
Chapter 5. Speed
Deliver Fast
Speed is the absence of waste.
If you diligently work to eliminate waste, you will increase the percentage of time you spend adding value during each process cycle. And you will deliver faster—probably much faster.
This fundamental lean equation works in manufacturing. It works in logistics. It works in office operations. PatientKeeper provides a good example of how this works in software development.
PatientKeeper
Five years ago a killer application emerged in the health care industry: Give doctors access to patient information on a PDA. Today (2006) PatientKeeper appears to be winning the race to dominate this exploding market. It has overwhelmed its competition with the capability to bring new products and features to market just about every week. The company’s 60 or so technical people produce more software than many organizations several times larger, and their software is certified to manage life-critical data. They don’t show any sign that complexity is slowing them down even though they sell to a variety of very large health care organizations and support several platforms that integrate with multiple backend systems.
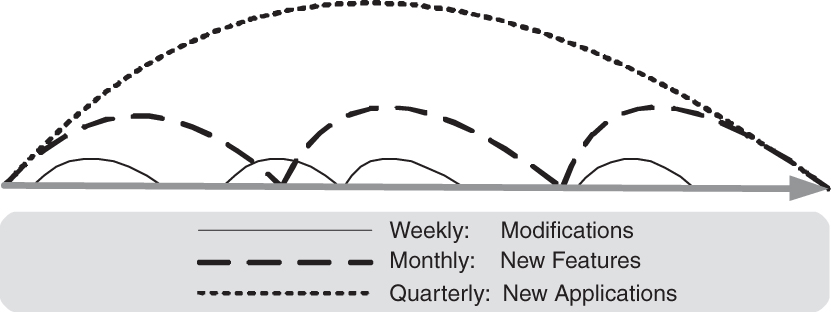
A key strategy that has kept PatientKeeper at the front of the pack is an emphasis on unprecedented speed in delivering features. For the past three years, PatientKeeper has delivered about 45 software releases a year to large health care organizations using simultaneous overlapping iterations (or Sprints) (see Figure 5.1). Every iteration ends in a live release at a customer site. Every one is delivered on time.
PatientKeeper CTO Jeff Sutherland explains how this works:2
• All Sprints result in a production release of software.
• QA starts testing as soon as development updates the first code. They can independently kick off the build process and direct it to any QA server.
• By mid-Sprint, the install team deploys Release Candidate1into the customer’s test environment. Now the customer is testing along side internal QA.
• As soon as customer starts feeding back issues, they are addressed by development along with any other issues QA finds.
• Functionality which the customers view as essential to go live continues to surprise us right until the end of the Sprint. We embrace those surprises as it makes the product better faster for all customers.
• It typically takes two or three Release Candidates to go live. All development tasks are complete, all QA issues addressed, and all customer issues completed. QA has run a regression test on the entire system.
• Everyone goes live together at the end of the Sprint. Could be a multi-hospital system with hundreds of physician PDA users and thousands of Web users. We typically take 3–5 customers live at the end of a Sprint.
• Done means all customers are live with no outstanding critical issues. Note that in this scenario, the customer and installation teams are as tightly in the loop as QA and development.
At PatientKeeper, product managers are responsible for deciding exactly what customers want and creating fine-grain definitions of features that are ready for coding. That means, for example, that the product manager has verified a user interface capability through prototypes and possibly focus groups, and made final, detailed decisions on how the interface will work. No attempt is made to distinguish feature requests from defects; they all go into an automated backlog. The product manager is responsible for assigning backlog items to releases.
Development teams are assigned to releases, which consist of assigned backlog items. A developer takes an item from the backlog, breaks it into tasks, and estimates each task. The estimates are entered into the system and rolled up automatically to the backlog item. At the end of each day, it takes no more than a minute for each developer to enter into the tracking system the time spent on each task and its estimated percent complete. With this data in the tracking system, anyone in the company can obtain solid information about how much more time is necessary to complete every release under development.
The rule is that all releases must be on time, so if the system shows that there is too much work, backlog items are removed from the release to match required work to the capacity of the development teams. Because the tracking system gives accurate, up-to-date information about the time to complete any collection of backlog items, tradeoffs can be accurately identified, and valid decisions can be made. Priorities are resolved at weekly meetings which are attended by all the relevant decision makers, including the CEO. Program managers implement the decisions by changing the assignment of backlog items to a release, and development teams self-organize to resolve any problems.
PatientKeeper is fast: It can deliver any application it chooses to develop in 90 days or less. It will not surprise anyone who understands lean that the company has to maintain superb quality in order to support such rapid delivery. Jeff Sutherland explains that rapid cycle time:3
• Increases learning tremendously.
• Eliminates buggy software because you die if you don’t fix this.
• Fixes the install process because you die if you have to install 45 releases this year and install is not easy.
• Improves the upgrade process because there is a constant flow of upgrades that are mandatory. Makes upgrades easy.
• Forces implementation of sustainable pace..... You die a death of attrition without it.
Although this mode of operation seems natural at PatientKeeper, it amazes outsiders. One of the keys is that everyone in the company works together in a spirit of trust, respect, commitment, and continuous improvement. Teams include product managers, developers, QA, and product support. The lead architect is the most experienced and trusted engineer in the company.
Time: The Universal Currency
Everything that goes wrong in a process shows up as a time delay. Defects add delay. Complexity slows things down. Low productivity shows up as taking more time. Change intolerance makes things go very slowly. Building the wrong thing adds a huge delay. Too many things in process create queues and slows down the flow.
Time, specifically cycle time, is the universal lean measurement that alerts us when anything is going wrong. A capable development process is one that transforms identified customer needs into delivered customer value at a reliable, repeatable cadence, which we call cycle time. It is this cycle time that paces the organization, causes value to flow, forces quality to be built into the product, and clarifies the capacity of the organization.
A lean organization makes sure that processes are both available when work arrives at the process, and capable of doing the job expected of the process.4 You can find out if your processes are available and capable by looking for the red flag called “expediting.” Expediting happens when work arrives at a process and gets stuck in a queue, but someone thinks the work is so important that they personally “push it through.” If requests are regularly pushed through the system by an “expediter,” something is wrong. Either the process is not available when work comes in, or it is not capable of doing the work.
What does this mean for software development? Consider a software maintenance department that has guaranteed response times of two hours for an emergency, one day for a normal problem, and two weeks for lower priority changes. When an emergency occurs, the department can promise a two hour maximum response time and probably deliver a lot faster. When other requests arrive, it can also promise a reliable response time compatible with the type of request. Since the department has a reliable and repeatable cadence of work, it has established a predictable level of work that can be done. When this threshold is reached, routine requests are turned down or backup capacity is engaged.
Lean organizations evaluate their operational performance by measuring the end-to-end cycle time of core business processes. The value stream maps in Chapter 4 mapped an end-to-end process that started and ended with a customer. They laid out the steps and totaled up the time from concept to launch (for products), or from customer request to deployed software. Excellent performance comes from completing this cycle with as little wasted time and effort as possible.
The best way to measure the quality of a software development process is to measure the average end-to-end cycle time of the development process. Specifically, what is the average time it takes to repeatedly and reliably go from concept to cash or from customer order to deployed software? The idea is not to measure one instance of this cycle time; measure the average time it takes your organization to go from customer need to need filled.
Queuing Theory
Queuing theory is the study of waiting lines or queues. We certainly have queues in software development—we have lists of requests from customers and lists of defects we intend to fix. Queuing theory has a lot to offer in helping manage those lists.
Little’s Law
Little’s Law states that in a stable system, the average amount of time it takes something to get through a process is equal to the number of things in the process divided by their average completion rate (see Figure 5.2).

In the last section we said that the objective of a lean development organization is to reduce the cycle time. This equation gives us a clear idea of how to do that. One way to decrease cycle time is get things done faster—increase the average completion rate. This usually means spending more money. If we don’t have extra money to spend, the other way to reduce cycle time is to reduce the number of things in process. This takes a lot of intellectual fortitude, but it usually doesn’t require much money.5
Variation and Utilization
Little’s Law applies to stable systems, but there are a couple of things that make systems unstable. First there is variation—stuff happens. Variation is often dealt with by reducing the size of batches moving through the system. For example, many stores have check-out lanes for “10 items or less” to reduce the variation in checkout time for that line. Let’s say you have some code to integrate into a system. If it’s six weeks’ worth of work, you can be sure there will be a lot of problems. But if it’s only 60 minutes of work, the amount of stuff that can go wrong is limited. If you have large projects, schedule variation will be enormous. Small projects will exhibit considerably less schedule variation.
High utilization is another thing that makes systems unstable. This is obvious to anyone who has ever been caught in a traffic jam. Once the utilization of the road goes above about 80 percent, the speed of the traffic starts to slow down. Add a few more cars and pretty soon you are moving at a crawl. When operations managers see their servers running at 80 percent capacity at peak times, they know that response time is beginning to suffer, and they quickly get more servers.
Since Google was organized by a bunch of scientists studying data mining, it’s not surprising that their server structure reflects a keen understanding of queuing theory. First of all, they store data in small batches. Instead of big servers with massive amounts of data on each one, Google has thousands upon thousands of small, inexpensive servers scattered around the world, connected through a very sophisticated network. The servers aren’t expected to be 100 percent reliable; instead, failures are expected and detected immediately. It’s not a big deal when servers fail, because data has been split into tiny pieces and stored in lots of places. So when servers fail and are automatically removed from the network, the data they held is found somewhere else and replicated once again on a working server. Users never know anything happened; they still get almost instantaneous responses.
If you have ever wondered why Google chose to dedicate 20 percent of its scientists’ and engineers’ time for work on their own projects, take a look at the graph in Figure 5.3. This figure shows that cycle time starts to increase at just above 80 percent utilization, and this effect is amplified by large batches (high variation). Imagine a group of scientists who study queuing theory for a living. Suppose they find themselves running a company that must place the highest priority on bringing new products to market. For them, creating 20 percent slack in the development organization would be the most logical decision in the world. It’s curious that observers applaud Google for redundant servers but do not understand the concept of slack in a development organization.
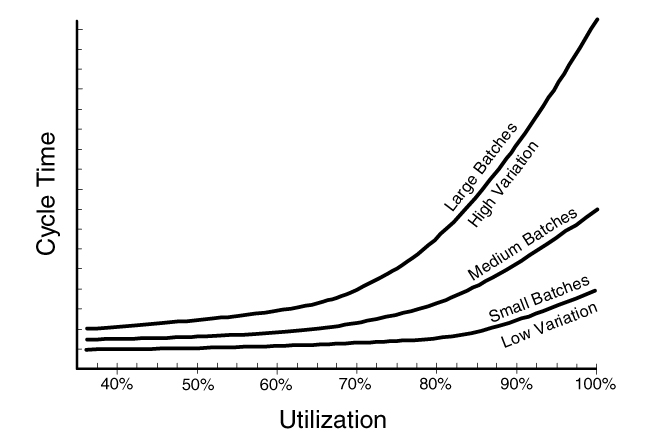
Most operations managers would get fired for trying to get maximum utilization out of each server, because it’s common knowledge that high utilization slows servers to a crawl. Why is it that when development managers see a report saying that 90 percent of their available hours were used last month, their reaction is, “Oh look! We have time for another project!” Clearly these managers are not applying queuing theory to the looming traffic jam in their department.
You can’t escape the laws of mathematics, not even in a development organization. If you focus on driving utilization up, things will slow down. If you think that large batches of work are the path to high utilization, you will slow things down even further, and reduce utilization in the process. If, however, you assign work in small batches and concentrate on flow, you can actually achieve very good utilization—but utilization should never be your primary objective.
Reducing Cycle Time
Let’s agree, at least for the moment, that our objective is to reduce the average cycle time from concept to cash or from customer need to deployed software. How do we go about accomplishing this goal? Queuing theory gives us several textbook ways to reduce cycle time:
1. Even out the arrival of work
2. Minimize the number of things in process
3. Minimize the size of things in process
4. Establish a regular cadence
5. Limit work to capacity
6. Use pull scheduling
Even Out the Arrival of Work
At the heart of every lean process is an even level of work. In a factory, for example, a monthly plan to build 10,000 widgets translates into building one widget every minute. The factory work is then paced to produce at a steady rate of one widget per minute.
The budgeting and approval processes are probably the worst offenders when it comes to creating a steady flow of development work. Requests are queued for months at a time, and large projects may wait for the annual budgeting cycle for approval. Some think that by considering all proposals at the same time, an organization can make a better choice about how to spend its budget. However, this practice creates long queues of work to be done, and if all of the work is released at the same time, it wreaks havoc on the development organization. Moreover, it means that decisions are made well out of sync with need, and by the time the projects are started, the real need in the business will probably have experienced considerable change. Tying project approvals to the budgeting cycle is generally unnecessary and usually unrealistic in all but the slowest moving businesses.
Queues at the beginning of the development process may seem like a good place to hold work so that it can be released to the development organization at an even pace. But those queues should be no bigger than necessary to even out the arrival of work. Often we find that work arrives at a steady pace, and if that is the case, then long queues are really unnecessary.
Minimize the Number of Things in Process
In manufacturing, people have learned that a lot of in-process-inventory just gums up the works and slows things down. Somehow we don’t seem to have learned this same lesson in development. We have long release cycles and let stuff accumulate before releasing it to production. We have approval processes that dump work into an organization far beyond its capacity to respond. We have sequential processes that build up an amazing amount of unsynchronized work. We have long defect lists. Sometimes we are even proud of how many defects we’ve found. This partially done work is just like the inventory in manufacturing—it slows down the flow, it hides quality problems, it grows obsolete, usually pretty rapidly.
One of the less obvious offenders is the long list of customer requests that we don’t have time for. Every software development organization we know of has more work to do that in can possibly accommodate, but the wise ones do not accept requests for features that they cannot hope to deliver. Why should we keep a request list short? From a customer’s perspective, once something has been submitted for action, the order has been placed and our response time is being measured. Queues of work waiting for approval absorb energy every time they are estimated, reprioritized, and discussed at meetings. To-do queues often serve as buffers that insulate developers from customers; they can be used to obscure reality and they often generate unrealistic expectations.
Minimize the Size of Things in Process
The amount of unfinished work in an organization is a function of either the length of its release cycle or the size of its work packages. Keeping the release cycle short and the maximum work package size small is a difficult discipline. The natural tendency is to stretch out product releases or project durations, because the steps involved in releasing work to production seem to involve so much work. However, stretching out the time between releases is moving in exactly the wrong direction from a lean perspective. If a release seems to take a long time, don’t stretch out releases. Find out what is causing all the time and address it. If something is difficult, do it more often, and you’ll get a lot better at it.
Establish a Regular Cadence
Iterations are the cadence of a development organization. Every couple of weeks something gets done. After a short time people begin to count on it. They can make plans based on a track record of delivery. The amount of work that can be accomplished in an iteration quickly becomes apparent; after a short time people stop arguing about it. They can commit to customers with confidence. There is a steady heartbeat that moves everything through the system at a regular pace. A regular cadence produces the same effect as line leveling in manufacturing.
What should the cadence be? One friend favors one week iterations. He finds it’s just long enough to get customers with emergencies to be sure the problem is real before his team dives in and just short enough to deliver very timely work. Another friend swears by 30 days, because it gives the team time to think things through before they start coding, yet is short enough that managers can wait until the next iteration to ask for changes.
The cadence is right when work flows evenly. If there is a big flurry of activity at the end of an iteration then the iteration length is probably too long; shorter iterations will help to even out the workload. Cadence should be short enough that customers can wait until the end of an iteration to ask for changes, yet long enough to allow the system to stabilize. This is best understood by considering a household thermostat. If the thermostat turns on the furnace the instant the temperature falls below the temperature setting, and turns it off the instant the temperature rises above the setting, the furnace will cycle on and off too frequently for its own good. So thermostats have a lag built into them. They wait for the temperature to drop a degree or two below the setting before turning on the furnace, and they wait until the temperature goes a degree or two above the setting before turning the furnace off. This lag in response is small enough so you don’t feel much difference, and big enough to keep the furnace from oscillating. Use the same concept when finding the right cadence for your situation.
Limit Work to Capacity
Far too often we hear that the marketing department or the business unit, “Has to have it all by such-and-such a date,” without regard for the development organization’s capacity to deliver. Not only does this show lack of respect for the people developing the product, it also slows down development considerably. We know what happens to computer systems when we exceed their capacity—it’s called thrashing.
Time sometimes seems to be elastic in a development organization. People can and do work overtime, and when this happens in short bursts they can even accomplish more this way. However, sustained overtime is not sustainable. People get tired and careless at the end of a long day, and more often that not, working long hours will slow things down rather than speed things up. Sometimes an organization tries to work so far beyond its capacity that it begins to thrash. This can happen even if there appear to be enough people, if key roles are not filled and a critical area of development is stretched beyond its capacity to respond.
Use Pull Scheduling
When a development team selects the work it will commit to for an iteration, the rule is that team members select only those (fine-grain) items they are confident that they can complete. During the first couple of iterations, they might guess wrong and select too much work. But soon they establish a team velocity, giving them the information they need to select only what is reasonable. In effect, the development team is “pulling” work from a queue. This pull mechanism limits the work expected of the team to its capacity. In the unlikely event that the team finishes ahead of time, more work can always be pulled out of the queue. Despite the fact that everyone always has work, the pull system has slack, because if emergencies arise or things go wrong, the team can adapt either by terminating the current iteration or by officially moving some items to the next iteration. Finally, since the team is working on the most important features from a customers’ perspective, they are working on the right things.
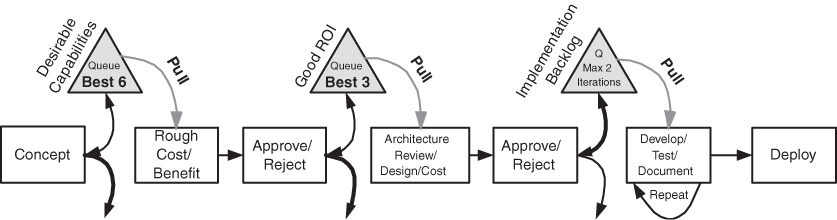
Cascading queues (as shown in Figure 5.4) are possible, and are often used at organizational boundaries. Queues are a useful management tool, because they allow managers to change priorities and manage cycle time while letting the development teams manage their own work. But queues are not an ideal solution. When they are used, here are some general rules to follow:
1. Queues must be kept short—perhaps two cycles of work. It is the length of the queues that governs the average cycle time of a request through the development process.
2. Managers can reorganize or change items at any time that they are in a queue. But once teams start to work on an item, they should not interfere with day-to-day development.
3. Teams pull work from a queue and work at a regular cadence until that work is done. It is this pull system that keeps teams busy at all times while limiting work to capacity.
4. Queues should not be used to mislead people into thinking that their requests are going to be dealt with if the team does not have the capacity to respond.
Summary
The measure of a mature organization is the speed at which it can reliably and repeatedly execute its core processes. The core process in software development is the end-to-end process of translating a customer need into deployed product. Thus, we measure our maturity by the speed with which we can reliably and repeatedly translate customers’ needs into high quality, working software that is embedded in a product which solves the customers’ whole problem.
Try This
1. How many defects are in your defect queue? How fast do they arrive? At what rate do they get resolved? At that rate, how many days, weeks, months, or years of work do you have in your defect queue? How many of the defects in your queue do you have a reasonable expectation to resolve? How much time do you spend on managing and reviewing the queue? Is it worth it?
2. How many requests are on your list of things to do? At what rate do they arrive? How much time, on the average, has already been spent on each item? How much time do you spend on managing and reviewing the queue? How much work (in days, weeks, months, or years) do you have on your list of things to do? Do you keep things in the list that you will never get around to? Why? What percent of the queue does this represent?
3. Does high utilization of people’s available time cause logjams in your environment? Does your organization measure “resource” (i.e., people) utilization? If so, what kind of impact does this measurement have: Is it taken seriously? Does it drive behavior? Is that behavior beneficial?
4. What determines your batch size: Release schedule? Project size? Can you reduce time between releases or the size of projects? What is a reasonable target? What would it take to change to that target?
5. At a team meeting, review the list of ways to reduce cycle time:
• Even Out the Arrival of Work
• Minimize the Number of Things in Process
• Minimize the Size of Things in Process
• Establish a Regular Cadence
• Limit Work to Capacity
• Use Pull Scheduling
Which one of these shows the most promise for your environment? Experiment by implementing the most promising approach and measure what happens to cycle time.
Endnotes
1. From Jeff Sutherland, “Future of Scrum: Parallel Pipelining of Sprints in Complex Projects,” Research Report, Agile 2005. Used with permission.
2. Posted on [email protected] on September 25, 2005. The fourth point is from message 9404, August 5, 2005, message 8849. Used with permission.
3. Posted on [email protected] on November 21, 2004, message 5439. Used with permission.
4. See www.lean.org.
5. See Michael George and Stephen Wilson, Conquering Complexity in Your Business: How Wal-Mart, Toyota, and Other Top Companies Are Breaking Through the Ceiling on Profits and Growth, McGraw-Hill, 2004, p. 37.