
8. Miscellany
Swift is a vibrant and evolving language with many features that don’t fit tidily under a single umbrella. This chapter introduces an assortment of topics that did not otherwise have proper homes elsewhere in this book but that still deserve your attention.
Statement Labels
In various languages, commands like break, continue, return, and goto address program flow, enabling you to conditionally redirect execution from loops, switches, and other scopes. Swift offers control flow features including continue and break for loops, break and fallthrough for switches, and so forth. Here’s an example that uses continue to skip a print statement whenever an index is odd:
for index in 0...5 {
if index % 2 != 0 {continue}
print(index) // prints 0, 2, 4
}
Less widely known is that Swift also offers statement labels. These mark points at which execution continues outside the default nearest scope. You see an example of this in the following snippet, which marks the outer for loop with an outerloop label:
outerloop: for outer in 0...3 {
for inner in 0...3 {
if (outer == inner) {continue outerloop}
print(outer, inner)
// (1, 0), (2, 0), (2, 1), (3, 0), (3, 1), (3, 2)
}
}
Statement labels let you continue not just to the next iteration of the innermost loop but to any level. Whenever the values of inner and outer equate to each other in this example, control redirects to the outer loop and continues to the next value. In this example, the printed value of inner never matches or exceeds that of outer. These labels, which may look familiar to D and Rust developers, control which flow a continue or break statement applies to.
Swift allows you to mark loop statements, conditionals, and do statements with labels. (In fact, you cannot break out of a do or if block without a label.) Each label is an arbitrary developer-selected identifier, such as outerloop. You place the label on the same line as the keyword that starts the statement, followed by a colon. This next snippet demonstrates do-statement control flow and includes a statement label redirection using break:
print("Starting")
labelpoint: do {
// Waits to execute until the scope ends
defer{print("Leaving do scope")}
// This will always print
print("Always prints")
// Toss a coin and optionally leave the scope
let coin = Int(arc4random_uniform(2))
print("Coin toss: " + (coin == 0 ? "Heads" : "Tails"))
if coin == 0 {break labelpoint}
// Prints if scope execution continues
print("Tails are lucky")
}
print("Ending")
In this example, the do scope executes synchronously in code. This code prints Starting, executes the do statement, and then prints Ending. When the coin toss is heads, the break statement redirects to the label at the start of the do scope and continues execution to the next statement. The Tails are lucky line isn’t printed.
Unlike with goto statements, you cannot break to any label in your app, just to associated ones. The advantage of this flow is that it allows you to shortcut local scopes and continue execution on demand. The break provides a kind of “return” statement, like you’d use in closures.
In this example, as with all other scopes, a defer statement executes at the end of its parent scope, regardless of the circumstances of its ending. This behavior includes labeled redirects. You can return, break, throw an error, and so on. If you leave the scope, the defer runs upon exit.
Custom Operators
Operators enable you to break out of the function-name-followed-by-parentheses-and-arguments mold to use more natural mathematical relationships between arguments. Swift operators behave like functions but differ in syntax. An operator is usually placed just before or after the item it works on (prefix and postfix form) or between two operands (infix form), where it combines those values into some result. Swift’s built-in operators include mathematical operations like ++, +, and - and logical ones like && and ||, among many others.
Swift also offers operator customization, which provides two significant features. First, you can extend existing operators to your custom types. You can, for example, add instances together using a plus sign by applying code that adds their properties. In this example, a custom operator implementation extends the semantics of what + means. Second, you can declare new operators such as dot products and cross products using a wide range of primarily Unicode-sourced characters. This allows you to introduce custom operator syntax to your code.
Declaring Operators
You declare custom operators at the global level. Use the operator keyword and mark your declaration with prefix, infix, or postfix, depending on the style of operator you’re defining. The following operator prints and returns a value, allowing the printing to occur as a side effect in normal evaluation:
postfix operator *** {}
postfix func ***<T>(item: T)-> T {print(item); return item}
You can also write an infix custom operator to mesh a format string with arguments:
infix operator %%% {}
func %%%(lhs: String, rhs: [CVarArgType]) -> String {
return String(format: lhs, arguments: rhs)
}
You’d call the %%% operator like this:
print("%zd & %@" %%% [59, "Bananas" as NSString]) // "59 & Bananas"
This next example performs a case-insensitive regular expression match on a string using Foundation calls:
// Regex match. Requires Foundation.
infix operator ~== {
associativity none
precedence 90
}
func ~==(lhs: String, rhs: String) -> Range<String.Index>? {
return lhs.rangeOfString(rhs,
options: [.RegularExpressionSearch, .CaseInsensitiveSearch],
range: lhs.startIndex..<lhs.endIndex,
locale: nil)
}
The braces that follow an infix operator declaration can include information about associativity (left, right, or none) and precedence, which defaults to a level of 100. A precedence level increases operator priority as the value rises and decreases as it falls. Associativity defines how operators of the same precedence group together in the absence of explicit parentheses. With left-associative operators, operations are grouped from the left; with right-associative operators, they are grouped from the right. A non-associative operator prevents chaining.
Conforming with Operators
If an operator is already defined, you don’t redeclare it when implementing it for custom types. For example, the Equatable protocol requires the == operator. To conform, you declare the protocol and implement == at the global level:
struct MyStruct {let item: Int}
extension MyStruct: Equatable {}
func ==(lhs: MyStruct, rhs: MyStruct)-> Bool {return lhs.item == rhs.item}
The preceding example uses a trivial structure with a single integer property. In Swift, it’s common to work with generic types, as in the following snippet:
struct MyGenericStruct<T: Equatable> {let item: T}
extension MyGenericStruct: Equatable {}
func ==<T>(lhs: MyGenericStruct<T>, rhs: MyGenericStruct<T>)-> Bool {
return lhs.item == rhs.item
}
Here you see a more real-world use case where the generic struct is composed of a property that is itself equatable. To conform the entire structure, the == implementation must be itself genericized to limit the application to same-type structs.
Evaluating Operator Trade-offs
Custom operators enable you to move code away from their function forms using a more natural expressions, such as A ∈ B vs. ∈(A, B), but they do so with a non-trivial cost:
![]() You are limited to the characters you can use for operators: /, =, -, +, !, *, %, <, >, &, |, ^, ?, or ~ plus the limited set of legal Unicode that is detailed in Apple’s documentation.
You are limited to the characters you can use for operators: /, =, -, +, !, *, %, <, >, &, |, ^, ?, or ~ plus the limited set of legal Unicode that is detailed in Apple’s documentation.
![]() You cannot override already-reserved uses such as =, ->, //, /*, and */.
You cannot override already-reserved uses such as =, ->, //, /*, and */.
![]() You cannot confuse the compiler, which is looking for optional-handling operators ending with
You cannot confuse the compiler, which is looking for optional-handling operators ending with ! and ?, even if the grammar suggests that your operators are otherwise legal. For example, if you want to write a factorial operator (normally !) and a choose operator (normally parentheses with one number placed above the other), how would you select operator characters, given the limitations of the Swift grammar?
![]() You want to select operators whose meaning is easily recognized and whose use is easily recalled. Further, to construct Unicode operators in code, you may need to use copy/paste from reference sheets or complex keyboard entry.
You want to select operators whose meaning is easily recognized and whose use is easily recalled. Further, to construct Unicode operators in code, you may need to use copy/paste from reference sheets or complex keyboard entry.
As these limitations suggest, you should use novel operators sparingly and meaningfully. Overloading the meaning of existing operators may be more generally productive than introducing new operators.
Array Indexing
Array lookups can fail, and when they do, it’s usually loudly and uncomfortably. Attempt to access an out-of-range index and get ready to experience an application crash. This is not a feature you can guard against or conditionally try with an error handler. You must deal with the natural fallout, which is this:
fatal error: Array index out of range
Fortunately, you can implement a safe custom workaround, as you see in Recipe 8-1. Swift’s support of custom subscripts and subscript labels, such as myArray[safe: index], makes it safer to check arbitrary indices than to look up myArray[index] directly. This recipe creates a labeled subscript extension. It checks index validity before returning an optional result.
Recipe 8-1 Adding Index Safety to Arrays
extension Array {
subscript (safe index: Int) -> Element? {
return (0..<count).contains(index) ? self[index] : nil
}
}
This implementation returns nil for out-of-bounds indices and wrapped .Some(x) values otherwise. To use this approach, your code must expect optional return values and adapt to unwrap them before use. In the following example, Swift’s guard statement assigns unwrapped versions of these lookups to local variables, skipping processing in the case of a failed index:
let tests: [UInt] = [1, 50, 2, 6, 0]
for indexTest in tests {
guard let value = alphabet[safe: indexTest] else {continue}
print("(indexTest): (value) is valid")
}
When using safe indexing, consider how to react to out-of-bounds conditions. You can throw an error, continue on by ignoring the failure, or exit the current scope. Sometimes the best way to fail is to allow your application to terminate, in which case you can discover and re-architect around logical errors that led to the failure in the first place. Limit use of safe lookups to situations in which you do not have control over potentially bad data and when you wish to provide a robust and recoverable mechanism for handling data–index mismatches.
In theory, you can extend safe lookups to any collection type. The following snippet creates a generic implementation that works with any collection type with a comparable index:
extension CollectionType where Index: Comparable {
subscript (safe index: Index) -> Generator.Element? {
guard startIndex <= index && index < endIndex else {
return nil
}
return self[index]
}
}
In practice, there are few collections outside of arrays where using this approach makes any sense.
Multi-indexed Array Access
Swift enables you to use subscripting with multiple indices. For example, you might create an array and want to index it with myArray[3, 5] or myArray[7, 9, 16]. Implementing a general solution involves some trickery. While you can easily build a custom subscript when you know a priori the number of elements you’re aiming for, extending behavior to an arbitrary argument count is less straightforward.
The following extension returns two items at a time:
// Two at a time
extension Array {
subscript(i1: Int, i2:Int) -> [Element] {
return [self[i1], self[i2]]
}
}
This is easy to implement, and Swift can easily use parameter matching to figure out the overloaded results you’re aiming for.
You must take care when extending this behavior for an arbitrary number of arguments. The following approach won’t work but will lead to infinite loops and failed execution. Swift cannot distinguish this parameter declaration from an override of the standard single-item indexing. Variadic parameters accept zero or more values of a specified type, so [2], [2, 4], [2, 4, 6], and [2, 4, 6, 8] all match this declaration:
subscript(i1: Int, i2:Int...)
To Swift, (Int, Int...) is virtually identical to (Int) at runtime, and the compiler chooses your override in preference to the original implementation for single-parameter lookups. That’s where the infinite loops arise. The single-index requests that are needed to gather result components inadvertently self-reference. You need a subscript signature that won’t confuse Swift in this way. A proper solution uses two non-variadic arguments followed by a third variadic one, creating a “use this implementation only for two or more parameters” scenario.
Recipe 8-2 provides a working solution. When you provide at least two subscript arguments to this Array extension, Swift knows to use the right subscripting implementation.
Recipe 8-2 Multiple-Array Subscripting
extension Array {
// specifying two initial parameters differentiates
// this implementation from the default subscript
subscript(i1: Int, i2: Int, rest: Int...) -> [Element] {
get {
var result: [Element] = [self[i1], self[i2]]
for index in rest {
result.append(self[index])
}
return result
}
set (values) {
for (index, value) in zip([i1, i2] + rest, values) {
self[index] = value
}
}
}
}
Wrapped Indices
One way to avoid out-of-bounds conditions is to wrap indices so overflows and underflows still map into legal ranges. For example, for an array consisting of five items, the sixth item would wrap around to the first element, and the minus-first element (-1) would wrap around to the last. Recipe 8-3 implements a simple modulo approach which ensures that an integer always maps to a valid index.
Recipe 8-3 Using Subscript Wrapping
extension Array {
subscript (wrap index: Int) -> Element? {
if count == 0 {return nil}
return self[(index % count + count) % count]
}
}
myArray[wrap:-1] // last element
Array Slices
In Swift, a slice points into an existing array without creating a new copy. Slices describe rather than duplicate. You encounter them when performing lookups, as in the following example. This snippet builds a new array and then creates a slice by indexing:
var myArray = "abcdefgh".characters.map({String($0)}) // Array<String>
let slice = myArray[2...3] // ArraySlice<String>
You can mostly treat the slice as if it were a standard array. If you count the new slice, it reports two members. You can index it as well, although the indices retain their original numbering. You can look up slice[2] (which is c) but not slice[0]. The latter will error even though myArray[0] is valid.
A few more points:
![]() Arrays are value types. If you mutate
Arrays are value types. If you mutate myArray after creating a slice, that updated value does not propagate to the already-created slice.
![]() You can reference the
You can reference the startIndex and endIndex of the slice as well as the complete range (indices).
![]() Enumerated array slices (
Enumerated array slices (slice.enumerate()) lose their indices. The count starts at 0 because all sequence counts start at zero. It’s a sequence thing, not a slice thing.
You work around the enumeration issue by zipping together the slice with its indices. The following function creates an enumeration that preserves the slice ordering:
extension ArraySlice {
func enumerateWithIndices() -> AnySequence<(Index, Generator.Element)> {
return AnySequence(zip(indices, self))
}
}
General Subscripting
Swift subscripts extend beyond collections. If you can imagine a way to index an object internally, you can build a custom subscript to access it. Supply an argument (and, optionally, an external label, as Swift supports subscript labels) and calculate a logical value based on that argument. Recipe 8-4 demonstrates custom subscripting by accessing a UIColor instance by RGBA channel. As not all UIColor instances provide RGBA values, this implementation returns 0.0 for unfetchable channels.
Recipe 8-4 Subscripting Colors
public typealias RGBColorTuple =
(red: CGFloat, green: CGFloat, blue: CGFloat, alpha: CGFloat)
public extension UIColor {
public var channels: RGBColorTuple? {
var (r, g, b, a): RGBColorTuple = (0.0, 0.0, 0.0, 0.0)
let gettableColor = self.getRed(&r, green: &g, blue: &b, alpha: &a)
return gettableColor ? (red: r, green: g, blue: b, alpha: a) : nil
}
public enum RGBAChannel {case Red, Green, Blue, Alpha}
public subscript (channel: RGBAChannel) -> CGFloat {
switch channel {
case .Red: return channels?.red ?? 0.0
case .Green: return channels?.green ?? 0.0
case .Blue: return channels?.blue ?? 0.0
case .Alpha: return channels?.alpha ?? 0.0
}
}
}
In this color example, you can use the public Channel enumeration to individually access each channel using standard subscripting:
let color = UIColor.magentaColor()
color[.Red] // 1
color[.Green] // 0
color[.Blue] // 1
color[.Alpha] // 1
I love how Swift enables you to declare and initialize all the variables at once, which you see in the implementation of the channels property. You can easily extend this implementation for other color spaces such as hue-saturation-brightness.
Parameter-less Subscripting
As well as supporting labels, Swift enables you to implement zero-argument subscripting. The following implementation mimics the custom *** print-and-pass-through operator described earlier in this chapter:
public protocol SubscriptPrintable {
subscript() -> Self {get}
}
public extension SubscriptPrintable {
subscript() -> Self {
print(self); return self
}
}
extension Int: SubscriptPrintable {}
5[] // whee!
Kevin Ballard, who discovered this little feature, had a slightly better use for it. He implemented a simple way to offer get-and-set access to an unsafe mutable pointer’s memory:
extension UnsafeMutablePointer {
subscript() -> T {
get {
return memory
}
nonmutating set {
memory = newValue
}
}
}
String Utilities
String is a workhorse type, used throughout a programmer’s day. The following sections introduce a variety of handy approaches to getting the most out of Swift’s String type.
Repeat Initializers
Both strings and arrays allow you to construct new instances with a count and a value:
public init(count: Int, repeatedValue c: Character)
public init(count: Int, repeatedValue: Self.Generator.Element)
You pass a character to the string initializer and any legal element to the array one:
let s = String(count: 5, repeatedValue: Character("X")) // "XXXXX"
let a = Array(count: 3, repeatedValue: "X") // ["X", "X", "X"]
let a2 = Array(count: 2, repeatedValue: [1, 2]) // [[1, 2], [1, 2]]
Most typically, you use the array approach to construct a zero-initialized buffer:
let buffer = Array<Int8>(count: 512, repeatedValue: 0)
Strings and Radix
Swift’s radix initializer enables you to convert integers into base-specific representations including binary, octal, and hex:
String(15, radix:2) // 1111
String(15, radix:8) // 17
String(15, radix:16) // f
Recipe 8-5 builds on this, creating string properties for integers and integer properties for strings that enable simple back-and-forth conversion.
Recipe 8-5 Converting Strings to and from Base Systems
extension String {
var boolValue: Bool {return (self as NSString).boolValue}
}
// Support Swift prefixes (0b, 0o, 0x) and Unix (0, 0x / 0X)
extension String {
var binaryValue: Int {
return strtol(self.hasPrefix("0b") ?
String(self.characters.dropFirst(2)) : self, nil, 2)}
var octalValue: Int {
return strtol(self.hasPrefix("0o") ?
String(self.characters.dropFirst(2)) : self, nil, 8)}
var hexValue: Int {
return strtol(self, nil, 16)}
var uBinaryValue: UInt {
return strtoul(self.hasPrefix("0b") ?
String(self.characters.dropFirst(2)) : self, nil, 2)}
var uOctalValue: UInt {
return strtoul(self.hasPrefix("0o") ?
String(self.characters.dropFirst(2)) : self, nil, 8)}
var uHexValue: UInt {
return strtoul(self, nil, 16)}
func pad(width: Int, character: Character) -> String {
return String(
count: width - self.characters.count,
repeatedValue: character) + self
}
}
extension Int {
var binaryString: String {return String(self, radix:2)}
var octalString: String {return String(self, radix:8)}
var hexString: String {return String(self, radix:16)}
}
String Ranges
Many people consider ranges to be portable things. For example, Foundation’s NSRange consists of a simple integer position and length and can be used with any object that supports integer-based indexing. Now consider the example in Figure 8-1, which fetches a Swift String.Index range from a string and then attempts to reuse that range to fetch items from other strings.
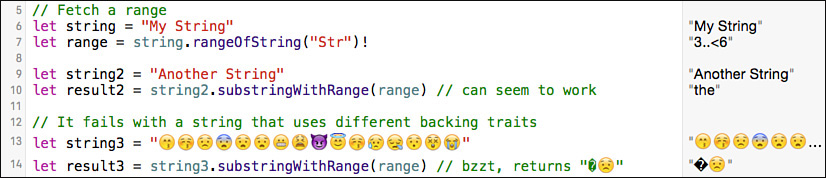
You cannot apply the range returned from the initial string to string3 even though both items are typed String and their ranges are typed String.Index. The backing character stores do not match. You shouldn’t assume that the range from "My String" works with "Another String" either. Even if strings are both ASCII, they can use different internal encodings. The range may appear to work with another string with the same basic properties, but this is not reliable, and it may just as easily misbehave.
Create range portability by abstracting ranges using startIndex, endIndex, and the distanceTo and advancedBy functions, as in Recipe 8-6.
Recipe 8-6 Creating String Index Portability
extension String {
func toPortable(range: Range<String.Index>) -> Range<Int> {
let start = self.startIndex.distanceTo(range.startIndex)
let end = self.startIndex.distanceTo(range.endIndex)
return start..< end
}
func fromPortable(range: Range<Int>) -> Range<String.Index> {
let start = startIndex.advancedBy(range.startIndex)
let end = startIndex.advancedBy(range.endIndex)
return start..<end
}
}
Cast ranges to portable form by using the original string. Then conform them to a specific string before using them to index that new string. Each portability cast operates in O(n), so use these advisedly. This recipe does not perform range checking or other safety checks. Using the right character stride length does not immunize you from errors, either. When you address indices outside string bounds, a string-adjusted range crashes just as nastily as a natively created range does:
let portableRange = string.toPortable(range)
let threeSpecific = string3.fromPortable(portableRange)
let result4 = string3.substringWithRange(threeSpecific) // correct
Always follow the golden rule of Swift String indices: “Never use String.Index with a string other than the string it belongs to.” This generalizes to a don’t-share-needles-or-indices rule for every index type. This recipe enables you to move indices to and away from the strings they represent, but it provides no further guarantees of safety.
String Splitting
Segmenting a string is a common task. You might split at word boundaries by finding spaces or line boundaries by checking for carriage returns. Although you can decompose a string into characters and split from there, I find it more convenient to use a string-level entry point for split operations. Recipe 8-7 builds two String functions. One mimics the signature of the character-specific split function. The other simply accepts a character as its parameter.
Recipe 8-7 Splitting a String at Character Matches
extension String {
public func split(
maxSplit: Int = .max,
allowEmptySlices: Bool = false,
@noescape isSeparator:
(Character) throws -> Bool) rethrows -> [String] {
return try self.characters.split(
maxSplit,
allowEmptySlices: allowEmptySlices,
isSeparator: isSeparator)
.map({String($0)})
}
public func split(character: Character) -> [String] {
return self.split{$0 == character}
}
}
String Subscripts
Recipe 8-8 extends the way you can look up and manipulate the contents of strings. It offers ways to retrieve information using integer-based indices that abstract away from the specifics of backing stores and internal implementations. The result is a general-purpose approach to get and set parts of a string as if it were a well-behaved sequence of characters instead of a wildly unpredictable data type.
This approach is not ideal, and I recommend that you avoid it where possible. Each integer-based operation is O(n), and you can trivially end up with O(n^2) or worse performance with this approach. Beyond the performance issues, you’re basically fighting Swift and its best practices. I include this example solely as a nod to the fact that this is one of the backward-compatibility “moving to Swift” challenges that people approach me about over and over.
Recipe 8-8 Subscripting Strings
extension String {
// Convert int range to string-specific range
public func rangeFromIntRange(range: Range<Int>) ->
Range<String.Index> {
let start = startIndex.advancedBy(range.startIndex)
let end = startIndex.advancedBy(range.endIndex)
return start..<end
}
// Substring within range
public func just(desiredRange: Range<Int>) -> String {
return substringWithRange(rangeFromIntRange(desiredRange))
}
// Substring at one index
public func at(desiredIndex: Int) -> String {
return just(desiredIndex...desiredIndex)
}
// Substring excluding range
public func except(range: Range<Int>) -> String {
var copy = self
copy.replaceRange(rangeFromIntRange(range), with:"")
return copy
}
// The setters in the following two subscript do not enforce
// length equality. You can replace 1...100 with, for example, "foo"
public subscript (aRange: Range<Int>) -> String? {
get {return just(aRange)}
set {replaceRange(rangeFromIntRange(aRange), with:newValue ?? "")}
}
public subscript (i: Int) -> String? {
get {return at(i)}
set {self[i...i] = newValue}
}
}
Foundation Interoperability
It’s impossible to consider Swift without taking Cocoa and Foundation into account. Swift lives within the umbra of Apple’s existing APIs, and it’s “transparent” bridging between Swift strings and Foundation’s NSString isn’t always as seamless as one might wish. Recipe 8-9 offers ways to force strings into one world or the other, using simple property implementations.
Recipe 8-9 Moving to and from Foundation
extension String {
public var ns: NSString {return self as NSString}
}
public extension NSString {
public var swift: String {return self as String}
}
Joining and Extending
Swift’s standard library offers several functions that help you combine items together. For example, you can easily calculate the nth factorial by reducing terms:
func factorial(n: Int) -> Int{return (1...n).reduce(1, combine:*)}
The joinWithSeparator function operates in a similar manner, specifying how to combine items in a sequence. For example, you might create comma-delineated strings or intersperse one array among others:
["a", "b", "c"].joinWithSeparator(", ") // "a, b, c"
print(Array([[1, 2], [1, 2], [1, 2]]
.joinWithSeparator([0]))) // [1, 2, 0, 1, 2, 0, 1, 2]
The sequence must be composed of strings or items that are themselves of sequence type, so you can use this with arrays but not with, for example, integers. Both strings and arrays offer additional functions to insert, append, remove, and replace elements, courtesy of the Swift standard library.
Permutation Generator
Swift’s Permutation Generator adapts a collection and a sequence of its indices to present collection members in a different order. As this generator isn’t actually limited to strict permutations and can be used in ways that repeat or skip indices, it might be better called something like an “objects-at-indices” generator.
Recipe 8-10 demonstrates a common use case, randomly mixing up indices to scramble a collection. It demonstrates how you build a basic generator by passing collection elements and a sequence—in this case, a lazily generated random sequence. This implementation converts the scrambled index generator built with anyGenerator into a sequence using AnySequence, a simple solution for moving between the two.
Recipe 8-10 Scrambled Collections
extension CollectionType {
// Return a scrambled index generator
func generateScrambledIndices() -> AnyGenerator<Self.Index> {
var indices = Array(self.startIndex..<self.endIndex)
return anyGenerator {
if indices.count == 0 {return nil}
// Select a random index and remove it from future use
let nextIndex = arc4random_uniform(UInt32(indices.count))
let nextItem = indices.removeAtIndex(Int(nextIndex))
return nextItem
}
}
// Create a permutation generator to present the scrambled indices
func generateScrambled() ->
PermutationGenerator<Self,AnySequence<Self.Index>> {
return PermutationGenerator(elements: self,
indices: AnySequence(self.generateScrambledIndices()))
}
}
Notice how the generator returned by generateScrambledIndices() holds onto the state declared in its creating scope, specifically the indices array. This generator-building function approach enables you to build generators with associated state.
The Permutation Generator isn’t limited to random scrambles. You can use the same approach to build a strideable sequence. Striding enables you to traverse elements at set interval distances, as in Recipe 8-11, or to return members using any other computed walk-through.
Recipe 8-11 Striding Indices with a Permutation Generator
extension CollectionType {
func generateWithStride(interval: Self.Index.Distance = 1) ->
PermutationGenerator<Self,AnySequence<Self.Index>> {
var index = startIndex
let generator: AnyGenerator<Self.Index> = anyGenerator {
// Return a value and advance by the stride interval
defer { index = index.advancedBy(interval, limit: self.endIndex) }
return index == self.endIndex ? nil : index
}
return PermutationGenerator(elements:self,
indices: AnySequence(generator))
}
}
The length of the returned collection needn’t match that of the original. Recipe 8-12 generates multiple copies of each element, transforming, for example, a collection of A, B, C into A, A, A, B, B, B, C, C, C, using a custom multiplicity count supplied to the generator.
Recipe 8-12 A Multiple-Instance Collection
extension CollectionType {
func generateMultiple(count count: Int = 1) ->
PermutationGenerator<Self,AnySequence<Self.Index>> {
var index = startIndex; var current = 0
let generator: AnyGenerator<Self.Index> = anyGenerator {
defer {
if (current + 1) == count {
index = index.advancedBy(1, limit: self.endIndex)
}
current = (current + 1) % count
}
return index == self.endIndex ? nil : index
}
return PermutationGenerator(elements:self,
indices: AnySequence(generator))
}
}
Wrap-up
This chapter provides just a taste of the many features Swift offers that extend beyond basic development. Learning Swift is a continuous experience both as the language itself grows and you push boundaries as a programmer. I encourage you to dive into Swift’s documentation and its standard library to explore and discover the features available to you.