
There’s a big world out there; hopefully, lots of its inhabitants will be interested in your application or applet. The Internet, after all, effortlessly spans the barriers between countries. On the other hand, when you write your applet in U.S. English, using the ASCII character set, you are putting up a barrier. For example, even within countries that can (more or less) function using the ASCII character set, things as basic as dates and numbers are displayed differently. To a German speaker, 3/4/95 means something different than it does to an English speaker. Or, an applet like our retirement calculator from Chapter 10 of Volume 1 could confuse people who do not use the “.” to separate the integer and fractional parts of a number. (And, of course, the directions are in English.) Now, it is true that many Internet users are able to read English, but they will certainly be more comfortable with applets or applications that are written in their own language and that present data in the format they are most familiar with. Imagine, for example, that you could write a retirement calculator applet that would change how it displays its results depending on the location of the machine that is downloading it. This kind of applet is immediately more valuable—and smart companies will recognize its value.
Java was the first language designed from the ground up to support internationalization. From the beginning, Java had the one essential feature needed for effective internationalization: it used Unicode for all strings. Unicode support makes it easy to write Java programs that manipulate strings in any one of multiple languages.
NOTE

To those who do not own the Unicode specification [1] or who are not familiar with it at all: you can see the two-byte encoding scheme it uses for various character sets by visiting www.unicode.org.
However, there is a lot more to internationalizing programs than just Unicode support since, unfortunately, it is not enough for a programming language to support Unicode. Operating systems and even browsers may not necessarily be Unicode ready. For example, it is almost always necessary to have a translation layer between the character sets and fonts of the host machine and the Unicode-centric Java Virtual Machine. Also, dates, times, currencies—even numbers are formatted differently in different parts of the world. You need an easy way to configure menu and button names, message strings, and keyboard shortcuts for different languages. You need a way to trigger the changes based on information that the ambient machine can report to your program.
None of these issues were addressed in the 1.0 release of Java. The 1.1 release contains fairly extensive support for internationalization, although not all of it is working properly, and not all of it is as easy to use as it should be.
In this chapter, you’ll see how to write internationalized Java 1.1 programs. You will see how to localize date and time, numbers and text, and graphical user interfaces, and you’ll look at the tools that the JDK and Java 1.1 offer for writing internationalized Java programs. (And, by the way you will see how to write a retirement calculator applet that can change how it displays its results depending on the location of the machine that is downloading it (English, German, and Chinese, in our case.)
NOTE
We do not discuss the tools that Java supports for creating new language-specific elements. If you need to build a Brooklyn- or Texas-centric locale, please consult the API documentation.
When looking at an application that is adapted to an international market, the most obvious difference you notice is the language. This observation is actually a bit too limiting for true internationalization: Countries can share a common language, but you still may need to do some work in order to make computer users of both countries happy [2].
In all cases, menus, button labels, and program messages will need to be translated to the local language; they may also need to be rendered in a different script. There are many more subtle differences, for example, numbers are formatted quite differently in English and in German. The number
123,456.78
should be displayed as
123.456,78
to a German user. That is, the role of the decimal point and the decimal comma separator are reversed! There are similar variations in the display of dates. In the United States, dates are somewhat irrationally displayed as month/day/year. Germany uses the more sensible order of day/month/year, whereas in China, the usage is year/month/day. Thus, the date
3/22/61
should be presented as
22.03.1961
to a German user. Of course, if the month names are written out explicitly, then the difference in languages becomes apparent. The English
March 22, 1961
should be presented as
22. März 1961
in German or
in Chinese.
You saw in Volume 1 that the java.text class has methods that can format numbers, currencies, and dates. These methods can, in fact, do much more when you give them a parameter that describes the location. To invoke these methods in a non-country-specific way, you only have to supply objects of the Locale class. A locale describes
A language
A location
Optionally, a variant
For example, in the United States, you use a locale with
language=English, location=United States.
In Germany, you use a locale with
language=German, location=Germany.
Switzerland has four official languages (German, French, Italian, and Rhaeto-Romance). A German speaker in Switzerland would want to use a locale with
language=German, location=Switzerland
This locale would make formatting work similarly to how it would work for the German locale; however, currency values would be expressed in Swiss francs, not German marks, for example.
Variants are, fortunately, rare and are needed only for exceptional or system-dependent situations. For example, the Norwegians are having a hard time agreeing on the spelling of their language (a derivative of Danish). They use two spelling rule sets, a traditional one called Bokmål and a new one called Nynorsk. The traditional spelling would be expressed as a variant
language=Norwegian, location=Norway, variant=Bokmål
It is also possible to encode platform-dependent information in the variant. To express the language and location in a concise and standardized manner, Java uses codes that were defined by the International Standards Organization. The language is expressed as a lowercase two-letter code, following ISO-639, and the country code is expressed as an uppercase two-letter code, following ISO-3166. Tables 9-1 and 9-2 show some of the most common codes.
NOTE
For a full list of ISO-639 codes, see, for example, http://www.ics.uci.edu/pub/ietf/http/related/iso639.txt. You can find a full listof the ISO-3166 codes at a number of sites, including http://www.chemie.fu-berlin.de/diverse/doc/ISO_3166.html.
Table 9-1. Common ISO-639 language codes
|
Language |
Code |
|---|---|
|
Chinese |
|
|
Danish |
|
|
Dutch |
|
|
English |
|
|
French |
|
|
Finnish |
|
|
German |
|
|
Greek |
|
|
Italian |
|
|
Japanese |
|
|
Korean |
|
|
Norwegian |
|
|
Portuguese |
|
|
Spanish |
|
|
Swedish |
|
|
Turkish |
|
Table 9-2. Common ISO-3166 country codes
|
Country |
Code |
|---|---|
|
Austria |
|
|
Belgium |
|
|
Canada |
|
|
China |
|
|
Denmark |
|
|
Finland |
|
|
Germany |
|
|
Great Britain |
|
|
Greece |
|
|
Ireland |
|
|
Italy |
|
|
Japan |
|
|
Korea |
|
|
the Netherlands |
|
|
Norway |
|
|
Portugal |
|
|
Spain |
|
|
Sweden |
|
|
Switzerland |
|
|
Taiwan |
|
|
Turkey |
|
|
United States |
|
These codes do seem a bit random, especially since some of them are derived from local languages (German = Deutsch = de, Chinese = zhongwen = zh ), but they are, at least, standardized.
To describe a locale, you concatenate the language, country code, and variant (if any) and pass this string to the constructor of the Locale class. The variant is optional.
Locale germanGermany = new Locale("de", "DE");
Local germanSwitzerland = new Locale("de", "CH");
Locale norwegianNorwayBokmål = new Locale("no", "NO", "B");If you want to specify a locale that describes a language only and not a location, use an empty string as the second argument of the constructor.
Locale german = new Locale("de");These kinds of locales can be used only for language-dependent lookups. Since the locales do not specify the location where German is spoken, you cannot use them to determine local currency and date formatting preferences.
For your convenience, Java predefines a number of locale objects:
Locale.CANADA Locale.CANADA_FRENCH Locale.CHINA Locale.FRANCE Locale.GERMANY Locale.ITALY Locale.JAPAN Locale.KOREA Locale.PRC Locale.TAIWAN Locale.UK Locale.US
Java also predefines a number of language locales that specify just a language without a location.
Locale.CHINESE Locale.ENGLISH Locale.FRENCH Locale.GERMAN Locale.ITALIAN Locale.JAPANESE Locale.KOREAN Locale.SIMPLIFIED_CHINESE Locale.TRADITIONAL_CHINESE
Besides constructing a locale or using a predefined one, you have two other methods for obtaining a locale object.
The static getDefault method of the Locale class gets the default locale as stored by the local operating system. Similarly, in an applet, the getLocale method returns the locale of the user viewing the applet. Finally, all locale-dependent utility classes can return an array of the locales they support. For example,
Locale[] supportedLocales = DateFormat.getAvailableLocales();
returns all arrays that the DateFormat class can handle. For example, in Java 1.1, the DateFormat class knows how to format dates in Chinese but not in Vietnamese. Therefore, the getAvailableLocales() returns the Chinese locales but no Vietnamese ones.
Once you have a locale, what can you do with it? Not much, as it turns out. The only useful methods in the Locale class are the ones for identifying the language and country codes. The most important one is getDisplayName . It returns a string describing the locale. This string does not contain the cryptic two-letter codes, but it is in a form that can be presented to a user, such as
German (Switzerland)
Actually, there is a problem here. The display name is issued in the default locale. That may not be appropriate. If your user already selected German as the preferred language, you probably want to present the string in German. You can do just that by giving the German locale as a parameter: The code
Locale loc = new Locale("de", "CH");
System.out.println(loc.getDisplayName(Locale.GERMAN));prints out
Deutsch (Schweiz)
But the real reason you need a Locale object is to feed it to locale-aware methods. For example, the toLowerCase and toUpperCase methods of the String class can take an argument of type Locale because the rules for forming uppercase letters differ by locale. In France, accents are generally dropped for uppercase letters. But in French-speaking Canada, they are retained. For example, the upper case of “étoile” (star) in France would be “ETOILE,” but in Canada it would be “ÉTOILE.”
String star = "étoile"; String fr = star.toUpperCase(Locale.FRANCE)); // should return "ETOILE" String ca = star.toUpperCase(Locale.CANADA_FRENCH)); // returns "ÉTOILE"
Well, not quite: actually, this is the way it is supposed to work, but in the version of Java 1.1 that we have, the toUpperCase method does not pay attention to the French locale. Still, we hope we have given you an idea of what you will be able to do with a Locale object. (Actually, you can give a Locale object to many other methods that carry out locale-specific tasks. You will see many examples in the following sections.)
java.util.Locale

static Locale getDefault()returns the default locale.
static void setDefault(Locale)sets the default locale.
String getDisplayName()returns a name describing the locale, expressed in the current locale.
String getDisplayName(Locale l)returns a name describing the locale, expressed in the given locale.
String getLanguage()returns the language code, a lowercase two-letter ISO-639 code.
String getDisplayLanguage()returns the name of the language, expressed in the current locale.
String getDisplayLanguage(Locale l)returns the name of the language, expressed in the given locale.
String getCountry()returns the country code as an uppercase two-letter ISO-3166 code.
String getDisplayCountry()returns the name of the country, expressed in the current locale.
String getDisplayCountry(Locale l)returns the name of the country, expressed in the given locale.
String getVariant()returns the variant string.
String getDisplayVariant()returns the name of the variant, expressed in the current locale.
String getDisplayVariant(Locale l)returns the name of the variant, expressed in the given locale.
String toString()returns a description of the locale, with the language, country, and variant separated by underscores (e.g.,
"de_CH").
We already mentioned how number and currency formatting is highly locale dependent. Java supplies a collection of formatter objects that can format and parse numeric values in the java.text class. You go through the following steps to format a number for a particular locale.
Get the locale object, as described in the preceding section.
Use a “factory method” to obtain a formatter object.
Use the formatter object for formatting and parsing.
The factory methods are static methods of the NumberFormat class that take a Locale argument. There are three factory methods: getNumberInstance, getCurrencyInstance, and getPercentInstance . These objects can format and parse numbers, currency amounts, and percentages, respectively. For example, here is how you can format a currency value in German:
Locale loc = new Locale("de", "DE");
NumberFormat currFmt = NumberFormat.getCurrencyInstance(loc);
double amt = 123456.78;
System.out.println(currFmt.format(amt));This code prints
123.456,78 DM
Note that the currency symbol is DM and that it is placed at the end of the string. Also, note the reversal of decimal points and decimal commas.
Conversely, if you want to read in a number that was entered or stored using the conventions of a certain locale, then you use the parse method, which automatically uses the default locale. For example, the following code parses the value that the user typed into a text field. The parse method, can deal with decimal points and commas, as well as digits in other typefaces.
TextField inputField; . . . NumberFormat fmt = NumberFormat.getNumberInstance(); // get number formatter for default locale Number input = fmt.parse(inputField.getText().trim()); double x = input.doubleValue();
The return type of parse is the abstract type Number . The returned object is either a Double or a Long wrapper object, depending on whether the parsed number was a floating-point number. If you don’t care about the distinction, you can simply use the doubleValue method of the Numbe r class to retrieve the wrapped number.
If the number is not in the correct form, the method throws a ParseException . For example, leading white space in the string is not allowed. (Call trim to remove it.) However, any characters that follow the number in the string are simply ignored, so no exception is thrown.
Note that the classes returned by the getXxxInstance factory methods are not actually of type NumberFormat . The NumberFormat type is an abstract class, and the actual formatters belong to one of its subclasses. The factory methods merely know how to locate the object that belongs to a particular locale. It is quite obvious that it takes effort to produce a formatter object for a particular locale. So, of course, Java 1.1 supports only a limited number of localized formatters—more should follow over time, and you can, of course, write your own.
You can get a list of the currently supported locales with the static getAvailableLocales method. That method returns an array of the locales for which number formatter objects can be obtained.
The sample program for this section lets you experiment with number formatters (see Figure 9-1). The list box at the top of the figure contains all locales with number formatters. You can choose between number, currency, and percentage formatters. Each time you make another choice, the number in the text field is reformatted. If you go through a few locales, then you get a good impression of how many ways there are to format a number or currency value. You can also type a different number and click on the Parse button to call the parse method, which tries to parse what you entered. If your input is successfully parsed, then it is passed to format and the result is displayed. If parsing fails, then a “Parse error” message is displayed in the text box.
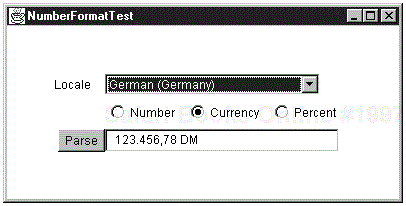
The code is shown in Example 9-1. It is fairly straightforward. In the constructor, we call NumberFormat.getAvailableLocales . For each locale, we call getDisplayName, and we fill a choice component with the strings it returns. Whenever the user selects another locale or clicks on one of the radio buttons, we create a new formatter object and update the text field. When the user clicks on the Parse button, we call the parse method to do the actual parsing, based on the locale selected.
Example 9-1. NumberFormatTest.java
import java.awt.*;
import java.awt.event.*;
import java.text.*;
import java.util.*;
import corejava.*;
public class NumberFormatTest extends CloseableFrame
implements ActionListener, ItemListener
{ public NumberFormatTest()
{ Panel p = new Panel();
addCheckbox(p, "Number", cbGroup, true);
addCheckbox(p, "Currency", cbGroup, false);
addCheckbox(p, "Percent", cbGroup, false);
setLayout(new GridBagLayout());
GridBagConstraints gbc = new GridBagConstraints();
gbc.fill = GridBagConstraints.NONE;
gbc.anchor = GridBagConstraints.EAST;
add(new Label("Locale"), gbc, 0, 0, 1, 1);
add(p, gbc, 1, 1, 1, 1);
add(parseButton, gbc, 0, 2, 1, 1);
gbc.anchor = GridBagConstraints.WEST;
add(localeChoice, gbc, 1, 0, 1, 1);
add(numberText, gbc, 1, 2, 1, 1);
locales = NumberFormat.getAvailableLocales();
for (int i = 0; i < locales.length; i++)
localeChoice.add(locales[i].getDisplayName());
localeChoice.select(
Locale.getDefault().getDisplayName());
currentNumber = 123456.78;
updateDisplay();
localeChoice.addItemListener(this);
parseButton.addActionListener(this);
}
public void add(Component c, GridBagConstraints gbc,
int x, int y, int w, int h)
{ gbc.gridx = x;
gbc.gridy = y;
gbc.gridwidth = w;
gbc.gridheight = h;
add(c, gbc);
}
public void addCheckbox(Panel p, String name,
CheckboxGroup g, boolean v)
{ Checkbox c = new Checkbox(name, g, v);
c.addItemListener(this);
p.add(c);
}
public void actionPerformed(ActionEvent evt)
{ if (evt.getSource() == parseButton)
{ String s = numberText.getText();
try
{ Number n = currentNumberFormat.parse(s);
if (n != null)
{ currentNumber = n.doubleValue();
updateDisplay();
}
else
{ numberText.setText("Parse error: " + s);
}
}
catch(ParseException e)
{ numberText.setText("Parse error: " + s);
}
}
}
public void itemStateChanged(ItemEvent evt)
{ if (evt.getStateChange() == ItemEvent.SELECTED)
updateDisplay();
}
public void updateDisplay()
{ Locale currentLocale = locales[
localeChoice.getSelectedIndex()];
currentNumberFormat = null;
String s = cbGroup.getSelectedCheckbox().getLabel();
if (s.equals("Number"))
currentNumberFormat
= NumberFormat.getNumberInstance(currentLocale);
else if (s.equals("Currency"))
currentNumberFormat
= NumberFormat.getCurrencyInstance(currentLocale);
else if (s.equals("Percent"))
currentNumberFormat
= NumberFormat.getPercentInstance(currentLocale);
String n = currentNumberFormat.format(currentNumber);
numberText.setText(n);
}
public static void main(String[] args)
{ Frame f = new NumberFormatTest();
f.setSize(400, 200);
f.show();
}
private Locale[] locales;
private double currentNumber;
private Choice localeChoice = new Choice();
private Button parseButton = new Button("Parse");
private TextField numberText = new TextField(30);
private CheckboxGroup cbGroup = new CheckboxGroup();
private NumberFormat currentNumberFormat;
}java.text.NumberFormat
static Locale[] getAvailableLocales()returns an array of
Localeobjects for whichNumberFormatformatters are available.static NumberFormat getNumberInstance()static NumberFormat getNumberInstance(Locale l)static NumberFormat getCurrencyInstance()static NumberFormat getCurrencyInstance(Locale l)static NumberFormat getPercentInstance()static NumberFormat getPercentInstance(Locale l)return a formatter for numbers, currency amounts, or percentage values for the current locale or for the given locale.
String format(double x)String format(long x)return the string resulting from formatting the given floating-point number or integer.
Number parse(String s)parses the given string and returns the number value, as a
Doubleif the input string described a floating-point number, and as aLongotherwise. The beginning of the string must contain a number; no leading white space is allowed. The number can be followed by other characters, which are ignored. Throws aParseExceptionif parsing was not successful.void setParseIntegerOnly(boolean)/booleangetParseIntegerOnly()sets or gets a flag to indicate whether this formatter should parse only integer values.
void setGroupingUsed(boolean)/boolean isGroupingUsed()sets or gets a flag to indicate whether this formatter emits and recognizes decimal separators (such as
100,000).void setMinimumIntegerDigits(int)/intgetMinimumIntegerDigits()void setMaximumIntegerDigits(int)/intgetMaximumIntegerDigits()void setMinimumFractionDigits(int)/intgetMinimumFractionDigits()void setMaximumFractionDigits(int)/intgetMaximumFractionDigits()]set or get the maximum or minimum number of digits allowed in the integer or fractional part of a number.
When you are formatting date and time, there are four locale-dependent issues you need to worry about:
The names of months and weekdays should be presented in the local language.
There will be local preferences for the order of year, month, and day.
The Gregorian calendar may not be the local preference for expressing dates.
The time zone of the location must be taken into account.
The Java DateFormat class handles these issues. It is easy to use and quite similar to the NumberFormat class. First, you get a locale. You can use the default locale or call the static getAvailableLocales method to obtain an array of locales that support date formatting. Then, you call one of the three factory methods:
fmt = DateFormat.getDateInstance(dateStyle, loc); fmt = DateFormat.getTimeInstance(timeStyle, loc); fmt = DateFormat.getDateTimeInstance(dateStyle, timeStyle, loc);
To specify the desired style, these factory methods have a parameter which is one of the following constants:
DateFormat.DEFAULT DateFormat.FULL (e.g., Thursday, September 18, 1997 8:42:46 o'clock AM PDT for the U.S. locale) DateFormat.LONG (e.g., September 18, 1997 8:42:46 AM PDT for the U.S. locale) DateFormat.MEDIUM (e.g., 18-Sep-97 8:42:46 AM for the U.S. locale) DateFormat.SHORT (e.g., 9/18/97 8:42 AM for the U.S. locale)
The factory method returns a formatting object that you can then use to format dates.
Date now = new Date(); String s = fmt.format(now);
Just as with the NumberFormat class, you can use the parse method to parse a date that the user typed. For example, the following code parses the value that the user typed into a text field.
TextField inputField; . . . DateFormat fmt = DateFormat.getDateInstance(DateFormat.MEDIUM); // get date formatter for default locale Date input = fmt.parse(inputField.getText().trim());
If the number was not typed correctly, this code throws a ParseException . Note that leading white space in the string is not allowed here, either. You should again call trim to remove it. However, any characters that follow the number in the string will again be ignored. Unfortunately, the user must type the date exactly in the expected format. For example, if the format is set to MEDIUM in the U.S. locale, then dates are expected to look like
18-Sep-97
If the user types
September 18, 1997
or
9/18/97
then a parse error results.
A lenient flag interprets dates leniently. For example, February 30, 1999 will be automatically converted to March 2, 1999 . This seems dangerous, but, unfortunately, it is the default. You should probably turn off this feature. The calendar object that is used to interpret the parsed date will throw an IllegalArgumentException when the user enters an invalid day/month/year combination.
Example 9-2 shows the DateFormat class in action. You can select a locale and see how the date and time are formatted in different places around the world. If you see question-mark characters in the output, then you don’t have the fonts installed for displaying characters in the local language. For example, if you pick a Chinese locale, the date may be expressed as
1997?9?19?
Figure 9-2 shows the program running under Chinese Windows; as you can see, it correctly displays the output.
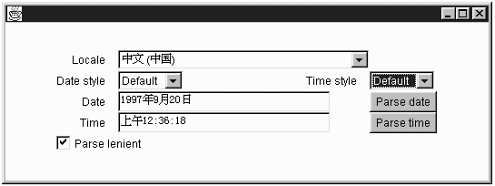
You can also experiment with parsing. Type in a date or time, click the Parse lenient checkbox if desired, and click on the Parse date or Parse time button.
Example 9-2. DateFormatTest.java
import java.awt.*;
import java.awt.event.*;
import java.text.*;
import java.util.*;
import corejava.*;
public class DateFormatTest extends CloseableFrame
implements ActionListener, ItemListener
{ public DateFormatTest()
{ setLayout(new GridBagLayout());
GridBagConstraints gbc = new GridBagConstraints();
gbc.fill = GridBagConstraints.NONE;
gbc.anchor = GridBagConstraints.EAST;
add(new Label("Locale"), gbc, 0, 0, 1, 1);
add(new Label("Date style"), gbc, 0, 1, 1, 1);
add(new Label("Time style"), gbc, 2, 1, 1, 1);
add(new Label("Date"), gbc, 0, 2, 1, 1);
add(new Label("Time"), gbc, 0, 3, 1, 1);
gbc.anchor = GridBagConstraints.WEST;
add(localeChoice, gbc, 1, 0, 2, 1);
add(dateStyleChoice, gbc, 1, 1, 1, 1);
add(timeStyleChoice, gbc, 3, 1, 1, 1);
add(dateText, gbc, 1, 2, 2, 1);
add(dateParseButton, gbc, 3, 2, 1, 1);
add(timeText, gbc, 1, 3, 2, 1);
add(timeParseButton, gbc, 3, 3, 1, 1);
add(lenientCheckbox, gbc, 0, 4, 2, 1);
locales = DateFormat.getAvailableLocales();
for (int i = 0; i < locales.length; i++)
localeChoice.add(locales[i].getDisplayName());
localeChoice.select(
Locale.getDefault().getDisplayName());
currentDate = new Date();
currentTime = new Date();
updateDisplay();
localeChoice.addItemListener(this);
dateStyleChoice.addItemListener(this);
timeStyleChoice.addItemListener(this);
dateParseButton.addActionListener(this);
timeParseButton.addActionListener(this);
}
public void add(Component c, GridBagConstraints gbc,
int x, int y, int w, int h)
{ gbc.gridx = x;
gbc.gridy = y;
gbc.gridwidth = w;
gbc.gridheight = h;
add(c, gbc);
}
public void actionPerformed(ActionEvent evt)
{ if (evt.getSource() == dateParseButton)
{ String d = dateText.getText();
try
{ currentDateFormat.setLenient
(lenientCheckbox.getState());
Date date = currentDateFormat.parse(d);
currentDate = date;
updateDisplay();
}
catch(ParseException e)
{ dateText.setText("Parse error: " + d);
}
catch(IllegalArgumentException e)
{ dateText.setText("Argument error: " + d);
}
}
else if (evt.getSource() == timeParseButton)
{ String t = timeText.getText();
try
{ currentDateFormat.setLenient
(lenientCheckbox.getState());
Date date = currentTimeFormat.parse(t);
currentTime = date;
updateDisplay();
}
catch(ParseException e)
{ timeText.setText("Parse error: " + t);
}
catch(IllegalArgumentException e)
{ timeText.setText("Argument error: " + t);
}
}
}
public void itemStateChanged(ItemEvent evt)
{ if (evt.getSource() instanceof Choice)
{ if (evt.getStateChange() == ItemEvent.SELECTED)
updateDisplay();
}
}
public void updateDisplay()
{ Locale currentLocale = locales[
localeChoice.getSelectedIndex()];
int dateStyle = dateStyleChoice.getValue();
currentDateFormat
= DateFormat.getDateInstance(dateStyle,
currentLocale);
String d = currentDateFormat.format(currentDate);
dateText.setText(d);
int timeStyle = timeStyleChoice.getValue();
currentTimeFormat
= DateFormat.getTimeInstance(timeStyle,
currentLocale);
String t = currentTimeFormat.format(currentTime);
timeText.setText(t);
}
public static void main(String[] args)
{ Frame f = new DateFormatTest();
f.setSize(400, 200);
f.show();
}
private Locale[] locales;
private Date currentDate;
private Date currentTime;
private DateFormat currentDateFormat;
private DateFormat currentTimeFormat;
private Choice localeChoice = new Choice();
private EnumChoice dateStyleChoice
= new EnumChoice(DateFormat.class,
new String[] { "Default", "Full", "Long",
"Medium", "Short" });
private EnumChoice timeStyleChoice
= new EnumChoice(DateFormat.class,
new String[] { "Default", "Full", "Long",
"Medium", "Short" });
private Button dateParseButton = new Button("Parse date");
private Button timeParseButton = new Button("Parse time");
private TextField dateText = new TextField(30);
private TextField timeText = new TextField(30);
private TextField parseText = new TextField(30);
private Checkbox lenientCheckbox
= new Checkbox("Parse lenient", true);
}
class EnumChoice extends Choice
{ public EnumChoice(Class cl, String[] labels)
{ for (int i = 0; i < labels.length; i++)
{ String label = labels[i];
String name = label.toUpperCase().replace(' ', '_'),
int value = 0;
try
{ java.lang.reflect.Field f = cl.getField(name);
value = f.getInt(cl);
}
catch(Exception e)
{ label = "(" + label + ")";
}
table.put(label, new Integer(value));
add(label);
}
select(labels[0]);
}
public int getValue()
{ return ((Integer)table.get(getSelectedItem())).intValue();
}
private Hashtable table = new Hashtable();
}java.text.DateFormat
static Locale[] getAvailableLocales()returns an array of
Localeobjects for whichDateFormatformatters are available.static DateFormat getDateInstance(int dateStyle)static DateFormat getDateInstance(int dateStyle, Locale l)static DateFormat getTimeInstance(int timeStyle)static DateFormat getDateTimeInstance(int timeStyle, Locale l)static DateFormat getDateTimeInstance(int dateStyle, int timeStyle)static DateFormat getDateTimeInstance(int dateStyle, int timeStyle, Locale l)return a formatter for date, time, or date and time for the default locale or the given locale.
Parameters:
dateStyle, timeStyleone of
DEFAULT,FULL,LONG,MEDIUM,SHORTString format(Date d)returns the string resulting from formatting the given date/time.
Date parse(String s)parses the given string and returns the date/time described in it. The beginning of the string must contain a date or time; no leading white space is allowed. The date can be followed by other characters, which are ignored. Throws a
ParseExceptionif parsing was not successful.void setLenient(boolean)/boolean isLenient()sets or gets a flag to indicate whether parsing should be lenient or strict. In lenient mode, dates such as
February 30, 1999will be automatically converted toMarch 2, 1999. The default is lenient mode.void setCalendar(Calendar)/Calendar getCalendar()sets or gets the calendar object used for extracting year, month, day, hour, minute, and second from the
Dateobject. Use this method if you do not want to use the default calendar for the locale (usually the Gregorian calendar).void setTimeZone(TimeZone)/TimeZone getTimeZone()sets or gets the time zone object used for formatting the time. Use this method if you do not want to use the default time zone for the locale. The default time zone is the time zone of the default locale, as obtained from the operating system. For the other locales, it is the preferred time zone in the geographical location.
setNumberFormat(NumberFormat)/NumberFormat getNumberFormat()sets or gets the number format used for formatting the numbers used for representing year, month, day, hour, minute, and second.
There are many localization issues to deal with when you display even the simplest text in an internationalized application. In this section, we work on the presentation and manipulation of text strings. For example, the sorting order for strings is clearly locale specific. Obviously, you also need to localize the text itself: directions, labels, and messages will all need to be translated. (Later in this chapter, you’ll see how to build resource bundles. These let you collect a set of message strings that work for a particular language.)
Sorting strings in alphabetical order is easy when the strings are made up of only English ASCII characters. You just compare the strings with the compareTo method of the String class. The value of
a.compareTo(b)
is a negative number if a is lexicographically less than b, 0 if they are identical, and positive otherwise.
Unfortunately, unless all your words are in uppercase English ASCII characters, this method is useless. The problem is that the compareTo method in Java uses the values of the Unicode character to determine the ordering. For example, lowercase characters have a higher Unicode value than do uppercase characters, and accented characters have even higher values. This leads to absurd results; for example, the following five strings are ordered according to Java’s compareTo method:
America Zulu ant zebra Ångstrom
For dictionary ordering, you want to consider upper case and lower case to be equivalent. To an English speaker, the sample list of words would be ordered as
America Ångstrom ant zebra Zulu
However, that order would not be acceptable to a Danish user. In Danish, the letter Å is a different letter than the letter A, and it is collated after the letter Z! That is, a Danish user would want the words to be sorted as
America ant zebra Zulu Ångstrom
Fortunately, once you are aware of the problem, collation is quite easy in Java.
As always, you start by obtaining a Locale object. Then, you call the getInstance factory method to obtain a Collator object. Finally, you use the compare method of the collator, not the compareTo method of the String class, whenever you want to sort strings.
Locale loc = . . .; Collator coll = Collator.getInstance(loc); if (coll.compare(a, b) < 0) . . .;
To show how the compare method is used for collation, here is a simple, inefficient insertion sort that is location sensitive:
Vector string = . . .;
Vector sortedStrings = new Vector();
for (int i = 0; i < strings.size(); i++)
{ boolean inserted = false;
String a = (String)strings.elementAt(i);
for (int j = 0; j < sortedStrings.size()
&& !inserted; j++)
{ String b = (String)sortedStrings.elementAt(j);
int d = coll.compare(a, b);
if (d <= 0)
{ sortedStrings.insertElementAt(a, j);
inserted = true;
}
}
if (!inserted) sortedStrings.addElement(a);
}The sample code at the end of this section lets you collate a list of words in all locales that support collation. (As before, you can obtain an array of locales with the getAvailableLocales method.) The compare method is used to sort a vector of strings with this code.
You can set a collator’s strength to select how selective it should be. Character differences are classified as primary, secondary, and tertiary. For example, in English, the difference between “A” and “Z” is considered primary, the difference between “A” and “Å” is secondary, and between “A” and “a” is tertiary.
By setting the collator’s strength to Collator.PRIMARY, you tell it to pay attention only to primary differences. By setting it to Collator.SECONDARY, the collator will take secondary differences into account. That is, two strings will be more likely to be considered different when the strength is set to “secondary.” For example,
// assuming English locale
String a = "Angstrom";
String b = "Ångstrom";
coll.setStrength(Collator.PRIMARY);
if (coll.compare(a, b) == 0) System.out.print("same");
else System.out.print("different");
// will print "same"
coll.setStrength(Collator.SECONDARY);
if (coll.compare(a, b) == 0) System.out.print("same");
else System.out.print("different");
// will print "different"Table 9-3 shows how a sample set of strings is sorted with the three collation strengths. Note that the strength indicates only whether two strings are considered identical.
Table 9-3. Collation with different strengths
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
|
|
|
Finally, there is one technical setting, the decomposition mode. The default, “canonical decomposition,” is appropriate for most use. If you choose “no decomposition,” then accented characters are not decomposed into their base form + accent. This option is faster, but it gives correct results only when the input does not contain accented characters. (It never makes sense to sort accented characters by their Unicode values.) Finally, “full decomposition” analyzes Unicode variants, that is, Unicode characters that ought to be considered identical. For example, Japanese displays have two ways of showing English characters, called half-width and full-width. The half-width characters have normal character spacing, whereas the full-width characters are spaced in the same grid as the ideographs. (One could argue that this is a presentation issue and it should not have resulted in different Unicode characters, but we don’t make the rules.) With full decomposition, half-width and full-width variants of the same letter are recognized as identical.
It is wasteful to have the collator decompose a string many times. If one string is compared many times against other strings, then you can save the decomposition in a collation key object. The getCollationKey method returns a CollationKey object that you can use for further, faster comparisons. Here is an example:
String a = . . .;
CollationKey aKey = coll.getCollationKey(a);
if (aKey.compareTo(coll.getCollationKey(b) == 0) // fast
comparison
. . .The program in Example 9-3 lets you experiment with collation order. Type a word into the text field and click on Add to add it to the list of words. Each time you add another word or change the locale, strength, or decomposition mode, the list of words is sorted again. An = sign indicates words that are considered identical (see Figure 9-3).
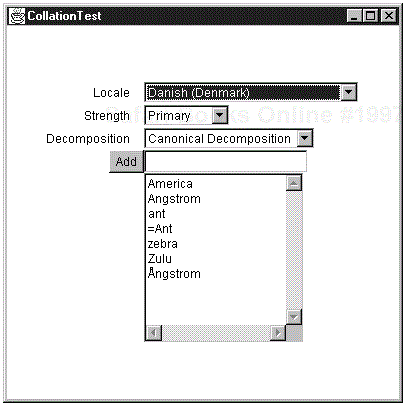
There are a few interesting points about the code you may want to keep in mind. First, a vector, strings, keeps the current collection of input strings. The sort method sorts them into a vector, sortedStrings . Next, we call the updateDisplay method whenever a word is added or a choice has changed, which, in turn, calls sort and then sends the sorted strings to the text area. The only mysterious feature about the code is probably the EnumChoice class. We used this class to solve the following technical problem. We wanted to fill a choice box with the values Primary, Secondary, and Tertiary, and then automatically convert the user’s selection to the integer value Collation.PRIMARY, Collation.SECONDARY and Collation.TERTIARY . To do this, we convert the user’s choice to upper case, replace all spaces with underscores, and then use reflection to find the value of the static field with that name. (See Chapter 5 of Volume 1 for more details about reflection.)
Example 9-3. CollationTest.java
import java.io.*;
import java.awt.*;
import java.awt.event.*;
import java.text.*;
import java.util.*;
import corejava.*;
public class CollationTest extends CloseableFrame
implements ActionListener, ItemListener
{ public CollationTest()
{ setLayout(new GridBagLayout());
GridBagConstraints gbc = new GridBagConstraints();
gbc.fill = GridBagConstraints.NONE;
gbc.anchor = GridBagConstraints.EAST;
add(new Label("Locale"), gbc, 0, 0, 1, 1);
add(new Label("Strength"), gbc, 0, 1, 1, 1);
add(new Label("Decomposition"), gbc, 0, 2, 1, 1);
add(addButton, gbc, 0, 3, 1, 1);
gbc.anchor = GridBagConstraints.WEST;
add(localeChoice, gbc, 1, 0, 1, 1);
add(strengthChoice, gbc, 1, 1, 1, 1);
add(decompositionChoice, gbc, 1, 2, 1, 1);
add(newWord, gbc, 1, 3, 1, 1);
add(sortedWords, gbc, 1, 4, 1, 1);
locales = Collator.getAvailableLocales();
for (int i = 0; i < locales.length; i++)
localeChoice.add(locales[i].getDisplayName());
localeChoice.select(
Locale.getDefault().getDisplayName());
strings.addElement("America");
strings.addElement("ant");
strings.addElement("Zulu");
strings.addElement("zebra");
strings.addElement("Ångstrom");
strings.addElement("Angstrom");
strings.addElement("Ant");
updateDisplay();
addButton.addActionListener(this);
localeChoice.addItemListener(this);
strengthChoice.addItemListener(this);
decompositionChoice.addItemListener(this);
}
public void add(Component c, GridBagConstraints gbc,
int x, int y, int w, int h)
{ gbc.gridx = x;
gbc.gridy = y;
gbc.gridwidth = w;
gbc.gridheight = h;
add(c, gbc);
}
public void actionPerformed(ActionEvent evt)
{ String arg = evt.getActionCommand();
if (arg.equals("Add"))
{ strings.addElement(newWord.getText());
updateDisplay();
}
}
public void updateDisplay()
{ Locale currentLocale = locales[
localeChoice.getSelectedIndex()];
currentCollator
= Collator.getInstance(currentLocale);
currentCollator.setStrength(strengthChoice.getValue());
currentCollator.setDecomposition(
decompositionChoice.getValue());
sort();
sortedWords.setText("");
for (int i = 0; i < sortedStrings.size(); i++)
sortedWords.append(sortedStrings.elementAt(i) + "
");
}
public void sort()
{ /* this really should be replaced with a better
sort algorithm
*/
sortedStrings = new Vector();
for (int i = 0; i < strings.size(); i++)
{ boolean inserted = false;
String s = (String)strings.elementAt(i);
for (int j = 0; j < sortedStrings.size()
&& !inserted; j++)
{ int d = currentCollator.compare(s,
(String)sortedStrings.elementAt(j));
if (d < 0)
{ sortedStrings.insertElementAt(s, j);
inserted = true;
}
else if (d == 0)
{ sortedStrings.insertElementAt("=" + s, j + 1);
inserted = true;
}
}
if (!inserted) sortedStrings.addElement(s);
}
}
public void itemStateChanged(ItemEvent evt)
{ if (evt.getSource() instanceof Choice)
{ if (evt.getStateChange() == ItemEvent.SELECTED)
updateDisplay();
}
}
public static void main(String[] args)
{ Frame f = new CollationTest();
f.setSize(400, 400);
f.show();
}
private Locale[] locales;
private Vector strings = new Vector();
private Vector sortedStrings = new Vector();
private Collator currentCollator;
private Choice localeChoice = new Choice();
private EnumChoice strengthChoice
= new EnumChoice(Collator.class,
new String[] { "Primary", "Secondary", "Tertiary" });
private EnumChoice decompositionChoice
= new EnumChoice(Collator.class,
new String[] { "Canonical Decomposition",
"Full Decomposition", "No Decomposition" });
private TextField newWord = new TextField(20);
private TextArea sortedWords = new TextArea(10, 20);
private Button addButton = new Button("Add");
}
class EnumChoice extends Choice
{ public EnumChoice(Class cl, String[] labels)
{ for (int i = 0; i < labels.length; i++)
{ String label = labels[i];
String name = label.toUpperCase().replace(' ', '_'),
int value = 0;
try
{ java.lang.reflect.Field f = cl.getField(name);
value = f.getInt(cl);
}
catch(Exception e)
{ label = "(" + label + ")";
}
table.put(label, new Integer(value));
add(label);
}
select(labels[0]);
}
public int getValue()
{ return ((Integer)table.get(getSelectedItem())).intValue();
}
private Hashtable table = new Hashtable();
}java.text.Collator
static Locale[] getAvailableLocales()returns an array of
Localeobjects for whichCollatorobjects are available.static Collator getInstance()static Collator getInstance(Locale l)return a collator for the default locale or the given locale.
int compare(String a, String b)returns a negative value if
acomes beforeb, 0 if they are considered identical, a positive value otherwise.boolean equals(String a, String b)returns
trueif they are considered identical,falseotherwise.void setStrength(int strength) / int getStrength()sets or gets the strength of the collator. Stronger collators tell more words apart. Strength values are
Collator.PRIMARY,Collator.SECONDARY, andCollator.TERTIARY.void setDecomposition(int decomp) / int getDecompositon()sets or gets the decomposition mode of the collator. The more a collator decomposes a string, the more strict it will be in deciding whether two strings ought to be considered identical. Decomposition values are
Collator.NO_DECOMPOSITION, Collator.CANONICAL_DECOMPOSITION, andCollator.FULL_DECOMPOSITION.CollationKey getCollationKey(String a)returns a collation key that contains a decomposition of the characters in a form that can be quickly compared against another collation key.
Consider a “sentence” in an arbitrary language: Where are its “words”? Answering this question sounds trivial, but once you deal with multiple languages, then just as with collation, it isn’t as simple as you might think. Actually the situation is even worse than you might think—consider the problem of determining where a character starts and ends. If you have a string such as "Hello", then it is trivial to break it up into five individual characters: H|e|l|l|o . But accents throw a monkey wrench into this simple model. There are two ways of describing an accented character such as ä, namely, the character ä itself (Unicode u00E4 ) or the character a followed by a combining diaeresis ¨ (Unicode u0308 ). That is, the string with four Unicode characters Ba¨r is a sequence of three logical characters: B|a¨|r . This situation is still relatively easy; it gets much more complex for Asian languages such as the Korean Hangul script.
What about word breaks? Word breaks, of course, are at the beginning and the end of a word. In English, this is simple: sequences of characters are words. For example, the word breaks in
The quick, brown fox jump-ed over the lazy dog.
are
The| |quick|,| |brown| |fox| |jump-ed| |over| |the| |lazy| |dog.|
(The hyphen in jump-ed indicates a soft hyphen.)
Line boundaries are positions where a line can be broken on the screen or in printed text. In English text, this is relatively easy. Lines can be broken before a word or after a hyphen. For example, the line breaks in our sample sentence are
The |quick, |brown |fox |jump-|ed |over |the |lazy |dog.|
Note that line breaks are the points where a line can be broken, not the points where the lines are actually broken.
Determining character, word, and line boundaries is simple for European and Asian ideographic scripts, but it is quite complex for others, such as Devanagari, the script used to write classical Sanskrit and modern Hindi.
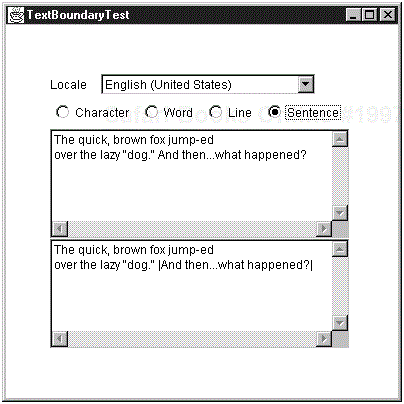
Finally, you will want to know about breaks between sentences. In English, for example, sentence breaks occur after periods, exclamation marks, and question marks. Use the BreakIterator class to find out where you can break text up into components such as characters, words, lines, and sentences. You would use these classes when writing code for editing, displaying, and printing text.
Luckily, the break iterator class does not blindly break sentences at every period. It knows about the rules for periods inside quotation marks, and about “…” ellipses. For example, the string
The quick, brown fox jumped over the lazy "dog." And then . . . what happened?
is broken into two sentences.
The quick, brown fox jumped over the lazy "dog." |And then . . . what happened?|
Here is an example of how to program with break iterators. As always, you first get a break iterator with a static factory method. You can request one of four iterators to iterate through characters, words, lines, or sentences. Note that once you have a particular iterator object, such as one for sentences, it can iterate only through sentences. More generally, a break iterator can iterate only through the construct for which it was created. For example, the following code lets you analyze individual words:
Locale loc = . . .; BreakIterator wordIter = BreakIterator.getWordInstance(loc);
Once you have an iterator, you give it a string to iterate through.
String msg = " The quick, brown fox"; wordIter.setText(msg);
Then, call the first method to get the offset of the first boundary.
int f = wordIter.first(); // returns 3
In our example, this call to first returns a 3—which is the offset of the first space inside the string. You keep calling the next method to get the offsets for the next tokens. You know there are no more tokens when a call to next returns the constant BreakIterator.DONE . For example, here is how you can iterate through the remaining word breaks:
int to;
while ((to = currentBreakIterator.next()) !=
BreakIterator.DONE)
{ // do something with to
}The program in Example 9-4 lets you type text into the text area on the top of the frame. Then, select the way you want to break the text (character, word, line, or sentence). You then see the text boundaries in the text area on the bottom (see Figure 9-4).
Example 9-4. TextBoundaryTest.java
import java.awt.*;
import java.awt.event.*;
import java.text.*;
import java.util.*;
import corejava.*;
public class TextBoundaryTest extends CloseableFrame
implements ItemListener
{ public TextBoundaryTest()
{ Panel p = new Panel();
addCheckbox(p, "Character", cbGroup, false);
addCheckbox(p, "Word", cbGroup, false);
addCheckbox(p, "Line", cbGroup, false);
addCheckbox(p, "Sentence", cbGroup, true);
setLayout(new GridBagLayout());
GridBagConstraints gbc = new GridBagConstraints();
gbc.fill = GridBagConstraints.NONE;
gbc.anchor = GridBagConstraints.EAST;
add(new Label("Locale"), gbc, 0, 0, 1, 1);
gbc.anchor = GridBagConstraints.WEST;
add(localeChoice, gbc, 1, 0, 1, 1);
add(p, gbc, 0, 1, 2, 1);
add(inputText, gbc, 0, 2, 2, 1);
add(outputText, gbc, 0, 3, 2, 1);
localeChoice.addItemListener(this);
locales = Collator.getAvailableLocales();
for (int i = 0; i < locales.length; i++)
localeChoice.add(locales[i].getDisplayName());
localeChoice.select(
Locale.getDefault().getDisplayName());
inputText.setText("The quick, brown fox jump-ed
"
+ "over the lazy "dog." And then...what happened?");
updateDisplay();
}
public void addCheckbox(Panel p, String name,
CheckboxGroup g, boolean v)
{ Checkbox c = new Checkbox(name, g, v);
c.addItemListener(this);
p.add(c);
}
public void add(Component c, GridBagConstraints gbc,
int x, int y, int w, int h)
{ gbc.gridx = x;
gbc.gridy = y;
gbc.gridwidth = w;
gbc.gridheight = h;
add(c, gbc);
}
public void updateDisplay()
{ Locale currentLocale = locales[
localeChoice.getSelectedIndex()];
BreakIterator currentBreakIterator = null;
String s = cbGroup.getSelectedCheckbox().getLabel();
if (s.equals("Character"))
currentBreakIterator
= BreakIterator.getCharacterInstance(currentLocale);
else if (s.equals("Word"))
currentBreakIterator
= BreakIterator.getWordInstance(currentLocale);
else if (s.equals("Line"))
currentBreakIterator
= BreakIterator.getLineInstance(currentLocale);
else if (s.equals("Sentence"))
currentBreakIterator
= BreakIterator.getSentenceInstance(currentLocale);
String text = inputText.getText();
currentBreakIterator.setText(text);
outputText.setText("");
int from = currentBreakIterator.first();
int to;
while ((to = currentBreakIterator.next()) !=
BreakIterator.DONE)
{ outputText.append(text.substring(from, to) + "|");
from = to;
}
outputText.append(text.substring(from));
}
public void itemStateChanged(ItemEvent evt)
{ if (evt.getStateChange() == ItemEvent.SELECTED)
{ updateDisplay();
}
}
public static void main(String[] args)
{ Frame f = new TextBoundaryTest();
f.setSize(400, 400);
f.show();
}
private Locale[] locales;
private BreakIterator currentBreakIterator;
private Choice localeChoice = new Choice();
private TextArea inputText = new TextArea(6, 40);
private TextArea outputText = new TextArea(6, 40);
private CheckboxGroup cbGroup = new CheckboxGroup();
}java.text.BreakIterator
static Locale[] getAvailableLocales()returns an array of
Localeobjects for whichBreakIteratorobjects are available.static BreakIterator getCharInstance()static BreakIterator getCharInstance(Locale l)static BreakIterator getWordInstance()static BreakIterator getWordTimeInstance(Locale l)static BreakIterator getLineInstance()static BreakIterator getLineInstance(Locale l)static BreakIterator getSentenceInstance()static BreakIterator getSentenceInstance(Locale l)return a break iterator for characters, words, lines, and sentences for the default or the given locale.
void setText(String text)/String getText()sets or gets the text to be scanned.
void setText(String text)/String getText()sets or gets the text to be scanned.
int first()moves the current boundary to the first boundary position in the scanned string and returns the index.
int next()moves the current boundary to the next boundary position and returns the index. Returns
BreakIterator.DONEif the end of the string has been reached.int previous()Move the current boundary to the previous boundary position and return the index. Returns
BreakIterator.DONEif the beginning of the string has been reached.int last()moves the current boundary to the last boundary position in the scanned string and returns the index.
int current()returns the index of the current boundary.
int next(int n)moves the current boundary to the
nth boundary position from the current one and returns the index. Ifnis negative, then the position is set closer to the beginning to the string. ReturnsBreakIterator.DONEif the end or beginning of the string has been reached.int following(int pos)moves the current boundary to the first boundary position after offset
posin the scanned string and returns the index. The returned value is always larger thanposorBreakIterator.DONE.
In the early days of “mail-merge” programs, you had strings like:
"On {2}, a {0} destroyed {1} houses and caused {3} of
damage."where the numbers in braces were placeholders for actual names and values. This technique is actually very convenient for doing certain kinds of internationalization, and Java has a convenience MessageFormat class to allow formatting text that has a pattern. The basic way of using this class follows these steps.
Write the pattern as a string. You can use up to 10 placeholders
{0}…{9}. You can use each placeholder more than once.Construct a
MessageFormatobject with the pattern string as the constructor parameter.Build an array of objects to substitute for the placeholders. The number inside the braces refers to the index in the array of objects.
Call the
formatmethod with the array of objects as a parameter.
Here is an example of these steps. We first supply the array of objects for the placeholders.
String pattern =
"On {2}, a {0} destroyed {1} houses and caused {3} of
damage.";
MessageFormat msgFmt = new MessageFormat(pattern);
Object[] msgArgs = {
"hurricane",
new Integer(99),
new GregorianCalendar(1999, 0, 1).getTime(),
new Double(10E7)
};
String msg = msgFmt.format(msgArgs);
System.out.println(msg);The number of the placeholder refers to the index in the object array. For example, the first placeholder {2} is replaced with msgArgs[2] . Since we need to supply objects, we have to remember to wrap integers and floating-point numbers in their Integer and Double wrappers before passing them. Notice the cumbersome construction of the date that we used. The format method expects an object of type Date, but the Date(int, int, int) constructor is deprecated in favor of the Calendar class. Therefore, we have to create a Calendar object and then call the getTime (sic) method to convert it to a Date object.
This code prints:
On 1/1/99 12:00 AM, a hurricane destroyed 99 houses and caused 100,000,000 of damage.
That is a start, but it is not perfect. We don’t want to display the time “12:00 AM,” and we want the damage amount printed as a currency value. The way we do this is by supplying an (optional) format for some or all of the placeholders. There are two ways to supply formats:
By adding them to the pattern string
By calling the
setFormatorsetFormatsmethod
Let’s do the easy one first. We can set a format for each individual occurrence of a placeholder. In our example, we want the first occurrence of a placeholder (which is placeholder {2} ) to be formatted as a date, without a time field. And we want the fourth placeholder to be formatted as a currency. Actually, the placeholders are numbered starting at 0, so we actually want to set the formats of placeholders 0 and 3. We will use the formatters that you saw earlier in this chapter, namely, DateFormat.getDateInstance(loc) and NumberFormat.getCurrencyInstance(loc), where loc is the locale we want to use. Conveniently, all formatters have a common base class Format . The setFormat method of the MessageText class receives an integer, the 0-based count of the placeholder to which the format should be applied, and a Format reference.
To build the format we want, we simply set the formats of placeholders 0 and 3 and then call the format method.
msgFmt.setFormat(0, DateFormat.getDateInstance(DateFormat.LONG, loc)); msgFmt.setFormat(3, NumberFormat.getCurrencyInstance(loc)); String msg = msgFmt.format(msgArgs); System.out.println(msg);
Now, the printout is
On January 1, 1999, a hurricane destroyed 99 houses and caused $100,000,000.00 of damage.
Next, rather than setting the formats individually, we can pack them into an array. Use null if you don’t need any special format.
Format argFormats[] =
{ DateFormat.getDateInstance(DateFormat.LONG, loc),
null,
null,
NumberFormat.getCurrencyInstance(loc)
};
msgFmt.setFormats(argFormats);Note that the msgArgs and the argFormats array entries do not correspond to one another. The msgArgs indexes correspond to the number inside the {} delimiters. The argFormats indexes correspond to the position of the {} delimiters inside the message string. This arrangement sounds cumbersome, but there is a reason for it. It is possible for the placeholders to be repeated in the string, and each occurrence may require a different format. Therefore, the formats must be indexed by position. For example, if the exact time of the disaster was known, we might use the date object twice, once to extract the day and once to extract the time.
String pattern =
"On {2}, a {0} touched down at {2} and destroyed {1}
houses.";
MessageFormat msgFmt = new MessageFormat(pattern);
Format argFormats[] =
{ DateFormat.getDateInstance(DateFormat.LONG, loc),
null,
DateFormat.getTimeInstance(DateFormat.SHORT, loc),
null
};
msg.setFormats(argFormats);
Object[] msgArgs = {
"hurricane",
new Integer(99),
new GregorianCalendar(1999, 0, 1, 11, 45, 0).getTime(),
};
String msg = msgFmt.format(msgArgs);
System.out.println(msg);This example code prints:
On January 1, 1999, a hurricane touched down at 11:45 AM and destroyed 99 houses.
Note that the placeholder {2} was printed twice, with two different formats!
Rather than setting placeholders dynamically, we can also set them in the message string. For example, here we specify the date and currency formats directly in the message pattern.
"On {2,date,long}, a {0} destroyed {1} houses and caused {3,number,currency} of damage."
If you specify formats directly, you don’t need to make a call to setFormat or setFormats . In general, you can make the placeholder index be followed by a type and a style. Separate the index, type, and style by commas. The type can be any of:
number time date choice
If the type is number, then the style can be:
integer currency percent
or it can be a number format pattern such as $,##0 . (See Chapter 3 of Volume 1 for a discussion of number format patterns.)
If the type is either time or date, then the style can be:
short medium long full
or a date format pattern. (See the documentation of the SimpleDateFormat class for more information about the possible formats.)
Choice formats are more complex, and we take them up in the next section.
java.text.MessageFormat
MessageFormat(String pattern)constructs a message format object with the specified pattern.
void setLocale(Locale loc)/Locale getLocale()sets or gets the locale to be used for the placeholders in the message.
void setFormats(Format[] formats)/Format[] getFormats()sets or gets the formats to be used for the placeholders in the message.
setFormat(int i, Format format)sets the formats to be used for the
ith placeholder in the message.String format(Object[] args)formats the objects by using
args[i]as input for placeholder{i}.
Let’s look closer at the pattern of the preceding section:
"On {2}, a {0} destroyed {1} houses and caused {3} of damage."If we replace the disaster placeholder {0} with "earthquake", then the sentence is not grammatically correct in English.
On January 1, 1999, a earthquake destroyed ...
That means what we really want to do is integrate the article “a” into the placeholder:
"On {2}, {0} destroyed {1} houses and caused {3} of damage."Then, the {0} would be replaced with "a hurricane" or "an earthquake" . That is especially appropriate if this message needs to be translated into a language where the gender of a word affects the article. For example, in German, the pattern would be
"{0} zerstörte am {2} {1} Häuser und richtete einen Schaden von
{3} an."The placeholder would then be replaced with the grammatically correct combination of article and noun, such as "Ein Hurrikan", "Eine Naturkatastrophe" .
Now let us turn to the {1} parameter. If the disaster isn’t all that catastrophic, then {1} might be replaced with the number 1, and the message would read:
On January 1, 1999, a mudslide destroyed 1 houses and ...
We would ideally like the message to vary according to the placeholder value, so that it can read
no houses one house 2 houses . . .
depending on the placeholder value. The ChoiceFormat class was designed to let you do this. A ChoiceFormat object is constructed with two arrays:
An array of limits
An array of format strings
double[] limits = . . .; String[] formatStrings = . . .; ChoiceFormat choiceFmt = new ChoiceFormat(limits, formatStrings); double input; String s = choiceFmt.format(input);
The limits and formatStrings arrays must have the same length. The numbers in the limits array must be in ascending order. Then, the format method checks between which limits the input falls. If
limits[i] <= input && input < limits[i + 1]
then formatStrings[i] is used to format the input. If the input is at least as large as the last limit, then the last format string is used. And, if the input is less than limits[0], then formatStrings[0] is used anyway.
For example, consider these limits and format strings:
double[] limits = {0, 1, 2};
String[] formatStrings = {"no house", "one house", "many
houses"};Table 9-4 shows the return values of the call to
String selected = choiceFmt.format(input);
Table 9-4. String selected by ChoiceFormat
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
NOTE
This example shows that the designer of the ChoiceFormat class was a bit muddleheaded. If you have three strings, you need two limits to separate them. In general, you need one fewer limit than you have strings. Thus, the first limit is meaningless, and you can simply set the first and second limit to the same number. For example, the following code works fine:
double[] limits = {1, 1, 2};
String[] formatStrings = {"no house", "one house", "many
houses"};
ChoiceFormat choiceFmt = new ChoiceFormat(limits,
formatStrings);Of course, in our case, we don’t want to return "many houses" if the number of houses is 2 or greater. We still want the value to be formatted. Here is the code to format the value:
double[] limits = {0, 1, 2};
String[] formatStrings = {"no house", "one house", "{1}
houses"};
ChoiceFormat choiceFmt = new ChoiceFormat(limits,
formatStrings);
msgFmt.setFormat(2, choiceFmt);That is, we create the choice format object and set it as the format to use for the third placeholder (because the count is 0-based).
Why do we use {1} in the format string? The usage is a little mysterious. When the message format applies the choice format on the placeholder, the choice format returns "{1} houses" . That string is then formatted again by the message format, and the answer is spliced into the result. As a rule, you should always feed back the same placeholder that was used to make the choice. Otherwise, you can create weird effects.
You can add formatting information to the returned string, for example,
String[] formatStrings
= {"no house", "one house", "{1, number, integer} houses"};As you saw in the preceding section, it is also possible to express the choice format directly in a format string. When the format type is choice, then the next parameter is a list of pairs, each pair consisting of a limit and a format string, separated by a # . The pairs themselves are separated by | . Here is how to express the house format:
{1,choice,0#no houses|1#one house|2#{1} houses}Thus, there are three sets of choices:
0#no houses
1#one house
2#{1} housesThe first one is used if the placeholder value is < 1, the second is used if the value is at least one but < 2, and the third is used if it is at least 2.
NOTE
As previously noted, the first limit is meaningless. But here you can’t set the first and second limits to the same value; the format parser complains that
1#no houses|1#one house|2#{1} housesis an invalid choice. In this case, you must set the first limit to any number that is strictly less than the second limit.
The syntax would have been a lot clearer if the designer of this class realized that the limits belong between the choices, such as
no houses|1|one house|2|{1} houses
// not the actual formatIf we put the choice string inside the original message string, then we get the rather monstrous format instruction:
String pattern =
"On {2,date,long}, {0} destroyed {1,choice,0#no houses|1#one
house|2#{1} houses}
and caused {3,number,currency} of damage.";Or, in German,
String pattern =
"{0} zerstörte am {2,date,long} {1,choice,0#kein Haus|1#ein
Haus|2#{1} Häuser}
und richtete einen Schaden von {3,number,currency} an.";Note that the ordering of the words is different in German, but the array of objects you pass to the format method is the same. The order of the placeholders in the format string takes care of the changes in the word ordering.
java.text.ChoiceFormat
ChoiceFormat(String pattern)constructs a choice format from a pattern string containing a
|delimited set of pairs, each of which is of the formlimit#formatString.ChoiceFormat(double limits[], String formatStrings[])constructs a choice format with the given limits and formats. The limits must be increasing. If
inputis the value to be formatted, then it is formatted with theformatString[i]whereiis the smallest index such thatlimits[i] <= input. However, all inputs that are less thanlimits[1]are formatted withformatString[0].
As you know, Java itself is fully Unicode based. However, operating systems typically have their own, homegrown, often incompatible, character encoding, such as ISO 8859-1 (an 8-bit code sometimes called the “ANSI” code) in the United States or BIG5 in Taiwan. So the input that you receive from a user might be in a different encoding system, and the strings that you show to the user must eventually be encoded in a way that the local operating system understands.
Of course, inside your program, you should always use Unicode characters. You have to hope that the implementation of the Java Virtual Machine on that platform successfully converts input and output between Unicode and the local character set. For example, if you set a button label, you specify the string in Unicode, and it is up to the Java Virtual Machine to get the button to display your string correctly. Similarly, when you call getText to get user input from a text box, you get the string in Unicode, no matter how the user entered it.
However, you need to be careful with text files. Never read a text file one byte at a time! Always use the InputStreamReader or FileReader classes that were described in Chapter 1. These classes automatically convert from a particular character encoding to Unicode. By default, they use the local encoding scheme but as you saw in Chapter 1, you can specify the encoding in the constructor of the InputStreamReader class, for example,
InputStreamReader = new InputStreamReader(in, "8859_1");
Unfortunately, there is currently no connection between locales and character encodings. For example, if your user has selected the Chinese Traditional locale zh_TW, there is no Java method that tells you that the BIG5 character encoding would be the most appropriate.
When writing text files, you need to decide:
Is the output of the text file intended for humans to read or for use with other programs on their local machines?
Is the output simply going to be fed into the same or another Java program?
If the output is intended for human consumption or a non-Unicode-enabled program, you’ll need to convert it to the local character encoding by using a PrintWriter, as you saw in Chapter 1. Otherwise, just use the writeUTF method of the DataOutputStream to write the string in Unicode Text Format. Then, of course, the Java program reading the file must open it as a DataInputStream and read the string with the readUTF method.
TIP
In the case of input to a Java program, an even better choice is to use serialization. Then, you never have to worry at all how strings are saved and loaded.
Of course, with both data streams and object streams, the output will not be in human-readable form.
It is worth keeping in mind that you, the Java programmer, will need to communicate with the Java compiler. And, you do that with tools on your local system. For example, you may use the Chinese version of NotePad to write your Java source code files. The resulting source code files are not portable because they use the local character encoding (GB or BIG5, depending on which Chinese operating system you use). Only the compiled class files are portable—they will automatically use the UTF encoding for identifiers and strings. That means that even when a Java program is compiling and running, three character encodings are involved:
Source files: local encoding
Class files: UTF
Virtual machine: Unicode
To make your source files portable, restrict yourself to using the plain ASCII encoding. That is, you should change all non-ASCII characters to their equivalent Unicode encodings. For example, rather than using the string "Häuser", use "Hu0084user" . The JDK contains a utility, native2ascii, that you can use to convert the native character encoding to plain ASCII. This utility simply replaces every non-ASCII character in the input with a u followed by the four hex digits of the Unicode value. To use the native2ascii program, simply provide the input and output file names.
native2ascii Myfile.java Myfile.temp
You can convert the other way with the -reverse option:
native2ascii -reverse Myfile.java Myfile.temp
And you can specify another encoding with the -encoding option. The encoding name must be one of the ones listed in the encodings table in Chapter 1.
native2ascii -encoding Cp437 Myfile.java Myfile.temp
Finally, we strongly recommend that you restrict yourself to plain ASCII class names. Since the name of the class also turns into the name of the class file, you are at the mercy of the local file system to handle any non-ASCII coded names—and it will almost certainly not do it right. For example, depressingly enough, Windows 95 uses yet another character encoding, the so-called Code Page 437 or original PC encoding, for its file names. Windows 95 makes a valiant attempt to translate between ANSI and original names, but the Java class loader does not. (NT is much better this way.) For example, if you make a class Bär, then the JDK class loader will complain that it “cannot find class B∑r.” There is a reason for this behavior, but you don’t want to know. Simply stick to ASCII for your class names until all computers around the world offer consistent support for Unicode.
When localizing an application, you’ll probably have a dauntingly large number of message strings, button labels, and so on, that all need to be translated. To make this task feasible, you’ll want to define the message strings in an external location, usually called a resource. The person carrying out the translation can then simply edit the resource files without having to touch the source code of the program.
NOTE
Java resources are not the same as Windows or Macintosh resources. A Windows executable program stores resources such as menus, dialog boxes, icons, and messages in a section separate from the program code. A resource editor can be used to inspect and update these resources without affecting the program code.
Java, unfortunately, does not have a mechanism for storing external resources in class files. Instead, all resource data must be put in a class, either as static variables or as return values of method calls. You create a different class for each locale, and then the getBundle method of the ResourceBundle class automatically locates the correct class for your locale.
NOTE
Chapter 10 of Volume 1 describes a concept of file resources, where data files, sounds, and images can be placed in a JAR file. The getResource method of the class Class finds the file, opens it and returns a URL to the resource. Why? When you write a program that needs access to files, it needs to find the files. By placing the files into the JAR file, you leave the job of finding the files to the class loader, which already knows how to locate the class files. While this mechanism does not directly support internationalization, it is useful for locating localized property files, and we take advantage of it in the next section.
When localizing an application, you need to make a set of classes that describe the locale-specific items (such as messages, labels, and so on) for each locale that you want to support. Each of these classes must extend the class ResourceBundle . (You’ll see a little later the details involved in designing these kinds of classes.) You also need to use a naming convention for these classes, where the name of the class corresponds to the locale. For example, resources specific for Germany go to the class ProgramResources_de_DE, while those that are shared by all German-speaking countries go into ProgramResources_de . Taiwan-specific resources go into ProgramResources_zh_TW, and any Chinese language strings go into ProgramResources_zh . In general, use
ProgramResources_language_countryfor all country-specific resources, and use
ProgramResources_languagefor all language-specific resources. Finally, as a fallback, you can put the US English strings and messages into the class ProgramResources, without any suffix. Then, compile all these classes and store them with the other application classes for the project.
Once you have a class for the resource bundle, you load it with the command
ResourceBundle currentResources =
ResourceBundle.getBundle("ProgramResources", currentLocale);The getBundle method attempts to load the class that matches the current locale by language, country, and variant. If it is not successful, then the variant, country, and language are dropped in turn. That is, the getBundle method tries to load one of the following classes until it is successful.
ProgramResources_language_country_variant ProgramResources_language_country ProgramResources_language ProgramResources
If all these atttempts are unsuccessful, then the getBundle method tries all over again, only this time it uses the default locale instead of the current locale. If even these attempts fail, the method throws a MissingResourceException .
Once the getBundle method has located a class, say, ProgramResources_de_DE, it will still keep looking for ProgramResources_de and ProgramResources . If these classes exist, they become the parents of the ProgramResources_de_DE class in a resource hierarchy. Later, when looking up a resource, the getObject method will search the parents if the lookup was not successful in the current class. That is, if a particular resource was not found in ProgramResources_de_DE, then the ProgramResources_de and ProgramResources will be queried as well.
This is clearly a very useful service and one that would be incredibly tedious to program by hand. Java’s resource mechanism lets you locate the class that is the best match for localization information. It is very easy to add more and more localizations to an existing program: all you have to do is add additional resource classes.
Now that you know how a Java program can locate the correct resource, we show you how to place the language-dependent information into the resource class. Ultimately, it would be nice if you could get tools that even a non-programmer could use to define and modify resources. We hope and expect that developers of integrated Java environments will eventually provide such tools. But right now, creating resources still involves some programming. We take that up next.
In Java, you place resources inside classes that extend the ResourceBundle class. Each resource bundle implements a lookup table. When you design a program, you provide a key string for each setting you want to localize, and you use that key string to retrieve the setting.
String computeButtonLabel
= (String)resources.getObject("computeButton");
Color backgroundColor
= (Color)resources.getObject("backgroundColor");
double[] paperSize
= (double[])resources.getObject("defaultPaperSize");As you can see, it is quite convenient that a resource bundle can store objects of any kind. Not all localized settings are strings!
TIP
You do not need to place all resources for your application into a single bundle. You could have one bundle for button labels, one for error messages, and so on.
For example, you can write the following classes to provide English and German resources.
public class ProgramResources_de extends ResourceBundle
{ public static Object getObject(String key)
if (key.equals("computeButton"))
return "Rechnen";
else if (key.equals("backgroundColor")
return Color.black;
else if (key.equals("defaultPaperSize")
return new double[] { 210, 297 };
}
public class ProgramResources_en_US extends ResourceBundle
{ public static Object getObject(String key)
if (key.equals("computeButton"))
return "Compute";
else if (key.equals("backgroundColor")
return Color.blue;
else if (key.equals("defaultPaperSize")
return new double[] { 216, 279 };
}NOTE
Everyone on the planet, with the exception of the United States and Canada, uses ISO 216 paper sizes. For more information, see http://www.ft.uni-erlangen.de/∼mskuhn/iso-paper.html. According to the U.S. Metric Association (http://lamar.colostate.edu/∼hillger), there are only three countries in the world that have not yet officially adopted the metric system, namely, Liberia, Myanmar (Burma), and the United States of America. U.S. businesses that wish to extend their export market further need to go metric. See http://ts.nist.gov/ts/htdocs/200/202/mpo_reso.htm for a useful set of links to information about the metric (SI) system.
Of course, it is extremely tedious to write this kind of code for every resource bundle. The Java standard library provides two convenience classes, ListResourceBundle and PropertyResourceBundle, to make the job easier.
The ListResourceBundle lets you place all your resources into an object array, and then it does the lookup for you. You need to supply the following skeleton:
public class ProgramResource_language_country
extends ListResourceBundle
{ public Object[][] getContents() { return contents; }
static final Object[][] contents =
{ // localization information goes here
}
}For example,
public class ProgramResource_de
extends ListResourceBundle
{ public Object[][] getContents() { return contents; }
static final Object[][] contents =
{ { "computeButton", "Rechnen" },
{ "backgroundColor", Color.black },
{ "defaultPaperSize", new double[] { 210, 297 } }
}
}
public class ProgramResource_en_US
extends ListResourceBundle
{ public Object[][] getContents() { return contents; }
static final Object[][] contents =
{ { "computeButton", "Compute" },
{ "backgroundColor", Color.blue },
{ "defaultPaperSize", new double[] { 216, 279 } }
}
}Note that you need not supply the getObject lookup method. Java provides it in the base class ListResourceBundle .
As an alternative, if all your settings are strings, you can use the more convenient PropertyResourceBundle . You place all your strings into a property file, as described in Chapter 11 of Volume 1. This is simply a text file with one key/value pair per line. A typical file would look like this:
computeButton=Rechnen backgroundColor=black defaultPaperSize=210x297
Then, you open a stream to the property file and pass it to the PropertyResourceBundle constructor.
InputStream in = . . .; // open property file
PropertyResourceBundle currentResources
= new PropertyResourceBundle(in);Placing all resources into a text file is enormously attractive. It is much easier for the person performing the localization, especially if he or she is not a Java programmer, to understand a text file than a file with Java code. The downside is that your program must parse strings (such as the paper size "210x297" in the example above.) The best solution is therefore to put the string resources into property files and use a ListResourceBundle for those resource objects that are not strings.
We still have one remaining issue: How can the running Java program locate the file that contains the localized strings? Naturally, that file is best placed with the class files of the application, preferably inside a JAR file. Then, we can use the getResourceAsStream method of the Class class. The method will find the right file and open it.
in = Program.class.getResourceAsStream("ProgramProperties_de.
txt");
PropertyResourceBundle currentResources
= new PropertyResourceBundle(in);It would be nice if the PropertyResourceBundle class could look for resource text files in the same way that the ResourceBundle class looks for class files. Unfortunately, it does not. Thus, you have to write a class file to accompany every text file. Fortunately, writing such as class file is completely mechanical. For example, here is the class file that loads ProgramResources_de.txt .
public class ProgramProperties_de
extends PropertyResourceBundle
{ ProgramProperties_de() throws IOException
{ super(ProgramProperties_de.class.getResourceAsStream
("ProgramProperties_de.txt"));
}
}You need to produce two files: the class file and the property file, a text file containing key/value pairs. Place both the class file and property file in the same location in the directory or JAR file.
However, before you actually try to carry out this scheme, be advised that there is a fatal flaw in the current version of Java.
Note

In Java1.1, the PropertyResourceBundle class can read only ISO 8859-1 characters (that is, the 8-bit characters sometimes called the “ANSI” code). Property files are read a byte at a time, with no character code conversion. No other Unicode characters can be specified in a property file.
This flaw (which will eventually be remedied when the Properties class is reimplemented to be locale aware) makes the PropertyResourceBundle class unsuitable for storing translated messages. You can get away with using it for Western European languages, but it is not a general solution. At this point, we recommend that you use the ListResourceBundle and hope for better language and tool support in the near future.
java.util.ResourceBundle
static ResourceBundle getBundle(String baseName, Locale loc)static ResourceBundle getBundle(String baseName)load the resource bundle class with the given name, for the given locale or the default locale, and its parent classes. If the resource bundle classes are located in a package, then the base name must contain the full package name, such as
"intl.ProgramResources". The resource bundle classes must bepublicso that thegetBundlemethod can access them.Object getObject(String)looks up an object from the resource bundle or its parents.
String getString(String)looks up an object from the resource bundle or its parents and casts it as a string.
String[] getObject(String)looks up an object from the resource bundle or its parents and casts it as a string array.
Enumeration getKeys()returns an enumeration object to enumerate the keys of this resource bundle. It enumerates the keys in the parent bundles as well.
We have spent a lot of time showing you how to localize your applications. Now, we explain how localization requires you to change the kind of code you write. For example, you have to be much more careful how you code your event handlers for user interface events. Consider the following common style of programming:
public class MyApplet implements ActionListener
{ public void init()
{ Button cancelButton = new Button("Cancel");
cancelButton.addActionListener(this);
. . .
}
public void actionPerformed(ActionEvent evt)
{ String arg = evt.getActionCommand();
if (arg.equals("Cancel"))
doCancel();
else . . .
}
. . .
private Button cancelButton;
}This example is the standard way to write code, and it works fine as long as you never internationalize the interface. Once you do, you are hosed. This code will not work in an internationalized project that adjusts (as it should) the names of the buttons. When the button name is translated to German, “Cancel” turns into “Abbrechen.” Then, the name will need to be updated automatically in both the init method and the actionPerformed method. This is clearly error prone—it is a well-known corollary to Murphy’s theorem in computer science that two entities that are supposed to stay in synch, won’t. In this case, if you forget to update one of the occurrences of the string, then the button won’t work. There are three ways you can eliminate this potential problem.
Use inner classes instead of separate
actionPerformedprocedures.Identify components by their reference, not their label.
Use the
nameattribute to identify components.
Let us look at these three strategies one by one.
Rather than having one handler that handles many actions, you can easily define a separate handler for every component. For example,
cancelButton = new Button("Cancel");
cancelButton.addActionListener(new ActionListener()
{ public void actionPerformed(ActionEvent e)
{ doCancel(); } } );This code creates an inner class that listens just to the Cancel button. Since the button and its listener are now tightly joined, there is no more code to parse the button label. Hence, there is only one occurrence of the label string to localize.
You may not like inner classes, either because they are confusing to read or because each inner class results in an additional class file. The next choice, therefore, is to make the button into an instance variable and compare its reference against the source of the command.
public class MyApplet implements ActionListener
{ public void init()
{ cancelButton = new Button("Cancel");
cancelButton.addActionListener(this);
. . .
}
public void actionPerformed(ActionEvent evt)
{ Object source = evt.getSource();
if (source == cancelButton)
doCancel();
else . . .
}
. . .
private Button cancelButton;
}The disadvantage of this approach is that every user interface element must be stored in an instance variable, and the actionPerformed method must have access to the variables.
Finally, you can give any class that inherits from Component (such as the Button class) a name property, much as Visual Basic gives each component a name. This name may or may not be distinct from its label in a specific locale, but this is irrelevant; the name property stays constant regardless of locale changes. For example, if you give a cancel button the name "Cancel", this is not a visual attribute of the button, it is simply a (text) string associated to the button. (Think of it as a property of the button—see Chapter 6 for more on properties.) When an action event is triggered, you first get the source and then you can find the name attribute of the source.
public class MyApplet implements ActionListener
{ public void init()
{ Button cancelButton = new Button("Cancel");
cancelButton.setName("Cancel");
cancelButton.addActionListener(this);
. . .
}
public void actionPerformed(ActionEvent evt)
{ Component source = (Component)evt.getSource();
if (source.getName().equals("Cancel"))
doCancel();
else . . .
}
. . .
}The possibility of having a name attribute for AWT components was added to Java in version 1.1. At the same time, the Java developers added a second attribute, the current locale, to the Component class. Usually, components do not have their own locale, but they inherit a locale from their parent. Top-level components such as windows and applets have their locales set to the system locale when they are created. You can determine the locale of any component with the getLocale method.
Typically, you use the getLocale method in an applet to tell you the locale of the client computer that executes your code. You can then adapt the behavior of the code to the locale of the user.
java.awt.Component
void setName(String s)/String getName()sets or gets a component name, an arbitrary tag associated with the component.
Locale getLocale()gets the current locale of the component. The current locale is typically inherited from the parent. If the component has not yet been attached to a parent and no locale was set, then an
IllegalComponentStateexception is thrown.
java.awt.Applet
Locale getLocale()gets the current locale of the applet. The curent locale is determined from the client computer that executes the applet.
In this section, we apply the material from this chapter to localize the retirement calculator from Chapter 10 of Volume 1. The retirement calculator now works in three locales (English, German, and Chinese). Here is what we needed to do.
The labels, buttons and messages were translated into German and Chinese from the original English. You can find them in the classes
RetireResources_de,RetireResources_zh, andRetireResources. (English is used as the fallback.) To generate the Chinese messages, we first typed the file in Chinese Windows 95 and then used thenative2asciiutility to convert the characters to Unicode.Whenever the locale changed, we reset the labels and reformatted the contents of the text fields.
The numeric fields handle numbers, currency amounts, and percentages in the local format. This was a tedious change, and we did not implement error-handling in this program. The code would have been a lot simpler if we had access to friendly and locale-aware input field beans.
The computation field uses a
MessageFormat. The format string is stored in the resource bundle of each language. Unfortunately, there is a bug in the version ofMessageFormatwe had available—it pays no attention to its locale when formatting currencies.Just to show that it could be done, we used different colors for the bar graph, depending on the language chosen by the user.
Examples 9-5 through 9-8 show the code. Figures 9-5 and 9-6 show the outputs in German and Chinese. You need to run the Chinese program under Chinese Windows or manually install the Chinese fonts. Otherwise, all Chinese characters show up as “missing character” icons.
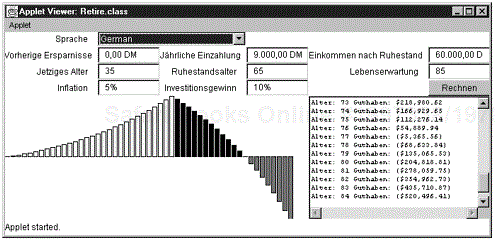
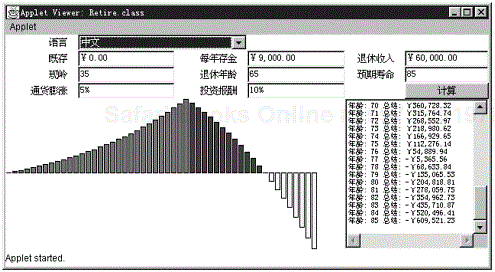
NOTE
This applet was harder to write than a typical localized application because the user can change the locale on the fly. The applet, therefore, had to be prepared to redraw itself whenever the user selects another locale. Normally, you will not need to work so hard. You can simply call getLocale() to find the locale of your user’s system and then use it for the entire duration of the application.
In sum, while the Java localization mechanism still has some rough edges, it does have one major virtue. Once you have organized your application for localization, it is extremely easy to add more localized versions. You simply provide more resource files, and they will be automatically loaded when a user wants them.
Example 9-5. Retire.java
import java.awt.*;
import java.awt.event.*;
import java.applet.*;
import java.util.*;
import java.text.*;
import java.io.*;
import corejava.*;
public class Retire extends Applet
implements ActionListener, ItemListener
{ public void init()
{ GridBagLayout gbl = new GridBagLayout();
setLayout(gbl);
GridBagConstraints gbc = new GridBagConstraints();
gbc.weightx = 100;
gbc.weighty = 100;
gbc.fill = GridBagConstraints.NONE;
gbc.anchor = GridBagConstraints.EAST;
add(languageLabel, gbc, 0, 0, 1, 1);
add(savingsLabel, gbc, 0, 1, 1, 1);
add(contribLabel, gbc, 2, 1, 1, 1);
add(incomeLabel, gbc, 4, 1, 1, 1);
add(currentAgeLabel, gbc, 0, 2, 1, 1);
add(retireAgeLabel, gbc, 2, 2, 1, 1);
add(deathAgeLabel, gbc, 4, 2, 1, 1);
add(inflationPercentLabel, gbc, 0, 3, 1, 1);
add(investPercentLabel, gbc, 2, 3, 1, 1);
gbc.fill = GridBagConstraints.HORIZONTAL;
gbc.anchor = GridBagConstraints.WEST;
add(localeChoice, gbc, 1, 0, 2, 1);
add(savingsField, gbc, 1, 1, 1, 1);
add(contribField, gbc, 3, 1, 1, 1);
add(incomeField, gbc, 5, 1, 1, 1);
add(currentAgeField, gbc, 1, 2, 1, 1);
add(retireAgeField, gbc, 3, 2, 1, 1);
add(deathAgeField, gbc, 5, 2, 1, 1);
add(inflationPercentField, gbc, 1, 3, 1, 1);
add(investPercentField, gbc, 3, 3, 1, 1);
computeButton.setName("computeButton");
computeButton.addActionListener(this);
add(computeButton, gbc, 5, 3, 1, 1);
add(retireCanvas, gbc, 0, 4, 4, 1);
gbc.fill = GridBagConstraints.BOTH;
add(retireText, gbc, 4, 4, 2, 1);
retireText.setEditable(false);
retireText.setFont(new Font("Monospaced", Font.PLAIN, 10));
info.savings = 0;
info.contrib = 9000;
info.income = 60000;
info.currentAge = 35;
info.retireAge = 65;
info.deathAge = 85;
info.investPercent = 0.1;
info.inflationPercent = 0.05;
localeChoice.addItemListener(this);
locales = new Locale[]
{ Locale.US, Locale.CHINA, Locale.GERMANY };
for (int i = 0; i < locales.length; i++)
localeChoice.add(locales[i].getDisplayLanguage());
localeChoice.select(0);
setCurrentLocale();
}
void updateDisplay()
{ languageLabel.setText(res.getString("language"));
savingsLabel.setText(res.getString("savings"));
contribLabel.setText(res.getString("contrib"));
incomeLabel.setText(res.getString("income"));
currentAgeLabel.setText(res.getString("currentAge"));
retireAgeLabel.setText(res.getString("retireAge"));
deathAgeLabel.setText(res.getString("deathAge"));
inflationPercentLabel.setText
(res.getString("inflationPercent"));
investPercentLabel.setText
(res.getString("investPercent"));
computeButton.setLabel(res.getString("computeButton"));
doLayout();
}
void setCurrentLocale()
{ currentLocale
= locales[localeChoice.getSelectedIndex()];
res = ResourceBundle.getBundle("RetireResources",
currentLocale);
currencyFmt
= NumberFormat.getCurrencyInstance(currentLocale);
numberFmt
= NumberFormat.getNumberInstance(currentLocale);
percentFmt
= NumberFormat.getPercentInstance(currentLocale);
updateDisplay();
updateInfo();
updateData();
updateGraph();
}
void updateInfo()
{ savingsField.setText(currencyFmt.format(info.savings));
contribField.setText(currencyFmt.format(info.contrib));
incomeField.setText(currencyFmt.format(info.income));
currentAgeField.setText(numberFmt.format(info.currentAge));
retireAgeField.setText(numberFmt.format(info.retireAge));
deathAgeField.setText(numberFmt.format(info.deathAge));
investPercentField.setText
(percentFmt.format(info.investPercent));
inflationPercentField.setText
(percentFmt.format(info.inflationPercent));
}
void updateData()
{ retireText.setText("");
MessageFormat retireMsg = new MessageFormat
(res.getString("retire"));
retireMsg.setLocale(getLocale());
for (int i = info.currentAge; i <= info.deathAge; i++)
{ Object[] args = { new Integer(i),
new Double(info.getBalance(i)) };
retireText.append(retireMsg.format(args) + "
");
}
}
void updateGraph()
{ info.colorPre = (Color)res.getObject("colorPre");
info.colorGain = (Color)res.getObject("colorGain");
info.colorLoss = (Color)res.getObject("colorLoss");
retireCanvas.redraw(info);
}
public void add(Component c, GridBagConstraints gbc,
int x, int y, int w, int h)
{ gbc.gridx = x;
gbc.gridy = y;
gbc.gridwidth = w;
gbc.gridheight = h;
add(c, gbc);
}
public void itemStateChanged(ItemEvent evt)
{ if (evt.getStateChange() == ItemEvent.SELECTED)
{ setCurrentLocale();
}
}
void getInfo() throws ParseException
{ info.savings =
currencyFmt.parse
(savingsField.getText()).doubleValue();
info.contrib =
currencyFmt.parse
(contribField.getText()).doubleValue();
info.income =
currencyFmt.parse
(incomeField.getText()).doubleValue();
info.currentAge =
(int)numberFmt.parse
(currentAgeField.getText()).longValue();
info.retireAge =
(int)numberFmt.parse
(retireAgeField.getText()).longValue();
info.deathAge =
(int)numberFmt.parse
(deathAgeField.getText()).longValue();
info.investPercent = percentFmt.parse
(investPercentField.getText()).doubleValue();
info.inflationPercent = percentFmt.parse
(inflationPercentField.getText()).doubleValue();
}
public void actionPerformed(ActionEvent evt)
{ Component source = (Component)evt.getSource();
if (source.getName().equals("computeButton"))
{ try
{ getInfo();
updateData();
updateGraph();
} catch(ParseException e) {}
updateInfo();
}
}
private TextField savingsField = new TextField(10);
private TextField contribField = new TextField(10);
private TextField incomeField = new TextField(10);
private TextField currentAgeField = new TextField(4);
private TextField retireAgeField = new TextField(4);
private TextField deathAgeField = new TextField(4);
private TextField inflationPercentField = new TextField(6);
private TextField investPercentField = new TextField(6);
private TextArea retireText = new TextArea(10, 25);
private RetireCanvas retireCanvas = new RetireCanvas();
private Button computeButton = new Button();
private Label languageLabel = new Label();
private Label savingsLabel = new Label();
private Label contribLabel = new Label();
private Label incomeLabel = new Label();
private Label currentAgeLabel = new Label();
private Label retireAgeLabel = new Label();
private Label deathAgeLabel = new Label();
private Label inflationPercentLabel = new Label();
private Label investPercentLabel = new Label();
private RetireInfo info = new RetireInfo();
private Locale[] locales;
private Locale currentLocale;
private Choice localeChoice = new Choice();
private ResourceBundle res;
NumberFormat currencyFmt;
NumberFormat numberFmt;
NumberFormat percentFmt;
}
class RetireInfo
{ public double getBalance(int year)
{ if (year < currentAge) return 0;
else if (year == currentAge)
{ age = year;
balance = savings;
return balance;
}
else if (year == age)
return balance;
if (year != age + 1)
getBalance(year - 1);
age = year;
if (age < retireAge)
balance += contrib;
else
balance -= income;
balance = balance
* (1 + (investPercent - inflationPercent));
return balance;
}
double savings;
double contrib;
double income;
int currentAge;
int retireAge;
int deathAge;
double inflationPercent;
double investPercent;
Color colorPre;
Color colorGain;
Color colorLoss;
private int age;
private double balance;
}
class RetireCanvas extends Canvas
{ public RetireCanvas()
{ setSize(400, 200);
}
public void redraw(RetireInfo newInfo)
{ info = newInfo;
repaint();
}
public void paint(Graphics g)
{ if (info == null) return;
int minValue = 0;
int maxValue = 0;
int i;
for (i = info.currentAge; i <= info.deathAge; i++)
{ int v = (int)info.getBalance(i);
if (minValue > v) minValue = v;
if (maxValue < v) maxValue = v;
}
if (maxValue == minValue) return;
Dimension d = getSize();
int barWidth = d.width / (info.deathAge
- info.currentAge + 1);
double scale = (double)d.height
/ (maxValue - minValue);
for (i = info.currentAge; i <= info.deathAge; i++)
{ int x1 = (i - info.currentAge) * barWidth + 1;
int y1;
int v = (int)info.getBalance(i);
int height;
int yOrigin = (int)(maxValue * scale);
if (v >= 0)
{ y1 = (int)((maxValue - v) * scale);
height = yOrigin - y1;
}
else
{ y1 = yOrigin;
height = (int)(-v * scale);
}
if (i < info.retireAge)
g.setColor(info.colorPre);
else if (v >= 0)
g.setColor(info.colorGain);
else
g.setColor(info.colorLoss);
g.fillRect(x1, y1, barWidth - 2, height);
g.setColor(Color.black);
g.drawRect(x1, y1, barWidth - 2, height);
}
}
private RetireInfo info = null;
}Example 9-6. RetireResources.java
import java.util.*;
import java.awt.*;
public class RetireResources
extends java.util.ListResourceBundle
{ public Object[][] getContents() { return contents; }
static final Object[][] contents =
{ // BEGIN LOCALIZE
{ "language", "Language" },
{ "computeButton", "Compute" },
{ "savings", "Prior Savings" },
{ "contrib", "Annual Contribution" },
{ "income", "Retirement Income" },
{ "currentAge", "Current Age" },
{ "retireAge", "Retirement Age" },
{ "deathAge", "Life Expectancy" },
{ "inflationPercent", "Inflation" },
{ "investPercent", "Investment Return" },
{ "retire", "Age: {0,number} Balance:
{1,number,currency}" },
{ "colorPre", Color.blue },
{ "colorGain", Color.white },
{ "colorLoss", Color.red }
// END LOCALIZE
};
}Example 9-7. RetireResources_de.java
import java.util.*;
import java.awt.*;
public class RetireResources_de
extends java.util.ListResourceBundle
{ public Object[][] getContents() { return contents; }
static final Object[][] contents =
{ // BEGIN LOCALIZE
{ "language", "Sprache" },
{ "computeButton", "Rechnen" },
{ "savings", "Vorherige Ersparnisse" },
{ "contrib", "J‰hrliche Einzahlung" },
{ "income", "Einkommen nach Ruhestand" },
{ "currentAge", "Jetziges Alter" },
{ "retireAge", "Ruhestandsalter" },
{ "deathAge", "Lebenserwartung" },
{ "inflationPercent", "Inflation" },
{ "investPercent", "Investitionsgewinn" },
{ "retire", "Alter: {0,number} Guthaben:
{1,number,currency}" },
{ "colorPre", Color.yellow },
{ "colorGain", Color.black },
{ "colorLoss", Color.red }
// END LOCALIZE
};
}Example 9-8. RetireResources_zh.java
import java.util.*;
import java.awt.*;
public class RetireResources_zh
extends java.util.ListResourceBundle
{ public Object[][] getContents() { return contents; }
static final Object[][] contents =
{ // BEGIN LOCALIZE
{ "language", "u8bedu8a00" },
{ "computeButton", "u8ba1u7b97" },
{ "savings", "u65e2u5b58" },
{ "contrib", "u6bcfu5e74u5b58u91d1" },
{ "income", "u9000u4f11u6536u5165" },
{ "currentAge", "u73b0u5cad" },
{ "retireAge", "u9000u4f11u5e74u9f84" },
{ "deathAge", "u9884u671fu5bffu547d" },
{ "inflationPercent", "u901au8d27u81a8u6da8" },
{ "investPercent", "u6295u8d44u62a5u916c" },
{ "retire",
"u5e74u9f84: {0,number} u603bu7ed3:
{1,number,currency}" },
{ "colorPre", Color.red },
{ "colorGain", Color.blue },
{ "colorLoss", Color.yellow }
// END LOCALIZE
};
}