
Content Management
So far, the previous sections have discussed only search, storage and retrieval issues. Content management is a more systematic view, but it also implies the question of ownership, and hence governance—the control of who may use what, when they may use it, and in what manner. It’s therefore understandable if momentary confusion can set in when studying peer technology solutions to content control issues.
It’s true, p2p content management as applied to governance is filled with paradox and contradiction because of the mixed viewpoints encountered.
On the one hand, p2p is said to empower users by allowing them to control their own resources. This is the case for simple, fully atomistic networks.
On the other, some p2p solutions remove resource and content control from everyone, except for the functions of publishing and updating. No less atomistic, all control is distributed over network services that function automatically according to some rules set.
Meanwhile, corporate or other environments wish to have all the benefits of p2p networking, yet still retain central control over content access and distribution.
Not to mention all the in-between solutions that might have a bit of this and a bit of that.
So, it all depends.…
But in fact, it turns out that we can implement functional governance even in the absence of clear-cut ownership in the traditional sense. Let’s see how.
Governance requires the ability to describe and effect content activities, and to support their tendency to change over time. Simple governance may require nothing more than support for distributed authoring with remote document locking, access control and versioning. This support can be automated and integrates well into the basic p2p outlook, no matter how ownership as such is assigned.
More complicated governance often relies on notification services that bring changes or access attempts to the immediate attention of subscribing users/owners. Mobile task descriptions that anyone with authority and capability can fulfill might also be supported. Further along the scale, proposed or implemented functionality for the management of digital rights is yet another expression of the kind of detailed governance that could be implemented in p2p contexts.
Storage and Retrieval
Storage and retrieval of content are intimately interlinked, for obvious reasons. The focus may be heavily on “content” here, but to a large extent, the models are applicable to any resource deployment, for example, including network services.
The basic content storage models are illustrated in Figure 3.1:
Figure 3.1. Storage models. In the distributed model, shown at right, one often calls the service-managed store a virtual distributed filesystem.
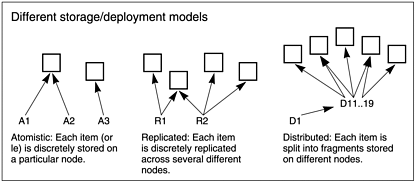
Atomistic (shared from local store)
Replicated (shared from multiple sources)
Distributed (shared from virtual store)
Practical content-sharing implementations commonly mix elements of two or more of these models. For example, atomistic implementations often show (at least implicit) replication due to the content duplication caused by locally determined sharing of popular and just-downloaded files. In more advanced (usually publishing) systems, replication is an intentional feature, often made adaptive to demand.
Distributed systems also commonly implement replication of the fragments to ensure availability or improve retrieval performance. Both replication and distribution are important enough in this context that they are often implemented for retrieval functionality even when the storage model is initially purely atomistic. Swarmcast, discussed in Chapter 8, is but one example.
Improving Retrieval Performance
Client software can have great freedom in implementing the functionality based on the basic p2p protocol, or even in extending it in useful ways. Gnutella provides a good example of such developer freedom.
A common feature to enhance the download experience is to track multiple occurrences of the same file on different nodes and automatically try each node in turn until a download transfer is established. The user will usually see a status during the attempt—something like “trying host 1 (of 3)”. Extended information for that file shows the individual host addresses and other characteristics, such as transfer rate and client type. The client can then retry the others on a lost connection.
A major improvement in download performance, on the other hand, is the ability to resume a transfer at a specified offset in the file, instead of just starting over. This must be implemented in the software at both ends of the connection.
Resuming transfer might seem trivial enough to implement when dealing with the same physical file on the same host. The downloading client specifies that the host should advance its pointer a certain number of bytes into the file, assuming that the protocol (or a client extension to it) provides a mechanism for such an instruction.
The file must have in this context a persistent, unique identity, on the client side coupled with the host identity, so that the file can be identified and the transfer resumed even after the connection is broken and established again later. Many file-sharing hosts can have dynamic network identities, and the file identity descriptor might therefore not reliably persist across connection sessions.
A feature that depends on mapping identical files on different hosts is the ability to skip from an established connection to an alternate host in mid-transfer, for example on a lost connection. One reason for forcing skip manually might be that the actual bandwidth allocated to the download by the first selected host is far less than the stated rate, making the initial transfer unacceptably slow. An example of both a lost connection and a skipped host for the same file is illustrated in Figure 3.2.
Figure 3.2. File-sharing clients generally have the ability to identify identical files stored at several nodes, and try each in turn until a download connection is established. A host can also be substituted (skipped) in mid-transfer for performance reasons.

A third feature, relying on more advanced resume-transfer coding in the client, allows downloading different file fragments in parallel from multiple hosts. The ability to access multiple hosts for the same content, in sequence or in parallel, is a powerful way to work around the main disadvantage of discrete files in atomistic content storage, that of dependence on single nodes for retrieval.
There are few more frustrating experiences than interminably waiting for a large file in a slow download, only to lose the connection with only a few kilobytes left to completion. Strategies that automate reliable transfer are very valuable.
Bit 3.8 Transfer resume and multiple host sourcing must be considered almost essential features in content sharing and distribution.Transfer resume is still not supported by many Internet file-repository servers, so in that respect, even the simplest p2p clients are more advanced. |
Determining what constitutes identical content across multiple hosts is nontrivial, however, given the freedom in client design. The content descriptor (usually file properties information) sent by each host must be constructed and compared in a sensible way—a file’s name, length, and checksum would be minimum data for a reasonably confident match. In atomistic sharing, the filename is arbitrarily assigned by each user, and not that good an identifier even for general searches.
This identification situation is easier to resolve in the network publishing implementations because they have built-in functionality for tracking content, which automatically provides persistent and unique identification on a network-wide basis. In this context, clients don’t need to deal directly with the issue at all.
Encryption Helps Identification
These days, unique content identity is often based on hashed keys and checksums calculated on the entire content. These methods are often implemented hand-in-hand with public key encryption to safeguard the content.
The trend in all areas is for greater security and integrity of content, using public key encryption and digital signatures, and fortunately, this technology also provides reliable built-in mechanisms for uniquely identifying particular content in p2p contexts. If the hash is generated from the actual content, then two identical hashes by definition mean that the content is identical.
Hashed keys do have a problem in that the human-readable form of seemingly random characters in a long string is not especially convenient to handle directly for the user. In the simplest cases where access is through a hyperlink-aware interface, such as in a Web browser, the messy detail can easily be hidden behind a meaningful text anchor. This kind of solution is found in several technologies that use hashed keys as primary identifiers and retrieval handles.
As they become more common, many hash-key systems for resolving identity are fortunately evolving better client interfaces that make the key handling transparent to the user. While the easy solution of a Web interface through the system Web browser has a sort of instant gratification, it does impose a number of restrictions in how the keys can be handled, and lacks the potential for automation and agency that are natural extensions to most p2p usage situations.
A second issue is also resolved with the addition of encryption and hashes— namely, ensuring that the content is what one expects it to be, unaltered. As it stands, both users and client implementations show an amazing level of blind trust when retrieving content from essentially anonymous sources. Especially if the content is some form of executable file, it becomes crucial for the user to know that it has not been tampered with, infected with virus, or even replaced by a trojan that will wreak havoc with the user’s system. Digital signatures and hashes based on content are currently the best way of ensuring the authenticity of content.
What’s still lacking in this context is a widespread trust and authentication system, so that content hashes can be verified against secure sources to prove that the content does in fact originate with the purported creator. The extensive infrastructure solutions for the new Internet, some aspects of which are dealt with in Chapters 9 and 10, include components intended to create this kind of trust infrastructure. Other implementations might include smaller-scale or partial solutions to the problem. The discussions in Part III also return to issues of trust.