
Chapter 2. Data Model–Driven Management
This chapter covers
The operator requirements, leading to the NETCONF and YANG specifications
YANG as a data modeling language
The data model properties and types
The different encodings (XML, JSON, and so on) and protocols (NETCONF, RESTCONF, and so on)
The server and client architecture
The datastore concept
Code rendering from data model–driven management
A real-life service scenario, putting all the pieces together
This chapter describes the architecture behind data model–driven management and covers high-level concepts with a minimum of technical detail. Occasionally, specific points are made or examples are given that contain concepts that have not yet been explained. Don’t fret. Chapter 3, “YANG Explained,” and Chapter 4, “NETCONF, RESTCONF, and gNMI Explained,” clarify it all. At the end of the chapter, you will understand the data model–driven management reference model and how all the different building blocks fit together.
The Beginning: A New Set of Requirements
During a workshop organized in 2002 between network operators and protocol developers, the operators voiced their opinion that the developments in IETF did not really address the requirements for network management. The “Overview of the 2002 IAB Network Management Workshop” (RFC 3535) documented the outcomes of this dialog to guide the IETF focus on future work regarding network management.
The workshop identified a list of relevant technologies (available or under active development) with their strengths and weaknesses. Among others, Simple Network Management Protocol (SNMP) and the command-line interface (CLI) were covered. As mentioned in Chapter 1, “The Network Management World Must Change: Why Should You Care?”, the SNMP protocol is not well adapted to be used for configuration but is well suited for monitoring, whereas the CLI is a very fragile application programming interface (API). Since no published material at the time clearly documented the collective requirements of the operators, they were asked to identify their needs not sufficiently addressed in standards. The results produced during the breakout session resulted in the following list of operator requirements (quoted from RFC 3535):
The output of this workshop focused on current problems. The observations were reasonable and straightforward, including the need for transactions, rollback, low implementation costs, and the ability to save and restore the device’s configuration data. Many of the observations give insight into the problems operators were having with existing network management solutions, such as the lack of full coverage of device capabilities and the ability to distinguish between configuration data and other types of data.
Some of the requirements outlined by the operators include ease of use for any new management system. This ease of use includes the ability to manage a network as a whole and not just a device in the network. In addition, there should be a clear distinction between a device’s configuration state, operational state, and statistics information. The configuration state is everything explicitly configured (for example, IP addresses assigned manually to network interfaces), the operational state is the state learned from interaction with other devices (for example, an IP address obtained from a Dynamic Host Configuration Protocol [DHCP] server), and the statistics are the usage and error counters obtained by the device. Furthermore, the requirements mention that it should also be possible to stage a configuration, to validate it before committing, and to roll back the previous configuration in case of failure.
It is important to note that, even though this document dates from 2003, its requirements and recommendations are still very valid. Every protocol designer involved in automation should read this document—and even re-read it on a regular basis. This is the primary reason for including the preceding 14 requirements in this book.
Based on those operator requirements, the NETCONF working group1 was formed the same year and the NETwork CONFiguration (NETCONF) protocol was created. This protocol defines a simple mechanism where network management applications, acting as clients, can invoke operations on the devices, which act as servers. The NETCONF specification (RFC 4741) defines a small set of operations but goes out of its way to avoid making any requirements on the data carried in those operations, preferring to allow the protocol to carry any data. This “data model agnostic” approach allows data models to be defined independently.
Lacking a means of defining data models, the NETCONF protocol was not usable for standards-based work. Existing data modeling languages such as the XML Schema Definition (XSD) [https://tools.ietf.org/html/rfc6244#ref-W3CXSD]2 and the Document Schema Definition Languages (DSDL; ISODSDL)3 were considered but were rejected because of the problem of domains having little natural overlap. Defining a data model or protocol that is encoded in XML is a distinct problem from defining an XML document. The use of NETCONF operations places requirements on the data content that are not shared with the static document problem domain addressed by schema languages like XSD and RELAX NG.
In 2007 and 2008, the issue of a data modeling language for NETCONF was discussed in the IETF Operations and Management area as well as in the Application area. Consequently, the NETMOD working group4 was formed. Initially named after “NETCONF modeling,” since NETCONF was the initial protocol to operate YANG-based devices, a recent charter update modified it to “Network modeling” to stress the fact that multiple protocols can make use of YANG modules these days.
Considering that the operators’ requirements are now 15 years old, it might seem like a long time for the data model–driven management paradigm to take off. This is a fair point, but it is important to observe that new management protocols take longer to adopt and deploy compared to nonmanagement protocols. As an example, specifying a new routing protocol (segment routing comes to mind)5 and deploying it in production may take a couple of years, but for management protocols (IPFIX6 or NETCONF comes to mind), the lifecycle is longer—up to 10 years. The reason is simple: The new management protocols must ideally be supported on all devices, old and new, as a prerequisite before the new network management systems start transitioning to the new management paradigm. However, these days, data model–driven management based on YANG/NETCONF is a well-established trend in the industry.
Network Management Is Dead, Long Live Network Management
A fundamental shift started in the industry some years ago: A transition from network operators managing the network to operations engineers automating the network. This transition resulted from the combination of multiple trends, as discussed in Chapter 1. These included the multiplication of the number of devices in the network, the increased number of network management configuration transactions per second (with the strong desire to lower the operational expenditure [OpEx]), the shift to virtualization, faster and faster services deployments, a new licensing model on a pay-per-usage basis—and maybe simply the realization that network management is essential to conduct business.
This transition brought the world of operations and development closer together. New buzzwords appeared: controller, DevOps, network programmability, management plane, network APIs, and so on. And new initiatives blossomed:
Some in the open source world, such as OpenFlow,7 OpenStack,8 OpenDaylight,9 Open Vswitch,10 and OpenConfig11
Some in the research community, such as mapping the Unified Modeling Language (UML)12 to YANG
Some in standards organizations, such as the NETCONF and NETMOD working groups at the IETF, where some of the core building blocks for data model–driven management are specified
Interestingly, this new sandbox attracted many nontraditional, so-called network management people. Some came with a development background, some came from different technology areas, and some just surfed the wave. In the end, this was a good thing! For quite some time we were thinking of telling those people that their jobs were actually network management related. Although this was certainly the case, we didn’t want scare them away by labeling their new job with old-school terminology: network management. However, having an automation-related job is certainly cool these days. Therefore, to respect people’s sensibilities, a slightly less provocative section title would be “Network Management Is Dead, Long Live Automation,” or even “Network Management Is Dead, Long Live DevOps.”
Humor aside, the point is that the industry changed. It is common sense today to include security in all aspects of networking: from simply paying attention to the web server file permissions, to moving a web server to the secure Hypertext Transfer Protocol (HTTPS), to the full authentication and authorization mechanisms, and finally to the “let’s encrypt everything” paradigm. The industry slowly but surely will reach this point for automation. As mentioned already, some operators rightly assert nowadays, “If a feature cannot be automated, it does not exist.” Therefore, let’s assert that the coming years will be the years of automation.
YANG: The Data Modeling Language
YANG has been mentioned numerous times so far, but what is it exactly? YANG is an API contract language. This means that you can use YANG to write a specification for what the interface between a client and server should be on a particular topic, as shown in Figure 2-1. A specification written in YANG is referred to as a “YANG module,” and a set of YANG modules are collectively often called a “YANG model.” A YANG model typically focuses on the data that a client manipulates and observes using standardized operations, with a few actions and notifications sprinkled in. Note that, in the NETCONF and RESTCONF terms, the controller is the client and the network elements are the server, as the controller initiates the configuration session. It’s interesting to note that YANG is not an acronym—at least, it’s never expanded or referenced as an acronym in any documentation. However, there is a special meaning behind the term, as a kind of joke. Indeed, it stems from Yet Another Next Gen (data modeling language).
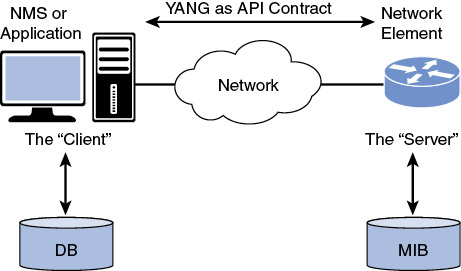
Figure 2-1 The Basic Model
Say you are designing the next cool server application. This application may or may not have some sort of interface for ordinary users, but it will almost certainly have a management interface, which the owner of the application can use to administrate and monitor the application. Obviously, this administrative interface needs to have a clear and concise API.
A YANG-based server publishes a set of YANG modules, which taken together form the system’s YANG model. These YANG modules declare what a client can do. The four areas listed next are the same for all applications, but the specific data and operations will vary. For the sake of clarity, let’s say that the application is a router. Other applications might have wildly different kinds of data and operations—it all comes down to what the YANG model contains.
Configure: For example, decide where the log files are stored, state which speed a network interface uses, and declare whether a particular routing protocol is disabled or enabled, and if so, which peers it will have.
Monitor status: For example, read how many lost packets there are on each network interface, check what the fan speeds are, and list which peers are actually alive in the network.
Receive notifications: For example, hear that a virtual machine is now ready for work, be warned of the temperature crossing a configured threshold, or be alerted of repeated login failures.
Invoke actions: For example, reset the lost packet counters, run a traceroute from the system to some address, or execute a system reboot.
As the author of the next cool application, it is up to you to decide what goes in the YANG module for your application. In the context of YANG, the application is an abstract service, such as a Layer 3 virtual private network (L3VPN) or access control service. Those applications often use networking devices, such as a router, load balancer, and base station controller. They could equally well be devices from other domains, such as a power distribution grid controller, a warehouse robot control system, and an office building control system. What else goes in your YANG module? In collaboration with the application operations engineer, you are perhaps able to select which authentication mechanism the application will use and where the authentication server sits. You may also want to provide the operations engineer with an operational status field indicating how many users are currently served by your application. Maybe the application will have a notification to report users abusing the application in some way? How about an action to produce a debug dump of the database contents for troubleshooting? In the end, your application would probably have a lot more that goes in the management interface.
The YANG model of a device is often called its “schema,” as in database schema or blueprint. A schema is basically the structure and content of messages exchanged between the application and the device. This is very different from the instance data—the actual configuration and monitoring data in the system. The instance data describes the current configuration and the current monitoring values. The schema describes the potential configuration, potential monitoring data, potential notifications, and potential actions a manager decides to execute.
The YANG language also incorporates a level of extensibility and flexibility not present in other model languages. New modules can augment the data hierarchies defined in other modules, seamlessly adding data at appropriate places in the existing data organization. YANG also permits new statements to be defined, allowing the language itself to be expanded in a consistent way. Note that the YANG model (keep in mind the API contract) does not change unless there is a software upgrade of the server, or perhaps if a license for a new feature is installed. The instance data changes as soon as a manager decides to change the configuration or if the system state changes due to internal or external events.
A small YANG model may declare just a dozen different elements, or even a single one (for example, a model that just defines the reboot operation). Some YANG models are very large, however, with thousands of elements. In a car or factory, each element would correspond to a button, control dial, indicator gauge, meter, or light. A modern car might have over a hundred elements on the dashboard and around the vehicle. A nuclear power plant might have over a thousand. Core routers are vastly more complicated, however, with well over 100,000 control interface elements.
Since the schema defines elements that can have many instances (for example, interfaces or access control rules), the instance data can be very much larger than the schema, with many millions of instances.
The YANG language itself is defined by the Internet Engineering Task Force (IETF).13 The latest version is YANG 1.1, defined in RFC 7950, and YANG 1.0 is an older version defined in RFC 6020. As of this writing, both YANG 1.0 and YANG 1.1 are in popular use. This new YANG 1.1 (RFC 7950) does not obsolete YANG 1.0 (RFC 6020). YANG 1.1 is a maintenance release of the YANG language, addressing ambiguities and defects in the original specification. As a reference, YANG concepts are explained in Chapter 3. The extra YANG 1.1 capabilities are documented in Section 1.1 of RFC 7950. These days, YANG 1.1 should be the default when you’re writing YANG modules.
The Key to Automation? Data Models
In the world of data model–driven management, as the name implies, the essential part is the set of data models. From the data models, you deduce APIs. Figure 2-2 displays a YANG data model (granted, an incomplete one, but sufficient at this point in time) on the left and RESTCONF RPCs (GET, POST, PUT, and DELETE) to manage the respective resources on the right. Paying attention to the color scheme, notice how the RESTCONF operations are built from the YANG module keywords, showing how the APIs are generated from a YANG model.

Figure 2-2 Data Model–Driven Management Example with RESTCONF
Discussing how data models generate APIs is a good segue to stress one more time the differences between information models and data models. As specified in “On the Difference Between Information Models and Data Models” (RFC 3444), covered in Chapter 1, the main purpose of an information model is to model managed objects at a conceptual level, independent of any specific implementations or protocols used to transport the data. An extra distinction, in light of this YANG module figure, is that data models generate APIs. This is a key message: Automation is driven by APIs (not models that are a means to an end). However, an information model, typically expressed in Unified Modeling Language (UML) do not generate the full APIs, as they lack some of the implementation- and protocol-specific details (for example, rules that explain how to map managed objects onto lower-level protocol constructs). Generating APIs from UML is, however, a field of research and experimentation. In the authors’ view, if the information model would contain all the information to generate complete APIs, then that information model is really a data model.
To get a bit more concrete on the difference between an information model and data model, let’s consider an example. A UML information model might declare that a book object should have title, author, ISBN, language, and price attributes. It might say that the title should be a string, the author should be a reference to an author object, and the price should be a numeric type.
To turn that UML information model into a data model, you would need to add additional information—for example, that ISBNs need to adhere to a very particular format in order to be valid, that the author relation is mandatory while language is not, or that a book isn’t eligible for sale if its price is zero. You would also need to state that there will be a list of books called the catalog and that this list is to be indexed by title. It is only when you add this sort of detailed information that the model becomes usable as an API—that is, as a contract between the client and server where both peers know what to expect and implement for.
YANG and the Operators Requirements
The YANG language addressed many of the issues raised during the “Overview of the 2002 IAB Network Management Workshop” (RFC 3535), as expressed in “An Architecture for Network Management Using NETCONF and YANG” (RFC 6244). Indeed, per RFC 6244, the YANG language was created to address the following requirements:
Ease of use: YANG is designed to be human friendly, simple, and readable. Many tricky issues remain due to the complexity of the problem domain, but YANG strives to make them more visible and easier to deal with.
Configuration and state data: YANG clearly divides configuration data from other types of data.
Generation of deltas: A YANG module gives enough information to generate the delta needed to change between two configuration data sets.
Text friendly: YANG modules are very text friendly, as is the data they define.
Task oriented: A YANG module can define specific tasks as RPC operations. A client can choose to invoke the RPC operation or to access any underlying data directly.
Full coverage: YANG modules can be defined that give full coverage to all the native capabilities of the device. Giving this access avoids the need to resort to the command-line interface (CLI) using tools such as Expect [EXPECT].14
Timeliness: YANG modules can be tied to CLI operations, so all native operations and data are immediately available.
Implementation difficulty: YANG’s flexibility enables modules that can be more easily implemented. Adding “features” and replacing “third normal form” with a natural data hierarchy should reduce complexity. YANG moves the implementation burden from the client to the server, where SNMP was simple for the server. Transactions are key for client-side simplicity.
Simple data modeling language: YANG has sufficient power to be usable in other situations. In particular, on-box APIs and a native CLI can be integrated to simplify the infrastructure.
Human-friendly syntax: YANG’s syntax is optimized for the reader, specifically the reviewer, on the basis that this is the most common human interaction.
Semantic mismatch: Richer, more descriptive data models will reduce the possibility of semantic mismatch. With the ability to define new primitives, YANG modules will be more specific in content, allowing more enforcement of rules and constraints.
Internationalization: YANG uses UTF-8 (RFC 3629) encoded Unicode characters.
Note
While the authors have tried to detail the high-level concepts and advantages in this chapter, understandably if you are not yet familiar with YANG, some points will make more sense after you read Chapter 3.
Properties of Good Data Models
Although there are many ways to design good management interfaces (or API contracts), there are even more ways to design bad ones. Just like there are certain properties to look for when writing good contracts, there are certain things to look for when designing an interface. In fact, the list of good properties for these two activities is essentially the same, as displayed in the bullet list that follows. To make this point, the following bullet points are taken from the legal website www.ohiobar.org. It’s like designing a domain-specific language (DSL), with verbs, nouns, adjectives, and so on, plus (grammar) rules for how these elements may be combined. The most expressive, and therefore useful, languages generally have relatively few words, but focus on how the words can be combined into a near infinite number of different messages.
Accuracy: The most important aspect of a contract is that it is accurate and therefore makes the reaction of the other party predictable. If there are many exceptions (ifs, whens, and buts) beyond what is mentioned in the contract, the contract loses its value. The contract needs to use relevant terminology correctly, be precise, and cover all cases.
Clarity: Unless all parties come to the same understanding when reading the contract, interoperability is not going to happen. The language needs to be unambiguous, internally consistent, and use familiar terms. The document must be structured in a way that is easy to consume. Defaults enhance the clarity on what happens when a short message does not mention everything. Consistency constraints clarify how meaningful messages can be constructed.
Efficiency: A classic way to make sure a contract is not read is to make it very long. An even more sure way is to start repeating yourself. When the same lengthy wording appears in section after section, the readability and maintainability are lost. Repeating patterns are great, but only if referenced and reused, rather than repeated each time.
Simplicity: While it is tempting to use complicated in-group terms and language, it is usually better to write for a wider audience that may not understand the topic the contract is about at the same depth as the authors. Another important simplicity aspect is to write with the principle of least surprise (a.k.a. the principle of least astonishment) in mind. If something breaks an established pattern, either redesign or make it stand out as different.
Resonance: Make sure the contract stays on topic. If the topic is wide, several modular contracts in a suite may make it easier to consume. The contract should spell out sensible defaults to allow the parties to be lazy. The contract needs to consider the needs and terminology of both parties (or all if more than two).
Although YANG adheres to these properties, at this point you might be wondering, why YANG and not another schema language—for example, the Common Information Model (CIM), specified in the Distributed Management Task Force (DMTF)? A pragmatic answer is, YANG was defined as the modeling language for the NETCONF protocol, and although it has pros and cons compared to other modeling languages, the designers within the IETF community chose YANG.
The Different Types of YANG Modules
With the success of YANG as a modeling language, the industry is creating many YANG models to ease automation. YANG modules come from three different sources these days:
Standards development organizations (SDOs)
Consortiums, forums, and open source projects
Native/proprietary YANG models
While Chapter 6, “YANG Data Modeling Developments in the Industry,” covers the YANG data modeling developments in the industry in more much detail, in this chapter we just cover and compare the preceding three categories. The goal of this section is to highlight a couple of differences from the YANG models’ point of view.
As the SDO that specified the YANG language, the IETF was the initial SDO specifying the YANG modules—first in the NETMOD working group and then in different working groups with specific expertise. Different SDOs followed the trend, including the IEEE and ITU-T.15
Also, some consortiums, forums, and open source projects contributed to the YANG models development. To name a few, in no particular order, OpenConfig,11 MEF Forum,16 OpenDaylight,11 Broadband Forum,17 and Open ROADM18 all contributed.
The SDO-produced YANG modules receive the most attention (at least for the IETF, in which the book’s authors participate) as they are reviewed by many people. This review process comes at the cost of taking a long time to finalize the specifications. When developing applications around those YANG modules, it is important to understand that they contain a kind of common denominator, as opposed to the full coverage of the different experimental or proprietary features proposed by the different networking vendors. Extensions for those experimental and proprietary features must be developed on top of the standard YANG models.
On the other end, YANG models produced by consortiums, forums, and open source projects are most of the time targeted toward specific use cases, thus proposing complete solutions. When centered on use cases, a few committers maintain the coherence of the different YANG models, thus guaranteeing the consistency of the entire solution. Quick iterations of the YANG modules certainly improve the speed of delivery, based on the experience gained, but can be perceived as a burden for implementers who have to always keep their developments up to date with the latest version. Note that, in the case of open source projects, code is proposed next to the YANG models. Among all the open source projects, OpenConfig is worth mentioning, as it is getting some traction in the industry (more on this in Chapter 4).
The final category is “native YANG models,” also called “proprietary YANG models.” In order to offer some automation right now, with full coverage (for the entire set of supported features), some networking vendors propose YANG models, based on their proprietary implementations. Most of the time those YANG models are generated from internal databases or CLI representations, which implies that automation across vendors proved difficult. In case of generated YANG models, another potential issue is that new software versions can generate non-backward-compatible YANG modules, mapping the internal backward incompatibility. According to the YANG specifications, changes to published modules are not allowed if they have any potential to cause interoperability problems between a client using an original specification and a server using an updated specification. Expressed differently, a new module name is necessary if there are non-backward-compatible changes. However, in practice, that rule is not always followed. Therefore, there are discussions at the IETF to revise the YANG module update procedures (that is, to relax the rules concerning the condition of documenting the non-backward-compatible changes).
The industry has started to centralize all important YANG modules in GitHub [https://github.com/YangModels/yang], with the YANG Catalog [https://yangcatalog.org/]19 as the graphical interface. Those are two excellent starting points if you are not sure where to begin.
Mapping YANG Objects from MIB Modules
Before we begin this section about generating YANG modules as a translation from Management Information Based (MIB) modules, you should note that it refers to a couple of technical concepts introduced in later in this chapter and in the next two chapters. Since there is no other natural place to discuss mapping YANG objects from MIB modules later in the book, you are advised to re-read this section once you have mastered YANG and NETCONF.
When the IETF started its modeling work, there were no YANG modules (although there were plenty of MIB modules) to be used with the SNMP protocol. As already mentioned, many MIB modules were actively used for monitoring in network management. Therefore, it was only natural to invent a method to leverage what was good from SNMP and convert the MIB modules into YANG modules.
“Translation of Structure of Management Information Version 2 (SMIv2) MIB Modules to YANG Modules” (RFC 6643) describes a translation of SMIv2 (RFC 2578, RFC2579, and RFC 2580) MIB modules into YANG modules, enabling read-only access to SMIv2 objects defined in SMIv2 MIB modules via NETCONF. While this translation is of great help to access MIB objects via NETCONF, there is no magic bullet.
First off, the result of the translation of SMIv2 MIB modules into YANG modules, even if SMIv2 objects are read-write or read-create, consists of read-only YANG objects. One reason is that the persistency models of the underlying protocols, SNMP and NETCONF, are quite different. With SNMP, the persistence of a writable object depends either on the object definition itself (that is, the text in the DESCRIPTION clause) or the persistency properties of the conceptual row it is part of, sometimes controlled via a columnar object using the StorageType textual convention. With NETCONF, the persistence of configuration objects is determined by the properties of the underlying datastore. Furthermore, NETCONF, as defined in RFC 6241, does not provide a standard operation to modify operational state. The <edit-config> and <copy-config> operations only manipulate configuration data. You might say that the mapping of read-write or read-create objects is a moot point as there are not many of them in MIB modules. This is correct. Keep in mind that MIB modules do a good job of monitoring but have failed to emerge as a standard for configuring networks.
Second, using the MIB-translated YANG models along with the YANG-defined models still raises a basic problem of data model mapping because the MIB and YANG worlds specify conceptual objects differently. “Translation of Structure of Management Information Version 2 (SMIv2) MIB Modules to YANG Modules” (RFC 6643) might be of some help in creating the YANG module. In practice, new data structures are often created instead of using a mix of hand-edited (in case of MIB data naming misalignment with the YANG data structures or in case of writable objects) and auto-generated YANG modules. As an example, the YANG Interface Management (RFC 7223) followed this approach.
The Management Architecture
From an architecture point of view, there are multiple API locations, all deduced from YANG modules. A controller typically configures network elements (routers and switches in the networking world) based on the network element YANG modules—typically network interfaces, routing, quality of service, and so on—as shown in Figure 2-3.
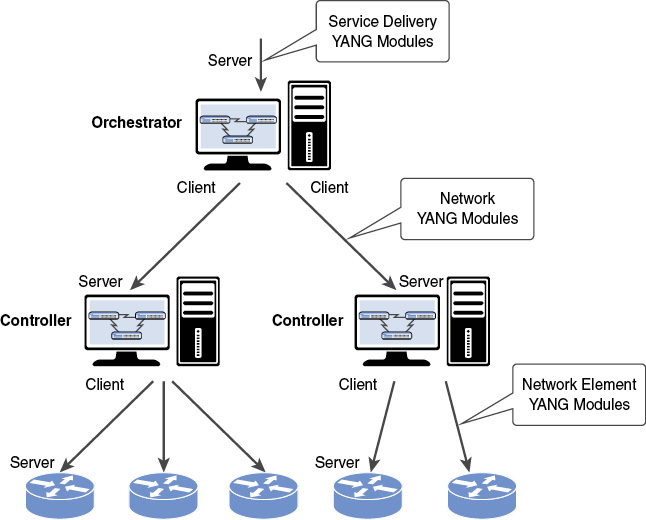
Figure 2-3 The Management Architecture
Controllers focus on one specific network domain or a specific technology. On top of the controllers, the orchestrator configures one or more controllers based on the network YANG modules’ APIs. With the architecture in Figure 2-3 in mind, let’s introduce the notion of northbound and southbound interfaces. From a controller point of view (as an example), the northbound interface is the interface toward the orchestrator, whereas the southbound interface is the one toward the server. Operators can also automate the orchestrator northbound interface to create/modify/delete their services, based on the service delivery YANG modules. A service YANG model is the management interface toward a software application, whereas a device YANG model is generally attached to a physical or virtual device. The classical service example is a Layer 3 virtual private network, or L3VPN, which touches the configuration on multiple devices in the network, configuring network element YANG modules on each point. Then this service is decomposed in the controller, where the required servers are configured.
Note that separating the controller and orchestrator in two different systems is not a requirement: An orchestrator might also handle the tasks of the controller system or connect directly to network elements without any controller function. Examples of systems that can take on various roles in this space are OpenDaylight,11 Network Services Orchestrator (NSO), Contrail, and CloudOpera.
Coming back to the different types of YANG modules, having network element YANG modules standardized for the industry offers some easier automation in case of cross-vendor development. The service delivery YANG modules, on the other hand, are mainly proprietary, as operators tend to differentiate themselves from the competition. There are two notable exceptions with the standardization of the L3VPN service delivery (RFC 8299) and L2VPN service delivery (soon an RFC). More details on the different YANG module types can be found in “YANG Module Classification” (RFC 8199) and “Service Modules Explained” (RFC 8309).
There is a need for standard mechanisms to allow system owners to control read, write, and execute access for particular parts of the YANG tree to different kinds of users. The Network configuration Access Control Model (NACM; RFC 8341) specifies the access control mechanisms for the operations and content layers of NETCONF and RESTCONF, thanks to the ietf-netconf-acm YANG module. This is the role-based access control (RBAC) mechanism most commonly used in the YANG model–driven world.
Data Model–Driven Management Components
Data model–driven management is built on the idea of applying modeling languages to formally describe data sources and APIs. This includes the ability to generate behavior and code from the models. YANG is the data model language of choice; it allows a modeler to create a data model, to define the organization of the data in that model, and to define constraints on that data. Once published, the YANG module acts as a contract between the client and server, with each party understanding how its peer expects it to behave. A client knows how to create valid data for the server and knows what data will be sent from the server. A server knows the rules that govern the data and how it should behave.
As displayed in Figure 2-4, which covers the data model–driven management components, once the YANG models are specified and implemented, a network management system (NMS) can select a particular encoding (XML, JSON, protobuf, thrift, you name it) and a particular protocol (NETCONF, RESTCONF, or gNMI/gRPC) for transport. Yes, there are differences in capabilities between the different protocols and, yes, there are some limitations in the combination of the encodings and protocols (marked by the arrows in the figure), and those are reviewed later in this chapter.
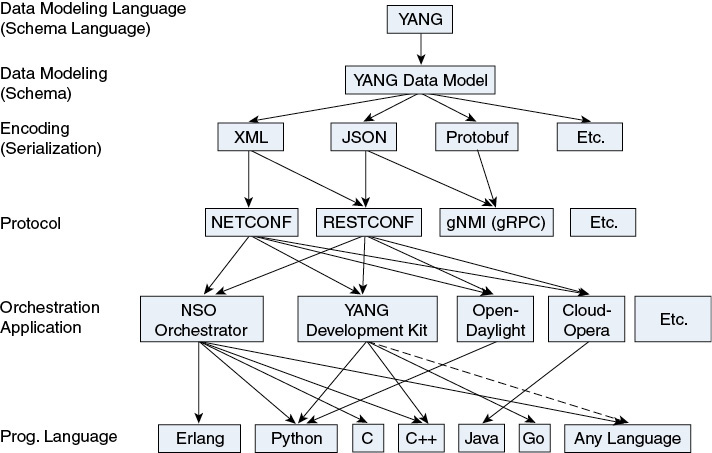
Figure 2-4 The Data Model–Driven Management Components
Typically, an orchestrator delivers service automation through multiple protocols/encodings. Based on the encoding and protocol selections, you can generate behavior or code to access the YANG objects on managed devices (for example, in Python, C++, Go, or basically any programming language). Note that as time passed, more and more arrows were added to this figure. In the end, all combinations become possible.
Orchestrators use code generation in their automation. A good showcase to demonstrate data model–driven management concepts and how the related code is rendered might be an open source tool such as the YANG Development Kit (YDK), which provides APIs directly based on YANG models and ready to use in scripts. The main goal of YDK is to reduce the learning curve involved with YANG data models by expressing the model semantics in an API and abstracting the protocol/encoding details. Example 2-1 shows a sample Python program illustrating the use of a generated API, oc-interfaces.py, which in turn is derived from the open-config-interfaces YANG module.
Example 2-1 Python YDK Example of Configuring a BGP Session
from __future__ import print_function
from ydk.types import Empty, DELETE, Decimal64
from ydk.services import CRUDService
import logging
from session_mgr import establish_session, init_logging
from ydk.models.openconfig.openconfig_interfaces import Interfaces
from ydk.errors import YError
def print_interface(interface):
print('*' * 28)
print('Interface %s'%interface.name)
if interface.config is not None:
print(' config')
print(' name:-%s'% interface.config.name)
if interface.config.type is not None:
print(' type:-%s'%interface.config.type.__class__)
print(' enabled:-%s'%interface.config.enabled)
if interface.state is not None:
print(' state')
print(' name:-%s'% interface.state.name)
if interface.state.type is not None:
print(' type:-%s'%interface.state.type.__class__)
print(' enabled:-%s'%interface.state.enabled)
if interface.state.admin_status is not None:
enum_str = 'DOWN'
if interface.state.admin_status == interface.state.AdminStatusEnum.UP:
enum_str = 'UP'
print(' admin_status:-%s'%enum_str)
if interface.state.oper_status is not None:
oper_status_map = { interface.state.OperStatusEnum.UP : 'UP',
interface.state.OperStatusEnum.DOWN : 'DOWN',
interface.state.OperStatusEnum.TESTING : 'TESTING',
interface.state.OperStatusEnum.UNKNOWN: 'UNKNOWN',
interface.state.OperStatusEnum.DORMANT : 'DORMANT',
interface.state.OperStatusEnum.NOT_PRESENT :
'NOT_PRESENT',
}
print(' oper_status:-%s'%oper_status_map[interface.state.oper_status])
if interface.state.mtu is not None:
print(' mtu:-%s'%interface.state.mtu)
if interface.state.last_change is not None:
print(' last_change:-%s'%interface.state.last_change)
if interface.state.counters is not None:
print(' counters')
print(' in_unicast_pkts:-%s'%interface.state.counters
.in_unicast_pkts)
print(' in_octets:-%s'%interface.state.counters.in_octets)
print(' out_unicast_pkts:-%s'%interface.state.counters
.out_unicast_pkts)
print(' out_octets:-%s'%interface.state.counters.out_octets)
print(' in_multicast_pkts:-%s'%interface.state.counters
.in_multicast_pkts)
print(' in_broadcast_pkts:-%s'%interface.state.counters
.in_broadcast_pkts)
print(' out_multicast_pkts:-%s'%interface.state.counters
.out_multicast_pkts)
print(' out_broadcast_pkts:-%s'%interface.state.counters
.out_broadcast_pkts)
print(' out_discards:-%s'%interface.state.counters.out_discards)
print(' in_discards:-%s'%interface.state.counters.in_discards)
print(' in_unknown_protos:-%s'%interface.state.counters
.in_unknown_protos)
print(' in_errors:-%s'%interface.state.counters.in_errors)
print(' out_errors:-%s'%interface.state.counters.out_errors)
print(' last_clear:-%s'%interface.state.counters.last_clear)
if interface.state.ifindex is not None:
print(' ifindex:-%s'%interface.state.ifindex)
print('*' * 28)
def read_interfaces(crud_service, provider):
interfaces_filter = Interfaces()
try:
interfaces = crud_service.read(provider, interfaces_filter)
for interface in interfaces.interface:
print_interface(interface)
except YError:
print('An error occurred reading interfaces.')
def create_interfaces_config(crud_service, provider):
interface = Interfaces.Interface()
interface.config.name = 'LoopbackYDK'
interface.name = interface.config.name
try:
crud_service.create(provider, interface)
except YError:
print('An error occurred creating the interface.')
if __name__ == "__main__":
init_logging()
provider = establish_session()
crud_service = CRUDService()
read_interfaces(crud_service, provider)
provider.close()
exit()
Obviously, other tools for code generation exist; for example, in the world of OpenConfig, see http://www.openconfig.net/software/.20
Notice that the primary source of information to generate code is the set of YANG modules. This is the reason why the IETF and the industry in general are spending so much energy specifying these YANG modules as precisely as possible.
The Encoding (Protocol Binding and Serialization)
If YANG plus a YANG model can be compared to a language such as English, defined by a dictionary of known words and a grammar describing how the words can be combined, you still need to work out an encoding for your language before you can communicate. English has two very commonly used encodings: text and voice. The text encoding can be further divided into computer encodings like ASCII, Windows-1252, and UTF-8. Text can also be encoded as pixels of different colors in a photo file, as ink on paper, microfiche, or grooves on a stone or a copper plate.
Similarly, there are several different encodings of messages (also known as protocol bindings or serialization) relating to YANG-based models, each more or less suitable depending on the context. The most commonly mentioned (and used) YANG-related encodings are XML, JavaScript Object Notation (JSON; in two variants), and protobuf. As time has passed, new encodings have emerged. For example, this section also covers Concise Binary Object Representation (CBOR).
Figure 2-4, shown earlier in this chapter, displays the different possible encodings for a specific protocol. Keep in mind that more encodings are available all the time: It makes sense as, in the end, an encoding is just... an encoding.
XML
Ask most IT professionals if they know XML, and the reply is invariably “yes.” As most IT folks know, XML stands for Extensible Markup Language. If you ask the same IT professionals to outline the extensibility mechanism in XML, however, only a tiny fraction will give you a reasonable reply. This is why there is a brief recap of the most important XML features, including the extensibility mechanism, in Chapter 3.
Most people think of XML as those HTML-like text documents full of angle brackets (<some>xml</some>), which may seem as a rather small and simple concept. It is not, however. XML and its family of related standards is a complicated and far-reaching dragon. It has a well-designed extensibility mechanism that allows XML-based content to evolve nicely over time, it has a query language called XPath, it has a schema language called XML Schema, and it has a transformation language called XSLT—just to mention a few features. Keep in mind that a schema is the definition of the structure and content of data (names, types, ranges, and defaults).
Because of these qualities and the abundant availability of tools, the NETCONF working group decided to base its protocol on XML for the message encoding. In the beginning, before YANG was invented, a lot of people assumed that NETCONF would be modeled using XML Schema Description (XSD). It was even used, together with a set of additional mapping conventions, as the official modeling language for about half a year. This was when the group was attempting to craft the first standard models for NETCONF. Then a serious flaw was found in one of the early models made by the NETCONF gurus. This led to a rather heated debate around how such a major flaw could be introduced and not be found in review by even the inner circle of NETCONF pundits. The root cause for the situation was eventually declared to be the hard-to-read nature of XML Schema. This situation triggered tiny teams from separate organizations across the industry to get together to define a new schema language, with the fundamental requirement that models must be easy to read and write. Those team members’ names are found in RFC 6020. Today, this language is known as YANG.
This explains why the ties between NETCONF and XML were (and remain) very strong, and even why YANG 1.0 depends on XML mechanisms quite a bit. With different encodings these days, YANG 1.1 is designed as much more neutral to the protocol encodings.
JSON
As the demand for a REST-based approach similar to the functionality standardized in NETCONF was rising, the NETCONF WG started developing RESTCONF.21 REST-based transports use a fairly wide variety of message encodings, but there is no question that the most popular one is JavaScript Object Notation (JSON). It has its roots in the way objects are represented in JavaScript: It was a very simple collection of encoding rules that fit on a single page. This simplicity was a major driver for JSON’s popularity. Today there is a clear, precise, and language-independent definition of JSON in RFC 7159, and further updated in RFC 8259.
While simplicity is always welcome, the downside is that JSON in its simple form handled many use cases quite poorly. For example, there were no mechanisms for evolution and extension, no counterpart of the YANG namespace mechanism. Another example is that JSON has a single number type with an integer precision of about 53 bits in typical implementations. The 64-bit integers in YANG therefore must be encoded as something other than as numbers (strings). To handle these and many other similar-but-not-so-obvious mapping cases, a set of encoding conventions were needed on top of JSON itself (just like with XSD for XML, as mentioned earlier). For the YANG-to-RESTCONF mapping, these conventions are found in “JSON Encoding of Data Modeled with YANG” (RFC 7951; do not confuse this with RFC 7159, mentioned earlier, despite their similar numbers). The general JSON community is also working with standardization around additional use cases for JSON, and today JSON is approaching XML in versatility and complexity.
Besides JSON, the RESTCONF specification (RFC 8040) also defines how to encode the data as XML. Some RESTCONF servers support JSON, some XML, and many support both. When the encoding is JSON, it really means JSON as specified in RFC 7159, plus all the conventions in RFC 7951.
Google Protobufs
Protocol buffers, or protobufs, are another supported encoding in gNMI. Protobufs were originally invented by Google and are widely used in much of Google’s products and services, where communication over the wire or data storage is required.
You specify how you want the information you are serializing to be structured by defining protocol buffer message types in .proto files. Once you define your messages, you run the protocol buffer compiler for your application’s language on your .proto file to generate data access classes. Protobufs have built-in support for versioning and extensibility, which many see as an edge over JSON. The messaging mechanism is openly available with bindings for a long list of languages, which has led to very broad usage.
Protobufs come in two formats: self-describing and compact. The self-describing mode is three times larger in terms of bits on the wire. The compact mode is a tight binary form, which has the advantage of saving space on the wire and in memory. As a consequence, this mode is two times faster. This encoding is therefore well suited for telemetry, where a lot a data is pushed at high frequency toward a collector. On the other hand, the compact format is hard to debug or trace—without the .proto files, you cannot tell the names, meaning, or full data types of fields.
CBOR
Concise Binary Object Representation (CBOR) is another encoding being discussed, and is particularly useful for small, embedded systems, typically from the Internet of Things (IoT). CBOR is super-efficient, as it compresses even the identifiers. CBOR is used in connection with the CoAP Management Interface (CoMI) protocol on the client side.
As of this writing, CBOR (RFC 7049) is not in wide use with YANG-based servers, but discussions are ongoing in the IETF CORE (Constrained RESTful Environments) working group, where a document called “CBOR Encoding of Data Modeled with YANG” is being crafted.
The Server Architecture: Datastore
In the typical YANG-based solution, the client and server are driven by the content of YANG modules. The server includes the definitions of the modules as metadata that is available to the NETCONF/RESTCONF engine. This engine processes incoming requests, uses the metadata to parse and verify the request, performs the requested operation, and returns the results to the client, as shown in Figure 2-5.
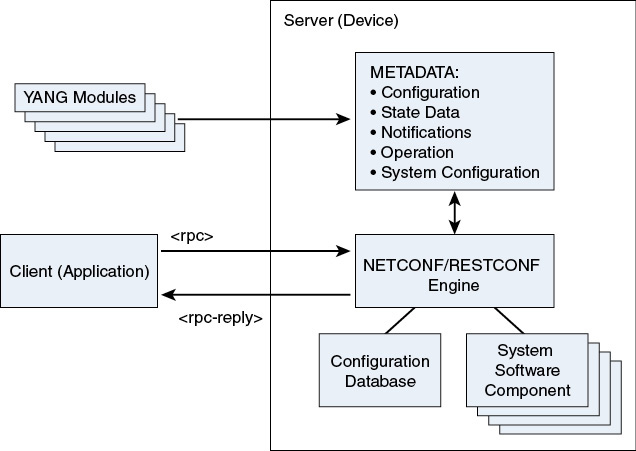
Figure 2-5 The Server Architecture (RFC 6244)
The YANG modules, which model a specific problem domain, are loaded, compiled, or coded into the server.
The sequence of events for the typical NETCONF client/server interaction occur as follows:
A client application opens a NETCONF session to the server (device).
The client and server exchange <hello> messages containing the list of capabilities supported by each side. This hello exchange includes the list of YANG 1.0 modules supported by the server.
The client builds and sends an operation defined in the YANG module, encoded in XML, within NETCONF’s <rpc> element.
The server receives and parses the <rpc> element.
The server verifies the contents of the request against the data model defined in the YANG module.
The server performs the requested operation, possibly changing the configuration datastore.
The server builds the response message, containing the response itself, any requested data, and any errors.
The server sends the response, encoded in XML, within NETCONF’s <rpc-reply> element.
The client receives and parses the <rpc-reply> element.
The client inspects the response and processes it as needed.
The Protocols
As a quick introduction before we dive into the different protocols, Table 2-1 provides a comparison of the most common protocols used in data model–driven management: NETCONF, RESTCONF, and gNMI.
Table 2-1 Quick NETCONF/RESTCONF/gNMI Protocol Comparison
|
NETCONF |
RESTCONF |
gNMI |
|---|---|---|---|
Message and Payload Encoding |
XML. |
JSON or XML. |
gNMI notifications with JSON (two variants) or protobuf payload. |
Operation Semantics |
NETCONF specific; network-wide transactions. |
RESTCONF specific, based on HTTP verbs. Single-target, single-shot transactions. |
gNMI specific. Single-target, single-shot, sequenced transactions. |
RPC Mechanism |
NETCONF specific; XML based. |
REST style. |
gRPC. |
Transport Stack |
SSH/TCP/IP. |
HTTP/TLS/TCP/IP. |
HTTP2/TLS/TCP/IP. |
NETCONF
The NETCONF protocol addressed many of the issues raised during the “Overview of the 2002 IAB Network Management Workshop” (RFC 3535). Here are just a few of them:
Transactions: NETCONF provides a transaction mechanism that guarantees the configuration is correctly and entirely applied.
Dump and restore: NETCONF provides the ability to save and restore configuration data. This can also be performed for a specific YANG module.
Configuration handling: NETCONF addresses the ability to distinguish between distributing configuration data and activating it.
NETCONF provides a transaction mechanism, which is a major advantage compared to a protocol such as SNMP. A transaction is characterized by the “ACID test” (which comes from the database world):
Atomicity: All-or-nothing. Either the entire change is applied or it is discarded. This constitutes a major advantage for error handling.
Consistency: All-at-once. The data needs to be valid with respect to YANG rules. There is no concept of time inside the transaction, no “before” and “after.” No “first this, then that.” This is great for simplicity.
Independence: No cross-talk. Multiple clients can make configuration changes simultaneously without the transactions interfering with each other.
Durability: Once executed, the transaction is guaranteed to stick, even if there is a power outage or a software crash. In other words, “when it’s done, it’s done.”
Here is how RFC 6241, “Network Configuration Protocol (NETCONF),” defines the NETCONF protocol:
XML’s hierarchical data representation allows complex networking data to be rendered in a natural way. Example 2-2 places network interfaces in the OSPF routing protocol areas. The <ospf> element contains a list of <area> elements, each of which contains a list of <interface> elements. The <name> element identifies the specific area or interface. Additional configuration for each area or interface appears directly inside the appropriate element.
Example 2-2 OSPF Areas NETCONF Configuration
<ospf xmlns="http://example.org/netconf/ospf">
<area>
<name>0.0.0.0</name>
<interface>
<name>ge-0/0/0.0</name>
<!-- The priority for this interface -->
<priority>30</priority>
<metric>100</metric>
<dead-interval>120</dead-interval>
</interface>
<interface>
<name>ge-0/0/1.0</name>
<metric>140</metric>
</interface>
</area>
<area>
<name>10.1.2.0</name>
<interface>
<name>ge-0/0/2.0</name>
<metric>100</metric>
</interface>
<interface>
<name>ge-0/0/3.0</name>
<metric>140</metric>
<dead-interval>120</dead-interval>
</interface>
</area>
</ospf>
NETCONF includes mechanisms for controlling configuration datastores. Each datastore is a specific collection of configuration data to be used as source or target of the configuration-related operations. The device indicates whether it has a distinct “startup” configuration datastore, whether the current or “running” datastore is directly writable, and whether there is a “candidate” configuration datastore where configuration changes can be made that will not affect the device operations until a “commit-configuration” operation is invoked.
The NETCONF protocol provides a small set of low-level operations, invoked as RPCs from the client (the application) to the server (running on the device), to manage device configurations and retrieve device state information. The base protocol provides operations to retrieve, configure, copy, and delete configuration datastores. The Table 2-2 lists these operations.
Table 2-2 NETCONF Operations
Operation |
Description |
|---|---|
get-config |
Retrieve all or part of a configuration datastore. |
edit-config |
Change the contents of a configuration datastore. |
copy-config |
Copy one configuration datastore to another. |
delete-config |
Delete the contents of a configuration datastore. |
lock |
Prevent changes to a datastore from another party. |
unlock |
Release a lock on a datastore. |
get |
Retrieve the running configuration and device state information. |
close-session |
Request a graceful termination of the NETCONF session. |
kill-session |
Force the termination of another NETCONF session. |
get-data |
More flexible way to retrieve configuration and device state information. Only available on some newer systems (requires the Network Management Datastore Architecture (NMDA, [RFC8342]) support, which you will learn about in chapter 3) |
edit-data |
More flexible way to change the contents of a configuration datastore. Only available on some newer systems (requires NMDA support). |
NETCONF’s “capability” mechanism allows the device to announce the set of capabilities that the device supports, including protocol operations, datastores, data models, and other capabilities, as shown in Table 2-3. These are announced during session establishment as part of the <hello> message. A client can inspect the hello message to determine what the device is capable of and how to interact with the device to perform the desired tasks. This alone is a real advantage compared to a protocol such as SNMP. In addition, NETCONF fetches state data, receives notifications, and invokes additional RPC methods defined as part of a capability.
Table 2-3 Optional NETCONF Capabilities
Capability |
Description |
|---|---|
:writable-running |
Allow writing directly to the running configuration datastore so that changes take effect immediately. |
:candidate |
Support a separate candidate configuration datastore so that changes are validated first and activated later. |
:confirmed-commit |
Allow activating the candidate configuration during a trial period. If anything goes wrong during the trial period, or if the manager does not approve it, the transaction rolls back automatically. Required for network-wide transactions. |
:rollback-on-error |
Rollback in case of error. This is the core capability for transaction support. Without this capability, NETCONF becomes less useful than SNMP. |
:validate |
Support validating a configuration without activating it. Required for network-wide transactions. |
This collection of capabilities effectively offers a robust network-wide configuration, via the :rollback-on-error, :candidate, :confirmed-commit, and :validate capabilities. With this ACID concept in place, you can view the network as a distributed database. When a change is attempted that affects multiple devices, these capabilities hugely simplify the management of failure scenarios, resulting in the ability to have transactions that dependably succeed or fail atomically. This network-wide transaction mechanism is known as a three-phase transaction (PREPARE, COMMIT, and CONFIRM) in the database world.
NETCONF also defines a means of sending asynchronous notifications from the server to the client, described in RFC 5277.
In terms of security, NETCONF runs over transport protocols secured by Secure Shell (SSH), or optionally HTTP/TLS (Transport Layer Security), allowing secure communications and authentication using well-trusted technology.
RESTCONF
Just as NETCONF defines configuration datastores and a set of Create, Read, Update, Delete, Execute (CRUDX) operations to be used to access these datastores, RESTCONF specifies HTTP methods to provide the same operations. Exactly like NETCONF, RESTCONF is a programmatic interface for accessing data defined in YANG.
So why did the IETF specify yet another protocol, similar to NETCONF? In Chapter 1, you learned that automation is only as good as your toolchain. Furthermore, at this point in this book, you understand a key message: In the world of data model–driven management, what is important is the set of YANG data modules from which APIs are deduced. Therefore, because some operations engineers were developing HTTP-based tools, it was natural to specify a data model–driven management protocol using the same HTTP-based toolchain.
The following is from the RESTCONF specifications (RFC 8040) so that you will understand the relationship between NETCONF and RESTCONF.
Note that Chapter 4 provides a more technical comparison of NETCONF and RESTCONF. RESTCONF adds a new possible encoding, as compared to NETCONF, because it supports XML or JSON. With RESTCONF, the server reports each YANG module, any deviations, and features it supports using the ietf-yang-library YANG module, defined in the YANG Module Library (RFC 7895) and the brand new YANG library [RFC8525] that obsoletes the previous version.
The RESTCONF protocol has no concept of multiple calls making up a transaction. Each RESTCONF call is a transaction by itself, as it uses the HTTP POST, PUT, PATCH, and DELETE methods to edit data resources represented by YANG data models. RESTCONF lacks any way of validating without also activating a configuration. However, the validation is implicit, part of the RESTCONF calls, which succeed or fail transactionally.
With the capabilities of NETCONF in mind, the natural service automation flow is the NETCONF <lock> operation (on the running and candidate datastores), editing the configuration in the candidate configuration datastore, validating the configuration, committing to apply the configuration in the candidate datastore to the running datastore, and finally the unlock operations. These operations are done on multiple devices in parallel from an orchestrator, to achieve network-wide transactions. RESTCONF doesn’t provide the notion of locking, candidate configuration, or commit operations; the configuration changes are applied immediately. RESTCONF does not support transactions that happen in three phases (PREPARE, COMMIT, and CONFIRM). However, it supports transactions that happen in two phases (PREPARE and COMMIT), but only for data given in a single REST call.
Therefore, RESTCONF does not support network-wide transactions, but only device-by-device configuration. RESTCONF is therefore suitable between a portal and an orchestrator (because there is only one), but not from an orchestrator toward a network with many devices.
It is a little bit over-simplistic to think that, if you are a web developer, you “just” select RESTCONF as the protocol, as opposed to NETCONF. However, remember the importance of tooling. Automation in general, and specifically network configuration, implies the integration of an entire toolchain. And, if the existing toolchain (for example, storage and compute) is centered around HTTP, the RESTCONF option might be the best one. In the end, it is all about seamless integration and reduced costs.
It’s important to understand the disadvantages of using RESTCONF for device configuration so that you know the consequences of choosing RESTCONF simply because it uses HTML. As a piece of advice, when you have the choice (that is, you are not constrained by the toolchain), use NETCONF for network elements configuration. RESTCONF might be fine as the northbound interface of the orchestrator or/and controller.
gNMI (gRPC)
The gRPC Network Management Interface (gNMI) protocol comes from the OpenConfig consortium,20 a group of network operators led by Google, with the following mission: “OpenConfig is an informal working group of network operators sharing the goal of moving our networks toward a more dynamic, programmable infrastructure by adopting software-defined networking principles such as declarative configuration and model-driven management and operations.”
The initial focus of OpenConfig was on compiling a consistent set of vendor-neutral data models written in YANG, based on actual operational needs from use cases and requirements from multiple network operators. While OpenConfig continues to evolve the set of YANG modules, Google developed gNMI as a unified management protocol for streaming telemetry and configuration management that leverages the open source gRPC23 framework.
There is sometimes a confusion between gNMI and gRPC—hence the two names in this section. To clarify, gNMI is the management protocol and gRPC is the underlying RPC framework.
One of the gNMI encodings is protobuf, discussed earlier. Protobufs have the advantage of being more compact on the wire, but they also provide an operationally more complex deployment. With NETCONF and RESTCONF, only the YANG schema is required to understand the payload. With gNMI over gRPC with protobuf transport, distribution of .proto files is also required. This adds complexity, especially when some devices are upgraded and so on.
CoMI
The CoAP Management Interface (CoMI) protocol extends the set of YANG-based protocols (NETCONF/RESTCONF/gNMI) with the capability to manage constrained devices and networks.
The Constrained Application Protocol (CoAP; RFC 7252) is designed for machine-to-machine (M2M) applications such as smart energy, smart city, and building control, for use with constrained nodes and constrained (for example, low-power, lossy) networks. The IoT nodes often have 8-bit microcontrollers with small amounts of ROM and RAM, while constrained networks such as IPv6 over low-power wireless personal area networks (6LoWPANs) often have high packet error rates and a typical throughput of tens of kilobits per second.
Those constrained devices must be managed in an automatic fashion to handle the large quantities of devices that are expected in future installations. Messages between devices need to be as small and infrequent as possible. The implementation complexity and runtime resources also need to be as small as possible.
CoMI specifies a network management interface for those constrained devices and networks, where CoAP is used to access datastore and data node resources specified in YANG. CoMI uses the YANG-to-CBOR mapping24 and converts YANG identifier strings to numeric identifiers for payload size reduction. In terms of protocol stack comparison, CoMI runs on top of CoAP, which in turn runs on top of User Datagram Protocol (UDP), while NETCONF/RESTCONF/gNMI all run on top of Transmission Control Protocol (TCP).
At the time of writing, CoMI is in its last stage of standardization at the IETF.
The Programming Language
Good scripts are based on good application programming interfaces (APIs). An API is a set of functions and procedures that allow the creation of applications that access the features or data of an operating system, application, or other service. Fundamentally, an API should provide the following features:
Abstraction: The programmable API should abstract away the complexities of the underlying implementation. The network programmer should not need to know unnecessary details, such as a specific order of configurations or specific steps to take if something fails. Configurations should function more like filling in a high-level checklist (these are the settings you need; now the system can go figure out how to properly group and order them).
Data specification: The key thing an API does—whether it is a software or network API—is provide a specification for the data. First, it answers the question of what the data is—integer, string, or other type of value. Next, it specifies how that data is organized. In traditional programming, that would be called the data structure—though in the world of network programmability, the more common term is “schema,” also known as “data models.”
Means of accessing the data: Finally, the API provides a standardized framework for how to read and manipulate the device’s data.
You saw a YANG Development Kit (YDK)25 example earlier (refer to Example 2-1). The main goal of YDK is to reduce the learning curve of YANG data models by expressing the model semantics in an API and abstracting protocol/encoding details. YDK is composed of a core package that defines services and providers, plus one or more module bundles26 that are based on YANG models. Each module bundle is generated using a bundle profile and the ydk-gen tool. YDK-Py27 provides Python APIs for several model bundles. Similarly, YDK-Cpp28 includes C++ and Go APIs for the same bundles. A similar bundle exists for the C language.
Taking some more examples from the OpenConfig world this time, here are some more tools currently available:
Ygot29 (YANG Go Tools): For generating Go structures or protobufs from YANG modules.
Pyangbind:31 A plug-in for pyang that converts YANG data models into a Python class hierarchy.
These examples prove one more time the importance of the toolchain, of which the programming language (C, C++, Python, Go, you name it) is just one component. Assuming that the operations engineers were developing and supporting scripts based on a specific language, it makes perfect sense to continue developing the YANG-based automation scripts in the same programming language.
Telemetry
The inefficiencies associated with a polling mechanism like SNMP needed to be removed. Network operators poll periodically because they want the data at regular intervals. So why not just send them the data they want when they want it and skip the overhead of polling? Thus the idea of “streaming” was born. Instead of pulling data off the network, you can sit back and let the network push it for you to a collector.
From Chapter 1, you already know that telemetry is a trend in the industry. Telemetry is a new approach for network monitoring in which data is streamed from network devices continuously using a push model and provides near real-time access to operational statistics. You can precisely define what data you want to subscribe to using standard YANG models, with no CLI required. It allows network devices to continuously stream real-time configuration and operating state information to subscribers. Structured data is published at a defined cadence or on-change, based on the subscription criteria and data type. Telemetry data must be structured in a sensible way to make it easy for monitoring tools to ingest. In other words, good telemetry data must be model based—hence the term data model—driven telemetry, even if everyone uses the term telemetry. The networking industry has converged on YANG as a data modeling language for networking data, making it the natural choice for telemetry. Whether you prefer your data in native, OpenConfig, or IETF YANG models, data model–driven telemetry delivers it to you.
Of course, you want all this data to be easy to use because you know that sooner or later someone will come to your desk and ask for data analytics. Telemetry data needs to be normalized for efficient consumption by Big Data tools. In the software world, encodings such as JSON, protobuf, and XML are widely used to transfer data between software applications. These encodings have an abundance of open source software APIs that make it easy to manipulate and analyze the data.
In terms of protocols, two are possible: the OpenConfig streaming telemetry and the IETF push mechanism. The OpenConfig streaming telemetry uses protobuf as the encoding: The protobuf compact mode is perfectly suited for this, as an efficient encoding (at the cost of managing the .proto files). In the IETF push mechanism, subscriptions are created over existing NETCONF sessions and are developed using XML RPCs. The establish-subscription RPC is sent from a client or collector to the network device.
Model-driven telemetry is your first step in a journey that will transform how you monitor and operate networks. With the power of telemetry, you will discover things you never imagined and will begin to ask more and better questions. More on telemetry can be found in Chapter 6.
The Bigger Picture: Using NETCONF to Manage a Network
It happens so easily when talking about management protocols that the conversation ends up being about its components—the client, server, and protocol details. The most important topic is somehow lost. The core of the issue is really the use cases you want to implement and how they can be realized. The overarching goal is to simplify the life of the network operator. “Ease of use is a key requirement for any network management technology from the operators point of view” (RFC 3535, Requirement #1).
Network operators say they would want to “concentrate on the configuration of the network as a whole rather than individual devices” (RFC 3535, Requirement #4). Since the building blocks of networks are devices and cabling, there is really no way to avoid managing devices. The point the operators are trying to make, however, is that a raised abstraction level is convenient when managing networks. They would like to do their management using network-level concepts rather than device-level commands.
This is seen as a good case for network management system (NMS) vendors, but in order for the NMS systems to be reasonably small, simple, and inexpensive, great responsibility falls on the management protocol. Thirty years of industry NMS experience has taught us time after time that with poorly designed management protocols, NMS vendors routinely fail on all three accounts.
What does NETCONF do to support the NMS development? Let’s have a look at the typical use case in network management: how to provision an additional leg on an L3VPN.
At the very least, a typical L3VPN consists of the following:
Consumer Edge (CE) devices located near the endpoints of the VPN, such as a store location, branch office, or someone’s home
Provider Edge (PE) devices located on the outer rim of the provider organization’s core network
A core network connecting all the hub locations and binding to all PE devices
A monitoring solution to ensure the L3VPN is performing according to expectations and promises
A security solution to ensure privacy and security
In order to add an L3VPN leg to the network, the L3VPN application running in the NMS must touch at least the CE device on the new site, the PE device to which the CE device is connected, the monitoring system, and probably a few devices related to security. It could happen that the CE is a virtual device, in which case the NMS may have to speak to some container manager or virtual infrastructure manager (VIM) to spin up the virtual machine (VM). Sometimes 20 devices or so must be touched in order to spin up a single L3VPN leg. All of them are required for the leg to be functional. All firewalls and routers with access control lists (ACLs) need to get their updates, or traffic does not flow. Encryption needs to be set up properly at both ends, or traffic is not safe. Monitoring needs to be set up, or loss of service is not detected.
To implement the new leg in the network using NETCONF, the manager runs a network-wide transaction toward the relevant devices, updating the candidate datastore on them and validating it; if everything is okay, the manager then commits that change to the :running datastore. “It is important to distinguish between the distribution of configurations and the activation of a certain configuration. Devices should be able to hold multiple configurations.” (RFC 3535, Requirement #13). Here are the steps the manager takes in more detail:
STEP 1. Figure out which devices need to be involved to implement the new leg, according to topology and requested endpoints.
STEP 2. Connect to all relevant devices over NETCONF and then lock (<lock>) the NETCONF datastores :running and :candidate on those devices.
STEP 3. Clear (<discard-changes>) the :candidate datastore on the devices.
STEP 4. Compute the required configuration change for each device.
STEP 5. Edit (<edit-config>) each device’s :candidate datastore with the computed change.
STEP 6. Validate (<validate>) the :candidate datastore.
In transaction theory, transactions have two (or three) phases when successful. All the actions up until this point were in the transaction’s PREPARE phase. At the end of the PREPARE phase, all devices must report either <ok> or <rpc-error>. This is a critical decision point. Transaction theorists often call this the “point of no return.”
If any participating device reports <rpc-error> up to this point, the transaction has failed and goes to the ABORT phase. Nothing happens to the network. The NMS safely drops the connection to all devices. This means the changes were never activated and the locks now released.
In case all devices report <ok> here, the NMS proceeds to the COMMIT phase.
Next, commit (<commit>) each device’s :candidate datastore. This activates the change.
Splitting the work to activate a change into a two-phase commit with validation in between may sound easy and obvious when described this way. At the same time, you must acknowledge that this is quite revolutionary in the network management context—not because it’s hard to do, but because of what it enables.
Unless you have programmed NMS solutions, it’s hard to imagine the amount of code required in the NMS to detect and resolve any errors if the devices do not support transactions individually. In the example, you even had network-wide transactions. In a mature NMS, about half the code is devoted to error detection and recovery from a great number of situations. This recovery code is also the most expensive part to develop since it is all about corner cases and situations that are supposed not to happen. Such situations are complicated to re-create for testing, and even to think up.
The cost of a software project is largely proportional to the amount of code written, so this means more than half of the cost of the traditional NMS is removed when the devices support network-wide transactions.
The two-phase, network-wide transaction just described is widely used with NETCONF devices today. This saves a lot of code but is not failsafe. The <commit> operation could fail, the connection to a device could be lost, or a device might crash or not respond while sending out the <commit> to all devices. This would lead to some devices activating the change, while others do not. In order to tighten this up even more, NETCONF also specifies a three-phase network-wide transaction that managers may want to use.
By supplying the flag <confirmed> in the preceding <commit> stage, the transaction enters the third CONFIRM phase (going from PREPARE to COMMIT followed by CONFIRM). If the NMS sends this flag, the NMS must come back within a given time limit to reconfirm the change.
If no confirmation is received at the end of the time limit, or if the connection to the NMS is lost, each device rolls back to the previous configuration state. While the transaction timer is running, the NMS indulges in all sorts of testing and measurement operations, to verify that the L3VPN leg it just created functions as intended. And if not, simply close the connections to all the devices involved in the transaction to make it all go away. If all looks good, commit and unlock, as follows:
STEP 1. Give another <commit>, this time without the <confirmed> flag.
STEP 2. Unlock (<unlock>) the :running and :candidate datastores.
There are a lot more options and details on NETCONF network-wide transactions that could be discussed here, but the important points were made, so let’s tie this off. With this sort of underlying technology, the NMS developers can become real slackers. Well, not really, but they do get twice as many use cases completed compared to life without transactions. Those use cases also work a lot more reliably. This discussion highlights the value of network-wide transactions. “Support for configuration transactions across a number of devices would significantly simplify network configuration management” (RFC 3535, Requirement #5).
Let’s zoom out one level more and see how the network-wide transactions fit into the bigger picture. Look at network management from a control-theory perspective. As any electrical or mechanical engineer knows, the proper way to build a control system that works well in a complex environment is to get a feedback loop into the design. The traditional control-theory picture is shown in Figure 2-6.
Figure 2-6 Feedback Loop
Translating that into your network management context, the picture becomes what is shown in Figure 2-7.
Figure 2-7 Feedback Loop in Network Management
As you can see in this figure, a mechanism to push and pull configurations to and from the network is obviously required. “A mechanism to dump and restore configurations is a primitive operation needed by operators. Standards for pulling and pushing configurations from/to devices are desirable” (RFC 3535, Requirement #7).
The network-wide transaction is an important mechanism for the manager to control the network. Without it, the manager would become both very much more complex and less efficient (in other words, the network would be consistent with the intent a lesser portion of the time). In order to close the loop, each of the other steps is just as important, however. When the monitoring reads the state of the network, it leverages the NETCONF capability to separate configuration from other data. “It is necessary to make a clear distinction between configuration data, data that describes operational state, and statistics. Some devices make it very hard to determine which parameters were administratively configured and which were obtained via other mechanisms such as routing protocols” (RFC 3535, Requirement #2).
With NETCONF, this data is delivered using standardized operations (<get> and <get-config>) with semantics consistent across devices. “It is required to be able to fetch separately configuration data, operational state data, and statistics from devices, and to be able to compare these between devices” (RFC 3535, Requirement #3). The data structure is consistent, too, through the use of standardized YANG models on the devices.
The diff engine then compares the intent performance to the original intent to see how well the current strategy to implement the intent works (remember the intent-based networking trend in Chapter 1), and it compares the actual network configuration with the desired one. If a change in strategy is required or desired (for example, because a peer went down, or the price of computing is lower in a different data center now), the manager computes a new desired configuration and sends it to the network. “Given configuration A and configuration B, it should be possible to generate the operations necessary to get from A to B with minimal state changes and effects on network and systems. It is important to minimize the impact caused by configuration changes” (RFC 3535, Requirement #6).
Clearly, for this to work, the definition of a transaction needs to be pretty strong. The diff engine computes an arbitrary bag of changes in no particular order. The complexity of the manager increases steeply if it has to sequence all of the diffs in some particular way. And unless that particular way is described in machine-readable form for every device in the network, that NMS remains a dream.
Therefore, it follows that the transaction definition used with NETCONF must describe a set of changes, that taken together and when applied to the current configuration must be consistent and make sense. It’s about consistent configurations, not about atomic sequences of changes. “It must be easy to do consistency checks of configurations over time and between the ends of a link in order to determine the changes between two configurations and whether those configurations are consistent” (RFC 3535, Requirement #8).
This is not the same as a sequence of operations that are carried out in the order they are given, and where each intermediate step must be a valid configuration in itself. The server (device) side is clearly easier to implement if the proper sequencing comes from the manager, like the tradition in the SNMP world, which is why many implementers are tempted to go with this interpretation. Let’s state clearly then that NETCONF transactional consistency is at the end of the transaction. Otherwise, the feedback controller use case dies, and you would be back to simple scripts shooting configurations at a network in the dark.
The same feedback capability is essential in those networks where human operators are allowed or required to meddle with the network at the same time as the manager. This is a common operational reality today and invariably leads to unforeseen situations. Unless there is a mechanism with a feedback loop that can compute new configurations and adjust to the ever-changing landscape, the more sophisticated use cases will never emerge.
Interview with the Experts
Q&A with Jürgen Schönwälder
Jürgen Schönwälder is professor of computer science at Jacobs University Bremen. His research interests include network management and measurement, network security, embedded systems, and distributed systems. He has co-authored more than 40 network management–related specifications and standards in the IETF, with major contributions to network management protocols (SNMP and NETCONF) and associated data modeling languages (SMIv2, SMIng, and YANG). He supervised the work on YANG 1.1 while serving as co-chair of the NETMOD working group.
Question:
Jürgen, you have been a key designer for many protocols and data models at the IETF, starting with SNMP, MIB, NETCONF, RESTCONF, and YANG. What is so special about data model–driven management based on YANG?
Answer:
Network management was always about automation. I got involved in network management technologies in the early 1990s, when SNMP became widely implemented and deployed. The design of SNMP was relatively simple (let’s ignore the ASN.1/BER details, which clearly were not that simple), but due to the way data was organized and communicated, SNMP was relatively difficult to use to automate configuration tasks. Even basic operations like retrieving a snapshot of the configuration of a device for backup and restore purposes was difficult to implement via SNMP. (Some devices allowed you to trigger configuration snapshots via SNMP, but the configuration data was then typically delivered via FTP in a proprietary format.)
Given the assembly language nature of SNMP, operators often found it more convenient to configure devices via proprietary command-line interfaces. Since command-line interfaces were not designed to be used as programmatic APIs, automation via scripted command-line interfaces turned out to be somewhat brittle since the data representation was often optimized for human readers but not for programmatic access.
While there were attempts to evolve the SNMP technology and its data modeling language at the beginning of this millennium, they failed to reach sufficient momentum, and the IETF finally started an effort to create a new management protocol to solve the configuration management problem. The goal was to provide a robust API to manage the configuration of a device. Once the initial protocol work was done, a group of people gathered in 2007 to design a data modeling language supporting the new configuration protocol, which was the origin of YANG. All this took place at a time where XML and XML Schema were hot topics in the industry, but the designers of YANG felt that a domain-specific language was needed that’s easier to read and write than XML Schema and is designed to assemble rather complex data models in an incremental fashion.
At the same time, configurations of devices became increasingly dynamic, amplifying the need for robust configuration transactions running almost constantly and affecting many devices. The YANG language started to fill a niche, as it was readily available, including basic tool support. While YANG originally used XML to encode instance data, it was relatively straightforward to support other data representations. In addition, the YANG language was designed to be extensible. As a consequence, vendors and operators were able to replace proprietary APIs with APIs that were driven by YANG data models, even though in several cases nonstandard data encodings and protocols were used. The fact that YANG allowed this to happen was a benefit for its adoption. Another driving force was the movement toward software-defined networks, where certain control functions are moved from devices to external controllers. YANG started to play a role here as well, both as an interface to the devices managed by a controller (the southbound interface) but also as a higher-level interface toward other controller and service management systems (the northbound interface).
While YANG was a success story, there is ongoing work to further improve the technology. Just recently, an architecture for network management datastores was published, which develops the architectural concept of datastores, on which YANG rests, further. Once implemented, applications managing devices or controllers will be able to access configuration data at different stages in the internal configuration processing workflows of devices and controllers and key metadata becomes available, explaining how a specific setting became effective, which enables new applications that can reason about why the actual behavior of a device differs from its intended behavior.
Data-driven management via programmatic APIs derived from YANG data models started to evolve network management toward service management. In the future, one can expect that there will be less focus on the individual devices and their APIs. Novel network and service programming concepts will appear, allowing network operators to build and extend service management systems orchestrating complex services at a much higher pace than ever before.
Summary
This chapter is by no means a complete account of everything you can do in YANG, but it aims at providing you a good grasp of all the most important concepts, what problems YANG solves, and how to go about making new YANG models.
In particular, you learned about the data model–driven management architecture and components. YANG is an API-contract language that creates a specification for the interface between a client and server (configure, monitor status, receive notifications, and invoke actions). The most common protocols used are NETCONF, RESTCONF, and gNMI, for which you understand the pros and cons in light of the tooling environment. Those protocols support different encodings: XML, JSON, protobuf, and so on. In the end, those data models generate APIs to be used directly in programming, thus hiding the low-level details of a YANG model or an encoding.
Even though “Overview of the 2002 IAB Network Management Workshop” (RFC 3535) is 15 years old, the requirements in this document are still applicable and relevant today. Therefore, this document is a good read for anyone wanting to understand the issues faced by operators.
References in This Chapter
To further extend your knowledge, you should look at the RFCs as a next step. They are actually quite readable and a good source of detailed information, and many have usage examples. In particular, have a look at the items referenced in Table 2-4.
Table 2-4 YANG-Related Documents for Further Reading
Topic |
Content |
|---|---|
https://tools.ietf.org/html/rfc3535 Operator requirements in terms of network management. Still valid today. |
|
http://tools.ietf.org/html/rf6244 “An Architecture for Network Management Using NETCONF and YANG” (RFC 6244) |
|
https://datatracker.ietf.org/wg/netconf/documents/ The IETF Network Configuration Working Group. This is the group that defines NETCONF and RESTCONF. Look here for the latest drafts and RFCs. |
|
https://datatracker.ietf.org/wg/netmod/documents/ The IETF Network Modeling Working Group. This is the group that defines YANG and many of the YANG modules. Look here for the latest drafts and RFCs. |
|
|
Catalog of YANG modules, searchable on keywords and metadata. Also has YANG tools for validation, browsing, dependency graphs, and REGEX validation. At the time of writing, there are about 3,500 YANG modules in the catalog. |
|
http://tools.ietf.org/html/rfc8199 and http://tools.ietf.org/html/rfc8309 The different YANG module types. |
Endnotes
1. https://datatracker.ietf.org/wg/netconf/charter
2. https://tools.ietf.org/html/rfc6244#ref-W3CXSD
3. https://tools.ietf.org/html/rfc6244#ref-ISODSDL
4. https://datatracker.ietf.org/wg/netmod/charter/
5. https://datatracker.ietf.org/doc/rfc8402/
6. https://datatracker.ietf.org/doc/rfc7011/
7. https://www.sdncentral.com/what-is-openflow/
9. http://www.opendaylight.org/
14. https://core.tcl.tk/expect/index
15. https://www.itu.int/en/ITU-T/Pages/default.aspx
17. https://www.broadband-forum.org/
18. http://www.openroadm.org/home.html
20. http://www.openconfig.net/software/
21. https://datatracker.ietf.org/doc/rfc8040/
22. https://tools.ietf.org/html/rfc8040#ref-REST-Dissertation
24. https://datatracker.ietf.org/doc/draft-ietf-core-yang-cbor/
25. https://developer.cisco.com/site/ydk/
26. https://github.com/CiscoDevNet/ydk-gen/blob/master/profiles/bundles
27. https://github.com/CiscoDevNet/ydk-py
28. https://github.com/CiscoDevNet/ydk-cpp
29. https://github.com/openconfig/ygot