
Chapter 6. Connecting to Services
Connecting to services is a fairly easy task, but there are some things to consider when running in a production environment. This chapter discusses blocking I/O, parallelism, and how to tackle these problems in Ruby 1.8, 1.9, and JRuby. It also covers how to gather performance statistics to ensure that service owners are meeting requirements. Finally, examples show how to test and mock service calls and methods for running in development mode.
Blocking I/O, Threading, and Parallelism
One of the core requirements for creating a working services architecture is the ability to run requests in parallel. Without parallelism, you’d be unable to make more than a couple service calls within the client’s request/response lifecycle. For instance, consider an example in which each service takes 30 milliseconds to respond. Further assume that it takes 10 service requests to get all the data needed to respond to a single request. When run serially, these requests would take a total of 3 seconds. When run in parallel, it should be only a little over 30 milliseconds, with maybe a few extra milliseconds for actual I/O and overhead.
This example highlights the importance of running requests in parallel. There are two approaches for achieving parallelism with requests: asynchronous and multithreaded I/O. Each of these approaches is a solution to the problem of blocking I/O. That is, when performing I/O operations (such as transferring data over a network), code execution blocks and waits for a response. Let’s take a look at how each of these approaches solves this problem.
Asynchronous I/O
Asynchronous I/O is an approach that lets a program continue to execute while waiting for data. In the case of the previous example, with 10 service requests, the first request starts, and execution moves on to starting the other nine before the first request completes. A typical pattern with asynchronous I/O is to create handler code that gets called when each request is done, commonly referred to as a reactor design pattern.
Implementations of the reactor design pattern exist for Ruby in the form of the EventMachine (http://rubyeventmachine.com/), Revactor (http://revactor.org), and NeverBlock (http://github.com/oldmoe/neverblock) libraries. The goal of these libraries is to let your program continue to execute while waiting for I/O. Coverage of the specific reactor libraries is beyond the scope of this book. Instead, this chapter covers Typhoeus, which supports asynchronous HTTP calls via libcurl-multi, an asynchronous request library written in C. Another option for performing asynchronous requests is the Curb library, which also includes bindings to libcurl-multi.
Multi-threading
Multi-threaded models are another approach for achieving parallelism for service requests. The goal in a multi-threaded services client is to put each of the blocking I/O calls in a thread of its own. This way, program execution can continue in the primary thread while the worker threads wait for requests to complete. To understand how this works inside Ruby, we need to take quick detour to discuss threading models.
Each of the Ruby implementations takes a slightly different approach to implementing threading. The differences between implementations lie mainly in the types of threads they use. The two kinds of threads are green, or user-level, threads and native, or kernel-level, threads. Kernel-level threads are managed by the underlying operating system. This means that the operating system is responsible for scheduling their execution. If one of the threads is waiting on I/O, the operating system can automatically move over to another thread.
User-level threads rely on the Ruby interpreter to schedule their execution. Multiple user-level threads run within a single kernel-level thread. What this means for service requests is that I/O within user-level threads blocks execution on all other user-level threads. Of course, this defeats the goal of running requests in parallel.
In the Ruby implementations, Ruby 1.8 has a user-level thread implementation. This has a negative impact on the performance of multi-threaded service clients in Ruby 1.8. Ruby 1.9 uses kernel-level threads, but it has a global interpreter lock (GIL). This means that even though the threads are kernel level, only one can run at a time in the interpreter. This can also have a negative impact on performance. JRuby and Rubinius use regular kernel-level threads that are scheduled by the operating system.
The different types of threading in the Ruby implementations means that threaded I/O performance can vary quite a bit from implementation to implementation. Java users are accustomed to using multi-threaded techniques for achieving parallelism, but with Ruby, you have to be a bit more careful. The difference in performance depends on how much data is returned in the service request and the response time of the services being called.
In tests using the different Ruby implementations, asynchronous clients are almost always faster than multi-threaded clients. However, the difference between them can be quite small, depending on the specific case. Testing and benchmarking your approach is always the best way to ensure that you’re achieving your desired performance.
Typhoeus
Typhoeus is a Ruby library with native C extensions to libcurl and libcurl-multi. libcurl-multi provides an interface for performing asynchronous requests. This makes Typhoeus an implementation that uses the asynchronous I/O reactor style to achieve parallelism. Typhoeus has been tested with Ruby 1.8.6, 1.8.7, and 1.9.1.
Before you can run through these examples, you first need to install the library. Typhoeus requires a current version of libcurl, which can be found at http://curl.haxx.se/libcurl/. Once libcurl is installed, you can Typhoeus with the following:
gem install pauldix-typhoeus --source=http://gems.github.com
Making Single Requests
Now that you have Typhoeus installed, you’re ready to make some requests. Typhoeus has three classes that manage making HTTP requests: request, response, and hydra. The request class contains all the information about a request, including the URI, the headers, the request body, and other parameters, such as timeout and authentication. The response object holds information about the response, including the HTTP status code, the headers, the body, and the time taken. hydra is the class that manages requests and runs them in parallel.
The following is a simple example:

This example shows how to create a single request to a server running on the local machine. First, you create the hydra object that will manage requests. Then you create the request object. The example also passes a timeout value that gives the request 100 milliseconds to complete before it times out. At this point, the request has not yet been run. Before you run it, you assign an on_complete handler. This block of code is called after the request completes. The block is yielded a response object.
Finally, you queue up the request in the hydra object and run it. run is a blocking call that does not return until all queued requests are called. For a single request, this looks like a lot of effort compared to a regular Net::HTTP call. Only when you run more requests do the advantages of this asynchronous style become apparent.
For single requests like the preceding example, Typhoeus has a few shortcut methods to reduce the amount of setup and code required and run them right away:
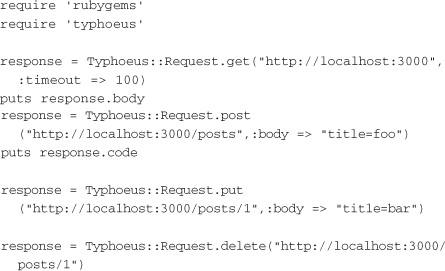
This example shows running GET, PUT, POST, and DELETE requests. The options hash takes all the same options that the Request constructor takes. The request is run immediately and the resulting response object is returned.
Making Simultaneous Requests
Now it’s time to look at a more complex example. For this example, you’ll return to the social feed reader application and produce a set of requests for a user’s reading list. That is, given a user ID, you want to pull the sorted list of feed entries that the user has to read, along with any ratings information for each entry. Calls to multiple services have to be made to get this data. First, you call the feed subscriptions service to get a list of entries for a user’s reading list. Once that list is returned, you make calls to the entry service to pull back the data for each entry. Finally, you make a call to the ratings service to get the ratings for each of the entries in this list.
The following example shows how you would make those calls using Typhoeus:

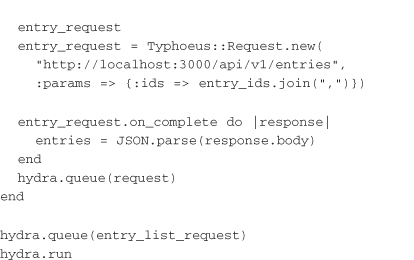
This code example is a bit messy because it keeps everything in one place, but this makes it easier to see exactly what is happening. (Chapter 7, “Developing Service Client Libraries,” covers how to write clean libraries with code reuse of parsing logic.) Now it’s time to examine what is going on in the example.
First, you initialize the variables that will be accessed from the completion handlers of the requests. Then you create the GET request for the reading list. The handler for the reading list request is the interesting part. First, you parse the response. As with the collection-based requests in the previous chapter, you can assume that the body is a hash with an element called entries that contains the entry IDs. This is the only part of the response needed to make the other requests.
Once the entry IDs have been returned in the first request, you can build requests to the entry and ratings services. The ratings service request gives the ratings of the entry IDs that are passed in the params hash. The on_complete handler assigns the parsed response to be used later. The same is done with the request to the entry service (which returns the full entry). Each of these requests is added to the hydra queue.
Finally, the fully built entry_list_request is added to the hydra queue and a blocking call is made to run. Let’s take a look at how the call to run hydra proceeds. First, the entry list request is run. The on_complete handler is called when it is complete. The ratings and entry requests are added to the queue, and the on_complete block returns. At this point, hydra picks back up and runs the two requests in parallel. When either one finishes, its on_complete block is run.
The important thing to take note of is that the on_complete handlers for the ratings and entry requests are not guaranteed to run in any particular order. The entry request could complete and run its on_complete block before the ratings request, despite the fact that they appear in opposite order in code. Given the way the example is structured, this isn’t a concern. However, if you had built in some code on the entry request on_complete handler which assumed that the ratings request on_complete handler had already been run, you’d have a problem.
This section is meant to serve merely as an introduction to Typhoeus and the common asynchronous programming style used in other reactor libraries. Many event-driven libraries include the idea of completion handlers or callbacks that are run on events. Typhoeus is covered in greater detail, along with how to write clean libraries, in Chapter 7, “Developing Service Client Libraries.”
Multi-threaded Requests
One option for performing requests in parallel is to run them in multiple threads. However, this isn’t as straightforward in Ruby as it is in other languages. Because of the user-level threads in Ruby 1.8 and the global interpreter lock in Ruby 1.9, the performance of threaded requests may not actually reflect true parallelism. Still, there are some performance gains in running multiple requests via threads. Here is an example of using standard Net::HTTP in a multi-threaded fashion:
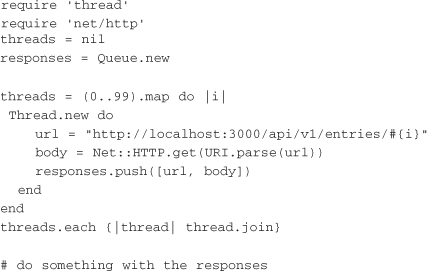
This example creates a new thread for each request to be run. The responses are put onto a queue. The use of the queue is important because it is thread-safe. Then it iterates over the threads and makes sure each one has completed before execution continues. When all requests are complete, it’s possible to do some processing with the responses.
The following example uses a thread pool:
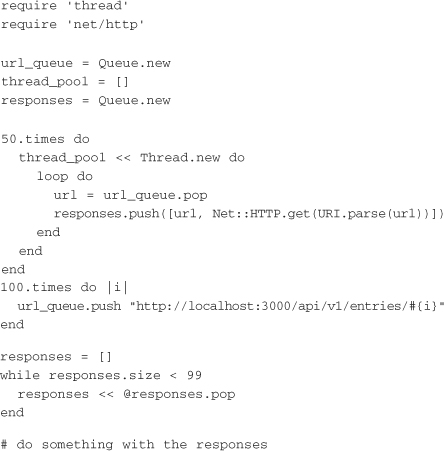
A thread pool is usually more efficient in systems that use native threads because of the higher overhead in setting them up. The thread pool sets up the threads once and reuses them to make connections over time. You’d want to use this method when running Ruby 1.9, MacRuby, Rubinius, or JRuby. Here’s what is going on in this example. First, it sets up the variables that the thread pool will be using. Then the threads in the pool are started—in this case, a total of 50 threads. This represents the maximum number of concurrent requests that can be made. Each of these waits for a URI on the queue and runs the request. A more complex example would put full request objects into the queue. Now that the thread pool is running, the script can simply queue up URIs to be requested. Finally, the example pulls responses from the responses queue until all have returned.
The two threaded examples are fairly simple and not entirely complete. A real-world set of service requests would require a bit more complexity. Specifically, it would need to call out to different services after some requests finish. However, these examples show the basics of how to run multi-threaded requests.
JRuby
In JRuby, there are multiple options for running requests in parallel. Because of JRuby’s kernel-level threads, parallelism can be achieved through multi-threaded clients. It’s possible to use a thread pool model with Net::HTTP as in the previous section, or you can take advantage of some Java libraries. Here is a quick example that uses the built-in Java concurrency library for running requests inside a thread pool:

Here is what’s going on in this example. First, it brings in the necessary Java libraries to handle the thread pool. The Executors Java class includes a factory to generate a thread pool. In order to use the thread pool, you first need to create a class that implements the Callable interface. This is where the request class comes in. Including the Callable interface in the class translates to telling Java that request implements the interface. It must define the method call to conform to that interface. In the example, call simply runs the request using the JRuby Net::HTTP implementation.
When the request class has been defined, everything is ready to make the necessary calls. First, the example creates the thread pool and specifies that it should run 50 concurrent threads. Now it’s ready to submit jobs to the pool for execution. The request objects are initialized and submitted to the thread pool. The submit method returns an instance of the Java Future class. The return value of the request’s call method can be accessed through this object. Indeed, that’s what is happening later, when looping through futures to get the value of each request. Finally, the thread pool has to be shut down for the script to complete and exit.
While the previous example uses Net::HTTP, JRuby gives you access to everything in Java, including a solid HTTP client. The Apache Commons HTTP Client (http://hc.apache.org/httpcomponents-client/index.html) is a Java library for performing HTTP requests. It’s a mature library that includes a fairly expansive feature set. Specific coverage is beyond the scope of this book, but if you’re running on JRuby, it’s one of the better options for making HTTP requests.
Logging for Performance
One of the keys to running a reliable architecture is logging. Having consistent client-side logging provides you with the additional information you need to ensure that service operators are fulfilling the overall architecture performance needs. Because you know that you’ll want logging across all your service requests, it helps to build it in on some global level.
Typhoeus includes a simple method for adding handlers to every request. Here is an example:

The hydra object can also take an on_complete handler that will be called after each request completes. In the body of this handler, you’re checking to make sure the response code is in the 200–500 range. You expect some 400 errors due to data validation problems. You’re really only concerned about differentiating regular requests from server errors. Once you’ve logged the details about the request, hydra continues and calls the request object’s on_complete handler.
When you have the request info logged to a file, you can calculate some useful statistics. These are the most important things you’d want to calculate:
• Average response time
• Minimum response time
• Maximum response time
• Number of failures and percentage of requests that fail
• Percentage of requests served within certain time
Tracking these statistics over time gives you an indication of how well services are performing. For production systems, tracking these statistics also gives you indications about when systems are starting to slow down under load. Whether you’re using Typhoeus or another library, it’s a good idea to log information about every request sent out. Later, you can visit these logs to see how your services are performing.
Handling Error Conditions
It helps to think up front about how your clients will handle error conditions. Some error conditions can be anticipated and programmed against, while others need to be caught and logged for later inspection. Identifying what you want to do for each error condition can be tricky. Let’s go through some of the errors you might encounter.
One of the basic error conditions you expect is a general data error. These are the 400 errors that your services are throwing to indicate data validation problems. In this case, you can handle the error and bubble it up to the user like a standard ActiveRecord data validation.
The other errors are unexpected ones. For some of these, you can log them and continue execution without the response. Consider the previous example involving building a user’s reading list. You made three calls to build the list: first to get the entry IDs, second to get the ratings for these entries, and third to get the entries themselves. If the request to get the entry ratings failed, it’s still conceivable that you could render the page without ratings. It’s not ideal, but it’s better than throwing an error to the user.
Finally, there are conditions that are considered unrecoverable. These errors prevent you from continuing. When you face such an error, you might want to retry the request. Typhoeus has built-in retry logic to make this operation easy. You simply pass in the number of retries as an option to the request constructor, like this:
![]()
Note that Typhoeus triggers a retry only if the response code is in the 0–199 or 500+ range. Any response code within 200–499 will not be retried. If you want finer-grained retry logic, it’s easy to write your own within the request handler, like this:
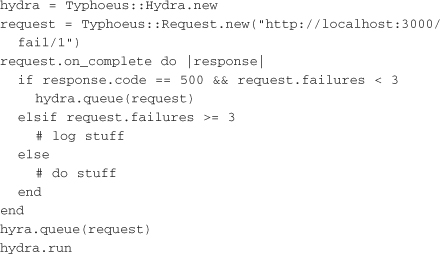
With this example we’re only retrying if the response code is 500. Also, we’re only trying the request again if we’ve failed less than three times. After three failures we’ll log the error and throw an exception.
Testing and Mocking Service Calls
Proper testing is a key component in building a successful application architecture. When writing clients, you need to consider how you want to test the service calls and how you want other libraries that use the clients to mock out their functionality. For testing your service clients, the best option is to mock at the lowest level. That is, you should mock at the level of the HTTP request.
Typhoeus includes functionality for mocking out requests based on the URI and method. The following example shows the usage:
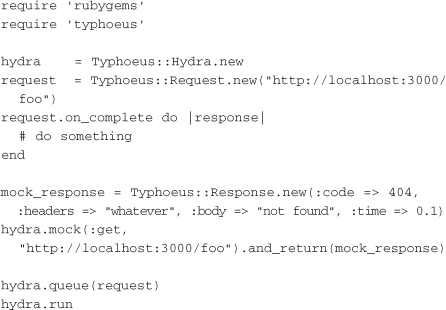
You can see that the setup of the request in this example looks just like a regular Typhoeus request. Lines 10–13 set up the mocking portion. First, you create a response object. In this example, you’re mocking out a 404 NOT FOUND response. The call to hydra.mock tells hydra that the mock response should be returned on a GET to http://localhost:3000/foo. When the request is queued up and run, the request’s on_complete handler is called with the mock response object.
Using mock response objects to test the service client helps to avoid calls to a running service. However, as the example shows, the mock response object is closely tied to the API of the service being called. If at some later time you change the URI or the service response body, this test won’t tell you that your client is now broken. Because of this, it’s also a good idea to include a full integration test to ensure that the service being called works the way the client expects it to.
If you’re not using Typhoeus to make requests, you have a few other options. For Net::HTTP, a good option for mocking at the request level is Blaine Cook’s FakeWeb (http://fakeweb.rubyforge.org). Another option is to wrap all calls to your HTTP library in a single class that can be mocked.
Requests in Development Environments
In a typical Rails application, a developer can run most of the environment locally on his or her machine. This means that when you’re developing, you’re able to make calls to the database directly. However, with service-based environments, you probably won’t be able to run every service on your development computer. This means you have to think about how development environments connect to services for testing purposes.
The simplest setup for development environments is to have each service running where it is accessible to each developer. Of course, this removes the ability to develop locally without a network connection. Another option is to build a development mode into each service client. Ultimately, running development environments with services can be tricky. Writing solid tests and mocking out the service calls is the cleanest method for developing against services. The next chapter explores how to write clients that include mocking functionality that hides the underlying service details.
Conclusion
This chapter covers the basics of connecting to services. Making requests in parallel is a necessary component of building service clients that perform well enough to be run inside the request/response lifecycle. To achieve this, requests can be run asynchronously or in multiple threads. Generally, asynchronous clients perform a little better than multi-threaded clients, but this may vary depending on the specific environment.
The next chapter goes into the details about how to write fully featured client libraries. The goal is to write clients that are well tested, that support mocking, and that provide simple, readable interfaces.