategies,” page 385, we’ll see that this is not necessarily the case. Rather, signals provide a range of mechanisms to use for managing parent notification when a child process dies.
The BSD wait3() and wait4() system calls are useful if you’re interested in the resources used by a child process. They are nonstandard (meaning not part of POSIX) but widely available, including on GNU/Linux. The declarations are as follows:
#include <sys/types.h> Common #include <sys/time.h> Not needed under GNU/Linux, but improves portability #include <sys/resource.h> #include <sys/wait.h> pid_t wait3 (int *status, int options, struct rusage *rusage); pid_t wait4 (pid_t pid, int *status, int options, struct rusage *rusage);
The status variable is the same as for wait() and waitpid(). All the macros described earlier (WIFEXITED(), etc.) can also be used with it.
The options value is also the same as for waitpid(): either 0 or the bitwise OR of one or both of WNOHANG and WUNTRACED.
wait3() behaves like wait(), retrieving information about the first available zombie child, and wait4() is like waitpid(), retrieving information about a particular process. Both return the PID of the reaped child, -1 on error, or 0 if no process is available and WNOHANG was used. The pid argument can take on the same values as the pid argument for waitpid().
The key difference is the struct rusage pointer. If not NULL, the system fills it in with information about the process. This structure is described in POSIX and in the getrusage(2) manpage:
struct rusage {
struct timeval ru_utime; /* user time used */
struct timeval ru_stime; /* system time used */
long ru_maxrss; /* maximum resident set size */
long ru_ixrss; /* integral shared memory size */
long ru_idrss; /* integral unshared data size */
long ru_isrss; /* integral unshared stack size */
long ru_minflt; /* page reclaims */
long ru_majflt; /* page faults */
long ru_nswap; /* swaps */
long ru_inblock; /* block input operations */
long ru_oublock; /* block output operations */
long ru_msgsnd; /* messages sent */
long ru_msgrcv; /* messages received */
long ru_nsignals; /* signals received */
long ru_nvcsw; /* voluntary context switches */
long ru_nivcsw; /* involuntary context switches */
};
Pure BSD systems (4.3 Reno and later) support all of the fields. Table 9.2 describes the availability of the various fields in the struct rusage for POSIX and Linux.
Table 9.2. Availability of struct rusage fields
Field | POSIX | Linux |
|---|---|---|
| ✓ | ≥ 2.4 |
| ✓ | ≥ 2.4 |
| ≥ 2.4 | |
| ≥ 2.4 | |
| ≥ 2.4 | |
| ≥ 2.6 | |
| ≥ 2.6 |
Only the fields marked “POSIX” are defined by the standard. While Linux defines the full structure, the 2.4 kernel maintains only the user-time and system-time fields. The 2.6 kernel also maintains the fields related to context switching.[3]
The fields of most interest are ru_utime and ru_stime, the user and system CPU times, respectively. (User CPU time is time spent executing user-level code. System CPU time is time spent in the kernel on behalf of the process.)
These two fields use a struct timeval, which maintains time values down to microsecond intervals. See Section 14.3.1, “Microsecond Times: gettimeofday()”, page 544, for more information on this structure.
In 4.2 and 4.3 BSD, the status argument to wait() and wait3() was a union wait. It fit into an int and provided access to the same information as the modern WIFEXITED() etc. macros do, but through the union’s members. Not all members were valid in all situations. The members and their uses are described in Table 9.3.
Table 9.3. The 4.2 and 4.3 BSD union wait
POSIX macro | Union member | Usage | Meaning |
|---|---|---|---|
|
|
| True if normal exit. |
|
|
| Exit status if not by signal. |
|
|
| True if death by signal. |
|
|
| Signal that caused termination. |
|
|
| True if stopped. |
|
|
| Signal that caused stopping. |
|
|
| True if child dumped core. |
POSIX doesn’t standardize the union wait, and 4.4 BSD doesn’t document it, instead using the POSIX macros. GLIBC jumps through several hoops to make old code using it continue to work. We describe it here primarily so that you’ll recognize it if you see it; new code should use the macros described in Section 9.1.6.1, “Using POSIX Functions: wait() and waitpid(), page 306.
A process group is a group of related processes that should be treated together for job control purposes. Processes with the same process group ID are members of the process group, and the process whose PID is the same as the process group ID is the process group leader. New processes inherit the process group ID of their parent process.
We have already seen that waitpid() allows you to wait for any process in a given process group. In Section 10.6.7, “Sending Signals: kill() and killpg(),” page 376, We’ll also see that you can send a signal to all the processes in a particular process group as well. (Permission checking always applies; you can’t send a signal to a process you don’t own.)
Job control is an involved topic, one that we’ve chosen not to delve into for this volume. However, here’s a quick conceptual overview.
The terminal device (physical or otherwise) with a user working at it is called the controlling terminal.
A session is a collection of process groups associated with the controlling terminal. There is only one session per terminal, with multiple process groups in the session. One process is designated the session leader; this is normally a shell that can do job control, such as Bash, pdksh, zsh, or ksh93.[4] We refer to such a shell as a job control shell.
Each job started by a job control shell, be it a single program or a pipeline, receives a separate process group identifier. That way, the shell can manipulate the job as a single entity, although it may have multiple processes.
The controlling terminal also has a process group identifier associated with it. When a user types a special character such as CTRL-C for “interrupt” or CTRL-Z for “stop,” the kernel sends the given signal to the processes in the terminal’s process group.
The process group whose process group ID is the same as that of the controlling terminal is allowed to read from and write to the terminal. This is called the foreground process group. (It also receives the keyboard-generated signals.) Any other process groups in the session are background process groups and cannot read from or write to the terminal; they receive special signals that stop them if they try.
Jobs move in and out of the foreground, not by a change to an attribute of the job, but rather by a change to the controlling terminal’s process group. It is the job control shell that makes this change, and if the new process group was stopped, the shell continues it by sending a “continue” signal to all members of the process group.
In days of yore, users often used serial terminals connected to modems to dial in to centralized minicomputer Unix systems. When the user closed the connection (hung up the phone), the serial line detected the disconnection and the kernel sent a “hangup” signal to all processes connected to the terminal.
This concept remains: If a hangup occurs (serial hardware does still exist and is still in use), the kernel sends the hangup signal to the foreground process group. If the session leader exits, the same thing happens.
An orphaned process group is one where, for every process in the group, that process’s parent is also in the group or the parent is in a different session. (This can happen if a job control shell exits with background jobs running.) Running processes in an orphaned process group are allowed to run to completion. If there are any already stopped processes in an orphaned process group when it becomes orphaned, the kernel sends those processess a hangup signal and then a continue signal. This causes them to wake up so that they can exit instead of remaining stopped forever.
For compatibility with older systems, POSIX provides multiple ways to retrieve process group information:
#include <unistd.h> pid_t getpgrp(void); POSIX pid_t getpgid(pid_t pid); XSI
The getpgrp() function returns the current process’s process group ID.getpgid() is an XSI extension. It returns the process group ID of the given process pid. A pid of 0 means “the current process’s process group.” Thus ’getpgid(0)’ is the same as ’getpgrd()’. For general programming, getpgrp() should be used.
4.2 and 4.3 BSD also have a getpgrp() function, but it acts like the POSIX getpgid() function, requiring apid argument. Since modern systems support POSIX, you should use the POSIX version in new code. (If you think this is confusing, you’re right. Multiple ways to do the same thing are a normal result of design-by-committee, since the committee feels that it must please everyone.)
Two functions set the process group:
#include <unistd.h> int setpgid(pid_t pid, pid_t pgid); POSIX int setpgrp(void); XSI
The setpgrp() function is simple: It sets the process group ID to be the same as the process ID. Doing so creates a new process group in the same session, and the calling process becomes the process group leader.
The setpgid() function is intended for job control use. It allows one process to set the process group of another. A process may change only its own process group ID or the process group ID of a child process, and then only if that child process has not yet done an exec. Job control shells make this call after the fork, in both the parent and the child. For one of them the call succeeds, and the process group ID is changed. (Otherwise, there’s no way to guarantee the ordering, such that the parent could change the child’s process group ID before the child execs. If the parent’s call succeeds first, it can move on to the next task, such as manipulating other jobs or the terminal.)
With setpgid(), pgid must be an existing process group that is part of the current session, effectively joining pid to that process group. Otherwise, pgid must be equal to pid, creating a new process group.
There are some special case values for both pid and pgid:
| In this case, |
| This sets the process group ID for the given process to be the same as its PID. Thus, ’ |
In all cases, session leaders are special; their PID, process group ID, and session ID values are all identical, and the process group ID of a session leader cannot be changed. (Session IDs are set with setsid() and retrieved with getsid(). These are specialized calls: see the setsid(2) and getsid(2) manpages.)
Interprocess communication (IPC) is what it sounds like: a way for two separate processes to communicate. The oldest IPC mechanism on Unix systems is the pipe: a oneway communication channel. Data written into one end of the channel come out the other end.
Pipes manifest themselves as regular file descriptors. Without going to special lengths, you can’t tell if a file descriptor is a file or a pipe. This is a feature; programs that read standard input and write standard output don’t have to know or care that they may be communicating with another process. Should you need to know, the canonical way to check is to attempt ’lseek(fd, 0L, SEEK_CUR)’ on the file descriptor; this call attempts to seek zero bytes from the current position, that is, a do-nothing operation[5] This operation fails for pipes and does no damage for other files.
The pipe() system call creates a pipe:
#include <unistd.h> POSIX
int pipe(int filedes[2]);
The argument value is the address of a two-element integer array. pipe() returns 0 upon success and -1 if there was an error.
If the call was successful, the process now has two additional open file descriptors. The value in filedes[0] is the read end of the pipe, and filedes[1] is the write end. (A handy mnemonic device is that the read end uses index 0, analogous to standard input being file descriptor 0, and the write end uses index 1, analogous to standard output being file descriptor 1.)
As mentioned, data written into the write end are read from the read end. When you’re done with a pipe, you close both ends with a call to close(). The following simple program, ch09-pipedemo.c, demonstrates pipes by creating one, writing data to it, and then reading the data back from it:
1 /* ch09-pipedemo.c --- demonstrate I/O with a pipe. */ 2 3 #include <stdio.h> 4 #include <errno.h> 5 #include <unistd.h> 6 7 /* main --- create a pipe, write to it, and read from it. */ 8 9 int main(int argc, char **argv) 10 { 11 static const char mesg[] = "Don't Panic!"; /* a famous message */ 12 char buf[BUFSIZ]; 13 ssize_t rcount, wcount; 14 int pipefd[2]; 15 size_t l; 16 17 if (pipe(pipefd) < 0) { 18 fprintf(stderr, "%s: pipe failed: %s ", argv[0], 19 strerror(errno)); 20 exit(1); 21 } 22 23 printf("Read end = fd %d, write end = fd %d ", 24 pipefd[0], pipefd[1]); 25 26 l = strlen(mesg); 27 if ((wcount = write(pipefd[1], mesg, l)) != l) { 28 fprintf(stderr, "%s: write failed: %s ", argv[0], 29 strerror(errno)); 30 exit(1); 31 } 32 33 if ((rcount = read(pipefd[0], buf, BUFSIZ)) != wcount) { 34 fprintf(stderr, "%s: read failed: %s ", argv[0], 35 strerror(errno)); 36 exit(1); 37 } 38 39 buf[rcount] = '�'; 40 41 printf("Read <%s> from pipe ", buf); 42 (void) close(pipefd[0]); 43 (void) close(pipefd[1]); 44 45 return 0; 46 }
Lines 11–15 declare local variables; of most interest is mesg, which is the text that will traverse the pipe.
Lines 17–21 create the pipe, with error checking; lines 23–24 print the values of the new file descriptors (just to prove that they won’t be 0, 1, or 2).
Line 26 gets the length of the message, to use with write(). Lines 27–31 write the message down the pipe, again with error checking.
Lines 33–37 read the contents of the pipe, again with error checking.
Line 39 supplies a terminating zero byte, so that the read data can be used as a regular string. Line 41 prints the data, and lines 42–43 close both ends of the pipe. Here’s what happens when the program runs:
$ ch09-pipedemo
Read end = fd 3, write end = fd 4
Read <Don't Panic!> from pipe
This program doesn’t do anything useful, but it does demonstrate the basics. Note that there are no calls to open() or creat() and that the program isn’t using its three inherited file descriptors. Yet the write() and read() succeed, proving that the file descriptors are valid and that data that go into the pipe do come out of it.[6] Of course, had the message been too big, our program wouldn’t have worked. This is because pipes have only so much room in them, a fact we discuss in the next section.
Like other file descriptors, those for a pipe are inherited by a child after a fork and if not closed, are still available after an exec. We see shortly how to make use of this fact and do something interesting with pipes.
Pipes buffer their data, meaning that data written to the pipe are held by the kernel until they are read. However, a pipe can hold only so much written but not yet read data. We can call the writing process the producer, and the reading process the consumer. How does the system manage full and empty pipes?
When the pipe is full, the system automatically blocks the producer the next time it attempts to write() data into the pipe. Once the pipe empties out, the system copies the data into the pipe and then allows the write() system call to return to the producer.
Similarly, if the pipe is empty, the consumer blocks in the read() until there is more data in the pipe to be read. (The blocking behavior can be turned off; this is discussed in Section 9.4.3.4, “Nonblocking I/O for Pipes and FIFOs,” page 333.)
When the producer does a close() on the pipe’s write end, the consumer can successfully read any data still buffered in the pipe. After that, further calls to read() return 0, indicating end of file.
Conversely, if the consumer closes the read end, a write() to the write end fails—drastically. In particular, the kernel sends the producer a “broken pipe” signal, whose default action is to terminate the process.
Our favorite analogy for pipes is that of a husband and wife washing and drying dishes together. One spouse washes the dishes, placing the clean but wet plates into a dish drainer by the sink. The other spouse takes the dishes from the drainer and dries them. The dish washer is the producer, the dish drainer is the pipe, and the dish dryer is the consumer.[7]
If the drying spouse is faster than the washing one, the drainer becomes empty, and the dryer has to wait until more dishes are available. Conversely, if the washing spouse is faster, then the drainer becomes full, and the washer has to wait until it empties out before putting more clean dishes into it. This is depicted in Figure 9.3.
With traditional pipes, the only way for two separate programs to have access to the same pipe is through file descriptor inheritance. This means that the processes must be the children of a common parent or one must be an ancestor of the other.
This can be a severe limitation. Many system services run as daemons, disconnected long-running processes. There needs to be an easy way to send data to such processes (and possibly receive data from them). Files are inappropriate for this; synchronization is difficult or impossible, and pipes can’t be created to do the job, since there are no common ancestors.
To solve this problem, System III invented the notion of a FIFO. A FIFO,[8] or named pipe, is a file in the filesystem that acts like a pipe. In other words, one process opens the FIFO for writing, while another opens it for reading. Data then written to the FIFO are read by the reader. The data are buffered by the kernel, not stored on disk.
Consider a line printer spooler. The spooler daemon controls the physical printers, creating print jobs that print one by one. To add a job to the queue, user-level line-printer software has to communicate with the spooler daemon. One way to do this is for the spooler to create a FIFO with a well-known filename. The user software can then open the FIFO, write a request to it, and close it. The spooler sits in a loop, reading requests from the FIFO and processing them.
The mkfifo() function creates FIFO files:
#include <sys/types.h> POSIX
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);
The pathname argument is the name of the FIFO file to create, and mode is the permissions to give it, analogous to the second argument to creat() or the third argument to open() (see Section 4.6, “Creating Files,” page 106). FIFO files are removed like any other, with remove() or unlink() (see Section 5.1.5.1, “Removing Open Files,” page 127).
The GNU/Linux mkfifo(3) manpage points out that the FIFO must be open both for reading and writing at the same time, before I/O can be done: “Opening a FIFO for reading normally blocks until some other process opens the same FIFO for writing, and vice versa.” Once a FIFO file is opened, it acts like a regular pipe; that is, it’s just another file descriptor.
The mkfifo command brings this system call to the command level. This makes it easy to show a FIFO file in action:
$ mkfifo afifo Create a FIFO file $ ls -l afifo Show type and permissions, note leading 'p' prw-r--r-- 1 arnold devel 0 Oct 23 15:49 afifo $ cat < afifo & Start a reader in the background [1] 22100 $ echo It was a Blustery Day > afifo Send data to FIFO $ It was a Blustery Day Shell prompts, cat prints data Press ENTER to see job exit status [1]+ Done cat <afifo cat exited
At this point, the pieces of the puzzle are almost complete. fork() and exec() create processes and run programs in them. pipe() creates a pipe that can be used for IPC. What’s still missing is a way to move the pipe’s file descriptors into place as standard output and standard input for a pipeline’s producer and consumer.
The dup() and dup2() system calls, together with close(), let you move (well, copy) an open file descriptor to another number. The fcntl() system call lets you do the same thing and manipulate several important attributes of open files.
Two system calls create a copy of an open file descriptor:
#include <unistd.h> POSIX
int dup(int oldfd);
int dup2(int oldfd, int newfd);
The functions are as follows:
int dup(int oldfd)
Returns the lowest unused file descriptor value; it is a copy of
oldfd.dup()returns a nonnegative integer on success or-1on failure.
int dup2(int oldfd, int newfd)
Makes newfd be a copy of
oldfd; ifnewfdis open, it’s closed first, as if byclose().dup2()returns the new descriptor or-1if there was a problem.
Remember Figure 9.1, in which two processes shared pointers to the same file entry in the kernel’s file table? Well, dup() and dup2() create the same situation, within a single process. See Figure 9.4.
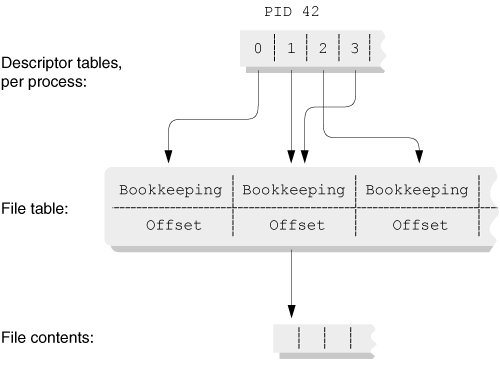
In this figure, the process executed ’dup2(1, 3)’ to make file descriptor 3 a copy of standard output, file descriptor 1. Exactly as described before, the two descriptors share the file offset for the open file.
In Section 4.4.2, “Opening and Closing Files,” page 93, we mentioned that open() (and creat()) always returns the lowest unused integer file descriptor value for the file being opened. Almost all system calls that return new file descriptors follow this rule, not just open() and creat(). (dup2() is an exception since it provides a way to get a particular new file descriptor, even if it’s not the lowest unused one.)
Given the “return lowest unused number” rule combined with dup(), it’s now easy to move a pipe’s file descriptors into place as standard input and output. Assuming that the current process is a shell and that it needs to fork two children to set up a simple two-stage pipeline, here are the steps:
Create the pipe with
pipe(). This must be done first so that the two children can inherit the open file descriptors.Fork what we’ll call the “left-hand child”. This is the one whose standard output goes down the pipe. In this child, do the following:
Use ’
close(pipefd[0])’ since the read end of the pipe isn’t needed in the left-hand child.Use ’
close(1)’ to close the original standard output.Use ’
dup(pipefd[1])’ to copy the write end of the pipe to file descriptor1.Use ’
close(pipefd[1])’ since we don’t need two copies of the open descriptor.Exec the program to be run.
Fork what we’ll call the “right-hand child”. This is the one whose standard input comes from the pipe. The steps in this child are the mirror image of those in the left-hand child:
Use ’
close(pipefd[1])’ since the write end of the pipe isn’t needed in the right-hand child.Use ’
close(0)’ to close the original standard input.Use ’
dup(pipefd[0])’ to copy the read end of the pipe to file descriptor0.Use ’
close(pipefd[0])’ since we don’t need two copies of the open descriptor.Exec the program to be run.
In the parent, close both ends of the pipe: ’
close(pipefd[0]); close(pipefd[1])’.Finally, use
wait()in the parent to wait for both children to finish.
Note how important it is to close the unused copies of the pipe’s file descriptors. As we pointed out earlier, a file isn’t closed until the last open file descriptor for it is closed. This is true even though multiple processes share the file descriptors. Closing unused file descriptors matters because the process reading from the pipe won’t get an end-of-file indication until all the copies of the write end have been closed.
In our case, after the two children are forked, there are three processes, each of which has copies of the two pipe file descriptors: the parent and the two children. The parent closes both ends since it doesn’t need the pipe. The left-hand child is writing down the pipe, so it has to close the read end. The right-hand child is reading from the pipe, so it has to close the write end. This leaves exactly one copy of each file descriptor open.
When the left-hand child finishes, it exits. The system then closes all of its file descriptors. When that happens, the right-hand child finally receives the end-of-file notification, and it too can then finish up and exit.
The following program, ch09-pipeline.c, creates the equivalent of the following shell pipeline:
$ echo hi there | sed s/hi/hello/g
hello there
Here’s the program:
1 /* ch09-pipeline.c --- fork two processes into their own pipeline.
2 Minimal error checking for brevity. */
3
4 #include <stdio.h>
5 #include <errno.h>
6 #include <sys/types.h>
7 #include <sys/wait.h>
8 #include <unistd.h>
9
10 int pipefd[2];
11
12 extern void left_child(void), right_child(void);
13
14 /* main --- fork children, wait for them to finish */
15
16 int main(int argc, char **argv)
17 {
18 pid_t left_pid, right_pid;
19 pid_t ret;
20 int status;
21
22 if (pipe(pipefd) < 0) { /* create pipe, very first thing */
23 perror("pipe");
24 exit(1);
25 }
26
27 if ((left_pid = fork()) < 0) { /* fork left-hand child */
28 perror("fork");
29 exit(1) ;
30 } else if (left_pid == 0)
31 left_child();
32
33 if ((right_pid = fork()) < 0) { /* fork right-hand child */
34 perror("fork");
35 exit(1);
36 } else if (right_pid == 0)
37 right_child();
38
39 close(pipefd[0]); /* close parent's copy of pipe */
40 close(pipefd[1]);
41
42 while ((ret = wait(& status)) > 0) { /* wait for children */
43 if (ret == left_pid)
44 printf("left child terminated, status: %x
", status);
45 else if (ret == right_pid)
46 printf("right child terminated, status: %x
", status);
47 else
48 printf("yow! unknown child %d terminated, status %x
",
49 ret, status);
50 }
51
52 return 0;
53 }
Lines 22–25 create the pipe. This has to be done first.
Lines 27–31 create the left-hand child, and lines 33–37 create the right-hand child. In both instances, the parent continues a linear execution path through main() while the child calls the appropriate function to manipulate file descriptors and do the exec.
Lines 39–40 close the parent’s copy of the pipe.
Lines 42–50 loop, reaping children, until wait() returns an error.
55 /* left_child --- do the work for the left child */ 56 57 void left_child(void) 58 { 59 static char *left_argv[] = { "echo", "hi", "there", NULL }; 60 61 close(pipefd[0]); 62 close(1); 63 dup(pipefd[1]); 64 close(pipefd[1]); 65 66 execvp("echo", left_argv); 67 _exit(errno == ENOENT ? 127 : 126); 68 } 69 70 /* right_child --- do the work for the right child */ 71 72 void right_child(void) 73 { 74 static char *right_argv[] = { "sed", "s/hi/hello/g", NULL }; 75 76 close(pipefd[1]); 77 close(0); 78 dup(pipefd[0]); 79 close(pipefd[0]); 80 81 execvp("sed", right_argv); 82 _exit(errno == ENOENT ? 127 : 126); 83 }
Lines 57–68 are the code for the left-hand child. The procedure follows the steps given above to close the unneeded end of the pipe, close the original standard output, dup() the pipe’s write end to 1, and then close the original write end. At that point, line 66 calls execvp(), and if it fails, line 67 calls _exit(). (Remember that line 67 is never executed if execvp() succeeds.)
Lines 72–83 do the similar steps for the right-hand child. Here’s what happens when it runs:
$ ch09-pipeline Run the program left child terminated, status: 0 Left child finishes before output(!) hello there Output from right child right child terminated, status: 0 $ ch09-pipeline Run the program again hello there Output from right child and ... right child terminated, status: 0 Right child finishes before left one left child terminated, status: 0
Note that the order in which the children finish isn’t deterministic. It depends on the system load and many other factors that can influence process scheduling. You should be careful to avoid making ordering assumptions when you write code that creates multiple processes, particularly the code that calls one of the wait() family of functions.
The whole process is illustrated in Figure 9.5.
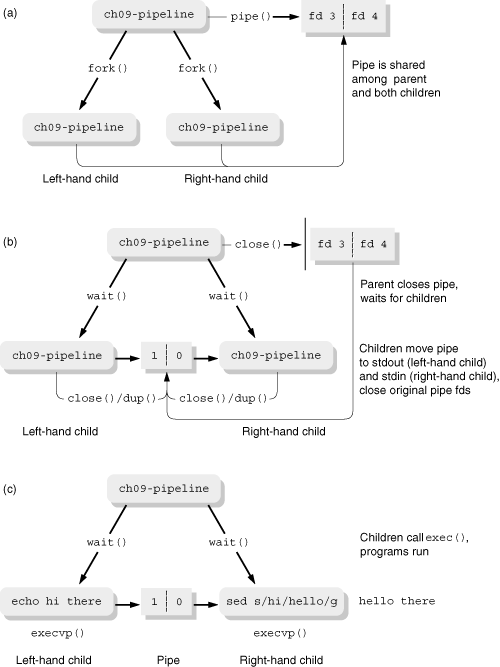
Figure 9.5 (a) depicts the situation after the parent has created the pipe (lines 22–25) and the two children (lines 27–37).
Figure 9.5 (b) shows the situation after the parent has closed the pipe (lines 39–40) and started to wait for the children (lines 42–50). Each child has moved the pipe into place as standard output (left child, lines 61–63) and standard input (lines 76–78).
Finally, Figure 9.5 (c) depicts the situation after the children have closed off the original pipe (lines 64 and 79) and called execvp() (lines 66 and 81).
Many modern Unix systems, including GNU/Linux, support special files in the /dev/fd directory.[9] These files represent open file descriptors, with names such as /dev/fd/0, /dev/fd/1, and so on. Passing such a name to open() returns a new file descriptor that is effectively the same as calling dup() on the given file descriptor number.
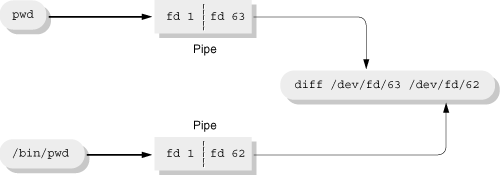
These special files find their use at the shell level: The Bash, ksh88 (some versions) and ksh93 shells supply a feature called process substitution that makes it possible to create nonlinear pipelines. The notation at the shell level is ’<(...)’ for input pipelines, and ’>(...)’ for output pipelines. For example, suppose you wish to apply the diff command to the output of two commands. You would normally have to use temporary files:
command1 > /tmp/out.$$.1 command2 > /tmp/out.$$.2 diff /tmp/out.$$.1 /tmp/out.$$.2 rm /tmp/out.$$.1 /tmp/out.$$.2
With process substitution, it looks like this:
diff <(command1) <(command2)
No messy temporary files to remember to clean up. For example, the following command shows that our home directory is a symbolic link to a different directory:
$ diff <(pwd) <(/bin/pwd)
1c1
< /home/arnold/work/prenhall/progex
---
> /d/home/arnold/work/prenhall/progex
The plain pwd is the one built in to the shell: It prints the current logical pathname as managed by the shell with cd. The /bin/pwd program does a physical filesystem walk to print the pathname.
How does process substitution work? The shell creates the subsidiary commands[10] (’pwd’ and ’/bin/pwd’). Each one’s output is connected to a pipe, with the read end open on a new file descriptor for the main process (’diff’). The shell then passes the names of files in /dev/fd to the main process as the command-line argument. We can see this by turning on execution tracing in the shell:
$ set -x Turn on execution tracing $ diff <(pwd) <(/bin/pwd) Run command + diff /dev/fd/63 /dev/fd/62 Shell trace: main program, note arguments ++ pwd Shell trace: subsidiary programs ++ /bin/pwd 1c1 Output from diff < /home/arnold/work/prenhall/progex --- > /d/home/arnold/work/prenhall/progex
This is illustrated in Figure 9.6.
If your system has /dev/fd, you may be able to take advantage of this facility as well. Do be careful, though, to document what you’re doing. The file descriptor manipulation at the C level is considerably less transparent than the corresponding shell notations!
The fcntl() (“file control”) system call provides control over miscellaneous attributes of either the file descriptor itself or the underlying open file. The GNU/Linux fcntl(2) manpage describes it this way:
#include <unistd.h> POSIX
#include <fcntl.h>
int fcntl(int fd, int cmd);
int fcntl(int fd, int cmd, long arg);
int fcntl(int fd, int cmd, struct flock *lock);
In other words, it takes at least two arguments; based on the second argument, it may take a third one.
The last form, in which the third argument is a pointer to a struct flock, is for doing file locking. File locking is a large topic in it own right; we delay discussion until Section 14.2, “Locking Files,” page 531.
After a fork() and before an exec(), you should make sure that the new program inherits only the open files it needs. You don’t want a child process messing with the parent’s open files unless it’s supposed to. On the flip side, if a parent has lots of files open, that will artificially limit the number of new files the child can open. (See the accompanying sidebar.)
Organizationally, this behavior may present a problem. The part of your program that starts a new child shouldn’t particularly need access to the other part(s) of your program that manipulate open files. And a loop like the following is painful, since there may not be any open files:
int j;
for (j = getdtablesize(); j >= 3; j--) /* close all but 0, 1, 2 */
(void) close(j);
The solution is the close-on-exec flag. This is an attribute of the file descriptor itself, not the underlying open file. When this flag is set, the system automatically closes the file when the process does an exec. By setting this flag as soon as you open a file, you don’t have to worry about any child processes accidentally inheriting it. (The shell automatically sets this flag for all file descriptors it opens numbered 3 and above.)
The cmd argument has two values related to the close-on-exec flag:
F_GETFD
Retrieves the file descriptor flags. The return value is the setting of all the file descriptor flags or
-1on error.
F_SETFD
Sets the file descriptor flags to the value in
arg(the third argument). The return value is0on success or-1on error.
At the moment, only one “file descriptor flag” is defined: FD_CLOEXEC. This symbolic constant is a POSIX invention,[11] and most code uses a straight 1 or 0:
if (fcntl(fd, F_SETFD, 1) < 0) ... /* set close-on-exec, handle any errors */ if (fcntl(fd, F_GETFD) == 1) ... /* close-on-exec bit is already set */
However, the POSIX definition allows for future extension, and thus the correct way to write such code is more along these lines:
int fd; long fd_flags; if ((fd_flags = fcntl(fd, F_GETFD)) < 0) Retrieve flags /* handle error */ fd_flags |= FD_CLOEXEC; Add close-on-exec flag if (fcntl(fd, F_SETFD, fd_flags) < 0) Set flags /* handle error */
Note
The close-on-exec flag is a property of the descriptor, not the underlying file. Thus, the new descriptor returned by dup() or dup2() (or by fcntl() with F_DUPD, as we’re about to see) does not inherit the close-on-exec flag setting of the original descriptor. If you want it set for the new file descriptor also, you must remember to do it yourself. This behavior makes sense: If you’ve just called dup(), copying one end of a pipe to 0 or 1, you don’t want the system to close it for you as soon as the process does an exec!
A Close-on-exec War Story from gawk
6 Within the awk language, I/O statements use a redirection notation similar to that of the shell. This includes one-way pipes to and from subprocesses:
print "something brilliant" > "/some/file" Output to file getline my_record < "/some/other/file Input fromfile print "more words of wisdom" | "a_reader process" Output to
The awk interpreter has an open file descriptor for all file redirections, and for the pipe notations that create a subprocess, the awk interpreter creates a pipe and then does a fork and exec of a shell to run the command as given by the string.
Now, on modern systems, part of the C runtime startup code (that runs before main() is called) needs to temporarily open files in order to manage the use of shared libraries. This means that there must be at least one or two unused file descriptors available to a brand-new program after an exec, or the program just won’t run.
One day, a user reported that when the awk program had the maximum number of files open, any child process that it tried to fork and exec for a pipeline would fail to start!
You can probably guess what was happening. The child shell inherited all the open file descriptors that gawk itself was using for its redirections. We modified gawk to set the close-on-exec flag for all file and pipe redirections, and that fixed the problem.
When fcntl()’s cmd argument is F_DUPFD, the behavior is similar, but not quite identical, to dup2(). In this case, arg is a file descriptor representing the lowest acceptable value for the new file descriptor:
int new_fd = fcntl(old_fd, F_DUPFD, 7); Return value is between 7 and maximum, or
You can simulate the behavior of dup(), which returns the lowest free file descriptor, by using ’fcntl(old_fd, F_DUPFD, 0)’.
If you remember that file descriptors are just indexes into an internal table, understanding how this function works should be clear. The third argument merely provides the index at which the kernel should start its search for an unused file descriptor.
Whether to use fcntl() with F_DUPFD or dup() or dup2() in your own code is largely a matter of taste. All three APIs are part of POSIX and widely supported. We have a mild preference for dup() and dup2() since those are more specific in their action, and thus are more self-documenting. But because all of them are pretty simple, this reasoning may not convince you.
In Section 4.6.3, “Revisiting open()”, page 110, we provided the full list of O_xx flags that open() accepts. POSIX breaks these down by function, classifying them as described in Table 9.4.
Table 9.4. O_xx flags for open(), creat() and fcntl()
Category | Functions | Flags |
|---|---|---|
File access |
|
|
File creation |
|
|
File status |
|
|
Besides setting the various flags initially with open(), you can use fcntl() to retrieve the current settings, as well as to change them. This is done with the F_GETFL and F_SETFL values for cmd, respectively. For example, you might use these commands to change the setting of the nonblocking flag, O_NONBLOCK; like so:
int fd_flags;
if ((fd_flags = fcntl(fd, F_GETFL)) < 0)
/* handle error */
if ((fd_flags & O_NONBLOCK) != 0) { /* Nonblocking flag is set */
fd_flags &= ~O_NONBLOCK; /* Clear it */
if (fcntl(fd, F_SETFL, fd_flags) != 0) /* Give kernel new value */
/* handle error */
}
Besides the modes themselves, the O_ACCMODE symbolic constant is a mask you can use to retrieve the file access modes from the return value:
fd_flags = fcntl(fd, F_GETFL);
switch (fd_flags & O_ACCESS) {
case O_RDONLY:
...action for read-only...
break;
case O_WRONLY:
... action for write-only...
break;
case O_RDWR:
... action for read-write...
break;
}
POSIX requires that O_RDONLY, O_RDWR, and O_WRONLY be bitwise distinct; thus, code such as just shown is guaranteed to work and is an easy way to determine how an arbitrary file descriptor was opened.
By using F_SETFL, you can change these modes as well, although permission checking still applies. According to the GNU/Linux fcntl(2) manpage, the O_APPEND flag cannot be cleared if it was used when the file was opened.
Earlier, we used the metaphor of two people washing and drying dishes, and using a dish drainer to describe the way a pipe works; when the drainer fills up, the dishwasher stops, and when it empties out, the dishdryer stops. This is blocking behavior: The producer or consumer blocks in the call to write() or read(), waiting either for more room in the pipe or for more data to come into it.
In the real world, a human being waiting for the dish drainer to empty out or fill up would not just stand by, immobile.[12] Rather, the idle one would go and find some other kitchen task to do (such as sweeping up all the kids’ crumbs on the floor) until the dish drainer was ready again.
In Unix/POSIX parlance, this concept is termed nonblocking I/O. That is, the requested I/O either completes or returns an error value indicating no data (for the reader) or no room (for the writer). Nonblocking I/O applies to pipes and FIFOs, not to regular disk files. It can also apply to certain devices, such as terminals, and to network connections, both of which are beyond the scope of this volume.
The O_NONBLOCK flag can be used with open() to specify nonblocking I/O, and it can be set or cleared with fcntl(). For open() and read(), nonblocking I/O is straightforward.
Opening a FIFO with O_NONBLOCK set or clear displays the following behavior:
open("/fifo/file", O_RDONLY, mode)
Blocks until the FIFO is opened for writing.
open("/fifo/file", O_RDONLY|O_NONBLOCK, mode)
Opens the file, returning immediately.
open("/fifo/file", O_WRONLY, mode)
Blocks until the FIFO is opened for reading.
open("/fifo/file", O_WRONLY|O_NONBLOCK, mode)
As described for regular pipes, a read() of a FIFO that is no longer open for writing returns end-of-file (a return value of 0). The O_NONBLOCK flag is irrelevant in this case. Things get more interesting for an empty pipe or FIFO: one that is still open for writing but that has no data in it:
read(fd, buf, count), and O_NONBLOCK clear
read(fd, buf, count), and O_NONBLOCK set
The
read()returns-1immediately, witherrnoset toEAGAIN.
Finally, write() behavior is more complicated. To discuss it we have to first introduce the concept of an atomic write. An atomic write is one in which all the requested data are written together, without being interleaved with data from other writes. POSIX defines the constant PIPE_BUF in <unistd.h>. Writes of amounts less than or equal to PIPE_BUF bytes to a pipe or FIFO either succeed or block, according to the details we get into shortly. The minimum value for PIPE_BUF is _POSIX_PIPE_BUF, which is 512. PIPE_BUF itself can be larger; current GLIBC systems define it to be 4096, but in any case you should use the symbolic constant and not expect PIPE_BUF to be the same value across different systems.
In all cases, for pipes and FIFOs, a write() appends data to the end of the pipe. This derives from the fact that pipes don’t have file offsets: They aren’t seekable.
Also in all cases, as mentioned, writes of up to PIPE_BUF are atomic: The data are not interleaved with the data from other writes. Data from a write of more than PIPE_BUF bytes can be interleaved with the data from other writes on arbitrary boundaries. This last means that you cannot expect every PIPE_BUF subchunk of a large amount of data to be written atomically. The O_NONBLOCK setting does not affect this rule.
As with read(), when O_NONBLOCK is not set, write() blocks until all the data are written.
Things are most complicated with O_NONBLOCK set. For a pipe or FIFO, the behavior is as follows:
space ≥ nbytes | space < nbytes | |
|
|
|
space > 0 | space = 0 | |
|
|
|
For nonpipe and non-FIFO files to which O_NONBLOCK can be applied, the behavior is as follows:
space > 0 |
|
space = 0 |
|
Although there is a bewildering array of behavior changes based on pipe/nonpipe, O_NONBLOCK set or clear, the space available in the pipe, and the size of the attempted write, the rules are intended to make programming straightforward:
End-of-file is always distinguishable:
read()returns zero bytes.If no data are available to be read,
read()either succeeds or returns a “nothing to read” indication:EAGAIN, which means “try again later”.If there’s no room to write data,
write()either blocks until it can succeed (O_NONBLOCKclear) or it fails with a “no room right now” error:EAGAIN.When there’s room, as much data will be written as can be, so that eventually all the data can be written out.
In summary, if you intend to use nonblocking I/O, any code that uses write() has to be able to handle a short write, where less than the requested amount is successfully written. Robust code should be written this way anyway: Even for a regular file it’s possible that a disk could become full and that a write() will only partially succeed.
Furthermore, you should be prepared to handle EAGAIN, understanding that in this case write() failing isn’t necessarily a fatal error. The same is true of code that uses nonblocking I/O for reading: recognize that EAGAIN isn’t fatal here either. (It may pay, though, to count such occurrences, giving up after too many.)
Nonblocking I/O does complicate your life, no doubt about it. But for many applications, it’s a necessity that lets you get your job done. Consider the print spooler again. The spooler daemon can’t afford to sit in a blocking read() on the FIFO file to which incoming jobs are submitted. It has to be able to monitor running jobs as well and possibly periodically check the status of the printer devices (for example, to make sure they have paper or aren’t jammed).
The fcntl() system call is summarized in Table 9.5.
Table 9.5. fcntl() summary
cmd value | arg value | Returns |
|---|---|---|
| Lowest new descriptor | Duplicate of the |
| Retrieve file descriptor flags (close-on-exec). | |
| New flag value | Set file descriptor flags (close-on-exec). |
| Retrieve flags on underlying file. | |
| New flag value | Set flags on underlying file. |
The file creation, status, and access flags are copied when a file descriptor is duplicated. The close-on-exec flag is not.
A two-way pipe connects two processes bidirectionally. Typically, for at least one of the processes, both standard input and standard output are set up on pipes to the other process. The Korn shell (ksh) introduced two-way pipes at the language level, with what it terms a coprocess:
database engine command and arguments |& Start coprocess in background print -p "database command" Write to coprocess read -p db_response Read from coprocess
Here, database engine represents any back-end program that can be driven by a front end, in this case the ksh script. database engine has standard input and standard output connected to the shell by way of two separate one-way pipes.[13] This is illustrated in Figure 9.7.
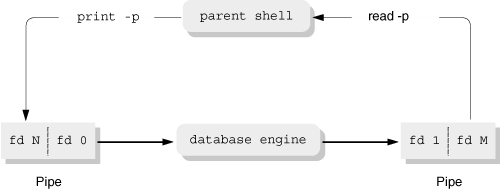
In regular awk, pipes to or from subprocesses are one-way: There’s no way to send data to a program and read a response back from it—you have to use a temporary file. GNU awk (gawk) borrows the ’|&’ notation from ksh to extend the awk language:
print "a command" |& "database engine" Start coprocess, write to it "database engine" |& getline db_response Read from coprocess
gawk also uses the ’|&’ notation for TCP/IP sockets and BSD portals, which aren’t covered in this volume. The following code from io.c in the gawk 3.1.3 distribution is the part of the two_way_open() function that sets up a simple coprocess: It creates two pipes, forks the child process, and does all the file descriptor manipulation. We have omitted a number of irrelevant pieces of code (this function is bigger than it should be):
1561 static int 1562 two_way_open (const char *str, struct redirect *rp) 1563 { ... 1827 /* case 3: two way pipe to a child process */ 1828 { 1829 int ptoc[2], ctop[2]; 1830 int pid; 1831 int save_errno; 1835 1836 if (pipe(ptoc) < 0) 1837 return FALSE; /* errno set, diagnostic from caller */ 1838 1839 if (pipe(ctop) < 0) { 1840 save_errno = errno; 1841 close(ptoc[0]); 1842 close(ptoc[1]); 1843 errno = save_errno; 1844 return FALSE; 1845 }
The first step is to create the two pipes. ptoc is “parent to child,” and ctop is “child to parent.” Bear in mind as you read the code that index 0 is the read end and that index 1 is the write end.
Lines 1836–1837 create the first pipe, ptoc. Lines 1839–1845 create the second one, closing the first one if this fails. This is important. Failure to close an open but unused pipe leads to file descriptor leaks. Like memory, file descriptors are a finite resource, and once you run out of them, they’re gone.[14] The same is true of open files: Make sure that all your error-handling code always closes any open files or pipes that you won’t need when a failure happens.
save_errno saves the errno values as set by pipe(), on the off chance that close() might fail (line 1840). errno is then restored on line 1843.
1906 if ((pid = fork()) < 0) { 1907 save_errno = errno; 1908 close(ptoc[0]); close(ptoc[1]); 1909 close(ctop[0]); close(ctop[1]); 1910 errno = save_errno; 1911 return FALSE; 1912 }
Lines 1906–1912 fork the child, this time closing both pipes if fork() failed. Here too, the original errno value is saved and restored for later use in producing a diagnostic.
1914 if (pid == 0) { /* child */ 1915 if (close(1) == -1) 1916 fatal(_("close of stdout in child failed (%s)"), 1917 strerror(errno)); 1918 if (dup(ctop[1]) != 1) 1919 fatal(_("moving pipe to stdout in child failed (dup: %s)"), strerror(errno)); 1920 if (close(0) == -1) 1921 fatal(_("close of stdin in child failed (%s)"), 1922 strerror(errno)); 1923 if (dup(ptoc[0]) != 0) 1924 fatal(_("moving pipe to stdin in child failed (dup: %s)"), strerror(errno)); 1925 if ( close(ptoc[0]) == -1 || close(ptoc[1]) == -1 1926 || close(ctop[0]) == -1 || close(ctop[1]) == -1) 1927 fatal(_("close of pipe failed (%s)"), strerror(errno)); 1928 /* stderr does NOT get dup'ed onto child's stdout */ 1929 execl("/bin/sh", "sh", "-c", str, NULL); 1930 _exit(errno == ENOENT ? 127 : 126); 1931 }
Lines 1914–1931 handle the child’s code, with appropriate error checking and messages at each step. Line 1915 closes standard output. Line 1918 copies the child-to-parent pipe write end to 1. Line 1920 closes standard input, and line 1923 copies the parent-to-child read end to 0. If this all works, the child’s standard input and output are now in place, connected to the parent.
Lines 1925–1926 close all four original pipe file descriptors since they’re no longer needed. Line 1928 reminds us that standard error remains in place. This is the best decision, since the user will see errors from the coprocess. An awk program that must capture standard error can use the ’2>&1’ shell notation in the command to redirect the coprocess’s standard error or send it to a separate file.
Finally, lines 1929–1930 attempt to run execl() on the shell and exit appropriately if that fails.
1934 /* parent */ 1935 rp->pid = pid; 1936 rp->iop = iop_alloc(ctop[0], str, NULL); 1937 if (rp->iop ==NULL) { 1938 (void) close(ctop[0]); 1939 (void) close(ctop[1]); 1940 (void) close(ptoc[0]); 1941 (void) close(ptoc[1]); 1942 (void) kill(pid, SIGKILL); /* overkill? (pardon pun) */ 1943 1944 return FALSE; 1945 }
The first step in the parent is to manage the input end, from the coprocess. The rp pointer points to a struct redirect, which maintains a field to hold the child’s PID, a FILE * for output, and an IOBUF * pointer named iop. The IOBUF is a gawk internal data structure for doing input. It, in turn, keeps a copy of the underlying file descriptor.
Line 1935 saves the process ID value. Line 1936 allocates a new IOBUF for the given file descriptor and command string. The third argument here is NULL: It allows the use of a preallocated IOBUF if necessary.
If the allocation fails, lines 1937–1942 clean up by closing the pipes and sending a “kill” signal to the child process to cause it to terminate. (The kill() function is described in Section 10.6.7, “Sending Signals: kill() and killpg(),” page 376.)
1946 rp->fp = fdopen(ptoc[1], "w"); 1947 if (rp->fp == NULL) { 1948 iop_close(rp->iop); 1949 rp->iop = NULL; 1950 (void) close(ctop[0]); 1951 (void) close(ctop[1]); 1952 (void) close(ptoc[0]); 1953 (void) close(ptoc[1]); 1954 (void) kill(pid, SIGKILL); /* overkill? (pardon pun) */ 1955 1956 return FALSE; 1957 }
Lines 1946–1957 are analogous. They set up the parent’s output to the child, saving the file descriptor for the parent-to-child pipe write end in a FILE * by means of fdopen(). If this fails, lines 1947–1957 take the same action as before: closing all the pipe descriptors and sending a signal to the child.
From this point on, the write end of the parent-to-child pipe, and the read end of the child-to-parent pipe are held down in the larger structures: the FILE * and IOBUF, respectively. They are closed automatically by the regular routines that close these structures. However, two tasks remain:
1960 os_close_on_exec(ctop[0], str, "pipe", "from"); 1961 os_close_on_exec(ptoc[1], str, "pipe", "from"); 1962 1963 (void) close(ptoc[0]); 1964 (void) close(ctop[1]); 1966 1967 return TRUE; 1968 } ... 1977 }
Lines 1960–1961 set the close-on-exec flag for the two descriptors that will remain open. os_close_on_exec() is a simple wrapper routine that does the job on Unix and POSIX-compatible systems, but does nothing on systems that don’t have a close-on-exec flag. This buries the portability issue in a single place and avoids lots of messy #ifdefs throughout the code here and elsewhere in io.c.
Finally, lines 1963–1964 close the ends of the pipes that the parent doesn’t need, and line 1967 returns TRUE, for success.
Job control is complicated, involving process groups, sessions, the wait mechanisms, signals, and manipulation of the terminal’s process group. As such, we’ve chosen not to get into the details. However, you may wish to look at these books:
Advanced Programming in the UNIX Environment, 2nd edition, by W. Richard Stevens and Stephen Rago. Addison-Wesley, Reading Massachusetts, USA, 2004. ISBN: 0-201-43307-9.
This book is both complete and thorough, covering elementary and advanced Unix programming. It does an excellent job of covering process groups, sessions, job control, and signals.
The Design and Implementation of the 4.4 BSD Operating System, by Marshall Kirk McKusick, Keith Bostic, Michael J. Karels, and John S. Quarterman. Addison-Wesley, Reading, Massachusetts, USA, 1996. ISBN: 0-201-54979-4.
This book gives a good overview of the same material, including a discussion of kernel data structures, which can be found in section 4.8 of that book.
New processes are created with
fork(). After a fork, both processes run the same code, the only difference being the return value:0in the child and a positive PID number in the parent. The child process inherits copies of almost all the parent’s attributes, of which the open files are perhaps the most important.Inherited shared file descriptors make possible much of the higher-level Unix semantics and elegant shell control structures. This is one of the most fundamental parts of the original Unix design. Because of descriptor sharing, a file isn’t really closed until the last open file descriptor is closed. This particularly affects pipes, but it also affects the release of disk blocks for unlinked but still open files.
The
getpid()andgetppid()calls return the current and parent process ID numbers, respectively. A process whose parent dies is reparented to the specialinitprocess, PID1. Thus, it’s possible for the PPID to change, and applications should be prepared for this.The
nice()system call lets you adjust your process’s priority. The nicer you are to other processes, the lower your priority, and vice versa. Only the superuser can be less nice to other processes. On modern systems, especially single-user ones, there’s no real reason to change the nice value.The
exec()system calls starts a new program running in an existing process. Six different versions of the call provide flexibility in the setup of argument and environment lists, at the cost of initial confusion as to which one is best to use. Two variants simulate the shell’s path searching mechanism and fall back to the use of the shell to interpret the file in case it isn’t a binary executable; these variants should be used with care.The new program’s value for
argv[0]normally comes from the filename being executed, but this is only convention. As withfork(), a significant but not identical set of attributes is inherited across an exec. Other attributes are reset to reasonable default values.The
atexit()function registers callback functions to run in LIFO order when a program terminates. Theexit(),_exit(), and_Exit()functions all terminate the program, passing an exit status back to the parent.exit()cleans up openFILE* streams and runs functions registered withatexit(). The other two functions exit immediately and should be used only when an exec has failed in a forked child. Returning frommain()is like callingexit()with the given return value. In C99 and C++, falling off the end ofmain()is the same as ’exit(0)’ but is bad practice.wait()andwaitpid()are the POSIX functions for recovering a child’s exit status. Various macros let you determine whether the child exited normally, and if so, to determine its exit status, or whether the child suffered death-by-signal and if so, which signal committed the crime. With specific options,waitpid()also provides information about children that haven’t died but that have changed state.GNU/Linux and most Unix systems support the BSD
wait3()andwait4()functions. GNU/Linux also supports the obsolescentunion wait. The BSD functions provide astruct rusage, allowing access to CPU time information, which can be handy. Ifwaitpid()will suffice though, it’s the most portable way to go.Process groups are part of the larger job control mechanism, which includes signals, sessions, and manipulation of the terminal’s state.
getpgrp()returns the current process’s process group ID, andgetpgid()returns the PGID of a specific process. Similarly,setpgrp()sets the current process’s PGID to its PID, making it a process group leader;setpgid()lets a parent process set the PGID of a child that hasn’t yet exec’d.Pipes and FIFOs provide a one-way communications channel between two processes. Pipes must be set up by a common ancestor, whereas a FIFO can be used by any two processes. Pipes are created with
pipe(), and FIFO files are created withmkfifo(). Pipes and FIFOs buffer their data, stopping the producer or consumer as the pipe fills up or empties out.dup()anddup2()create copies of open file descriptors. In combination withclose(), they enable pipe file descriptors to be put in place as standard input and output for pipelines. For pipes to work correctly, all copies of unused ends of the pipes must be closed before exec’ing the target program(s)./dev/fdcan be used to create nonlinear pipelines, as demonstrated by the Bash and Korn shell’s process substitution capability.fcntl()is a catchall function for doing miscellaneous jobs. It manages attributes of both the file descriptor itself and the file underlying the descriptor. In this chapter, we saw thatfcntl()is used for the following:Duplicating a file descriptor, simulating
dup()and almost simulatingdup2().Retrieving and setting the close-on-exec flag. The close-on-exec flag is the only current file descriptor attribute, but it’s an important one. It is not copied by a
dup()action but should be explicitly set on any file descriptors that should not remain open after an exec. In practice, this should be done for most file descriptors.Retrieving and setting flags controlling the underlying file. Of these,
O_NONBLOCKis perhaps the most useful, at least for FIFOs and pipes. It is definitely the most complicated flag.
Write a program that prints as much information as possible about the current process: PID, PPID, open files, current directory, nice value, and so on. How can you tell which files are open? If multiple file descriptors reference the same file, so indicate. (Again, how can you tell?)
How do you think
atexit()stores the pointers to the callback functions? Implementatexit(), keeping the GNU “no arbitrary limits” principle in mind. Sketch an outline (pseudocode) forexit(). What information (<stdio.h>library internals) are you missing, the absence of which prevents you from writingexit()?The
xargsprogram is designed to run a command and arguments multiple times, when there would be too many arguments to pass directly on the command line. It does this by reading lines from standard input, treating each line as a separate argument for the named command, and bundling arguments until there are just enough to still be below the system maximum. For example:$ grep ARG_MAX /usr/include/*.h /usr/include/*/*.h Command line bash: /bin/grep: Argument list too long Shell's error message $ find /usr/include -name '*.h' | xargs grep ARG_MAX find and xargs works /usr/include/sys/param.h:#define NCARGS ARG_MAX ...
The constant
ARG_MAXin<limits.h>represents the combined total memory used by the environment and the command-line arguments. The POSIX standard doesn’t say whether this includes the pointer arrays or just the strings themselves.Write a simple version of
xargsthat works as described. Don’t forget the environment when calculating how much space you have. Be sure to manage your memory carefully.The layout of the
statusvalue filled in bywait()andwaitpid()isn’t defined by POSIX. Historically though, it’s a 16-bit value that looks as shown in Figure 9.8.A nonzero value in bits 0–7 indicates death-by-signal.
All 1-bits in the signal field indicates that the child process stopped. In this case, bits 9–15 contain the signal number.
A 1-bit in bit 8 indicates death with core dump.
If bits 0–7 are zero, the process exited normally. In this case, bits 9–15 are the exit status.
Given this information, write the POSIX
WIFEXITED()et al. macros.Remembering that
dup2()closes the requested file descriptor first, implementdup2()usingclose()andfcntl(). How will you handle the case thatfcntl()returns a value lower than the one requested?Does your system have a
/dev/fddirectory? If so, how is it implemented?Write a new version of
ch09-pipeline.cthat forks only one process. After forking, the parent should rearrange its file descriptors and exec one of the new programs itself.(Hard.) How can you tell if your process ever called
chroot()? Write a program that checks and prints a message indicating yes or no. Can your program be fooled? If so, how?Does your system have a
/procdirectory? If so, what kind of per-process information does it make available?

[1] Such processes often display childlike behavior.
[2] We are not making this up. The terminology is indeed rather morbid, but such was the original Unix designers’ sense of humor.
[3] Double-check the getrusage(2) manpage if your kernel is newer, because this behavior may have changed.
[4] Well, csh and tcsh can be included in this category too, but we prefer Bourne-style shells.
[5] Such an operation is often referred to as a no-op, short for “no operation”.
[6] We’re sure you weren’t worried. After all, you probably use pipelines from the shell dozens of times a day.
[7] What they ate for dinner is left unspecified.
[8] FIFO is an acronym for “first in first out.” This is the way pipes work.
[9] On GNU/Linux systems, /dev/fd is a symbolic link to /proc/self/fd, but since /dev/fd is the common place, that’s what you should use in your code.
[10] Although we’ve shown simple commands, arbitrary pipelines are allowed.
[11] The POSIX standard purposely does not give it a value. However, for old code to continue to work, the only value any implementation could sensibly use is 1.
[12] Well, we’re ignoring the idea that two spouses might want to talk and enjoy each other’s company.
[13] There is only one default coprocess (accessible with ’read -p’ and ’print -p’) at a time. Shell scripts can use the exec command with a special redirection notation to move the coprocess’s file descriptors to specific numbers. Once this is done, another coprocess can be started.
[14] Well, you can close them, obviously. But if you don’t know they’re open, then they’re lost just as effectively as memory through a memory leak.