
Chapter 7. Vulnerability patterns as a new assurance content
Keywords
Keywords vulnerability
vulnerability pattern
standard protocol for exchanging system facts
knowledge discovery metamodel
Common Weakness Enumeration (CWE)
Abstract
The NIST SCAP Ecosystem successfully addresses the exchanges of knowledge for vulnerability management for the known vulnerabilities in commercial off-the-shelf software products. A larger ecosystem for assurance beyond the current SCAP has to involve machine-readable vulnerability patterns as content that can be consumed by code analysis tools and web scanning tools.
In order for cybersecurity knowledge to be systematically collected and accumulated, it should be unlocked from the tools and distributed from the few experts onto the larger community. This means that knowledge such as knowledge captured by the Common Weakness Enumeration (CWE) should be turned into a commodity, unlocked from proprietary tools into a normalized, interconnected “grid” that leads to explosive growth in how this knowledge is utilized. The key contribution of the OMG Software Assurance Ecosystem is the standard protocol for exchanging system facts, in addition to which vulnerability patterns can be formalized and utilized by analysis tools for detecting vulnerabilities. Turning collective knowledge into machine-readable content for tools is discussed in this chapter, while the practicality of this approach is discussed in Chapters 9, 10 and 11.
I have now in my hands all the threads which have formed such a tangle.
—Conan Doyle, The Study in Scarlet
7.1. Beyond current SCAP ecosystem
In many organizations, the internal security professionals are adept at finding and responding to information about the latest vulnerabilities to the commercial software products employed within business critical systems under their supervision. A great many security resources, both online and printed, are available from Security Information Providers, ready to help explain and address the potential vulnerabilities of the known products, or the off-the-shelf vulnerabilities, as described in Chapter 6. However, those who are responsible for the security and integrity of your systems face two problems: (1) the hit-or-miss disclosure of vulnerabilities in commercial software, and (2) presence of unknown vulnerabilities in the custom (in-house developed) applications that connect to and run on the top of commercial software.
Most organizations can do very little about the hit-or-miss disclosure of vulnerabilities in the off-the-shelf software deployed throughout the business. Your organization must rely on the software provider to have initiated appropriate quality controls and security testing, and provide bug-fixes or patches as necessary.
In the case of custom (in-house developed) applications, some organizations conduct a thorough security review of the system by performing a multi-tier assessment application assessment that consists of four levels: secure coding assessment, component-level assessment, security architecture assessment, and policy compliance assessment. Each level provides a progressively higher level of assurance. The organization selects which level best fits its assurance need.
A secure coding assessment focuses on the implementation layer of the application to identify code-level vulnerabilities. It tends toward more of an audit of coding practices (especially if the organization conducts manual reviews). While a coding assessment often initially appears to be more valuable, most organizations soon find that such a review often fails to identify most deployment issues.
Component-level assessment focuses on both the structural flaws that impact the security of an application's physical architecture and implementation security vulnerabilities that spread through key architectural/structural components affecting the application's architecture. To identify these flaws, component-level assessment performs the discovery of architectural components, applications entry points, data access points, third-party services (including the runtime platform), and data flows between them.
Security architecture assessment focuses on validating that safeguards are meeting security objectives. This assessment level utilizes and further deepens analysis of the previous two assessment levels to identify component-level threats, vectors of attack into application, and safeguards. The next step is to perform an analysis to uncover the adequacy and efficiency of identified safeguards.
Policy compliance assessment focuses on validating that the application and processes deployed to build applications are in compliance with outlined security polices. It validates that security engineering principles are followed in identifying security controls required by security polices, and by utilizing the previous three assessment levels it establishes traceability links to policies. Any discrepancy is marked as a possible vulnerability.
This four-level assessment approach focuses at detecting and eliminating vulnerabilities. The first three levels of the assessment deal with formal artifacts, such as the source and binary code, or the system in operation, and involve automated search for known vulnerability patterns either by analyzing code or by testing the system in operation. It is important to mention that these are not simple patterns of text; vulnerability patterns describe a unit of behavior that usually includes one or more statements and a pattern rule that describes constraints for a data-flow path connecting those statements. Patterns can describe desired or undesired units of behavior. A pattern that describes an undesired unit of behavior is very often referred to as an antipattern; however, an antipattern that has security implications is referred to as security weakness or a vulnerability pattern. An example of a desired pattern associated with security would be an “authentication pattern,” while a vulnerability pattern from the same class would be an “authentication bypass.” Vulnerabilities that can be described by a pattern that can be recognized in one of the system views were referred to in Chapter 6 as discernable vulnerabilities.
Knowledge of identifiable vulnerability patterns can be embedded into automated tools that provide deep analysis of the formal artifacts or interact with the system in operation and detect potential vulnerabilities. Improvements to the entire cyberdefence ecosystem can be achieved when the knowledge of vulnerability patterns is developed independently of the tools, as machine-readable vendor-independent content that is accumulated, updated, accredited, and then distributed to multiple vulnerability analysis tools.
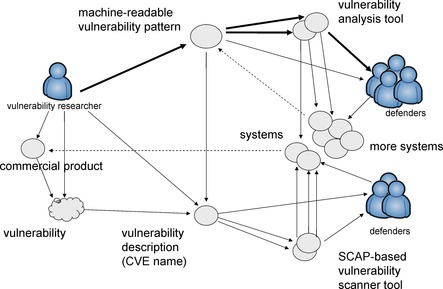
The SCAP Ecosystem [NIST SP800-126] described in Chapter 6, successfully addresses the exchange of knowledge related to the off-the-shelf vulnerabilities that is simply a record of a certain security issue in a certain version of a commercially available product. The description of the problem itself in SCAP is informal. A larger ecosystem for vulnerability management (beyond the current SCAP) has to involve machine-readable vulnerability patterns as content that can be consumed by code analysis tools and web scanning tools. As shown in Figure 1, SCAP could be extended to include formalized vulnerability patterns described in the following scenario:
• The researcher evaluates a system and locates vulnerability. Then the researcher describes this vulnerability (creates vulnerability knowledge). This knowledge includes identification of the product (product name, vendor, and version) and some description of the problem. Another kind of vulnerability is a misconfiguration of a certain product. Description of this kind of vulnerability additionally includes the particular configuration settings.
• More defenders can then apply this knowledge to other systems by searching for a product or its configuration with the version mentioned in the vulnerability using a standard product description (SCAP CPE) or configuration description (SCAP CCE).
• This knowledge can also be used to build a vulnerability scanner tool that will automatically search for affected products and generate a report. Ideally, the vulnerability description is an input to the vulnerability scanner. Vulnerability descriptions are stored in vulnerability databases. The vulnerability scanner can be used by more researchers, in a more systematic way, as well as faster and cheaper. The vulnerability description becomes a product. The vulnerability description format enables an ecosystem of vulnerability researchers and consumers. Additional meta-data can be associated with the vulnerability description, for example, the machine-readable description of (SCAP CVSS).
 |
| Figure 1 Potential expansion of SCAP to include vulnerability patterns |
The above scenario describes the current SCAP, and is illustrated at the bottom part of Figure 1. The next step is to go deeper into the nature of the vulnerability and describe it in terms of identifiable system facts in the form of a machine-readable vulnerability pattern. This new scenario is illustrated at the top part of Figure 1.
The researcher creates a machine-readable pattern, describing the vulnerability in terms of system facts. This pattern can be used to search for the same vulnerability in other systems by inspecting their elements and looking for the occurrences of the vulnerability pattern. The vulnerability pattern can be made available to other researchers and can be imported into a vulnerability analyzer tool. The difference between a SCAP-based vulnerability scanner and a vulnerability analyzer is that the input to the scanner is the inventory of the system, including its configuration settings, while the input to the analyzer is an internal representation of the system, the implementation facts, or some logical model of the system. The SCAP OVAL language addresses vulnerability scanners by providing a common machine-readable format for describing off-the-shelf vulnerabilities that can be imported into scanner tools that determine versions of products and product configuration settings. On the other hand, vulnerability analyzers must understand the internal logical elements of the products either by parsing the source code, or by reverse engineering the binaries, or by dissecting the communication protocols. When the vulnerability analyzer is available, it can process many more systems systematically, regardless of whether these systems are off-the-shelf or in-house, already deployed or still under development, while the SCAP-based scanner can only deal with known off-the-shelf commercial products and their configurations.
7.2. Vendor-neutral vulnerability patterns
There are multiple existing approaches to the classification of software vulnerabilities, but they all suffer from the fact that they do not enable automation. Rather than focusing on the high-fidelity description of systems traceable to the artifacts (code, binaries or protocols), they focus on informal descriptions of vulnerabilities themselves.
It is important to understand that vulnerability patterns are described in terms of the system facts. Since many automated vulnerability detection tools utilize a proprietary internal representation of the system under analysis, their vulnerability patterns are wedded to their proprietary internal formats, which creates a technical barrier to sharing vulnerability patterns. The key contribution of the OMG Software Assurance Ecosystem is the vendor-neutral standard protocol for exchanging system facts, described in Chapter 11. This protocol can be used as the foundation for the vendor-neutral formalization of vulnerability patterns. This chapter provides the introduction into formalization of vulnerability patterns as vendor-neutral machine-readable content for analysis tools, while further practical details of this approach are discussed in Chapters 9, 10 and 11.
Current SCAP lacks the protocol for exchanging machine-readable vulnerability patterns. In order to introduce such protocol, descriptions of vulnerabilities must be first generalized and then formalized as vendor-neutral machine-readable vulnerability patterns so that they can be turned into a commodity, unlocked from proprietary tools into a normalized, interconnected ecosystem.
The Common Weakness Enumeration (CWE) project led by MITRE [CWE], [Martin 2007] gathered and generalized many known off-the-shelf vulnerabilities, including informal descriptions of some vendor-specific patterns as well as the existing theoretical classifications of vulnerabilities into a comprehensive catalog of software weaknesses. Formalization of informal descriptions of vulnerabilities into machine-readable vulnerability patterns has started by the Department of Defense (DoD) research project focused on developing formal white-box vulnerability patterns (i.e. patterns that are based on system facts) and linking them to informal descriptions from the CWE catalog. These patterns are referred to as software fault patterns (SFPs). SFP is described as a faulty computation, where the computation is defined by system artifacts such as code, database schemas, and platform configuration and, formalized as a fact-oriented statement, focusing at the characteristic structural elements (identifiable locations in some system views or footholds) and the necessary conditions for the connecting elements of code (the code path) that can be systematically determined by data-flow analysis tools. Computations and the corresponding discernable vocabulary for various system views was described in Chapter 4.
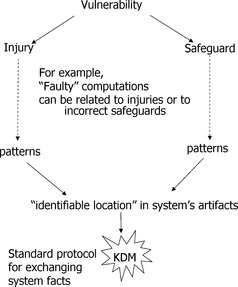
The vendor-neutral protocol for system facts used in this approach is defined in ISO 19506 Knowledge Discovery Metamodel (KDM) [KDM 2006], [ISO 19506], described in Chapter 11. The project focused at the faulty computations that directly cause injury or those that are related to failed safeguards. Figure 2 shows how vulnerability patterns are using the Knowledge Discovery Metamodel.
 |
| Figure 2 Vulnerability pattern and KDM |
7.3. Software fault patterns
The SFP is a generalized description of a family of faulty computations in the software. SFPs map to multiple elements of the CWE in such a way that each individual CWE element in the family can be defined as a specialization of the SFP. A specialization of an SFP is characterized by the same generic foothold and same generic pattern rules, and may add one or more specific footholds and pattern rules. Thus the extent of the specialized SFP is the subset of the extent of the base SFP. The descriptions from CWE were used as a source of definitions of all the “faulty computations” in order to determine SFPs.
SFP descriptions consist of footholds (easily identifiable locations in the system that are necessary elements of the corresponding computations, and that can be detected by linear queries into the fact repository); and pattern rules (conditions that determine the rest of the computation between the footholds, and which typically require comprehensive control- and data- flow analysis to detect). Footholds are identifiable characteristics of certain common “steps” performed by software systems.
Certain sequences of steps are common to large families of systems. For example, such common sequences are related to input processing, authentication, access control, cryptography, information output, resource management, memory buffer management, and exception management. The catalog of faulty computations should focus on computations that are common to large families of systems. However, it should scale well to enable customization for a very targeted assessment. In order to express SFPs as identifiable footholds and associated pattern rules that enable grouping by specialization in a consistent, measurable, and comparable way, conceptual and logical models are developed that follow the fact-oriented approach described in Chapter 9 and focus on essential characteristics expressed as:
• Elements;
• Relations between elements;
• Rules describing relations.
Multiple physical models can be automatically derived from the logical model for selected implementation and imported into existing analyzer tools.
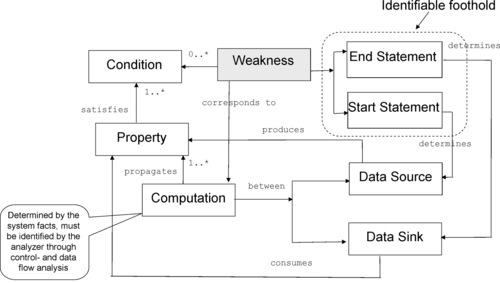
A conceptual model of an SFP is presented in Figure 3. The conceptual model facilitates white-box definitions of SFPs. It removes any ambiguity from the SFP and focuses on white-box discernable properties of the vulnerability traceable to the program elements. Each pattern has a start and an end statement connected by a path constrained by particular conditions. The start statement determines the source of data, while the end statement determines the data sink and the complete pattern describes any computation between the start and end statements that propagates certain data properties satisfying the given end-to-end data condition associated with the computation. The start- and/or end- statement contain at least one identifiable foothold.
 |
| Figure 3 Weakness conceptual model |
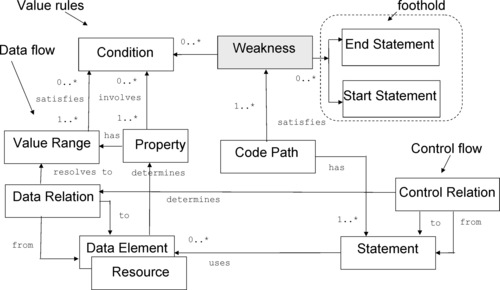
The logical model expands on the conceptual model to show how the computation is presented in the code and also to show what properties are taken into account when the code path is computed. The logical model adds concrete details to the definition of a “computation” and a “property” in white-box terms. The logical model in Figure 4 shows how the SFP patterns are further formalized to produce machine-readable SFPs by further mapping the corresponding elements to the standard protocol for representing system facts.
 |
| Figure 4 Logical weakness model |
These models facilitate a certain structure of the definition of each weakness and provide a natural separation point between the definition of a weakness from the apparatus required to determine the corresponding computation (illustrated in Figure 5). This is the key to using weakness definitions as the common content for the multitude of weakness detection tools. In particular, Software Fault Patterns involve an Application Programmer Interface (API) to the control- and data flow analysis capabilities that search for the code path based on the start- and end-statement patterns and the conditions. The structure of the definition facilitates clustering based on specialization, which is essential for the process that creates a natural clusterization of the CWE based on the common footholds and conditions, outlined later in this chapter.
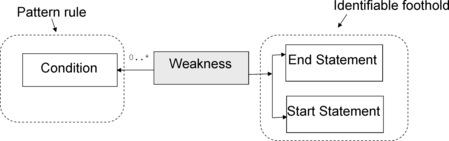 |
| Figure 5 Weakness definition separated from the corresponding computation |
Vulnerability is defined as “a bug, flaw, weakness, or exposure of an application, system, device, or service that could lead to a failure of confidentiality, integrity, or availability.” It can therefore be technically interpreted as a computation that can be exploited to produce injury. Certain computations in the system are designed to mitigate the vulnerabilities. These computations and the corresponding mechanisms and “locations” in the code are called “safeguards.” A “faulty computation” is defined as either a computation that has direct injury or a computation that corresponds to an incorrect safeguard.
A “computation foothold” is an identifiable construct, an entry point, or an Application Programming Interface (API) call present at a specific location recognizable in the system's artifacts, which is a necessary element of the computation. Certain constructs in the code can directly cause injury under certain conditions. Such locations are footholds for the corresponding faulty computation sequences. Safeguards (as computation sequences) also have footholds related to the safeguard itself, as well as to the protected region. SFPs are elements of the catalog of the unique locations in the code associated with faulty computations that either directly cause injury or cause safeguards to be ineffective. Software Fault Patterns are parameterized by the concrete platform knowledge because the start- and end-statement often involve concrete system call signatures.
This viewpoint is constructive and systematic and therefore enables automation. A uniform viewpoint makes the SFP approach systematic and repeatable.
As the DoD research in this area is still on going, in the following sections of this chapter we present detailed views of a few SFPs arranged into natural clusters based on common footholds and conditions that could be further classified into two categories: safeguard and direct injury. The following sections illustrate the search for the identifiable footholds for the SFPs. The entire collection of 640 CWE elements was analyzed and grouped into clusters based on the common characteristics mentioned in the informal descriptions from CWE, then these characteristics were further analyzed to identify discernable footholds, if any.
7.3.1. Safeguard clusters and corresponding SFPs
The following three clusters of SFPs are examples of safeguard category.
7.3.1.1. Authentication
This cluster of software faults relates to establishing the identity of an actor associated with the computation, or the identity of the endpoint involved in the computation through a certain channel. The authentication cluster is closely related to access control, which focuses on resource access by an authenticated actor with appropriate access rights, as well as ownership of the resources by the authenticated actors.
The common characteristics of the authentication cluster include the following (see Figure 6):
• Authentication token, including password;
• Authenticated actor, its identity, and management;
• Authentication check;
• Management of actors;
• Guarded region of code where the access to resources or information assets is made.
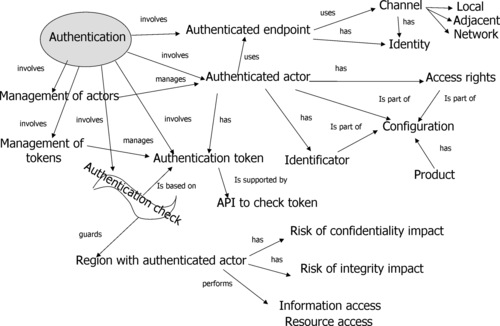 |
| Figure 6 Authentification cluster properties |
This cluster contains 43 CWEs. Only 14 CWEs contribute to SFPs. The major challenge of the authentication cluster is the lack of good footholds for the white-box description. The biggest challenge is to identify the boundaries of the authentication code that distinguishes it from the corresponding guarded region.
The authentication cluster includes the following nine secondary clusters. However, currently only six have contributed to extraction of SFPs (marked in the following list):
• Authentication bypass—This cluster covers situations related to incomplete authentication steps; there is no sufficient identifiable footholds in this cluster. However, once the statements of the Authentication code are identified by the analyst, it becomes possible to analyze authentication bypass.
• Faulty endpoint authentication (SFP)—This cluster covers scenarios involved in endpoint authentication; the foothold in this scenario is a certain condition that uses an inappropriate authentication mechanism.
• Missing endpoint authentication (SFP)—This cluster covers scenarios where the endpoint authentication is absent. The foothold of this scenario is the resource access or a critical operation.
• Digital certificate—This cluster covers specific authentication issues related to digital certificate management. There are no sufficient identifiable footholds in this cluster
• Missing authentication (SFP)—This cluster covers scenarios where the authentication is absent and the resource access or critical operation occurs at a code region where the corresponding actor is not authenticated.
• Insecure authentication policy—This cluster covers miscellaneous policy issues related to authentication. There is no sufficient identifiable footholds in the CWEs in this cluster.
• Multiple binds to the same port (SFP)—This cluster covers a specific pattern describing multiple binds to the same port.
• Hardcoded sensitive data (SFP)—This cluster covers various situations where the sensitive data involved in authentication checks are hardcoded.
• Unrestricted authentication (SFP)—This cluster covers specific situations in which there is a loopback in the authentication region, leading back to the authentication, without sufficient control.
7.3.1.2. Access control
This cluster of software faults relates to validating resource owners and their permissions. The common characteristics of this cluster include the following (see Figure 7):
• Authenticated actor, its identity, and management;
• Access rights and their management;
• Resource, protected resource;
• Resource ownership;
• Access control check, guarded region;
• Resource access operation;
• Operation that sets access rights on a resource;
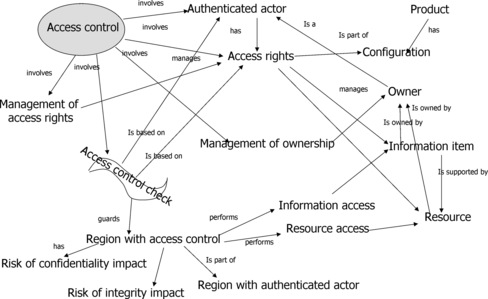 |
| Figure 7 Access control cluster properties |
There are 16 CWEs in this cluster. Most CWEs in this cluster lack identifiable footholds.
The access control cluster includes the following three secondary clusters, however only one of these clusters helped create the SFP (marked in the following list):
• Insecure resource access (SFP)—This cluster covers situations related to the bypass of access control checks.
• Access management—This cluster covers various situations related to the management of resource owners and access rights. There is no sufficient white-box content in CWE descriptions for this cluster.
• Insecure resource permissions—This cluster covers various scenarios related to setting the permissions of the resources. The foothold of this scenario is the operation that sets resource permissions (such as resource creation, cloning, or explicit permission setting).
7.3.1.3. Privilege
This cluster of software faults relates to code regions with inappropriate privilege level. The common characteristics of this cluster include the following (see Figure 8):
• Privilege level;
• Privileged operation;
• Region with elevated privilege;
• Privilege check;
• Operations to change privilege.
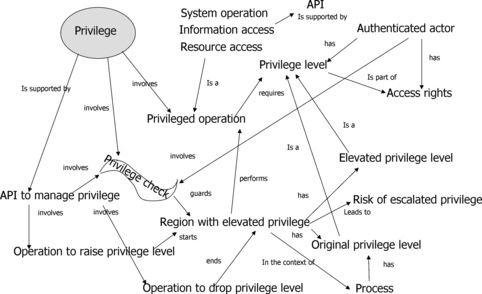 |
| Figure 8 Privilage cluster property |
There are 12 CWEs in this cluster. Most CWE descriptions do not have sufficient white-box content.
This cluster has only one secondary cluster that contributed to creation of the privilege SFP.
7.3.2. Direct injury clusters and corresponding SFPs
The following five clusters of SFPs are examples of this category.
7.3.2.1. Information leak
This cluster of software faults relates to the export of sensitive information from an application and several related issues. The common characteristics of this cluster include:
• Sensitive data is defined as data that flows from sensitive operations or flows into sensitive operations as the key parameter. “Sensitive” is the role that a data element plays in a certain context. It can be identified based on the APIs that are involved in producing/consuming/transforming the data element. If a data element was passed to a password management function, it can be assumed to be a password. If a data element is passed to a function that is known to require a private key, it is a private key.
• Information export operations (includes storing, logging, releasing as an error message, releasing as a debug message, as well as other exposures);
This cluster contains 94 CWEs. Most CWEs lack identifiable footholds, so only 37 contribute to SFPs.
The information leak cluster includes the following 12 secondary clusters. However, eight of them contribute to creation of SFPs (marked in the following list):
• Exposed data in motion (SFP)—This cluster covers various situations related to the data movements, which leads to information leaks, where there is corresponding code with sufficient foothold for a white-box description.
• Exposure through storing (SFP)—This cluster covers various situations related to the data at rest, which leads to information leaks, where there is corresponding code with sufficient foothold for a white-box description.
• Exposed data at rest (SFP)—This cluster covers various situations related to the data at rest, which leads to information leaks, as there is no corresponding code or no sufficient foothold for a white-box description.
• Exposure through logging (SFP)—This cluster covers various situations related to the data in use, which leads to information leaks through logging, where there is corresponding code with sufficient foothold for a white-box description.
• Exposure through debug message (SFP)—This cluster covers various situations related to the data in use, which leads to information leaks through debug messages, where there is corresponding code with sufficient foothold for a white-box description.
• Exposure through error message (SFP)—This cluster covers various situations related to the data in use, which leads to information leaks through error messages, where there is corresponding code with sufficient foothold for a white-box description.
• Inappropriate cleanup (SFP)—This cluster covers several buffer cleanup weaknesses.
• Insecure session management—This cluster covers several scenarios related to information leaks between sessions; CWEs in this cluster do not have sufficient white-box content.
• Programmatic exposures of data (SFP)—This cluster covers several scenarios related to miscellaneous constructs leading to information release.
• Other exposures—This cluster covers various miscellaneous scenarios leading to information leaks, not covered by the previous clusters. CWEs in this cluster do not have sufficient white-box content.
• State disclosure—This cluster covers various situations of state disclosure, which releases knowledge of some aspects of the internal state of the application. CWEs in this cluster do not have sufficient white-box content.
• Exposure through temporary files—This cluster covers scenarios related to temporary files management, in particular to their names. CWEs in this cluster do not have sufficient white-box content.
7.3.2.2. Memory management
This cluster of weaknesses relates to the management of memory buffers (as opposed to access to memory buffers). Common characteristics of this cluster include:
• Buffer, including stack and heap buffers; static and dynamic buffers;
• Buffer identity (pointer, name);
• Buffer allocation operation;
• Buffer release operation;
• Management of buffer identities.
This cluster contains six CWEs. All of the CWEs in this cluster are based on discernable properties and are therefore covered by few SFPs.
The memory management cluster includes the following two secondary clusters, both of which contribute to creation of SFPs:
• Faulty memory release (SFP)—This cluster covers various scenarios related to incorrect release of memory buffers. The foothold of this scenario is the buffer release operation.
• Failure to release memory (SFP)—This cluster covers various scenarios where the identity of a memory buffer is mismanaged, resulting in so-called memory leaks.
7.3.2.3. Memory access
This cluster of software faults is related to access to memory buffers. Common characteristics of this cluster include:
• Buffer, including stack and heap buffers; static and dynamic buffers;
• Buffer identity (pointer, name);
• Buffer access operations, including implicit buffer access (also known as string expansion);
• Operations involving buffer;
• Pointer uses, including pointer export.
This cluster contains 22 CWEs, 21 of which are based on discernable properties and are therefore covered by few SFPs.
The memory access cluster includes the following six secondary clusters, and all of them contribute in the creation of SFPs:
• Faulty pointer use (SFP)—This cluster covers common scenarios of using incorrect pointers to buffers.
• Faulty pointer creation (SFP)—This cluster is closely related to faulty pointer use, but focuses on the scenarios where faulty pointers are usually created (rather than the places where they are used).
• Faulty buffer access (SFP)—This cluster covers the common scenarios related to various buffer overflows, underflows, and related weaknesses.
• Faulty string expansion (SFP)—This cluster covers scenarios related to the use of certain API calls that involve implicit buffers and may lead to buffer overflows.
• Incorrect buffer length computation (SFP)—This cluster covers scenarios related to several known situations where the length of a buffer is incorrectly computed.
• Improper NULL termination (SFP)—This cluster covers scenarios related to several operations involving a buffer, which may lead to buffer overflows due to mismatch in data terminators within the data stored in the buffer.
7.3.2.4. Path resolution
This cluster of software faults is related to access to file resources using complex file names. The software faults in this cluster are related to the so-called path traversal functionality, which is provided by most file systems where the file system interprets the complex file name using a set of implicit rules. These faults are a common cause of security vulnerabilities. The common characteristics of this cluster include:
• File resources;
• File name, including special characters and their interpretation;
• File identity;
• Chroot jail (the mechanism to restrict interpretation of complex file names);
• Path equivalence.
There are 51 CWEs in this cluster. 43 CWEs in the cluster are based on discernable properties and are covered by few SFPs.
The path resolution cluster includes the following three secondary clusters, and all contribute to creation of SFPs:
• Path traversal (SFP)—This cluster covers the majority of patterns leading to path traversal vulnerabilities. The foothold of the corresponding SFP is the file access operation where the file name originates from the user input (is “tainted”).
• Failed chroot jail (SFP)—This cluster covers a specific situation related to incorrect establishment of a chroot jail.
• Link in resource name resolution (SFP)—This cluster covers situations related to the use of symbolic links to file resources.
7.3.2.5. Tainted input
This cluster groups software faults related to injection of user-controlled data into various destination commands. This cluster focuses on data validation issues. The common characteristics of this cluster include:
• Destination command or construct;
• Data validation, special characters, and their interpretation;
• Tainted values;
• Channel (input channel);
• Input transformation (encoding, canonicalization, etc.);
• Input handling (processing complex input structures).
This cluster contains 137 CWEs, 74 of which contribute to SFPs and 63 are non discernable.
The tainted input cluster includes the following six secondary clusters from which four contribute in the creation of SFPs:
• Tainted input to command (SFP)—This cluster covers various scenarios that involve data validation, in particular the special characters for various destinations commands.
• Tainted input to variable (SFP)—This cluster covers scenarios where the destination of the tainted values is not an API call, but some construct, for example, a basic condition, a loop condition, and so on.
• Tainted input to environment (SFP)—This cluster covers scenarios where the tainted values affect various elements of the computation environment, which has an indirect effect on the computation itself.
• Faulty input transformation—This cluster covers several scenarios related to the transformation of input, such as encoding and canonicalization.
• Incorrect input handling—This cluster covers several scenarios related to the processing of complex input structures.
• Composite tainted input (SFP)—This cluster is introduced to describe vulnerabilities in which user-controlled input contributes to other weaknesses, for example, a buffer overflow in which the buffer length is tainted data.
Tainted input secondary clusters that have discernable properties consist of three types: Tainted Input to Command (TIC) Type, Tainted Input to Environment (TIE), and Tainted Input to Variable (TIV).
Many elements of the Common Weakness Enumeration (CWE) describe well-known code faults that however do not directly produce injury. For example, integer overflow is a serious implementation issue (a software bug), however it does not produce injury on its own, only if the faulty value is used in some other context, such as a loop header or a buffer operation. Additional SFPs do describe these issues as well, so that they can be used in combination with more pure vulnerability patterns, however in the system assurance context such conditions often contribute to false positive reports that are costly to process and eliminate. The objective of vulnerability patterns is to provide machine-readable content for code analysis tools that can generate evidence in support of a security assurance case, rather than simply detect implementation bugs.
7.4. Example software fault pattern
To illustrate software fault patterns as machine-readable content we describe a single concrete SFP from the Tainted Input into Command (TIV) cluster. This SFP is a formalization of the CWE 134 “Uncontrolled Format String.”
The description of this weakness available in CWE is very informal; it reads as follows: “The software uses externally-controlled format strings in printf-style functions, which can lead to buffer overflows or data representation problems.”
The white-box content can be distilled from this description, under the guidance provided by the conceptual weakness model shown in Figure 3.
Distilled Whitebox Content
Definition: A weakness where the code path has:
1. start statement that accepts input
2. end statement that passes a format string to format string function where
a. the input data is part of the format string and
b. the format string is incorrectly validated
where “incorrectly validated” is defined through the following scenarios:
a. not validated
b. accepts elements that lead to a buffer overflow of the format string function
This content can be further formalized by the following statement in SBVR Structured English (further described in Chapter 10):
Uncontrolled Format String is a weaknesswhere thecode pathhasastart statementthatacceptsinputandhasanend statementthatpasses aformat stringto a format string functionwhere theinputis part oftheformat stringand theformat stringis incorrectly validated.
Supporting Noun Concepts
weakness
statement
end statement
start statement
format string
input
format string function
Supporting Verb Concepts
code pathhasstatement
code pathhasstart statement
code pathhasend statement
statementacceptsinput
statementpassesdata elementtofunction
data elementis part ofdata element
inputis incorrectly validated
The identifiable foothold of this pattern is:
Statementthatpassesformat stringtoformat string function
The condition of this patterns is:
Valueofthedata elementthatis passed totheformat string functionincludes incorrectly validatedinputthatis accepted byastatement.
Algorithmically, this pattern can be used to detect vulnerability as follows:
1. Locate statement that passes format string to a format string function.
2. Perform data-flow analysis to compute the set of possible values of the format string.
3. Check the value-set. The CWE 134 “Uncontrolled format string” is detected if the value-set contains a special value ‘tainted,’ which means that there exists a local code path on which the format string includes input from the user and the input is incorrectly validated.
These considerations, together with the guidance provided by the Logical Weakness Model (Figure 4), lead to the following statement in SBVR Structured English:
ControlElementhasUncontrolled Format Stringweaknessatcode pathif theControlElementcontainsanActionElementand theActionElementpassesformat stringtoformat string functionand theformat stringsatisfies uncontrolled format string condition intheControlElementandtheActionElementatthecode path.
ControlElement and ActionElement are KDM terms, corresponding to a named unit of behavior (e.g., a function in the C programming language), and a statement, respectively.
Further,
Data Elementsatisfies uncontrolled format string condition inControl ElementandActionElementatcode pathif aValueis a data-flow solution fortheData ElementattheActionElementand theValueis taintedin which case thecode pathcorresponds totheControlElementandtheActionElementfortheData Elementand theValue.
Here, the uncontrolled format string condition is defined in terms of the analysis tool API. On the other hand, the definition of an ActionElement that passes a format string to format string function can be done entirely based on the standard vocabulary provided by the Knowledge Discovery Metamodel (KDM).
We are using the SBVR Structured English, described in Chapter 10, to represent the formalization statements. SBVR defines the set of facts that is the meaning of these statements. SVBR also defines a canonical XML interchange format. Further details of this formalization are provided in Chapter 10.
Bibliography
[CWE] CWE, Common Weakness Enumeration, http://cwe.mitre.org.
ISO/IEC 19506 Architecture Driven Modernization—Knowledge Discovery Metamodel. (2009) .
KDM Object Management Group, The Knowledge Discovery Metamodel (KDM). (2006) .
R. Martin, Being Explicit About Security Weaknesses, CrossTalk, The Journal of Defense Software Engineering (2007); March.
NIST Special Publication SP800-126. The Technical Specification for the Security Content Automation Protocol (SCAP). SCAP Version 1.0, Quinn, S., Waltermire, D., Johnson,C., Scarfone, K., Banghart, J
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.