
Chapter 1. Why hackers know more about our systems
Abstract
Cyberattacks are on the rise despite our efforts to build systems that are safe and secure. Attackers are motivated to acquire deep knowledge about our systems, exploit inadequate defenses, share their knowledge, and weaponize it into attack tools. System builders often lack cybersecurity skills, while at the same time there are barriers to accumulate and share cybersecurity knowledge. Also, our knowledge of a given system dissipates as we implement the system, while the capabilities to rediscover this knowledge are often lacking. The OMG Software Assurance Ecosystem offers a systematic approach to discovering and exchanging cybersecurity and system knowledge; and provides guidance on how to transform this knowledge into machine-readable content for automated tools that can make assurance cost-efficient and affordable. The ecosystem is build around several standard information exchange protocols. The goal of the ecosystem is to close the gap with attackers, and to produce confidence in cybersystems.
Keywords
cybersystem, cyberattack, cybercrime, malware, hackers, cybersecurity, security, cyberdefense, confidence, risk, system assurance, cost of confidence, ecosystem, knowledge, knowledge exchange, knowledge discovery, knowledge gap, knowledge sharing, vulnerability detection, standard information exchange protocol, common vocabulary, linguistic model
We live in a world comprised of systems and risk.
—Clifton A. Ericson II, Hazard Analysis Techniques for System Safety
Throughout history, each technological advance has inevitably become the target of those who seek to subvert it.
—David Icove, Computer Crime
1.1. Operating in cyberspace involves risks
To be effective during an operation, organizations need to be agile, mobile, and robust with a flexible service-oriented user experience. Delivering this need means relying heavily on Web and Internet services technology that enables organizations and their clients to synergistically work together by automating end-to-end information exchange processes for seamless collaboration and operation of fully automated information systems that work 24/7 without human intervention. However, along with these enhanced information exchange capabilities come significant security, privacy, and regulatory concerns and challenges.
Cyber criminals have also undergone a remarkable transformation as they exploit the global scale and connectivity of cyberspace and convergence of services onto the Internet, where a significant amount of financial and business transactions are taking place [Icove 1995]. Cyber criminals evolved from lone hackers driven by curiosity and the desire to make a point about the freedom of information into sophisticated, transnational networks of organized criminals who commit large-scale online crimes for significant profit. Over the past three decades, hackers managed to accumulate an arsenal of cyber attack methods. According to the Inquiry into Cyber Crime, performed by the Australian Parliament [Australia 2010], cyber crime “operates on an industrial scale and has become an increasingly important issue for the global community.”
Furthermore, cyber-warfare became a reality that cannot be ignored since the 21st century battlefield includes not only the corn fields, deserts, mountain passes, and pine woods, but also the virtual communities in cyberspace along the information highways and back-roads supported by computers and mobile phones, and the miles of fiber optic cables, copper wires, the numerous network equipment boxes, and the very airwaves of the electromagnetic spectrum [Carr 2010]. This includes the nations' critical infrastructure and enterprise information systems, all the way down to the desktops and laptops in businesses and homes. The critical infrastructure is composed of many sectors that are in every nation's core industries—chemical, telecommunications, banking and finance, energy, agriculture and food, and defense—and bring us the services on which we all depend—water, postal and shipping, electrical power, public health and emergency services, and transportation. Each sector is extremely complex and to varying degrees is dependent on all the others.
Cyberspace and physical space are increasingly intertwined and software controlled. Each of the systems can affect our safety and security, and they have a unique design and a unique set of components; additionally, they contain inherent hazards that present unique mishap risks. We are constantly making a trade-off between accepting the benefits of a system versus the mishap risk it presents. As we develop and build systems, we should be concerned about eliminating and reducing mishap risk. Security services need to be seamlessly integrated into this new environment in order to assist civilian management and military commanders in recognizing the new information security threats posed by Web and Internet services-enabled activity, calculating the residual risk, and implementing appropriate security countermeasures to maintain order and control. Some risks are small and can be easily accepted, while other risks are so large that they must be dealt with immediately. While the trust side of the security equation has received a great deal of attention in the world of security, this growing reliance on Web and Internet services raises security issues that cannot be mitigated by traditional authentication processes. Although it remains important to know whether to trust information, it is becoming imperative to verify that there is no threat-related activity associated with this information.
Developing effective approaches to verify that systems operate as intended, that information can be trusted with confidence, and that no threat-related activity would follow is a key component in achieving systems security posture needed to defend against current and future attacks.
In particular, as mentioned in the 2008 OCED/APEC report, malware threat “is increasingly a shared concern for governments, businesses, and individuals in OECD countries and APEC economies. As governments rely evermore on the Internet to provide services for citizens, they face complex challenges in securing information systems and networks from attack or penetration by malicious actors. Governments are also being called on by the public to intervene and protect consumers from online threats such as ID theft. The past five years have indeed brought a surge in the use of malware to attack information systems for the purpose of gathering information, stealing money and identities, or even denying users access to essential electronic resources. Significantly, the capability also exists to use malware to disrupt the functioning of large information systems, surreptitiously modify the integrity of data, and to attack the information systems that monitor and/or operate major systems of the critical infrastructure” [OECD 2008].
1.2. Why hackers are repeatedly successful
Hackers seem to know more about our systems than we do. Does this sound strange to you? Shouldn't we—the designers, developers, implementers, administrators, and defenders—have the “home advantage”? Yet hackers keep finding means of taking over our systems. New security incidents are reported weekly, while software vendors are reacting to the incidents by issuing patches to their products. The industry seems to be trying to catch up with the hackers, hoping that the “good guys” will discover vulnerabilities quicker than the “bad guys” so that the software builders can patch systems before incidents happen.
For now let's assume that a “vulnerability” is a certain unit of knowledge about a fault in a system that allows exploiting this system in unauthorized and possibly even malicious ways. These faults are primarily caused by human error, poor requirements specifications, poor development processes, rapidly changing technology, and poor understanding of threats. Some faults are introduced deliberately through the supply chain and slip through into delivered systems due to poor development and acquisition processes. The industry came to the realization that with traditional system security engineering, error-free, failure-free, and risk-free operation is not usually achievable within acceptable cost and time constraints over the system life cycle [ISO 15443].
So why do attackers know more about our systems than developers and defenders? They are more efficient in discovering knowledge about our systems and are better at distributing this knowledge throughout their communities. How do hackers discover knowledge? Hackers relentlessly study our systems and invent new ways to attack them. Some hackers have the advantage of having access to the details of the entire development process of a system they attack and knowledge of the systems that have already been put into operation. Hackers study the source code whether they can obtain it by legal or illegal means, especially for the critical proprietary and network-based systems. But hackers also study machine code and study systems by interacting with them, where no code is required. Hackers take advantage of:
• The fact that systems are often built from commercial off-the-shelf components, including a small number of the base hardware and software platforms;
• Time flexibility – they are usually not constrained in their analysis of our systems, even though such analysis may be quite time-consuming, and;
• Vulnerable legacy systems – a vast majority of systems are still legacy systems developed with lax security requirements.
However, what makes attackers extremely efficient is extensive knowledge sharing. Since this is an important aspect for consideration in a defenders community, let's examine how knowledge sharing is done.
Attackers vary in their knowledge and capability. It is an exaggeration to say that every attacker knows more about every system than any defender or developer of that system. In the attacker community, individuals have different skills and play different roles: there are few highly skilled security researchers (known as the “elite hackers”), and a larger number of less skilled attackers (known as the “script kiddies”). However, the attacker community—a nebulous assembly of groups of like-minded individuals—is very efficient in using computer communications, and social networks to share knowledge. In fact, the hackers of the early days started as the enthusiasts of the emerging computer technology, communications, and networking. Attackers have been able to accumulate significant amounts of knowledge on how to attack systems. In addition, there are individuals who transform the theoretical knowledge of the attacks into the attack scripts and tools—attack knowledge is rather practical, and tools do play a critical role in attacking cyber systems. So, theoretical knowledge is transformed into automated attack weapons that require little technical skills. Attackers are willing to share, not just their knowledge, but also their tools and “weapons,” which become available to the individuals who are willing to launch attacks. As a result, an efficient ecosystem emerges, which amplifies the results of a few highly skilled hackers, and feeds a larger number of less skilled but highly motivated criminalized attackers. Hackers may not be systematic in what they do, but they succeed in industrializing their knowledge.
A large part of modern attack weapons is known as malware. According to an earlier cited OECD report [OECD 2008], malware is a general term for a piece of software inserted into an information system to cause harm to that system or other systems, or to subvert them for use other than that intended by their owners. Malware can gain remote access to an information system, record and send data from that system to a third party without the user's permission or knowledge, conceal that the information system has been compromised, disable security measures, damage the information system, or otherwise affect the data and system integrity. Different types of malware are commonly described as viruses, worms, trojan horses, backdoors, keystroke loggers, rootkits, or spyware. Malware shrinks the time between the discovery of vulnerabilities in software products and their exploitation and makes cyber attacks repeatable, which undermines the effectiveness of current security technologies and other defenses.
The skills within the defender community also vary greatly from the elite security researchers (who are sometimes hard to distinguish from the elite hackers) all the way to the administrators of home computer systems. However, the defender community lacks efficiency in their knowledge sharing due to too many barriers designed to retain competitive edge, expand market space, enhance offerings, etc.
1.3. What are the challenges in defending cybersystems?
Defense of cybersecurity systems involves understanding the risks, managing the vulnerabilities, adding safeguards, and responding to the incidents. The foundation of this understanding is knowledge related to (1) what are you defending, (2) what are you defending against, (3) what are vulnerabilities you need to mitigate and (4) what safeguards are included. Defense is conducted throughout the entire life cycle of the system. While long-term strategy involves better security engineering to develop more secure systems, the cyberdefense community needs to defend existing systems by adding safeguards in the form of patches to existing system elements, adding new security components, improving security procedures, improving configurations, and providing training.
1.3.1. Difficulties in understanding and assessing risks
Over many years the industry and the defense organizations have been developing in-house and third party approaches to evaluate and measure security posture of systems. Although significant progress has been made in understanding and documenting “what” needs to be evaluated together with expected results (e.g., Common Criteria [ISO 15408]), the lack of efficient approaches that address the “how” component made these evaluation methods underutilized. Currently, vendors who hope (or have hoped) to have their software systems certified are influenced by the slogan “Fewer is Better.” The fewer the security requirements to evaluate, the better their chances for success, and the process will be faster and less costly. This is a key reason why many systems are not being evaluated for environments requiring high robustness.
Understanding and assessing risks of the systems in cyberspace is a very challenging task. There is a whole industry that has been trying to crack this challenge for some time, and for that reason, it is important that we understand what the influencers of the challenge are by examining how systems are being developed and managed throughout their life cycles, and by examining the systems' complexities. Examining the key development trends and their management will give us a better understanding of areas that are necessary to cover in security evaluation approaches.
The system complexity trends have been impacted by a rapid pace of software evolution as new technologies and supported feature sets continue to introduce ever greater levels of complexity to an already complex system of networked and autonomous software components.
1.3.2. Complex supply chains
A majority of development trends make it very difficult to assess security posture of systems, making the software and the processes for developing and acquiring software a material weakness. Some of the key trends include:
1. Heavy reliance on COTS/Open Source products further impacted by globalization trends where modern software development and supply chain support are becoming increasingly distributed worldwide. What at first might seem a great trend for producing low-cost systems quickly can turn into a nightmare for businesses where these systems are deployed. By outsourcing, using developers from foreign and unevaluated domestic suppliers, or using supply chain components often developed with a focus only on functionality for the lowest possible price without regard to its resistance to attack makes our businesses exposed and vulnerable to attacks. For these reasons, assessing the security posture of systems needs to go beyond evaluating the software application; it needs to include evaluation of the software supply chain, the development process, and pedigree of the development team to address growing concerns regarding the ability of an adversary to subvert the software supply chain and insiders' attacks.
2. Enhancements of legacy systems, since there was a vast amount of useful, deployed, operational legacy software developed at the time when security requirements were more relaxed. These legacy software systems still represent an enormous commercial value, and therefore, there is a growing need to prolong their lifespan through maintenance efforts, and to enhance them to accommodate new market requirements and governmental regulations. However, as an existing system gets larger and more complex, its design erodes, which hinders system comprehension, compromises architectural integrity, and decreases maintenance productivity. This creates severe problems moving forward. The system becomes more defect-prone and at the same time, it becomes resistant to enhancement. In this situation, any attempt to retrofit secure coding practices in order to stop security erosion of the system would just aggravate the issue—it would produce a large number of changes and the associated risk from the unforeseen impact these changes introduce into the software could be so overwhelming that it would impact the business of the organization. These costly and risky methods are never implemented. As a consequence, very often quick fixes are introduced with many shortcuts and only a partial investigation for possible “weak links.” New functionality is usually “shoehorned” into the preexisting architecture in a response to yet another security panic, which further compromises the security of the system. So the big question is: “How can we assess the security posture of such a system?”
3. Another key trend is increasing migration to net-centric environments and service-oriented architectures. The assessment must provide assurance that software components can be trusted to interact securely without supervision considering the following:
• Noncompliance with open standards and protocols. Complex protocols could be considered overkill or redundant, so altering some of the steps might seem a good idea at the time. Although normal operations might not be impacted, it could certainly jeopardize the security guarantees the protocol offers.
• Vulnerabilities associated with Web service configuration files. Web services are designed to provide greater flexibility to application platforms; however, this comes with security challenges since complexity in service configuration files might lead to mistakes that become vulnerabilities in the service.
• Software vulnerabilities. Very often the legacy software that originally was not designed to operate on a network is integrated into a network-centric system. Suddenly, a flood of code vulnerabilities are exposed, making the entire system more vulnerable.
1.3.3. Complex system integrations
“As the complexity of a particular system can be viewed as the degree of difficulty in predicting the properties of the system if the properties of the system's parts are given” [Weaver 1948] it will greatly influence evaluation methodology and should play a key component in risk assessment and management.
We all agree that the current software systems are larger and continue to grow in sheer size and complexity. Very rarely does a software development project start from a clean sheet of paper. More than half of all code written today is based on enhancements and maintenance of existing functions. More often than not, new features or functionality on top of an existing code base is a large, complex piece of software that has evolved into conflicting or challenging designs that often resists evolution and/or bug fixes. Furthermore, market consolidation brings the challenge of integrating these components into net-centric systems from mergers and acquisition activities, making an existing system even larger, more complex, and harder to comprehend. The system's structure includes interconnected software components that were developed using differing methodologies, a variety of technologies, and under varying constraints and assumptions. At the same time, the documentation of such systems is never up-to-date and the information available is largely folk- or judgment-driven in nature and difficult to access. The only thing trusted to be an up-to-date source is the code itself; however, comprehension of such a code is further obscured by uncontrolled use of multiple programming languages, allowing developers to freely express themselves in more artistic ways. This causes the lack of control over software architecture, leading to erosion of the initial structural concepts of the system, increasing a system's complexity even more. This is a major source of latent security defects that assessment should uncover.
1.3.4. Limitations of system assessment practices
The majority of system assessments primarily focus on assessing and evaluating the development process and a product's documentation, rather than the formal artifacts. Formal security analysis is rarely performed and can be characterized at the most as opportunistic. Although the development process provides a structured way of developing the system, and as such, greatly influences security posture of the system, it still only provides a single data point to corroborate the system security, leaving some major assessment methodology gaps such as:
• Assessment information obtained informally – Assessment information is usually collected through interviews and documentation sampling, providing results that can be subjective, and therefore not likely repeatable.
• Reliance on documents that might not be up-to-date – The product's documentation, even if kept up-to-date, is typically manually generated and intended for manual review, leading to a very subjective interpretation not necessarily reflecting properties of an implemented system's artifact.
• Lack of formal traceability between obtained information and system artifacts – Obtained information is usually not well “connected” to the system artifacts and as the result fails to detect the real vulnerabilities and does not offer ways to improve security posture and our confidence in it.
System development usually follows one of several development processes: waterfall, iterative (e.g., agile, Rapid Application Development (RAD), Capability Maturity Model (CMM), Model Driven Architecture (MDA)), or some custom process. Besides providing a structured way to develop the product, it also provides a framework for establishing multi-segmented traceability by connecting high level policy to objectives, requirements, design specification (captured as document or prototype), and implementation of system artifacts. However, once a product is fully developed, that structure is often dissolved, creating a traceability gap between requirements and the corresponding system artifacts. Because of this traceability gap the current assessment approaches resist automation, and as the result the formal analysis of the artifacts is either skipped entirely, or at some rare occasions substituted by a very laborious and costly application of formal methods applied to manually developed models. Neither approach addresses software supply chain and pedigree of the development team.
Recently, with development of new technologies in the area of white-box and black-box vulnerability detection it became possible to automate some of the security testing for software and networked systems. Although a very powerful, cost-effective way of examining formal artifacts, the results are not conclusive when determining trustworthiness of the system. This is due to issues associated with the way these technologies are implemented in commercial tools and how these tools are applied on the given system. Let's examine these technologies and tools in more detail.
1.3.5. Limitations of white-box vulnerability detection
There are two types of security testing methods: white-box testing and black-box testing.
White-box testing is based on knowledge of the system internals derived directly from the code (source or binary). The white-box testing is associated with testing of the software and has inside-out focus, targeting particular constructs, statements, code paths, or code sections. A technology used in security white-box vulnerability testing is known as static analysis and is commercialized in source and binary code analyzer tools. The promise of this technology is the 100% coverage of all code paths in the system. However, tools implementing this technology have several weaknesses producing inconclusive evidence of a system's trustworthiness.
1. Lack of complete system coverage – The tools provide some capabilities with proprietary and limited functionality, with each tool providing value only in subsets of the enterprise application space causing the need to use more than one static analysis tool to combine their strengths and avoid their weaknesses. As mentioned in the recent comparison of static analysis tools performed at NSA [Buxbaum 2007] “Organizations trying to automate the process of testing software for vulnerabilities have no choice but to deploy a multitude of tools.” Since current source/binary code analysis tools offer little interoperability, it is costly to evaluate, select and integrate the set of tools that provide an adequate coverage for the breadth of languages, platforms, and technologies that typical systems contain. Findings in one vulnerability report are not necessarily aligned with the pattern and condition of the vulnerability and therefore, reports from two tools for the same vulnerability many not be the same. For example, the evidence for buffer overflow vulnerability is scattered throughout the code: it involves a buffer write operation, a data item being written, another place where the buffer is allocated, and yet another place where the length of the buffer is calculated. There is a code path that allows an attacker to exploit the buffer overflow by providing some input into the application. In addition, a buffer overflow may be caused by another problem, such as an integer overflow. All this evidence has to be considered and reported in a single buffer overflow report using a common vocabulary and structure. Failure to use a common reporting standard leads to a situation where it is hard to merge reports from multiple vulnerability detection tools and achieve a significant improvement in the overall report quality, because the lack of interoperability and the common vocabulary makes it hard to 1) select the vulnerability that is reported by multiple tools; 2) for a given vulnerability, estimate the coverage of the same vulnerability pattern throughout the entire system; and 3) get coverage of the system by the multitude of tools.
2. Lack of aid in understanding the system – Vulnerability detections tools do not aid the team in understanding the system under assessment, an activity that is required for the evaluation team to make a conclusion about a system's trustworthiness, as well as to detect vulnerabilities that are specific to the system under evaluation—the knowledge that cannot be brought by the off-the-shelf vulnerability detection tools.
An automatic static analysis tool goes through the code, parses it, analyzes it, and searches for patterns of vulnerabilities. As a result, the tool produces a report describing the findings. As part of this process, a great deal of detailed knowledge of the system is generated because finding vulnerabilities requires a fine-grained understanding of the structure, control, and data flow of each application. However, as soon as the report is produced, this detailed knowledge disappears. It can no longer be used to systematically reproduce the analysis or to aid the assessment team to understand the system. It is only the list of vulnerabilities that they are provided with. A similar situation occurs during compilation. A compiler generates large amounts of fine-grained knowledge about the system, only to be discarded as soon as the object file is generated.
However, a consistent approach to representing and accumulating this knowledge is critical for a systematic and cost-efficient security evaluation, because not only do all code analysis capabilities need to share this knowledge, but also any inconsistencies in addressing the basic knowledge of the system will lead to bigger inconsistencies in derived reports.
An exploitable vulnerability is a complex phenomenon, so there are multiple possibilities to report it in a multitude of ways. The industry of vulnerability detection tools is still immature. There is no standardization on the nomenclature of vulnerabilities or on the common reporting practices, although several community efforts are emerging.
It is easy to make a case for the multi-stage analysis where a particular vulnerability detection capability is just one of the “data feeds” into the integrated system assessment model.
• First, the original vulnerability analysis has to be augmented with additional assessment evidence, which is usually not provided by an off-the-shelf tool. For example, such evidence can be collected from people, processes, technology, and the environment of the system under evaluation. In addition, in a large number of situations, the findings from the automatic vulnerability detection capabilities need to be augmented by the results of the manual code reviews or evaluations of formal models.
• Second, there is a gap between the off-the-shelf vulnerabilities that an automatic tool is looking for and the needs of a given system with its unique security functional requirements and threat model. Usually there are not enough inputs for an automatic tool to detect these vulnerabilities, so these analyses need to be performed. The inputs that are required for the additional vulnerability analysis are similar to the original analysis. This knowledge may include the specific system context, including the software and hardware environment in which the application operates, the threat model, specific architecture of the system, and other factors.
• Third, other kinds of analysis in the broader context of systems assurance needs to be performed, in particular, architectural analysis, software complexity metrics, or penetration (black-box) testing.
In order to obtain a cohesive view of the security application, software evaluation teams often need to do painful point-to-point integrations between existing vulnerability detection capabilities and tools. Rarely do organizations choose this path.
3. Massive production of false positives and false negatives – There are some fundamental barriers to comprehensive code analysis, which leads to limitations of the vulnerability detection tools, and subsequently, to false negative and false positive report findings. In order to analyze a computation, all system components have to be considered, including the so-called application code, as well as the runtime platform and all runtime services, as some of the key control and data flow relationships are provided by the runtime framework, as the computation flows through the application code into the runtime platform and services and back to the application code. Application code alone, often written in more than one programming language, in most cases does not provide an adequate picture of the computation, as some segments of the flow are determined by the runtime platform and are not visible in the application code. For example, while a large number of control flow relationships between different activities in the application code are explicit (such as statements in a sequence, or calls from a statement to another procedure), some control flow relations are not visible in the code, including the so-called callbacks, where the application code registers a certain activity with the runtime framework (for example, an event handler or an interrupt handler) and it is the runtime framework that initiates the activity. Without the knowledge of such implicit relationships, the system knowledge is incomplete, leading to massive false positive and false negative entries in the report. While numbers of generated false negatives are unknown, the numbers of generated false positives are staggeringly high and “weeding” through a report to identify true positives is a costly process, causing limited use of such tools. To reduce the number of false reports some tools simply skip situations where they can not fully analyze a potential vulnerability within a short timeframe.
1.3.6. Limitations of black-box vulnerability detection
Black-box testing, otherwise known as dynamic testing, is designed for behavioral observation of the system in operation. It has outside-in focus, targeting functional requirements. The activity includes an expert simulating a malicious attack. Testers almost always make use of tools to simplify dynamic testing of the system for any weaknesses, technical flaws, or vulnerabilities. Currently tools in this area are categorized based on their focus of specific areas they are targeting. These areas include network security and software security, where software security is comprised of database security, security subsystems, and Web application security.
• Network security testing tools are focused on identifying vulnerabilities in externally accessible network-connected devices. This activity is performed by either placing packets on the wire to interrogate a host for unknown services or vulnerabilities, or by “sniffing” network traffic to identify a list of active systems, active services, active applications, and even active vulnerabilities. In this case, “sniffing” is considered less intrusive and performs a continuous analysis effort while packet injection techniques produce a picture of the network at a given point in time. The strengths and weaknesses related to network security tools could be characterized as follows:
• Packet injection techniques
• Strengths: can be used independent of any network management or system administration information making a much more objective security audit of any system or network and providing accurate information about which services are running, which hosts are active, and if there are any vulnerabilities present.
• Weaknesses: since scanning takes a long time and is intrusive, this type of scanning is performed less often where most solutions opt to reduce the number of ports scanned or the vulnerabilities checked, leading to undiscovered new hosts and a variety of vulnerabilities. In addition, due to restrictive security polices, it is very common for network security groups in large enterprises to be restricted from scanning specific hosts or networks, causing many vulnerabilities to be missed.
• Sniffing techniques
• Strengths: minimal network impact and time needed for scan (scan can be running 24/7).
• Weaknesses: for host or server to be scanned, it needs to communicate on the network, which might lead to discovery of the presence of a server at the same time a probing hacker does.
Both techniques deal with very complex log files and they need expertise to interpret them; however, most network administrators do not have sufficient experience and expertise to either properly discern false positives or set priorities for what security holes should be fixed first, which might lead to some critical vulnerabilities not being addressed in time.
In summary, weaknesses of each technique leads to a number of false positives and false negatives, making assessments costly (“weeding” through false positives) and not so assuring (not knowing what has been missed).
Techniques used in black-box software security testing are known as penetration testing. A penetration test uses a malicious attacker behavior to determine which vulnerabilities can be exploited and what level of access can be gained. Unlike network security tools, penetration tools generally focus on penetrating ports 80 (HTTP) and 443 (HTTPS). These ports are traditionally allowed through a firewall to support Web servers. This way they can identify Web applications' and Web services-based applications' vulnerabilities and misbehaviors.
Here are some characteristics of a typical penetration test:
• Strength: A relatively small toolset is needed and serves as a good starting point for more in-depth vulnerability testing. High degree of information accuracy when vulnerability is reported.
• Weaknesses: High number of false negatives and some false positives. Penetration testing works only on a tightly defined scope, such as Web applications and database servers as a less structured process (at least during the system exploration and enumeration phases), which leads to the conclusion that this technique is as good as the tests they run. Penetration technique does not provide the whole security picture, especially for systems that are only accessible via the internal network, and it can be time sensitive. These weaknesses can cause many vulnerabilities to be missed (high number of false negatives) and some server responses could be misinterpreted, causing false positives to be reported.
However, recent developments in the technology areas of System Assurance offer the most promising and practical way to enhance a vendor's ability to develop and deliver software systems that can be evaluated and certified at high assurance levels while breaking the current bottleneck, which involves a laborious, unpredictable, lengthy, and costly evaluation process. These breakthrough technologies bring automation to the system assurance process.
This book provides technology guidance to achieve automation in system assurance.
1.4. Where do we go from here?
A system assessment must discover security vulnerabilities in the system of interest. Majority of current assessment practices are relatively informal and very subjective. Due to difficulties caused by development trends and systems' complexities, they focus primarily on evaluating the development process and a product's documentation rather than formal artifacts. Security testing is rarely performed and can be characterized at the most as opportunistic. The only exception is evaluation methodology for high robustness, at which point formal methods are applied to assess a system's formal artifacts. However, this process is laborious and costly, the key reasons why most systems are not being evaluated in this way. For all these reasons, it is becoming increasingly difficult to establish or verify whether or not software is sufficiently trustworthy, and as complications will likely continue to evolve, a new approach needs to be developed to provide credible, repeatable, and cost-efficient ways for assessing a system's trustworthiness and for managing assurance risks; an approach that will still give us systematic and methodical system coverage in identifying and mitigating vulnerabilities.
Having in mind the internal complexity of the system and complexity of development trends and development environment, the only way to achieve this new approach is by implementing automated model-driven assessment.
Over the years, we have followed uptake of model-driven development where more and more new features, applications, and even systems are modeled in an implementation-independent way to express technical, operational, and business requirements and designs. These models are prototyped, inspected, verified, and validated before design is implemented. In a majority of the cases, once design is implemented, models and their prototypes are discarded. The reason is that throughout the implementation process, some of the designs are changed due to various reasons (e.g., impact of chosen implementation technologies) and going back to update models and prototypes to keep them current is expensive. In other words, trusted traceability is broken.
If we are able to regenerate trusted models directly from the only up-to-date system artifact, which is code itself, we would be able to recreate a process where models could be assessed and evaluated in a very practical, systematic, and cost-effective way. To achieve this goal of reestablishing trustworthy models, the following needs to be addressed:
1. Knowledge about a system's artifacts belonging to system of interest is captured and represented in a unified way, ensuring discovery and unified representation of system artifacts at the higher level of abstractions (e.g., design, architecture, and processes) without losing traceability down to the code.
2. Knowledge connecting high level requirements, goals, or policies with system's artifacts that implemented them is rediscovered and captured, providing end-to-end traceability.
3. Threat knowledge is collected, captured, and managed in relation to system's artifacts identified as system inputs.
4. Vulnerability knowledge is understood, captured, and managed in the form of standardized machine-readable content. To be successful in communicating with an IT or network systems and engineering groups, knowledge of vulnerabilities is crucial.
5. Standard-based tool infrastructure is set up that would collect, manage, analyze. and report on required knowledge and provide higher automation in achieving the ultimate goal by integrating a large set of individual tools to offset their limitations and weaknesses and integrate their strengths.
1.4.1. Systematic and repeatable defense at affordable cost
Consequently, this approach would create confidence in the security posture of systems. By regaining knowledge of our systems, and accumulating the knowledge of the attackers and their methods, we would be able to reason about the security mechanisms of our systems and clearly and articulately communicate and justify our solutions. This involves a clear and comprehensive game plan, which anticipates the possible moves of the opponent and uses the home advantage and the initiative to build a reasonably strong defense.
It is the nature of cybersecurity to provide a reasonable, justifiable answer to the question of whether the countermeasures implemented in the target system adequately mitigate all threats to that system. This answer is what is sometimes called the security posture of the system. Evaluating security posture requires detailed knowledge, in particular, the knowledge of the factors internal to the system, such as the system boundaries, components, access points, countermeasures, assets, impact, policy, design, etc., as well as the factors that are external, such as threats, hazards, capability and motivations of the threat agents, etc. As vulnerability can be described as a situation where a particular threat is not mitigated, this would mean that there exists a possibility of an attack, waiting for a motivated attacker to discover this situation, and execute the attack steps.
Answering the cybersecurity question is not easy due to the uncertainty factor. There is a great deal of uncertainty associated with any external factors, but there is uncertainty associated with the internal factors too, because our knowledge of the complex target system is not perfect. There may be some uncertainty about the impacts of the incidents to the business and even about the validity of the security policy. In a slightly different sense, there is uncertainty about the behavior of the system, but this uncertainty is only related to the current state of our knowledge, and can be removed (at a certain cost) by analyzing the system deeper.
Two disciplines, security engineering and risk assessment, address the cybersecurity question from different perspectives. Security engineering addresses this question in a practical way by selecting the countermeasures and building the target system. It emphasizes building the system rather than communicating the knowledge about the system, although some design documentation may be one of the outputs of a solid engineering process. Security engineering often uses “tried and tested” solutions based on “best practices,” and selects countermeasures from catalogs. This pragmatic approach avoids analysis of threats and their mitigation by the security architecture, so justification is often done by reference to the recommended catalog of countermeasures. A clear, comprehensive, and defensible justification of the system's security architecture ought to be one of the mainstream activities of security engineering; however, there is little evidence that this is being done, in part because of the mismatch in the qualifications required for systems engineering, system validation, and verification on one hand, and the security validation, verification, and assurance on the other hand. It is not uncommon to push some uncertainty to the market as the system is released and patched later as the vulnerability is found by someone else and reported back to the engineering team.
Risk assessment is usually considered to be part of management and governance of the system. Risk assessment answers the cybersecurity question by evaluating the system. Usually there are two points in the system life cycle when such evaluation takes place: one as early as possible, right after the countermeasures have been selected, and the other one as late as possible, when the entire system has been implemented, and it is ready to be put into operation. The decision-making process of risk assessment involves analyzing the threats to the system, the countermeasures, and vulnerabilities. The emphasis of risk assessment is to identify the risks that need to be managed, and not to communicate the knowledge about the system. Neither is a clear, comprehensible, and defensible justification of the system's security architecture a mainstream activity of risk assessment. The nature of the risk assessment is that it identifies problems—not justifies that the available solution is adequate.
Risk assessment provides a probabilistic approach to dealing with uncertainty in our knowledge about the system. Lower end varieties of risk assessment teams offer a “best practice” approach, often based on the ‘best guess.” This works, because risk assessment is a pragmatic discipline, which generates the list of risks to manage and the list of recommendations of new countermeasures that would lower the risk. Since risk assessment is part of the ongoing risk management, any miscalculations can be addressed as more operational data becomes available. Risk assessment provides input to engineering, which evaluates the recommendations and implements them.
As you can see, justifying system's security posture, and communicating this knowledge in a clear, comprehensive, and defensible way, is not addressed by either security engineering or risk assessment. Engineering builds solutions. Validation and verification justify that the solution corresponds to the requirements, objectives, and policy. Risk assessment looks for problems, identifies them, and justifies significance of their existence. Risk assessment also recommends mitigating solutions. On the other hand, assurance is considered by many as an optional activity that is applicable only for a limited number of high-profile systems where high security and safety is a “must have,” such as in nuclear reactors. The reason is the perceived high cost of assurance activities. However, it is important to note that assurance closes some gaps in both security engineering and risk analysis.
The Information and Communication Technology (ICT) security community refers to ”Assurance” as confidence and trust that a product or service will function as advertised and provide the intended results or the product or service will be replaced or reconditioned. It refers to the security of the product or service and that the product or service fulfills the requirements of the situation, satisfying the Security Requirements.
The Cybersecurity Assurance community expands this Assurance description to explicitly talk about vulnerabilities. The National Defense Industrial Association (NDIA) Engineering for System Assurance Guidebook [NDIA 2008] defines “Assurance” as “justified measures of confidence that the system functions as intended and is free of exploitable vulnerabilities, either intentionally or unintentionally designed or inserted as part of the system at any time during the life cycle.” This new definition, besides arguing positive properties, “does functions as intended,” adds a need for arguing negative properties, and “does not contain exploitable vulnerabilities,” which requires more comprehensive assurance methods. This book describes a framework for implementing comprehensive assurance for cybersecurity with emphasis on automation.
The Cybersecurity community more often refers to “Assurance” as “System Assurance” or “Software Assurance” (emphasizing importance of vulnerabilities in software itself). According to the Cybersecurity community, the system assurance as a discipline studies the methods of justifying cybersecurity. It is a systematic discipline that focuses on how to provide justification that the security posture is adequate. System assurance develops a clear, comprehensive, and defensible argument for security of the system. In order to support the argument, concrete and compelling evidence must be collected. One of the sources of evidence is system analysis. System assurance deals with uncertainty through a special kind of reasoning that involves the architecture of the target system. Instead of a never-ending process of seeking more and more data to eliminate the fundamental uncertainty, system assurance uses the layered defense considerations to address the unknowns. Needless to say, the assurance argument benefits from the available knowledge related to both the external and the internal factors of cybersecurity.
The reasoning provided by the system assurance discipline is used both in the context of engineering as well as risk assessment. System assurance is a form of systematic, repeatable, and defensible system evaluation that provides more detailed results than a traditional “best-practice” approach. The key difference of the system assurance approach and traditional risk assessment is that assurance justifies the claims about the security posture of the system. Assurance is a direct way to build confidence in the system. Deficit of assurance can be directly transformed into the requirements for additional countermeasures. On the other hand, while evidence of risks, produced by detecting vulnerabilities, can also be transformed into countermeasures, it does not build confidence in the system, because the absence of vulnerabilities makes only a weak indirect case about the security posture of the system. This is why we need system assurance. This is why we need to move beyond detecting vulnerabilities.
The answer to weaponized exploits and malware is to automate security analysis, automate checklists involved in threat and risk analysis and use the assurance case as a planning tool for establishing defense in depth.
From the system assurance perspective, deficiencies in the argument indicate defects in the defense. Particular points in the architecture of the system that prevent us from building a defensible assurance argument are the candidates for the engineering to fix. The new, improved mechanisms will directly support the assurance argument and, at the same time, improve the security posture of the system.
Collecting evidence for assurance, in particular within the layered defense argument, is more demanding on the depth and accuracy of the system analysis and the accuracy of the corresponding data.
1.4.2. The OMG software assurance ecosystem
An ecosystem refers to a community of participants in knowledge-intensive exchanges involving an explicit and growing shared body of knowledge and corresponding automated tools for collecting, analyzing, and reporting on the various facets of knowledge, as well as a market where participants exchange tools, services, and content in order to solve significant problems. The essential characteristic of an ecosystem is establishment of knowledge content as a product. An ecosystem involves a certain communication infrastructure, sometimes referred to as “plumbing,” based on the number of knowledge-sharing protocols provided by a number of knowledge-management tools.
The purpose of the ecosystem within a cybersecurity community is to facilitate collection and accumulation of cybersecurity knowledge needed for assurance, and to ensure its efficient and affordable delivery to the defenders of cybersystems, as well as to other stakeholders. An important feature of the cybersecurity knowledge is separation between the general knowledge (applicable to large families of systems) and concrete knowledge (accurate facts related to the system of interest). To illustrate this separation, a certain area at the bottom of the ecosystem “marketplace” in the middle of Figure 1 represents concrete knowledge, while the rest represents general knowledge. Keep in mind that “concrete” facts are specific to the system of interest, so, the “concrete knowledge” area represents multiple local cyberdefense environments, while the “general knowledge” area is the knowledge owned by the entire cyberdefense community. The icons titled “defender,” “inspector,” and “stakeholder” in Figure 1 represent people interested in providing assurance of one individual system. Basically, this is your team.
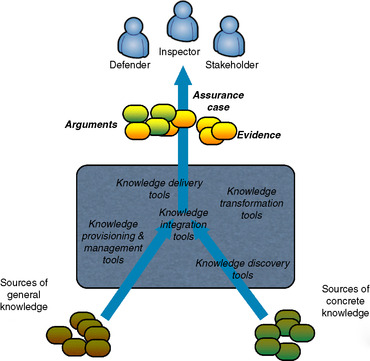 |
| Figure 1 Knowledge sharing within the ecosystem |
The OMG Software Assurance Ecosystem defines a stack of standard protocols for the knowledge-based tools, including knowledge discovery tools, knowledge integration tools, knowledge transformation tools, knowledge provisioning and management tools, and knowledge delivery tools.
1.4.3. Linguistic modeling to manage the common vocabulary
The key requirement for knowledge exchange between tools in the ecosystem is a common, agreed upon vocabulary that represents the conceptual commitment of the participants. However, much of the computer security information gathered and disseminated by individuals and organizations cannot currently be combined or compared because a common vocabulary has yet to emerge in the field of computer security. Numerous individuals and organizations regularly gather and disseminate information related to computer security. This information describes security events, as well as the characteristics of computer and network systems. Unfortunately, much of this computer security information cannot be combined without significant manual effort because the terms currently used in the field of computer security tend to be unique to different individuals and organizations.
Devising a common vocabulary for cybersecurity is the first logical step in the industry evolution from proprietary, in-house, stovepipe solutions to efficient and collaborative cybersecurity ecosystem that can take advantage of the economies of scale. Established standard vocabulary brings several tangible benefits and justifies the efforts required. Indeed, at the heart of any security assessment project there is a need to manage and integrate multiple pieces of information from different sources. Standard vocabulary decouples producers of cybersecurity knowledge from the consumers of knowledge and the distribution channels, and consequently opens up the market of efficient tools that can take advantage of the economies of scale. A single coherent picture that is both accurate and comprehensive enough is necessary to reason about the security of the system and to build a defendable assurance case. Knowledge-based systems and services are expensive to build, test, and maintain. Several technical problems stand in the way of shared, reusable, knowledge-based systems. Like conventional applications, knowledge-based systems are based on heterogeneous hardware platforms, programming languages, and network protocols. However, knowledge-based systems pose special requirements for interoperability. Such systems operate on and communicate using machine-readable knowledge content. They ask queries and give answers. They take “background knowledge” as an input and exchange derived knowledge. For such knowledge-level communication, we need conventions at three levels: knowledge representation format, communication protocol, and specification of the content of shared knowledge. Standard knowledge representation formats and communication protocols are independent of the content of knowledge being exchanged or communicated. A common language is used for standardization of the knowledge content. In general, agreeing upon a vocabulary for a phenomenon makes systematic studies possible. In particular, standardization of the cybersecurity vocabulary brings the following benefits:
• A common language for intrusions and vulnerabilities enables us to compile statistics, observe patterns, and draw other conclusions from collected intrusion and vulnerability data. This process will extend our knowledge of the phenomenon, provide an efficient way to close the knowledge gap with attackers, and will make it possible to strengthen systems against intrusions using this knowledge.
• An established taxonomy would be useful when reporting incidents to incident response teams, such as the CERT Coordination Center. It could also be used in the bulletins issued by incident response teams in order to warn system owners and administrators of new security flaws that can be exploited in intrusions.
• If the common language included a grading of the severity or impact of the intrusion or the vulnerability, system owners and administrators would be helped in prioritizing their efforts.
A common language is a linguistic model of a domain that is used to compose complex statements about the domain. The foundation of a linguistic model is a vocabulary. From a finite, well-defined vocabulary one can compose a large number of coherent sentences. A body of formally represented knowledge is based on a conceptualization: the objects, concepts, and other entities that are presumed to exist in some area of interest and the relationships between them. A conceptualization is an abstract, simplified view of the world that we wish to represent for some purpose. Every knowledge base, knowledge-based system, or knowledge-level agent is committed to some conceptualization, explicitly or implicitly. That is one reason why vocabulary, rather than format is the focus of linguistic models. The set of objects that can be represented by the statements of a linguistic model is called the universe of discourse. This set of objects, and the discernable relationships among them, are reflected in the vocabulary as a set of terms. In such a vocabulary, definitions associate the names of objects and concepts in the universe of discourse with human-readable text describing what the names are meant to denote, and formal rules that constrain the interpretation and well-formed use of these terms.
Pragmatically, a common language defines the vocabulary with which queries and assertions are exchanged among participants of the ecosystem. Conceptual commitments are agreements to use the shared vocabulary in a coherent and consistent manner. The agents sharing a vocabulary need not share a knowledge base; each knows things the other does not, and an agent that commits to a conceptualization is not required to answer all queries that can be formulated in the shared vocabulary. In short, a commitment to a common vocabulary is a guarantee of consistency, and supports multiple implementation choices with respect to queries and assertions using the vocabulary. A vocabulary serves a different purpose than a knowledge base: a shared language need only describe a vocabulary for talking about a domain, whereas a knowledge base may include the knowledge needed to solve a problem or answer arbitrary queries about a domain. Knowledge base includes concrete and specific operational facts.
Linguistic models include the following three important parts:
• Representation of the things in the domain, also known as taxonomy. Taxonomy focuses on the noun concepts. Landwehr et al. made the following observation in his work on a cybersecurity taxonomy: “A taxonomy is not simply a neutral structure for categorizing specimens. It implicitly embodies a theory of the universe from which those specimens are drawn. It defines what data are to be recorded and how like and unlike specimens are to be distinguished” [Landwehr 1994]. Taxonomy does not resist automation if it supports definitions that can be interpreted as queries into an appropriate knowledge base. Unfortunately, several taxonomies already proposed in the field of cybersecurity resist automation. The art of making discernable definition involves careful selection of the characteristics that are aligned with the conceptual commitment.
• Representation of the relationships in the domain. Nouns alone are insufficient for constructing rich statements about a domain. Connections between nouns are generally expressed using verbs and verb phrases that relate appropriate terms. These noun and verb combinations are called sentential forms and are the basic blocks that permit complex sentences to be made about the domain.
• Mechanism for constructing statements in the vocabulary of noun and verb concepts. In addition to the vocabulary of terms and sentential forms, a linguistic model must include the mechanism for combining them into meaningful statements.
1.5. Who should read this book?
This book is designed and intended for anyone who wants a detailed understanding of how to perform system security assurance in a more objective, systematic, repeatable, and automated way. The audience for this book includes:
• Security and security assessment professionals who want to achieve efficient, comprehensive, and repeatable assessment process, and
• Security consumers interested in a cost-effective assessment process with objective results. Security consumers include the personnel in the following roles within the organization: technical, program/project, and security management.
Bibliography
In: The Parliament of the Commonwealth of Australia, House of Representatives, Standing Committee on Communications (2010) Hackers, Fraudsters and Botnets: Tackling the Problem of Cyber Crime. The Report of the Inquiry into Cyber Crime. Canberra, Australia. ISBN 978-0-642-79313-3. (2010).
P. Buxbaum, All for one, but not one for all. Government Computer News, March 19, 2007. (2007) ;http://gcn.com/Issues/2007/03/March-19-2007.aspx.
J. Carr, Inside Cyber Warfare, O'Reilly & Associates, Inc. (2010) ; Sebastopol, CA.
D. Icove, K. Seger, W. VonStorch, Computer Crime: A Crime Fighter's Handbook. (1995) O'Reilly & Associates, Inc; Sebastopol, CA.
In: ISO/IEC 15443-1:2005 Information Technology – Security Techniques – A Framework for IT Security Assurance. Part 1: Overview and Framework. (2005).
In: ISO/IEC 15408-1:2005 Information Technology – Security Techniques – Evaluation Criteria for IT Security Part 1: Introduction and General Model. (2005).
C. Landwehr, A.R. Bull, J. McDermott, W. Choi, A taxonomy of computer program security flaws, ACM Computing Surveys26 (3) (1994) 211–254.
NDIA, Engineering for System Assurance Guidebook, (2008) .
OECD, Malicious Software (Malware). A security threat to the Internet economy, Ministerial Background Report. (2008) ; DSTI/ICCP/REG(2007)/5/FINAL.
W. Weaver, Science and complexity, American Scientist36 (4) (1948) 536.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.