
Chapter 12. Ontologies: RDF Business Models
Since the focus of this book is more on the practical usage of RDF than the more theoretical Semantic Web, I wasn’t sure about covering ontologies. After all, in a white paper at Stanford University, Tom Gruber described ontology thus:
An ontology is a specification of a conceptualization.
It’s a bit difficult to determine how to incorporate a discussion of a concept based on such an elusive definition into a book that begins with Practical. However, looking at examples of ontologies, in particular OIL, DAML+OIL, and the W3C’s current OWL (Web Ontology Language) effort, it seemed to me that ontologies do fit into a book with Practical in the title, because an ontology is really the definition of the business rules associated with a vocabulary. In other words: ontologies are business models. According to the Web Ontology Language (OWL) Use Cases and Requirements document:
An ontology formally defines a common set of terms that are used to describe and represent a domain. Ontologies can be used by automated tools to power advanced services such as more accurate Web search, intelligent software agents and knowledge management
Following on the relational model analogy discussed in earlier chapters, if RDF is analogous to the relational data model and SQL is analogous to RDF/XML, then ontologies built on RDF/XML are equivalent to large architected business applications such as SAP, PeopleSoft, and Oracle’s Financial and Warehouse applications. This equation definitely opened a home for ontologies in this book, and this chapter is it.
Tip
Tom Gruber’s paper at Stanford is at http://www-ksl.stanford.edu/kst/what-is-an-ontology.html. The OWL Use Cases and Requirements document is at http://www.w3.org/TR/webont-req/. The W3C’s OWL effort is accessible at the W3C Web Ontology site at http://www.w3.org/2001/sw/WebOnt/.
Why Ontology?
Since we spent two chapters discussing how to create RDF vocabularies using a combination of RDF and RDFS elements (Chapter 5 and Chapter 6), you may be wondering why we would need an ontology on top of this. What can ontology provide that the RDF Schema doesn’t?
RDFS imposes fairly loose constraints on vocabularies. For instance, there’s nothing in the schema that restricts the cardinality of a specific property or that provides information that two properties are disjoint (i.e., can’t use one when using the other). An ontology language such as OWL adds additional constraints that increase the accuracy of implementations of a given vocabulary. More than that, though, they allow additional information to be inferred about the data, though it may not be specifically recorded.
RDFS provides properties, such as subClassOf, that define relationships between
two classes—one is a subclass of, or inherits from, a second class. This
also applies to an ontology language, but it can add additional class
characteristics, such as its uniqueness, that aren’t defined within
RDFS.
We can develop a vocabulary, an ontology if you will, using just RDFS, but it won’t be as precise or as comprehensive as one that also incorporates ontological elements from DAML+OIL/OWL; the more precise you are with data specification, the better off you’ll be.
Brief History of the Ontology Movement
The current ontology effort at the W3C is OWL, which was rooted in the DAML (DARPA Agent Markup Language) project — specifically the ontology language originating from this project: DAML+OIL.
Though you’ll see DAML+OIL, OIL (Ontology Inference Layer) originated separately in Europe starting in 1997. It was preceded by SHOE (Simple HTML Ontology Extensions) in 1995. OIL is particularly relevant in a book on RDF because it was the first ontology based on RDF as well as the XML Schema.
The first release of DARPA’s DAML was in 2000, following early standardization work on the part of the W3C. One year after DAML was released, a joint ontology language, DAML+OIL, was released. An early press release on DAML+OIL appearing in the Cover Pages (at http://xml.coverpages.org/ni2001-03-28-a.html), said the following:
The reference description document characterizes DAML+OIL as “a semantic markup language for Web resources.” It builds on earlier W3C standards such as RDF and RDF Schema, and extends these languages with richer modeling primitives.
The first version of DAML+OIL was released in December of 2000, and the current version was released in March 2001. At the time, one of the primitives that DAML+OIL provided was data typing, which the first RDF specification didn’t provide.
What’s interesting with DAML+OIL is that the classes and
properties and their relation to each other as defined in the document
are extremely similar to those shown in RDFS (as described in Chapter 5). For instance, a daml:Class element categorizes elements that
are classes. There is also the concept of property, defined through
daml:ObjectProperty, but there is a
conceptual difference between class and property in DAML+OIL and class
and property in RDFS. However, exactly what this conceptual difference
is has been the focus of considerable debate within the Semantic Web
community.
In the www-rdf-logic mailing list, a
thread started once about the difference between rdfs:Class and daml:Class (at http://lists.w3.org/Archives/Public/www-rdf-logic/2002Mar/0017.html).
Exactly when does one use rdfs:Class
and when does one use daml:Class?
General consensus tends to support the view that RDFS describes metadata, including DAML+OIL itself. However, one should use DAML+OIL elements to define actual instances of data, such as elements as they are defined in my PostCon vocabulary. This does make sense and supports the view that I have of DAML+OIL as compared to RDFS: that DAML+OIL is a way of describing a generalized business model, such as those defined in PeopleSoft and SAP, while RDFS is the metalanguage that defines DAML+OIL, equivalent to the relational data model used to define the databases that support PeopleSoft and SAP.
Unfortunately, this view hasn’t received complete concurrence from all parties, and there is considerable bleed-through of the use of one schema over the other or, said another way, lack of clarity between the layers of the architecture, using the parlance of the community that works closely with ontologies and RDF.
The W3C entered the picture more fully when it formed the Semantic Web Activity Group in February 2001 and followed up with the creation of the Ontology Working Group. An announcement in August 2001 revealed the intent of incorporating the work of the DAML and OIL groups into the W3C Semantic Web activities (from http://lists.w3.org/Archives/Public/www-rdf-logic/2001Aug/0014.html):
The current international collaboration between DAML and OIL groups on a Web ontology layer is expected to become a part of this W3C Activity.
Though not necessarily a part of the effort, DAML+OIL provided the foundation for the W3C ontology effort. The Web Ontology (WebOnt) Working Group was formally launched in November 2001, and work began on defining the language necessary for an ontology layer—OWL, the Web Ontology Language.
Tip
This chapter primarily focuses on OWL, but you can review the earlier DAML+OIL specifications at http://www.w3.org/TR/daml+oil-reference. In particular, a sample ontology at http://www.w3.org/TR/daml+oil-walkthru/daml+oil-ex.daml provides a good snapshot of the state of DAML+OIL at the time the work on OWL began. Lastly, the DAML Ontology Library has a listing of ontologies defined using DAML+OIL, at http://www.daml.org/ontologies/. A DAML+OIL-to-OWL converter is at http://www.mindswap.org/2002/owl.html.
OWL Use Cases and Requirements
As with most W3C efforts, you can track the progress of work within any one activity by the state and version of the documents released. The first document released by the WebOnt group on OWL listed a set of requirements for an ontology language, followed by documents for test cases, abstract syntax and semantics, and, finally, a language reference and user guide.
The roots for OWL exist in the OWL Use Cases and Requirements document, released in July 2002 and recently updated. According to this document, we’ve been working with ontologies all along by using vocabularies such as ones I’ve used in the book like Dublin Core and PostCon. These are ontologies because they define the data for a specific knowledge domain, which is what the Use Case and Requirements document defines as ontology.
Specifically, ontology encompasses four concepts:
Classes
Relationships between classes
Properties of classes
Constraints on relationships between the classes and properties of the classes
When you consider that these concepts can be used, equally, with RDF and RDFS, you can see why there is some confusion about where RDFS ends and OWL begins. The Use Cases document, while demonstrative of applications facilitated by the use of an ontology, didn’t exactly help with clarifying when to use OWL and when to use RDFS, other than suggesting use of RDFS for defining OWL and then using OWL for everything else.
Tip
One interesting example of an OWL use case is the ontology web portal, OntoWeb, at http://ontoweb.aifb.uni-karlsruhe.de/.
In addition to use cases, design goals given in the document were:
Ontologies must be sharable, so that more than one business within a particular business domain could use the same ontology defined for that domain.
Evolving ontologies should be given version numbers and the schema defining the ontology given a separate URI for each new version (such as PostCon with its http://burningbird.net/postcon/elements/1.0/version). Ontologies would then be related through the use of
rdfs:subClassOf.Ontologies must be interoperable.
Inconsistencies in ontologies must be detected automatically to prevent them from occurring.
Ontologies must balance expressivity and scalability.
Ontologies must be consistent with other standards.
Internationalization must be supported.
None of the use cases or design goals is overwhelmingly complex, except possibly testing for inconsistencies. The next document in the series released by the working group then contained test cases to see if the OWL met the various design goals.
Tip
The most recent version of the Use Cases and Requirements document can be found at http://www.w3.org/TR/webont-req/.
OWL Specifications
OWL has no shortage of associated documents:
Requirements for a Web Ontology Language
Web Ontology Language (OWL) Guide Version 1.0
OWL Web Ontology Language 1.0 Reference
Web Ontology Language (OWL) Abstract Syntax and Semantics
Web Ontology Language (OWL) Test Cases
Feature Synopsis for OWL Lite and OWL
We just looked at the Requirements document. The other documents somewhat mirror their counterparts over at the RDF Working Group, with the OWL Guide being comparable to the RDF Primer, the OWL Reference to the Syntax document, and the OWL Abstract Syntax and Semantics document to a combination of the RDF Concepts and Semantics documents. The test cases for both are similar; though the OWL feature synopsis doesn’t necessarily map to an existing RDF document, it seems similar to a reference card for OWL.
After reviewing the use cases and requirements governing the design of OWL, the next document to review to better understand OWL would be the guide. Just as does its counterpart in RDF, the RDF Primer, the guide provides a general overview of OWL and the associated effort.
OWL Guide 1.0
A further clarification of ontology is provided in the OWL Guide, when it describes how an ontology differs from an XML Schema. According to the guide:
An ontology differs from an XML schema in that it is a knowledge representation, not a message format.
This is an important point. XML Schemas and message-based uses of XML focus on specific pieces of data and specific uses of data, such as sending a message and processing its results. Nothing within basic XML or within the XML Schema allows one to derive information outside of the context of the specific use. For instance, the tool I used to maintain a weblog might support SOAP requirements that allow me to publish a new posting, but nothing associated with the SOAP request allows me, or anyone, to learn more about that specific posting, or even the weblog, other than what’s included within the transaction. OWL differs from XML Schema (as well as SOAP and many of the other uses of XML) in that it allows you to record data about an object outside of any specific transaction associated with that data. It allows you to record knowledge. OWL (and by its association, RDF) focuses on data rather than process.
The guide provides an overview of three different types of OWL:
- OWL Lite
Supports simple classifications, allowing only cardinalities (member count) of 0 or 1 and only minimal constraints. An example would be a taxonomy.
- OWL DL
Supports more complex ontologies, but with some guarantees, such as processing finishing in finite time, restricting elements to be one type, and so on. According to the guide, it’s called DL, meaning “description logics.”
- OWL Full
Full support for maximum freedom of RDF, with no computational guarantees and the possibility of indefinite processing time.
These specific designations have more to do with what certain tools can and will support, which of course influences the design and implementation of a specific ontology. Looking at PostCon’s RDFS definition, PostCon could be ported to an ontology, with any restrictions and constraints added to it fitting comfortably within those allowed by OWL DL.
The rest of the guide then covers the basic components of OWL. Later, as we review each of these, I’ll demonstrate the concepts by porting PostCon over to OWL, to supplement the example of the Wine ontology used within the OWL document.
Tip
At this point, you may want to take a look at a tutorial on OWL, “Ontology Development 101: A Guide to Creating Your First Ontology,” found at http://www.ksl.stanford.edu/people/dlm/papers/ontology-tutorial-noy-mcguinness-abstract.html.
OWL Reference 1.0
The OWL Reference document provides the formal specification of the language. It is equivalent to the XML specification for RDF/XML covered in Chapter 3 and Chapter 4. However, unlike the RDF document, the OWL documents are a work in progress and far from complete.
The section of most interest in the reference is the one covering the language structure. Unlike RDF, the OWL vocabulary is quite large. Like RDF, though, it makes use of elements from RDFS (and from RDF).
Tip
The Reference document can be found at http://www.w3.org/TR/owl-ref/. The prefix
for the OWL namespace used in the OWL documents is owl, a convention I’ll follow in this
chapter. OWL is based on RDF and RDFS, which means it must first and
foremost validate as proper RDF/XML.
The Reference document breaks the structure of OWL down into separate components, most of which are already familiar to you from previous chapters, such as the concepts of classes, properties, and enumerations (collections). Section 12.5 provides an overview of these items. However, OWL also has several concepts unique to it, such as the Boolean combination of class expressions and property restrictions, which add the additional layer of reasoning you would expect for a language defining a business domain. These warrant a closer examination, which occurs in Section 12.6.
You’ll sometimes find reference to owl:Thing in the document, but it doesn’t
show in any formal definition of elements, though it is listed as a
term. This element represents the class of all classes and is an
artifact of the DAML+OIL effort from which OWL is derived.
OWL Abstract Syntax and Semantics
The Abstract Syntax and Semantics document provides a breakdown of the model theoretical axioms and rules guiding the implementation and interpretation of OWL. It provides a semantic definition of what is a “fact” within OWL, as well as a high-level overview of how OWL differs from DAML+OIL and how OWL Lite differs from the full-featured OWL.
Tip
The WebOnt is considering making a minor modification to the name of this document, changing it to Semantics and Abstract Syntax.
A major difference between OWL and OWL Lite is the inclusion of what the document calls OWL descriptions. The formal definition of a description is:
< description> ::= <classID>
| <restriction>
| unionOf( {<description>} )
| intersectionOf( {<description>} )
| complementOf( <description> )
| oneOf({<individualID>} )Primarily, an OWL description is one of a class identifier, a property restriction, or a complex class association. These descriptions enhance the reasoning inherent within OWL ontology—reasoning that goes beyond that allowed in RDFS.
Regarding the separation of OWL and OWL Lite in this chapter, for the most part Section 12.5 applies to both OWL and OWL Lite, though the data typing discussed in the section is beyond OWL Lite. Additionally, the property restrictions covered in “Bits of Knowledge: More Complex OWL Constructs” apply to both. However, the discussion about complex classes in this section applies purely to the fully featured OWL, as these make up most of the options from the OWL description just provided.
Another section in the Abstract document, “RDFS-Compatible Model-Theoretic Semantics,” provides a semantic description of the relationship between OWL and RDFS. Though much of the section is given over to theorems and proofs, the first part provides a basic overview describing the compatibility between the two. In particular, it describes the differences between OWL Full and OWL DL.
Tip
This chapter focuses on OWL Lite and OWL Full. You’ll want to check out the Abstract document for more information on OWL DL. The latest document can be found at http://www.w3.org/TR/owl-semantics/.
Feature Synopsis for OWL Lite and OWL
The Feature Synopsis document provides a summary of features for OWL and OWL Lite. It makes a good “in a nutshell” review of the material and is definitely worth a read as you learn more about OWL.
Tip
Access the recent version of the Synopsis document at http://www.w3.org/TR/owl-features/..
Basic Constructs of OWL
In this section, we’ll look at the basic elements of OWL, those that exist regardless of the ontology being defined. If you’re familiar with RDFS (as covered in Chapter 5), most of these should be familiar to you. Specifically, in this section we’ll cover the following OWL elements:
|
|
|
|
|
|
|
|
|
|
|
|
RDF Schema and OWL are compatible, which is why you’ll see RDFS elements within the OWL element set. However, the direction of this compatibility is one way — only from RDF and RDF to OWL; you won’t see OWL elements within the RDF Schema.
You start an OWL ontology with the header, covered next.
OWL Header
The first component is the outer OWL block, delimited by
owl:Ontology,
containing version information (through owl:versionInfo) and
an imports section (through owl:imports). The
imports section includes an rdf:resource attribute that points to a
separate RDF resource providing definitions used with the ontology.
This could include the complete schema for the ontology.
Redefining PostCon as an OWL ontology rather than a vocabulary defined directly in RDFS, the OWL header would be similar to the following:
<rdf:RDF
xmlns:pstcn="http://burningbird.net/postcon"
xmlns:owl ="http://www.w3.org/2002/07/owl#"
xmlns:rdf ="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:xsd ="http://www.w3.org/2000/10/XMLSchema#">
<owl:Ontology rdf:about="http://burningbird.net/postcon">
<owl:comment>PostContent Management</owl:comment>
<owl:versionInfo>
$Id: ch12.xml,v 1.5 2003/07/17 20:16:25 chodacki Exp $
</owl:versionInfo>
<dc:creator>Shelley Powers</dc:creator>
<dc:title>PostCon</dc:title>
</owl:Ontology>
</rdf:RDF>The namespaces are familiar as is the use of the outer rdf:RDF opening and closing tags. However,
note that I used a different namespace for PostCon. I’m not defining a
schema for the existing RDF vocabulary—I’m creating a new ontology,
from the ground up, using RDF/XML and based on the business domain
behind the vocabulary.
New material introduced in the header is the outer Ontology block to contain the ontological definitions and the version information elements, as well as the ontology comments. This section could also have included an import statement, to import another ontology, but none is defined for PostCon at this moment. Importing differs from inclusion of a namespace by incorporating that ontology’s assertions into the ontology currently being defined, therefore making them part of the knowledge base on which the new ontology is being built.
The version information shown is one difference between RDF and OWL—OWL assumes that different versions of the ontology will be developed, therefore it’s imperative to maintain this type of information with the document for each version.
Dublin Core elements are included in the header to provide title, creator, and other information, since this ontology is a published resource, and DC was designed to document metadata about published resources. It’s not required—really, little of this material is required—but any extra information helps.
Between the OWL header and the final RDF closing tag is the definition of the classes and properties of the ontology itself.
OWL Classes and Individuals
Not unlike RDFS, OWL classes define entities via properties. The classes defined for the PostCon ontology should therefore be similar to those defined with RDFS in Chapter 6. What might be more apparent with OWL is the hierarchical nature of the classes.
In PostCon, there is a Resource, which is basically anything being
tracked with the PostCon system. During the tracking process, the
Resource moves from location to
location, each of which is tracked as a movement. It still has all the
characteristics of being a Resource; the movement doesn’t change this.
However, there are new characteristics associated with the item. The
ResourceMovement, then, becomes a
subclass of Resource. In addition,
there are other resources that are related in some way to the Resource. RelatedResource is also defined as a
subclass of Resource:
<owl:Class rdf:ID="Resource" /> <owl:Class rdf:ID="RelatedResource"> <owl:subClassOf rdf:resource="#Resource" /> </owl:Class> <owl:Class rdf:ID="ResourceMovement"> <owl:subClassOf rdf:resource="#Resource" /> </owl:Class>
There are other possible classes within PostCon — for instance, different types of resources, such as photos, text documents, music, and video—each of which has different properties unique to the type of the object.
However, within the PostCon system, much of the uniqueness of each individual object can be described using the same properties. For instance, a requirement for viewing a video file is a browser plug-in that enables this, a requirement for a music file is the same, and so on. Each type of object has a requirement, and one property can capture this requirement for all the types. In this case, rather than each object type being a separate class, they’re all instances of the same class. In ontological terms, each of these types of resource is an individual member of the class, rather than a subclass of it.
OWL Simple Properties and Complex Data Types
An OWL property is really not that much different from a
property defined in RDFS. They share the same use of rdfs:domain and
rdfs:range, but in addition,
constraints that aren’t defined in RDFS can be applied to OWL
properties.
In PostCon, one property of a resource movement is its movement type information. The definition for it in OWL is very similar to what we would find in the RDF Schema:
<owl:ObjectProperty rdf:ID="movementType"> <rdfs:domain rdf:resource="#ResourceMovement"> <rdfs:range rdf:resource="" /> </owl:ObjectProperty>
The property movementType has
a domain of ResourceMovement, which
means that any resource with this property is a ResourceMovement. If a property inherits all
the characteristics of another, it’s a subproperty of the original,
noted in OWL with the subPropertyOf
property.
However, where RDFS and OWL differ, quite dramatically, is in data typing. Both specifications use XML Schema data types; both allow the use of data type within the schema definition (within the class definition for OWL, RDFS for RDF); and both allow annotation of instances with data type (individual for OWL, in actual properties in RDF). The two differ in that RDF limits data types to those types that can be referenced by URI, such as the predefined schema instances (in http://www.w3.org/TR/xmlschema-2/). OWL extends the concept of data type to include creating classes of data types that are then used to constrain the range of properties.
To demonstrate, consider the movementType property just defined using
ObjectProperty. The domain is
ResourceMovement, and we could say
it has a range of rdf:Property, which
would be correct; however, it would also be too diffuse, because
movementType has one other
constraint attached to it: there are only three allowable values,
"Add", "Drop", and "Move". Within RDFS there is nothing to
automatically constrain the data used with movementType other than to use xsd:string to state it’s a string and
rdf:Property to state it’s a
property.
In OWL, though, we can do much more. Borrowing from the design of the data types for the example Wine ontology in the OWL Guide, I created a custom XML Schema data type definition file as follows:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns="http://burningbird.net/postcon/postcon-pstcn.xsd">
<xsd:simpleType name="movementTypes">
<xsd:restriction base="xsd:string">
<xsd:enumeration value="Add"/>
<xsd:enumeration value="Drop"/>
<xsd:enumeration value="Move"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:schema>This new simple type has a base restriction of string, but it also lists an enumeration of
allowable values—"Add", "Drop", and "Move". To tie this into my ontology, I
would then create a data typing class to represent this movement
type:
<owl:Class rdf:ID="MovementType" />
I can then tie the data
type restrictions to the MovementType class, using DataTypeProperty:
<owl:DataTypeProperty rdf:ID="movementTypeValue"> <rdfs:domain rdf:resource="#MovementType" /> <rdfs:range rdf:resource="pstcn:movementType"/> </owl:DataTypeProperty>
Finally, I can complete the property definition for movementType, by adding an rdf:range that uses the new data type
class:
<owl:ObjectProperty rdf:ID="movementType"> <rdfs:domain rdf:resource="#ResourceMovement" /> <rdf:range rdf:resource="#MovementType" /> </owl:ObjectProperty>
This seems a bit complex, but one restriction on allowable
values for rdf:range is that they
must be class values, such as rdf:Property. Using this approach, the RDF
Schema requirements are met, but the greater needs of the
ontology—being allowed to specify an enumeration of allowed items—are
also met.
Bits of Knowledge: More Complex OWL Constructs
The example in the last section that allowed us to define a more complex data type for a specific property begins to demonstrate the divergence between RDFS and OWL—this ability to attach more nuances of meaning to the data being modeled, beyond nuances defined in RDF. Rightfully so—the relational data model provides the structure necessary to build generic data types that can manage all data; complex business models such as SAP and PeopleSoft use the relational model as a base for more complex models representing more specific business models. The two layers of relational data are complementary rather than competitive, just as the two layers of RDF/RDFS and OWL are complimentary rather than competitive.
The OWL elements we’ll cover in this section are:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The element names themselves indicate their functional value within OWL.
Increasing the Power of the Property
A property in RDF provides information about the entity it’s describing, but the information tends to be somewhat linear. There are two types of information properties in an RDF record: an actual instance of data, such as a string containing a name or another resource, continuing the node-arc-node-arc-node path within the model.
In ontologies, properties can be much more active in their description of the knowledge described in the ontology with the aid of some enhancements built directly into the ontology language. OWL categorizes these property enhancements into characteristics and restrictions.
Property characteristics
Property characteristics increase our ability to record our understanding about the data we’re describing in such a way that automated tools can infer much more of the reasoning we used when we pulled all this data together. In any model, there’s a reason why we included this property or that entity, and not all of these reasons can be determined with the constructs supported in RDF or even with other data models such as the relational or object-oriented models.
To demonstrate the property characteristics, some new
assumptions and additions to the existing PostCon ontology are made.
In the current understanding of PostCon, a resource within the
system would also exist as one resource on the server. However,
there’s nothing in the system that enforces this—a single web
resource doesn’t have to exist in one physical entity. For instance,
an “article” such as the one used throughout the book, “Tale of Two
Monsters: Legends” could be separated across many pages, but still
be treated as a single entity within the system. To capture this
information, a new property, partOf, can be defined and used as follows
within the PostCon ontology:
<Resource rdf:ID="Section1"> <partOf rdf:resource="#monsters1" /> </Resource> <Resource rdf:ID="monsters1"> </Resource>
With the new property, sections of an article can be split
into further sections and so on, with each child section attached to
the parent section through partOf.
This is an effective way to manage larger resources, but one thing lost with this structure is the fact that all of the sections ultimately roll up into one document, with each child section rolling up into the parent section, which may then roll up into another section and so on. However, OWL property characteristics provide a way to capture this type of information.
One property characteristic is the TransitiveProperty. The logic associated
with this property is:
P(x,y) and P(y,z) implies P(x,z)
Using TransitiveProperty in
PostCon would result in something similar to the following:
<owl:ObjectProperty rdf:ID="partOf"> <rdf:type rdf:resource="owl:TransitiveProperty" /> <rdfs:domain rdf:resource="&owl;Thing" /> <rdfs:range rdf:resource="#Resource" /> </owl:ObjectProperty> <Resource rdf:ID="sectionHeader1a"> <partOf rdf:resource="sectionHeader1" /> </Resource> <Region rdf:ID="sectionHeader1"> <partOf rdf:resource="#monsters1" /> </Region>
The TransitiveProperty
characteristic is attached to the property partOf. This property is used to attach
the "sectionHeader1a" section to
the parent section, "sectionHeader1". When the parent section
is then attached to the main article, "monsters1", by the use of TransitiveProperty, the "sectionHeader1a" is also defined to be
“part of” the top-level document. No special processing or
understanding of the domain would be necessary to intuit this
information because it’s provided with the characteristic.
A second property characteristic is the SymmetricProperty.
The logic for it is:
P(x,y) iff P(y,x)
With the new PostCon property, sections can be marked as peers
to each other through the use of SymmetricProperty applied to a new
predicate, sectionPeer:
<owl:ObjectProperty rdf:ID="sectionPeer"> <rdf:type rdf:resource="&owl;SymmetricProperty" /> <rdfs:domain rdf:resource="#Resource" /> <rdfs:range rdf:resource="#Resource" /> </owl:ObjectProperty> <Resource rdf:ID="sectionHeader1a"> <partOf rdf:resource="#sectionHeader1" /> <sectionPeer rdf:resource="#sectionHeader1b" /> </Resource> <Resource rdf:ID="sectionHeader1b"> <partOf rdf:resource="#sectionHeader1" /> <sectionPeer rdf:resource="#sectionHeader1a" /> </Resource>
A third property characteristic is FunctionalProperty, with the logic:
P(x,y) and P(x,z) implies y = z
Earlier in the section on data types, we created a custom data
type, MovementType, to specify
that allowable values be within a given set. The data type was
attached to a specific property, movementType, which then became functional
(noted by FunctionalProperty) in
that all movement types can be assigned only one value, and the
value must be from the allowable types:
<owl:Class rdf:ID="MovementType" /> <owl:ObjectProperty rdf:ID="movementType"> <rdf:type rdf:resource="&owl;FunctionalProperty" /> <rdfs:domain rdf:resource="#ResourceMovement" /> <rdf:range rdf:resource="#MovementType" /> </owl:ObjectProperty>
The inverseOf
characteristic is pretty straightforward: a new property can be
defined as the inverse of an existing property. The logic for it
is:
P1(x,y) iff P2(y,x)
If partOf shows a child
section’s relationship to a parent section, then the property
hasChild would define a parent
section’s relationship to one of its children:
<owl:ObjectProperty rdf:ID="hasChild"> <owl:inverseOf rdf:resource="#partOf" /> </owl:ObjectProperty>
Finally, the last property characteristic is InverseFunctionalProperty, which combines
the logic of both the inverse and
the FunctionalProperty:
P(y,x) and P(z,x) implies y = z
We can consider partOf as
functional (as defined by FunctionalProperty), because a section is
part of another section, and that other section only (a functional
constraint). And if partOf is
functional, then the inverse functional equivalent of partOf would be the hasChild property:
<owl:ObjectProperty rdf:ID="partOf"> <rdf:type rdf:resource="&owl;FunctionalProperty" /> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="childOf"> <rdf:type rdf:resource="&owl;InverseFunctionalProperty" /> <owl:inverseOf rdf:resource="#partOf" /> </owl:ObjectProperty>
Properties can be further refined through restrictions, discussed next.
Property restrictions
If property characteristics enhance reasoning by extending the meaning behind element relationships with each other, than property restrictions fine-tune the reasoning by restricting properties within specific contexts.
Returning to PostCon, the Resource class has two subclasses,
ResourceMovement and RelatedResource:
<owl:Class rdf:ID="Resource" /> <owl:Class rdf:ID="RelatedResource"> <owl:subClassOf rdf:resource="#Resource" /> </owl:Class> <owl:Class rdf:ID="ResourceMovement"> <owl:subClassOf rdf:resource="#Resource" /> </owl:Class>
In the RDF Schema for PostCon, both of these classes would
have "reason" as a predicate,
explaining the association between the classes. In addition,
ResourceMovement also has
movementType.
Instead of having two different properties, we could have just
the one — reason — and then
attach a property restriction — allValuesFrom — to
it, restricting values for this property to MovementType values only. The use of this
restriction is demonstrated in the following code:
<owl:Class rdf:ID="ResourceMovement">
<owl:subClassOf rdf:resource="#Resource" />
<rdfs:subClassOf>
<owl:Restriction>
<owl:onProperty rdf:resource="#reason" />
<owl:allValuesFrom rdf:resource="#MovementType" />
</owl:Restriction>
</rdfs:subClassOf>
</owl:Class>Restrictions differ from characteristics in that restrictions
apply to a sub-set of the data, rather than globally to all data. In
this use of allValuesFrom, the
restriction applies to the reason
property only when it’s used within the ResourceMovement class, not when its used
in the RelatedResource
class.
A less restricted version of allValuesFrom is someValuesFrom,
used to specify that at least one of the properties restricted, in
this case reason, must point to a
specific MovementType.
Another restriction is cardinality. Cardinality indicates the exact number of individual instances of a property allowed within a class — not the maximum or minimum number, but the exact number that must exist.
Returning to PostCon, each individual ResourceMovement can have one and only one
movementType property. This
restriction would be modeled in OWL with the following:
<owl:Class rdf:ID="ResourceMovement">
<rdfs:subClassOf>
<owl:Restriction>
<owl:onProperty rdf:resource="#movementType"/>
<owl:cardinality>1</owl:cardinality>
</owl:Restriction>
</rdfs:subClassOf>
</owl:Class>According to the OWL Guide, OWL Lite can specify values of
only 0 or 1 for the cardinality restriction. However, for OWL Full,
in addition to the use of the cardinality restriction, owl:maxCardinality
can be used to set an upper cardinality, while owl:minCardinality
can be used to set the lower. Setting both defines a range.
The last property restriction is hasValue, used
with a class to differentiate those with properties from a specific
range. Again returning to ResourceMovement, the use of hasValue could be used to differentiate
ResourceMovement from RelatedResource, by adding the restriction
that ResourceMovement classes
have a movementType pointing to
the MovementType class:
<owl:Class rdf:ID="ResourceMovement">
<rdfs:subClassOf>
<owl:Restriction>
<owl:onProperty rdf:resource="#movementType"/>
<owl:hasValue rdf:resource="#MovementType" />
</owl:Restriction>
</rdfs:subClassOf>
</owl:Class>The more uses of property characteristics and restrictions placed on objects in the ontology, the better able tools are to make strong inferences about the true meaning of the data being defined.
Complex Classes
More complex class relationships exist than just the
simple hierarchy defined through the use of subClassOf. These relationships are managed
through a set of properties that controls how one class relates to
another. These class expressions, as OWL defines them, are based on
typical set operations used elsewhere, such as in logic or math. All
classes constructed using set operations, such as intersectionOf, are closed, explicitly
stating the parameters of class membership for a specific
class.
Intersection
An intersection of a class and one or more properties
is created using the intersectionOf property. All members of a
class defined with intersectionOf are
explicitly defined by the intersection of the class membership and
the property or properties specified.
One change that could be made to PostCon is to differentiate
between types of resources, based on the assumption that different
types of resources have different information associated with them.
If we do classify resources in this manner, then we’ll also want to
explicitly state without equivocation which class each resource
would belong in. In the following OWL definition, the new resource
class, XMLResource, is restricted
to members that belong to the Resource class and also belong to all
things that are based on XML:
<owl:Class rdf:ID="XMLResource">
<owl:intersectionOf rdf:parseType="Collection">
<owl:Class rdf:about="#Resource" />
<owl:Restriction>
<owl:onProperty rdf:resource="#hasFormat" />
<owl:hasValue rdf:resource="#XML" />
</owl:Restriction>
</owl:intersectionOf>
</owl:Class>The XMLResource class
consists of a class defining a set of properties, all of which can
be used to describe something formatted as XML. The intersection
would then be “Resource” and “things formatted as XML.” The Collection parseType is a required attribute in the
class definition because the class is being constructed to define a
collection of like material.
Rather than base the intersection on a specific property, you
can also just specify an intersection of classes. In the following,
a new class, RSSXMLResource, is
defined as the intersection between XMLResource and another new complex class,
RSSResource:
<owl:Class rdf:ID="RSSXMLResource">
<owl:intersectionOf rdf:parseType="Collection">
<owl:Class rdf:about="#XMLResource" />
<owl:Class rdf:about="#RSSResource" />
</owl:intersectionOf>
</owl:Class>Members of RSSXMLResource
would be resources formatted as XML but based on some RSS
vocabulary; RSS documents that are not XML formatted wouldn’t be
included, and neither would XML documents that aren’t based on RSS.
RSS 1.0 (RDF/RSS) would be a member of this class.
Union
The unionOf
construct creates a class whose members combine the properties of
both classes being joined. A demonstration of this is the following,
which defines a new class, called WebpageResource. This combines the
properties of XMLResource and a
new class, HTMLResource:
<owl:Class rdf:ID="WebpageResource">
<owl:unionOf rdf:parseType="Collection">
<owl:Class rdf:about="#XMLResource" />
<owl:Class rdf:about="#HTMLResouce" />
</owl:unionOf>
</owl:Class>XML, XHTML, and HTML pages would all be members of this class.
Complement
A class that consists of all members of a specific
domain that do not belong to a specific class can be created using
the complementOf construct.
Continuing our classification of PostCon resources, all web
resources that aren’t HTML, XML, or XHTML can be lumped into one
class membership using a class definition like the following:
<owl:Class rdf:ID="WebResource" />
<owl:Class rdf:ID="NotWebPage">
<owl:complementOf rdf:resource="#WebpageResource" />
</owl:Class>According to the OWL documentation, complementOf is usually used with other
set operations. With PostCon, this increasingly complex construct
could be used to define a class that contains all members of
resources that are not XML-formatted RSS with the following
definition:
<owl:Class rdf:ID="NotRSSXMLResource">
<owl:intersectionOf rdf:parseType="Collection">
<owl:Class rdf:about="#Resource"/>
<owl:Class>
<owl:complementOf>
<owl:Class rdf:ID="RSSXMLResource">
<owl:intersectionOf rdf:parseType="Collection">
<owl:Class rdf:about="#XMLResource" />
<owl:Class rdf:about="#RSSResource" />
</owl:intersectionOf>
</owl:Class>
</owl:complementOf>
</owl:Class>
</owl:intersectionOf>
</owl:Class>If a circle were drawn around XML-formatted RSS files,
everything outside of this circle that is a Resource would belong to NotRSSXMLResource.
Enumeration
An enumeration is a class with a predetermined, closed
set of members. Applied to web resources, this could be an
enumeration of graphics types supported at a particular web site, as
shown in the following, using the OWL enumeration operator, oneOf:
<owl:Class rdf:ID="GraphicResource">
<rdfs:subClassOf rdf:resource="#Resource"/>
<owl:oneOf rdf:parseType="Collection">
<owl:Thing rdf:about="#JPEG"/>
<owl:Thing rdf:about="#PNG"/>
<owl:Thing rdf:about="#GIF"/>
</owl:oneOf>
</owl:Class>The list could, of course, be extended to include other graphics types. A member of an enumerated class belongs to one, and only one, of the collection members.
Disjoint
Finally, the last complex class construction is the
disjoint construct, which lists all of the classes that a particular
class is guaranteed not to be a member of. As an example, the
following defines a new class, TextFile, guaranteed not to be a member of
the GraphicResource and VideoResource classes:
<owl:Class rdf:ID="TextFile"> <rdfs:subClassOf rdf:resource="#Resource"/> <owl:disjointWith rdf:resource="#GraphicResource"/> <owl:disjointWith rdf:resource="#VideoResource"/> </owl:Class>
The Complementary Nature of RDF and OWL
Previous sections barely skimmed the richness of OWL, though they have shown that regardless of the complexity of the constructs, they remain valid RDF/XML. In fact, if you open up the Wine ontology that the OWL group uses for its examples, located at http://www.w3.org/TR/owl-guide/wine.owl, you’ll find that it validates. You’ll want to turn on the graph option first, and you should be prepared to wait because wine.owl is quite large.
So, when should you use just RDF Schema and when should you use OWL?
If you’re defining a fairly simple vocabulary primarily for your own use (and I use RDF/XML for a dozen different little applications at my site), and if you’re concerned primarily with the striped nature of RDF/XML, you’ll most likely want to just define your vocabulary in RDF and RDFS.
However, if you’re documenting a model of a specific domain and you hope to encourage others to use it and, best of all, be able to use the data to make sophisticated queries, you’re going to want to use OWL to take advantage of its many inferential enhancements.
Before we leave this chapter, we’ll take a quick glance at a couple of editors specialized for ontologies. Take what you’ve learned in this chapter out for a spin.
Ontology Tools: Editors
Ontology editors can also be RDFS editors, but they usually have extended services and features to meet the increased demand in sophistication of the ontology. In this section, we’ll look at two such editors: SMORE and Protégé.
SMORE—Semantic Markup, Ontology, and RDF Editor
Much of the effort on behalf of both RDF and OWL is predicated on the Semantic Web, so the lack of tools that connect traditional web creation tools such as a WYSIWYG editor for HTML with support for newer technologies, such as an ontology editor, is rather surprising. However, SMORE — the Semantic Markup, Ontology, and RDF Editor — is an application that incorporates four separate applications into one to provide just such support. SMORE, another application written in Java, is one of the interesting products to come out of the Semantic Web Research Group, along with several converters, RDF scrapers, and other useful tools and utilities.
Tip
The Semantic Web Research Group’s web site is at http://www.mindswap.org/. You can download SMORE from http://www.mindswap.org/~aditkal/editor.shtml. The tool is freely available.
SMORE opens with an interface consisting of four separate windows within one frame. Each window contains a separate application: a web browser in one, a web ontology browser in another, a WYSIWYG HTML editor in a third, and a semantic data representation in the fourth. Figure 12-1 shows the tool just after it opens.
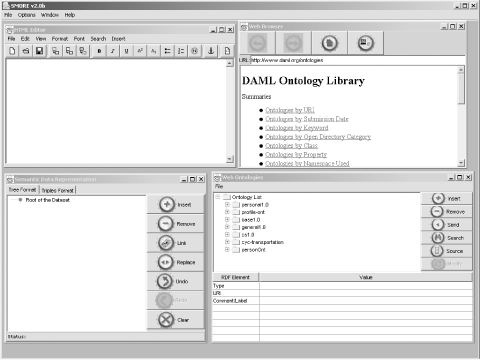
All four applications are integrated with one another. When examining the ontological class in the ontology browser, clicking on the source opens the RDF/XML for the class in the web browser; right-clicking on a term in the WYSIWYG HTML editor adds the term to the semantic data representation under development, and so on.
Warning
Opening an HTML document in the editor caused the application to fail, throwing several Java exceptions. This should be fixed when this book hits the streets.
Documentation on using the tool can be found in Help.
Protégé
Protégé is a Java-based ontology editor that provides the mechanisms to create ontologies and then allows you to save them as plain text, into JDBC-accessible datastores, and as RDF/XML. Installation consists of downloading the tool and then clicking the installer that the Java applet in the installation page recommends for your system.
Tip
The Protégé home page is at http://protege.stanford.edu, and the download page is at http://protege.stanford.edu/download/prerelease/index.html. The system has installers for, and been tested with, Windows, Mac OS X, AIX, Solaris, Linux, HP-UX, and generic Unix and other Java supportive platforms. I tested Version 1.8 for this chapter, within my Windows 2000 box. The extensive documentation can be viewed online at http://protege.stanford.edu/useit.html.
Figure 12-2 shows the editor when it’s first opened up, with the existing demonstration project, Newspaper, loaded.
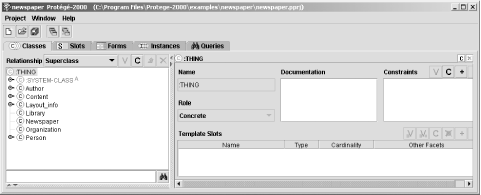
The tabbed interface allows you to define new classes and subclasses in the first page, in addition to adding properties (which the tool, in line with much of the ontology effort, calls slots). If a class has a key figure next to it, such as Person in Figure 12-2, clicking on the key displays or hides the class subclasses. Define a new class by clicking the high-level THING and then clicking the C toolbar item in the left toolbar, just over the Classes.
The next tab shows the slots (properties) defined in the ontology, as shown in Figure 12-3.
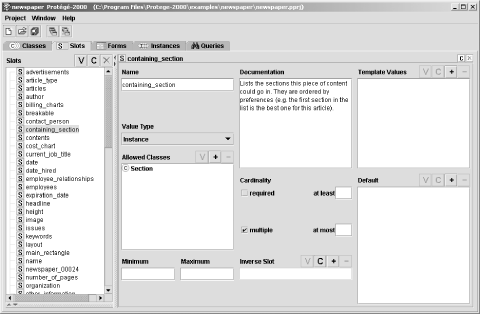
For each property, you can specify a name, provide
documentation, restrict the range of classes, specify its cardinality,
and create an inverse slot (equivalent to the inverseOf property characteristic described
before).
The next tab provides a form designer window that allows you to define a form used to record individual ontology members (instances). Clicking on a class in the left window opens the default (or saved customized) form in the right. At that point, you can do things such as move the form fields around, resize them, and so on.
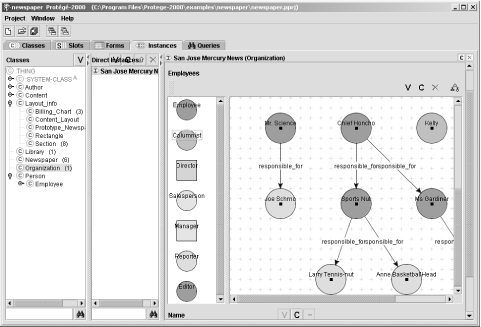
The last tab is where the forms customized in the previous tab are displayed, allowing you to record instance data for the ontology. In addition, data that’s already been recorded displays when the form is opened, as shown in Figure 12-4, including a mapping between a higher-level class instance and repeating properties. Note in the form that data entry doesn’t have to be limited to plain text fields.
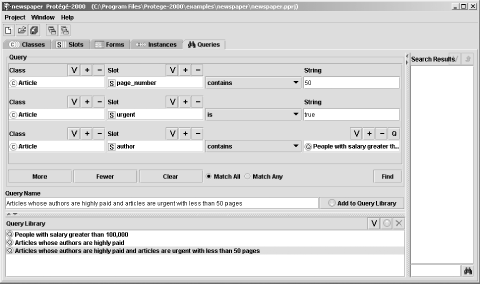
Finally, the last tab is used to enter queries about the data stored within the project. As with other query systems against RDF data described in earlier chapters, the queries are built as triples—subject, object, and predicate. Several can be combined, and a query can even be used as the object in a triple, as shown in Figure 12-5.
Again, the project can be saved at any time and can also be exported as the previously mentioned RDF/XML, JDBC, or text. In addition, the tool can also generate HTML of the contents, with all the proper hypertext links between classes, subclasses, slots, and so on maintained. Additionally, there’s a metrics function available from the Project menu that provides instance information.