
Scalability Barriers
A fundamental problem when deploying any system is the issue of scalability. Something that works well in the small prototype scale might later behave differently, become unstable, or even stop working when fully deployed and taken past a particular size. A subtly different usage pattern than envisioned can also cause unexpected difficulties that relate to local scaling effects.
Understanding both the limits of a design and the reasons for these constraints is important. Examining practical networks illustrates both something of such limits and how the original models can be adapted for better performance. While some of this material could have been presented together with the particular implementation, it would easily have disappeared in the other technical detail. Besides, the scalability analysis really has more relevance to the deployment discussion because it lends a practical view to the abstract issues discussed so far.
Connectivity and Scale
The historical overview already mentioned physical connectivity as a general constraint of any network when scaling up the number of nodes. The mathematical relation of (n2-n)/2 connections for n nodes, for large n approximately just n2, very quickly makes applying other physical network topologies than direct one-to-one physical ones essential.
In both LAN and Internet contexts, larger networks are subdivided into smaller local groups with single connection points in each acting as gateways. Although the abstract addressing model makes connections in a virtual p2p network look like point-to-point, the actual message routing instead follows a more hierarchical model. The relatively few main data conduits are then dimensioned to handle the resulting greater flow. This makes both logistic and economic sense, even though it introduces a number of dependencies and vulnerabilities into the network. Figure 5.1 illustrates this relationship between abstract and physical connectivity for two nodes establishing a p2p connection.
Figure 5.1. In practical networks such as the Internet, physical connectivity between individual nodes is limited to higher-level “hosts” that are in turn connected to high-capacity “backbones” between hosts.

The details of physical network design fall outside the scope of this book, and in any case, an extensive body of study of the topic is available. It’s instead assumed that the available network connectivity is adequate for the purposes of any virtual p2p architecture dealt with here. Like that of telephony, the growth of the Internet has provided a background infrastructure as a sort of public utility, so this assumption is a reasonable one. When relevant, however, constraints imposed on p2p networks by typical user connectivity are examined in their proper context.
Addressability and Scale
In addition to connectivity, each participating node in a p2p network needs a unique address. The nature of the addressing model depends on many factors, and its constraints in turn determine how well the network scales.
Atomistic p2p networks are dependent on the addressing model of the underlying network. As a rule, they are also dependent on fixed addresses.
Internet connectivity is based on the IP numbering model, which originally assumed that any connected machine was at a fixed location with a permanent IP number. However, a certain measure of portability emerged with the domain namespace abstraction, in that DNS translation could map a particular domain to its currently assigned IP number. Domains can be moved freely as long as the authoritative DNS entry is always updated to point to the correct host. Any user has the choice of specifying a known IP number to a particular connection or specifying a domain and letting DNS ensure that the correct connection is established.
The main problem stemming from the current IP numbering implementation (IPv4) is that the scheme has a theoretical limit of something over 4.2 billion unique addresses. When IPv4 was defined in 1984, this limit seemed vastly overdimensioned. However, the way these addresses were originally assigned in large blocks and the subsequent explosion of Internet users meant that the demand soon outstripped the availability of unique IP numbers. Connectivity suppliers began to reuse their IP numbers as dynamic assignments from the static block they controlled, and virtual hosting suppliers began to assign multiple domains to the same static IP.
IP constraints are not directly a problem for p2p. Instead, innovative solutions to manage translation between user namespace and IP address allowed a remarkable growth curve for some of the most popular IM technologies. It took 16 years for the number of registered Internet domains to reach 25 million. It took only 4 years for the number of p2p user addresses to reach a conservative estimate of some 200 million.
Server-mediated p2p networks can manage alternative addressing models and better cope with issues such as transient or roaming connectivity. An early example of network independent addressing is the ICQ chat user directory service (discussed in Chapter 6). Introduced in 1996, ICQ was the first large-scale system to provide p2p connectivity for intermittently connected PC users. ICQ maintained its own user directory and mapped these “addresses” to currently online users.
Each registered ICQ client is assigned a unique user ID in the form of a number. For one user to chat with another, the ICQ directory server must track each online client and translate user ID to Internet IP-address. The user client updates the central directory by reporting its presence to an available directory server whenever connectivity is established or user status changes.
Bit 5.3 Offline, a peer user’s real network address is unknown.This characteristic of p2p networks is why presence information is needed. |
Unlike in a telephone system, a messaging user can’t “dial up” a user who isn’t already online. A particular user’s client is accessible for incoming requests only when that client registers its current IP identity with the directory server. Because the user ID is fixed and tied to the client as the basis for the user directory, handling transient users with varying network identity is a transparent process.
To structure the following discussion, we examine situations in each of the common p2p architectures discussed in Chapter 2, starting with the “pure” atomistic one. However, note that most implementations probably can and do function in several modes depending on context. For example, Microsoft’s NetMeeting can adhere to the atomistic model when conferencing with other clients at known IP addresses. On the other hand, it’s common to connect to a central server to first determine user availability in a user-centric directory maintained there.
Scalability in the Atomistic Model
Traditionally, atomistic p2p networks have been considered limited to on the order of hundreds of nodes, say 200. In early LAN and for example Workgroups networking, where one deals with generally fixed and known identities, the administration of many distributed PC resources, permissions, and availability tends to become unmanageable far sooner. Perhaps 10 to 20 nodes was considered the practical limit, beyond which one turned to server-controlled solutions, such as the Windows NT domain model that was developed for this reason.
Some might argue that these LAN networks were not pure atomistic p2p models because they effectively relied on an external administrative “server” (and bottleneck, the network administrator) to manage the resources! It was stated earlier that one of the characteristics of p2p is that the resources are managed by the nodes—traditional centralized management of LAN resources goes against that.
In the more fluid atomistic p2p networks that form over the Internet, there is no comparable central administration, only a standardized protocol and the software implementations that adhere to it. The simplest and so far very common approach is to implement a broadcast-route protocol.
Bit 5.4 Broadcast-route in p2p refers to request propagation.Each request message received by a host is broadcast to every open connection but not back to the connection the request arrived on. The host also typically performs filtering of “bad”, duplicate, and “expired” requests (as determined by protocol rules), updating any relevant data fields and counters in request headers as it does so. Responses are routed back along the path the originating request came from. |
Those who have applied theoretical analysis of tree graphs to broadcast-route peer networks have tended to make some rather broad, even simplistic assumptions, and they have derived upper bounds on practical network size that have proven unfounded in real p2p webs—an example analysis is given later in this section. The user-relevant behavioral constraints of the dynamic network depend on considerably more factors than such analysis examines. The Internet’s exponential growth has consistently confounded expectations for this very reason.
Let’s now examine the dynamic performance issues that are the subject of such analysis attempts, and start with the fundamental issue of bandwidth limits.
Basic Bandwidth Constraints
Theoretically, there’s no question that the major performance issue in atomistic p2p networks is the bandwidth constraints exhibited by individual nodes. The relationship is just a simple application of the law of the weakest link.
In simple atomistic architecture solutions, network traffic is passed along between nodes without any regard to the capabilities of the individual nodes. The implicit assumption is that all nodes are equal and consequently all possible routes through the network are equal. This assumption is valid only insofar as the nodes can adequately and transparently handle requests and throughput.
Individual node constraints are particularly relevant to common Internet p2p networks where many nodes participate in a transient way and over low-bandwidth dial-up. As a rule, p2p messages are passed using TCP, which as a reliable protocol entails handshaking and a specific cut-off point when the data path’s lowest bandwidth limit becomes saturated. At that point, the node software can do one of three things, any of which increases latency (delays), disrupts connectivity, or both:
Drop (or refuse) the actual connection, losing many requests during downtime, and especially responses due to lost return path. Lost responses tend to cause repeat broadcasts of unfulfilled requests, further exacerbating and spreading the bandwidth congestion. This is a bad thing.
Drop the data (usually a request or response), which is like breaking the connection but only affects this particular request or response. However, dropped data also shrinks the effective user reach of search or discovery.
Try to buffer the data in hope that it will be able to send it later. At best, the action only introduces latency, but it can still trigger a repeat request broadcast. Buffering costs memory at the node.
While latency may seem the lesser evil, its consequences can be bad enough. Most obviously, it means you have to wait longer for requests to propagate and responses to return—seconds turn to long minutes. Less obviously, increased latency means, for example, that the finite stack space (allocated in the node applications for those ID and return path stores, providing the routing table) fills up or overflows. When that happens, return paths are lost, compromising the discovery and search functionality, ultimately to the point where users find the network useless.
The data-buffering option in the TCP connection context is largely out of the control of the p2p application programmer; it happens deep in the networking code as a way of ensuring data transfer reliability at the expense of latency, until criticality is reached. This behavior is optimized for transient data burst situations, and the application layer remains unaware of the accrued delays until the deeper layer runs out of TCP buffers. At this point, it’s too late to do anything about the situation because the system’s connectivity response has just been hosed. Besides, by then, network timeouts are likely to have occurred elsewhere along the data path.
As overall loading rises above some threshold value in enough nodes with less capacity margins, this kind of network tends to show sudden unstable behavior. It will as a rule not scale very well, unless the client software or network protocols can implement more intelligent strategies or be more forgiving of data transfer latencies.
Bit 5.6 At any loading, there will always be some nodes in the network that drop or delay requests due to local bandwidth saturation.This is another major source of broken connectivity and discarded messages, but is not critical to the network as a whole until enough nodes reach their maximum capacity. |
In the simple atomistic model, Amdahl’s Law is therefore an absolute.
The Gnutella Bottleneck
Gnutella (see Chapter 7) provided a practical example of this vulnerability in July 2000, when it started to very rapidly receive more members. This influx came at a time when it first became apparent that Napster might be shut down.
Users of Gnutella reported increasing difficulties and markedly poorer performance during this period when the average query rate in the network doubled. A later and sustained usage surge resulted in widespread speculation that the Gnutella network was collapsing and would ultimately disappear.
In September 2000, the development company Clip2 Distributed Search Solutions published a report on p2p scalability with a particular focus on the observed degradation of the Gnutella network. Titled Bandwidth Barriers to Gnutella Network Scalability, the report is found at www.clip2.com/dss_barrier.html.
As passing testimony to the general volatility of the p2p and dot-com arena, Clip2 DSS discontinued its p2p network tracking, reflector and host-cache services, and development as of sometime around July-August 2001. A Web-visit in 2002 shows only the short text that Clip2 has ceased operations, yet the deep link to the report document is still valid. I therefore remind readers that although the Internet addresses given in the book are repeatedly verified during writing and production, some might become invalid by the time you read this.
The report provides more than just speculation and is interesting reading whether or not one accepts all the conclusions. An attempt to quantify performance constraints in Gnutella’s broadcast-route design suggested that the network, as implemented then, had a critical threshold of some 10 queries per second. When the average query rate increased further (for example due to a larger membership base), overall performance invariably plummeted. Queries are a broadcast-type message passed on from node to node, and they affect all nodes in broadcast networks equally within their range of time to live (TTL). As such, they constitute a reasonable measurement of loading.
This loading metric was derived mainly from how increased queries resulted in fewer nodes responding to internode pings. The report theorized that this bottleneck reflected the saturation point for the slower dial-up nodes in the network, whose bandwidth ceiling of 56Kbps (57.6 kbps, ISO) make them not up to the peer demands of the larger network. A large enough number of Gnutella nodes were modem based to have their limitations determine overall network performance.
Based on visual inspections of Napster client lists of online users, from where many of the new Gnutella users came at the time, I might even conjecture that modem dial-up at 56Kbps or less then dominated the user base. Undeniable is that Gnutella’s atomistic model and egalitarian view of all nodes being equal resulted in a clearly definable “scalability barrier” as far as further growth was concerned. We can examine the technical side in more detail to understand why.
The analysis of Gnutella traffic showed that it comprised five common message types at any node. Apart from the broadcast queries already mentioned, there was a regular exchange of “pings” with typically three other nodes. These pings alone at 10 queries per second would consume on the order of 17 kbps for the sending node. Nodes respond to pings with their “pongs”, adding to the load. In addition, hit results are sent back up the query path. Finally, older Gnutella software contributed measurably to the flow with broadcast push requests passed along by other nodes.
Even assuming lower bounds, the aggregate volume of this traffic at 10 queries per second translated to in excess of 67 kbps, which is clearly enough to saturate the ability of any modem-connected node, even single-channel ISDN, to respond to further queries. As each node reaches saturation, it no longer responds to new messages and thus effectively disappears from the network, compromising network cohesiveness. If enough nodes drop out under load, a point comes when the p2p network fragments, or even collapses from the perspective of later queries.
The report concludes by making the plausible assumption that for any (or at least any atomistic) p2p network, the specific saturation point is determined by the lowest common bandwidth among the nodes. Were 33Kbps and 56Kbps modem connectivity replaced generally by better bandwidth, for example, the saturation query rate would merely be raised correspondingly, not eliminated.
Bandwidth Bottleneck Solutions
Still, it’s valid to ask how serious a practical problem this least-common-bandwidth issue really is. Gilder’s Law, introduced in Chapter 1, implies that the average bandwidth capacity doubles every six months. That rate would automatically make the bandwidth bottleneck problem a consistently receding one, would it not?
In fact, this problem and its possible solutions are already well known from other network contexts that have seen rapid and large growth: the telephone system and the Internet. There, too, ever-increasing bandwidth has often come to the rescue. From the user’s point of view: Just wait a few months and somebody, somewhere, will throw enough bandwidth at the congestion points to make the problem go away.
Increasing bandwidth is by no means a panacea, but thanks to Gilder’s Law, it’s one easy solution; as network (and dial-up) components are replaced with newer ones over time, the bandwidth increase is automatically deployed throughout the network. Conscious and directed upgrades merely amplify the effect and make it quicker.
Although bandwidth loading tends to rapidly increase to take advantage of increased resources, a perceived performance improvement is almost always noted. It can be interesting to revisit the Gnutella situation as it was only a year later. The average number of connected nodes seemed to be higher, 5 to 7, and a subjective impression suggested that more users had moved from 56Kbps modem to higher bandwidth connectivity such as cable, ISDN, or DSL. This would seem to bear out Gilder’s Law (factor 2 to 4 in this time frame) and imply that the network now had on average a richer interconnectivity (from average 3 to average 6 connections). We might then expect oscillation between congested and improved states, as bandwidth and loading take turns in playing catch-up to the latest increase of the other.
Another solution deals with deploying more intelligent routing of messages through the network. The older broadcast-push method was replaced by a more efficient and less bandwidth-costly routed-push solution, for example. Various other changes to improve network stability also improved effective bandwidth.
One can encourage “trunk lines” and “backbones” as main conduits between major traffic centers, based on nodes and connections that have especially high reliability and throughput. Over time, the network will then become redesigned to reflect and strengthen this multitier hierarchy, simply because most of the upgrade resources will be directed to these critical paths and super-servers. The current Internet, and now Internet2, exemplifies the practical result of such a drift away from the original flat p2p design of ARPANET and the early Internet.
Similar avenues of development in the Gnutella network include
Moving from simple broadcast to more optimized query routing. Several more sophisticated p2p solutions examined later provide successful examples of this approach.
Relaxing the reliable-TCP constraint on broadcast queries and so lowering overhead by accepting unreliable transport forwarding. Using UDP (User Datagram Protocol) instead is an example.
Considering ways of introducing a two-tier system. Some form of “super-peer” nodes with proven bandwidth, capability, and reliability to handle the bulk of node communication can act as a high-performance backbone.
Proof-of-concept experiments of this last solution were tried with a Clip2 Reflector, whereby messages could be routed through predetermined and robust paths. This routing solution does lead to a stratified network and has certain disadvantages.
As implied by the Internet example, introducing preferred nodes moves the network away from the original p2p design towards an implied hierarchy that introduces identifiable, localized vulnerabilities. If a connection goes down in a flat-design p2p system, it’s doubtful that anyone would notice; there is no dependency on one single path. If a backbone connection goes down, on the other hand, many users experience severe slowdowns or even outages of service, even when the rest of the network tries to route around the problem.
While bandwidth, routing, and tier strategies might all have relevance to your p2p deployment, some of the implementations discussed in later chapters provide examples of other, less obvious strategies for conserving bandwidth and routing traffic, strategies that don’t compromise the essential p2p design philosophy.
One proposed general solution to the bandwidth/latency meltdown in the Gnutella context is a special routing algorithm, worth mentioning here if only to indulge in some techno-nerd analysis. It’s called the Flow Control Algorithm for distributed broadcast-route networks with reliable (usually TCP) transport links.
The Flow Control Algorithm
The Flow Control Algorithm ( FCA) is designed for Gnutella-type networks that use reliable transport links (such as TCP). Usefulness of the algorithm is not limited to only TCP-based networks, however, but is also applicable to “unreliable” transport protocols like UDP because applications using this frequently utilize reliable protocols (for example, Internet Point-to-Point Protocol, PPP) at some other level.
The FCA approach tries to apply a form of intelligent flow control to how a node forwards request and response messages and a sensible priority scheme to how it drops messages that won’t fit into the connections. In addition, a predictive algorithm guesses statistical request-response traffic to winnow excessive requests. The intent is to satisfy the following conditions:
Allow an infinitely scalable broadcast search network by avoiding the saturation effect of unlimited request/response forwarding.
Keep broadcast search delay to a technically reasonable minimum, to avoid excessive request/response buffering.
Allow tolerant connectivity between servents with varying link capacities, so that high-capacity nodes don’t saturate low-bandwidth connections.
Make a best-effort attempt to share connections irrespective of bandwidth and thus also be reasonably resistant to DoS attacks that try to swamp node capacity over a particular connection.
Be backward compatible with an existing server/client code base.
The functionality is realized by coding three control components into the client software that handles node connectivity and message forwarding: outgoing flow, Q-algorithm dispatcher, and fairness arbiter, as illustrated in Figure 5.2.
Figure 5.2. Principle functionality blocks of the flow control algorithm solution. The aggregate flow control performs a simple receipt check on receiving nodes, prevents overloading, and arbitrates fair connection usage.

The outgoing FCA component uses the simplest “zig-zag” data receipt confirmation possible between the clients on the application level of the protocol. In Gnutella, ping messages with a TTL value of 1 are inserted into the outgoing data stream at regular intervals (every 512 bytes). The only expected replies to this are pong messages from the immediate connection neighbor, where the ping expires. Any received pong thus confirms that at least the preceding data segment (of 512 bytes) was received by the neighbor node and that it’s safe to send the next segment.
The bandwidth overhead for this receipt mechanism is a tolerable 10 percent, and the maximum network layer buffering never exceeds the chosen segment size plus the corresponding ping/pong pair. The gain lies in never saturating the connection.
A number of refinements to the basic principle ensure low latency even when faced with ping loss or incorrect ping forwarding by noncompliant client software.
The direct cost to client performance is a lower maximum transfer rate over the connection due to that receipt overhead, although the effective rate is usually throttled by client settings anyway. The outgoing flow control must also manage queued requests and responses that are to be forwarded to the connection, or dropped if there is no pong response for a longer time. This is done in concert with the Q block, with priority given to low-hop response forwarding—it’s deemed more important to reliably service nearer destinations and shorter routes.
The Q-algorithm block acts as a dispatcher and is implemented on the receiving end of a connection. Its job is to analyze the incoming requests and to determine which of them should be broadcast over other connections (that is, passed to the respective outgoing flow control block) and which should just be dropped. It tries to arbitrate the available forwarding capacity between requests and responses, favoring responses because these represent a greater investment of network resources.
Because responses to incoming requests will be routed back along the same connection, it also tries to limit forwarded requests to minimize the risk that later responses will overflow the backlink channel. The theory gets a bit obtuse at this point, as we’re dealing with statistical expectations, but the guiding principle is that it’s far less damaging to the network to drop requests than to drop responses. Broadcast requests are likely to propagate anyway through alternative routes.
The fairness arbiter block is a logical extension to the outgoing flow control block, and its purpose is to ensure that the available outgoing connection bandwidth (as regulated by the outgoing component) is “fairly distributed” between the back-traffic (defined by responses) intended for that connection and the forward-traffic (or requests) from the other connections—the latter being the total output of their Q-algorithms. In addition, it tries to distribute the forward capacity fairly between these connections. The guiding principle is that no stream or a group of streams should be able to monopolize the bandwidth of any connection.
The main constraint to the applicability of FCA is that the requests and responses should not be cast larger than some reasonable size (typically, on the order of 3KB). This practical limit is usually satisfied, although it must be noted that the Gnutella protocol allows these message types to be up to 64KB in size. More detail on FCA can be found at one of several Gnutella development sites.
Presence Transience and Event Horizon Constraints
Characteristic of most p2p networks, and broadcast-route ones in particular, is the “ event-horizon” limit. In more general terms: How many of the other connected nodes in the network can you “see” from any one node at any given time?
The constraint is simply, that if you can’t discover a node through response analysis in an atomistic p2p network, you have no way of knowing that it exists (as a current address), or whether it is connected and available (as a presence state). Some networks with different request-routing strategies, such as Freenet, deliberately obfuscate visibility in the interests of security. In these cases, you really don’t “see” past the immediate neighbor nodes, but then don’t need to either.
When peer clients are desktop applications for sharing, common behavior by some users is to log in to the network only when looking for or downloading a file. A guesstimate of average session duration for a typical dial-up Gnutella user is therefore on the order of only an hour or so, with perhaps a couple of sessions per day—that roughly translates to a daily 1 in 10 chance of detecting this user based on presence alone! Overly pessimistic perhaps, but indicative. We might note that some recent clients (designed for 24/7 connectivity) are rather difficult to shut down or disconnect completely. Instead, they default to a hidden or background state, where they continue to relay network packets while the user works with other things.
The event-horizon effect further limits visible nodes to at best a few tens of thousands, but in conjunction with widely varying node branching is usually more like a few hundred to a few thousand. So, on the face of it, your typical Internet p2p network suddenly seems very limited, no matter how many potential members or installed clients it has in absolute numbers. The network appears badly fragmented into an unknown number of much smaller disconnected subwebs, each of which seems to manifest some fundamental scalability limit of the network.
Fortunately, matters aren’t that grim at all. In fact, some advocates claim that even simple broadcast-route p2p networks can be made “infinitely” scalable given the right set of conditions and node behavior. We’ve neglected a few things in this quick look at these apparent limitations.
First, detection at a given time is only part of the story. Assume that you are connected and see a particular subweb based on your connections to immediate hosts. Both your connections, and those of the nodes further out, are constantly changing. Over time, your event horizon encompasses different subsets of all potential members—a full day’s session might therefore easily detect ten or twenty times the total visible at any given moment, just not all at once.
Knowing a node address, your chances of contacting this node increase significantly because you’re no longer limited to the times when that node is inside your current topology’s horizon, only to the times when it’s available anywhere at all on the network. This is particularly applicable to messaging or content search, because if a detected host address is retained, you can probably still reach that node even when a later discovery or search would fail to find it.
Scalability in the User-Centric Model
The addition of a central server component to manage a user directory allows for a much improved scalability and, at least in theory, the visibility of all present nodes. Network performance is limited mainly by the nature of the directory, the capacity of the servers and connectivity. There is no need to fill bandwidth with general broadcast messages or relayed queries. Ah, the digital silence.…
The load experienced by the central server is in principle minimal because any data transfers initiated between nodes occur in a direct p2p connection. Traffic with the server is mainly due to clients registering with the directory service to announce their availability and to client requests for information supplied by the server. The other major server load occurs when a user performs a search in the directory for other users who meet particular criteria.
Various implementations can keep client connections alive for the duration of the user session to exchange supplementary information or track p2p status. Some automatically offer to transfer new client versions when they detect that the current one is old. Such additional features consume more server resources and can limit how large a network can effectively be supported.
Napster’s Compromises
It’s interesting to review the public understanding of p2p as popularized by Napster, which was not an atomistic model as most assumed, nor did it allow access to all the content available from peers connected at any given time. This perspective gives a more realistic view of network statistics for other, similar sharing technologies.
Instead, Napster was a simplified, and in some ways incomplete implementation of the user-centric model of p2p. Content was indexed indirectly. The strong point, and a major contributor to Napster’s popularity, was user convenience and relatively rapid response times to queries. As its phenomenal growth showed, the Napster model also scaled well—in fact far beyond expectations. Implemented optimization strategies were aimed at giving reasonable results for the majority of users, insensitivity to transient connectivity, and perceived fast response.
The basic connection model for the original Napster is shown in Figure 5.3, and it indicates a few of the hidden optimization characteristics. First of all, the Napster client software automatically connected not to a specific server, but to a special connection host. The connection host received information about the availability and relative loading of Napster servers within a particular group—apparently five to each site cluster. It then assigned (at random) a lightly loaded server in a local cluster to the connecting client. The client proceeded to register with the assigned server, providing information about user identity, connection type and speed, and shared files.
Figure 5.3. Napster’s server-mediated p2p model. User A connects to the “first available” server assigned by a connection host. The initial user/file list is based on the users recently connected to the same server.
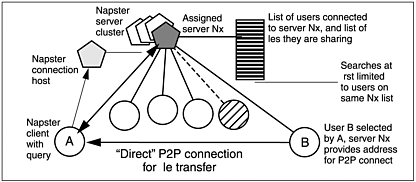
The directory service provided a list of users and their shared files. Selecting one initiated a server-mediated connection attempt between the endpoint clients. Once established, further communication and file transfer occurred in “direct” mode. Server loading was restricted to data needed to administer clients and the list.
The list of available users and shared files was initially restricted to those users registered with the same server. Most people assumed, in part because of the global users and shared files statistics shown in the client window, that all online users and files were always available. This assumption was simply not true, and the search mechanism was further restricted by how the directory service was implemented.
When the user submitted a search query, the search had two basic criteria for completion: either 100 hits found or 15 seconds elapsed. The underlying search database was initially restricted to only recently connected users on the same server. If the search completed with less than 100 hits found and elapsed time allowed, the query was passed on to a (randomly chosen?) neighbor server and another segment of the total database. Bandwidth and server requirements were thus kept to a minimum, and scalability was very good as long as the number of servers and their performance/ connectivity was adequate to the active user base.
Although this solution clearly gives a “snappy” response for impatient users compared to the usual search waits in an atomistic p2p network such as Gnutella, it presents certain disadvantages. One is that the search response of “no hits” is misleading. The negative response means only that no hit was found in the current (and local subset) database within the mandated 15 seconds. Repeated searches might well respond differently. Furthermore, the database is dynamic because users log in or drop out all the time. Finally, because a client connects to a randomly selected server, it will see a different subset of the total database for each session.
Admittedly, this analysis is fairly specific to Napster’s former architecture, but it is a reasonably clear and well-documented illustration of the kind of trade-off that might be hidden behind the scenes in any directory-based search that caters to user convenience—commonly expressed as minimizing user wait.
Scalability in the Data-Centric Model
The data-centric p2p model is similar to the user-centric one, but instead of server mediation providing a directory service to identify nodes (that is, users), it uses an index service to directly track data or resource location. In practical implementations, server mediation often adds both directory and index services in some form, possibly deriving one from the other, so it can be difficult to assign a particular p2p implementation to exclusively one or the other model.
Scalability considerations are similar to the user directory model, but a purely resource-centric implementation might easily be a significantly more static situation, in that resources as a whole are likely to be significantly less transient than human users dropping in and out of the network to chat or swap files. Machines and software are, as yet, less mobile than people in terms of connectivity change, making directory management and server loading less demanding, and useful network size larger.
While networks such as Napster obfuscated the issue of “reach” (that is to say, what and how much was available to a search query), it is perhaps a reasonable design objective not to cater to the human trait of wanting to reach everything all at once. Dealing with distributed resources in general, often replicated, it should be sufficient to find the first available instance that meets the request requirements. Therefore, searches need not be comprehensive. Dealing with human connectivity is more difficult because the desired match to a search request can be a single target instance (usually a person) at a single location, which does rather presume a comprehensive search of the entire network, ideally without too long a wait.
We could distill out of this discussion the realization that if search is a significant functionality in the directory or index model, then it is the one component in the implementation that will require the most thought, work, and optimization to be useful. Otherwise decent p2p implementations can be seriously crippled by deficient or incomplete search functionality, and it’s an area that is under constant development. Witness the different strategies taken by the implementations covered. Different situations require different solutions.
As the “content” in the network increases, the importance of a good search component will increase even faster. Anyone who doubts this need only look as far as the Internet, where it’s estimated that the relative importance of good search engines has increased far faster than the growth of content. I won’t bother to try and correlate this estimate with the power curves for relationships and value, tempting as that might seem. Personally, I invariably start looking for information on the Web with a proven search engine such as Google (www.google.com) and rarely go to the traditional hierarchical directories that were the mainstay of finding content in earlier years. It’s faster, and in most cases, it’s more than good enough.
An Adaptive Large-Scale Solution
In discussing bandwidth constraints, the focus so far has been on the problems with broadcast queries and managing traffic flow over TCP connections with known neighboring nodes. This focus is natural, considering that “secure” connectivity is desired—that is to say, we require protocol-based acknowledgement that packets are received and messages passed on. Other strategies are possible.
One such innovative alternative is represented by the Alpine (Adaptive Large-scale Peer2peer Networking) protocol. Rather than describe it in the file-sharing implementation section (for example, in Chapter 7), I chose to examine it here in the scalability section because the applicability is not only specific to file sharing, but might have far-reaching implications for peer networking in general. In any case, the current software stands at only version beta-01 (source and *nix binaries).
Alpine (www.cubicmetercrystal.com/alpine) is a messenging protocol intended for massive concurrent peer connectivity. It is defined in open source software released under the GNU Lesser General Public License. Both a peer-based application (as a client+server pair) and a network infrastructure, it is designed for decentralized information location and discovery. It is not designed for large-scale data transport between peers, which is instead normally handed off to some other transfer protocol, such as Swarmcast, Freenet, HTTP, or FTP.
The short feature summary runs as follows:
High concurrent connection support (over 10,000 nodes)
Adaptive configuration for enhanced accuracy and quality of responses
True flat peer network, with no hierarchy or central servers
Low communication overhead (small UDP packets, no forwarding)
Module support to allow extensions to query and transport operations
How does it do this? Normal TCP connections demand far too much overhead for large numbers of concurrent connections (which might also be constrained by hard-coded limits, as in Windows 2000 patched to update SP2).
Alpine allows the transparent multiplexing of a vast number of connections on a single UDP connection, what its author Martin Peck (“coderman”) calls an adaptive social discovery mechanism suitable for use in large peer-based networks. Distributed TCP (DTCP) is used for simple query and control type messages, and the process is akin to how addressed packet broadcasting at the lower network level multiplexes multiple higher-level connections over a single physical line.
Just as network devices can “sniff out” destination information from headers, Alpine applications share the same UDP connection, yet still use individual routing when relevant. To the host system, these many connections look like normal UDP traffic going over a single UDP port—the overhead associated with each connection is therefore very minimal. This is implied by the bus-like schematic in Figure 5.4. The 4-byte addressing allows for a theoretical 4 billion unique endpoints, but other constraint factors such as host memory, activities and bandwidth limits suggest practical network sizes of tens to hundreds of thousands of nodes.
Figure 5.4. Conceptual difference between traditional TCP-connected nodes and the multiplexed UDP scheme implemented by the Alpine protocol. The addressable broadcast in the latter can provide an unreliable endpoint connection for simple control and query messages.

The essential characteristic for this kind of connectivity is that neither timeout nor completion status is associated with individual messages. Any query that is broadcast is completely unreliable. If you get a response back from a peer, great. If not, then no big loss, the next peer may have the response you are looking for.
A Social Discovery Analogue
The social discovery aspect is based on an analogue with how people find out things— experience. You know who to ask and where to turn when looking for specific answers, because in the past, you have learned about the particular interests and proficiencies of each person you can contact. Over time you develop a detailed map of people and resources that are proficient at certain things. In this view, broadcast queries, such as in the original Gnutella, are like standing in the local mall’s parking lot on a busy shopping day, shouting out your questions to the wind in the hope that random passersby might have the answers you seek.
Alpine clients continually discover new peers on the network to communicate with and determine which proficiencies each may have, based on the messages that flow on the common UDP connection that defines the network. With every query or operation performed, a client also determines how proficient a given peer is for certain tasks. Peers who are very proficient and helpful become important members of a peer group, which are then utilized in preference to lesser-known peers. This combines a local services directory with a form of reputation system, which includes resistance to spamming and malicious node behavior.
Protocol Overview
DTCP is a lightweight and compact datagram protocol that allows
Connection multiplexing for large numbers of concurrent connections
Connection persistence despite changes in IP address or port for endpoints
Support for NAT discovery and dual NAT communication
Both reliable and unreliable packet transfer
Although not very final at this point, the groundwork has been laid for the bare minimum protocol required for basic operation. Refinements and extensions are still in the works, so this description is more functional than precise.
Connection setup consists of each peer selecting an available ID for the other, unique in the local space, and handshaking on this selection to inform the other which identity should be used in further messages. Thereafter, messages sent from either endpoint are recognized on reception by referencing this identity, which remains constant irrespective of variable IP/port until this virtual connection is terminated. An important reason for having identity set by the other side is to prevent casual spoofing, although it should be noted that this common strategy is like many adequate precautions ultimately vulnerable to packet sniffing at the endpoint.
Two kinds of data packet transfers are supported:
Unreliable packet transfer, which is identical in functionality to the UDP datagram transfer. This is a best effort, unreliable packet transfer, and the normal mode of messages between peers.
Reliable packet transfer, which incorporates timers and retransmission to guarantee delivery. An exponential backoff algorithm is required to avoid collisions when retransmitting unacknowledged packets, and only a single packet is allowed in route for a given endpoint at any time.
NAT discovery allows an address-translated peer to learn its outside address equivalent (as requesting endpoint) for use in further operations that need an explicit endpoint address. Poll and Ack packets correspond to ping and pong to test endpoint connectivity established from the values received.
Queries and responses provide the basic discovery mechanism. A query is sent in to the peers in a particular affinity group (or the default one). This progresses in a linear fashion until a sufficient number of resources are located, or until the user terminates the query process. Optimization is achieved by ordering the query sequence according to associated quality values in peer profiles maintained locally and trying to identify the peers that perform best within different query categories.
Peer profiles and ratings are implemented as protocol values pertaining to bandwidth, quality, and affinity. Using these, Alpine avoids congestion by keeping the connection pool tuned to the appropriate size with the correct types of DTCP peers to minimize query request loading. Each client can halt, slow, alter, or resume any peer query at will to optimize use of limited bandwidth. You can set precisely how much bandwidth you want the DTCP stack to use for reception and broadcast, and it can be set on a peer or peer-group basis, along with a cap on number of concurrent peers.
This strategy has higher-level implications and interactions with the reputation system, because you control exactly how often or how much response you provide to incoming queries. If you are getting swamped, for example, you will respond to less and less queries—your quality in the eyes of those peers will drop. As a consequence of their preference logic, you will then receive less queries: self-regulating loading.
Neither congestion control nor performance tuning is implemented at the DTCP layer. Instead, such refinements are specifically intended for the protocol implemented atop DTCP, a clever strategy which provides the flexibility required to support specific types of traffic. The protocol stack is a complete and functional component in its own right. If desired, you could use it directly for any type of low-bandwidth, disperse messaging type of data transfer.
Peer Affinity
Alpine maintains two main categories of information for every peer in the connection pool. The first is the peer’s quality and affinity to the queries performed. The second tracks peer resource impact, including but not limited to bandwidth usage.
If a peer responds to a query, its affinity value increases. Otherwise unchanged, the value can be decreased—for example, for responses with worthless content. Relative affinity value subsequently affects the order in which peers are queried, using a weighted, fuzzy algorithm designed to preserve some dynamic behavior, so that untested or low-affinity peers always get a fair chance to prove their worth. Server behavior defaults towards reliable by remaining online in the background (as a daemon process) even if the client and visible interface is shut down.
Logical connectivity between peers can actually span separate online sessions at either endpoint because the messages are tied by locally assigned identity and UDP connectivity, not any specific TCP socket with defined timeout. This promotes history building and peer profiling in the reputation system.
A similar set of values tracks the bandwidth that a peer uses when sending packets to you. Peers that use large amounts of bandwidth in relation to the other peers in your pool will be the first to be dropped if bandwidth exceeds the allocation threshold of the server. This mechanism provides a relief valve should traffic start to increase towards congestion.
The discovery protocol allows a client to gradually build local lists based on affinity groups maintained by other peers with high affinity. In this way, your perceived network can reliably scale with consistent quality to an arbitrary, but user-controlled size, no matter how large the total network is.
Search and delivery protocols are both implemented as core components in the basic server. Search functionality can be modified and extended using modules, and hit returns can be configured based on among other things the affinity values. An interesting application of this fine tuning is that trusted peers can be sent more or better information than untrusted ones. Standard HTTP and FTP protocols are considered the default for transfers. Additional protocols and transports can be added using a component interface to define extra modules.
Client and server communicate through a CORBA (Common Object Request Broker Architecture) interface, and can be disassociated so that on a local LAN, only one machine runs the full server, while the others only have the client half. It’s envisioned that flexible support for alternative interfaces, such as RPC (Remote Procedure Call), XML-RPC, SOAP (Simple Object Access Protocol), or DCOM (Distributed Common Object Model), could easily be added.
When Traditional Solutions Are Better
Interestingly, some considerations are presented in the Alpine overview about when existing mechanisms might be preferable to Alpine in search contexts.
When the target has a very specific name. Then a search engine like Google, or a hashed-index system like Freenet, is probably more efficient in large networks with indexed material.
Keyword-based or fuzzy-logic search are also well-implemented on Web search engines, though it’s noted that Alpine might excel when dealing with dynamic content that can’t be pre-indexed. However, if a centralized server search technology can be used, this alternative should still be considered.
If correlation between peer-stored content and peer group category is weak, other search mechanisms might be better. In other words, because Alpine is adaptive and preferential in which peers are contacted, weakly associated content on other peers is easily overlooked.
Performing searches many times per second consumes a fair amount of bandwidth to query a large set of peers. The protocol uses an iterative unicast operation to send query packets directly to peers, and this process could saturate uplink connectivity if used excessively.
Reliable queries are unsuited to Alpine, based as it is on unreliable UDP. In other words, applications that, for example, need a query receipt mechanism must rely on some other protocol to implement it.