
Many times I’ve heard statements like, "We’re secure—we use cryptography.." The saying in cryptographic circles is, "If you think crypto can solve the problem, you probably don’t understand the problem." It’s unfortunate that so many developers think crypto, as it’s often abbreviated, is the panacea for all security issues. Well, I hate to say it, but it isn’t! Crypto can help secure data from specific threats, but it does not secure the application from coding errors. Crypto can provide data privacy and integrity, facilitate strong authentication, and much more, but it will not mitigate programming errors such as buffer overruns in your code.
In this chapter, I’ll focus on some of the common mistakes people make when using cryptography, including using poor random numbers, using passwords to derive cryptographic keys, using poor key management techniques, and creating their own cryptographic functions. I’ll also look at using the same stream-cipher encryption key, bit-flipping attacks against stream ciphers, and reusing a buffer for plaintext and ciphertext. Note that this chapter and the next (Chapter 9) are inextricably linked—cryptography often relies on secret data, and the next chapter describes protecting secret data in detail.
Let’s get started with a topic of great interest to me: using random numbers in secure applications.
Oftentimes your application needs random data to use for security purposes, such as for passwords, encryption keys, or a random authentication challenge (also referred to as a nonce). Choosing an appropriate random-number generation scheme is paramount in secure applications. In this section, we’ll look at a simple way to generate random, unpredictable data.
Note
A key is a secret value that one needs to read, write, modify, or verify secured data. An encryption key is a key used with an encryption algorithm to encrypt and decrypt data.
I once reviewed some C++ source code that called the C run-time rand function to create a random password. The problem with rand, as implemented in most C run-time libraries, is its predictability. Because rand is a simple function that uses the last generated number as the seed to create the next number, it can make a password derived from rand easy to guess. The code that defines rand looks like the following, from the Rand.c file in the Microsoft Visual C++ 7 C Run-time (CRT) source code. I’ve removed the multithreaded code for brevity.
int __cdecl rand (void) {
return(((holdrand =
holdrand * 214013L + 2531011L) >> 16) & 0x7fff);
}Here’s a version documented in ??? of Brian Kernighan and Dennis Ritchie’s classic tome The C Programming Language, Second Edition (Prentice Hall PTR, 1988):
unsigned long int next = 1;
int rand(void)
{
next = next * 1103515245 + 12345;
return (unsigned int)(next/65536) % 32768;
}This type of function is common and is referred to as a linear congruential function.
A good random number generator has three properties: it generates evenly distributed numbers, the values are unpredictable, and it has a long and complete cycle (that is, it can generate a large number of different values and all of the values in the cycle can be generated). Linear congruential functions meet the first property but fail the second property miserably! In other words, rand produces an even distribution of numbers, but each next number is highly predictable! Such functions cannot be used in secure environments. Some of the best coverage of linear congruence is in Donald Knuth’s The Art of Computer Programming, Volume 2: Seminumerical Algorithms (Addison-Wesley, 1998). Take a look at the following examples of rand-like functions:
‘ A VBScript example
‘ Always prints 73 22 29 92 19 89 43 29 99 95 on my computer.
‘ Note: The numbers may vary depending on the VBScript version.
Randomize 4269
For i = 0 to 9
r = Int(100 * Rnd) + 1
WScript.echo(r)
Next
//A C/C++ Example
//Always prints 52 4 26 66 26 62 2 76 67 66 on my computer.
#include <stdlib.h>
void main() {
srand(12366);
for (int i = 0; i < 10; i++) {
int i = rand() % 100;
printf("%d ", i);
}
}
# A Perl 5 Example
# Always prints 86 39 24 33 80 85 92 64 27 82 on my computer.
srand 650903;
for (1 .. 10) {
$r = int rand 100;
printf "$r ";
}
//A C# example
//Always prints 39 89 31 94 33 94 80 52 64 31 on my computer.
using System;
class RandTest {
static void Main() {
Random rnd = new Random(1234);
for (int i = 0; i < 10; i++) {
Console.WriteLine(rnd.Next(100));
}
}
}As you can see, these functions are not random—they are highly predictable. (Note that the numbers output by each code snippet might change with different versions of operating system or the run-time environment, but they will always remain the same values so long as the underlying environment does not change.)
Important
Don’t use linear congruential functions, such as the CRT rand function, in security-sensitive applications. Such functions are predictable, and if an attacker can guess your next random number, she might be able to attack your application.
Probably the most famous attack against predictable random numbers is against an early version of Netscape Navigator. In short, the random numbers used to generate the Secure Sockets Layer (SSL) keys were highly predictable, rendering SSL encryption useless. If an attacker can predict the encryption keys, you may as well not bother encrypting the data! The story originally broke on BugTraq and can be read at http://online.securityfocus.com/archive/1/3791.
Here’s another example. Interestingly, and perhaps ironically, there was a bug in the way the original CodeRed worm generated "random" computer IP addresses to attack. Because they were predictable, every computer infected by this worm attacked the same list of "random" IP addresses. Because of this, the worm ended up reinfecting the same systems multiple times! You can read more about this at http://www.avp.ch/avpve/worms/iis/bady.stm.
Another great example of a random number exploit was against ASF Software’s Texas Hold ’Em Poker application. Reliable Software Technologies—now Cigital, http://www.cigital.com—discovered the vulnerability in late 1999. This "dealer" software shuffled cards by using the Borland Delphi random number function, which is simply a linear congruential function, just like the CRT rand function. The exploit required that five cards from the deck be known, and the rest of the deck could then be deduced! You can find more information about the vulnerability at http://www.cigital.com/news/gambling.html.
The simple remedy for secure systems is to not call rand and to call instead a more robust source of random data in Windows, such as CryptGenRandom, which has two of the properties of a good random number generator: unpredictability and even value distribution. This function, declared in WinCrypt.h, is available on just about every Windows platform, including Windows 95 with Internet Explorer 3.02 or later, Windows 98, Windows Me, Windows CE v3, Windows NT 4, Windows 2000, Windows XP, and Windows .NET Server 2003.
At a high level, the process for deriving random numbers by using CryptGenRandom is outlined in Figure 8-1.
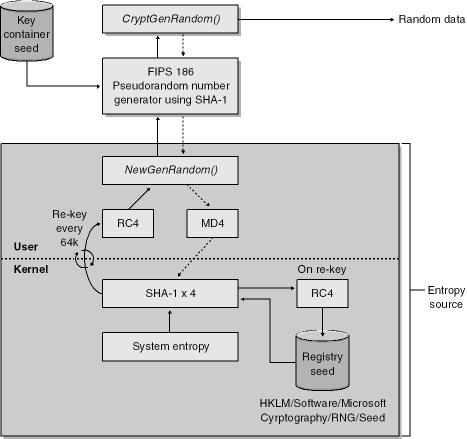
Figure 8-1. High-level view of the process for creating random numbers in Windows 2000 and later. The dotted lines show the flow of optional entropy provided by the calling code.
Note
For those who really want to know, random numbers are generated as specified in FIPS 186-2 appendix 3.1 with SHA-1 as the G function.
CryptGenRandom gets its randomness, also known as system entropy, from many sources in Windows 2000 and later, including the following:
The current process ID (GetCurrentProcessID).
The current thread ID (GetCurrentThreadID).
The ticks since boot (GetTickCount).
The current time (GetLocalTime).
Various high-precision performance counters (QueryPerformanceCounter).
An MD4 hash of the user’s environment block, which includes username, computer name, and search path. MD4 is a hashing algorithm that creates a 128-bit message digest from input data to verify data integrity.
High-precision internal CPU counters, such as RDTSC, RDMSR, RDPMC (x86 only—more information about these counters is at http://developer.intel.com/software/idap/resources/technical_collateral/pentiumii/RDTSCPM1.HTM).
Low-level system information: Idle Process Time, Io Read Transfer Count, I/O Write Transfer Count, I/O Other Transfer Count, I/O Read Operation Count, I/O Write Operation Count, I/O Other Operation Count, Available Pages, Committed Pages, Commit Limit, Peak Commitment, Page Fault Count, Copy On Write Count, Transition Count, Cache Transition Count, Demand Zero Count, Page Read Count, Page Read I/O Count, Cache Read Count, Cache I/O Count, Dirty Pages Write Count, Dirty Write I/O Count, Mapped Pages Write Count, Mapped Write I/O Count, Paged Pool Pages, Non Paged Pool Pages, Paged Pool Allocated space, Paged Pool Free space, Non Paged Pool Allocated space, Non Paged Pool Free space, Free System page table entry, Resident System Code Page, Total System Driver Pages, Total System Code Pages, Non Paged Pool Lookaside Hits, Paged Pool Lookaside Hits, Available Paged Pool Pages, Resident System Cache Page, Resident Paged Pool Page, Resident System Driver Page, Cache manager Fast Read with No Wait, Cache manager Fast Read with Wait, Cache manager Fast Read Resource Missed, Cache manager Fast Read Not Possible, Cache manager Fast Memory Descriptor List Read with No Wait, Cache manager Fast Memory Descriptor List Read with Wait, Cache manager Fast Memory Descriptor List Read Resource Missed, Cache manager Fast Memory Descriptor List Read Not Possible, Cache manager Map Data with No Wait, Cache manager Map Data with Wait, Cache manager Map Data with No Wait Miss, Cache manager Map Data Wait Miss, Cache manager Pin-Mapped Data Count, Cache manager Pin-Read with No Wait, Cache manager Pin Read with Wait, Cache manager Pin-Read with No Wait Miss, Cache manager Pin-Read Wait Miss, Cache manager Copy-Read with No Wait, Cache manager Copy-Read with Wait, Cache manager Copy-Read with No Wait Miss, Cache manager Copy-Read with Wait Miss, Cache manager Memory Descriptor List Read with No Wait, Cache manager Memory Descriptor List Read with Wait, Cache manager Memory Descriptor List Read with No Wait Miss, Cache manager Memory Descriptor List Read with Wait Miss, Cache manager Read Ahead IOs, Cache manager Lazy-Write IOs, Cache manager Lazy-Write Pages, Cache manager Data Flushes, Cache manager Data Pages, Context Switches, First Level Translation buffer Fills, Second Level Translation buffer Fills, and System Calls.
System exception information consisting of Alignment Fix up Count, Exception Dispatch Count, Floating Emulation Count, and Byte Word Emulation Count.
System lookaside information consisting of Current Depth, Maximum Depth, Total Allocates, Allocate Misses, Total Frees, Free Misses, Type, Tag, and Size.
System interrupt information consisting of context switches, deferred procedure call count, deferred procedure call rate, time increment, deferred procedure call bypass count, and asynchronous procedure call bypass count.
System process information consisting of Next Entry Offset, Number Of Threads, Create Time, User Time, Kernel Time, Image Name, Base Priority, Unique Process ID, Inherited from Unique Process ID, Handle Count, Session ID, Page Directory Base, Peak Virtual Size, Virtual Size, Page Fault Count, Peak Working Set Size, Working Set Size, Quota Peak Paged Pool Usage, Quota Paged Pool Usage, Quota Peak Non Paged Pool Usage, Quota Non Paged Pool Usage, Page file Usage, Peak Page file Usage, Private Page Count, Read Operation Count, Write Operation Count, Other Operation Count, Read Transfer Count, Write Transfer Count, and Other Transfer Count.
The resulting byte stream is hashed with SHA-1 to produce a 20-byte seed value that is used to generate random numbers according to FIPS 186-2 appendix 3.1. Note that the developer can provide extra entropy by providing a buffer of data. Refer to the CryptGenRandom documentation in the Platform SDK for more information about the user-provided buffer. Hence, if the user provides additional data in the buffer, this is used as an element in the witches’ brew to generate the random data. The result is a cryptographically random number generator.
You can call CryptGenRandom in its simplest form like this:
#include <windows.h> #include <wincrypt.h> ... HCRYPTPROV hProv = NULL; BOOL fRet = FALSE; BYTE pGoop[16]; DWORD cbGoop = sizeof pGoop; if (CryptAcquireContext(&hProv, NULL, NULL, PROV_RSA_FULL, CRYPT_VERIFYCONTEXT)) if (CryptGenRandom(hProv, cbGoop, &pGoop)) fRet = TRUE; if (hProv) CryptReleaseContext(hProv, 0);
However, the following C++ class, CCryptRandom, is more efficient because the calls to CryptAcquireContext (time-intensive) and CryptReleaseContext, which create and destroy a reference to a Cryptographic Service Provider (CSP), are encapsulated in the class constructors and destructors. Therefore, as long as you do not destroy the object, you don’t need to take the performance hit of calling these two functions repeatedly.
/*
CryptRandom.cpp
*/
#include <windows.h>
#include <wincrypt.h>
#include <iostream.h>
class CCryptRandom {
public:
CCryptRandom();
virtual ~CCryptRandom();
BOOL get(void *lpGoop, DWORD cbGoop);
private:
HCRYPTPROV m_hProv;
};
CCryptRandom::CCryptRandom() {
m_hProv = NULL;
CryptAcquireContext(&m_hProv,
NULL, NULL,
PROV_RSA_FULL, CRYPT_VERIFYCONTEXT);
if (m_hProv == NULL)
throw GetLastError();
}
CCryptRandom::~CCryptRandom() {
if (m_hProv) CryptReleaseContext(m_hProv, 0);
}
BOOL CCryptRandom::get(void *lpGoop, DWORD cbGoop) {
if (!m_hProv) return FALSE;
return CryptGenRandom(m_hProv, cbGoop,
reinterpret_cast<LPBYTE>(lpGoop));
}
void main() {
try {
CCryptRandom r;
//Generate 10 random numbers between 0 and 99.
for (int i=0; i<10; i++) {
DWORD d;
if (r.get(&d, sizeof d))
cout << d % 100 << endl;
}
} catch (...) {
//exception handling
}
}You can find this example code with the book’s sample files in the folder Secureco2Chapter08. When you call CryptGenRandom, you’ll have a very hard time determining what the next random number is, which is the whole point!
Tip
For performance reasons, you should call CryptAcquireContext infrequently and pass the handle around your application; it is safe to pass and use the handle on different threads.
Also, note that if you plan to sell your software to the United States federal government, you’ll need to use FIPS 140-1–approved algorithms. As you might guess, rand is not FIPS-approved. The default versions of CryptGenRandom in Windows 2000 and later are FIPS-approved.
If you must create cryptographically secure random numbers in managed code, you should not use code like the code below, which uses a linear congruence function, just like the C run-time rand function:
//Generate a new encryption key. byte[] key = new byte[32]; new Random().NextBytes(key);
Rather, you should use code like the following sample code in C#, which fills a 32-byte buffer with cryptographically strong random data:
using System.Security.Cryptography;
try {
byte[] b = new byte[32];
new RNGCryptoServiceProvider().GetBytes(b);
//display results
for (int i = 0; i < b.Length; i++)
Console.Write("{0} ", b[i].ToString("x"));
} catch(CryptographicException e) {
Console.WriteLine(e.Message);
}The RNGCryptoServiceProvider class calls into CryptoAPI and CryptGenRandom to generate its random data. The same code in Microsoft Visual Basic .NET looks like this:
Imports System.Security.Cryptography
Dim b(32) As Byte
Dim i As Short
Try
Dim r As New RNGCryptoServiceProvider()
r.GetBytes(b)
For i = 0 To b.Length - 1
Console.Write("{0}", b(i).ToString("x"))
Next
Catch e As CryptographicException
Console.WriteLine(e.Message)
End TryIf your application is written using ASP.NET, you can simply call the managed classes outlined in the previous section to generate quality random numbers. If you are using a COM-aware Web server technology, you could call into the CAPICOM v2 Utilities object, which supports a GetRandom method to generate random numbers. The code below shows how to do this from an ASP page written in Visual Basic Scripting Edition (VBScript):
<%
set oCC = CreateObject("CAPICOM.Utilities.1")
strRand = oCC.GetRandom(32,-1)
’ Now use strRand
’ strRand contains 32 bytes of Base64 encoded random data
%>Note the GetRandom method is new to CAPICOM version 2; it was not present in CAPICOM version 1. You can download the latest CAPICOM from http://www.microsoft.com/downloads/release.asp?ReleaseID=39546.
Cryptographic algorithms encrypt and decrypt data by using keys, and good keys are hard to guess and long. To make cryptographic algorithms usable by human beings, we don’t use very good keys—we use passwords or pass-phrases that are easy to remember. Let’s say you’re using an application that employs the Data Encryption Standard (DES) cryptographic algorithm. DES requires a 56-bit key. A good DES key has equal probability of falling anywhere in the range 0–2^56–1 (that is, 0 to 72,057,594,037,927,899). However, passwords usually contain easy-to-remember ASCII values, such as A–Z, a–z, 0–9, and various punctuation symbols, and these values form a vastly reduced subset of possible values.
An attacker who knows that you’re using DES and passwords gathered from your users need not attempt to check every value from 0–256–1 to guess the key used to encrypt the data. He need only attempt all possible passwords that contain the easy-to-remember ASCII group of values; this is a really easy problem to solve for the attacker!
Note
I have to admit to being a Perl nut. In April 2001, on the Fun With Perl mailing list—you can sign up at http://www.technofile.org/depts/mlists/fwp.html—someone asked for the shortest Perl code that produces a random eight-character password. The following code was one of the shortest examples; it’s hardly random, but it is cute!
print map chr 33+rand 93, 0..7
Claude Shannon, a pioneer in information science, produced a research paper in 1948 titled "A Mathematical Theory of Communication" that addressed the randomness of the English language. Without going into the math involved, I can tell you that the effective bit length of a random password is log2(n^m), where n is the pool size of valid characters and m is the length of the password. The following VBScript code shows how to determine the effective bit size of a password, based on its length and complexity:
Function EntropyBits(iNumValidValues, iPwdSize) If iNumValidValues <= 0 Then EntropyBits = 0 Else EntropyBits = iPwdSize * log(iNumValidValues) / log(2) End If End Function ‘ Check a password made from A-Z, a-z, 0-9 (62 chars) ‘ and eight characters in length. WScript.echo(EntropyBits(62, 8))
Here’s the same thing in C/C++:
#include <math.h>
#include <stdio.h>
double EntropyBits(double valid, double size) {
return valid ? size * log(valid) / log(2):0;
}
void main() {
printf("%f", EntropyBits(62, 8));
}Important
The effective bit size of a password is an important variable when calculating its effective strength, but you should also consider whether the password can be guessed. For example, I have a dog, Major, and it would be awful of me to create a password like Maj0r, which would be easy for someone who knew a little about me to guess.
Do not underestimate the power of social engineering attacks. A friend of mine is a big fan of Victor Hugo’s Les Misérables, and recently he received a smartcard for his home computer. Not so surprisingly, I determined the PIN in one guess—it was 24601, Jean Valjean’s prisoner number.
Let me give you an idea of how bad many passwords are. Remember that DES, considered insecure for long-lived data, uses a 56-bit key. Now look at Table 8-1 to see the available-character pool size and password length required in different scenarios to create equivalent 56-bit and 128-bit keys.
Table 8-1. Available Characters and Password Lengths for Two Keys
|
Scenario |
Available Characters |
Required Password Length for 56-Bit Key |
Required Password Length for 128-Bit Key |
|---|---|---|---|
|
Numeric PIN |
10 (0–9) |
17 |
40 |
|
Case-insensitive alpha |
26 (A–Z or a–z) |
12 |
28 |
|
Case-sensitive alpha |
52 (A–Z and a–z) |
10 |
23 |
|
Case-sensitive alpha and numeric |
62 (A–Z, a–z, and 0–9) |
10 |
22 |
|
Case-sensitive alpha, numeric, and punctuation |
93 (A–Z, a–z, 0–9, and punctuation) |
9 |
20 |
If you gather keys or passwords from users, you should consider adding information to the dialog box explaining how good the password is based on its entropy. Figure 8-2 shows an example.
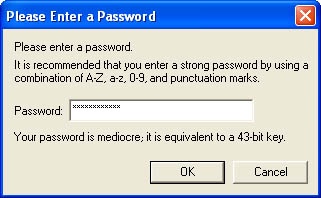
Figure 8-2. An example of a password entry dialog box informing the user of the relative strength of the password the user entered.
Important
If you must use passwords from users to generate keys, make sure the passwords are long and highly random. Of course, people do not remember random data easily. You need to find a happy balance between randomness and ease of recall. For an enlightening document about password weakness, read "The Memorability and Security of Passwords—Some Empirical Results" at http://www.ftp.cl.cam.ac.uk/ftp/users/rja14/tr500.pdf.
More Information
In Windows .NET Server 2003 and later, you can validate password compliance with your corporate password policy by calling NetValidatePasswordPolicy. A C++ sample, ChkPwd, is included with the book’s sample files in the folder Secureco2Chapter08.
Another great document regarding random numbers in secure applications is an Internet draft written by Donald Eastlake, Jeffrey Schiller, and Steve Crocker: "Randomness Requirements for Security," which replaces RFC 1750. This is a technical yet practical discussion of random number generation. At the time of this writing, the document had expired, but the last document name was draft-eastlake-randomness2-02. You may want to search for it using your favorite Internet search engine.
Key management is generally considered the weakest link of cryptographic applications and hard to get right. Using cryptography is easy; securely storing, exchanging, and using keys is hard. All too often, good systems are let down by poor key management. For example, hard-coding a key in an executable image is trivial to break, even when people don’t have access to your source code.
If a key is a simple text string such as This1sAPa$sword, you can use a tool (such as one named Strings) to dump all the strings in a .DLL or .EXE to determine the password. Simple trial and error by the attacker will determine which string contained in the file is the correct key. Trust me: such strings are extremely easy to break. File a bug if you see lines such as these:
//SSsshh!! Don’t tell anyone. char *szPassword="&162hV1);sWa1";
And what if the password is highly random, as a good key should be? Surely a tool like Strings will not find the key because it’s not an ASCII string. It too is easy to determine because the key data is random! Code and static data are not random. If you create a tool to scan for entropy in an executable image, you will quickly find the random key.
In fact, such a tool has been created by a British company named nCipher (http://www.ncipher.com). The tool operates by attaching itself to a running process and then scanning the process memory looking for entropy. When it finds areas of high randomness, it determines whether the data is a key, such as a key used for SSL/TLS. Most of the time, it gets it right! A document outlining this sort of attack, "Playing Hide and Seek with Stored Keys," is available at http://www.ncipher.com/products/rscs/downloads/whitepapers/keyhide2.pdf. nCipher has kept the tool to itself.
More Information
Refer to Chapter 9 for information about storing secret information in software.
Important
Do not hard-code secret keys in your code, and that includes resource files (.RC files) and configuration files. They will be found out; it is just a matter of time. If you think no one will work it out, you are sadly mistaken.
There are two classes of keys: short-term keys and long-term keys. Short-term keys are often called ephemeral keys and are used by numerous networking protocols, such as IPSec, SSL/TLS, RPC, and DCOM. The key generation management process is hidden from the application and the user.
Long-term keys are used for authentication, integrity, and nonrepudiation and can be used to establish ephemeral keys. For example, when using SSL/TLS, the server uses its private key—identified by its public key certificate—to help generate ephemeral keys for each encrypted SSL/TLS session. It’s a little more complex than this, but you get the idea.
Long-term keys are also used to protect persistent data held in databases and files, and because of their long-term nature, attackers could attempt to break the key over a long period of time. Obviously, long-term keys must be generated and protected securely. Now let’s look at some good key management practices.
Encrypted data should be protected with an appropriately long encryption key. Obviously, the shorter the key, the easier it is to attack. However, the keys used for different algorithms are attacked in different ways. For example, attacking most symmetric ciphers, such as DES and RC4, requires that the attacker try every key. However, attacking RSA (an asymmetric cipher) keys requires that the attacker attempt to derive the random values used to create the public and private keys. This is a process called factoring. Because of this, you cannot say that a 112-bit 3DES key is less secure than a 512-bit RSA key because they are attacked in different ways. In fact, in this case, a 512-bit RSA key can be factored faster than performing a brute-force attack against the 112-bit 3DES key space.
More Information
Take a look at "Cryptographic Challenges" at http://www.rsasecurity.com/rsalabs/challenges for information about attacking DES by brute force and RSA by factoring.
However, if you protect symmetric keys using asymmetric keys, you should use an appropriately long asymmetric key. Table 8-2, derived from an Internet draft "Determining Strengths For Public Keys Used For Exchanging Symmetric Keys" at http://ietf.org/internet-drafts/draft-orman-public-key-lengths-05.txt, gives an idea for the key-size relationships.
Table 8-2. Key-Size Equivalences
|
Symmetric Key Size (Bits) |
Equivalent RSA Modulus Size (Bits) |
Equivalent DSA Subgroup Size (Bits) |
|---|---|---|
|
70 |
947 |
128 |
|
80 |
1228 |
145 |
|
90 |
1553 |
153 |
|
100 |
1926 |
184 |
|
150 |
4575 |
279 |
|
200 |
8719 |
373 |
|
250 |
14596 |
475 |
This table tells us that to protect an 80-bit symmetric key using RSA, the RSA key must be at least 1228 bits. If the latter is shorter than that, it will be easier for a hacker to break the RSA key than it will to attempt a brute-force attack against the 80-bit key.
Important
Do not protect a 128-bit AES key by using a 512-bit RSA key!
When using secret information such as cryptographic keys and passwords, you must keep the keys close to the point where they encrypt and decrypt data. The rationale is simple: highly "mobile" secrets stay secret only a short time! As a friend once said to me, "The value of a secret is inversely proportional to its availability." Or, put another way, "A secret known by many is no longer a secret!" This applies not only to people knowing a secret but also to code that uses secret data. As I mentioned earlier in this book, all code has bugs, and the more code that has access to secret data, the greater the chance the secret will be exposed to an attacker. Take a look at Figure 8-3.
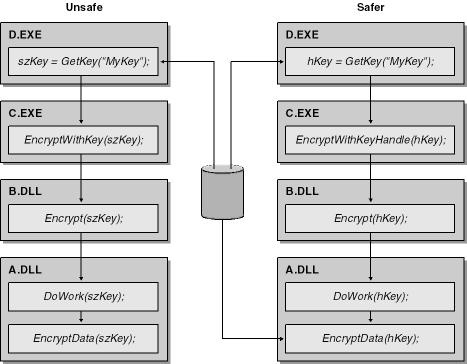
Figure 8-3. Allowing keys to roam through an application and keeping keys close to the point where they are used.
The example on the left of Figure 8-3 shows the password passed from function to function and executable to executable. GetKey reads the password from a persistent store and passes the password through EncryptWithKey, Encrypt, DoWork, and ultimately to EncryptData. This is a poor design because a security flaw in any of the functions could leak the private password to an assailant armed with a debugger.
The example on the right is a better design. GetKeyHandle acquires a handle to the password and passes the handle eventually to EncryptData, which then reads the key from the persistent store. If any of the intermediate functions are compromised, the attacker has access only to the handle and not to the password directly.
Important
Secret data, including passwords, passed throughout an application is more likely to be compromised than secret data maintained in a central location and used only locally.
Microsoft CryptoAPI includes the CryptGenKey function to generate a cryptographically strong key, yet you never see the key value directly. Rather, you access it using a handle to the key. The key is protected by CryptoAPI, and all references to the key are made through the handle. If you need to store the key in some form of persistent storage, such as a floppy disk, a database, a file, or the registry, you can export the key by using the CryptExportKey function and import the key from the persistent store by using CryptImportKey. The key is protected by either a public key in a certificate (and later decrypted with the private key) or, new in Windows 2000 and later, a symmetric key. The key is never in plaintext except deep inside CryptoAPI, and hence the key is safer. Plaintext refers to text that hasn’t been encrypted. Sometimes it’s also called cleartext.
The following C++ code shows how to generate and export a private key:
/*
ProtectKey.cpp
*/
#include "stdafx.h"
using namespace std;
//Get the symmetric exchange key used to encrypt the key.
void GetExchangeKey(HCRYPTPROV hProv, HCRYPTKEY *hXKey) {
//The key-exchange key comes from an external source.
HCRYPTHASH hHash;
BYTE bKey[16];
if (!GetKeyFromStorage(bKey, sizeof bKey))
throw GetLastError();
if (!CryptCreateHash(hProv, CALG_SHA1, 0, 0, &hHash))
throw GetLastError();
if (!CryptHashData(hHash, bKey, sizeof bKey, 0))
throw GetLastError();
if (!CryptDeriveKey(hProv, CALG_3DES, hHash, CRYPT_EXPORTABLE,
hXKey))
throw GetLastError();
}
void main() {
HCRYPTPROV hProv = NULL;
HCRYPTKEY hKey = NULL;
HCRYPTKEY hExchangeKey = NULL;
LPBYTE pbKey = NULL;
try {
if (!CryptAcquireContext(&hProv, NULL, NULL,
PROV_RSA_FULL,
CRYPT_VERIFYCONTEXT))
throw GetLastError();
//Generate two 3DES keys, and mark them as exportable.
//Note: these keys are kept in CryptoAPI at this point.
if (!CryptGenKey(hProv, CALG_3DES, CRYPT_EXPORTABLE, &hKey))
throw GetLastError();
//Get a key that we can use to encrypt the two 3DES keys.
GetExchangeKey(hProv, &hExchangeKey);
//Determine blob size.
DWORD dwLen = 0;
if (!CryptExportKey(hKey, hExchangeKey,
SYMMETRICWRAPKEYBLOB,
0, pb Key, &dwLen))
throw GetLastError();
pbKey = new BYTE[dwLen]; //Array to hold 3DES keys
ZeroMemory(pbKey, dwLen);
/if(!pbKey)throwError_NOT_ENOUGH_MEMORY;
//Now get the shrouded blob.
if (!CryptExportKey(hKey, hExchangeKey,
SYMMETRICWRAPKEYBLOB, 0, pbKey, &dwLen))
throw GetLastError();
cout << "Cool, " << dwLen
<< " byte wrapped key is exported."
<< endl;
//Write shrouded key to Key.bin; overwrite if needed
//using ostream::write() rather than operator<<,
//as the data may contain NULLs.
ofstream file("c:\keys\key.bin", ios_base::binary);
file.write(reinterpret_cast<const char *>(pbKey ), dwLen);
file.close();
} catch(DWORD e) {
cerr << "Error " << e << hex << " " << e << endl;
}
// Clean up.
if (hExchangeKey) CryptDestroyKey(hExchangeKey);
if (hKey) CryptDestroyKey(hKey);
if (hProv) CryptReleaseContext(hProv, 0);
if (pbKey) delete [] pbKey;
}You can also find the example code with the book’s sample files in the folder Secureco2Chapter08. Note that the GetExchangeKey function is only an example—your application will need to have a version of this function to acquire the key-exchange key from its storage location or possibly from the user. From now on, you can acquire the shrouded key from storage and use it to encrypt and decrypt data without knowing what the key actually is! This application generates two Triple-DES (3DES) keys. 3DES is an encrypting algorithm that processes data three times in succession with three different keys. It’s more difficult to break than straight DES.
Exchanging keys is a subset of key management, and it is a huge headache. After all, if an attacker can compromise the key exchange process, he might access the keys used to encrypt data and therefore be able defeat the application. The main threats to insecure or weak key exchange include information disclosure and tampering. Both could lead to spoofing attacks if the key is used to authenticate the end points or is used to sign some data. Remember: verifying a signature is proving the authenticity and integrity of a signed document, and if the key used to sign the document is compromised, then the integrity of the document cannot be ascertained with confidence.
When exchanging keys, there are a number of best practices to follow:
Some keys should never be exchanged! Private keys used to sign data are private. (That’s why they are called private keys!) So ask yourself, "Does my application require that I share this key?" You’ll be surprised how often you realize you do not need to exchange a key and you can use some other security protocol that mitigates the need to perform key exchange.
Obviously, do not embed the key in your code. You may have solved the key exchange problem, because you have no keys to exchange; however, you have a very serious key management problem if the key is disclosed by an attacker, and you can bet it will be. You can read more about storing secrets in Chapter 9.
Don’t rule out supporting a "sneaker-net" solution. After all, you mitigate the problem of a hacker accessing the key as it travels across the network if your application supports transferring the key by using humans rather than a piece of wire. There are usability issues to worry about, but this might be a viable option if the security of the application outweighs the extra effort required of the user. This is one mode used by the IPSec administration tool in Windows 2000 and beyond. Figure 8-4 shows the IPSec dialog box for using a certificate that you could distribute by sneaker-net.
Consider using a protocol that performs key exchange for you so that you don’t need to. This works only for ephemeral or short-lived data, such as data that travels over the network. For example, SSL/TLS and IPSec perform a key exchange prior to transferring data. However, if you persist data in the registry or a database, you cannot use this mode.
Finally, if you must perform key exchange, use a tried and trusted exchange mechanism such as Diffie-Hellman key agreement or RSA key exchange and do not create your own key exchange protocol. Chances are you’ll get it horrendously wrong and your keys will be vulnerable to disclosure and tampering threats.
I cringe when I hear, "Yeah, we got crypto. We created our own algorithm—it rocks!" Or, "We didn’t trust any of the known algorithms since they are well known, so we created our own algorithm. That way we’re the only ones that know it, and it’s much more secure." Producing good cryptographic algorithms is a difficult task, one that should be undertaken only by those who well understand how to create such algorithms. Code like the following is bad, very bad:
void EncryptData(char *szKey,
DWORD dwKeyLen,
char *szData,
DWORD dwDataLen) {
for (int i = 0; i < dwDataLen; i++) {
szData[i] ^= szKey[i % dwKeyLen];
}
}This code simply XORs the key with the plaintext, resulting in the "ciphertext," and I use the latter term loosely! Ciphertext refers to the text that has been encrypted with an encryption key. The key is weak because it is so trivial to break. Imagine you are an attacker and you have no access to the encryption code. The application operates by taking the user’s plaintext, "encrypting" it, and storing the result in a file or the registry. All you need to do is XOR the ciphertext held in the file or registry with the data you originally entered, and voilà, you have the key! A colleague once told me that we should refer to such encryption as encraption!
Do not do this! The best way to use encryption is to use tried and trusted encryption algorithms defined in libraries such as CryptoAPI included with Windows. In fact, alarm bells should ring in your mind if you encounter words such as hide, obfuscate, or encode when reading the specification of a feature you are implementing!
The following sample code, written in Microsoft JScript using the CAPICOM library, shows how to encrypt and decrypt a message:
var CAPICOM_ENCRYPTION_ALGORITHM_RC2 = 0;
var CAPICOM_ENCRYPTION_ALGORITHM_RC4 = 1;
var CAPICOM_ENCRYPTION_ALGORITHM_DES = 2;
var CAPICOM_ENCRYPTION_ALGORITHM_3DES = 3;
var oCrypto = new ActiveXObject("CAPICOM.EncryptedData");
//Encrypt the data.
var strPlaintext = "In a hole in the ground...";
oCrypto.Content = strPlaintext;
//Get key from user via an external function.
oCrypto.SetSecret(GetKeyFromUser());
oCrypto.Algorithm = CAPICOM_ENCRYPTION_ALGORITHM_3DES;
var strCiphertext = oCrypto.Encrypt(0);
//Decrypt the data.
oCrypto.Decrypt(strCiphertext);
if (oCrypto.Content == strPlaintext) {
WScript.echo("Cool!");
}Note
What’s CAPICOM? CAPICOM is a COM component that performs cryptographic functions. The CAPICOM interface can sign data, verify digital signatures, and encrypt and decrypt data. It can also be used to check the validity of digital certificates. CAPICOM was first made public as part of the Windows XP Beta 2 Platform SDK. You need to register Capicom.dll before using it. The redistributable files for this DLL are available at http://www.microsoft.com/downloads/release.asp?releaseid=39546.
Important
Do not, under any circumstances, create your own encryption algorithm. The chances are very good that you will get it wrong. For Win32 applications, use CryptoAPI. For script-based applications (VBScript, JScript, and ASP), use the CAPICOM library. Finally, for .NET applications (including ASP.NET), use the classes in the System.Security.Cryptography namespace.
A stream cipher is a cipher that encrypts and decrypts data one unit at a time, where a unit is usually 1 byte. (RC4 is the most famous and most used stream cipher. In addition, it is the only stream cipher provided in the default CryptoAPI installation in Windows.) An explanation of how stream ciphers work will help you realize the weakness of using the same stream-cipher key. First an encryption key is provided to an internal algorithm called a keystream generator. The keystream generator outputs an arbitrary length stream of key bits. The stream of key bits is XORed with a stream of plaintext bits to produce a final stream of ciphertext bits. Decrypting the data requires reversing the process: XORing the key stream with the ciphertext to yield plaintext.
A symmetric cipher is a system that uses the same key to encrypt and decrypt data, as opposed to an asymmetric cipher, such as RSA, which uses two different but related keys to encrypt and decrypt data. Other examples of symmetric ciphers include DES, 3DES, AES (Advanced Encryption Standard, the replacement for DES), IDEA (used in Pretty Good Privacy [PGP]), and RC2. All these algorithms are also block ciphers; they encrypt and decrypt data a block at a time rather than as a continuous stream of bits. A block is usually 64 or 128 bits in size.
Using stream ciphers, you can avoid the memory management game. For example, if you encrypt 13 bytes of plaintext, you get 13 bytes of ciphertext back. However, if you encrypt 13 bytes of plaintext by using DES, which encrypts using a 64-bit block size, you get 16 bytes of ciphertext back. The remaining three bytes are padding because DES can encrypt only full 64-bit blocks. Therefore, when encrypting 13 bytes, DES encrypts the first eight bytes and then pads the remaining five bytes with three bytes, usually null, to create another eight-byte block that it then encrypts. Now, I’m not saying that developers are lazy, but, frankly, the more you can get away with not having to get into memory management games, the happier you may be!
People also use stream ciphers because they are fast. RC4 is about 10 times faster than DES in software, all other issues being equal. As you can see, good reasons exist for using stream ciphers. But pitfalls await the unwary.
First, stream ciphers are not weak; many are strong and have withstood years of attack. Their weakness stems from the way developers use the algorithms, not from the algorithms themselves.
Note that each unique stream-cipher key derives the same key stream. Although we want randomness in key generation, we do not want randomness in key stream generation. If the key streams were random, we would never be able to find the key stream again, and hence, we could never decrypt the data. Here is where the problem lies. If a key is reused and an attacker can gain access to one ciphertext to which she knows the plaintext, she can XOR the ciphertext and the plaintext to derive the key stream. From now on, any plaintext encrypted with that key can be derived. This is a major problem.
Actually, the attacker cannot derive all the plaintext of the second message; she can derive up to the same number of bytes that she knew in the first message. In other words, if she knew the first 23 bytes from one message, she can derive the first 23 bytes in the second message by using this attack method.
To prove this for yourself, try the following CryptoAPI code:
/*
RC4Test.cpp
*/
#define MAX_BLOB 50
BYTE bPlainText1[MAX_BLOB];
BYTE bPlainText2[MAX_BLOB];
BYTE bCipherText1[MAX_BLOB];
BYTE bCipherText2[MAX_BLOB];
BYTE bKeyStream[MAX_BLOB];
BYTE bKey[MAX_BLOB];
//////////////////////////////////////////////////////////////////
//Setup - set the two plaintexts and the encryption key.
void Setup() {
ZeroMemory(bPlainText1, MAX_BLOB);
ZeroMemory(bPlainText2, MAX_BLOB);
ZeroMemory(bCipherText1, MAX_BLOB);
ZeroMemory(bCipherText2, MAX_BLOB);
ZeroMemory(bKeyStream, MAX_BLOB);
ZeroMemory(bKey, MAX_BLOB);
strncpy(reinterpret_cast<char*>(bPlainText1),
"Hey Frodo, meet me at Weathertop, 6pm.", MAX_BLOB-1);
strncpy(reinterpret_cast<char*>(bPlainText2),
"Saruman has me prisoner in Orthanc.", MAX_BLOB-1);
strncpy(reinterpret_cast<char*>(bKey),
GetKeyFromUser(), MAX_BLOB-1); // External function
}
//////////////////////////////////////////////////////////////////
//Encrypt - encrypts a blob of data using RC4.
void Encrypt(LPBYTE bKey,
LPBYTE bPlaintext,
LPBYTE bCipherText,
DWORD dwHowMuch) {
HCRYPTPROV hProv;
HCRYPTKEY hKey;
HCRYPTHASH hHash;
/*
The way this works is as follows:
Acquire a handle to a crypto provider.
Create an empty hash object.
Hash the key provided into the hash object.
Use the hash created in step 3 to derive a crypto key. This key
also stores the algorithm to perform the encryption.
Use the crypto key from step 4 to encrypt the plaintext.
*/
DWORD dwBuff = dwHowMuch;
CopyMemory(bCipherText, bPlaintext, dwHowMuch);
if (!CryptAcquireContext(&hProv, NULL, NULL, PROV_RSA_FULL,
CRYPT_VERIFYCONTEXT))
throw;
if (!CryptCreateHash(hProv, CALG_MD5, 0, 0, &hHash))
throw;
if (!CryptHashData(hHash, bKey, MAX_BLOB, 0))
throw;
if (!CryptDeriveKey(hProv, CALG_RC4, hHash,
CRYPT_EXPORTABLE,
&hKey))
throw;
if (!CryptEncrypt(hKey, 0, TRUE, 0,
bCipherText,
&dwBuff,
dwHowMuch))
throw;
if (hKey) CryptDestroyKey(hKey);
if (hHash) CryptDestroyHash(hHash);
if (hProv) CryptReleaseContext(hProv, 0);
}
void main() {
Setup();
//Encrypt the two plaintexts using the key, bKey.
try {
Encrypt(bKey, bPlainText1, bCipherText1, MAX_BLOB);
Encrypt(bKey, bPlainText2, bCipherText2, MAX_BLOB);
} catch (...) {
printf("Error - %d", GetLastError());
return;
}
//Now do the "magic."
//Get each byte from the known ciphertext or plaintext.
for (int i = 0; i < MAX_BLOB; i++) {
BYTE c1 = bCipherText1[i]; //Ciphertext #1 bytes
BYTE p1 = bPlainText1[i]; //Plaintext #1 bytes
BYTE k1 = c1 ^ p1; //Get keystream bytes.
BYTE p2 = k1 ^ bCipherText2[i]; //Plaintext #2 bytes
// Print each byte in the second message.
printf("%c", p2);
}
}You can find this example code with the book’s sample files in the folder Secureco2Chapter08. When you run this code, you’ll see the plaintext from the second message, even though you knew the contents of the first message only!
In fact, it is possible to attack stream ciphers used this way without knowing any plaintext. If you have two ciphertexts, you can XOR the streams together to yield the XOR of the two plaintexts. And it’s feasible to start performing statistical frequency analysis on the result. Letters in all languages have specific occurrence rates or frequencies. For example, in the English language, E, T, and A are among the most commonly used letters. Given enough time, an attacker might be able to determine the plaintext of one or both messages. (In this case, knowing one is enough to know both.)
Note
To be accurate, you should never use the same key to encrypt data regardless of symmetric encryption algorithm, including block ciphers such as DES and 3DES. If two plaintexts are the same text or certain parts of the plaintexts are the same, the ciphertexts might be the same. The attacker might not know the plaintext, but he does know that the plaintexts are the same or that a portion of the plaintexts is the same. That said, sometimes the attacker does know some plaintext. For example, many file types contain well-defined headers, which can often be easily deduced by an attacker.
My first thought is that if you must use the same key more than once, you need to revisit your design! That said, if you absolutely must use the same key when using a stream cipher, you should use a salt and store the salt with the encrypted data. A salt is a value, selected at random, sent or stored unencrypted with the encrypted message. Combining the key with the salt helps foil attackers.
Salt values are perhaps most commonly used in UNIX-based systems, where they are used in the creation of password hashes. Password hashes were originally stored in a plaintext, world-readable file (/etc/passwd) on those systems. Anyone could peruse this file and compare his or her own password hash with those of other users on the system. If two hashes matched, the two passwords were the same! Windows does not salt its passwords, although in Windows 2000 and later the password hashes themselves are encrypted prior to permanent storage, which has the same effect. This functionality, known as Syskey, is optional (but highly recommended) on Windows NT 4.0 Service Pack 3 and later.
You can change the CryptoAPI code, shown earlier in "The Pitfalls of Stream Ciphers," to use a salt by making this small code change:
if (!CryptCreateHash(hProv, CALG_MD5, 0, 0, &hHash)) throw; if (!CryptHashData(hHash, bKey, MAX_BLOB,0)) throw; if (!CryptHashData(hHash, bSalt, cbSaltSize, 0)) throw; if (!CryptDeriveKey(hProv, CALG_RC4, hHash, CRYPT_E XPORTABLE, &hKey)) throw;
This code simply hashes the salt into the key; the key is secret, and the salt is sent with the message unencrypted.
Important
The bits in a salt value consist of random data. The bits in the key must be kept secret, while the bits in the salt value can be made public and are transmitted in the clear. Salt values are most useful for transmitting or storing large numbers of nearly identical packets using the same encryption key. Normally, two identical packets would encrypt into two identical ciphertext packets. However, this would indicate to an eavesdropper that the packets are identical, and the packets might then be attacked simultaneously. If the salt value is changed with every packet sent, different ciphertext packets will always be generated, even if the plaintext packets are the same. Because salt values need not be kept secret and can be transmitted in plaintext with each ciphertext packet, it is much easier to change salt values once per packet than it is to change the key value itself.
Note
All ciphers in the .NET Framework classes are block ciphers. Therefore, you have little chance of making the kinds of mistakes I’ve described in this section when you use these classes.
As I’ve already mentioned, a stream cipher encrypts and decrypts data, usually 1 bit at a time, by XORing the plaintext with the key stream generated by the stream cipher. Because of this, stream ciphers are susceptible to bit-flipping attack. Because stream ciphers encrypt data 1 bit at a time, an attacker could modify 1 bit of ciphertext and the recipient might not know the data had changed. This is particularly dangerous if someone knows the format of a message but not the content of the message.
Imagine you know that the format of a message is
hh:mm dd-mmm-yyyy. bbbbbbbbbbbbbbbbbbbbbbbbbbbb
where hh is hour using 24-hour clock, mm is minutes, dd is day, mmm is a three-letter month abbreviation, yyyy is a full four-digit year, and bbbbb is the message body. Squirt decides to send a message to Major. Before encryption using a stream cipher, the message is
16:00 03-Sep-2004. Meet at the dog park. Squirt.
Note
We assume that Squirt and Major have a predetermined shared key they use to encrypt and decrypt data.
As you can see, Squirt wants to meet Major at the dog park at 4 P.M. on September 3, 2004. As an attacker, you do not have the plaintext, only the ciphertext and an understanding of the message format. However, you could change one or more of the encrypted bytes in the time and date fields (or any field, for that matter) and then forward the changed message to Major. There would be no way for anyone to detect that a malicious change had taken place. When Major decrypts the message, the time will not read 16:00, and Major will not make it to the dog park at the allotted time. This is a simple and possibly dangerous attack!
You can prevent bit-flipping attacks by using a digital signature or a keyed hash (explained shortly). Both of these technologies provide data-integrity checking and authentication. You could use a hash, but a hash is somewhat weak because the attacker can change the data, recalculate the hash, and add the new hash to the data stream. Once again, you have no way to determine whether the data was modified.
If you choose to use a hash, keyed hash, or digital signature, your encrypted data stream changes, as shown in Figure 8-5.
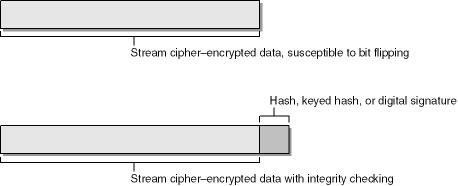
As I’ve already mentioned, you can hash the data and append the hash to the end of the encrypted message, but this method is not recommended because an attacker can simply recalculate the hash after changing the data. Using keyed hashes or digital signatures provides better protection against tampering.
A keyed hash is a hash that includes some secret data, data known only to the sender and recipients. It is typically created by hashing the plaintext concatenated to some secret key or a derivation of the secret key. Without knowing the secret key, you could not calculate the proper keyed hash.
Note
A keyed hash is one kind of message authentication code (MAC). For more information, see "What Are Message Authentication Codes" at http://www.rsasecurity.com/rsalabs/faq/2-1-7.html.
The diagram in Figure 8-6 outlines how a keyed-hash encryption process operates.
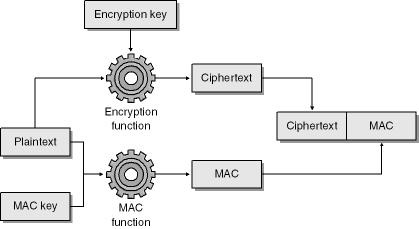
Developers make a number of mistakes when creating keyed hashes. Let’s look at some of these mistakes and then at how to generate a keyed hash securely.
Not using a key whatsoever when using a keyed hash is a surprisingly common mistake—this is as bad as creating only a hash! Do not fall into this trap.
Another common mistake, because of its ease, is using the same key to encrypt data and key-hash data. When you encrypt data with one key, K1, and key-hash the data with another, K2, the attacker must know K1 to decrypt the data and must know K2 to change the data. If you encrypt and key-hash the data with K1 only, the attacker need only determine one key to decrypt and tamper with the data.
Both CryptoAPI and the .NET Framework classes provide support for key-hashing data. The following is some example CryptoAPI code that key-hashes data and uses an algorithm named hash-based message authentication code (HMAC). You can also find a similar code listing with the book’s sample files in the folder Secureco2Chapter08MAC. More information about the HMAC algorithm can be found in RFC 2104 (http://www.ietf.org/rfc/rfc2104.txt).
/*
MAC.cpp
*/
#include "stdafx.h"
DWORD HMACStuff(void *szKey, DWORD cbKey,
void *pbData, DWORD cbData,
LPBYTE *pbHMAC, LPDWORD pcbHMAC) {
DWORD dwErr = 0;
HCRYPTPROV hProv;
HCRYPTKEY hKey;
HCRYPTHASH hHash, hKeyHash;
try {
if (!CryptAcquireContext(&hProv, 0, 0,
PROV_RSA_FULL, CRYPT_VERIFYCONTEXT))
throw;
//Derive the hash key.
if (!CryptCreateHash(hProv, CALG_SHA1, 0, 0, &hKeyHash))
throw;
if (!CryptHashData(hKeyHash, (LPBYTE)szKey, cbKey, 0))
throw;
if (!CryptDeriveKey(hProv, CALG_DES,
hKeyHash, 0, &hKey))
throw;
//Create a hash object.
if(!CryptCreateHash(hProv, CALG_HMAC, hKey, 0, &hHash))
throw;
HMAC_INFO hmacInfo;
ZeroMemory(&hmacInfo, sizeof(HMAC_INFO));
hmacInfo.HashAlgid = CALG_SHA1;
if(!CryptSetHashParam(hHash, HP_HMAC_INFO,
(LPBYTE)&hmacInfo,
0))
throw;
//Compute the HMAC for the data.
if(!CryptHashData(hHash, (LPBYTE)pbData, cbData, 0))
throw;
//Allocate memory, and get the HMAC.
DWORD cbHMAC = 0;
if(!CryptGetHashParam(hHash, HP_HASHVAL, NULL, &cbHMAC, 0))
throw;
//Retrieve the size of the hash.
*pcbHMAC = cbHMAC;
*pbHMAC = new BYTE[cbHMAC];
if (NULL == *pbHMAC)
throw;
if(!CryptGetHashParam(hHash, HP_HASHVAL, *pbHMAC, &cbHMAC, 0))
throw;
SetLastError()
} catch(...) {
dwErr = GetLastError();
printf("Error - %d
", GetLastError());
}
if (hProv) CryptReleaseContext(hProv, 0);
if (hKeyHash) CryptDestroyKey(hKeyHash);
if (hKey) CryptDestroyKey(hKey);
if (hHash) CryptDestroyHash(hHash);
return dwErr;
}
void main() {
//Key comes from the user.
char *szKey = GetKeyFromUser();
DWORD cbKey = lstrlen(szKey);
if (cbKey == 0) {
printf("Error – you did not provide a key.
");
return -1;
}
char *szData="In a hole in the ground...";
DWORD cbData = lstrlen(szData);
//pbHMAC will contain the HMAC.
//The HMAC is cbHMAC bytes in length.
LPBYTE pbHMAC = NULL;
DWORD cbHMAC = 0;
DWORD dwErr = HMACStuff(szKey, cbKey,
szData, cbData,
&pbHMAC, &cbHMAC);
//Do something with pbHMAC.
delete [] pbHMAC;
}Creating a keyed hash in the .NET Framework is almost the same as creating a nonkeyed hash; the only difference is you include a key when creating a keyed hash:
HMACSHA1 hmac = new HMACSHA1(); hmac.Key = key; byte [] hash = hmac.ComputeHash(message);
In this example, key and message are provided elsewhere in the code and hash is the resulting HMAC.
Important
When creating a keyed hash, use the operating system or the .NET Framework class libraries. It’s much easier than doing the work yourself.
Digital signatures differ from keyed hashes, and from MACs in general, in a number of ways:
You create a digital signature by encrypting a hash with a private key. MACs use a shared session key.
Digital signatures do not use a shared key; MACs do.
You could use a digital signature for nonrepudiation purposes, legal issues aside. You can’t use a MAC for such purposes because more than one party shares the MAC key. Either party having knowledge of the key could produce the MAC.
Digital signatures are somewhat slower than MACs, which are very quick.
Despite these differences, digital signatures provide for authentication and integrity checking, just as MACs do. The process of creating a digital signature is shown in Figure 8-7.
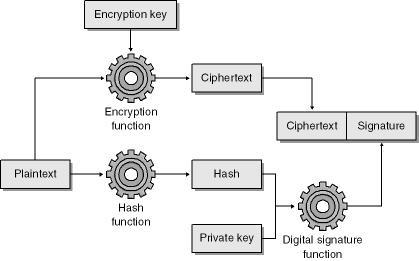
Anyone who has access to your public key certificate can verify that a message came from you—or, more accurately, anyone who has your private key! So you should make sure you protect the private key from attack.
CAPICOM offers an incredibly easy way to sign data and to verify a digital signature. The following VBScript code signs some text and then verifies the signature produced by the signing process:
strText = "I agree to pay the lender $42.69."
Set oDigSig = CreateObject("CAPICOM.SignedData")
oDigSig.Content = strText
fDetached = TRUE
signature = oDigSig.Sign(Nothing, fDetached)
oDigSig.Verify signature, fDetachedNote a few points about this code. Normally, the signer would not verify the signature once it is created. It’s usually the message recipient who determines the validity of the signature. The code produces a detached signature, which is just the signature and not a message and the signature. Finally, this code will use or prompt the user to select a valid private key with which to sign the message.
Digital signatures are a breeze in the .NET Framework. However, if you want to access a certificate a private key stored by CryptoAPI, you’ll need to call CryptoAPI or CAPICOM directly from managed code because the System.Security.Cryptography.X509Certificates does not interoperate with CryptoAPI stores. A great example of how to do this appears in .NET Framework Security (Addison-Wesley Professional, 2002). (Details of the book are in the bibliography.) This book is a must-read for anyone doing security work with the .NET Framework and the common language runtime.
Important
When hashing, MACing or signing data, make sure you include all sensitive data in the result. Any data not covered by the hash can be tampered with, and may be used as a component of a more complex attack.
Important
Use a MAC or a digital signature to verify that encrypted data has not been tampered with.
At first sight, using the same buffer for storing plaintext and then encrypting the plaintext to produce ciphertext might seem benign. And in most cases it is. In multithreaded environments, however, it isn’t. Imagine you had a race condition in your code and didn’t know it. (Race conditions are conditions caused by unexpected critical dependence on the relative timing of events in software. They typically occur with synchronization errors.) Let’s be frank: you never know you have a serious race condition until it’s too late! Imagine also that the normal process flow of your application is as follows:
Load buffer with plaintext.
Encrypt buffer.
Send buffer contents to the recipient.
It looks fine. However, imagine you have a multithreaded application and, for some reason, the last two stages are swapped because of a race condition:
Load buffer with plaintext.
Send buffer context to the recipient.
Encrypt buffer.
The recipient just received some plaintext! This was a bug fixed in Internet Information Server 4. Under extreme load and rare conditions, the server would follow this pattern and send one unencrypted packet of data to the user when using SSL to protect the data channel from the server to the user. The damage potential was small: only one packet was sent to the user (or possibly an attacker). And when the user received the packet, the client software would tear down the connection. That said, the problem was fixed by Microsoft. More information about the vulnerability can be found at http://www.microsoft.com/technet/security/bulletin/MS99-053.asp.
The fix was to use two buffers, one for plaintext and the other for ciphertext, and to make sure that the ciphertext buffer was zeroed out across calls. If another race condition manifested itself, the worst outcome would be the user receiving a series of zeros, which is a better outcome than the plaintext being sent. The pseudocode for this fix looks like this:
char *bCiphertext = new char[cbCiphertext]; ZeroMemory(bCiphertext, cbCiphertext); SSLEncryptData(bPlaintext, cbPlaintext, bCiphertext, cbCiphertext); SSLSend(socket, bCiphertext, cbCiphertext); ZeroMemory(bCiphertext, cbCiphertext); delete [] bCipherText;
Never use one buffer for plaintext and ciphertext. Use two buffers, and zero out the ciphertext buffer between calls.
There is a small set of cryptographic design concepts you can use to mitigate threats identified in your system design phase. Table 8-3 is not meant to be exhaustive, but it will give you an idea of the technologies at your disposal.
Table 8-3. Common Cryptographic Solutions to Threats
|
Threat |
Mitigation Technique |
Example Algorithms |
|---|---|---|
|
Information disclosure |
Data encryption using a symmetric cipher. |
RC2, RC4, DES, 3DES, AES (was Rijndael) |
|
Tampering |
Data and message integrity using hash functions, message authentication codes, or digital signatures. |
SHA-1, SHA-256, SHA-384, SHA-512, MD4, MD5, HMAC, RSA digital signatures, DSS digital signatures, XML DSig |
|
Spoofing |
Authenticate data is from the sender. |
Public key certificates and digitial signatures |
Many applications include cryptographic algorithms for numerous reasons. However, it’s surpising that few people can tell you why a particular algorithm was used and why. It’s worthwhile taking the time to document why you chose the algorithms used in the code and then having someone who understands crypto look at the document to determine whether the algorithms are appropriate.
I once received an email from a developer asking whether his code should encrypt the administrator’s password by using MD4 or MD5. The answer is obvious, right? Actually, no, it’s not. My first response to this question was to ask why they needed to store an admin password in the first place. The next response was MD4 and MD5 are not encryption algorithms; they are hash functions. They are cryptographic algorithms, but they do not provide secrecy as encryptions do.
Tip
Document your reasons for choosing your cryptographic algorithms, and have someone who understands cryptography review your rationales for choosing the algorithms you used.
Cryptography is not difficult to add to your application because there are so many high-level cryptographic APIs available to the application developer. However, such functionality can be misused easily. Exercise caution when you choose cryptographic technologies. Do the chosen technologies mitigate the appropriate issues in your threat model? Above all, have someone who understands how to use crypto review the designs and the code for errors.