

Chapter 3, “Fundamentals of Video Compression,” covered the basic principles of video coding algorithms. This appendix describes the details of four standard codecs: H.261, H.263, H.264, and MPEG-4, Part 2.
The H.261 codec was developed by the ITU (International Telecommunications Union). H.261 is a legacy codec used for only two purposes:
H.323 requires that video endpoints support the H.261 format.
H.261 provides interoperability with legacy endpoints.
Table A-1 shows the video frame parameters for H.261.
Technically, H.261 defines frames that may occur only at intervals corresponding to 29.97 Hz. However, it allows the encoder to send a lower frame rate, achieved by “dropping” a pre-fixed number of consecutive frames between each sent frame. If the encoder plans to send video at a fixed lower frame rate, that lower frame rate is not signaled in the bitstream, but it can be transmitted out of band.
Table A-2 shows the characteristics of motion vectors (MV) for H.261 coding. The allowable options are the simplest for any of the standard codecs and allow a single MV per macroblock (MB).
Table A-2. Motion Vector Attributes for H.261
Motion Vector Attribute | Attribute Options |
|---|---|
MV per MB | 1. |
MV H / V range | [–15, +16]. |
MV resolution | Single pel for luma and chroma. |
Chroma MV calculation | Divide the luma MV by 2, and then truncate to single pel accuracy. |
MV inter groups of blocks (GOB) restrictions | Not restricted to the same GOB. |
MV frame restrictions | MVs are restricted to within frame boundaries. |
MV prediction | H.261 codes the MV difference from an inter MB to the left. |
Overlapped block motion compensation (OBMC) | None. |
H.261 does not perform prediction of pixel values in the spatial domain; the algorithm applies a discrete cosine transform (DCT) directly to either original pixel values or residual pixel values. Table A-3 shows the characteristics of DCT coding for H.261.
Table A-4 shows the characteristics of the quantization process used in the H.261 standard, after the DCT.
Table A-4. Quantization Attributes for H.261
Quantization Attribute | Attribute Options |
|---|---|
Step size changes | The step size can change by any amount from MB to MB. |
Intra DC coefficient | This value is quantized without a dead zone, with a step size of 8, represented in 8 bits. |
Matrix quantization: No | |
Quantizer step size range: 31 | |
Values: [2, 4, 6, ... 60, 62], with a dead zone | |
Quantizer clipping: [–127, +127] |
Table A-5 shows the methods by which the H.261 codec applies entropy coding to each bitstream element. H.261 uses a fixed-length code for the intra DC coefficients and variable-length coding (VLC) for other elements of the bitstream. H.261 does not use an arithmetic coder.
Table A-6 shows that two of the more significant advanced features commonly available in other codecs are not options for H.261.
Table A-7 shows that H.261 offers forward error correction as the only kind of built-in data resiliency.
The H.261 codec is the only codec in this appendix that applies a loop filter to the predicted frame. This loop filter simply blurs the reconstructed frame before the frame is used as a predicted frame. The loop filter might be necessary when the video sequence has objects with sharp edges. Because H.261 is limited to MVs with single-pel accuracy, sharp edges in the original frame and predicted frame might not line up. The result is a residual image containing high-frequency edge-difference information. These high frequency-edges result in larger values for AC DCT coefficients and in turn increase the bit rate of the output stream. The goal of the loop filter is to blur the predicted frame slightly, to soften the sharp edges of the residual image. Other codecs use MVs with subpixel accuracy and do not have this alignment problem.
The H.263 codec was developed by the ITU. H.263 and went through three iterations. The first version of the standard was finalized in 1995 and added many enhancements relative to H.261. In the following tables, this version is referred to as Base H.263. The next two iterations of H.263 were issued in 1998 and 2000, with the following further enhancements:
H.263v2 (aka, H.263+ or H.263 1998)—. Sixteen annexes were added, up to annex T. In addition, the specification added supplemental enhancement info.
H.263v3 (aka H.263++ or H.263 2000)—. This version added annexes U, V, W, and X.
H.263v3 encompasses Base H.263 and H.263v2. This discussion covers H.263v3 and includes the common annexes supported by many codecs. The next section, “Additional H.263 Annexes,” covers the remaining annexes.
The H.263 codec defines nine profiles and multiple levels in annex X. The profiles define the allowed features, such as the use of B-frames. Levels define allowable frame sizes, bit rates, and frame rates.
Table A-8 shows the source video formats possible with H.263.
Table A-8. Video Formats for H.263
Video Parameter | Parameter Options |
|---|---|
Interlace-specific coding | No. However, encoders can flag an image as being from either the top field or bottom field. |
Color format | YCbCr, 4:2:0 interstitial. |
Frame sizes | Five standard sizes: sub-QCIF, QCIF, CIF, 4CIF, 16CIF, plus a custom size. |
Aspect ratios | Standard aspect ratios and custom aspect ratios. |
Frame rate | Standard 29.97 or a custom frequency. The encoder can also skip frames to lower the final frame rate. |
The segmentation of each frame into GOBs and MBs is similar to H.261: Each frame is segmented into GOBs or slices. GOBs span the entire width of an image and consist of rows of MBs.
Table A-9 shows the features and limitations of MVs in H.263.
Table A-9. Motion Vector Attributes for H.263
Motion Vector Attribute | Attribute Options |
|---|---|
MV per MB | Base H.263: 1. |
Annex F: 4 MV per MB (cannot be used with B pictures from annex O). | |
MV H / V range | Base H.263: [–16, 15.5] (also applies to B pictures). |
Annex D: The maximum possible range is [–31.5, 31.5], but complex rules restrict the final range. | |
MV resolution | 1/2 pel for luma and chroma. |
Chroma MV calculation | Average of all MV in the MB, rounded to the nearest 1/2 pel. |
MV inter GOB or slice restrictions | Base H.263: not restricted to the same GOB. |
Annex K: slice mode: no interslice dependencies allowed. | |
Annex R: independent segment decoding mode: no inter GOB dependencies allowed. | |
MV frame restrictions | Base H.263: MV restricted to within frame boundaries. |
Annex D, F, J, or the B and EP pictures of annex O: MV can refer to pixels outside the frame. | |
Base H.263: (1 MV per MB): The MV prediction is obtained by applying a median filter to the MVs from three surrounding MBs. | |
Annex F, four MVs per MB (1 MV per 8×8 block): The MV prediction is obtained by applying a median filter to the MVs from three surrounding 8×8 blocks. | |
OBMC | Base H.263: No. |
Annex F, for P pictures only, not B pictures. |
Table A-10 shows the attributes and characteristics of the H.263 DCT.
For intrablocks in either intra- or interframes, annex I allows three possible modes for intra coefficient prediction, signaled explicitly. This prediction uses information from the block to the left and the block above the current block. Figure A-1 shows the blocks used in the calculations.
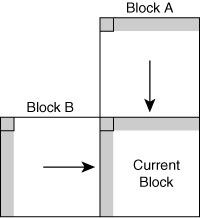
Using these surrounding blocks, the calculations for the three modes are as follows:
DC mode, which involves the prediction of only the DC coefficient by taking the average of the DC coefficients from blocks A and B. The resulting MB uses the normal zigzag scan.
Vertical+DC mode, which predicts the DC coefficient plus the first row of AC coefficients. The prediction comes from the corresponding row of coefficients in the adjacent block above the current block. This mode uses an alternate-horizontal scanning pattern.
Horizontal+DC mode, which predicts the DC coefficient plus the first column of AC coefficients. The prediction comes from the corresponding column of coefficients in the adjacent block to the left of the current block. This mode uses an alternate-vertical scanning pattern.
Table A-11 shows the basic attributes and characteristics of the quantization process in H.263.
Table A-11. Quantization for H.263
Quantization Attribute | Attribute Options |
|---|---|
Matrix quantization | No. |
Step size change | Base H.263: The quantization step size can change by a small amount from MB to MB; the change is restricted to –2, –1, 0, 1, 2. |
Annex T: The quantization value can change by a large amount. | |
Intra DC coefficient | Base H.263: exactly the same as H.261; no dead zone, step size = 8. |
Annex I: The intra DC coefficient uses the same quantization value as the intra AC coefficients. |
Table A-12 shows the variations in quantizer capabilities for intra AC coefficients and inter AC + inter DC coefficients for H.263.
Table A-12. Quantization for Intra AC and Inter AC + DC Coefficients for H.263
Quantizer Attribute | Attribute Options |
|---|---|
Quantizer step size range | 31 values: [2, 4, 6, ... 60, 62], with a dead zone. |
Quantizer clipping | For DC and AC: [–127, +127]. |
Quantizer variations | Annex T: Step sizes for chroma are lower than for luma, and clipping values are higher, to accommodate lower values of the quantizer. |
In H.263 annex I (advanced intra coding mode), all modes use a special VLC table for both DC and AC coefficients. In addition, the DC coefficient is handled the same as the AC coefficients.
Table A-13 shows the attributes and characteristics of entropy coding in H.263.
Table A-13. Entropy Coding for H.263
Characteristics | |
|---|---|
Intra DC coefficients | Base H.263: 8 bits, fixed length |
Annex I: same as the AC coefficients | |
Other coefficients | Nonreversible VLC; run and length coded jointly |
Annex S: use intra VLC for all inter coefficients | |
Annex T: extended nonreversible VLC table | |
MV | Nonreversible VLC |
Annex D: special VLC table, reversible VLC | |
Arithmetic coder options | Base H.263: no |
Annex E: N-array arithmetic coder, which applies to all elements in the bitstream | |
Zigzag scanning options | Base H.263: normal zigzag |
Annex I: one of three selections for advanced intra prediction |
Base H.263 does not support B-frames; however, B-frames are supported in annex O. B-frames in direct mode do not include a delta MV to compensate for a deviation from linear prediction. The possible prediction modes for B-frames include the following:
Direct mode, with no delta vector
Bidirectional prediction, using two MVs
Forward prediction only, using one MV
Backward prediction only, using one MV
In addition to B-frames in annex O, H.263 offers PB-frames, defined in annexes G and M. A single PB-frame consolidates two consecutive frames: a frame represented by the B-part of a PB-frame, followed by a frame represented by the P-part of a PB-frame. To prevent confusion, use the term B-frame to refer to only the standalone B-frames of annex O, and use the terms B-part and P-part to refer to the respective parts of a PB-frame, defined in annexes G and M. For PB-frames, H.263 consolidates the B-part and the P-part for several reasons:
To process the B-part, both the encoder and decoder must first process the following P-part. Therefore, because the B-part must be delayed by a frame time, no latency hit occurs by packaging the B- and P-parts together in one unit.
By using PB-frames, the encoder avoids reordering frames in the IPB sequence.
PB-frames are intended to be used in IPB frame sequences where B-type frames occur only once in a row. Therefore, it is allowable to include the next P-frame along with the current B-frame.
For the definition of PB-frames, annex M supersedes annex G: Use Annex G only if you need to interoperate with legacy equipment that is limited to annex G.
Table A-14 shows the PB-frame capabilities of the Base H.263 codec and the enhanced capabilities of annexes G and M.
Table A-14. PB-Frames for H.263
Codec Implementation | PB-Frame Capabilities |
|---|---|
Base H.263 | No PB-frames. |
Annex G | PB-frames consist of a B-part and a P-part. |
The B-part uses the direct mode only: It uses the P MV plus a delta vector. | |
Intrablocks in the P-frame must still have MVs to provide an MV for the direct mode of the B-part. | |
All blocks in the B-part of a PB-frame are intercoded. | |
Annex M | All features of annex G. |
Bidirectional mode: It is actually a direct mode, but with no delta vector. | |
Forward prediction, using 1 MV (predicted from the block to the left). | |
Backward prediction only mode: No MV is used for this mode; instead, the corresponding block in the next frame is used. |
The forward prediction mode of annex M applies only a single forward MV to the B-part of the MB. This mode is useful if there is a scene cut immediately after the B-part and before the next P-part.
The backward prediction mode of annex M is used if the B-part of the PB-frame immediately follows a scene cut. In this case, the prediction just uses the corresponding block in the following P-part, without using MVs.
The Base H.263 codec cannot implement scalability. However, annex O supports three scalability options:
Temporal scalability—. B-frames allow either the encoder or decoder to discard frames.
SNR scalability—. The encoder provides an enhancement layer with the same image dimensions as the base layer.
Spatial scalability—. Base layer pictures can be scaled up by a factor of 2 in the horizontal direction, the vertical direction, or both directions, before the addition of an enhancement layer.
In H.263, spatial and SNR scalability is achieved with layers of enhancement. Each layer of enhancement provides a residual layer, which is added to the underlying reconstructed layer to produce a new reconstructed layer. Each residual layer is created by taking the difference between the original image sequence and the underlying reconstructed layer. This process is essentially a prediction loop, which uses the underlying reconstructed layer as the prediction. The prediction loop then codes the residual difference between the prediction layer and the original layer. However, in this case, no MVs are used to create the prediction.
The residual layer can be coded using EI pictures and EP pictures:
An EI picture is an intraframe because it does not depend on other frames in the same enhancement layer. An EI picture codes the residual enhancement layer. EI pictures of annex O cannot be used with annexes D, E, F, P, Q, or S.
An EP picture is an interframe because it may apply motion-compensated prediction to previous frames in the same enhancement layer. An EP picture codes the residual enhancement layer. To create a residual layer picture, the EP picture codes the residual created by subtracting the residual layer picture from the previous motion-compensated frame in the same layer. EP pictures of annex O cannot be used with annex E or F.
The Base H.263 codec supports GOBs, but not slices. Annex K supports slices and provides two features related to slices:
Arbitrary-shaped slices—. Slices can either have a collection of MBs or be defined as a rectangular selection of MBs.
Arbitrary slice ordering—. Slices may appear in the bitstream in any order.
Annex K imposes several restrictions on slices:
Prediction is restricted to the slice, which means that MVs or intra coefficients from outside the slice cannot be used as part of a prediction loop.
Independent segment decoding (annex R) may impose more restrictions on usage of slices.
Data independence is supported in annex R, which ensures that no slices have dependencies with each other. When the bitstream uses GOBs rather than slices, a GOB may omit the GOB header, which indicates that the GOB uses the same state information from the previous GOB. However, when a GOB header is present, it means that the GOB changes the state information. Annex R prevents inter GOB dependency if a GOB header is present. Annex R ensures data independence for the following:
MVs
Deblocking filters
Bilinear prediction used for spatial scalability
Annex R imposes several restrictions:
When used with slices, the bitstream must use the rectangular slice submode.
Boundary extrapolation must be used when referring to regions outside the current segment.
In OBMC mode, MVs from other segments are not used; instead, the MV of the current block is used.
Annex R cannot be used with annex P (reference picture resampling mode).
Annex V provides data partitioning. It reorganizes the bitstream as follows:
All the MB headers are sent together, using a reversible VLC.
All the coded MVs in the slice are sent together.
All the coded DCT coefficients in the slice are sent together.
Markers separate each of the sections. Annex V also specifies the use of a reversible VLC table for the MVs. In addition, annex V must be used with annex K. Annex V can be used with annex O, cannot use annex E (arithmetic coding) or U, and should not be used with annex H.
Finally, H.263 allows the use of FEC, detailed in annex H.
This section delves into less frequently used annexes. These annexes might be used in video conferencing endpoints in the future to implement specialized functionality.
Annex C provides facilities to support switched multipoint operation. The following facilities are defined:
Freeze picture request causes the decoder to freeze the displayed picture until a freeze picture release signal is received or a timeout period of at least 6 seconds has expired. This signal is transmitted either by external means such as H.245 or by using supplemental services (annex L).
Fast update request causes the encoder to encode its next picture in intra mode. This signal is transmitted using external signaling.
Freeze picture release is a signal from an encoder that has responded to a fast update request. It allows the decoder to exit its freeze picture mode and display the picture. This signal is transmitted in the PTYPE field of the H.263 bitstream in the first picture header coded in response to a fast update.
Continuous Presence and Video Multiplexing (CPM) is a feature that can be negotiated via external means such as H.245. It allows up to four H.263 bitstreams to be multiplexed as independent “subbitstreams” in one video bitstream. Encoders may signal this mode using the CPM field in the picture header in the H.263 bitstream. This mode is intended for circuit-switched networks such as ISDN, which have no support for bitstream multiplexing.
This annex provides an opportunity for an encoder to send commands to the decoder. These command requests include the following:
Full picture freeze request.
Partial picture freeze request.
Resizing partial picture freeze request.
Partial picture freeze release.
Full picture snapshot tag. This indicates that the current picture is labeled for external use as a still image snapshot of the video content. This option is useful for conference recording.
Partial picture snapshot tag. The same as the preceding except that it indicates a partial rectangle within a picture.
Video time segment start tag. It indicates the start of a video sequence label for external use.
Video time segment end tag. It indicates the end of the labeling of a video sequence for external use.
Progressive refinement segment end tag.
Chroma keying information. This indicates that the “chroma keying” technique is used to represent transparent and semitransparent pixels in the decoded video picture. This mode might be interesting in the case of text overlay.
The use of this annex is signaled in the picture header of the H.263 bitstream using the PEI/PSUPP fields. Decoders not implementing annex L can discard the supplementary information.
This annex provides a reference picture selection mode. This mode provides two features:
The encoder can use a number of picture memories and select one of them as the reference picture in the encoding of the current frame. The amount of picture memory available at the decoder might be signaled via external means to help the memory management in the encoder.
The decoder may use a back channel to send the encoder information on which parts of which pictures have been correctly decoded at the decoder. This mode can help the encoder choose a reference picture from its picture memories that suppresses the temporal error propagation because of interframe coding.
This mode has low computational complexity but high memory requirements on both the encoder and the decoder. The use of this annex is indicated in the picture header of the bitstream using bit 11 of the OPPTYPE subfield in the PLUSPTYPE field.
This annex provides a reference picture resampling mode. This feature is a resampling process that can be applied to the previous decoded picture to generate a warped picture for use in predicting the current picture. This mode is used in specifying the relationship between the current picture and its reference if the source format differs. This mode may be used in restricted scenarios defined during capability negotiations. For example, encoders/decoders might support only factor of 4 picture resizing. This mode gives the encoder the capability to make trade-offs between spatial and temporal resolutions. The factor of 4 upsampling/downsampling does not add much computational complexity on the encoder or the decoder, because it requires a simple fixed filter.
The use of this annex is indicated in the picture header of the bitstream using bit 4 of the mandatory MPPTYPE subfield in the PLUSPTYPE field.
This annex provides a reduced resolution update mode. This mode is used for fast-moving video sequences. The encoder is allowed to send update information for a picture that is encoded at a reduced resolution while preserving the detail in a higher-resolution reference image. This creates a final image at the higher resolution. This capability allows the coder to increase the picture update rate while maintaining its subjective quality.
The syntax of the bitstream when using this mode is identical to the syntax when the mode is not used; however, the semantics differ. In this mode, the portion of the picture covered by an MB is twice as wide and twice as high as normal. Hence, approximately a quarter of the number of MBs are available in the normal picture. MVs are calculated for blocks twice the size (32×32 and 16×16). However, the DCT is describing an 8×8 block on a reduced-resolution version of the picture.
The use of this annex is indicated in the picture header using bit 5 of the mandatory MPPTYPE subfield in the PLUSPTYPE field.
This annex provides an enhanced reference picture selection mode. Annex U provides benefits for both error resilience and coding efficiency by using a memory buffer of reference pictures. It allows the following:
Pictures to be predicted from multiple reference pictures at the MB level. This mode enhances the coding efficiency.
Motion compensation to be extended to prediction from multiple pictures. Each MV is extended by a picture reference number that may index any of the multiple reference pictures. This added flexibility enhances the coding efficiency.
A multibuffer control mechanism is used. The mechanism is either a sliding window mechanism or an “Adaptive Memory Control” that provides more flexibility.
A submode can be used for subpicture removal. This feature reduces the amount of memory needed to store the reference pictures. The support of this submode and the allowed fragmentation of the pictures into subpictures are negotiated via external means such as H.245.
A submode can be used for enabling two-picture backward prediction in B pictures. The support of this submode is negotiated via external means.
For error resilience, a backward channel message can be used to allow the decoder to inform the encoder which pictures or parts of pictures have been correctly decoded. The signaling of this channel is outside the scope of this annex.
The use of this annex is indicated in the picture header of the bitstream using bit 16 of the OPPTYPE subfield of the PLUSPTYPE field.
This annex provides additional supplemental enhancement information. Annex W defines two values that were reserved in annex L:
Fixed-point inverse DCT (IDCT) indicates that a particular IDCT approximation is used to construct the bitstream. The annex specifies a particular reference IDCT implementation.
Picture message indicates one or more octets representing message data. The annex specifies several message types:
Arbitrary binary data.
Arbitrary text.
Copyright text.
Caption text. Note that this recommendation puts no restriction on how caption text is actually displayed and stored at the decoder.
Video description text. Again, this recommendation puts no restriction on how this text is actually displayed and stored at the decoder.
Uniform resource identifier. This recommendation does not specify how the decoder might use this identifier.
Current picture header repetition.
Previous picture header repetition.
Next picture header repetition, reliable temporal reference (TR).
Next picture header repetition, unreliable TR.
Interlaced field indication. This message indicates that the current picture was not actually scanned as a progressive-scan picture; that is, it contains only half of the lines of the full-resolution source picture. This message will not be used except if the decoder signals its capability using external means such as H.245.
Picture number.
The use of this annex is signaled in the picture header of the H.263 bitstream using the PEI/PSUPP fields, similar to annex L.
Annex X defines profiles and levels for H.263. Of particular interest for video conferencing is section 2.6, which defines profile 5, also known as the Conversational High Compression (CHC) profile. This profile allows low-latency, real-time video encoding for video conferencing endpoints. This profile defines several features and limitations:
All the attributes of the H.263 Baseline profile, in addition to the following.
Annex F, advanced prediction mode, which allows four MVs per MB, and the use of OBMC.
Annex D, unrestricted motion Vector Mode. MVs can refer to areas outside the frame. In addition, this mode allows for larger MV ranges.
Annex U, enhanced reference picture selection mode, which allows the bitstream to refer to multiple previous reference frames for motion compensation.
The H.264 codec was jointly developed by two standards bodies: the ITU and the ISO/IEC (International Organization for Standardization / International Electrotechnical Commission). As a result, H.264 can be found in two different documents: the ITU document H.264, and the ISO document MPEG-4, Part 10. H.264 is also known by its more generic name AVC, for Advanced Video Codec.
H.264 has superior performance compared to previous standards such as H.263 or MPEG-4, Part 2. For the same perceptual quality or peak signal-to-noise ratio (PSNR), H.264 generates bit rates that are 30 percent to 50 percent less than H.263 or a MPEG-4 simple profile. However, this improvement in performance comes at a cost of CPU cycles. H.264 encoders may have a CPU load that is about four times that of other codecs, and H.264 decoders may consume up to three times the CPU load of other decoders.
All profiles of H.264 have several distinguishing features:
Deblocking filter.
MVs may apply to blocks as small as 4×4 pixels.
Each MV may specify a different reference image.
1/4 pel MVs for luma.
1/8 pel MVs for chroma.
Content-adaptive VLC-based entropy coding (CAVLC).
Each profile also defines a set of features optimized for a particular application. The H.264 Baseline profile is intended for video conferencing and wireless, with the following attributes:
I and P picture types only
No interlace: no field coding or MB switching between field and frame
No support for switching P- frames or switching I-frames
No arithmetic coder
Supports flexible MB ordering (FMO), arbitrary slice ordering (ASO), and redundant slices (RS)
H.264 Extended profile is designed for streaming over the Internet and contains all baseline features in addition to these attributes:
No arithmetic coder
Support for I-, P-, and B-frames
Interlace support: picture and MB-level frame/field switching
Support for switching P- frame and switching I-frames
Data partitioning
Supports FMO, ASO, and RS
H.264 Main profile is intended for broadcast and entertainment, with these characteristics:
All baseline features except enhanced error resilience features (FMO, ASO, RS)
Support for I-, P-, and B-frames
Interlace support: picture and MB-level frame/field switching
Content-adaptive binary arithmetic coder (CABAC)
A later addition to H.264 included the Fidelity Range Extensions (FRExt), which added the following capabilities:
Profiles added by FRExt include the following:
H.264 High profile (HP), which includes support for the Main profile, in addition to the following:
8×8 transform mode
Custom quantization scaling matrices
Separate Cb and Cr quantization control
Monochrome format
H.264 High 10 profile (Hi10P), which includes support for the High profile, plus 9 and 10 bits per sample
H.264 High 4:2:2 profile (H422P), which includes support for the High 10 profile, plus 4:2:2 support
H.264 High 4:4:4 profile (H444P), which includes support for the High 4:2:2 profile, plus 4:4:4 support
H.264 also defines multiple levels that place upper limits on the bit rate, frame size, total buffer size, and so on.
Table A-15 shows the source video formats possible with H.264.
Table A-15. Video Formats for H.264
Video Parameter | Parameter Options |
|---|---|
Interlace-specific coding | Yes, on a per-MB basis |
Types of interlace coding | Merged, or field/frame coding per MB pair (each MB representing a different field) |
Color format | Base: YCbCr, 4:2:0 co-sited/interstitial |
FRExt: also 4:2:2 and 4:4:4 | |
Frame sizes | Limited by the level definitions |
Aspect ratios | Many preset aspect ratios, plus a custom aspect ratio |
Frame rate | No settings or limits |
For the purpose of assigning MVs, each 16×16 MB may be segmented in several ways: as a 16×16 block, as two 8×16 blocks, as two 16×8 blocks, or as four 8×8 blocks. The four 8×8 segmentation mode allows any of the 8×8 blocks to be further subdivided as two 4×8 blocks, two 8×4 blocks, or four 4×4 blocks, as shown in Figure A-2.
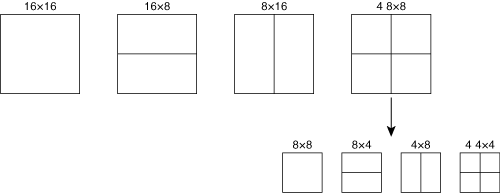
As a result, an H.264 MB may contain 16 4×4 blocks, and in a B-frame, each block may have up to two MVs, for a total of 32 possible MVs per MB. Further, each MV may refer to a different reference frame. Each MV may also have an associated weighting, w, and offset, o, and these parameters are applied to the predicted pixels referenced by the MV. The weighting and offset are useful to generate predictions for scene cuts and cross-fades.
Luma MVs with an accuracy of 1/4 pel may be specified. Given a 1/4 pel accurate MV, the predicted pixels are interpolated in a two-step process:
MVs at 1/2 pel locations are calculated with high precision using a six-tap one-dimensional filter.
If necessary, 1/4 pel MVs are interpolated using bilinear interpolation on the 1/2 pel accurate values.
The codec achieves 1/8 pel resolution for chroma predicted blocks by using linear interpolation.
Table A-16 shows the features and limitations of MVs in H.264.
Table A-16. Motion Vectors for H.264
Attribute Options | |
|---|---|
MV block sizes | Motion vectors can apply to block sizes of 16×16, 16×8, 8×16, 8×8, 8×4, 4×8, or 4×4 |
MVs per MB | Up to 32 |
MV prediction | Uses a median filter, applied to the MV of three nearby blocks |
MV resolution | 1/4 pel for luma, 1/8 pel for chroma |
Luma 1/2 pel | Attained with a one-dimensional six-tap filter |
Luma 1/4 pel | Attained with a bilinear filter applied to the two nearest 1/2 pel interpolated values |
Chroma 1/8 pel interpolation | Linear interpolation |
MV H / V range | Set by the level |
Unrestricted MVs | Yes |
MV restricted to the same slice | Yes |
H.264 supports B-frames, with four different modes:
Forward only (1 MV)
Backward only (1 MV)
Bidirectional (2 MV)
Direct mode, with no delta vector
H.264 has an intra prediction mode that predicts pixels in the spatial domain before the intra transform process. For luminance, the encoder can use two different modes: a 16×16 prediction mode or a 4×4 prediction mode. For chrominance, the encoder can use an 8×8 prediction mode. In both cases, the pixels inside the block are predicted from previously decoded pixels adjacent to the block.
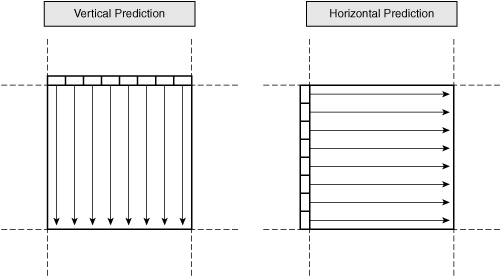
The 16×16 prediction mode has four methods of prediction. Figure A-3 shows two modes.
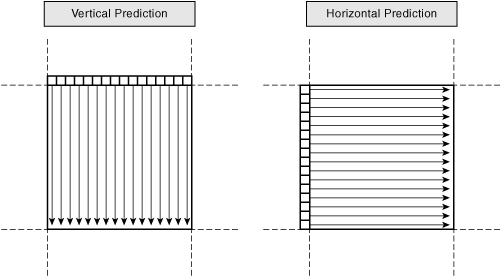
In the vertical prediction mode, the horizontal sequence of pixels just above the current block is used to predict the pixels inside the block by sweeping these pixels downward. The horizontal prediction mode uses the vertical line of pixels to the left and sweeps them horizontally. The 16×16 prediction mode also has two other variations:
A DC prediction mode, where all interior pixels are estimated with a single value by using the average value of surrounding edge pixels.
A planar prediction mode, which uses surrounding pixels at the top and left of the block to interpolate each pixel in the interior of the 16×16 block. The interpolation process operates by modeling the interior pixels as a plane in three dimensions, with the pixel values defining the height of the plane above the 16×16 grid.
Figure A-4 shows the edge pixels used for the 4×4 intra prediction modes.
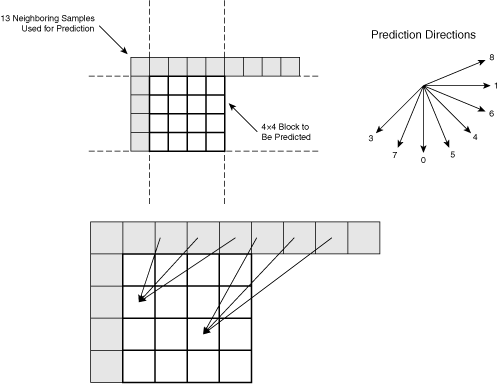
In addition to the nine neighboring pixels to the left and above the 4×4 block, this prediction mode uses four previously decoded pixels to the right. Eight of the nine variations of the 4×4 intra prediction mode use simulated motion to interpolate the interior pixels. Each of these modes corresponds to a direction, shown by the eight direction arrows. The edge pixels are “swept” over the 4×4 pixel block to interpolate the interior pixels. The bottom diagram in Figure A-4 shows the interpolation dependencies of two interior pixels for mode 3 as a function of edge pixels. In addition to the eight simulated motion directions, the 4×4 intra prediction mode has a DC prediction, where all interior pixels are estimated with a single value by using the average value of surrounding edge pixels.
Figure A-5 shows two of the four prediction modes for 8×8 chrominance blocks.
Like the 16×16 prediction mode, the other two modes for chrominance consist of a DC prediction mode and a planar prediction mode.
Unlike the 8×8 transform of most other codecs, H.264 initially defined a 4×4 integer-based transform. The transform provides almost as much frequency separation as the 8×8 DCT but has a simpler integer implementation. The FRExt subsequently added the option of an 8×8 integer-based transform.
H.264 takes a two-stage approach when applying the 4×4 transform:
As shown in Figure A-6, when the MB is segmented into 16 4×4 blocks, and when the MB is entirely intracoded, the DC coefficients from each 4×4 block are arranged in a new 4×4 block and then are transformed using a simplified 4×4 transform.
As shown in Figure A-7, for all modes (intra and inter), a similar process is applied to the DC coefficients of the chroma blocks: The DC values are arranged into a 2×2 array and then are processed with a 2×2 transform.
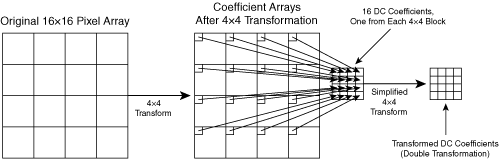
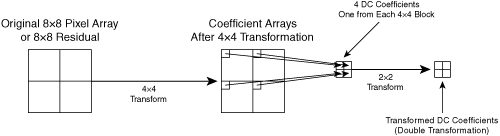
Table A-17 shows the characteristics of the quantizer for H.264.
Table A-17. Quantization for H.264
Quantization Attribute | Attribute Options |
|---|---|
Quantizer dead zone | No. |
Quantizer clipping | No upper limit on the input quantizer value. |
Matrix quantization | Except for secondary DC 4×4 luma and DC 2×2 chroma mode, H.264 always uses matrix quantization, based on fixed quantization tables. |
Step size | Q has a range of [0, 51] and is used to generate the matrix of quantization values. |
Q can change by a large amount per MB [–26, +25]. | |
Intra DC coefficient | The quantizer is less coarse than for other coefficients. |
Chroma Q values | For higher Q values, step sizes for chroma are lower. |
An innovation in the H.264 codec is backward zigzag scanning in the entropy coder. Instead of scanning from large-coefficient values (upper left of the transform) to small-coefficient values (lower right of the transform), the entropy coder scans in the reverse direction. This approach allows the adaptive VLC process to better predict future coefficient values.
In addition, the codec takes advantage of a characteristic of most transform coefficients: Nonzero coefficients near the lower-right corner of the transform often have a value of either +1 or –1. The entropy coder has a “trailing 1s” special case to efficiently code these values.
The only variation on the zigzag scan is used for field coding, as shown in Figure A-8.
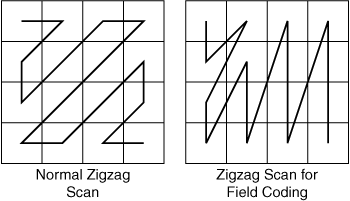
When field coding, each MB contains data from only a single field. As a result, the content in a field-coded MB contains every other line of video from the frame, which means there is less vertical pixel-to-pixel correlation. As a result, the MBs tend to have high vertical frequencies, corresponding to larger coefficients on the left half of the 4×4 block. As a result, the zigzag pattern for field coding scans the block from left to right.
Table A-18 shows the attributes of entropy coding in H.264.
Table A-18. Entropy Coding for H.264
Attribute | Characteristics |
|---|---|
Reversible VLC tables | No. |
Regular syntax | Exp-Golomb table. |
Backward zigzag scanning. | |
The run and level are not coded jointly. | |
H.264 codes the number of coefficients using a context-adaptive VLC table. | |
H.264 codes the zero-run length sequence using a context-adaptive VLC. | |
H.264 codes the coefficient levels using a fixed VLC table. | |
H.264 codes trailing ones (+1 or –1) as a special case. | |
MV | Motion vectors are coded using a modified Exp-Golomb, nonadaptive VLC. |
Arithmetic coder | CABAC. |
Zigzag DCT scanning options | Two zigzag patterns: one for frame coding and one for field coding. |
H.264 has a deblocking filter that may be applied to the 16×16 MB boundary, or optionally to 4×4 block boundaries. The deblocking filter is an adaptive one-dimensional filter applied to vertical edges and then to horizontal edges. The filter is highly adaptive and modifies two edge pixels on each side of the block boundary. For chrominance pixels, the deblocking filter is applied to the 8×8 block boundary only.
Table A-19 shows that H.264 offers many types of data resiliency.
The higher complexity and flexibility of the H.264 codec allows it to deliver superior performance relative to the other codecs. An article published by the IEEE in 2003, “Rate-Constrained Coder Control and Comparison of Video Coding Standards,” provides PSNR/bit rate graphs for several test sequences using real-time encoding. The results show H.264, Baseline profile, as the clear leader:
The H.264 Baseline profile had a 28 percent bit rate reduction compared to the H.263 Conversational High Compression profile.
The H.264 Baseline profile had a 30 percent bit rate reduction compared to MPEG-4, Part 2 (Simple profile).
The H.264 Baseline profile had a 41 percent bit rate reduction compared to the H.263 Baseline profile.
H.264-SVC is a scalable extension to H.264. It allows scalability in the spatial domain and the temporal domain. The essential innovation of H.264-SVC is the ability to incorporate motion-compensated temporal filtering (MCTF). This scheme separates the video sequence into temporal sub-bands and also minimizes the bit rate of the coded sub-bands by motion-compensating them.
The MPEG-4, Part 2 codec was developed by the ISO/IEC. The formal codec designation is ISO/IEC 14496-2. It is used mostly in 3G mobile phones, still cameras, and IP video cameras.
MPEG-4, Part 2 defines several profiles. One of the profiles is called the Short Header profile, which is simply the H.263 video stream encapsulated with MPEG-4 video stream headers.
For video conferencing, the common profiles for MPEG-4, Part 2 consist of the Simple profile and the Advanced Simple profile (ASP).
The following list describes the Simple profile:
Used primarily in cell phones
Uses the short header option, which is identical to H.263
I- and P-frames only (no B-frames)
Uses a simpler quantization algorithm called Method 2
Motion estimation limited to 1/2 pel accuracy
Goes up to CIF resolution and 384 kbps (at the L3 level)
ASP includes all features in the Simple profile, plus the following:
Interlacing
B-frames
An alternative quantization method called Method 1
1/4 pel accurate MVs
Global motion compensation, in which four MVs are applied to edges of the picture
Table A-20 shows the source video formats and options possible with MPEG-4, Part 2.
Table A-20. Video Formats for MPEG-4, Part 2
Video Parameter | Parameter Options |
|---|---|
Interlace support | Field/frame coding per MB: The top half of the MB is one field, and the bottom half is the other field. |
Color format | YCbCr, 4:2:0 interstitial/co-sited. |
Frame sizes | There are no standard sizes: All sizes are custom. |
Aspect ratios | Five standard aspect ratios, and custom aspect ratios. |
Frame rate | There are no standard frame rates: All frame rates are custom. |
Table A-21 shows the features and limitations of MVs in H.264.
Table A-21. Motion Vectors for MPEG-4, Part 2
Motion Vector Attribute | Attribute Options |
|---|---|
MV block sizes | Progressive: 16×16 or 8×8 frame blocks. |
Interlaced: 16×8 field blocks. | |
MV resolution | 1/4 pel for luma, 1/2 pel for chroma. |
Luma 1/2 pel interpolation | Attained with a two-dimensional linear filter. |
Chroma 1/2 pel interpolation | Attained with a two-dimensional linear filter. |
Luma 1/4 pel interpolation | 1/4 pel accuracy for luma is a two-stage process: First, a one-dimensional eight-tap filter is used to get 1/2 pel sample values. Then 1/4 pel sample values are calculated using a linear interpolation on the 1/2 pel values. |
MV per MB | Up to four. |
Yes. | |
Unrestricted MVs | Yes. |
MV prediction | Uses a median filter, applied to the MV of three nearby blocks. |
Impact on field coding | A field-predicted MV has only two MVs: one for the top field, and one for the bottom field. |
The transform used for MPEG-4, Part 2 is an 8×8 DCT.
MPEG-4, Part 2 has a method of predicting intrablock coefficients for 8×8 blocks that is similar to H.263 annex I. The method of prediction is implicitly specified using two gradients calculated from surrounding blocks:
The horizontal gradient, between the 8×8 block above and to the left of the current block and the 8×8 block above the current block. This gradient is calculated using the inverse quantized DC values of those blocks.
The vertical gradient, between the 8×8 block above and to the left of the current block and the 8×8 block to the left of the current block. This gradient is calculated using the inverse quantized DC values of those blocks.
If the horizontal gradient is larger, the encoder uses the block above the current block to predict values in the current block:
For the DC coefficient: Use the decoded DC value from the block above.
For the AC coefficients: Predict the top row of AC coefficients using the top row from the block above.
This mode uses an alternate-horizontal zigzag scan.
If the vertical gradient is larger, the encoder uses the block to the left to predict values in the current block:
For the DC coefficient: Use the decoded DC value from the block to the left.
For the AC coefficients: Predict the left column of AC coefficients using the left column from the block to the left.
This mode uses the alternate-vertical zigzag scan.
MPEG-4, Part 2 has two quantization methods, referred to as the first and second quantization methods.
The first quantization method includes the following characteristics:
The intra DC coefficient is quantized using a quantizer that is a function of the overall quantization parameter.
Other coefficients are quantized using matrix quantization. The algorithm uses one matrix for the intra coefficients and one for inter coefficients.
The bitstream can specify a custom quantization matrix.
The second quantization method includes the following characteristics:
The intra DC coefficient is quantized using a quantizer that is a function of the overall quantization parameter.
Other coefficients are quantized using a simple static quantizer value (no matrix).
Table A-22 shows the attributes of entropy coding in MPEG-4, Part 2.
MPEG-4, Part 2 supports B-frames, with four different modes:
Table A-23 identifies the annexes and codecs supported by different enterprise endpoints.
Table A-23. Endpoint Codec Support
Endpoint | Bit Rate | Codecs | H.263 Annexes Supported | Comments |
|---|---|---|---|---|
Polycom View Station | 64 kbps or 128 kbps | G.728, H.263 | F, I, T | Polycom View Station shows that it supports annexes F, I, and T at 64K and 128K bit rates. |
Polycom VSX 3000/7000 | 128 kbps to 2 Mbps | PCMU, PCMA, G.722, G.722.1, G.728, G.729, H.261, H.263, H.263-1998, H.264 | — | VSX 3000 and VSX 7000 also support SIP signaling. |
Cisco soft clients: Cisco Unified Personal Communicator (CUPC), Cisco Unified Video Advantage (CUVA) | 64 kbps to 1.5 Mbps | H.263, H.263-1998, H.264, G.711 | — | — |
Tandberg 7980 IP phones | 128 kbps to 1.5 Mbps | G.711, H.263 | None | — |
E-Conf | 128 kbps to 768 kbps | PCMA, PCMU, G.722, G.723, H.261, H.263, and H.263-1998 | I, J, K, T | E-Conf Version 4 supports H.264 baseline profile. |
Windows Messenger | 128 kbps | PCMU, H.261, and H.263 | None | — |
Table A-24 summarizes the major features of each codec. This table reflects the capabilities of all optional annexes of each codec.
Table A-24. Codec Feature Comparison
H.261 | H.263 | MPEG-4, Part 2 | H.264 | |
|---|---|---|---|---|
Maximum MVs per MB | 1 | 4 | 4 | 32 |
Interlace support | No | No | Yes | Yes |
Luma MV accuracy | 1 | 1/2 | 1/4 | 1/4 |
Smallest luma block sizes for MV | 16×16 | 8×8 | 8×8 | 4×4 |
OBMC | No | Yes | Yes | No |
Transform | 8×8 DCT | 8×8 DCT | 8×8 DCT | 4×4 integer, 8×8 integer |
Prediction of DCT coefficients | No | Yes | Yes | No |
Prediction of spatial values | No | No | No | Yes |
Arithmetic coder | No | Yes | Yes | Yes |
Reversible VLC | No | Yes | Yes | No |
B-frames | No | Yes | Yes | Yes |
Deblocking filter | No | Yes | Yes | Yes |
Scalability mode | No | Yes | Yes | Yes |
In general, the codec descriptions reveal that advanced codecs offer more flexibility for the encoder at each stage of the pipeline. The H.264 codec can assign up to 32 MVs per MB, with each MV pointing to a different reference image and carrying a different weighting value. In contrast, the simpler H.261 codec applies a single MV to an MB. However, to take full advantage of this flexibility, the H.264 encoder requires significantly more CPU power.
ITU-T Recommendation H.264 / ISO/IEC 14496-10, March 2005. Advanced video coding for generic audiovisual services.
ITU-T Recommendation H.261, March 1993. Video Codec for Audiovisual Services at p x 64 kbits.
ITU-T Recommendation H.263, January 2005. Video coding for low bit rate communications.
MPEG-4, Part 2: ISO/IEC 14496-2: Coding of audio-visual objects—Part 2, Visual, Third Edition. May 2004.
Wiegand, T., H. Schwarz, A. Joch, F. Kossentini, and G. J. Sullivan. Rate-Constrained Coder Control and Comparison of Video Coding Standards. IEEE Transactions on Circuits and Systems for Video Technology, Vol. 13, Issue 7. July 2003.