
Chapter 7. Editing, Parsing, and Browsing RDF/XML
Up to this point the only “moving parts” associated with RDF/XML have been those associated with the RDF Validator. Chances are good that this will always be your most important tool when working with RDF/XML. However, the RDF Validator isn’t the only helpful tool, utility, or application for reading, validating, or writing serialized RDF. Several editors, parsers, browsers, and converters are available; we’ll look at some of them in this chapter.
Though much of the technology associated with RDF and RDF/XML is geared toward developers, using many of the RDF/XML utilities requires little or no development experience. You may have to have to have certain software installed, but for the most part, it is either easy to install or is installed on your system.
All the applications and utilities in this chapter are a great way of getting familiar with RDF/XML whether you’re a markup person, a developer, or just an interested bystander, because all the applications focus on either reading or creating RDF/XML—not on the development necessary to get to that point.
BrownSauce
After you’ve worked with RDF/XML for a while, you can read the formatted data and the structures quite easily. However, many people prefer to use a visual tool of some form for this purpose. There are graphical tools and editors, which I’ll discuss later, but for now I want to demonstrate BrownSauce, a specialized RDF/XML browser.
One of the most useful tools I used while writing this book was BrownSauce, a Java-based RDF/XML browser created by Damian Steer. It’s web based but can run locally on your desktop even if you don’t have a web server installed; the only requirement is a Java Runtime Environment (JRE). BrownSauce parses RDF/XML documents and transforms them into a very readable format. One of its better features is its addition of hypertext links from the properties and classes in the RDF/XML document to the actual vocabulary schema definition in a separate page.
Tip
BrownSauce is open source and based on Jena (which is covered in the next chapter). However, you don’t have to be Java literate to use BrownSauce. You do need support for the Java Runtime, such as 1.4 (find this at http://javasoft.com), but once that’s installed, BrownSauce provides all the other Java classes you’ll need. Download BrownSauce at http://brownsauce.sourceforge.net/. The version I used in the book is 0.1.2, running on Windows 2000 and Linux.
Once you’ve downloaded and installed BrownSauce, following the installation instructions, start the Java-based server that allows you to access the application by double-clicking on run.bat if you’re running a Windows system or by running run.sh in a shell if you’re a Unix or Mac OS X user. BrownSauce starts in port 8080 by default so you’ll access the browser (typically) using:
http://localhost:8080/brownsauce/brownsauce.html
When the main BrownSauce page opens, you’re shown two rows of form fields. The first row contains fields for entering a source and a resource URI. The first two fields enable browsing for a specific RDF resource within a given RDF/XML document. This tends to be what I use. For instance, to look at the example RDF/XML document used in the previous chapters, I’ll enter the following values:
Source: http://burningbird.net/articles/monsters1.rdf Resource: http://burningbird.net/articles/monsters1.htm
The page that opens, shown in Figure 7-1, displays all the predicates for the resource and their associated values.
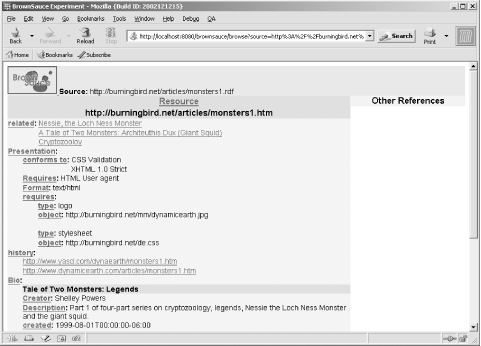
As you can see from the figure, the display is quite easy to read,
making effective use of whitespace. All non-hypertext-linked values are
literals from the model—those items that would be drawn with a
rectangular box within an RDF directed graph. What’s interesting is that
BrownSauce looked for a subproperty of rdfs:label — in this case the dc:title attribute from the main resource —
and actually used different CSS styling in the page to make it stand
out. (Yet another reason to make use of existing vocabularies such as
Dublin Core as much as possible: many tools will already be aware of
them and able to treat them specially.)
In addition, BrownSauce also made other subtle modifications to
the values it found to make the content more readable. As an
illustration, the pstcn:currentStatus
predicate was displayed as Current Status in the document. The label
was, again, pulled from the rdfs:label property within the PostCon
schema—another reason to make sure your RDF Schema document is
up-to-date and accessible.
BrownSauce also resolves some of the more complex RDF/XML
constructs. For instance, the rdf:Seq that lists the
history of a specific resource defined in the document is shown only by
the predicate name, with hypertext link items to each event’s resource
for additional information. In addition, the use of rdf:value, which is a
structured resource, is resolved to the type information (pstcn:type) and an object reference to the
actual value itself.
All of the predicates are hypertext linked. If you click on one of them, information from the schema for the item is displayed. Clicking on Current Status opens a new page with schema information for the status element, as shown in Figure 7-2.
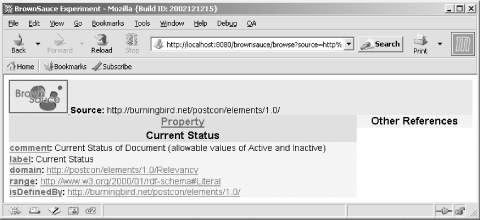
BrownSauce loads all the schemas from all the vocabularies, so no
matter what predicate you click, you should find the schema definition
if one has been provided. And if rdfs:comment and rdfs:label
predicates are used, these will be shown also. (Yet another reason to
make sure you use RDFS predicates rather than Dublin Core to describe
schema elements, as some vocabularies have done.)
You can modify BrownSauce’s appearance by modifying the accompanying bs.css file. Schemas are cached, which makes reading additional documents using the same schemas quicker.
BrownSauce doesn’t provide parsed access to data, nor does it allow you to edit it. What it does do is provide a human-readable format for examining RDF/XML documents. In particular, if you’re defining domain data using RDF/XML, BrownSauce allows the domain experts who may not be RDF literate a chance to look at the data without having to be comfortable with either XML or RDF/XML. No matter how comfortable you are with RDF/XML, BrownSauce is a great tool to test your documents, your vocabulary, and the vocabulary’s associated schema.
Parsers
RDF/XML parsers are usually included as part of a broader API. For instance, Jena has a parser, as do other APIs in other languages. Parsers aren’t typically accessed directly, however, because you generally want to do something else with all that data after parsing it into an application-specific stream of data.
However, accessing parsers directly can be handy for a couple of reasons. The primary reason is to validate an RDF/XML document—a compliant RDF/XML parser should return meaningful error messages and warnings when it encounters erroneous or suspicious RDF/XML. Another reason to run a parser directly is to create another serialization of the RDF/XML, but in a different format, such as a set of N-Triples. When I’m creating a new RDF application, I run my example RDF/XML documents through an N-Triples parser to get the N-Triples; I then use these to help with my coding of the application.
Tip
I parse RDF/XML into triples because most RDF APIs provide methods for working with triples, not the higher-level construct view. As an example, instead of creating an RDF container directly, you’ll usually have to create all the triples that represent the statements underlying the container. This is demonstrated more clearly in the next several chapters.
In this section, we’ll take a quick look at some parsers, beginning with ARP, the parser that forms the core of the well-used RDF Validator.
ARP2
ARP stands for Another RDF/XML Parser. ARP2 is the second generation of this parser, which has been modified to work with the newest RDF specifications. ARP is part of the Jena Toolkit, discussed in Chapter 8, but is also a separate installation in its own right. You can download and install ARP without having to download and install Jena. However, you have to have Java installed, at least JRE 1.4 or above.
Tip
ARP is installed with Jena, or you can access it directly at http://www.hpl.hp.com/semweb/arp.htm . If you do download and install ARP as a separate processor, intending it to coexist with a separate installation of Jena, make sure that you don’t have the separate ARP in your classpath, or you could have problems working with Jena.
Normally ARP is used within another application, but there is one class that you can access at the command line as a method of testing the viability of your RDF/XML document—the NTriple class. Once ARP2 is installed, you can run NTriple from the command line thus:
java com.hp.hpl.jena.rdf.arp.NTriple http://burningbird.net/articles/monsters1.rdf
NTriple produces either a listing of N-Triples from the RDF/XML, or produces errors if there’s something wrong with the syntax. A partial sampling of the command-line output from the parser of the file shown in the command line is given in Example 7-1.
http://burningbird.net/articles/monsters1.htm> <http://www.w3.org/1999/02/22-rdf-syntax-
ns#type> <http://burningbird.net/postcon/elements/1.0/Resource> .
_:jARP1 <http://purl.org/dc/elements/1.1/title> "Tale of Two Monsters: Legends" .
_:jARP1 <http://purl.org/dc/terms/abstract> "
When I think of "monsters" I
think of the creatures of
legends and tales, from the books and movies, and
I think of the creatures that have entertained me for years.
" .
_:jARP1 <http://purl.org/dc/elements/1.1/description> "
Part 1 of four-part
series on cryptozoology, legends,
Nessie the Loch Ness Monster and the giant
squid.
" .
_:jARP1 <http://purl.org/dc/elements/1.1/created> "1999-08-01T00:00:00-06:00" .
_:jARP1 <http://purl.org/dc/elements/1.1/creator> "Shelley Powers" .
_:jARP1 <http://purl.org/dc/elements/1.1/publisher> "Burningbird Network" .
<http://burningbird.net/articles/monsters1.htm> <http://burningbird.net/postcon/elements/
1.0/Bio> _:jARP1 .
_:jARP2 <http://burningbird.net/postcon/elements/1.0/currentStatus> "Active" .
_:jARP2 <http://purl.org/dc/terms/valid> "2003-12-01T00:00:00-06:00" .
_:jARP2 <http://purl.org/dc/elements/1.1/subject> "legends" .
_:jARP2 <http://purl.org/dc/elements/1.1/subject> "giant squid" .
_:jARP2 <http://purl.org/dc/elements/1.1/subject> "Loch Ness Monster" .
_:jARP2 <http://purl.org/dc/elements/1.1/subject> "Architeuthis Dux" .
_:jARP2 <http://purl.org/dc/elements/1.1/subject> "Nessie" .
_:jARP2 <http://purl.org/dc/terms/isReferencedBy> "http://www.pibburns.com/cryptozo.htm" .
_:jARP2 <http://purl.org/dc/terms/references> "http://www.nrcc.utmb.edu/" .
<http://burningbird.net/articles/monsters1.htm> <http://burningbird.net/postcon/elements/
1.0/Relevancy> _:jARP2 .Notice that the parser returns annotated text, showing line returns and maintaining the integrity of the text as it found it in the document.
Tip
The output from ARP demonstrates one of the dangers of manually creating RDF/XML—preservation of special characters and whitespace. It’s pretty common to break lines or line characters up when you type something manually, but such whitespace will be retained unnecessarily when the RDF/XML is read in by a parser such as ARP. If you create RDF/XML manually, drop whitespace unless it’s an integral part of the text.
The NTriple command format is:
java <class-path> com.hp.hpl.jena.arp.NTriple ( [ -[xstfu]][ -b xmlBase -[eiw] NNN[,NNN...] ] [ file ] [ url ] )...
Note, though, that with the release of ARP2 that I downloaded (which was alpha), I had to change the classpath to com.hp.hpl.jena.rdf.arp.NTriple. NTriple can work with files on a filesystem or accessed through a URL. The other options for NTriple are given in Table 7-1.
Option | Description |
| Set XML base to URI or absolute URL. |
| Document is completely RDF/XML (not embedded) and
may not have |
| No triples, errors only. |
| Lax mode, suppress warnings. |
| Strict mode, transform most warnings to errors. |
| Allow unqualified attributes. |
| All errors are final and processing stops when it reaches first. |
| Show line numbers for triples. |
| Treat specified warnings as errors. |
| Ignore numbered error/warning conditions. |
In particular, if you’re working with the new RDF/XML
specification constructs, such as rdf:nodeID or rdf:datatype, you may want to test it with
ARP, suppressing triples. Example
7-2 shows an RDF/XML document that’s actually generated by
Jena. It features the newer rdf:nodeID attribute, which breaks down on
older parsers. However, I modified the file to change one of the
legitimate uses of rdf:resource to
rdf:about (in bold).
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:NS0='http://burningbird.net/postcon/elements/1.0/'
xmlns:dc='http://purl.org/dc/elements/1.0/'
>
<rdf:Description rdf:nodeID='A0'>
<dc:creator>Shelley Powers</dc:creator>
<dc:publisher>Burningbird</dc:publisher>
<dc:title xml:lang='en'>Tale of Two Monsters: Legends</dc:title>
</rdf:Description>
<rdf:Description rdf:about='http://burningbird.net/articles/monsters1.htm'>
<NS0:related rdf:about='http://burningbird.net/articles/monsters2.htm'/>
<NS0:related rdf:resource='http://burningbird.net/articles/monsters3.htm'/>
<NS0:Bio rdf:nodeID='A0'/>
</rdf:Description>
</rdf:RDF>Running the NTriple application with the -t option returns the following error from
this file:
C:>java com.hp.hpl.jena.rdf.arp.NTriple -t c:writing
dfbookjavapracRDFThird
.rdf
Error: file:/c:/writing/rdfbook/java/pracRDFThird.rdf[12:77]: {E201} Syntax error
when processing attribute rdf:about.
Cannot have attribute rdf:about in this context.As you can see, ARP2 not only finds the error, it also gives you the location of the error and the reason the error occurs.
ARP2 works from the command line only, but if you’re more interested in a parser with a GUI frontend, you might want to try out ICS-FORTH’s Validating RDF Parser.
ICS-FORTH Validating RDF Parser
The ICS-FORTH Validating RDF Parser (VRP), like ARP, is part of a suite of tools but can also be downloaded separately. In addition, again like ARP, the only requirement to run the tool is a Java Runtime Environment installed, JRE 1.4 or up.
Tip
You can download ICS-FORTH’s Validating RDF Parser from the following location: http://athena.ics.forth.gr:9090/RDF/. You can also get access to it as part of the RDFSuite.
VRP is a set of Java classes that you can use within your own Java classes. However, the parser also comes with a Swing-based GUI frontend that you can use directly without having to touch any code. To access the GUI for the parser, once you’ve downloaded and unzipped the file containing the source, you’re ready to start using it. Start up the parser by typing the following line:
java -classpath <path to VRP directory>/classes GUI.VRPGUI
The page that opens has two text input fields, one for an input file and one for recording the results. Below these are a set of checkboxes that switch on specific tests, such as ones for checking the syntax, checking for class hierarchy loops, and so on. Figure 7-3 shows the tool after I validated the test document (at http://burningbird.net/articles/monsters1.rdf ), asking for validation only and having the tool test the syntax and class and property hierarchy loops. VRP can also open an HTML or XHTML document with RDF/XML embedded in it (as described in Chapter 3).
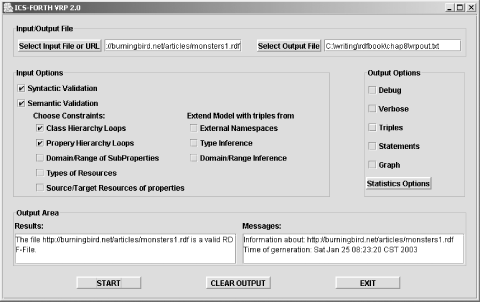
As you can see from the image, VRP has several input and output
options. For instance, I can run the test again, this time checking
the Triples, Statements, and Graph options for output. The tool first
asks me for permission to overwrite the output file and then runs the
tests, printing output to the Results window in the application as
well as to the file. The Graph option provides a text description of
what would be the RDF directed graph rather than a true graphical
representation. A sampling from this file, the classes as defined in
the RDFS graph output, are shown in Example 7-3. Note that the
information associated with each schema class, such as the isDefinedBy, comment, and label information, isn’t showing in the
graph, though we know it to be present in the schema.
The classes of the Model: http://burningbird.net/postcon/elements/1.0/#Movement subClassOf: [] comment: [] label: [] seeAlso: [] isDefinedBy: [] value: [] type: [] http://www.w3.org/1999/02/22-rdf-syntax-ns#Seq subClassOf: [] comment: [] label: [] seeAlso: [] isDefinedBy: [] value: [] type: [] http://burningbird.net/postcon/elements/1.0/#Resource subClassOf: [] comment: [] label: [] seeAlso: [] isDefinedBy: [] value: [] type: []
The version of the tool I used expands the absolute URIs for the
classes and properties by converting them to URI fragments, such as
#Resource and #Movement, before concatenating them to the
URI. The base URI is specified with a trailing slash, just as occurs
with the Dublin Core schema. The relative URIs should not have been
“corrected” to URI fragments before resolution into absolute URIs.
Because of this correction, the schema elements could not resolve
correctly (as they did within BrownSauce).
Warning
VRP generates Unix-style line-feeds. If you’re using the product in Windows, make sure you view the result using a test reader that compensates for this. For example, use Wordpad not Notepad.
This could be why the tool didn’t pick up the schema information for the items, or why it may not open related schema documents. Hard to say. One thing the tool does do is correctly resolve the RDF classes in the document, as compared to the RDF properties. This can be very helpful when you’re creating an RDF Schema for a vocabulary and do not recall which elements are classes and which are properties.
The checks you can perform on a specific document are:
- Syntax check
Checks whether the RDF/XML of the document conforms to the updated RDF/XML specification.
- Semantic check: class hierarchy loop
Checks for loops in subclass hierarchy (parent class identifying itself as child of child class and so on).
- Semantic check: property hierarchy loop
Same as previous but for properties.
- Semantic check: domain/range of subproperties
A property’s domain and range are a sum of its subproperties’ domains and ranges.
- Semantic check: resources of properties
Source/target property values should be instances of domain/range of property.
- Semantic check: types of resources
Assigned RDF or XML type.
- Extend model: external namespace
Connects to external namespaces to merge in their triples.
- Extend model: type inference
Infer type of resource.
- Extend model: domain/range inference
Infer domain/range from superproperty.
The semantic check for types of resources failed with all models I tested this against, including Dublin Core, RSS, and FOAF (Friend of a Friend) RDF/XML documents. This check is looking for a specific type information for each resource, something not available in most models. However, the example PostCon vocabulary file (at http://burningbird.net/articles/monsters1.rdf ) did pass all other tests. When I selected the option to include external namespace triples, the model again failed, but the results as a graph were quite interesting.
The results include information from the schema for PostCon,
such as the following for the pstcn:movementType property:
http://burningbird.net/postcon/elements/1.0/movementType range: [http://www.w3.org/2000/01/rdf-schema#Literal] domain: [http://postcon/elements/1.0/Movement] subPropertyOf: [] links: comment: [Type of Movement (allowable values of Move, Add, Remove)] label: [Movement Type] seeAlso: [] isDefinedBy: [http://burningbird.net/postcon/elements/1.0/] value: [] type: [http://www.w3.org/1999/02/22-rdf-syntax-ns#Property]
Notice the links property and
that it has no value. However, later in the document, you’ll see the
graph for pstcn:movementType:
http://burningbird.net/postcon/elements/1.0/#movementType range: [] domain: [] subPropertyOf: [] links: (http://www.yasd.com/dynaearth/monsters1.htm, Add) (http://www. dynamicearth.com/articles/monsters1.htm, Move) (http:/burningbird.net/articles/ monsters1.htm, Move) comment: [] label: [] seeAlso: [] isDefinedBy: [] value: [] type: []
Again, the automatic use of fragment identifiers breaks the
information up; however, combine both blocks and you have a relatively
good idea of all the dimensions of the PostCon property pstcn:movementType.
In addition to Graph, other VRP outputs are:
- Debug
Shows tokens generated by Lexar, the lexicon analyzer
- Verbose
Details actions VRP takes
- Triples
Model triples
- Statements
Model statements
- Statistic options
Provides other information such as number of resources, statements, and time taken for some of the processes
I would definitely consider running VRP against an in-progress vocabulary while you’re designing your schema and then try it with External Namespaces as a test with some of your models as a check on the schema.
Editors
As I stated earlier, after some time you can become comfortable enough with RDF/XML to read and write the documents manually. But why bother? If you need to manually write an RDF/XML document, you’re better off doing so with a specialized RDF editor.
IsaViz
One of the more popular editors is IsaViz, a visual RDF/XML editing tool written in Java. In fact, like so many other RDF/XML tools, it makes use of many of the Jena classes, making Jena the most commonly used API of all (which is why it has its own chapter).
Tip
You can access documentation and software for IsaViz at http://www.w3.org/2001/11/IsaViz/. By the time this book hits the streets, the version of IsaViz will be compliant with the released RDF specifications as described earlier in the book.
Once you’ve downloaded and installed IsaViz, you can run it using run.sh on Unix or OS X or run.bat on Windows. Several windows open, each containing a portion of the GUI for the application. Since IsaViz is such a graphical tool, much of this section is going to be pretty pictures, demonstrating different aspects of the tool.
IsaViz opens as a new project; you can either manually start creating a new RDF model or import one in either N-Triples format or from RDF/XML. We’ll start with importing the test RDF/XML document into the editor, just to see how it works. You can import an existing document by selecting File, and then Import, and then selecting whether to Merge the model into the existing project or Replace it. Since the existing project doesn’t have any model elements, I picked Replace and then provided the URL for the RDF/XML document.
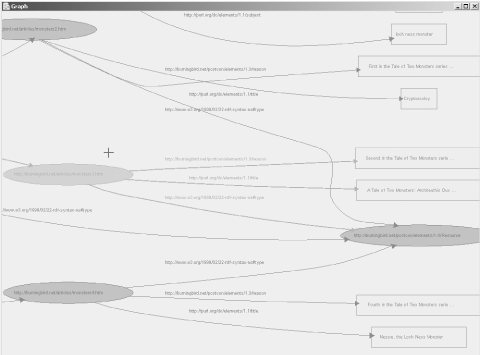
In a surprisingly short amount of time, IsaViz loaded the model and displayed an RDF graph of it in the graph frame, as shown in Figure 7-4.
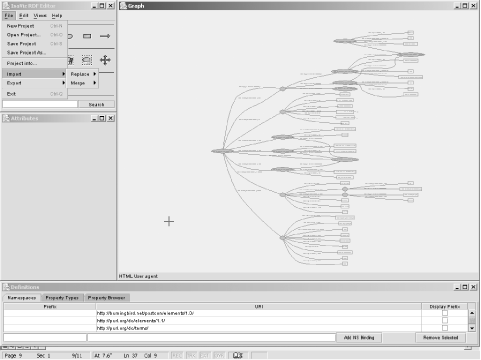
The full view of the model is a bit hard to read, but if you right-click on portions of the model in the Graph frame, the focus changes and the view zooms in so that you can look at the details. Left-clicking on any of the items in the model displays attribute information about the item in the Attributes frame. The complete listing of properties is shown at the bottom, in the Definitions frame. Project and model management is managed in the last frame, the Editor.
Clicking on the model, zooming in to the top resource, and left-clicking displays attribute information, as shown in Figure 7-5.
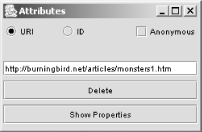
Clicking the Delete button removes the resource from the model, and clicking Show Properties opens another window with a listing of all resource properties, as shown in Figure 7-6. In the picture, the only properties that show are those that belong to the immediate resource.

The bottom frame window of IsaViz contains three tabbed windows, one showing the namespaces in the model, one showing the property types, and one showing the properties for the selected resource. You don’t have to click on the resource within the graph to select it—you can also use the Edit menu in the IsaViz Editor window and search for a specific resource or object value.
You can zoom in on the model, by clicking the Shift key and then right-clicking in the model and dragging to the top to zoom in and to the bottom to zoom out. Holding the Shift key and clicking on a specific item also recenters the window on that item. To move around the model, right-click anywhere on it and drag to the top, bottom, right, or left to move in that direction.
If you want to select a portion of the graph, click the Select icon in the IsaViz Editor window and then click on whatever you want to select. If you want to select a resource and all of its predicates, hold the Shift down as you select the item. The selected items are highlighted in a bold outline, as shown in Figure 7-7.
In addition to examining the model, you can also edit or add to it. As stated earlier, delete an item by selecting it and then clicking Delete from the Attributes view. You can add a new resource, property, or literal by clicking on the appropriate item in the IsaViz Editor window, shown in Figure 7-8, and then clicking on the model. A definition window opens, and you can add the URI or value or predicate URI for the item.
To add a predicate between the subject oval and the object, select the arrow icon, click first on the resource and then on the object—the arc between the nodes is drawn.
Once you’re all finished with the project, you can save for further edits, or you can export multiple views of it. IsaViz allows you to export an RDF/XML file, an N-Triples file, a PNG graphic, or an SVG graphic. Figure 7-9 shows the directed graph for the article RDF/XML after all but one predicate has been deleted from the top-level resource, exported as a PNG file.
IsaViz is an absolutely essential tool to have if you’re working with RDF.
RDF Editor in Java
As with many other applications and utilities, the RDF Editor in Java (referred to as REJ from this point) derives much of its RDF processing power from Jena. On top of Jena’s functionality is a simple, easy-to-use text-based RDF editing tool that’s compatible with X11 and Windows.
Tip
You can download the RDF Editor in Java from SourceForge at http://sourceforge.net/projects/rdfeditor/.
REJ has a simple interface, which makes it fairly simple to learn how to use. It opens with the RDF/XML-specific tags and namespace already inserted into a blank document. You can continue to add to the model in the page, or you can open an existing model.
Just to see how the tool works, I opened the test RDF/XML document. To the right of the document window is a little ruler. If you move the glider, the element selected changes, as shown in Figure 7-10.
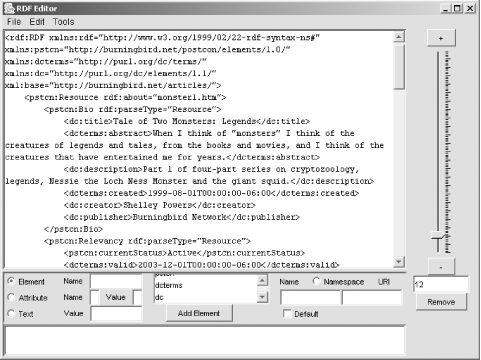
You can also move the selection by clicking the plus (+) button to move up, and the minus (-) button to move the selection down. The element’s position relative to the rest of the page is shown in the window below the ruler.
Once an element is selected, you can delete it and replace the element. For instance, in Figure 7-10, clicking the Remove button removes the text. Clicking on the Text radio button to the left of the control bar at the bottom sets the page up for accepting a literal. Once the value is entered in the field next to the Text radio button, I click the button next to it, which is now labeled PCDATA, and the text is inserted into the document at that point.
You can also add new elements, attributes, namespaces—all using the control bar at the bottom, which changes to fit whatever option you’re in, as shown in Figure 7-11. Once you’ve added the new element, you can then add literals, other elements, and attributes to it.
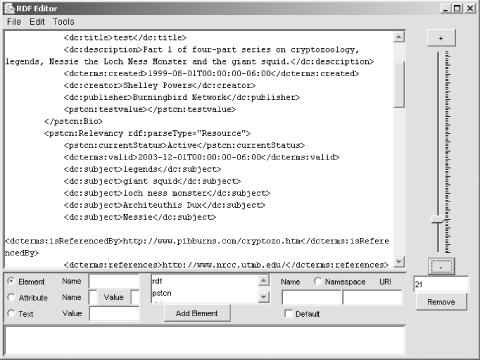
Once you’re finished with the model, you can save the RDF/XML document to a new or existing file. You can also generate an N-Triples report from the model by selecting Tools and then selecting the N-Triples Report. The results are printed out in the bottom window and can also be saved.
Not a lot of bells and whistles, but REJ is a good choice if you’re already comfortable with RDF/XML .