
Chapter 10. Controlling Change in Production Environments
If you know neither the enemy nor yourself, you will succumb in every battle.
—Sun Tzu
In engineering and chemistry circles, the word stability is defined as a resistance to deterioration, or alternatively as a constancy in makeup and composition. Something is “highly instable” if its composition changes regardless of the actual rate of activity within the system, and it is “stable” if its composition remains constant and it does not disintegrate or deteriorate. In the hosted services world, as well as with enterprise systems, one way to create a stable service is simply to not allow activity on it and to limit the number of changes made to the system. The term “changes,” in the previous sentence, is an indication of activities that an engineering team might take in reference to a system, such as modifying configuration files or updating a revision of code on the system. Unfortunately for many of us, the elimination of changes within a system, while potentially improving stability, will limit the ability of our businesses to grow. Therefore, we must not simply allow changes, but both enable and embrace changes while simultaneously implementing processes that manage the risk to availability that these changes present.
Our experience has taught us that a large portion of incidents in a production environment are caused or triggered by software and hardware changes. Without active change management with the intent of reducing risk, services will deteriorate or disintegrate (that is, become unavailable). It follows that you must manage change to ensure that you have a scalable service and happy customers.
Having processes that help you manage the effect of your changes is critical to your scalability success. These processes become even more important in a world of continuous delivery, where changes happen throughout the day and where short spans of time separate the ideation of an action and the implementation of that action. The absence of any process to help manage the risk associated with change is a surefire way to cause both you and your customers a great deal of heartache. Thinking back to our “shareholder” test, can you really see yourself walking up to one of your largest shareholders and saying, “We will never log our changes or attempt to manage them, because doing so is a complete waste of time”? You’re highly unlikely to make such a statement, at least if you want to keep your job. With that in mind, let’s explore the world of change management and change identification.
What Is a Change?
Sometimes, teams define a change as any action that has the possibility of breaking a service, system, or application. The primary problem with this “classic” definition is its failure to acknowledge that change is necessary in any system that we hope to evolve and grow. The tone of the definition is pejorative in nature—it implies that a change is a risk and that risk is always bad. While change absolutely represents a risk, this is not inherently bad. Without risk, we cannot have a return on our investment. Put another way, there are no risk-free returns. Products that are lucky enough to experience rapid growth in acquired users or transactions require new servers and capacity to fulfill additional user and transaction demand. Product teams that are seeking to add functionality to increase user engagement need to add new services or modify existing services. Successful product teams may want to increase what they charge for their product or service. All of these actions are changes, and while they all carry some level of risk, they also represent some potential future value.
Our preferred definition of a change is agnostic to both the risk and the value creation elements inherent to said change. A change is any action you take to modify a product or service (including system data). Modifying the prices of products is a change, as is modifying the schema that supports those products in a relational database. Changes are actions you make in regard to a product or system to modify its behavior, enhance its value, or extend its capacity.
Changes include modifications in configuration, such as altering values used during startup or run time of your operating systems, databases, proprietary applications, firewalls, network devices, and so on. Changes also include any modifications to code, additions of hardware, removal of hardware, connection of network cables to network devices, and powering systems on and off. As a general rule, whenever one of your employees needs to touch, twiddle, prod, or poke any piece of hardware, software, or firmware, it is a change.
Change Identification
The very first thing you should do to limit the impact of changes is to ensure that each and every change that goes into your production environment gets logged with the following data:
• Exact time and date of the change
• System undergoing change
• Actual change
• Expected results of the change
• Contact information of the person making the change
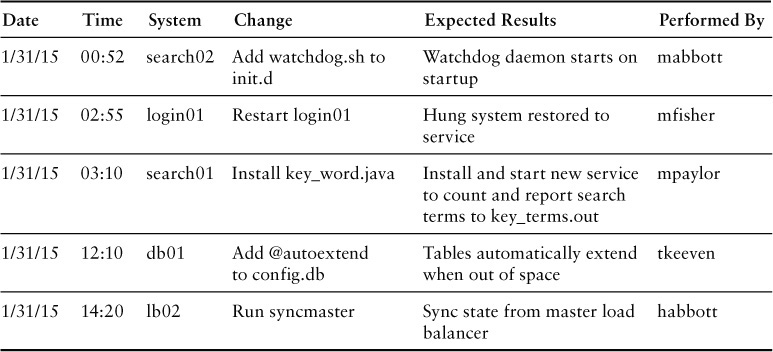
An example of the minimum necessary information for a change log is included in Table 10.1. To understand why you should include all of the information from these five items, let’s examine a hypothetical event with the AKF Partners Web site (www.akfpartners.com). While it is not a revenue-generating site, AKF Partners relies on this Web site to promote its services and bring in new clients. We also host a blog rich in content focused on helping current and future clients solve many pressing needs within their product teams. The AKF Partners Web site has login and client authentication functionality that allows clients access to white papers, proprietary research, and data collected on usage statistics for technology. Our internal definition of a crisis is anything greater than a 10% failure rate for any critical component (login is considered to be critical). When that threshold is exceeded, Mike Fisher, the AKF Partners crisis manager, is paged, and he starts to assemble the crisis management team with the composition discussed in Chapter 9. Once Mike has everyone assembled, what do you think should be the first question that he asks?
We often get answers to this query ranging from “What is going on right now?” to “How many customers are impacted?” to “What are the customers experiencing?” All of these are good questions and absolutely should be asked, but they are not the question that is most likely to reduce the duration and impact of an outage. The question Mike should ask first is “What changed most recently?” In our experience, changes are the leading cause of incidents in production environments.
Asking this question gets people thinking about what they did that might have caused the problem at hand. It focuses the team on attempting to quickly undo anything that is correlated in time to the beginning of the incident. It is the best opening question for any incident, from one with a small customer impact to a major crisis. It is a question focused on restoration of service rather than problem resolution.
One of the most humorous answers we encounter time and again after asking, “What changed most recently?” goes like this: “We just changed the configuration of the blah service but that can’t possibly be the cause of this problem!” Collectively, we’ve heard this phrase hundreds, if not thousands, of times in our careers. From this experience, we can almost guarantee that when you hear this answer, you have found the cause of the incident. Focus on this change as the most likely cause! In our experience, the person might as well have said, “I caused this—sorry!” Okay, back to more serious matters.
Rarely will everyone who has made a change be present when you are troubleshooting an incident. As such, you really need a place to easily collect the information identified earlier. The system that stores this information does not need to be an expensive third-party change management and logging tool. It can just as easily be a shared email folder, with all changes identified in the subject line and sent to the folder at the time of the actual change by the person making the change. We have seen companies a few hundred people in size effectively use email folders to communicate and identify changes. Larger companies probably need more functionality, including a way to query the system by the subsystem being affected, the type of change, and so on. But all companies need a place to log changes so that they can quickly recover from those that have an adverse customer or stakeholder impact. This change identification log, wherever it may be, should provide the definitive answer to the “What changed most recently?” question.
Change Management
Change identification is a component of a much larger and more complex process called change management. The intent of change identification is to limit the impact of any change by being able to determine its correlation in time to the start of an event and thereby its probability of causing that event. This limitation of impact increases your ability to scale, because it ensures that less time is spent working on value-destroying incidents. The intent of change management is to limit the probability of changes causing production incidents by controlling them through their release into the production environment and by logging them as they are introduced to production. Great companies implement change management to increase the rate of change, thereby benefiting from the value inherent in change while minimizing the associated risks.
Change identification is a point-in-time action, where someone indicates a change has been made and moves on to other activities. By comparison, change management is a life-cycle process whereby changes are
• Proposed
• Approved
• Scheduled
• Implemented and logged
• Validated as successful
• Reviewed and reported on over time
The change management process may start as early as when a project is going through its business validation (or return on investment analysis), or it may start as late as when a project is ready to be moved into the production environment. Change management also includes a process of continual process improvement whereby metrics regarding incidents and resulting impact are collected to improve the change management process.
Note that none of these activities, from proposal to reporting, needs to be a manual process. In the world of continuous integration and continuous delivery, each can be an automated task. For instance, once a product change (e.g., a code commit) has passed all appropriate tests, the continuous delivery framework can auto-approve and schedule the change so that it does not conflict with other changes. The system can then implement the change, perform automatic validation, and (of course) log the exact time of the change. Some of our clients extend this concept to implement “standard changes” that may include such activities as configuration changes and capacity adds. These changes are common and repeatable tasks, but still bear some risk and, therefore, must be logged for identification. The use of the word “process” here does not indicate human intervention; in fact, each step can be automated.
The one exception to this is the need to review the efficacy and impact of changes over time. While our process may be completely automated, as in the case of a well-designed continuous delivery process, it still must be evaluated to ensure it is meeting our organization’s needs. Which improvements can we make? Where is the continuous delivery process not meeting our end objectives? Where can we make tweaks to more effectively manage our risk and maximize value creation?
Change Proposal
As described earlier, the proposal for a change can occur anywhere in your change management cycle. The IT Service Management (ITSM) and ITIL frameworks hint at identification occurring as early in the cycle as the business analysis for a change. Within these frameworks, the change proposal is called a request for change. Opponents to ITSM actually cite the inclusion of business/benefit analysis within the change process as one of the reasons that the ITSM and ITIL are not good frameworks. These critics insist that the business benefit analysis and feature/product selection steps have nothing to do with managing change. Although we agree that these are two separate processes, we also believe that a business benefit analysis should be performed at some point. If business benefit analysis isn’t conducted as part of another process, including it within the change management process is a good first step. That said, this book deals with scalability and not with product and feature selection, so we will simply state that such a benefit analysis should occur somewhere.
The most important point to remember regarding a change proposal is that it kicks off all other activities. Ideally, it will occur early enough to allow some evaluation as to the impact of the change and its relationship with other changes. For the change to actually be “managed,” we need to know certain things about the proposed change:
• The system, subsystem, and component being changed
• The expected result of the change
• How the change is to be performed
• Known risks associated with the change
• The relationship of the change to other systems and recent or planned changes
You might decide to track significantly more information than this, but we consider the preceding items to be the minimum information necessary to properly plan change schedules. As we indicated earlier, none of these needs to be manual in nature and none of the data elements fly in the face of a continuous delivery processes. It is easy, upon submitting a product for integration, testing, and deployment, to identify each of these areas within the continuous delivery framework.
The system undergoing change is important because we hope to limit the number of changes to a given system during a single time interval. Consider that a system is the equivalent of a runway at an airport. We don’t want two changes colliding on the same system because if a problem arises during the change, we won’t immediately know which change caused it. Similarly, we want the ability to monitor and measure the results of each change independently of the others. As such, the change management process or continuous delivery system needs to know the item being changed, down to the granularity of what is actually being modified. For instance, if we are making a software change and a single large executable or script contains 100% of the code for that subsystem, we need only identify that we are changing out that executable or script. In contrast, if we are modifying one of several hundred configuration files, we should identify exactly which file is being modified. If we are changing a file, configuration, or software on an entire pool of servers with similar functionality, the pool is the most granular thing being changed and should be so identified.
Architecture here plays a huge role in helping us increase change velocity. If our technology platform comprises a number of discrete services, we have increased the number of venues in which changes have been made—equivalent to increasing the number of airports or runways on which we can land planes in our aircraft analogy. The result is a greater throughput of total changes: Aircraft now have more landing slots. If the services communicate asynchronously, we would have a few more concerns, but we are also likely more willing to take risks. Conversely, if the services communicate synchronously, there isn’t much more fault tolerance than is available with a monolithic system (see Chapter 21, Creating Fault-Isolative Architectural Structures). If Service A and Service B communicate synchronously to produce a result, we can’t change them at exactly the same time because then we would have no clue which change was proximate to a potential incident. Returning to the aircraft analogy, landing slots are not increased for change management. The expected result of the change is important because we want to be able to verify later that the change was successful. For instance, if a change is being made to a Web server and is intended to allow more threads of execution in the Web server, we should state that as the expected result. If we are making a modification to our proprietary code to correct an error where the capital letter “Q” shows up as its hex value 51, we should indicate that outcome is intended.
Information regarding how the change is to be performed will vary with your organization and system. You may need to indicate precise steps if the change will take some time or requires a lot of work. For instance, if a server needs to be stopped and rebooted, that might affect which other changes can be happening at the same time. Providing the steps for the change also allows you to reproduce and improve the process when you need to repeat the change or roll out a similar change in the future, which will both reduce the time it takes to prepare the change the next time and reduce the risk of missing a step. The larger and more complex the steps for the change in production, the more you should consider requiring those steps to be clearly outlined.
Identifying the known risks of the change is an often-overlooked step. Very often, requesters of a change will quickly type in a commonly used risk to speed through the change request process. A little time spent in this area could pay huge dividends in avoiding a crisis. For example, if there is the risk that data corruption may occur if a certain database table is not “clean” or truncated prior to the change, this possibility should be pointed out during the change. The more risks that are identified, the more likely it is that the change will receive the proper management oversight and risk mitigation, and the higher the probability that the change will be successful. We cover risk identification and management in Chapter 16, Determining Risk, in much greater detail. With automated continuous delivery processes and systems, identification of a risk level or risk value may help the system determine how many changes can be applied in any given interval. We describe this process and consider how it applies to automated continuous delivery systems in the “Change Scheduling” section later in this chapter.
Complacency often sets in quickly with these processes, and teams are quick to assume that identifying risks is simply a “check the box” exercise. A great way to incent the appropriate behaviors and to get your team to analyze risks is to reward those team members who identify and avoid risks and to counsel those who have incidents that occur outside of the risk identification limits. This isn’t a new technique, but rather the application of tried-and-true management techniques. Another great tactic may be to show the team data from your environment indicating how changes have resulted in incidents. Remind the team that a little time spent managing risks can save a lot of time wasted on managing incidents.
Depending on the process that you ultimately develop, you may or may not decide to include a required or suggested date for your change to take place. We highly recommend developing a process that allows individuals to suggest a date and time; however, the approving and scheduling authorities should be responsible for deciding on the final date based on all other changes, business priorities, and risks. In the case of continuous delivery, suggested dates may be considered by the solution in identifying the optimal risk level for any given change interval.
Change Approval
Change approval is a simple portion of the change management process. Your approval process may simply be a validation that all of the required information necessary to “request” the change is indeed present (or that the change proposal has all required fields filled out appropriately). To the extent that you’ve implemented some form of the RASCI model, you may also decide to require that the appropriate A, or owner of the system in question, has signed off on the change and is aware of it. Another lightweight step that may expedite the approval process is to include a peer review or peer approval. In that case, the peer may be asked to review the steps for completeness and to help identify missing dependencies. The primary reason for the inclusion of this step in the change control process is to validate that everything that should happen prior to the change occurring has, in fact, happened. This is also the place at which changes may be questioned with respect to their priority relative to other changes.
An approval here is not a validation that the change will have the expected results; it simply means that everything has been discussed and that the change has met with the appropriate approvals in all other processes prior to rolling out to the system, product, or platform. Bug fixes, for instance, may have an abbreviated approval process compared to a complete reimplementation of the entire product, platform, or system. The former is addressing a current issue and might not require the approval of any organization other than QA, whereas the latter might require a final sign-off from the CEO.
Continuous delivery systems may auto-approve most types of changes but place others (e.g., data definition [DDL] changes, schema modifications to complex databases) on hold based on a predefined category or the risk level limit. Because QA is usually completely automated in such systems, the QA approval is achieved upon successful completion of the automated regression suite, including any new tests checked into the test suite for the purposes of testing the new functionality. Other major risk factors are evaluated by the algorithm codified within the continuous delivery solution, with major concerns kicked out for manual review, and all others scheduled for introduction into the production environment.
Change Scheduling
The process of scheduling changes is where most of the additional benefit of change management occurs relative to the benefit obtained when you implement change identification. This is the point where the real work of the “air traffic controllers” comes in. That is, a group tasked with ensuring that changes do not collide or conflict applies a set of rules identified by its management team to maximize change benefit while minimizing change risk.
The business rules will likely limit changes during peak utilization of your platform or system. If you experience the heaviest utilization rates between 10 a.m. and 2 p.m., it probably doesn’t make sense to roll out your largest and most disrupting changes during this time frame. In fact, you might limit or eliminate altogether changes during this time frame if your risk tolerance is low. The same might hold true for specific times of the year. Sometimes, though, as in very high-volume change environments, we simply don’t have the luxury of disallowing changes during certain portions of the day and we need to find ways to manage our change risks elsewhere.
This set of business rules might also include an analysis of the type of risk discussed in Chapter 16, Determining Risk. We are not arguing for an intensive analysis of risk or even indicating that your process absolutely needs to have risk analysis. Rather, we are stating that if you can develop a high-level, easy-to-use mechanism for risk analysis of the change, your change management process will be more robust and likely yield better results. Each change might include a risk profile of, say, high, medium, and low during the change proposal portion of the process. The company then might decide that it wants to implement no more than 3 high-risk changes, 6 medium-risk changes, and 20 low-risk changes during the same week. Assigning risk levels as simple as high, medium, and low also makes it easy to correlate incidents to risk levels and, therefore, to evaluate and improve your risk assessment process. Obviously, as the number of change requests increases over time, the company’s willingness to accept more risk on any given day within any given category will need to increase; otherwise, changes will back up in the queue and the time to market to implement any change will increase. One way to help both limit risk associated with change and increase change velocity is to implement fault-isolative architectures described in Chapter 21.
Another consideration during the change scheduling portion of the process might be the beneficial business impact of the change. This analysis ideally will be done in some other process, rather than being performed first for the benefit of change. That is, someone, somewhere will have decided that the initiative requiring the change will be of benefit to the company. If you can then represent that analysis in a lightweight way within the change process, it is very likely to inform better decisions around scheduling. If the risk analysis measures the product of the probability of failure multiplied by the effect of failure, the benefit assessment would then analyze the probability of success along with the impact of such success. The company would be incented to move as many high-value activities to the front of the queue as possible, while remaining wary not to starve lower-value changes.
An even better process would be to implement both processes, with each recognizing the other in the form of a cost–benefit analysis. Risk and reward might offset each other to create some value that the company determines, with guidelines being established to implement changes in any given day based on a risk–reward tradeoff between two values. We’ll cover the concepts of risk and benefit analysis in Chapter 16.
Change Implementation and Logging
Change implementation and logging is basically the function of implementing the change in a production environment in accordance with the steps identified within the change proposal and consistent with the limitations, restrictions, or requests identified within the change scheduling phase. This phase consists of two steps: logging the start time of the change and logging the completion time of the change. This is slightly more robust than the change identification process identified earlier in the chapter, but also will yield greater results in a high-change environment. If the change proposal does not include the name of the individual performing the change, the change implementation and logging steps should explicitly identify the individuals associated with the change. Clearly automated CD systems can do this easily, creating a great change management log to help aid in incident and problem management.
Change Validation
No process is complete without verification that you accomplished what you expected to accomplish. While this should seem intuitively obvious to the casual observer, how often have you asked yourself, “Why the heck didn’t Sue check that before she said she was done?” That question follows us outside the technology world and into everything in our life: The electrical contractor completes the work on your new home, but you find several circuits that don’t work; your significant other says that his portion of the grocery shopping is done, but you find five items missing; the systems administrator claims that he is done with rebooting and repairing a faulty system, but your application still doesn’t work.
Our point here is that you shouldn’t perform a change unless you know what you expect to get from that change. In turn, if you do not get that expected result, you should consider undoing the change and rolling back or at least pausing and discussing the alternatives. Maybe you made it halfway to where you want to be if it was a tuning change to help with scalability, and that’s good enough for now.
Validation becomes especially important in high-scalability environments. If your organization is a hyper-growth company, we highly recommend adding a scalability validation to every significant change. Did you change the load, CPU utilization, or memory utilization for the worse on any critical systems as a result of your change? If so, does that put you in a dangerous position during peak utilization/demand periods? The result of validation should either be an entry indicating when validation was complete by the person making the change, a rollback of the change if it did not meet the validation criteria, or an escalation to resolve the question of whether to roll back the change.
In CD systems, the payload delivery (also known as rollout or automated release) component may be augmented to include test scripts that validate the new system similar to how it was validated in the unit test suite. Additionally, DevOps or operations personnel should see key performance indicators identifying when new changes were delivered to the runtime environment. Such indicators may be plotted along the x-axis of the metrics and monitors that these personnel watch in real time so that they can correlate system behavior changes with new changes in the environment.
Change Review
The change management process should include a periodic review of its effectiveness. As explained in Chapter 5, Management 101, you simply cannot improve that which you do not measure. Key metrics to analyze during the change review include the following items:
• Number of change proposals submitted
• Number of successful change proposals (without incidents)
• Number of failed change proposals (without incidents but changes were unsuccessful and didn’t make it to the validation phase)
• Number of incidents resulting from change proposals
• Number of aborted changes or changes rolled back due to failure to validate
• Average time to implement a proposal from submission
Obviously, we are looking for data indicating the effectiveness of our process. If we have a high rate of change but also a high percentage of failures and incidents, something is definitely wrong with our change management process; in addition, something is likely wrong with other processes, our organization, and maybe our architecture. Aborted changes, on the one hand, should be a source of pride for the organization, confirming that the validation step is finding issues and keeping incidents from happening. On the other hand, they also serve as a source of future corrections to process or architecture, when the primary goal should be to have a successful change.
The Change Control Meeting
We’ve referred several times to a meeting wherein changes are approved and scheduled. ITIL and ITSM refer to such meetings and gatherings of people as the change control board or change approval board. Whatever you decide to call it, we recommend a regularly scheduled meeting with a consistent set of people. It is absolutely okay for this to be an additional responsibility for several individual contributors and/or managers within your organization; oftentimes, having a diverse group of folks from each of your technical teams and even some of the business teams leads to the most effective reviewing authority possible.
Depending on your rate of change, you should consider holding such a meeting once a day, once a week, or once a month. If the change implementers use diligence when filling out their change proposals with all required fields, the meetings can be short and efficient. Attendees ideally will include representatives from each of your technical organizations and at least one team outside of technology that can represent the business or customer needs. Typically, the head of the infrastructure or operations teams “chairs” the meeting, as he or she most often has the tools needed to review change proposals and completed or failed changes.
The team should have access to the database wherein the change proposals and completed changes are stored. It should also have a set of guidelines by which it analyzes changes and attempts to schedule them for production. Some of these guidelines were discussed previously in this chapter.
With automated delivery systems, such as exist within CD environments, meetings can occur less frequently and focus on changes that were rejected by the automated system. In such environments, meetings may also address the efficacy of the CD solution with an eye toward tweaking the system to allow for more risk, added control parameters, and other modifications.
Part of the change control meetings, on a somewhat periodic basis, should be a review of the change control process using the metrics we’ve identified. It is absolutely acceptable to augment these metrics. Where necessary, postmortems should be scheduled to analyze failures of the change control process. These postmortems should be run consistently with the postmortem process identified in Chapter 8, Managing Incidents and Problems. The output of these postmortem sessions should be tasks to correct issues associated with the change control process, or information that feeds into requests for architecture changes or changes to other processes.
Continuous Process Improvement
Besides the periodic internal review of the change control process identified in the “Change Control Meeting” section, you should implement a quarterly or annual review of the change control process. Are changes taking too long to implement as a result of the process? Are change-related incidents increasing or decreasing as a percentage of total incidents? Are risks being properly identified? Are validations consistently performed and consistently correct? As with any other process, the change control process should not be assumed to be correct, or to stay correct forever. Although it might work well for a year or two given some rate of change within your environment, as your organization grows in complexity, rate of change, and rate of transactions, this process very likely will need tweaking to continue to meet your needs. As discussed in Chapter 7, Why Processes Are Critical to Scale, no process is right for every stage of your company’s life span.
Conclusion
Change identification is a very lightweight process for very young and small companies. It is powerful in that it can help limit the negative impact on customers when changes go badly. However, as companies grow and their rate of change grows, they often need a much more robust process that more closely approximates an air traffic control system.
Change management is a process whereby a company attempts to take control of its changes. This process serves to safely manage changes, not to slow the change process down. Change management processes can vary from lightweight processes that simply attempt to schedule changes and avoid change-related conflicts to very mature processes that attempt to manage the total risk–reward tradeoff on any given day or hour within a system. As your company grows and as its need to manage change-associated risks grows, you will likely move from a simple change identification process to a very mature change management process that takes into consideration risk, reward, timing, and system dependencies.
Key Points
• A change happens whenever any employee needs to touch, twiddle, prod, or poke any piece of hardware, software, or firmware.
• Change identification is an easy process for young or small companies focused on being able to find recent changes and roll them back in the event of an incident.
• At a minimum, an effective change identification process should include the exact time and date of the change, the system undergoing change, the expected results of the change, and the contact information of the person making the change.
• The intent of change management is to limit the impact of changes by controlling them through their release into the production environment and by logging them as they are introduced to production.
• Change management consists of the following phases or components: change proposal, change approval, change scheduling, change implementation and logging, change validation, and change efficacy review.
• The change proposal kicks off the process and should contain, at a minimum, the following information: the system or subsystem being changed, the expected result of the change, information on how the change is to be performed, known risks, known dependencies, and relationships to other changes or subsystems.
• The change proposal in more advanced processes may also contain information regarding risk, reward, and suggested or proposed dates for the change.
• The change approval step validates that all information is correct and that the person requesting the change has the authorization to make the change.
• The change scheduling step is the process of limiting risk by analyzing dependencies, assessing rates of changes in subsystems and components, and minimizing the risk of an incident. Mature processes will include an analysis of risk and reward.
• The change implementation step is similar to the change identification lightweight process, but includes the logging of start and completion times within the changes database.
• The change validation step ensures that the change had the expected result. A failure here might trigger a rollback of the change, or an escalation if a partial benefit is achieved.
• The change review step is the change management team’s internal review of the change process and the results. It looks at data related to rates of changes, failure rates, impact to time to market, and so on.
• At the change control meeting, changes are approved, scheduled, and reviewed after their implementation. This meeting is typically chaired by the head of operations and/or infrastructure and has as its members participants from each engineering team and customer-facing business teams.
• The change management process should be reviewed by teams outside the change management team to determine its efficacy. A quarterly or annual review is appropriate and should be performed by the CTO/CIO and members of the executive staff of the company.
• For companies that practice continuous delivery, the notion of change management is codified within the automated system responsible for automated releases. Risk analysis, change identification, change approval, and level loading of risk are inherent within the CD solution.