
Hour 1. Welcome to the World of SQL
What You’ll Learn in This Hour:
• An introduction to and brief history of SQL
• An introduction to database management systems
• An overview of some basic terms and concepts
• An introduction to the database used in this book
Welcome to the world of SQL and the vast, growing database technologies of today’s businesses all over the world. By reading this book, you have begun accepting the knowledge that will soon be required for survival in today’s world of relational databases and data management. Unfortunately, because it is first necessary to provide the background of SQL and cover some preliminary concepts that you need to know, the majority of this hour is overview before we jump into actual coding. Bear with this hour of the book; this will be exciting, and the “boring stuff” in this hour definitely pays off.
SQL Definition and History
Every modern-day business has data, which requires some organized method or mechanism for maintaining and retrieving the data. When the data is kept within a database, this mechanism is referred to as a database management system (DBMS). Database management systems have been around for years, many of which started out as flat-file systems on a mainframe. With today’s technologies, the accepted use of database management systems has begun to flow in other directions, driven by the demands of growing businesses, increased volumes of corporate data, and of course, Internet technologies.
The modern wave of information management is primarily carried out through the use of a relational database management system (RDBMS), derived from the traditional DBMS. Modern databases combined with client/server and web technologies are typical combinations used by current businesses to successfully manage their data and stay competitive in their appropriate markets. The trend for many businesses is to move from a client/server environment to the Web, where location is not a restriction when users need access to important data. The next few sections discuss SQL and the relational database, the most common DBMS implemented today. A good fundamental understanding of the relational database and how to apply SQL to managing data in today’s information technology world is important to your understanding of the SQL language.
What Is SQL?
Structured Query Language (SQL) is the standard language used to communicate with a relational database. The prototype was originally developed by IBM using Dr. E.F. Codd’s paper (“A Relational Model of Data for Large Shared Data Banks”) as a model. In 1979, not long after IBM’s prototype, the first SQL product, ORACLE, was released by Relational Software, Incorporated (which was later renamed Oracle Corporation). Today it is one of the distinguished leaders in relational database technologies.
If you travel to a foreign country, you might be required to know that country’s language to get around. For example, you might have trouble ordering from a menu via your native tongue if the waiter speaks only his country’s language. Look at a database as a foreign land in which you seek information. SQL is the language you use to express your needs to the database. Just as you would order a meal from a menu in another country, you can request specific information from within a database in the form of a query using SQL.
What Is ANSI SQL?
The American National Standards Institute (ANSI) is an organization that approves certain standards in many different industries. SQL has been deemed the standard language in relational database communication, originally approved in 1986 based on IBM’s implementation. In 1987, the ANSI SQL standard was accepted as the international standard by the International Standards Organization (ISO). The standard was revised again in 1992 (SQL-92) and once again in 1999 (SQL-99). The newest standard is now called SQL-2008, which was officially adopted in July of 2008.
The New Standard: SQL-2008
SQL-2008 has nine interrelated documents, and other documents might be added in the near future as the standard is expanded to encompass newly emerging technology needs. The nine interrelated parts are as follows:
• Part 1: SQL/Framework— Specifies the general requirements for conformance and defines the fundamental concepts of SQL.
• Part 2: SQL/Foundation— Defines the syntax and operations of SQL.
• Part 3: SQL/Call-Level Interface— Defines the interface for application programming to SQL.
• Part 4: SQL/Persistent Stored Modules— Defines the control structures that then define SQL routines. Part 4 also defines the modules that contain SQL routines.
• Part 9: Management of External Data (SQL/MED)— Defines extensions to SQL to support the management of external data through the use of data-wrappers and datalink types.
• Part 10: Object Language Bindings— Defines extensions to the SQL language to support the embedding of SQL statements into programs written in Java.
• Part 11: Information and Definition Schemas— Defines specifications for the Information Schema and Definition Schema, which provide structural and security information related to SQL data.
• Part 13: Routines and Types Using the Java Programming Language— Defines the capability to call Java static routines and classes as SQL-invoked routines.
• Part 14: XML-Related Specifications— Defines ways in which SQL can be used with XML.
The new ANSI standard (SQL-2008) has two levels of minimal compliance that a DBMS may claim: Core SQL Support and Enhanced SQL Support. You can find a link to the ANSI SQL standard on this book’s web page, www.informit.com/title/9780672335419.
With any standard comes numerous, obvious advantages, as well as some disadvantages. Foremost, a standard steers vendors in the appropriate industry direction for development. In the case of SQL, a standard provides a basic skeleton of necessary fundamentals, which, as an end result, enables consistency between various implementations and better serves increased portability (not only for database programs, but databases in general and individuals who manage databases).
Some might argue that a standard is not so good, limiting the flexibility and possible capabilities of a particular implementation. However, most vendors who comply with the standard have added product-specific enhancements to standard SQL to fill in these gaps.
A standard is good, considering the advantages and disadvantages. The expected standard demands features that should be available in any complete SQL implementation and outlines basic concepts that not only force consistency between all competitive SQL implementations, but also increase the value of an SQL programmer.
An SQL implementation is a particular vendor’s SQL product, or RDBMS. It is important to note, as you will hear numerous times in this book, that implementations of SQL vary widely. There is no one implementation that follows the standard completely, although some are mostly ANSI-compliant. It is also important to note that in recent years the list of functionality within the ANSI standard that must be adhered to in order to be considered complaint has not changed dramatically. Hence, when new versions of RDBMS are released, they will most likely claim ANSI SQL compliance.
What Is a Database?
In simple terms, a database is a collection of data. Some like to think of a database as an organized mechanism that has the capability of storing information, through which a user can retrieve stored information in an effective and efficient manner.
People use databases every day without realizing it. A phone book is a database. The data contained consists of individuals’ names, addresses, and telephone numbers. The listings are alphabetized or indexed, which enables the user to reference a particular local resident with ease. Ultimately, this data is stored in a database somewhere on a computer. After all, each page of a phone book is not manually typed each year a new edition is released.
The database has to be maintained. As people move to different cities or states, entries might have to be added or removed from the phone book. Likewise, entries have to be modified for people changing names, addresses, telephone numbers, and so on. Figure 1.1 illustrates a simple database.
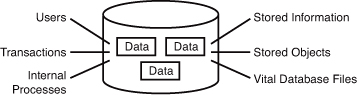
The Relational Database
A relational database is a database divided into logical units called tables, where tables are related to one another within the database. A relational database allows data to be broken down into logical, smaller, manageable units, enabling easier maintenance and providing more optimal database performance according to the level of organization. In Figure 1.2, you can see that tables are related to one another through a common key (data value) in a relational database.
Figure 1.2. The relational database.
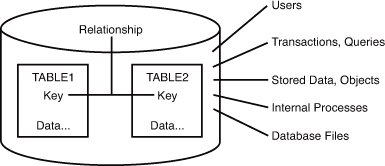
Again, tables are related in a relational database, allowing adequate data to be retrieved in a single query (although the desired data may exist in more than one table). By having common keys, or fields, among relational database tables, data from multiple tables can be joined to form one large set of data. As you venture deeper into this book, you see more of a relational database’s advantages, including overall performance and easy data access.
Client/Server Technology
In the past, the computer industry was predominately ruled by mainframe computers—large, powerful systems capable of high storage capacity and high data processing capabilities. Users communicated with the mainframe through dumb terminals—terminals that did not think on their own but relied solely on the mainframe’s CPU, storage, and memory. Each terminal had a data line attached to the mainframe. The mainframe environment definitely served its purpose and does today in many businesses, but a greater technology was soon to be introduced: the client/server model.
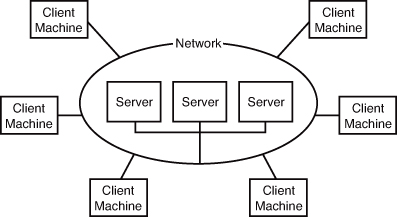
In the client/server system, the main computer, called the server, is accessible from a network—typically a local area network (LAN) or a wide area network (WAN). The server is normally accessed by personal computers (PCs) or by other servers, instead of dumb terminals. Each PC, called a client, is provided access to the network, allowing communication between the client and the server, thus explaining the name client/server. The main difference between client/server and mainframe environments is that the user’s PC in a client/server environment is capable of thinking on its own, capable of running its own processes using its own CPU and memory, but readily accessible to a server computer through a network. In most cases, a client/server system is much more flexible for today’s overall business needs and is much preferred.
Modern database systems reside on various types of computer systems with various operating systems. The most common types of operating systems are Windows-based systems, Linux, and command-line systems such as UNIX. Databases reside mainly in client/server and web environments. A lack of training and experience is the main reason for failed implementations of database systems. Nevertheless, an understanding of the client/server model and web-based systems, which will be explained in the next section, is imperative with the rising (and sometimes unreasonable) demands placed on today’s businesses as well as the development of Internet technologies and network computing. Figure 1.3 illustrates the concept of client/server technology.
Figure 1.3. The client/server model.
Web-Based Database Systems
Business information systems are moving toward web integration. Databases are now accessible through the Internet, meaning that customers’ access to an organization’s information is enabled through an Internet browser such as Internet Explorer or Firefox. Customers (users of data) are able to order merchandise, check on inventories, check on the status of orders, make administrative changes to accounts, transfer money from one account to another, and so forth.
A customer simply invokes an Internet browser, goes to the organization’s website, logs in (if required by the organization), and uses an application built into the organization’s web page to access data. Most organizations require users to register with them and issue a login and password to the customer.
Of course, many things occur behind the scenes when a database is being accessed via a web browser. SQL, for instance, can be executed by the web application. This executed SQL is used to access the organization’s database, return data to the web server, and then return that data to the customer’s Internet browser.
The basic structure of a web-based database system is similar to that of a client-server system from a user’s standpoint (refer to Figure 1.3). Each user has a client machine, which has a connection to the Internet and contains a web browser. The network in Figure 1.3 (in the case of a web-based database) just happens to be the Internet, as opposed to a local network. For the most part, a client is still accessing a server for information. It doesn’t matter that the server might exist in another state or even another country. The main point of web-based database systems is to expand the potential customer base of a database system that knows no physical location bounds, thus increasing data availability and an organization’s customer base.
Popular Database Vendors
Some of the most predominant database vendors include Oracle, Microsoft, Informix, Sybase, and IBM. These vendors distribute various versions of the relational database for a base license fee and are normally referred to as closed source. Many other vendors supply an open-source version of an SQL database (relational database). Some of these vendors include MySQL, PostgresSQL, and SAP. Although many more vendors exist than those mentioned, this list includes names that you might have recognized on the bookshelf, in the newspaper, in magazines, on the stock market, or on the World Wide Web.
Each vendor-specific implementation of SQL is unique in both features and nature. A database server is a product—like any other product on the market—manufactured by a widespread number of vendors. It is to the benefit of the vendor to ensure that its implementation is compliant with the current ANSI standard for portability and user convenience. For instance, if a company is migrating from one database server to another, it would be rather discouraging for the database users to have to learn another language to maintain functionality with the new system.
With each vendor’s SQL implementation, however, you find that there are enhancements that serve the purpose for each database server. These enhancements, or extensions, are additional commands and options that are simply a bonus to the standard SQL package and available with a specific implementation.
SQL Sessions
An SQL session is an occurrence of a user interacting with a relational database through the use of SQL commands. When a user initially connects to the database, a session is established. Within the scope of an SQL session, valid SQL commands can be entered to query the database, manipulate data in the database, and define database structures, such as tables. A session may be invoked by either direct connection to the database or through a front-end application. In both cases, sessions are normally established by a user at a terminal or workstation that communicates through a network with the computer that hosts the database.
CONNECT
When a user connects to a database, the SQL session is initialized. The CONNECT command is used to establish a database connection. With the CONNECT command, you can either invoke a connection or change connections to the database. For example, if you are connected as USER1, you can use the CONNECT command to connect to the database as USER2. When this happens, the SQL session for USER1 is implicitly disconnected. You would normally use the following:
CONNECT user@database
When you attempt to connect to a database, you are automatically prompted for a password that is associated with your current username. The username is used to authenticate you to the database, and the password is the key that allows entrance.
DISCONNECT and EXIT
When a user disconnects from a database, the SQL session is terminated. The DISCONNECT command is used to disconnect a user from the database. When you disconnect from the database, the software you are using might still appear to be communicating with the database, but you have lost your connection. When you use EXIT to leave the database, your SQL session is terminated, and the software that you are using to access the database is normally closed.
DISCONNECT
Types of SQL Commands
The following sections discuss the basic categories of commands used in SQL to perform various functions. These functions include building database objects, manipulating objects, populating database tables with data, updating existing data in tables, deleting data, performing database queries, controlling database access, and overall database administration.
The main categories are
• Data Definition Language (DDL)
• Data Manipulation Language (DML)
• Data Query Language (DQL)
• Data Control Language (DCL)
• Data administration commands
• Transactional control commands
Defining Database Structures
Data Definition Language (DDL) is the part of SQL that enables a database user to create and restructure database objects, such as the creation or the deletion of a table.
Some of the most fundamental DDL commands discussed during the following hours include
• CREATE TABLE
• ALTER TABLE
• DROP TABLE
• CREATE INDEX
• ALTER INDEX
• DROP INDEX
• DROP VIEW
These commands are discussed in detail during Hour 3, “Managing Database Objects,” Hour 17, “Improving Database Performance,” and Hour 20, “Creating and Using Views and Synonyms.”
Manipulating Data
Data Manipulation Language (DML) is the part of SQL used to manipulate data within objects of a relational database.
The three basic DML commands are
• INSERT
• UPDATE
• DELETE
These commands are discussed in detail during Hour 5, “Manipulating Data.”
Selecting Data
Though comprised of only one command, Data Query Language (DQL) is the most concentrated focus of SQL for modern relational database users. The base command is SELECT.
This command, accompanied by many options and clauses, is used to compose queries against a relational database. A query is an inquiry to the database for information. A query is usually issued to the database through an application interface or via a command-line prompt. You can easily create queries, from simple to complex, from vague to specific.
The SELECT command is discussed in exhilarating detail during Hours 7 through 16.
Data Control Language
Data control commands in SQL enable you to control access to data within the database. These Data Control Language (DCL) commands are normally used to create objects related to user access and also control the distribution of privileges among users. Some data control commands are as follows:
• GRANT
• REVOKE
• CREATE SYNONYM
You will find that these commands are often grouped with other commands and might appear in a number of lessons throughout this book.
Data Administration Commands
Data administration commands enable the user to perform audits and perform analyses on operations within the database. They can also be used to help analyze system performance. Two general data administration commands are as follows:
• START AUDIT
• STOP AUDIT
Do not get data administration confused with database administration. Database administration is the overall administration of a database, which envelops the use of all levels of commands. Data administration is much more specific to each SQL implementation than are those core commands of the SQL language.
Transactional Control Commands
In addition to the previously introduced categories of commands, there are commands that enable the user to manage database transactions:
• COMMIT— Saves database transactions
• ROLLBACK— Undoes database transactions
• SAVEPOINT— Creates points within groups of transactions in which to ROLLBACK
• SET TRANSACTION— Places a name on a transaction
Transactional commands are discussed extensively during Hour 6, “Managing Database Transactions.”
The Database Used in This Book
Before continuing with your journey through SQL fundamentals, the next step is introducing the tables and data that you use throughout the course of instruction for the next 23 one-hour lessons. The following sections provide an overview of the specific tables (the database) being used, their relationship to one another, their structure, and examples of the data contained.
Figure 1.4 reveals the relationship between the tables that you use for examples, quiz questions, and exercises in this book. Each table is identified by the table name as well as each residing field in the table. Follow the mapping lines to compare the specific tables’ relationship through a common field, in most cases referred to as the primary key (discussed in Hour 3).
Figure 1.4. Table relationships for this book.
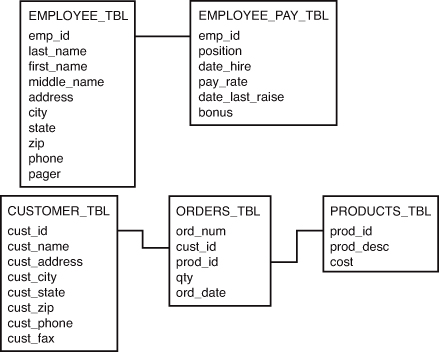
Table-Naming Standards
By the Way: Naming Standards
You should not only adhere to the object-naming syntax of any SQL implementation, but also follow local business rules and create names that are descriptive and related to the data groupings for the business.
Table-naming standards, as well as any standard within a business, are critical to maintaining control. After studying the tables and data in the previous sections, you probably noticed that each table’s suffix is _TBL. This is a naming standard selected for use, such as what’s been used at various client sites. The _TBL suffix simply tells you that the object is a table; there are many different types of objects in a relational database. For example, in later hours you see that the suffix _INX is used to identify indexes on tables. Naming standards exist almost exclusively for overall organization and assist immensely in the administration of any relational database. Remember, the use of a suffix is not mandatory when naming database objects. A naming convention is merely used to provide some order when creating objects. You may choose to utilize whatever standard you wish.
A Look at the Data
This section offers a picture of the data contained in each one of the tables used in this book. Take a few minutes to study the data, the variations, and the relationships between the tables and the data. Notice that some fields might not require data, which is specified when each table is created in the database.
EMPLOYEE_TBL
EMP_ID LAST_NAM FIRST_NA M ADDRESS CITY ST ZIP PHONE
-------------------------------------------------------------------------------
311549902 STEPHENS TINA D RR 3 BOX 17A GREENWOOD IN 47890 3178784465
442346889 PLEW LINDA C 3301 BEACON INDIANAPOLIS IN 46224 3172978990
213764555 GLASS BRANDON S 1710 MAIN ST WHITELAND IN 47885 3178984321
313782439 GLASS JACOB 3789 RIVER BLVD INDIANAPOLIS IN 45734 3175457676
220984332 WALLACE MARIAH 7889 KEYSTONE INDIANAPOLIS IN 46741 3173325986
443679012 SPURGEON TIFFANY 5 GEORGE COURT INDIANAPOLIS IN 46234 3175679007
EMPLOYEE_PAY_TBL
EMP_ID POSITION DATE_HIRE PAY_RATE DATE_LAST SALARY BONUS
-------------------------------------------------------------------------------
311549902 MARKETING 23-MAY-1999 01-MAY-2009 4000
442346889 TEAM LEADER 17-JUN-2000 14.75 01-JUN-2009
213764555 SALES MANAGER 14-AUG-2004 01-AUG-2009 3000 2000
313782439 SALESMAN 28-JUN-2007 2000 1000
220984332 SHIPPER 22-JUL-2006 11 01-JUL-2009
443679012 SHIPPER 14-JAN-2001 15 01-JAN-2009
CUSTOMER_TBL
CUST_ID CUST_NAME ADDRESS CUST_CITY ST ZIP CUST_PHONE CUST_FAX
-------------------------------------------------------------------------------
232 LESLIE GLEASON 798 HARDAWAY DR INDIANAPOLIS IN 47856 3175457690
109 NANCY BUNKER APT A 4556 WATERWAY BROAD RIPPLE IN 47950 3174262323
345 ANGELA DOBKO RR3 BOX 76 LEBANON IN 49967 7658970090
090 WENDY WOLF 3345 GATEWAY DR INDIANAPOLIS IN 46224 3172913421
12 MARYS GIFT SHOP 435 MAIN ST DANVILLE IL 47978 3178567221 3178523434
432 SCOTTYS MARKET RR2 BOX 173 BROWNSBURG IN 45687 3178529835 3178529836
333 JASONS AND DALLAS GOODIES LAFAYETTE SQ MALL INDIANAPOLIS IN 46222 3172978886 3172978887
21 MORGANS CANDIES AND TREATS 5657 W TENTH ST INDIANAPOLIS IN 46234 3172714398
43 SCHYLERS NOVELTIES 17 MAPLE ST LEBANON IN 48990 3174346758
287 GAVINS PLACE 9880 ROCKVILLE RD INDIANAPOLIS IN 46244 3172719991 3172719992
288 HOLLYS GAMEARAMA 567 US 31 WHITELAND IN 49980 3178879023
590 HEATHERS FEATHERS AND THINGS 4090 N SHADELAND AVE INDIANAPOLIS IN 43278 3175456768
610 REGANS HOBBIES 451 GREEN PLAINFIELD IN 46818 3178393441 3178399090
560 ANDYS CANDIES RR 1 BOX 34 NASHVILLE IN 48756 8123239871
221 RYANS STUFF 2337 S SHELBY ST INDIANAPOLIS IN 47834 3175634402
175 CAMERON'S PIES 178 N TIBBS AVON IN 46234 3174543390
290 CALEIGH'S KITTENS 244 WEST ST LEBANON IN 47890 3174867754
56 DANIELS SPANIELS 17 MAIN ST GREENWOOD IN 46578 3172319908
978 AUTUMN'S BASKETS 5648 CENTER ST SOUTHPORT IN 45631 3178887565
ORDERS_TBL
ORD_NUM CUST_ID PROD_ID QTY ORD_DATE
--------------------------------------------------
56A901 232 11235 1 22-OCT-2009
56A917 12 907 100 30-SEP-2009
32A132 43 222 25 10-OCT-2009
16C17 090 222 2 17-OCT-2009
18D778 287 90 10 17-OCT-2009
23E934 432 13 20 15-OCT-2009
PRODUCTS_TBL
PROD_ID PROD_DESC COST
------------------------------------------------
11235 WITCH COSTUME 29.99
222 PLASTIC PUMPKIN 18 INCH 7.75
13 FALSE PARAFFIN TEETH 1.10
90 LIGHTED LANTERNS 14.50
15 ASSORTED COSTUMES 10.00
9 CANDY CORN 1.35
6 PUMPKIN CANDY 1.45
87 PLASTIC SPIDERS 1.05
119 ASSORTED MASKS 4.95
A Closer Look at What Comprises a Table
The storage and maintenance of valuable data is the reason for any database’s existence. You have just viewed the data that is used to explain SQL concepts in this book. The following sections take a closer look at the elements within a table. Remember, a table is the most common and simple form of data storage.
Fields
Every table is broken into smaller entities called fields. A field is a column in a table that is designed to maintain specific information about every record in the table. The fields in the PRODUCTS_TBL table consist of PROD_ID, PROD_DESC, and COST. These fields categorize the specific information that is maintained in a given table.
Records, or Rows of Data
A record, also called a row of data, is each horizontal entry that exists in a table. Looking at the last table, PRODUCTS_TBL, consider the following first record in that table:
11235 WITCH COSTUME 29.99
The record is obviously composed of a product identification, product description, and unit cost. For every distinct product, there should be a corresponding record in the PRODUCTS_TBL table.
A row of data is an entire record in a relational database table.
Columns
A column is a vertical entity in a table that contains all information associated with a specific field in a table. For example, a column in the PRODUCTS_TBL having to do with the product description consists of the following:
WITCH COSTUME
PLASTIC PUMPKIN 18 INCH
FALSE PARAFFIN TEETH
LIGHTED LANTERNS
ASSORTED COSTUMES
CANDY CORN
PUMPKIN CANDY
PLASTIC SPIDERS
ASSORTED MASKS
This column is based on the field PROD_DESC, the product description. A column pulls information about a certain field from every record within a table.
Primary Keys
A primary key is a column that makes each row of data in the table unique in a relational database. The primary key in the PRODUCTS_TBL table is PROD_ID, which is typically initialized during the table creation process. The nature of the primary key is to ensure that all product identifications are unique, so that each record in the PRODUCTS_TBL table has its own PROD_ID. Primary keys alleviate the possibility of a duplicate record in a table and are used in other ways, which you will read about in Hour 3.
NULL Values
NULL is the term used to represent a missing value. A NULL value in a table is a value in a field that appears to be blank. A field with a NULL value is a field with no value. It is important to understand that a NULL value is different from a zero value or a field that contains spaces. A field with a NULL value is one that has been left blank during record creation. Notice that in the EMPLOYEE_TBL table, not every employee has a middle initial. Those records for employees who do not have an entry for middle initial signify a NULL value.
Additional table elements are discussed in detail during the next two hours.
Examples and Exercises
Many exercises in this book use the MySQL, Microsoft SQL Server, and Oracle databases to generate the examples. We decided to concentrate on these three database implementations because they allow freely distributed versions of their database to be available. This enables you to select an implementation of your choice, install it, and follow along with the exercises in the book. Note that because these databases are not 100% compliant to SQL-2008, the exercises might present slight variations or nonadoption of the ANSI standard. However, by learning the basics of the ANSI standard, you will be able in most cases to easily translate your skills between different database implementations.
Summary
You have been introduced to the standard language of SQL and have been given a brief history and thumbnail of how the standard has evolved over the past several years. Database systems and current technologies were also discussed, including the relational database, client/server systems, and web-based database systems, all of which are vital to your understanding of SQL. The main SQL language components and the fact that there are numerous players in the relational database market, and likewise, many different flavors of SQL, were discussed. Despite ANSI SQL variations, most vendors do comply to some extent with the current standard (SQL-2008), rendering consistency across the board and forcing the development of portable SQL applications.
The database that is used during your course of study was also introduced. The database, as you have seen it so far, has consisted of a few tables (which are related to one another) and the data that each table contains at this point (at the end of Hour 1). You should have acquired some overall background knowledge of the fundamentals of SQL and should understand the concept of a modern database. After a few refreshers in the Workshop for this hour, you should feel confident about continuing to the next hour.
Q&A
Q. If I learn SQL, will I be able to use any of the implementations that use SQL?
A. Yes, you will be able to communicate with a database whose implementation is ANSI SQL compliant. If an implementation is not completely compliant, you should be able to pick it up quickly with some adjustments.
Q. In a client/server environment, is the personal computer the client or the server?
A. The personal computer is known as the client, although a server can also serve as a client.
Q. Do I have to use _TBL for each table I create?
A. Certainly not. The use of _TBL is a standard chosen for use to name and easily identify the tables in your database. You could spell out TBL as TABLE, or you might want to avoid using a suffix. For example, EMPLOYEE TBL could simply be EMPLOYEE.
Workshop
The following workshop is composed of a series of quiz questions and practical exercises. The quiz questions are designed to test your overall understanding of the current material. The practical exercises are intended to afford you the opportunity to apply the concepts discussed during the current hour, as well as build upon the knowledge acquired in previous hours of study. Please take time to complete the quiz questions and exercises before continuing. Refer to Appendix C, “Answers to Quizzes and Exercises,” for answers.
Quiz
1. What does the acronym SQL stand for?
2. What are the six main categories of SQL commands?
3. What are the four transactional control commands?
4. What is the main difference between client/server and web technologies as they relate to database access?
5. If a field is defined as NULL, does something have to be entered into that field?
Exercises
1. Identify the categories in which the following SQL commands fall:
CREATE TABLE
DELETE
SELECT
INSERT
ALTER TABLE
UPDATE
2. Study the following tables, and pick out the column that would be a good candidate for the primary key:

3. Refer to Appendix B, “Using the Databases for Exercises.” Download and install one of the three database implementations on your computer to prepare for hands-on exercises in the following hours of instruction.