
Chapter 6. Knowledge of vulnerabilities as an element of cybersecurity argument
Abstract
This chapter explores vulnerability detection, which is often considered a dominant component of system assurance. The focus is on detecting off-the-shelf vulnerabilities, the corresponding information exchanges, the markets of the vulnerability knowledge, as well as the vulnerability detection ecosystem built around the NIST Security Content Automation Protocol (SCAP) standards. Vulnerability databases and ways of transforming vulnerability knowledge into machine-readable content are described. We describe the organization of two vulnerability databases and demonstrate how this knowledge can be added to the integrated system model.
Keywords
vulnerability, vulnerability database, vulnerability life cycle, Common Vulnerabilities and Exposures, CVE, Security Content Automation Protocol, SCAP
They attack when the opponent is unprepared and appear where least expected.
—Sun Tzu, The Art of War
6.1. Vulnerability as a unit of Knowledge
This chapter explores the current foundation of systems assurance—vulnerability detection. In Chapter 1 we introduced the concept of a vulnerability as a specific unit of knowledge related to a fault in the system that allows exploitation of the system. In Chapter 3 we related vulnerabilities to threats and safeguards and described three major kinds of vulnerabilities:
– off-the-shelf vulnerabilities – known vulnerabilities in commercial off-the-shelf products; once detected in a particular version of the product, these units of knowledge can be stored and accumulated because the same product is used in many other implemented systems. In a given system off-the-shelf vulnerabilities can be identified without the reference to threats;
– discernable vulnerabilities – vulnerabilities that can be detected based on a known pattern, again without the reference to the specific threats to the system of interest;
– unmitigated threats – vulnerabilities that are specific to the system of interest, when a particular threat is not adequately mitigated by the safeguards implemented in the system, as well as by any other features of the system of interest. Detection of these vulnerabilities requires comprehensive analysis of the system as described in Chapter 3.
The general guidance to the identification of threats for the purpose of systematically identifying unmitigated threats was provided in Chapter 5. This chapter addresses off-the-shelf vulnerabilities. Discernable vulnerabilities are addressed further in Chapter 7. In this chapter we discuss possibility of detecting off-the-shelf vulnerabilities, and the market of the vulnerability knowledge as well as the vulnerability detection ecosystem built around the NIST SCAP standards [NIST SP800-126].
While vulnerability knowledge is one of the most important parts of the systems assurance content, it must be integrated with other knowledge in order to enable assurance. The defense community must use systematic approaches that produce justifiable confidence in the effectiveness of defense mechanisms based on the adequate knowledge of their systems. The overview of the System Assurance process was given in Chapters 2 and 3 to guide in the transition from ad hoc vulnerability detection to systematic, fact-oriented and repeatable assurance.
6.1.1. What is vulnerability?
The term vulnerability refers to the features of a system that make it susceptible to a deliberate attack or hazardous event. This term originates from Latin noun vulnus—wound and the corresponding verb vulnero—to wound, injure, hurt, harm. The term vulnerability is an example of one of those tricky situations where the language makes it easy to create a useful word through the process known as objectification (creating a noun from a verb or an adjective; for example, doing → deed), that refers to several intuitive situations, but the overall extent of which is not quite as clear. You know that a system was impacted by an attack and therefore you know that the attack on the system took place and succeeded (from the defender's perspective you see the aftermath of the attack and often miss the events that lead to the preparation of the attack). In this case, it can be concluded that the system was vulnerable to the attack at what point the word vulnerability can be used to refer to the features of the system that made it vulnerable to the attack or to refer to the features of all systems that make them vulnerable to a similar attack, or to refer to features of all systems that make them vulnerable to all attacks. But, what are these features? What is the reality behind them? How do we systematically find them? The intentional scope of the objectified verb or adjective can be quite large and may include features of a different nature.
An intuitive example of vulnerability is a door or window in a residential home. Here is one of the expert reports on home intrusion that can be very much applied to a software system:
Statistics tell us that 70% of the burglars use some amount of force to enter a residential home, but their preference is to gain easy access through an open door or window. Although home burglaries may seem random in occurrence, they actually involve a selection process. The burglar's selection process is simple. Choose an unoccupied home with the easiest access, the greatest amount of cover, and with the best escape routes.
Remember, the burglar will simply bypass your home if it requires too much effort or requires more skill and tools than they possess. Windows are left unlocked and open at a much higher rate than doors, while sliding glass doors are secured only by latches and not locks. Most burglars enter via the front, back, or garage doors. Experienced burglars know that the garage door is usually the weakest point of entry followed by the back door. The average door strike plate is secured only by the softwood doorjamb molding – these lightweight moldings are construction/structure flaws and are easy to break.
Good neighbors should look out for each other, detecting any suspicious activity especially around weak points. In addition, alarm systems are at the top of a home security plan and home safes are excellent protection for valuable assets in case the intruder succeeds in entering the house.
The first step in protecting your house and assets is to harden the target or make your home more difficult to enter.
The same situation is with software systems—if weak features in the software are not identified, fixed, and protected by safeguards, they turn into vulnerabilities enabling the intruder to enter the system.
The concept of “vulnerability” is a powerful abstraction that allows us to collectively refer to a multitude of otherwise unrelated situations, events, and things from a particular viewpoint—how these situations, events, and things enable attacks. The concept of vulnerability is useful because it provides convenient shorthand for certain sentences (for example, “the increased budget for understanding the vulnerabilities in critical infrastructure”). This concept allows consideration of the systems in isolation from the details of the attacks and attackers (as these details are not always available), as well as in isolation from the details of the victim system (as hardly any organization is motivated to publish these details). So, the concept of “vulnerability” abstracts away the relationship between the system and the attacker, which uses a particular attack vector. It considers just the attack's footprint in the system regardless of the exact identity of the attacker and even the variations of the attack actions. Some usages may become disconnected from the discernable reality and result in ambiguous and even contentious statements. The fact-oriented approach and the linguistic analysis are the tools that are used to disentangle some of these ambiguous usages. Further details of the fact-oriented approach and linguistic analysis are provided in Chapters 9 and 10.
Why is the concept of a “vulnerability” relevant to system assurance? In fact, the concept of vulnerability happens to be quite central to the current mainstream approach to systems assurance. According to NDIA [NDIA 2008], system assurance is defined as the justified confidence that the system functions as intended and is free of exploitable vulnerabilities, either intentionally or unintentionally designed or inserted as part of the system at any time during the life cycle.
This approach is based on an observation that vulnerability has a somewhat deterministic nature: It is either “designed in” or “inserted” into the system, and once it is there, it stays there. For example, an unscrupulous construction worker could tamper with the latch on the sliding door while installing it. This creates the place on the house that is less resistant to forced entry. This is an example of a vulnerability intentionally inserted as part of the system. The construction worker can then sell this vulnerability to a burglar. The same vulnerability can occur unintentionally and unknowingly as the result of an incident at the sliding door factory. An example of a vulnerability “designed into the system,” an insecure operational procedure of the system, is the scenario when the homeowner can disarm the alarm and open the door to the burglar who shouts “Fire! Fire!” outside of the door. The first example involves the physical structure of the system, the second example involves the operating procedures and the states of the system.
From the assurance perspective, the following two questions need to be answered: “How do we systematically inspect the system for vulnerabilities?” and “How do we build confidence that the system is free from vulnerabilities?” This chapter addresses several knowledge aspects of this problem. How can we know what are all vulnerabilities? Can one produce a list of all vulnerabilities of a given system? How many vulnerabilities can a system have? Is there a finite number of them? How one can look for them?
The emphasis of this chapter is to provide a uniform view on the vulnerability knowledge so that vulnerability facts can be systematically managed throughout the system assurance process.
6.1.2. The history of vulnerability as a unit of knowledge
The notion of a vulnerability as a concrete technical defect that contributes to an attack that can be studied and cataloged (and thus the usage of the word “vulnerability” in the plural form), in short, the notion of a vulnerability as a unit of knowledge, began catching the public attention in the 1970s.
Brief analysis of the publications in the New York Times (see Table 1) shows the following distribution of the number of articles that mention the word “vulnerability” in singular form in comparison to the plural form “vulnerabilities”.
These statistics include all articles regardless of the context in which the term “vulnerability” is used. The most frequent contexts involve politics and defense, including the famous “window of vulnerability” theme of Ronald Reagan's presidential campaign of 1980, which was mentioned in 181 articles in the period of 1980–1989, two articles prior to this period, and six articles after this period. Since the 1980s, the attention of the public shifted toward the social impact of the computer systems. The increasing use of the plural form indicates the interest towards individual vulnerabilities as identifiable features, that can be enumerated and catalogued.
The catalogs of computer vulnerabilities, complete with rich technical detail, became publicly available in the late 1980s. Computer Emergency Response Team (CERT) started publishing technical advisories since it was established in 1988. CERT advisories provided timely information about current security issues, vulnerabilities, and availability of exploits. The independent Bugtraq mailing list was established in 1993 to raise awareness of the security issues in commercial software products and force better patching by vendors.
The particular event that has triggered the process of consolidation of the defender community was the so-called Morris worm incident that affected 10% of Internet systems in November 1988. A few months later the Computer Emergency Response Team Coordination Center (CERT/CC) was established at the Software Engineering Institute (SEI). SEI is a federally funded research and development center at Carnegie Mellon University in Pittsburgh, Pennsylvania. The Defense Advanced Research Projects Agency (DARPA) tasked the SEI with setting up a center to coordinate communication among experts during security emergencies and to help prevent future incidents. Although it was established as an incident response team, the CERT/CC has evolved beyond that, focusing instead on identifying and addressing existing and potential threats and the corresponding vulnerabilities, notifying systems administrators and other technical personnel of these vulnerabilities, and coordinating with vendors and incident response teams worldwide to address the vulnerabilities.
Since the 1970s, the academic community began studying the flaws, errors, defects, and vulnerabilities in computer systems that lead to their failure and abuse under deliberate attacks. Cautious at the beginning, the publications of the technical details of the vulnerabilities increased in the 1990s. Since then multiple taxonomies of computer vulnerabilities have been suggested and several online databases of computer vulnerabilities have been developed, detailing over 60,000 individual technical vulnerabilities in over 27,000 software products, covering the period of 45 years.
Likely, the most well known of computer vulnerability types—the buffer overflow—was understood as early as 1972, when the Computer Security Technology Planning Study laid out the technique: “The code performing this function does not check the source and destination addresses properly, permitting portions of the monitor to be overlaid by the user. This can be used to inject code into the monitor that will permit the user to seize control of the machine.” Today, the monitor would be referred to as the operating system kernel.
The earliest documented hostile exploitation of a buffer overflow was in 1988. It was one of several exploits used by the Morris worm to propagate itself over the Internet. The program exploited was a UNIX service called finger. Later, in 1995, Thomas Lopatic independently rediscovered the buffer overflow and published his findings on the Bugtraq security mailing list. A year later, in 1996, Elias Levy published in Phrack magazine the paper “Smashing the Stack for Fun and Profit,” a step-by-step introduction to exploiting stack-based buffer overflow vulnerabilities.
Since then, at least two major Internet worms have exploited buffer overflows to compromise a large number of systems. In 2001, the Code Red worm exploited a buffer overflow in Microsoft's Internet Information Services (IIS) 5.0, and in 2003, the SQL Slammer worm compromised machines running Microsoft SQL Server 2000.
Interest in the technical details of the impact of technology correlated with the successful deployment of computer networks and the subsequent rise of cybercrime. Several other technologies have created the network phenomenon, such as railways, telegraph, and telephone, but none of them caused such interest in the discussion of vulnerabilities as computer networks, partly because none of the previous technologies, while comparable in scope, have created bigger opportunities for abuse—as well as larger impact of their abuse and failure.
On the other hand, the problem of failures in engineering systems was not entirely new. Some argue, that the knowledge of the past failures is also the key to understanding the engineering profession: “the colossal disasters that do occur are ultimately failures of design, but the lessons learned from these disasters can do more to advance engineering knowledge than all the successful machines and structures in the world” [Petroski 1992]. The failures of computer systems have been discussed since soon after the first commercial computers were introduced in 1951. Initially these discussions were driven by the military community and were focused at handling of sensitive information in time-sharing computer systems. At nearly the same time, the public started discussion of the impact of information systems and computer networks on privacy. The concepts of computer security and privacy as we know them today, appeared at least in the mid-1960s. The concept of a vulnerability of computers has been discussed since back in 1965.
At the same time, the field of safety engineering has already been developing mathematical methods for analysis of random failures in systems, namely the Failure Modes, Effects, and Analysis (since 1949) and Fault Tree Analysis Method (since 1961). The concept of safeguards is old and well-established in the field of systems engineering. The challenge brought by the interconnected computer systems was that of the deliberate, non-random nature of the attacks that are aimed at inducing the failures and the enormous complexity of the systems.
6.1.3. Vulnerabilities and the phases of the system life cycle
Note that a design error or even an implementation error does not by itself produce injury (there is no harm from a software package when it is sitting on the shelf), unless the system is actually put into operation, is performing its function, and is running. And even then, the attacker has to exercise some control over the system to cause the system to produce some injury.
The key question is, “What exactly happens during the ‘exploitation of vulnerability’”? What “state of affairs” “can produce injury” and in what sense it “can be reached” by the attacker?
It is the system that produces injury during its operation. The attacker “exploits” the system by exercising control over the system by providing some specially crafted inputs to the system, and steering its behavior into the state where injury is produced.
The objective of system assessment is to analyze available artifacts of the system in order to systematically identify (predict) all states of the operation that may result in injury to system's assets (given a motivated and capable attacker).
A state is a certain sequence of events, part of the master sequence of events that corresponds to the overall behavior. Behavior of the system is in most cases potentially infinite (in practice; however, each behavior is always finite, because each system is at some point put into operation and usually is periodically stopped, even though some information systems run for months without interruption). The only practical way of describing infinite behavior is by considering the repeating sequences of events or states and describing them a cyclic state transition graph. This is always possible, in principle, since each system is determined by a finite set of rules (e.g., the instructions in the code), and each event in the behavior of the system is associated with a particular rule; for example, a fragment of code. One fragment of code is usually associated with multiple states. For example, the code contains an instruction: “display the price of the item,” which causes the appearance of the number at the screen. Depending on the choice of the event vocabulary, this may correspond to multiple states, for example, “a positive number is displayed” and “number zero is displayed.” The particular state (within the given event vocabulary) is determined by the previous behavior of the system, which in some cases may be influenced by the inputs from the attacker.
Some of the events can be described as threat events. Mistakes, errors, faults, or issues may be introduced at various stages of the system's life cycle (including the entirely incorrect requirements that the system is trying to implement). The system code has to be deployed and configured, producing the actual system ready to be put into operation. Until the system is put into operation nothing malicious can happen.
During the system's operation, there could also be errors in the operational procedures or the operator's errors that cause a threat event to occur.
Multiple publications attempt to distinguish several distinct categories of vulnerabilities. For example, it is useful to distinguish technology-related and organizational vulnerabilities:
• Technology-related is defined as any weakness that is introduced into the deployed system, whether introduced into the system code and not mitigated by the system configuration, or one introduced through the system configuration.
• Organizational is defined as any weakness in the operational procedures.
The stages at which faults can be introduced into the system are illustrated in Figure 1. This illustration is a guide for selection of the artifacts for analysis by automated tools, as well as the limitations of this approach.
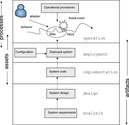 |
| Figure 1 Vulnerability and the system life cycle |
6.1.4. Enumeration of vulnerabilities as a knowledge product
So, individual vulnerabilities can be enumerated. Indeed, the system (or at least an off-the-shelf component) can be identified, followed by identification of distinct events through which injury can be produced. A distinct kind of injury corresponds to a distinct vulnerability. For example, you may identify vulnerabilities that allow remote execution of code on the attacked computer and another group that allows leaking of files from the attacked computer. But how do we know what the distinct vulnerabilities are that allow remote execution of code? The sources of ambiguities are variations in the steps leading to “exploitation,” raising the question: Are two different exploits that allow remote execution of code using the same vulnerability, or two different ones?
In order to address the ambiguities resulting from the variations in exploiting vulnerabilities, the distinguishing characteristic of the “location” of the vulnerability in the system code and the artifacts that are involved in producing injury can be considered. For example, a certain type of location can be defined as the offset in the executable file of the component. If two different exploits target a buffer overflow at the same location in the executable, then they use the same vulnerability. When the source code of the system is available, the location in the binary file can be substituted to the line number and position in a source file.
Distinction between vulnerability and an insecure configuration is useful when addressing the difference between the system code and deployed systems with various configurations. Vulnerability is determined by the software code, while an exposure is determined by the configuration of the system. On the other hand, an exposure is often supported by code. A very common exposure is a default password in a component, such as a router or a firewall. In some deployed systems the administrator will change the default password into a new one (hopefully, a strong password with 10 characters with lower case, uppercase, special characters and digits); however, some systems will be put into operations with the default password, in which case a vulnerability is created during the system configuration (by inaction, by not doing anything). However, this vulnerability is supported by the design of the code where either the default password is hardcoded or where the code assumes that the password is always present in the configuration file. Both situations support the inaction on behalf of the administrator. The exact location of this code is less obvious than in the case of code immediately responsible for injury, like a buffer overflow. This is a technical difficulty, but not a conceptual one. No matter how difficult it may be to establish the boundary for the authentication mechanism in the code, it is still possible to do so. Such a boundary will be part of the “location” of the exposure because the harm event here consists in passing this boundary with a default password, since obviously the attacker can download the administrator guide or try the default password. The system can have multiple configuration exposures; for example, a default administrator password and a default guest user password. These exposures have different locations, even if they use the same code for checking the password, as in the administrator password example above, the two situations will use different entry points.
To summarize, different vulnerabilities produce different kinds of injury and use different locations in the code of the system or an off-the-shelf component.
Based on these considerations, you can start accumulating technical knowledge about distinct vulnerabilities in systems.
There are three levels of technical knowledge related to vulnerabilities:
1. The knowledge that a distinct vulnerability exists in a particular system or commercial software product.
2. The knowledge of a working exploit for the vulnerability (at least one).
3. The knowledge of a pattern for the vulnerability (e.g., something that is the same for all buffer overflows regardless of where in the code or in which product they occur)
6.2. Vulnerability databases
The Morris Internet worm incident of 1988 was the turning point, when the cybersecurity community began accumulating knowledge on the technical details of vulnerabilities in commercial software products. Since then, several public vulnerability databases were established.
A vulnerability database is supported by a so-called Security information provider who tracks the new vulnerabilities and publishes alerts to a wide community of subscribers. A vulnerability database is a collection of records containing technical descriptions of vulnerabilities in computer systems. Some vulnerability databases are organized as simple unstructured mailing lists where messages are posted to announce a new vulnerability and discuss it. Others are more structured collections of records, more like real databases. Most security information providers offer search capabilities and RSS feeds. Several companies are offering secondary aggregation of the alerts from multiple databases. In Table 2, we provide a snapshot (as of mid-January 2010) current vulnerability databases.
A record in a vulnerability database is the current unit of knowledge of a technical vulnerability. It contains a brief description of the issue and lists the vulnerable products, mentioning the vendor, product name, and version. Each vulnerability entry is assigned a unique identifier. Most vulnerability databases allow search by vendor and product. Each record usually includes multiple references to related information, usually vendor information, other vulnerability databases, blogs, etc. Often, vulnerability is given a rating. It is very useful and recommended to use available information (through subscriptions) for risk assessment because most implemented systems involve off-the-shelf components. Choice of which database is better or more useful should be based on information needed by a given system in a given environment with a goal of achieving the confidence in a decision being made.
As your system uses multiple off-the-shelf components, there are numerous vulnerability facts that are available as input to the system assurance process. The key concern is to systematically manage these facts and integrate them with other units of knowledge for your system. Below we describe the conceptual commitment related to the vulnerability knowledge. As you will see, different vulnerability databases provide slightly different facts, so it is important to be able to collate these facts. In the section on NIST SCAP ecosystem and its common vulnerability identifier approach we will show the first solution to this problem. Further technical guidance to the OMG fact-oriented approach to integration of all units of cybersecurity knowledge is provided in Chapter 9.
6.2.1. US-CERT
US-CERT publishes information about a wide variety of vulnerabilities [US-CERT]. Vulnerabilities that meet a certain severity threshold are described in US-CERT Technical Alerts. However, it is difficult to measure the severity of a vulnerability in a way that is appropriate for all users. For example, a severe vulnerability in a rarely used application may not qualify for publication as a technical alert but may be very important to a system administrator who runs the vulnerable application. US-CERT Vulnerability Notes provide a way to publish information about these less-severe vulnerabilities.
Vulnerability notes include technical descriptions of the vulnerability, as well as the impact, solutions and workarounds, and lists of affected vendors. You can search the vulnerability notes database, or you can browse by several key fields. Help is available for customizing search queries and view features. You can customize database queries to obtain specific information, such as the 10 most recently updated vulnerabilities or the 20 vulnerabilities with the highest severity metric.
US-CERT also offers a subscription feed that lists the 30 most recently published vulnerability notes.
The US-CERT Vulnerability Notes Database contains two types of documents: Vulnerability Notes, which generally describe vulnerabilities independent of a particular vendor, and Vendor Information documents, which provide information about a specific vendor's solution to a problem. The fields in each of these documents are described here in more detail.
For the purpose of information consolidation between vulnerability entries from deferent databases it is useful to summarize presented information by the model in Figure 2
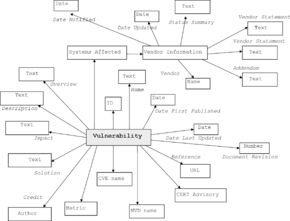 |
| Figure 2 Model of US-CERT vulnerability entries |
The diagram is a conceptual model of the US-CERT database, illustrating the noun concepts and their roles. These concepts are explained below. This is the vocabulary of concrete vulnerability facts that extends the generic terms given in Chapter 5.
Vulnerability ID – US-CERT assigns vulnerability ID numbers at random to uniquely identify a vulnerability. These IDs are four to six digits long and are frequently prefixed with “VU#” to mark them as vulnerability IDs; for example VU#492515. This ID is specific to vulnerability facts managed by the US-CERT database. Without standardization, such as the NIST SCAP, facts from a different vulnerability database may be difficult (or even impossible) to collate with the facts from US-CERT. Vulnerability is such a complex phenomenon, so it is not uncommon that two vulnerability researchers identify different states and locations as the vulnerability responsible to the same incident. The situation is further complicated by the fact that one security incident may involve multiple vulnerabilities.
Vulnerability name – The vulnerability name is a short description that summarizes the nature of the problem and the affected software product. While the name may include a clause describing the impact of the vulnerability, most names are focused on the nature of the defect that caused the problem to occur. For example, “Microsoft Explorer HTML object memory corruption vulnerability.”
Overview – The overview is an abstract of the vulnerability that provides a summary of the problem and its impact to the reader. The overview field was not originally in the database, so older documents may not include this information. For example, “An invalid pointer reference within Microsoft Internet Explorer may lead to execution of arbitrary code.”
Description – The vulnerability description contains one or more paragraphs of text describing the vulnerability.
Impact – The impact statement describes the benefit that an intruder might gain by exploiting the vulnerability. It also frequently includes preconditions the attacker must meet to be able to exploit the vulnerability. For example, “By convincing a user to load a specially crafted HTML document or Microsoft Office document, a remote, unauthenticated attacker may be able to execute arbitrary code or cause a denial-of-service condition.”
Solution – The solution section contains information about how to correct the vulnerability.
Systems affected – This section includes a list of systems that may be affected by the vulnerability including the information about vendors. The vendor name is a link to more detailed information from the vendor about the vulnerability in question. Additional summary information is provided for each vendor as well, including a status field indicating whether the vendor has any vulnerable products for the issue described in the vulnerability note, and dates when the vendor was notified and when the vendor information was last updated.
Date notified – This is the date that the vendor was notified of the vulnerability. In some cases, this may be the date that the vendor first contacted us, or it may be the earliest date when the vendor is known to have been aware of the vulnerability (for example, if they published a patch or an advisory).
Date updated – This is when the vendor information was last updated. As vendors produce patches and publish advisories, vendor statement, vendor information, or addendum fields may be updated, affecting this date.
Status summary – This field indicates, in broad terms, whether the vendor has any products that we consider to be vulnerable. In many cases, the relationship between a vendor's products and a vulnerability is more complex than a simple “Vulnerable” or “Not Vulnerable” field. Users are encouraged to read the detailed vendor statements and to use this field only as a broad indicator of whether any products might be vulnerable.
Vendor statement – This is the vendor's official response to our queries about the vulnerability. With little more than typographical edits, this information is provided directly by the vendor and does not necessarily reflect our opinions. In fact, vendors are welcome to provide statements that contradict other information in the vulnerability note. We suggest that the vendors include relevant information about correcting the problem, such as pointers to software patches and security advisories. We are highly confident that information in this field comes from the vendor. Statements are usually PGP signed or otherwise authenticated.
Vendor information – This is information we are reasonably confident is from the vendor. Typically, this includes public documents (that were not sent to us by the vendor) and statements that are not strongly authenticated.
Addendum – The addendum section contains one or more paragraphs of US-CERT comments on this vulnerability, especially when US-CERT disagrees with the vendor's assessment of the problem, when the vendor did not provide a statement.
References – The references are a collection of URLs at our web site and others providing additional information about the vulnerability.
Credit – This section of the document identifies who initially discovered the vulnerability, anyone who was instrumental in the development of the vulnerability note, and the primary author of the document.
Date public – This is the date on which the vulnerability was first known to the public. Usually this date is when the vulnerability note was first published, when an exploit was first discovered, when the vendor first distributed a patch publicly, or when a description of the vulnerability was posted to a public mailing list.
Date first published – This is the date when we first published the vulnerability note. This date should be the date public or later.
Date last updated – This is the date the vulnerability note was last updated. Each vulnerability note is updated as new information is received, or when a vendor information document changes for this vulnerability note.
CERT advisory – If a CERT Advisory was published for this vulnerability, this field will contain a pointer to that advisory. Beginning January 28, 2004, CERT Advisories became a core component of US-CERT Technical Alerts.
CVE name – The CVE name is a standardized identificator of a vulnerability, part of NIST SCAP. CVE name is the thirteen-character ID used by the “Common Vulnerabilities and Exposures” group to uniquely identify a vulnerability. The name is also a link to additional information on the CVE web site about the vulnerability. While the mapping between CVE names and US-CERT vulnerability IDs are usually pretty close, in some cases multiple vulnerabilities may map to one CVE name, or vice versa. The CVE group tracks a large number of security problems, not all of which meet the US-CERT criteria for being considered a vulnerability. For example, US-CERT does not track viruses or Trojan horse programs in the vulnerability notes database. A sample CVE name is “CVE-2010-0249.”
NVD name – The NVD name is usually the same as the CVE name. The name is also a link to additional information on the National Vulnerability Database (NVD) which is repository for the NSIT SCAP standardized content.
Metric – The metric value is a number between 0 and 180 that assigns an approximate severity to the vulnerability. This number considers several factors, including:
• Is information about the vulnerability widely available or known?
• Is the vulnerability being exploited?
• Is the Internet infrastructure at risk because of this vulnerability?
• How many systems on the Internet are at risk from this vulnerability?
• What is the impact of exploiting the vulnerability?
• How easy is it to exploit the vulnerability?
• What are the preconditions required to exploit the vulnerability?
Because the questions are answered with approximate values that may differ significantly from one site to another, users should not rely too heavily on the metric for prioritizing vulnerabilities. However, it may be useful for separating the very serious vulnerabilities from the large number of less severe vulnerabilities described in the database. Typically, vulnerabilities with a metric greater than 40 are candidates for US-CERT Technical Alerts. The questions are not all weighted equally, and the resulting score is not linear (a vulnerability with a metric of 40 is not twice as severe as one with a metric of 20).
Document revision – This field contains the revision number for this document. This field can be used to determine whether the document has changed since the last time it was viewed.
6.2.2. Open Source Vulnerability Database
This section illustrates the Open Source Vulnerability Database (OSVDB) [OSVDB].
Figure 3 illustrates the conceptual model of the OSVBD vulnerability database, focusing at the noun concepts and their roles.
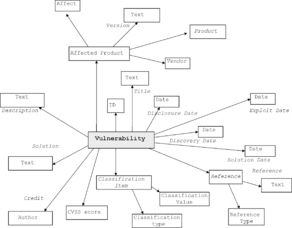 |
| Figure 3 Model of OSVDB vulnerability entries |
Vulnerability ID – OSVDB assigns unique vulnerability ID numbers to identify vulnerability. For example, 61697.
Title – The vulnerability title is a short description that summarizes the nature of the problem and the affected software product. While the name may include a clause describing the impact of the vulnerability, most names are focused on the nature of the defect that caused the problem to occur. For example, “Microsoft IE mshtml.dll Use-After-Free Arbitrary Code Execution (Aurora).”
Description – The vulnerability title is a short description that summarizes the nature of the problem and the affected software product. While the name may include a clause describing the impact of the vulnerability, most names are focused on the nature of the defect that caused the problem to occur.
Disclosure date – This is usually the same as Public Date in US-CERT. This is the date on which the vulnerability was first published. However, as opposed to US-CERT, OSVDB tracks separately the date when an exploit was first discovered, when the vendor first distributed a patch publicly, and when a description of the vulnerability was posted to a public mailing list.
Discovery date – This is the date on which the vulnerability was posted to a public mailing list.
Exploit date – This is the date on which the an exploit was first discovered.
Solution date – This is the date in which the vendor first distributed a patch publicly.
Classification – OSVDB provides own classification of vulnerabilities. The classification is a list of items, where each pair consists of a classification type (dimension of the classification vector) and a value. For example, a classification statement for 61697 is “Location: Local/Remote, Context Dependent; Attack Type: Input Manipulation; Impact: Loss of Integrity; Disclosure: Discovered in the Wild; OSVDB: web-related.”
Classification type – Classification vector is OSVDB includes the following dimensions: Location, Attack Type, Impact, Disclosure, and other.
Classification value –The classification value provides the value of a classification item on the dimension defined by the classification type. For example, Location type has the following values: Local, Remote, Dialup, Wireless, Mobile, Local/Remote, Context Dependent, and Unknown. Attack Type has the following values: Authentication Management, Cryptographic, Denial of Service, Information Disclosure, Infrastructure, Input Manipulation, Misconfiguration, Race Condition, Other, Unknown. Impact has the following values: Confidentiality, Integrity, Availability.
Solution – The solution section contains information about how to correct the vulnerability.
Affected products – This section includes a list of vendors who may be affected by the vulnerability. OSVDB contains normalized facts about {vendor, product, version} configurations, each can be annotated as Affected, Not Affected, or Possibly Affected. Vendor names and product names are enumerations specific to OSVDB (see Table 3).
| Affect type: | Affected |
| Vendor: | Microsoft Corporation |
| Product: | Internet Explorer |
| Version: | 6 SP1 |
References – The references are a collection of URLs at our web site and others providing additional information about the vulnerability. In OSVDB, each reference is annotated with the reference type. OSVDB provides references to other major vulnerability databases, such as Security Focus, Secunia, ISS X-Force, CVE, US-CERT, Security Tracker, and VUPEN; references to exploits, such as Metasploit and Milw0rm; and references to scanner tools signatures, such as Nessus Script ID, Nikto Item ID, OVAL ID, Packet Storm, Snort Signature ID, and Tenable PVS.
Credits – This section of the vulnerability record identifies the vulnerability researcher who initially discovered the vulnerability. At the time of writing, there were 4739 contributors to OSVDB.
6.3. Vulnerability life cycle
There are several events associated with vulnerability as a unit of knowledge of interest to the community: creation, discovery, disclosure, the release of a patch, publication, and automation of the exploitation. “Vulnerability life cycle” is illustrated at Figure 4. A “vulnerability life cycle” helps better understand possible sequences of events associated with a given vulnerability during its lifetime. This demonstrates above all that the off-the-shelf vulnerability knowledge is ad hoc, hit-and-miss, and must be integrated into more systematic approaches. New attacks demonstrate that hackers have knowledge of some vulnerabilities that are unknown to the product vendors and security information providers. There exist a market for vulnerability knowledge where a unit of vulnerability knowledge has a price tag from several thousand US dollars to a once reported $125.000 for a previously unknown vulnerability with a reliable exploit. The usual order of events in a vulnerability life cycle is as follows [Arbaugh 2000]:
• Creation. Vulnerabilities are usually created unintentionally, during system development. Vulnerability is caused by an incorrect design decision at one of the phases of the system life cycle. Mistakes and bugs that are discovered and fixed during the development and testing phases are not counted as vulnerabilities, only those flaws that are released into the operations of the system. If the creation is malicious and thus intentional, discovery and creation coincide. The time of vulnerability creation can be established in retrospect, after the vulnerability is discovered.
• Discovery. When someone discovers that a product has security or survivability implications, the flaw becomes vulnerability. It doesn't matter if the discoverer is part of the attacker or defender community. In many cases, there is no record of the original discovery event; the discoverer may never disclose his finding. When a vulnerability is first discovered by the vendor of the product, the fix may become available simultaneously with the disclosure, or in some cases even without the disclosure, when the fix is added into a large bundle. This is why patches from vendors are scrutinized by vulnerability researchers.
• Disclosure. The vulnerability is disclosed when the discoverer reveals details of the problem to a wider audience. For example, vulnerability announcement may be posted to a public mailing list such as Bugtraq. As a full-disclosure moderated mailing list, Bugtraq serves as a forum for detailed discussion and announcement of computer security vulnerabilities: What they are, how to exploit them, and how to fix them. Alternatively, details of the vulnerability may be communicated to the product vendor directly. Obviously, the many levels of disclosure comprise a vast continuum of who was informed and what aspect of the vulnerability the disclosure revealed. Currently ISO/IEC is working on a standard on Responsible Vulnerability Disclosure (ISO/IEC CD 29147).
• Correction. Vulnerability is correctable when the vendor or developer releases a software modification or configuration change that corrects the underlying flaw. After that, the administrator of the particular system affected by this vulnerability has the responsibility of applying the patch. Many systems for several years remain uncorrected and therefore vulnerable.
• Exploitation. The knowledge of the vulnerability can be expanded to the point when a particular sequence of actions is developed and tried, at least in the laboratory environment that actually penetrates at least one deployed system that uses the vulnerable product. There is a thriving community interested in successful exploits (representing various shades of penetration testers, vulnerability researchers, hackers, and criminals). Needless to say, some exploits never become public knowledge.
• Publicity. Vulnerability becomes public in several ways. A news story could bring attention to the problem, or an incident response center could issue a report concerning the vulnerability. Some vulnerabilities live a quiet life (never discovered, never disclosed, or disclosed only to a vendor and then quietly fixed). Disclosure to a public mailing list for the security community is a gray area. However, some vulnerabilities receive significant public attention, often because they were used by a high-profile cyber attack, or because the media picks up the story and expands it beyond the security community and the vendors.
• Scripting. Initially, successful exploitation of a new vulnerability requires moderate skill. However, once the steps leading to a successful exploitation are scripted, those with little or no skill can exploit the vulnerability to compromise systems. Scripting dramatically increases the size of the population that can exploit systems with that vulnerability. Further, although we use the term “scripting” in the sense of automating, this phase applies to any simplification of intrusion techniques that exploit the vulnerability, such as hacker “cookbooks” or detailed descriptions on how to exploit the vulnerability. In essence, at this point the vulnerability has been industrialized.
• Death. Vulnerability dies when the number of systems that can be exploited becomes insignificant because all systems at risk have been patched or retired. In practice, administrators can never patch all the systems at risk. Vulnerability creation, discovery and disclosure are casually related, so they always occur in this order. Disclosure can, however, occur almost simultaneously with discovery. After the initial disclosure, the vulnerability can be further disclosed, made public, scripted, or corrected in any order.
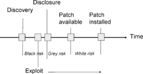 |
| Figure 4 Vulnerability life cycle |
6.4. NIST Security Content Automation Protocol (SCAP) Ecosystem
Standardization of vulnerability knowledge by NIST SCAP [NIST SP800-126] established a larger cyber security ecosystem, which allows automated exchanges of content and development of vulnerability management tools that can consume this standardized content and automate the key vulnerability management operations for the defender community. Security Content Automation Protocol (SCAP) has been developed to help provide organizations with a comprehensive, standardized approach to exchanging vulnerability knowledge as content for automated vulnerability management tools. SCAP comprises a suite of specifications for organizing and expressing vulnerability-related information in standardized ways. SCAP can be used for maintaining the security of enterprise systems, such as automatically verifying the installation of patches, checking system security configuration settings, and examining systems for signs of compromise.
6.4.1. Overview of SCAP ecosystem
SCAP has two major elements. First, it is a protocol—a suite of six open specifications that standardize the format and nomenclature by which security software communicates information about software flaws and security configurations. Each specification is also known as a SCAP component. Second, SCAP includes software flaw and security configuration standardized reference data, also known as SCAP content (see Tables 4 and 5).
The components are grouped by type:
• Enumerations, vulnerability measurement, and scoring, and
• Expression and checking languages.
The enumerations group has nomenclatures and dictionaries for security and product-related information.
SCAP has several uses, other than automating checks for known vulnerabilities, including automating the verification of security configuration settings, and generating reports that link low-level settings to high-level requirements.
6.4.2. Information exchanges in SCAP ecosystem
The next two characteristics of the NIST SCAP ecosystem are important to list and discuss since they are responsible for SCAP success and global improvement in security vulnerability management.
First, NIST standards for SCAP allow formal compliance checking. NIST has established the SCAP Product Validation program and SCAP Laboratory Accreditation program to certify compliance to SCAP. These programs work together to ensure that SCAP products are thoroughly tested and validated to conform to SCAP requirements. Given SCAP's complexity, this formal testing is needed to ensure that products properly implement SCAP. Acquisition officials have already embedded requirements for SCAP-validated products in their procurements. For example, U.S. Office of Management and Budget (OMB) requires federal agencies and agency IT providers to use SCAP-validated Federal Desktop Core Configuration (FDCC) scanners for testing and assessing FDCC compliance.
To help automate security configuration verification, organizations can use National Vulnerability Database (NVD) to identify and obtain SCAP-expressed security configuration checklists relevant for their systems' operating systems and applications. In some cases, a security configuration is mandated in policy (for example, the FDCC mandated for federal agency Windows XP and Vista hosts). In all other cases, selecting a checklist from the National Checklist Program (NCP) is highly recommended. Due to February 2008 modifications to Federal Acquisition Regulation (FAR) Part 39, federal agencies must procure IT products with relevant NCP checklists applied. NCP checklists are publicly vetted, and many offer manufacturer-endorsed methods of configuring and evaluating products.
Second, NIST SCAP facilitates separation of vulnerability knowledge from tools. This achieves two things: the openness of the ecosystem, and the possibility to assure the content. The NIST SCAP ecosystem emphasizes investment into the standard, rather than vendor lock-in into a proprietary “silo” tool and a proprietary vulnerability database. Information exchange between SCAP participants as shown below in the Figure 5 facilitates automation. The possibility of assuring the content in addition to running the automated tool is very important for building assurance case for security, as demonstrated in Chapters 2 and 3.
 |
| Figure 5 Information exchange between SCAP participants |
With a common agreed upon identifier of the vulnerability through defining CVE, all vulnerability databases and vulnerability management tools can reference this same object in their records and attach their unique additional facts to it. The alternative is very unattractive—pair-wise contracts for information exchanges between tools. CVE is a dictionary of unique, common names for publicly known software vulnerabilities. This common naming convention allows sharing of data within and among organizations and enables effective integration of services and tools.
Common identification of vulnerabilities is a critical first step in conceptual commitment for information exchanges of cybersecurity knowledge (see Figure 6). It allows cross-correlation between various units of knowledge that are of interest to the defender community. In particular, suppose a defender receives a security advisory for one Security Information Provider, which mentions a vulnerability involving a product from a vendor on a specific platform. A few days later, the vendor issues a security bulletin. Was the vendor referring to the same vulnerability? A search in another public vulnerability database lists several vulnerabilities for the same product. Is the initial vulnerability a new one? A few months later, the vendor releases a patch to a few vulnerabilities. Was the initial vulnerability fixed? The vulnerability scanner tool that is being used by the defender team has a separate database of signatures and assessment probes (checks that need to be performed to check for vulnerabilities). Does it cover the initial vulnerability? Another database is used by the Intrusion Detection Tool (IDS). Does it cover the initial vulnerability? Finally, the defender team wants to produce an enterprise-wide report to map the vulnerability to the host and network configuration, IDS logs, assessment results, and security policy. In order to achieve these integrations, a common key to different databases is needed. Such key is the unique CVE name assigned to each vulnerability. CVE name provides a logical bridge between multiple vulnerability management tools and facilitates integration. For example, a remediation tool may use CVE information from several scanning tools and monitoring sensors, enabling an integrated risk mitigation solution.
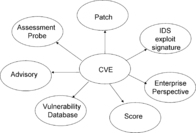 |
| Figure 6 CVE associations |
The idea of a common nomenclature seems very simple, but the biggest challenge to its successful implementation is to motivate the tool vendors and to have a mechanism that will resolve conflicts. Today CVE is the de facto standard in the industry, 145 organizations participate, representing 261 products and services. 93 products and services from 51 organizations are “CVE-compatible,” which means that the output contains CVE references that are up-to-date and searchable. CVE was developed and is currently maintained by MITRE corporation—a vendor-neutral not-for-profit organization, a Federal Funded Research and Development Center (FFRDC). The CVE ecosystem involves several CVE Numbering Authorities (CNA) and the CVE Editorial Board, which includes representatives from commercial security tool vendors, software vendors, members of academia, research institutions, government agencies, and prominent security experts. The CVE Editorial Board uses open and collaborative discussions to decide which vulnerabilities or exposures are included in the CVE List and determine the common name and description for each entry. A final CVE entry consists of a descriptive name, a brief description, and references to the vulnerability databases.
CVE as well as many other components of the SCAP were sponsored by the National Cyber Security Division of the US Department of Homeland Security. National Vulnerability Database (NVD) is the U.S. government repository of standards based vulnerability management data represented using the SCAP. This data enables automation of vulnerability management, security measurement, and compliance. NVD includes databases of security checklists, security vulnerabilities, misconfigurations, product names, and impact metrics.
Bibliography
W. Arbaugh, W. Fithen, J. McHugh, Windows of Vulnerability: A Case Study Analysis, Computervol. 33 (no. 12) (2000); Dec. 2000.
NIST Special Publication SP800-126. The Technical Specification for the Security Content Automation Protocol (SCAP). SCAP Version 1.0, Quinn, S., Waltermire, D.,Johnson, C., Scarfone, K., Banghart, J.
NDIA, Engineering for System Assurance Guidebook. (2008) .
OSVDB OSVDB, The Open Source Vulnerability Database, http://osvdb.org/.
H. Petroski, To engineer is human: the role of failure in successful design. (1992) Vintage Books.
CVE CVE, http://cve.mitre.org/; Common Vulnerabilities and Exposures (CVE).
[US-CERT] US-CERT, United States Computer Emergency Readiness Team, http://www.us-cert.gov/.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.