
Table variables are probably among the least understood T-SQL elements. Many myths and misconceptions surround them, and these are embraced even by experienced T-SQL programmers. One widespread myth is that table variables are memory-resident only with no physical representation. Another is that table variables are always preferable to temporary tables. In this section, I’ll dispel these myths and explain the scenarios in which table variables are preferable to temporary tables as well as scenarios in which they aren’t preferable. I’ll do so by first going through the fundamentals of table variables, just as I did with temporary tables, and follow with tangible examples.
You create a table variable using a DECLARE statement, followed by the variable name and the schema definition. You then refer to it as you do with permanent tables. Here’s a very basic example:
DECLARE @T1 TABLE(col1 INT); INSERT @T1 VALUES(1); SELECT * FROM @T1;
Many limitations apply to table variables but not to temporary tables. In this section, I’ll describe some of them, while others will be described in dedicated sections.
You cannot create explicit indexes on table variables, only PRIMARY KEY and UNIQUE constraints, which create unique indexes underneath the covers. You cannot create non-unique indexes. If you need an index on a non-unique column, you must add attributes that make the combination unique and create a PRIMARY KEY or UNIQUE constraint on the combination.
You cannot alter the definition of a table variable once it is declared. This means that everything you need in the schema must be included in the original DECLARE statement. This fact is limiting on one hand, but it also results in fewer recompilations. Remember that one of the triggers of recompilations is schema changes.
You cannot issue SELECT INTO and INSERT EXEC statements against a table variable in SQL Server 2000. SQL Server 2005 supports INSERT EXEC with table variables.
You cannot qualify a column name with a table variable name. This is especially an issue when referring to a table variable’s column in correlated subqueries with column name ambiguity.
In queries that modify table variables, parallel plans will not be used.
To dispel what probably is the most widespread myth involving table variables, let me state that they do have physical representation in tempdb, very similar to temporary tables. As proof, run the following code that shows which temporary tables currently exist in tempdb by querying metadata info, creates a table variable, and queries metadata info again:
SELECT TABLE_NAME FROM tempdb.INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME LIKE '%#%'; GO DECLARE @T TABLE(col1 INT); INSERT INTO @T VALUES(1); SELECT TABLE_NAME FROM tempdb.INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME LIKE '%#%';
When I ran this code, the first batch returned no output, while the second returned #0CBAE877, which is the name of the temporary table in tempdb that represents the table variable @T. Of course, you will probably get a different name when you run this code. But the point is to show that there is a hidden temporary table created behind the scenes. Just like temporary tables, a table variable’s pages will reside in cache when the table is small enough and when SQL Server has enough memory to spare. So the discussion about aspects of working with temporary tables with regard to tempdb applies to table variables as well.
The scope of a table variable is well defined. It is defined as the current level, and within it the current batch only, just as with any other variable. That is, a table variable is not accessible to inner levels, and not even to other batches within the same level. In short, you can use it only within the same batch it was created. This scope is much more limited than that of a local temporary table and is typically an important factor in choosing a temporary object type.
Unlike a temporary table, a table variable is not part of an outer transaction; rather, its transaction scope is limited to the statement level to support statement rollback capabilities only. If you modify a table variable and the modification statement is aborted, the changes of that particular statement will be undone. However, if the statement is part of an outer transaction that is rolled back, changes against the table variable that finished will not be undone. Table variables are unique in this respect.
You can rely on this behavior to your advantage. For example, suppose that you need to write an audit trigger that audits changes against some table. If some logical condition is met, you want to roll back the change; however, you still want to audit the attempted change. If you copy data from inserted/deleted to your audit tables, a rollback in the trigger will also undo the audit writes. If you first roll back the change and then try to audit it, deleted and inserted are empty. It’s a Catch-22 situation.
To solve the problem, you first copy data from inserted/deleted to table variables, issue a rollback, and then in a new transaction within the trigger, copy the data from the table variables to your audit tables. There’s no other simpler way around the problem.
The unique transaction context of table variables has performance advantages over temporary tables because less logging and locking are involved.
As I mentioned earlier, the optimizer doesn’t create distribution statistics or maintain accurate cardinality information for table variables as it does for temporary tables. This is one of the main factors you should consider when choosing a type of temporary object for a given task. The downside is that you might get inefficient plans when the optimizer needs to consult histograms to determine selectivity. This is especially a problem with big tables, where you might end up with excessive I/O. The upside is that table variables, for the very same reason, involve much fewer recompilations. Before making your choice, you need to figure out which is more expensive in the particular task you’re designating the temporary object for.
To explain the statistics aspect of table variables in a more tangible way, I’ll show you some queries, their execution plans, and their I/O costs.
Examine the following code, and request an estimated execution plan for it from SQL Server Management Studio (SSMS):
DECLARE @T TABLE
(
col1 INT NOT NULL PRIMARY KEY,
col2 INT NOT NULL,
filler CHAR(200) NOT NULL DEFAULT('a'),
UNIQUE(col2, col1)
);
INSERT INTO @T(col1, col2)
SELECT n, (n - 1) % 100000 + 1 FROM dbo.Nums
WHERE n <= 100000;
SELECT * FROM @T WHERE col1 = 1;
SELECT * FROM @T WHERE col1 <= 50000;
SELECT * FROM @T WHERE col2 = 1;
SELECT * FROM @T WHERE col2 <= 2;
SELECT * FROM @T WHERE col2 <= 5000;You can find the code to create and populate the Nums table in Chapter 1.
The estimated execution plans generated for these queries are shown in Figure 2-1.

The code creates a table variable called @T with two columns. The values in col1 are unique, and each value in col2 appears ten times. The code creates two unique indexes underneath the covers: one on col1, and one on (col2, col1).
The first important thing to notice in the estimated plans is the number of rows the optimizer estimates to be returned from each operator–1 in all five cases, even when looking for a non-unique value or ranges. You realize that unless you filter a unique column, the optimizer simply cannot estimate the selectivity of queries for lack of statistics. So it assumes 1 row. This hard-coded assumption is based on the fact that SQL Server assumes that you use table variables only with small sets of data.
As for the efficiency of the plans, the first two queries get a good plan (seek, followed by a partial scan in the second query). But that’s because you have a clustered index on the filtered column, and the optimizer doesn’t need statistics to figure out what the optimal plan is in this case. However, with the third and fourth queries you get a table scan (an unordered clustered index scan) even though both queries are very selective and would benefit from using the index on (col2, col1), followed by a small number of lookups. The fifth query would benefit from a table scan because it has low selectivity. Fortunately, it got an adequate plan, but that’s by chance. To analyze I/O costs, run the code after turning on the SET STATISTICS IO option. The amount of I/O involved with each of the last three queries is 2,713 reads, which is equivalent to the number of pages consumed by the table.
Next, go through the same analysis process with the following code, which uses a temporary table instead of a table variable:
SELECT n AS col1, (n - 1) % 100000 + 1 AS col2,
CAST('a' AS CHAR(200)) AS filler
INTO #T
FROM dbo.Nums
WHERE n <= 100000;
ALTER TABLE #T ADD PRIMARY KEY(col1);
CREATE UNIQUE INDEX idx_col2_col1 ON #T(col2, col1);
GO
SELECT * FROM #T WHERE col1 = 1;
SELECT * FROM #T WHERE col1 <= 50000;
SELECT * FROM #T WHERE col2 = 1;
SELECT * FROM #T WHERE col2 <= 2;
SELECT * FROM #T WHERE col2 <= 5000;The estimated execution plans generated for these queries are shown in Figure 2-2 and Figure 2-3.
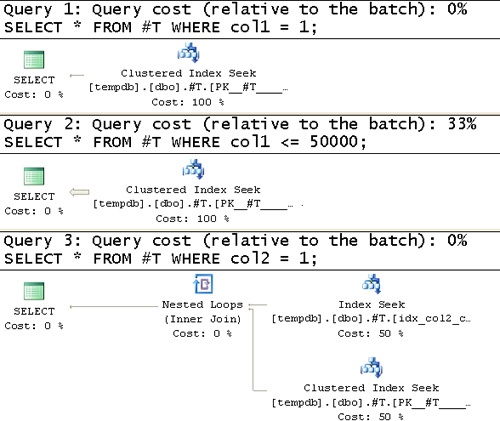
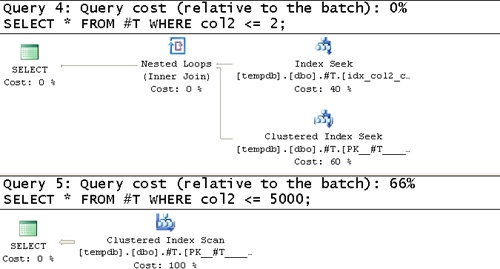
Now that statistics are available, the optimizer can make educated estimations. You can see that the estimated number of rows returned from each operator is more reasonable. You can also see that high-selectivity queries 3 and 4 use the index on (col2, col1), and the low selectivity query 5 does a table scan, as it should.
STATISTICS IO reports dramatically reduced I/O costs for queries 3 and 4. These are 5 and 8 reads, respectively, against the temporary table versus 2,713 for both queries against the table variable.
When you’re done, drop #T for cleanup:
DROP TABLE #T;