This section demonstrates some of the aspects and challenges of working with character data. I’ll cover character-related problems, including pattern matching, parsing, and case sensitivity.
SQL Server has limited support for pattern matching through the LIKE predicate and PATINDEX function. There’s still no support for regular expressions in T-SQL. ANSI supports regular expressions through an operator called SIMILAR TO.
Regarding the optimization of LIKE expressions, to be able to use an index efficiently in SQL Server 2000 you had to use a constant at the beginning of the pattern–for example, LastName LIKE N′A%′. Note that the optimizer could decide to use an index even when the pattern started with a wildcard based on generic query selectivity estimates, but those estimates were not very accurate. SQL Server 2005 enhances the optimization of LIKE predicates by collecting statistics about substrings within string column values, resulting in more accurate selectivity estimates. The optimizer will determine whether to use an index when the pattern starts with a wildcard in a more accurate manner than in SQL Server 2000.
If you manipulate the base column by using a function instead of the LIKE predicate, the expression won’t be a SARG, and an ordered index access method will not be considered. For example, the following code contains two queries that are logically equivalent–each returning the customers whose ID starts with the letter A:
USE Northwind; SELECT CustomerID, CompanyName, Country FROM dbo.Customers WHERE LEFT(CustomerID, 1) = N'A'; SELECT CustomerID, CompanyName, Country FROM dbo.Customers WHERE CustomerID LIKE N'A%';
The first query manipulates the base column using the LEFT function, and the second query uses the LIKE predicate. Examine the execution plans generated for these queries, which are shown in Figure 1-1.
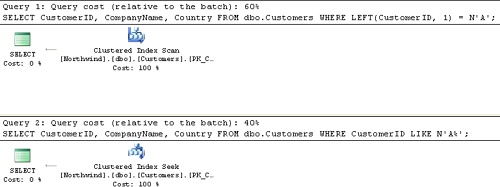
You will see that the plan for the LIKE query uses the index efficiently, whereas the plan for the LEFT query doesn’t.
As I mentioned earlier, LIKE predicates are limited to basic pattern matching. For example, they have no notion of repetitions. When you need to check for repetitions of a certain pattern, the task can be quite challenging. For example, say you have a VARCHAR column called sn in a table representing a serial number. You’re supposed to write a CHECK constraint that allows only digits in sn. If the length of the serial number you’re supporting is short and of a fixed length (say, 10 digits), the task is simple. Use the following CHECK constraint:
CHECK(sn LIKE '[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]')
However, if the length of the serial number can vary, you need a more dynamic solution that takes the actual length into consideration:
CHECK(sn LIKE REPLICATE('[0-9]', LEN(sn)))That’s all nice and well as long as the serial numbers are fairly short. However, if you need to support lengthy ones, this solution is inefficient and will slow down insertions into the table. Sometimes applying reverse logic can get you further than applying positive logic. Well, this case qualifies. Instead of using positive logic that says "all characters must be digits," use negative logic that says "no character can be a non-digit". In T-SQL, this translates to
CHECK(sn NOT LIKE '%[^0-9]%')
Some CHECK constraints involving pattern matching can be much more elaborate. For example, you’re given the following IPs table:
CREATE TABLE dbo.IPs(ip varchar(15) NOT NULL PRIMARY KEY);
And you’re supposed to add a CHECK constraint that validates IPs. For the sake of our exercise, a valid IP consists of four parts (octets) separated by dots, and each octet is a number in the range 0 through 255. Try to limit yourself to using pattern matching only. Bear in mind that if you attempt to convert substrings to numerics and they are not convertible, you will get a conversion error and not a CHECK constraint violation.
Here’s an example for a CHECK constraint that validates IPs using exclusively pattern-matching techniques:
ALTER TABLE dbo.IPs ADD CONSTRAINT CHK_IP_valid CHECK
(
-- 3 periods and no empty octets
ip LIKE '_%._%._%._%'
AND
-- not 4 periods or more
ip NOT LIKE '%.%.%.%.%'
AND
-- no characters other than digits and periods
ip NOT LIKE '%[^0-9.]%'
AND
-- not more than 3 digits per octet
ip NOT LIKE '%[0-9][0-9][0-9][0-9]%'
AND
-- NOT 300 - 999
ip NOT LIKE '%[3-9][0-9][0-9]%'
AND
-- NOT 260 - 299
ip NOT LIKE '%2[6-9][0-9]%'
AND
-- NOT 256 - 259
ip NOT LIKE '%25[6-9]%'
);The first two expressions verify that there are exactly three dots (at least 3, and not 4 or more) and at least one character in each octet. The third expression verifies that there are only digits and dots in the string. The rest actually verifies that the number in each octet is in the correct range. The first of those expressions verifies that four contiguous digits cannot be found–namely, there are at most 3. This means that the value is at most 999. The second expression verifies that if 3 contiguous digits are found, the first is not in the range 3 through 9, meaning that the value is at most 299. Similarly, the third expression verifies that if 3 contiguous digits are found and the first of them is 2, the second cannot be in the range 6 through 9, meaning that the value is at most 259. Finally, the last expression verifies that a three-digit value starting with 25 does not end with a value in the range 6 through 9, meaning that the value can be at most 255.
To test the CHECK constraint, run the following code, which adds valid IPs to the table, and notice that no error is generated:
INSERT INTO dbo.IPs VALUES('131.107.2.201'),
INSERT INTO dbo.IPs VALUES('131.33.2.201'),
INSERT INTO dbo.IPs VALUES('131.33.2.202'),
INSERT INTO dbo.IPs VALUES('3.107.2.4'),
INSERT INTO dbo.IPs VALUES('3.107.3.169'),
INSERT INTO dbo.IPs VALUES('3.107.104.172'),
INSERT INTO dbo.IPs VALUES('22.107.202.123'),
INSERT INTO dbo.IPs VALUES('22.20.2.77'),
INSERT INTO dbo.IPs VALUES('22.156.9.91'),
INSERT INTO dbo.IPs VALUES('22.156.89.32'),Next, run the following code, which inserts invalid IPs, and notice that all inserts produce a CHECK constraint violation:
INSERT INTO dbo.IPs VALUES('1.1.1.256'),
INSERT INTO dbo.IPs VALUES('1.1.1.1.1'),
INSERT INTO dbo.IPs VALUES('1.1.1'),
INSERT INTO dbo.IPs VALUES('1..1.1'),
INSERT INTO dbo.IPs VALUES('.1.1.1'),
INSERT INTO dbo.IPs VALUES('a.1.1.1'),Parsing character strings can also involve pattern matching. For example, suppose that you were asked to extract the individual octets of the IP addresses. Of course, the task would have been much simpler to begin with if you stored each IP address in four TINYINT columns, one for each octet. Or you could store IPs in a single column with a fixed-length portion dedicated to each octet–for example, BINARY(4). However, sometimes you need to cope with an existing design over which you have no control. Assume that this is such a case, and that you need to extract the individual octets out of the VARCHAR(15) IP strings stored in the IPs table.
The number of possible patterns for an IP address is limited because there are only up to 3 digits in each octet and in total only 4 octets. So there are only 81 (3^4) different patterns. You can create an auxiliary table and populate it with all possible patterns. For each pattern, you can also store the starting position and length of each octet, which you will later use in your SUBSTRING functions to extract octets. You can either manually populate such an auxiliary table, or create a virtual one with a query, and encapsulate it in a view as follows:
CREATE VIEW dbo.IPPatterns
AS
SELECT
REPLICATE('_', N1.n) + '.' + REPLICATE('_', N2.n) + '.'
+ REPLICATE('_', N3.n) + '.' + REPLICATE('_', N4.n) AS pattern,
N1.n AS l1, N2.n AS l2, N3.n AS l3, N4.n AS l4,
1 AS s1, N1.n+2 AS s2, N1.n+N2.n+3 AS s3, N1.n+N2.n+N3.n+4 AS s4
FROM dbo.Nums AS N1, dbo.Nums AS N2, dbo.Nums AS N3, dbo.Nums AS N4
WHERE N1.n <= 3 AND N2.n <= 3 AND N3.n <= 3 AND N4.n <= 3;
GOTo identify IP patterns using Nums you basically cross-join four instances of the Nums table, each representing a different octet. The length of each octet can vary in the range 1 through 3; therefore, the filter n <= 3 is used for each instance of Nums. The rest is done in the SELECT list. You generate the pattern made of underscores based on the octets’ lengths, separated by dots. For each octet, you also calculate its length (ln) and starting position (sn), which you will later use in SUBSTRING functions to extract the actual octets. Table 1-12 shows the content of the view (abbreviated), with the different IP patterns, along with the length and starting position of each octet.
Table 1-12. IP Patterns (abbreviated)
Pattern | l1 | l2 | l3 | l4 | s1 | s2 | s3 | s4 |
|---|---|---|---|---|---|---|---|---|
_._._._ | 1 | 1 | 1 | 1 | 1 | 3 | 5 | 7 |
_.__._._ | 1 | 2 | 1 | 1 | 1 | 3 | 6 | 8 |
_.___._._ | 1 | 3 | 1 | 1 | 1 | 3 | 7 | 9 |
_._.__._ | 1 | 1 | 2 | 1 | 1 | 3 | 5 | 8 |
_.__.__._ | 1 | 2 | 2 | 1 | 1 | 3 | 6 | 9 |
_.___.__._ | 1 | 3 | 2 | 1 | 1 | 3 | 7 | 10 |
_._.___._ | 1 | 1 | 3 | 1 | 1 | 3 | 5 | 9 |
_.__.___._ | 1 | 2 | 3 | 1 | 1 | 3 | 6 | 10 |
_.___.___._ | 1 | 3 | 3 | 1 | 1 | 3 | 7 | 11 |
_._._.__ | 1 | 1 | 1 | 2 | 1 | 3 | 5 | 7 |
... | ... | ... | ... | ... | ... | ... | ... | ... |
___.___.___.__ | 3 | 3 | 3 | 2 | 1 | 5 | 9 | 13 |
___._._.___ | 3 | 1 | 1 | 3 | 1 | 5 | 7 | 9 |
___.__._.___ | 3 | 2 | 1 | 3 | 1 | 5 | 8 | 10 |
___.___._.___ | 3 | 3 | 1 | 3 | 1 | 5 | 9 | 11 |
___._.__.___ | 3 | 1 | 2 | 3 | 1 | 5 | 7 | 10 |
___.__.__.___ | 3 | 2 | 2 | 3 | 1 | 5 | 8 | 11 |
___.___.__.___ | 3 | 3 | 2 | 3 | 1 | 5 | 9 | 12 |
___._.___.___ | 3 | 1 | 3 | 3 | 1 | 5 | 7 | 11 |
___.__.___.___ | 3 | 2 | 3 | 3 | 1 | 5 | 8 | 12 |
___.___.___.___ | 3 | 3 | 3 | 3 | 1 | 5 | 9 | 13 |
Now, whenever you need to extract the individual octets, simply join the table containing the IP addresses with the IPPatterns auxiliary table or view, based on the join condition ip LIKE pattern. Each IP will be matched with the pattern that it follows, and you will have access to the lengths and starting positions of the octets for extraction. For example, the following query extracts the octets from the IP addresses stored in the IPs table, producing the output shown in Table 1-13:
SELECT ip,
CAST(SUBSTRING(ip, s1, l1) AS TINYINT) AS o1,
CAST(SUBSTRING(ip, s2, l2) AS TINYINT) AS o2,
CAST(SUBSTRING(ip, s3, l3) AS TINYINT) AS o3,
CAST(SUBSTRING(ip, s4, l4) AS TINYINT) AS o4
FROM dbo.IPs
JOIN dbo.IPPatterns
ON ip LIKE pattern
ORDER BY o1, o2, o3, o4;Sensitivity of character-based data is dependent on the data’s collation properties. Most environments use SQL Server default case-insensitive collation. However, you might sometimes need to apply case-sensitive filters to case-insensitive data. Keep in mind that regardless of the sensitivity of the data based on the effective collation, its binary representation is always case sensitive. That is, ‘A’ and ‘a’ have different binary representations, but are treated as equal for sorting, comparison, and uniqueness if the effective collation is case insensitive.
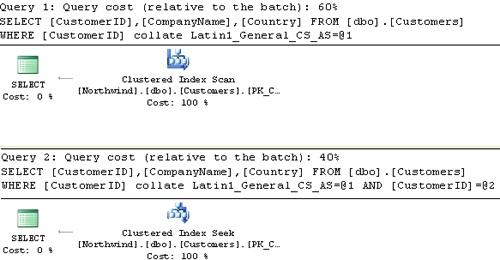
To apply a case-sensitive filter to case-insensitive data, you change the expression’s collation. For example, the following query returns details about the customer N′ALFKI′, using a case-sensitive filter:
USE Northwind; SELECT CustomerID, CompanyName, Country FROM dbo.Customers WHERE CustomerID COLLATE Latin1_General_CS_AS = N'ALFKI';
The problem with this solution is that because you applied manipulation to the base column CustomerID, the filter is not a SARG and the optimizer cannot consider using an index. To "fix" the problem, you can also add the case-insensitive filter just to allow the optimizer to consider the index:
SELECT CustomerID, CompanyName, Country FROM dbo.Customers WHERE CustomerID COLLATE Latin1_General_CS_AS = N'ALFKI' AND CustomerID = N'ALFKI';
Rows matching the case-insensitive filter are a superset of those matching the case-sensitive one. An index can be used here to access the rows that match the case-insensitive filter. SQL Server can then inspect those rows to see whether they also match the case-sensitive filter. Figure 1-2 shows the execution plans of both queries. You can see that the plan for the first query basically applies a table scan (an unordered clustered index scan), while the plan for the second query efficiently uses an index seek.