
Napster
The free-for-all music-exchange fest at Napster (www.napster.com) finally ended in June 2001, marking the close of a remarkable era during which the service registered some 65 million users in just 20 months, with billions of client swaps a month. As with IM clients, the number of real, unique users was probably much lower.
After its earlier skin change when it became part of Bertelsmann multimedia publishing, Napster tried to profile itself more as a commercial music download service, but despite its attempts to prevent commercial CD music files from appearing in the server database, users could still find and download as before. Continued efforts to implement content management and filtering of the eventually million or so music titles specified by the music distribution companies marked the last months of free operation. Before Napster’s servers shut down in July 2001, officially to upgrade its database software to support better file identification and stricter control as required by court order, membership was down from the 60 or 70 million claimed user peak to an estimated million or so, of whom perhaps 90 percent retained the client only to use it as a local MP3 player (or possibly connect to some alternative network set up with Napster-emulating servers).
Users who plan to remain as subscribers with Napster when it reopens need to upgrade to a new version of the client that actively supports content management— the new servers won’t support older versions. The company explains that many legally free files will always be available at the discretion of the users, but commercial tracks won’t unless purchased though its server-based download service. To protect this new system, Napster implements a filter that examines the digital structure of music files to verify their legality. In addition, in order to provide greater control over what is traded through its network, Napster developed a new, proprietary digital format (with the file extension .nap) to which MP3 music files will be converted.
This kind of central control (and client shutdown) is possible because the Napster architectural model is user-centric (UCP2P, introduced in Chapter 2). Clients go nowhere without the mediation of Napster’s database servers, and it’s reasonable to assume that this server dependency is strengthened in the new version.
After several delays and false starts, according to reports largely due to problems in achieving contractual agreements with the larger music distributors, the redesigned “clean” Napster network is scheduled to go back online in early 2002. Even so, a perceived monopoly situation due to the nature of the exclusive label contracts might still cause further delays and litigation threats. It remains to be seen how many users will accept this commercial model for music distribution, instead of permanently migrating to either Napster clone services or other free sharing networks.
Napster Architecture
Figure 7.1 depicts the essentials of Napster’s server-mediated architecture. Clients connect automatically to an internally designated “metaserver” that acts as common connection arbiter. This metaserver assigns at random an available, lightly loaded server from one of the clusters. Servers appeared to be clustered about five to a geographical site and Internet feed, and able to handle up to 15,000 users each.
Figure 7.1. Napster’s server-mediated p2p model. User A connects to the “first available” server assigned by a connection host. Lists of users and files are based on the users recently connected to the same server.
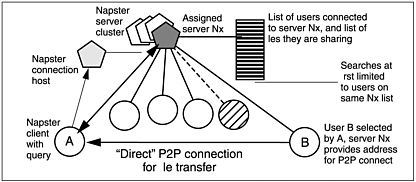
The client then registers with the assigned server, providing identity and shared file information for the server’s local database. In turn, the client receives information about connected users and available files from the server. Although formally organized around a user directory design, the Napster implementation is very data-centric. The primary UCP2P directory of users connected to a particular server is only used indirectly, to create file lists of content reported as shared by each node.
Users are almost always anonymous to each other; the user directory is never queried directly. The only interest is to search for content and determine a node from which to download. The directory therefore merely serves as a background translation service, from the host identity associated with particular content, to the currently registered IP address needed for a download connection to this client.
Network performance is tuned for quick server response to user queries, so searches are explicitly constrained in both scope (to a maximum of 100 hits) and time (15 seconds). Searches take place in the local files database maintained by the server but might (rarely) be passed on to neighboring servers in the same cluster.
Alternatives Gain Users
Characteristic for Napster was its exclusive focus on MP3-encoded music files. Although no other file types were supported, an intriguing subculture of client clones and tools soon arose, reverse-engineered from the Napster’s closed-source clients. This is further proof of the Chapter 1 assertion that people tend to use new technology for what they want to do, not necessarily for what it’s designed to do.
The intent behind the development was greater user control. For instance, a form of MP3 spoofing implemented by tools such as Wrapster could enclose an arbitrary file with a kind of wrapper that made it look like an MP3 file to the Napster servers. It would then appear in the server databases and be searchable by other clients wishing to download files other than music. An obstacle to this effort was that the artist-title description field allowed little information about the nonmusic file. This, the low ratio of nonmusic to music files, and the normal random distribution of connecting nodes conspired to make Napster’s scope-limited searches highly unlikely to find special content. Tools such as Napigator were developed to allow users to connect to specific servers, bypassing metaserver arbitration. In this way, certain servers became known as Wrapster hangouts—primary sites for nonmusic content. Users looking for this kind of content were then more likely find it.
Nonmusic exchanges over Napster proper were never more than marginal, at least compared to alternative, content-agnostic systems such as Gnutella. Some alternative Napster servers, such as OpenNap (started as “safe-havens” for Napster users when Napster began filtering content), did for a while begin to fill the gap, tying together former Napster clients, clones and variations with a new kind of server that extended the original Napster protocol to all file types.
No matter how much the Napster model was reengineered, however, the fundamental requirement of a “Napster-compatible” central server remained a serious constraint for a network based on this technology or any of its clones. To transcend this limitation, other protocols and architecture models are needed—for example, serverless networks in the style of Gnutella.