
Chapter 14. Text Processing
As a developer, I prefer editing in plain text. XML doesn’t count.
—Wesley Chun, July 2009
(verbally at OSCON conference)
In this chapter...
Regardless of what type of applications you create, inevitably, you will need to process human-readable data, which is referred to generally as text. Python’s standard library provides three text processing modules and packages to help you get this job done: csv, json, and xml. We’ll explore these briefly in that order in this chapter.
At the end, we’ll merge together XML along with some of the client-server knowledge you acquired from Chapter 2, “Network Programming,” and show you how to create XML-RPC services using Python. Because this style of programming isn’t considered text processing, and you’re not manipulating the XML itself, which is just the data transport format, just consider this last section as bonus material.
14.1. Comma-Separated Values
In the first section of this chapter, we’ll look at comma-separated values (CSV). We begin with a quick introduction then move to a code sample of how to use Python to read and write CSV files. Finally we revisit an old friend.
14.1.1. Introduction to Comma-Separated Values
Using CSVs is a common way to move data into and out of spreadsheet applications in plain text, as opposed to a proprietary binary file format. In fact, CSV doesn’t even represent true structured data; the contents of CSV files are just rows of string values delimited by commas. There are some subtleties with CSV formats, but in general, they’re fairly minor. In many cases, you actually don’t need the power of a CSV-oriented module.
Sounds pretty easy to parse, doesn’t it? Offhand, I’d say just do a str.split(',') and call it a day. However, we can’t do that because individual field values might contain embedded commas, hence the need for CSV-parsing and generating a library like Python’s csv module.
Let’s look at a quick example of taking data, writing CSV out to a file, and then reading the same data back. We’ll also have individual fields that include commas, as well, just to make things a bit more difficult. Example 14-1 presents csvex.py, a script that takes 3-tuples and writes each corresponding record to disk as a CSV file. Then, it reads and parses the previously-written CSV data.
Example 14-1. CSV Python 2 and Python 3-Compatible Example (csvex.py)
This simple script demonstrates writing out CSV data and reading it back in.
1 #!/usr/bin/env python
2
3 import csv
4 from distutils.log import warn as printf
5
6 DATA = (
7 (9, 'Web Clients and Servers', 'base64, urllib'),
8 (10, 'Web Programming: CGI & WSGI', 'cgi, time, wsgiref'),
9 (13, 'Web Services', 'urllib, twython'),
10 )
11
12 printf('*** WRITING CSV DATA')
13 f = open('bookdata.csv', 'w')
14 writer = csv.writer(f)
15 for record in DATA:
16 writer.writerow(record)
17 f.close()
18
19 printf('*** REVIEW OF SAVED DATA')
20 f = open('bookdata.csv', 'r')
21 reader = csv.reader(f)
22 for chap, title, modpkgs in reader:
23 printf('Chapter %s: %r (featuring %s)' % (
24 chap, title, modpkgs))
25 f.close()
Following is another example of writing scripts that are compatible with both Python 2 and 3. Regardless of which version you use, you get the following identical output:
$ python csvex.py
*** WRITING CSV DATA
*** REVIEW OF SAVED DATA
Chapter 9: 'Web Clients and Servers' (featuring base64, urllib)
Chapter 10: 'Web Programming: CGI & WSGI' (featuring cgi, time, wsgiref)
Chapter 13: 'Web Services' (featuring urllib, twython)
Line-by-Line Explanation
Lines 1–10
We first import the csv module as well as distutils.log.warn() as a proxy for the print statement or function. (It’s not really compatible except for a single string, but it gets the job done, provided you can work with its limitation.) Following the import statements is our data set. This is made up of 3-tuples that have columns representing chapter numbers, chapter titles, and modules and packages that are used in the code samples of their respective chapters.
Lines 12–17
These six lines are fairly self-explanatory. csv.writer() is a function that takes an open file (or file-like) object and returns a writer object. The writer features a writerow() method, which you use to output lines or rows of comma-separated data to the open file. After it has done its job, the file is closed.
Lines 19–25
In this section, csv.reader() is the opposing function which returns an iterable object that you can use to read in and parse each row of CSV data. Like csv.writer(), csv.reader() also takes an open file handle and returns a reader object. When you iterate through each row of data, the CSVs are automatically parsed and returned to you (line 22). We display the output then close the file when all rows have been processed.
In addition to csv.reader() and csv.writer(), the csv module also features the csv.DictReader and csv.DictWriter classes which read CSV data into a dictionary (with given field names provided or the first row if not) and write dictionary fields to a CSV file.
14.1.2. Stock Portfolio Example Reprise
Before moving on to another text processing format, take a look at another example. We’ll rewind a bit and re-examine the stock portfolio script, stock.py, from Chapter 13, “Web Services.” Rather than doing a str.split(','), we’ll port that application so that it uses the csv module, instead.
Also, instead of showing you all of the code, most of which is identical to stock.py, we’re going to focus only on the differences, or diffs, as engineers abbreviate it. Below is a quick review of the entire (Python 2) stock.py script (feel free to flip back to Chapter 13 for the line-by-line explanation):
#!/usr/bin/env python
from time import ctime
from urllib2 import urlopen
TICKs = ('yhoo', 'dell', 'cost', 'adbe', 'intc')
URL = 'http://quote.yahoo.com/d/quotes.csv?s=%s&f=sl1c1p2'
print '
Prices quoted as of: %s PDT
' % ctime()
print 'TICKER', 'PRICE', 'CHANGE', '%AGE'
print '------', '-----', '------', '----'
u = urlopen(URL % ','.join(TICKs))
for row in u:
tick, price, chg, per = row.split(',')
print tick, '%.2f' % float(price), chg, per,
u.close()
The output of both the original version as well as our modified version will be similar. Here’s one example execution as a reminder:
Prices quoted as of: Sat Oct 29 02:06:24 2011 PDT
TICKER PRICE CHANGE %AGE
------ ----- ------ ----
"YHOO" 16.56 -0.07 "-0.42%"
"DELL" 16.31 -0.01 "-0.06%"
"COST" 84.93 -0.29 "-0.34%"
"ADBE" 29.02 +0.68 "+2.40%"
"INTC" 24.98 -0.15 "-0.60%"
All we’re going to do is to copy the code from stock.py into a new script named stockcsv.py and make the changes necessary to use csv instead. Let’s see what the differences are, focusing on the code that follows the call to urlopen(). As soon as we have this open file, we assign it to csv.reader(), as shown here:
reader = csv.reader(u)
for tick, price, chg, pct in reader:
print tick.ljust(7), ('%.2f' % round(float(price), 2)).rjust(6),
chg.rjust(6), pct.rstrip().rjust(6)
u.close()
The for loop is mostly still the same, except that now we do not read in an entire row and split it on the comma. Instead, the csv module parses the data naturally for us and lets users specify the target field names as loop variables. Note the output is close but isn’t an exact match. Can you tell the difference (other than the timestamp)? Take a look:
Prices quoted as of: Sun Oct 30 23:19:04 2011 PDT
TICKER PRICE CHANGE %AGE
------ ----- ------ ----
YHOO 16.56 -0.07 -0.42%
DELL 16.31 -0.01 -0.06%
COST 84.93 -0.29 -0.34%
ADBE 29.02 +0.68 +2.40%
INTC 24.98 -0.15 -0.60%
The difference is subtle. There appears to be quotes around some of the fields in the str.split() version but not in the csv-processed version. Why is this happening? Recall from Chapter 13 that some values come back quoted and that there is an exercise at the end of that chapter for you to manually remove the extra quotes.
This isn’t an issue here as the csv module helps us process the CSV data, including finding and scrubbing the superfluous quotes that come from the Yahoo! server. Here’s a code snippet and output to confirm those extra quotes:
>>> from urllib2 import urlopen
>>> URL = 'http://quote.yahoo.com/d/quotes.csv?s=goog&f=sl1c1p2'
>>> u = urlopen(URL, 'r')
>>> line = u.read()
>>> u.close()
>>> line
'"GOOG",598.67,+12.36,"+2.11%"
'
The quotes are an extra hassle that developers don’t need to deal with; csv takes care of that for us, making the code a bit easier to read without the required extra string processing.
To improve on the data management, it would be even nicer if the data was structured in a more hierarchical fashion. For example, it would be good to have each row that comes back be part of a single object where the price, change, and percentage are attributes of that object. With a 4-value CSV row, there’s no indication which is the “primary key,” as it were, unless you use the first value or similar convention. This is where JSON might be a more appropriate tool for your applications.
14.2. JavaScript Object Notation
As you can gather from its name, JavaScript Object Notation, or JSON, comes from the world of JavaScript—it’s a subset of the language used specifically to pass around structured data. It is based on the ECMA-262 standard and is meant to be a lightweight data interchange alternative to the Extensible Markup Language (XML) which we’ll look at in the final section of this chapter. JSON is considered to be a more human-readable way of transporting structured data. You can learn more about JSON at http://json.org.
Support for JSON was officially added to the standard library in Python 2.6 via the json module. It is basically the now-integrated version of the external simplejson library, whose developers have maintained backward compatibility to 2.5. For more information, go to http://github.com/simplejson/simplejson.
Furthermore, json (thus also simplejson) provides an interface similar to those found in pickle and marshal, that is, dump()/load() and dumps()/loads(). In addition to the basic parameters, those functions also include various JSON-only options. The module also includes encoder and decoder classes, from which you can derive or use directly.
A JSON object is extremely similar to a Python dictionary, as demonstrated in the following code snippets, in which we use a dict to transfer data to a JSON object and then back again:
>>> dict(zip('abcde', range(5)))
{'a': 0, 'c': 2, 'b': 1, 'e': 4, 'd': 3}
>>> json.dumps(dict(zip('abcde', range(5))))
'{"a": 0, "c": 2, "b": 1, "e": 4, "d": 3}'
>>> json.loads(json.dumps(dict(zip('abcde', range(5)))))
{u'a': 0, u'c': 2, u'b': 1, u'e': 4, u'd': 3}
Notice that JSON only understands Unicode strings, so when translating back to Python, the last of the preceding examples (all Python 2) turns the keys into Unicode strings. Running the exact same line of code in Python 3 appears more normal without the Unicode string operator (the u designator in that precedes the opening quote):
>>> json.loads(json.dumps(dict(zip('abcde', range(5)))))
{'a': 0, 'c': 2, 'b': 1, 'e': 4, 'd': 3}
Python dicts are converted to JSON objects. Similarly, Python lists or tuples are considered JSON arrays:
>>> list('abcde')
['a', 'b', 'c', 'd', 'e']
>>> json.dumps(list('abcde'))
'["a", "b", "c", "d", "e"]'
>>> json.loads(json.dumps(list('abcde')))
[u'a', u'b', u'c', u'd', u'e']
>>> # ['a', 'b', 'c', 'd', 'e'] in Python 3
>>> json.loads(json.dumps(range(5)))
[0, 1, 2, 3, 4]
What are the other differences between Python and JSON data types and values? Table 14-1 highlights some of the key differences.
Table 14-1. Differences Between JSON and Python Types

Another subtle difference not shown in Table 14-1 is that JSON does not use single quotes/apostrophes; every string is delimited by using double quotes. Also, there are no extra trailing commas that Python programmers casually place at the end of each sequence or mapping element for convenience.
To helps us further visualize some of these differences, Example 14-2 presents dict2json.py, which is a script that is compatible with Python 2 and 3 that dumps the content of a dictionary out in four different ways, twice as a Python dict and twice as a JSON object.
Example 14-2. Python dict to JSON Example (dict2json.py)
This script converts a Python dict to JSON and displays it in multiple formats.
1 #!/usr/bin/env python
2
3 from distutils.log import warn as printf
4 from json import dumps
5 from pprint import pprint
6
7 BOOKs = {
8 '0132269937': {
9 'title': 'Core Python Programming',
10 'edition': 2,
11 'year': 2007,
12 },
13 '0132356139': {
14 'title': 'Python Web Development with Django',
15 'authors': ['Jeff Forcier', 'Paul Bissex', 'Wesley Chun'],
16 'year': 2009,
17 },
18 '0137143419': {
19 'title': 'Python Fundamentals',
20 'year': 2009,
21 },
22 }
23
24 printf('*** RAW DICT ***')
25 printf(BOOKs)
26
27 printf('
*** PRETTY_PRINTED DICT ***')
28 pprint(BOOKs)
29
30 printf('
*** RAW JSON ***')
31 printf(dumps(BOOKs))
32
33 printf('
*** PRETTY_PRINTED JSON ***')
34 printf(dumps(BOOKs, indent=4))
Line-by-Line Explanation
Lines 1–5
We import three functions to use in this script: 1) distutils.log.warn() as a substitute for the print statement in Python 2 and print() function in Python 3; 2) json.dumps() to return a JSON string representation of a Python object; and 3) pprint.pprint() that does simple pretty-printing of Python objects.
Lines 7–22
The BOOKs data structure is a Python dictionary representing books identified by their International Standard Book Numbers (ISBNs). Each book can have additional information such as title, author, publication year, etc. Instead of using a more “flat” data structure such as a list, we chose a dict because it lets us build a structured hierarchy of attributes. Note all the extra commas that will be removed in its equivalent JSON representation.
Lines 24–34
The remainder of this script performs all the output. The first is just a dump of the Python dict; nothing special here. Note our extra commas are also removed here. It’s mostly for human convenience that we use them in the source code. The second example is the same Python dict but seen through the eyes of a pretty-printer.
The last two outputs are in JSON format. The first is a plain JSON dump after conversion. The second is the additional pretty-printing functionality built into json.dumps(). You only need to pass in the indentation level to turn on this feature.
Executing this script in either Python 2 or 3 results in the following output:
$ python dict2json.py
*** RAW DICT ***
{'0132269937': {'edition': 2, 'year': 2007, 'title': 'Core Python
Programming'}, '0137143419': {'year': 2009, 'title': 'Python
Fundamentals'}, '0132356139': {'authors': ['Jeff Forcier',
'Paul Bissex', 'Wesley Chun'], 'year': 2009, 'title': 'Python
Web Development with Django'}}
*** PRETTY_PRINTED DICT ***
{'0132269937': {'edition': 2,
'title': 'Core Python Programming',
'year': 2007},
'0132356139': {'authors': ['Jeff Forcier', 'Paul Bissex', 'Wesley
Chun'],
'title': 'Python Web Development with Django',
'year': 2009},
'0137143419': {'title': 'Python Fundamentals', 'year': 2009}}
*** RAW JSON ***
{"0132269937": {"edition": 2, "year": 2007, "title": "Core Python
Programming"}, "0137143419": {"year": 2009, "title": "Python
Fundamentals"}, "0132356139": {"authors": ["Jeff Forcier",
"Paul Bissex", "Wesley Chun"], "year": 2009, "title": "Python
Web Development with Django"}}
*** PRETTY_PRINTED JSON ***
{
"0132269937": {
"edition": 2,
"year": 2007,
"title": "Core Python Programming"
},
"0137143419": {
"year": 2009,
"title": "Python Fundamentals"
},
"0132356139": {
"authors": [
"Jeff Forcier",
"Paul Bissex",
"Wesley Chun"
],
"year": 2009,
"title": "Python Web Development with Django"
}
}
This example demonstrates moving from dicts to JSON. You can also move data between lists or tuples and JSON arrays. The json module also provides classes for encoding and decoding of other Python data types to and from JSON. While we don’t cover all of these here, you can see that there is plenty to explore with JSON, other than the light introduction provided here.
Now let’s take a look at the 800-pound text formatting gorilla in the room, XML.
14.3. Extensible Markup Language
The third topic in data processing that we’re covering in this chapter is Extensible Markup Language (XML). Similar to our earlier exploration of CSV, we’ll have a brief introduction followed by a tutorial of how to process XML data by using Python. After a short code sample, we’ll parse some real data coming from the Google News service.
14.3.1. Introduction to XML
In the final section of this chapter, we’ll take a look at XML, an older structured data format which also claims to be a “plain text” format used to represent structured data. Although XML data is plain text, many argue that XML is not human-readable—and for good reason. It can be near illegible without the assistance of a parser. However, XML has been around longer and is still more widespread than JSON. There are XML parsers in nearly every programming language today.
XML is a restricted form of Standard Generalized Markup Language (SGML), itself an ISO standard (ISO 8879). XML traces its origins back to 1996, when the World Wide Web Consortium (W3C) formed a working group to design it. The first XML specification was published in 1998; the most recent update was released in 2008. You can think of XML as a subset of SGML. You can also consider HTML as an even smaller subset of SGML.
14.3.2. Python and XML
Python’s original support for XML occurred with the release of version 1.5 and the xmllib module. Since then, it has evolved into the xml package, which provides a variety of ways to both parse as well as construct XML documents.
Python supports both document object model (DOM) tree-structured as well as event-based Simple API for XML (SAX) processing of XML documents. The current version of the SAX specification is 2.0.1, so Python’s support generally refers to this as SAX2. The DOM standard is older and has been around for almost as long as XML itself. Both SAX and DOM support was added to Python in the 2.0 release.
SAX is a streaming interface, meaning that the documents are parsed and processed one line at a time via a continuous bytestream. This means that you can neither backtrack nor perform random access within an XML document. You can guess the tradeoff is event-based processors that are faster and more memory efficient, whereas tree-based parsers give you full access to the entire document in memory at any time.
We note for you here that the xml package depends on the availability of at least one SAX-compliant XML parser. At that time, this meant that users needed to find and download third-party modules or packages to help them meet this requirement. Fortunately starting in version 2.3, the Expat streaming parser became bundled in the standard library under the xml.parsers.expat name.
Expat came before SAX and is SAX-incompliant. However, you can use Expat to create SAX or DOM parsers. Also note that Expat exists for speed. It is quick because it is non-validating, meaning that it does not check for fully-compliant markup. As you can imagine, validating parsers are slower because of the required additional processing.
Python support for XML matured further in version 2.5 with the addition of ElementTree—a highly-popular, quick, and Pythonic XML document parser and generator—added to the standard library as xml.etree. ElementTree. We’ll be using ElementTree for all of our raw XML examples (with a bit of help from xml.dom.minidom) then show you some examples of writing client/server applications using Python’s XML-RPC support.
In Example 14-3 (dict2xml.py), we take structured data in a Python dictionary, use ElementTree to build up a valid XML document representing that data structure, use xml.dom.minidom to pretty-print it, and then finally, utilize various ElementTree iterators to parse and display relevant content from it.
Example 14-3. Converting a Python dict to XML (dict2xml.py)
This Python 2 script converts a dict to XML and displays it in multiple formats.
1 #!/usr/bin/env python
2
3 from xml.etree.ElementTree import Element, SubElement, tostring
4 from xml.dom.minidom import parseString
5
6 BOOKs = {
7 '0132269937': {
8 'title': 'Core Python Programming',
9 'edition': 2,
10 'year': 2006,
11 },
12 '0132356139': {
13 'title': 'Python Web Development with Django',
14 'authors': 'Jeff Forcier:Paul Bissex:Wesley Chun',
15 'year': 2009,
16 },
17 '0137143419': {
18 'title': 'Python Fundamentals',
19 'year': 2009,
20 },
21 }
22
23 books = Element('books')
24 for isbn, info in BOOKs.iteritems():
25 book = SubElement(books, 'book')
26 info.setdefault('authors', 'Wesley Chun')
27 info.setdefault('edition', 1)
28 for key, val in info.iteritems():
29 SubElement(book, key).text = ', '.join(str(val) .split(':'))
30
31 xml = tostring(books)
32 print '*** RAW XML ***'
33 print xml
34
35 print '
*** PRETTY-PRINTED XML ***'
36 dom = parseString(xml)
37 print dom.toprettyxml(' ')
38
39 print '*** FLAT STRUCTURE ***'
40 for elmt in books.getiterator():
41 print elmt.tag, '-', elmt.text
42
43 print '
*** TITLES ONLY ***'
44 for book in books.findall('.//title'):
45 print book.text
Running this script, which is easily portable to Python 3, results in the following output:
$ dict2xml.py
*** RAW XML ***
<books><book><edition>2</edition><authors>Wesley Chun</
authors><year>2006</year><title>Core Python Programming</title></
book><book><edition>1</edition><authors>Wesley Chun</
authors><year>2009</year><title>Python Fundamentals</title></
book><book><edition>1</edition><authors>Jeff Forcier, Paul Bissex,
Wesley Chun</authors><year>2009</year><title>Python Web Development
with Django</title></book></books>
*** PRETTY-PRINTED XML ***
<?xml version="1.0" ?>
<books>
<book>
<edition>
2
</edition>
<authors>
Wesley Chun
</authors>
<year>
2006
</year>
<title>
Core Python Programming
</title>
</book>
<book>
<edition>
1
</edition>
<authors>
Wesley Chun
</authors>
<year>
2009
</year>
<title>
Python Fundamentals
</title>
</book>
<book>
<edition>
1
</edition>
<authors>
Jeff Forcier, Paul Bissex, Wesley Chun
</authors>
<year>
2009
</year>
<title>
Python Web Development with Django
</title>
</book>
</books>
*** FLAT STRUCTURE ***
books - None
book - None
edition - 2
authors - Wesley Chun
year - 2006
title - Core Python Programming
book - None
edition - 1
authors - Wesley Chun
year - 2009
title - Python Fundamentals
book - None
edition - 1
authors - Jeff Forcier, Paul Bissex, Wesley Chun
year - 2009
title - Python Web Development with Django
*** TITLES ONLY ***
Core Python Programming
Python Fundamentals
Python Web Development with Django
Line-by-Line Explanation
Lines 1–21
The first half of this script is quite similar to that of dict2json.py that we presented in the previous section. Obvious changes include the imports of ElementTree and minidom. We are aware that you know what you need to do to make your code work for both Python 2 and 3, so we’ll leave out all the complexity and focus solely on a Python 2 solution.
Finally, the most subtle difference is that rather than being a list as it was in dict2json.py, the 'authors' field is a single colon-delimited string. This change is optional, however, and it can remain a list if desired.
The reason for changing it is to help simplify the data processing. One of the key places this is evident is in line 29. Another difference is that in the JSON example, we did not set a default author value if one was not provided and here we do. It’s easier to check for a colon (:) and not have to do an additional check if our data value is a string or a list.
Lines 23–29
The real work of this script happens here. We create a top-level object, books, and then attach everything else under that node. For each book, a book subnode is added, taking default values of authors and edition if not provided for in the original dictionary definition above. That’s followed by iterating over all key-value pairs and adding them as further subnodes of each book.
Lines 31–45
The final block of code dumps out the data in a variety of formats: raw XML, pretty-printed XML (with the help of the MiniDOM), iterating over all nodes as one large flat structure, and finally, demonstrating a simple search over an XML document.
14.3.3. XML In Practice
While the previous example shows the various things you can do to create and parse XML documents, it’s without a doubt that most applications are trying to do the latter rather than the former, so let’s look at another short application that parses data to produce useful information.
In Example 14-4, goognewsrss.py grabs the “Top Stories” feed from the Google News service and extracts the titles of the top five (by default) news stories as well as referral links to the actual stories themselves. The solution, goognewsrss.topnews() is a generator, easily identified by a yield expression. This means that individual pairs of (title, link) are emitted by the generator in an iterative fashion. Take a look at the code and see if you can figure out what is going on and guess the output (because as we won’t show any here). Why? That’s coming up next after the source.
Example 14-4. Parsing an Actual XML Stream (goognewsrss.py)
This script, which is compatible with Python 2 and 3, displays the top news stories (default is five) and their corresponding links from the Google News service.
1 #!/usr/bin/env python
2
3 try:
4 from io import BytesIO as StringIO
5 except ImportError:
6 try:
7 from cStringIO import StringIO
8 except ImportError:
9 from StringIO import StringIO
10
11 try:
12 from itertools import izip as zip
13 except ImportError:
14 pass
15
16 try:
17 from urllib2 import urlopen
18 except ImportError:
19 from urllib.request import urlopen
20
21 from pprint import pprint
22 from xml.etree import ElementTree
23
24 g = urlopen('http://news.google.com/news?topic=h&output=rss')
25 f = StringIO(g.read())
26 g.close()
27 tree = ElementTree.parse(f)
28 f.close()
29
30 def topnews(count=5):
31 pair = [None, None]
32 for elmt in tree.getiterator():
33 if elmt.tag == 'title':
34 skip = elmt.text.startswith('Top Stories')
35 if skip:
36 continue
37 pair[0] = elmt.text
38 if elmt.tag == 'link':
39 if skip:
40 continue
41 pair[1] = elmt.text
42 if pair[0] and pair[1]:
43 count -= 1
44 yield(tuple(pair))
45 if not count:
46 return
47 pair = [None, None]
48
49 for news in topnews():
50 pprint(news)
Before you execute the code, be sure to review the Terms of Service (ToS) found at the following page: http://news.google.com/intl/en_us/terms_google_news.html. It outlines the conditions under which you can use this Google service. The key is this phrase, “You may only display the content of the Service for your own personal use (i.e., non-commercial use) and may not otherwise copy, reproduce, alter, modify, create derivative works, or publicly display any content.”
What this means, of course, is that because this book is available to the public, I can’t actually paste a sample execution here, nor can I try to mask actual output as this would be modifying the contents, but you can do it privately on your own.
You will see a set of the top five news story titles and their links as 2-tuples. Note that because this is a live service with ever-changing content, running the script again at another time will most likely yield different results.
Line-by-Line Explanation
Lines 1–22
Yes, we’re aware that purists will note this is some ugly chunk of code due to the imports that make the code difficult to read, and I’d agree they have a point. However, in practice, when you have multiple versions of a language around executing production code, especially with Python 3 getting into the picture, there are going to be those “ifdef”-type of statements, and this is no exception. Let’s take them apart so that you can at least see what’s going on.
We are going to need a large string buffer with the interface of a file. In other words, this is one large string in-memory that supports the file interface; that is, it has file methods like write(). This would be the StringIO class. Data that comes off the network is usually in ASCII or pure bytes, not Unicode. So if we’re running Python 3, we need to use the io.BytesIO class as StringIO.
If we are using Python 2, Unicode isn’t part of the picture, so we would want to try to use the faster C-compiled cStringIO.StringIO class, if available. If not, our fallback is the original StringIO.StringIO class.
Next, we want this to be good for memory; thus, we would prefer the iterator version of the built-in zip() function, itertools.izip(). If izip() is available in the itertools module, we know we’re in Python 2; therefore, import it as zip(). Otherwise, we know we’re in Python 3 because izip() replaces and is renamed to zip(), meaning that we should just ignore the ImportError if not found. Note this code doesn’t use either zip() or izip(); for more information on this, see the Hacker’s Corner sidebar that’s coming up in just a bit.
The final special case is for the Python 2 urllib2 module, which has merged with a few others into Python 3’s urllib.request submodule. Whichever one comes back donates its urlopen() function for us to use.
Lastly, we’ll be using ElementTree as well as the pretty-printing pprint.pprint() function. The output generally wraps in this example, so we prefer this as an alternative to disutils.log.warn() for our output.
Lines 24–28
The data gathering in this application happens here. We start by opening up a connection to the Google News server and requesting the RSS output, which is in XML format. We read the entire feed and write that directly to our in-memory StringIO-equivalent file.
The topic requested is the headlining top stories, which is specified via the topic=h key-value pair. Other options include: ir for spotlight stories, w for world stories, n for USA stories, b for business, tc for technology, e for entertainment, s for sports, snc for science, and m for health.
The file to the Web connection is closed, and we pass the file-like object to the ElementTree.parse() function, which parses the XML document and returns an instance of the ElementTree class. Note that you can instantiate it yourself, because calling ElementTree.parse(f) is equivalent to ElementTree.ElementTree(file=f) in this example. Finally, we close the in-memory file.
Lines 30–50
The topnews() function does all the work in collating the output for the caller. We only want to return properly formatted news items, so we create a 2-tuple in the form of the pair list, with the first element for the title and the second, the link. Only when we have both do we yield the data item, at which point we either quit if we’ve returned the count requested (or the default of 5 if not provided) or just reset this 2-tuple.
We need special code for the first title, which isn’t really a story title as it is the news-type title. In our case, because we requested the headlines, we get back in the “title” field something that’s not a title to a news story, but rather, a title “category” with its contents as the exact string of “Top Stories”. We ignore these.
The final pair of lines in this script output the 2-tuples emitted by topnews().
![]() Core Tip (Hacker’s Corner): Reducing
Core Tip (Hacker’s Corner): Reducing topnews() down to one (long) line of Python
It is possible to reduce topnews() to just a nasty-looking one-liner:
topnews = lambda count=5: [(x.text, y.text) for x, y in zip
(tree.getiterator('title'), tree.getiterator('link')) if not
x.text.startswith('Top Stories')][:count]
Hope that doesn’t hurt your eyes too much. The secret sauce to making this possible is the ElementTree.getiterator() function and the assumption that all story data is formatted properly. Neither zip() nor itertools.izip() are used at all in the standard version of topnews(), but it is used here to pair up the titles and their corresponding links.
Text processing isn’t the only thing that XML can do. While the next section is clearly XML-related, you’ll find little or no XML at all. XML is a building block with which developers who provide online services can code at a higher-level of client/server computing. To put it simply, you’re not creating a service as much as you’re giving clients the ability to call functions, or more specifically, remote procedure calls (RPCs).
14.3.4. *Client-Server Services Using XML-RPC
XML-RPC was created in the late 1990s as a way to give developers a means to create a remote procedure call (RPC) service by using the HyperText Transfer Protocol (HTTP) as the transport mechanism, with the payload being an XML document.
This document contains both the name of the RPC as well as any parameters being sent to it for execution. XML-RPC then led to the creation of SOAP but is certainly not as complex as SOAP is. Since JSON is more human-readable than XML, it’s no surprise that there is a JSON-RPC as well, including a SOAP version named SOAPjr.
Python’s XML-RPC support comes in three packages: xmlrpclib on the client side, plus SimpleXMLRPCServer and DocXMLRPCServer on the server side. Logically, these three are reorganized into xmlrpc.client and xmlrpc.server in Python 3.x.
Example 14-5 presents is xmlrpcsrvr.py, which is a Python 2 script containing a single XML-RPC service with a wide variety of RPC calls. We’ll first show you the code then describe each of the services provided by the RPCs.
Example 14-5. XML-RPC Server Code (xmlrpcsrvr.py)
This is an example XML-RPC server that contains a variety of RPC functions.
1 #!/usr/bin/env python
2
3 import SimpleXMLRPCServer
4 import csv
5 import operator
6 import time
7 import urllib2
8 import twapi # twapi.py from the "Web Services" chapter
9
10 server = SimpleXMLRPCServer.SimpleXMLRPCServer(("localhost", 8888))
11 server.register_introspection_functions()
12
13 FUNCs = ('add', 'sub', 'mul', 'div', 'mod')
14 for f in FUNCs:
15 server.register_function(getattr(operator, f))
16 server.register_function(pow)
17
18 class SpecialServices(object):
19 def now_int(self):
20 return time.time()
21
22 def now_str(self):
23 return time.ctime()
24
25 def timestamp(self, s):
26 return '[%s] %s' % (time.ctime(), s)
27
28 def stock(self, s):
29 url = 'http://quote.yahoo.com/d/quotes.csv?s=%s&f=l1c1p2d1t1'
30 u = urllib2.urlopen(url % s)
31 res = csv.reader(u).next()
32 u.close()
33 return res
34
35 def forex(self, s='usd', t='eur'):
36 url = 'http://quote.yahoo.com/d/quotes.csv?s=%s%s=X&f=nl1d1t1'
37 u = urllib2.urlopen(url % (s, t))
38 res = csv.reader(u).next()
39 u.close()
40 return res
41
42 def status(self):
43 t = twapi.Twitter('twython')
44 res = t.verify_credentials()
45 status = twapi.ResultsWrapper(res.status)
46 return status.text
47
48 def tweet(self, s):
49 t = twapi.Twitter('twython')
50 res = t.update_status(s)
51 return res.created_at
52
53 server.register_instance(SpecialServices())
54
55 try:
56 print 'Welcome to PotpourriServ v0.1
(Use ^C to exit)'
57 server.serve_forever()
58 except KeyboardInterrupt:
59 print 'Exiting'
Line-by-Line Explanation
Lines 1–8
The various import statements include the most important one first, SimpleXMLRPCServer, as well as auxiliary statements that are used for the services provided. The services even include use of the Yahoo! stock quote server and Twitter code that is covered in Chapter 13.
We import all the standard library modules/packages first, followed by a user-level module, twapi, which we wrote to talk to the Twitter service. The order of the import statements follows the best practice guidelines: standard library, third-party, and then user-defined.
Lines 10–11
Once all the imports are out of the way, SimpleXMLRPCServer, establishes our service with the given hostname or IP address and port number. In this case, we just use localhost or 127.0.0.1. That is followed by the registration of the generally accepted XML-RPC introspection functions.
These functions allow clients to query the server to determine its capabilities. They assist the client in establishing what methods the server supports, how it can call a specific RPC, and whether there is any documentation for a specific RPC. The calls which resolve those questions are named system.listMethods, system.methodSignature, and system.methodHelp.
You can find the specifications for these introspection functions at http://scripts.incutio.com/xmlrpc/introspection.html. For an example of how to implement these explicitly, go to http://www.doughellmann.com/PyMOTW/SimpleXMLRPCServer/#introspection-api.
Lines 13–16
These four lines of code represent standard arithmetic functions that we want to make available via RPC. We use the pow() built-in function (BIF) and grab the others from the operator module. The server.register_ func-tion() function just makes them available for RPC client requests.
Lines 18–26
The next set of functions we want to add to our service are time-related. They also come in the form of a SpecialServices() class that we made up. There’s no real difference having the code outside or inside of a class, and we wanted to demonstrate that with the arithmetic functions and these three: now_int(), which returns the current time in seconds after the epoch; now_str(), which returns a Unix-friendly timestamp representing the current time in the local time zone; and the timestamp() utility function, which takes a string as input and returns a timestamp prepended to it.
Lines 28–40
Here, we borrow code liberally from Chapter 13, starting with the code that interfaces with the Yahoo! quote server. The stock() function takes the ticket symbol of a company, and then fetches the latest price, last change, change percentage, and the date and time of last trade. The forex() function does something similar but for currency exchange rates.
Using the code from Chapter 13 is optional, so if you haven’t covered that material yet, you can skip implementing either of these functions, as neither are necessary for learning XML-RPC concepts.
Lines 42–53
The last RPCs we’ll register utilize the Twitter code that we developed in Chapter 13 by using the Twython library. The status() function retrieves the current status of the current user, and tweet() posts a status update on behalf of that user. In the final line of this block, we register all functions in the SpecialServices class by using the register_instance() function.
Lines 55–59
The final five lines launch the service (via its infinite loop) as well as detect when the user wants to quit (via Ctrl+C from the keyboard).
Now that we have a server, what good does it do us if there’s no client code to take advantage of this functionality? In Example 14-6, we take a look at one possible client application, xmlrpcclnt.py. Naturally, you can execute this on any computer that can reach the server with the appropriate host/port address pair.
Example 14-6. Python 2 XML-RPC Client Code (xmlrpcclnt.py)
This is one possible client that makes calls to our XML-RPC server.
1 #!/usr/bin/env python
2
3 from math import pi
4 import xmlrpclib
5
6 server = xmlrpclib.ServerProxy('http://localhost:8888')
7 print 'Current time in seconds after epoch:', server.now_int()
8 print 'Current time as a string:', server.now_str()
9 print 'Area of circle of radius 5:', server.mul(pi, server.pow(5, 2))
10 stock = server.stock('goog')
11 print 'Latest Google stock price: %s (%s / %s) as of %s at %s' %
tuple(stock)
12 forex = server.forex()
13 print 'Latest foreign exchange rate from %s: %s as of %s at %s' %
tuple(forex)
14 forex = server.forex('eur', 'usd')
15 print 'Latest foreign exchange rate from %s: %s as of %s at %s' %
tuple(forex)
16 print 'Latest Twitter status:', server.status()
There isn’t much to the client piece here, but let’s take a look anyway.
Line-by-Line Explanation
Lines 1–6
To reach an XML-RPC server, you need the xmlrpclib module in Python 2. As mentioned earlier, in Python 3 you would use xmlrpc.client, instead. We also grab the π constant from the math module. In the first line of real code, we connect to the XML-RPC server, passing in our host/port pair as a URL.
Lines 7–16
Each of the remaining lines of code make one RPC request out to the XML-RPC server which returns the desired results. The only function not tested by this client is the tweet() function, which we’ll leave as an exercise for the reader. Making this many calls to the server might seem redundant, and it is, so that’s why at the end of the chapter you’ll find an exercise to address this issue.
With the server up, we can now run the client and see some input (your output will differ):
$ python xmlrpcclnt.py
Current time in seconds after epoch: 1322167988.29
Current time as a string: Thu Nov 24 12:53:08 2011
Area of circle of radius 5: 78.5398163397
Latest Google stock price: 570.11 (-9.89 / -1.71%) as of 11/23/2011 at
4:00pm
Latest foreign exchange rate from USD to EUR: 0.7491 as of 11/24/2011
at 3:51pm
Latest foreign exchange rate from EUR to USD: 1.3349 as of 11/24/2011
at 3:51pm
Latest Twitter status: @KatEller same to you!!! :-) we need a
celebration meal... this coming monday or friday? have a great
thanksgiving!!
Although we have reached the end of this chapter, we have only just scratched the surface of XML-RPC and JSON-RPC programming. For further reading, we suggest you take a look at self-documenting XML-RPC servers via the DocXMLRPCServer class, the various types of data structures you can return from an XML-RPC server (see the xmlrpclib/xmlrpc.client documentation), etc.
14.4. References
14.4.1. Additional Resources
There are plenty of online documents pertaining to all the material covered in this chapter. The following list, although not exhaustive, provides a considerable number of resources for you to explore:
• http://docs.python.org/library/csv
• http://simplejson.readthedocs.org/en/latest/
• http://pypi.python.org/pypi/simplejson
• http://github.com/simplejson/simplejson
• http://docs.python.org/library/json
• http://en.wikipedia.org/wiki/JSON
• http://en.wikipedia.org/wiki/XML
• http://docs.python.org/library/xmlrpclib
• http://docs.python.org/library/simplexmlrpcserver
• http://docs.python.org/library/docxmlrpcserver
• http://en.wikipedia.org/wiki/Expat_(XML)
• http://en.wikipedia.org/wiki/Xml-rpc
• http://scripts.incutio.com/xmlrpc/introspection.html
• http://en.wikipedia.org/wiki/JSON-RPC
• http://www.doughellmann.com/PyMOTW/SimpleXMLRPCServer/#introspection-api
For a deeper treatment on this subject, we recommend that you take a look at Text Processing in Python (Addison-Wesley, 2003), the classic Python treatise on this topic. There is another book on text processing called Python 2.6 Text Processing (Pact, 2010). Despite the title, the information found there can be used with most current Python releases.
14.5. Related Modules
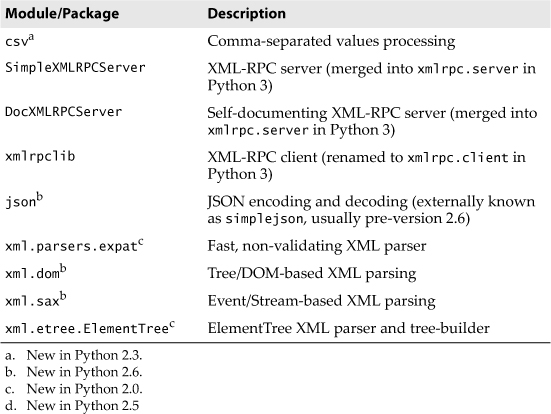
Table 14-2. Text-Processing-Related Modules
14.6. Exercises
CSV
14-1. CSV. What is the CSV format, and for what types of applications is it usually suited?
14-2. CSV vs. str.split(). Come up with some examples of data for which str.split(',') does not suffice, and where use of the csv module is really the only way to go.
14-3. CSV vs. str.split(). In Exercise Chapter 13, for 13-16, you were asked to make the output of stock.py more flexible, making all columns line up as much as possible, despite the varying length of stock ticker symbols, different stock prices and change in prices. Further update that modified script by switching from using str.split(',') to csv.reader().
14-4. Alternative CSV Formats. There are alternative delimiters used besides commas. For example, POSIX-compliant password files are colon (:) delimited, whereas e-mail addresses in Outlook are semi-colon (;) delimited. Create functions that can read or write documents using these alternative delimiters.
JSON
14-5. JSON. What are the differences in syntax between JSON format and Python dictionaries and lists?
14-6. JSON Arrays. The dict2json.py example only demonstrates converting from Python dicts to JSON objects. Create a sister script named lort2json.py to show moving from lists or tuples to JSON arrays.
14-7. Backward Compatibility. Running Example 14-2, dict2json.py, using Python 2.5 and older fails:
$ python2.5 dict2json.py
Traceback (most recent call last):
File "dict2json.py", line 12, in <module>
from json import dumps
ImportError: No module named json
a. What do you need to do to get this to run in older Python releases?
b. Modify the code in dict2json.py that imports JSON functionality to work with older versions of Python (for example, versions 2.4 and 2.5) as well as version 2.6 and newer.
14-8. JSON. Add new code to your stock.py example from Chapter 13 that retrieves stock quotes from Yahoo! Finance Service so that it returns a JSON string representing all of the stock data in a hierarchical data structure format, as opposed to just dumping the results on-screen.
14-9. JSON and Types/Classes. Write some script that encodes and decodes any type of Python object, such as numbers, classes, instances, etc.
XML and XML-RPC
14-10. Web Programming. Enhance the goognewsrss.py script to output formatted HTML representing anchors/links that can be piped directly to a flat .html file for browser rendering. The links should be correct/valid and ready for users to click and launch the corresponding Web pages.
14-11. Robustness. In xmlrpcsrvr.py, add support for the >, >=, <, <=, ==, != operations as well as true and floor division.
14-12. Twitter. In xmlrpcclnt.py, we did not test the SpecialServices. tweet() method. Add this functionality to your script.
14-13. CGIXMLRPCRequestHandler. By default, SimpleXMLRPCServer uses the SimpleXMLRPCRequestHandler handler class. What’s the difference between this handler and CGIXMLRPCRequestHandler? Create a new server that uses the CGIXMLRPCRequestHandler, instead.
14-14. DocXMLRPCServer. Investigate self-documenting XML-RPC servers, and then answer the following:
a. What are the differences between the SimpleXMLRPCServer and DocXMLRPCServer objects? Beyond that, what are the lower-level differences (over the network)?
b. Convert both your standard XML-RPC client and server to be self-documenting.
c. Also convert your CGI version from the previous problem to using the DocCGIXMLRPCRequestHandler class.
14-15. XML-RPC Multicalls. In xmlrpcclnt.py, we make individual requests to the server. Clients making multiple calls to the server will experience a performance improvement by being able to make a multicall, meaning multiple RPC calls with one service request to the server. Investigate the register_ multicall_functions() function, and then add this functionality to your server. Finally, modify your client to use multicall.
14-16. XML and XML-RPC. How is any of the XML-RPC material covered in this chapter related to XML at all? The material in the last section was quite different from the rest of the chapter; how does it tie together?
14-17. JSON-RPC vs. XML-RPC. What is JSON-RPC and how does it relate to XML-RPC?
14-18. JSON-RPC. Port both your XML-RPC client and server code to their equivalent jsonrpcsrvr.py and jsonrpcclnt.py.