
Chapter 3. The Basic Elements Within the RDF/XML Syntax
The usability of RDF is heavily dependent on the portability of the data defined in the RDF models and its ability to be interchanged with other data. Unfortunately, recording the RDF data in a graph—the default RDF documentation format—is not the most efficient means of storing or retrieving this data. Instead, transporting RDF data, a process known as serialization, usually occurs with RDF/XML.
Originally, the RDF model and the RDF/XML syntax were incorporated into one document, the Resource Description Framework (RDF) Model and Syntax Specification. However, when the document was updated, the RDF model was separated from the document detailing the RDF/XML syntax. Chapter 2 covered the RDF abstract model, graph, and semantics; this chapter provides a general introduction to the RDF/XML model and syntax (RDF M&S).
Tip
The original RDF M&S Specification can be found at http://www.w3.org/TR/REC-rdf-syntax/. The updated RDF/XML Syntax Specification (revised) can be found at http://www.w3.org/TR/rdf-syntax-grammar/.
Some RDF-specific aspects of RDF/XML at first make it seem overly complex when compared to non-RDF XML. However, keep in mind that RDF/XML is nothing more than well-formed XML, with an overlay of additional constraints that allow for easier interchange, collection, and mergence of data from multiple models. In most implementations, RDF/XML is parsable with straight XML technology and can be manipulated manually if you so choose. It’s only when the interchangeability of the data is important and the data can be represented only by more complex data structures and relationships that the more formalized elements of RDF become necessary. And in those circumstances, you’ll be glad that you have the extra capability.
Tip
All examples listed in the chapter are validated using the W3C’s RDF Validator, located at http://www.w3.org/RDF/Validator/.
Serializing RDF to XML
Serialization converts an object into a persistent form. The RDF/XML syntax provides a means of documenting an RDF model in a text-based format, literally serializing the model using XML. This means that the content must both meet all requirements for well-formed XML and the additional constraints of RDF. However, before showing you some of these constraints, let’s walk through an example of using RDF/XML.
Warning
RDF doesn’t require XML-style validity, just well-formedness. RDF/XML parsers and validators do not use DTDs or XML Schemas to ensure that the XML used is valid. Norman Walsh wrote a short article for xml.com on what it means for an XML document to be well formed and/or valid; it explains the two concepts in more detail. See it at http://www.xml.com/pub/a/98/10/guide3.html.
In Chapter 2, I discussed an article I wrote on the giant squid. Now, consider attaching context to it. Among the information that could be exposed about the article is that it explores the idea of the giant squid as a legendary creature from myths and lore; it discusses the current search efforts for the giant squid; and it provides physical characteristics of the creature. Putting this information into a paragraph results in the following:
The article on giant squids, titled "Architeuthis Dux," at http://burningbird.net/articles/monsters3.htm, written by Shelley Powers, explores the giant's squid's mythological representation as the legendary Kraken as well as describing current efforts to capture images of a live specimen. In addition, the article also provides descriptions of a giant squid's physical characteristics. It is part of a four-part series, described at http://burningbird.net/articles/monsters.htm and entitled "A Tale of Two Monsters."
Reinterpreting this information into a set of statements, each with a specific predicate (property or fact) and its associated value, I come up with the following list:
The article is uniquely identified by its URI,
http://burningbird.net/articles/monsters3.htm.The article was written by Shelley Powers—predicate is written by, value is Shelley Powers.
The article’s title is “Architeuthis Dux”—predicate is title, value is Architeuthis Dux.
The article is one of a four-part series—predicate is series member, value is http://burningbird.net/articles/monsters.htm.
The series is titled “A Tale of Two Monsters”—series predicate is title, value is A Tale of Two Monsters.
The article associates the giant squid with the legendary Kraken—predicate is associates, value is Kraken and giant squid.
The article provides physical descriptions of the giant squid—predicate is provides, value is physical description of giant squid.
Tip
Y ou’ll notice in this chapter and elsewhere in the book that I tend to use RDF statement and RDF triple seemingly interchangeably. However, I primarily use RDF statement when referring to the particular fact being asserted by an RDF triple and use RDF triple when referring to the actual, physical instantiation of the statement in RDF triple format.
Starting small, we’ll take a look at mapping the article and the author and title, only, into RDF. Example 3-1 shows this RDF mapping, wrapped completely within an XML document.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/">
<rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm">
<pstcn:author>Shelley Powers</pstcn:author>
<pstcn:title>Architeuthis Dux</pstcn:title>
</rdf:Description>
</rdf:RDF>Tracing the XML from the top, the first line is the traditional
XML declaration line. Following it is the RDF element, rdf:RDF, used to enclose the RDF-based
content.
Tip
If the fact that the content is RDF can be determined from the context of the XML, the containing RDF element isn’t necessary and can be omitted. In addition, the RDF content can be embedded within another document, such as an XML or HTML document, as will be discussed later in Section 3.8.
Contained as attributes within the RDF element is a listing of the
namespaces that identify the vocabulary for each RDF element. The first,
with an rdf prefix, is the namespace
for the RDF syntax; the second, with a prefix of pstcn, identifies elements I’ve created for
the example RDF in this book. The namespace references an existing
schema definition (see more on RDF Schemas in Chapter 5), but the schema itself doesn’t
have to exist on the Web, because it’s not used for validation. However,
as you will see in Chapter 5, there
is good reason to physically create the RDF Schema document in the
location given in the namespace URI.
In the example, after the enclosing rdf:RDF element is the RDF Description. An RDF Description begins with
the opening RDF Description tag, rdf:Description, which in this case includes
an attribute ( rdf:about) used to
identify the resource (the subject). The resource used within the
specific element could be an identifier to a resource defined elsewhere
in the document or the URI for the subject itself. In the example, the
resource identifier is the URI for the giant squid article page.
The RDF Description wraps one or more resource predicate/object pairs. The predicate objects (the values) can be either literals or references to another resource. Regardless of object type, each RDF statement is a complete triple consisting of subject-predicate-object. Figure 3-1 shows the relationship between the RDF syntax and the RDF trio from the example.
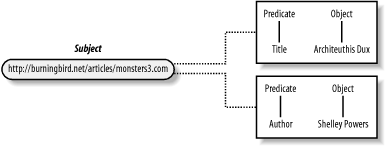
As you can see, a complete RDF statement consists of the resource, a predicate, and its value. In addition, as the figure shows, resources can be described by more than one property (in RDF parlance, the subject can participate in more than one RDF statement within the document).
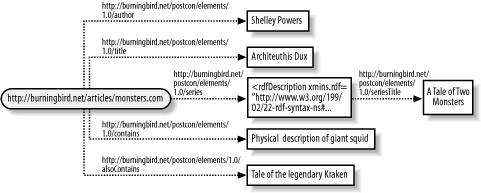
Running Example 3-1 through the RDF Validator results in a listing of N-Triples in the form of subject, predicate, and object:
<http://dynamicearth.com/articles/monsters3.htm>
<http://burningbird.net/postcon/elements/1.0/author> "Shelley Powers" .
<http://dynamicearth.com/articles/monsters3.htm>
<http://burningbird.net/postcon/elements/1.0/title> "Architeuthis Dux" .The N-Triples representation of each RDF statement shows the formal identification of each predicate, as it would be identified within the namespace schema.
The validator also provides a graphic representation of the statement as shown in Figure 3-2. As you can see, the representation matches that shown in Figure 3-1—offering validation that the model syntax used does provide a correct representation of the statements being modeled.

In Example 3-1,
the objects are literal values. However, there is another resource
described in the original paragraph in addition to the article itself:
the series the article is a part of, represented with the URI http://burningbird.net/articles/monsters.htm.
The series then becomes a new resource in the model but is still
referenced as a property within the original article description.
To demonstrate this, in Example 3-2 the RDF has been expanded to include the information about the series, as well as to include the additional article predicate/object pairs. The modifications to the original RDF/XML are boldfaced.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/">
<rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm">
<pstcn:author>Shelley Powers</pstcn:author>
<pstcn:title>Architeuthis Dux</pstcn:title>
<pstcn:series rdf:resource="http://burningbird.net/articles/monsters.htm" />
<pstcn:contains>Physical description of giant squids</pstcn:contains>
<pstcn:alsoContains>Tale of the Legendary Kraken</pstcn:alsoContains>
</rdf:Description>
<rdf:Description rdf:about="http://burningbird.net/articles/monsters.htm">
<pstcn:seriesTitle>A Tale of Two Monsters</pstcn:seriesTitle>
</rdf:Description>
</rdf:RDF>The rdf:resource attribute
within the pstcn:series predicate
references a resource object, in this case one that’s defined later in
the document and which has a predicate of its own, pstcn:seriesTitle. Though the statements for
the linked resource are separate from the enclosed statements in the
original resource within the RDF/XML, the RDF graph that’s generated in
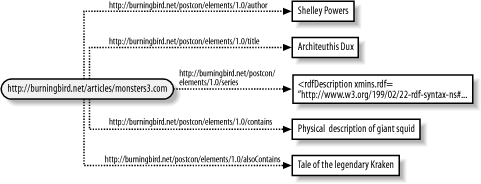
Figure 3-3 shows the linkage
between the two.
The linked resource could be nested directly within the original
resource by enclosing it within the original resource’s rdf:Description element, in effect nesting it
within the original resource description. Example 3-3 shows the syntax for the
example after this modification has been applied. As you can see with
this XML, the second resource being referenced within the original is
more apparent using this approach, though the two result in equivalent
RDF models.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/">
<rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm">
<pstcn:author>Shelley Powers</pstcn:author>
<pstcn:title>Architeuthis Dux</pstcn:title>
<pstcn:series>
<rdf:Description rdf:about=
"http://burningbird.net/articles/monsters.htm">
<pstcn:SeriesTitle>A Tale of Two Monsters</pstcn:SeriesTitle>
</rdf:Description>
</pstcn:series>
<pstcn:contains>Physical description of giant squids</pstcn:contains>
<pstcn:alsoContains>Tale of the Legendary Kraken</pstcn:alsoContains>
</rdf:Description>
</rdf:RDF>Though nesting one resource description in another shows the connection between the two more clearly, I prefer keeping them apart—it allows for cleaner RDF documents in my opinion. If nesting becomes fairly extreme—a resource is an object of another resource, which is an object of another resource, and so on—trying to represent all of the resources in a nested manner soon becomes unreadable (though automated processes have no problems with it).
Example 3-3 demonstrates a fundamental behavior with RDF/XML: subjects and predicates occur in layers, with subjects separated from other subjects by predicates and predicates separated from other predicates by subjects. Subjects are never nested directly within subjects, and predicates are never nested directly within predicates. This RDF/XML striping is discussed next.
Striped Syntax
In a document titled “RDF: Understanding the Striped RDF/XML Syntax” (found at http://www.w3.org/2001/10/stripes/), the author, Dan Brickley, talks about a specific pattern of node-edge-node that forms a striping pattern within RDF/XML. This concept has been included in the newer Syntax document as a method of making RDF/XML a little easier to read and understand.
If you look at Figure
3-3, you can see this in the thread that extends from the
subject (http://burningbird.net/articles/monsters3.htm)
to the predicate (pstcn:series) to
the object, which is also a resource (http://burningbird.net/articles/monsters.htm)
to another predicate (pstcn:seriesTitle) to another object, a
literal in this case (A Tale of Two
Monsters). In this thread, no two predicates are nested
directly within each other. Additionally, all nodes (subject or
object) are separated by an arc—a predicate—providing a
node-arc-node-arc-node... pattern.
Within RDF/XML this becomes particularly apparent when you highlight the predicates and their associated objects within the XML. Example 3-3 is replicated in Example 3-4, except this time the predicate/objects are boldfaced to make them stand out.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/">
<rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm">
<pstcn:author>Shelley Powers</pstcn:author>
<pstcn:title>Architeuthis Dux</pstcn:title>
<pstcn:series>
<rdf:Description rdf:about=
"http://dynamicearth.com/articles/monsters.htm">
<pstcn:seriesTitle>A Tale of Two Monsters</pstcn:seriesTitle>
</rdf:Description>
</pstcn:series>
<pstcn:contains>Physical description of giant squids</pstcn:contains>
<pstcn:alsoContains>Tale of the Legendary Kraken</pstcn:alsoContains>
</rdf:Description>
</rdf:RDF>Viewed in this manner, you can see the striping effect, whereby each predicate is separated by a resource, each resource by a predicate. This maps to the node-arc-node pattern established in the abstract RDF model based on directed graphs. This visualization clue can help you read RDF/XML more easily and allow you to differentiate between predicates and resources.
Tip
Another convention, though it isn’t a requirement
within the RDF specifications, is that all predicates (properties)
start with lowercase (such as title, author, and alsoContains), and all classes start with
an uppercase. However, in the examples just shown, other than the
classes defined within the RDF Schema (such as Description), there is no
implementation-specific class. Most of the XML elements present are
RDF/XML properties. Later we’ll see how to formally specify the
PostCon classes within the RDF/XML.
Predicates
As you’ve seen in the examples, a predicate value
(object) can be either a resource or a literal. If the object is a resource, an oval is drawn around it; otherwise, a rectangle is drawn. RDF parsers (and the RDF Validator)
know which is which by the context of the object itself. However,
there is a way that you can specifically mark the type of
property—using the rdf:parseType
attribute.
By default, all literals are plain literals and can be strings,
integers, and so on. Their format would be the string value plus an
optional xml:language. However, you
can also embed XML within an RDF document by using the rdf:parseType
attribute set to a value of "Literal". For instance, Example 3-5 shows the RDF/XML from
Example 3-4, but in this
case the pstcn:alsoContains
predicate has an XML-formatted value.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/">
<rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm">
<pstcn:author>Shelley Powers</pstcn:author>
<pstcn:title>Architeuthis Dux</pstcn:title>
<pstcn:series>
<rdf:Description rdf:about=
"http://dynamicearth.com/articles/monsters.htm">
<pstcn:seriesTitle>A Tale of Two Monsters</pstcn:seriesTitle>
</rdf:Description>
</pstcn:series>
<pstcn:contains>Physical description of giant squids</pstcn:contains>
<pstcn:alsoContains rdf:parseType="Literal">
<h1>Tale of the Legendary Kraken
</h1></pstcn:alsoContains>
</rdf:Description>
</rdf:RDF>Without the rdf:parseType="Literal" attribute, the
RDF/XML wouldn’t be valid. Running the text through the RDF Validator
results in the following error:
Error: {E202} Expected whitespace found: 'Tale of the Legendary Kraken'.[Line = 17, Column = 69Specifically, rdf:parseType="Literal" is a way of
embedding XML directly into an RDF/XML document. When used, RDF
processors won’t try to parse the element for additional RDF/XML when
it sees the XML tags. If you used rdf:parseType="Literal" with series, itself, the RDF parser would place
the literal value of the rdf:Description block within a rectangle,
rather than parse it out. You’d get a model similar to that shown in
Figure 3-4
Another rdf:parseType
option, "Resource", identifies the
element as a resource without having to use rdf:about or rdf:ID. In other words, the surrounding
rdf:Description tags would not be
necessary:
<rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm">
<pstcn:series rdf:parseType="Resource">
<pstcn:seriesTitle>A Tale of Two Monsters</pstcn:seriesTitle>
</pstcn:series>
...
</rdf:Description>The RDF/XML validates, and the RDF Validator creates an oval for
the property. However, it would add a generated identifier in the
oval, because the resource is a blank node. There is no place to add a
URI for the object in the bubble, because there is no resource
identifier for the series property. You can list the seriesTitle directly within the series
property, and the property would be attached to it in the RDF graph.
But there would be no way to attach a URI to the resource—it would
remain as a blank node.
The rdf:parseType property
can be used to mark a property as "Resource", even if there is no property
value given yet. For instance, in Example 3-6, the property is
marked as "Resource", but no value
is given.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/">
<rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm">
<pstcn:author rdf:parseType="Resource" />
</rdf:Description>
</rdf:RDF>This approach can be used to signify that the object value isn’t known but is nonetheless a valid property. Within the RDF directed graph resulting from this RDF/XML, an oval with a generated identifier is drawn to represent the object , as shown in Figure 3-5.
Namespaces and QNames
An important goal of RDF is to record knowledge in machine-understandable format and then provide mechanisms to facilitate the combination of the data. By allowing combinations of multiple models, additions can be incorporated without necessarily impacting an existing RDF Schema. To ensure that RDF/XML data from different documents and different specifications can be successfully merged, namespace support has been added to the specification to prevent element collision. (Element collision occurs when an element with the same name is identified in two different schemas used within the same document.)
Tip
Read more on XML namespaces in the document “Namespaces in XML” at http://www.w3.org/TR/1999/REC-xml-names-19990114/. You may also want to explore the commentary provided in “XML Namespace Myths Exploded,” available at http://www.xml.com/pub/a/2000/03/08/namespaces/index.html.
To add namespace support to an RDF/XML document, a namespace attribute can be added anywhere in the document; it is usually added to the RDF tag itself, if one is used. An example of this would be:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/">
In this XML, two namespaces are declared—the RDF/XML syntax namespace (a requirement) and the namespace for the PostCon vocabulary. The format of namespace declarations in RDF/XML usually uses the following format:
xmlns:name="URI of schema"The name doesn’t have to be provided if the namespace is assumed to be the default (no prefix is used) within the document:
xmlns="URI of schema"The namespace declaration for RDF vocabularies usually points to the URI of the RDF Schema document for the vocabulary. Though there is no formalized checking of this document involved in RDF/XML—it’s not a DTD—the document should exist as documentation for the schema. In particular, as we’ll see in later chapters, this schema is accessed directly by tools and utilities used to explore and view RDF/XML documents.
An element that has been known to generate a great deal of
conversation within the RDF/XML and XML community is the QName—a namespace
prefix followed by a colon (:)
followed by an XML local name. In the examples shown so far, all
element and attribute names have been identified using the QName, a
requirement within RDF/XML. An example use of a QName is:
<rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm">
<pstcn:author rdf:parseType="Literal" />
</rdf:Description>In this example, the QName for the RDF Description class and the
about and rdf:parseType attributes is rdf, a prefix for the RDF syntax URI, given
earlier. The QName for the author element is pstcn, the PostCon URI prefix.
The actual prefix used, such as rdf and pstcn, can vary between documents, primarily
because automated processes replace the prefix with the full namespace
URI when processing the RDF data. However, by convention, the creators
of a vocabulary usually set the particular prefix used, and users of
the vocabulary are encouraged to use the same prefix for consistency.
This makes the RDF/XML documents easier for humans to read.
In particular, the prefix for the RDF Syntax Schema is usually
given as rdf, the RDF Schema is
given as rdfs, and the Dublin Core
schema (described in Chapter 6)
is usually abbreviated as dc. And
of course, PostCon is given as pstcn.
Earlier I mentioned that the QName is controversial. The reason is twofold:
First, the RDF specification requires that all element and
attribute types in RDF/XML must be QNames. Though the reason for this
is straightforward—allowing multiple schemas in the same document—the
rule was not established with the very first releases of RDF/XML, and
there is RDF/XML in use today, such as in Mozilla, (described in Chapter 14), in which attributes such
as about are not decorated with the
namespace prefix.
In order to ensure that these pre-existing applications don’t break, the RDF Working Group has allowed some attributes to be non-namespace annotated. These attributes are:
IDbagID(removed from the specification based on last call comments)aboutresourceparseTypetype
When encountered, RDF/XML processors are required to expand these attributes by concatenating the RDF namespace to the attribute. Though these nonannotated attributes are allowed for backward compatibility, the WG (and yours truly) strongly recommend that you use QNames with your attributes. In fact, RDF/XML parsers may give a warning (but not an error) when these are used in a document. The only reason I include these nonannotated attributes in the book is so that you’ll understand why these still validate when you come upon them in older uses of RDF/XML.
Another controversy surrounding QNames is their use as attribute
values: specifically, using them as values for rdf:about or rdf:type. Example 3-7 shows an earlier
version of the RDF/XML vocabulary used for demonstrations throughout
the book and uses a QName for a attribute value. QName formatting is
boldfaced in the example.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:bbd="http://www.burningbird.net/schema#">
<rdf:Description rdf:about="http://www.burningbird.net/identifier/tutorials/xul.htm">
<bbd:bio rdf:resource="bbd:bio"/>
<bbd:relevancy rdf:resource="bbd:relevancy" />
</rdf:Description>
<rdf:Description rdf:about="bbd:bio">
<bbd:Title>YASD Does Mozilla/Navigator 6.0</bbd:Title>
<bbd:Description>Demonstrations of using XUL for interface development
</bbd:Description>
<bbd:CreationDate>May 2000</bbd:CreationDate>
<bbd:ContentAuthor>Shelley Powers</bbd:ContentAuthor>
<bbd:ContentOwner>Shelley Powers</bbd:ContentOwner>
<bbd:CurrentLocation>N/A</bbd:CurrentLocation>
</rdf:Description>
<rdf:Description rdf:about="bbd:relevancy">
<bbd:CurrentStatus>Inactive</bbd:CurrentStatus>
<bbd:RelevancyExpiration>N/A</bbd:RelevancyExpiration>
<bbd:Dependencies>None</bbd:Dependencies>
</rdf:Description>
</rdf:RDF>Running this example through the RDF Validator results in a perfectly good RDF graph and no errors or warnings. Many tools also have no problems with the odd use of QName. Apply this practice in your RDF/XML vocabulary, though, and you’ll receive howls from the RDF community—this is a bad use of QNames, though not necessarily a specifically stated invalid use of them. The relationship between QNames and URIs is still not completely certain.
RDF Blank Nodes
It would be easy to extrapolate a lot of meaning about blank nodes but, bottom line, a blank node represents a resource that isn’t currently identified. As with the infamous null value from the relational data model, there could be two reasons why the identifying URI is absent: either the value will never exist (isn’t meaningful) or the value could exist but doesn’t at the moment (currently missing).
Most commonly, a blank node—known as a bnode, or occasionally anonymous node—is used when a resource URI isn’t meaningful. An example of this could be a representation of a specific individual (since most of us don’t think of humans with URIs).
In RDF/XML, a blank node is represented by an oval (it is a resource), with either no value in the oval or a computer-generated identifier. The RDF/XML Validator generates an identifier, which it uses within the blank node to distinguish it from other blank nodes within the graph. Most tools generate an identifier for blank nodes to differentiate them.
In Example 3-8, bio attributes are grouped within an enclosing
PostCon bio resource. Since the bio
doesn’t have its own URI, a blank node represents it within the
model.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"
xml:base="http://burningbird.net/articles/">
<rdf:Description rdf:about="monsters1.htm">
<pstcn:bio>
<rdf:Description>
<pstcn:title>Tale of Two Monsters: Legends</pstcn:title>
<pstcn:description>
Part 1 of four-part series on cryptozoology, legends,
Nessie the Loch Ness Monster and the giant squid.
</pstcn:description>
<pstcn:created>1999-08-01T00:00:00-06:00</pstcn:created>
<pstcn:creator>Shelley Powers</pstcn:creator>
</rdf:Description>
</pstcn:bio>
</rdf:Description>
</rdf:RDF>Running this example through the RDF Validator gives the directed graph shown in Figure 3-6 (modified to fit within the page).
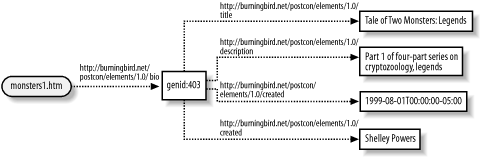
As you can see in the graph, the RDF Validator has
generated a node identifier for the blank node, genid:403. This identifier has no meaning
other than being a way to differentiate this blank node from other blank
nodes, within the graph and within the generated N-Triples.
Tip
Example 3-8 also uses
xml:base to establish a base URI
for the other URIs in the document, avoiding a lot of repetition. This
technique is described in more detail in Section 3.3.
Instead of letting the tools provide a blank node identifier, you
can provide one yourself. This is particularly useful if you want to
reference a resource that’s not nested within the outlying element but
occurs elsewhere in the page as a separate RDF/XML triple. The rdf:nodeID is used to provide a specific
identifier, as demonstrated in Example 3-9, when the embedded
bio is pulled out into a separate
triple. The rdf:nodeID attribute
is used within the predicate of the original triple, as well as within
the description of the newly created triple, as noted in bold
type.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"
xml:base="http://burningbird.net/articles/">
<rdf:Description rdf:about="monsters1.htm">
<pstcn:bio rdf:nodeID="monsters1">
</pstcn:bio>
</rdf:Description>
<rdf:Description rdf:nodeID="monsters1">
<pstcn:title>Tale of Two Monsters: Legends</pstcn:title>
<pstcn:description>
Part 1 of four-part series on cryptozoology, legends,
Nessie the Loch Ness Monster and the giant squid.
</pstcn:description>
<pstcn:created>1999-08-01T00:00:00-06:00</pstcn:created>
<pstcn:creator>Shelley Powers</pstcn:creator>
</rdf:Description>
</rdf:RDF>The rdf:nodeID is unique to the
document but not necessarily to all RDF/XML documents. When multiple RDF
models are combined, the tools used could redefine the identifier in
order to ensure that it is unique. The rdf:nodeID is not a way
to provide a global identifier for a resource in order to process it
mechanically when multiple models are combined. If you need this type of
functionality, you’re going to want to give the resource a formal URI,
even if it is only a placeholder URI until a proper one can be
defined.
URI References
All predicates within RDF/XML are given as URIs, and most resources—other than those that are treated as blank nodes—are also given URIs. A basic grounding of URIs was given in Chapter 2, but this section takes a look at how URIs are used within the RDF/XML syntax.
Resolving Relative URIs and xml:base
Not all URI references in a document are full URIs. It’s not
uncommon for relative URI references to be given, which then need to
be resolved to a base URI location. In the previous examples, the full
resource URI is given within the rdf:about attribute. Instead of using the full URI, the example
could be a relative URI reference, which resolves to the base document concatenated with the relative URI
reference. In the following, the relative URI reference "#somevalue.htm":
<rdf:Description rdf:about="#somevalue">
then becomes http://burningbird.net/articles/somedoc.htm#somevalue
if the containing document is http://burningbird.net/articles/somedoc.htm.
To resolve correctly, the relative URI reference must be given with
the format of pound sign (#)
followed by the reference ("#somevalue").
Normally, when a full URI is not provided for a specific
resource, the owning document’s URL is considered the base document
for forming full URIs given relative URI references. So if the
document is http://burningbird.net/somedoc.htm, the URI
base is considered to be this document, and changes of the document
name or URL change the URI for the resource.
With xml:base, you can
specify a base document that’s used to generate full URIs when given
relative URI references, regardless of the URL of the owning document.
This means that your URIs can be consistent regardless of document
renaming and movement.
The xml:base attribute
is added to the RDF/XML document, usually in the same element tag
where you list your namespaces (though it can be placed anywhere).
Redefining Example 3-6 with
xml:base and using a relative URI
reference would give you the RDF/XML shown in Example 3-10.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/
xml:base="http://burningbird.net/articles/">
<rdf:Description rdf:about="monsters3.htm">
<pstcn:author rdf:parseType="Literal" />
</rdf:Description>
</rdf:RDF>The URI for the article, given as relative "monsters3.htm", is correctly expanded to
the proper full URI of http://burningbird.net/articles/monsters3.htm.
Resolving References with rdf:ID
In the previous example, the rdf:about attribute was used to provide the
URI reference. Other ways of providing a URI for a resource are to use
the rdf:resource, rdf:ID, or rdf:bagID
attributes. The rdf:bagID attribute
is discussed in the next chapter, but we’ll take a quick look at
rdf:ID and rdf:resource.
Unlike the rdf:about
attribute, which refers to an existing resource, rdf:ID generates a URI by concatenating the
URI of the enclosing document (or the one provided by xml:base) to the identifier given, preceded
by the relative URI # symbol.
Rewriting Example 3-5 to use
rdf:ID for the second resource
results in the RDF/XML shown in Example 3-11.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/">
<rdf:Description rdf:ID="monsters3.htm">
<pstcn:author>Shelley Powers</pstcn:author>
<pstcn:title>Architeuthis Dux</pstcn:title>
<pstcn:series>
<rdf:Description rdf:ID="monsters.htm">
<pstcn:seriesTitle>A Tale of Two Monsters
</pstcn:seriesTitle>
</rdf:Description>
</pstcn:series>
<pstcn:contains>Physical description of giant squids</pstcn:contains>
<pstcn:alsoContains>Tale of the Legendary Kraken
</pstcn:alsoContains>
</rdf:Description>
</rdf:RDF>The generated RDF graph would show a resource giving the URI of
the enclosing document, a pound sign (#), and the ID. In this case, if the
enclosing document was at
http://burningbird.net/index.htm, it would show a
URI of http://burningbird.net/index.htm#monsters3.htm.
This same effect can be given with the rdf:about by using a URI of "#monsters".
As you can see, the URI of the resolved relative URI reference
doesn’t match that given previously: http://burningbird.net/index.htm#monsters3.htm
does not match http://burningbird.net/articles/monsters3.htm.
Based on this, I never use rdf:ID
for actual resources; I tend to use it when I’m defining a resource
that usually wouldn’t have an actual URI but would have one primarily
to support the required node-arc-node-arc-node nature of
RDF/XML.
For example, the pstcn:series
attribute given to the http://burningbird.net/articles/monsters.htm
URI really doesn’t exist—it’s a way of showing a relationship between
the article and a particular series, which has properties in its own
right though it does not actually exist as a single object. Instead of
using the full URI, what I could have done is use ID, as shown in Example 3-12.
<?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"xml:base="http://burningbird.net/articles/"><rdf:Description rdf:about="monsters3.htm"> <pstcn:author>Shelley Powers</pstcn:author> <pstcn:title>Architeuthis Dux</pstcn:title> <pstcn:series> <rdf:Description rdf:ID="monsters"> <pstcn:seriesTitle>A Tale of Two Monsters </pstcn:seriesTitle></rdf:Description></pstcn:series> <pstcn:contains>Physical description of giant squids</pstcn:contains> <pstcn:alsoContains>Tale of the Legendary Kraken </pstcn:alsoContains> </rdf:Description> </rdf:RDF>
The relative URI then resolves to http://burningbird.net/articles/#monsters,
forming a representation of the URI as an identifier rather than an
actual URL (a misunderstanding that can occur with URI references,
since not all URIs are URLs). The rdf:ID is considered to have reified the
statement (i.e., formally identified the statement within the model).
The discussion about reification is continued in Chapter 4.
Representing Structured Data with rdf:value
Not all data relations in RDF represent straight binary connections between resource and object value. Some data values, such as measurement, have both a value and additional information that determines how you treat that value. In the following RDF/XML:
<pstcn:lastEdited>18</pstcn:lastEdited>
the statement is ambiguous because we don’t know exactly what
18 means. Is it 18 days? Months?
Hours? Did a person identified by the number 18 edit it?
To represent more structured data, you can include the additional information directly in the value:
<pstcn:lastEdited>18 days</pstcn:lastEdit>
However, this type of intelligent data then requires that systems know enough to split the value from its qualifier, and this goes beyond what should be required of RDF parsers and processors. Instead, you could define a second vocabulary element to capture the qualifier, such as:
<pstcn:lastEdited>18</pstcn:lastEdited> <pstcn:lastEditedUnit>day</pstcn:lastEditedUnit>
This works, but unfortunately, there is a disconnect between the
value and the unit because the two are only indirectly related based on
their relationship with the resource. So the syntax is then refined,
which is where rdf:value enters the
picture. When dealing with structured data, the rdf:value predicate includes the actual value
of the structure—it provides a signal to the processor that the data
itself is included in this field, and all other members of the structure
are qualifiers and additional information about the structure.
Redefining the data would then result in:
<pstcn:lastEdited rdf:parseType="Resource">
<rdf:value>18</rdf:value>
<pstcn:lastEditedUnit>day</pstcn:lastEditedUnit>
</pstcn:lastEdited>Now, not only do we know that we’re dealing with structured data,
we know what the actual value, the kernel of the data so to speak, is by
the use of rdf:value. You could use
your own predicate, but rdf:value is
global in scope—it crosses all RDF vocabularies—making its use much more
attractive if you’re concerned about combining your vocabulary data with
other data.
The rdf:type Property
One general piece of information that is consistent about
an RDF resource—outside of the URI to uniquely identify it—is the
resource or class type. In the examples shown thus far, this value could
implicitly be "Web Resource" to refer
to all of the resources, or could be explicitly set to "article" for articles. All these would be
correct, depending on how generically you want to define the resource
and the other properties associated with the resource. To explicitly
define the resource type, you would use the RDF rdf:type property.
Usually the rdf:type property
is associated at the same level of granularity as the other properties.
As the resources defined using RDF in this chapter all have properties
associated more specifically with an article than a web resource, the
RDF type property would be "article"
or something similar.
In the next section, covering RDF containers, we will learn that the resource type for an RDF container would be the type of container rather than the type of the contained property or resource. Again, the type is equivalent to the granularity of the resource being described, and with containers, the resource is a canister (or group) of resources or properties rather than a specific resource or property.
The value of the RDF rdf:type
property is a URI identifying an rdfs:Class-typed resource (rdfs:Class is described in detail in Chapter 5). To demonstrate how to attach
an explicit type to a resource, Example 3-13 shows the resource
defined in the RDF/XML for Example
3-1, but this time explicitly defining an RDF Schema element for
the resource.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/">
<rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm">
<pstcn:Author>Shelley Powers</pstcn:Author>
<pstcn:Title>Architeuthis Dux</pstcn:Title>
<rdf:type rdf:resource="http://burningbird.net/postcon/elements/1.0/Article" />
</rdf:Description>
</rdf:RDF>The type property includes a resource reference for the schema
element, in this case for the Article
class.
Rather than formally list out an rdf:Description and then attach the rdf:type predicate to it, you can cut through
all of that using an RDF/XML shortcut. Incorporating the formal syntax
of the type property directly into XML, as before, the type property is
treated as an embedded element of the outer resource.
Within the shortcut, the type property is created directly as the element type rather than as a generic RDF Description element. This new syntax, demonstrated in Example 3-14, leads to correct interpretation of the RDF within an XML parser.
<?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"><pstcn:Article rdf:about="http://burningbird.net/articles/monsters3.htm"><pstcn:Author>Shelley Powers</pstcn:Author> <pstcn:Title>Architeuthis Dux</pstcn:Title></pstcn:Article></rdf:RDF>
Notice the capitalization of the first letter for Article. This provides a hint that the element
is a resource, rather than a predicate type.
This shortcut approach is particularly effective in ensuring that
there is no doubt as to the nature of the resource being described,
especially since formally listing an rdf:type predicate isn’t a requirement of the
RDF/XML. As you’ll see later, in Chapter
6, the PostCon vocabulary uses this shortcut technique to
identify the major resource as a web document.
Other RDF/XML shortcuts that can help cut through some of the rather stylized RDF/XML formalisms and make the underlying model a little more opaque are described in the next section.
RDF/XML Shortcuts
An RDF/XML shortcut is just what it sounds like—an abbreviated technique you can use to record one specific characteristic of an RDF model within RDF/XML. In the last section, we looked at using a shortcut to embed a resource’s type with the resource definition. Other RDF/XML shortcuts you can use include:
Separate predicates can be enclosed within the same resource block.
Nonrepeating properties can be created as resource attributes.
Empty resource properties do not have to be formally defined with description blocks.
The first shortcut or abbreviated syntax—enclosing all predicates (properties) for the same subject within that subject block—is so common that it’s unlikely you’ll find RDF/XML files that repeat the resource for each property. However, the RDF/XML in Example 3-13 is equivalent to that shown in Example 3-15.
<?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"><rdf:Description rdf:about="http://dynamicearth.com/articles/monsters3.htm"><pstcn:author>Shelley Powers</pstcn:author> </rdf:Description><rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm"><pstcn:title>Architeuthis Dux</pstcn:title> </rdf:Description> </rdf:RDF>
If you try this RDF/XML within the RDF Validator, you’ll get exactly the same model as you would with the RDF/XML from Example 3-1.
Tip
The RDF/XML from Examples Example 3-1 and Example 3-13 also demonstrates that you can generate an RDF graph from RDF/XML, but when you then convert it back into RDF/XML from the graph, you won’t always get the same RDF/XML that you started with. In this example, the graph for both RDF/XML documents would most likely reconvert back to the document shown in Example 3-1, rather than the one shown in Example 3-13.
For the second instance of abbreviated syntax, we’ll again return to RDF/XML in Example 3-1. Within this document, each of the resource properties is listed within a separate XML element. However, using the second abbreviated syntax—nonrepeating properties can be created as resource attributes—properties that don’t repeat and are literals can be listed directly in the resource element, rather than listed out as separate formal predicate statements.
Rewriting Example 3-1 as Example 3-16, you’ll quickly see the difference with this syntactic shortcut.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/">
<rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm"
pstcn:author="Shelley Powers"
pstcn:title="Architeuthis Dux" />
</rdf:RDF>As you can see, this greatly simplifies the RDF/XML. RDF parsers interpret the XML in Examples Example 3-1 and Example 3-14 as equivalent, as you can see if you run this newer example through the RDF Validator.
There are actually two different representations of the
third abbreviation type, having to do with formalizing predicate objects
that are resources. In the examples, RDF resources have been identified
within the <rdf:Description>...</rdf:Description> tags, using a formal
striped XML syntax format, even if the resource is an object of the
statement rather than the subject. However, the rdf:Description block doesn’t have to be
provided if the resource objects match one of two constraints.
The first constraint is that the resource object must have a URI
but must not itself have predicates. It is an empty element. For
instance, to record information about documents that are related to the
document being described, you could use a related predicate with an
rdf:resource value
giving the document’s URI, as shown in Example 3-17.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/">
<rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm">
<pstcn:Author>Shelley Powers</pstcn:Author>
<pstcn:Title>Architeuthis Dux</pstcn:Title>
<pstcn:related rdf:resource="http://burningbird.net/articles/monsters1.htm" />
</rdf:Description>
</rdf:RDF>You can also use the rdf:resource attribute to designate a resource
that’s described later in the document. This is an especially useful
technique if a resource object is identified early on, but you didn’t
know if the object had properties itself. If you discover properties for
the object at a later time, a separate rdf:Description can be defined for the
resource object, and the properties added to it.
In Example 3-17, the
related resource object is shown without properties itself. In Example 3-18, properties for this
resource have been given, in this case a reason that the resource object is related to
the original resource.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/">
<rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm">
<pstcn:Author>Shelley Powers</pstcn:Author>
<pstcn:Title>Architeuthis Dux</pstcn:Title>
<pstcn:related rdf:resource="http://burningbird.net/articles/monsters1.htm" />
</rdf:Description>
<rdf:Description rdf:about="http://burningbird.net/articles/monsters1.htm">
<pstcn:reason>First in the series</pstcn:reason>
</rdf:Description>
</rdf:RDF>Of course, this wouldn’t be RDF if there weren’t options in how
models are serialized with RDF/XML. Another variation on using rdf:resource for an object resource is to
identify the property object as a resource and then use the shortcut
technique shown earlier—adding predicates as attributes directly. With
this, you wouldn’t need to define a separate rdf:Description block just to add the related
property’s reason. In fact, Example
3-19 shows all of the shortcut techniques combined to simplify
one RDF/XML document.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/">
<pstcn:Article
pstcn:author="Shelley Powers"
pstcn:title="Architeuthis Dux"
rdf:about="http://dynamicearth.com/articles/monsters3.htm" >
<pstcn:related rdf:resource="http://burningbird.net/articles/monsters1.htm"
pstcn:reason="First in the series" />
</pstcn:Article>
</rdf:RDF>Again, running this example through the validator results in a graph that’s identical to that given if more formalized RDF/XML were used, as shown in Figure 3-7.
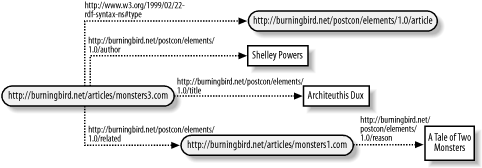
Which syntax should you use, formal or shortcut? According to the W3C Syntax Specification (revised), applications that can generate, query, or consume RDF are expected to support both the formal syntax and the abbreviated syntax, so you should be able to use both, either separately or together. The abbreviated syntax is less verbose, and the RDF model documented within the RDF is more clearly apparent. In fact, according to the specification, a benefit of using the abbreviated syntax is that the RDF model can be interpreted directly from the XML (with the help of some carefully designed DTDs).
What do I mean by that last statement? As an example, within the formal syntax, RDF properties are included as separate tagged elements contained within the outer RDF Description element. Opening an XML file such as this using an XML parser, such as in a browser, the properties would display as separate elements—connected to the description, true, but still showing, visibly, as separate elements.
Using the second form of the abbreviated syntax, the properties are included as attributes within the description tag and therefore don’t show as separate elements. Instead, they show as descriptive attributes of the element being described, the resource. With rules and constraints enforced through a DTD, the attributes can be interpreted, directly and appropriately, within an XML document using an XML parser (not a specialized RDF parser) as a resource with given attributes (properties) — not an element with embedded, nested elements contained within an outer element.
This same concept of direct interpretation of the RDF model applies to nested resources. Using the formal syntax, a property that’s also a resource is listed within a separate Description element and associated to the original resource through an identifier. An XML parser would interpret the two resources as separate elements without any visible association between the two. Using the abbreviated syntax, the resource property would be nested within the original resource’s description; an XML parser would show that the resource property is a separate element, but associated with the primary resource by being embedded within the opening and closing tags of this resource.
More on RDF Data Types
RDF data types were discussed in Chapter 2, but their impact extends beyond just the RDF abstract model and concepts. RDF data types have their own XML constructs within the RDF/XML specification.
For instance, you can use the xml:lang attribute to
specify a language for each RDF/XML element. In the examples in this
English-language book, the value would be "en", and would be included within an element
as follows:
<pstcn:reason xml:lang="en">First in the series</pstcn:reason>
You can find out more about xml:lang at
http://www.w3.org/TR/REC-xml#sec-lang-tag.
You can also specify a general type for a predicate object with
rdf:parseType. We’ve
seen rdf:parseType of "Resource", but you can also use rdf:parseType of "Literal":
<pstcn:reason xml:lang="en" rdf:parseType="Literal"><h1>Reason</h1></pstcn:reason>
By using rdf:parseType="Literal", you are telling the
RDF/XML parser to treat the contents of a predicate as a literal value
rather than parse it out for new RDF/XML elements. This allows you to
embed XML into an element that is not parsed.
Warning
Some implementations of RDF/XML specifically recommend using
rdf:parseType="Literal" as a way of
including unparsed XML within a document, to bypass having to
formalize the XML into an RDF/XML valid syntax. This attribute was
never intended to bypass best practices. If the data contained in the
attribute is recurring, best practice would be to formalize the XML
into RDF/XML and incorporate it into the vocabulary or create a new
vocabulary.
RDF also allows for typed literals, which contain a reference to the data type of the literal compatible with the XML Schema data types. In the N3 notation, the typed literal would look similar to the following, as pulled from the RDF Primer:
ex:index.html exterms:creation-date "1999-08-16"^^xsd:date .
The format of the literal string is value (1999-08-16), data type URI (^^ in this example), and XML Schema data type
(xsd:date).
As interesting as this format is, one could see how this approach
lacks some popularity, primarily because of the intelligence built
directly into the string, which can be missed depending on the XML
parser that forms the basis of the RDF/XML parser. Luckily, within
RDF/XML, the data type is specified as an attribute of the element,
using the rdf:datatype
attribute, as demonstrated in Example 3-20, which is a copy of
Example 3-1, but with data
typing added.
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/">
<rdf:Description rdf:about="http://burningbird.net/articles/monsters3.htm">
<pstcn:author rdf:datatype="http://www.w3.org/2001/XMLSchema#string">
Shelley Powers</pstcn:author>
<pstcn:title rdf:datatype="http://www.w3.org/2001/XMLSchema#string">
Architeuthis Dux</pstcn:title>
</rdf:Description>
</rdf:RDF>There is no requirement to use data types with literals—it is up to not only the vocabulary designer but also those who generate instances of the vocabulary to decide if they wish to use typed literals. No implicit semantics are attached to typed literals, by which I mean toolmakers are not obliged to double-check the validity of a particular literal against its type. Additionally, there’s no requirement that toolmakers even have to differentiate between the types or ensure that typed literals used in an instance map to the same typed literals for the RDF Schema of the vocabulary. Typed literals are more of a way to communicate data types between vocabulary users than between vocabulary-automated processes.
Tip
You can read more about XML Schema built-in data types at http://www.w3.org/TR/xmlschema-2/. XML.com also has a number of articles covering XML Schema and data typing in general.
RDF/XML: Separate Documents or Embedded Blocks
By convention, RDF/XML files are stored as separate documents and given the extension of .rdf (just rdf for Mac systems). The associated MIME type for an RDF/XML document is: application/rdf+xml.
There’s been considerable discussion about embedding RDF within other documents, such as within non-RDF XML and HTML. I’ve used RDF embedded within HTML pages, and I know other applications that have done the same.
The problem with embedding, particularly within HTML documents, is that it’s not a simple matter to separate the RDF/XML from the rest of the content. If the RDF/XML used consists of a resource and its associated properties listed as attributes of the resource, this isn’t a problem. An example of this would be:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description
about="http://burningbird.net/cgi-bin/mt-tb.cgi?tb_id=121"
dc:title="Good RSS"
dc:identifier="http://weblog.burningbird.net/archives/000619.php"
dc:subject="Technology"
dc:description="Mark Pilgrim and Sam Ruby created an RSS Validator for us to use
to validate our RSS feeds, and Bill Kearney was kind enough to host it. Many
appreciations, folks. I ran the Validator against my RSS feeds (both Userland..."
dc:creator="shelley"
dc:date="2002-10-2209:46:26-06:00" />
</rdf:RDF>This is RDF/XML that’s generated by a weblogging tool called Movable Type (found at http://moveabletype.org). It’s used for the tool’s trackback feature, which allows webloggers to notify each other when they reference each other’s posts in their own.
All of the data is contained in RDF/XML element attributes. Including all of the properties as attributes means that there is no visible XML content contained within any element and therefore parsed by the HTML parser and displayed in the page—all of the data is contained in RDF/XML element attributes.
This is pretty handy, but not all RDF/XML can use the abbreviated
syntax that allows us to convert RDF properties to XML attributes. In
those cases, the approach I use to embed RDF within an HTML document is
to include it within script tags, as
demonstrated in Example
3-21.
<script type="application/rdf+xml">
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:trackback="http://madskills.com/public/xml/rss/module/trackback/"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description
rdf:about="http://weblog.burningbird.net/fires/000805.htm"
trackback:ping="http://burningbird.net/cgi-bin/mt-tb.cgi/304"
dc:title="Apple's Open Core"
dc:identifier="http://weblog.burningbird.net/fires/000805.htm"
dc:subject="technology"
dc:description="As happened last year with the Macworld conference, you
might as well bag writing about anything else because this week will be
Apple, Apple, Apple. Two big stories - a newer, longer TiBook and Safari,
Apple's entry into the browsing market. I liked some features of the
new TiBook such as the backlit keyboard, which I think is one of the best
ideas I've heard with a laptop; I know I wish I had this with my
TiBook. However, I'm less impressed with the length of the TiBook -
17 inches. My 15 inch works nicely, I drag it about the house and everywhere
I go with no effort. All that extra length with the new TiBook does is make
it too long for most computer carry bags. Heck, it's too long for most
laps. What Apple needs to do is incorporate all the other goodies into its
15 inch model. Including the airport, Bluetooth, the graphics card, and that
nifty backlit feature. That would be a tasty morsel, and I'd be putting
up a PayPal donation button to have you all buy it for me. And the Titanium
PowerBooks are still the sexiest computer on earth. An even bigger..."
dc:creator="yasd"
dc:date="2003-01-08T09:34:36-06:00" />
</rdf:RDF>
</script>The HTML parser ignores the script contents, assuming that the
text/rdf content will be processed by
some application geared to this data type. This approach works rather
well except for one thing: it doesn’t allow an HTML page to validate as
XHTML. And many organizations insist that web pages validate as
XHTML.
To allow the page with the embedded RDF to validate, you can then surround the contents with HTML comments:
<!-- -- RDF/XML -- -->
Unfortunately, HTML comments are also XML comments, and any content within them tends to be ignored by most XML parsers, including RDF/XML parsers.
Until XML can be embedded into an XHTML document in such a way that allows the page to be validated, the only approach you can take for the RDF data is to include it in an external RDF document and then link the document into the XHTML page using the link element:
<link rel="meta" type="application/rdf+xml" title="RSS" href="http://burningbird.net/index.rdf" />
Another approach is to embed the RDF/XML into the XHTML using comments but to pull this data out and feed it directly to an RDF/XML parser. It’s a bit cumbersome, but doable, especially since most screen-scraping technologies such as Perl’s LWP provide for finding specific blocks of data and grabbing them directly.