
In this chapter
This chapter describes several extended APIs. The APIs here are similar in nature to those described earlier in the book or provide additional facilities. Some of them could not be discussed easily until after the prerequisite topics were covered.
The presentation order here parallels the order of the chapters in the first half of the book. The topics are not otherwise related to each other. We cover the following topics: dynamically allocating aligned memory; file locking; a number of calls that work with subsecond time values; and a more advanced suite of functions for storing and retrieving arbitrary data values. Unless stated otherwise, all the APIs in this chapter are included in the POSIX standard.
For most tasks, the standard allocation routines, malloc(), realloc(), and so on, are fine. Occasionally, though, you may need memory that is aligned a certain way. In other words, the address of the first allocated byte is a multiple of some number. (For example, on some systems, memory copies are significantly faster into and out of wordaligned buffers.) Two functions offer this service:
#include <stdlib.h> int posix_memalign(void **memptr, size_t alignment, size_t size); POSIX ADV void *memalign(size_t boundary, size_t size); Common
posix_memalign() is a newer function; it’s part of yet another optional extension, the “Advisory Information” (ADV) extension. The function works differently from most other allocation Linux APIs. It does not return –1 when there’s a problem. Rather, the return value is 0 on success or an errno value on failure. The arguments are as follows:
void **memptr
size_t alignment
The required alignment. It must be a multiple of
sizeof(void *)and a power of 2.
size_t size
The number of bytes to allocate.
memalign() is a nonstandard but widely available function that works similarly. The return value is NULL on failure or the requested storage on success, with boundary (a power of 2) indicating the alignment and size indicating the requested amount of memory.
Traditionally, storage allocated with memalign() could not be released with free(), since memalign() would allocate storage with malloc() and return a pointer to a suitably-aligned byte somewhere within that storage. The GLIBC version does not have this problem. Of the two, you should use posix_memalign() if you have it.
Modern Unix systems, including GNU/Linux, allow you to lock part or all of a file for reading and writing. Like many parts of the Unix API that developed after V7, there are multiple, conflicting ways to do file locking. This section covers the possibilities.
Just as the lock in your front door prevents unwanted entry into your home, a lock on a file prevents access to data within the file. File locking was added to Unix after the development of V7 (from which all modern Unix systems are descended) and thus, for a while, multiple, conflicting file-locking mechanisms were available and in use on different Unix systems. Both BSD Unix and System V had their own incompatible locking calls. Eventually, POSIX formalized the System V way of doing file locks. Fortunately, the names of the calls were different between System V and BSD, so GNU/Linux, in an effort to please everyone, supports both kinds of locks.
Table 14.1 summarizes the different kinds of locks.
There are multiple aspects to locking, as follows:
Record locking
Whole file locking
Read locking
Write locking
Advisory locking
An advisory lock closely matches your front-door lock. It’s been said that “locks keep honest people honest,” meaning that if someone really wishes to break into your house, he will probably find a way to do so, despite the lock in your front door. So too with an advisory lock; it only works when everyone attempting to access the locked file first attempts to acquire the lock. However, it’s possible for a program to completely ignore any advisory locks and do what it pleases with the file (as long as the file permissions allow it, of course).
Mandatory locking
Advisory locking is adequate for cooperating programs that share a private file, when no other application is expected to use the file. Mandatory locking is advisable in situations in which avoiding conflicting file use is critical, such as in commercial database systems.
POSIX standardizes only advisory locking. Mandatory locking is available on GNU/Linux, as well as on a number of commercial Unix systems, but the details vary. We cover the GNU/Linux details later in this section.
The fcntl() (file control) system call is used for file locking. (Other uses for fnctl() were described in Section 9.4.3, “Managing File Attributes: fcntl(),” page 328) It is declared as follows:
#include <unistd.h> POSIX #include <fcntl.h> int fcntl(int fd, int cmd); Not relevant for file locking int fcntl(int fd, int cmd, long arg); Not relevant for file locking int fcntl(int fd, int cmd, struct flock *lock);
The arguments are as follows:
| The file descriptor for the open file. |
| One of the symbolic constants defined in |
| A pointer to a |
Before looking at how to get a lock, let’s examine how to describe a lock to the operating system. You do so with the struct flock structure, which describes the byte range to be locked and the kind of lock being requested. The POSIX standard states that a struct flock contains “at least” certain members. This allows implementations to provide additional structure members if so desired. From the fcntl(3) manpage, slightly edited:
struct flock {
...
short l_type; Type of lock: F_RDLCK, F_WRLCK, F_UNLCK
short l_whence; How to interpret l_start: SEEK_SET, SEEK_CUR, SEEK_END
off_t l_start; Starting offset for lock
off_t l_len; Number of bytes to lock; 0 means from start to end-of-file
pid_t l_pid; PID of process blocking our lock (F_GETLK only)
...
};
The l_start field is the starting byte offset for the lock. l_len is the length of the byte range, that is, the total number of bytes to lock. l_whence specifies the point in the file that l_start is relative to; the values are the same as for the whence argument to lseek() (see Section 4.5, “Random Access: Moving Around within a File,” page 102), hence the name for the field. The structure is thus self-contained: The l_start offset and l_whence value are not related to the current file offset for reading and writing. Some example code might look like this:
struct employee { /* whatever */ }; /* Describe an employee */
struct flock lock; /* Lock structure */
...
/* Lock sixth struct employee */
lock.l_whence = SEEK_SET; /* Absolute position */
lock.l_start = 5 * sizeof(struct employee); /* Start of 6th structure */
lock.l_len = sizeof(struct employee); /* Lock one record */
Using SEEK_CUR or SEEK_END, you can lock ranges relative to the current position in the file, or relative to the end of the file, respectively. For these two cases, l_start may be negative, as long as the absolute starting position is not less than zero. Thus, to lock the last record in a file:
/* Lock last struct employee */ lock.l_whence = SEEK_END; /* Relative to EOF */ lock.l_start = -1 * sizeof(struct employee); /* Start of last structure */ lock.l_len = sizeof(struct employee); /* Lock one record */
Setting l_len to 0 is a special case. It means lock the file from the starting position indicated by l_start and l_whence through the end of the file. This includes any positions past the end of the file, as well. (In other words, if the file grows while the lock is held, the lock is extended so that it continues to cover the entire file.) Thus, locking the entire file is a degenerate case of locking a single record:
lock.l_whence = SEEK_SET; /* Absolute position */ lock.l_start = 0; /* Start of file */ lock.l_len = 0; /* Through end of file */
The fnctl(3) manpage has this note:
POSIX 1003.1–2001 allows
l_lento be negative. (And if it is, the interval described by the lock covers bytesl_start + l_lenup to and includingl_start –1.) However, for current kernels the Linux system call returnsEINVALin this situation.
(We note that the manpage refers to the 2.4.x series of kernels; it may pay to check the current manpage if your system is newer.)
Now that we know how to describe where in the file to lock, we can describe the type of the lock with l_type. The possible values are as follows:
Thus, the complete specification of a lock involves setting a total of four fields in the struct flock structure: three to specify the byte range and the fourth to describe the desired lock type.
The F_UNLCK value for l_type releases locks. In general, it’s easiest to release exactly the same locks that you acquired earlier, but it is possible to “split” a lock by releasing a range of bytes in the middle of a larger, previously locked range. For example:
struct employee { /* whatever */ }; /* Describe an employee */
struct flock lock; /* Lock structure */
...
/* Lock struct employees 6-8 */
lock.l_whence = SEEK_SET; /* Absolute position */
lock.l_start = 5 * sizeof(struct employee); /* Start of 6th structure */
lock.l_len = sizeof(struct employee) * 3; /* Lock three records */
...obtain lock (see next section)...
/* Release record 7: this splits the previous lock into two: */
lock.l_whence = SEEK_SET; /* Absolute position */
lock.l_start = 6 * sizeof(struct employee); /* Start of 7th structure */
lock.l_len = sizeof(struct employee) * 1; /* Unlock one record */
...release lock (see next section)...
Once the struct flock has been filled in, the next step is to request the lock. This step is done with an appropriate value for the cmd argument to fcntl():
| Inquire if it’s possible to obtain a lock. |
| Obtain or release a lock. |
| Obtain a lock, waiting until it’s available. |
The F_GETLK command is the “Mother may I?” command. It inquires whether the lock described by the struct flock is available. If it is, the lock is not placed; instead, the operating system changes the l_type field to F_UNLCK. The other fields are left unchanged.
If the lock is not available, then the operating system fills in the various fields with information describing an already held lock that blocks the requested lock from being obtained. In this case, l_pid contains the PID of the process holding the described lock.[1] There’s not a lot to be done if the lock is being held, other than to wait awhile and try again to obtain the lock, or print an error message and give up.
The F_SETLK command attempts to acquire the specified lock. If fcntl() returns 0, then the lock has been successfully acquired. If it returns -1, then another process holds a conflicting lock. In this case, errno is set to either EAGAIN (try again later) or EACCES (access denied). Two values are possible, to cater to historical systems.
The F_SETLKW command also attempts to acquire the specified lock. It differs from F_SETLK in that it will wait until the lock becomes available.
Once you’ve chosen the appropriate value for the cmd argument, pass it as the second argument to fcntl(), with a pointer to a filled-in struct flock as the third argument:
struct flock lock;
int fd;
...open file, fill in struct flock...
if (fcntl (fd, F_SETLK, & lock) < 0) {
/* Could not acquire lock, attempt to recover */
}
The lockf() function[2] provides an alternative way to acquire a lock at the current file position:
#include <sys/file.h> XSI
int lockf(int fd, int cmd, off_t len);
The file descriptor, fd, must have been opened for writing. len specifies the number of bytes to lock: from the current position (call it pos) to pos + len bytes if len is positive, or from pos - len to pos - 1 if len is negative. The commands are as follows:
The return value is 0 on success and -1 on error, with errno set appropriately. Possible error returns include:
| The file is locked, for |
| For |
| The operating system is unable to allocate a lock. |
[3] A deadlock is a situation in which two processes would both block, each waiting on the other to release a resource. | |
The combination of F_TLOCK and EDEADLK is useful: If you know that there can never be potential for deadlock, then use F_LOCK. Otherwise, it pays to be safe and use F_TLOCK. If the lock is available, you’ll get it, but if it’s not, you have a chance to recover instead of blocking, possibly forever, waiting for the lock.
When you’re done with a lock, you should release it. With fcntl(), take the original struct lock used to acquire the lock, and change the l_type field to F_UNLCK. Then use F_SETLK as the cmd argument:
lock.l_whence = ... ; /* As before */
lock.l_start = ... ; /* As before */
lock.l_len = ... ; /* As before */
lock.l_type = F_UNLCK; /* Unlock */
if (fcntl(fd, F_SETLK, & lock) < 0) {
/* handle error */
}
/* Lock has been released */
Code using lockf() is a bit simpler. For brevity, we’ve omitted the error checking:
off_t curpos, len; curpos = lseek(fd, (off_t) 0, SEEK_CUR); Retrieve current position len = ... ; Set correct number of bytes to lock lockf(fd, F_LOCK, len); Acquire lock ... use locked area here... lseek(fd, curpos, SEEK_SET); Return to position of lock lockf(fd, F_ULOCK, len); Unlock file
If you don’t explicitly release a lock, the operating system will do it for you in two cases. The first is when the process exits (either by main() returning or by the exit() function, which was covered in Section 9.1.5.1, “Defining Process Exit Status,” page 300). The other case is when you call close() on the file descriptor: more on this in the next section.
There are several caveats to be aware of when doing file locking:
As described previously, advisory locking is just that. An uncooperative process can do anything it wants behind the back (so to speak) of processes that are doing locking.
These calls should not be used in conjunction with the
<stdio.h>library. This library does its own buffering, and while you can retrieve the underlying file descriptor withfileno(), the actual position in the file may not be where you think it is. In general, the Standard I/O library doesn’t understand file locks.Bear in mind that locks are not inherited by child processes after a fork but that they do remain in place after an exec.
A
close()of any file descriptor open on the file removes all of the process’s locks on a file, even if other file descriptors remain open on it.
That close() works this way is unfortunate, but because this is how fcntl() locking was originally implemented, POSIX standardizes it. Making this behavior the standard avoids breaking existing Unix code.
4.2 BSD Unix introduced its own file locking mechanism, flock().[4] It is declared as follows:
#include <sys/file.h> Common
int flock(int fd, int operation);
The file descriptor fd represents the open file. These are the operations:
| |
| |
| |
| When bitwise-OR’d with |
By default, the lock requests will block (not return) if a competing lock exists. Once the competing lock is removed and the requested lock is obtained, the call returns. (This implies that, by default, there is potential for deadlock.) To attempt to obtain a lock without blocking, perform a bitwise OR of LOCK_NB with one of the other values for operation.
The salient points about flock() are as follows:
flock()locking is also advisory locking; a program that does no locking can come in and blast, with no errors, a file locked withflock().The whole file is locked. There is no mechanism for locking or unlocking just a part of the file.
How the file was opened has no effect on the type of lock that may be placed. (Compare this to
fcntl(), whereby the file must have been opened for reading for a read lock, or opened for writing for a write lock.)Multiple file descriptors open on the same file share the lock. Any one of them can be used to remove the lock. Unlike
fcntl(), when there is no explicit unlock, the lock is not removed until all open file descriptors for the file have been closed.Only one
flock()lock can be held by a process on a file; callingflock()successively with two different lock types changes the lock to the new type.On GNU/Linux systems,
flock()locks are completely independent offcntl()locks. Many commercial Unix systems implementflock()as a “wrapper” on top offcntl(), but the semantics are not the same.
We don’t recommend using flock() in new programs, because the semantics are not as flexible and because the call is not standardized by POSIX. Support for it in GNU/Linux is primarily for compatibility with software written for older BSD Unix systems.
Most commercial Unix systems support mandatory file locking, in addition to advisory file locking. Mandatory locking works only with fcntl() locks. Mandatory locking for a file is controlled by the file’s permission settings, in particular, by addition of the setgid bit to a file with the chmod command:
$ echo hello, world > myfile Create file $ ls -l myfile Show permissions -rw-r--r-- 1 arnold devel 13 Apr 3 17:11 myfile $ chmod g+s myfile Add setgid bit $ ls -l myfile Show new permissions -rw-r-Sr-- 1 arnold devel 13 Apr 3 17:11 myfile
The group execute bit should be left turned off. The S shows that the setgid bit is turned on but that execute permission isn’t; an s would be used if both were on.
The combination of setgid on and group execute off is generally meaningless. For this reason, it was chosen by the System V developers to mean “enforce mandatory locking.” And indeed, adding this bit is enough to cause a commercial Unix system, such as Solaris, to enforce file locks.
On GNU/Linux systems, the story is a little different. The setgid bit must be applied to a file for mandatory locking, but that alone is not enough. The filesystem containing the file must also be mounted with the mand option to the mount command.
We have already covered filesystems, disk partitions, mounting, and the mount command, mostly in Section 8.1, “Mounting and Unmounting Filesystems,” page 228. We can demonstrate mandatory locking with a small program and a test filesystem on a floppy disk. First, here’s the program:
1 /* ch14-lockall.c --- Demonstrate mandatory locking. */ 2 3 #include <stdio.h> /* for fprintf(), stderr, BUFSIZ */ 4 #include <errno.h> /* declare errno */ 5 #include <fcntl.h> /* for flags for open() */ 6 #include <string.h> /* declare strerror() */ 7 #include <unistd.h> /* for ssize_t */ 8 #include <sys/types.h> 9 #include <sys/stat.h> /* for mode_t */ 10 11 int 12 main(int argc, char **argv) 13 { 14 int fd; 15 int i, j; 16 mode_t rw_mode; 17 static char message[] = "hello, world "; 18 struct flock lock; 19 20 if (argc != 2) { 21 fprintf(stderr, "usage: %s file ", argv[0]); 22 exit(1); 23 } 24 25 rw_mode = S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH; /* 0644 */ 26 fd = open(argv[1], O_RDWR|O_TRUNC|O_CREAT|O_EXCL, rw_mode); 27 if (fd < 0) { 28 fprintf(stderr, "%s: %s: cannot open for read/write: %s , 29 argv[0], argv[1], strerror(errno)); 30 (void) close(fd); 31 return 1; 32 } 33 34 if (write(fd, message, strlen(message)) != strlen(message)) { 35 fprintf(stderr, "%s: %s: cannot write: %s ", 36 argv[0], argv[1], strerror(errno)); 37 (void) close(fd); 38 return 1; 39 } 40 41 rw_mode |= S_ISGID; /* add mandatory lock bit */ 42 43 if (fchmod(fd, rw_mode) < 0) { 44 fprintf(stderr, "%s: %s: cannot change mode to %o: %s ", 45 argv[0], argv[1], rw_mode, strerror(errno)); 46 (void) close(fd); 47 return 1; 48 } 49 50 /* lock the file */ 51 memset(& lock, '�', sizeof(lock)); 52 lock.l_whence = SEEK_SET; 53 lock.l_start = 0; 54 lock.l_len = 0; /* whole-file lock */ 55 lock.l_type = F_WRLCK; /* write lock */ 56 57 if (fcntl(fd, F_SETLK, & lock) < 0) { 58 fprintf(stderr, "%s: %s: cannot lock the file: %s ", 59 argv[0], argv[1], strerror(errno)); 60 (void) close(fd); 61 return 1; 62 } 63 64 pause(); 65 66 (void) close(fd); 67 68 return 0; 69 }
The program sets the permissions and creates the file named on the command line (lines 25 and 26). It then writes some data into the file (line 34). Line 41 adds the setgid bit to the permissions, and line 43 changes them. (The fchmod() system call was discussed in Section 5.5.2, “Changing Permissions: chmod() and fchmod(),” page 156.)
Lines 51–55 set up the struct flock to lock the whole file, and then the lock is actually requested on line 57. Once we have the lock, the program goes to sleep, using the pause() system call (see Section 10.7, “Signals for Interprocess Communication,” page 379). When done, the program closes the file descriptor and returns. Here is an annotated transcript demonstrating the use of mandatory file locking:
$ fdformat /dev/fd0 Format floppy disk Double-sided, 80 tracks, 18 sec/track. Total capacity 1440 kB. Formatting ... done Verifying ... done $ /sbin/mke2fs /dev/fd0 Make a Linux filesystem ... lots of output, omitted... $ su Become root, to use mount Password: Password does not echo # mount -t ext2 -o mand /dev/fd0 /mnt/floppy Mount floppy, with locking # suspend Suspend root shell [1]+ Stopped su $ ch14-lockall /mnt/floppy/x & Background program [2] 23311 holds lock $ ls -l /mnt/floppy/x Look at file -rw-r-Sr-- 1 arnold devel 13 Apr 6 14:23 /mnt/floppy/x $ echo something > /mnt/floppy/x Try to modify file bash2: /mnt/floppy/x: Resource temporarily unavailable Error returned $ kill %2 Kill program holding lock $ Press ENTER [2]- Terminated ch14-lockall /mnt/floppy/x Program died $ echo something > /mnt/floppy/x Retry modification, works $ fg Return to root shell su # umount /mnt/floppy Unmount floppy # exit Done with root shell $
As long as ch14-lockall is running, it holds the lock. Since it’s a mandatory lock, the shell’s I/O redirection fails. Once ch14-lockall exits, the lock is released, and the I/O redirection succeeds. As mentioned earlier, under GNU/Linux, not even root can override a mandatory file lock.
As an aside, floppy disks make excellent test beds for learning how to use tools that manipulate filesystems. If you do something that destroys the data on a floppy, it’s not likely to be catastrophic, whereas experimenting with live partitions on regular hard disks is much riskier.
The time() system call and time_t type represent times in seconds since the Epoch format. A resolution of one second really isn’t enough; today’s machines are fast, and it’s often useful to distinguish subsecond time intervals. Starting with 4.2 BSD, Berkeley Unix introduced a series of system calls that make it possible to retrieve and use subsecond times. These calls are available on all modern Unix systems, including GNU/Linux.
The first task is to retrieve the time of day:
#include <sys/time.h> XSI int gettimeofday(struct timeval *tv, void *tz); POSIX definition, not GLIBC's
gettimeofday() gets the time of day.[5] The return value is 0 on success, -1 for an error. The arguments are as follows:
struct timeval *tv
This argument is a pointer to a
struct timeval, described shortly, into which the system places the current time.
void *tz
This argument is no longer used; thus, it’s of type
void* and you should always passNULLfor it. (The manpage describes what it used to be and then proceeds to state that it’s obsolete. Read it if you’re interested in the details.)
The time is represented by a struct timeval:
struct timeval {
long tv_sec; /* seconds */
long tv_usec; /* microseconds */
};
The tv_sec value represents seconds since the Epoch; tv_usec is the number of microseconds within the second.
The GNU/Linux gettimeofday(2) manpage also documents the following macros:
#define timerisset(tvp) ((tvp)->tv_sec || (tvp)->tv_usec)
#define timercmp(tvp, uvp, cmp)
((tvp)->tv_sec cmp (uvp)->tv_sec ||
(tvp)->tv_sec == (uvp)->tv_sec &&
(tvp)->tv_usec cmp (uvp)->tv_usec)
#define timerclear(tvp) ((tvp)->tv_sec = (tvp)->tv_usec = 0)
These macros work on struct timeval * values; that is, pointers to structures, and their use should be obvious both from their names and the code. The timercmp() macro is particularly interesting: The third argument is a comparison operator to indicate the kind of comparison. For example, consider the determination of whether one struct timeval is less than another:
struct timeval t1, t2;
...
if (timercmp(& t1, & t2, <))
/* t1 is less than t2 */
The macro expands to
((& t1)->tv_sec < (& t2)->tv_sec || (& t1)->tv_sec == (& t2)->tv_sec && (& t1)->tv_usec < (& t2)->tv_usec)
This says “if t1.tv_sec is less than t2.tv_sec, OR if they are equal and t1.tv_usec is less than t2.tv_usec, then ....”
Section 5.5.3, “Changing Timestamps: utime(),” page 157, describes the utime() system call for setting the access and modification times of a given file. Some filesystems store these times with microsecond (or greater) resolution. Such systems provide the utimes() system call (note the trailing s in the name) to set the access and modification times with microsecond values:
#include <sys/time.h> XSI
int utimes(char *filename, struct timeval tvp[2]);
The tvp argument should point to an array of two struct timeval structures; the values are used for the access and modification times, respectively. If tvp is NULL, then the system uses the current time of day.
POSIX marks this as a “legacy” function, meaning that it’s standardized only to support old code and should not be used for new applications. The primary reason seems to be that there is no defined interface for retrieving file access and modification times that includes the microseconds value; the struct stat contains only time_t values, not struct timeval values.
However, as mentioned in Section 5.4.3, “Linux Only: Specifying Higher-Precision File Times,” page 143, Linux 2.6 (and later) does provide access to nanosecond resolution timestamps with the stat() call. Some other systems (such as Solaris) do as well.[6] Thus, utimes() is more useful than it first appears, and despite its official “legacy” status, there’s no reason not to use it in your programs.
The alarm() function (see Section 10.8.1, “Alarm Clocks: sleep(), alarm(), and SIGALRM,” page 382) arranges to send SIGALRM after the given number of seconds has passed. Its smallest resolution is one second. Here too, 4.2 BSD introduced a function and three different timers that accept subsecond times.
An interval timer is like a repeating alarm clock. You set the first time it should “go off” as well as how frequently after that the timer should repeat. Both of these values use struct timeval objects; that is, they (potentially) have microsecond resolution. The timer “goes off” by delivering a signal; thus, you have to install a signal handler for the timer, preferably before setting the timer itself.
Three different timers exist, as described in Table 14.2.
Table 14.2. Interval timers
Timer | Signal | Function |
|---|---|---|
|
| Runs in real time. |
|
| Runs when a process is executing in user mode. |
|
| Runs when a process is in either user or system mode. |
The use of the first timer, ITIMER_REAL, is straightforward. The timer runs down in real time, sending SIGALRM after the given amount of time has passed. (Because SIGALRM is sent, you cannot mix calls to setitimer() with calls to alarm(), and mixing them with calls to sleep() is also dangerous; see Section 10.8.1, “Alarm Clocks: sleep(), alarm(), and SIGALRM,” page 382.)
The second timer, ITIMER_VIRTUAL, is also fairly straightforward. It runs down when the process is running, but only in user-level (application) code. If a process is blocked doing I/O, such as to a disk or, more importantly, to a terminal, the timer is suspended.
The third timer, ITIMER_PROF, is more specialized. It runs down whenever the process is running, even if the operating system is doing something on behalf of the process (such as I/O). According to the POSIX standard, it is “designed to be used by interpreters in statistically profiling the execution of interpreted programs.” By setting both ITIMER_VIRTUAL and ITIMER_PROF to identical intervals and computing the difference between the times when the two timers go off, an interpreter can tell how much time it’s spending in system calls on behalf of the executing interpreted program.[7] (As stated, this is quite specialized.) The two system calls are:
#include <sys/time.h> XSI
int getitimer(int which, struct itimerval *value);
int setitimer(int which, const struct itimerval *value,
struct itimerval *ovalue);
The which argument is one of the symbolic constants listed earlier naming a timer. getitimer() fills in the struct itimerval pointed to by value with the given timer’s current settings. setitimer() sets the given timer with the value in value. If ovalue is provided, the function fills it in with the timer’s current value. Use an ovalue of NULL if you don’t care about the current value. Both functions return 0 on success or -1 on error.
A struct itimerval consists of two struct timeval members:
struct itimerval {
struct timeval it_interval; /* next value */
struct timeval it_value; /* current value */
};
Application programs should not expect timers to be exact to the microsecond. The getitimer(2) manpage provides this explanation:
Timers will never expire before the requested time, instead expiring some short, constant time afterwards, dependent on the system timer resolution (currently 10ms). Upon expiration, a signal will be generated and the timer reset. If the timer expires while the process is active (always true for
ITIMER_VIRT) the signal will be delivered immediately when generated. Otherwise the delivery will be offset by a small time dependent on the system loading.
Of the three timers, ITIMER_REAL seems most useful. The following program, ch14-timers.c, shows how to read data from a terminal, but with a timeout so that the program won’t hang forever waiting for input:
1 /* ch14-timers.c ---- demonstrate interval timers */ 2 3 #include <stdio.h> 4 #include <assert.h> 5 #include <signal.h> 6 #include <sys/time.h> 7 8 /* handler --- handle SIGALRM */ 9 10 void handler(int signo) 11 { 12 static const char msg[] = " *** Timer expired, you lose *** "; 13 14 assert(signo == SIGALRM); 15 16 write(2, msg, sizeof(msg) - 1); 17 exit(1); 18 } 19 20 /* main --- set up timer, read data with timeout */ 21 22 int main(void) 23 { 24 struct itimerval tval; 25 char string [BUFSIZ]; 26 27 timerclear(& tval.it_interval); /* zero interval means no reset of timer */ 28 timerclear(& tval.it_value); 29 30 tval.it_value.tv_sec = 10; /* 10 second timeout */ 31 32 (void) signal(SIGALRM, handler); 33 34 printf("You have ten seconds to enter your name, rank, and serial number: "); 35 36 (void) setitimer(ITIMER_REAL, & tval, NULL); 37 if (fgets(string, sizeof string, stdin) != NULL) { 38 (void) setitimer(ITIMER_REAL, NULL, NULL); /* turn off timer */ 39 /* process rest of data, diagnostic print for illustration */ 40 printf("I'm glad you are being cooperative. "); 41 } else 42 printf(" EOF, eh? We won't give up so easily! "); 43 44 exit(0); 45 }
Lines 10–18 are the signal handler for SIGALRM; the assert() call makes sure that the signal handler was set up properly. The body of the handler prints a message and exits, but it could do anything appropriate for a larger-scale program.
In the main() program, lines 27–28 clear out the two struct timeval members of the struct itimerval structure, tval. Then line 30 sets the timeout to 10 seconds. Having tval.it_interval set to 0 means there is no repeated alarm; it only goes off once. Line 32 sets the signal handler, and line 34 prints the prompt.
Line 36 sets the timer, and lines 37–42 print appropriate messages based on the user’s action. A real program would do its work at this point. What’s important to note is line 38, which cancels the timer because valid data was entered.
Note
There is a deliberate race condition between lines 37 and 38. The whole point is that if the user doesn’t enter a line within the timer’s expiration period, the signal will be delivered and the signal handler will print the “you lose” message.
Here are three successive runs of the program:
$ ch14-timers First run, enter nothing You have ten seconds to enter your name, rank, and serial number: *** Timer expired, you lose *** $ ch14-timers Second run, enter data You have ten seconds to enter your name, rank, and serial number: James Kirk, Starfleet Captain, 1234 I'm glad you are being cooperative. $ ch14-timers Third run, enter EOF(^D) You have ten seconds to enter your name, rank, and serial number: ^D EOF, eh? We won't give up so easily!
POSIX leaves it undefined as to how the interval timers interact with the sleep() function, if at all. GLIBC does not use alarm() to implement sleep(), so on GNU/Linux systems, sleep() does not interact with the interval timer. However, for portable programs, you cannot make this assumption.
The sleep() function (see Section 10.8.1, “Alarm Clocks:sleep(), alarm(), and SIGALRM,” page 382) lets a program sleep for a given number of seconds. But as we saw, it only took an integral number of seconds, making it impossible to delay for a short period, and it also can potentially interact with SIGALRM handlers. The nanosleep() function makes up for these deficiencies:
#include <time.h> POSIX TMR
int nanosleep(const struct timespec *req, struct timespec *rem);
This function is part of the optional “Timers” (TMR) extension to POSIX. The two arguments are the requested sleep time and the amount of time remaining should the sleep return early (if rem is not NULL). Both of these are struct timespec values:
struct timespec {
time_t tv_sec; /* seconds */
long tv_nsec; /* nanoseconds */
};
The tv_nsec value must be in the range 0–999,999,999. As with sleep(), the amount of time slept can be more than the requested amount of time, depending on when and how the kernel schedules processes for execution.
Unlike sleep(), nanosleep() has no interactions with any signals, making it generally safer and easier to use.
The return value is 0 if the process slept for the full time. Otherwise, it is -1, with errno indicating the error. In particular, if errno is EINTR, then nanosleep() was interrupted by a signal. In this case, if rem is not NULL, the struct timespec it points to is filled in with the remaining sleep time. This facilitates calling nanosleep() again to continue napping.
Although it looks a little strange, it’s perfectly OK to use the same structure for both parameters:
struct timespec sleeptime = /* whatever */ ; int ret; ret = nanosleep(& sleeptime, & sleeptime);
The struct timeval and struct timespec are similar to each other, differing only in the units of the second component. The GLIBC <sys/time.h> header file defines two useful macros for converting between them:
#include <sys/time.h> GLIBC
void TIMEVAL_TO_TIMESPEC(struct timeval *tv, struct timespec *ts);
void TIMEPSEC_TO_TIMEVAL(struct timespec *ts, struct timeval *tv);
Here they are:
# define TIMEVAL_TO_TIMESPEC(tv, ts) {
(ts)->tv_sec = (tv)->tv_sec;
(ts)->tv_nsec = (tv)->tv_usec * 1000;
}
# define TIMESPEC_TO_TIMEVAL(tv, ts) {
(tv)->tv_sec = (ts)->tv_sec;
(tv)->tv_usec = (ts)->tv_nsec / 1000;
}
#endif
Note
It is indeed confusing that some system calls use microsecond resolution and others use nanosecond resolution. This reason is historical: The microsecond calls were developed on systems whose hardware clocks did not have any higher resolution, whereas the nanosecond calls were developed more recently, for systems with much higher resolution clocks. C’est la vie. About all you can do is to keep your manual handy.
In Section 6.2, “Sorting and Searching Functions,” page 181, we presented functions for searching and sorting arrays. In this section, we cover a more advanced facility.
Arrays are about the simplest kind of structured data. They are easy to understand and use. They have a disadvantage, though, which is that their size is fixed at compile time. Thus, if you have more data than will fit in the array, you’re out of luck. If you have considerably less data than the size of your array, you’re wasting memory. (Although modern systems have large memories, consider the constraints of programmers writing software for embedded systems, such as microwave ovens or cell phones. On the other end of the spectrum, consider the problems of programmers dealing with very large amounts of inputs, such as weather simulations.)
The computer science field has invented numerous dynamic data structures, structures that grow and shrink in size on demand, that are more flexible than simple arrays, even arrays created and resized dynamically with malloc() and realloc(). Arrays also require re-sorting should new elements be added or removed.
One such structure is the binary search tree, which we’ll just call a “binary tree” for short. A binary tree maintains items in sorted order, inserting them in the proper place in the tree as they come in. Lookup in a binary tree is also fast, similar in time to binary search on an array. Unlike arrays, binary trees do not have to be re-sorted from scratch every time you add an item.
Binary trees have one disadvantage. In the case in which the input data is already sorted, the lookup time of binary trees reduces to that of linear searching. The technicalities of this have to do with how binary trees are managed internally, described shortly.
Some more formal data-structure terminology is now unavoidable. Figure 14.1 shows a binary tree. In computer science, trees are drawn starting at the top and growing downwards. The further down the tree you go, the higher depth you have. Each object within the tree is termed a node. At the top of the tree is the root node, with depth 0. At the bottom are the leaf nodes, with varying depth. In between the root and the leaves are zero or more internal nodes. Leaf nodes are distinguished by the fact that they have no subtrees hanging off them, whereas internal nodes have at least one subtree. Nodes with subtrees are sometimes referred to as parent nodes, with the subnodes being called children.
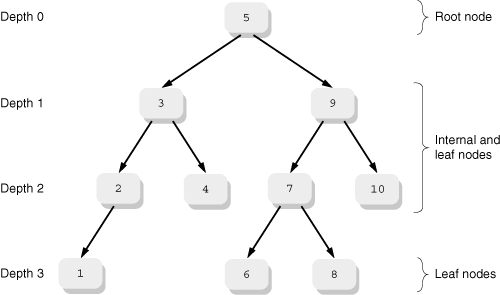
Plain binary trees are distinguished by the fact that nodes have no more than two children. (Trees with more than two nodes are useful but aren’t relevant here.) The children are referred to as the left and right children, respectively.
Binary search trees are further distinguished by the fact that the values stored in a left subchild are always less than the value stored in the node itself, and the values stored in the right subchild are always greater than the value in the node itself. This implies that there are no duplicate values within the tree. This fact also explains why trees don’t handle presorted data well: Depending on the sort order, each new data item ends up stored either to the left or to the right of the one before it, forming a simple linear list.
The operations on a binary tree are as follows:
Insertion
Lookup
Removal
Traversal
The operations just described correspond to the following functions:
#include <search.h> XSI void *tsearch(const void *key, void **rootp, int (*compare)(const void *, const void *)); void *tfind(const void *key, const void **rootp, int (*compare)(const void *, const void *)); void *tdelete(const void *key, void **rootp, int (*compare) (const void *, const void *)); typedef enum { preorder, postorder, endorder, leaf } VISIT; void twalk(const void *root, void (*action) (const void *nodep, const VISIT which, const int depth)); void tdestroy(void *root, void (*free_node) (void *nodep)); GLIBC
These functions were first defined for System V and are now formally standardized by POSIX. They follow the pattern of the others we saw in Section 6.2, “Sorting and Searching Functions,” page 181: using void * pointers for pointing at arbitrary data types, and user-provided comparison functions to determine ordering. As for qsort() and bsearch(), the comparison function must return a negative/zero/positive value when the key is compared with a value in a tree node.
These routines allocate storage for the tree nodes. To use them with multiple trees, you have to give them a pointer to a void * variable which they fill in with the address of the root node. When creating a new tree, initialize this pointer to NULL:
void *root = NULL; Root of new tree void *val; Pointer to returned data extern int my_compare(const void *, const void *); Comparison function extern char key[], key2[]; Values to insert in tree val = tsearch(key, & root, my_compare); Insert first item in tree ...fill key2 with a different value. DON'T modify root... val = tsearch(key2, & root, my_compare); Insert subsequent item in tree
As shown, the root variable should be set to NULL only the first time and then left alone after that. On each subsequent call, tsearch() uses it to manage the tree.
When the key being sought is found, both tsearch() and tfind() return pointers to the node containing it. They differ when the key is not found: tfind() returns NULL, and tsearch() inserts the new value into the tree and returns a pointer to it. The pointers returned by tsearch() and tfind() are to the internal tree nodes. They can be used as the value of root in subsequent calls in order to work on subtrees. As we will see shortly, the key value can be a pointer to an arbitrary structure; it’s not restricted to a character string as the previous example might imply.
These routines store only pointers to the data used for keys. Thus, it is up to you to manage the storage holding the data values, usually with malloc().
The tfind() and tsearch() functions search a binary tree for a given key. They take the same list of arguments: a key to search for; a pointer to the root of the tree, rootp; and compare, a pointer to a comparison function. Both functions return a pointer to the node that matches key.
Just how do you use the pointer returned by tfind() or tsearch()? What exactly does it point to, anyway? The answer is that it points to a node in the tree. This is an internal type; you can’t see how it’s defined. However, POSIX guarantees that this pointer can be cast to a pointer to a pointer to whatever you’re using for a key. Here is some fragmentary code to demonstrate, and then we show how this works:
struct employee { From Chapter 6
char lastname[30];
char firstname[30];
long emp_id;
time_t start_date;
};
/* emp_name_id_compare --- compare by name, then by ID */
int emp_name_id_compare(const void *e1p, const void *e2p)
{
...also from Chapter 6, reproduced in full later on...
}
struct employee key = { ... };
void *vp, *root;
struct employee *e;
...fill tree with data...
vp = tfind(& key, root, emp_name_id_compare);
if (vp != NULL) { /* it's there, use it */
e = *((struct employee **) vp); Retrieve stored data from tree
/* use info in *e ... */
}
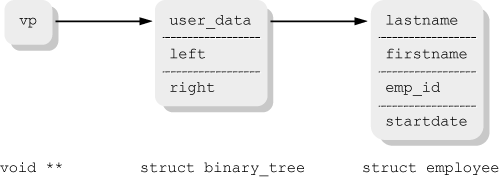
How can a pointer to a node double as a pointer to a pointer to the data? Well, consider how a binary tree’s node would be implemented. Each node maintains at least a pointer to the user’s data item and pointers to potential left and right subchildren. So, it has to look approximately like this:
struct binary_tree {
void *user_data; Pointer to user's data
struct binary_tree *left; Left subchild or NULL
struct binary_tree *right; Right subchild or NULL
...possibly other fields here...
} node;
C and C++ guarantee that fields within a struct are laid out in increasing address order. Thus, it’s true that ’& node.left < & node.right’. Furthermore, the address of the struct is also the address of its first field (in other words, ignoring type issues, ’& node == & node.user_data’).
Conceptually, then, here’s what ’e = *((struct employee **) vp);’ means:
vpis avoid*, that is, a generic pointer. It is the address of the internal tree node, but it’s also the address of the part of the node (most likely anothervoid*) that points to the user’s data.’
(struct employee **) vp’ casts the address of the internal pointer to the correct type; it remains a pointer to a pointer, but now to astruct employee. Remember that casts from one pointer type to another don’t change any values (bit patterns); they only change how the compiler treats the values for type considerations.’
* ((struct employee **) vp)’ indirects through the newly mintedstruct employee **, returning a usablestruct employee* pointer.’
e = *((struct employee **) vp)’ stores this value inefor direct use later.
The concept is illustrated in Figure 14.2.
You might consider defining a macro to simplify the use of the returned pointer:
#define tree_data(ptr, type) (*(type **) (ptr))
...
struct employee *e;
void *vp;
vp = tfind(& key, root, emp_name_id_compare);
if (vp != NULL) { /* it's there, use it */
e = tree_data(vp, struct employee);
/* use info in *e ... */
}
The twalk() function is declared as follows in <search.h>:
typedef enum { preorder, postorder, endorder, leaf } VISIT;
void twalk(const void *root,
void (*action) (const void *nodep, const VISIT which, const int depth));
The first parameter is the root of the tree (not a pointer to the root). The second is a pointer to a callback function, which is called with three arguments: a pointer to the tree node being visited, an enumerated type indicating how the given node is being visited, and an integer indicating the depth of the current node (the root is at depth 0, as explained earlier).
The use here of a callback function is the same as for nftw() (see Section 8.4.3.2, “The nftw() Callback Function,” page 263). There, the callback function is called for each object in the filesystem. Here, the callback function is called for each object stored in the tree.
There are several ways to traverse, or “walk”, a binary tree:
Left child, node itself, right child.
Node itself, left child, right child.
Left child, right child, node itself.
The GLIBC twalk() function uses the second of these: the node first, then the left child, then the right child. Each time a node is encountered, the node is said to be visited.[8] In the course of visiting a node’s child, the function must visit the node itself. Thus the values of type VISIT indicate at what stage this node is being encountered:
| Before visiting any children. |
| After visiting the first child but before visiting the second child. |
| After visiting both children. |
| This node is a leaf node, without children. |
Note
The terminology used here does not exactly match that used in formal data-structures texts. There, the terms used are inorder, preorder, and postorder, referring respectively to the three ways listed earlier for traversing a tree. Thus, twalk() uses a preorder traversal, but uses the preorder, etc., symbolic constants to indicate at what stage a node is being visited. This can be confusing.
The following program, ch14-tsearch.c, demonstrates building and traversing a tree. It reuses the struct employee structure and emp_name_id_compare() function from Section 6.2, “Sorting and Searching Functions,” page 181.
1 /* ch14-tsearch.c --- demonstrate tree management */ 2 3 #include <stdio.h> 4 #include <search.h> 5 #include <time.h> 6 7 struct employee { 8 char lastname[30]; 9 char firstname[30]; 10 long emp_id; 11 time_t start_date; 12 }; 13 14 /* emp_name_id_compare --- compare by name, then by ID */ 15 16 int emp_name_id_compare(const void *e1p, const void *e2p) 17 { 18 const struct employee *e1, *e2; 19 int last, first; 20 21 e1 = (const struct employee *) e1p; 22 e2 = (const struct employee *) e2p; 23 24 if ((last = strcmp(e1->lastname, e2->lastname)) != 0) 25 return last; 26 27 /* same last name, check first name */ 28 if ((first = strcmp(e1->firstname, e2->firstname)) != 0) 29 return first; 30 31 /* same first name, check ID numbers */ 32 if (e1->emp_id < e2->emp_id) 33 return -1; 34 else if (e1->emp_id == e2->emp_id) 35 return 0; 36 else 37 return 1; 38 } 39 40 /* print_emp --- print an employee structure during a tree walk */ 41 42 void print_emp(const void *nodep, const VISIT which, const int depth) 43 { 44 struct employee *e = *((struct employee **) nodep); 45 46 switch (which) { 47 case leaf: 48 case postorder: 49 printf("Depth: %d. Employee: ", depth); 50 printf(" %s, %s %d %s ", e->lastname, e->firstname, 51 e->emp_id, ctime(& e->start_date)); 52 break; 53 default: 54 break; 55 } 56 }
Lines 7–12 define the struct employee, and lines 14–38 define emp_name_id_compare().
Lines 40–56 define print_emp(), the callback function that prints a struct employee, along with the depth in the tree of the current node. Note the magic cast on line 44 to retrieve the pointer to the stored data.
58 /* main --- demonstrate maintaining data in binary tree */ 59 60 int main(void) 61 { 62 #define NPRES 10 63 struct employee presidents [NPRES]; 64 int i, npres; 65 char buf[BUFSIZ]; 66 void *root = NULL; 67 68 /* Very simple code to read data: */ 69 for (npres = 0; npres < NPRES && fgets(buf, BUFSIZ, stdin) != NULL; 70 npres++) { 71 sscanf(buf, "%s %s %ld %ld ", 72 presidents[npres].lastname, 73 presidents[npres].firstname, 74 & presidents[npres].emp_id, 75 & presidents[npres].start_date); 76 } 77 78 for (i = 0; i < npres; i++) 79 (void) tsearch(& presidents[i], & root, emp_name_id_compare); 80 81 twalk(root, print_emp); 82 return 0; 83 }
The goal of printing the tree is to print the contained elements in sorted order. Remember that twalk() visits intermediate nodes three times and that the left child is less than the node itself, while the right child is greater than the node. Thus, the switch statement prints the node’s information only if which is leaf, for a leaf node, or postorder, indicating that the left child has been visited, but not yet the right child.
The data used is the list of presidents, also from Section 6.2, “Sorting and Searching Functions,” page 181. To refresh your memory, the fields are last name, first name, employee number, and start time as a seconds-since-the-Epoch timestamp:
$ cat presdata.txt
Bush George 43 980013600
Clinton William 42 727552800
Bush George 41 601322400
Reagan Ronald 40 348861600
Carter James 39 222631200
The data are sorted based on last name, then first name, and then seniority. When run,[9] the program produces this output:
$ ch14-tsearch < presdata.txt
Depth: 1. Employee:
Bush, George 41 Fri Jan 20 13:00:00 1989
Depth: 0. Employee:
Bush, George 43 Sat Jan 20 13:00:00 2001
Depth: 2. Employee:
Carter, James 39 Thu Jan 20 13:00:00 1977
Depth: 1. Employee:
Clinton, William 42 Wed Jan 20 13:00:00 1993
Depth: 2. Employee:
Reagan, Ronald 40 Tue Jan 20 13:00:00 1981
Finally, you can remove items from a tree and, on GLIBC systems, delete the entire tree itself:
void *tdelete(const void *key, void **rootp,
int (*compare)(const void *, const void *));
/* GLIBC extension, not in POSIX: */
void tdestroy (void *root, void (*free_node) (void *nodep));
The arguments to tdelete() are the same as for tsearch(): the key, the address of the tree’s root, and the comparison function. If the given item is found in the tree, it is removed and tdelete() returns a pointer to the parent of the given node. Otherwise, it returns NULL. This behavior has to be managed carefully in your code if you need the original item being deleted, for example, to free its storage:
struct employee *e, key; Variable declarations void *vp, *root; ...fill in key for item to remove from tree... vp = tfind(& key, root, emp_name_id_compare); Find item to remove if (vp != NULL) { e = *((struct employee **) vp); Convert pointer free(e); Free storage } (void) tdelete(& key, & root, emp_name_id_compare); Now remove it from tree
Although not specified in the manpages or in the POSIX standard, under GNU/Linux, if you delete the item stored in the root node, the returned value is that of the new root node. For portable code, you should not necessarily rely on this behavior.
The tdestroy() function is a GLIBC extension. It allows you to destroy a whole tree. The first argument is the root of the tree. The second is a pointer to a function that releases the data pointed to by each node in the tree. If nothing needs to be done with these data (for example, they’re held in a regular array, as in our earlier example program), then this function should do nothing. Do not pass in a NULL pointer! Doing so results in a crash.
Occasionally, it’s necessary to allocate memory aligned at a certain boundary.
posix_memalign()does this. Its return value is different from that of most of the functions covered in this book: Caveat emptor.memalign()also allocates aligned memory, but not all systems support releasing that memory withfree().File locking with
fcntl()provides record locks, down to the level of the ability to lock single bytes within a file. Read locks prevent writing of the locked area, and a write lock prevents other processes from reading and writing the locked area. Locking is advisory by default, and POSIX standardizes only advisory locking. Most modern Unix systems support mandatory locking, using the setgid permission bit on the file and possibly additional filesystem mount options.On GNU/Linux, the
lockf()function acts as a wrapper around POSIX locking withfcntl(); the BSDflock()function’s locks are (on GNU/Linux) completely independent offcntl()locks. BSDflock()locks are whole-file locks only and do not work on remote filesystems. For these reasons,flock()locks are not recommended.gettimeofday()retrieves the time of day as a (seconds, microseconds) pair in astruct timeval. These values are used byutimes()to update a file’s accessed and modification times. Thegetitimer()andsetitimer()system calls use pairs ofstruct timevalsin astruct itimervalto create interval timers—alarm clocks that “go off” at a set time and continue to go off at a set interval thereafter. Three different timers provide control over the states in which the timer continues to run down.The
nanosleep()function uses astruct timespec, which specifies time in seconds and nanoseconds, to pause a process for a given amount of time. It has the happy trait of not interacting at all with the signal mechanism.The tree API is an additional set of data storage and search functions that maintains data in binary trees, the effect of which is to keep data sorted. The tree API is very flexible, allowing use of multiple trees and arbitrary data.
Write the
lockf()function, usingfcntl()to do the locking.The directory
/usr/src/linux/Documentationcontains a number of files that describe different aspects of the operating system’s behavior. Read the fileslocks.txtandmandatory.txtfor more information about Linux’s handling of file locks.Run the
ch14-lockallprogram on your system, without mandatory locking, and see if you can change the operand file.If you have a non-Linux system that supports mandatory locking, try the
ch14-lockallprogram on it.Write a function named
strftimes(), with the following API:size_t strftimes(char *buf, size_t size, const char *format, const struct timeval *tp);It should behave like the standard
strftime()function, except that it allows%qto mean “the current number of microseconds.”Using the
strftimes()function you just wrote, write an enhanced version ofdatethat accepts a format string beginning with a leading + and formats the current date and time. (See date(1).)The handling of the timeout in
ch14-timers.cis rather primitive. Rewrite the program to usesetjmp()after printing the prompt andlongjmp()from within the signal handler. Does this improve the structure or clarity of the program?We noted that
ch14-timers.ccontains a deliberate race condition. Suppose the user enters a response within the right time period, butch14-timersis suspended before the alarm can be canceled. What call can you make to cut down the size of the problem window?Draw the tree as shown by the output of
ch14-tsearchin Section 14.4.5, “Tree Traversal:twalk(),” page 557.Examine the file
/usr/share/dict/wordson a GNU/Linux system. (This is the spelling dictionary forspell; it might be in a different place on different systems.) The words exist in the file, one per line, in sorted order.First, use this
awkprogram to create a new list, in random order:$ awk '{ list[$0]++ } > END { for (i in list) print i }' /usr/share/dict/words > /tmp/wlist
Next, write two programs. Each should read the new list and store each word read into a tree and an array, respectively. The second program should use
qsort()to sort the array andbsearch()to search it.Retrieve the word ’
gravy’ from the tree or array. Time the two programs to see which one runs faster. You may need to put the word retrieval inside a loop that runs multiple times (say 1,000), to get running times that are long enough to show a difference.Use the output of
psto see how much memory each program uses.Rerun the two programs, using the original sorted dictionary file, and see how, if at all, the timing results change.
[1] The GNU/Linux fcntl(3) manpage points out that this may not be enough information; the process could be residing on another machine! There are other issues with locks held across a network; in general, using locks on filesystems mounted from remote computers is not a good idea.
[2] On GNU/Linux, lockf() is implemented as a “wrapper” around fcntl().
[4] It is fortunate that flock() is a different name from lockf(), since the semantics are different. It is also terribly confusing. Keep your manual handy.
[5] The gettimeofday(2) manpage documents a corresponding settimeofday() function, for use by the superuser (root) to set the time of day for the whole system.
[6] Unfortunately, there seems to be no current standard for the names of the members in the struct stat, making it an unportable operation.
[7] Doing profiling correctly is nontrivial; if you’re thinking about writing an interpreter, it pays to do your research first.
[8] Images come to mind of little binary data structures sitting down with each other over tea and cookies. Or at least that happens if you’ve been spending too much time in front of your computer...
[9] This output is for the U.S. Eastern Time zone.