
Chapter 8. Quality
Feedback
Customers who wanted new information systems used to be told that it would take a lot of time to develop high-quality software. But for some customers, this was simply not acceptable. Getting the software they needed—quickly—was essential for survival, yet they could not tolerate poor quality. When faced with no alternative but to break the compromise between quality and speed, a few companies have discovered that there is a way to develop superb software very fast—and in the process, they have created an enduring competitive advantage.
When it becomes a survival issue and old habits are not adequate to the task, better ways of developing new products have been invented out of necessity. In every case, these more robust development processes have two things in common:1
1. Excellent, rapid feedback
2. Superb, detailed discipline
The Polaris Program2
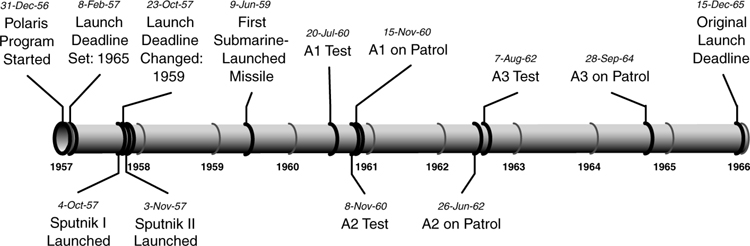
On October 4, 1957, a crisis hit the US Defense Department. The Soviet Union successfully launched Sputnik I, the first artificial satellite to orbit the world. The surprised American public reasoned that since the Soviets had already fired short-range missiles from surfaced submarines, and now that they had the technology to make long-range missiles, adding the two together would result in the capability to launch a nuclear weapon that could penetrate the country’s defenses. The crisis intensified a month later, when Sputnik II was launched. This was a much bigger satellite; it even carried a dog named Laika.
The US Navy had just started the Polaris program, a program to develop submarines that could launch missiles while submerged. The first Polaris submarine was scheduled to be operational in 1965. Obviously, taking nine years to launch the submarine was no longer acceptable. Two weeks after Sputnik I circled the world, the deadline was changed to 1959. Two-and-a-half years later, on June 9, 1959, the first Polaris missile was launched from a submarine. By the end of 1960 two Polaris submarines were patrolling at sea.3
How could such a technically complex objective that was supposed to take nine years be accomplished in such a short time? To begin with, the minute the deadline changed, Technical Director Vice Admiral Levering Smith focused his team on one simple objective: Deploy a force of submarines in the shortest possible time. This meant no wasted time, no extra features, and no delays—in short: Make every minute count.
Within weeks, Vice Admiral Smith had commandeered the two submarines currently under construction as attack submarines, and had them stretched out 130 feet (about 40 meters) to provide a place for missiles.4 Since 16 missiles would fit in the newly stretched submarines, 16 missiles is the standard number of missiles in a submarine to this day. Admiral Smith needed the submarines right away because he had modified the development objective from creating the ultimate system in nine years to creating a progression of systems: A1, A2, and A3.5 The A1 version would contain technology that could be deployed in about three years. The A2 version would be developed in parallel, but proceed more slowly to allow it to use more desirable technologies. The A3 version would incorporate everything learned in the development of the earlier versions.
Within each version, Admiral Smith orchestrated rapid, sharply focused increments of technical progress. He carefully controlled the systems design and tightly managed the interfaces between components, personally signing the coordination drawings. But rather than manage the details of the subsystems, he had several competing subsystems developed in virtually all areas of technical uncertainty. This allowed him to choose the best option once the technology had been developed. Finally, Admiral Smith demanded the highest reliability, so from the beginning Polaris submarines were tested thoroughly and had built-in redundancy.
As historian Harvey Sapolsky notes:6
The Polaris program is considered an outstanding success. The missile was deployed several years ahead of the original FBM [Fleet Ballistic Missile] schedule. There has been no hint of a cost overrun. As frequent tests indicate, the missile works. The submarine building was completed rapidly. Not surprisingly, the Special Projects Office is widely regarded as one of the most effective agencies within government.
The Polaris project gave us PERT (Program Evaluation and Review Technique), an innovative new scheduling system developed for the managing the Polaris program. PERT has been widely regarded as the reason for Polaris’s remarkable success, but Harvey Sapolsky calls this a myth.7 Sapolsky makes the case that the PERT system, at least in the early stages of the Polaris project, was mostly a façade to assure continued funding of the program. In those early years, PERT was unreliable as a scheduling system, because the technical objectives changed so fast and frequently that the PERT charts could not be kept up to date. Later on, the Polaris program was a victim of its own publicity; eventually its managers were required to use the PERT system that they had largely ignored and would have preferred to abandon.
Sapolsky attributes the success of the Polaris program not to PERT, but to the technical leadership of Admiral Smith and his laser-like focus on synchronized increments of technical progress, the option-based approach to developing components, the emphasis on reliability, and a deep sense of mission among all participants.8
Release Planning
When political events suddenly collapsed the Polaris program timeframe, the first thing Admiral Smith did was switch from a nine-year plan for the perfect system to an incremental plan for a minimalist system that would grow increasingly better. He planned to demonstrate the most risky capability (submarine-launched missile) one-quarter of the way into the program. Then he would develop the simplest system that could possibly work and deploy it as soon as possible (A1). At the same time, he would develop a better version and deploy it as a rapid follower (A2). Once the first version was deployed and the second version was well underway, he would start developing the “ultimate” version (A3). This approach resulted in significantly more capability, faster delivery, and lower cost than the original plan (see Figure 8.1).
If this approach is good for technically complex hardware, it’s even better for software. Let’s take a software development program through the same process.9 The program starts with the identification of a market need (or business need), product concept, target cost, and launch timing. This establishes the general constraints of the program. People experienced with the customer domain and the available technology make a quick “rough order of magnitude” determination of what capabilities the organization can reasonably expect to develop within the constraints.
Instead of spending the initial investment time developing a detailed long-range plan, we take a short time to create an incremental release plan. We plan near-term development to check out the most critical features and establish the underlying architecture. We plan an early launch of a minimum useful set of capabilities to start generating revenue (or payback). We stage additional releases to add more capabilities on a periodic basis.
Figure 8.2 shows a nine-month release plan divided into six releases of feature sets. Each release is further divided into three two-week iterations to develop the feature sets.

The goal of the first release is to develop the feature set that will establish feasibility and preliminary architecture, so it should create a thin slice through all layers of the application, showing how everything fits together. After that, feature sets should be chosen based on the following considerations:10
1. Feature sets with high value before lower value
2. Feature sets with high risk and high value before lower risk
3. Feature sets that will create significant new knowledge before those already well understood
4. Feature sets with a lower cost to develop or support before higher cost
A release plan gives you a basis for testing technical and market assumptions before investing a large amount of money in detailed plans. You can get an early reading of the plan’s feasibility by starting implementation and tracking progress. By the first release you will have real data to forecast the effort needed to implement the entire project far more accurately than if you had spent the same six weeks generating detailed requirements and plans.
If you implement a release plan and find that you are behind at the first release, you should assume that the plan is too aggressive. The preferred approach at this point is to simplify the business process or product under development, simplify the technical approach to implementing the features, or remove features entirely. It is generally best to maintain a fixed “timebox” of iterations and releases and limit features to those that can be fully implemented within the timebox.
There are certainly environments—games for example—where incremental releases to the public are not feasible. But in most of these environments incremental development is still a very good idea. You just “release” the product internally to an environment which is as close to the production environment as possible. Getting a product “ready to release” every three months gives everyone a concrete handle on actual progress. This is a particularly good way to manage risk in custom software development.
Architecture
During the first month of the accelerated Polaris program, Admiral Smith moved quickly to put boundaries on the system. The missiles were going into a submarine, two submarines were about to be built, and the practical amount these submarines could be lengthened was 130 feet. Sixteen missiles would fit in this space, and without further ado the highest level architectural constraints were established. After that it did not take very long to create the high-level systems design (architecture). It was pretty much dictated by the limited space of submarines and the existing missile technology. The underlying principle of the system design was to tightly define and control interfaces while making sure that subsystems were complete feature sets that could be developed and tested independently by different contractors with a minimum of communication. This was necessary because Admiral Smith’s small staff could not possibly get involved in the details of each subsystem, and in any case, giving contractor teams the freedom to be creative was necessary because the system required a host of innovations if it was going to work.
The starting point of large a complex system should be a divisible systems architecture that allows creative teams to work concurrently and independently on subsystems that deliver critical feature sets. A subsystem is a set of user-valued capabilities. It is not a layer—the idea is not to have separate teams develop the database layer, the user interface layer, and so on. A subsystem should be sized so that it can be developed by a team or closely associated group of teams.
As it becomes apparent that change tolerance is a key value in most software systems, architectures that support incremental development—such as service-oriented architectures and component-based architectures—are rapidly replacing monolithic architectures. Even with these architectures there are still some constraints, particularly those that deal with nonfunctional requirements (security, performance, extensibility, etc.), that are best considered before feature sets development begins. However, the objective of a good software architecture is to keep such irreversible decisions to a minimum and provide a framework that supports iterative development.
Architecture itself can, and usually should, be developed incrementally. In Software by Numbers, Mark Denne and Jane Cleland-Huang make the case that software architecture is composed of elements, and these elements should be developed as they become required by the feature sets currently under development. In successful products whose lifetimes span many years, a major architectural improvement can be expected every three years or so, as new applications are discovered and capabilities are required that were never envisioned in the original architecture. It is time to abandon the myth that architecture is something that must be complete before any development takes place.
Iterations
Iterative development is a style of development that creates synchronized increments of technical progress at a steady cadence. Figure 8.3 depicts a typical iterative software development process.
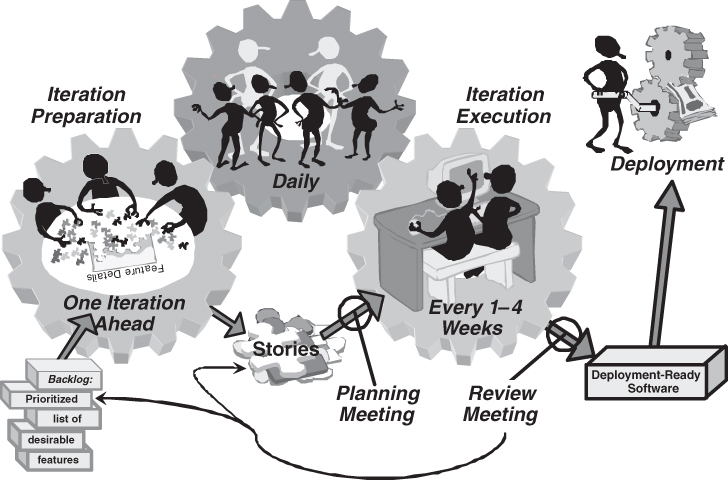
Starting at the lower left of Figure 8.3, we find a backlog, a prioritized list of desirable features described at a high level. Shortly before it is time to implement a feature it is analyzed by team members who understand the customer domain and the technology. They break it into “stories,”12 units of development that can be estimated reliably and completed within a few days. At a planning meeting, the team determines how many stories it can implement in the next iteration—based on its track record (velocity)—and commits to completing these stories. During the iteration the whole team meets briefly every day to talk about how iteration planning is going, keep on track toward meeting its implementation commitment, and to help each other out. At the end of the iteration, the stories must be done—integrated, tested, documented, and ready to use. A review meeting is held to demonstrate progress and obtain feedback, which may be captured as story or a change to the backlog. After a few iterations, a useful feature set is completed and ready to deploy.
We’ll now take a more detailed walk through a typical implementation of iterative software development (see Figure 8.4).

Preparation
Figure 8.4 begins with a backlog that is initially assembled at the beginning of the development effort. The backlog is a list of desirable features, constraints, needed tools, and so on. It is better used as a succinct product roadmap rather than a long queue of things to do. The backlog is dynamic—that is, it can be added to or subtracted from at will based on the team’s learning. Each backlog item has a rough estimate, and the total of all estimates gives a ballpark estimate of the time to complete the effort. Someone (the champion, or in Scrum, the Product Owner) is responsible for keeping the priorities of the backlog current with business needs.
Backlog items start out as large-grain bullet points, since the lean approach is to delay detailed analysis until the last responsible moment. As items near the top of the priority list they need to be broken into smaller, more manageable pieces. A backlog item is not ready to be developed until its design is packaged as one or more stories. The people who will implement each story must understand the story clearly enough to reliably estimate its implementation effort—reliable delivery requires reliable estimates.13 Each story should have some clear value from the perspective of the business, but the criteria for sizing a story is its implementation effort—a good story is typically one-half to four days of work. The people designing the product must decide if the value of the story is worth its implementation cost.
Backlog items are usually features expressed in terms of business goals; high-level goals can be more like epics than stories. Team members who have a good understanding of the customers’ job (Product Owners, analysts, etc.) lead the effort to break the epics into stories as they near the top of the priority list. Standard analysis techniques such as essential use cases combined with conceptual domain models, business rules and policies, and paper user interface (UI) prototypes are effective for thinking through this aspect of designing the product. If a use case is small enough, it may map to a story. Or it may take several stories over more than one iteration to realize the main scenario of a complicated use case with its associated interfaces, rules, and persistence.
The objective of iteration preparation is to design the portion of the “whole” product that will be developed next. Decisions need to be made about business rules, policies, workflow, functionality, and interface design. This design activity creates “just enough” carefully thought out stories “just-in-time” for the next iteration. A good story is a well-defined unit of implementer work, small enough so that it can be reliably estimated and completed within the next iteration. The objective is not to create extensive analysis documents for the entire product. Instead, the objective is to provide enough sample tests to make the business intent clear to the implementer.
Planning
At the beginning of an iteration there is a planning meeting. The whole team, in collaboration with the champion or Product Owner, estimates how long the top priority stories will take to develop, test, document, and deploy (or have ready for deployment). Team members pick the first story and commit to complete it. They pick a second story and decide whether they can commit to deliver this one as well. This process continues until the team members are no longer confident that they will be able to deliver the next story.14 Team members commit to an iteration goal, which describes the theme of the feature set they agreed to implement during the iteration. No one tells the team how much work it should take on, but after a few iterations, each team establishes its velocity, which gives everyone a good idea of how much the team can complete in an iteration.
Team members should regard the commitment as a pledge that they will work together as a team to accomplish the goal. Occasionally, a team may over-commit, or unexpected technical difficulties may arise. When this happens, the team should adapt to the situation in an appropriate manner, but they should also look for the root cause of the overcommitment and take countermeasures so that it does not happen again.
Implementation
During the iteration, the whole team works together to meet the iteration goal. Everyone attends a 10–15 minute daily meeting to discuss what each member accomplished since the last meeting, what they plan to do by the next meeting, what problems they are having, and where they need help. The team interaction at this meeting provides sufficient information for individual members to know what to do next to meet the team goal without being told.
The preferred approach is story-test driven development (also called acceptance-test driven development). Working one story at a time, team members focused on designing the functional details, workflow, and user interface work with the developers to express precisely what the product needs to do in terms of test cases. This discussion leads to a definition of the relevant variables and the applicable policies and business rules from the domain. Using this shared language, they define specific behaviors in terms of inputs or sequences of steps and expected results.15 While some team members flesh out a sufficient number of test instances, the developers create fixtures to interface the test cases to the application and they create the code to satisfy these test cases. When the developers need clarifications or additional detail, team members who understand the customer needs are available to discuss the issue and help define additional example tests to record the agreements reached. The full set of example tests becomes, in effect, a very detailed, self-verifying product design specification.
To implement behavior specified by a story test, developers use unit-test driven development. They start by selecting a simple behavior for the code that will contribute to the story-test objective. To implement that behavior the developers select suitably named objects, methods, and method parameters. Whenever possible they choose names consistent with the names used in the story-test. They document their design decision by writing a unit test, which fails until new code returns the intended behavior. They then write simple code to make this test pass without breaking any previous tests. The final step in the cycle is to assess the resulting code base and improve its design by refactoring it to remove any duplication, to make it simple and easy to understand, and to ensure that the intent of the code is clear. They repeat this cycle, adding each additional behavior until the selected story test passes. When the full set of story tests pass, it is time to go on to the next story.
A story is not done until the team updates associated sections of any user, customer, or regulatory compliance documentation as far as practical. There should be no partial credit for stories. Stories don’t count until their fully working code is integrated, tested, documented, and ready to deploy. At the end of each iteration, the goal is to have complete, “releasable” features. Some teams go further than this and release software into production at the end of each iteration.
Assessment
At the end of an iteration, a review meeting is held for the team to show all concerned how much value they have created. (Applause is appropriate.) If the review turns up anything that needs to be changed, small issues become new stories while larger issues go into the backlog where they will be prioritized with other items. And without further ado, the planning meeting for the next iteration commences.
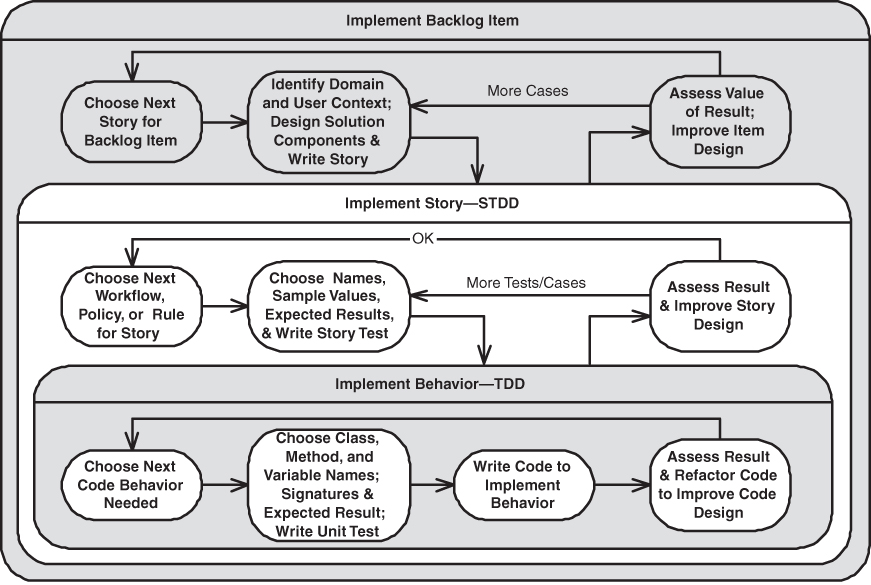
Notice that we have described three nested learning cycles, once for the entire iteration, once for each story, and once for each small piece for the code. (see Figure 8.5). The growing suites of story tests and unit tests express the current knowledge of how the product and the software need to work to do the customers’ job. As the team learns, the test suites will need to be adapted to express the newly created knowledge. The magic is that the tests make the cost of change very low because if anyone unintentionally breaks a design decision made earlier, a test will fail immediately, which alerts the team to stop the line until they fix the code and/or update the tests, which express the design.
Variation: User Interface
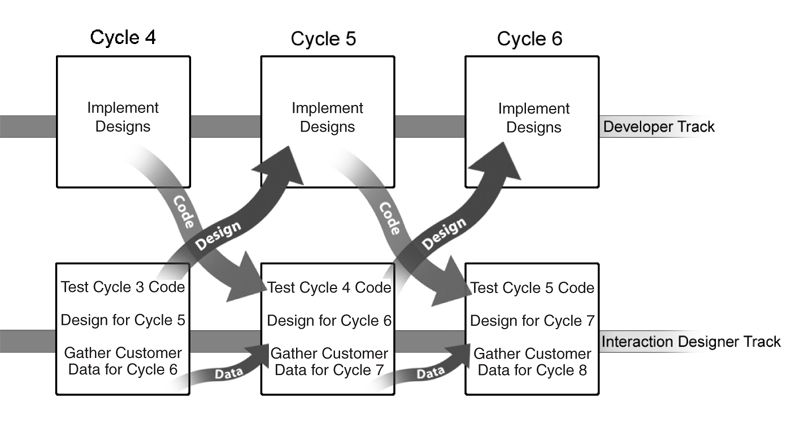
In practice most organizations modify the iterative process to suit their circumstances. One special context that may require modification is user interface development. In Chapter 3 we introduced Alias (now part of Autodesk), a 3-D graphics company whose products center on user interactions. Since excellent user interaction design is a key competitive advantage of the company, most development teams are assigned two dedicated interaction designers. During every iteration, these interaction designers have several jobs:
• Gather customer data for future iterations
• Test the user interaction developed in the previous iteration
• Answer questions that arise as coding proceeds in the current iteration
• Design in detail the user interface to be coded in the next iteration
Figure 8.6 shows how development proceeds. Before a user interaction design is coded, customer data is gathered, various options are tested through prototypes, and a detailed design ready for coding is finalized. Usability testing of the production code occurs one iteration after coding.
Discipline
We were teaching a class at a company whose development processes were relatively chaotic. The class went well until we got to the part on quality, and then a bit of discouragement set in. “You mean we have to do all that stuff? We thought lean meant going fast, but that quality stuff looks like a lot of work!” Indeed.
Shortly after that class, we gave a seminar to aerospace developers. When we got to the part on quality we heard: “Oh, we’ve been doing that for years.” And indeed they had. The people in this group probably knew as much about automated testing as anyone we have met.
You can’t go fast without building quality into the product, and that takes a lot of discipline. We find that such discipline is second nature to people working on life-critical systems, companies with Six Sigma programs, and organizations with high CMM assessments. But to a small and rapidly growing company that hasn’t thought much about quality, becoming lean means becoming very disciplined about the way software is developed.
The Five S’s
When we walk into a team room, we get an immediate feel for the level of discipline just by looking around. If the room is messy, the team is probably careless, and if the team is careless, you can be sure that the code base is messy. In an organization that goes fast, people know where to find what they need immediately because there is a place for everything and everything is in its place. In Mary’s manufacturing plant, housekeeping inspections were held weekly, and they included the programming area as well as the production floor.
The five S’s are a classic lean tool to organize a workspace so everything is at hand the moment it’s needed, and there is no extra clutter. The S’s stand for five Japanese words that start with an S: seiri, seiton, seiso, seiketsu, and shitsuke. They have been translated into five English words that also start with an S: sort, systematize, shine, standardize, and sustain.
We recently remodeled our kitchen, and as we moved into the new space we found ourselves using the five S’s to reconfigure our workspace.
1. Sort (Seiri): First we sorted through all our kitchen tools and set aside anything we had not used in the last year. Only the things we actually used went back into the kitchen.
2. Systematize (Seiton): The big project was to find a place for everything that would make it easy to find and close at hand. We moved shelves and invested in drawer organizers and wall hooks. We rearranged things several times before we found the right place for each tool and appliance.
3. Shine (Seiso): With everything finally put away, we cleaned up the kitchen and were ready to start cooking.
4. Standardize (Seiketsu): Then we agreed on two (new!) policies: We would fill and run the dishwasher every night, and we would put everything away first thing every morning.
5. Sustain (Shitsuke): Now we just have to keep up the discipline.
The software development workspace is not just the physical workroom, but also the desktop on a computer screen, the layout of the team server, and the code base everyone is working on. So after you apply the five S’s to the team room, think about applying it to the logical workspace behind the screen. And since software is a reflection the organization that developed it, take a good look at the code base as well.
1. Sort (Seiri): Sort through the stuff on the team workstations and servers, and find the old versions of software and old files and reports that will never be used any more. Back them up if you must, then delete them.
2. Systematize (Seiton): Desktop layouts and file structures are important. They should be crafted so that things are logically organized and easy to find. Any workspace that is used by more than one person should conform to a common team layout so people can find what they need every place they log in.
3. Shine (Seiso): Whew, that was a lot of work. Time to throw out the pop cans and coffee cups, clean the fingerprints off the monitor screens, and pick up all that paper. Clean up the whiteboards after taking pictures of the important designs that are sketched there.
4. Standardize (Seiketsu): Put some automation and standards in place to make sure that every workstation always has the latest version of the tools, backups occur regularly, and miscellaneous junk doesn’t accumulate.
5. Sustain (Shitsuke): Now you just have to keep up the discipline.
Standards
As we travel around the world, we have come to appreciate the importance of standards. We really appreciate the train system and metro transportation we find in almost every European city, but we are especially appreciative in the United Kingdom, because we try very hard not to drive a car there. We couldn’t avoid driving in New Zealand recently, but even after two weeks we had to be vigilant at every turn or we would find ourselves on the wrong side of the road. Every electrical gadget we own can operate on any voltage, and we carry a bag full of plug converters (see Figure 8.7). We have learned to think of temperatures in Celsius and distances in kilometers, but we have not gotten used to electrical switches where up is off.

Standards make it possible to operate reflexively and move information without conversion waste. A standardized infrastructure with a common architecture reduces complexity and thus lowers cost. Any organization that wants to move fast will have standards in place. Here are some of the standards that a software development organization should consider:
1. Naming conventions
2. Coding standards
3. User interaction conventions
4. File structures
5. Configuration management practices
6. Tools
7. Error log standards
8. Security standards
Of course, standards are useless on paper; they have to be used consistently to be valuable. In a lean environment, standards are viewed as the current best way to do a job, so they are always followed. The assumption, however, is that there is always a better way to do things, so everyone is actively encouraged to challenge every standard. Any time a better way can be found and proven to be more effective, it becomes the new standard. The discipline of following—and constantly changing—standards should be part of the fabric of an organization.
Code Reviews
“Are code reviews waste?” people often ask in our classes. Good question. We think that using code reviews to enforce standards or even to find defects is a waste. Code analyzers and IDE checks are the proper tools to enforce most standards, while automated testing practices are the proper way to avoid most defects. Code reviews should be focused on a different class of problems. For example, the code of inexperienced developers might be reviewed for simplicity, change tolerance, absence of repetition, and other good object-oriented practices. Code reviews can also be a good tool for raising awareness of issues such as complexity. One organization we know of computes the McCabe Cyclomatic Complexity Index19 for newly committed code, and when it reaches a threshold of 10, a code review is triggered.
Some policies that require code reviews prior to check-in create a large accumulation of partially done work waiting for review, but in a lean environment this is an unacceptable situation that should be avoided aggressively. One way to provide code review with no delays is to use some form of pairing while the code is being written.
Pairing
Pairing (also called pair programming) is the practice of having two people work side-by-side on the same task. This provides continuous code review in a flow rather than a batch. The judicious use of pairing can be very valuable. Developing code in pairs can enhance learning, teamwork, and problem-solving skills. Moreover, pairing often increases productivity because both the quality and the robustness of the code are enhanced when viewed through two sets of eyes. In addition, pairs tend to deflect interruptions and keep each other on task. Anyone who has ever programmed will tell you that developing software is a continuous exercise in solving problems, and pair problem solving is a pattern we find in many occupations. Pairing makes it easier to add new people to a team, because there is a built-in mentoring program.
Pairing is not for everyone nor for all situations. But pairing often creates synergy: Two people will frequently deliver more integrated, tested, defect-free code by working together than they could produce working separately. And pairing is one of the best ways to achieve the benefits of reviews without building up inventories of partially done work.
Mistake-Proofing
When you connect a projector to a laptop with a video cable, it’s difficult to plug it in wrong, because it is mistake-proof. One side is wider than the other and has more pins. After a quick look, most people will get it right. A USB cable, on the other hand, is not so simple. How many times do you try it one way, push a bit, realize that it’s backward, turn it over, and try again? Although it is virtually impossible to plug a USB cable in wrong, it is not always obvious which way it should be oriented. This cable is not quite mistake-proof enough for our tastes.
The worst offender, however, is no longer with us. The IDE cable appeared in 1984 on the IBM AT, where it was used to connect the hard drive to the system board. For many years, the cable had 40 holes that plugged into 40 pins on the disk drive. There was a red stripe down the side to let you know which side was for pin 1, but it was often difficult to tell where pin 1 was on the drive, or the stripe was hard to see, or you just weren’t paying attention. As a result, quite often the cable got attached upside down or misaligned, missing a couple of pins on one end or the other. Many a dead hard drive or fried controller can be attributed to the fact that this cable was not mistake-proof. Various indents and tabs were added to the drive and connector, but these were not consistently located and most were not effective. It took years for the industry to remove pin 20 from each disk drive, fill in pin 20 on the connector, and finally make it impossible to make a mistake with an IDE cable (see Figure 8.8).

When we ask in a class if anyone has ever assembled a PC with an un-keyed IDE cable, we usually get a few groans, as people who’ve been around a while raise their hands. Then we ask anyone who had ever made a mistake with an IDE cable to lower their hands. Invariably, all hands go down. We have also had our share of IDE cable misalignments, and we know two things: Everyone who ever plugged in unkeyed IDE cables considered themselves to be an expert, and everyone knew enough to be very careful. Yet almost every one of us has, at one time or another, made a mistake plugging in that cable.
Mistakes are not the fault of the person making them, they are the fault of the system that fails to mistake-proof the places where mistakes can occur. With software, anything that can go wrong will eventually go wrong—just ask the people in operations if you don’t believe us. So don’t waste time counting the number of times individuals are “responsible” for defects and pressuring them to be more careful. Every time a defect is detected, stop, find the root cause, and devise a way to prevent a similar defect from occurring in the future. Perhaps a new unit test might be the proper countermeasure, but a development team should think broadly about effective ways to mistake-proof code. Get testing and operations involved in identifying potential failure points and add mistake-proofing before defects occur.
Automation
One of most rewarding ways to mistake-proof development is to automate routine tasks.21 Even small teams should automate everything they can, and even occasional tasks should be candidates for automation. Automation not only avoids the eventual mistakes that people will always make, it shows respect for their intelligence. Repetitive tasks are not only error prone; they send the message that it’s OK to treat people like robots. People should not be doing things by rote; they should thinking about better ways of doing their job and solving problems.
Test-Driven Development
As we mentioned in Chapter 2, Shigeo Shingo taught that there are two kinds of tests: tests that find defects after they occur and tests to prevent defects.22 He regarded the first kind of tests as pure waste. The goal of lean software development is to prevent defects from getting into the code base in the first place, and the tool to do this is test-driven development.
“We can’t let testers write tests before developers write code,” one testing manger told us. “If we did that, the developers would simply write the code to pass the tests!” Indeed, that’s the point. Some people feel that a tester’s job is to interpret the specification and translate it into tests. Instead, why not get testers involved with writing the specifications in the form of executable tests to begin with? This has the advantage of mistake-proofing the translation process, and if it’s done with the right tools, it can also provide automatic traceability from specification to code. The more regulated your industry is, the more attractive executable specifications can be.
If the job of testing is to prevent defects rather than to find them, then we should consider what this means for the various kinds of tests that we typically employ. Brian Marick proposes that we look at testing from the four perspectives we see in Figure 8.9. This figure shows that testing has two purposes: We want to support programmers as they do their job, and we also need to critique the overall product that the software supports. We can do this from a technical perspective or from a business perspective. This gives us four general test categories, which we will describe briefly.
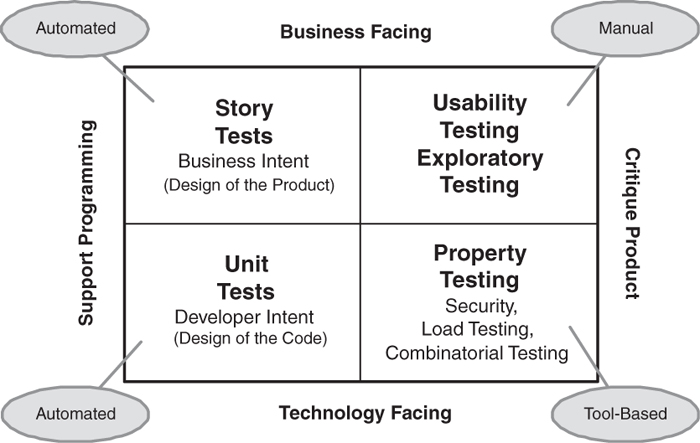
Unit Tests (Also Called Programmer Tests)
Unit tests are written by developers to test that their design intent is actually carried out by the code. When developers write these tests first, they find that the code design evolves from the tests, and in fact the unit test suite becomes the software design specification. Writing tests first usually gives a simpler design because writing code that is testable leads to loose coupling of the code. Because of this virtuous circle, once developers start using test-first development, they are reluctant to develop software any other way.
A selection of unit tests are assembled into a test harness that runs at build time. The build test suite must be fast. A build and test should take less than 10 minutes, or else developers will avoid using it. Therefore the code tested with the build test suite is frequently separated from the database with mock objects to speed up execution.
The reason unit tests are sometimes called programmer tests is because programmers use unit test tools to test more than small elements of code. Unit test tools are used to test at any level: unit, feature, or system.
Story Tests (Also Called Acceptance Tests)
Story tests identify the business intent of the system. They are the tests that determine whether the software will correctly support customers in getting their job done. When story tests are written before the code, they help everyone think through what the customers’ job really involves and how it will be supported by software. The team works through examples of what the system should do, and the story tests become a specification-by-example. If we are going to write a specification ahead of time, it may as well be executable to save the waste of writing tests later and then tracing code to specifications.
Automated story tests are not usually run through the user interface; they should generally be run underneath the user interface. In order for this to work, user interfaces should be a very thin presentation layer; all logic and policies should be at lower, separately testable layers. Usually the remaining user interaction layer can be thoroughly tested separately from the business logic.24
Story tests should be automated and run as often as practical. Generally they are not part of the build test suite because they usually require a server or database. However, a selection of story tests should be run every day, a more complete set should run every week, and every one should pass by the end of an iteration.
Usability and Exploratory Testing
Usability and exploratory tests are, by definition, manual tests. When a system passes its automated tests, we know that it does what it is supposed to do, but we do not know how it will be perceived by users or what else it might do that we haven’t thought to test for. During usability tests, actual users try out the system. During exploratory tests, skilled testing specialists find out what the system does at the boundaries or with unexpected inputs. When exploratory tests uncover an area of the code that is not robust, a test should be written to show developers what needs to be done, and the test should be added to the test harness.
Property Testing
Property testing includes the so-called nonfunctional requirements such as response time, scaling, robustness, and so on. Specialized tools exist to test systems under load, to check for security problems, and so on. There are also tools that generate combinatorial tests that test every possible configuration the system might encounter. If these tools are appropriate for your environment, invest in them and develop the skills to use them well. Start using them early in the development process. Apply them in an environment that is as close as you can get to actual operational conditions.
Configuration Management
Configuration management is a central discipline in any software development environment, and agile practices create significant demands on a configuration management system. Consider that:
1. Any area of code can be worked on by several people at a time.
2. Releases are small and frequent.
3. As one set of features is released to production, new features are being developed.
4. The entire code base constantly undergoes refactoring (continuous improvement).
The configuration management system is the librarian that checks out code lines to people who will change them, then files the new versions correctly when they are checked back in. It can be used to manage repositories of not only code, but also documentation and test results, a particularly useful feature in a regulated environment. Every development organization should have a configuration management system that supports the scenarios used in the organization, and it should establish policies governing how the system is used.
Here are some typical scenarios handled by configuration management systems:25
1. Developers check out files into their private workspace. They make changes, then just before checking the code back in, they merge the changes with the current code base on their machine and do a private build and test. If everything works, they check their new code into the configuration management system, which triggers a public build and test.
2. At the time of a release, a branch is created that includes all the code to be included in the release. Developers continue adding new features to the main code line. Any changes that are made in the release during testing or maintenance are merged back into the main code line as soon as possible. (When code is released as part of the iteration, or a branch is deployed without modification, this scenario is unnecessary.)
Continuous Integration
Whenever code is checked out to a private workspace or branched into a separate code line, incompatibilities will arise across the two code lines. The longer parallel code lines exist, the more incompatibilities there will be. The more frequently they are integrated, the easier it will be to spot incipient problems and determine their cause. This is so fundamental that you would expect continuous integration to be standard practice everywhere. But it’s not so simple. First of all, it is counterintuitive for developers to check in their code frequently; their instincts are to make sure that an entire task is complete before making it public. Secondly, lengthy set-up times exacerbate the problem. Private builds take time. Checking in code takes time. Public builds and tests can take a lot of time. Stopping to fix problems discovered in the builds and tests can really slow things down. So there is strong incentive to accumulate large batches of code before integrating it into the code base.
Stretching out the time between integration is false economy. The lean approach is to attack the set-up time and drive it down to the point where continuous integration is fast and painless. This is a difficult discipline, partly because developing a rapid build and test capability requires time, skill, and ongoing attention, and partly because stopping to fix problems can be distracting. But a great epiphany occurs once a software development team finds ways to do rapid builds and continuous integration and everyone faithfully stops to fix problems as soon as they are detected. We have been told many times that this is a very difficult discipline to put in place, but once it is working, no one would ever think of going back to the old way of doing things. Invariably teams experience an accelerating ability to get work done, which makes believers out of the skeptics.
Nested Synchronization
As we mentioned earlier in this chapter, large systems should have a divisible architecture that allows teams to work concurrently and independently on subsystems. But that is not the whole story. What happens when the independent teams try to merge these subsystems? In theory, the interfaces have been well defined and are stable, and there are no surprises when the subsystems are eventually integrated. In practice, it hardly ever works that way. In fact, the failure of subsystem integration at the end of development programs has been one of the biggest causes of escalating schedules, escalating costs, and failed programs.
If you think of software as a tree and the subsystems as branches, you might get a picture of where the problem might be. Generally you would not grow branches separately from each other and then try to graft them onto the trunk of a tree. Similarly, we should not be developing subsystems separately from each other and then try to graft them onto a system. We should grow subsystems from a live trunk—if the trunk doesn’t exist, we should build it first. The subsystems will then be organically integrated with the system, and we don’t have to worry about trying to graft everything together at the end.
The rule we stated for parallel code lines also holds for larger subsystems: The longer parallel development efforts exist, the more incompatibilities there will be. The more frequently they are integrated, the easier it will be to spot incipient problems and determine their cause. Instead of defining interfaces and expecting them to work, we should actually build the interfaces first, get them working, and then build the subsystems, synchronizing them with each other as frequently as practical.
How does this work in practice? It starts with continuous integration. Several times a day developers check in code, which triggers an automatic build and test to verify that everything is still synchronized at the micro level. An acceptance test harness is run overnight. Various configurations and platforms may be tested over the weekend. Every iteration the entire code base is synchronized and brought to a “releasable” state. It may also be synchronized with other subsystems or perhaps with hardware. Every release the code is deployed to synchronize with customers.
With large systems and geographically dispersed teams, nested synchronization is even more critical, because it provides a basis for continual communication and regularly aggregates the collective knowledge of the teams in one place. Teams working on closely related subsystems should synchronize their work by working off of a common code base. Major subsystems should be brought together at the end of every iteration. On large projects, the entire system should be synchronized as frequently as practical. Using Polaris as an example, full-system synchronization points occurred when the first missile was launched, when the A1 was tested, when it deployed, and so on. These full-system synchronization points were never more than 18 months apart, and you can be sure that there were many more subsystem synchronization points. Although 18 months may seem like a long time, full-system synchronization occurred six times more frequently than called for in the original Polaris schedule.
Full-system synchronization means bringing the system into a “ready to release” state, as far as that is practical. If there are any live field tests that can be run, synchronization points are the time to run them. All participating teams and key customers should be involved in analysis and critical decision making at each synchronization point. Major synchronization points are not a one-day event. They are several days set aside to thoroughly analyze the system’s readiness, absorb what has been learned, focus on key decisions that must be made at that point, make any necessary course corrections, plan the next stage in some detail, and celebrate the current success.
Try This
1. We have used the terms “release plan,” “backlog,” and “product road map” more or less interchangeably. Do these terms mean the same thing in your environment? If not, how and why are they different? How long is each one, in terms of weeks of work?
2. How long is an iteration in your environment? Why do you use that cadence? Does the work of clearly defining the details of the customer problem happen inside of or prior to the iteration?
3. Discuss in a team meeting: What is the difference between story-test driven development and unit-test driven development? What are the advantages and disadvantages of each? Which do you use? Which should you use?
4. On a scale of 0–5 (with 0 = low and 5 = high) rate your organization on:
a. Standardized architecture
b. Standardized tools
c. Coding conventions
d. Configuration management
e. Automated unit tests
f. Automated acceptance tests
g. One-click build and test
h. Continuous integration
i. Automated release
j. Automated installation
Total your score.
5. At your next team meeting, ask the team to take a look at your team room. Rate its general appearance on a scale of 0–5 (high). Now rate the general neatness and simplicity of your code base on the same scale. Are the results similar? If you have a score of 3 or lower, propose to the team that you do a 5S exercise, first on the room and then on the code base.
6. Who is responsible for setting standards? Who should be? How closely are standards followed? How easily are they changed? Is there a connection between the last two answers in your organization?
Endnotes
1. See Kim B. Clark and Takahiro Fujimoto, Product Development Performance, Harvard Business School Press, 1991.
2. The Aegis Program and the Atlas Program have similar histories; however, the Polaris Program has superior independent and unbiased documentation.
3. “The Polaris: A Revolutionary Missile System and Concept,” by Norman Polmar, Naval Historical Colloquium on Contemporary History Project, at www.history.navy.mil/colloquia/cch9d.html, January 17, 2006.
4. Ibid.
5. See Harvey Sapolsky, The Polaris System Development: Bureaucratic and Programmatic Success in Government, Harvard University Press, 1972.
6. Ibid., p. 11.
9. For a thorough background on planning, see Mike Cohn’s Agile Estimating and Planning, Addison-Wesley, 2005.
10. Ibid., pp. 80–87.
11. Screen Beans art is used with permission of A Bit Better Corporation. Screen Beans is a registered trademark of A Bit Better Corporation.
12. For the details of using user stories, see Mike Cohn’s User Stories Applied, Addison-Wesley, 2004.
13. For details on estimating stories, see Mike Cohn’s Agile Estimating and Planning, Addison-Wesley, 2005.
14. Ibid.
15. See Eric Evans, Domain Driven Design, Addison-Wesley, 2003.
16. Rick Mugridge and Ward Cunningham, Fit for Developing Software: Framework for Integrated Tests, Prentice Hall, 2005.
17. From Lynn Miller, director of user interface development, Autodesk, Toronto, used with permission. Originally published in “Case Study of Customer Input for a Successful Product,” Experience Report, Agile 2005.
18. From private e-mail communication. Used with permission.
19. The McCabe Cyclomatic Complexity Index is a measure of the number of execution paths through a program. See “A Complexity Measure,” by Thomas J. McCabe, IEEE Transactions on Software Engineering, Vol. Se-2, No.4, December 1976.
20. From a presentation at the Twin Cities OTUG meeting, on June 17, 2003, and later conversations. Used with permission.
21. For the ideas on what and how to automate, see Pragmatic Project Automation: How to Build, Deploy and Monitor Java Applications, by Mike Clark, Pragmatic Press, 2004. See also Pragmatic Project Automation for .NET by Ted Neward and Mike Clark, Pragmatic Press, forthcoming.
22. See Shigeo Shingo, Study of ‘Toyota’ Production System, Productivity Press, 1981, Chapter 2.3.
23. From Brian Marick, “Agile Testing Directions,” available at www.testing.com/cgi-bin/blog/2003/08/21-agile-testing-project-1. Used with permission.
24. Visually oriented interaction layers such as those found in graphical programs, games, and similar software are more likely to require manual inspection than transaction-oriented interfaces.
25. For many additional scenarios and considerations on how to use configuration management systems, see Brad Appleton’s articles at: www.cmwiki.com/AgileSCMArticles.