
Historical Analogies
Modern peer technologies owe much to what has gone on before, both directly and indirectly. This slight detour outlines some of the precursor technologies and attendant growth of communication infrastructure.
Telephony
The analog telephone was an early extension to direct person-to-person connectivity. In fact, telephony could be considered the first large-scale peer network technology, developed in the dark ages before computers. Although the endpoints were the fixed telephone locations (homes and offices) of the people who wanted to connect, rather than the individuals themselves, most users easily accepted this accessibility limitation, and usage confounded the experts. After all, nobody would ever want to use a telephone to talk to another person. This view caused significant problems for the early advocates to raise capital to build the infrastructure.
At least one early metropolitan telephone network, created in 1893 by Tidvadar Puskás in Budapest, Hungary, was instead initially used as a broadcast system. (Puskás was a colleague to Thomas Edison, who returned to Hungary with broad rights to Edison inventions and with a bold vision to build a new infrastructure.)
In the Budapest system, the central exchange sent a simultaneous ring signal to all subscriber homes. People lifted their handsets or connected external speakers to listen; they didn’t speak into the device at all. The exchange instead broadcast official announcements or news, or even live evening concerts—a very early example of what we now call streaming media!
As subscriber call usage later increased, this “talking newspaper” service was made optional and then moved to a separate line. This system is today cited as an early experiment in wire radio broadcasting, but it’s seldom mentioned in telephony contexts. It never amounted to more than a passing curiosity, despite the grand visions expressed by Puskás during its early deployment.
The early history of the telephone tells us something important about how people use technology, especially new technology.
Bit 1.10 People use technologies to achieve their own goals.The normal application of any given technology will probably arise more from unexpected user innovations, than from any explicit design intentions. |
The rapid growth of person-to-person calls was an unexpected side effect of early telephony network growth. It developed spontaneously among users.
Informal ring protocols arose on the early “party line” connections where many devices shared and could listen in on the same line. Just as a central operator could use two signals to indicate that someone in say the Smith household should pick up to receive a call, anyone else on the line could also generate a similar ring pattern to originate a call. Reaching other “local networks” required the assistance of switchboard operators.
Development of automatic switching exchanges and the deployment of multiple virtual-pair lines later made “placing a person to person call” a matter of endpoint connections set up by just dialing a number. A more reliable privacy was also ensured, instead of the loose social convention that others on a shared line shouldn’t listen in on “private” calls. New user services needed to be developed, such as subscriber directories, which further enhanced network usefulness to the user.
Early dismissal of telephony technology by the experts and caustic comments by contemporaries notwithstanding, telephones became ubiquitous, even essential, with transparent global direct dialing further contributing to its utility. Now, mobile phones are becoming just as common, and global roaming third-generation (3G) 24/7 Internet mobile connectivity is already being deployed in field trials. We are therefore on the verge of telephony as a true person-to-person network, the connectivity endpoints no longer tied to physical locations but to the bearer, anywhere. A merging of telephony and computer communication into the same device/infrastructure can’t help but profoundly affect the future of p2p implementations.
The rapid development of national and global telephone infrastructures is fascinating in its own right, but it’s high time to get back to the main purpose of this chapter. The point of this historical summary is to draw conceptual parallels with familiar technology and to point out that the same connectivity infrastructure can be used in different ways. How it is used can determine how future functionality will be enhanced. Virtual-pair switching exchanges and direct dialing ultimately depended on a user demand for more end-to-end direct connectivity. Its availability made the technology attractive for more users and thus drove greater demand. As the number of subscribers increased, so too did the perceived value of the network.
Internet Infrastructure
In a way similar to telephony usage, the personal use of computer networks (for example, e-mail and chat) grew out of individual efforts to provide the software and protocols for it, frequently at variance with official design and intention.
Interestingly, although the official projects could fail, individual and unofficial experiments sometimes came to overshadow the original intentions. Contrary to popular myth, the precursor computer networks to ARPANET, eventually leading to our Internet, were in fact “failed” projects to share expensive contractor mainframe resources, for example to implement transparent process migration. The usually cited project motivation to create a decentralized, damage tolerant, post-apocalypse command network is nothing more than a retrofit misinterpretation. It probably stems from how the contractors motivated further funding when unintended aspects of the network showed greater promise than the original contract goal.
Functional automatic resource sharing did emerge but only later as an enhancement to an already extensive and global Internet infrastructure—I witnessed one early experiment in 1981. Even then, few could imagine that only a few decades later, a largely academic/corporate network would have turned into a global public utility for information transportation. No single entity planned the Internet that way—it just evolved from seemingly unrelated innovations and deployments.
Early connectivity design often relied on and was influenced by the existing telephony network and what had been learned from it. Later design and deployment has been a decentralized process—a curious blend of anarchy and consensus that remains even today. This makes researching the history of the Internet a daunting task, because the descriptions are so dependent on chosen focus and sometimes contradictory sources. Luckily, we need here only touch on a few significant issues relevant to overall development.
Initially, the early machines, large and at fixed locations, simply phoned each other as required to exchange information over modem. Some of these connections soon became permanent over dedicated leased lines. Packet switching later separated physical connectivity details from the logical data transmission layer.
Later developments added network-specific layers of addressing and resource-sharing capabilities. The machines already had local operator chat capabilities, so it wasn’t long before “relay” programs were added to allow operators at remote sites to exchange messages between sites. When this started to interfere with file exchanging, because the 9600 bps channel bandwidth quickly got saturated by the higher priority chat relay, the new chat capability was deemed important enough that programmers reworked the code to be less obtrusive rather than lose it. In effect, this form of operator-to-operator relayed chat was the first p2p messaging system.
IP Addressing
When the Internet Protocol ( IP) numbering scheme was designed as a way of addressing resources across the network, it was only natural that it was adapted to the then current shape of the network and its parts. The core of this scheme is a uniquely assigned 32-bit number, commonly written out as four dotted “class” components, as in “A.B.C.D”, or “192.168.1.22” to give a typical LAN example.
Historically, these classes did represent the assignment of entire blocks of numbers to subnets with corresponding requirements on how many nodes they needed to support. This kind of wasteful correlation became impossible to sustain as demand for IP numbers soon outstripped availability.
Packets of data can be routed to the correct destination in an efficient and decentralized way by assigning address blocks to particular machines that in turn maintain lists of subgroups assigned at that level, and so on, until a list designates individual machines at the next subordinate level. For human ease of use, the Domain Name System ( DNS) was added, a hierarchical naming system of Internet domains. Delegation of assigning and tracking name-number relationships within each level’s subnet is handled with authoritative DNS servers at that level.
Let us compare telephone and Internet addressing. In Figure 1.4, the schematic diagrams show how a representational name is translated to a physical address in order to achieve direct connectivity.
Figure 1.4. Comparing infrastructure, telephony and Internet, with respect to how representational naming is used to address a given endpoint.
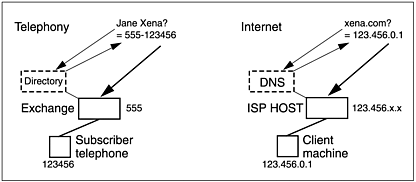
Landline telephone connectivity is currently based on subscriber number tied to a location (and local exchange), with added prefixes for region, operator and country. Mobile telephony is tied to either a particular handset or identity chip, not any fixed location. Telephone directory services are available to the subscriber in various forms: printed books, operator assistance, automated databases, and personal lists. It seems likely that future directory services will gain an extra abstraction layer to hide numbers and the functionality to autodial from a representational name. Mobile phones incorporate some of this functionality, translating from local names list to autodial number at the press of a button.
Internet addressing is currently based on IP numbers that are tied to physical machines. More specifically, an IP number is tied to the machine’s network interface card (NIC). The Internet domain namespace provides an abstract representational model with names that are easier to remember, and DNS servers on the Internet implement the directory service that automatically maps between the two.
Just as names can be reassociated to new telephone numbers, domains can also move to different IP numbers. Because DNS access is integrated with the use of client software, users need normally not concern themselves with the machine-level addressing when they use domain names.
These days, the most any user comes into contact with the “raw” IP numbers is when dealing with a LAN. Historically, certain blocks of the entire A.B.C.D range were reserved for local networks, and routers are (or should be) implemented so that packets addressed to one of these reserved IP numbers is never passed onto the general network. The most well-known IP addresses are 127.0.0.1 ( loopback or localhost), 192.168.x.x (the most commonly used LAN range), and 10.x.x.x (used mainly within the networks of large corporations or ISPs—Internet service providers).
In person-to-person communication terms, we can note that e-mail addressing is firmly tied to domains, so users who own their own domains have permanent mailbox addresses no matter what their current location or Internet host. Users without their own domains are not so lucky, although knowing the IP of a mailbox server allows one to address an e-mail explicitly to that machine.
It’s important for later discussion to note that current Internet domain addressing by definition maps to particular (permanent) resources, in practice host machines at known locations. DNS granularity does not resolve individuals and was never designed to do so. The closest thing to it is the e-mail address, which should be seen as just another resource on some host: a mailbox. Seen mailbox to mailbox, the Internet has long been a p2p network built on the e-mail transport protocol.
Bit 1.11 The Internet paradigm is addressing resources, not individuals.Any p2p implementation that targets individual users must currently provide supplementary directory services with finer granularity than DNS. |
Although Internet addressing can seem similar to how landline telephony maps numbers to individual households, a host machine with a single IP number might in some ways more resemble a public telephone in a village square. Reliably reaching a particular individual can be difficult. This caveat has had crucial impact on design decisions when implementing individual peer-to-peer technology over the Internet. We examine this topic and the issue of identity in more detail in Chapter 2.
A related constraint is the similarity to landline telephony in the assumption that the addressed is in a fixed location with continuous connectivity.
Bit 1.12 Domain addressing assumes static IP and constant connectivity.In most cases, the unavailability of a particular resource on the Internet at any time is considered an “error condition”. For most individuals, however, Internet connectivity remains by contrast a transient, exceptional state. |
Internet and the Individual
The growth of the number of individuals with intermittent and variable PC connectivity has increasingly made the original addressing model inappropriate to the needs of the majority of Internet users.
The PC revolution, followed by the explosion in home Internet access, had immediate consequences for how connected machines were identified. Static addressing granularity is limited. ISP hosts own fixed IP number blocks and simply can’t give all dial-up users their own IP number. Instead, each user is for the duration of a dial-up session allocated a different, dynamic IP number from a smaller, common pool of available numbers—known as DHCP allocation.
Therefore, IP addressing doesn’t at present correlate reliably with either PC or individual identities—although this situation might change dramatically as the next standard, known as IPv6, is deployed to provide a vastly greater pool of numbers. Currently, a particular IP number can easily represent many different users at different times, or even many different users at the same time. The former is true for dial-up, the latter for users on a LAN communicating with the Internet through a gateway or firewall machine. Even though each LAN computer has a unique local identity, all are identified from the Internet as having the same IP number, the public IP of the gateway machine. Multiple, unrelated Web sites with different domains might also share a common IP number, solely by being hosted on the same machine.
In addition, an individual might have several different access options—from home, from work, or on the road—and by extension, different Internet identities. From the people point of view—in other words, usage—it’s the individual identity that’s usually the most interesting or important property.
Bit 1.13 The p2p focus is mainly on individual or content identity.Any p2p implementation that targets individual users must cope with shared IP, dynamic IP allocation, and erratic or roaming connectivity. |
Identity resolution is one reason why p2p technologies hold such great appeal and promise; many of them do track individual identity in spite of the machine-bound granularity of IP addressing and the variable nature of a person’s location. Others are designed to track or search for content, also irrespective of location.
This endpoint “ delocalization” process is similar to what has already been happening in telephony. From a situation where you knew (or could derive from the number) an exact physical location for the person answering, but not necessarily the identity, phone numbers are today increasingly relocatable to arbitrary locations. In the case of a cell phone number in particular, you almost always know who will answer, but almost never from where—a complete reversal of the first paradigm.
The Internet has less attraction to individual users as a fixed infrastructure (traditional IP addressing) than as an overlay of a virtual infrastructure that is user-centric or content-centric and highly tolerant of arbitrary locality and presence—the p2p model. Some analysts therefore prefer to derive from this context an absolute defining requirement of variable connectivity for determining whether or not a given implementation is truly p2p. However, I believe that such a definition is overly simplistic. It’s only a pragmatic reflection of the fact that intermittent connectivity and variable addresses describe how the current majority of p2p nodes connect.
Bit 1.14 (Current) p2p treats intermittent variable connectivity as the norm.In effect, this requires reliable and persistent user identification through mechanisms other than the current DNS and IP addressing schemes. |
This view of p2p wasn’t true earlier, albeit many new p2p advocates don’t seem to consider the old technology worthy of the p2p moniker. Furthermore, the context can change dramatically in the near future, as noted in the previous mention of IPv6, when for instance 3G mobile connectivity could provide static, individual IP addressing for any number of devices, irrespective of type, location, or motion—a permanent mobile identity with a granularity far exceeding any requirements for simply uniquely identifying individuals.
A new generation of p2p technologies might therefore revert to treating static IP identities as the norm. Such a change would have a significant impact on many aspects of p2p implementation in ways that are today considered unrealistic. Just think of the changes that ubiquitous mobile phones have brought to telephony. Such speculations properly belong to Part III of this book, however. For now, the focus must remain on the historical facts in relation to the present.
Infrastructure Centralizes
The increasing load on what became the Internet, the explosive growth of its user base and the emergence of its new face, the Web, were all factors that drove development away from the early peer network to a more hierarchical infrastructure.
The resultant trend was towards client-server (cS) relationships where the great majority of users were seen as passive recipients of static, server-stored information. This trend also applied to e-mail, as mailboxes were centralized away from user endpoints to main ISP server farms. In addition, it applied to the collectively posted form of e-mail, newsgroups, a massive p2p network of servers for transport and storage, where users hold traditional client-to-server sessions to read or post.
Parallel to this divisive trend, a tendency emerged in Internet connectivity to funnel data transfers up to high-bandwidth (backbone) connections between top-level servers, further distancing the Internet from its p2p roots. Figure 1.5 illustrates this tendency as a comparison between simple structures. The recent deployment of Internet2, a separate higher-capacity backbone network, added a further dimension of segregation to the basic connectivity structure.
Figure 1.5. Simple comparison of a true peer network (early Internet) to a more server centric model with hierarchical connectivity down to user clients (later Internet, especially the Web).
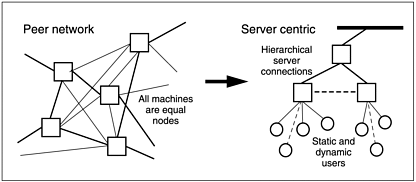
Centralization introduces vulnerabilities and risks, or in some cases temptations. It’s comparatively easy to corrupt or censor information that resides in well-defined, static locations or that travels predictable routes. Individuals can be tracked and profiles made of what they access, where and when they access it, who they contact, and what they write. Becoming the target of unwanted electronic advertising (spam) is a minor inconvenience compared to the full potential for misuse. It’s also easier to disrupt functionality when the system is more centralized.
As always, when structures become more centralized, countering forces arise to promote a return to decentralized structures. In various contexts, this fueled attempts to use the existing Internet connectivity to realize virtual networks that would behave like p2p ones as far as their specific (user) functionality was concerned.
Bit 1.15 Internet p2p is a reaction to the server-centric structure.Much of the impetus behind various Internet peer technologies can be seen as a reaction away from server-centric content and passive clients, back to free exchange between individual combined client-server nodes in the network. |
Protocol Layers
Later discussions refer to “protocol layers”. Putting this term in proper context requires at least some understanding of the implied abstraction model.
As a common base for discussion of networking interfaces, the Open Systems Interconnect (OSI) reference model was created. Although rarely used in practical implementations, mainly because of its perceived overkill, the seven-layer OSI model (an ISO standard) is commonly used when discussing other implementations. We might for instance in this light examine the four-layer Internet TCP/IP model, which predates OSI by many years and was originally known as the “ DARPA model” after the US government agency that initially developed TCP/IP.
Comparing the TCP/IP and OSI models schematically, Figure 1.6 shows their relationship. Each layer defines a particular structure in the data flow. Physically, the network sees only bits flowing by, which is handled at the lowest level of protocol, the framed packets of data of a standard size that the network interface sends and receives. At this level, packets are packets, whatever they contain.
Figure 1.6. Comparing the Internet TCP/IP model with the OSI reference model. While data physically flows between the physical layer, higher level layers logically appear to be directly interconnected.

The next higher level is the network level, which defines the protocol used to handle the packets—for example, TCP/IP in the Internet. One can therefore see a virtual connection between the transport layers on either end of a communication and discuss how the devices communicate without needing to look at details of how packets are framed and sent. Above this, yet often considered in the same context, is the Internet host level, the transport layer that applications must communicate with in order to talk to other machines.
The top of the Internet stack is the application and process layer, which is the program code that wishes to connect and communicate over the network. Layer abstraction means that the application needs to know only about the program interface (API) to the transport layer, not the specifics of protocol or hardware.
This design approach all allows easy exchange of components at any level. One can recognize the same abstraction levels in the Windows network model, where the user configures the bindings (interfaces) by installing a NIC, a protocol, and a client, which represent none other than the three main layers of the model.