
Chapter 9. RDF and Perl, PHP, and Python
There is commonality among many of the APIs that manipulate RDF/XML, regardless of the programming language in which the API is implemented. Usually a new model is created, some form of storage mechanism is assigned to it, and statements are added to it by first creating the resource, predicate, and object associated with the statement, and then creating the statement itself. This similarity of procedure is one of the advantages to the metadata structure of RDF—a fundamental data structure transcends implementation. This basic data structure was apparent in the last chapter, which manipulated RDF using Java. This same data structure and similarity of actions are also apparent in this chapter, which looks at working with RDF/XML using what I call the three Ps of programming.
If you’ve worked on web development, particularly within a Unix environment, chances are you’ve used at least one of the three Ps: Perl, PHP, or Python. Perl has become ubiquitous across most Unix environments (which now include Mac OS X); with the help of ActiveState, Perl is also fairly common in Windows. PHP is now beginning to rival ASP as the web scripting language of choice, especially since PHP is designed to work with Apache, the most widely used web server in the world. Python is much newer, but is increasing in popularity at a rapid pace due to the extremely loyal following it has attracted.
Considering the popularity of these three languages, it’s not a surprise that each boasts more than one language-based RDF/XML API or other technology. It would be difficult to find and cover every Perl-, PHP-, and Python-based RDF/XML API. Instead, in this chapter, I focus on the APIs that have had recent updates and/or are most widely used. This includes the APIs I’ve used in my own projects, noted in the discussions.
Tip
The online book support site lists download locations for the most recent PHP, Perl, and Python RDF/XML tools, utilities, and APIs. For more on Perl, see the Perl resource site at http://perl.com. The main Python site is http://python.org, and PHP’s main site is http://php.net.
RDF/XML and Perl
There would seem to be a natural fit between Perl, a language known for its parsing and pattern-matching capability, and RDF. When I went searching for Perl APIs, I was surprised to find that several I discovered had not been updated for months (sometimes years) or were seriously incomplete. However, I was able to find a couple of Perl APIs that are active, are being supported, and provide much of the functionality necessary for working with the RDF data model through RDF/XML.
Tip
The W3C had a Perl library that included an RDF Parser, perllib, found at http://www.w3.org/1999/02/26-modules/. However, there hasn’t been a solid release of the Perl modules associated with it in quite some time, and the only activity that’s occurred in relation to it is buried in the CVS files for the API. Because there hasn’t been a release of the API in some time, I decided not to include it in this chapter.
Ginger Alliance PerlRDF
I found the Ginger Alliance Perl APIs by searching for
RDF within CPAN, the repository of Perl on the Internet (accessible
at http://perl.com). The organization provides
Perl modules that can parse, store, and query Notation3 (RDF::Notation3) as well as RDF/XML (RDF::Core), but we’ll cover only the RDF/XML
module in this book.
The RDF::Core modules for
RDF/XML allow you to parse and store an existing RDF/XML document, add
to it, and query it using function calls, as well as serialize a new
or modified model. You can store the module in memory, within a
PostgreSQL database or in Berkeley DB.
Model Persistence and Basic Querying
RDF models can be built within the code or parsed in
from an external file. First, though, you have to create a storage
mechanism to store the data. PerlRDF gives you a choice of storing a
model in memory or in a Berkeley DB or PostgreSQL database. The
RDF::Core::Storage object manages
the memory access, and it has three different implementations for the
three different storage mechanisms.
RDF::Core::Storage::Memory manages in-memory
storage. This object won’t persist after the Perl application
terminates or goes out of scope, and the only unique method is
new, which takes no
parameters:
require RDF::Core::Storage::Memory; my $storage = new RDF::Core::Storage::Memory;
The RDF::Core
Berkeley DB object, RDF::Core::Storage::DB_File, utilizes the
existing Berkeley Database DB_File
Perl module for much of its functionality. DB_File uses the tie function to bind the DB object functions
to the database file on disk, hiding much of the detail of database
management. Unlike the memory method, the DB_File object’s new method takes several parameters:
- Name
The name used as the first part of the name for several files, to support the structures necessary to store the RDF model.
- Flags, Mode
Equivalent to the flags and mode used with the Berkeley DB
dbopenmethod. Examples of flags areO_RDONLY,O_RDRW, andO_CREAT. By default,O_RDONLYandO_RDRWare used. The default mode is 0666.- MemLimit
Controls the number of statements returned within an enumerator (to be discussed) if nonzero.
- Sync
Number of wire transfer processes to complete before synchronizing memory data with storage or zero to not force synchronization.
In the following code, a storage object is instantiated, set to
the current directory with the name of rdfdata, and given a MemLimit set to 500 statements; all other
values are set to default:
require RDF::Core::Storage::DB_File;
my $storage = new RDF::Core::Storage::DB_File(Name =>'./rdfdata',
MemLimit => 5000,
); The last storage mechanism supported in RDF::Core, RDF::Core::Storage::PostGres uses the
PostgreSQL data store to persist the RDF model. Its new method takes the following
options:
- ConnecStr
PostgreSQL connection string
- DBUser, DBPassword
Database user and password
- Model
Distinguish between models (can store than one model in PostgreSQL database)
After a storage object is instantiated, the methods to manipulate its data are the same regardless of the underlying physical storage mechanism.
Building an RDF Model
A basic procedure is used with PerlRDF to create a new RDF model. First, create the storage mechanism; next, create the model and each of the components of an RDF statement, assigning them to a new statement. Finally, add the statement to the model. That’s all you need to add a new triple to an RDF model. The power of this Perl module is in its simplicity of use.
To demonstrate this, Example
9-1 shows a simple application that creates a new model using a
Berkeley database, adds a couple of statements for the same resource,
and then serializes the model to RDF/XML. The first statement adds an
rdf:type of PostCon Resource to the
main resource; the second adds a movement type predicate. Note that
predicate objects are created directly from the subject object, though
the two aren’t associated within the model until they’re added to the
model. Also note that literals are specific instances of Perl objects,
in this case RDF::Core::Literal.
use strict;
require RDF::Core::Storage::Memory;
require RDF::Core::Model;
require RDF::Core::Statement;
require RDF::Core::Model::Serializer;
require RDF::Core::Literal;
# create storage object
my $storage = new RDF::Core::Storage::Memory;
my $model = new RDF::Core::Model (Storage => $storage);
my $subject =
new RDF::Core::Resource('http://burningbird.net/articles/monsters1.rdf'),
my $predicate =
$subject->new('http://www.w3.org/1999/02/22-rdf-syntax-ns#type'),
my $object =
new RDF::Core::Resource('http://burningbird.net/postcon/elements/1.0/Resource'),
my $statement = new RDF::Core::Statement($subject, $predicate, $object);
$model->addStmt($statement);
$model->addStmt(new RDF::Core::Statement($subject,
$subject->new('http://burningbird.net/postcon/elements/1.0/movementType'),
new RDF::Core::Literal('Move')));
my $xml = '';
my $serializer = new RDF::Core::Model::Serializer(Model=>$model,
Output=>$xml
);
$serializer->serialize;
print "$xml
";Running this application results in the following RDF/XML:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:a="http://burningbird.net/postcon/elements/1.0/" > <rdf:Description about="http://burningbird.net/articles/monsters1.rdf"> <rdf:type rdf:resource="http://burningbird.net/postcon/elements/1.0/Resource"/> <a:movementType>Move</a:movementType> </rdf:Description> </rdf:RDF>
PerlRDF hasn’t been updated to reflect the W3C’s recommendation
to qualify all attributes; in this case about should become rdf:about. However, this isn’t an error, and
the most that happens when testing this in the RDF Validator is that
you’ll get a warning:
Warning: {W101} Unqualified use of rdf:about has been deprecated.[Line = 5, Column = 72]Tip
It was a simple matter to fix this directly, within
the Serializer.pm. In both
instances of an "about" element
being printed out (contained within quotes, use your text editor’s
search function to find these), replace "about" with "rdf:about". The rest of the examples in
this chapter reflect this change.
Additional statements can be built and added on using the same
approach. If the statement can be modeled as a particular N-Triple, it
can be added as a statement to the model using RDF::Core, including blank nodes.
In Example 9-2, the
code will add the N-Triples statements equivalent to the newer RDF
construct, rdf:value. From
monsters1.rdf, this looks like the following
using the more formalized syntax:
<pstcn:presentation rdf:parseType="Resource">
<pstcn:requires rdf:parseType="Resource">
<pstcn:type>stylesheet</pstcn:type>
<rdf:value>http://burningbird.net/de.css</rdf:value>
</pstcn:requires>
</pstcn:presentation>Technically, no specific method is included in RDF::Core for creating the formalized
rdf:value syntax, but one’s not
needed as long as you can add statements for each N-Triple that
results when the syntax is broken down into triples. In the case of
rdf:value, the N-Triples for the
rdf:value construct associated with
the stylesheet in monsters1.rdf are (from the RDF
Validator):
_:jARP24590 <http://burningbird.net/postcon/elements/1.0/type> "stylesheet" . _:jARP24590 <http://www.w3.org/1999/02/22-rdf-syntax-ns#value> "http://burningbird.net/de.css" . _:jARP24589 <http://burningbird.net/postcon/elements/1.0/requires> _:jARP24590 . <http://burningbird.net/articles/monsters1.htm> <http://burningbird.net/postcon/elements/1.0/presentation> _:jARP24589 .
Breaking this down into actions, first a blank node must be
created and added as a statement with the resource monsters1.htm and a given predicate of
http://burningbird.net/postcon/elements/1.0/presentation.
This blank node is then used as the resource for the next statement
that’s added, which adds another blank node, this one with the
predicate of http://burningbird.net/postcon/elements/1.0/requires.
In this example, the RDF::Core
object NodeFactory creates the
blank nodes for both.
Next, the second blank node that was created is used to add the
next statement, with a predicate of http://www.w3.org/1999/02/22-rdf-syntax-ns#value
and value of http://burningbird.net/de.css. The last
statement has a predicate of http://burningbird.net/postcon/elements/1.0/type
and a value of stylesheet. Since
blank nodes created by NodeFactory
are RDF::Core::Resource objects,
they can also create predicates for each of the statements.
use strict;
require RDF::Core::Storage::Memory;
require RDF::Core::Model;
require RDF::Core::Statement;
require RDF::Core::Model::Serializer;
require RDF::Core::Literal;
require RDF::Core::NodeFactory;
# create storage object
my $storage = new RDF::Core::Storage::Memory;
my $model = new RDF::Core::Model (Storage => $storage);
# new subject and new resource factory
my $subject =
new RDF::Core::Resource('http://burningbird.net/articles/monsters1.rdf'),
my $factory =
new RDF::Core::NodeFactory(BaseURI=>'http://burningbird.net/articles/'),
# create bnode for presentation
my $bPresentation = $factory->newResource;
# create bnode for requires
my $bRequires = $factory->newResource;
# add presentation
my $predicate =
$subject->new('http://burningbird.net/postcon/elements/1.0/presentation'),
my $statement =
new RDF::Core::Statement($subject, $predicate, $bPresentation);
$model->addStmt($statement);
# add requires
$model->addStmt(new RDF::Core::Statement($bPresentation,
$bPresentation->new('http://burningbird.net/postcon/elements/1.0/requires'),
$bRequires));
# add rdf:value
$model->addStmt(new RDF::Core::Statement($bRequires,
$bRequires->new('http://www.w3.org/1999/02/22-rdf-syntax-ns#value'),
new RDF::Core::Literal('http://burningbird.net/de.css')));
# add value type
$model->addStmt(new RDF::Core::Statement($bRequires,
$bRequires->new('http://burningbird.net/postcon/elements/1.0/type'),
new RDF::Core::Literal('stylesheet')));
my $xml = '';
my $serializer = new RDF::Core::Model::Serializer(Model=>$model,
Output=>$xml
);
$serializer->serialize;
print "$xml
";Running the application results in the following RDF/XML output:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:a="http://burningbird.net/postcon/elements/1.0/" > <rdf:Description rdf:about="http://burningbird.net/articles/monsters1.htm"> <a:presentation> <rdf:Description> <a:requires> <rdf:Description> <rdf:value>http://burningbird.net/de.css</rdf:value> <a:type>stylesheet</a:type> </rdf:Description> </a:requires> </rdf:Description> </a:presentation> </rdf:Description> </rdf:RDF>
Plugging this into the RDF Validator and asking for N-Triples output returns the following N-Triples:
_:jARP24933 <http://www.w3.org/1999/02/22-rdf-syntax-ns#value> "http://burningbird.net/de.css" . _:jARP24933 <http://burningbird.net/postcon/elements/1.0/type> "stylesheet" . _:jARP24932 <http://burningbird.net/postcon/elements/1.0/requires> _:jARP24933 . <http://burningbird.net/articles/monsters1.htm> <http://burningbird.net/postcon/elements/1.0/presentation> _:jARP24932 .
This maps back to the original N-Triples that we used to build
the statements in the first place. As the generated N-Triples
demonstrate, the subgraph of the monsters1.rdf
directed graph that’s specific to the use of rdf:value is identical to using the more
formalized syntax for this construct. Regardless of the complexity of
the model, the same procedure can be used to add all statements.
In addition to building a model from scratch, you can also read RDF models in from external resources such as an RDF/XML document, demonstrated in the next section.
Parsing RDF/XML Documents
Using RDF::Core to
parse and query an RDF file is much simpler than creating an RDF model
within code, something true of all APIs and parsers used in this
book.
Whether you build the RDF model directly in the code or read it
in, you still have to create a storage object and attach it to a model
before you can start adding statements. However, when you read in a
model from an external source, you can use the RDF::Core::Model::Parser object to read in
the RDF/XML directly and generate the appropriate statements.
Tip
One major different between reading RDF statements in from an RDF/XML file and reading a file in using a parser is that the API may not support all the current constructs within the RDF/XML document, especially if you’re using some of the more specialized XML shortcuts. As you read in the data, you may run into problems. If this happens, then you’ll want to modify the RDF/XML, transforming the shortcut to the more formalized syntax to reflect the N-Triples that the parser can process.
To demonstrate how simple it is to read in an RDF/XML document,
the code in Example 9-3
reads in the monsters1.rdf file,
storing it in a Berkeley DB datastore. The application then calls
getStmts on the model, returning an
RDF::Core::Enumerator object, which
is used to print out the N-Triples defined within the document.
use strict;
require RDF::Core::Model;
require RDF::Core::Model::Parser;
require RDF::Core::Enumerator;
require RDF::Core::Statement;
require RDF::Core::Storage::DB_File;
# create storage
my $storage = new RDF::Core::Storage::DB_File(Name =>'./rdfdata',
MemLimit => 5000,
);
# create model and map to storage
my $model = new RDF::Core::Model (Storage => $storage);
# define parser options and parse external RDF/XML document
my %options = ( Model => $model,
Source => "/home/shelleyp/www/articles/monsters1.rdf",
SourceType => 'file',
BaseURI => "http://burningbird.net/",
InlineURI => "http://burningbird.net/"
);
my $parser = new RDF::Core::Model::Parser(%options);
$parser->parse;
# enumerate through statements, printing out labels
my $enumerator = $model->getStmts;
my $statement = $enumerator->getFirst;
while (defined $statement) {
print $statement->getLabel."
";
$statement = $enumerator->getNext
}
# close enumerator
$enumerator->close;The Berkeley DB file prefix is rdfdata, and several files will be generated
with this prefix. The options for the parser include the file location
for the RDF/XML document, the fact that it’s being read in as a file
and not a URL, and a base and an inline URI. The base URI is used to
resolve relative URIs, while the inline URI is for blank node
resources. RDF::Core generates a
blank node identifier consisting of this inline URI and a separate
number for each blank node within the document.
When the application is run, the N-Triples are printed out to
system output, which can then be piped to a file to persist the
output. A sampling of these N-Triples representing the subgraph we’ve
been using for the example, the rdf:value syntax, is:
<http://burningbird.net/articles/monsters1.htm> <http://burningbird.net/postcon/ elements/1.0/presentation> <http://burningbird.net/3> . <http://burningbird.net/3> <http://burningbird.net/postcon/elements/1.0/requires> <http://burningbird.net/4> . <http://burningbird.net/4> <http://burningbird.net/postcon/elements/1.0/type> "stylesheet". <http://burningbird.net/4> <http://www.w3.org/1999/02/22-rdf-syntax-ns#value> "http:/ /burningbird.net/de.css" .
Though the blank node identifiers are different from those generated by the RDF Validator, the statements are equivalent.
Now that the RDF/XML document has been read in, we can access it within the database to perform more selective queries.
Querying RDF with RDF::Core
In the last section, the code read the RDF/XML into a persistent Berkeley Database. Instead of going back against the document, we’ll use the database for queries in the next examples.
You might want to see how many statements have a given
predicate. To count statements matching a specific value in any one of
the triple components, use countStmts, passing in appropriate search
parameters for subject, predicate, and object. The number of
statements found matching the given values is returned. Passing an
undefined parameter signals that any value found for the specific
items is a match. In Example
9-4, we’re interested in only the statements that use the
predicate http://burningbird.net/postcon/elements/1.0/reason.
The code loads the database and accesses the countStmts directly on the RDF::Core::Storage object (the Model
object has a countStmts function,
too).
use strict;
require RDF::Core::Storage::DB_File;
require RDF::Core::Resource;
# load model from storage
my $storage = new RDF::Core::Storage::DB_File(Name =>'./rdfdata',
MemLimit => 500);
# objects must be defined
my $subject;
my $object;
# initiate predicate
my $predicate =
new RDF::Core::Resource('http://burningbird.net/postcon/elements/1.0/reason'),
# get count of statements for predicate and print
my $val = $storage->countStmts($subject, $predicate, $object);
print $val . "
";When run, the application returns a value of 6, matching the number of statements that have the given predicate. If you’re interested only in statements with a given predicate and subject, you could define the subject object in addition to the predicate:
my $subject = new RDF::Core::Resource("http://burningbird.net/articles/monsters4.htm");The value then returned is 1, for one record found matching that combination of subject and predicate.
Tip
You’ll also need to add in the RDF::Core::Literal class if you want to
match on the subject in this example.
If you’re interested in finding data to go with the count of
statements, you can modify the code to use the method getStmts instead, returning an enumerator,
which you can then traverse to get the data you’re interested
in.
The RDF::Core classes also
support a more sophisticated querying capability similar to RDQL
(discussed in detail in the next chapter). As with RDQL, the query
language supported with RDF::Core
supports select, from, and where keywords for the results, source, and
search parameters. Three objects process RDQL queries in RDF::Core:
- RDF::Core::Functions
A mapping between a row of data and a function handler
RDF::Core::EvaluatorAn evaluator object passed to the query to be used to evaluate the specific query
RDF::Core::QueryA query object
The RDF::Core::Functions
class contains a package of functions used to drill down to specific
schema elements within the query set. It’s instantiated first, taking
optional instances of the model being queried, an instance of the RDF
Schema model, and a factory object.
The RDF::Core::Evaluator
class is what evaluates a specific query, passed in as a string,
formed from RDQL. When it’s instantiated, it can take an instance of
the model being queried, the instance of the Functions class, as well
as the factory class and a hash containing namespaces and their
associated prefixes, or it can default for a default namespace. The
last option is a reference to a function defined in the code to be
called for each row returned in the query set. If this isn’t provided,
then the result is returned as an array of rows.
The RDF::Core::Query class
pulls the other objects and the query string together, returning an
array of rows (statements) matching the query or passing the row to a
function defined within the function object to process each row. The
documentation included with RDF::Core::Query provides a description of
the query language supported with RDF::Core including examples.
Tip
Another excellent Perl-based RDF API is RDFStore, written by Alberto Reggiori. This API is based on the Stanford Java API created by Sergey Melnik. Access it at http://rdfstore.sourceforge.net/.
RDF API for PHP
Few languages have achieved faster acceptance than PHP. ISPs now install support for PHP when they install Apache, so most people have access to this server-side tag-based scripting language. And where there’s scripting, there’s support for RDF. PHP boasts two RDF APIs: the RDF API for PHP and the RDF-specific classes within the PHP XML classes. The latter is covered in the next chapter; this chapter focuses on the RDF API for PHP, which I’ll refer to as RAP for brevity.
Tip
The RDF API for PHP (RAP) home page is at http://www.wiwiss.fu-berlin.de/suhl/bizer/rdfapi/. The SourceForge project for the API is at http://sourceforge.net/projects/rdfapi-php/.
Basic Building Blocks
The RAP classes are split into three main packages:
model, syntax, and util. The model package includes all the
classes to create or read specific elements of an RDF model, including
reading or creating complete statements from a model or their
individual components. These classes are:
-
BlankNode Used to create a blank node, to get the bnode identifier, or check equality between two bnodes
-
Literal Support for model literals
-
Model Contains methods to build or read a specific RDF model
-
Node An abstract RDF node
-
Resource Support for model resources
-
Statement Creating or manipulating a complete RDF triple
RAP doesn’t, at this time, support persistence to a database
such as MySQL or Berkeley DB, but you can serialize the data through
RdfSerializer, which
is one of the two syntax classes. To read a serialized model, you
would then use the other syntax class, RdfParser.
The util class Object is another
abstract class with some general methods overloaded in classes built
on it, so it’s of no interest for our purposes. However, the
RDFUtil class
provides some handy methods, including the method writeHTMLTable to output an RDF/XML document
in nice tabular form.
Building an RDF Model
Creating a new RDF model and adding statements to it using RAP is extremely easy. Start by creating a new RDF graph (data model) and then just add statements to it, creating new resources or literals as you go. The best way to see how to create a new graph is to look at a complete example of creating a model and then outputting the results to a page.
In the first example of this API, the path from the top-level
resource all the way through the first movement is created as a
subgraph of the larger monsters1.rdf model. Since
movements in this model are coordinated through an RDF container,
rdf:Seq, information related to the
container must also be added to ensure that the generated RDF/XML maps
correctly to the original RDF/XML of the full model. The N-Triples for
just this path, as generated by the RDF Validator, are:
<http://burningbird.net/articles/monsters1.htm> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://burningbird.net/postcon/ elements/1.0/Document> . <http://burningbird.net/articles/monsters1.htm> <http://burningbird.net/postcon/ elements/1.0/history> _:jARP31427 . _:jARP31427 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://www.w3.org/1999/02/22-rdf-syntax-ns#Seq> . _:jARP31427 <http://www.w3.org/1999/02/22-rdf-syntax-ns#_1> <http://www.yasd.com/ dynaearth/monsters1.htm> . <http://www.yasd.com/dynaearth/monsters1.htm> <http://burningbird.net/postcon/ elements/1.0/movementType> "Add" .
In the script, the first two lines map the RDF API directories and should reflect your own installation. This test script was built on a Linux box, which the path to the API reflects. Following the global directory definitions, a new model, as well as the top-level resource (since this will be used more than once in the page), is created. Added to the new model is a new statement consisting of the top-level resource as the subject, a new resource created for the predicate, and the object. In this case, the top-level resource is defined as a PostCon Document class.
Following the initial statement, a blank node is created to
represent the rdf:Seq object using
the label history, and a type
resource identifying it as rdf:Seq
is added to the model. The first of the movements is added using the
container element URI and giving as object the URI of the movement
object. In the last statement, the movementType property is added for this
resource, as shown in Example
9-5. To observe the resulting model, it’s serialized using the
RDFUtil::writeHTML class, to
generate a table of statements. And then the model is serialized to
RDF/XML, using the RDFSerializer
class.
<?php
define("RDFAPI_INCLUDE_DIR", "./../api/");
include(RDFAPI_INCLUDE_DIR . "RDFAPI.php");
// New Model, set base URI
$model = new Model( );
$model->setBaseURI("http://burningbird.net/articles/");
// first statement
$mainsource = new Resource("monsters1.htm");
$model->add(new Statement($mainsource, $RDF_type,
new
Resource("http://burningbird.net/postcon/elements/1.0/Document")));
$history = new BlankNode("history");
$model->add(new Statement($mainsource,
new
Resource("http://burningbird.net/postcon/elements/1.0/history"),
$history));
// Define RDF Bag
$model->add(new Statement($history, $RDF_type, $RDF_Seq));
$movement = new Resource("http://www.yasd.com/dynaearth/monsters1.htm");
$model->add(new Statement($history,
new Resource(RDF_NAMESPACE_URI . "_1"),
$movement));
$model->add(new Statement($movement,
new
Resource("http://burningbird.net/postcon/elements/1.0/movementType"),
new Literal("Add", "en")));
// Output as table
RDFUtil::writeHTMLTable($model);
file://Serialize and output model
$ser = new RDFSerializer( );
$ser->addNamespacePrefix("pstcn",
"http://burningbird.net/postcon/elements/1.0/");
$rdf =& $ser->serialize($model);
echo "<p><textarea cols='110' rows='20'>" . $rdf . "</textarea>";
file://Save the model to a file
$ser->saveAs($model,"rdf_output.rdf");
?>When this script is included within HTML and accessed via the Web, the result looks similar to Figure 9-1.
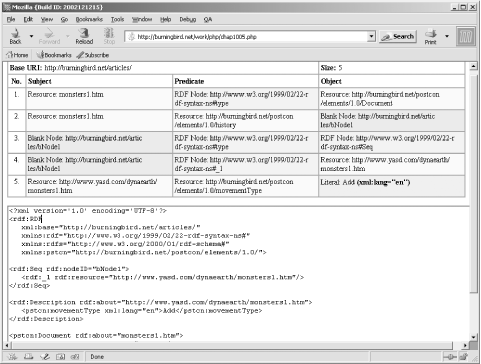
If you want to persist the serialized result of the model, use PHP’s own file I/O functions to save the generated RDF/XML to a file. Note that the figure shows bnodes as URI, which isn’t proper format. However, this is an internally generated value that has no impact on the validity of the RDF/XML.
Example 9-6 contains the script to open this serialized RDF/XML and iterate through it (this script was provided by the RAP creator, Chris Bizer).
<?php
// Include RDF API
define("RDFAPI_INCLUDE_DIR", "./../api/");
include(RDFAPI_INCLUDE_DIR . "RDFAPI.php");
// Create new Parser
$parser = new RdfParser( );
// Parse document
$model =& $parser->generateModel("rdf_output.rdf");
// Get StatementIterator
$it = $model->getStatementIterator( );
// Traverse model and output statements
while ($it->hasNext( )) {
$statement = $it->next( );
echo "Statement number: " . $it->getCurrentPosition( ) . "<BR>";
echo "Subject: " . $statement->getLabelSubject( ) . "<BR>";
echo "Predicate: " . $statement->getLabelPredicate( ) . "<BR>";
echo "Object: " . $statement->getLabelObject( ) . "<P>";
}
?>You can add or subtract statements on a given model, check to see if the model contains a specific statement, and even find the intersection or combination of multiple models, using the Model class. However, one of the most frequent activities you’ll likely do is query the model.
RDF and Python: RDFLib
It would be difficult not to see the natural fit between Python and RDF. Of course, Python programmers would say the same happens with all uses of Python, but when you see how quick and simple it is to build an RDF/XML model from scratch using the Python RDF library, RDFLib, you might think about switching regardless of what language you normally use.
Tip
RDFLib was created by Daniel Krech. Download the most recent release of RDFLib at http://rdflib.net. I used RDFLib 1.2.3 on Windows 2000 when writing this section. RDFLib requires Python 2.2.1 or later. Additional software is required if you want to use the rdflib.Z informationStore, providing support for contexts in addition to persistent triples.
RDFLib is actually a part of a larger application framework, Redfoot, discussed in Chapter 12. However, RDFLib is a separate, fully RDF functional API. If there’s any additional need with the API, it’s documentation, which is quite scarce for the product. However, the libraries are so intuitive, one could almost say that the documentation isn’t needed.
All the unique components of an RDF model have been defined as Python objects in RDFLib:
In addition, RDFLib.constants
contains definitions for the RDF properties such as type and
value.
Example 9-7 implements a subgraph of the test RDF/XML document (monsters1.rdf) defined in the following snippet of XML:
<pstcn:Resource rdf:about="monsters1.htm">
<pstcn:presentation rdf:parseType="Resource">
<pstcn:requires rdf:parseType="Resource">
<pstcn:type>stylesheet</pstcn:type>
<rdf:value>http://burningbird.net/de.css</rdf:value>
</pstcn:requires>
</pstcn:presentation>
</pstcn:Resource>To begin, a Namespace object is
created for the PostCon namespace, in addition to a TripleStore used for the model in progress.
Following this, the top-level resource is created using URIRef, which is then added as a triple with
the RDF type and the PostCon Document
type. After that, it’s just a matter of creating the appropriate type of
object and adding more triples. Note that Namespace manages the namespace annotations
for all of the objects requiring one, such as all of the predicates. At
the end, the triples are printed out to standard output, and the model
is serialized to RDF/XML.
from rdflib.URIRef import URIRef
from rdflib.Literal import Literal
from rdflib.BNode import BNode
from rdflib.Namespace import Namespace
from rdflib.constants import TYPE, VALUE
# Import RDFLib's default TripleStore implementation
from rdflib.TripleStore import TripleStore
# Create a namespace object
POSTCON = Namespace("http://burningbird.net/postcon/elements/1.0/")
store = TripleStore( )
store.prefix_mapping("pstcn", "http://http://burningbird.net/postcon/elements/1.0/")
# Create top-level resource
monsters = URIRef(POSTCON["monsters1.htm"])
# Add type statement
store.add((monsters, TYPE, POSTCON["Document"]))
# Create bnode and add as statement
presentation = BNode( );
store.add((monsters, POSTCON["presentation"],presentation))
# Create second bnode, add
requires = BNode( );
store.add((presentation, POSTCON["requires"], requires))
# add two end nodes
type = Literal("stylesheet")
store.add((requires, POSTCON["type"],type))
value = Literal("http://burningbird.net/de.css")
store.add((requires, VALUE, value))
# Iterate over triples in store and print them out
for s, p, o in store:
print s, p, o
# Serialize the store as RDF/XML to the file subgraph.rdf
store.save("subgraph.rdf")Just this small sample demonstrates how simple RDFLib is to use. The generated RDF/XML looks similar to the following, indentation and all, which is a nice little feature of the library.
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:n4="http://burningbird.net/postcon/elements/1.0/"
xmlns:pstcn="http://http://burningbird.net/postcon/elements/1.0/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
>
<n4:Document rdf:about="http://burningbird.net/postcon/elements/1.0/monsters1.htm">
<n4:presentation>
<rdf:Description>
<n4:requires>
<rdf:Description>
<n4:type>stylesheet</n4:type>
<rdf:value>http://burningbird.net/de.css</rdf:value>
</rdf:Description>
</n4:requires>
</rdf:Description>
</n4:presentation>
</n4:Document>
</rdf:RDF>Testing this in the RDF Validator results in a directed graph equivalent to the subgraph found in the larger model, and equivalent to the graph generated earlier in the chapter with the Perl modules.
You can also load an existing RDF/XML document into a TripleStore and then run queries against the
triples. Example 9-8 contains
a small Python application that loads monsters1.rdf
into a TripleStore and then looks for
all subjects of class Movement. These are passed into an inner loop and
used to look up the movement type for each Movement.
from rdflib.Namespace import Namespace
from rdflib.constants import TYPE
# Import RDFLib's default TripleStore implementation
from rdflib.TripleStore import TripleStore
# Create a namespace object
POSTCON = Namespace("http://burningbird.net/postcon/elements/1.0/")
DC = Namespace("http://purl.org/dc/elements/1.1/")
store = TripleStore( )
store.load("http://burningbird.net/articles/monsters1.rdf");
# For each pstcn:Movement print out movementType
for movement in store.subjects(TYPE, POSTCON["Movement"]):
for movementType in store.objects(movement, POSTCON["movementType"]):
print "Moved To: %s Reason: %s" % (movement, movementType)This application prints out the movement resource objects as well as the movement types:
Moved To: http://burningbird.net/burningbird.net/articles/monsters1.htm Reason: Move Moved To: http://www.yasd.com/dynaearth/monsters1.htm Reason: Add Moved To: http://www.dynamicearth.com/articles/monsters1.htm Reason: Move
The TripleStore document
triple_store.html in the RDFLib documentation
describes the TripleStore.triples
method and the variations on it that you can use for queries. The method
used differs but the basic functionality remains the same as that just
demonstrated.
Tip
Another open source and Python-based RDF API is 4RDF and its Versa query language, a product of Fourthought. 4RDF is part of 4Suite, a set of tools for working with XML, XSLT, and RDF. More information is available at http://fourthought.com.