
Chapter 5
Risk
Nothing will ever be attempted if all possible objections must be first overcome.
Samuel Johnson
The idea of risk conjures up feelings of danger of personal or organizational safety. While some people find flirting with danger exhilarating, everyone ultimately wants to avoid its repercussions. For IT, risk is the probability of not reliably delivering a product or service to the right people at the right time in a sufficiently safe and secure fashion that allows them to successfully pursue their target outcomes. With IT embedded in critical parts of our daily lives, avoiding IT failures is increasingly important. This makes it important for the provider, the customer, and their staff to have confidence in the way any probable and intolerably dangerous hazards are identified, assessed, and mitigated.
Unfortunately, managing IT risk has become more difficult. Rather than the single locally run piece of software of old, IT solutions are far more likely to consist of a large number of interdependent components. These services are frequently delivered by multiple organizations, many who rely upon global supply chains themselves to deliver their piece of the puzzle. Such complexity breaks many of the techniques of traditional risk management. Having so many providers in the delivery chain makes it difficult, if not impossible, for any organization to see deeply enough across the technology stack to count on compliance procedures to expose and control risk. As the SolarWinds hacks of 2020 spectacularly revealed (see sidebar), it takes only one hazard from a single link in the chain to affect everyone.
Modern IT solutions require a better way to assess and manage risk. Rather than continuing to rely upon using compliance processes to find potential hazards and then mitigate their risks, we need to look at what we know about the delivery and operational ecosystem. This includes how much visibility we have into the elements that comprise the ecosystem, as well as the predictability and orderliness of its dynamics.
In this chapter, we will explore how order and predictability affect risk and the decision-making process. We will also cover a number of techniques to help mitigate risks from unknown and unknowable hazards in your ecosystem.
Cynefin and Decision Making
We know that environments can differ in complexity. The more complex and dynamic an environment, the more context and situational awareness we need to confidently make effective decisions in it. However, being complex and dynamic doesn’t necessarily equate to there being more, or more severe, risky hazards. For instance, a meat cutter in a meatpacking plant works in a far less complex environment than a commodities futures trader, yet most would agree that the meat cutter faces a higher risk of injury or death from a bad workplace decision.
Where there is a difference is in the way that decision risk is managed. While the risks for the meat cutter are more severe, their number is small and well known. Most risks to the meat cutter can be mitigated through scripted procedures that can be closely monitored, such as ensuring that cutting tools are sharp and in good working condition, only using such tools in particular ways, and avoiding slippery surfaces.
The commodities trader, on the other hand, faces a wide variety of ways that seemingly sound decisions can go bad, from bad weather and pest outbreaks to unexpected bumper harvests and political events that dramatically change the supply and demand dynamics of the market. For commodities traders, a scripted set of procedures would do little to uncover, let alone manage, any risks. Instead, they have to constantly seek out the most up-to-date relevant contextual information and adjust their positions within the bounds of their risk tolerance accordingly.
This relationship between contextual dynamics and the suitability of an approach became apparent to David Snowden while working on the problem of knowledge management and organizational strategy. From his work he developed a sensemaking framework called Cynefin. His framework is a complexity thinking tool designed to help people sense the situational context in which they are operating in order to make better decisions.1 Snowden has continued to work and tune the framework, which has grown into a particularly useful guide to help people recognize the dynamics of the domain they are working in and understand why an approach that worked well in one context can fail miserably in another.2
1. David J. Snowden and Mary E. Boone, “A Leader’s Framework for Decision Making,” Harvard Business Review, November 2007 https://hbr.org/2007/11/a-leaders-framework-for-decision-making
2. The Cynefin Framework, https://thecynefin.co
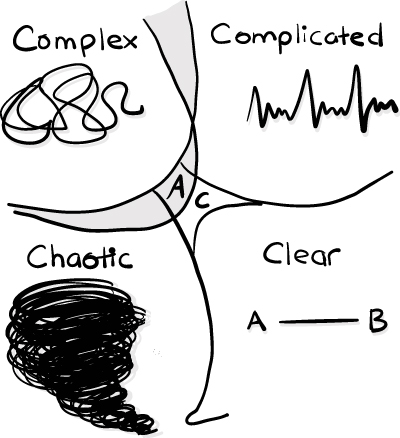
Figure 5.1
Cynefin framework.
The Cynefin framework consists of five contextual domains: clear, complicated, complex, chaotic, and confusion. Each domain is defined by the nature of the relationship between cause and effect, with clear and complicated domains being two forms of ordered systems, while complex and chaotic domains are forms of unordered systems.
While some environments are more likely to find themselves in a particular contextual domain than the others, any number of developments can raise or lower complexity that shifts an environment into a different domain. This often not only breaks existing risk management but can create delivery friction and cause situational awareness to degrade.
Learning how to recognize which domain your organization is in at a given time can help you find the best approach to manage any risk. It can also be a useful way to spot and mitigate many of the common behaviors that often erode the quality of decision making in them.
Let’s take a look at each domain to get a better idea of the different dynamics of each.
Ordered Systems
Ordered systems are those where a particular input or action will directly and predictably produce the same result. This clear and observable relationship between cause and effect holds true regardless of whether specific expertise is required to execute it. As such, the system can be pulled apart and put back together in a straightforward way like a machine.
As you will see, it is the level of expertise required to see the cause-and-effect linkage to make an effective decision that separates the clear and complicated contextual domains. This difference also plays a significant role in how best to manage risk in each.
Clear: “The Domain of Best Practice”

Figure 5.2
The clear domain —simple and obvious.
Clear contexts are those where the problem is well understood and the solution is evident, thus making for perfect situational awareness. Snowden refers to these as “known knowns.”3 The act of problem solving requires no real expertise, just the ability to capture the issue, categorize it, and respond following established practice for the problem category. As the problem is already known, all the work can be scripted ahead of time, either in written form for someone to follow step by step, or as an automated tool that can be activated at the appropriate time.
3. Ibid, p. 3
The earlier scenario of a meatpacking plant is a good example of an ordered system operating in the Clear contextual domain. While an experienced meat cutter might be faster and less likely to get injured than someone new on the job, there is little discernible difference from the actions of cutting up carcasses of the same type that cannot be scripted.
Clear contexts fit well for Taylorist method-driven management models, introduced in Chapter 2, “How We Make Decisions.” Work can be defined and planned well in advance with instructions, coming from the top down, detailing clearly defined best practice. Likewise, risk can be managed by ensuring that workers closely adhere to instructions which explicitly check for known potential hazards, such as the state of tools and surfaces in the meatpacking example. The clear domain is the desired realm of Tier 1 helpdesks and support functions in traditional service management, as instructions can be placed in runbooks that can be searched and followed by the most junior technician.
There are two types of challenges that can plunge a clear contextual environment into chaos that is difficult to recover from. The first danger is that with so much of the actual thinking and directing happening from the top down, it is easy for conditions to shift that cause awareness gaps to form. With people working in such environments so used to following the routine, they often miss the warning signs of an imminent hazard until it is too late to react. Not only is this bad for delivery, the resulting failure and chaos can cause a precipitous drop in worker trust of management that further degrades organizational awareness.
Figure 5.3
Even if the domain is clear, you still need to see it.
There is also a second danger of the people working in the ecosystem becoming so attached to their past experiences, training, and successes that they become blind to new ways of thinking and struggle to learn and improve. Past rules become immutable in their minds, even when evidence of their diminishing suitability builds around them. Established firms that were once successful and large bureaucracies often fall into this trap, forfeiting success to more dynamic or suitable alternatives.
Complicated: “The Domain of Experts”

Figure 5.4
Some problems are complicated enough that they need an expert to solve.
The complicated contextual domain is the realm of the skilled expert. Unlike the clear domain, there are enough “known unknowns” that it is no longer possible for management to rely solely upon reusable scripts that an unskilled worker can follow to solve a situation. Instead, some level of domain expertise is required to both analyze what is going on and decide a suitably effective course of action. Typical examples of such expertise include an auto mechanic, an electronics repair person, or an IT desktop support specialist. Likely, all have been trained to match symptoms with known solutions they can confidently execute.
Rather than spending time scripting and enforcing methods, managers break the delivery domain by resource skill type, staffing and allocating tasks according to the perceived demand need. As a result, risk is usually managed through top-down change-gate processes. These are processes that serialize delivery into separate design, development, test, and release stages, each separated by a change management review at the end of each stage where conditions can be reviewed to uncover potential problems that need addressing.
Despite being seemingly straightforward, there are a number of challenges that traditional complicated contextual domain risk management processes tend to struggle to adequately address. One is the danger of becoming overly reliant on narrowly focused skilled specialists. As they are typically incentivized only on how well they perform their specialty, their narrow focus often fragments organizational situational awareness along functional or specialty lines.
Organizations that rely upon skilled specialists are also dependent upon them to deliver innovation and improvements. This can be problematic when specialists who are incentivized to justify their value feel threatened by any change that might diminish their value. They might overlook or dismiss new concepts that they do not know or that they feel endanger their value. Similarly, competing specialists can also engage in endless debates and “analysis paralysis” that create hard-to-solve decision friction that can prevent the organization from resolving an issue and moving forward.
Unordered Systems
Unordered systems are those where causality can only be determined in hindsight, if at all, even when the system is stable. Constraints and behavior evolve over time through the interaction of components. In such systems no amount of analysis will help with predicting systemic behaviors, making it impossible to deconstruct and reassemble like an ordered system.
Being that the cause-and-effect linkage is not immediately apparent, unordered systems are also ones where it is far from easy to use ordered system–style controls to manage risk. This makes shifts into an unordered system domain particularly perilous for organizations that rely upon clear and complicated risk management approaches. The disappearance of the relationship between cause and effect can make organizations miss fatal hazards entirely, or worse, not be able to handle them when they are encountered.
In fact, such a shift can seem so nonsensical that those expecting an ordered system may refuse to believe that any risk management breakdown is anything more than existing methods not being done with sufficient vigor. Rather than changing approaches, they increase the rigidity of their failing processes, adding additional processes, documentation, and governance that are of little help in eliminating the unpredictability emerging from the ecosystem itself.
In order to better understand what is happening, let’s look at these two very different unordered system domains.
Complex: “The Domain of Emergence”

Figure 5.5
The complex domain.
When there are unknown unknowns in the ecosystem that cause the same action to produce different results when repeated, it is likely you have moved into a complex context. In the complex domain the environment is in constant flux, hiding cause-and-effect relationships in a mass of seemingly randomly moving pieces. Not only is it no longer clear if there is a right answer to a problem, but it can even be difficult to find the right questions to ask. Solutions that may seem obvious in hindsight only become apparent once they are discovered, or emerge, through continual experimentation.
This need to continually probe and test the dynamics of the ecosystem in order to problem solve and make effective decisions in it mirrors many elements of Boyd’s OODA loop discussed in Chapter 2, “How We Make Decisions.” It allows those in it to find ways to learn through an ongoing series of experiments to observe how system elements affect the behavior of the overall system. This increases the amount of feedback available to make it easier to spot shifts and emerging patterns that can then be used to improve decision efficacy.
Relying upon experimentation rather than process controls and expert feedback can feel dangerously risky to those used to ordered systems. No longer can risk be “controlled” through top-down processes. Not only that, but the need for continual experimentation necessitates that the working environment be both tolerant of failure and safe to fail in. Failure alone cannot be automatically viewed as an unacceptable hazard, let alone a sign of a shortfall in risk management.
However, there are a number of elements that people overlook when managing risk in a complex domain ecosystem. The first is that a tolerance for failure is not a license to experiment in ways that create unacceptable amounts of risk. No one succeeds by rashly throwing experimental changes into critical production services that will likely impact customers negatively. There needs to be enough situational awareness to allow people to mitigate any excessive risks that might otherwise make it unsafe for an experiment to fail.
This leads us into the second challenge. Despite being in an unordered system domain, it is still important to continually invest effort in creating order and transparency where you can. Good configuration management, packaging, and deployment practices are extremely valuable for reducing ecosystem noise that can make gaining situational awareness far more difficult than it needs to be.
Time and again, I encounter organizations that push code live and manually change configurations without bothering to capture the changes sufficiently to enable the organization to understand and easily re-create the changes in the future when needed. This not only creates fragile snowflake instances, their irreproducibility means that any destructive event (whether a failed drive, an accidental deletion or overwrite, or a ransomware encryption attack) can become dangerously unrecoverable.
The same goes for serverless architectures where insufficient care and consideration is spent understanding and mapping out their event-driven architecture. I have seen all sorts of race conditions and data mangling occur from unexpected event flows. Similarly, I have seen organizations that had so many production configuration switches and A/B testing combinations left live in production that no customer journey was definitively known or repeatable, making troubleshooting and dependency management nearly impossible.
One final area of concern comes from organizations that retain job and team silos. Above all, for experimentation to work well everyone needs to hold the same shared target outcomes. This helps to not only maintain cross-organizational alignment but also minimize the number of times an incorrect hypothesis needs to be disproven.
Silos make this difficult. They both unnecessarily fragment situational awareness and lead to the setting of localized targets that can easily become disjointed or compete with one another. This not only can make it difficult for solutions to emerge but can plunge the organization into an even more unordered contextual domain: the chaotic.
Chaotic: “The Domain of Rapid Response”

Figure 5.6
The chaotic domain, where everything feels out of control.
Problems in the chaotic domain tend to resemble a runaway freight train full of explosives engulfed in flame. The environment has ceased to function with any semblance of stability, making it the immediate priority to contain and establish order. It is the domain of the “unknowable,” where everything is collapsing catastrophically with no clear sign of a root cause or how to fix it. In effect, this makes it the domain that delivery teams should rightly fight hard to prevent.
In chaos the relationships between cause and effect are impossible to determine because the dynamics shift constantly with no manageable pattern. Situational awareness has been lost, and with it the ability to make all but the most rudimentary decisions. Such crises require decisive action to immediately triage and address the most pressing issues. Success for those who find themselves in the chaotic domain requires the following:
Identify and protect the most important areas in critical danger that can be saved.
Quickly delineate zones of stability and crisis.
Improve the flow of information wherever possible to improve awareness of and track the situation.
Establish effective lines of communication to reduce confusion and help marshal resources to contain threats.
Seek to stabilize and move the situation from chaos to complexity.
This all has to be done while quelling the desire for people within such an environment to panic.
The occasional foray into the chaotic domain can sometimes be therapeutic for organizations that have become ossified and need to be shaken up. These experiences create an opportunity to break with old concepts that are no longer fit for purpose and spur innovation and new ways of working. In fact, it is not uncommon for transformational leaders to nudge an organization into chaos in order to speed up the adoption of necessary changes.
However, the chaotic domain is not one that organizations can afford to remain in for any length of time. It is extremely stressful, and the lack of stability often drives away any sensible customers and staff alike. It is so dangerous that military strategists like Sun Tzu and Boyd encourage destabilizing the enemy by causing the dynamics of the battlefield to change faster than their decision process can handle. This is often referred to as “getting inside the enemy’s decision loop.”
There are some who thrive on the adrenaline rush and sense of heroism that can come with rushing into the crisis. They go to great lengths to seek it out, sometimes to the point of consciously or subconsciously creating the very conditions that push the organization into chaos themselves. They often crave the cult-like adoration that being seen as a hero can create. These groups can be thought of as the dictators and the firefighter arsonists.
The Dictators and the Firefighter Arsonists

Figure 5.7
The dictator.
Have you ever wondered why there are some people who seem to be content in, or even enjoy, environments that seem perpetually in chaos? You may even have gone further, wondering how dictators like Stalin, Mao, Saddam Hussain, and the Kims of North Korea were able to retain power despite having regularly purged their ranks in ways that seemingly weaken their nation’s capabilities. Such dictators seem to intentionally perpetuate the very chaos that is destroying what they should be protecting.
Some look to placate personal insecurities, while others want to experience that ego high they get by playing the hero. Frequently, it is some dynamic in the way that recognition and rewards are given either in the current organization or from one in the past that causes both types of people to act in ways that instill organizational chaos. It is important to recognize their danger signs, as well as the structures that can circumscribe their impact in case you someday discover one in your midst.
Dictators are the more dangerous of the two groups. Rather than helping the organization in the pursuit of target outcomes, they are instead constantly looking for ways to destabilize others. Sometimes the targets are potential rivals they want to undermine in order to gain advantage over. Other times the goal is simply to make their own area look comparatively better than others. Some particularly sadistic ones simply want to feel some sense of power and control that is ordinarily out of reach, even at the expense of the larger organization. The fact that the instability they cause may be costly to the organization is irrelevant as long as they achieve their personal aims.
Contrary to popular belief, such people do not need to be in a high position within an organization or have a particularly vast scope of authority. In fact, the most formidable ones sit at key pinch points and gatekeeping roles within the ecosystem. I have encountered them in roles as vast as Finance and Vendor Management, Legal, Architecture, IT Operations, Project & Program Management, and even IT desktop support. This gives them undue influence far beyond their assigned responsibilities, thereby enabling them to potentially endanger the overall goals of the business and desired outcomes of customers.
Common dictator patterns include threatening to slow, stop, or even force an alternative decision in a seemingly arbitrary way under the umbrella of protecting the company from an unseen or imagined risk. One example I have seen is forcing the use of a particular technology or architecture, claiming that it is the “only approved and acceptable option,” even when it is clearly inappropriate for the task at hand. Such behavior can force those having to navigate the gate to plead or make suboptimal choices in order to avoid missing deadlines or looking bad.
Another common example of a potential dictator is a developer or operations person who refuses to share with others on the team the intricacies of how to handle a particular subsystem. Their protected knowledge stunts the situational awareness, and thus overall decision-making abilities, of the entire organization. Intentionally or not, they use their knowledge to hold others in the organization hostage.
It is important to investigate the root cause for the behavior. Some who are lured into dictator-like behavior may be looking for control, whether to wield it over team members or to control the work itself and how it is prioritized. However, sometimes such behavior is caused by organizations that regularly act in ways that destroy trust. In such cases, the potential dictator may fear team members “messing things up” with no accountability, or that they themselves are not valued and are at risk of losing their job.
While dictators in leadership positions can use crises to drive needed change, some instead use them to quash such efforts, to reassert their control. They can commandeer resources and shut down viable alternatives under the banner of safety and security from perceived organizational threats. This is an effective means for crippling rivals and quashing ideas they find dangerous before the ideas can be proven to be viable and safe alternatives.
Figure 5.8
The firefighter arsonist at work.
Firefighter arsonists have entirely different motivations from dictators. They enjoy the thrill and label of heroism that comes with subduing chaos. They often seek out roles that allow them to rush to the rescue but are uninterested in any sort of crisis prevention.
Often you can tell that your organization is vulnerable to firefighter arsonists if individual heroes are regularly identified and celebrated. Public recognition for hard work can be extremely attractive, especially if other more healthy forms of recognition, such as shared pride in delivering products or services that really help others or the ability to regularly gain valuable career growth, are not readily attainable.
While there are some who crave the attention that comes with tackling crises, not all firefighter arsonists deliberately create a crisis. In fact, many people become unintentional arsonists by narrowly focusing on their immediate area of responsibility and not taking ownership for how their role and the work they do helps the organization achieve its objectives. This functional focus, which is often reinforced by the organization and the way it evaluates individual performance, causes some to ignore or not feel responsible for what is happening upstream or downstream. Others insist upon performing their role in accordance with some prescribed process or long-established practice, believing that they are working in an ordered domain even when there may be external signs that those processes and practices are negatively affecting the health of the larger ecosystem.
By maintaining this siloed view, such IT firefighter arsonists may add features that they know will earn them kudos without thinking of how they will be used, or how the health of the underlying code will be supported and maintained. They might ignore the value in unit testing, sensible repository structures, frequent check-ins, automated build systems, continuous integration, automated deployment, or environment hygiene. Often they will use the excuse that such activities are wasteful or are not conducive to their “more effective” way of working. In reality, the pushback typically is due to deep-seated concerns that no one of sufficient importance will recognize and give them credit for such efforts. Likewise, they will triage an outage and create workarounds for bugs out of expediency to get back to more interesting work without seeking to understand the root cause of the problem or how to prevent it from reoccurring.
One of the most effective ways to deal with dictators and arsonists is to look at what in the ecosystem might be causing them to act the way they do. Does the organization reward bad behavior? Is there little trust or transparency? Are roles and responsibilities laid out in a fragmented way that discourages people to see the whole? Is there an organizational culture that encourages following processes over delivering outcomes? Are there organizational bottlenecks managed by someone not accountable for helping deliver the target outcomes that matter to the customer? These are important places to investigate in order to minimize or eliminate the underlying root causes whenever possible.
Another strategy that helps flush out such dysfunction is to rotate duties. This can help widen people’s feelings of responsibility and desire to collaborate, particularly if they believe that they might fall foul of suddenly being responsible for the unknown. Rotation forces people to investigate and learn.
The Domain of Confusion

Figure 5.9
Sally realizes that she just entered the land of confusion.
Much like being between gears in a car, confusion is a domain of transition that sits in the fifth quadrant in the middle between the systems and other domains. It is like being lost in a dense forest. The primary goal when you find yourself in confusion is to gather more information so that you can orient yourself and move into a known domain where you can then take the appropriate action. Few find themselves in confusion for long, if for no other reason than because it is the domain of decision paralysis.
Reimagining Risk Management
While understanding the complexity of the domain that you are operating in is important for helping you avoid approaching risk management the wrong way, there are several actions you can take that can help reduce risk and improve your ability to make effective decisions regardless of domain complexity. Each will likely sound fairly obvious at first glance, and all are elements that can be found throughout this book.
Let’s take a look at each of the actions.
Have Clear and Understood Target Outcomes
Many of us in IT focus so much on the risk of failing to meet deadlines, service failures, missing service level commitments, and security breaches that we often forget the most important risk: the risk that our work will not achieve the needs and target outcomes of the customer.
One of the biggest causes for failing to meet target outcomes is simply not knowing or understanding well enough what they are. This can occur because no one bothers to mention them, or what is shared is either output-based or localized to individual silos and not aligned across the organization and with the needs of the customer. Similarly, few discuss fully the anti-goals, or what hazards and situations must be avoided and why. Chapter 11, “Mission Command,” goes into great depth about both the causes for these common dysfunctions and ways to avoid or overcome them.
Knowing and understanding the target outcomes is important for everyone in every type of complexity domain. This even includes the Clear domain. While tasks might be so obvious in a Clear domain that management can script them, there is actually a lot of value in making sure the workers performing the tasks know what they are for and what outcomes they are trying to achieve.
This was a key part of the Job Instruction part of Training Within Industry, the program considered as one of the leading sources of many of the founding principles of Lean Manufacturing that the US military used to train new factory workers to help the war effort during World War II. While work was broken down into small pieces and scripted, workers were also told what outcome the work was trying to achieve. The idea was that by knowing the target outcome, workers could use that knowledge to find and suggest improvements that superiors might not have noticed that can better achieve the outcome. Having a clear purpose also has a great side benefit of being motivating to workers.
Make the Best Choice the Easiest Choice
Figure 5.10
The best choice should be the easiest to execute.
Whether it is manually performing quick hacks to production or choosing a shortcut that reuses an unreliable or insecure piece of software, a lot of poor decisions are made because the chosen action is quicker or easier than the best choice. Choosing the shortcut simply because it is quick and easier might seem absurd due to the risks involved. Yet time, resource, and budgetary pressures themselves are often viewed as immediate risks that need to be mitigated. The more serious risks they create are not only distant, but those who ultimately have to deal with them are frequently different.
The best way to mitigate such risks is to make it far easier and obviously beneficial to choose the best, and ultimately less risky, choice for the organization and customer. One approach is to use an idea from Lean Manufacturing of making it so that parts can only be assembled the right way. Network RJ-45 jacks and USB cables are common physical examples. Software packaging and various forms of defined and managed access controls and versioning for service APIs can make it so that software can be installed only in the right place with the right dependencies, and that services can talk only to services with the right access and version details.
When it comes to minimizing manual hacks, the first step is to make the environment such that using traceable and reproducible approaches is faster, requires less effort, and is longer lasting than any alternatives. Automated hands-free build, deploy, and configuration management tools that reduce the effort and friction to make changes certainly help. I usually pair this with eliminating all need for any sort of shell or administrative access where manual changes can be put in place. I do this by putting in place tools that can perform those activities in a reproducible and trackable way. I also put in place a system that regularly polls for configuration and state of deployed instances. If any irregularities are detected, those instances can be either immediately and automatically shut down and quarantined for later examination, or automatically destroyed and rebuilt from the last known good configuration state. Such an approach makes it extremely difficult, if not nearly impossible, to make unknown out-of-band changes.
The next step is to find ways to make the total cost and risk profile of using a quick but poorly suited solution visible. It is important to note that the time and cost pressures that make suboptimal solutions appear attractive often ignore the total cost of ownership (TCO) in the form of support, maintenance, and risks to the organization’s ability to satisfy its customers. Sometimes this is caused by a project team that is not responsible for the ongoing costs and success of a solution after delivery. Other times someone in the decision chain is suffering from a sunk cost fallacy bias (mentioned in Chapter 6, “Situational Awareness”), hoping to somehow recoup money already spent regardless of the solution’s suitability for the task.
To capture the TCO, I use a combination of the data collected by the Queue Master and the data in the team’s workflow board (as discussed in Chapter 12, “Workflow”), along with any instrumentation data (or lack thereof) showing how well the solution performs to meet customer outcomes. Such information can often be reshaped in a monetary (such as people and resource costs for support and maintenance, as well as risks to contractual commitment costs and lost customer revenue) or lost opportunity form (such as resources that must be committed to supporting and maintaining the solution instead of being used for other initiatives, as well as risk exposures to any known potential unrecoverable faults or security breaches).
I find that such cost information not only helps with rebalancing the consideration of near- and long-term costs, but also helps create a means for putting project teams on the hook for ongoing costs. This might not be easy to do yourself if you are an individual contributor. However, by creating the means for collecting and reporting cost-benefit data around the options being considered, management has a way of ensuring that project teams are aware that they must choose between committing resources to pick up excess costs or having their sponsors be charged back for them.
Continually Improve Ecosystem Observability

Figure 5.11
Improving ecosystem observability helps you understand what dynamics you are up against.
It is difficult to mitigate risks that you cannot find or know anything about. This is why it is critical to continually look for ways to improve the observability of the state and interactions of elements throughout your ecosystem.
It is easy to assume that everything is automatically observable by default in an ordered system domain and hidden in an unordered system domain. Neither is necessarily true.
In ordered systems everything might be visible but enough context is obscured that awareness degrades. This obscuring of problems is remarkably common. For manufacturers, tools and materials on a workbench can look both ordinary and expected yet be hiding a number of serious problems, from misplaced or broken tools to defective material. Lean Manufacturers use color coding for tools, carts, and workspaces to make it obvious when anything is out of place or to make it clear when an item is broken or defective. In IT, simple tasks like restarting a service, creating accounts, or even pushing an update to an environment can hide everything from defects and demands on team resources to potential security concerns. This is why such items are captured and tracked by the Queue Master, as mentioned in Chapter 13, “Queue Master,” and reviewed regularly for improvement.
In unordered systems, not bothering to improve observability just makes it more difficult for context to emerge or activities to be directed to stabilize a chaotic situation. There are lots of ways throughout the service delivery lifecycle to greatly reduce the noise in an unordered system domain. The first is to organize your service ecosystem “workbench.” This includes the following actions:
Make sure all code, packages, configurations, and (if possible) tools and tests used to deliver and maintain the services are revision controlled and tracked throughout their lifecycle. The goal is to put in the key data needed to be able to re-create and “walk” the delivery and maintenance chain based on release, time, and deployment environment.
Capture and track any changes to your ecosystem. Who updated the code/package/configuration/tool/test/deploy targets, when was it updated, what was changed, and why was it changed? This should allow you to trace back to when errors or vulnerabilities were introduced in order to help with troubleshooting, understanding the length and extent of any potential exposure, and ultimately fixing the problem.
Capture and track your dependency chain. Are there third-party technologies or services you rely upon? If so, where are the touch points? How much visibility do you have into the stack to determine their stability and security? What are the effects to your delivery and production service capabilities if they fail or are compromised in some way?
Part of your service workbench also includes the environment that you use to build and run your services. Ensuring good environment hygiene is a good way to ensure that as much of the configuration of the delivery and operational environments are known and reproducible as possible. To do this, the team should aim to achieve the following:
Put mechanisms in place so that every instance can be destroyed, and the entire stack confidently re-created identically from scratch from the component level. Along with what versions of components are deployed, I also like to track the last date each component was rebuilt from scratch. That allows you to spot potential blind spots that may need to be investigated.
Implement mechanisms so that anyone authorized can, with a known level of confidence, generate a full configuration manifest of an instance without using “discovery tools.” This allows you to track what you have, as well as spot potential vulnerability areas and their impacts quickly.
Ensure that there are mechanisms in place that allow the team to confidently track and trace through component, instance, and environment changes over time without resorting to digging through change requests and guessing. They can use this date to confidently reproduce the configuration that was live at a given date.
Understand the data stack and the flow of data across the service ecosystem. There are many aspects that are important to know, such as:
Where is the data located, where does it flow, and how does it move across your delivery ecosystem?
What is the security/protection/privacy profile of each data element, and how is it secured and verified?
How does that data profile affect where the data can be placed, who can use it, and how long it can be retained?
What data qualities impact the performance and availability of various services?
How are these data qualities captured, tracked, tested, and verified as part of delivery?
How would the ecosystem be restored, how long would it take to restore it, and are there any data synchronization or alignment issues that would need to be addressed (and, if so, how)?
Finally, there are other areas throughout your delivery lifecycle where data can and should be collected and regularly reviewed and analyzed as part of the delivery team’s tactical and strategic review cycles that can help uncover potential risk areas. Many of these areas are covered in Chapter 11, “Instrumentation,” and include the following:
Code and build statistics
Person, tool, and service access control lists and the mechanisms to track and audit access events and resulting activities
Team stability and communication patterns
Responsiveness and reliability of each external delivery and maintenance supply chain dependencies
Code management efficacy
Bug densities and integration issues
Incident histories
Production load and performance statistics
Code instrumentation
Customer usage patterns and journey flows across your service ecosystem
Environment configuration management hygiene levels
Customer tolerances for degraded performance and failure
Security incidents and impact severities
Each of these is likely to produce some level of insight into the health and stability of various elements of your ecosystem.
Where they become particularly powerful is when these mechanisms are used together. For instance, someone can look at customer usage patterns that trace when and how they use a service. This data can be combined with incident and performance statistics to see if there are any interesting correlations that may indicate a problem. The results can then be matched with code instrumentation to determine which pieces of code and infrastructure are being exercised at those moments. From there, delivery teams can review the code and infrastructure that make up those exercised components to see if any are new or have a history of instability or brittleness.
Over time, such mechanisms can be used to help two useful patterns emerge. The first is an indication of potential risk areas that may need extra attention to better understand and ultimately mitigate. Secondly, the data from these mechanisms can provide clues of changing patterns that may indicate new emerging risks or even an unexpected shift in domain complexity. This information can be used to help the organization prepare and more proactively manage these risks.
Summary
As the service delivery ecosystem has become increasingly dynamic, interconnected, and important to customers, the flaws in the more traditional ways of managing risk in IT have become apparent. The move to DevOps is an opportunity to rethink how best to perform risk management. Understanding the dynamics and contextual domain of your delivery ecosystem can help you spot where the wrong policies and behaviors can expose you and your customer to problematic delivery and operational risks. By ensuring that everyone knows and shares the same target outcomes, all while putting in place mechanisms that improve observability as well as make it both easier and more likely that better and less risky decisions will be taken, you can both deliver more reliably and securely to meet your customer’s needs.