
Chapter 6. Database Programming
Did you really name your son Robert’); DROP TABLE Students;-- ?
—Randall Munroe, XKCD, October 2007
In this chapter...
• ORMs
In this chapter, we discuss how to communicate with databases by using Python. Files or simplistic persistent storage can meet the needs of smaller applications, but larger server or high-data-volume applications might require a full-fledged database system, instead. Thus, we cover both relational and non-relational databases as well as Object-Relational Mappers (ORMs).
6.1. Introduction
This opening section will discuss the need for databases, present the Structured Query Language (SQL), and introduce readers to Python’s database application programming interface (API).
6.1.1. Persistent Storage
In any application, there is a need for persistent storage. Generally, there are three basic storage mechanisms: files, a database system, or some sort of hybrid, such as an API that sits on top of one of those existing systems, an ORM, file manager, spreadsheet, configuration file, etc.
In the Files chapter of Core Python Language Fundamentals or Core Python Programming, we discussed persistent storage using both plain file access as well as a Python and database manager (DBM), which is an old Unix persistent storage mechanism, overlay on top of files, that is, *dbm, dbhash/bsddb files, shelve (combination of pickle and DBM), and using their dictionary-like object interface.
This chapter will focus on using databases for the times when files or creating your own data storage system does not suffice for larger projects. In such cases, you will have many decisions to make. Thus, the goal of this chapter is to introduce you to the basics and show you as many of your options as possible (and how to work with them from within Python) so that you can make the right decision. We start off with SQL and relational databases first, because they are still the prevailing form of persistent storage.
6.1.2. Basic Database Operations and SQL
Before we dig into databases and how to use them with Python, we want to present a quick introduction (or review if you have some experience) to some elementary database concepts and SQL.
Underlying Storage
Databases usually have a fundamental persistent storage that uses the file system, that is, normal operating system files, special operating system files, and even raw disk partitions.
User Interface
Most database systems provide a command-line tool with which to issue SQL commands or queries. There are also some GUI tools that use the command-line clients or the database client library, affording users a much more comfortable interface.
Databases
A relational database management system (RDBMS) can usually manage multiple databases, such as sales, marketing, customer support, etc., all on the same server (if the RDBMS is server-based; simpler systems are usually not). In the examples we will look at in this chapter, MySQL demonstrates a server-based RDBMS because there is a server process running continuously, waiting for commands; neither SQLite nor Gadfly have running servers.
Components
The table is the storage abstraction for databases. Each row of data will have fields that correspond to database columns. The set of table definitions of columns and data types per table all put together define the database schema.
Databases are created and dropped. The same is true for tables. Adding new rows to a database is called inserting; changing existing rows in a table is called updating; and removing existing rows in a table is called deleting. These actions are usually referred to as database commands or operations. Requesting rows from a database with optional criteria is called querying.
When you query a database, you can fetch all of the results (rows) at once, or just iterate slowly over each resulting row. Some databases use the concept of a cursor for issuing SQL commands, queries, and grabbing results, either all at once or one row at a time.
SQL
Database commands and queries are given to a database via SQL. Not all databases use SQL, but the majority of relational databases do. Following are some examples of SQL commands. Note that most databases are configured to be case-insensitive, especially database commands. The accepted style is to use CAPS for database keywords. Most command-line programs require a trailing semicolon (;) to terminate a SQL statement.
Creating a Database
CREATE DATABASE test;
GRANT ALL ON test.* to user(s);
The first line creates a database named “test,” and assuming that you are a database administrator, the second line can be used to grant permissions to specific users (or all of them) so that they can perform the database operations that follow.
Using a Database
USE test;
If you logged into a database system without choosing which database you want to use, this simple statement allows you to specify one with which to perform database operations.
Dropping a Database
DROP DATABASE test;
This simple statement removes all the tables and data from the database and deletes it from the system.
Creating a Table
CREATE TABLE users (login VARCHAR(8), userid INT, projid INT);
This statement creates a new table with a string column login and a pair of integer fields, userid and projid.
Dropping a Table
DROP TABLE users;
This simple statement drops a database table, along with all its data.
Inserting a Row
INSERT INTO users VALUES('leanna', 2111, 1);
You can insert a new row in a database by using the INSERT statement. You specify the table and the values that go into each field. For our example, the string 'leanna' goes into the login field, and 2111 and 1 to userid and projid, respectively.
Updating a Row
UPDATE users SET projid=4 WHERE projid=2;
UPDATE users SET projid=1 WHERE userid=311;
To change existing table rows, you use the UPDATE statement. Use SET for the columns that are changing and provide any criteria for determining which rows should change. In the first example, all users with a “project ID” (or projid) of 2 will be moved to project #4. In the second example, we take one user (with a UID of 311) and move him to project #1.
Deleting a Row
DELETE FROM users WHERE projid=%d;
DELETE FROM users;
To delete a table row, use the DELETE FROM command, specify the table from which you want to delete rows, and any optional criteria. Without it, as in the second example, all rows will be deleted.
Now that you are up to speed on basic database concepts, it should make following the rest of the chapter and its examples much easier. If you need additional help, there are plenty of database tutorial books available that can do the trick.
6.1.3. Databases and Python
We are going to cover the Python database API and look at how to access relational databases from Python—either directly through a database interface, or via an ORM—and how you can accomplish the same task but without necessarily having to give explicit commands in SQL.
Topics such as database principles, concurrency, schema, atomicity, integrity, recovery, proper complex left JOINs, triggers, query optimization, transactions, stored procedures, etc., are all beyond the scope of this text, and we will not be discussing them in this chapter other than direct use from a Python application. Rather, we will present how to store and retrieve data to and from RDBMSs while playing within a Python framework. You can then decide which is best for your current project or application and be able to study sample code that can get you started instantly. The goal is to get you on top of things as quickly as possible if you need to integrate your Python application with some sort of database system.
We are also breaking out of our mode of covering only the “batteries included” features of the Python Standard Library. While our original goal was to play only in that arena, it has become clear that being able to work with databases is really a core component of everyday application development in the Python world.
As a software engineer, you can probably only make it so far in your career without having to learn something about databases: how to use one (command-line and/or GUI interfaces), how to extract data by using the SQL, perhaps how to add or update information in a database, etc. If Python is your programming tool, then a lot of the hard work has already been done for you as you add database access to your Python universe. We first describe what the Python database API, or DB-API is, then give examples of database interfaces that conform to this standard.
We will show some examples using popular open-source RDBMSs. However, we will not include discussions of open-source versus commercial products. Adapting to those other RDBMS systems should be fairly straightforward. A special mention will be given to Aaron Watters’s Gadfly database, a simple RDBMS written completely in Python.
The way to access a database from Python is via an adapter. An adapter is a Python module with which you can interface to a relational database’s client library, usually in C. It is recommended that all Python adapters conform to the API of the Python database special interest group (DB-SIG). This is the first major topic of this chapter.
Figure 6-1 illustrates the layers involved in writing a Python database application, with and without an ORM. The figure demonstrates that the DB-API is your interface to the C libraries of the database client.

Figure 6-1. Multitiered communication between application and database. The first box is generally a C/C++ program, whereas DB-API-compliant adapters let you program applications in Python. ORMs can simplify an application by handling all of the database-specific details.
6.2. The Python DB-API
Where can one find the interfaces necessary to talk to a database? Simple. Just go to the database topics section at the main Python Web site. There you will find links to the full and current DB-API (version 2.0), existing database modules, documentation, the special interest group, etc. Since its inception, the DB-API has been moved into PEP 249. (This PEP supersedes the old DB-API 1.0 specification, which is PEP 248.) What is the DB-API?
The API is a specification that states a set of required objects and database access mechanisms to provide consistent access across the various database adapters and underlying database systems. Like most community-based efforts, the API was driven by strong need.
In the “old days,” we had a scenario of many databases and many people implementing their own database adapters. It was a wheel that was being reinvented over and over again. These databases and adapters were implemented at different times by different people without any consistency of functionality. Unfortunately, this meant that application code using such interfaces also had to be customized to which database module they chose to use, and any changes to that interface also meant updates were needed in the application code.
SIG for Python database connectivity was formed, and eventually, an API was born: the DB-API version 1.0. The API provides for a consistent interface to a variety of relational databases, and porting code between different databases is much simpler, usually only requiring tweaking several lines of code. You will see an example of this later on in this chapter.
6.2.1. Module Attributes
The DB-API specification mandates that the features and attributes listed below must be supplied. A DB-API-compliant module must define the global attributes as shown in Table 6-1.
Table 6-1. DB-API Module Attributes

Data Attributes
apilevel
This string (not float) indicates the highest version of the DB-API with which the module is compliant, for example, 1.0, 2.0, etc. If absent, 1.0 should be assumed as the default value.
threadsafety
This an integer that can take the following possible values:
• 0: Not threadsafe, so threads should not share the module at all
• 1: Minimally threadsafe: threads can share the module but not connections
• 2: Moderately threadsafe: threads can share the module and connections but not cursors
• 3: Fully threadsafe: threads can share the module, connections, and cursors
If a resource is shared, a synchronization primitive such as a spin lock or semaphore is required for atomic-locking purposes. Disk files and global variables are not reliable for this purpose and can interfere with standard mutex operation. See the threading module or go back to Chapter 4, “Multithreaded Programming,” for more information on how to use a lock.
paramstyle
The API supports a variety of ways to indicate how parameters should be integrated into an SQL statement that is eventually sent to the server for execution. This argument is just a string that specifies the form of string substitution you will use when building rows for a query or command (see Table 6-2).
Table 6-2. paramstyle Database Parameter Styles

Function Attribute(s)
connect() Function access to the database is made available through Connection objects. A compliant module must implement a connect() function, which creates and returns a Connection object. Table 6-3 shows the arguments to connect().
Table 6-3. connect() Function Attributes

You can pass in database connection information as a string with multiple parameters (DSN) or individual parameters passed as positional arguments (if you know the exact order), or more likely, keyword arguments. Here is an example of using connect() from PEP 249:
connect(dsn='myhost:MYDB',user='guido',password='234$')
The use of DSN versus individual parameters is based primarily on the system to which you are connecting. For example, if you are using an API like Open Database Connectivity (ODBC) or Java DataBase Connectivity (JDBC), you would likely be using a DSN, whereas if you are working directly with a database, then you are more likely to issue separate login parameters. Another reason for this is that most database adapters have not implemented support for DSN. The following are some examples of non-DSN connect() calls. Note that not all adapters have implemented the specification exactly, e.g., MySQLdb uses db instead of database.
• MySQLdb.connect(host='dbserv', db='inv', user='smith')
• PgSQL.connect(database='sales')
• psycopg.connect(database='template1', user='pgsql')
• gadfly.dbapi20.connect('csrDB', '/usr/local/database')
• sqlite3.connect('marketing/test')
Exceptions
Exceptions that should also be included in the compliant module as globals are shown in Table 6-4.
Table 6-4. DB-API Exception Classes

6.2.2. Connection Objects
Connections are how your application communicates with the database. They represent the fundamental mechanism by which commands are sent to the server and results returned. Once a connection has been established (or a pool of connections), you create cursors to send requests to and receive replies from the database.
Connection Object Methods
Connection objects are not required to have any data attributes but should define the methods shown in Table 6-5.
Table 6-5. Connection Object Methods

When close() is used, the same connection cannot be used again without running into an exception.
The commit() method is irrelevant if the database does not support transactions or if it has an auto-commit feature that has been enabled. You can implement separate methods to turn auto-commit off or on if you wish. Since this method is required as part of the API, databases that do not support transactions should just implement “pass” for this method.
Like commit(), rollback() only makes sense if transactions are supported in the database. After execution, rollback() should leave the database in the same state as it was when the transaction began. According to PEP 249, “Closing a connection without committing the changes first will cause an implicit rollback to be performed.”
If the RDBMS does not support cursors, cursor() should still return an object that faithfully emulates or imitates a real cursor object. These are just the minimum requirements. Each individual adapter developer can always add special attributes specifically for their interface or database.
It is also recommended but not required for adapter writers to make all database module exceptions (see earlier) available via a connection. If not, then it is assumed that Connection objects will throw the corresponding module-level exception. Once you have completed using your connection and cursors are closed, you should commit() any operations and close() your connection.
6.2.3. Cursor Objects
Once you have a connection, you can begin communicating with the database. As we mentioned earlier in the introductory section, a cursor lets a user issue database commands and retrieve rows resulting from queries. A Python DB-API cursor object functions as a cursor for you, even if cursors are not supported in the database. In this case, if you are creating a database adapter, you must implement cursor objects so that they act like cursors. This keeps your Python code consistent when you switch between database systems that support or do not support cursors.
Once you have created a cursor, you can execute a query or command (or multiple queries and commands) and retrieve one or more rows from the results set. Table 6-6 presents Cursor object data attributes and methods.
Table 6-6. Cursor Object Attributes


The most critical attributes of cursor objects are the execute*() and the fetch*() methods; all service requests to the database are performed by these. The arraysize data attribute is useful in setting a default size for fetchmany(). Of course, closing the cursor is a good thing, and if your database supports stored procedures, then you will be using callproc().
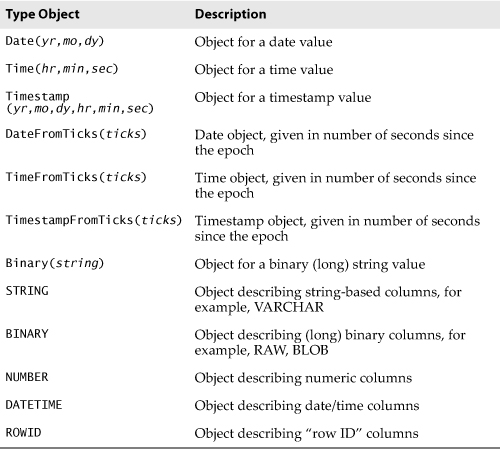
6.2.4. Type Objects and Constructors
Oftentimes, the interface between two different systems are the most fragile. This is seen when converting Python objects to C types and vice versa. Similarly, there is also a fine line between Python objects and native database objects. As a programmer writing to Python’s DB-API, the parameters you send to a database are given as strings, but the database might need to convert it to a variety of different, supported data types that are correct for any particular query.
For example, should the Python string be converted to a VARCHAR, a TEXT, a BLOB, or a raw BINARY object, or perhaps a DATE or TIME object if that is what the string is supposed to be? Care must be taken to provide database input in the expected format; therefore, another requirement of the DB-API is to create constructors that build special objects that can easily be converted to the appropriate database objects. Table 6-7 describes classes that can be used for this purpose. SQL NULL values are mapped to and from Python’s NULL object, None.
Table 6-7. Type Objects and Constructors
Changes to API Between Versions
Several important changes were made when the DB-API was revised from version 1.0 (1996) to 2.0 (1999):
• The required dbi module was removed from the API.
• Type objects were updated.
• New attributes were added to provide better database bindings.
• callproc() semantics and the return value of execute() were redefined.
• Conversion to class-based exceptions.
Since version 2.0 was published, some of the additional, optional DB-API extensions that you just read about were added in 2002. There have been no other significant changes to the API since it was published. Continuing discussions of the API occur on the DB-SIG mailing list. Among the topics brought up over the last five years include the possibilities for the next version of the DB-API, tentatively named DB-API 3.0. These include the following:
• Better return value for nextset() when there is a new result set.
• Switch from float to Decimal.
• Improved flexibility and support for parameter styles.
• Prepared statements or statement caching.
• Refine the transaction model.
• State the role of API with respect to portability.
• Add unit testing.
If you have strong feelings about the API or its future, feel free to participate and join in the discussion. Here are some references that you might find handy.
• http://python.org/topics/database
• http://linuxjournal.com/article/2605 (outdated but historical)
• http://wiki.python.org/moin/DbApi3
6.2.5. Relational Databases
So, you are now ready to go, but you probably have one burning question: “which interfaces to database systems are available to me in Python?” That inquiry is similar to, “which platforms is Python available for?” The answer is, “Pretty much all of them.” Following is a broad (but not exhaustive) list of interfaces:
Commercial RDBMSs
• IBM Informix
• Sybase
• Oracle
• Microsoft SQL Server
• IBM DB2
• SAP
• Embarcadero Interbase
• Ingres
Open-Source RDBMSs
• MySQL
• PostgreSQL
• SQLite
• Gadfly
Database APIs
• JDBC
• ODBC
Non-Relational Databases
• MongoDB
• Redis
• Cassandra
• SimpleDB
• CouchDB
• Bigtable (via Google App Engine Datastore API)
To find an updated (but not necessarily the most recent) list of what databases are supported, go to the following Web site:
http://wiki.python.org/moin/DatabaseInterfaces
6.2.6. Databases and Python: Adapters
For each of the databases supported, there exists one or more adapters that let you connect to the target database system from Python. Some databases, such as Sybase, SAP, Oracle, and SQLServer, have more than one adapter available. The best thing to do is to determine which ones best fit your needs. Your questions for each candidate might include: how good is its performance, how useful is its documentation and/or Web site, whether it has an active community or not, what is the overall quality and stability of the driver, etc. You have to keep in mind that most adapters provide just the basic necessities to get you connected to the database. It is the extras that you might be looking for. Keep in mind that you are responsible for higher-level code like threading and thread management as well as management of database connection pools, etc.
If you are squeamish and want less hands-on interaction—for example, if you prefer to do as little SQL or database administration as possible—then you might want to consider ORMs, which are covered later in this chapter.
Let’s now look at some examples of how to use an adapter module to communicate with a relational database. The real secret is in setting up the connection. Once you have this and use the DB-API objects, attributes, and object methods, your core code should be pretty much the same, regardless of which adapter and RDBMS you use.
6.2.7. Examples of Using Database Adapters
First, let’s look at a some sample code, from creating a database to creating a table and using it. We present examples that use MySQL, PostgreSQL, and SQLite.
MySQL
We will use MySQL as the example here, along with the most well-known MySQL Python adapter: MySQLdb, a.k.a. MySQL-python—we’ll discuss the other MySQL adapter, MySQL Connector/Python, when our conversation turns to Python 3. In the various bits of code that follow, we’ll also expose you (deliberately) to examples of error situations so that you have an idea of what to expect, and for which you might want to create handlers.
We first log in as an administrator to create a database and grant permissions, then log back in as a normal client, as shown here:
>>> import MySQLdb
>>> cxn = MySQLdb.connect(user='root')
>>> cxn.query('DROP DATABASE test')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
_mysql_exceptions.OperationalError: (1008, "Can't drop, database
'test'; database doesn't exist")
>>> cxn.query('CREATE DATABASE test')
>>> cxn.query("GRANT ALL ON test.* to ''@'localhost'")
>>> cxn.commit()
>>> cxn.close()
In the preceding code, we did not use a cursor. Some adapters have Connection objects, which can execute SQL queries with the query() method, but not all. We recommend you either not use it or check your adapter to ensure that it is available.
The commit() was optional for us because auto-commit is turned on by default in MySQL. We then connect back to the new database as a regular user, create a table, and then perform the usual queries and commands by using SQL to get our job done via Python. This time we use cursors and their execute() method.
The next set of interactions shows us creating a table. An attempt to create it again (without first dropping it) results in an error:
>>> cxn = MySQLdb.connect(db='test')
>>> cur = cxn.cursor()
>>> cur.execute('CREATE TABLE users(login VARCHAR(8), userid INT)')
0L
Now we will insert a few rows into the database and query them out:
>>> cur.execute("INSERT INTO users VALUES('john', 7000)")
1L
>>> cur.execute("INSERT INTO users VALUES('jane', 7001)")
1L
>>> cur.execute("INSERT INTO users VALUES('bob', 7200)")
1L
>>> cur.execute("SELECT * FROM users WHERE login LIKE 'j%'")
2L
>>> for data in cur.fetchall():
... print '%s %s' % data
...
john 7000
jane 7001
The last bit features updating the table, either by updating or deleting rows:
>>> cur.execute("UPDATE users SET userid=7100 WHERE userid=7001")
1L
>>> cur.execute("SELECT * FROM users")
3L
>>> for data in cur.fetchall():
... print '%s %s' % data
...
john 7000
jane 7100
bob 7200
>>> cur.execute('DELETE FROM users WHERE login="bob"')
1L
>>> cur.execute('DROP TABLE users')
0L
>>> cur.close()
>>> cxn.commit()
>>> cxn.close()
MySQL is one of the most popular open-source databases in the world, and it is no surprise that a Python adapter is available for it.
PostgreSQL
Another popular open-source database is PostgreSQL. Unlike MySQL, there are no less than three Python adapters available for Postgres: psycopg, PyPgSQL, and PyGreSQL. A fourth, PoPy, is now defunct, having contributed its project to combine with that of PyGreSQL in 2003. Each of the three remaining adapters has its own characteristics, strengths, and weaknesses, so it would be a good idea to practice due diligence to determine which is right for you.
Note that while we demonstrate the use of each of these, PyPgSQL has not been actively developed since 2006, whereas PyGreSQL released its most recent version (4.0) in 2009. This inactivity clearly leaves psycopg as the sole leader of the PostgreSQL adapters, and this will be the final version of this book featuring examples of those adapters. psycopg is on its second version, meaning that even though our examples use the version 1 psycopg module, when you download it today, you’ll be using psycopg2, instead.
The good news is that the interfaces are similar enough that you can create an application that, for example, measures the performance between all three (if that is a metric that is important to you). The following presents the setup code to get a Connection object for each adapter.
psycopg
>>> import psycopg
>>> cxn = psycopg.connect(user='pgsql')
PyPgSQL
>>> from pyPgSQL import PgSQL
>>> cxn = PgSQL.connect(user='pgsql')
PyGreSQL
>>> import pgdb
>>> cxn = pgdb.connect(user='pgsql')
Here is some generic code that will work for all three adapters:
>>> cur = cxn.cursor()
>>> cur.execute('SELECT * FROM pg_database')
>>> rows = cur.fetchall()
>>> for i in rows:
... print i
>>> cur.close()
>>> cxn.commit()
>>> cxn.close()
Finally, you can see how the output from each adapter is slightly different from one another.
PyPgSQL
sales
template1
template0
psycopg
('sales', 1, 0, 0, 1, 17140, '140626', '3221366099', '', None, None)
('template1', 1, 0, 1, 1, 17140, '462', '462', '', None, '{pgsql=C*T*/
pgsql}')
('template0', 1, 0, 1, 0, 17140, '462', '462', '', None, '{pgsql=C*T*/
pgsql}')
PyGreSQL
['sales', 1, 0, False, True, 17140L, '140626', '3221366099', '', None,
None]
['template1', 1, 0, True, True, 17140L, '462', '462', '', None,
'{pgsql=C*T*/pgsql}']
['template0', 1, 0, True, False, 17140L, '462', '462', '', None,
'{pgsql=C*T*/pgsql}']
SQLite
For extremely simple applications, using files for persistent storage usually suffices, but the most complex and data-driven applications demand a full relational database. SQLite targets the intermediate systems, and indeed is a hybrid of the two. It is extremely lightweight and fast, plus it is serverless and requires little or no administration.
SQLite has experienced a rapid growth in popularity, and it is available on many platforms. With the introduction of the pysqlite database adapter in Python 2.5 as the sqlite3 module, this marks the first time that the Python Standard Library has featured a database adapter in any release.
It was bundled with Python not because it was favored over other databases and adapters, but because it is simple, uses files (or memory) as its back-end store like the DBM modules do, does not require a server, and does not have licensing issues. It is simply an alternative to other similar persistent storage solutions included with Python but which happens to have a SQL interface.
Having a module like this in the standard library allows you to develop rapidly in Python by using SQLite, and then migrate to a more powerful RDBMS such as MySQL, PostgreSQL, Oracle, or SQL Server for production purposes, if this is your intention. If you don’t need all that horsepower, sqlite3 is a great solution.
Although the database adapter is now provided in the standard library, you still have to download the actual database software yourself. However, once you have installed it, all you need to do is start up Python (and import the adapter) to gain immediate access:
>>> import sqlite3
>>> cxn = sqlite3.connect('sqlite_test/test')
>>> cur = cxn.cursor()
>>> cur.execute('CREATE TABLE users(login VARCHAR(8),
userid INTEGER)')
>>> cur.execute('INSERT INTO users VALUES("john", 100)')
>>> cur.execute('INSERT INTO users VALUES("jane", 110)')
>>> cur.execute('SELECT * FROM users')
>>> for eachUser in cur.fetchall():
... print eachUser
...
(u'john', 100)
(u'jane', 110)
>>> cur.execute('DROP TABLE users')
<sqlite3.Cursor object at 0x3d4320>
>>> cur.close()
>>> cxn.commit()
>>> cxn.close()
Okay, enough of the small examples. Next, we look at an application similar to our earlier example with MySQL, but which does a few more things:
• Creates a database (if necessary)
• Creates a table
• Inserts rows into the table
• Updates rows in the table
• Deletes rows from the table
• Drops the table
For this example, we will use two other open-source databases. SQLite has become quite popular of late. It is very small, lightweight, and extremely fast for all of the most common database functions. Another database involved in this example is Gadfly, a mostly SQL-compliant RDBMS written entirely in Python. (Some of the key data structures have a C module available, but Gadfly can run without it [slower, of course].)
Some notes before we get to the code. Both SQLite and Gadfly require that you specify the location to store database files (MySQL has a default area and does not require this information). The most current incarnation of Gadfly is not yet fully DB-API 2.0 compliant, and as a result, it is missing some functionality, most notably the cursor attribute, rowcount, in our example.
6.2.8. A Database Adapter Example Application
In the example that follows, we demonstrate how to use Python to access a database. For the sake of variety and exposing you to as much code as possible, we added support for three different database systems: Gadfly, SQLite, and MySQL. To mix things up even further, we’re first going to dump out the entire Python 2.x source, without a line-by-line explanation.
The application works in exactly the same ways as described via the bullet points in the previous subsection. You should be able to understand its functionality without a full explanation—just start with the main() function at the bottom. (To keep things simple, for a full system such as MySQL that has a server, we will just login as the root user, although it’s discouraged to do this for a production application.) Here’s the source code for this application, which is called ushuffle_db.py:
#!/usr/bin/env python
import os
from random import randrange as rand
COLSIZ = 10
FIELDS = ('login', 'userid', 'projid')
RDBMSs = {'s': 'sqlite', 'm': 'mysql', 'g': 'gadfly'}
DBNAME = 'test'
DBUSER = 'root'
DB_EXC = None
NAMELEN = 16
tformat = lambda s: str(s).title().ljust(COLSIZ)
cformat = lambda s: s.upper().ljust(COLSIZ)
def setup():
return RDBMSs[raw_input('''
Choose a database system:
(M)ySQL
(G)adfly
(S)QLite
Enter choice: ''').strip().lower()[0]]
def connect(db):
global DB_EXC
dbDir = '%s_%s' % (db, DBNAME)
if db == 'sqlite':
try:
import sqlite3
except ImportError:
try:
from pysqlite2 import dbapi2 as sqlite3
except ImportError:
return None
DB_EXC = sqlite3
if not os.path.isdir(dbDir):
os.mkdir(dbDir)
cxn = sqlite3.connect(os.path.join(dbDir, DBNAME))
elif db == 'mysql':
try:
import MySQLdb
import _mysql_exceptions as DB_EXC
except ImportError:
return None
try:
cxn = MySQLdb.connect(db=DBNAME)
except DB_EXC.OperationalError:
try:
cxn = MySQLdb.connect(user=DBUSER)
cxn.query('CREATE DATABASE %s' % DBNAME)
cxn.commit()
cxn.close()
cxn = MySQLdb.connect(db=DBNAME)
except DB_EXC.OperationalError:
return None
elif db == 'gadfly':
try:
from gadfly import gadfly
DB_EXC = gadfly
except ImportError:
return None
try:
cxn = gadfly(DBNAME, dbDir)
except IOError:
cxn = gadfly()
if not os.path.isdir(dbDir):
os.mkdir(dbDir)
cxn.startup(DBNAME, dbDir)
else:
return None
return cxn
def create(cur):
try:
cur.execute('''
CREATE TABLE users (
login VARCHAR(%d),
userid INTEGER,
projid INTEGER)
''' % NAMELEN)
except DB_EXC.OperationalError:
drop(cur)
create(cur)
drop = lambda cur: cur.execute('DROP TABLE users')
NAMES = (
('aaron', 8312), ('angela', 7603), ('dave', 7306),
('davina',7902), ('elliot', 7911), ('ernie', 7410),
('jess', 7912), ('jim', 7512), ('larry', 7311),
('leslie', 7808), ('melissa', 8602), ('pat', 7711),
('serena', 7003), ('stan', 7607), ('faye', 6812),
('amy', 7209), ('mona', 7404), ('jennifer', 7608),
)
def randName():
pick = set(NAMES)
while pick:
yield pick.pop()
def insert(cur, db):
if db == 'sqlite':
cur.executemany("INSERT INTO users VALUES(?, ?, ?)",
[(who, uid, rand(1,5)) for who, uid in randName()])
elif db == 'gadfly':
for who, uid in randName():
cur.execute("INSERT INTO users VALUES(?, ?, ?)",
(who, uid, rand(1,5)))
elif db == 'mysql':
cur.executemany("INSERT INTO users VALUES(%s, %s, %s)",
[(who, uid, rand(1,5)) for who, uid in randName()])
getRC = lambda cur: cur.rowcount if hasattr(cur, 'rowcount') else -1
def update(cur):
fr = rand(1,5)
to = rand(1,5)
cur.execute(
"UPDATE users SET projid=%d WHERE projid=%d" % (to, fr))
return fr, to, getRC(cur)
def delete(cur):
rm = rand(1,5)
cur.execute('DELETE FROM users WHERE projid=%d' % rm)
return rm, getRC(cur)
def dbDump(cur):
cur.execute('SELECT * FROM users')
print '
%s' % ''.join(map(cformat, FIELDS))
for data in cur.fetchall():
print ''.join(map(tformat, data))
def main():
db = setup()
print '*** Connect to %r database' % db
cxn = connect(db)
if not cxn:
print 'ERROR: %r not supported or unreachable, exiting' % db
return
cur = cxn.cursor()
print '
*** Create users table (drop old one if appl.)'
create(cur)
print '
*** Insert names into table'
insert(cur, db)
dbDump(cur)
print '
*** Move users to a random group'
fr, to, num = update(cur)
print ' (%d users moved) from (%d) to (%d)' % (num, fr, to)
dbDump(cur)
print '
*** Randomly delete group'
rm, num = delete(cur)
print ' (group #%d; %d users removed)' % (rm, num)
dbDump(cur)
print '
*** Drop users table'
drop(cur)
print '
*** Close cxns'
cur.close()
cxn.commit()
cxn.close()
if __name__ == '__main__':
main()
Trust me, this application runs. It’s available for download from this book’s Web site if you really want to try it out. However, before we execute it here in the book, there’s one more matter to take care of. No, we’re not going to give you the line-by-line explanation yet.
Don’t worry, the line-by-line is coming up, but we wanted to use this example for another purpose: to demonstrate another example of porting to Python 3 and how it’s possible to build scripts that will run under both Python 2 and 3 with a single source .py file and without the need for conversion using tools like 2to3 or 3to2. After the port, we’ll officially make it Example 6-1. Furthermore, we’ll use and reuse the attributes from this example in the examples for the remainder of the chapter, porting it to use ORMs as well as non-relational databases.
Porting to Python 3
A handful of porting recommendations are provided in the best practices chapter of Core Python Language Fundamentals, but we wanted to share some specific tips here and implement them by using ushuffle_db.py.
One of the big porting differences between Python 2 and 3 is print, which is a statement in Python 2 but a built-in function (BIF) in Python 3. Instead of using either, you can proxy for both by using the distutils.log.warn() function—at least you could at the time of this writing. It’s identical in Python 2 and 3; thus, it doesn’t require any changes. To keep the code from getting confusing, we rename this function to printf() in our application, in homage to the print/print()-equivalent in C/C++. Also see the related exercise at the end of this chapter.
The second tip is for the Python 2 BIF raw_input(). It changes its name to input() in Python 3. This is further complicated by the fact that there is also an input() function in Python 2 that is a security hazard and removed from the language. In other words, raw_input() replaces and is renamed to input() in Python 3. To continue honoring C/C++, we call this function scanf() in our application.
The next tip is to remind you of the changes in the syntax for handling exceptions. This subject is covered in detail in the Errors and Exceptions chapter of Core Python Language Fundamentals and Core Python Programming. You can read more about the update there, but for now, the fundamental change that you need to know about is this:
Old: except Exception, instance
New: except Exception as instance
However, this only matters if you save the instance because you’re interested in the cause of the exception. If it doesn’t matter or you’re not intending to use it, just leave it out. There’s nothing wrong with just: except Exception.
That syntax does not change between Python 2 and 3. In earlier editions of this book, we used except Exception, e. For this edition, we’ve removed the “, e” altogether rather than changing it to “as e” to make porting easier.
Finally, the last change we’re going to do is tied specifically to our example, whereas those other changes are general porting suggestions. At the time of this writing, the main C-based MySQL-Python adapter, better known by its package name, MySQLdb, has not yet been ported to Python 3. However, there is another MySQL adapter, and it’s called MySQL Connector/Python and has a package name of mysql.connector.
MySQL Connector/Python implements the MySQL client protocol in pure Python, so neither MySQL libraries nor compilation are necessary, and best of all, there is a port to Python 3. Why is this a big deal? It gives Python 3 users access to MySQL databases, that’s all!
Making all of these changes and additions to ushuffle_db.py, we arrive at what I’d like to refer to as the “universal” version of the application, ushuffle_dbU.py, which you can see in Example 6-1.
Example 6-1. Database Adapter Example (ushuffle_dbU.py)
This script performs some basic operations by using a variety of databases (MySQL, SQLite, Gadfly). It runs under Python 2 and 3 without any code changes, and components will be (re)used in future sections of this chapter.
1 #!/usr/bin/env python
2
3 from distutils.log import warn as printf
4 import os
5 from random import randrange as rand
6
7 if isinstance(__builtins__, dict) and 'raw_input' in __builtins__:
8 scanf = raw_input
9 elif hasattr(__builtins__, 'raw_input'):
10 scanf = raw_input
11 else:
12 scanf = input
13
14 COLSIZ = 10
15 FIELDS = ('login', 'userid', 'projid')
16 RDBMSs = {'s': 'sqlite', 'm': 'mysql', 'g': 'gadfly'}
17 DBNAME = 'test'
18 DBUSER = 'root'
19 DB_EXC = None
20 NAMELEN = 16
21
22 tformat = lambda s: str(s).title().ljust(COLSIZ)
23 cformat = lambda s: s.upper().ljust(COLSIZ)
24
25 def setup():
26 return RDBMSs[raw_input('''
27 Choose a database system:
28
29 (M)ySQL
30 (G)adfly
31 (S)QLite
32
33 Enter choice: ''').strip().lower()[0]]
34
35 def connect(db, DBNAME):
36 global DB_EXC
37 dbDir = '%s_%s' % (db, DBNAME)
38
39 if db == 'sqlite':
40 try:
41 import sqlite3
42 except ImportError:
43 try:
44 from pysqlite2 import dbapi2 as sqlite3
45 except ImportError:
46 return None
47
48 DB_EXC = sqlite3
49 if not os.path.isdir(dbDir):
50 os.mkdir(dbDir)
51 cxn = sqlite.connect(os.path.join(dbDir, DBNAME))
52
53 elif db == 'mysql':
54 try:
55 import MySQLdb
56 import _mysql_exceptions as DB_EXC
57
58 try:
59 cxn = MySQLdb.connect(db=DBNAME)
60 except DB_EXC.OperationalError:
61 try:
62 cxn = MySQLdb.connect(user=DBUSER)
63 cxn.query('CREATE DATABASE %s' % DBNAME)
64 cxn.commit()
65 cxn.close()
66 cxn = MySQLdb.connect(db=DBNAME)
67 except DB_EXC.OperationalError:
68 return None
69 except ImportError:
70 try:
71 import mysql.connector
72 import mysql.connector.errors as DB_EXC
73 try:
74 cxn = mysql.connector.Connect(**{
75 'database': DBNAME,
76 'user': DBUSER,
77 })
78 except DB_EXC.InterfaceError:
79 return None
80 except ImportError:
81 return None
82
83 elif db == 'gadfly':
84 try:
85 from gadfly import gadfly
86 DB_EXC = gadfly
87 except ImportError:
88 return None
89
90 try:
91 cxn = gadfly(DBNAME, dbDir)
92 except IOError:
93 cxn = gadfly()
94 if not os.path.isdir(dbDir):
95 os.mkdir(dbDir)
96 cxn.startup(DBNAME, dbDir)
97 else:
98 return None
99 return cxn
100
101 def create(cur):
102 try:
103 cur.execute('''
104 CREATE TABLE users (
105 login VARCHAR(%d),
106 userid INTEGER,
107 projid INTEGER)
108 ''' % NAMELEN)
109 except DB_EXC.OperationalError, e:
110 drop(cur)
111 create(cur)
112
113 drop = lambda cur: cur.execute('DROP TABLE users')
114
115 NAMES = (
116 ('aaron', 8312), ('angela', 7603), ('dave', 7306),
117 ('davina',7902), ('elliot', 7911), ('ernie', 7410),
118 ('jess', 7912), ('jim', 7512), ('larry', 7311),
119 ('leslie', 7808), ('melissa', 8602), ('pat', 7711),
120 ('serena', 7003), ('stan', 7607), ('faye', 6812),
121 ('amy', 7209), ('mona', 7404), ('jennifer', 7608),
122 )
123
124 def randName():
125 pick = set(NAMES)
126 while pick:
127 yield pick.pop()
128
129 def insert(cur, db):
130 if db == 'sqlite':
131 cur.executemany("INSERT INTO users VALUES(?, ?, ?)",
132 [(who, uid, rand(1,5)) for who, uid in randName()])
133 elif db == 'gadfly':
134 for who, uid in randName():
135 cur.execute("INSERT INTO users VALUES(?, ?, ?)",
136 (who, uid, rand(1,5)))
137 elif db == 'mysql':
138 cur.executemany("INSERT INTO users VALUES(%s, %s, %s)",
139 [(who, uid, rand(1,5)) for who, uid in randName()])
140
141 getRC = lambda cur: cur.rowcount if hasattr(cur,
'rowcount') else -1
142
143 def update(cur):
144 fr = rand(1,5)
145 to = rand(1,5)
146 cur.execute(
147 "UPDATE users SET projid=%d WHERE projid=%d" % (to, fr))
148 return fr, to, getRC(cur)
149
150 def delete(cur):
151 rm = rand(1,5)
152 cur.execute('DELETE FROM users WHERE projid=%d' % rm)
153 return rm, getRC(cur)
154
155 def dbDump(cur):
156 cur.execute('SELECT * FROM users')
157 printf('
%s' % ''.join(map(cformat, FIELDS)))
158 for data in cur.fetchall():
159 printf(''.join(map(tformat, data)))
160
161 def main():
162 db = setup()
163 printf('*** Connect to %r database' % db)
164 cxn = connect(db)
165 if not cxn:
166 printf('ERROR: %r not supported or unreachable, exit' % db)
167 return
168 cur = cxn.cursor()
169
170 printf('
*** Creating users table')
171 create(cur)
172
173 printf('
*** Inserting names into table')
174 insert(cur, db)
175 dbDump(cur)
176
177 printf('
*** Randomly moving folks')
178 fr, to, num = update(cur)
179 printf(' (%d users moved) from (%d) to (%d)' % (num, fr, to))
180 dbDump(cur)
181
182 printf('
*** Randomly choosing group')
183 rm, num = delete(cur)
184 printf(' (group #%d; %d users removed)' % (rm, num))
185 dbDump(cur)
186
187 printf('
*** Dropping users table')
188 drop(cur)
189 printf('
*** Close cxns')
190 cur.close()
191 cxn.commit()
192 cxn.close()
193
194 if __name__ == '__main__':
195 main()
Line-by-Line Explanation
Lines 1–32
The first part of this script imports the necessary modules, creates some global constants (the column size for display and the set of databases we are supporting), and features the tformat(), cformat(), and setup() functions.
After the import statements, you’ll find some curious code (lines 7–12) that finds the right function to which to alias from scanf(), our designated command-line user input function. The elif and else are simpler to explain: we’re checking to see if raw_input() exists as a BIF. If it does, we’re in Python (1 or) 2 and should use that. Otherwise, we’re in Python 3 and should use its new name, input().
The other bit of complexity is the if statement. __builtins__ is only a module in your application. In an imported module, __builtins__ is a dict. The conditional basically says that if we were imported, check if ‘raw_input’ is a name in this dictionary; otherwise, it’s a module, so drop down to the elif and else. Hope that makes sense!
With regard to the tformat() and cformat() functions, the former is the format string for showing the titles; for instance, “tformat” means “titlecase formatter.” It’s just a cheap way to take names from the database, which can be all lowercase (such as what we have), first letter capped correctly, all CAPS, etc., and make all the names uniform. The latter function’s name stands for “CAPS formatter.” All it does is take each column name and turn it into a header by calling the str.upper() method.
Both formatters left-justify their output and limit it to ten characters in width because it’s not expected the data will exceed that—our sample data certainly doesn’t, so if you want to use your own, change COLSIZ to whatever works for your data. It was simpler to write these as lambdas rather than traditional functions although you can certainly do that, as well.
One can argue that this is probably a lot of effort to do this when all scanf() will do is prompt the user in setup() to select the RDBMS to use for any particular execution of this script (or derivatives in the remainder of the chapter). However, the point is to show you some code that you might be able to use elsewhere. We haven’t claimed that this is a script you’d use in production have we?
We already have the user output function—as mentioned earlier, we’re using distutils.log.warn() in place of print for Python 2 and print() for Python 3. In our application, we import it (line 3) as printf().
Most of the constants are fairly self-explanatory. One exception is DB_EXC, which stands for DataBase EXCeption. This variable will eventually be assigned the database exception module for the specific database system with which users choose to use to run this application. In other words, for users who choose MySQL, DB_EXC will be _mysql_exceptions, etc. If we built this application in a more object-oriented way, we would have a class in which this would simply be an instance attribute, such as self.db_exc_module.
Lines 35–99
The guts of consistent database access happen here in the connect() function. At the beginning of each section (“section” here refers to each database’s if clause), we attempt to load the corresponding database modules. If a suitable one is not found, None is returned to indicate that the database system is not supported.
Once a connection is made, all of other code is database and adapter independent and should work across all connections. (The only exception in our script is insert().) In all three subsections of this set of code, you will notice that a valid connection should be passed back as cxn.
If SQLite is chosen, we attempt to load a database adapter. We first try to load the standard library’s sqlite3 module (Python 2.5+). If that fails, we look for the third-party pysqlite2 package. This is to support version 2.4.x and older systems with the pysqlite adapter installed. If either is found, we then check to ensure that the directory exists, because the database is file based. (You can also choose to create an in-memory database by substituting :memory: as the filename.) When the connect() call is made to SQLite, it will either use one that already exists or make a new one using that path if one does not exist.
MySQL uses a default area for its database files and does not require this to come from the user. The most popular MySQL adapter is the MySQLdb package, so we try to import this first. Like SQLite, there is a “plan B,” the mysql.connector package—a good choice because it’s compatible with both Python 2 and 3. If neither is found, MySQL isn’t supported and None is returned.
The last database supported by our application is Gadfly. (At the time of this writing, this database is mostly, but not fully, DB-API-compliant, and you will see this in this application.) It uses a startup mechanism similar to that of SQLite: it starts up with the directory where the database files should be. If it is there, fine, but if not, you have to take a roundabout way to start up a new database. (Why this is, we are not sure. We believe that the startup() functionality should be merged into that of the constructor gadfly.gadfly().)
Lines 101–113
The create() function creates a new users table in our database. If there is an error, it is almost always because the table already exists. If this is the case, drop the table and re-create it by recursively calling this function again. This code is dangerous in that if the recreation of the table still fails, you will have infinite recursion until your application runs out of memory. You will fix this problem in one of the exercises at the end of the chapter.
The table is dropped from the database with the one-liner drop(), written as a lambda.
Lines 115–127
The next blocks of code feature a constant set of NAMES and user IDs, followed by the generator randName(). NAMES is a tuple that must be converted to a set for use in randName() because we alter it in the generator, removing one name at a time until the names are exhausted. Because this is destructive behavior and is used often in the application, it’s best to set NAMES as the canonical source and just copy its contents to another data structure to be destroyed each time the generator is used.
Lines 129–139
The insert() function is the only other place where database-dependent code lives. This is because each database is slightly different in one way or another. For example, both the adapters for SQLite and MySQL are DB-API-compliant, so both of their cursor objects have an executemany() function, whereas Gadfly does not, so rows must be inserted one at a time.
Another quirk is that both SQLite and Gadfly use the qmark parameter style, whereas MySQL uses format. Because of this, the format strings are different. If you look carefully, however, you will see that the arguments themselves are created in a very similar fashion.
What the code does is this: for each name-userID pair, it assigns that individual to a project group (given by its project ID or projid). The project ID is chosen randomly out of four different groups (randrange(1,5)).
Line 141
This single line represents a conditional expression (read as: Python ternary operator) that returns the rowcount of the last operation (in terms of rows altered), or if the cursor object does not support this attribute (meaning it is not DB-API–compliant), it returns –1.
Conditional expressions were added in Python 2.5, so if you are using version 2.4.x or older, you will need to convert it back to the “old-style” way of doing it:
getRC = lambda cur: (hasattr(cur, 'rowcount')
and [cur.rowcount] or [-1])[0]
If you are confused by this line of code, don’t worry about it. Check the FAQ to see why this is, and get a taste of why conditional expressions were finally added to Python in version 2.5. If you are able to figure it out, then you have developed a solid understanding of Python objects and their Boolean values.
Lines 143–153
The update() and delete() functions randomly choose folks from one group. If the operation is update, move them from their current group to another (also randomly chosen); if it is delete, remove them altogether.
Lines 155–159
The dbDump() function pulls all rows from the database, formats them for printing, and displays them to the user. The displayed output requires the assistance of the cformat() (to display the column headers) and tformat() (to format each user row).
First, you should see that the data was extracted after the SELECT by the fetchall() method. So as we iterate each user, take the three columns (login, userid, projid) and pass them to tformat() via map() to convert them to strings (if they are not already), format them as titlecase, and then format the complete string to be COLSIZ columns, left-justified (right-hand space padding).
Lines 161–195
The director of this movie is main(). It makes individual calls to each function described above that defines how this script works (assuming that it does not exit due to either not finding a database adapter or not being able to obtain a connection [lines 164–166]). The bulk of it should be fairly self-explanatory, given the proximity of the output statements. The last bits wrap up the cursor and connection.
6.3. ORMs
As seen in the previous section, a variety of different database systems are available today, and most of them have Python interfaces with which you can harness their power. The only drawback to those systems is the need to know SQL. If you are a programmer who feels more comfortable with manipulating Python objects instead of SQL queries, yet still want to use a relational database as your data back-end, then you would probably prefer to use ORMs.
6.3.1. Think Objects, Not SQL
Creators of these systems have abstracted away much of the pure SQL layer and implemented objects in Python that you can manipulate to accomplish the same tasks without having to generate the required lines of SQL. Some systems allow for more flexibility if you do have to slip in a few lines of SQL, but for the most part, you can avoid almost all the general SQL required.
Database tables are magically converted to Python classes with columns and features as attributes, and methods responsible for database operations. Setting up your application to an ORM is somewhat similar to that of a standard database adapter. Because of the amount of work that ORMs perform on your behalf, some things are actually more complex or require more lines of code than using an adapter directly. Hopefully, the gains you achieve in productivity make up for a little bit of extra work.
6.3.2. Python and ORMs
The most well-known Python ORMs today are SQLAlchemy (http://sqlalchemy.org) and SQLObject (http://sqlobject.org). We will give you examples of both because the systems are somewhat disparate due to different philosophies, but once you figure these out, moving on to other ORMs is much simpler.
Some other Python ORMs include Storm, PyDO/PyDO2, PDO, Dejavu, PDO, Durus, QLime, and ForgetSQL. Larger Web-based systems can also have their own ORM component such as WebWare MiddleKit and Django’s Database API. Be advised that “well-known” does not mean best for your application. Although these others were not included in our discussion, that does not mean that they would not be right for your application.
Setup and Installation
Because neither SQLAlchemy nor SQLObject are in the standard library, you’ll need to download and install them on your own. (Usually this is easily taken care of with the easy_install or pip tools.)
At the time of this writing, all of the software packages described in this chapter are available in Python 2; only SQLAlchemy, SQLite, and the MySQL Connector/Python adapter are available in Python 3. The sqlite3 package is part of the standard library for Python 2.5+ and 3.x, so you don’t need to do anything unless you’re using version 2.4 and older.
If you’re starting on a computer with only Python 3 installed, you’ll need to get Distribute (which includes easy_install) first. You’ll need a Web browser (or the curl command if you have it) and to download the installation file (available at http://python-distribute.org/distribute_setup.py), and then get SQLAlchemy with easy_install. Here is what this entire process might look like on a Windows-based PC:
C:WINDOWSTemp>C:Python32python distribute_setup.py
Extracting in c:docume~1wesleylocals~1 emp mp8mcddr
Now working in c:docume~1wesleylocals~1 emp mp8mcddrdistribute-
0.6.21
Installing Distribute
warning: no files found matching 'Makefile' under directory 'docs'
warning: no files found matching 'indexsidebar.html' under directory
'docs'
creating build
creating buildsrc
:
Installing easy_install-3.2.exe script to C:python32Scripts
Installed c:python32libsite-packagesdistribute-0.6.21-py3.2.egg
Processing dependencies for distribute==0.6.21
Finished processing dependencies for distribute==0.6.21
After install bootstrap.
Creating C:python32Libsite-packagessetuptools-0.6c11-py3.2.egg-info
Creating C:python32Libsite-packagessetuptools.pth
C:WINDOWSTemp>
C:WINDOWSTemp>C:Python32Scriptseasy_install sqlalchemy
Searching for sqlalchemy
Reading http://pypi.python.org/simple/sqlalchemy/
Reading http://www.sqlalchemy.org
Best match: SQLAlchemy 0.7.2
Downloading http://pypi.python.org/packages/source/S/SQLAlchemy/
SQLAlchemy-0.7.2.tar.gz#md5=b84a26ae2e5de6f518d7069b29bf8f72
:
Adding sqlalchemy 0.7.2 to easy-install.pth file
Installed c:python32libsite-packagessqlalchemy-0.7.2-py3.2.egg
Processing dependencies for sqlalchemy
Finished processing dependencies for sqlalchemy
6.3.3. Employee Role Database Example
We will port our user shuffle application ushuffle_db.py to both SQLAlchemy and SQLObject. MySQL will be the back-end database server for both. You will note that we implement these as classes because there is more of an object feel to using ORMs, as opposed to using raw SQL in a database adapter. Both examples import the set of NAMES and the random name chooser from ushuffle_db.py. This is to avoid copying and pasting the same code everywhere as code reuse is a good thing.
6.3.4. SQLAlchemy
We start with SQLAlchemy because its interface is somewhat closer to SQL than SQLObject’s. SQLObject is simpler, more Pythonic, and faster, whereas SQLAlchemy abstracts really well to the object world and also gives you more flexibility in issuing raw SQL, if you have to.
Examples 6-2 and 6-3 illustrate that the ports of our user shuffle examples using both these ORMs are very similar in terms of setup, access, and overall number of lines of code. Both also borrow the same set of functions and constants from ushuffle_db{,U}.py.
Example 6-2. SQLAlchemy ORM Example (ushuffle_sad.py)
This user shuffle Python 2.x and 3.x-compatible application features the SQLAlchemy ORM paired up with MySQL or SQLite databases as back-ends.
1 #!/usr/bin/env python
2
3 from distutils.log import warn as printf
4 from os.path import dirname
5 from random import randrange as rand
6 from sqlalchemy import Column, Integer, String, create_engine, exc, orm
7 from sqlalchemy.ext.declarative import declarative_base
8 from ushuffle_dbU import DBNAME, NAMELEN, randName,
FIELDS, tformat, cformat, setup
9
10 DSNs = {
11 'mysql': 'mysql://root@localhost/%s' % DBNAME,
12 'sqlite': 'sqlite:///:memory:',
13 }
14
15 Base = declarative_base()
16 class Users(Base):
17 __tablename__ = 'users'
18 login = Column(String(NAMELEN))
19 userid = Column(Integer, primary_key=True)
20 projid = Column(Integer)
21 def __str__(self):
22 return ''.join(map(tformat,
23 (self.login, self.userid, self.projid)))
24
25 class SQLAlchemyTest(object):
26 def __init__(self, dsn):
27 try:
28 eng = create_engine(dsn)
29 except ImportError:
30 raise RuntimeError()
31
32 try:
33 eng.connect()
34 except exc.OperationalError:
35 eng = create_engine(dirname(dsn))
36 eng.execute('CREATE DATABASE %s' % DBNAME).close()
37 eng = create_engine(dsn)
38
39 Session = orm.sessionmaker(bind=eng)
40 self.ses = Session()
41 self.users = Users.__table__
42 self.eng = self.users.metadata.bind = eng
43
44 def insert(self):
45 self.ses.add_all(
46 Users(login=who, userid=userid, projid=rand(1,5))
47 for who, userid in randName()
48 )
49 self.ses.commit()
50
51 def update(self):
52 fr = rand(1,5)
53 to = rand(1,5)
54 i = -1
55 users = self.ses.query(
56 Users).filter_by(projid=fr).all()
57 for i, user in enumerate(users):
58 user.projid = to
59 self.ses.commit()
60 return fr, to, i+1
61
62 def delete(self):
63 rm = rand(1,5)
64 i = -1
65 users = self.ses.query(
66 Users).filter_by(projid=rm).all()
67 for i, user in enumerate(users):
68 self.ses.delete(user)
69 self.ses.commit()
70 return rm, i+1
71
72 def dbDump(self):
73 printf('
%s' % ''.join(map(cformat, FIELDS)))
74 users = self.ses.query(Users).all()
75 for user in users:
76 printf(user)
77 self.ses.commit()
78
79 def __getattr__(self, attr): # use for drop/create
80 return getattr(self.users, attr)
81
82 def finish(self):
83 self.ses.connection().close()
84
85 def main():
86 printf('*** Connect to %r database' % DBNAME)
87 db = setup()
88 if db not in DSNs:
89 printf('
ERROR: %r not supported, exit' % db)
90 return
91
92 try:
93 orm = SQLAlchemyTest(DSNs[db])
94 except RuntimeError:
95 printf('
ERROR: %r not supported, exit' % db)
96 return
97
98 printf('
*** Create users table (drop old one if appl.)')
99 orm.drop(checkfirst=True)
100 orm.create()
101
102 printf('
*** Insert names into table')
103 orm.insert()
104 orm.dbDump()
105
106 printf('
*** Move users to a random group')
107 fr, to, num = orm.update()
108 printf(' (%d users moved) from (%d) to (%d)' % (num, fr, to))
109 orm.dbDump()
110
111 printf('
*** Randomly delete group')
112 rm, num = orm.delete()
113 printf(' (group #%d; %d users removed)' % (rm, num))
114 orm.dbDump()
115
116 printf('
*** Drop users table')
117 orm.drop()
118 printf('
*** Close cxns')
119 orm.finish()
120
121 if __name__ == '__main__':
122 main()
Line-by-Line Explanation
Lines 1–13
As expected, we begin with module imports and constants. We follow the suggested style guideline of importing Python Standard Library modules first (distutils, os.path, random), followed by third-party or external modules (sqlalchemy), and finally, local modules to our application (ushuffle_dbU), which in our case is providing the majority of the constants and utility functions.
The other constant contains the Database Source Names (DSNs), which you can think of as database connection URIs. In previous editions of this book, this application only supported MySQL, so we’re happy to be able to add SQLite to the mix. In the ushuffle_dbU.py application seen earlier, we used the file system with SQLite. Here we’ll use the in-memory version (line 12).
![]() Core Note: Active Record pattern
Core Note: Active Record pattern
Active Record is a software design pattern (http://en.wikipedia.org/wiki/Active_record_pattern) that ties manipulation of objects to equivalent actions on a database. ORM objects essentially represent database rows such that when an object is created, a row representing its data is written to the database automatically. When an object is updated, so is the corresponding row. Similarly, when an object is removed, its row in the database is deleted.
In the beginning, SQLAlchemy didn’t have an Active Record flavored declarative layer to make working with the ORM less complex. Instead, it followed the “Data Mapper” pattern in which objects do not have the ability to modify the database itself; rather, they come with actions that the user can call upon to make those changes happen. Yes, an ORM can substitute for having to issue raw SQL, but developers are still responsible for explicitly making the equivalent database operations to persist additions, updates, and deletions.
A desire for an Active Record-like interface spawned the creation of projects like ActiveMapper and TurboEntity. Eventually, both were replaced by Elixir (http://elixir.ematia.de), which became the most popular declarative layer for SQLAlchemy. Some developers find it Rails-like in nature, whereas others find it overly simplistic, abstracting away too much functionality.
However, SQLAlchemy eventually came up with its own declarative layer which also adheres to the Active Record pattern. It’s fairly lightweight, simple, and gets the job done, so we’ll use it in our example because it’s is more beginner-friendly. However, if you do find it too lightweight, you can still use the __table__ object for more traditional access.
Lines 15–23
The next code block represents the use of SQLAlchemy’s declarative layer. Its use defines objects that, as manipulated, will result in the equivalent database operation. As mentioned in the preceding Core Note, it might not be as feature-rich as the third-party tools, but it suffices for our simple example here.
To use it, you must import sqlalchemy.ext.declarative_base (line 7) and use it to make a Base class (line 15) from which you derive your data subclasses (line 16).
The next part of the class definition contains the __tablename__ attribute, which is the database table name to which it is mapped. Alternatively, you can define a lower-level sqlalchemy.Table object explicitly, in which case you would alias to __table__, instead. In this application, we’re taking a hybrid approach, mostly using the objects for row access, but we’ve saved off the table (line 41) for table-level actions (create and drop).
After that are the “column” attributes; check the docs for all allowed data types. Finally, we have an __str__() method definition which returns a human-readable string representation of a row of data. Because this output is customized (with the help of the tformat() function), we don’t recommend this in practice. If you wanted to reuse this code in another application, that’s made more difficult because you might wish the output to be formatted differently. More likely, you’ll subclass this one and modify the child class __str__() method, instead. SQLAlchemy does support table inheritance.
Lines 25–42
The class initializer, like ushuffle_dbU.connect(), does everything it can to ensure that there is a database available, and then saves a connection to it. First, it attempts to use the DSN to create an engine to the database. An engine is the main database manager. For debugging purposes, you might wish to see the ORM-generated SQL. To do that, just set the echo parameter, e.g., create_engine('sqlite:///:memory:', echo=True).
Engine creation failure (lines 29–30) means that SQLAlchemy isn’t able to support the chosen database, usually an ImportError, because it cannot find an installed adapter. In this case, we fail back to the setup() function to inform the user.
Assuming that an engine was successfully created, the next step is to try a database connection. A failure usually means that the database itself (or its server) is reachable, but in this case, the database you want to use to store your data does not exist, so we attempt to create it here and retry the connection (lines 34–37). Notice that we were sneaky in using os.path. dirname() to strip off the database name and leave the rest of the DSN intact so that the connection works (line 35).
This is the only place you will see raw SQL (line 36) because this type of activity is typically an operational task, not application-oriented. All other database operations happen under the table (pun not originally intended) via object manipulation or by calling a database table method via delegation (more on this a bit later in lines 44–70).
The last section of code (lines 39–42) creates a session object to manage individual transaction-flavored objects involving one or more database operations that all must be committed for the data to be written. We then save the session object plus the user’s table and engine as instance attributes. The additional binding of the engine to the table’s metadata (line 42) means to bind all operations on this table to the given engine. (You can bind to other engines or connections.)
Lines 44–70
These next three methods represent the core database functionality of row insertion (lines 44–49), update (lines 51–60), and deletion (lines 62–70). Insertion employs a session.add_all() method, which takes an iterable and builds up a set of insert operations. At the end, you can decide whether to issue a commit as we did (line 49) or a rollback.
Both update() and delete() feature a session query and use the query.filter_by() method for lookup. Updating randomly chooses members from one product group (fr) and moves them to another project by changing those IDs to another value (to). The counter (i) tracks the rowcount of how many users were affected. Deleting involves randomly choosing a theoretical company project by ID (rm) that was cancelled, and because of which, employees laid-off. Both commit via the session object once the operations are carried out.
Note that there are equivalent query object update() and delete() methods that we aren’t using in our application. They reduce the amount of code necessary as they operate in bulk and return the rowcount. Porting ushuffle_sad.py to using these methods is an exercise at the end of the chapter.
Here are some of the more commonly-used query methods:
• filter_by() Extract values with specific column values as keyword parameters.
• filter() Similar to filter_by() but more flexible as you provide an expression, instead. For example: query.filter_by(userid=1) is the same as query.filter(Users.userid==1).
• order_by() Analogous to the SQL ORDER BY directive. The default is ascending. You’ll need to import sqlalchemy.desc() for descending sort.
• limit() Analogous to the SQL LIMIT directive.
• offset() Analogous to the SQL OFFSET directive.
• all() Return all objects that match the query.
• one() Return only one (the next) object that matches the query.
• first() Return the first object that matches the query.
• join() Create a SQL JOIN given the desired JOIN criteria.
• update() Bulk update rows.
• delete() Bulk delete rows.
Most of these methods result in another Query object and can thus be chained together, for example, query.order_by(desc(Users.userid)). limit(5).offset(5).
If you wish to use LIMIT and OFFSET, the more Pythonic way is to take your query object and apply a slice to it, for example, query.order_by (User.userid) [10:20] for the second group of ten users with the oldest user IDs.
To see Query methods, read the documentation at http://www.sqlalchemy.org/docs/orm/query.html#sqlalchemy.orm.query.Query. JOINs are a large topic on their own, so there is additional and more specific information at http://www.sqlalchemy.org/docs/orm/tutorial.html#ormtutorial-joins. You’ll get a chance to play with some of these methods in the chapter exercises.
So far, we’ve only discussed querying, thus row-level operations. What about table create and drop actions? Shouldn’t there be functions that look like the following?
def drop(self):
self.users.drop()
Here we made a decision to use delegation again (as introduced in the object-oriented programming chapter in Core Python Language Fundamentals or Core Python Programming). Delegation is where missing attributes in an instance are required from another object in our instance (self.users) which has it; for example, wherever you see __getattr__(), self.users. create(), self.users.drop(), etc. (lines 79–80, 98–99, 116), think delegation.
Lines 72–77
The responsibility of displaying proper output to the screen belongs to the dbDump() method. It extracts the rows from the database and pretty-prints the data just like its equivalent in ushuffle_dbU.py. In fact, they are nearly identical.
Lines 79–83
We just discussed delegation, and using __getattr__() lets us deliberately avoid creating drop() and create() methods because it would just respectively call the table’s drop() or create() methods, anyway. There is no added functionality, so why create yet another function to have to maintain? We would like to remind you that __getattr__() is only called whenever an attribute lookup fails. (This is as opposed to __getattribute__(), which is called, regardless.)
If we call orm.drop() and find no such method, getattr(orm, 'drop') is invoked. When that happens, __getattr__() is called and delegates the attribute name to self.users. The interpreter will find that self.users has a drop attribute and pass that method call to it: self. users.drop().
The last method is finish(), which does the final cleanup of closing the connection. Yes, we could have written this as a lambda but chose not to in case cleaning up of cursors and connections, etc. requires more than a single statement.
Lines 85–122
The main() function drives our application. It creates a SQLAlchemyTest object and uses that for all database operations. The script is the same as that of our original application, ushuffle_dbU.py. You will notice that the database parameter db is optional and does not serve any purpose here in ushuffle_sad.py or the upcoming SQLObject version, ushuffle_ so.py. This is a placeholder for you to add support for other RDBMSs in these applications (see the exercises at the end of the chapter).
Upon running this script, you might get output that looks like this on a Windows-based PC:
C:>python ushuffle_sad.py
*** Connect to 'test' database
Choose a database system:
(M)ySQL
(G)adfly
(S)QLite
Enter choice: s
*** Create users table (drop old one if appl.)
*** Insert names into table
LOGIN USERID PROJID
Faye 6812 2
Serena 7003 4
Amy 7209 2
Dave 7306 3
Larry 7311 2
Mona 7404 2
Ernie 7410 1
Jim 7512 2
Angela 7603 1
Stan 7607 2
Jennifer 7608 4
Pat 7711 2
Leslie 7808 3
Davina 7902 3
Elliot 7911 4
Jess 7912 2
Aaron 8312 3
Melissa 8602 1
*** Move users to a random group
(3 users moved) from (1) to (3)
LOGIN USERID PROJID
Faye 6812 2
Serena 7003 4
Amy 7209 2
Dave 7306 3
Larry 7311 2
Mona 7404 2
Ernie 7410 3
Jim 7512 2
Angela 7603 3
Stan 7607 2
Jennifer 7608 4
Pat 7711 2
Leslie 7808 3
Davina 7902 3
Elliot 7911 4
Jess 7912 2
Aaron 8312 3
Melissa 8602 3
*** Randomly delete group
(group #3; 7 users removed)
LOGIN USERID PROJID
Faye 6812 2
Serena 7003 4
Amy 7209 2
Larry 7311 2
Mona 7404 2
Jim 7512 2
Stan 7607 2
Jennifer 7608 4
Pat 7711 2
Elliot 7911 4
Jess 7912 2
*** Drop users table
*** Close cxns
C:>
Explicit/“Classical” ORM Access
We mentioned early on that we chose to use the declarative layer in SQLAlchemy for our example. However, we feel it’s also educational to look at the more “explicit” form of ushuffle_sad.py (User shuffle SQLAlchemy declarative), which we’ll name as ushuffle_sae.py (User shuffle SQLAlchemy explicit). You’ll notice that they look extremely similar to each other.
A line-by-line explanation isn’t provided due to its similarity with ushuffle_sad.py, but it can be downloaded from http://corepython.com. The point is to both preserve this from previous editions as well as to let you compare explicit versus declarative. SQLAlchemy has matured since the book’s previous edition, so we wanted to bring it up-to-date, as well. Here is ushuffle_sae.py:
#!/usr/bin/env python
from distutils.log import warn as printf
from os.path import dirname
from random import randrange as rand
from sqlalchemy import Column, Integer, String, create_engine,
exc, orm, MetaData, Table
from sqlalchemy.ext.declarative import declarative_base
from ushuffle_dbU import DBNAME, NAMELEN, randName, FIELDS,
tformat, cformat, setup
DSNs = {
'mysql': 'mysql://root@localhost/%s' % DBNAME,
'sqlite': 'sqlite:///:memory:',
}
class SQLAlchemyTest(object):
def __init__(self, dsn):
try:
eng = create_engine(dsn)
except ImportError, e:
raise RuntimeError()
try:
cxn = eng.connect()
except exc.OperationalError:
try:
eng = create_engine(dirname(dsn))
eng.execute('CREATE DATABASE %s' % DBNAME).close()
eng = create_engine(dsn)
cxn = eng.connect()
except exc.OperationalError:
raise RuntimeError()
metadata = MetaData()
self.eng = metadata.bind = eng
try:
users = Table('users', metadata, autoload=True)
except exc.NoSuchTableError:
users = Table('users', metadata,
Column('login', String(NAMELEN)),
Column('userid', Integer),
Column('projid', Integer),
)
self.cxn = cxn
self.users = users
def insert(self):
d = [dict(zip(FIELDS, [who, uid, rand(1,5)]))
for who, uid in randName()]
return self.users.insert().execute(*d).rowcount
def update(self):
users = self.users
fr = rand(1,5)
to = rand(1,5)
return (fr, to,
users.update(users.c.projid==fr).execute(
projid=to).rowcount)
def delete(self):
users = self.users
rm = rand(1,5)
return (rm,
users.delete(users.c.projid==rm).execute().rowcount)
def dbDump(self):
printf('
%s' % ''.join(map(cformat, FIELDS)))
users = self.users.select().execute()
for user in users.fetchall():
printf(''.join(map(tformat, (user.login,
user.userid, user.projid))))
def __getattr__(self, attr):
return getattr(self.users, attr)
def finish(self):
self.cxn.close()
def main():
printf('*** Connect to %r database' % DBNAME)
db = setup()
if db not in DSNs:
printf('
ERROR: %r not supported, exit' % db)
return
try:
orm = SQLAlchemyTest(DSNs[db])
except RuntimeError:
printf('
ERROR: %r not supported, exit' % db)
return
printf('
*** Create users table (drop old one if appl.)')
orm.drop(checkfirst=True)
orm.create()
printf('
*** Insert names into table')
orm.insert()
orm.dbDump()
printf('
*** Move users to a random group')
fr, to, num = orm.update()
printf(' (%d users moved) from (%d) to (%d)' % (num, fr, to))
orm.dbDump()
printf('
*** Randomly delete group')
rm, num = orm.delete()
printf(' (group #%d; %d users removed)' % (rm, num))
orm.dbDump()
printf('
*** Drop users table')
orm.drop()
printf('
*** Close cxns')
orm.finish()
if __name__ == '__main__':
main()
The noticeable major differences between ushuffle_sad.py and ushuffle_sae.py are:
• Creates a Table object instead of declarative Base object
• Our election not to use Sessions; instead performing individual units of work, auto-commit, non-transactional, etc.
• Uses the Table object for all database interaction rather than Session Querys
To show sessions and explicit operations are not tied together, you’ll get an exercise to roll Sessions into ushuffle_sae.py. Now that you’ve learned SQLAlchemy, let’s move onto SQLObject and see a similar tool.
SQLObject
SQLObject was Python’s first major ORM. In fact, it’s a decade old! Ian Bicking, its creator, released the first alpha version to the world in October 2002. (SQLAlchemy didn’t come along until February 2006.) At the time of this writing, SQLObject is only available for Python 2.
As we mentioned earlier, SQLObject is more object-flavored (some feel more Pythonic) and implemented the Active Record pattern for implicit object-to-database access early on but doesn’t give you as much freedom to use raw SQL for more ad hoc or customized queries. Many users claim that it is easy to learn SQLAlchemy, but we’ll let you be the judge. Take a look at ushuffle_so.py in Example 6-3, which is our port of ushuffle_ dbU.py and ushuffle_sad.py to SQLObject.
Example 6-3. SQLObject ORM Example (ushuffle_so.py)
This user shuffle Python 2.x and 3.x-compatible application features the SQLObject ORM paired up with MySQL or SQLite databases as back-ends.
1 #!/usr/bin/env python
2
3 from distutils.log import warn as printf
4 from os.path import dirname
5 from random import randrange as rand
6 from sqlobject import *
7 from ushuffle_dbU import DBNAME, NAMELEN, randName, FIELDS,
tformat, cformat, setup
8
9 DSNs = {
10 'mysql': 'mysql://root@localhost/%s' % DBNAME,
11 'sqlite': 'sqlite:///:memory:',
12 }
13
14 class Users(SQLObject):
15 login = StringCol(length=NAMELEN)
16 userid = IntCol()
17 projid = IntCol()
18 def __str__(self):
19 return ''.join(map(tformat,
20 (self.login, self.userid, self.projid)))
21
22 class SQLObjectTest(object):
23 def __init__(self, dsn):
24 try:
25 cxn = connectionForURI(dsn)
26 except ImportError:
27 raise RuntimeError()
28 try:
29 cxn.releaseConnection(cxn.getConnection())
30 except dberrors.OperationalError:
31 cxn = connectionForURI(dirname(dsn))
32 cxn.query("CREATE DATABASE %s" % dbName)
33 cxn = connectionForURI(dsn)
34 self.cxn = sqlhub.processConnection = cxn
35
36 def insert(self):
37 for who, userid in randName():
38 Users(login=who, userid=userid, projid=rand(1,5))
39
40 def update(self):
41 fr = rand(1,5)
42 to = rand(1,5)
43 i = -1
44 users = Users.selectBy(projid=fr)
45 for i, user in enumerate(users):
46 user.projid = to
47 return fr, to, i+1
48
49 def delete(self):
50 rm = rand(1,5)
51 users = Users.selectBy(projid=rm)
52 i = -1
53 for i, user in enumerate(users):
54 user.destroySelf()
55 return rm, i+1
56
57 def dbDump(self):
58 printf('
%s' % ''.join(map(cformat, FIELDS)))
59 for user in Users.select():
60 printf(user)
61
62 def finish(self):
63 self.cxn.close()
64
65 def main():
66 printf('*** Connect to %r database' % DBNAME)
67 db = setup()
68 if db not in DSNs:
69 printf('
ERROR: %r not supported, exit' % db)
70 return
71
72 try:
73 orm = SQLObjectTest(DSNs[db])
74 except RuntimeError:
75 printf('
ERROR: %r not supported, exit' % db)
76 return
77
78 printf('
*** Create users table (drop old one if appl.)')
79 Users.dropTable(True)
80 Users.createTable()
81
82 printf('
*** Insert names into table')
83 orm.insert()
84 orm.dbDump()
85
86 printf('
*** Move users to a random group')
87 fr, to, num = orm.update()
88 printf(' (%d users moved) from (%d) to (%d)' % (num, fr, to))
89 orm.dbDump()
90
91 printf('
*** Randomly delete group')
92 rm, num = orm.delete()
93 printf(' (group #%d; %d users removed)' % (rm, num))
94 orm.dbDump()
95
96 printf('
*** Drop users table')
97 Users.dropTable()
98 printf('
*** Close cxns')
99 orm.finish()
100
101 if __name__ == '__main__':
102 main()
Line-by-Line Explanation
Lines 1–12
The imports and constant declarations for this module are practically identical to those of ushuffle_sad.py, except that we are using SQLObject instead of SQLAlchemy.
Lines 14–20
The Users table extends the SQLObject.SQLObject class. We define the same columns as before and also provide an __str__() for display output.
Lines 22–34
The constructor for our class does everything it can to ensure that there is a database available and returns a connection to it, just like our SQLAlchemy example. Similarly, this is the only place you will see real SQL. The code works as described in the following, which bails on all errors:
• Try to establish a connection to an existing table (line 29); if it works, we are done. It has to dodge exceptions like an RDBMS adapter being available and the server online, and then beyond that, the existence of the database.
• Otherwise, create the table; if so, we are done (lines 31–33).
• Once successful, we save the connection object in self.cxn.
Lines 36–55
The database operations happen in these lines. We have Insert (lines 36–38), Update (lines 40–47), and Delete (lines 49–55). These are analogous to the SQLAlchemy equivalents.
![]() Core Tip (Hacker’s Corner): Reducing
Core Tip (Hacker’s Corner): Reducing insert() down to one (long) line of Python
We can reduce the code from the insert() method into a more obfuscated “one-liner:”
[Users(**dict(zip(FIELDS, (who, userid, rand(1,5)))))
for who, userid in randName()]
We’re not in the business to encourage code that damages readability or executes code explicitly by using a list comprehension; however, the existing solution does have one flaw: it requires you to create new objects by explicitly naming the columns as keyword arguments. By using FIELDS, you don’t need to know the column names and wouldn’t need to fix as much code if those column names changed, especially if FIELDS was in some configuration (not application) module.
Lines 57–63
This block starts with the same (and expected) dbDump() method, which pulls the rows from the database and displays things nicely to the screen. The finish() method (lines 62–63) closes the connection. We could not use delegation for table drop as we did for the SQLAlchemy example because the would-be delegated method for it is called dropTable(), not drop().
Lines 65–102
This is the main() function again. It works just like the one in ushuffle_sad.py. Also, the db argument and DSNs constant are building blocks for you to add support for other RDBMSs in these applications (see the exercises at the end of the chapter).
Here is what your output might look like if you run ushuffle_so.py (which is going to be nearly identical to the output from the ushuffle_ dbU.py and ushuffle_sa?.py scripts):
$ python ushuffle_so.py
*** Connect to 'test' database
Choose a database system:
(M)ySQL
(G)adfly
(S)QLite
Enter choice: s
*** Create users table (drop old one if appl.)
*** Insert names into table
LOGIN USERID PROJID
Jess 7912 2
Ernie 7410 1
Melissa 8602 1
Serena 7003 1
Angela 7603 1
Aaron 8312 4
Elliot 7911 3
Jennifer 7608 1
Leslie 7808 4
Mona 7404 4
Larry 7311 1
Davina 7902 3
Stan 7607 4
Jim 7512 2
Pat 7711 1
Amy 7209 2
Faye 6812 1
Dave 7306 4
*** Move users to a random group
(5 users moved) from (4) to (2)
LOGIN USERID PROJID
Jess 7912 2
Ernie 7410 1
Melissa 8602 1
Serena 7003 1
Angela 7603 1
Aaron 8312 2
Elliot 7911 3
Jennifer 7608 1
Leslie 7808 2
Mona 7404 2
Larry 7311 1
Davina 7902 3
Stan 7607 2
Jim 7512 2
Pat 7711 1
Amy 7209 2
Faye 6812 1
Dave 7306 2
*** Randomly delete group
(group #3; 2 users removed)
LOGIN USERID PROJID
Jess 7912 2
Ernie 7410 1
Melissa 8602 1
Serena 7003 1
Angela 7603 1
Aaron 8312 2
Jennifer 7608 1
Leslie 7808 2
Mona 7404 2
Larry 7311 1
Stan 7607 2
Jim 7512 2
Pat 7711 1
Amy 7209 2
Faye 6812 1
Dave 7306 2
*** Drop users table
*** Close cxns
$
6.4. Non-Relational Databases
At the beginning of this chapter, we introduced you to SQL and looked at relational databases. We then showed you how to get data to and from those types of systems and presented a short lesson in porting to Python 3, as well. Those sections were followed by sections on ORMs and how they let users avoid SQL by taking on more of an “object” approach, instead. However, under the hood, both SQLAlchemy and SQLObject generate SQL on your behalf. In the final section of this chapter, we’ll stay on objects but move away from relational databases.
6.4.1. Introduction to NoSQL
Recent trends in Web and social services have led to the generation of data in amounts and/or rates greater than relational databases can handle. Think Facebook or Twitter scale data generation. Developers of Facebook games or applications that handle Twitter stream data, for example, might have applications that need to write to persistent storage at a rate of millions of rows or objects per hour. This scalability issue has led to the creation, explosive growth, and deployment of non-relational or NoSQL databases.
There are plenty of options available here, but they’re not all the same. In the non-relational (or non-rel for short) category alone, there are object databases, key-value stores, document stores (or datastores), graph databases, tabular databases, columnar/extensible record/wide-column databases, multivalue databases, etc. At the end of the chapter, we’ll provide some links to help you with your NoSQL research. At the time of this writing, one of the more popular document store non-rel databases is MongoDB.
6.4.2. MongoDB
MongoDB has experienced a recent boost in popularity. Besides users, documentation, community, and professional support, it has its own regular set of conferences—another sign of adoption. The main Web site claims a variety of marquee users, including Craigslist, Shutterfly, foursquare, bit.ly, SourceForge, etc. See http://www.mongodb.org/display/DOCS/Production+Deployments for these and more. Regardless of its user base, we feel that MongoDB is a good choice to introduce readers to NoSQL and document datastores. For those who are curious, MongoDB’s document storage system is written in C++.
If you were to compare document stores (MongoDB, CouchDB, Riak, Amazon SimpleDB) in general to other non-rel databases, they fit somewhere between simple key-value stores, such as Redis, Voldemort, Amazon Dynamo, etc., and column-stores, such as Cassandra, Google Bigtable, and HBase. They’re somewhat like schemaless derivatives of relational databases, simpler and less constrained than columnar-based storage but more flexible than plain key-value stores. They generally store their data as JavaScript Object Notation (JSON) objects, which allows for data types, such as strings, numbers, lists, as well as for nesting.
Some of the MongoDB (and NoSQL) terminology is also different from those of relational database systems. For example, instead of thinking about rows and columns, you might have to consider documents and collections, instead. To better wrap your head around the change in terms, you can take a quick look at the SQL-to-Mongo Mapping Chart at http://www.mongodb.org/display/DOCS/SQL+to+Mongo+Mapping+Chart
MongoDB in particular stores its JSON payloads (documents)—think a single Python dictionary—in a binary-encoded serialization, commonly known as BSON format. However, regardless of its storage mechanism, the main idea is that to developers, it looks like JSON, which in turn looks like Python dictionaries, which brings us to where we want to be. MongoDB is popular enough to have adapters available for most platforms, including Python.
6.4.3. PyMongo: MongoDB and Python
Although there are a variety of MongoDB drivers for Python, the most formal of them is PyMongo. The others are either more lightweight adapters or are special-purpose. You can perform a search on mongo at the Cheeseshop (http://pypi.python.org) to see all MongoDB-related Python packages. You can try any of them, as you prefer, but our example in this chapter uses PyMongo.
Another benefit of the pymongo package is that it has been ported to Python 3. Given the techniques already used earlier in this chapter, we will only present one Python application that runs on both Python 2 and 3, and depending on which interpreter you use to execute the script, it in turn will utilize the appropriately-installed version of pymongo.
We won’t spend much time on installation as that is primarily beyond the scope of this book; however, we can point you to mongodb.org to download MongoDB and let you know that you can use easy_install or pip to install PyMongo and/or PyMongo3. (Note: I didn’t have any problems getting pymongo3 on my Mac, but the install process choked in Windows.) Whichever one you install (or both), it’ll look the same from your code: import pymongo.
To confirm that you have MongoDB installed and working correctly, check out the QuickStart guide at http://www.mongodb.org/display/DOCS/Quickstart and similarly, to confirm the same for PyMongo, ensure that you can import the pymongo package. To get a feel for using MongoDB with Python, run through the PyMongo tutorial at http://api.mongodb.org/python/current/tutorial.html.
What we’re going to do here is port our existing user shuffle (ushuffle_*.py) application that we’ve been looking at throughout this chapter to use MongoDB as its persistent storage. You’ll notice that the flavor of the application is similar to that of SQLAlchemy and SQLObject, but it is even less substantial in that there isn’t as much overhead with MongoDB as there is a typical relational database system such as MySQL. Example 6-4 presents the Python 2 and 3-compatible ushuffle_mongo.py, followed by the line-by-line explanation.
Example 6-4. MongoDB Example (ushuffle_mongo.py)
Our user shuffle Python 2.x and 3.x-compatible MongoDB and PyMongo application.
1 #!/usr/bin/env python
2
3 from distutils.log import warn as printf
4 from random import randrange as rand
5 from pymongo import Connection, errors
6 from ushuffle_dbU import DBNAME, randName, FIELDS, tformat, cformat
7
8 COLLECTION = 'users'
9
10 class MongoTest(object):
11 def __init__(self):
12 try:
13 cxn = Connection()
14 except errors.AutoReconnect:
15 raise RuntimeError()
16 self.db = cxn[DBNAME]
17 self.users = self.db[COLLECTION]
18
19 def insert(self):
20 self.users.insert(
21 dict(login=who, userid=uid, projid=rand(1,5))
22 for who, uid in randName())
23
24 def update(self):
25 fr = rand(1,5)
26 to = rand(1,5)
27 i = -1
28 for i, user in enumerate(self.users.find({'projid': fr})):
29 self.users.update(user,
30 {'$set': {'projid': to}})
31 return fr, to, i+1
32
33 def delete(self):
34 rm = rand(1,5)
35 i = -1
36 for i, user in enumerate(self.users.find({'projid': rm})):
37 self.users.remove(user)
38 return rm, i+1
39
40 def dbDump(self):
41 printf('
%s' % ''.join(map(cformat, FIELDS)))
42 for user in self.users.find():
43 printf(''.join(map(tformat,
44 (user[k] for k in FIELDS))))
45
46 def finish(self):
47 self.db.connection.disconnect()
48
49 def main():
50 printf('*** Connect to %r database' % DBNAME)
51 try:
52 mongo = MongoTest()
53 except RuntimeError:
54 printf('
ERROR: MongoDB server unreachable, exit')
55 return
56
57 printf('
*** Insert names into table')
58 mongo.insert()
59 mongo.dbDump()
60
61 printf('
*** Move users to a random group')
62 fr, to, num = mongo.update()
63 printf(' (%d users moved) from (%d) to (%d)' % (num, fr, to))
64 mongo.dbDump()
65
66 printf('
*** Randomly delete group')
67 rm, num = mongo.delete()
68 printf(' (group #%d; %d users removed)' % (rm, num))
69 mongo.dbDump()
70
71 printf('
*** Drop users table')
72 mongo.db.drop_collection(COLLECTION)
73 printf('
*** Close cxns')
74 mongo.finish()
75
76 if __name__ == '__main__':
77 main()
Line-by-Line Explanation
Lines 1–8
The main import line is to bring in PyMongo’s Connection object and the package’s exceptions (errors). Everything else you’ve seen earlier in this chapter. Like the ORM examples, we yet again borrow most constants and common functions from our earlier ushuffle_dbU.py application. The last statement sets our collection (“table”) name.
Lines 10–17
The first part of the initializer for our MongoTest class creates a connection, raising an exception if the server cannot be reached (lines 12–15). The next two lines are very easy to skip over because they look like mere assignments, but under the hood, these create a database or reuse an existing one (line 16) and create or reuse an existing “users” collection, which you can sort of consider as analogous to a database table.
Tables have defined columns then rows for each record, whereas collections don’t have any schema requirements; they have individual documents for each record. You will notice the conspicuous absence of a “data model” class definition in this part of the code. Each record defines itself, so to speak—whatever record you save is what goes into the collection.
Lines 19–22
The insert() method adds values to a MongoDB collection. A collection is made up of documents. You can think of a document as a single record in the form of a Python dictionary. We create one by using the dict() factory function of those for each record, and all are streamed to the collection’s insert() method via a generator expression.
Lines 24–31
The update() method works in the same manner as earlier in the chapter. The difference is the collection’s update() method which, gives developers more options than a typical database system. Here, (lines 29–30) we use the MongoDB $set directive, which updates an existing value explicitly.
Each MongoDB directive represents a modifier operation that is both highly-efficient, useful, and convenient to the developer when updating existing values. In addition to $set, there are also operations for incrementing a field by a value, removing a field (key-value pair), appending and removing values to/from an array, etc.
Working backward somewhat, before the update, however, we first need to query for all the users in the system (line 28) to find those with a project ID (projid) that matches the group we want to update. To do this, you use the collection find() method and pass in the criteria. This takes the place of a SQL SELECT statement.
It’s also possible to use the Collection.update() method to modify multiple documents; you would just need to set the multi flag to True. The only bad news with this is that it currently doesn’t return the total number of documents modified.
For more complex queries than just the single criteria for our simple script, check the corresponding page in the official documentation at http://www.mongodb.org/display/DOCS/Advanced+Queries.
Lines 33–38
The delete() method reuses the same query as for update(). Once we have all the users that match the query, we remove() them one at a time (lines 36–37) and return the results. If you don’t care about the total number of documents removed, then you can simply make a single call to self.users.remove(), which deletes all documents from a collection.
Lines 40–44
The query performed in dbDump() has no criteria (line 42), so all users in the collection are returned, followed by the data, string-formatted and displayed to the user (lines 43–44).
Lines 46–47
The final method defined and called during application execution disconnects from the MongoDB server.
Lines 49–77
The main() driver function is self-documenting and following the exact same script as the previous applications seen in this chapter: connect to database server and do preparation work; insert users into the collection (“table”) and dump database contents; move users from one project to another (and dump contents); remove an entire group (and dump contents); drop the entire collection; and then finally, disconnect.
While this closes our look at non-relational databases for Python, it should only be the beginning for you. As mentioned at the beginning of this section, there are plenty of NoSQL options to look at, and you’ll need to investigate and perhaps prototype each to determine which among them might be the right tool for the job. In the next section, we give various additional references for you to read further.
6.4.4. Summary
We hope that we have provided you with a good introduction to using relational databases with Python. When your application’s needs go beyond those offered by plain files, or specialized files, such as DBM, pickled, etc., you have many options. There are a good number of RDBMSs out there, not to mention one completely implemented in Python, freeing you from having to install, maintain, or administer a real database system.
In the following section, you will find information on many of the Python adapters plus database and ORM systems. Furthermore, the community has been augmented with non-relational databases now to help out in those situations when relational databases don’t scale to the level that your application needs.
We also suggest checking out the DB-SIG pages as well as the Web pages and mailing lists of all systems of interest. Like all other areas of software development, Python makes things easy to learn and simple to experiment with.
6.5. Related References
Table 6-8 lists most of the common databases available, along with working Python modules and packages that serve as adapters to those database systems. Note that not all adapters are DB-API-compliant.
Table 6-8. Database-Related Modules/Packages and Web sites


In addition to the database-related modules/packages, the following are yet more online references that you can consider:
Python and Databases
• wiki.python.org/moin/DatabaseProgramming
• wiki.python.org/moin/DatabaseInterfaces
Database Formats, Structures, and Development Patterns
• en.wikipedia.org/wiki/DSN
• www.martinfowler.com/eaaCatalog/dataMapper.html
• en.wikipedia.org/wiki/Active_record_pattern
• blog.mongodb.org/post/114440717/bson
Non-relational Databases
• en.wikipedia.org/wiki/Nosql
• nosql-database.org/
• www.mongodb.org/display/DOCS/MongoDB,+CouchDB,+MySQL+Compare+Grid
6.6. Exercises
Databases
6-1. Database API. What is the Python DB-API? Is it a good thing? Why (or why not)?
6-2. Database API. Describe the differences between the database module parameter styles (see the paramstyle module attribute).
6-3. Cursor Objects. What are the differences between the cursor execute*() methods?
6-4. Cursor Objects. What are the differences between the cursor fetch*() methods?
6-5. Database Adapters. Research your RDBMS and its Python module. Is it DB-API compliant? What additional features are available for that module that are extras not required by the API?
6-6. Type Objects. Study using Type objects for your database and DB-API adapter, and then write a small script that uses at least one of those objects.
6-7. Refactoring. In the ushuffle_dbU.create() function, a table that already exists is dropped and re-created by recursively calling create() again. This is dangerous, because if recreation of the table fails (again), you will then have infinite recursion. Fix this problem by creating a more practical solution that does not involve copying the create query (cur.execute()) again in the exception handler. Extra Credit: Try to recreate the table a maximum of three times before returning failure back to the caller.
6-8. Database and HTML. Take any existing database table, and use your Web programming knowledge to create a handler that outputs the contents of that table as HTML for browsers.
6-9. Web Programming and Databases. Take our user shuffle example (ushuffle_db.py) and create a Web interface for it.
6-10. GUI Programming and Databases. Take our user shuffle example (ushuffle_db.py) and throw a GUI for it.
6-11. Stock Portfolio Class. Create an application that manages the stock portfolios for multiple users. Use a relational database as the back-end and provide a Web-based user interface. You can use the stock database class from the object-oriented programming chapter of Core Python Language Fundamentals or Core Python Programming.
6-12. Debugging & Refactoring. The update() and remove() functions each have a minor flaw: update() might move users from one group into the same group. Change the random destination group to be different from the group from which the user is moving. Similarly, remove() might try to remove people from a group that has no members (because they don’t exist or were moved up with update()).
ORMs
6-13. Stock Portfolio Class. Create an alternative solution to the Stock Portfolio ( Exercise 6-11) by using an ORM instead of direct to an RDBMS.
6-14. Debugging and Refactoring. Port your solutions to Exercise 6-13 to both the SQLAlchemy and SQLObject examples.
6-15. Supporting Different RDBMSs. Take either the SQLAlchemy (ushuffle_sad.py) or SQLObject (ushuffle_so.py) application, which currently support MySQL and SQLite, and add yet another relational database of your choice.
For the next four exercises, focus on the ushuffle_dbU.py script, which features some code near the top (lines 7–12) that determines which function should be used to get user input from the command-line.
6-16. Importing and Python. Review that code again. Why do we need to check if __builtins__ is a dict versus a module?
6-17. Porting to Python 3. Using distutils.log.warn() is not a perfect substitute for print/print(). Prove it. Provide code snippets to show where warn() is not compatible with print().
6-18. Porting to Python 3. Some users believe that they can use print() in Python 2 just like in Python 3. Prove them wrong. Hint: From Guido himself: print(x, y)
6-19. Python Language. Assume that you want to use print() in Python 3 but distutils.log.warn() in Python 2, and you want to use the printf() name. What’s wrong with the code below?
from distutils.log import warn
if hasattr(__builtins__, 'print'):
printf = print
else:
printf = warn
6-20. Exceptions. When establishing our connection to the server using our designated database name in ushuffle_sad.py, a failure (exc.OperationalError) indicated that our table did not exist, so we had to back up and create the database first before retrying the database connection. However, this is not the only source of errors: if using MySQL and the server itself is down, the same exception is also thrown. In this situation, execution of CREATE DATABASE will fail, as well. Add another handler to take care of this situation, raising RuntimeError back to the code attempting to create an instance.
6-21. SQLAlchemy. Augment the ushuffle_sad.dbDump() function by adding a new default parameter named newest5 which defaults to False. If True is passed in, rather than displaying all users, reverse sort the list by order of Users.userid and show only the top five representing the newest employees. Make this special call in main() right after the call to orm.insert() and orm.dbDump().
a. Use the Query limit() and offset() methods.
b. Use the Python slicing syntax, instead.
The updated output would look something like this:
. . .
Jess 7912 4
Aaron 8312 3
Melissa 8602 2
*** Top 5 newest employees
LOGIN USERID PROJID
Melissa 8602 2
Aaron 8312 3
Jess 7912 4
Elliot 7911 3
Davina 7902 3
*** Move users to a random group
(4 users moved) from (3) to (1)
LOGIN USERID PROJID
Faye 6812 4
Serena 7003 2
Amy 7209 1
. . .
6-22. SQLAlchemy. Change ushuffle_sad.update() to use the Query update() method, dropping down to 5 lines of code. Use the timeit module to show whether it’s faster than the original.
6-23. SQLAlchemy. Same as Exercise 6-22 but for ushuffle_ sad.delete(), use the Query delete() method.
6-24. SQLAlchemy. In the explicitly non-declarative version of ushuffle_sad.py, ushuffle_sae.py, we removed the use of the declarative layer as well as sessions. While using an Active Record model is more optional, the concept of Sessions isn’t a bad idea at all. Change all of the code that performs database operations in ushuffle_sae.py so that they all use/share a Session object, as in the declarative ushuffle_sad.py.
6-25. Django Data Models. Take the Users data model class, as implemented in our SQLAlchemy or SQLObject examples, and create the equivalent by using the Django ORM. You might want to read ahead to Chapter 11, “Web Frameworks: Django.”
6-26. Storm ORM. Port the ushuffle_s*.py application to the Storm ORM.
Non-Relational (NoSQL) Databases
6-27. NoSQL. What are some of reasons why non-relational databases have become popular? What do they offer over traditional relational databases?
6-28. NoSQL. There are at least four different types of non-relational databases. Categorize each of the major types and name the most well-known projects in each category. Note the specific ones that have at least one Python adapter.
6-29. CouchDB. CouchDB is another document datastore that’s often compared to MongoDB. Review some of the online comparisons in the final section of this chapter, and then download and install CouchDB. Morph ushuffle_mongo.py into a CouchDB-compatible ushuffle_couch.py.