
Chapter 3. Crimeware and Peer-to-Peer Networks
Minaxi Gupta, Markus Jakobsson, Andrew Kalafut, and Sid Stamm
This chapter contains two sections on the spread of malware over peer-to-peer networks. The bulk of the chapter is devoted to traditional peer-to-peer file-sharing networks, which are considered in the first section. The second section considers the propagation of malware among social networks. In a sense, these are also peer-to-peer networks, but here a peer is not just an adjacent node in an overlay network, but rather a friend or colleague to whom the malware is transmitted.
3.1 Malware in Peer-to-Peer Networks*
The peer-to-peer (P2P) technology offers a unique way for user machines across the Internet to connect to each other and form large networks. These networks can be harnessed for sharing various kinds of resources, including content, processing power, storage, and bandwidth. Among the most popular uses of P2P networks are sharing and distribution of files. Accordingly, various software implementations of the P2P technology specializing in file sharing are available, including Limewire [238]. Unfortunately, the popularity of these networks also makes them attractive vehicles for spreading various kinds of malware, including crimeware, which is often used for financial gain. As we will see in this section, hundreds of different types of malware have invaded these networks, including worms, viruses, downloaders, backdoors, dialers, adware, and keyloggers. Fortunately, our research also shows that most of it can be defended against using clever filtering techniques involving names and sizes of files containing malware.
3.1.1 Introduction
Peer-to-peer networks specializing in file sharing fall in two broad categories: centralized P2P networks such as Napster [267] and decentralized unstructured networks such as Limewire [238]. Irrespective of flavor, getting a file from a P2P network involves two distinct phases: the query phase and the download phase. In the case of centralized P2P networks, the content search is facilitated by (replicated) central servers. All participants of such networks know the whereabouts of these servers. The servers keep track of which user has which file and use this information to direct querying users to the IP (Internet Protocol) addresses of holders of the content that they desire. Upon receiving the reply from the server, the querying peer can directly download the content from one or more sources.
Decentralized P2P networks differ from centralized P2P networks in the manner in which the content search is conducted. Peers in such networks stay connected to each other for content search purposes. When a peer wants to search for a file, it sends a request with keywords to all nodes to which it is connected. Given that a peer typically connects to four to seven other peers, this implies that the content search request is seen by four to seven directly connected peers. They respond positively if they have the desired content. In addition, they forward the query to the peers to which they are connected. These recipients also respond positively if they have what the querier is looking for. In addition, they forward the query further.
This process continues until the number of hops, or hopcount, specified by the original querier is exhausted. To ensure that a content search query is forwarded only as many hops as the querier specifies, each peer that sees the query decrements the hopcount before forwarding the query to its neighbors. When the hopcount reaches zero, the query is dropped.
Upon receiving all responses for its query, the querier picks who it is going to download the file from and downloads the material as it would in the case of centralized P2P networks, by connecting directly. Most popular decentralized P2P networks today are variants of the basic content search and download functionality described here.
Two options for defending against malware in P2P networks are available. The first option relies on identifying malware through antivirus tools after the content has been downloaded. This approach is versatile, in that it protects users’ machines from incoming malware irrespective of its source. However, it also has several shortcomings:
• An actual download of the entire file must occur before the antivirus software can scan it. Users on slow connections or those downloading from other users with slow connections may end up spending several hours on a download, only to find that it contains malware.
• While antivirus software may prevent a user from running downloaded malware, it does nothing to prevent the spread of malware, via P2P networks or otherwise. Thus the files containing malware will continue to be served through the shared P2P directories even after the antivirus software has identified the malware.
• This approach is effective only on known malware.
• Although simple in theory, this approach is not practical because it relies on users’ diligence in keeping their antivirus software running and up-to-date.
The second option is to filter potentially malicious responses in the query phase itself. This approach is efficient because it prevents an actual download of malware-containing files. By not downloading malicious files, it also prevents the spread of malware to the rest of the population. Additionally, it does not require user intervention. However, the filtering must be done only with knowledge about information contained in query responses—namely, the query string itself, file name, size, and the IP address of the offering peer.
The Limewire [238] Gnutella [146] client takes this approach to filter malicious responses. Specifically, Limewire flags the responses returned as the result of a query as malicious if (1) the file name or metadata does not match the words contained in the query; (2) the extension of the returned file is not considered by Limewire to match the file type asked for; or (3) Limewire believes the response contains the Mandragore worm.1 Such responses are not shown to the user. Although this approach seems promising, the criteria used by Limewire fail to produce the desired results. In fact, our tests show that Limewire detects only 8.8% of malicious responses, with a very high false-positive rate of 40.8%.
The rest of this section focuses on two P2P networks, Limewire and OpenFT [294]. For both of these networks, we study how much malware is present in these networks. We also investigate practical methods by which malware in P2P networks can be filtered in the query phase itself.
3.1.2 Data Collection
Several considerations drove the choice of these two P2P networks as targets for study. First, to record queries and responses generated in a P2P network, we needed decentralized P2P networks in which queries and their responses are visible to all peers that route the query. This ruled out Napster [267], Bittorrent [41], and distributed hash table-based P2P networks. Also, the chosen P2P networks had to have a mature open-source implementation to allow instrumentation. This precluded the use of closed-source P2P networks such as KaZaa and the eDonkey 2000 network, which is used by eMule [102]. Accordingly, we chose Gnutella [146] as the first P2P network, which is among the top 10 most popular file-sharing programs. We also chose OpenFT, which is another P2P file-sharing network whose structure and operation are similar to the structure and operation of the Gnutella network. We now outline the basic functionality of Gnutella and OpenFT.
Limewire
Gnutella is a popular P2P file-sharing protocol with many available client implementations, of which Limewire [238] is one. In older versions of the Gnutella protocol, all nodes were equal. In the current version of the Gnutella protocol, nodes in the system can operate in two different modes: as a leaf or as an ultrapeer. Leafs connect to a small number of ultrapeers, and see very little query traffic because ultrapeers do not pass most queries on to leafs. The ultrapeers pass queries on to the leaf nodes only if they believe the leaf has a matching file. Ultrapeers connect to other ultrapeers and legacy nodes not implementing the ultrapeer system. These connections are used for forwarding search queries. Responses to these searches may be sent back along the reverse path through the ultrapeer, or they may be sent out-of-band directly to the originator of the query.
OpenFT
OpenFT is a P2P file-sharing protocol that is very similar in operation to Gnutella. In OpenFT, a node can run in three different modes. A user node is similar to a Gnutella leaf, and a search node is similar to a Gnutella ultrapeer. A third type of node, an index node, maintains a list of search nodes and collects statistics. We use the OpenFT plug-in to the giFT file transfer program, which is the original OpenFT client.
P2P Software Instrumentation
To collect the necessary data for our study, we made several modifications to both Limewire and OpenFT.
First, in both systems, we disabled the normal mechanisms for choosing the node type, and instead forced our Limewire node to connect as an ultrapeer and our OpenFT node to connect as a search node.
Second, we made our modified Limewire client alter all queries passing through our node to disable out-of-band replies, as this option is set by default in many clients to reduce the amount of traffic to nodes in the P2P network but would prevent us from detecting the query responses. These modifications should have had little externally visible impact on the P2P networks.
Third, to identify malware, we added to these programs the ability to automatically download files seen in query responses and scan them for malware.
Finally, we modified Limewire and OpenFT to store the queries and their replies in a database. This allowed us to infer query strings, file names and sizes, and IP addresses of the responding hosts. The database also stored information about the files we downloaded, including the file name, the file size, and whether it contained malware.
Malware Identification
To identify malware, we scanned all downloaded files with a popular open-source antivirus software, ClamAV [405]. We aggressively updated our local copy of the ClamAV signature database, downloading a new copy if it had been modified every 2 hours.
On average, we saw 792,066 responses per day in Limewire and 675,141 responses per day in OpenFT. This made it necessary to be clever in file downloading strategies. First, we leveraged the common belief that most malware attaches itself to nonmedia files and that even the malware believed to accompany media files actually comes with codecs that the media files require, which are executable files. Thus we downloaded with a 100% probability if the file extension contained in a response was one considered to be a program file, archive file, or a Microsoft Office file. The extensions corresponding to these formats are ace, arj, awk. bin, bz2, cab, csh, cue, deb, doc, dmg, exe, gz, gzip, hqx, iso, jar, jnlp, lzh, lha, mdb, msi, msp, nrg, pl, ppt, rar, rpm, sh, shar, sit, tar, taz, tgz, xls, z, zip, zoo, and 7z, a total of 37 different ones. All other files, including the more popular media files, were downloaded with a 1% probability in Limewire. Given that we did not find any malware in any of the files downloaded with a 1% probability, we concluded that this was a reasonable strategy. In fact, the file extension can be used as a first-order filter, in that responses containing file names with extensions outside of this list do not have to be subject to filtering tests. Subsequently in this section, we refer to the file extensions we downloaded files for as the nonmedia file extensions.
To further keep the number of downloads manageable, we considered files to be identical if their names and sizes matched, and we did not download files considered to be identical more than once. We took several steps to confirm that we did not miss new malware because of this strategy. First, if we downloaded a file and did not find malware in it, we waited until seven days from the time we first saw the file and then attempted to download it again. This allowed us to catch malware that may not have had signatures in the system yet when first seen. This strategy detected a small number of additional malware not detected on the first scan. Second, we attempted to re-download a malware-containing file again with a 5% probability. Out of 11,534 unique files classified as malware that were re-downloaded, all were classified as the same malware when re-downloaded, indicating that our criterion for considering files to be identical was reasonable.
3.1.3 Malware Prevalence
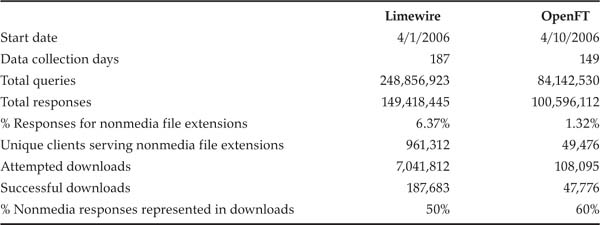
Data collection on Limewire and OpenFT ran for more than seven months, in two separate periods of approximately three months each, with a break in between of approximately six weeks where no data was collected. Table 3.1 presents an overview of the collected data. OpenFT was a much less popular P2P system, as evidenced by the one order of magnitude less search and response traffic. Also noteworthy is the percentage of responses that corresponded to the nonmedia file extensions. They were two orders of magnitude less than the total number of responses witnessed in each of the two networks. Additionally, although the number of successful downloads was much less than the number of attempted downloads, many files were seen several times and we had to successfully download them only once to know whether they were malicious. The files we were able to download correspond in this way to more than half of the nonmedia responses seen.
Table 3.1. Aggregate statistics of collected data.
Overall, we found 170 distinct pieces of malware in Limewire, including worms, viruses, downloaders, backdoors, dialers, adware, and keyloggers. Of these, 94 were seen only in the first data collection period, and 23 were seen only in the second half. The remaining 53 existed throughout the data collection period. OpenFT also witnessed a similar trend, with 106 distinct pieces seen over the entire course of data collection. Of these, 27 were seen only in the first half of our data collection, 42 were seen only in the second half, and 37 persisted through both. This finding emphasizes the longetivity of malware present in P2P networks.
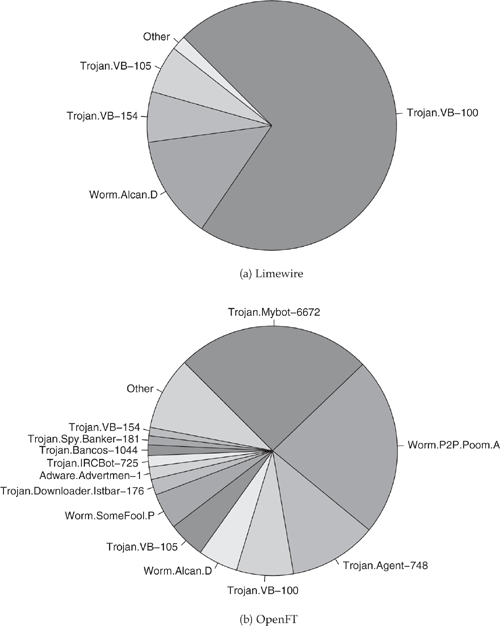
Figure 3.1 shows the breakdown of malicious responses corresponding to the top malware. These programs contributed at least 1% of the malicious responses in each system. Figure 3.1(a) shows that in Limewire, a large proportion of malicious responses—more than 98%—came from just four distinct malware, with the top one contributing 72% itself. Even though no one malware dominated as dramatically as the top one in Limewire, the story was the same in OpenFT. According to Figure 3.1(b), the top individual malware in OpenFT accounted for about 25% of malicious responses seen. The 13 malware samples shown in the figure together account for 90% of the malicious responses seen in the system. Overall, a small number of distinct malware contributed to 90% or more of the malicious responses in both Limewire and OpenFT. Further, all of the top four malware samples in Limewire and 7 of the 13 malware samples in OpenFT persisted throughout the data collection period.
Figure 3.1. Proportion of malicious responses from distinct malware accounting for more than 1% of malicious responses.
Breaking malicious responses down by file type, we found that an alarming number of downloadable responses containing zip files contained malware in Limewire. In particular, 88.5% of responses containing zip files were infected. Three other file formats also contained malware: rar (16.7% of responses containing rar files), exe (12.0% of responses containing exe files), and one response containing a doc file. In comparison, we found five file types infected in OpenFT, the same as those on Limewire, with the addition of sit. Also, the percentage of infected responses for all file types was smaller in OpenFT.
3.1.4 Filtering Malware
We tested a range of filters to explore the extent to which P2P networks can be defended against malware. The filters were based on information available during the query phase—namely, query strings, file names and sizes contained in responses, and IP addresses of hosts that responded. Each of these pieces of information forms a criterion. As an example, a filter based on the file size criterion maintained the percentage of “good” and malicious files seen at each file size and started filtering responses when the percentage of malicious files exceeded a certain threshold. Although each peer could independently perform the filtering, a more efficient mechanism would be for ultrapeers to filter responses on behalf of the leaf nodes that connect to it. This avoids having the leaf nodes download files and scan them for viruses.
We designed filters by considering each criterion both individually and in combination with other criteria. The composite filters were created in two ways. The first type of filters were OR-based filters; they combined multiple single-criterion filters with a logical OR. If a response would be filtered by either of the single-criterion filters, it was filtered by the composite OR-based filter. The second type were AND-based filters; they tracked the amount of malware meeting the filtering criteria for each pair of values of the two criteria involved. For example, a composite AND-based filter based on file size and host IP address filtered responses based on the percentage of past responses containing malware for each file size/host IP pair. Note the difference between this and a simple logical AND of two single-criterion filters, which could not be expected to perform better than the single-criterion filters it is composed of.
Two terms are used throughout the rest of this section. The first, sensitivity, is a measure of how effective a particular filter was in blocking malicious responses. The second, false-positive rate, is a measure of how many clean responses the filter blocked incorrectly. Our goal was to achieve the highest possible sensitivity while keeping the false-positive rate low. Formally, sensitivity and false-positive rate as used in this work are defined as follows:

The effect of each filter was simulated with a set threshold percentage X. If more than X percent of responses satisfied the criterion for the filter at any point of time in our data, we blocked that response from the user. By using such percentage-based thresholds, the filters could adapt on their own to the content on the system. For example, if the filters were blocking files of a specific size when a good file started appearing at that size more often than the malicious one did, that size eventually became unfiltered. For each criterion, we experimented with a range of threshold percentages, between 10% and 95%, in 5% increments. At each threshold, the sensitivity and false-positive rate produced by each filter were recorded. Each filter was tested for both Limewire and OpenFT, as well as using the data from one network to make filtering decisions in the other network.
3.1.5 Single-Criterion Filters
We now describe the results obtained for filters based on a single criterion. Specifically, we tested the efficacy of filtering based on file names, file sizes contained in the responses, IP addresses of hosts sending the responses, and query strings that yielded those responses.
File Size–Based Filters
A file size–based filter filters malicious responses based on the file size contained in the response. An ultrapeer could identify sizes of files contained in malicious responses and leaf nodes could filter based on that information. Although simple in theory, two questions needed to be answered to judge the practicality of this filter.
• What if “good” files also share the filtered sizes?
• What happens if malware is polymorphic?
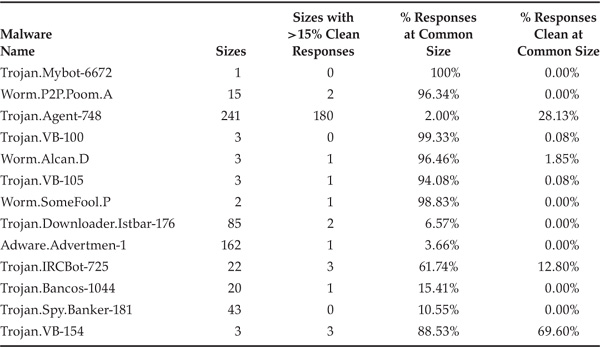
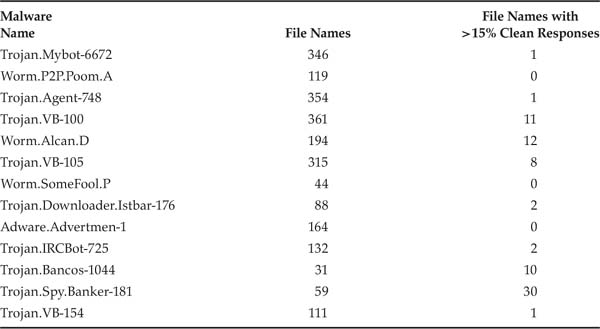
We answer these questions in the context of top malware in Limewire and OpenFT, which accounted for 98% and 90%, respectively, of total malicious responses in each system. Tables 3.2 and 3.3 provide data to answer these questions. The first observation we make from these tables is that malware came in multiple sizes in all but one case. This could be a result of polymorphism or perhaps because malware attached itself to files of various sizes. However, in all cases in Limewire and most cases in OpenFT, most of the malicious responses attributable to a particular malware showed up at one particular size. We also notice that in only a few cases, the most common size for top malware was also a popular size for good files. Collectively, these observations lead us to believe that a file size–based filter is likely to have a high sensitivity and low false positives for the most common sizes of malware. The major exception to this belief is Trojan.VB-154, for which the most common size accounted for 70% to 76% of clean responses as well.
Table 3.2. Malware returning more than 1% of malicious responses in Limewire, with number of file sizes this malware was seen at, number of these with more than 15% of responses clean, percentage of responses containing this malware at its most common file size, and percentage of all responses at this size clean.

Table 3.3. Malware returning more than 1% of malicious responses in OpenFT, with file size statistics. Column descriptions are the same as in Table 3.2.
Another observation from Tables 3.2 and 3.3 is that at most file sizes that the top malware came in, the percentage of malicious responses heavily dominated the clean ones. The exceptions to this were Trojan.VB-154 and Trojan.Agent-748, the latter only in Limewire. For all the others, even if a significant percentage of their sizes encountered a large proportion of clean responses at those sizes, it did not happen for the malware size that dominated. Overall, this implies that irrespective of whether the malware is polymorphic, it is possible to filter it based on file size alone as long as a relatively smaller percentage of good files show up at those sizes. This also leads to the interesting observation that polymorphism may not be the best strategy for an adversary to defeat this filter. As long as a much smaller percentage of good file sizes appears at those sizes, the malicious responses can always be filtered. Further, defeating the filter by monitoring the sizes of popular good files and producing malware at those exact sizes would entail a constant supervision of the P2P networks, for popular files change often per our observation of Limewire and OpenFT.
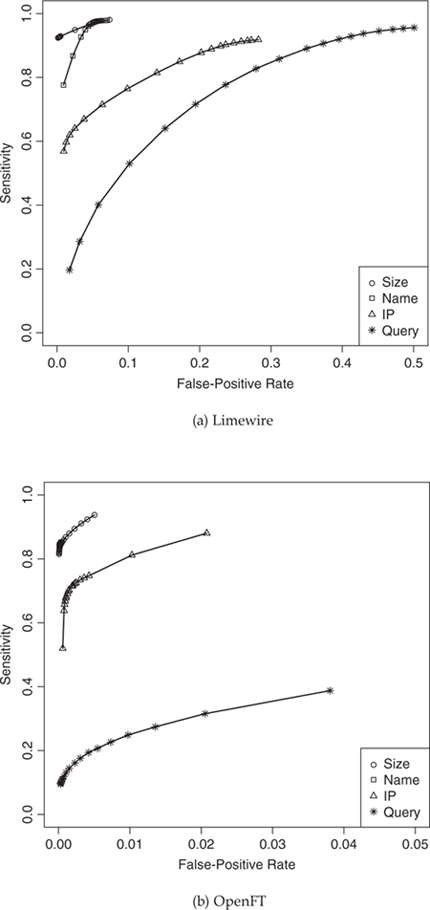
Filter Performance. The filter maintained the percentage of good and malicious responses seen at every file size. It filtered responses when this percentage exceeded a certain threshold. We tested a range of thresholds, between 10% and 95%, in increments of 5%. Overall, this filter performed remarkably well at all thresholds in both systems, as expected. Its sensitivity ranged from 98% to 92% in Limewire. The corresponding false positives ranged from 7% to 0.14%. The trends were the same for OpenFT, in that the sensitivity ranged from 94% to 82% and the corresponding false positives ranged from 0.5% to 0.01%. Figures 3.2(a) and 3.2(b) show the receiver operating characteristic (ROC) curves for Limewire and OpenFT, respectively. These curves show the trade-off between sensitivity and false-positive rate as we varied the threshold. Clearly, the file size–based filter offered high sensitivity at very low false-positive rates for the entire range of thresholds. (We discuss the ROC curves for other filters laterly.)
Figure 3.2. ROC curves for single-criterion filters.
Previously Unknown Malware. Given that the file size–based filter performed so well for known malware, it is natural to wonder how it would do for previously unknown malware. To get an intuitive feel for how the filter would perform without being bootstrapped with sizes of malware, we looked at the sizes and frequencies of malware and compared them to the corresponding numbers for good files. In our data, malware came in many different sizes, ranging from 5.7KB to 824MB in Limewire and 7.3KB to 206MB in OpenFT. In comparison, the smallest and largest good file sizes, respectively, in these systems were 3 bytes and 1.91GB in Limewire and 1 byte and 1.94GB in OpenFT. This implies that the malware file sizes were a subset of those of the good files. The frequencies with which each file size showed up share this feature as well. On the days that a good file was returned in a response, its accesses might range from 1 per day to 1242 per day in Limewire and from 1 per day to 82 per day in OpenFT. In comparison, malware frequencies ranged from 1 per day to 451 per day in Limewire and 1 per day to 36 per day in OpenFT. Both of these sets of numbers point to the similarity in accesses of malware and good files, which may imply that malware in P2P networks today does not exhibit remarkably different characteristics that the filter could exploit. Indeed, we found this result in our tests to see whether malware could be filtered by simply observing swings in accesses to files of certain sizes.
This observation has several potential implications. First, malware currently spreads relatively slowly and persists in the P2P networks for a long time, which justifies the feasibility of using file size–based filters. Second, by taking into account the frequency of a file being seen, it is possible to adapt this filter for fast-spreading zero-day malware2 which will exhibit different access patterns from other good files. Finally, although the filter will not be able to capture the slower zero-day malware initially, its slower speed allows virus signatures to be made available, which the filter can then use to block the malicious responses.
File Name–Based Filters
Filters The file name–based filter works the same way as the file size–based filter. The only difference is that it uses the file name returned in the response to filter malicious responses. As before, to judge the practicality of this filter, we ask two questions:
• How often do good files share the same names as those that contain malware?
• How effective is the filter likely to be when malware changes file names frequently?
The first observation is that malware in both Limewire and OpenFT showed up in many more file names than sizes. As a comparison of Tables 3.4 and 3.5 with Tables 3.2 and 3.3 reveals, most of the top malware showed up in one to three orders of magnitude more file names than file sizes. However, file names belonging to malware were rarely witnessed in clean responses as well. Specifically, in most cases, less than 10% of malicious files shared their names with good files when the good files accounted for a significant percentage (15% in Tables 3.4 and 3.5) of total responses for those file names. This bodes well for the performance of this filter.
Table 3.4. Malware returning more than 1% of malicious responses in Limewire, with file name statistics.

Table 3.5. Malware returning more than 1% of malicious responses in OpenFT, with file name statistics.
Another thing that differentiated file names of malware from their file sizes was the fact that hardly any file names were among the top malware. Not depicted in Tables 3.4 and 3.5 is the fact that topmost malware in Limewire appeared with its most common file name only 2.2% of the times it was seen. The situation was similar, but not as extreme, in OpenFT. Here, the single most common malware occurred with the same name only 0.62% of the time, but all others occurred at their most common name more often.
Filter Performance. Just as we did for the file size–based filter, we tested the file name–based filter on a range of threshold percentages, from 10% to 95%, in increments of 5%. This filter also performed remarkably well, and expectedly so. The only difference was that at higher thresholds, especially at the 90% and 95% thresholds in Limewire, the sensitivity fell off more quickly and the false positives did not fall off as quickly as they did for the file size–based filter. In particular, the sensitivity for this filter ranged from 98% to 78% in Limewire. The corresponding range for false positives was 7% to 1%. The corresponding numbers for OpenFT were 85% to 83% and 0.05% to 0.01%. We note that for the same thresholds, OpenFT experienced a lower false-positive rate and sensitivity than Limewire. Finally, the ROC curves for this filter exhibited similar trends as for the file size–based filter, as depicted in Figures 3.2(a) and 3.2(b). (In the case of OpenFT, the curve for name is obscured from view by the curve for size.)
Previously Unknown Malware. The issues in detecting previously unknown malware through this filter remain the same as for the file size–based filter. We do not repeat the discussion in the interest of brevity.
Host IP–Based Filters
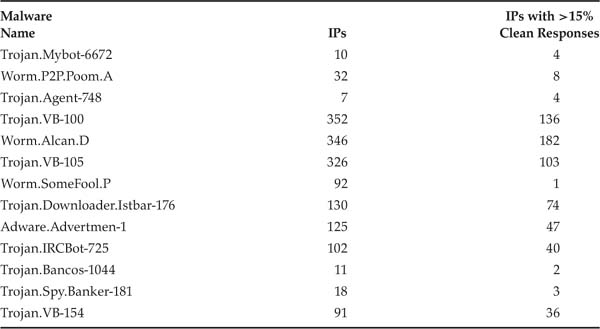
Next, we considered filtering malicious responses based on identifying the IP addresses of hosts serving that malware. Similar to the file size–based and file name–based filters, we tested the feasibility of using host IPs for filtering malicious responses. Tables 3.6 and 3.7 show the number of unique IP addresses serving the top malware and the percentage of those IPs that offered good files more than 15% of the time. In Limewire, 6% to 60% of IPs serving malware were also serving good files more than 15% of the time. The range was 1% to 57% for OpenFT.
Table 3.6. Malware returning more than 1% of malicious responses in Limewire, with host IP statistics.

Table 3.7. Malware returning more than 1% of malicious responses in OpenFT, with host IP statistics.
Both of these observations do not seem to bode well for the host IP–based filter. Further, a filter based on the host IP faces other issues unrelated to P2P networks: The use of network address translation (NAT) and Dynamic Host Configuration Protocol (DHCP) make it hard to be certain that the same IP denotes the same host, especially over a long time scale, such as that of the data collected here.
Filter Performance. We tested this filter on the same range of thresholds as the file size–based and file name–based filters. As expected, this filter performed poorly. The best sensitivity it offered was less than 50% for both Limewire and OpenFT. As the sensitivity approached acceptable ranges, the false-positive rate increased, hitting as high as 30% for Limewire. The false-positive rate for OpenFT remained low, closer to 2%, and some thresholds offered sensitivity as high as 90%. The reason this filter performed reasonably well in OpenFT had to do with the total percentage of infected hosts in OpenFT. Specifically, only 5.4% of hosts in OpenFT were infected with any malware. By comparison, 52% of hosts in Limewire were infected. The ROC curves depicted in Figures 3.2(a) and 3.2(b) show the range of sensitivity and thresholds experienced at various thresholds.
Query String–Based Filters
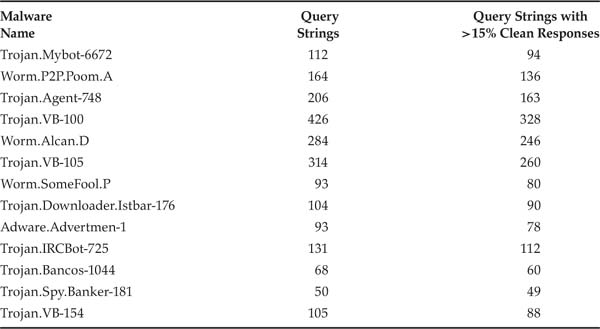
The last filter we tested based on information available during the query phase involved query strings. We tested this filter in the same way we tested the file size–, file name–, and host IP–based filters. Tables 3.8 and 3.9 contain information with which to judge the expected performance of this filter. Specifically, for both Limewire and OpenFT, a large number of query strings ended up returning the top malware. Limewire, being the more popular system, exhibited at least two orders of more queries than OpenFT that returned malware. In both systems, however, a significant percentage of queries that returned malware, ranging from about 33% to as high as 98%, also returned at least 15% good files—indicating that this filter was unlikely to fare well.
Table 3.8. Malware returning more than 1% of malicious responses in Limewire, with query string statistics.
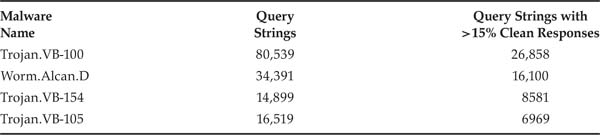
Table 3.9. Malware returning more than 1% of malicious responses in OpenFT, with query string statistics.
Filter Performance. This filter performed the worst of the four filters explored. The trade-offs between sensitivity and false positives remained unacceptable for the entire range of thresholds tested. As an example, when the false-positive rate was less than 5%, the sensitivity was a mere 30% in Limewire. Similarly, when the sensitivity approached 90%, the false-positive rate was close to 50%. At all thresholds, the false-positive rate continued to be low for OpenFT, less than 5%. However, the maximum sensitivity achieved by this filter was a mere 40%. The ROC curves in Figures 3.2(a) and 3.2(b) depict these observations.
3.1.6 Single-Criterion Filters Across Networks
In this section, we discuss our tests of whether the filters developed for one P2P network could be used in another network. If so, then information from one system could be used for filtering in another, or information from multiple systems could be used to increase the effectiveness of filters in any of them.
First, we observed that 57 malware samples were common to both Limewire and OpenFT, or 34% of distinct malware in Limewire and 54% in OpenFT. In fact, in terms of responses containing these malware, these samples accounted for 99.9% of the malicious responses in Limewire and 71.2% in OpenFT. The main reason the number was lower for OpenFT was because the most commonly seen malware in OpenFT, Trojan.Mybot-6672, was never seen in Limewire. Still, this commonality was high enough that we expected a reasonably good chance that information from one system would be useful in filtering in the other.
Next, we looked at commonality specifically regarding the criteria we attempted to filter on. We focused only on file size and file names here owing to their performance in each system. Table 3.10 shows that although the commonality in file sizes was not very high across Limewire and OpenFT, the common file sizes accounted for a large proportion of the malicious responses. Using file names from Limewire in OpenFT also holds promise. However, the reverse does not look promising.
Table 3.10. Commonality of malicious file sizes and names across Limewire and OpenFT and the percentage of responses they accounted for.

Filter Performance Across Systems. The filters we simulated here were similar to those used in Section 3.1.5. The only difference is that here the decision to filter a response was based on what was seen previously in the other system. Overall, we found that in both directions, both filters performed close to how they were expected to perform based on the commonality. Thus filtering malware in one network can be bootstrapped with information from the other. Specifically, using OpenFT data in Limewire yielded sensitivities for the file size–based filter in the range of 95% to 88% when thresholds varied between 10% to 95%. The false-positive rates were less than 1% at higher thresholds. Using file names from OpenFT produces poor filtering results, because the commonality was low to begin with. Irrespective of the threshold, using Limewire file sizes in OpenFT produced a sensitivity of 46% to 49%, which mimics the commonality. The false-positive rate was less than 0.5% in all cases. The sensitivities using file names from Limewire to filter in OpenFT also mimicked the commonality.
3.1.7 Composite Filters
Next, we investigated the possibility of combining multiple criteria to generate better filters that would produce high sensitivity while keeping the false-positive rate low.
Composite Filters for Individual Networks
We began with the OR-based filters. These filters are combinations of two individual filters joined with a logical OR. If a response matches either of the individual filters, it matches the OR-based filter.
We tested all combinations of OR filters that could be composed using each of the filtering criteria—namely, file size, file name, host IP, and query strings. In general, the OR-based filters performed quite well, improving upon the results produced with the filters based on individual criteria. For the sake of brevity, here we present only the results of the filter composed of file size and file name, file size OR file name, because each of these individual criteria performed the best.
For all ranges of thresholds tested, the file size OR file name filter had a sensitivity of more than 99% for Limewire, which is several percentage points higher than any of the individual filters for all false positives. The false-positive rate was higher at lower thresholds but dropped down to 1% at a threshold of 95%. The trend was the same for OpenFT, where this composite filter improved the sensitivity of the best individual filter by several percentage points. The sensitivity for this filter in OpenFT ranged from 93% to 95%. All of the false-positive rates were less than 0.5%.
We next explored the AND-based filters. These filters filter based on how many malicious responses have been previously seen as matching on both criteria they are composed of. By being more precise in adding and removing filters only from the pairs of values that need them, instead of adding and removing filters based on individual values of one criterion, it should be possible to filter more effectively than with single-criterion filters.
While not performing extremely poorly, all of the AND composite filters, with the exception of the file size AND file name filter, performed somewhat worse than we intuitively expected. Even this filter only marginally improved the results of the individual filters. To keep the discussion concise, we omit the details of these results.
Investigating why the performance was worse than expected, we found that this result was mainly attributable to the number of combinations of values. No matter what the threshold, the first time we saw a pair of values, the filter was never able to identify it as malicious. With enough pairs of values actually present in the system, this shortcoming can bring down the amount we are able to detect. By comparing the number of these value pairs occurring in malicious responses to the number of malicious responses seen, we determined the maximum percentage detectable after accounting for these. We found that this flaw was, indeed, the cause of the poorer-than-expected performance of these filters. In all cases, the sensitivity we actually achieved was lower than the maximum possible by no more than 3%.
Composite Filters Across Networks
We also investigated whether composite filters could be used to achieve better results when filtering across systems. We tested the entire range of both OR-based and AND-based composite filters from one network into the other. To keep the discussion concise, here we briefly mention the performance of the best composite filter, file size OR file name, across the two networks. For this filter, we saw a marginal improvement over what the file size–based filter could achieve across systems on its own, 92.0% sensitivity compared to 91.9% in Limewire, and 50.4% compared to 48.8% in OpenFT. For the AND-based composite filters, the results did not approach those indicated by the commonality of the individual criteria. This finding shows that the commonality of these values in the two systems did not extend to commonality in which values appear together.
Conclusion
In this section, we looked at malware prevalence in the Limewire P2P network using query-response data collected over a period of seven months. We found that even though a wide variety of malware pervaded these systems, only a handful of programs were behind most of the malicious responses. In fact, many were common across Limewire and OpenFT and persisted throughout the data collection period. We used these observations in devising practical filtering criteria to defend against malware in these systems. Our approach to filtering detected malicious responses without requiring a download of the actual file. This saved time that would otherwise have been wasted downloading malicious files, and it prevented the spread of such files.
Our filters were based on information available during the query phase, including file sizes, file names, host IP addresses, and query strings. The filters based on file size and file name performed remarkably well, filtering 94% to 98% of responses in OpenFT and Limewire. Their success resulted from the rarity of “good” files sharing their names and sizes with malware. This relationship held even when the malware was polymorphic and changed its name and size upon execution. We also found that it was possible to filter malicious responses in one system using information from the other system, because Limewire and OpenFT often encounter the same files. Further, combining multiple filtering criteria boosted the filtering capabilities of single-criterion filters, allowing them to filter 95% to 99% of malware-containing responses without penalizing the clean responses.
As described, our filters relied on the presence of malware signatures to bootstrap themselves. This raises questions about how to counter the previously unknown, (i.e., zero-day worms). While the filters are unlikely to know how to distinguish between good files and zero-day worms if the propagation of worms is similar to good files, they should be able to identify high-speed zero-day worms by monitoring the frequency of file names and sizes and by flagging unusually “active” files as malware.
Finally, our filters could be implemented simply on a real system. In ultrapeer-based P2P networks such as Limewire or OpenFT, an ultrapeer would run and download all of the files indicated by responses with file extensions considered to be at high risk for malware. It would scan those files for malware and track the necessary percentages of malicious responses at various file sizes, file names, query strings, or host IP addresses to determine what to filter. The threshold percentage used in determining what to filter can be automatically adjusted over time by tracking false-positive rates. Such a node on the system could then block the malicious responses. For greater effectiveness, implementing ultrapeers could trade information on what to block. Alternatively, to put more control at the end systems, other P2P users could periodically be updated on these filters and would choose what to block based on them.
3.2 Human-Propagated Crimeware*
People are naturally drawn to web sites containing fun content or something humorous, and they generally want to share that experience with their friends. In turn, their friends generally enjoy the site and will often share it with their friends, too. This scheme is considered human propogation: referral to a location based on recommendation of peers. This method of propogation cannot be stopped by any packet-inspecting firewall, email server, or virus detection engine. It has, and always will be, a reliable method of disseminating information.
3.2.1 The Problem
One morning, Alice is checking her email. Among the large number of junk email messages, she notices one with a subject of “Help Find Ashley Flores!” Curious, she opens the email. Alice is greeted with a picture of a 16-year-old girl and a note from her mother begging for help finding Ashley. The message asks two things: (1) If you’ve seen her, let me know; and (2) send this message to all of your friends to spread the word. Alice feels really bad about the missing girl, especially because she has a daughter of her own, so she forwards the message to as many people as she can find in her address book.
What Alice doesn’t know is that Ashley Flores is not lost—this is a hoax. Alice was captivated by the email, however, and felt compelled to share it with everyone she could. This is an exemplary case of human-propogated information. Of course, people share more than just details about lost girls. They also share videos, links to funny web sites, and many other types of data that could be infected with viruses.
3.2.2 Infection Vectors
The fact that Alice forwarded the hoax to all of her friends is, in itself, not a problem. Dangerous situations pop up when the information that is the subject of discussion has the ability to infect its viewers’ computers. Most of these infection vectors share one feature: They quickly draw immense numbers of people to the site, and they are forgotten after a while. These characteristics are ideal for spreading malware, because a drawn-out, gradual propogation may more easily be detected.
Viral videos. YouTube and Google Video are just two examples of sites where one can find videos that captivate their viewers, and anyone can share material. Many other web sites also host this kind of material, and it circulates widely. Oftentimes, these popular videos are displayed through proprietary media players (e.g., Flash, Java applet, ActiveX controls)—all of which have the potential to do more than just display video. Knock-off sites of these popular content distribution sites could have the potential to serve infecting content.
Games and fads. The number of online game web sites attests to the fact that people enjoy playing games while on the web. Every once in a while, a new game emerges whose popularity grows like wildfire—and, of course, appears somehow on the web. In 2005, sudoku grew in popularity and has popped up in many forms on the web. When people discover new immersive games (such as sudoku or online chess), they often share them with their friends; this is especially the case with multiplayer games such as go, chess, or checkers.
Besides videos and games, many other web fads are shared among friends. Any website that is shared among friends is given an unwarranted trust. The rationale is akin to this: “If my friend Bob thinks the site is safe, it must be.” Unfortunately, Bob may have misjudged the site, and it may actually be an infection vector for malware.
3.2.3 Case Study: Signed Applets
In mid-2005, Carlton Draught let loose on the Internet an impressive advertisement—its “Big Ad.” Served up by a web site, visitors could watch the video as it streamed to their computers, even in full-screen mode. The video was constructed in an “epic” style (very big, looked very expensive and impressive), and the advertisement’s site was received by Internet patrons impressively fast; after being online for only one day, the advertisement had been viewed 162,000 times [131]. Two weeks later, when the advertisement made its debut on television, the online version had been viewed more than 1 million times, from 132 countries [131].
The success of socio-viral marketing is evident in the case of Carlton Draught’s brilliant move. Thanks to a custom video-streaming technology built by Vividas, the popular advertisement was disseminated across the globe with a blistering speed and breadth. This word-of-mouth content delivery mechanism could also easily be adopted by crimeware-possessing hackers, who often see opportunity where others do not.
Distributing Full-Screen Video. The distribution of the Big Ad was shared among Internet users mostly by word-of-mouth (or email, blog, and so on). Meanwhile, the customized video-streaming software on the Big Ad web site used widely available technologies—namely, Java applets and binary executables. This allowed the ad to be displayed as “streamed” content on the web while full screen—a feature usually reserved for desktop applications.
A visitor to the Carlton Draught web site is prompted by his or her browser about a signed Java applet that is being served. An applet is a compiled Java program that, when signed and authorized by a user, has more access to the user’s computer than standard parts of web pages such as JavaScript or HTML. This prompt asks the visitor if he or she would like to trust the applet. The prompt displayed by Firefox 1.5 is shown in Figure 3.3. Once its applet is authorized, the Carlton Draught site uses the applet to download and install the Vividas media player onto the visitor’s computer. This executable program is then run to provide access to streaming media that is presented in full screen. The result is a video that starts to play immediately.
Figure 3.3. The prompt Firefox 1.5 provides before running a signed (trusted) Java applet. It shows who signed the applet and who issued the certificate. Once the certificate is accepted by the visitor, the associated signed applet has elevated access on the user’s computer, such as access to the file system.
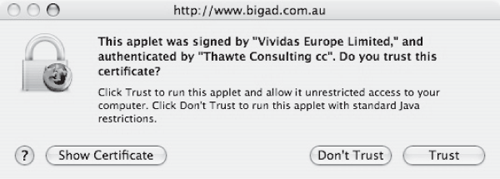
Making It a Truly Viral Video. The web site can install programs on the client’s computer only because the Java applets used are signed; signed applets are given more access to users’ computers in the belief that people will properly authenticate a signed applet—by checking the certificate—before running it. Many people, however, ignore the content of the “Want to trust this applet?” dialog that is displayed by their browsers and simply click the “Trust” button. This check is performed so users can decide whether to trust an applet and thus give it more access to their PCs.
A malicious person could make a copy of the web site (by downloading all of the files and putting them on the user’s own web server), and then modify the signed applet files to do what he or she wants. Of course, the user is required to re-sign the applet files before deploying augmented copies (the old signature will be invalid owing to the changed content), but browsers still allow people to “trust” any signed applet, whether it is authenticated with an authority-issued certificate or a self-signed certificate that anyone can create. These self-signed certificates can easily be created without help from an authority (such as Verisign or Thawte). Although these certificates provide the same functionality to applets, the owner of the certificate has not been deemed “trusted” by any authority. As mentioned before, many people don’t know or care about the difference between the two types of certificates and will allow any signed applet to run on their machines.
The ability to download and install arbitrary executables onto a computer would allow an evil person to install malware instead of a media player. An even more malicious person could do both, making it seem as if all that was run was a media player, when, in fact, other software was installed in the background. People who visit the evildoer’s copy of a signed-applet deploying site could then become infected with malware while having the same experience as visitors who visit the legitimate site.
Getting In on the Action. An attacker with a mirrored (but infected) copy of this popular advertisement could draw people to his or her site by using many different techniques. For example, in the case of Carlton Draught, the domain www.bigad.com.au was registered to host the advertisement. A similar domain could be registered and used by the contact (e.g., bigad.net, bigad.com, verybigad.com.au, verybigad.com). This tactic capitalizes on people who do not remember the web site’s real address properly, but only the content of the advertisement. People recall that it was a very big ad and, therefore, may mistakenly “remember” the address as verybigad.com. This mechanism is similar to the one used in cousin-domain phishing attacks [202]. Cousin-domain attacks rely on using a domain similar to a legitimate one (for example, bonkofamerica.com versus bankofamerica.com) to fool visitors into trusting the phishing site. They may mimic target domains in a conceptual manner, as democratic-party.us mimics democrats.org, or rely on typos, as is described in Chapter 10.
Additionally, an attacker may spread the word by getting listed in search engines such that people who type “very big ad” are drawn to the attacker’s site. This takes a significant effort, but can be sped up by participating in a web ring or other heavily linked network (because many search engines rank sites based on the number of links to a page).
A third method to spread the word about the attacker’s look-alike site is to send spam. The attacker could obtain a mail list in the same way spammers do, and then circulate a very simple email linking to his or her copy of the site. The email circulated would be spoofed, or appear to come from a legitimate authority instead of the attacker himself. It is straightforward to spoof an email: One simply needs to provide a false sender to the mail relay server. These spoofed emails can seem especially credible to recipients if the original has received media coverage, so the email sent by the attacker could resemble something like this:
Involuntary assistance (luck) might also be a factor in the success of an attacker’s mirror site. After two weeks of Internet buzz surrounding the bigad.com.au site, the advertisement was aired on television. This airing increased exposure to more people who may have not known about the ad, and some of them probably sought a copy of the advertisement online. These people (who had not seen the original site) would be most vulnerable to spam messages mentioning the attacker’s copy as well as to search engines that index the attacker’s site above the real one.
Experimental Evidence
In 2006, an experiment [388] was conducted to assess the effect of human-propogated malware that could be delivered from a web site mirroring the Carlton Draught Big Ad site. A copy of the bigad.com.au site was erected at verybigad.com, and then its URL was circulated to a few people. After a few weeks, people from all over the globe had accessed the simulated attack site. The researchers modified the signed applets, re-signed them with an untrusted certificate, and then served the modified copies to see whether people would trust modified, signed Java applets. This was done to simulate the steps an attacker would take in to place malware into the copied and signed applet.
Erecting a Mirror. A copy of the bigad.com.au site was created in a very simple fashion: All of the files served by the main site were downloaded and assembled onto a second web server referred to by the address registered by the researchers, verybigad.com. The HTML files, Java applets, and streamed media files were all copied.
To simulate an attack, the Java applet JAR files housing the streaming media playing software were decompressed, and their signatures were removed. A self-signed certificate was created and signed by an unknown entity that the researchers called “Key Authority.” Next, the applet’s code files were augmented to write the remote user’s IP address to a log file, thereby recording who allowed the applet to execute. The researchers then re-created and signed with the new, self-signed certificate. The modified JAR files took the place of the legitimate ones on the verybigad.com copy of the web site.
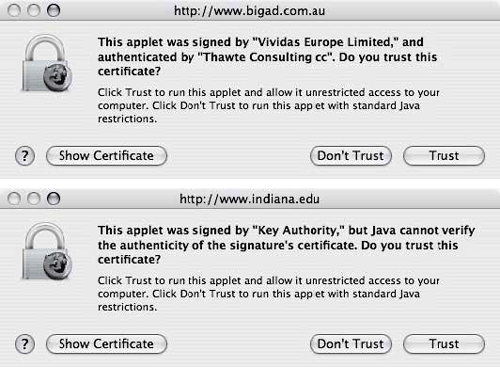
When visiting the new verybigad.com web site, a visitor’s experience would mimic exactly a visit to the legitimate bigad.com.au web site except for different certificate information in the browser’s “Would you like to run this applet” prompt (Figure 3.4). This slight difference is not necessarily enough to prevent people from trusting the evil copy of the big advertisement.
Figure 3.4. The prompt Firefox 1.5 provides before running a signed (trusted) Java applet. The applet referenced in the top dialog is verified with an authoritative certificate issued by Thawte and should be trusted. The bottom one, signed by “Key Authority,” is self-signed and should not be trusted.
Results. The researchers found that roughly 70% of the visitors to the copy site loaded the self-signed applet. They suggest that this result is a low estimate, owing to some difficulties encountered in deploying the site; clients with some versions of Internet Explorer were not properly delivered the applet, so they could not run it. This added to the number of hits to the site that did not load the applet (though not necessarily due to conscious choice).
Spreading through word of mouth (or email, instant message, and so forth), the experimental copy of the big advertisement was viewed by people from all over the globe (Figure 3.5).
Figure 3.5. Visitors during the verybigad.com experiment, which started with 12 people in Indiana, United States.
