
Gnutella
Originally, Gnutella (“new-tella”) was the name of a prototype client developed during just a few weeks in March 2000 by Justin Frankel and Tom Pepper, the same “Gnullsoft” team that created WinAmp, the first popular MP3 player.
In the release of the beta-test version, almost everyone saw a competitor to Napster designed to overcome its restrictions and limitations for swapping music files. This was perhaps a natural if hasty conclusion based on the timing of the release. Tom Pepper solemnly maintains that their prototype client was actually developed to swap recipes—the name a play on the “Nutella” brandname of a hazelnut/chocolate sandwich spread used in desserts and baking.
The issue of original intent quickly became moot when America Online (AOL), which had just acquired Frankel’s and Pepper’s company Nullsoft, learned of the project. AOL immediately stopped further work on Gnutella software and pulled the prototype from the server just hours after its release. The story would have ended there, except for some covert assistance and inspired reverse-engineering by Bryan Mayland, an open-source developer. He quickly posted the deduced Gnutella protocol on the Web, which fired considerable interest in the developer community. Before long, the Open Source Gnutella project was cooking around the protocol.
Gnutella is now a generic term with several meanings: the protocol, the open source technology, and the deployed Internet network (Gnutella Net, or just gNET). The site www.gnutellanews.com, a primary resource, defines Gnutella this way:
Gnutella is a fully-distributed information-sharing technology. Loosely translated, it is what puts the power of information-sharing back into your hands.
Another good resource is www.gnutella.co.uk, one of the first Gnutella Web sites.
The Gnutella manifesto—or less formally, attitude—is simply that atomistic peer architecture is how the Internet is supposed to be—no portals, no central authorities, no content control. Most open source p2p technologies manifest the same philosophy, more or less. Link, connect to, and share—do— anything with anyone. The decisions and details of when, how and what are left entirely up to the individual.
Bit 7.1 Gnutella is a common peer protocol, not any specific application.While most implemented clients focus on file sharing and file search, it’s possible to do much more than this using the Gnutella protocol or extensions to it. |
Infrastructure
Table 7.1 shows the component breakdown of Gnutella, with the caveat that it summarizes only popular current clients specialized for file sharing and does not indicate in any way any inherent limitations in the Gnutella architecture itself.
| Component | Specific forms | Comments |
|---|---|---|
| Identity | Unique message descriptor ID derived from current IP number and port | The popular file-transfer clients don’t actively support any direct naming scheme for active nodes but only track message ID. |
| Presence | Usually online, offline, or one of a number of preset or custom states | Presence is implemented in the client’s IRC chat component. |
| Roster | Only indirectly through local host cache | Manual contacting of specific IP nodes is possible. The chat component has more options. |
| Agency | Simple filters (screen) | Search, throttle bandwidth usage. |
| Browsing | (Sometimes) | Some clients allow browsing shared file directory in another client node. |
| Architecture | Atomistic, mappable, possible evolution to two-tier | Reach bounded by TTL count, topology in constant change. |
| Protocol | Open, HTTP, ping/pong | Extensions possible. |
As perceived today, Gnutella is primarily a file-sharing and exchange network that supports arbitrary file types. There are no central servers, and hence no central shutdown point. The private or public network is defined solely by whatever clients are currently in communication with each other. Collecting responses to client announcements to the network allows each connected user to build a local map of this network. There may be multiple networks, depending on how clients are configured to connect, or alternatively, a local network of Gnutella clients on a LAN.
To begin with, the specious gnutella.net, com, and org domains all merely pointed to a really simple status page with a count of active nodes (many thousands) and available file library (often in the ten millions of megabytes), as seen from that particular node in gNet. The gnutella.com domain appears lately to have changed into a growing portal site for the user and developer community. The associated gnutellameter.com site purports to show realtime network status in a variety of formats. The Gnutella Network Snapshot comprises a number of sorted query lists compiled from well-situated nodes to give an indication of network activity.
As a connected user, you have similar and more information directly available in many clients (for example, Gnucleus). The difference is that the connectivity is seen from your own position in the network—a more relevant view in any case.
Gnutella was often seen as a viable contender to Napster, not least because of this lack of a central shutdown point. Several Gnutella-protocol clients were in fact narrowly designed for MP3 file exchange only. Both the threats and actual closure of “free” Napster caused marked flows of users to Gnutella as a result.
The lack of central control points in Gnutella means that the legal responsibility for file transfers rests entirely with the users. Depending on your viewpoint, this is either a good thing or a bad thing—undeniable is that on gNET, you can find dubious content and illegal copies of pretty much anything at some time or another. Thus it boils down to the issues of whether, as a Gnutella node, you share inappropriate files, or search for and then decide to download files that might be considered illegal. Either way, it’s a conscious decision and deliberate action by any user. Much like life :)
Client Software
There is no single, standard Gnutella client software. Instead one finds a diverse collection of clients that all support the basic Gnutella protocol. These clients can all communicate with each other, but developers are free to implement functionality and extensions as they see fit. This freedom of implementation and extension has some interesting consequences, discussed later.
Gnutella specifications and most clients are open source (as GnuGPL), but a few closed-source applications also exist. Clients are often rapidly evolving test versions; new ones appear, and others become “archived” (meaning orphaned software). A few have become established. They range from user-simple connect-search-download clients, to nerd-friendly applications with lots of node/packet statistics and logs.
The www.gnutelliums.com Web site maintains a comprehensive directory of Gnutella client downloads for the major platforms Windows, Linux/Unix, Java, and Macintosh. Table 7.2 shows the clients current at the time of writing, but the pace of development is rapid and changes are likely by the time you read this.
Connecting to Others
Logging on to the public Gnutella Network is likened to wading into a sea of people— faces in all directions, and a sort of horizon beyond which you see nothing. Each time you join the network, you wade into a different part of the virtual crowd and see a different selection of nodes. You talk to the nearest neighbors, and through them to others. Each session, it’s a selection of different people and different information.
| Windows 32-bit | Linux/Unix | MacIntosh | Comments |
|---|---|---|---|
| Gnotella | Gnutella clone, graphic plots of dataflow, skins. (2.3MB) | ||
| Mactella | Gnutella clone. (500KB) | ||
| Gnucleus | Nerd-friendly options and statistics, node mapping option. (1.8MB) | ||
| BearShare | Well-made and quite popular. (1.2MB) Unwary users will be subjected to alertbox advertising unless these components not installed. | ||
| LimeWire | LimeWire | LimeWire | Java-based. Very popular. Has many sophisticated control features. (3–10MB depending on platform). |
| Phex | Phex | Phex | Java-based development of (now unsupported) Furi (1.6MB, Java runtime files needed). |
| Hagelslag | Dutch Gnutella implementation. (140KB) | ||
| Qtella | Written in C++ / qt library. (150KB) | ||
| Gnewtellium | MP3 files only (32KB), based on (now unsupported) Win32 Newtella. | ||
| Gnut | Command-line client for any POSIX system. (280KB) |
You can connect in principle with any of those you detect around you, but as in real life, many are too busy talking to others to pay much attention. Some will pointedly ignore you. Others just exchange a few words and move on. Eventually you find a suitable number to maintain longer contact with, who can reliably pass along queries and results. People come and go all the time, and the local configuration changes constantly, so over time you will be connecting with different ones.
Atomistic p2p networks such as Gnutella are highly dynamic and lack (or at least don’t require) central address lists. Pragmatics, however, dictate that some form of bootstrap list is available for initial discovery, so clients do incorporate a few such options. The discovery process is discussed further in the protocol section.
This sea-of-people image is certainly apt on one level, but it obscures an essential feature: random physical location. Your nearest neighbors can be physically very remote indeed. Tracking node connectivity over time, and determining actual node location from the IP numbers, gives an appreciation of the global and dynamic reach of the Gnutella Network over the Internet. Some clients, such as BearShare seen in Figure 7.2, helpfully perform automatic DNS lookup and display little icons and country flags in the connectivity origin field.
Figure 7.2. Composite from Bearshare Gnutella client illustrating both the way your immediate connections change over time and the global cross section of nodes that make up a local web of “neighbor” nodes.

Broadcast-Routing Strategy
The horizon effect is a result of inherent (virtual) segmentation of the network, a design decision that (currently, with default client settings) limits the node count to about 15,000 on gNet as seen from any node—a client’s potential reach. Older analysis suggested much more severe network segmentation with a reach of only a few thousand nodes or less, even in ideally balanced and equally distributed topologies, but this value is in practice very sensitive to many factors.
Nodes continually drift in and out of reach in an evolutionary process, in turn influencing which nodes you can reach through them. Over say a few hours, you might reach four times as many nodes as you see at any one time.
The main reason for the horizon effect is that messages have a time-to-live ( TTL) counter. Typically, the TTL is set between 5 and 7, and the value is decremented by each node as it relays the message. Another counter tracks the number of hops. A simple example of the principle is illustrated in Figure 7.3. The critical values of TTL and number of node connections, together with each node’s capacity and bandwidth, combine to determine network performance and stability. Some clients allow the user to manually adjust TTL and the number of keep-alive nodes, and thus to some extent extend the effective horizon.
Figure 7.3. How decrementing TTL (and discarding duplicates) ensures that a relayed message eventually stops spreading through the network.
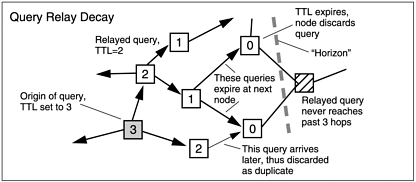
Ideally, all messages live out their TTL, but sometimes a message is discarded by a node as a bad packet. The reason can be that the total number of hops exceeds a node’s set limit, a duplicate is received, or the message is damaged or can’t be parsed in some way. TTL-expired messages are often included in bad packet statistics.
Table 7.3 gives a good idea of how potential (or ideal) reach varies geometrically as a function of two parameters, connectivity and TTL. The previous example with TTL=3 would thus have, according to the math, a maximum reach of 21 (assuming all nodes connected to three unique neighbors). The shaded region in the table is where most Gnutella clients operate, although usually not achieving these ideal reach values because actual node branching varies considerably from case to case.
Bit 7.2 TTL value is the only mechanism to expire descriptors on the network.For this reason, each client examines TTL in passing messages and adjusts higher values down to its own TTL setting, which clamps TTL to a consensus maximum. |
| TTL=2 | TTL=3 | TTL=4 | TTL=5 | TTL=6 | TTL=7 | |
|---|---|---|---|---|---|---|
| N=2 | 4 | 6 | 8 | 10 | 12 | 14 |
| N=3 | 9 | 21 | 45 | 93 | 189 | 381 |
| N=4 | 16 | 52 | 160 | 484 | 1456 | 4372 |
| N=5 | 25 | 105 | 425 | 1705 | 6825 | 27305 |
| N=6 | 36 | 186 | 936 | 4686 | 23436 | 117186 |
| N=7 | 49 | 301 | 1813 | 10885 | 65317 | 391909 |
| N=8 | 64 | 456 | 3200 | 22408 | 156864 | 1098056 |
The value of TTL should probably never be set above 8 for risk of drowning the network in excessive query relaying. Client software tends to enforce upper limits here, ignoring and replacing higher settings in relayed messages. On the other hand, super-peer networks might operate with locally much higher values of N.
Network reach in practice is illustrated in Figure 7.4, where distribution mapping two connected nodes provide contrasting topologies. The first suggests an average N of over 4, a distribution and reach fairly close to ideal, and with potential access to a large library of files. The second, with a paltry 46 nodes after the same seven hops, shows several nodes with few friends. Poor path expansion severely limits searches, and impoverished node paths are good candidates for pruning. Reach may be understated, however, as newer clients no longer respond to multihop pings.
Figure 7.4. Composite from Gnucleus client showing varying network reach as a function of how well each connected node branches to others.

Looking at summed statistics for good client connectivity, Figure 7.5 shows that connectivity to five nodes provides access to something approximating the potential reach of N=4, TTL=7, despite lackluster statistics from a few of these node trees.
Figure 7.5. Summed statistics for client connectivity, where previously analyzed node trees converge. Identifying node numbers are masked in the capture for the purposes of this illustration.

As noted earlier, there is inherent drift in the connection map, and over time the distribution map will look very different. But there’s no need to wait passively; manual improvement and change is possible. The occasional, judicious culling of poorly performing nodes in the connection list allows new, probably better connections to form—a process not dissimilar to discarding poor cards in a poker hand and hoping for a better draw. This simple measure goes a long way to improving reach in the short term. Clients can also be set to automatically drop connections to nodes with less than a stated number of friends or those with no shared content.
Protocol
The Gnutella protocol is firmly anchored in the established HTTP protocol for the Internet. The defining point is that all nodes are “equal-rights”, and the software acts as both server and client—a “ servent”. The functionality focus of the protocol is on distributed search for content.
Gnutella is open source and the protocol relatively simple, making it suitable as a kind of baseline comparison technology in this book. The full protocol details are published in various locations on the Web, but the essentials are explained in some detail in this section for the sake of later comparisons.
This basic protocol has been extended by some clients. For instance, Gnotella can include extra transfer statistics in the QueryHit message. BearShare as of v1.3.0 also extends the QueryHit result with more information about servent and transfer statistics, plus a field for proprietary data. Newer clients are extending the protocol to handle multiple download sources and other features. The insertion points seem reasonable, and the extra data should be ignored by clients without these extensions.
However, protocol extensions can be somewhat fragile in a mixed-client environment. For example, some (older) clients may misinterpret extended QueryHit messages and mangle them. Other nodes discard damaged QueryHits, so these can’t be guaranteed to reach the original Query node in mixed-client networks.
The Gnutella protocol currently defines only five descriptors (for message types) to implement network functionality. They are listed in Table 7.4, along with explanatory comments relevant to nodes sending or receiving them.
Message examples are given later for different situations, showing just how servent message exchanges are structured for the common query-response pairs.
Each descriptor message is in turn defined by a message header, the components of which are given by Table 7.5. This header too is a fairly simple implementation with only five field types. The description in the table should be adequate to understand the context in which each is used.
Bit 7.3 Gnutella message headers have no special framing sequences.Currently, the only way to reliably parse the network data stream of message descriptors is by examining each header’s Payload Length to find the start of the next descriptor—the price paid for open-ended simplicity, perhaps? |
This parsing constraint means that there is no built-in fault tolerance or recovery for descriptors that a node fails to parse—the messages are just discarded.
| Header field | Description |
|---|---|
| Descriptor ID | A 16-byte (128-bit) string that uniquely identifies the descriptor on the network. As a rule, a function of the sending node’s address, it is used in Pong and QueryHit as a destination (originator) identifier. |
| Payload Descriptor | Identifies the kind of descriptor. Currently used: 0x00 = Ping, 0x01 = Pong, 0x40 = Push 0x80 = Query, 0x81 = QueryHit |
| TTL | A counter specifying the number of times remaining for the descriptor to be forwarded before it is discarded. Each servent decrements TTL before passing it on to another node. |
| Hops |
Hops value tracks the number of times the descriptor has been forwarded. The TTL and Hops fields of the header must satisfy (or be adjusted to) the following condition:
TTL(0) = TTL(i) + Hops(i) where TTL(0) is usually the current servent’s setting. |
| Payload Length | The length of the descriptor immediately following this header. The next descriptor header is located exactly this number of bytes from the end of this header (there are no gaps or pad bytes in the Gnutella data stream). |
Because of the lack of framing sequences or other “eye-catchers” in the data stream, the protocol specification urges that servents rigorously validate the Payload Length field for each fixed length descriptor received. In the event a servent finds itself out of sync with an input stream, it should drop the connection associated with the stream—following the worst-case assumption that the upstream servent is either generating or forwarding invalid descriptors.
Connection and Discovery
Gnutella clients communicate by default on port 6346 (or 6347) using the normal Web protocol HTTP 1.0—each in effect functioning as a miniature browser/server application. Any port however can be specified. Some clients have built-in Web browser windows and can browse target server directories if it is allowed, while others hand off any Web page presentation to the system’s default browser.
Establishing a connection to the network is a matter of making a TCP/IP connection to an existing node and sending the HTTP header message:
GNUTELLA CONNECT/<protocol version string>
A servent wishing to accept the connection must then respond with:
GNUTELLA OK
Any other response indicates unwillingness to accept the connection.
A servent may actively reject an incoming connection request for a variety of reasons. The user might have set the servent to not accept any incoming connections at all, preferring to maintain outgoing ones. Incoming connection slots are limited in any case by a client setting and may already be filled. A servent might not support the same version of the protocol and decline for this reason.
Nodes already connected in the network can map active node addresses through ping-pong responses from other nodes, but the Gnutella protocol doesn’t specify any initial method to discover currently active nodes prior to joining. In the beginning, quasi-permanent node addresses were distributed through other, manual channels, and new users would enter them into a client until a connection could be established.
These days, node address acquisition for new nodes is usually handled automatically, through host cache services implemented on selected “permanent” network nodes with published addresses—for example the client home site, or from particular IRC channels with automatic response ’bots (short for virtual robots).
Clients preset in this way can automatically maintain local lists based on such downloads and later use recent node history from the local cache. Alternatively, the user can try manually entered node addresses. Independent Web sites, such as the zeropaid.com file-sharing portal, also provide updated Gnutella nodelists for download or manual entry.
Once connected to an active node, clients can map other nodes from received pongs, possibly after sending further ping descriptors up the network, and continue to establish connections with more nodes. A visualized example of such a network map constructed from node responses is shown in Figure 7.6, albeit limited to a hop depth of only four in order not to become too cluttered.
Figure 7.6. Example of connection map created from node responses and visualized to depth 4 in Gnucleus using the GraphViz package.
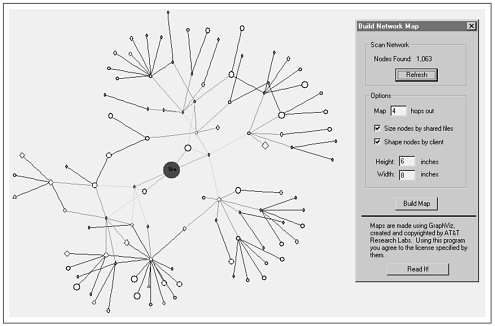
Ping-pong messages represent a significant portion of the total network traffic in a peer network of this kind, together as much as two-thirds or three-quarters of all messages through any connection, and the Gnutella protocol therefore strongly recommends minimizing the number and frequency of pings sent by any one client. The general discussion of scalability in Chapter 5, which used an analysis of a Gnutella network as an example, noted that just sending pings alone consumed a significant fraction of available client bandwidth, perhaps routinely fully a third for 56Kbps modem users. A recent trend is for clients not to respond to multihop pings.
The protocol further specifies a routing policy that a pong may only be sent back along the same path that the originating ping traversed. To comply, each servent maintains a cache of all the ping IDs it has seen in a kind of routing table, with information about which connection delivered it. Servents simply discard any received pong that doesn’t match a seen ping. In addition, the ID cache allows a servent to discard duplicate descriptors, usually due to loops in the ad hoc network topology.
Bit 7.4 Pong data can refer to an arbitrary node.The protocol doesn’t require that an issued pong must refer to the same node that issues it. Usually it does, but it might in fact point to another host. A servent might send a series of pongs in response, including cached ones from other nodes. |
Implementing Search
The core of a Gnutella network is the search, performed by sending a Query message. The normal broadcast-route method means each servent that receives the query—and determines that it is valid, not a duplicate, and still has time to live—caches the ID to its routing table (as for pings) and forwards the query to all its other connections. The software then performs a search on local content.
In addition to the query string, the descriptor payload starts with a field specifying a minimum supported transfer rate for response. A pragmatic way to conserve network bandwidth, the value tells servents with lower maximum rates to not bother responding. However, they will still forward the query as before.
Servents with a hit match to a query string respond with a QueryHit message, the body of which provides information needed to evaluate the host and contact it for transfer. QueryHit messages are sent back to the network, but the header contains the same descriptor ID as the Query. This allows the query client to correctly identify and associate QueryHit messages received from the data stream with the Query messages it initiated. Servents implement the same routing policy for QueryHit as for pongs.
Bit 7.5 Constantly changing topology means discarded descriptors.Shifts in connection topology can destroy original paths. The local routing requirements mean that new nodes in a path initially discard all responses instead of passing them on—a major source of “bad” messages and failed discovery or search. |
A typical transfer session is initiated by the Query client attempting to directly contact a QueryHit-identified servent. The fetch syntax used for the direct connection attempt is placed in the header directed to the target host. The end-of-line marker used throughout is the DOS-standard cr+lf, not as some might expect Unix/Web lf.
GET /get/<File Index>/<File Name>/ HTTP/1.0 Connection: Keep-Alive Range: bytes=0- User-Agent: <Agent Identifier>
If all is well, the target servent responds by sending an acknowledgment header:
HTTP 200 OK Server: <Agent Identifier> Content-type: application/binary Content-length: 4356789
A successful handshake response allows the requesting servent to start the download. It’s up to the user to determine whether bandwidth and reliability make the selected host worth continuing the download with. If the target servent is firewalled, such direct contacts from outside will fail. The backup method on failure is to try a “push” request passed up the node tree the same way that the original query was sent.
Bit 7.6 Gnutella transfer requires at least one servent with no firewall.If both requesting and target servents are firewalled, then no transfer is possible. Other implementations sometimes get around this constraint. One possibility that can be implemented by Gnutella clients is to use a third, open node as a relay. |
Push descriptors are routed like Pong or QueryHit responses, only according to the servent identifier field (from QueryHit), not the descriptor ID. The assumption is that since the target servent could read and process the query, it will also see the push. The servent acquires the IP address of the query client from the push descriptor. It can then from inside its firewall initiate direct contact and send a GIV transfer offer:
GIV <File Index>:<Servent Identifier>/<File Name>
The requesting site can from the offer extract the required file parameters and construct the same GET header as in the previous case to start receiving the file.
Transfer Issues
While file transfers occur directly between the two end nodes and therefore don’t load the network, they do share the respective end-node bandwidth with normal network loading and other transfers in progress from either side. In addition, transfer bandwidth is often throttled in host clients so that “uploads” can never go faster than a preset rate, say perhaps 33Kbps, despite otherwise high bandwidth at the host.
It’s not unusual to start a large download only to discover that the effective transfer rate falls to unacceptable values. At that point, the sensible user looks elsewhere, to other hosts. Clients such as Gnucleus can allow progression to the “next” host of several for a particular file.
Bit 7.7 A user can leave the network to improve download performance.In some cases, a user might decide that an initiated transfer is important enough that all node bandwidth be dedicated to receiving it. Disconnecting from the network at this time can give marked transfer improvement. A shorter download time also increases the probability that the transfer completes successfully in a single session. |
The Range parameter in the message implies the ability to resume interrupted transfers from a given offset, which most servents support. Resume is a valuable, perhaps even essential feature in transient networks where any sending host might disconnect at whim, disrupting an ongoing transfer.
Support for downloading different file segments from several alternate hosts simultaneously is successively being introduced in newer client versions (for example, LimeWire 1.9 and Gnucleus 1.6). Parallel downloads of offset data greatly improves both efficiency and reliability of transfers and is often a technique implemented in more advanced, distributed protocols (see Chapters 8 and 9).
In both resume and multihost cases, the issue is to correctly identify that the sources in fact are exact copies of the same file. A simple method is to offset fragments with a small overlap and test that this data always matches. When resuming a transfer at a later time, the receiving client must remember the addresses (often as IP numbers) of the hosts associated with that particular file. Otherwise, the user is forced to perform a new search. The risk then is that the shifting network topology no longer includes hosts with an “identical” copy—or it might not find that file at all.
Bit 7.8 The ability to resume transfer might be dependent on client state.The list of transfer host addresses might be kept in a transient store, subject to loss. |
Different client implementations might handle partial-transfer resumes differently, caching vital node and file data only temporarily. User interactions with the client software (for instance, closing result window, performing new search, or requesting re-search) can unexpectedly cause the loss of such information. Not all user manuals are especially forthcoming on this problem.
Gnutella Scalability
Network scalability is discussed at length in the AP2P section of Chapter 5, using Gnutella as an example. A Gnutella network exemplifies well both the advantages and disadvantages of an atomistic peer architecture, especially in the context of what is sometimes called the Transient Web. Just as was experienced with the Internet, as the network grows, so too do the inherent scalability constraints in the basic architecture increasingly come into play.
A second-generation (Gnutella2) architecture is being deployed with a super-peer layer of clients to form a more reliable and persistent backbone. Probably this will also give the option of some permanent nodelist servers to make it easier for new users to connect to the network the first time. Super-peers are “elected” locally by virtue of their better bandwidth and capacity to form the mainstay of connectivity, thus retaining most of the atomistic and decentralized nature of the original AP2P model. The approach makes the network far less sensitive to the transient connectivity and limited bandwidth caused by the large number of dial-up users.
Predefined Networks
Installing and using Gnutella in a limited corporate intranet context is not difficult; recall that the network is defined by the topology of active nodes and a client list of nodes to try when joining. The administration involved is mainly deploying the most suitable clients with an approved nodelist. Some clients (such as Gnotella) even provide a settings dialog explicitly for forming a “subnet” for this very purpose— otherwise, the connection seed list must be edited by hand.
Forming a limited network is not the problem. The main risk in the limited network context is that if any one node should connect outside the prescribed list of nodes, that will instantly make the rest of the network and its effective nodelist available from outside. It only takes one client acting alone to subvert the closed network, unless explicit filtering or external measures can prevent connection casts outside the approved range of nodes. Rogue connectivity can also be caused by a virus (for example, Mandragore), unless client machine firewall software detects the ruse.
Bit 7.9 The Gnutella connectivity model is “allow” unless explicitly denied.The default settings in most atomistic p2p clients currently allow arbitrary outbound connections. The same settings also allow anyone to initiate inbound connections to the client and freely download shared content from it. |
The Risks
Granted that typical client software allows extensive filtering of which node connections it will accept and some restrictions on content sharing, but it must be explicitly configured in each. You therefore should preconfigure all participating clients in a closed network the same way to accept only nodes within, for instance, the same subnet. Correspondingly, they should also be preconfigured with only an approved nodelist to try when joining, removing any references to external sites.
Even so, if just one client bridges to an external network, then the private network becomes at least visible from outside due to the nature of the ping discovery process. Such external connectivity might occur because some user manually connects to the public Gnutella network to look for something while still a member of the local client network. This projected visibility increases the risk for directed probes or attacks on these now discovered nodes. If node filtering is insufficient in clients, then unauthorized sharing of content might also occur due to the default trust inherent in the basic Gnutella system.
Bit 7.10 Gnutella clients are natural gateway servers between networks.Any Gnutella servent has this automatic ability to bridge between different virtual Gnutella-protocol networks by virtue of multiple node connections. |
We can also note in passing that many recent client implementations, such as Gnucleus, support automatic detection of and upgrading to newer versions. Although convenient in that new versions of software can easily propagate through the network, this does pose something of a reliability and security issue. Lacking digital signature checks, for example, malicious software could conceivably be inserted from outside in this way. One reason for this risk is again the implicit trust built into the design and default configuration.
These issues were discussed from a general viewpoint in the Chapter 4 section on security. Ensuring adequate security in the current Gnutella implementations is to a large extent a matter of manual precautions and sensible defaults. The complete user control of the individual client does mean however that any one user might change settings or make connections that can be detrimental to the rest of the local network.
Solutions to better p2p security are coming as the technology matures—for example, in the form of more automated trust and reputation management. Some of the other architectures in this book deal with these issues already.